- Lucene 教程
- Lucene - 首页
- Lucene - 概述
- Lucene - 环境设置
- Lucene - 第一个应用程序
- Lucene - 索引类
- Lucene - 搜索类
- Lucene - 索引过程
- Lucene - 索引操作
- Lucene - 搜索操作
- Lucene - 查询编程
- Lucene - 分析
- Lucene - 排序
- Lucene 有用资源
- Lucene - 快速指南
- Lucene - 有用资源
- Lucene - 讨论
Lucene - 搜索操作
搜索过程是 Lucene 提供的核心功能之一。下图说明了该过程及其用途。IndexSearcher 是搜索过程的核心组件之一。
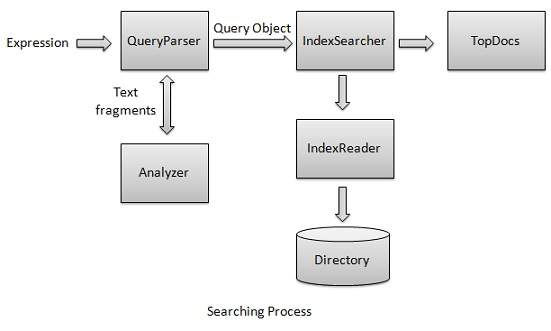
我们首先创建包含索引的Directory(s),然后将其传递给IndexSearcher,后者使用IndexReader打开Directory。然后,我们使用Term创建一个Query,并通过将Query传递给搜索器来使用IndexSearcher进行搜索。IndexSearcher返回一个TopDocs对象,其中包含搜索详细信息以及作为搜索结果的Document的文档ID。
我们现在将向您展示一个分步方法,并帮助您使用一个基本示例理解索引过程。
创建 QueryParser
QueryParser 类将用户输入解析为 Lucene 可理解格式的查询。请按照以下步骤创建 QueryParser:
步骤 1 - 创建 QueryParser 对象。
步骤 2 - 使用具有版本信息和要在此查询上运行的索引名称的标准分析器初始化创建的 QueryParser 对象。
QueryParser queryParser;
public Searcher(String indexDirectoryPath) throws IOException {
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
创建 IndexSearcher
IndexSearcher 类充当核心组件,搜索在索引过程中创建的索引。请按照以下步骤创建 IndexSearcher:
步骤 1 - 创建 IndexSearcher 对象。
步骤 2 - 创建一个 Lucene 目录,该目录应指向要存储索引的位置。
步骤 3 - 使用索引目录初始化创建的 IndexSearcher 对象。
IndexSearcher indexSearcher;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
}
进行搜索
请按照以下步骤进行搜索:
步骤 1 - 通过 QueryParser 解析搜索表达式来创建 Query 对象。
步骤 2 - 通过调用 IndexSearcher.search() 方法进行搜索。
Query query;
public TopDocs search( String searchQuery) throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
获取文档
以下程序演示如何获取文档。
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
关闭 IndexSearcher
以下程序演示如何关闭 IndexSearcher。
public void close() throws IOException {
indexSearcher.close();
}
示例应用程序
让我们创建一个测试 Lucene 应用程序来测试搜索过程。
| 步骤 | 描述 |
|---|---|
| 1 | 如Lucene - 第一个应用程序章节中所述,在com.tutorialspoint.lucene包下创建一个名为LuceneFirstApplication的项目。您也可以使用Lucene - 第一个应用程序章节中创建的项目来理解搜索过程。 |
| 2 | 如Lucene - 第一个应用程序章节中所述,创建LuceneConstants.java,TextFileFilter.java和Searcher.java。保持其余文件不变。 |
| 3 | 创建如下所示的LuceneTester.java。 |
| 4 | 清理并构建应用程序,以确保业务逻辑按要求工作。 |
LuceneConstants.java
此类用于提供可在示例应用程序中使用的各种常量。
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
此类用作.txt文件过滤器。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Searcher.java
此类用于读取对原始数据生成的索引,并使用 Lucene 库搜索数据。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}
LuceneTester.java
此类用于测试 Lucene 库的搜索功能。
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) +" ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}
数据和索引目录创建
我们使用了 10 个名为 record1.txt 到 record10.txt 的文本文件,其中包含学生姓名和其他详细信息,并将它们放在 E:\Lucene\Data 目录中。测试数据。应创建索引目录路径为 E:\Lucene\Index。在Lucene - 索引过程章节中运行索引程序后,您可以在该文件夹中看到创建的索引文件列表。
运行程序
完成源代码、原始数据、数据目录、索引目录和索引的创建后,您可以通过编译和运行程序继续进行。为此,请保持LuceneTester.Java文件选项卡处于活动状态,并使用 Eclipse IDE 中提供的“运行”选项,或使用Ctrl + F11编译和运行您的LuceneTester应用程序。如果您的应用程序成功运行,它将在 Eclipse IDE 的控制台中打印以下消息:
1 documents found. Time :29 ms File: E:\Lucene\Data\record4.txt