面向对象Python速成指南
面向对象Python - 简介
编程语言不断涌现,不同的方法论也是如此。面向对象编程就是这样一种方法论,在过去几年中变得非常流行。
本章讨论Python编程语言的特性,这些特性使其成为一种面向对象编程语言。
语言编程分类方案
Python可以归类于面向对象编程方法论。下图显示了各种编程语言的特性。观察使Python面向对象的特性。
| 语言类别 | 类别 | 语言 |
|---|---|---|
| 编程范式 | 过程式 | C, C++, C#, Objective-C, Java, Go |
| 脚本式 | CoffeeScript, JavaScript, Python, Perl, PHP, Ruby | |
| 函数式 | Clojure, Erlang, Haskell, Scala | |
| 编译类别 | 静态 | C, C++, C#, Objective-C, Java, Go, Haskell, Scala |
| 动态 | CoffeeScript, JavaScript, Python, Perl, PHP, Ruby, Clojure, Erlang | |
| 类型类别 | 强类型 | C#, Java, Go, Python, Ruby, Clojure, Erlang, Haskell, Scala |
| 弱类型 | C, C++, C#, Objective-C, CoffeeScript, JavaScript, Perl, PHP | |
| 内存类别 | 托管 | 其他 |
| 非托管 | C, C++, C#, Objective-C |
什么是面向对象编程?
面向对象意味着面向对象。换句话说,这意味着功能上倾向于对对象建模。这是用于通过描述对象的集合及其数据和行为来建模复杂系统的一种技术。
Python,一种面向对象编程(OOP)语言,是一种编程方法,它专注于使用对象和类来设计和构建应用程序。面向对象编程(OOP)的主要支柱是继承、多态、抽象和封装。
面向对象分析(OOA)是对问题、系统或任务进行检查,并识别对象及其之间交互的过程。
为什么要选择面向对象编程?
Python的设计采用了面向对象的方法。OOP提供以下优点:
提供清晰的程序结构,使之易于映射现实世界的问题及其解决方案。
方便维护和修改现有代码。
增强程序模块化,因为每个对象独立存在,可以轻松添加新功能而不会影响现有功能。
为代码库提供了一个良好的框架,程序员可以轻松地适应和修改提供的组件。
提高代码可重用性
过程式编程与面向对象编程
过程式编程源于基于函数/过程/例程概念的结构化编程。在过程式编程中,易于访问和更改数据。另一方面,面向对象编程(OOP)允许将问题分解成许多称为对象的单元,然后围绕这些对象构建数据和函数。它比过程或函数更强调数据。此外,在OOP中,数据是隐藏的,外部过程无法访问。
下图中的表格显示了POP和OOP方法的主要区别。
过程式面向对象编程(POP)与面向对象编程(OOP)的区别。
| 过程式面向对象编程 | 面向对象编程 | |
|---|---|---|
| 基于 | 在POP中,整个重点在于数据和函数 | OOP基于现实世界场景。整个程序被分成称为对象的小部分 |
| 可重用性 | 代码重用有限 | 代码重用 |
| 方法 | 自顶向下方法 | 面向对象设计 |
| 访问说明符 | 没有 | 公共、私有和保护 |
| 数据移动 | 数据可以在系统中从一个函数自由地移动到另一个函数 | 在OOP中,数据可以通过成员函数相互移动和通信 |
| 数据访问 | 在POP中,大多数函数使用全局数据共享,可以从系统中的一个函数自由地访问另一个函数 | 在OOP中,数据不能从一个方法自由地移动到另一个方法,它可以保存在公共或私有中,因此我们可以控制数据的访问 |
| 数据隐藏 | 在POP中,没有特定的方法来隐藏数据,因此安全性较低 | 它提供数据隐藏,因此更安全 |
| 重载 | 不可能 | 函数和运算符重载 |
| 示例语言 | C, VB, Fortran, Pascal | C++, Python, Java, C# |
| 抽象 | 在过程级别使用抽象 | 在类和对象级别使用抽象 |
面向对象编程的原则
面向对象编程(OOP)基于对象而不是动作,数据而不是逻辑的概念。为了使编程语言面向对象,它应该具有启用使用类和对象以及实现和使用基本面向对象原则和概念(即继承、抽象、封装和多态)的机制。
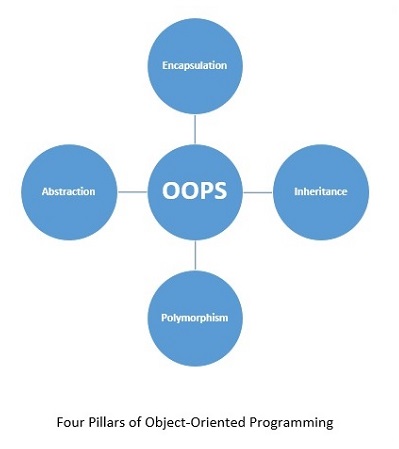
让我们简要了解面向对象编程的每个支柱:
封装
此属性隐藏不必要的细节,并使程序结构更容易管理。每个对象的实现和状态都隐藏在定义良好的边界后面,这为使用它们提供了一个简洁明了的接口。实现此目的的一种方法是将数据设为私有。
继承
继承,也称为泛化,允许我们捕获类和对象之间的层次关系。例如,“水果”是“橙子”的泛化。从代码重用的角度来看,继承非常有用。
抽象
此属性允许我们隐藏细节,并仅公开概念或对象的必要特征。例如,驾驶踏板车的人知道按下喇叭会发出声音,但他不知道按下喇叭时声音是如何产生的。
多态
多态意味着多种形式。也就是说,事物或行为以不同的形式或方式存在。多态的一个很好的例子是类中的构造函数重载。
面向对象的Python
Python编程的核心是对象和OOP,但是您不必将自己限制在通过将代码组织成类来使用OOP。OOP补充了Python的整体设计理念,并鼓励一种简洁实用的编程方式。OOP还有助于编写更大更复杂的程序。
模块与类和对象
模块就像“字典”
使用模块时,请注意以下几点:
Python模块是一个封装可重用代码的包。
模块位于包含__init__.py文件的文件夹中。
模块包含函数和类。
使用import关键字导入模块。
回想一下,字典是键值对。这意味着如果您有一个键为EmployeID的字典,并且想要检索它,那么您必须使用以下几行代码:
employee = {“EmployeID”: “Employee Unique Identity!”}
print (employee [‘EmployeID])
您必须按照以下过程处理模块:
模块是一个包含一些函数或变量的Python文件。
导入您需要的文件。
现在,您可以使用“.”(点)运算符访问该模块中的函数或变量。
考虑一个名为employee.py的模块,其中包含一个名为employee的函数。该函数的代码如下所示:
# this goes in employee.py def EmployeID(): print (“Employee Unique Identity!”)
现在导入模块,然后访问函数EmployeID:
import employee employee. EmployeID()
您可以在其中插入一个名为Age的变量,如下所示:
def EmployeID(): print (“Employee Unique Identity!”) # just a variable Age = “Employee age is **”
现在,以以下方式访问该变量:
import employee employee.EmployeID() print(employee.Age)
现在,让我们将其与字典进行比较:
Employee[‘EmployeID’] # get EmployeID from employee Employee.employeID() # get employeID from the module Employee.Age # get access to variable
请注意,Python中存在共同模式:
采用键=值样式的容器
通过键的名称从中获取某些内容
将模块与字典进行比较时,两者都相似,但以下几点除外:
在字典的情况下,键是字符串,语法为[key]。
在模块的情况下,键是标识符,语法为.key。
类就像模块
模块是一个特殊的字典,可以存储Python代码,以便您可以使用“.”运算符访问它。类是一种将函数和数据的组合放入容器中以便您可以使用“.”运算符访问它们的方法。
如果您必须创建一个类似于employee模块的类,您可以使用以下代码:
class employee(object):
def __init__(self):
self. Age = “Employee Age is ##”
def EmployeID(self):
print (“This is just employee unique identity”)
注意 - 首选类而不是模块,因为您可以原样重用它们而不会造成太多干扰。而对于模块,您只有一个用于整个程序。
对象就像迷你导入
类就像一个迷你模块,您可以使用称为实例化的概念以与类类似的方式导入它。请注意,当您实例化一个类时,您会得到一个对象。
您可以实例化一个对象,类似于将类像函数一样调用,如下所示:
this_obj = employee() # Instantiatethis_obj.EmployeID() # get EmployeId from the class print(this_obj.Age) # get variable Age
您可以通过以下三种方式中的任何一种来执行此操作:
# dictionary style Employee[‘EmployeID’] # module style Employee.EmployeID() Print(employee.Age) # Class style this_obj = employee() this_obj.employeID() Print(this_obj.Age)
面向对象Python - 环境设置
本章将详细解释如何在本地计算机上设置Python环境。
先决条件和工具包
在继续学习Python之前,我们建议您检查是否满足以下先决条件:
您的计算机上安装了最新版本的Python
安装了IDE或文本编辑器
您具备使用Python进行编写和调试的基本知识,也就是说,您可以在Python中执行以下操作:
能够编写和运行Python程序。
调试程序并诊断错误。
使用基本数据类型。
编写for循环、while循环和if语句
编写函数
如果您没有任何编程语言经验,您可以在以下网站找到许多Python入门教程:
https://www.tutorialpoints.com/安装Python
以下步骤详细介绍了如何在本地计算机上安装Python:
步骤1 - 前往Python官方网站 https://pythonlang.cn/,点击下载菜单,选择最新版本或任何您选择的稳定版本。
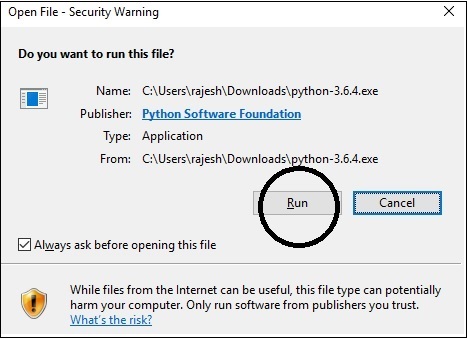
步骤2 - 保存您下载的Python安装程序exe文件,下载完成后打开它。单击运行,默认情况下选择下一步选项,然后完成安装。
步骤3 - 安装完成后,您应该会看到如下所示的Python菜单。通过选择IDLE(Python GUI)启动程序。
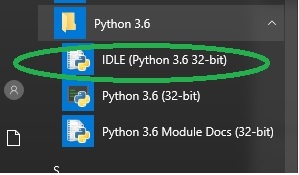
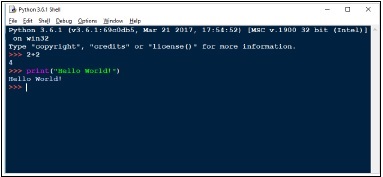
这将启动Python shell。输入简单的命令来检查安装。
选择IDE
集成开发环境 (IDE) 是一种面向软件开发的文本编辑器。您需要安装一个IDE来控制编程流程,并在使用Python时将项目组合在一起。以下是一些可在线使用的IDE。您可以根据自己的方便选择一个。
- Pycharm IDE
- Komodo IDE
- Eric Python IDE
注意 - Eclipse IDE主要用于Java,但它有一个Python插件。
Pycharm

Pycharm是一个跨平台IDE,是目前最流行的IDE之一。它提供代码辅助和分析,包括代码补全、项目和代码导航、集成单元测试、版本控制集成、调试等等。
下载链接
https://www.jetbrains.com/pycharm/download/#section=windows支持的语言 - Python、HTML、CSS、JavaScript、CoffeeScript、TypeScript、Cython、AngularJS、Node.js、模板语言。
截图
为什么选择PyCharm?
PyCharm为用户提供以下功能和优势:
- 跨平台IDE,兼容Windows、Linux和Mac OS
- 包含Django IDE,以及CSS和JavaScript支持
- 包含数千个插件、集成终端和版本控制
- 与Git、SVN和Mercurial集成
- 为Python提供智能编辑工具
- 易于与Virtualenv、Docker和Vagrant集成
- 简单的导航和搜索功能
- 代码分析和重构
- 可配置的注入
- 支持大量的Python库
- 包含模板和JavaScript调试器
- 包含Python/Django调试器
- 可与Google App Engine、其他框架和库一起使用。
- 具有可自定义的UI,提供VIM仿真。
Komodo IDE

这是一个多语言IDE,支持100多种语言,基本上用于Python、PHP和Ruby等动态语言。这是一个商业IDE,提供21天的免费试用,功能齐全。ActiveState是管理Komodo IDE开发的软件公司。它还提供Komodo的精简版,称为Komodo Edit,用于简单的编程任务。
此IDE包含从最基本到高级的所有功能。如果您是学生或自由职业者,则可以以几乎一半的实际价格购买它。但是,对于来自认可机构和大学的教师和教授来说,它是完全免费的。
它拥有您进行Web和移动开发所需的所有功能,包括对所有语言和框架的支持。
下载链接
Komodo Edit(免费版)和Komodo IDE(付费版)的下载链接如下:
Komodo Edit (免费)
https://www.activestate.com/komodo-editKomodo IDE (付费)
https://www.activestate.com/komodo-ide/downloads/ide截图
为什么选择PyCharm?
- 功能强大的IDE,支持Perl、PHP、Python、Ruby以及更多语言。
- 跨平台IDE。
它包括基本功能,例如集成调试器支持、自动完成、文档对象模型 (DOM) 查看器、代码浏览器、交互式shell、断点配置、代码分析、集成单元测试。简而言之,它是一个具有许多提高生产率功能的专业IDE。
Eric Python IDE

这是一个用于Python和Ruby的开源IDE。Eric是一个功能齐全的编辑器和IDE,用Python编写。它基于跨平台Qt GUI工具包,集成了高度灵活的Scintilla编辑器控件。IDE非常可配置,可以选择使用哪些功能,哪些不使用。您可以从以下链接下载Eric IDE:
https://eric-ide.python-projects.org/eric-download.html为什么选择Eric?
- 出色的缩进,错误高亮。
- 代码辅助
- 代码补全
- 使用PyLint进行代码清理
- 快速搜索
- 集成的Python调试器。
截图
选择文本编辑器
您可能并不总是需要IDE。对于学习使用Python或Arduino进行编码的任务,或者在shell脚本中编写快速脚本以帮助您自动化某些任务时,简单轻便的代码中心文本编辑器就足够了。此外,许多文本编辑器还提供语法高亮显示和程序内脚本执行等功能,类似于IDE。以下是一些文本编辑器:
- Atom
- Sublime Text
- Notepad++
Atom文本编辑器

Atom是由GitHub团队构建的可修改文本编辑器。它是一个免费且开源的文本和代码编辑器,这意味着所有代码都可以供您阅读、修改以供自己使用,甚至可以贡献改进。它是一个跨平台文本编辑器,兼容macOS、Linux和Microsoft Windows,支持用Node.js编写的插件和嵌入式Git Control。
下载链接
https://atom.io/截图
支持的语言
C/C++、C#、CSS、CoffeeScript、HTML、JavaScript、Java、JSON、Julia、Objective-C、PHP、Perl、Python、Ruby on Rails、Ruby、Shell脚本、Scala、SQL、XML、YAML等等。
Sublime Text编辑器

Sublime Text是一个专有软件,它提供免费试用版供您在购买前测试。根据stackoverflow.com,它是第四大最流行的开发环境。
它提供的一些优势包括其令人难以置信的速度、易用性和社区支持。它还支持许多编程语言和标记语言,用户可以使用插件添加功能,这些插件通常由社区构建和维护,并根据自由软件许可证进行管理。
截图
支持的语言
- Python、Ruby、JavaScript等。
为什么选择PyCharm?
自定义键绑定、菜单、代码片段、宏、补全等等。
自动完成功能
- 使用代码片段、字段标记和占位符快速插入文本和代码。
快速打开
跨平台支持Mac、Linux和Windows。
将光标跳转到您想要的位置
选择多行、单词和列
Notepad ++

这是一个免费的源代码编辑器和Notepad替代品,支持从汇编到XML以及包括Python在内的多种语言。它在MS Windows环境下运行,其使用受GPL许可证管辖。除了语法高亮显示外,Notepad++还具有一些对编码人员特别有用的功能。
截图
主要功能
- 语法高亮显示和语法折叠
- PCRE(Perl兼容正则表达式)搜索/替换
- 完全可自定义的GUI
- 自动完成
- 选项卡式编辑
- 多视图
- 多语言环境
- 可以使用不同的参数启动
支持的语言
- 几乎所有语言(60多种语言),如Python、C、C++、C#、Java等。
面向对象的Python - 数据结构
从语法的角度来看,Python数据结构非常直观,它们提供了大量的操作选择。您需要根据数据涉及的内容、是否需要修改数据、数据是否是固定数据以及需要什么类型的访问(例如开头/结尾/随机等)来选择Python数据结构。
列表
列表表示Python中最通用的数据结构类型。列表是一个容器,它在方括号之间保存用逗号分隔的值(项目或元素)。当我们想要处理多个相关值时,列表非常有用。由于列表将数据保存在一起,因此我们可以对多个值同时执行相同的方法和操作。列表索引从零开始,与字符串不同,列表是可变的。
数据结构 - 列表
>>> >>> # Any Empty List >>> empty_list = [] >>> >>> # A list of String >>> str_list = ['Life', 'Is', 'Beautiful'] >>> # A list of Integers >>> int_list = [1, 4, 5, 9, 18] >>> >>> #Mixed items list >>> mixed_list = ['This', 9, 'is', 18, 45.9, 'a', 54, 'mixed', 99, 'list'] >>> # To print the list >>> >>> print(empty_list) [] >>> print(str_list) ['Life', 'Is', 'Beautiful'] >>> print(type(str_list)) <class 'list'> >>> print(int_list) [1, 4, 5, 9, 18] >>> print(mixed_list) ['This', 9, 'is', 18, 45.9, 'a', 54, 'mixed', 99, 'list']
访问Python列表中的项目
列表的每个项目都分配了一个数字——这就是该数字的索引或位置。索引始终从零开始,第二个索引为一,依此类推。要访问列表中的项目,我们可以在方括号内使用这些索引号。例如,请观察以下代码:
>>> mixed_list = ['This', 9, 'is', 18, 45.9, 'a', 54, 'mixed', 99, 'list'] >>> >>> # To access the First Item of the list >>> mixed_list[0] 'This' >>> # To access the 4th item >>> mixed_list[3] 18 >>> # To access the last item of the list >>> mixed_list[-1] 'list'
空对象
空对象是最简单、最基本的Python内置类型。我们在不知不觉中多次使用它们,并将其扩展到我们创建的每个类。编写空类的主要目的是暂时阻止某些东西,然后扩展并向其添加行为。
向类添加行为意味着用对象替换数据结构并更改对它的所有引用。因此,在创建任何内容之前,检查数据(是否是伪装的对象)非常重要。观察以下代码以更好地理解
>>> #Empty objects >>> >>> obj = object() >>> obj.x = 9 Traceback (most recent call last): File "<pyshell#3>", line 1, in <module> obj.x = 9 AttributeError: 'object' object has no attribute 'x'
因此,从上面我们可以看到,不可能直接在实例化的对象上设置任何属性。当Python允许对象具有任意属性时,它需要一定的系统内存来跟踪每个对象具有哪些属性,用于存储属性名称及其值。即使不存储任何属性,也会为潜在的新属性分配一定的内存。
因此,默认情况下,Python禁用对象和几个其他内置对象的任意属性。
>>> # Empty Objects
>>>
>>> class EmpObject:
pass
>>> obj = EmpObject()
>>> obj.x = 'Hello, World!'
>>> obj.x
'Hello, World!'
因此,如果我们想将属性组合在一起,我们可以像上面代码中所示的那样将它们存储在空对象中。但是,这种方法并不总是建议的。请记住,只有当您想要同时指定数据和行为时,才应使用类和对象。
元组
元组类似于列表,可以存储元素。但是,它们是不可变的,因此我们无法添加、删除或替换对象。元组由于其不可变性而提供的首要好处是,我们可以将它们用作字典中的键,或者在对象需要哈希值的其他位置。
元组用于存储数据,而不是行为。如果您需要行为来操作元组,则需要将元组传递给执行该操作的函数(或另一个对象上的方法)。
由于元组可以充当字典键,因此存储的值彼此不同。我们可以通过逗号分隔值来创建一个元组。元组用括号括起来,但并非强制性。以下代码显示了两个相同的赋值。
>>> stock1 = 'MSFT', 95.00, 97.45, 92.45
>>> stock2 = ('MSFT', 95.00, 97.45, 92.45)
>>> type (stock1)
<class 'tuple'>
>>> type(stock2)
<class 'tuple'>
>>> stock1 == stock2
True
>>>
定义元组
元组与列表非常相似,只是所有元素都用括号括起来,而不是方括号。
就像切片列表时得到一个新列表一样,切片元组时也会得到一个新的元组。
>>> tupl = ('Tuple','is', 'an','IMMUTABLE', 'list')
>>> tupl
('Tuple', 'is', 'an', 'IMMUTABLE', 'list')
>>> tupl[0]
'Tuple'
>>> tupl[-1]
'list'
>>> tupl[1:3]
('is', 'an')
Python元组方法
以下代码显示了Python元组中的方法:
>>> tupl
('Tuple', 'is', 'an', 'IMMUTABLE', 'list')
>>> tupl.append('new')
Traceback (most recent call last):
File "<pyshell#148>", line 1, in <module>
tupl.append('new')
AttributeError: 'tuple' object has no attribute 'append'
>>> tupl.remove('is')
Traceback (most recent call last):
File "<pyshell#149>", line 1, in <module>
tupl.remove('is')
AttributeError: 'tuple' object has no attribute 'remove'
>>> tupl.index('list')
4
>>> tupl.index('new')
Traceback (most recent call last):
File "<pyshell#151>", line 1, in <module>
tupl.index('new')
ValueError: tuple.index(x): x not in tuple
>>> "is" in tupl
True
>>> tupl.count('is')
1
从上面显示的代码中,我们可以理解元组是不可变的,因此:
您不能向元组添加元素。
您不能追加或扩展方法。
您不能从元组中删除元素。
元组没有remove或pop方法。
元组中可用的方法包括计数和索引。
字典
字典是Python的内置数据类型之一,它定义了键和值之间的一对一关系。
定义字典
观察以下代码,了解如何定义字典:
>>> # empty dictionary
>>> my_dict = {}
>>>
>>> # dictionary with integer keys
>>> my_dict = { 1:'msft', 2: 'IT'}
>>>
>>> # dictionary with mixed keys
>>> my_dict = {'name': 'Aarav', 1: [ 2, 4, 10]}
>>>
>>> # using built-in function dict()
>>> my_dict = dict({1:'msft', 2:'IT'})
>>>
>>> # From sequence having each item as a pair
>>> my_dict = dict([(1,'msft'), (2,'IT')])
>>>
>>> # Accessing elements of a dictionary
>>> my_dict[1]
'msft'
>>> my_dict[2]
'IT'
>>> my_dict['IT']
Traceback (most recent call last):
File "<pyshell#177>", line 1, in <module>
my_dict['IT']
KeyError: 'IT'
>>>
从上面的代码我们可以看出
首先,我们创建一个包含两个元素的字典,并将其赋值给变量my_dict。每个元素都是一个键值对,整个元素集合用花括号括起来。
数字1是键,msft是其值。类似地,2是键,IT是其值。
您可以通过键获取值,但反之则不行。因此,当我们尝试使用my_dict['IT']时,它会引发异常,因为IT不是键。
修改字典
观察以下代码,了解如何修改字典:
>>> # Modifying a Dictionary
>>>
>>> my_dict
{1: 'msft', 2: 'IT'}
>>> my_dict[2] = 'Software'
>>> my_dict
{1: 'msft', 2: 'Software'}
>>>
>>> my_dict[3] = 'Microsoft Technologies'
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies'}
从上面的代码我们可以看出:
字典中不能有重复的键。更改现有键的值将删除旧值。
您可以随时添加新的键值对。
字典没有元素之间顺序的概念。它们只是简单的无序集合。
在字典中混合数据类型
观察以下代码,了解如何在字典中混合数据类型:
>>> # Mixing Data Types in a Dictionary
>>>
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies'}
>>> my_dict[4] = 'Operating System'
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies', 4: 'Operating System'}
>>> my_dict['Bill Gates'] = 'Owner'
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies', 4: 'Operating System',
'Bill Gates': 'Owner'}
从上面的代码我们可以看出:
字典值不仅可以是字符串,还可以是任何数据类型,包括字符串、整数,甚至字典本身。
与字典值不同,字典键的限制更多,但可以是任何类型,例如字符串、整数或其他任何类型。
从字典中删除项目
观察以下代码,了解如何从字典中删除项目:
>>> # Deleting Items from a Dictionary
>>>
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies', 4: 'Operating System',
'Bill Gates': 'Owner'}
>>>
>>> del my_dict['Bill Gates']
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies', 4: 'Operating System'}
>>>
>>> my_dict.clear()
>>> my_dict
{}
从上面的代码我们可以看出:
del - 允许您通过键从字典中删除单个项目。
clear - 删除字典中的所有项目。
集合
Set() 是一个无序集合,没有重复的元素。虽然单个项目是不可变的,但集合本身是可变的,也就是说我们可以向集合中添加或删除元素/项目。我们可以对集合执行并集、交集等数学运算。
虽然集合通常可以使用树来实现,但Python中的集合可以使用哈希表来实现。这使得它成为一种高度优化的检查特定元素是否包含在集合中的方法。
创建集合
集合是通过将所有项目(元素)放在花括号{}内,用逗号分隔,或者使用内置函数set()来创建的。观察以下代码:
>>> #set of integers
>>> my_set = {1,2,4,8}
>>> print(my_set)
{8, 1, 2, 4}
>>>
>>> #set of mixed datatypes
>>> my_set = {1.0, "Hello World!", (2, 4, 6)}
>>> print(my_set)
{1.0, (2, 4, 6), 'Hello World!'}
>>>
集合的方法
观察以下代码,了解集合的方法:
>>> >>> #METHODS FOR SETS
>>>
>>> #add(x) Method
>>> topics = {'Python', 'Java', 'C#'}
>>> topics.add('C++')
>>> topics
{'C#', 'C++', 'Java', 'Python'}
>>>
>>> #union(s) Method, returns a union of two set.
>>> topics
{'C#', 'C++', 'Java', 'Python'}
>>> team = {'Developer', 'Content Writer', 'Editor','Tester'}
>>> group = topics.union(team)
>>> group
{'Tester', 'C#', 'Python', 'Editor', 'Developer', 'C++', 'Java', 'Content
Writer'}
>>> # intersets(s) method, returns an intersection of two sets
>>> inters = topics.intersection(team)
>>> inters
set()
>>>
>>> # difference(s) Method, returns a set containing all the elements of
invoking set but not of the second set.
>>>
>>> safe = topics.difference(team)
>>> safe
{'Python', 'C++', 'Java', 'C#'}
>>>
>>> diff = topics.difference(group)
>>> diff
set()
>>> #clear() Method, Empties the whole set.
>>> group.clear()
>>> group
set()
>>>
集合的操作符
观察以下代码,了解集合的操作符:
>>> # PYTHON SET OPERATIONS
>>>
>>> #Creating two sets
>>> set1 = set()
>>> set2 = set()
>>>
>>> # Adding elements to set
>>> for i in range(1,5):
set1.add(i)
>>> for j in range(4,9):
set2.add(j)
>>> set1
{1, 2, 3, 4}
>>> set2
{4, 5, 6, 7, 8}
>>>
>>> #Union of set1 and set2
>>> set3 = set1 | set2 # same as set1.union(set2)
>>> print('Union of set1 & set2: set3 = ', set3)
Union of set1 & set2: set3 = {1, 2, 3, 4, 5, 6, 7, 8}
>>>
>>> #Intersection of set1 & set2
>>> set4 = set1 & set2 # same as set1.intersection(set2)
>>> print('Intersection of set1 and set2: set4 = ', set4)
Intersection of set1 and set2: set4 = {4}
>>>
>>> # Checking relation between set3 and set4
>>> if set3 > set4: # set3.issuperset(set4)
print('Set3 is superset of set4')
elif set3 < set4: #set3.issubset(set4)
print('Set3 is subset of set4')
else: #set3 == set4
print('Set 3 is same as set4')
Set3 is superset of set4
>>>
>>> # Difference between set3 and set4
>>> set5 = set3 - set4
>>> print('Elements in set3 and not in set4: set5 = ', set5)
Elements in set3 and not in set4: set5 = {1, 2, 3, 5, 6, 7, 8}
>>>
>>> # Check if set4 and set5 are disjoint sets
>>> if set4.isdisjoint(set5):
print('Set4 and set5 have nothing in common\n')
Set4 and set5 have nothing in common
>>> # Removing all the values of set5
>>> set5.clear()
>>> set5 set()
面向对象Python - 构建块
在本章中,我们将详细讨论面向对象的术语和编程概念。类只是一个实例的工厂。这个工厂包含蓝图,描述了如何制作实例。实例或对象是由类构造的。在大多数情况下,我们可以拥有一个类的一个以上实例。每个实例都有一组属性,这些属性在类中定义,因此特定类的每个实例都应该具有相同的属性。
类捆绑:行为和状态
类允许您将对象的行为和状态捆绑在一起。观察下图以更好地理解:
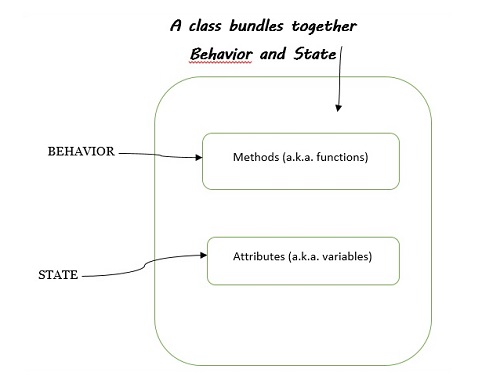
讨论类捆绑时,以下几点值得注意:
单词行为与函数相同 - 它是一段执行某些操作(或实现行为)的代码。
单词状态与变量相同 - 它是存储类中值的地方。
当我们将类的行为和状态一起断言时,这意味着一个类打包了函数和变量。
类具有方法和属性
在Python中,创建方法定义了类的行为。方法这个词是在类中定义的函数的OOP名称。总结一下:
类函数 - 是方法的同义词
类变量 - 是名称属性的同义词。
类 - 具有精确行为的实例的蓝图。
对象 - 类的一个实例,执行在类中定义的功能。
类型 - 指示实例所属的类
属性 - 任何对象值:object.attribute
方法 - 在类中定义的“可调用属性”
观察以下代码示例:
var = “Hello, John” print( type (var)) # < type ‘str’> or <class 'str'> print(var.upper()) # upper() method is called, HELLO, JOHN
创建和实例化
以下代码显示了如何创建我们的第一个类以及它的实例。
class MyClass(object): pass # Create first instance of MyClass this_obj = MyClass() print(this_obj) # Another instance of MyClass that_obj = MyClass() print (that_obj)
在这里,我们创建了一个名为MyClass的类,它不执行任何任务。MyClass类中的参数object涉及类继承,将在后面的章节中讨论。上面代码中的pass表示此块为空,即它是一个空的类定义。
让我们创建一个MyClass()类的实例this_obj并打印它,如下所示:
<__main__.MyClass object at 0x03B08E10> <__main__.MyClass object at 0x0369D390>
在这里,我们创建了一个MyClass的实例。十六进制代码指的是对象存储的地址。另一个实例指向另一个地址。
现在让我们在MyClass()类中定义一个变量,并从该类的实例中获取该变量,如下面的代码所示:
class MyClass(object): var = 9 # Create first instance of MyClass this_obj = MyClass() print(this_obj.var) # Another instance of MyClass that_obj = MyClass() print (that_obj.var)
输出
执行上面给出的代码时,您可以观察到以下输出:
9 9
由于实例知道它是从哪个类实例化的,因此当请求从实例获取属性时,实例会查找属性和类。这称为属性查找。
实例方法
在类中定义的函数称为方法。实例方法需要一个实例才能调用它,并且不需要装饰器。创建实例方法时,第一个参数始终是self。虽然我们可以用任何其他名称来调用它 (self),但建议使用 self,因为它是一种命名约定。
class MyClass(object):
var = 9
def firstM(self):
print("hello, World")
obj = MyClass()
print(obj.var)
obj.firstM()
输出
执行上面给出的代码时,您可以观察到以下输出:
9 hello, World
请注意,在上例程序中,我们定义了一个带有 self 作为参数的方法。但是我们不能调用该方法,因为我们没有声明任何参数。
class MyClass(object):
def firstM(self):
print("hello, World")
print(self)
obj = MyClass()
obj.firstM()
print(obj)
输出
执行上面给出的代码时,您可以观察到以下输出:
hello, World <__main__.MyClass object at 0x036A8E10> <__main__.MyClass object at 0x036A8E10>
封装
封装是OOP的基本原理之一。OOP使我们能够隐藏对象内部工作机制的复杂性,这对开发人员有以下好处:
简化并易于理解如何使用对象,而无需了解内部结构。
任何更改都易于管理。
面向对象编程严重依赖封装。封装和抽象(也称为数据隐藏)这两个术语经常互换使用。它们几乎是同义词,因为抽象是通过封装实现的。
封装为我们提供了一种限制对某些对象组件访问的机制,这意味着对象内部表示无法从对象定义外部看到。对这些数据的访问通常是通过特殊方法实现的 - Getter 和 Setter。
这些数据存储在实例属性中,可以从类外部的任何地方进行操作。为了保护它,这些数据应该只使用实例方法访问。不应允许直接访问。
class MyClass(object):
def setAge(self, num):
self.age = num
def getAge(self):
return self.age
zack = MyClass()
zack.setAge(45)
print(zack.getAge())
zack.setAge("Fourty Five")
print(zack.getAge())
输出
执行上面给出的代码时,您可以观察到以下输出:
45 Fourty Five
数据应仅在正确和有效的情况下存储,使用异常处理结构。正如我们上面看到的,对 setAge() 方法的用户输入没有限制。它可以是字符串、数字或列表。因此,我们需要检查上面的代码以确保存储的正确性。
class MyClass(object):
def setAge(self, num):
self.age = num
def getAge(self):
return self.age
zack = MyClass()
zack.setAge(45)
print(zack.getAge())
zack.setAge("Fourty Five")
print(zack.getAge())
Init 构造函数
__init__ 方法会在类的对象实例化后立即隐式调用。这将初始化对象。
x = MyClass()
上面显示的代码行将创建一个新实例并将此对象分配给局部变量 x。
实例化操作,即调用类对象,会创建一个空对象。许多类都喜欢创建具有自定义为特定初始状态的实例的对象。因此,类可以定义一个名为“__init__()”的特殊方法,如下所示:
def __init__(self): self.data = []
Python 在实例化期间调用 __init__ 以定义一个附加属性,该属性应在实例化类时发生,这可能是为该对象设置一些起始值或运行实例化时所需例程。因此,在这个例子中,可以通过以下方式获得一个新的、已初始化的实例:
x = MyClass()
__init__() 方法可以具有单个或多个参数,以获得更大的灵活性。init 代表初始化,因为它初始化实例的属性。它被称为类的构造函数。
class myclass(object):
def __init__(self,aaa, bbb):
self.a = aaa
self.b = bbb
x = myclass(4.5, 3)
print(x.a, x.b)
输出
4.5 3
类属性
在类中定义的属性称为“类属性”,在函数中定义的属性称为“实例属性”。定义时,这些属性前面不加 self,因为这些是类的属性,而不是特定实例的属性。
类属性既可以被类本身 (className.attributeName) 访问,也可以被类的实例 (inst.attributeName) 访问。因此,实例可以访问实例属性和类属性。
>>> class myclass(): age = 21 >>> myclass.age 21 >>> x = myclass() >>> x.age 21 >>>
类属性可以在实例中被覆盖,即使这不是破坏封装的好方法。
Python 中有一个属性查找路径。首先是在类中定义的方法,然后是上面的类。
>>> class myclass(object): classy = 'class value' >>> dd = myclass() >>> print (dd.classy) # This should return the string 'class value' class value >>> >>> dd.classy = "Instance Value" >>> print(dd.classy) # Return the string "Instance Value" Instance Value >>> >>> # This will delete the value set for 'dd.classy' in the instance. >>> del dd.classy >>> >>> # Since the overriding attribute was deleted, this will print 'class value'. >>> print(dd.classy) class value >>>
我们在实例 dd 中覆盖了“classy”类属性。当它被覆盖时,Python 解释器读取覆盖的值。但是一旦新的值用“del”删除,实例中不再存在覆盖的值,因此查找向上移动一级并从类中获取它。
使用类和实例数据
在本节中,让我们了解类数据如何与实例数据相关。我们可以将数据存储在类中或实例中。当我们设计一个类时,我们决定哪些数据属于实例,哪些数据应该存储到整个类中。
实例可以访问类数据。如果我们创建多个实例,则这些实例可以访问它们各自的属性值以及整个类数据。
因此,类数据是在所有实例之间共享的数据。观察下面的代码以更好地理解:
class InstanceCounter(object):
count = 0 # class attribute, will be accessible to all instances
def __init__(self, val):
self.val = val
InstanceCounter.count +=1 # Increment the value of class attribute, accessible through class name
# In above line, class ('InstanceCounter') act as an object
def set_val(self, newval):
self.val = newval
def get_val(self):
return self.val
def get_count(self):
return InstanceCounter.count
a = InstanceCounter(9)
b = InstanceCounter(18)
c = InstanceCounter(27)
for obj in (a, b, c):
print ('val of obj: %s' %(obj.get_val())) # Initialized value ( 9, 18, 27)
print ('count: %s' %(obj.get_count())) # always 3
输出
val of obj: 9 count: 3 val of obj: 18 count: 3 val of obj: 27 count: 3
简而言之,类属性对于类的所有实例都是相同的,而实例属性对于每个实例都是特定的。对于两个不同的实例,我们将拥有两个不同的实例属性。
class myClass:
class_attribute = 99
def class_method(self):
self.instance_attribute = 'I am instance attribute'
print (myClass.__dict__)
输出
执行上面给出的代码时,您可以观察到以下输出:
{'__module__': '__main__', 'class_attribute': 99, 'class_method': <function myClass.class_method at 0x04128D68>, '__dict__': <attribute '__dict__' of 'myClass' objects>, '__weakref__': <attribute '__weakref__' of 'myClass' objects>, '__doc__': None}
实例属性**myClass.__dict__** 如下所示:
>>> a = myClass()
>>> a.class_method()
>>> print(a.__dict__)
{'instance_attribute': 'I am instance attribute'}
面向对象快捷方式
本章详细介绍了Python中的各种内置函数、文件I/O操作和重载概念。
Python内置函数
Python解释器有一些称为内置函数的函数,可以随时使用。在最新版本中,Python包含68个内置函数,如下表所示:
| 内置函数 | ||||
|---|---|---|---|---|
| abs() | dict() | help() | min() | setattr() |
| all() | dir() | hex() | next() | slice() |
| any() | divmod() | id() | object() | sorted() |
| ascii() | enumerate() | input() | oct() | staticmethod() |
| bin() | eval() | int() | open() | str() |
| bool() | exec() | isinstance() | ord() | sum() |
| bytearray() | filter() | issubclass() | pow() | super() |
| bytes() | float() | iter() | print() | tuple() |
| callable() | format() | len() | property() | type() |
| chr() | frozenset() | list() | range() | vars() |
| classmethod() | getattr() | locals() | repr() | zip() |
| compile() | globals() | map() | reversed() | __import__() |
| complex() | hasattr() | max() | round() | |
| delattr() | hash() | memoryview() | set() | |
本节简要讨论一些重要的函数:
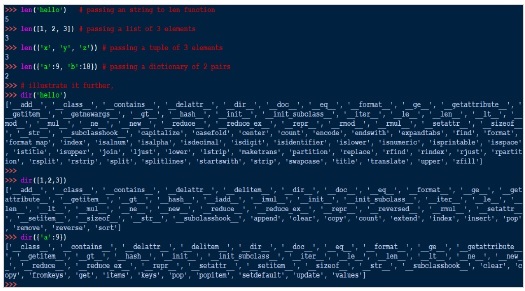
len() 函数
len() 函数获取字符串、列表或集合的长度。它返回对象的长度或项目数,其中对象可以是字符串、列表或集合。
>>> len(['hello', 9 , 45.0, 24]) 4
len() 函数内部的工作方式类似于**list.__len__()** 或 **tuple.__len__()**。因此,请注意,len() 仅适用于具有 __len__() 方法的对象。
>>> set1
{1, 2, 3, 4}
>>> set1.__len__()
4
但是,在实践中,我们更倾向于使用 **len()** 而不是 **__len__()** 函数,原因如下:
它更高效。并且不必编写特定方法来拒绝访问诸如 __len__ 之类的特殊方法。
易于维护。
它支持向后兼容性。
reversed(seq)
它返回反向迭代器。seq 必须是一个具有 __reversed__() 方法或支持序列协议(__len__() 方法和 __getitem__() 方法)的对象。当我们想要从后往前循环遍历项目时,它通常用于 **for** 循环。
>>> normal_list = [2, 4, 5, 7, 9]
>>>
>>> class CustomSequence():
def __len__(self):
return 5
def __getitem__(self,index):
return "x{0}".format(index)
>>> class funkyback():
def __reversed__(self):
return 'backwards!'
>>> for seq in normal_list, CustomSequence(), funkyback():
print('\n{}: '.format(seq.__class__.__name__), end="")
for item in reversed(seq):
print(item, end=", ")
最后的 for 循环打印普通列表的反向列表以及两个自定义序列的实例。输出显示 **reversed()** 对所有三个都起作用,但在我们定义 **__reversed__** 时结果大相径庭。
输出
执行上面给出的代码时,您可以观察到以下输出:
list: 9, 7, 5, 4, 2, CustomSequence: x4, x3, x2, x1, x0, funkyback: b, a, c, k, w, a, r, d, s, !,
enumerate
**enumerate()** 方法为可迭代对象添加计数器并返回 enumerate 对象。
enumerate() 的语法为:
enumerate(iterable, start = 0)
这里第二个参数 **start** 是可选的,默认情况下索引从零 (0) 开始。
>>> # Enumerate >>> names = ['Rajesh', 'Rahul', 'Aarav', 'Sahil', 'Trevor'] >>> enumerate(names) <enumerate object at 0x031D9F80> >>> list(enumerate(names)) [(0, 'Rajesh'), (1, 'Rahul'), (2, 'Aarav'), (3, 'Sahil'), (4, 'Trevor')] >>>
因此,**enumerate()** 返回一个迭代器,该迭代器产生一个元组,该元组对传递的序列中的元素进行计数。由于返回值是迭代器,因此直接访问它并没有多大用处。enumerate() 的更好方法是在 for 循环中进行计数。
>>> for i, n in enumerate(names):
print('Names number: ' + str(i))
print(n)
Names number: 0
Rajesh
Names number: 1
Rahul
Names number: 2
Aarav
Names number: 3
Sahil
Names number: 4
Trevor
标准库中还有许多其他函数,这里还有另一个更广泛使用的函数列表:
**hasattr、getattr、setattr** 和 **delattr**,允许通过其字符串名称来操作对象的属性。
**all** 和 **any**,它们接受一个可迭代对象,如果所有或任何项目计算结果为真,则返回 **True**。
**zip**,它接受两个或多个序列并返回一个新的元组序列,其中每个元组包含每个序列中的单个值。
文件 I/O
文件的概念与面向对象编程术语相关。Python 已将操作系统提供的接口封装在允许我们使用文件对象的抽象中。
**open()** 内置函数用于打开文件并返回文件对象。它是两个参数中最常用的函数:
open(filename, mode)
open() 函数调用两个参数,第一个是文件名,第二个是模式。这里的模式可以是 'r'(只读模式)、'w'(只写,同名现有文件将被擦除)和 'a'(打开文件进行追加,写入文件的所有数据都会自动添加到结尾)。'r+' 打开文件进行读写。默认模式是只读。
在 Windows 上,附加到模式的 'b' 将以二进制模式打开文件,因此还有 'rb'、'wb' 和 'r+b' 等模式。
>>> text = 'This is the first line'
>>> file = open('datawork','w')
>>> file.write(text)
22
>>> file.close()
在某些情况下,我们只想追加到现有文件而不是覆盖它,为此我们可以提供 'a' 值作为模式参数,以追加到文件末尾,而不是完全覆盖现有文件内容。
>>> f = open('datawork','a')
>>> text1 = ' This is second line'
>>> f.write(text1)
20
>>> f.close()
一旦打开文件进行读取,我们可以调用 read、readline 或 readlines 方法来获取文件的内容。read 方法将文件的全部内容作为 str 或 bytes 对象返回,具体取决于第二个参数是否为 'b'。
为了可读性,并避免一次读取大型文件,最好直接在文件对象上使用 for 循环。对于文本文件,它将一次读取一行,我们可以在循环体中处理它。但是,对于二进制文件,最好使用 read() 方法读取固定大小的数据块,并传递一个参数来指定要读取的最大字节数。
>>> f = open('fileone','r+')
>>> f.readline()
'This is the first line. \n'
>>> f.readline()
'This is the second line. \n'
写入文件,通过文件对象的 write 方法将字符串(二进制数据的字节)对象写入文件。writelines 方法接受一系列字符串并将每个迭代值写入文件。writelines 方法不会在序列中的每个项目后追加换行符。
最后,当我们完成文件读取或写入时,应该调用 close() 方法,以确保将任何缓冲写入写入磁盘,文件已正确清理,并且与文件绑定的所有资源都已释放回操作系统。调用 close() 方法是一种更好的方法,但在技术上,这会在脚本退出时自动发生。
方法重载的替代方法
方法重载是指拥有多个同名但接受不同参数集的方法。
对于单个方法或函数,我们可以自己指定参数的数量。根据函数定义,它可以调用零个、一个、两个或多个参数。
class Human:
def sayHello(self, name = None):
if name is not None:
print('Hello ' + name)
else:
print('Hello ')
#Create Instance
obj = Human()
#Call the method, else part will be executed
obj.sayHello()
#Call the method with a parameter, if part will be executed
obj.sayHello('Rahul')
输出
Hello Hello Rahul
默认参数
函数也是对象
可调用对象是可以接受某些参数并可能返回对象的 对象。函数是 Python 中最简单的可调用对象,但还有其他对象,例如类或某些类实例。
Python 中的每个函数都是一个对象。对象可以包含方法或函数,但对象不一定是函数。
def my_func():
print('My function was called')
my_func.description = 'A silly function'
def second_func():
print('Second function was called')
second_func.description = 'One more sillier function'
def another_func(func):
print("The description:", end=" ")
print(func.description)
print('The name: ', end=' ')
print(func.__name__)
print('The class:', end=' ')
print(func.__class__)
print("Now I'll call the function passed in")
func()
another_func(my_func)
another_func(second_func)
在上面的代码中,我们能够将两个不同的函数作为参数传递到我们的第三个函数中,并为每个函数获得不同的输出:
The description: A silly function The name: my_func The class:Now I'll call the function passed in My function was called The description: One more sillier function The name: second_func The class: Now I'll call the function passed in Second function was called
可调用对象
正如函数是可以设置属性的对象一样,也可以创建一个可以像函数一样调用的对象。
在 Python 中,任何具有 __call__() 方法的对象都可以使用函数调用语法进行调用。
继承和多态性
继承和多态性——这是 Python 中一个非常重要的概念。如果你想学习,必须更好地理解它。
继承
面向对象编程的主要优势之一是重用。继承是实现相同目标的一种机制。继承允许程序员首先创建一个通用类或基类,然后将其扩展到更专业的类。它允许程序员编写更好的代码。
使用继承,您可以使用或继承基类中可用的所有数据字段和方法。稍后您可以添加您自己的方法和数据字段,因此继承提供了一种组织代码的方法,而不是从头开始重写代码。
在面向对象的术语中,当类 X 扩展类 Y 时,Y 被称为超类/父类/基类,X 被称为子类/子类/派生类。这里需要注意的一点是,只有非私有的数据字段和方法才能被子类访问。私有数据字段和方法只能在类内部访问。
创建派生类的语法为:
class BaseClass: Body of base class class DerivedClass(BaseClass): Body of derived class
继承属性
现在看看下面的例子:
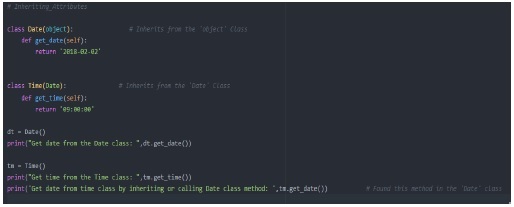
输出

我们首先创建了一个名为 Date 的类并将对象作为参数传递,这里对象是 Python 提供的内置类。稍后我们创建了另一个名为 time 的类并调用 Date 类作为参数。通过此调用,我们可以访问 Time 类中 Date 类中的所有数据和属性。正因为如此,当我们尝试从我们之前创建的 Time 类对象 tm 获取 get_date 方法时是可能的。
对象.属性查找层次结构
- 实例
- 类
- 此类继承的任何类
继承示例
让我们仔细看看继承示例:
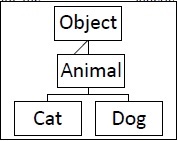
让我们创建几个类来参与示例:
- Animal——模拟动物的类
- Cat——Animal 的子类
- Dog——Animal 的子类
在 Python 中,类的构造函数用于创建对象(实例)并为属性赋值。
子类的构造函数总是调用父类的构造函数来初始化父类中属性的值,然后它开始为其属性赋值。
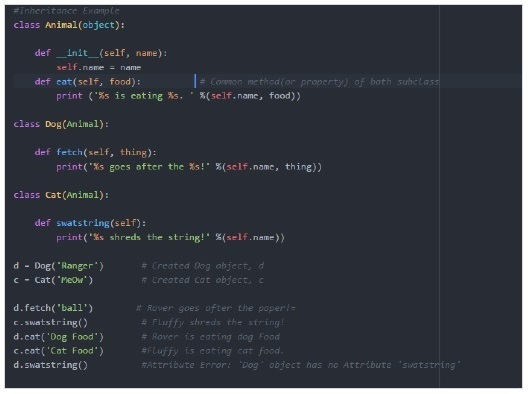
输出
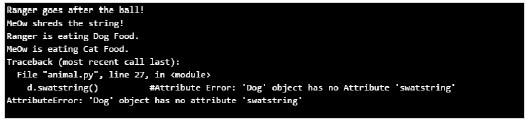
在上面的例子中,我们看到了在父类中放置的命令属性或方法,以便所有子类或子类都将从父类继承该属性。
如果子类尝试从另一个子类继承方法或数据,那么它将引发错误,正如我们看到 Dog 类尝试从 cat 类调用 swatstring() 方法时一样,它会引发错误(在我们的例子中是 AttributeError)。
多态性(“多种形态”)
多态性是 Python 中类定义的一个重要特性,当您在类或子类中具有常用命名的方 法时,就会使用它。这允许函数在不同时间使用不同类型的实体。因此,它提供了灵活性和松散耦合,以便代码可以随着时间的推移而扩展和轻松维护。
这允许函数使用任何这些多态类的对象,而无需了解类之间的区别。
多态可以通过继承来实现,子类利用基类方法或覆盖它们。
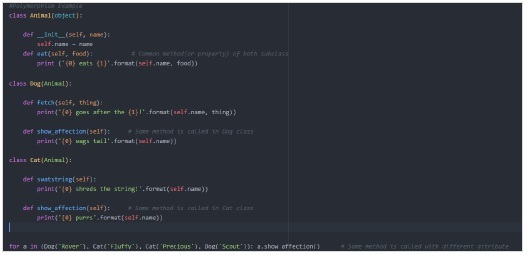
让我们用之前的继承示例来理解多态的概念,并在两个子类中添加一个名为show_affection的公共方法:
从这个例子我们可以看出,它指的是一种设计,其中不同类型的对象可以以相同的方式处理,或者更具体地说,两个或多个类具有相同名称的方法或公共接口,因为相同的方法(以下示例中的show_affection)可以使用任何类型的对象调用。
输出

所以,所有动物都会表达感情(show_affection),但它们表达的方式不同。“show_affection”行为因此是多态的,因为它根据动物的不同而表现不同。因此,“动物”这个抽象概念实际上并没有“表达感情”,但具体的动物(如狗和猫)对“表达感情”这个动作有具体的实现。
Python本身就有一些多态的类。例如,len()函数可以用于多个对象,并且所有对象都根据输入参数返回正确的输出。
方法覆盖
在Python中,当子类包含一个覆盖超类方法的方法时,你也可以通过调用超类方法来调用
Super(Subclass, self).method而不是self.method。
示例
class Thought(object):
def __init__(self):
pass
def message(self):
print("Thought, always come and go")
class Advice(Thought):
def __init__(self):
super(Advice, self).__init__()
def message(self):
print('Warning: Risk is always involved when you are dealing with market!')
继承构造函数
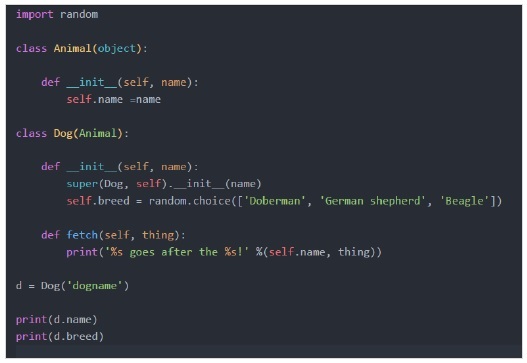
如果我们从之前的继承示例来看,`__init__`位于父类中,因为子类dog或cat在其内部没有`__init__`方法。Python使用继承属性查找在animal类中查找`__init__`。当我们创建子类时,它首先会在dog类中查找`__init__`方法,如果没有找到,则会查找父类Animal,并在那里找到并调用它。因此,随着我们类设计的复杂化,我们可能希望首先通过父类构造函数处理实例,然后通过子类构造函数处理实例。
输出

在上例中,所有动物都有一个名字,所有狗都有一个特定的品种。我们用super调用了父类构造函数。所以狗有它自己的`__init__`,但是首先发生的事情是我们调用super。Super是一个内置函数,它被设计用来将一个类与其超类或父类关联起来。
在这种情况下,我们说的是获取狗的超类,并将狗实例传递给这里所说的任何方法,即构造函数`__init__`。换句话说,我们用狗对象调用父类Animal的`__init__`。你可能会问,为什么我们不直接用狗实例来调用Animal `__init__`,我们可以这样做,但是如果动物类的名称将来发生变化会怎样?如果我们想重新排列类层次结构,让狗继承自另一个类呢?在这种情况下使用super允许我们保持事物模块化,易于更改和维护。
所以在本例中,我们能够将一般的`__init__`功能与更具体的函数结合起来。这给了我们一个机会,可以将公共功能与特定功能分开,从而消除代码重复,并以反映系统整体设计的方式将类关联起来。
结论
`__init__`就像任何其他方法一样;它可以被继承。
如果一个类没有`__init__`构造函数,Python将检查其父类以查看是否可以找到一个。
一旦找到一个,Python就会调用它并停止查找。
我们可以使用super()函数调用父类中的方法。
我们可能希望在父类以及我们自己的类中进行初始化。
多重继承和查找树
顾名思义,Python中的多重继承是指一个类继承自多个类。
例如,一个孩子继承了父母双方的性格特征(母亲和父亲)。
Python多重继承语法
要使一个类继承自多个父类,我们在定义派生类时将这些类的名称写在派生类的括号内。我们将这些名称用逗号分隔。
以下是一个例子:
>>> class Mother: pass >>> class Father: pass >>> class Child(Mother, Father): pass >>> issubclass(Child, Mother) and issubclass(Child, Father) True
多重继承是指继承自两个或多个类。当子类继承自父类,而父类又继承自祖先类时,复杂性就出现了。Python会遍历继承树,查找从对象读取的请求属性。它将检查实例、类本身、父类,最后是祖先类。现在问题出现了,将按什么顺序搜索类——广度优先还是深度优先?默认情况下,Python使用深度优先。
这就是为什么在下图中,Python首先在A类中搜索dothis()方法。所以以下示例中的方法解析顺序将是
MRO:D→B→A→C
请看下面的多重继承图:
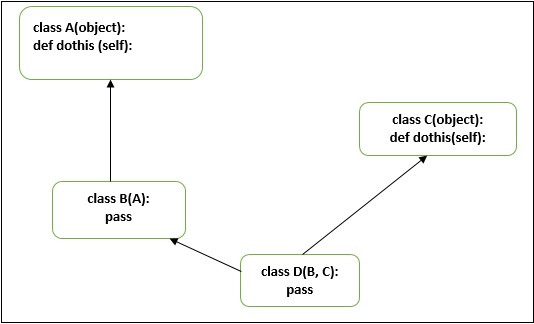
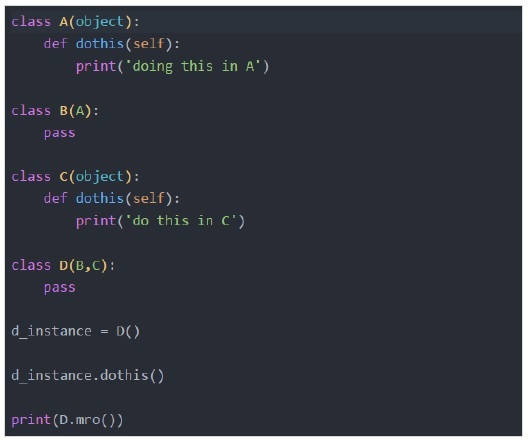
让我们来看一个例子来理解Python的“mro”特性。
输出
示例3
让我们再来看一个“菱形”多重继承的例子。
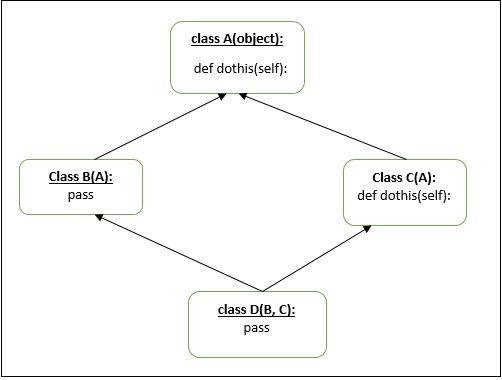
上图将被认为是模棱两可的。根据我们之前的例子理解“方法解析顺序”,即mro将是D→B→A→C→A,但事实并非如此。在从C获取第二个A时,Python将忽略之前的A。所以在这种情况下,mro将是D→B→C→A。
让我们根据上图创建一个示例:
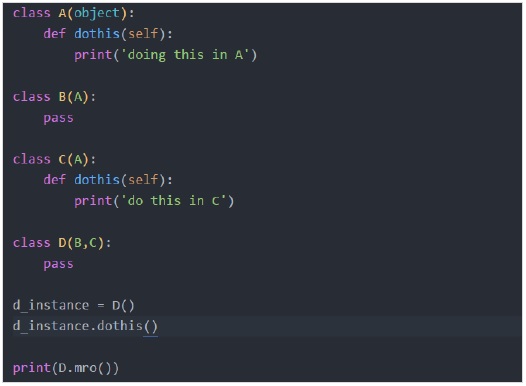
输出

理解上述输出的简单规则是:如果同一个类出现在方法解析顺序中,则该类的早期出现将从方法解析顺序中删除。
总之:
任何类都可以继承自多个类。
Python通常在搜索继承类时使用“深度优先”顺序。
但是当两个类继承自同一个类时,Python会从mro中删除该类的第一次出现。
装饰器、静态方法和类方法
函数(或方法)由def语句创建。
尽管方法的工作方式与函数完全相同,只有一点不同,即方法的第一个参数是实例对象。
我们可以根据它们的行为对方法进行分类,例如
简单方法 - 在类外部定义。此函数可以通过提供实例参数来访问类属性。
def outside_func(():
实例方法 -
def func(self,)
类方法 - 如果我们需要使用类属性。
@classmethod def cfunc(cls,)
静态方法 - 没有关于类的任何信息。
@staticmethod def sfoo()
到目前为止,我们已经看到了实例方法,现在是时候深入了解其他两种方法了:
类方法
@classmethod 装饰器是一个内置函数装饰器,它将调用它的类或调用它的实例的类作为第一个参数传递。该评估的结果会覆盖你的函数定义。
语法
class C(object):
@classmethod
def fun(cls, arg1, arg2, ...):
....
fun: function that needs to be converted into a class method
returns: a class method for function
它们可以访问这个cls参数,但不能修改对象实例状态。这需要访问self。
它绑定到类,而不是类的对象。
类方法仍然可以修改适用于类的所有实例的类状态。
静态方法
静态方法既不接受self参数也不接受cls(类)参数,但它可以自由地接受任意数量的其他参数。
语法
class C(object): @staticmethod def fun(arg1, arg2, ...): ... returns: a static method for function funself.
- 静态方法既不能修改对象状态也不能修改类状态。
- 它们在可以访问的数据方面受到限制。
何时使用什么
我们通常使用类方法来创建工厂方法。工厂方法为不同的用例返回类对象(类似于构造函数)。
我们通常使用静态方法来创建实用程序函数。
Python设计模式
概述
现代软件开发需要解决复杂的业务需求。它还需要考虑诸如未来的可扩展性和可维护性等因素。良好的软件系统设计对于实现这些目标至关重要。设计模式在这样的系统中扮演着重要的角色。
为了理解设计模式,让我们考虑下面的例子:
每辆车的设计都遵循一个基本的设计模式,四个轮子、方向盘、核心驱动系统(如油门-刹车-离合器)等。
所以,所有重复建造/生产的东西,在其设计中不可避免地遵循某种模式……无论是汽车、自行车、比萨饼、自动取款机,还是任何东西……甚至你的沙发床。
在软件中对某些逻辑/机制/技术进行编码几乎已经成为标准方式的设计,因此被称为或被研究为软件设计模式。
为什么设计模式很重要?
使用设计模式的好处是:
通过经过验证的方法帮助你解决常见的設計问题。
由于它们有良好的文档记录,因此理解上没有歧义。
减少整体开发时间。
帮助你比其他方法更容易地处理未来的扩展和修改。
由于它们是针对常见问题的经过验证的解决方案,因此可以减少系统中的错误。
设计模式的分类
GoF(四人帮)设计模式分为三类:创建型、结构型和行为型。
创建型模式
创建型设计模式将对象创建逻辑与系统的其余部分分离。创建型模式会为你创建对象,而不是你创建对象。创建型模式包括抽象工厂、生成器、工厂方法、原型和单例。
由于语言的动态特性,创建型模式在Python中并不常用。而且语言本身也提供了我们创建足够优雅方式所需的所有灵活性,我们很少需要在其之上实现任何东西,例如单例或工厂。
此外,这些模式提供了一种创建对象的方式,同时隐藏创建逻辑,而不是直接使用new运算符实例化对象。
结构型模式
有时,你不需要从头开始,而是需要使用一组现有的类来构建更大的结构。这就是结构型类模式使用继承来构建新结构的地方。结构型对象模式使用组合/聚合来获得新的功能。适配器、桥接器、组合、装饰器、外观、享元和代理是结构型模式。它们提供了组织类层次结构的最佳方法。
行为型模式
行为型模式提供了处理对象之间通信的最佳方法。属于此类别的模式有:访问者、责任链、命令、解释器、迭代器、中介者、备忘录、观察者、状态、策略和模板方法是行为型模式。
因为它们代表系统的行为,所以它们通常用来描述软件系统的功能。
常用的设计模式
单例模式
这是所有设计模式中最具争议和最著名的模式之一。它用于过度面向对象的语言,并且是传统面向对象编程的重要组成部分。
单例模式用于:
需要实现日志记录时。日志记录器实例由系统的所有组件共享。
配置文件使用它,因为需要维护信息缓存并由系统中的所有各种组件共享。
管理数据库连接。
以下是 UML 图:

class Logger(object):
def __new__(cls, *args, **kwargs):
if not hasattr(cls, '_logger'):
cls._logger = super(Logger, cls).__new__(cls, *args, **kwargs)
return cls._logger
在此示例中,Logger 是一个单例。
调用 `__new__` 时,它通常会构造该类的新的实例。当我们重写它时,我们首先检查我们的单例实例是否已被创建。如果没有,我们使用 super 调用来创建它。因此,无论何时我们在 Logger 上调用构造函数,我们总是获得完全相同的实例。
>>> >>> obj1 = Logger() >>> obj2 = Logger() >>> obj1 == obj2 True >>> >>> obj1 <__main__.Logger object at 0x03224090> >>> obj2 <__main__.Logger object at 0x03224090>
面向对象 Python - 高级特性
在本节中,我们将了解 Python 提供的一些高级特性。
类设计中的核心语法
在本节中,我们将了解 Python 如何允许我们在类中利用运算符。Python 很大程度上是对象和对象上的方法调用,即使它被一些方便的语法隐藏,这也是如此。
>>> var1 = 'Hello' >>> var2 = ' World!' >>> var1 + var2 'Hello World!' >>> >>> var1.__add__(var2) 'Hello World!' >>> num1 = 45 >>> num2 = 60 >>> num1.__add__(num2) 105 >>> var3 = ['a', 'b'] >>> var4 = ['hello', ' John'] >>> var3.__add__(var4) ['a', 'b', 'hello', ' John']
因此,如果我们必须将魔术方法 `__add__` 添加到我们自己的类中,我们也可以这样做吗?让我们尝试一下。
我们有一个名为 Sumlist 的类,它有一个构造函数 `__init__`,它将列表作为名为 my_list 的参数。
class SumList(object):
def __init__(self, my_list):
self.mylist = my_list
def __add__(self, other):
new_list = [ x + y for x, y in zip(self.mylist, other.mylist)]
return SumList(new_list)
def __repr__(self):
return str(self.mylist)
aa = SumList([3,6, 9, 12, 15])
bb = SumList([100, 200, 300, 400, 500])
cc = aa + bb # aa.__add__(bb)
print(cc) # should gives us a list ([103, 206, 309, 412, 515])
输出
[103, 206, 309, 412, 515]
但是,许多方法是由其他魔术方法内部管理的。以下是一些方法:
'abc' in var # var.__contains__('abc')
var == 'abc' # var.__eq__('abc')
var[1] # var.__getitem__(1)
var[1:3] # var.__getslice__(1, 3)
len(var) # var.__len__()
print(var) # var.__repr__()
继承内置类型
类也可以继承自内置类型,这意味着继承自任何内置类型并利用在那里找到的所有功能。
在下面的示例中,我们继承自字典,但随后我们实现了它的一个方法 `__setitem__`。当我们在字典中设置键值对时,会调用此 (setitem)。由于这是一个魔术方法,因此会隐式调用它。
class MyDict(dict):
def __setitem__(self, key, val):
print('setting a key and value!')
dict.__setitem__(self, key, val)
dd = MyDict()
dd['a'] = 10
dd['b'] = 20
for key in dd.keys():
print('{0} = {1}'.format(key, dd[key]))
输出
setting a key and value! setting a key and value! a = 10 b = 20
让我们扩展之前的示例,下面我们调用了两个魔术方法 `__getitem__` 和 `__setitem__`,在处理列表索引时最好调用它们。
# Mylist inherits from 'list' object but indexes from 1 instead for 0!
class Mylist(list): # inherits from list
def __getitem__(self, index):
if index == 0:
raise IndexError
if index > 0:
index = index - 1
return list.__getitem__(self, index) # this method is called when
# we access a value with subscript like x[1]
def __setitem__(self, index, value):
if index == 0:
raise IndexError
if index > 0:
index = index - 1
list.__setitem__(self, index, value)
x = Mylist(['a', 'b', 'c']) # __init__() inherited from builtin list
print(x) # __repr__() inherited from builtin list
x.append('HELLO'); # append() inherited from builtin list
print(x[1]) # 'a' (Mylist.__getitem__ cutomizes list superclass
# method. index is 1, but reflects 0!
print (x[4]) # 'HELLO' (index is 4 but reflects 3!
输出
['a', 'b', 'c'] a HELLO
在上面的示例中,我们在 Mylist 中设置了一个包含三个项目的列表,并隐式调用 `__init__` 方法,当我们打印元素 x 时,我们得到包含三个项目的列表(['a','b','c'])。然后我们将另一个元素添加到此列表中。稍后我们请求索引 1 和索引 4。但是如果你看到输出,我们得到的是我们请求的 (index-1) 元素。我们知道列表索引从 0 开始,但这里的索引从 1 开始(这就是为什么我们得到列表的第一个项目的原因)。
命名约定
在本节中,我们将了解我们将用于变量(尤其是私有变量)的名称以及全球 Python 程序员使用的约定。虽然变量被指定为私有变量,但在 Python 中不存在隐私,这是设计使然。像任何其他有良好文档记录的语言一样,Python 具有它提倡的命名和样式约定,尽管它不强制执行它们。Python 的创始人 Guido van Rossum 编写了一份样式指南,其中描述了最佳实践和名称的使用,称为 PEP8。以下是此指南的链接:https://pythonlang.cn/dev/peps/pep-0008/
PEP 代表 Python 增强提案,是一系列在 Python 社区中分发的文档,用于讨论提出的更改。例如,建议所有:
- 模块名称 - all_lower_case
- 类名和异常名 - CamelCase
- 全局名称和局部名称 - all_lower_case
- 函数和方法名称 - all_lower_case
- 常量 - ALL_UPPER_CASE
这些只是建议,如果愿意,你可以有所不同。但是由于大多数开发人员遵循这些建议,因此你的代码的可读性可能会降低。
为什么要遵守约定?
我们可以遵循 PEP 建议,因为它允许我们获得:
- 对绝大多数开发人员来说更熟悉
- 对大多数阅读你代码的人来说更清晰
- 将与在同一代码库上工作的其他贡献者的风格相匹配
- 专业软件开发人员的标志
- 每个人都会接受你。
变量命名 - “公共”和“私有”
在 Python 中,当我们处理模块和类时,我们将某些变量或属性指定为私有。在 Python 中,不存在“私有”实例变量,除非在对象内部,否则无法访问它。私有只是意味着它们并非旨在被代码用户使用,而是旨在在内部使用。通常,大多数 Python 开发人员都遵循一种约定,即以下划线为前缀的名称,例如 _attrval(下面的示例)应被视为 API 或任何 Python 代码(无论是函数、方法还是数据成员)的非公共部分。以下是我们遵循的命名约定:
公共属性或变量(旨在被此模块的导入者或此类的用户使用) - regular_lower_case
私有属性或变量(模块或类内部使用) - _single_leading_underscore
不应进行子类化的私有属性 - __double_leading_underscore
魔术属性 - __double_underscores__(使用它们,不要创建它们)
class GetSet(object):
instance_count = 0 # public
__mangled_name = 'no privacy!' # special variable
def __init__(self, value):
self._attrval = value # _attrval is for internal use only
GetSet.instance_count += 1
@property
def var(self):
print('Getting the "var" attribute')
return self._attrval
@var.setter
def var(self, value):
print('setting the "var" attribute')
self._attrval = value
@var.deleter
def var(self):
print('deleting the "var" attribute')
self._attrval = None
cc = GetSet(5)
cc.var = 10 # public name
print(cc._attrval)
print(cc._GetSet__mangled_name)
输出
setting the "var" attribute 10 no privacy!
面向对象 Python - 文件和字符串
字符串
字符串是在每种编程语言中最常用的数据类型。为什么?因为我们比数字更了解文本,所以在写作和谈话中我们使用文本和单词,同样在编程中我们也使用字符串。在字符串中,我们解析文本,分析文本语义,并进行数据挖掘——所有这些数据都是人类使用的文本。Python 中的字符串是不可变的。
字符串操作
在 Python 中,字符串可以用多种方式标记,可以使用单引号(')、双引号(")甚至三引号('''),如果是多行字符串。
>>> # String Examples
>>> a = "hello"
>>> b = ''' A Multi line string,
Simple!'''
>>> e = ('Multiple' 'strings' 'togethers')
字符串操作非常有用,并且在每种语言中都广泛使用。程序员经常需要分解字符串并仔细检查它们。
可以迭代字符串(逐字符)、切片或连接。语法与列表相同。
str 类在其上有很多方法,使操作字符串更容易。dir 和 help 命令在 Python 解释器中提供了关于如何使用它们的指导。
以下是一些我们常用的字符串方法。
| 序号 | 方法和描述 |
|---|---|
| 1 | isalpha() 检查所有字符是否都是字母 |
| 2 | isdigit() 检查数字字符 |
| 3 | isdecimal() 检查十进制字符 |
| 4 | isnumeric() 检查数字字符 |
| 5 | find() 返回子字符串的最高索引 |
| 6 | istitle() 检查标题大小写的字符串 |
| 7 | join() 返回连接的字符串 |
| 8 | lower() 返回小写字符串 |
| 9 | upper() 返回大写字符串 |
| 10 | partition() 返回一个元组 |
| 11 | bytearray() 返回给定字节大小的数组 |
| 12 | enumerate() 返回一个枚举对象 |
| 13 | isprintable() 检查可打印字符 |
让我们尝试运行几个字符串方法:
>>> str1 = 'Hello World!'
>>> str1.startswith('h')
False
>>> str1.startswith('H')
True
>>> str1.endswith('d')
False
>>> str1.endswith('d!')
True
>>> str1.find('o')
4
>>> #Above returns the index of the first occurence of the character/substring.
>>> str1.find('lo')
3
>>> str1.upper()
'HELLO WORLD!'
>>> str1.lower()
'hello world!'
>>> str1.index('b')
Traceback (most recent call last):
File "<pyshell#19>", line 1, in <module>
str1.index('b')
ValueError: substring not found
>>> s = ('hello How Are You')
>>> s.split(' ')
['hello', 'How', 'Are', 'You']
>>> s1 = s.split(' ')
>>> '*'.join(s1)
'hello*How*Are*You'
>>> s.partition(' ')
('hello', ' ', 'How Are You')
>>>
字符串格式化
在 Python 3.x 中,字符串的格式化方式发生了变化,现在它更合乎逻辑并且更灵活。可以使用 format() 方法或 % 符号(旧样式)在格式字符串中进行格式化。
字符串可以包含文字文本或由大括号 {} 分隔的替换字段,每个替换字段可以包含位置参数的数字索引或关键字参数的名称。
语法
str.format(*args, **kwargs)
基本格式化
>>> '{} {}'.format('Example', 'One')
'Example One'
>>> '{} {}'.format('pie', '3.1415926')
'pie 3.1415926'
下面的示例允许重新排列显示顺序,而无需更改参数。
>>> '{1} {0}'.format('pie', '3.1415926')
'3.1415926 pie'
填充和对齐字符串
可以将值填充到特定长度。
>>> #Padding Character, can be space or special character
>>> '{:12}'.format('PYTHON')
'PYTHON '
>>> '{:>12}'.format('PYTHON')
' PYTHON'
>>> '{:<{}s}'.format('PYTHON',12)
'PYTHON '
>>> '{:*<12}'.format('PYTHON')
'PYTHON******'
>>> '{:*^12}'.format('PYTHON')
'***PYTHON***'
>>> '{:.15}'.format('PYTHON OBJECT ORIENTED PROGRAMMING')
'PYTHON OBJECT O'
>>> #Above, truncated 15 characters from the left side of a specified string
>>> '{:.{}}'.format('PYTHON OBJECT ORIENTED',15)
'PYTHON OBJECT O'
>>> #Named Placeholders
>>> data = {'Name':'Raghu', 'Place':'Bangalore'}
>>> '{Name} {Place}'.format(**data)
'Raghu Bangalore'
>>> #Datetime
>>> from datetime import datetime
>>> '{:%Y/%m/%d.%H:%M}'.format(datetime(2018,3,26,9,57))
'2018/03/26.09:57'
字符串是 Unicode
作为不可变 Unicode 字符集合的字符串。Unicode 字符串提供了创建可在任何地方运行的软件或程序的机会,因为 Unicode 字符串可以表示任何可能的字符,而不仅仅是 ASCII 字符。
许多 IO 操作只知道如何处理字节,即使字节对象指的是文本数据。因此,了解如何在字节和 Unicode 之间进行交换非常重要。
将文本转换为字节
将字符串转换为字节对象称为编码。有许多编码形式,最常见的是:PNG;JPEG、MP3、WAV、ASCII、UTF-8 等。此外,这(编码)是一种以字节表示音频、图像、文本等的格式。
此转换可以通过 encode() 完成。它以编码技术作为参数。默认情况下,我们使用 'UTF-8' 技术。
>>> # Python Code to demonstrate string encoding
>>>
>>> # Initialising a String
>>> x = 'TutorialsPoint'
>>>
>>> #Initialising a byte object
>>> y = b'TutorialsPoint'
>>>
>>> # Using encode() to encode the String >>> # encoded version of x is stored in z using ASCII mapping
>>> z = x.encode('ASCII')
>>>
>>> # Check if x is converted to bytes or not
>>>
>>> if(z==y):
print('Encoding Successful!')
else:
print('Encoding Unsuccessful!')
Encoding Successful!
将字节转换为文本
将字节转换为文本称为解码。这是通过 decode() 实现的。如果我们知道用于对其进行编码的编码,则可以将字节字符串转换为字符字符串。
因此,编码和解码是相反的过程。
>>>
>>> # Python code to demonstrate Byte Decoding
>>>
>>> #Initialise a String
>>> x = 'TutorialsPoint'
>>>
>>> #Initialising a byte object
>>> y = b'TutorialsPoint'
>>>
>>> #using decode() to decode the Byte object
>>> # decoded version of y is stored in z using ASCII mapping
>>> z = y.decode('ASCII')
>>> #Check if y is converted to String or not
>>> if (z == x):
print('Decoding Successful!')
else:
print('Decoding Unsuccessful!') Decoding Successful!
>>>
文件 I/O
操作系统将文件表示为字节序列,而不是文本。
文件是磁盘上用于存储相关信息的命名位置。它用于永久存储磁盘中的数据。
在 Python 中,文件操作按以下顺序进行。
- 打开文件
- 读取或写入文件(操作)。打开文件
- 关闭文件。
Python 使用适当的 decode(或 encode)调用包装传入(或传出)的字节流,因此我们可以直接处理 str 对象。
打开文件
Python 有一个内置函数 open() 用于打开文件。这将生成一个文件对象,也称为句柄,因为它用于相应地读取或修改文件。
>>> f = open(r'c:\users\rajesh\Desktop\index.webm','rb') >>> f <_io.BufferedReader name='c:\\users\\rajesh\\Desktop\\index.webm'> >>> f.mode 'rb' >>> f.name 'c:\\users\\rajesh\\Desktop\\index.webm'
要从文件读取文本,我们只需要将文件名传递给函数。文件将被打开以进行读取,并且字节将使用平台默认编码转换为文本。
异常和异常类
通常,异常是任何异常情况。异常通常表示错误,但有时它们有意地放入程序中,例如提前终止过程或从资源短缺中恢复。有许多内置异常,它们指示诸如读取文件末尾之后或除以零之类的条件。我们可以定义我们自己的异常,称为自定义异常。
异常处理使您可以优雅地处理错误并对错误执行有意义的操作。异常处理有两个组成部分:“抛出”和“捕获”。
识别异常(错误)
Python 中发生的每个错误都会导致异常,这将是其错误类型标识的错误条件。
>>> #Exception
>>> 1/0
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
1/0
ZeroDivisionError: division by zero
>>>
>>> var = 20
>>> print(ver)
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
print(ver)
NameError: name 'ver' is not defined
>>> #Above as we have misspelled a variable name so we get an NameError.
>>>
>>> print('hello)
SyntaxError: EOL while scanning string literal
>>> #Above we have not closed the quote in a string, so we get SyntaxError.
>>>
>>> #Below we are asking for a key, that doen't exists.
>>> mydict = {}
>>> mydict['x']
Traceback (most recent call last):
File "<pyshell#15>", line 1, in <module>
mydict['x']
KeyError: 'x'
>>> #Above keyError
>>>
>>> #Below asking for a index that didn't exist in a list.
>>> mylist = [1,2,3,4]
>>> mylist[5]
Traceback (most recent call last):
File "<pyshell#20>", line 1, in <module>
mylist[5]
IndexError: list index out of range
>>> #Above, index out of range, raised IndexError.
捕获/捕获异常
当程序中发生异常情况并且你希望使用异常机制来处理它时,你“抛出异常”。try 和 except 关键字用于捕获异常。每当 try 块中发生错误时,Python 都会查找匹配的 except 块来处理它。如果存在,执行将跳转到那里。
语法
try: #write some code #that might throw some exception except <ExceptionType>: # Exception handler, alert the user
try 子句中的代码将逐条语句执行。
如果发生异常,则将跳过 try 块的其余部分,并将执行 except 子句。
try: some statement here except: exception handling
让我们编写一些代码来查看在程序中不使用任何错误处理机制时会发生什么。
number = int(input('Please enter the number between 1 & 10: '))
print('You have entered number',number)
只要用户输入数字,上述程序就会正常工作,但是如果用户尝试输入其他数据类型(例如字符串或列表)会发生什么?
Please enter the number between 1 > 10: 'Hi'
Traceback (most recent call last):
File "C:/Python/Python361/exception2.py", line 1, in <module>
number = int(input('Please enter the number between 1 & 10: '))
ValueError: invalid literal for int() with base 10: "'Hi'"
现在,ValueError 是一个异常类型。让我们尝试使用异常处理重写上面的代码。
import sys
print('Previous code with exception handling')
try:
number = int(input('Enter number between 1 > 10: '))
except(ValueError):
print('Error..numbers only')
sys.exit()
print('You have entered number: ',number)
如果我们运行程序并输入字符串(而不是数字),我们可以看到得到不同的结果。
Previous code with exception handling Enter number between 1 > 10: 'Hi' Error..numbers only
引发异常
要从你自己的方法中引发异常,你需要使用像这样的 raise 关键字
raise ExceptionClass(‘Some Text Here’)
让我们来看一个例子
def enterAge(age):
if age<0:
raise ValueError('Only positive integers are allowed')
if age % 2 ==0:
print('Entered Age is even')
else:
print('Entered Age is odd')
try:
num = int(input('Enter your age: '))
enterAge(num)
except ValueError:
print('Only positive integers are allowed')
运行程序并输入正整数。
预期输出
Enter your age: 12 Entered Age is even
但是当我们尝试输入负数时,我们会得到:
预期输出
Enter your age: -2 Only positive integers are allowed
创建自定义异常类
你可以通过扩展 BaseException 类或 BaseException 的子类来创建一个自定义异常类。
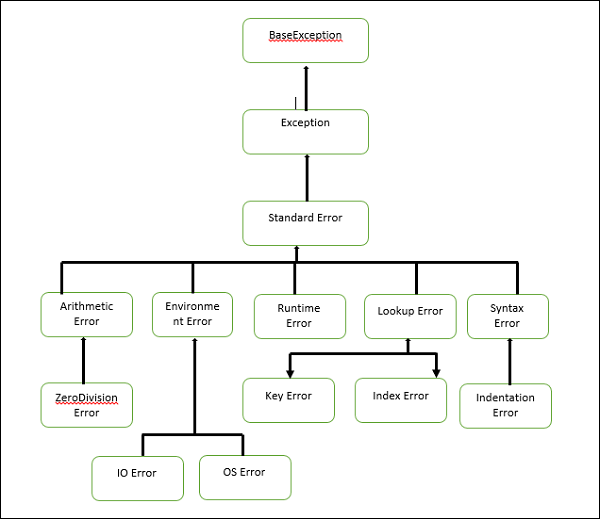
从上图我们可以看到,Python 中的大多数异常类都扩展自 BaseException 类。你可以从 BaseException 类或其子类派生你自己的异常类。
创建一个名为 NegativeNumberException.py 的新文件并编写以下代码。
class NegativeNumberException(RuntimeError):
def __init__(self, age):
super().__init__()
self.age = age
上面的代码创建了一个名为 NegativeNumberException 的新异常类,它只包含一个构造函数,该构造函数使用 super().__init__() 调用父类构造函数并设置年龄。
现在,要创建你自己的自定义异常类,我们将编写一些代码并导入新的异常类。
from NegativeNumberException import NegativeNumberException
def enterage(age):
if age < 0:
raise NegativeNumberException('Only positive integers are allowed')
if age % 2 == 0:
print('Age is Even')
else:
print('Age is Odd')
try:
num = int(input('Enter your age: '))
enterage(num)
except NegativeNumberException:
print('Only positive integers are allowed')
except:
print('Something is wrong')
输出
Enter your age: -2 Only positive integers are allowed
另一种创建自定义异常类的方法。
class customException(Exception):
def __init__(self, value):
self.parameter = value
def __str__(self):
return repr(self.parameter)
try:
raise customException('My Useful Error Message!')
except customException as instance:
print('Caught: ' + instance.parameter)
输出
Caught: My Useful Error Message!
异常层次结构
内置异常的类层次结构为:
+-- SystemExit +-- KeyboardInterrupt +-- GeneratorExit +-- Exception +-- StopIteration +-- StopAsyncIteration +-- ArithmeticError | +-- FloatingPointError | +-- OverflowError | +-- ZeroDivisionError +-- AssertionError +-- AttributeError +-- BufferError +-- EOFError +-- ImportError +-- LookupError | +-- IndexError | +-- KeyError +-- MemoryError +-- NameError | +-- UnboundLocalError +-- OSError | +-- BlockingIOError | +-- ChildProcessError | +-- ConnectionError | | +-- BrokenPipeError | | +-- ConnectionAbortedError | | +-- ConnectionRefusedError | | +-- ConnectionResetError | +-- FileExistsError | +-- FileNotFoundError | +-- InterruptedError | +-- IsADirectoryError | +-- NotADirectoryError | +-- PermissionError | +-- ProcessLookupError | +-- TimeoutError +-- ReferenceError +-- RuntimeError | +-- NotImplementedError | +-- RecursionError +-- SyntaxError | +-- IndentationError | +-- TabError +-- SystemError +-- TypeError +-- ValueError | +-- UnicodeError | +-- UnicodeDecodeError | +-- UnicodeEncodeError | +-- UnicodeTranslateError +-- Warning +-- DeprecationWarning +-- PendingDeprecationWarning +-- RuntimeWarning +-- SyntaxWarning +-- UserWarning +-- FutureWarning +-- ImportWarning +-- UnicodeWarning +-- BytesWarning +-- ResourceWarning
面向对象 Python - 对象序列化
在数据存储的上下文中,序列化是将数据结构或对象状态转换为可以存储(例如,在文件或内存缓冲区中)或传输并在以后重建的格式的过程。
在序列化中,对象被转换为可以存储的格式,以便以后能够反序列化它并从序列化格式中重新创建原始对象。
Pickle
Pickling 是将 Python 对象层次结构转换为字节流(通常不可读)以写入文件的过程,这也被称为序列化。Unpickling 是反向操作,其中字节流被转换回可工作的 Python 对象层次结构。
Pickle 是存储对象的运行时最简单的方法。Python Pickle 模块是一种面向对象的方法,可以直接以特殊的存储格式存储对象。
它能做什么?
- Pickle 可以非常轻松地存储和复制字典和列表。
- 存储对象属性并将它们恢复到相同的状态。
Pickle 不能做什么?
- 它不保存对象的代码。只有它的属性值。
- 它不能存储文件句柄或连接套接字。
简而言之,我们可以说,pickling 是一种将数据变量存储到文件和从文件中检索数据变量的方法,其中变量可以是列表、类等。
要进行 Pickle 操作,你必须:
- 导入 pickle
- 将变量写入文件,例如
pickle.dump(mystring, outfile, protocol),
其中第 3 个参数 protocol 是可选的。要进行 unpickling 操作,你必须:
导入 pickle
将变量写入文件,例如
myString = pickle.load(inputfile)
方法
pickle 接口提供四种不同的方法。
dump() − dump() 方法序列化到打开的文件(类文件对象)。
dumps() − 序列化到字符串
load() − 从类文件对象反序列化。
loads() − 从字符串反序列化。
基于上述过程,以下是“pickling”的示例。
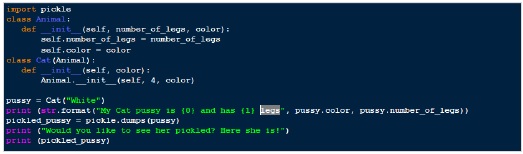
输出
My Cat pussy is White and has 4 legs Would you like to see her pickled? Here she is! b'\x80\x03c__main__\nCat\nq\x00)\x81q\x01}q\x02(X\x0e\x00\x00\x00number_of_legsq\x03K\x04X\x05\x00\x00\x00colorq\x04X\x05\x00\x00\x00Whiteq\x05ub.'
因此,在上例中,我们创建了一个 Cat 类的实例,然后我们对其进行了 pickling,将我们的“Cat”实例转换为简单的字节数组。
这样,我们可以轻松地将字节数组存储在二进制文件或数据库字段中,并在以后的时间从我们的存储支持中将其恢复到原始形式。
此外,如果你想创建一个包含 pickled 对象的文件,可以使用 dump() 方法(而不是 dumps() 方法),同时传递一个打开的二进制文件,pickling 结果将自动存储在文件中。
[….] binary_file = open(my_pickled_Pussy.bin', mode='wb') my_pickled_Pussy = pickle.dump(Pussy, binary_file) binary_file.close()
Unpickling
将二进制数组转换为对象层次结构的过程称为 unpickling。
unpickling 过程是通过使用 pickle 模块的 load() 函数完成的,它从简单的字节数组返回完整的对象层次结构。
让我们在上一个示例中使用 load 函数。
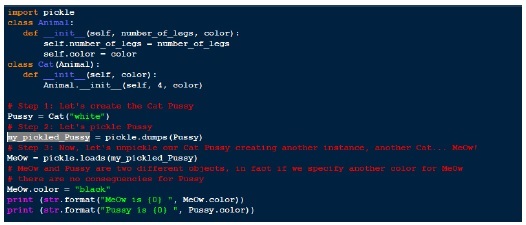
输出
MeOw is black Pussy is white
JSON
JSON(JavaScript 对象表示法)是 Python 标准库的一部分,是一种轻量级的数据交换格式。它易于人类阅读和编写。它易于解析和生成。
由于其简单性,JSON 是一种存储和交换数据的方法,这是通过其 JSON 语法实现的,并用于许多 Web 应用程序中。由于它是人类可读的格式,这可能是它在数据传输中使用的原因之一,此外它在处理 API 时也很有效。
JSON 格式化数据的示例如下:
{"EmployID": 40203, "Name": "Zack", "Age":54, "isEmployed": True}
Python 使得使用 Json 文件变得简单。为此目的使用的模块是 JSON 模块。此模块应包含在你的 Python 安装中(内置)。
让我们看看如何将 Python 字典转换为 JSON 并将其写入文本文件。
JSON 到 Python
读取 JSON 表示将 JSON 转换为 Python 值(对象)。json 库将 JSON 解析为 Python 中的字典或列表。为此,我们使用 loads() 函数(从字符串加载),如下所示:

输出

下面是一个示例 json 文件:
data1.json
{"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}}
上面的内容(Data1.json)看起来像一个常规字典。我们可以使用 pickle 存储此文件,但其输出不是人类可读的格式。
JSON(Java Script 对象通知)是一种非常简单的格式,这就是它流行的原因之一。现在让我们通过下面的程序来看一下 json 输出。
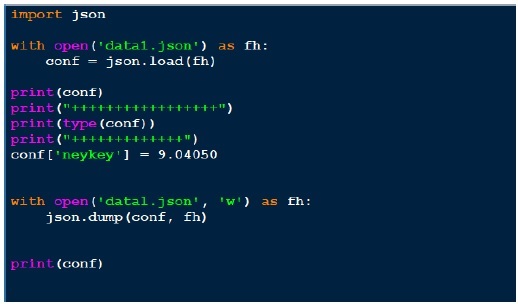
输出
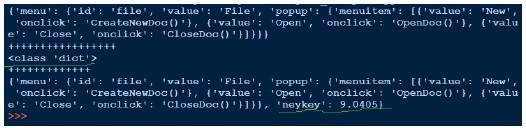
在上面,我们打开 json 文件 (data1.json) 进行读取,获取文件句柄并传递给 json.load 并获取对象。当我们尝试打印对象的输出时,它与 json 文件相同。尽管对象的类型是字典,但它显示为 Python 对象。写入 json 与我们看到的 pickle 一样简单。我们在上面加载 json 文件,添加另一个键值对并将其写回同一个 json 文件。现在如果我们查看 data1.json,它看起来不同,即与我们之前看到的格式不同。
为了使我们的输出看起来相同(人类可读的格式),在程序的最后一行添加几个参数:
json.dump(conf, fh, indent = 4, separators = (‘,’, ‘: ‘))
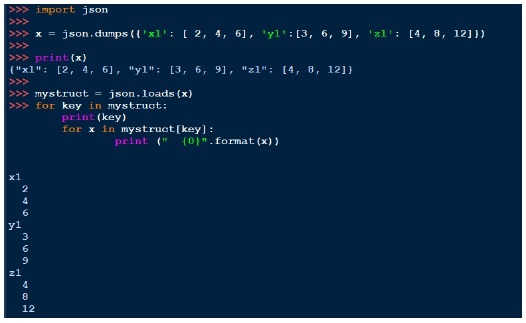
与 pickle 类似,我们可以使用 dumps 打印字符串,使用 loads 加载字符串。下面是一个例子:
YAML
YAML 可能是所有编程语言中最友好的数据序列化标准。
Python yaml 模块称为 pyaml
YAML 是 JSON 的替代方案:
人类可读的代码 − YAML 是最容易让人阅读的格式,以至于甚至它的首页内容也以 YAML 显示来强调这一点。
紧凑的代码 − 在 YAML 中,我们使用空格缩进表示结构,而不是括号。
关系数据的语法 − 对于内部引用,我们使用锚点 (&) 和别名 (*)。
它广泛用于查看/编辑数据结构的一个领域 − 例如配置文件、调试期间的转储和文档标题。
安装 YAML
由于 yaml 不是内置模块,我们需要手动安装它。在 Windows 机器上安装 yaml 的最佳方法是通过 pip。在你的 Windows 终端上运行以下命令来安装 yaml:
pip install pyaml (Windows machine) sudo pip install pyaml (*nix and Mac)
运行上述命令后,屏幕将显示类似下面的内容,具体取决于当前的最新版本。
Collecting pyaml Using cached pyaml-17.12.1-py2.py3-none-any.whl Collecting PyYAML (from pyaml) Using cached PyYAML-3.12.tar.gz Installing collected packages: PyYAML, pyaml Running setup.py install for PyYAML ... done Successfully installed PyYAML-3.12 pyaml-17.12.1
要测试它,请转到 Python shell 并导入 yaml 模块,导入 yaml,如果没有发现错误,那么我们可以说安装成功。
安装 pyaml 后,让我们看看下面的代码:
script_yaml1.py
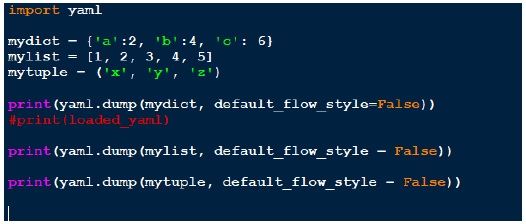
在上面,我们创建了三种不同的数据结构:字典、列表和元组。在每个结构上,我们都执行 yaml.dump。重要的是屏幕上如何显示输出。
输出
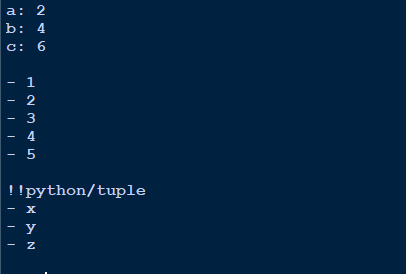
字典输出看起来很清晰,即键:值。
空格用于分隔不同的对象。
列表用破折号 (-) 表示。
元组首先用 !!Python/tuple 表示,然后与列表的格式相同。
加载 yaml 文件
假设我有一个 yaml 文件,其中包含:
--- # An employee record name: Raagvendra Joshi job: Developer skill: Oracle employed: True foods: - Apple - Orange - Strawberry - Mango languages: Oracle: Elite power_builder: Elite Full Stack Developer: Lame education: 4 GCSEs 3 A-Levels MCA in something called com
现在让我们编写一个代码,通过 yaml.load 函数加载此 yaml 文件。以下是相同的代码。
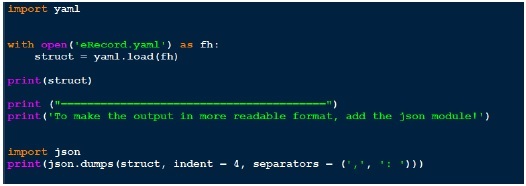
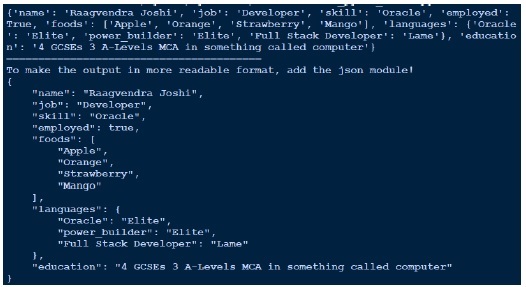
由于输出看起来不太可读,我最终使用了 json 来美化它。比较我们获得的输出和我们拥有的实际 yaml 文件。
输出
软件开发最重要的方面之一是调试。在本节中,我们将看到使用内置调试器或第三方调试器的不同 Python 调试方法。
PDB – Python 调试器
PDB 模块支持设置断点。断点是程序的有意暂停,你可以在其中获取有关程序状态的更多信息。
要设置断点,请插入以下行:
pdb.set_trace()
示例
pdb_example1.py import pdb x = 9 y = 7 pdb.set_trace() total = x + y pdb.set_trace()
我们在这个程序中插入了一些断点。程序将在每个断点 (pdb.set_trace()) 处暂停。要查看变量的内容,只需键入变量名。
c:\Python\Python361>Python pdb_example1.py > c:\Python\Python361\pdb_example1.py(8)<module>() -> total = x + y (Pdb) x 9 (Pdb) y 7 (Pdb) total *** NameError: name 'total' is not defined (Pdb)
按 c 或 continue 继续程序执行,直到下一个断点。
(Pdb) c --Return-- > c:\Python\Python361\pdb_example1.py(8)<module>()->None -> total = x + y (Pdb) total 16
最终,你将需要调试更大的程序——使用子例程的程序。有时,你试图查找的问题可能位于子例程内。考虑以下程序。
import pdb def squar(x, y): out_squared = x^2 + y^2 return out_squared if __name__ == "__main__": #pdb.set_trace() print (squar(4, 5))
现在运行上面的程序:
c:\Python\Python361>Python pdb_example2.py > c:\Python\Python361\pdb_example2.py(10)<module>() -> print (squar(4, 5)) (Pdb)
我们可以使用 ? 获取帮助,但箭头指示即将执行的行。此时,点击 s 以 s 进入该行很有帮助。
(Pdb) s --Call-- >c:\Python\Python361\pdb_example2.py(3)squar() -> def squar(x, y):
这是一个对函数的调用。如果你想概述你在代码中的位置,请尝试 l:
(Pdb) l 1 import pdb 2 3 def squar(x, y): 4 -> out_squared = x^2 + y^2 5 6 return out_squared 7 8 if __name__ == "__main__": 9 pdb.set_trace() 10 print (squar(4, 5)) [EOF] (Pdb)
您可以按 n 键跳转到下一行。此时您位于 out_squared 方法内部,并且可以访问在函数内声明的变量,例如 x 和 y。
(Pdb) x 4 (Pdb) y 5 (Pdb) x^2 6 (Pdb) y^2 7 (Pdb) x**2 16 (Pdb) y**2 25 (Pdb)
因此我们可以看到 ^ 运算符不是我们想要的,我们需要使用 ** 运算符来进行平方运算。
这样我们就可以在函数/方法内部调试程序了。
日志记录
日志记录模块自 Python 2.3 版本以来一直是 Python 标准库的一部分。因为它是一个内置模块,所以所有 Python 模块都可以参与日志记录,这样我们的应用程序日志可以包含您自己的消息以及来自第三方模块的消息。它提供了很大的灵活性和功能。
日志记录的优势
诊断日志记录 − 它记录与应用程序操作相关的事件。
审计日志记录 − 它记录用于业务分析的事件。
消息按“严重性”级别写入和记录 &minu
DEBUG (debug()) − 开发诊断消息。
INFO (info()) − 标准“进度”消息。
WARNING (warning()) − 检测到非严重问题。
ERROR (error()) − 遇到错误,可能很严重。
CRITICAL (critical()) − 通常是致命错误(程序停止)。
让我们看看下面的简单程序:
import logging
logging.basicConfig(level=logging.INFO)
logging.debug('this message will be ignored') # This will not print
logging.info('This should be logged') # it'll print
logging.warning('And this, too') # It'll print
我们在上面按严重性级别记录消息。首先我们导入模块,调用 basicConfig 并设置日志级别。我们上面设置的级别是 INFO。然后我们有三个不同的语句:debug 语句、info 语句和 warning 语句。
logging1.py 的输出
INFO:root:This should be logged WARNING:root:And this, too
由于 info 语句在 debug 语句下面,我们无法看到 debug 消息。要在输出终端中也获得 debug 语句,我们只需要更改 basicConfig 级别。
logging.basicConfig(level = logging.DEBUG)
在输出中我们可以看到:
DEBUG:root:this message will be ignored INFO:root:This should be logged WARNING:root:And this, too
而且默认行为意味着如果我们不设置任何日志级别,则为 warning。只需注释掉上面程序中的第二行并运行代码。
#logging.basicConfig(level = logging.DEBUG)
输出
WARNING:root:And this, too
Python 内置的日志级别实际上是整数。
>>> import logging >>> >>> logging.DEBUG 10 >>> logging.CRITICAL 50 >>> logging.WARNING 30 >>> logging.INFO 20 >>> logging.ERROR 40 >>>
我们还可以将日志消息保存到文件中。
logging.basicConfig(level = logging.DEBUG, filename = 'logging.log')
现在所有日志消息都将写入当前工作目录中的文件 (logging.log),而不是屏幕。这是一种更好的方法,因为它允许我们对收到的消息进行后期分析。
我们还可以设置日志消息的时间戳。
logging.basicConfig(level=logging.DEBUG, format = '%(asctime)s %(levelname)s:%(message)s')
输出将类似于:
2018-03-08 19:30:00,066 DEBUG:this message will be ignored 2018-03-08 19:30:00,176 INFO:This should be logged 2018-03-08 19:30:00,201 WARNING:And this, too
基准测试
基准测试或性能分析基本上是为了测试代码的执行速度以及瓶颈在哪里?这样做的主要原因是为了优化。
timeit
Python 自带一个名为 timeit 的内置模块。您可以使用它来计时小的代码片段。timeit 模块使用特定于平台的时间函数,以便您可以获得尽可能准确的计时结果。
因此,它允许我们比较两种代码的执行时间,然后优化脚本以获得更好的性能。
timeit 模块具有命令行界面,但也可以导入。
有两种方法可以调用脚本。让我们先使用脚本,为此运行以下代码并查看输出。
import timeit
print ( 'by index: ', timeit.timeit(stmt = "mydict['c']", setup = "mydict = {'a':5, 'b':10, 'c':15}", number = 1000000))
print ( 'by get: ', timeit.timeit(stmt = 'mydict.get("c")', setup = 'mydict = {"a":5, "b":10, "c":15}', number = 1000000))
输出
by index: 0.1809192126703489 by get: 0.6088525265034692
我们在上面使用了两种不同的方法,即通过下标和 get 来访问字典键值。我们执行语句 100 万次,因为对于非常小的数据,它的执行速度太快了。现在我们可以看到索引访问比 get 快得多。我们可以多次运行代码,并且时间执行会略有变化,以便更好地理解。
另一种方法是在命令行中运行上述测试。让我们来做吧:
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict['c']"
1000000 loops, best of 3: 0.187 usec per loop
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict.get('c')"
1000000 loops, best of 3: 0.659 usec per loop
上述输出可能因您的系统硬件以及当前在您的系统中运行的所有应用程序而异。
如果我们想调用函数,可以在下面使用 timeit 模块。因为我们可以在函数中添加多个语句进行测试。
import timeit
def testme(this_dict, key):
return this_dict[key]
print (timeit.timeit("testme(mydict, key)", setup = "from __main__ import testme; mydict = {'a':9, 'b':18, 'c':27}; key = 'c'", number = 1000000))
输出
0.7713474590139164
面向对象 Python - 库
Requests − Python Requests 模块
Requests 是一个 Python 模块,它是一个优雅而简单的 Python HTTP 库。有了它,您可以发送各种 HTTP 请求。使用此库,我们可以添加标头、表单数据、多部分文件和参数,并访问响应数据。
由于 Requests 不是内置模块,因此我们需要先安装它。
您可以通过在终端中运行以下命令来安装它:
pip install requests
安装模块后,您可以通过在 Python shell 中键入以下命令来验证安装是否成功。
import requests
如果安装成功,您将不会看到任何错误消息。
发出 GET 请求
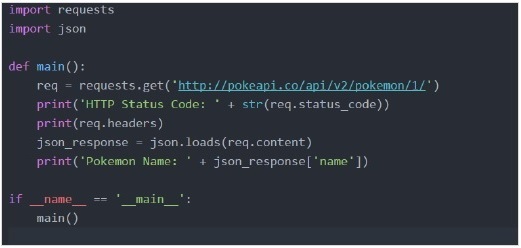
作为一个例子,我们将使用“pokeapi”。
输出:

发出 POST 请求
requests 库方法适用于当前使用的所有 HTTP 动词。如果您想向 API 端点发出简单的 POST 请求,您可以这样做:
req = requests.post(‘http://api/user’, data = None, json = None)
这将与我们之前的 GET 请求完全一样,但是它有两个额外的关键字参数:
data 可以用字典、文件或字节填充,这些数据将传递到 POST 请求的 HTTP 主体中。
json 可以用 json 对象填充,该对象也将传递到 HTTP 请求的主体中。
Pandas:Python 库 Pandas
Pandas 是一个开源 Python 库,它使用其强大的数据结构提供高性能的数据操作和分析工具。Pandas 是数据科学中最广泛使用的 Python 库之一。它主要用于数据整理,并且有充分的理由:强大的和灵活的功能组。
构建在 Numpy 包之上,关键数据结构称为 DataFrame。这些数据框允许我们以观测行和变量列的形式存储和操作表格数据。
有几种方法可以创建 DataFrame。一种方法是使用字典。例如:
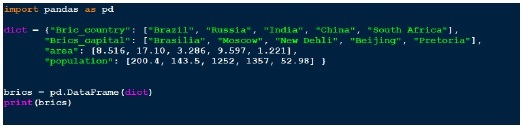
输出
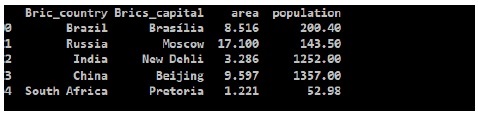
从输出中我们可以看到新的 brics DataFrame,Pandas 为每个国家/地区分配了一个键作为数值 0 到 4。
如果我们不想使用从 0 到 4 的索引值,而是想要不同的索引值,例如两位字母的国家代码,你也可以很容易地做到这一点:
在上面的代码中添加以下一行,得到
brics.index = ['BR', 'RU', 'IN', 'CH', 'SA']
输出

索引 DataFrames
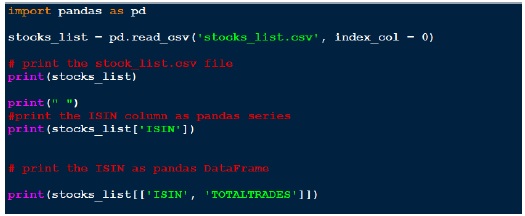
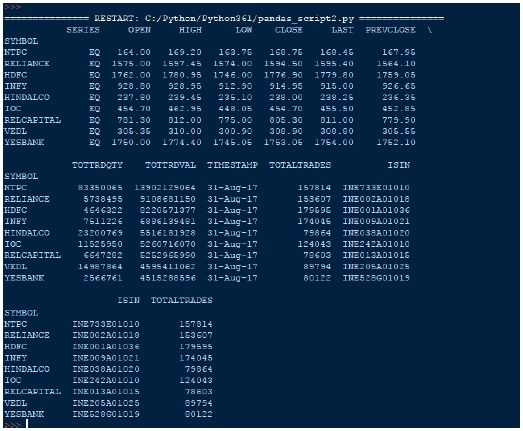
输出
Pygame
Pygame 是一个开源的跨平台库,用于制作多媒体应用程序,包括游戏。它包含旨在与 Python 编程语言一起使用的计算机图形和声音库。您可以使用 Pygame 开发许多很酷的游戏。
概述
Pygame 由多个模块组成,每个模块处理一组特定的任务。例如,display 模块处理显示窗口和屏幕,draw 模块提供绘制形状的函数,key 模块与键盘配合使用。这些只是该库的一些模块。
Pygame 库的主页位于 https://www.pygame.org/news
要制作 Pygame 应用程序,请按照以下步骤操作:
导入 Pygame 库
import pygame
初始化 Pygame 库
pygame.init()
创建窗口。
screen = Pygame.display.set_mode((560,480)) Pygame.display.set_caption(‘First Pygame Game’)
初始化游戏对象
在此步骤中,我们加载图像、加载声音、进行对象定位、设置一些状态变量等。
启动游戏循环。
它只是一个循环,我们不断处理事件、检查输入、移动对象并绘制它们。循环的每次迭代都称为一帧。
让我们将上述所有逻辑放在下面的一个程序中:
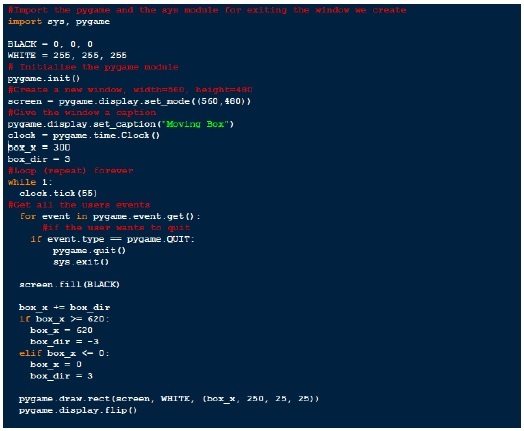
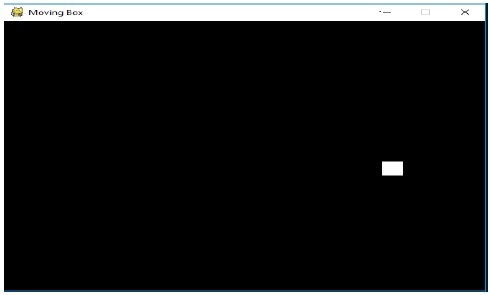
Pygame_script.py
输出
Beautiful Soup:使用 Beautiful Soup 进行网页抓取
网页抓取背后的基本思想是从网站上获取数据,并将其转换为可用于分析的某种格式。
它是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。使用您最喜欢的解析器,它提供以惯用方式导航、搜索和修改解析树的方法。
由于 BeautifulSoup 不是内置库,因此我们需要在尝试使用它之前安装它。要安装 BeautifulSoup,请运行以下命令
$ apt-get install Python-bs4 # For Linux and Python2 $ apt-get install Python3-bs4 # for Linux based system and Python3. $ easy_install beautifulsoup4 # For windows machine, Or $ pip instal beatifulsoup4 # For window machine
安装完成后,我们就可以运行一些示例并详细探索 Beautifulsoup 了:
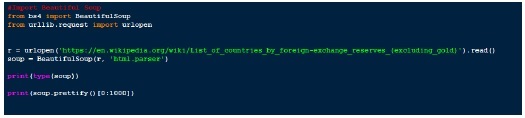
输出
以下是一些导航该数据结构的简单方法:
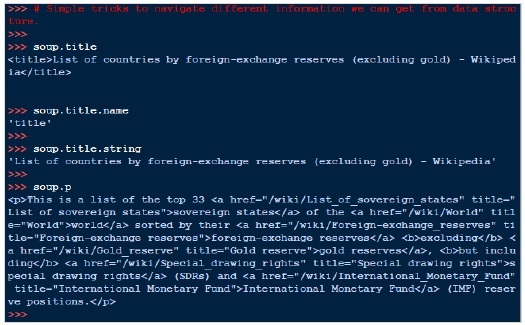
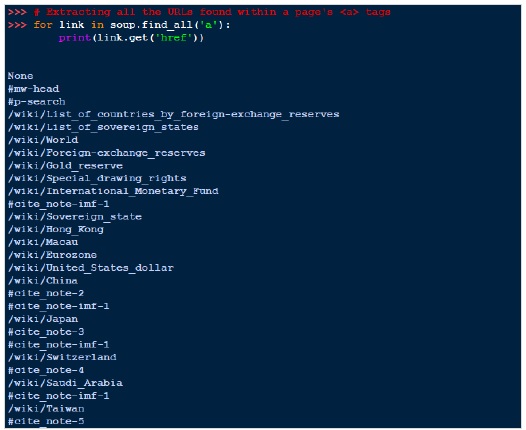
一个常见的任务是提取页面 <a> 标记中找到的所有 URL:
另一个常见的任务是从页面中提取所有文本: