- MongoEngine 教程
- MongoEngine - 首页
- MongoEngine - MongoDB
- MongoEngine - MongoDB Compass
- MongoEngine - 对象文档映射器
- MongoEngine - 安装
- MongoEngine - 连接到 MongoDB 数据库
- MongoEngine - 文档类
- MongoEngine - 动态模式
- MongoEngine - 字段
- MongoEngine - 添加/删除文档
- MongoEngine - 查询数据库
- MongoEngine - 过滤器
- MongoEngine - 查询操作符
- MongoEngine - QuerySet 方法
- MongoEngine - 排序
- MongoEngine - 自定义 QuerySet
- MongoEngine - 索引
- MongoEngine - 聚合
- MongoEngine - 高级查询
- MongoEngine - 文档继承
- MongoEngine - 原子更新
- MongoEngine - Javascript
- MongoEngine - GridFS
- MongoEngine - 信号
- MongoEngine - 文本搜索
- MongoEngine - 扩展
- MongoEngine 有用资源
- MongoEngine 快速指南
- MongoEngine - 有用资源
- MongoEngine - 讨论
MongoEngine 快速指南
MongoEngine - MongoDB
在过去十年中,NoSQL 数据库的普及率不断上升。在当今实时 Web 应用程序的世界中,移动和嵌入式设备产生了海量数据。传统的关联数据库(如 Oracle、MySQL 等)不适合处理字符串。由于这些数据库具有固定且预定义的模式,并且不可扩展,因此处理此类数据也很困难。NoSQL 数据库具有灵活的模式,并以分布式方式存储在大量社区服务器上。
NoSQL 数据库根据数据的组织方式进行分类。MongoDB 是一种流行的文档存储 NoSQL 数据库。MongoDB 数据库的基本组成部分称为文档。文档是以 JSON 格式存储的键值对集合。多个文档存储在一个集合中。集合可以被认为类似于任何关系数据库中的表,而文档类似于表中的一行。但是,需要注意的是,由于 MongoDB 是无模式的,因此集合中每个文档的键值对数量不必相同。
MongoDB 由 MongoDB Inc. 开发。它是一个通用的分布式基于文档的数据库。它提供企业版和社区版。Windows 操作系统的社区版的最新版本可以从 https://fastdl.mongodb.org/win32/mongodb-win32-x86_64-2012plus-4.2.6-signed.msi 下载。
将 MongoDB 安装到您选择的文件夹中,并使用以下命令启动服务器:
D:\mongodb\bin>mongod
服务器现在已准备好接收 27017 端口上的传入连接请求。MongoDB 数据库存储在 bin/data 目录中。此位置可以通过上述命令中的 –dbpath 选项更改。
在另一个命令终端中,使用以下命令启动 MongoDB 控制台:
D:\mongodb\bin>mongo
MongoDB 提示符与我们在 MySQL 或 SQLite 终端中通常看到的类似。所有数据库操作,例如创建数据库、插入文档、更新和删除以及检索文档,都可以在控制台中完成。
E:\mongodb\bin>mongo
MongoDB shell version v4.0.6
connecting to: mongodb://127.0.0.1:27017/?gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("0d848b11-acf7-4d30-83df-242d1d7fa693") }
MongoDB server version: 4.0.6
---
>
默认使用的数据库是 test。
> db Test
使用“use”命令可以将任何其他数据库设置为当前数据库。如果指定的数据库不存在,则会创建一个新的数据库。
> use mydb switched to db mydb
请参阅我们在 MongoDB 上的详细教程:https://tutorialspoint.com/mongodb/index.htm。
MongoEngine - MongoDB Compass
MongoDB 还开发了一个用于处理 MongoDB 数据库的 GUI 工具。它被称为 MongoDB Compass。这是一个方便的工具,无需手动编写查询即可执行所有 CRUD 操作。它有助于执行许多活动,例如索引、文档验证等。
从 https://mongodb.ac.cn/download-center/compass 下载 MongoDB Compass 的社区版并启动 **MongoDBCompassCommunity.exe**(确保在启动 Compass 之前 MongoDB 服务器正在运行)。通过提供正确的主机和端口号连接到本地服务器。
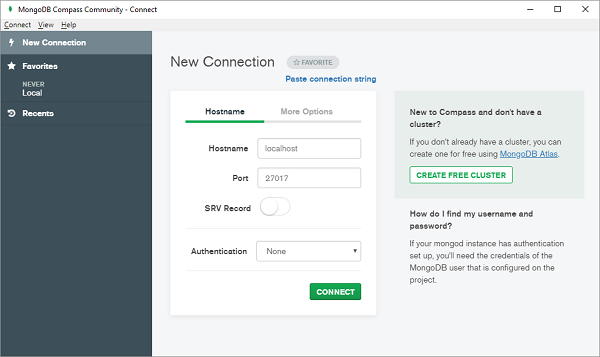
所有当前可用的数据库都将列出如下:
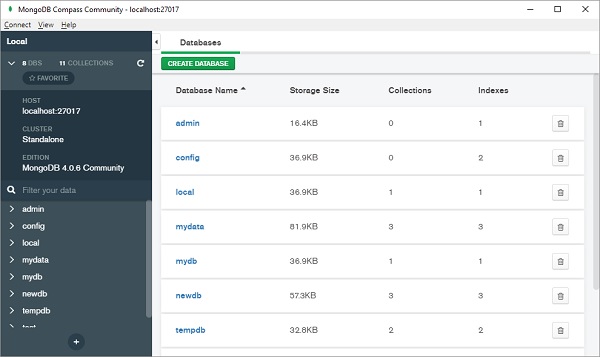
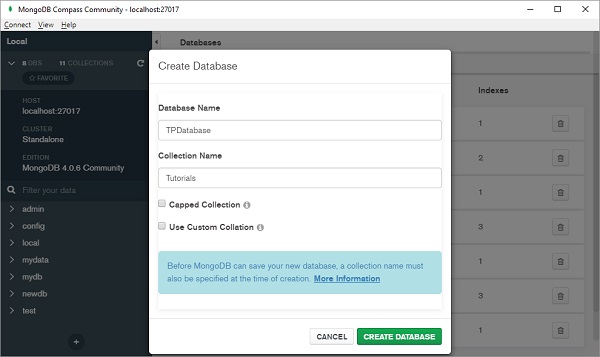
单击 + 按钮(显示在左侧面板底部)以创建新的数据库。
从列表中选择数据库名称并选择一个集合,如下所示:
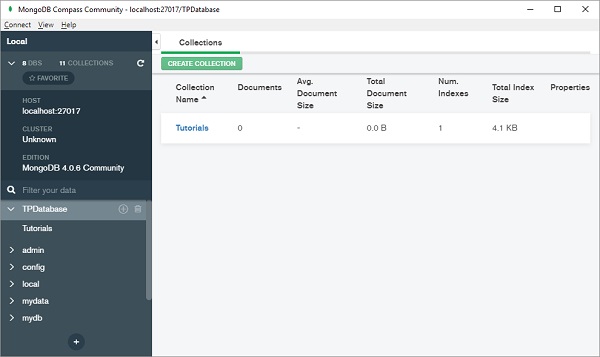
您可以直接添加文档或从 CSV 或 JSON 文件导入。
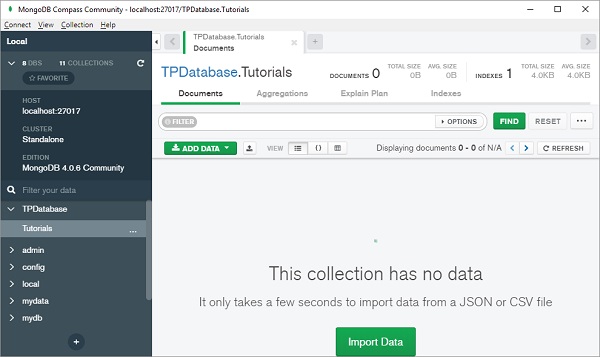
从“添加数据”下拉菜单中选择“插入文档”。
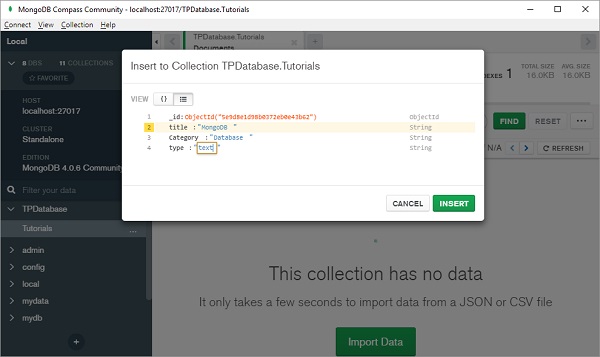
添加的文档将以 JSON、列表或表格形式显示:
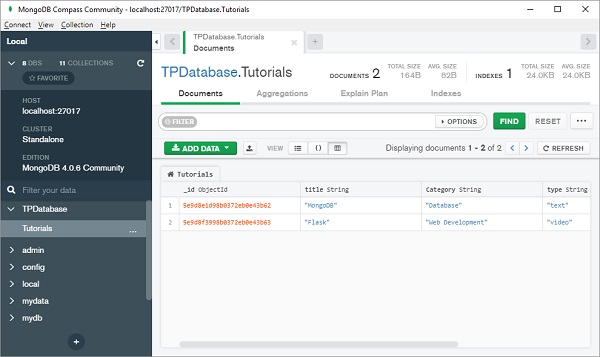
请注意,就像关系数据库中的表有一个主键一样,MongoDB 数据库中的文档也有一个名为“**_id**”的特殊键,它是自动生成的。
MongoDB Inc. 提供了一个 Python 驱动程序,用于连接 MongoDB 数据库。它被称为 **PyMongo**,其使用方法类似于标准 SQL 查询。
安装 PyMongo 模块后,我们需要 MongoClient 类的对象来与 MongoDB 服务器交互。
<<< from pymongo import MongoClient <<< client=MongoClient()
使用以下语句创建新的数据库:
db=client.mydatabase
对该数据库的 CRUD 操作使用 insert_one()(或 insert_many())、find()、update() 和 delete() 等方法执行。PyMongo 库的详细讨论可在 https://tutorialspoint.com/python_data_access/python_mongodb_introduction.htm 找到。
但是,除非将 Python 的用户定义对象转换为 MongoDB 的数据类型,否则无法将其存储在数据库中。这就是我们需要 **MongoEngine** 库的地方。
MongoEngine - 对象文档映射器
MongoDB 是一个基于文档的数据库。每个文档都是字段和值的 JSON 式表示。MongoDB 中的文档大致相当于 RDBMS 表中的一行(MongoDB 中表的等效项是集合)。即使 MongoDB 不强制执行任何预定义的模式,文档中的字段对象也具有一定的数据类型。MongoDB 数据类型与 Python 的主要数据类型非常相似。如果要存储 Python 用户定义类的对象,则必须手动将它的属性解析为等效的 MongoDB 数据类型。
MongoEngine 在 PyMongo 之上提供了一个方便的抽象层,并将 Document 类的每个对象映射到 MongoDB 数据库中的文档。MongoEngine API 由 Hary Marr 于 2013 年 8 月开发。MongoEngine 的最新版本是 0.19.1。
MongoEngine 之于 MongoDB,就像 SQLAlchemy 之于 RDBMS 数据库。MongoEngine 库提供了一个 Document 类,用作定义自定义类的基类。此类的属性构成 MongoDB 文档的字段。Document 类定义了执行 CRUD 操作的方法。在后续主题中,我们将学习如何使用它们。
MongoEngine - 安装
要使用 MongoEngine,您需要已经安装 MongoDB,并且 MongoDB 服务器应该像前面描述的那样运行。
安装 MongoEngine 最简单的方法是使用 PIP 安装程序。
pip install mongoengine
如果您的 Python 安装没有安装 Setuptools,则必须从 https://github.com/MongoEngine/mongoengine 下载 MongoEngine 并运行以下命令:
python setup.py install
MongoEngine 具有以下依赖项:
pymongo>=3.4
six>=1.10.0
dateutil>=2.1.0
pillow>=2.0.0
要验证正确的安装,请运行 import 命令并检查版本,如下所示:
>>> import mongoengine >>> mongoengine.__version__ '0.19.1'
连接到 MongoDB 数据库
如前所述,您应该首先使用 mongod 命令启动 MongoDB 服务器。
MongoEngine 提供 connect() 函数来连接到正在运行的 mongodb 服务器实例。
from mongoengine import connect connect(‘mydata.db’)
默认情况下,MongoDB 服务器在 localhost 上的 27017 端口运行。要自定义,您应该向 connect() 提供主机和端口参数:
connect('mydata.db', host='192.168.1.1', port=12345)
如果数据库需要身份验证,则应提供其凭据,例如用户名、密码和 authentication_source 参数。
connect('mydata.db', username='user1', password='***', authentication_source='admin')
MongoEngine 还支持 URI 样式连接而不是 IP 地址。
connect('mydata.db', host='mongodb:///database_name')
connect() 函数还有另一个可选参数,称为 replicaset。MongoDB 是一个分布式数据库。为了确保高可用性,通常在一个服务器上存储的数据会在许多服务器实例中复制。MongoDB 中的副本集是一组 mongod 进程,在这些进程上维护相同的数据集。副本集是所有生产部署的基础。
connect(host='mongodb:///dbname?replicaSet=rs-name')
副本集方法定义如下:
| rs.add() | 将成员添加到副本集。 |
| rs.conf() | 返回副本集配置文档。 |
| rs.freeze() | 阻止当前成员在一段时间内当选为主节点。 |
| rs.initiate() | 初始化一个新的副本集。 |
| rs.reconfig() | 通过应用新的副本集配置对象来重新配置副本集。 |
| rs.remove() | 从副本集中移除成员。 |
MongoEngine 还允许连接到多个数据库。您需要为每个数据库提供唯一的别名。例如,以下代码将 Python 脚本连接到两个 MongoDB 数据库。
connect(alias='db1', db='db1.db') connect(alias='db2', db='db2.db')
MongoEngine - 文档类
MongoEngine 被称为 ODM(**对象文档映射器**)。MongoEngine 定义了一个 Document 类。这是一个基类,其继承类用于定义存储在 MongoDB 数据库中的文档集合的结构和属性。此子类的每个对象都构成数据库中集合中的文档。
此 Document 子类中的属性是各种 Field 类的对象。以下是一个典型的 Document 类的示例:
from mongoengine import *
class Student(Document):
studentid = StringField(required=True)
name = StringField(max_length=50)
age = IntField()
def _init__(self, id, name, age):
self.studentid=id,
self.name=name
self.age=age
这类似于 SQLAlchemy ORM 中的模型类。默认情况下,数据库中集合的名称是 Python 类的名称,其名称转换为小写。但是,可以在 Document 类的 meta 属性中指定不同的集合名称。
meta={collection': 'student_collection'}
现在声明此类的对象并调用 save() 方法以将文档存储到数据库中。
s1=Student('A001', 'Tara', 20)
s1.save()
MongoEngine - 动态模式
MongoDB 数据库的优点之一是它支持动态模式。要创建一个支持动态模式的类,请从 DynamicDocument 基类继承它。以下是具有动态模式的 Student 类:
>>> class student(DynamicDocument): ... name=StringField()
第一步是像以前一样添加第一个文档。
>>> s1=student()
>>> s1.name="Tara"
>>> connect('mydb')
>>> s1.save()
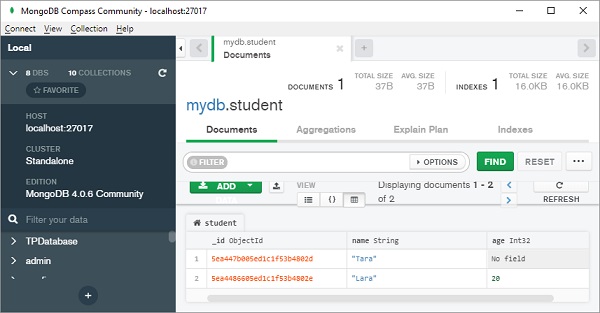
现在向第二个文档添加另一个属性并保存。
>>> s2=student() >>> setattr(s2,'age',20) >>> s2.name='Lara' >>> s2.save()
在数据库中,学生集合将显示具有动态模式的两个文档。
文档类的元数据字典可以通过指定max_documents和max_size来使用带上限的集合。
max_documents − 集合中允许存储的最大文档数。
max_size − 集合的最大大小(以字节为单位)。MongoDB内部和之前的mongoengine会将max_size向上舍入到下一个256的倍数。
如果未指定max_size而指定了max_documents,则max_size默认为10485760字节(10MB)。
文档类的其他参数列在下面:
| objects | 访问时延迟创建的QuerySet对象。 |
| cascade_save() | 递归保存文档上的任何引用和泛型引用。 |
| clean() | 在运行验证之前执行文档级别数据清理的钩子。 |
| create_index() | 根据需要创建给定的索引。 |
| drop_collection() | 删除数据库中与此文档类型关联的整个集合。 |
| from_json() | 将json数据转换为文档实例。 |
| modify() | 执行数据库中文档的原子更新,并使用更新后的版本重新加载文档对象。 |
| pk | 获取主键。 |
| save() | 将文档保存到数据库。如果文档已存在,则将更新它,否则将创建它。返回保存的对象实例。 |
| delete() | 从数据库中删除当前文档。 |
| insert() | 执行批量插入操作。 |
MongoEngine - 字段
MongoEngine文档类具有一个或多个属性。每个属性都是Field类的一个对象。BaseField是所有字段类型的基类。BaseField类构造函数具有以下参数:
BaseField(db_field, required, default, unique, primary_key)
db_field表示数据库字段的名称。
required参数决定此字段的值是否必填,默认为false。
default参数包含此字段的默认值。
unique参数默认为false。如果希望此字段对每个文档具有唯一值,则将其设置为true。
primary_key参数默认为false。设置为true可将此字段设为主键。
有许多从BaseField派生的Field类。
数值字段
IntField(32位整数)、LongField(64位整数)、FloatField(浮点数)字段构造函数具有min_value和max_value参数。
还有一个DecimalField类。此字段对象的 value 是一个浮点数,其精度可以指定。DecimalField类定义了以下参数:
DecimalField(min_value, max_value, force_string, precision, rounding)
| min_value | 指定最小可接受值。 |
| max_value | 指定字段可以具有的最大值。 |
| force_string | 如果为True,则此字段的值将存储为字符串。 |
| precision | 将浮点表示限制为位数。 |
| rounding | 根据以下预定义常量对数字进行舍入:decimal.ROUND_CEILING(朝正无穷大方向舍入)、decimal.ROUND_DOWN(朝零方向舍入)、decimal.ROUND_FLOOR(朝负无穷大方向舍入)、decimal.ROUND_HALF_DOWN(最接近的,与零相近时朝零方向舍入)、decimal.ROUND_HALF_EVEN(最接近的,与零相近时朝最近的偶数舍入)、decimal.ROUND_HALF_UP(最接近的,与零相近时远离零方向舍入)、decimal.ROUND_UP(远离零方向舍入)、decimal.ROUND_05UP(如果朝零方向舍入后的最后一位数字为0或5,则远离零方向舍入;否则朝零方向舍入)。 |
文本字段
StringField对象可以存储任何Unicode值。您可以在构造函数中指定字符串的min_length和max_length。URLField对象是一个StringField,具有将输入验证为URL的功能。EmailField将字符串验证为有效的电子邮件表示形式。
StringField(max-length, min_length) URLField(url_regex) EmailField(domain_whiltelist, allow_utf8_user, allow_ip_domain)
domain_whitelist参数包含您不支持的无效域列表。如果设置为True,allow_utf8_user参数允许字符串包含UTF8字符作为电子邮件的一部分。allow_ip_domain参数默认为false,但如果为true,它可以是有效的IPV4或IPV6地址。
以下示例使用数值字段和字符串字段:
from mongoengine import *
connect('studentDB')
class Student(Document):
studentid = StringField(required=True)
name = StringField()
age=IntField(min_value=6, max-value=20)
percent=DecimalField(precision=2)
email=EmailField()
s1=Student()
s1.studentid='001'
s1.name='Mohan Lal'
s1.age=20
s1.percent=75
s1.email='mohanlal@gmail.com'
s1.save()
执行上述代码后,学生集合将显示如下文档:

ListField
此类型的字段包装任何标准字段,从而允许将多个对象用作数据库中的列表对象。此字段可以与ReferenceField一起使用以实现一对多关系。
上述示例中的学生文档类修改如下:
from mongoengine import *
connect('studentDB')
class Student(Document):
studentid = StringField(required=True)
name = StringField(max_length=50)
subjects = ListField(StringField())
s1=Student()
s1.studentid='A001'
s1.name='Mohan Lal'
s1.subjects=['phy', 'che', 'maths']
s1.save()
添加的文档以JSON格式显示如下:
{
"_id":{"$oid":"5ea6a1f4d8d48409f9640319"},
"studentid":"A001",
"name":"Mohan Lal",
"subjects":["phy","che","maths"]
}
DictField
DictField类的一个对象存储Python字典对象。在相应的数据库字段中,这也将被存储。
在上面的例子中,我们将ListField的类型更改为DictField。
from mongoengine import *
connect('studentDB')
class Student(Document):
studentid = StringField(required=True)
name = StringField(max_length=50)
subjects = DictField()
s1=Student()
s1.studentid='A001'
s1.name='Mohan Lal'
s1.subjects['phy']=60
s1.subjects['che']=70
s1.subjects['maths']=80
s1.save()
数据库中的文档如下所示:
{
"_id":{"$oid":"5ea6cfbe1788374c81ccaacb"},
"studentid":"A001",
"name":"Mohan Lal",
"subjects":{"phy":{"$numberInt":"60"},
"che":{"$numberInt":"70"},
"maths":{"$numberInt":"80"}
}
}
ReferenceField
MongoDB文档可以使用此类型的字段来存储对另一个文档的引用。这样,我们就可以像在RDBMS中一样实现连接。ReferenceField构造函数使用其他文档类的名称作为参数。
class doc1(Document): field1=StringField() class doc2(Document): field1=StringField() field2=ReferenceField(doc1)
在下面的示例中,StudentDB数据库包含两个文档类:student和teacher。Student类的文档包含对teacher类对象的引用。
from mongoengine import *
connect('studentDB')
class Teacher (Document):
tid=StringField(required=True)
name=StringField()
class Student(Document):
sid = StringField(required=True)
name = StringField()
tid=ReferenceField(Teacher)
t1=Teacher()
t1.tid='T1'
t1.name='Murthy'
t1.save()
s1=Student()
s1.sid='S1'
s1.name='Mohan'
s1.tid=t1
s1.save()
运行上述代码并在Compass GUI中验证结果。在StudentDB数据库中创建了对应于两个文档类的两个集合。
添加的教师文档如下:
{
"_id":{"$oid":"5ead627463976ea5159f3081"},
"tid":"T1",
"name":"Murthy"
}
学生文档的内容如下所示:
{
"_id":{"$oid":"5ead627463976ea5159f3082"},
"sid":"S1",
"name":"Mohan",
"tid":{"$oid":"5ead627463976ea5159f3081"}
}
请注意,Student文档中的ReferenceField存储相应Teacher文档的_id。访问时,Student对象会自动转换为引用,并在访问相应的Teacher对象时取消引用。
要添加对正在定义的文档的引用,请使用“self”代替其他文档类作为ReferenceField的参数。需要注意的是,使用ReferenceField可能会导致文档检索方面的性能下降。
ReferenceField构造函数还有一个可选参数reverse_delete_rule。它的值决定了如果引用的文档被删除该怎么做。
可能的值如下:
DO_NOTHING (0) - 什么也不做(默认)。
NULLIFY (1) - 将引用更新为null。
CASCADE (2) - 删除与引用关联的文档。
DENY (3) - 阻止删除引用对象。
PULL (4) - 从引用的ListField中删除引用。
您可以使用引用列表实现一对多关系。假设学生文档必须与一个或多个教师文档相关联,则Student类必须具有ReferenceField实例的ListField。
from mongoengine import *
connect('studentDB')
class Teacher (Document):
tid=StringField(required=True)
name=StringField()
class Student(Document):
sid = StringField(required=True)
name = StringField()
tid=ListField(ReferenceField(Teacher))
t1=Teacher()
t1.tid='T1'
t1.name='Murthy'
t1.save()
t2=Teacher()
t2.tid='T2'
t2.name='Saxena'
t2.save()
s1=Student()
s1.sid='S1'
s1.name='Mohan'
s1.tid=[t1,t2]
s1.save()
在Compass中验证上述代码的结果后,您会发现学生文档具有两个教师文档的引用:
Teacher Collection
{
"_id":{"$oid":"5eaebcb61ae527e0db6d15e4"},
"tid":"T1","name":"Murthy"
}
{
"_id":{"$oid":"5eaebcb61ae527e0db6d15e5"},
"tid":"T2","name":"Saxena"
}
Student collection
{
"_id":{"$oid":"5eaebcb61ae527e0db6d15e6"},
"sid":"S1","name":"Mohan",
"tid":[{"$oid":"5eaebcb61ae527e0db6d15e4"},{"$oid":"5eaebcb61ae527e0db6d15e5"}]
}
DateTimeField
DateTimeField类的一个实例允许在MongoDB数据库中使用日期格式的数据。MongoEngine查找Python-DateUtil库以解析适当日期格式的数据。如果当前安装中没有此库,则使用内置time模块的time.strptime()函数表示日期。此类型字段的默认值为当前日期时间实例。
DynamicField
此字段可以处理不同且变化类型的数据。此类型的字段由DynamicDocument类内部使用。
ImageField
此类型的字段对应于文档中可以存储图像文件的字段。此类的构造函数可以接受size和thumbnail_size参数(均以像素大小表示)。
MongoEngine - 添加/删除文档
我们已经使用Document类的save()方法向集合中添加文档。save()方法可以借助以下参数进一步自定义:
| force_insert | 默认为False,如果设置为True,则不允许更新现有文档。 |
| validate | 验证文档;设置为False以跳过。 |
| clean | 调用文档clean方法,validate参数应为True。 |
| write_concern | 将用作生成的getLastError命令的选项。例如,save(..., write_concern={w: 2, fsync: True}, ...) 将等待至少两台服务器记录写入,并将强制在主服务器上执行fsync。 |
| cascade | 设置级联保存的标志。您可以通过在文档__meta__中设置“cascade”来设置默认值。 |
| cascade_kwargs | 要传递给级联保存的可选关键字参数。等同于cascade=True。 |
| _refs | 级联保存中使用的已处理引用的列表。 |
| save_condition | 仅当数据库中的匹配记录满足条件时才执行保存。如果条件不满足,则引发OperationError。 |
| signal_kwargs | 要传递给信号调用的kwargs字典。 |
您可以在调用save()之前设置用于验证文档的清理规则。通过提供自定义clean()方法,您可以执行任何预验证/数据清理。
class MyDocument(Document):
...
...
def clean(self):
if <condition>==True:
msg = 'error message.'
raise ValidationError(msg)
请注意,只有在启用验证并调用save()时才会调用清理。
Document类还有一个insert()方法用于执行批量插入。它具有以下参数:
| doc_or_docs | 要插入的文档或文档列表。 |
| load_bulk | 如果为True,则返回文档实例列表。 |
| write_concern | 额外的关键字参数将传递给insert(),它将用作生成的getLastError命令的选项。 |
| signal_kwargs | (可选) 要传递给信号调用的kwargs字典。 |
如果文档包含任何ReferenceField对象,则默认情况下,save()方法不会保存对这些对象的任何更改。如果您希望也保存所有引用(注意每个保存都是一个单独的查询),则将cascade作为True传递给save方法将级联任何保存。
从其集合中删除文档非常容易,只需调用delete()方法即可。请记住,只有在文档之前已保存的情况下,它才会生效。delete()方法具有以下参数:
| signal_kwargs | (可选) 要传递给信号调用的kwargs字典。 |
| write_concern | 传递的额外关键字参数将用作生成的getLastError命令的选项。 |
要删除数据库中的整个集合,请使用drop_collecction()方法。此方法将删除与该文档类型关联的数据库中的整个集合。如果文档未设置集合(例如,如果它是抽象的),则该方法会引发OperationError。
文档类中的modify()方法执行数据库中文档的原子更新并重新加载其更新版本。如果文档已更新,则返回True;如果数据库中的文档与查询不匹配,则返回False。请注意,如果方法返回True,则对文档所做的所有未保存更改都将被拒绝。
参数
| query | 只有当数据库中的文档与查询匹配时,才会执行更新。 |
| update | Django风格的更新关键字参数 |
MongoEngine - 查询数据库
connect()函数返回一个MongoClient对象。使用此对象可用的list_database_names()方法,我们可以检索服务器上的数据库数量。
from mongoengine import *
con=connect('newdb')
dbs=con.list_database_names()
for db in dbs:
print (db)
还可以使用list_collection_names()方法获取数据库中集合的列表。
collections=con['newdb'].list_collection_names() for collection in collections: print (collection)
如前所述,Document类具有objects属性,该属性允许访问与数据库关联的对象。
newdb数据库具有与下面的Document类对应的products集合。要获取所有文档,我们使用方法objects属性如下:
from mongoengine import *
con=connect('newdb')
class products (Document):
ProductID=IntField(required=True)
Name=StringField()
price=IntField()
for product in products.objects:
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
输出
ID: 1 Name: Laptop Price: 25000 ID: 2 Name: TV Price: 50000 ID: 3 Name: Router Price: 2000 ID: 4 Name: Scanner Price: 5000 ID: 5 Name: Printer Price: 12500
MongoEngine - 过滤器
objects属性是一个QuerySet管理器。它在访问时创建并返回一个QuerySet。可以使用字段名称作为关键字参数对查询进行过滤。例如,从上面的products集合中,要打印产品名称为“TV”的文档的详细信息,我们使用Name作为关键字参数。
for product in products.objects(Name='TV'):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
您可以使用QuerySet对象的filter方法来对查询应用过滤器。以下代码片段也返回名称为“TV”的产品详细信息。
qset=products.objects
for product in qset.filter(Name='TV'):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
MongoEngine - 查询操作符
除了=运算符用于检查相等性之外,MongoEngine中还定义了以下逻辑运算符。
| ne | 不等于 |
| lt | 小于 |
| lte | 小于或等于 |
| gt | 大于 |
| gte | 大于或等于 |
| not | 否定标准检查,可以在其他运算符之前使用 |
| in | 值在列表中 |
| nin | 值不在列表中 |
| mod | value % x == y,其中x和y是提供的两个值 |
| all | 提供的列表中的每个项目都在数组中 |
| size | 数组的大小是 |
| exists | 字段的值存在 |
这些运算符必须用双下划线__附加到字段名称。
要使用大于(gt)运算符,请使用以下格式:
#using greater than operator
for product in products.objects(price__gt=10000):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
输出
ID: 1 Name: Laptop Price: 25000 ID: 2 Name: TV Price: 50000 ID: 5 Name: Printer Price: 12500
in运算符类似于Python的in运算符。对于与列表中的名称匹配的产品名称,使用以下代码:
for product in products.objects(Name__in=['TV', 'Printer']):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
输出
ID: 2 Name: TV Price: 50000 ID: 5 Name: Printer Price: 12500
您可以使用以下运算符作为正则表达式的快捷方式来对查询应用过滤器:
| exact | 字符串字段完全匹配值 |
| iexact | 字符串字段完全匹配值(不区分大小写) |
| contains | 字符串字段包含值 |
| icontains | 字符串字段包含值(不区分大小写) |
| startswith | 字符串字段以值开头 |
| istartswith | 字符串字段以值开头(不区分大小写) |
| endswith | 字符串字段以值结尾 |
| iendswith | 字符串字段以值结尾(不区分大小写) |
| match | 执行$elemMatch,以便您可以匹配数组中的整个文档 |
例如,以下代码打印名称中包含“o”的产品详细信息:
for product in products.objects(Name__contains='o'):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
输出
ID: 1 Name: Laptop Price: 25000 ID: 3 Name: Router Price: 2000
在另一个字符串查询示例中,以下代码显示以“er”结尾的名称:
for product in products.objects(Name__endswith='er'):
print ('ID:',product.ProductID, 'Name:',product.Name, 'Price:',product.price)
输出
ID: 3 Name: Router Price: 2000 ID: 4 Name: Scanner Price: 5000 ID: 5 Name: Printer Price: 12500
MongoEngine - QuerySet 方法
QuerySet对象拥有以下用于查询数据库的有用方法。
first()
返回满足查询的第一个文档。以下代码将返回products集合中的第一个文档,其价格<20000。
qset=products.objects(price__lt=20000)
doc=qset.first()
print ('Name:',doc.Name, 'Price:',doc.price)
输出
Name: Router Price: 2000
exclude()
这将导致从Query Set中排除提到的字段。这里,使用Document类的to_json()方法来获取Document的JSON化版本。ProductID字段将不会出现在结果中。
for product in products.objects.exclude('ProductID'):
print (product.to_json())
输出
{"_id": {"$oid": "5c8dec275405c12e3402423c"}, "Name": "Laptop", "price": 25000}
{"_id": {"$oid": "5c8dec275405c12e3402423d"}, "Name": "TV", "price": 50000}
{"_id": {"$oid": "5c8dec275405c12e3402423e"}, "Name": "Router", "price": 2000}
{"_id": {"$oid": "5c8dec275405c12e3402423f"}, "Name": "Scanner", "price": 5000}
{"_id": {"$oid": "5c8dec275405c12e34024240"}, "Name": "Printer", "price": 12500}
fields()
使用此方法来操作在查询集中加载哪些字段。使用字段名称作为关键字参数,设置为1表示包含,设置为0表示排除。
for product in products.objects.fields(ProductID=1,price=1): print (product.to_json())
输出
{"_id": {"$oid": "5c8dec275405c12e3402423c"}, "ProductID": 1, "price": 25000}
{"_id": {"$oid": "5c8dec275405c12e3402423d"}, "ProductID": 2, "price": 50000}
{"_id": {"$oid": "5c8dec275405c12e3402423e"}, "ProductID": 3, "price": 2000}
{"_id": {"$oid": "5c8dec275405c12e3402423f"}, "ProductID": 4, "price": 5000}
{"_id": {"$oid": "5c8dec275405c12e34024240"}, "ProductID": 5, "price": 12500}
在fields()方法中将字段关键字参数设置为0与exclude()方法的效果类似。
for product in products.objects.fields(price=0): print (product.to_json())
输出
{"_id": {"$oid": "5c8dec275405c12e3402423c"}, "ProductID": 1, "Name": "Laptop"}
{"_id": {"$oid": "5c8dec275405c12e3402423d"}, "ProductID": 2, "Name": "TV"}
{"_id": {"$oid": "5c8dec275405c12e3402423e"}, "ProductID": 3, "Name": "Router"}
{"_id": {"$oid": "5c8dec275405c12e3402423f"}, "ProductID": 4, "Name": "Scanner"}
{"_id": {"$oid": "5c8dec275405c12e34024240"}, "ProductID": 5, "Name": "Printer"}
only()
此方法的效果类似于fields()方法。查询集中将只显示与关键字参数对应的字段。
for product in products.objects.only('Name'):
print (product.to_json())
输出
{"_id": {"$oid": "5c8dec275405c12e3402423c"}, "Name": "Laptop"}
{"_id": {"$oid": "5c8dec275405c12e3402423d"}, "Name": "TV"}
{"_id": {"$oid": "5c8dec275405c12e3402423e"}, "Name": "Router"}
{"_id": {"$oid": "5c8dec275405c12e3402423f"}, "Name": "Scanner"}
{"_id": {"$oid": "5c8dec275405c12e34024240"}, "Name": "Printer"}
sum()
此方法计算查询集中给定字段的总和。
average()
此方法计算查询集中给定字段的平均值。
avg=products.objects.average('price')
ttl=products.objects.sum('price')
print ('sum of price field',ttl)
print ('average of price field',avg)
输出
sum of price field 94500 average of price field 18900.0
MongoEngine - 排序
QuerySet的order_by()函数用于以排序的方式获取查询结果。用法如下:
Qset.order_by(‘fieldname’)
默认情况下,排序顺序为升序。对于降序,请将“-”符号附加到字段名称。例如,要按价格升序获取列表:
from mongoengine import *
con=connect('newdb')
class products (Document):
ProductID=IntField(required=True)
company=StringField()
Name=StringField()
price=IntField()
for product in products.objects.order_by('price'):
print ("Name:{} company:{} price:{}".format(product.Name, product.company, product.price))
输出
Name:Router company:Iball price:2000 Name:Scanner company:Cannon price:5000 Name:Printer company:Cannon price:12500 Name:Laptop company:Acer price:25000 Name:TV company:Philips price:31000 Name:Laptop company:Dell price:45000 Name:TV company:Samsung price:50000
以下代码将按名称降序获取列表:
for product in products.objects.order_by('-Name'):
print ("Name:{} company:{} price:{}".format(product.Name, product.company, product.price))
输出
Name:TV company:Samsung price:50000 Name:TV company:Philips price:31000 Name:Scanner company:Cannon price:5000 Name:Router company:Iball price:2000 Name:Printer company:Cannon price:12500 Name:Laptop company:Acer price:25000 Name:Laptop company:Dell price:45000
您还可以对多个字段进行排序。此代码将按公司、价格升序获取列表。
for product in products.objects.order_by('company','price'):
print ("Name:{} company:{} price:{}".format(product.Name, product.company, product.price))
输出
Name:Laptop company:Acer price:25000 Name:Scanner company:Cannon price:5000 Name:Printer company:Cannon price:12500 Name:Laptop company:Dell price:45000 Name:Router company:Iball price:2000 Name:TV company:Philips price:31000 Name:TV company:Samsung price:50000
MongoEngine - 自定义 QuerySet
默认情况下,文档类上的objects属性返回一个QuerySet,而不应用任何过滤器。但是,您可以在修改queryset的文档上定义一个classmethod。此类方法应该接受两个参数——doc_cls和queryset,并且需要用queryset_manager()装饰才能被识别。
@queryset_manager
def qry_method(docs_cls,queryset):
….
----
在下面的示例中,名为products的文档类有一个用@queryset_manager装饰的expensive_prods()方法。该方法本身会对queryset应用过滤器,以便只返回价格>20000的对象。此方法现在是默认的文档查询,products类的objects属性返回过滤后的文档。
from mongoengine import *
con=connect('newdb')
class products (Document):
ProductID=IntField(required=True)
company=StringField()
Name=StringField()
price=IntField()
@queryset_manager
def expensive_prods(docs_cls,queryset):
return queryset.filter(price__gt=20000)
for product in products.expensive_prods():
print ("Name:{} company:{} price:{}".format(product.Name, product.company, product.price))
输出
Name:Laptop company:Acer price:25000 Name:TV company:Samsung price:50000 Name:TV company:Philips price:31000 Name:Laptop company:Dell price:45000
如果您希望自定义过滤文档的方法,首先声明QuerySet类的子类,并将其用作meta字典中queryset_class属性的值。
下面的示例使用MyQuerySet类作为自定义queryset的定义。此类中的myqrymethod()过滤名称字段以“er”结尾的文档。在products类中,meta属性引用此queryset子类作为queryset_class属性的值。
from mongoengine import *
con=connect('newdb')
class MyQuerySet(QuerySet):
def myqrymethod(self):
return self.filter(Name__endswith='er')
class products (Document):
meta = {'queryset_class': MyQuerySet}
ProductID=IntField(required=True)
company=StringField()
Name=StringField()
price=IntField()
for product in products.objects.myqrymethod():
print ("Name:{} company:{} price:{}".format(product.Name, product.company, product.price))
输出
Name:Router company:Iball price:2000 Name:Scanner company:Cannon price:5000 Name:Printer company:Cannon price:12500
MongoEngine - 索引
索引集合可以加快查询处理速度。默认情况下,每个集合都会在_id字段上自动建立索引。此外,您还可以在一个或多个字段上创建索引。
使用Compass,我们可以非常轻松地构建索引。单击下图所示“索引”选项卡上的“创建索引”按钮:
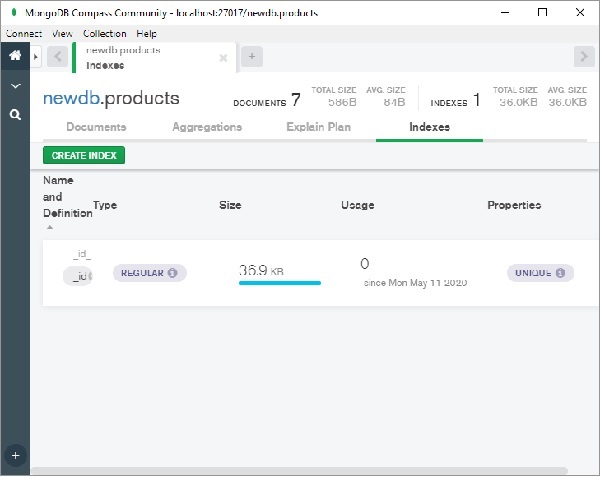
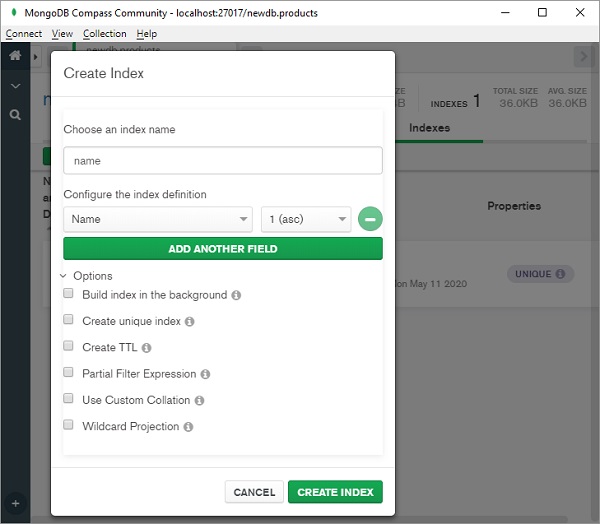
将出现一个对话框,如图所示。选择索引名称、要索引的字段、索引顺序(升序或降序)和其他选项。
使用MongoEngine时,索引是通过在Document类定义的meta字典中指定“indexes”键来创建的。
indexes属性的值是一个字段列表。在下面的示例中,我们要求student集合中的文档根据name字段建立索引。
from mongoengine import *
con=connect('mydata')
class student(Document):
name=StringField(required=True)
course=StringField()
meta = {'indexes':['name']}
s1=student()
s1.name='Avinash'
s1.course='DataScience'
s1.save()
s2=student()
s2.name='Anita'
s2.course='WebDesign'
s2.save()
默认情况下,索引顺序为升序。可以通过在前面添加“+”表示升序或“-”表示降序来指定顺序。
要创建复合索引,请使用字段名称的元组,可以选择附加“+”或“-”符号来指示排序顺序。
在下面的示例中,student文档类包含name和course上的复合索引定义(注意course字段前缀为“-”符号,这意味着索引按name升序和course降序构建)。
from mongoengine import *
con=connect('mydata')
class student(Document):
name=StringField(required=True)
course=StringField()
meta = {'indexes':[('name','-course')]}
s1=student()
s1.name='Avinash'
s1.course='DataScience'
s1.save()
s2=student()
s2.name='Anita'
s2.course='WebDesign'
s2.save()
MongoDB Compass将显示索引如下:
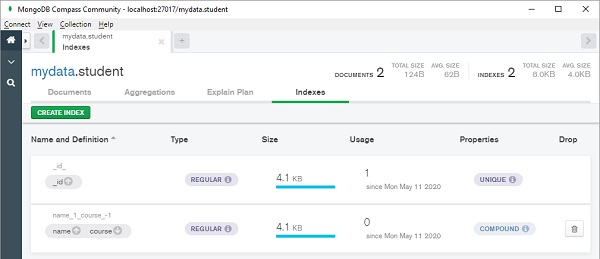
“indexes”的值可以是具有各种选项的字典,如下所示:
| fields | 要索引的字段。 |
| cls | 如果启用allow_inheritance,您可以配置是否应自动添加_cls字段。 |
| sparse | 索引是否应为稀疏索引。 |
| unique | 索引是否应为唯一索引。 |
| expireAfterSeconds | 通过设置秒数来自动使集合中的数据过期 |
| name | 允许您指定索引的名称 |
| collation | 允许创建不区分大小写的索引 |
以下示例在name字段上创建索引,该索引在3600秒后过期。
from mongoengine import *
con=connect('mydata')
class student(Document):
name=StringField(required=True)
course=StringField()
meta = {'indexes':[{
'fields': ['name'],
'expireAfterSeconds': 3600
}
]
}
要指定文本索引,请在字段名称前添加“$”符号;对于哈希索引,请使用“#”作为前缀。
如此指定的索引会在文档添加到集合时自动创建。要禁用自动创建,请在meta属性中将“auto_create_index”设置为False。
我们有Document类中的list_indexes()方法,该方法显示可用索引的列表。
print (student.list_indexes())
[[('name', 1)], [('_id', 1)]]
要在meta字典中不存在的字段上创建索引,请使用create_index()方法。以下代码将在course字段上创建索引:
class student(Document):
name=StringField(required=True)
course=StringField()
meta = {'indexes':[{
'fields': ['name'],
'expireAfterSeconds': 3600
}
]}
student.create_index(['course'])
MongoEngine - 聚合
术语“聚合”用于处理数据并返回计算结果的操作。在集合中的文档的一个或多个字段上查找总和、计数和平均值可以称为聚合函数。
MongoEngine提供aggregate()函数,该函数封装了PyMongo的聚合框架。聚合操作使用集合作为输入,并返回一个或多个文档作为结果。
MongoDB使用数据处理管道的概念。一个管道可以有多个阶段。基本阶段提供过滤器并像查询一样操作。其他阶段提供用于按一个或多个字段分组和/或排序、字符串连接任务、数组聚合工具等的工具。
以下阶段在MongoDB管道创建中定义:
| 名称 | 描述 |
|---|---|
| $project | 通过添加新字段或删除现有字段来重塑流中的每个文档。 |
| $match | 过滤文档流,只允许匹配的文档以未修改的形式传递到下一阶段。$match使用标准的MongoDB查询。 |
| $redact | 通过基于文档本身存储的信息来限制每个文档的内容来重塑每个文档。 |
| $limit | 限制要以未修改的形式传递到管道的文档 |
| $skip | 跳过前 n 个文档,并将剩余文档未经修改地传递到管道。 |
| $group | 根据给定的标识符表达式对输入文档进行分组,并将累加器表达式应用于每个组。输出文档仅包含标识符字段和累加字段。 |
| $sort | 根据指定的排序键重新排序文档流。 |
| $out | 将聚合管道的结果文档写入集合。 |
聚合表达式使用字段路径访问输入文档中的字段。要指定字段路径,请使用以美元符号 $ 为前缀的字段名称的字符串。表达式可以使用一个或多个布尔运算符($and、$or、$not)和比较运算符($eq、$gt、$lt、$gte、$lte 和 $ne)。
以下算术表达式也用于聚合:
| $add | 将数字相加以返回总和。接受任意数量的参数表达式。 |
| $subtract | 返回从第一个值减去第二个值的结果。 |
| $multiply | 将数字相乘以返回乘积。接受任意数量的参数表达式。 |
| $divide | 返回第一个数字除以第二个数字的结果。接受两个参数表达式。 |
| $mod | 返回第一个数字除以第二个数字的余数。接受两个参数表达式。 |
以下字符串表达式也可用于聚合:
| $concat | 连接任意数量的字符串。 |
| $substr | 返回字符串的子字符串,从指定的索引位置开始到指定的长度。 |
| $toLower | 将字符串转换为小写。接受单个参数表达式。 |
| $toUpper | 将字符串转换为大写。接受单个参数表达式。 |
| $strcasecmp | 执行字符串比较,如果两个字符串等效则返回 0,如果第一个字符串大于第二个字符串则返回 1,如果第一个字符串小于第二个字符串则返回 -1。 |
为了演示 **aggregate()** 函数在 MongoEngine 中的工作方式,让我们首先定义一个名为 orders 的 Document 类。
from mongoengine import *
con=connect('mydata')
class orders(Document):
custID = StringField()
amount= IntField()
status = StringField()
然后我们在 orders 集合中添加以下文档:
| _id | custID | amount | status |
|---|---|---|---|
| ObjectId("5eba52d975fa1e26d4ec01d0") | A123 | 500 | A |
| ObjectId("5eba536775fa1e26d4ec01d1") | A123 | 250 | A |
| ObjectId("5eba53b575fa1e26d4ec01d2") | B212 | 200 | D |
| ObjectId("5eba540e75fa1e26d4ec01d3") | B212 | 400 | A |
aggregate() 函数用于查找仅当 status 等于 'A' 时每个 custID 的 amount 字段的总和。相应地,管道构建如下。
管道中的第一阶段使用 $match 过滤 status='A' 的文档。第二阶段使用 $group 标识符根据 CustID 对文档进行分组,并计算 amount 的总和。
pipeline = [
{"$match" : {"status" : "A"}},
{"$group": {"_id": "$custID", "total": {"$sum": "$amount"}}}
]
此管道现在用作 aggregate() 函数的参数。
docs = orders.objects().aggregate(pipeline)
我们可以使用 for 循环迭代文档游标。完整的代码如下:
from mongoengine import *
con=connect('mydata')
class orders(Document):
custID = StringField()
amount= IntField()
status = StringField()
pipeline = [
{"$match" : {"status" : "A"}},
{"$group": {"_id": "$custID", "total": {"$sum": "$amount"}}}
]
docs = orders.objects().aggregate(pipeline)
for doc in docs:
print (x)
对于给定的数据,将生成以下输出:
{'_id': 'B212', 'total': 400}
{'_id': 'A123', 'total': 750}
MongoEngine - 高级查询
为了提高检索文档中字段子集的效率,请使用 Objects 属性的 only() 方法。这将显著提高性能,特别是对于长度极长的字段(例如 ListField)。将所需字段传递给 only() 函数。如果在执行 only() 查询后访问其他字段,则返回默认值。
from mongoengine import *
con=connect('newdb')
class person (Document):
name=StringField(required=True)
city=StringField(default='Mumbai')
pin=IntField()
p1=person(name='Himanshu', city='Delhi', pin=110012).save()
doc=person.objects.only('name').first()
print ('name:',doc.name)
print ('city:', doc.city)
print ('PIN:', doc.pin)
输出
name: Himanshu city: Mumbai PIN: None
**注意** - city 属性的值用作默认值。由于 PIN 未指定默认值,因此它打印 None。
如果需要缺失的字段,可以调用 reload() 函数。
当文档类具有 ListField 或 DictField 时,在迭代过程中,任何 DBREf 对象都会自动取消引用。为了进一步提高效率,特别是如果文档具有 ReferenceField,可以使用 select_related() 函数限制查询数量,该函数将 QuerySet 转换为列表并影响取消引用。
MongoEngine API 包含 Q 类,该类可用于构建包含多个约束的高级查询。Q 表示查询的一部分,可以通过关键字参数语法和二进制 & 和 | 运算符进行初始化。
person.objects(Q(name__startswith=’H’) &Q(city=’Mumbai’))
MongoEngine - 文档继承
可以定义任何用户定义的 Document 类的继承类。如果需要,继承类可以添加额外的字段。但是,由于这样的类不是 Document 类的直接子类,因此它不会创建新的集合,而是其对象存储在其父类使用的集合中。在父类中,元属性 ‘**allow_inheritance**’。在下面的示例中,我们首先将 employee 定义为文档类并将 allow_inheritance 设置为 true。salary 类派生自 employee,并添加了两个字段 dept 和 sal。Employee 和 salary 类的对象都存储在 employee 集合中。
在下面的示例中,我们首先将 employee 定义为文档类并将 allow_inheritance 设置为 true。salary 类派生自 employee,并添加了两个字段 dept 和 sal。Employee 和 salary 类的对象都存储在 employee 集合中。
from mongoengine import *
con=connect('newdb')
class employee (Document):
name=StringField(required=True)
branch=StringField()
meta={'allow_inheritance':True}
class salary(employee):
dept=StringField()
sal=IntField()
e1=employee(name='Bharat', branch='Chennai').save()
s1=salary(name='Deep', branch='Hyderabad', dept='Accounts', sal=25000).save()
我们可以验证如下两个文档是否存储在 employee 集合中:
{
"_id":{"$oid":"5ebc34f44baa3752530b278a"},
"_cls":"employee",
"name":"Bharat",
"branch":"Chennai"
}
{
"_id":{"$oid":"5ebc34f44baa3752530b278b"},
"_cls":"employee.salary",
"name":"Deep",
"branch":"Hyderabad",
"dept":"Accounts",
"sal":{"$numberInt":"25000"}
}
请注意,为了识别相应的 Document 类,MongoEngine 添加了一个 “_cls” 字段并将它的值设置为 "employee" 和 "employee.salary"。
如果要为一组 Document 类提供额外的功能,但又无需继承的开销,可以先创建一个 **抽象** 类,然后从同一个类派生一个或多个类。要使类成为抽象类,请将元属性 ‘abstract’ 设置为 True。
from mongoengine import *
con=connect('newdb')
class shape (Document):
meta={'abstract':True}
def area(self):
pass
class rectangle(shape):
width=IntField()
height=IntField()
def area(self):
return self.width*self.height
r1=rectangle(width=20, height=30).save()
MongoEngine - 原子更新
原子性是 ACID 事务属性之一。数据库事务必须是不可分割且不可约分的,以便它要么完全发生,要么根本不发生。此属性称为原子性。MongoDB 只支持单文档的原子性,而不支持多文档事务。
MongoEngine 提供以下方法用于对 QuerySet 进行原子更新。
**update_one()** - 覆盖或添加查询匹配的第一个文档。
**update()** - 对查询匹配的字段执行原子更新。
**modify()** - 更新文档并返回它。
可以使用这些方法的以下修饰符。(这些修饰符在字段之前,而不是之后)。
| set | 设置特定值。 |
| unset | 删除特定值。 |
| inc | 将值增加给定数量。 |
| dec | 将值减少给定数量。 |
| push | 将值附加到列表。 |
| push_all | 将多个值附加到列表。 |
| pop | 根据值删除列表的第一个或最后一个元素。 |
| pull | 从列表中删除值。 |
| pull_all | 从列表中删除多个值。 |
| add_to_set | 仅当值不在列表中时才将其添加到列表。 |
以下是一个原子更新示例,我们首先创建一个名为 tests 的 Document 类并在其中添加一个文档。
from mongoengine import *
con=connect('newdb')
class tests (Document):
name=StringField()
attempts=IntField()
scores=ListField(IntField())
t1=tests()
t1.name='XYZ'
t1.attempts=0
t1.scores=[]
t1.save()
让我们使用 **update_one()** 方法将 name 字段从 XYZ 更新为 MongoDB。
tests.objects(name='XYZ').update_one(set__name='MongoDB')
push 修饰符用于在 ListField (scores) 中添加数据。
tests.objects(name='MongoDB').update_one(push__scores=50)
要将 attempts 字段加 1,可以使用 inc 修饰符。
tests.objects(name='MongoDB').update_one(inc__attempts=1)
更新后的文档如下所示:
{
"_id":{"$oid":"5ebcf8d353a48858e01ced04"},
"name":"MongoDB",
"attempts":{"$numberInt":"1"},
"scores":[{"$numberInt":"50"}]
}
MongoEngine - Javascript
MongoEngine 的 QuerySet 对象具有 **exec_js()** 方法,该方法允许在 MongoDB 服务器上执行 Javascript 函数。此函数处理以下参数:
exec_js(code, *field_names, **options)
其中,
**code** - 包含要执行的 Javascript 代码的字符串。
**fields** - 将在函数中使用,并将作为参数传递。
**options** - 你希望函数可用的选项(通过 Javascript 中的 options 对象访问)。
此外,还有一些其他变量可用于函数的范围,如下所示:
**collection** - 与 Document 类对应的集合的名称。这应该用于从 Javascript 代码中的 db 获取 Collection 对象。
**query** - 由 QuerySet 对象生成的查询;在 Javascript 函数中传递到 Collection 对象上的 find() 方法。
**options** - 包含传递到 exec_js() 的关键字参数的对象。
请注意,MongoEngine 文档类中的属性可能在数据库中使用不同的名称(使用 Field 构造函数的 db_field 关键字参数设置)。
class BlogPost(Document): title = StringField(db_field='doctitle')
为此,存在一种机制可以在 Javascript 代码中用数据库字段名称替换 MongoEngine 字段属性。
当访问集合对象上的字段时,请使用方括号表示法,并在 MongoEngine 字段名称前添加波浪号 (~) 符号。波浪号后面的字段名称将转换为数据库中使用的名称。
document': doc[~title];
请注意,当 Javascript 代码引用嵌入文档中的字段时,应在嵌入文档中字段的名称之前使用 EmbeddedDocumentField 的名称后跟一个点。
MongoEngine - GridFS
在 MongoDB 中,大于 16 MB 的文件使用 GridFS 规范存储。文件被分成多个块,每个块的默认大小为 255KB。大块可以根据需要任意大。GridFS 使用两个集合,一个用于块,另一个用于元数据。
如果要访问文件而不必将其完全加载到内存中,可以使用 GridFS 存储任何文件。
MongoEngine API 通过 **FileField** 对象支持 GridFS。使用此对象,可以插入和检索数据。FileField 对象的 **put()** 方法有助于将文件写入文档的一部分。
from mongoengine import *
con=connect('newdb')
class lang (Document):
name=StringField()
developer=StringField()
logo=FileField()
l1=lang()
l1.name='Python'
l1.developer='Van Rossum'
f=open('pylogo.png','rb')
l1.logo.put(f,content_type='image/png')
l1.save()
FileField 的内容可以通过 Python 的 File 对象的 read() 方法检索。
logo = l1.logo.read()
还有一个 **delete()** 方法用于删除存储的文件。
l1 = lang.objects(name='Python').first() l1.logo.delete() l1.save()
请注意,FileField 只存储单独 GridFS 集合中文件的 ID。因此,delete() 方法不会物理删除文件。
**replace()** 方法有助于用另一个文件替换文件的引用。
l1 = lang.objects(name='Python').first()
f=open('newlogo.png','rb')
l1.logo.replace(f,content_type='image/png')
l1.save()
MongoEngine - 信号
信号是由发送者对象分发的事件,任意数量的接收者对象可以订阅此类事件。信号接收者可以订阅特定的发送者,也可以接收来自许多发送者的信号。
在 MongoEngine 中,信号处理由 blinker 库支持,这意味着你需要使用 pip 实用程序安装它。mongoengine.signals 模块包含以下信号的定义:
| pre_init | 在创建新的 Document 或 EmbeddedDocument 实例期间调用,并在收集构造函数参数后但对其进行任何额外处理之前执行。 |
| post_init | 在完成新的 Document 或 EmbeddedDocument 实例的所有处理后调用。 |
| pre_save | 在 save() 内调用,在执行任何操作之前。 |
| pre_save_post_validation | 在 save() 内调用,在验证发生后但在保存之前。 |
| post_save | 在 save() 内调用,在大多数字操作(验证、插入/更新)成功完成之后。传递一个额外的布尔关键字参数以指示保存是插入还是更新。 |
| pre_delete | 在 delete() 内调用,在尝试删除操作之前。 |
| post_delete | 在 delete() 内调用,在成功删除记录后。 |
| pre_bulk_insert | 在验证要插入的文档后,但在写入任何数据之前调用。 |
| post_bulk_insert | 批量插入操作成功后调用。一个额外的布尔参数 `loaded` 用于标识文档的内容:`True` 表示文档实例,`False` 表示插入记录的主键值列表。 |
然后将事件处理函数附加到 `Document` 类。注意,**`EmbeddedDocument`** 仅支持 `pre/post_init` 信号。`pre/post_save` 等应仅附加到 `Document` 类。
您还可以使用装饰器快速创建多个信号并将它们作为类装饰器附加到您的 `Document` 或 `EmbeddedDocument` 子类。
在下面的示例中,作为信号处理程序演示,我们还使用了 Python 的标准库模块——`logging` 并将日志级别设置为调试。
from mongoengine import * from mongoengine import signals import logging logging.basicConfig(level=logging.DEBUG)
然后,我们编写一个文档类,以便在 `newdb` 数据库中创建相应的集合。在类内部,定义了两个类方法 `pre_save()` 和 `post_save()` 方法,它们旨在在文档保存到 `Author` 集合之前和之后调用。
class Author(Document):
name = StringField()
def __unicode__(self):
return self.name
@classmethod
def pre_save(cls, sender, document, **kwargs):
logging.debug("Pre Save: %s" % document.name)
@classmethod
def post_save(cls, sender, document, **kwargs):
logging.debug("Post Save: %s" % document.name)
if 'created' in kwargs:
if kwargs['created']:
logging.debug("Created")
else:
logging.debug("Updated")
这两个类方法都定义了用于类名、发送者对象和文档的参数,以及可选的关键字参数列表。
最后,我们注册信号处理程序。
signals.pre_save.connect(Author.pre_save, sender=Author) signals.post_save.connect(Author.post_save, sender=Author)
当我们创建一个 `Document` 子类的实例时,控制台日志将显示由各个事件处理程序处理的预保存和后保存信号。
Author(name="Lathkar").save()
Python 控制台报告日志如下:
DEBUG:root:Pre Save: Lathkar DEBUG:root:Post Save: Lathkar DEBUG:root:Created
MongoEngine - 文本搜索
MongoDB 支持使用查询运算符对字符串内容执行文本搜索。如前所述,要设置文本索引,请在索引名称前加上 `$` 符号。对于文本索引,已索引字段的权重表示该字段相对于文本搜索分数中的其他已索引字段的重要性。您还可以在类的元数据字典中指定默认语言。
支持的语言列表可在 https://docs.mongodb.com/manual/reference/text-search-languages/ 找到。MongoEngine API 包含用于 `QuerySet` 对象的 `search_text()` 方法。要在已索引字段中搜索的字符串作为参数给出。
在下面的示例中,我们首先定义一个名为 `lang` 的 `Document` 类,其中包含两个字符串字段:语言名称及其功能。我们还在这两个字段上创建索引,并分别设置权重。
from mongoengine import *
con=connect('newdb')
class lang (Document):
name=StringField()
features=StringField()
meta = {'indexes': [
{'fields': ['$name', "$features"],
'default_language': 'english',
'weights': {'name': 2, 'features': 10}
}]
}
l1=lang()
l1.name='C++'
l1.features='Object oriented language for OS development'
l1.save()
l2=lang()
l2.name='Python'
l2.features='dynamically typed and object oriented for data science, AI and ML'
l2.save()
l3=lang()
l3.name='HTML'
l3.features='scripting language for web page development'
l3.save()
为了搜索单词“oriented”,我们使用 `search_text()` 方法如下:
docs=lang.objects.search_text('oriented')
for doc in docs:
print (doc.name)
上述代码的输出将是描述中包含单词“oriented”的语言名称(在本例中为“Python”和“C++”)。
MongoEngine - 扩展
MongoEngine 与以下库完美集成:
marshmallow_mongoengine
marshmallow 是一个与 ORM/ODM/框架无关的序列化/反序列化库,用于将复杂数据类型(如对象)转换为和从原生 Python 数据类型转换。使用 MongoEngine 的此扩展,我们可以轻松执行序列化/反序列化操作。
首先,像往常一样创建一个 `Document` 类,如下所示:
import mongoengine as me class Book(me.Document): title = me.StringField()
然后使用以下代码生成 marshmallow 模式:
from marshmallow_mongoengine import ModelSchema
class BookSchema(ModelSchema):
class Meta:
model = Book
b_s = BookSchema()
使用以下代码保存文档:
book = Book(title='MongoEngine Book').save()
然后使用以下代码使用 `dump()` 和 `load()` 执行序列化/反序列化:
data = b_s.dump(book).data b_s.load(data).data
Flask-MongoEngine
这是一个 Flask 扩展,它提供了与 MongoEngine 的集成。此库可以轻松处理应用程序的 MongoDB 数据库连接管理。您还可以使用 WTForms 作为模型的模型表单。
安装 `flask-mongoengine` 包后,使用以下设置初始化 Flask 应用程序:
from flask import Flask
from flask_mongoengine import MongoEngine
app = Flask(__name__)
app.config['MONGODB_SETTINGS'] = {
'db': 'mydata',
'host': 'localhost',
'port':27017
}
db = MongoEngine(app)
然后使用以下代码定义一个 `Document` 子类:
class book(me.Document): name=me.StringField(required=True)
访问特定路由时,声明上述类的对象并调用 `save()` 方法。
@app.route('/')
def index():
b1=book(name='Introduction to MongoEngine')
b1.save()
return 'success'
extras-mongoengine
此扩展包含其他字段类型和其他功能。
Eve-MongoEngine
Eve 是一个为人类设计的开源 Python REST API 框架。它允许轻松构建和部署高度可定制、功能齐全的 RESTful Web 服务。
Eve 由 Flask 和 Cerberus 提供支持,它提供对 MongoDB 数据存储的原生支持。Eve-MongoEngine 提供 MongoEngine 与 Eve 的集成。
使用以下代码安装并导入扩展:
import mongoengine from eve import Eve from eve_mongoengine import EveMongoengine
配置设置并初始化 Eve 实例。
my_settings = {
'MONGO_HOST': 'localhost',
'MONGO_PORT': 27017,
'MONGO_DBNAME': 'eve_db'
app = Eve(settings=my_settings)
# init extension
ext = EveMongoengine(app)
定义如下所示的 `Document` 类:
class Person(mongoengine.Document): name = mongoengine.StringField() age = mongoengine.IntField()
添加模型并运行应用程序,最后使用以下代码:
ext.add_model(Person) app.run()
Django-MongoEngine
此扩展旨在将 MongoEngine 与 Django API 集成,Django API 是一个非常流行的 Python Web 开发框架。该项目仍在开发中。