- Microsoft Cognitive Toolkit (CNTK) 教程
- 首页
- 简介
- 入门
- CPU 和 GPU
- CNTK - 序列分类
- CNTK - 逻辑回归模型
- CNTK - 神经网络 (NN) 概念
- CNTK - 创建第一个神经网络
- CNTK - 训练神经网络
- CNTK - 内存数据集和大型数据集
- CNTK - 性能评估
- 神经网络分类
- 神经网络二元分类
- CNTK - 神经网络回归
- CNTK - 分类模型
- CNTK - 回归模型
- CNTK - 内存不足的数据集
- CNTK - 监控模型
- CNTK - 卷积神经网络
- CNTK - 循环神经网络
- Microsoft Cognitive Toolkit 资源
- Microsoft Cognitive Toolkit - 快速指南
- Microsoft Cognitive Toolkit - 资源
- Microsoft Cognitive Toolkit - 讨论
CNTK - 性能评估
本章将解释如何在 CNKT 中衡量模型性能。
验证模型性能的策略
构建机器学习模型后,我们通常使用一组数据样本对其进行训练。通过这种训练,我们的机器学习模型学习并得出一些一般规则。当我们将新的样本(即与训练时提供的样本不同的样本)馈送到模型时,机器学习模型的性能就至关重要。在这种情况下,模型的行为会有所不同。它在对这些新样本进行良好预测方面可能表现更差。
但是,模型也必须适用于新样本,因为在生产环境中,我们将获得与用于训练目的的样本数据不同的输入。这就是为什么我们应该使用一组与用于训练目的的样本不同的样本集来验证机器学习模型的原因。在这里,我们将讨论两种不同的技术来创建用于验证神经网络的数据集。
留出数据集
这是创建用于验证神经网络的数据集最简单的方法之一。顾名思义,在这种方法中,我们将从训练中保留一组样本(例如 20%),并用它来测试我们机器学习模型的性能。下图显示了训练样本和验证样本之间的比例:
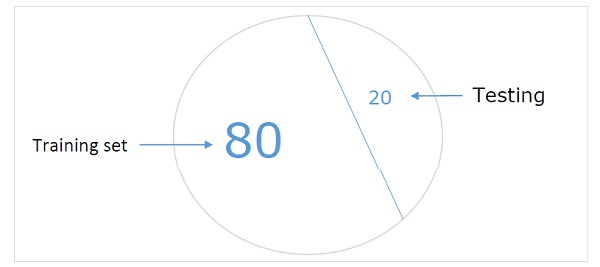
留出数据集模型确保我们有足够的数据来训练我们的机器学习模型,同时我们也有合理的样本数量来很好地衡量模型的性能。
为了包含在训练集和测试集中,最好从主数据集中选择随机样本。这确保了训练集和测试集之间的均匀分布。
以下是一个示例,我们使用scikit-learn库中的train_test_split函数生成我们自己的留出数据集。
示例
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# Here above test_size = 0.2 represents that we provided 20% of the data as test data.
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors=3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)
输出
Predictions: ['versicolor', 'virginica']
使用 CNTK 时,每次训练模型时都需要随机化数据集的顺序,因为:
深度学习算法受随机数生成器的影响很大。
我们在训练期间向神经网络提供样本的顺序会极大地影响其性能。
使用留出数据集技术的主要缺点是它不可靠,因为有时我们会得到非常好的结果,但有时我们会得到不好的结果。
K 折交叉验证
为了使我们的机器学习模型更可靠,有一种称为 K 折交叉验证的技术。从本质上讲,K 折交叉验证技术与之前的技术相同,但它会重复多次——通常大约 5 到 10 次。下图表示其概念:
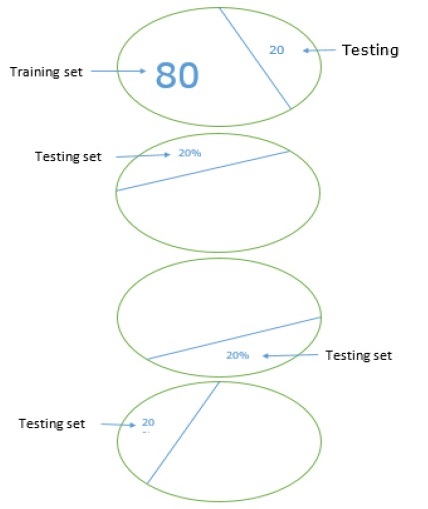
K 折交叉验证的工作原理
可以通过以下步骤了解 K 折交叉验证的工作原理:
步骤 1 - 与留出数据集技术一样,在 K 折交叉验证技术中,首先需要将数据集分成训练集和测试集。理想情况下,比例为 80-20,即 80% 的训练集和 20% 的测试集。
步骤 2 - 接下来,我们需要使用训练集训练我们的模型。
步骤 3 - 最后,我们将使用测试集来衡量模型的性能。留出数据集技术和 k 折交叉验证技术之间的唯一区别在于,上述过程通常会重复 5 到 10 次,最后计算所有性能指标的平均值。该平均值将是最终的性能指标。
让我们来看一个使用小型数据集的示例:
示例
from numpy import array
from sklearn.model_selection import KFold
data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
kfold = KFold(5, True, 1)
for train, test in kfold.split(data):
print('train: %s, test: %s' % (data[train],(data[test]))
输出
train: [0.1 0.2 0.4 0.5 0.6 0.7 0.8 0.9], test: [0.3 1. ] train: [0.1 0.2 0.3 0.4 0.6 0.8 0.9 1. ], test: [0.5 0.7] train: [0.2 0.3 0.5 0.6 0.7 0.8 0.9 1. ], test: [0.1 0.4] train: [0.1 0.3 0.4 0.5 0.6 0.7 0.9 1. ], test: [0.2 0.8] train: [0.1 0.2 0.3 0.4 0.5 0.7 0.8 1. ], test: [0.6 0.9]
正如我们所看到的,由于使用了更现实的训练和测试场景,k 折交叉验证技术为我们提供了更稳定的性能衡量,但缺点是验证深度学习模型时需要花费大量时间。
CNTK 不支持 k 折交叉验证,因此我们需要编写我们自己的脚本来执行此操作。
检测欠拟合和过拟合
无论我们使用留出数据集还是 k 折交叉验证技术,我们都会发现用于训练的数据集和用于验证的数据集的指标输出将有所不同。
检测过拟合
过拟合现象是指我们的机器学习模型对训练数据建模非常好,但在测试数据上表现不佳,即无法预测测试数据的情况。
当机器学习模型学习训练数据中的特定模式和噪声到一定程度时,就会发生这种情况,这会对其从训练数据泛化到新数据(即未见数据)的能力产生负面影响。此处,噪声是数据集中不相关的或随机的信息。
以下是我们可以用来检测我们的模型是否过拟合的两种方法:
过拟合模型将对我们用于训练的相同样本表现良好,但它将对新样本(即与训练不同的样本)表现非常差。
如果测试集上的指标低于我们在训练集上使用的相同指标,则模型在验证期间过拟合。
检测欠拟合
在我们的机器学习中可能出现的另一种情况是欠拟合。这是一种情况,我们的机器学习模型没有很好地对训练数据进行建模,并且无法预测有用的输出。当我们开始训练第一个周期时,我们的模型将欠拟合,但在训练过程中将变得不那么欠拟合。
检测我们的模型是否欠拟合的一种方法是查看训练集和测试集的指标。如果测试集上的指标高于训练集上的指标,则我们的模型将欠拟合。