- 面向对象分析与设计 教程
- 面向对象分析与设计 - 首页
- 面向对象分析与设计 - 面向对象范式
- 面向对象分析与设计 - 面向对象模型
- 面向对象分析与设计 - 面向对象系统
- 面向对象分析与设计 - 面向对象原则
- 面向对象分析与设计 - 面向对象分析
- 面向对象分析与设计 - 动态建模
- 面向对象分析与设计 - 功能建模
- 面向对象分析与设计 - UML分析模型
- 面向对象分析与设计 - UML基本符号
- 面向对象分析与设计 - UML结构图
- 面向对象分析与设计 - UML行为图
- 面向对象分析与设计 - 面向对象设计
- 面向对象分析与设计 - 实现策略
- 面向对象分析与设计 - 测试与质量保证
- 面向对象分析与设计 有用资源
- 面向对象分析与设计 - 快速指南
- 面向对象分析与设计 - 有用资源
面向对象分析与设计 - 快速指南
面向对象分析与设计 - 面向对象范式
简史
面向对象范式起源于一种新的编程方法的初始概念,而对设计和分析方法的兴趣则来得较晚。
第一种面向对象语言是 Simula(模拟真实系统),由挪威计算中心的研究人员于 1960 年开发。
1970 年,艾伦·凯和他在施乐帕洛阿尔托研究中心的团队创建了一台名为 Dynabook 的个人电脑,以及第一种纯面向对象编程语言 (OOPL) - Smalltalk,用于为 Dynabook 编程。
在 1980 年代,Grady Booch 发表了一篇题为“面向对象设计”的论文,主要介绍了 Ada 编程语言的设计。在随后的版本中,他将自己的想法扩展到了一种完整的面向对象设计方法。
在 1990 年代,Coad 将行为思想融入面向对象方法。
其他重要的创新包括 James Rumbaugh 的对象建模技术 (OMT) 和 Ivar Jacobson 的面向对象软件工程 (OOSE)。
面向对象分析
面向对象分析 (OOA) 是识别软件工程需求并将软件规范以软件系统对象模型的形式开发的过程,该模型包含相互交互的对象。
面向对象分析与其他形式的分析的主要区别在于,在面向对象方法中,需求围绕对象组织,对象集成了数据和函数。它们以系统交互的现实世界对象为模型。在传统的分析方法中,这两个方面——函数和数据——被分别考虑。
Grady Booch 将 OOA 定义为:“面向对象分析是一种分析方法,它从问题域词汇中发现的类和对象的视角来检查需求”。
面向对象分析 (OOA) 的主要任务包括:
- 识别对象
- 通过创建对象模型图来组织对象
- 定义对象的内部结构或对象属性
- 定义对象的行为,即对象动作
- 描述对象如何交互
OOA 中常用的模型包括用例和对象模型。
面向对象设计
面向对象设计 (OOD) 涉及实现面向对象分析过程中产生的概念模型。在 OOD 中,分析模型中与技术无关的概念被映射到实现类,识别约束并设计接口,从而产生解决方案域的模型,即关于如何在具体技术上构建系统的详细描述。
实现细节通常包括:
- 重构类数据(如有必要),
- 实现方法,即内部数据结构和算法,
- 实现控制,以及
- 实现关联。
Grady Booch 将面向对象设计定义为:“一种设计方法,它包含面向对象分解的过程以及用于描绘正在设计系统的逻辑和物理以及静态和动态模型的符号”。
面向对象编程
面向对象编程 (OOP) 是一种基于对象的编程范式(同时具有数据和方法),旨在结合模块化和可重用性的优点。对象,通常是类的实例,用于相互交互以设计应用程序和计算机程序。
面向对象编程的重要特征包括:
- 程序设计中的自下而上的方法
- 程序围绕对象组织,并分组到类中
- 关注数据以及操作对象数据的方法
- 通过函数进行对象之间的交互
- 通过创建新类并向现有类添加功能来重用设计
面向对象编程语言的一些示例包括 C++、Java、Smalltalk、Delphi、C#、Perl、Python、Ruby 和 PHP。
Grady Booch 将面向对象编程定义为:“一种实现方法,其中程序被组织成协作的对象集合,每个对象都表示某个类的实例,并且所有类都是通过继承关系联合起来的类层次结构的成员”。
OOAD - 对象模型
对象模型以对象的术语可视化软件应用程序中的元素。在本章中,我们将深入了解面向对象系统的一些基本概念和术语。
对象和类
对象和类的概念内在关联,构成了面向对象范式的基础。
对象
对象是面向对象环境中一个现实世界的元素,可能具有物理或概念上的存在。每个对象都具有:
标识,将其与系统中的其他对象区分开来。
状态,确定对象的特征属性以及对象持有的属性的值。
行为,表示对象以其状态变化的形式执行的外部可见活动。
可以根据应用程序的需求对对象进行建模。对象可能具有物理存在,例如客户、汽车等;或无形的概念存在,例如项目、流程等。
类
类表示具有相同特征属性并表现出共同行为的对象集合。它提供了可以从中创建对象的蓝图或描述。创建作为类成员的对象称为实例化。因此,对象是类的实例。
类的组成部分包括:
要从类实例化的一组对象的属性。通常,一个类的不同对象在属性的值上存在一些差异。属性通常称为类数据。
一组操作,描述类的对象的属性。操作也称为函数或方法。
示例
让我们考虑一个简单的类 Circle,它表示二维空间中的几何图形圆。该类的属性可以识别如下:
- x-coord,表示中心的 x 坐标
- y-coord,表示中心的 y 坐标
- a,表示圆的半径
其一些操作可以定义如下:
- findArea(),计算面积的方法
- findCircumference(),计算周长的的方法
- scale(),增加或减少半径的方法
在实例化期间,至少为某些属性分配值。如果我们创建一个对象 my_circle,我们可以分配如下值:x-coord:2,y-coord:3,a:4 来描述其状态。现在,如果在 my_circle 上执行操作 scale(),缩放因子为 2,则变量 a 的值将变为 8。此操作会改变 my_circle 的状态,即对象表现出某些行为。
封装和数据隐藏
封装
封装是将属性和方法都绑定到类中的过程。通过封装,可以隐藏类的内部细节。它允许仅通过类提供的接口从外部访问类的元素。
数据隐藏
通常,类的设计方式使得其数据(属性)只能被其类方法访问,并与外部的直接访问隔离。这个隔离对象数据的过程称为数据隐藏或信息隐藏。
示例
在 Circle 类中,可以通过使属性对类外部不可见并向类添加另外两个访问类数据的方法来实现数据隐藏,即:
- setValues(),为 x-coord、y-coord 和 a 分配值的方法
- getValues(),检索 x-coord、y-coord 和 a 值的方法
这里,对象 my_circle 的私有数据不能被任何未封装在 Circle 类中的方法直接访问。而应通过 setValues() 和 getValues() 方法访问。
消息传递
任何应用程序都需要大量对象以和谐的方式交互。系统中的对象可以使用消息传递相互通信。假设一个系统有两个对象:obj1 和 obj2。如果 obj1 希望 obj2 执行其方法之一,则对象 obj1 会向对象 obj2 发送消息。
消息传递的特性包括:
- 两个对象之间的消息传递通常是单向的。
- 消息传递使所有对象之间的交互成为可能。
- 消息传递本质上涉及调用类方法。
- 不同的进程中的对象可以参与消息传递。
继承
继承是一种机制,它允许通过扩展和完善现有类的功能来创建新类。现有类称为基类/父类/超类,新类称为派生类/子类/子类。子类可以继承或派生超类(超类)的属性和方法,前提是超类允许这样做。此外,子类可以添加自己的属性和方法,并可以修改任何超类方法。继承定义了“是-a”关系。
示例
从 Mammal 类可以派生出许多类,例如 Human、Cat、Dog、Cow 等。人类、猫、狗和奶牛都具有哺乳动物的独特特征。此外,每个都有其自身的特定特征。可以说奶牛“是-a”哺乳动物。
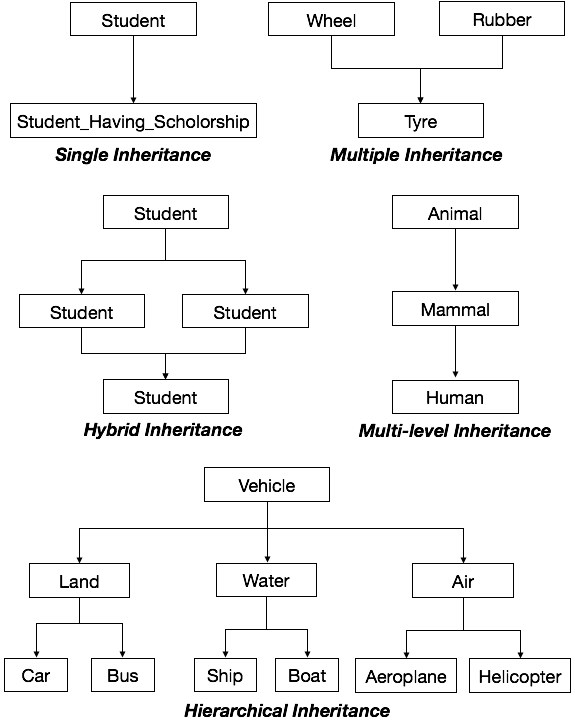
继承类型
单继承 - 子类派生自单个超类。
多继承 - 子类派生自多个超类。
多层继承 - 子类派生自超类,而超类又派生自另一个类,依此类推。
层次继承 - 一个类有多个子类,每个子类可能又有后续子类,继续多个级别,以形成树状结构。
混合继承 - 多继承和多层继承的组合,以形成网状结构。
下图描述了不同类型继承的示例。
多态性
多态性最初是一个希腊词,意思是能够采用多种形式。在面向对象范式中,多态性意味着以不同的方式使用操作,具体取决于它们正在操作的实例。多态性允许具有不同内部结构的对象具有共同的外部接口。多态性在实现继承时特别有效。
示例
让我们考虑两个类 Circle 和 Square,每个类都有一个方法 findArea()。尽管类中方法的名称和用途相同,但内部实现,即计算面积的过程对于每个类都是不同的。当 Circle 类的对象调用其 findArea() 方法时,操作会找到圆的面积,而不会与 Square 类的 findArea() 方法发生冲突。
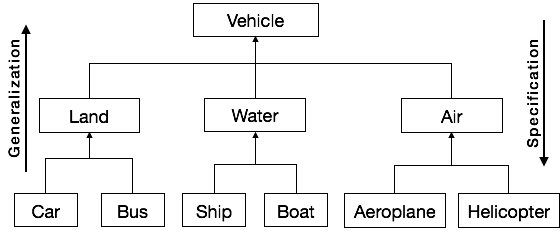
泛化和特化
泛化和特化表示类之间层次关系,其中子类继承自超类。
泛化
在泛化过程中,类的共同特征被组合以形成更高层次结构中的类,即子类被组合以形成一个泛化的超类。它表示“是-a-kind-of”关系。例如,“汽车是陆地车辆的一种”,或“船是水上车辆的一种”。
特化
专业化是泛化的逆过程。在这里,对象的组的区分特征被用来从现有的类中形成专门的类。可以说,子类是超类的专业化版本。
下图显示了泛化和专业化的示例。
链接和关联
链接
链接表示一个连接,通过该连接,一个对象与其他对象协作。Rumbaugh 将其定义为“对象之间的物理或概念连接”。通过链接,一个对象可以调用方法或遍历另一个对象。链接描述了两个或多个对象之间的关系。
关联
关联是一组具有共同结构和共同行为的链接。关联描述了一个或多个类的对象之间的关系。链接可以定义为关联的一个实例。
关联的度
关联的度表示参与连接的类的数量。度可以是一元的、二元的或三元的。
一元关系连接同一类的对象。
二元关系连接两个类的对象。
三元关系连接三个或更多类的对象。
关联的基数比率
二元关联的基数表示参与关联的实例的数量。基数比率有三种类型,即 -
一对一 - 类 A 的单个对象与类 B 的单个对象相关联。
一对多 - 类 A 的单个对象与类 B 的多个对象相关联。
多对多 - 类 A 的一个对象可能与类 B 的多个对象相关联,反之亦然,类 B 的一个对象可能与类 A 的多个对象相关联。
聚合或组合
聚合或组合是类之间的关系,通过这种关系,一个类可以由其他类的任何对象的组合构成。它允许对象直接放置在其他类的主体中。聚合被称为“部分-整体”或“具有-一个”关系,能够从整体导航到其部分。聚合对象是由一个或多个其他对象组成的对象。
示例
在“汽车具有-一个发动机”的关系中,汽车是整体对象或聚合体,而发动机是汽车的“部分”。聚合可以表示 -
物理包含 - 例如,计算机由显示器、CPU、鼠标、键盘等组成。
概念包含 - 例如,股东具有-一个股份。
对象模型的优点
既然我们已经了解了与面向对象相关的核心概念,那么值得注意的是该模型提供的优势。
使用对象模型的优点是 -
它有助于更快地开发软件。
易于维护。假设一个模块出现错误,那么程序员可以修复该特定模块,而软件的其他部分仍然可以正常运行。
它支持相对轻松的升级。
它能够重用对象、设计和功能。
它降低了开发风险,尤其是在复杂系统集成方面。
面向对象分析与设计 - 面向对象系统
我们知道,面向对象建模 (OOM) 技术通过使用围绕对象组织的模型来可视化应用程序中的事物。任何软件开发方法都经历以下阶段 -
- 分析,
- 设计,以及
- 实现。
在面向对象的软件工程中,软件开发人员在最终以任何特定的编程语言或软件工具表示之前,会根据面向对象的概念识别和组织应用程序。
面向对象软件开发的阶段
使用面向对象方法进行软件开发的主要阶段是面向对象分析、面向对象设计和面向对象实现。
面向对象分析
在此阶段,对问题进行表述,识别用户需求,然后基于现实世界中的对象构建模型。分析会生成有关所需系统应如何工作以及如何开发的模型。这些模型不包括任何实现细节,以便任何非技术应用程序专家都能理解和检查。
面向对象设计
面向对象设计包括两个主要阶段,即系统设计和对象设计。
系统设计
在此阶段,设计所需系统的完整架构。该系统被认为是一组交互的子系统,而子系统又由分层交互的对象组成,这些对象被分组到类中。系统设计是根据系统分析模型和提出的系统架构进行的。这里重点在于构成系统的对象,而不是系统中的过程。
对象设计
在此阶段,基于系统分析阶段开发的模型和系统设计阶段设计的体系结构开发设计模型。识别所有所需的类。设计人员决定是否 -
- 从头创建新的类,
- 以其原始形式使用任何现有类,或
- 从现有类继承新类。
建立识别出的类之间的关联并识别类的层次结构。此外,开发人员设计类的内部细节及其关联,即每个属性的数据结构和操作的算法。
面向对象实现和测试
在此阶段,将对象设计中开发的设计模型转换为适当的编程语言或软件工具中的代码。创建数据库并确定特定的硬件需求。代码成型后,将使用专门的技术对其进行测试,以识别和消除代码中的错误。
面向对象分析与设计 - 面向对象原则
面向对象系统的原则
面向对象系统的概念框架基于对象模型。面向对象系统中有两类元素 -
主要元素 - 主要指如果模型缺少任何一个这些元素,它就不再是面向对象的。四个主要元素是 -
- 抽象
- 封装
- 模块化
- 层次结构
次要元素 - 次要指这些元素很有用,但不是对象模型不可或缺的部分。三个次要元素是 -
- 类型化
- 并发
- 持久性
抽象
抽象意味着专注于 OOP 中元素或对象的本质特征,忽略其无关或偶然的属性。本质特征与使用对象的上下文相关。
Grady Booch 对抽象的定义如下 -
“抽象表示对象的本质特征,这些特征将其与所有其他类型的对象区分开来,从而相对于查看者的视角提供清晰定义的概念边界。”
示例 - 当设计 Student 类时,包含属性 enrolment_number、name、course 和 address,而排除 pulse_rate 和 size_of_shoe 等特征,因为它们与教育机构的视角无关。
封装
封装是将属性和方法都绑定到类中的过程。通过封装,可以隐藏类的内部细节以防止外部访问。类具有提供用户界面的方法,通过这些方法可以使用类提供的服务。
模块化
模块化是将问题(程序)分解成一组模块的过程,以降低问题的整体复杂性。Booch 将模块化定义为 -
“模块化是系统的一个属性,该系统已分解成一组内聚且松散耦合的模块。”
模块化与封装本质上是相关的。模块化可以被视为将封装的抽象映射到具有模块内高内聚性和模块间交互或耦合性低的真实物理模块的一种方式。
层次结构
用 Grady Booch 的话说,“层次结构是抽象的排序或排序”。通过层次结构,系统可以由相互关联的子系统组成,这些子系统可以拥有自己的子系统,依此类推,直到达到最小的级别组件。它使用“分而治之”的原则。层次结构允许代码重用。
OOA 中的两种层次结构是 -
“IS-A”层次结构 - 它定义了继承中的层次关系,通过该关系,可以从超类派生多个子类,这些子类可能再次拥有子类,依此类推。例如,如果我们从 Flower 类派生一个 Rose 类,我们可以说玫瑰“是-一个”花。
“PART-OF”层次结构 - 它定义了聚合中的层次关系,通过该关系,一个类可以由其他类组成。例如,一朵花由萼片、花瓣、雄蕊和心皮组成。可以说,花瓣是花的“部分”。
类型化
根据抽象数据类型的理论,类型是一组元素的特征。在 OOP 中,类被视为具有与任何其他类型不同的属性的类型。类型化是强制执行对象是单个类或类型的实例的概念。它还强制执行不同类型的对象通常不能互换;并且只有在绝对需要时才能以非常有限的方式互换。
两种类型的类型化是 -
强类型 - 在这里,对对象的运算在编译时进行检查,如 Eiffel 编程语言。
弱类型 - 在这里,可以向任何类发送消息。操作仅在执行时进行检查,如 Smalltalk 编程语言。
并发
操作系统中的并发允许同时执行多个任务或进程。当系统中存在单个进程时,据说存在单个控制线程。但是,大多数系统有多个线程,一些处于活动状态,一些等待 CPU,一些处于挂起状态,一些已终止。具有多个 CPU 的系统本质上允许并发的控制线程;但是,在单个 CPU 上运行的系统使用适当的算法来为线程提供公平的 CPU 时间,以实现并发。
在面向对象的环境中,存在活动对象和非活动对象。活动对象具有独立的控制线程,可以与其他对象的线程并发执行。活动对象彼此之间以及与纯顺序对象同步。
持久性
对象占用内存空间并在特定时间段内存在。在传统编程中,对象的生存期通常是创建它的程序的执行生存期。在文件或数据库中,对象的生存期长于创建对象的进程的持续时间。对象即使在其创建者停止存在后继续存在,这种属性称为持久性。
面向对象分析与设计 - 面向对象分析
在软件开发的系统分析或面向对象分析阶段,确定系统需求,识别类并识别类之间的关系。
三种与面向对象分析结合使用的分析技术是对象建模、动态建模和功能建模。
对象建模
对象建模根据对象开发软件系统的静态结构。它识别对象、对象可以分组到的类以及对象之间的关系。它还识别表征每个类的主要属性和操作。
对象建模的过程可以在以下步骤中可视化 -
- 识别对象并将其分组到类中
- 识别类之间的关系
- 创建用户对象模型图
- 定义用户对象属性
- 定义应在类上执行的操作
- 审查术语表
动态建模
在分析了系统的静态行为之后,需要检查其随时间和外部变化而产生的行为。这就是动态建模的目的。
动态建模可以定义为“描述单个对象如何响应事件的方式,这些事件可以是其他对象触发的内部事件,也可以是外部世界触发的外部事件”。
动态建模的过程可以可视化为以下步骤:
- 识别每个对象的状态
- 识别事件并分析动作的适用性
- 构建动态模型图,包括状态转换图
- 用对象属性表示每个状态
- 验证绘制的状态转换图
功能建模
功能建模是面向对象分析的最后一个组成部分。功能模型显示了对象内部执行的过程以及数据在方法之间移动时如何变化。它指定了对象建模操作的含义和动态建模的动作。功能模型对应于传统结构化分析中的数据流图。
功能建模的过程可以可视化为以下步骤:
- 识别所有输入和输出
- 构建显示功能依赖关系的数据流图
- 说明每个功能的目的
- 识别约束
- 指定优化标准
结构化分析与面向对象分析
结构化分析/结构化设计 (SASD) 方法是基于瀑布模型的传统软件开发方法。使用 SASD 开发系统的阶段如下:
- 可行性研究
- 需求分析与规格说明
- 系统设计
- 实施
- 实施后审查
现在,我们将了解结构化分析方法和面向对象分析方法的相对优势和劣势。
面向对象分析的优缺点
| 优点 | 缺点 |
|---|---|
| 关注数据而不是像结构化分析中的过程。 | 功能在对象内受限。这对于本质上是过程性或计算性的系统可能是一个问题。 |
| 封装和数据隐藏的原则帮助开发人员开发无法被系统其他部分篡改的系统。 | 它无法识别哪些对象会生成最佳的系统设计。 |
| 封装和数据隐藏的原则帮助开发人员开发无法被系统其他部分篡改的系统。 | 面向对象的模型不容易显示系统中对象之间的通信。 |
| 它通过模块化有效地管理软件复杂性。 | 无法在一个图中表示所有对象之间的接口。 |
| 与遵循结构化分析的系统相比,它更容易从小型系统升级到大型系统。 |
结构化分析的优缺点
| 优点 | 缺点 |
|---|---|
| 由于它采用自顶向下的方法,与面向对象分析的自底向上方法相反,因此比 OOA 更容易理解。 | 在传统的结构化分析模型中,一个阶段必须在下一个阶段完成之前完成。这在设计中提出了一个问题,特别是如果出现错误或需求发生变化时。 |
| 它基于功能。识别总体目的,然后进行功能分解以开发软件。这种强调不仅可以更好地理解系统,而且还可以生成更完整的系统。 | 构建系统的初始成本很高,因为需要一次性设计整个系统,几乎没有后期添加功能的选择。 |
| 其中的规范是用简单的英语编写的,因此非技术人员可以更容易地分析。 | 它不支持代码重用。因此,开发时间和成本天生就很高。 |
OOAD - 动态建模
动态模型表示系统的时变方面。它关注系统中对象状态的时间变化。主要概念包括:
状态,即对象生命周期中特定条件下的情况。
转换,状态的变化
事件,触发转换的事件
动作,由于某些事件而发生的、不间断且原子的计算,以及
转换的并发性。
状态机模拟对象在其生命周期中由于某些事件以及由于事件发生的动作而穿过多个状态时的行为。状态机通过状态转换图以图形方式表示。
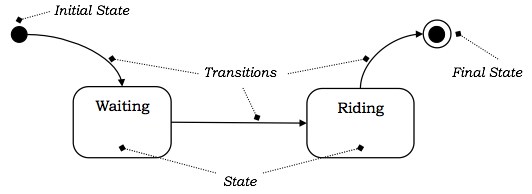
状态和状态转换
状态
状态是由对象在特定时间段内具有的属性值给出的抽象。它是在对象生命周期中持续有限时间段的一种情况,在此期间它满足某些条件、执行某些活动或等待某些事件发生。在状态转换图中,状态由圆角矩形表示。
状态的组成部分
名称 - 字符串区分一个状态与另一个状态。状态可能没有任何名称。
进入/退出动作 - 它表示在进入和退出状态时执行的活动。
内部转换 - 状态内的变化,不会导致状态发生变化。
子状态 - 状态内的状态。
初始状态和最终状态
对象的默认起始状态称为其初始状态。最终状态表示状态机执行的完成。初始状态和最终状态是伪状态,除了名称外,可能没有常规状态的组成部分。在状态转换图中,初始状态由实心黑圆表示。最终状态由包含在另一个未填充黑圆内的实心黑圆表示。
转换
转换表示对象状态的变化。如果对象在某个状态下发生事件,则对象可能会根据指定的条件执行某些活动并更改状态。在这种情况下,据说发生了状态转换。转换给出了第一个状态和新状态之间的关系。转换以从源状态到目标状态的实心有向弧以图形方式表示。
转换的五个部分是:
源状态 - 受转换影响的状态。
事件触发器 - 发生的事件,如果满足保护条件,则导致源状态中的对象发生转换。
保护条件 - 布尔表达式,如果为真,则在收到事件触发器时导致转换。
动作 - 由于某些事件而发生在源对象上的不可中断且原子的计算。
目标状态 - 转换完成后到达的目标状态。
示例
假设一个人从 X 地点乘坐出租车到 Y 地点。该人的状态可能是:等待(等待出租车)、乘坐(他已获得出租车并在其中行驶)和到达(他已到达目的地)。下图描绘了状态转换。
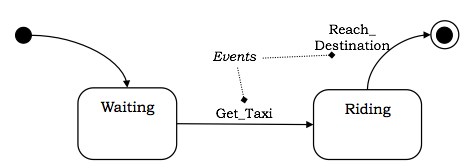
事件
事件是一些可以触发对象或一组对象的状态转换的事件。事件在时间和空间上都有位置,但没有与其关联的时间段。事件通常与某些动作相关联。
事件的示例包括鼠标点击、按键、中断、堆栈溢出等。
触发转换的事件写在状态图的弧线旁边。
示例
考虑上图所示的示例,当这个人获得出租车时,从等待状态到乘坐状态的转换发生。同样,当他到达目的地时,最终状态也随之到达。这两个事件可以称为 Get_Taxi 和 Reach_Destination。下图显示了状态机中的事件。
外部事件和内部事件
外部事件是从系统用户传递到系统内对象的那些事件。例如,用户鼠标点击或按键是外部事件。
内部事件是系统内一个对象传递到另一个对象的那些事件。例如,堆栈溢出、除零错误等。
延迟事件
延迟事件是那些没有被对象在当前状态下立即处理的事件,而是排队以便稍后在其他状态下由对象处理。
事件类
事件类表示一组具有共同结构和行为的事件。与对象类一样,事件类也可以组织成层次结构。事件类可能与其关联的属性相关联,时间是一个隐式属性。例如,我们可以考虑航空公司航班起飞的事件,我们可以将其归类为以下类别:
Flight_Departs (航班号,出发城市,到达城市,航线)
动作
活动
活动是对对象状态的操作,需要一些时间段。它们是系统中正在进行的执行,可以被打断。活动显示在活动图中,这些图描绘了从一个活动到另一个活动的流程。
动作
动作是由于某些事件而执行的原子操作。原子是指动作是不可中断的,即,如果动作开始执行,它就会运行到完成,而不会被任何事件中断。动作可能对触发事件的对象或对该对象可见的其他对象进行操作。一组动作构成一个活动。
进入动作和退出动作
进入动作是在进入状态时执行的动作,无论导致进入该状态的转换是什么。
同样,在离开状态时执行的动作,无论导致离开该状态的转换是什么,都称为退出动作。
场景
场景是对指定动作序列的描述。它描述了对象经历特定动作序列时的行为。主要场景描述了基本序列,次要场景描述了备选序列。
动态建模图
动态建模主要使用两种图:
交互图
交互图描述了不同对象之间的动态行为。它包含一组对象、它们之间的关系以及对象发送和接收的消息。因此,交互图模拟了一组相互关联的对象的行为。交互图的两种类型是:
序列图 - 它以表格方式表示消息的时间顺序。
协作图 - 它表示通过顶点和弧发送和接收消息的对象的结构组织。
状态转换图
状态转换图或状态机描述单个对象的动态行为。它说明了对象在其生命周期中经历的状态序列、状态的转换、导致转换的事件和条件以及由于事件引起的响应。
事件并发
在一个系统中,可能存在两种类型的并发。它们是:
系统并发
在这里,并发是在系统级别建模的。整个系统被建模为状态机的聚合,其中每个状态机与其他状态机并发执行。
对象内部并发
在这里,一个对象可以发出并发事件。一个对象可能具有由子状态组成的状态,并且每个子状态中都可能发生并发事件。
与对象内部并发相关的概念如下:
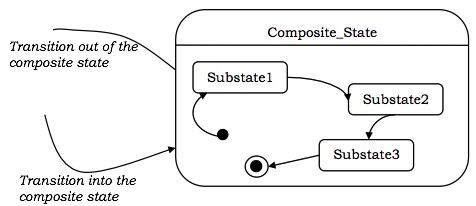
简单状态和复合状态
简单状态没有子结构。包含嵌套在其内部的更简单状态的状态称为复合状态。子状态是嵌套在另一个状态内的状态。它通常用于降低状态机的复杂性。子状态可以嵌套到任意多个级别。
复合状态可以具有顺序子状态或并发子状态。
顺序子状态
在顺序子状态中,执行控制依次从一个子状态传递到另一个子状态。在这些状态机中,最多只有一个初始状态和一个最终状态。
下图说明了顺序子状态的概念。
并发子状态
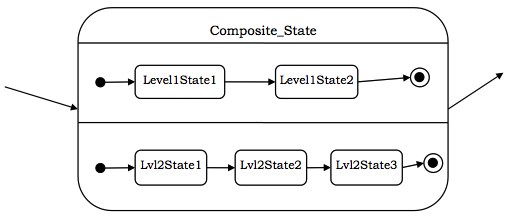
在并发子状态中,子状态并行执行,或者换句话说,每个状态在其内部都有并发执行的状态机。每个状态机都有自己的初始状态和最终状态。如果一个并发子状态在其最终状态之前到达其最终状态,则控制在其最终状态等待。当所有嵌套的状态机都到达其最终状态时,子状态会重新加入到单个流程中。
下图显示了并发子状态的概念。
OOAD - 功能建模
功能建模提供了面向对象分析模型的过程视角以及系统应该做什么的概述。它借助数据流图 (DFD) 定义了系统中内部过程的功能。它描述了数据值的函数推导,而没有指示它们在计算时是如何推导出来的,或者为什么需要计算它们。
数据流图
功能建模通过 DFD 的层次结构来表示。DFD 是一个系统的图形表示,它显示了系统的输入、对输入的处理、系统的输出以及内部数据存储。DFD 说明了对对象或系统执行的一系列转换或计算,以及影响转换的外部控制和对象。
Rumbaugh 等人将 DFD 定义为:“数据流图是一个图形,它显示了数据值从对象中的源通过转换它们的进程到其他对象上的目标的流动。”
DFD 的四个主要部分是:
- 进程,
- 数据流,
- 参与者,以及
- 数据存储。
DFD 的其他部分是:
- 约束,以及
- 控制流。
DFD 的特征
进程
进程是转换数据值的计算活动。整个系统可以被视为一个高级别进程。一个进程可以进一步细分为更小的组件。最低级别的进程可能是一个简单的函数。
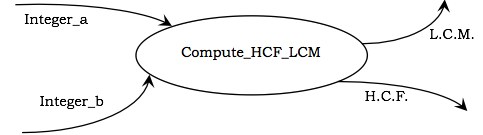
在 DFD 中的表示 - 进程表示为一个椭圆,其名称写在其中,并包含固定数量的输入和输出数据值。
示例 - 下图显示了一个进程 Compute_HCF_LCM,它接受两个整数作为输入并输出它们的 HCF(最大公约数)和 LCM(最小公倍数)。
数据流
数据流表示两个进程之间的数据流。它可能在参与者和进程之间,或者在数据存储和进程之间。数据流表示计算某一点处数据项的值。此值不会因数据流而改变。
在 DFD 中的表示 - 数据流用有向弧或箭头表示,并用其携带的数据项的名称标记。
在上图中,Integer_a 和 Integer_b 表示进程的输入数据流,而 L.C.M. 和 H.C.F. 是输出数据流。
数据流可能在以下情况下分叉:
输出值发送到多个位置,如下图所示。这里,输出箭头未标记,因为它们表示相同的值。
数据流包含聚合值,并且每个组件都发送到不同的位置,如下图所示。这里,每个分叉组件都已标记。

参与者
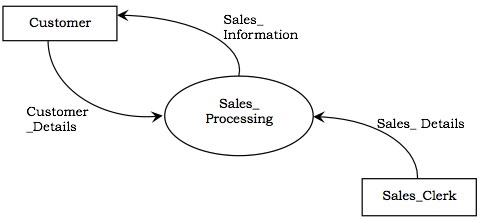
参与者是主动对象,它们通过产生数据并将其输入到系统或使用系统产生的数据来与系统交互。换句话说,参与者充当数据的源和接收器。
在 DFD 中的表示 - 参与者用矩形表示。参与者连接到输入和输出,并位于 DFD 的边界上。
示例 - 下图显示了参与者,即柜台销售系统中的客户和销售员。
数据存储
数据存储是被动对象,充当数据存储库。与参与者不同,它们不能执行任何操作。它们用于存储数据和检索存储的数据。它们表示数据库中的数据结构、磁盘文件或表格。
在 DFD 中的表示 - 数据存储用包含数据存储名称的两条平行线表示。每个数据存储至少连接到一个进程。输入箭头包含修改数据存储内容的信息,而输出箭头包含从数据存储检索的信息。当要检索部分信息时,输出箭头将被标记。未标记的箭头表示完全数据检索。双向箭头表示检索和更新。
示例 - 下图显示了一个数据存储 Sales_Record,它存储所有销售的详细信息。数据存储的输入包括销售的详细信息,例如项目、计费金额、日期等。要查找平均销售额,该过程检索销售记录并计算平均值。
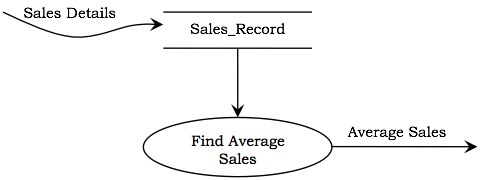
约束
约束指定需要随时间满足的条件或限制。它们允许添加新规则或修改现有规则。约束可以出现在面向对象分析的所有三个模型中。
在对象建模中,约束定义了对象之间的关系。它们还可以定义对象在不同时间可能获取的不同值之间的关系。
在动态建模中,约束定义了不同对象的状态和事件之间的关系。
在功能建模中,约束定义了对转换和计算的限制。
表示 - 约束以花括号内的字符串形式呈现。
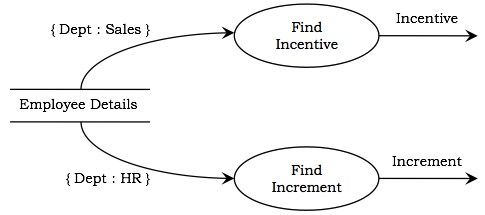
示例 - 下图显示了计算公司员工工资的 DFD 的一部分,该公司决定向销售部门的所有员工提供激励,并提高人力资源部门所有员工的工资。可以看出,约束 {Dept:Sales} 导致仅当部门为销售时才计算激励,并且约束 {Dept:HR} 导致仅当部门为人力资源时才计算增量。
控制流
一个进程可能与某个布尔值相关联,并且仅当该值为真时才进行评估,尽管它不是进程的直接输入。这些布尔值称为控制流。
在 DFD 中的表示 - 控制流用从产生布尔值的进程到受其控制的进程的虚线弧表示。
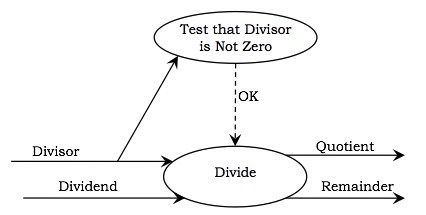
示例 - 下图表示算术除法的 DFD。除数被测试为非零。如果它不是零,则控制流 OK 的值为真,随后除法过程计算商和余数。
开发系统的 DFD 模型
为了开发系统的 DFD 模型,构建了 DFD 的层次结构。顶层 DFD 包含一个进程和与其交互的参与者。
在每个后续的较低级别,逐渐包含更多详细信息。一个进程被分解成子进程,识别子进程之间的数据流,确定控制流,并定义数据存储。在分解进程时,进程的输入或输出数据流应与 DFD 下一级的输入或输出数据流匹配。
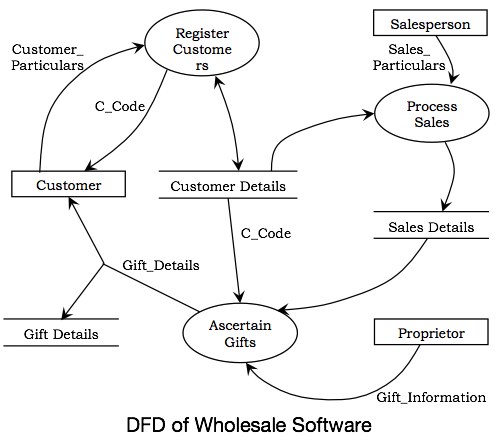
示例 - 让我们考虑一个软件系统,批发商软件,它使批发商店的交易自动化。该商店批量销售,其客户包括商人以及零售商店的店主。每个客户都被要求注册其个人信息,并获得唯一的客户代码 C_Code。一旦销售完成,商店就会注册其详细信息并发送货物进行发货。每年,商店都会向其客户分发圣诞礼物,包括银币或金币,具体取决于总销售额和业主的决定。
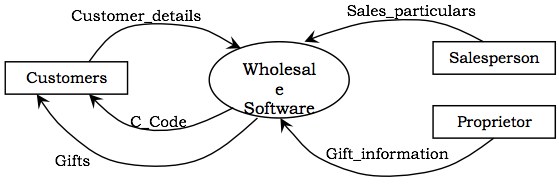
批发软件的功能模型如下所示。下图显示了顶层 DFD。它将软件显示为单个进程以及与之交互的参与者。
系统中的参与者是:
- 客户
- 销售人员
- 业主
在下一级 DFD 中,如下图所示,识别了系统的主要进程,定义了数据存储,并建立了进程与参与者以及数据存储的交互。
在系统中,可以识别出三个进程,它们是:
- 注册客户
- 处理销售
- 确定礼物
所需的数据存储是:
- 客户详细信息
- 销售详细信息
- 礼品详细信息
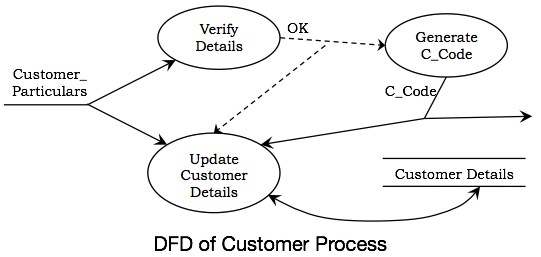
下图显示了进程“注册客户”的详细信息。其中包含三个进程:验证详细信息、生成 C_Code 和更新客户详细信息。输入客户详细信息后,将对其进行验证。如果数据正确,则生成 C_Code 并更新数据存储“客户详细信息”。
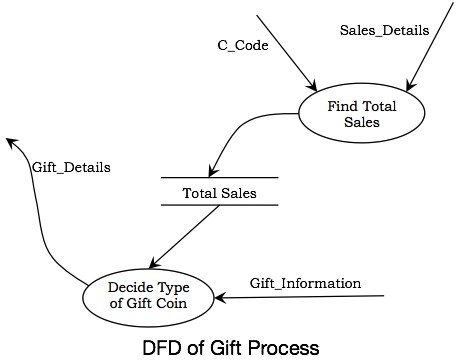
下图显示了进程“确定礼物”的扩展。其中包含两个进程:查找总销售额和确定礼物币种。查找总销售额进程计算每个客户的年度总销售额并记录数据。以该记录和业主的决定作为输入,通过确定礼物币种进程分配礼物币。
DFD 的优缺点
| 优点 | 缺点 |
|---|---|
| DFD 描述了系统的边界,因此有助于描绘外部对象和系统内部进程之间的关系。 | 创建 DFD 需要很长时间,这在实际应用中可能不可行。 |
| 它们帮助用户了解系统。 | DFD(数据流图)不提供任何关于时间相关行为的信息,即它们没有指定转换何时完成。 |
| 图形表示充当程序员开发系统的蓝图。 | 它们没有阐明计算的频率或计算的原因。 |
| DFD提供关于系统流程的详细信息。 | DFD的准备是一个复杂的过程,需要相当的专业知识。此外,非技术人员难以理解。 |
| 它们用作系统文档的一部分。 | 准备方法是主观的,留有很大的不精确空间。 |
对象模型、动态模型和功能模型之间的关系
对象模型、动态模型和功能模型对于完整的面向对象分析是互补的。
对象建模以对象的术语开发软件系统的静态结构。因此,它显示了系统中的“执行者”。
动态建模开发对象响应外部事件的时间行为。它显示了对对象执行的操作序列。
功能模型概述了系统应该做什么。
功能模型和对象模型
从对象模型的角度来看,功能模型的四个主要部分是:
过程 - 过程暗示了需要实现的对象的方法。
参与者 - 参与者是对象模型中的对象。
数据存储 - 这些要么是对象模型中的对象,要么是对象的属性。
数据流 - 流向或流出参与者的数据表示对对象的操作或由对象进行的操作。流向或流出数据存储的数据表示查询或更新。
功能模型和动态模型
动态模型说明了何时执行操作,而功能模型说明了如何执行操作以及需要哪些参数。由于参与者是活动对象,因此动态模型必须指定它何时行动。数据存储是被动对象,它们只响应更新和查询;因此,动态模型不需要指定它们何时行动。
对象模型和动态模型
动态模型显示了对象的狀態以及在事件发生时对对象执行的操作以及随后的状态变化。对象模型显示了由于更改而导致的对象状态。
面向对象分析与设计 - UML分析模型
统一建模语言(UML)是一种面向对象分析与设计(OOAD)的图形语言,它提供了一种标准的方式来编写软件系统的蓝图。它有助于可视化、指定、构建和记录面向对象系统的工件。它用于描述复杂系统中的结构和关系。
简史
它开发于 20 世纪 90 年代,是几种技术的融合,主要包括 Grady Booch 的 OOAD 技术、James Rumbaugh 的 OMT(对象建模技术)和 Ivar Jacobson 的 OOSE(面向对象软件工程)。UML 试图标准化 OOAD 的语义模型、语法符号和图。
UML 中的系统和模型
系统 - 一组为了实现某些目标而组织在一起的元素构成一个系统。系统通常被划分为子系统,并用一组模型来描述。
模型 - 模型是对系统的简化、完整且一致的抽象,用于更好地理解系统。
视图 - 视图是从特定角度对系统模型的投影。
UML 的概念模型
UML 的概念模型包含三个主要元素:
- 基本构建块
- 规则
- 通用机制
基本构建块
UML 的三个构建块是:
- 事物
- 关系
- 图
事物
UML 中有四种事物,即:
结构事物 - 这些是 UML 模型的名词,表示静态元素,这些元素可以是物理的也可以是概念上的。结构事物包括类、接口、协作、用例、活动类、组件和节点。
行为事物 - 这些是 UML 模型的动词,表示随时间和空间变化的动态行为。两种行为事物是交互和状态机。
分组事物 - 它们包含 UML 模型的组织部分。只有一种分组事物,即包。
注释事物 - 这些是 UML 模型中的解释,表示用于描述元素的注释。
关系
关系是事物之间的连接。UML 中可以表示的四种关系类型是:
依赖 - 这是两个事物之间的语义关系,其中一个事物的变化会导致另一个事物的变化。前者是独立的事物,后者是依赖的事物。
关联 - 这是表示具有共同结构和共同行为的一组链接的结构关系。
泛化 - 这表示泛化/特化关系,其中子类从超类继承结构和行为。
实现 - 这是两个或多个分类器之间的语义关系,其中一个分类器规定了一个契约,其他分类器确保遵守该契约。
图
图是对系统的图形表示。它包含一组元素,通常以图的形式表示。UML 总共包括九种图,即:
- 类图
- 对象图
- 用例图
- 顺序图
- 协作图
- 状态图
- 活动图
- 组件图
- 部署图
规则
UML 有许多规则,以便模型在语义上自洽,并与系统中其他模型和谐地相关联。UML 对以下内容有语义规则:
- 名称
- 范围
- 可见性
- 完整性
- 执行
通用机制
UML 有四种通用机制:
- 规范
- 修饰
- 通用划分
- 扩展机制
规范
在 UML 中,每个图形表示后面都有一个文本语句,表示语法和语义。这些是规范。规范提供了一个语义后平面,其中包含系统的所有部分以及不同路径之间的关系。
修饰
UML 中的每个元素都有唯一的图形表示法。此外,还有表示元素重要方面的符号,例如名称、范围、可见性等。
通用划分
面向对象系统可以通过多种方式进行划分。两种常见的划分方式是:
类和对象的划分 - 类是一组相似对象的抽象。对象是具有系统中实际存在的具体实例。
接口和实现的划分 - 接口定义了交互规则。实现是接口中定义规则的具体实现。
扩展机制
UML 是一种开放式语言。可以以受控的方式扩展 UML 的功能,以满足系统的要求。扩展机制包括:
构造型 - 它扩展了 UML 的词汇表,通过它可以从现有构建块创建新的构建块。
标记值 - 它扩展了 UML 构建块的属性。
约束 - 它扩展了 UML 构建块的语义。
面向对象分析与设计 - UML基本符号
UML 为每个构建块定义了特定的符号。
类
类由一个矩形表示,该矩形具有三个部分:
- 顶部部分包含类的名称
- 中间部分包含类属性
- 底部部分表示类操作
属性和操作的可见性可以用以下方式表示:
公有 - 公有成员在系统的任何地方都可见。在类图中,它以符号“+”为前缀。
私有 - 私有成员仅在类内部可见。无法从类外部访问它。私有成员以符号“−”为前缀。
保护 - 保护成员在类内部以及从该类继承的子类中可见,但在类外部不可见。它以符号“#”为前缀。
抽象类的类名以斜体显示。
示例 - 让我们考虑前面介绍的 Circle 类。Circle 的属性是 x-coord、y-coord 和 radius。操作是 findArea()、findCircumference() 和 scale()。假设 x-coord 和 y-coord 是私有数据成员,radius 是受保护的数据成员,并且成员函数是公有的。下图给出了类的图示表示。

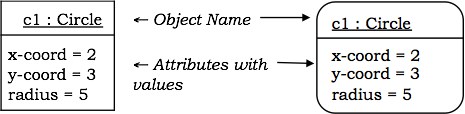
对象
对象表示为一个具有两个部分的矩形:
顶部部分包含对象的名称以及它是其实例的类的名称或包的名称。名称采用以下形式:
对象名 - 类名
对象名 - 类名 :: 包名
类名 - 匿名对象的情况
底部部分表示属性的值。它采用属性名 = 值的形式。
有时对象使用圆角矩形表示。
示例 - 让我们考虑一个名为 c1 的 Circle 类的对象。我们假设 c1 的中心位于 (2, 3),c1 的半径为 5。下图描绘了该对象。
组件
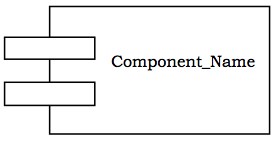
组件是系统的物理且可替换的部分,它符合并提供了一组接口的实现。它表示类和接口等元素的物理打包。
符号 - 在 UML 图中,组件表示为一个带选项卡的矩形,如下面的图所示。
接口
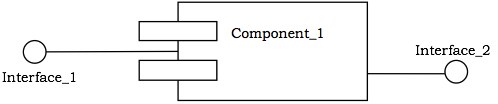
接口是类或组件的方法的集合。它指定了类或组件可能提供的服务集。
符号 - 通常,接口绘制为一个圆圈及其名称。接口几乎总是附加到实现它的类或组件。下图给出了接口的符号。
包
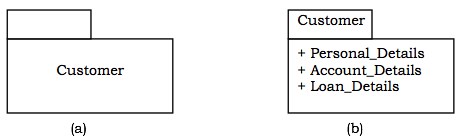
包是一组组织好的元素。包可以在其中包含结构事物,例如类、组件和其他包。
符号 - 在图形上,包表示为一个带选项卡的文件夹。包通常只绘制其名称。但是它可能包含有关包内容的更多详细信息。请参见下图。
关系
不同类型关系的符号如下:

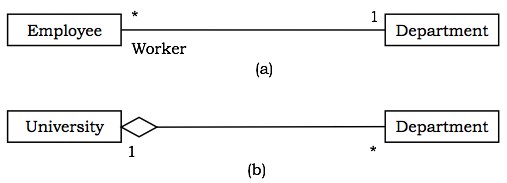
通常,关系中的元素在关系中扮演特定的角色。角色名称表示参与特定上下文的元素的行为。
示例 - 下图显示了类之间不同关系的示例。第一张图显示了两个类 Department 和 Employee 之间的关联,其中一个部门可能有许多员工在其中工作。Worker 是角色名称。Department 旁边的“1”和 Employee 旁边的“*”表示基数比率是一对多。第二张图描绘了聚合关系,大学是许多部门的“整体”。
OOAD - UML 结构图
UML 结构图分类如下:类图、对象图、组件图和部署图。
类图
类图对系统的静态视图进行建模。它包含系统的类、接口和协作;以及它们之间的关系。
系统类图
让我们考虑一个简化的银行系统。
一个银行有多个分支机构。在每个区域,一个分支机构被指定为区域总部,负责监督该区域的其他分支机构。每个分支机构可以有多个账户和贷款。账户可以是储蓄账户或活期账户。客户可以同时开立储蓄账户和活期账户。但是,客户不得拥有多个储蓄账户或活期账户。客户也可以从银行获得贷款。
下图显示了相应的类图。
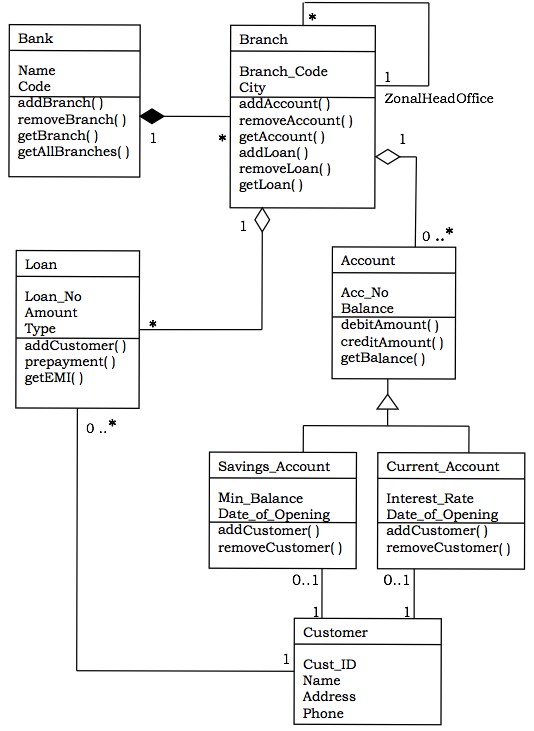
系统中的类
银行、分支机构、账户、储蓄账户、活期账户、贷款和客户。
关系
一个银行“拥有”多个分支机构 - 组合关系,一对多
具有区域总部角色的分支机构监督其他分支机构 - 一元关联,一对多
一个分支机构“拥有”多个账户 - 聚合关系,一对多
从账户类中继承了两个类,即储蓄账户和活期账户。
一个客户可以拥有一个活期账户 - 关联关系,一对一
一个客户可以拥有一个储蓄账户 - 关联关系,一对一
一个分支机构“拥有”多个贷款 - 聚合关系,一对多
一个客户可以获得多个贷款 - 关联关系,一对多
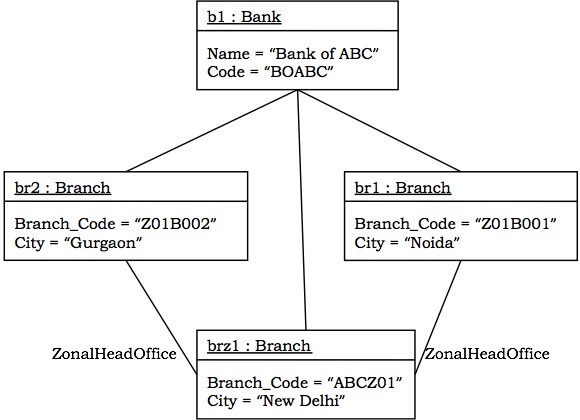
对象图
对象图对一组对象及其在某一时刻的链接进行建模。它显示了类图中事物的实例。对象图是交互图的静态部分。
示例 - 下图显示了银行系统类图一部分的对象图。
组件图
组件图显示了一组组件之间的组织和依赖关系。
组件图包含 -
- 组件
- 接口
- 关系
- 包和子系统(可选)
组件图用于 -
通过正向和反向工程构建系统。
在使用面向对象编程语言开发系统时,对源代码文件的配置管理进行建模。
在数据库建模中表示模式。
对动态系统的行为进行建模。
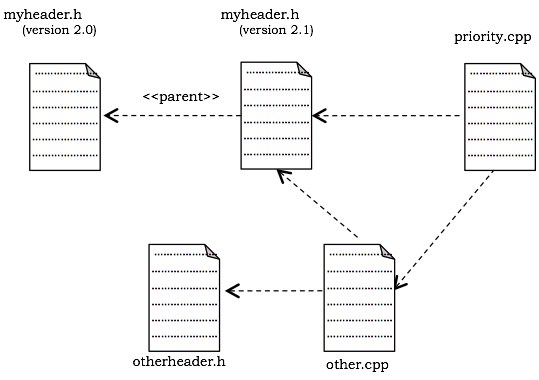
示例
下图显示了一个组件图,用于对使用 C++ 开发的系统的源代码进行建模。它显示了四个源代码文件,即 myheader.h、otherheader.h、priority.cpp 和 other.cpp。显示了 myheader.h 的两个版本,从最新版本追溯到其祖先版本。文件 priority.cpp 对 other.cpp 具有编译依赖关系。文件 other.cpp 对 otherheader.h 具有编译依赖关系。
部署图
部署图重点关注运行时处理节点及其驻留在这些节点上的组件的配置。它们通常由节点和依赖关系或节点之间的关联组成。
部署图用于 -
对嵌入式系统中的设备进行建模,这些设备通常由软件密集型硬件集合组成。
表示客户机/服务器系统的拓扑结构。
对完全分布式系统进行建模。
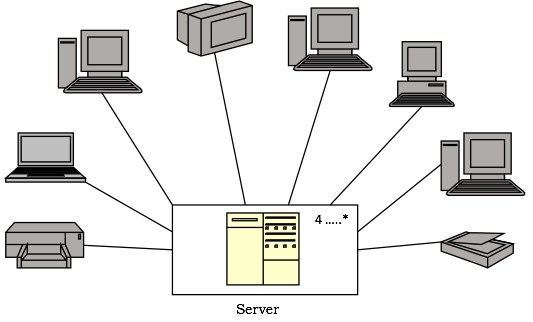
示例
下图显示了遵循客户机/服务器架构的计算机系统的拓扑结构。该图说明了一个被构造型为服务器的节点,该节点包含处理器。该图表明在系统中部署了四个或更多服务器。连接到服务器的是客户端节点,其中每个节点代表一个终端设备,例如工作站、笔记本电脑、扫描仪或打印机。节点使用清晰地描绘现实世界等效项的图标来表示。
面向对象分析与设计 - UML行为图
UML 行为图可视化、指定、构建和记录系统的动态方面。行为图分为以下几类:用例图、交互图、状态图和活动图。
用例模型
用例
用例描述系统执行的一系列操作,从而产生可见的结果。它显示了系统外部的事物与系统本身的交互。用例可以应用于整个系统,也可以应用于系统的一部分。
参与者
参与者表示用例的用户扮演的角色。参与者可以是人(例如学生、客户)、设备(例如工作站)或其他系统(例如银行、机构)。
下图显示了名为“学生”的参与者和名为“生成绩效报告”的用例的表示法。

用例图
用例图呈现了系统中元素行为方式的外部视图,以及如何在上下文中使用它们。
用例图包含 -
- 用例
- 参与者
- 关系,如依赖、泛化和关联
用例图用于 -
通过将系统的所有活动都包含在一个矩形中,并专注于与之交互的系统外部的参与者来对系统的上下文进行建模。
从外部视角对系统的需求进行建模。
示例
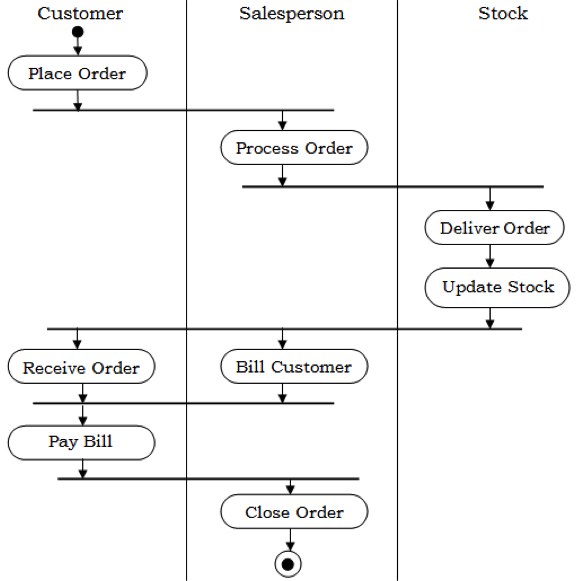
让我们考虑一个自动化交易房屋系统。我们假设系统具有以下功能 -
交易房屋与两种类型的客户进行交易,即个人客户和公司客户。
客户下订单后,销售部门会处理订单,并向客户提供账单。
系统允许经理管理客户账户并回复客户提出的任何查询。
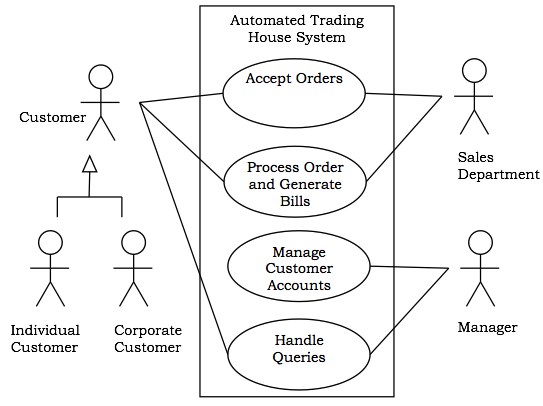
交互图
交互图描述了对象及其关系的交互。它们还包括它们之间传递的消息。交互图有两种类型 -
- 顺序图
- 协作图
交互图用于对以下内容进行建模 -
使用顺序图按时间顺序对控制流进行建模。
使用协作图对组织的控制流进行建模。
顺序图
顺序图是交互图,它根据时间说明消息的顺序。
表示法 - 这些图采用二维图表的形式。启动交互的对象放置在 x 轴上。这些对象发送和接收的消息放置在 y 轴上,按照从上到下的时间递增顺序排列。
示例 - 自动化交易房屋系统的顺序图如下所示。
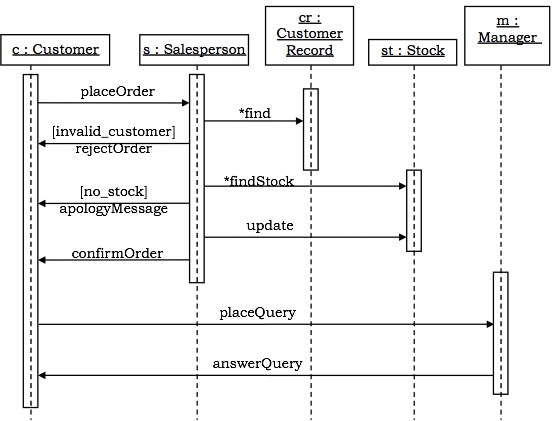
协作图
协作图是交互图,它说明了发送和接收消息的对象的结构。
表示法 - 在这些图中,参与交互的对象使用顶点显示。连接对象的链接用于发送和接收消息。消息显示为带标签的箭头。
示例 - 自动化交易房屋系统的协作图如下所示。
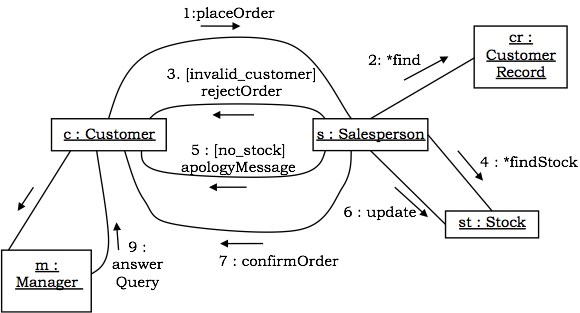
状态图
状态图显示了一个状态机,该状态机描述了对象从一个状态到另一个状态的控制流。状态机描绘了对象由于事件而经历的状态序列以及对事件的响应。
状态图包含 -
- 状态:简单或复合
- 状态之间的转换
- 导致转换的事件
- 事件导致的操作
状态图用于对本质上具有反应性的对象进行建模。
示例
在自动化交易房屋系统中,让我们将订单建模为一个对象并跟踪其序列。下图显示了相应的状态图。
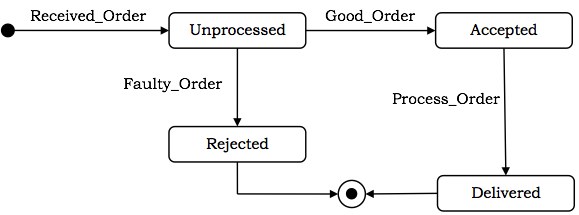
活动图
活动图描述了活动流,活动是状态机中正在进行的非原子操作。活动导致操作,操作是原子操作。
活动图包含 -
- 活动状态和动作状态
- 转换
- 对象
活动图用于对以下内容进行建模 -
- 参与者与系统交互时所看到的流程。
- 使用流程图详细说明操作或计算。
示例
下图显示了自动化交易房屋系统一部分的活动图。
面向对象分析与设计 - 面向对象设计
在分析阶段之后,概念模型将使用面向对象设计 (OOD) 进一步开发成面向对象模型。在 OOD 中,分析模型中与技术无关的概念映射到实现类,识别约束并设计接口,从而生成解决方案域的模型。简而言之,构建了详细的描述,指定了如何在具体技术上构建系统。
面向对象设计的阶段可以识别为 -
- 定义系统的上下文
- 设计系统架构
- 识别系统中的对象
- 构建设计模型
- 指定对象接口
系统设计
面向对象系统设计包括定义系统的上下文,然后设计系统的架构。
上下文 - 系统的上下文具有静态和动态部分。系统的静态上下文使用整个系统的简单框图进行设计,该框图扩展为子系统的层次结构。子系统模型由 UML 包表示。动态上下文描述了系统如何与其环境交互。它使用用例图进行建模。
系统架构 - 系统架构是在系统上下文的基礎上,根据架构设计原则以及领域知识设计的。通常,系统被划分为多个层,并且每个层都被分解以形成子系统。
面向对象分解
分解是指根据分治原则,将一个大型复杂系统划分为具有较低复杂性的较小子组件的层次结构。系统的每个主要组件称为子系统。面向对象分解识别系统中各个独立的对象以及这些对象之间的通信。
分解的优点是 -
各个组件的复杂性较低,因此更易于理解和管理。
它能够分配具有专业技能的劳动力。
它允许替换或修改子系统而不会影响其他子系统。
识别并发
并发允许多个对象同时接收事件,并且多个活动同时执行。并发在动态模型中识别和表示。
为了启用并发,每个并发元素都被分配了一个单独的控制线程。如果并发是在对象级别,则两个并发对象被分配两个不同的控制线程。如果单个对象的两个操作本质上是并发的,则该对象将在不同的线程之间拆分。
并发与数据完整性、死锁和饥饿问题相关联。因此,在需要并发时需要制定明确的策略。此外,并发需要在设计阶段本身被识别,而不能留到实现阶段。
识别模式
在设计应用程序时,一些普遍接受的解决方案被用于某些类别的应用程序。这些是设计模式。模式可以定义为一组记录在案的构建块,这些构建块可用于某些类型的应用程序开发问题。
一些常用的设计模式是 -
- 外观模式
- 模型视图分离模式
- 观察者模式
- 模型视图控制器模式
- 发布订阅模式
- 代理模式
控制事件
在系统设计期间,需要识别可能在系统对象中发生的事件并进行适当处理。
事件是重要事件的规范,它在时间和空间上都有位置。
可以建模四种类型的事件,即 -
信号事件 - 由一个对象抛出并由另一个对象捕获的命名对象。
调用事件 - 表示操作调度的同步事件。
时间事件 - 表示时间流逝的事件。
更改事件 - 表示状态更改的事件。
处理边界条件
系统设计阶段需要解决整个系统以及每个子系统的初始化和终止。记录的不同方面如下 -
系统的启动,即系统从非初始化状态到稳定状态的转换。
系统的终止,即关闭所有正在运行的线程,清理资源以及要发送的消息。
系统的初始配置以及在需要时对系统进行重新配置。
预见系统故障或意外终止。
边界条件使用边界用例建模。
对象设计
在子系统层次结构开发完成后,识别系统中的对象并设计其细节。在这里,设计人员详细说明了在系统设计期间选择的策略。重点从应用领域概念转向计算机概念。分析过程中识别出的对象被详细阐述以进行实现,目的是最大限度地减少执行时间、内存消耗和总体成本。
对象设计包括以下阶段:
- 对象识别
- 对象表示,即设计模型的构建
- 操作分类
- 算法设计
- 关系设计
- 外部交互控制的实现
- 将类和关联打包到模块中
对象识别
对象设计的第一个步骤是对象识别。在面向对象分析阶段识别的对象被分组到类中并进行细化,以便它们适合实际实现。
此阶段的功能包括:
识别和细化每个子系统或包中的类
定义类之间链接和关联
设计类之间的层次关联,即泛化/特化和继承
设计聚合
对象表示
一旦识别出类,就需要使用对象建模技术对其进行表示。此阶段主要涉及构建UML图。
需要生成两种类型的设计模型:
静态模型 - 使用类图和对象图描述系统的静态结构。
动态模型 - 描述系统的动态结构并使用交互图和状态图显示类之间的交互。
操作分类
在此步骤中,通过组合OOA阶段开发的三个模型(即对象模型、动态模型和功能模型)来定义对对象执行的操作。操作指定要做什么,而不是如何做。
关于操作,执行以下任务:
开发系统中每个对象的状态转换图。
为对象接收的事件定义操作。
识别一个事件触发同一对象或不同对象中其他事件的情况。
识别操作中的子操作。
将主要操作扩展到数据流图。
算法设计
使用算法定义对象中的操作。算法是解决操作中规定的问题的逐步过程。算法侧重于如何完成。
对于给定的操作,可能存在多个算法。一旦识别出备选算法,就会为给定的问题域选择最优算法。选择最优算法的指标包括:
计算复杂度 - 复杂度根据计算时间和内存需求确定算法的效率。
灵活性 - 灵活性确定所选算法是否可以在各种环境中适当地实现,而不会损失适用性。
可理解性 - 这决定了所选算法是否易于理解和实现。
关系设计
在对象设计阶段需要制定实现关系的策略。要解决的主要关系包括关联、聚合和继承。
关于关联,设计人员应执行以下操作:
确定关联是单向还是双向。
分析关联路径并在必要时更新它们。
在多对多关系的情况下,将关联实现为一个单独的对象;在一对一或一对多关系的情况下,实现为指向其他对象的链接。
关于继承,设计人员应执行以下操作:
调整类及其关联。
识别抽象类。
在需要时做出共享行为的规定。
控制的实现
对象设计人员可以合并状态图模型策略的改进。在系统设计中,制定了实现动态模型的基本策略。在对象设计期间,此策略得到适当地完善以进行适当的实现。
实现动态模型的方法包括:
将状态表示为程序中的位置 - 这是传统的过程驱动方法,其中控制位置定义程序状态。有限状态机可以实现为程序。转换形成输入语句,主控制路径形成指令序列,分支形成条件,反向路径形成循环或迭代。
状态机引擎 - 此方法通过状态机引擎类直接表示状态机。此类通过应用程序提供的转换和动作集执行状态机。
控制作为并发任务 - 在这种方法中,对象在编程语言或操作系统中实现为任务。在这里,事件实现为任务间调用。它保留了真实对象的固有并发性。
打包类
在任何大型项目中,将实现细致地划分为模块或包都很重要。在对象设计期间,类和对象被分组到包中,以使多个组能够协作处理项目。
打包的不同方面包括:
隐藏内部信息以防止外部查看 - 它允许将类视为“黑盒”,并允许更改类实现,而无需任何类的客户端修改代码。
元素的连贯性 - 如果元素(例如类、操作或模块)根据一致的计划进行组织,并且其所有部分都具有内在联系,以便它们服务于共同的目标,则该元素是连贯的。
物理模块的构建 - 以下指南有助于构建物理模块:
模块中的类应表示相同复合对象中的类似事物或组件。
紧密连接的类应位于同一模块中。
未连接或弱连接的类应放置在单独的模块中。
模块应具有良好的内聚性,即其组件之间的高度协作。
模块应与其他模块的耦合度低,即模块之间的交互或相互依赖性应最小。
设计优化
分析模型捕获有关系统的逻辑信息,而设计模型添加详细信息以支持高效的信息访问。在实现设计之前,应对其进行优化,以使实现更有效。优化的目标是最大限度地减少时间、空间和其他指标方面的成本。
但是,设计优化不应过度,因为易于实现、可维护性和可扩展性也是重要的考虑因素。通常会发现,经过完美优化的设计效率更高,但可读性和可重用性较差。因此,设计人员必须在这两者之间取得平衡。
可以为设计优化执行的各种操作包括:
- 添加冗余关联
- 省略不可用的关联
- 算法优化
- 保存派生属性以避免重新计算复杂表达式
添加冗余关联
在设计优化期间,检查是否可以通过派生新关联来降低访问成本。尽管这些冗余关联可能不会添加任何信息,但它们可能会提高整体模型的效率。
省略不可用的关联
关联过多可能会使系统难以理解,从而降低系统的整体效率。因此,在优化期间,会删除所有不可用的关联。
算法优化
在面向对象的系统中,数据结构和算法的优化以协作的方式进行。一旦类设计到位,就需要优化操作和算法。
算法优化通过以下方式获得:
- 重新排列计算任务的顺序
- 反转循环的执行顺序,使其与功能模型中规定的顺序相反
- 删除算法中的死路径
保存和存储派生属性
派生属性是指其值作为其他属性(基本属性)的函数计算的属性。每次需要时重新计算派生属性的值是一个耗时的过程。为了避免这种情况,可以计算这些值并以计算形式存储。
但是,这可能会导致更新异常,即基本属性值发生变化而派生属性值没有相应变化。为了避免这种情况,采取以下步骤:
每次更新基本属性值时,也重新计算派生属性。
定期以组的形式重新计算和更新所有派生属性,而不是在每次更新后更新。
设计文档
文档是任何软件开发过程中必不可少的一部分,它记录了制作软件的过程。对于任何非平凡的软件系统,都需要记录设计决策,以便将设计传递给他人。
使用领域
尽管是辅助产品,但良好的文档是必不可少的,尤其是在以下领域:
- 在设计由多个开发人员开发的软件时
- 在迭代软件开发策略中
- 在开发软件项目的后续版本时
- 用于评估软件
- 用于查找测试条件和测试区域
- 用于维护软件。
内容
有益的文档应主要包含以下内容:
高级系统架构 - 流程图和模块图。
关键抽象和机制 - 类图和对象图。
说明主要方面行为的场景 - 行为图
特征
良好文档的特征包括:
简洁且同时明确、一致和完整
可追溯到系统的需求规范
结构良好
图解而不是描述性
面向对象分析与设计 - 实现策略
实现面向对象的设计通常涉及使用标准的面向对象编程语言 (OOPL) 或将对象设计映射到数据库。在大多数情况下,它涉及两者。
使用编程语言实现
通常,将对象设计转换为代码的任务是一个简单的过程。任何面向对象编程语言,如 C++、Java、Smalltalk、C# 和 Python,都包含表示类的规定。在本章中,我们将使用 C++ 对该概念进行举例说明。
下图显示了使用 C++ 表示 Circle 类。

实现关联
大多数编程语言不提供直接实现关联的构造。因此,实现关联的任务需要仔细考虑。
关联可以是单向的或双向的。此外,每个关联可以是一对一、一对多或多对多。
单向关联
为了实现单向关联,应注意维护单向性。不同多重性的实现如下:
可选关联 - 在这里,参与对象之间可能存在或可能不存在链接。例如,在下图中客户与活期账户之间的关联中,客户可能拥有或可能不拥有活期账户。

为了实现,将活期账户的对象作为客户中的属性包含在内,该属性可能为 NULL。使用 C++ 实现:
class Customer {
private:
// attributes
Current_Account c; //an object of Current_Account as attribute
public:
Customer() {
c = NULL;
} // assign c as NULL
Current_Account getCurrAc() {
return c;
}
void setCurrAc( Current_Account myacc) {
c = myacc;
}
void removeAcc() {
c = NULL;
}
};
一对一关联 - 在这里,一个类的实例与关联类的正好一个实例相关联。例如,部门和经理之间存在一对一关联,如下面的图所示。

这是通过在Department中包含一个Manager对象来实现的,该对象不应为NULL。使用C++的实现 -
class Department {
private:
// attributes
Manager mgr; //an object of Manager as attribute
public:
Department (/*parameters*/, Manager m) { //m is not NULL
// assign parameters to variables
mgr = m;
}
Manager getMgr() {
return mgr;
}
};
一对多关联 - 在这里,一个类的实例与关联类的多个实例相关联。例如,考虑下图中Employee和Dependent之间的关联。

这是通过在Employee类中包含一个Dependents列表来实现的。使用C++ STL list容器的实现 -
class Employee {
private:
char * deptName;
list <Dependent> dep; //a list of Dependents as attribute
public:
void addDependent ( Dependent d) {
dep.push_back(d);
} // adds an employee to the department
void removeDeoendent( Dependent d) {
int index = find ( d, dep );
// find() function returns the index of d in list dep
dep.erase(index);
}
};
双向关联
要实现双向关联,需要维护两个方向的链接。
可选或一对一关联 - 考虑Project和Project Manager之间的一对一双向关联关系,如下图所示。

使用C++的实现 -
Class Project {
private:
// attributes
Project_Manager pmgr;
public:
void setManager ( Project_Manager pm);
Project_Manager changeManager();
};
class Project_Manager {
private:
// attributes
Project pj;
public:
void setProject(Project p);
Project removeProject();
};
一对多关联 - 考虑Department和Employee之间的一对多关联关系,如下图所示。

使用C++ STL list容器的实现
class Department {
private:
char * deptName;
list <Employee> emp; //a list of Employees as attribute
public:
void addEmployee ( Employee e) {
emp.push_back(e);
} // adds an employee to the department
void removeEmployee( Employee e) {
int index = find ( e, emp );
// find function returns the index of e in list emp
emp.erase(index);
}
};
class Employee {
private:
//attributes
Department d;
public:
void addDept();
void removeDept();
};
将关联作为类实现
如果关联有一些关联的属性,则应使用单独的类来实现。例如,考虑下图中Employee和Project之间的一对一关联。
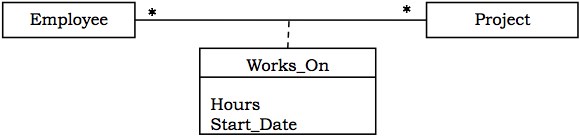
使用C++实现WorksOn
class WorksOn {
private:
Employee e;
Project p;
Hours h;
char * date;
public:
// class methods
};
实现约束
类中的约束限制了属性可能取的值的范围和类型。为了实现约束,在从类实例化对象时,将为属性分配一个有效的默认值。每当在运行时更改值时,都会检查该值是否有效。无效值可以通过异常处理例程或其他方法来处理。
示例
考虑一个Employee类,其中age是一个属性,其值范围为18到60。以下C++代码包含了它 -
class Employee {
private: char * name;
int age;
// other attributes
public:
Employee() { // default constructor
strcpy(name, "");
age = 18; // default value
}
class AgeError {}; // Exception class
void changeAge( int a) { // method that changes age
if ( a < 18 || a > 60 ) // check for invalid condition
throw AgeError(); // throw exception
age = a;
}
};
实现状态图
有两种替代的实现策略来在状态图中实现状态。
类中的枚举
在这种方法中,状态由数据成员(或一组数据成员)的不同值表示。这些值由类中的枚举明确定义。转换由更改相关数据成员值的成员函数表示。
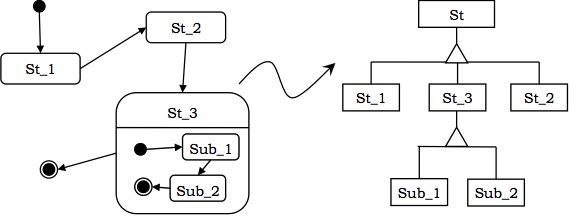
在泛化层次结构中排列类
在这种方法中,状态以一种可以由公共指针变量引用的方式排列在泛化层次结构中。下图显示了从状态图到泛化层次结构的转换。
对象映射到数据库系统
对象的持久性
开发面向对象系统的一个重要方面是数据的持久性。通过持久性,对象的生命周期比创建它的程序更长。持久性数据保存在辅助存储介质上,在需要时可以从那里重新加载。
RDBMS概述
数据库是相关数据的有序集合。
数据库管理系统(DBMS)是一组软件,用于促进定义、创建、存储、操作、检索、共享和删除数据库中的数据。
在关系数据库管理系统(RDBMS)中,数据存储为关系或表,其中每一列或字段表示一个属性,每一行或元组表示一个实例的记录。
每一行都由一组选定的最小属性唯一标识,称为主键。
外键是作为相关表主键的属性。
在RDBMS中将类表示为表
要将类映射到数据库表,每个属性都表示为表中的一个字段。将现有属性(或属性)分配为主键,或添加一个单独的ID字段作为主键。可以根据需要水平或垂直地划分类。
例如,Circle类可以转换为如下图所示的表。
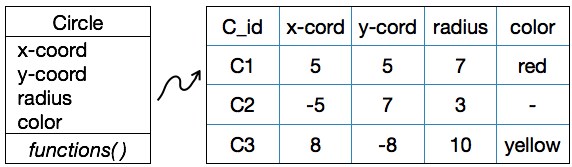
Schema for Circle Table: CIRCLE(CID, X_COORD, Y_COORD, RADIUS, COLOR) Creating a Table Circle using SQL command: CREATE TABLE CIRCLE ( CID VARCHAR2(4) PRIMARY KEY, X_COORD INTEGER NOT NULL, Y_COORD INTEGER NOT NULL, Z_COORD INTEGER NOT NULL, COLOR );
将关联映射到数据库表
一对一关联
要实现1:1关联,任何一个表的primaryKey都会被分配为另一个表的foreignKey。例如,考虑Department和Manager之间的关联 -

创建表的SQL命令
CREATE TABLE DEPARTMENT ( DEPT_ID INTEGER PRIMARY KEY, DNAME VARCHAR2(30) NOT NULL, LOCATION VARCHAR2(20), EMPID INTEGER REFERENCES MANAGER ); CREATE TABLE MANAGER ( EMPID INTEGER PRIMARY KEY, ENAME VARCHAR2(50) NOT NULL, ADDRESS VARCHAR2(70), );
一对多关联
要实现1:N关联,关联1侧的表的primaryKey将被分配为关联N侧的表的foreignKey。例如,考虑Department和Employee之间的关联 -

创建表的SQL命令
CREATE TABLE DEPARTMENT ( DEPT_ID INTEGER PRIMARY KEY, DNAME VARCHAR2(30) NOT NULL, LOCATION VARCHAR2(20), ); CREATE TABLE EMPLOYEE ( EMPID INTEGER PRIMARY KEY, ENAME VARCHAR2(50) NOT NULL, ADDRESS VARCHAR2(70), D_ID INTEGER REFERENCES DEPARTMENT );
多对多关联
要实现M:N关联,将创建一个新关系来表示关联。例如,考虑Employee和Project之间的以下关联 -
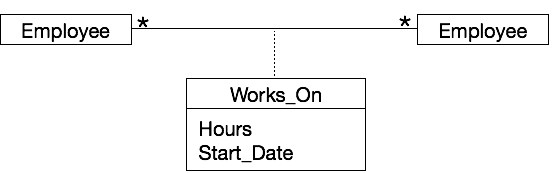
Works_On表的模式 - WORKS_ON (EMPID, PID, HOURS, START_DATE)
创建Works_On关联的SQL命令 - CREATE TABLE WORKS_ON
( EMPID INTEGER, PID INTEGER, HOURS INTEGER, START_DATE DATE, PRIMARY KEY (EMPID, PID), FOREIGN KEY (EMPID) REFERENCES EMPLOYEE, FOREIGN KEY (PID) REFERENCES PROJECT );
将继承映射到表
要映射继承,基表的主键将被分配为派生表的主键以及外键。
示例

面向对象分析与设计 - 测试与质量保证
一旦程序代码编写完成,就必须对其进行测试以检测并随后处理其中的所有错误。为了测试目的,使用多种方案。
另一个重要方面是程序的目的适用性,它确定程序是否实现了其目标。适用性定义了软件质量。
测试面向对象系统
测试是在软件开发过程中的一项持续活动。在面向对象系统中,测试包括三个级别,即单元测试、子系统测试和系统测试。
单元测试
在单元测试中,测试各个类。查看类的属性是否按设计实现,以及方法和接口是否没有错误。单元测试是实现结构的应用程序工程师的责任。
子系统测试
这涉及测试特定的模块或子系统,是子系统负责人负责的。它涉及测试子系统内的关联以及子系统与外部的交互。子系统测试可用作每个新发布的子系统版本的回归测试。
系统测试
系统测试涉及将系统作为一个整体进行测试,是质量保证团队的责任。当组装新版本时,团队通常会将系统测试用作回归测试。
面向对象测试技术
灰盒测试
可以为测试面向对象程序而设计的不同类型的测试用例称为灰盒测试用例。一些重要的灰盒测试类型包括 -
基于状态模型的测试 - 这包括状态覆盖、状态转换覆盖和状态转换路径覆盖。
基于用例的测试 - 测试每个用例中的每个场景。
基于类图的测试 - 测试每个类、派生类、关联和聚合。
基于序列图的测试 - 测试序列图中消息中的方法。
子系统测试技术
子系统测试的两种主要方法是 -
基于线程的测试 - 集成并测试实现子系统中单个用例所需的所有类。
基于使用的测试 - 测试每个层次结构级别上的模块的接口和服务。测试从单个类到包含类的较小模块开始,逐渐到较大的模块,最后到所有主要子系统。
系统测试类别
Alpha测试 - 由开发软件的组织内的测试团队执行。
Beta测试 - 由选定的合作客户组执行。
验收测试 - 客户在接受交付成果之前执行。
软件质量保证
软件质量
Schulmeyer和McManus将软件质量定义为“整个软件产品的适用性”。高质量的软件完全按照其预期执行,并根据用户制定的需求规范的满意度进行解释。
质量保证
软件质量保证是一种确定软件产品在多大程度上适合使用的 методология。确定软件质量包含的活动包括 -
- 审计
- 制定标准和指南
- 生成报告
- 审查质量体系
质量因素
正确性 - 正确性确定软件需求是否得到适当满足。
可用性 - 可用性确定软件是否可以被不同类别的用户(初学者、非技术人员和专家)使用。
可移植性 - 可移植性确定软件是否可以在具有不同硬件设备的不同平台上运行。
可维护性 - 可维护性确定纠正错误和更新模块的难易程度。
可重用性 - 可重用性确定模块和类是否可以重用于开发其他软件产品。
面向对象度量
度量可以广泛地分为三类:项目度量、产品度量和过程度量。
项目度量
项目度量使软件项目经理能够评估正在进行的项目的状况和绩效。以下度量适用于面向对象软件项目 -
- 场景脚本数量
- 关键类数量
- 支持类数量
- 子系统数量
产品度量
产品度量衡量已开发软件产品的特性。适用于面向对象系统的产品度量包括 -
每个类的Method数量 - 它确定类的复杂性。如果假设一个类中的所有方法都同样复杂,那么具有更多方法的类更复杂,因此更容易出错。
继承结构 - 具有多个小型继承格子的系统比具有单个大型继承格子的系统结构更好。作为经验法则,继承树的层数不应超过7(±2),并且树应保持平衡。
耦合和内聚 - 耦合低且内聚高的模块被认为设计得更好,因为它们允许更大的可重用性和可维护性。
类的响应 - 它衡量类实例调用的方法的效率。
过程度量
过程度量有助于衡量流程的执行情况。它们在所有项目中长期收集。它们用作长期软件流程改进的指标。一些过程度量包括 -
- KLOC(千行代码)数量
- 缺陷去除效率
- 测试期间检测到的平均故障次数
- 每个KLOC的潜在缺陷数量