- OpenNLP 教程
- OpenNLP - 首页
- OpenNLP - 概述
- OpenNLP - 环境配置
- OpenNLP - 参考 API
- OpenNLP - 句子检测
- OpenNLP - 分词
- 命名实体识别
- OpenNLP - 词性标注
- OpenNLP - 句子解析
- OpenNLP - 句子组块
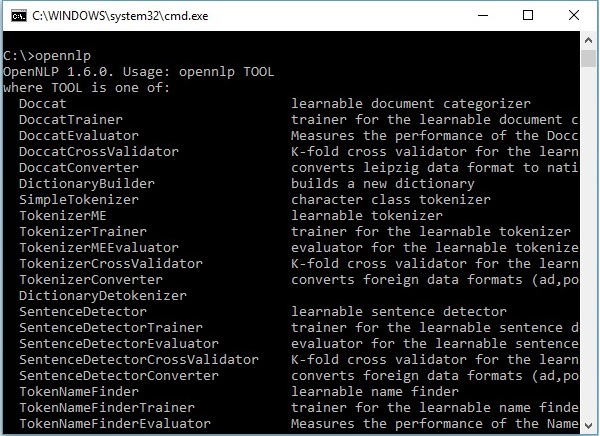
- OpenNLP - 命令行界面
- OpenNLP 有用资源
- OpenNLP 快速指南
- OpenNLP - 有用资源
- OpenNLP - 讨论
OpenNLP 快速指南
OpenNLP - 概述
NLP 是一套用于从自然语言来源(例如网页和文本文档)中提取有意义和有用信息的工具。
什么是 OpenNLP?
Apache OpenNLP 是一个开源的 Java 库,用于处理自然语言文本。您可以使用此库构建高效的文本处理服务。
OpenNLP 提供的服务包括分词、句子分割、词性标注、命名实体提取、组块、解析和共指消解等。
OpenNLP 的特性
以下是 OpenNLP 的显著特性:
命名实体识别 (NER) - OpenNLP 支持 NER,您可以使用它即使在处理查询时也能提取地点、人物和事物的名称。
摘要 - 使用摘要功能,您可以总结 NLP 中的段落、文章、文档或它们的集合。
搜索 - 在 OpenNLP 中,即使给定的单词被更改或拼写错误,也可以在给定的文本中识别给定的搜索字符串或其同义词。
标注 (POS) - NLP 中的标注用于将文本分解成各种语法元素以进行进一步分析。
翻译 - 在 NLP 中,翻译有助于将一种语言翻译成另一种语言。
信息分组 - NLP 中的此选项将文档内容中的文本信息分组,就像词性一样。
自然语言生成 - 它用于从数据库生成信息并自动化信息报告,例如天气分析或医疗报告。
反馈分析 - 顾名思义,NLP 收集了人们关于产品的各种反馈,以分析产品在赢得他们芳心的成功程度。
语音识别 - 虽然分析人类语音很困难,但 NLP 有一些内置功能可以满足此要求。
OpenNLP API
Apache OpenNLP 库提供类和接口来执行各种自然语言处理任务,例如句子检测、分词、查找名称、词性标注、句子组块、解析、共指消解和文档分类。
除了这些任务外,我们还可以为任何这些任务训练和评估我们自己的模型。
OpenNLP 命令行界面 (CLI)
除了库之外,OpenNLP 还提供了一个命令行界面 (CLI),我们可以在其中训练和评估模型。我们将在本教程的最后一章详细讨论这个主题。
OpenNLP 模型
为了执行各种 NLP 任务,OpenNLP 提供了一组预定义的模型。此集合包含针对不同语言的模型。
下载模型
您可以按照以下步骤下载 OpenNLP 提供的预定义模型。
步骤 1 - 点击以下链接打开 OpenNLP 模型的索引页面:http://opennlp.sourceforge.net/models-1.5/。
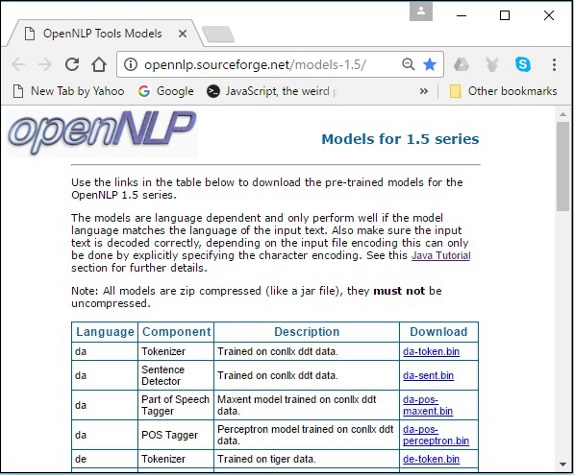
步骤 2 - 访问给定链接后,您将看到各种语言的组件列表及其下载链接。在这里,您可以获取 OpenNLP 提供的所有预定义模型的列表。
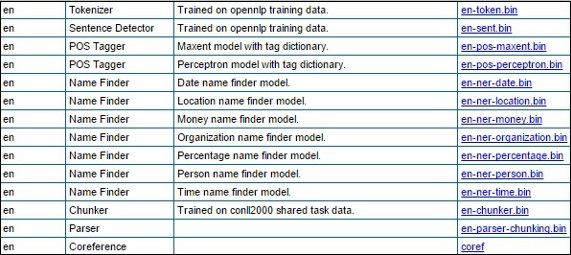
通过点击各自的链接,将所有这些模型下载到C:/OpenNLP_models/>文件夹中。所有这些模型都依赖于语言,使用这些模型时,您必须确保模型语言与输入文本的语言匹配。
OpenNLP 的历史
2010 年,OpenNLP 进入 Apache 孵化器。
2011 年,Apache OpenNLP 1.5.2 孵化版发布,同年毕业成为顶级 Apache 项目。
2015 年,OpenNLP 1.6.0 发布。
OpenNLP - 环境配置
在本节中,我们将讨论如何在您的系统中设置 OpenNLP 环境。让我们从安装过程开始。
安装 OpenNLP
以下是将Apache OpenNLP 库下载到您的系统的步骤。
步骤 1 - 点击以下链接打开Apache OpenNLP的主页:https://opennlp.apache.org/。
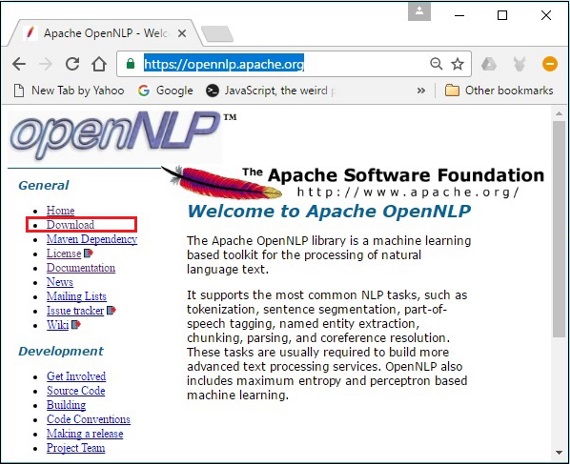
步骤 2 - 现在,点击下载链接。点击后,您将被定向到一个页面,您可以在其中找到各种镜像,这些镜像将重定向您到 Apache 软件基金会分发目录。
步骤 3 - 在此页面中,您可以找到下载各种 Apache 分发的链接。浏览它们并找到 OpenNLP 分发版并点击它。
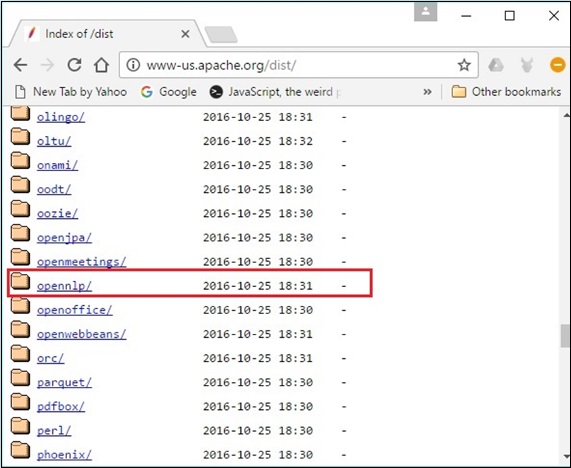
步骤 4 - 点击后,您将被重定向到一个目录,您可以在其中看到 OpenNLP 分发的索引,如下所示。
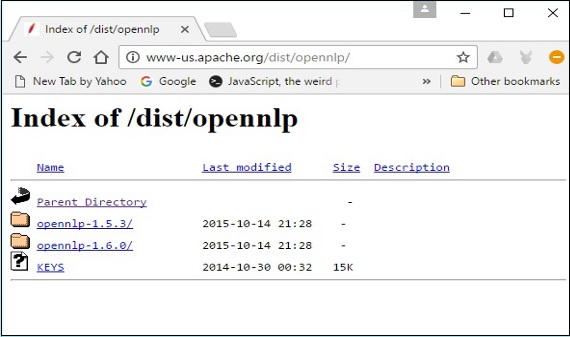
从可用的分发版中点击最新版本。
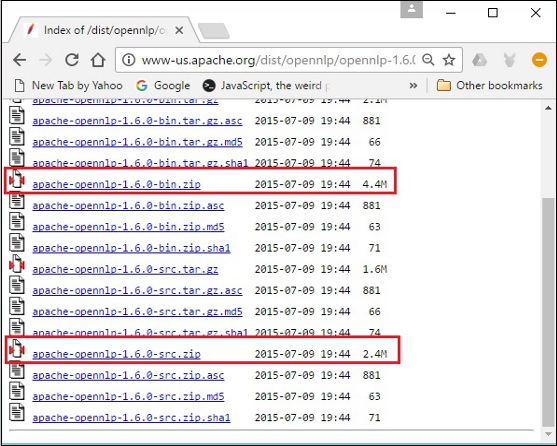
步骤 5 - 每个分发版都提供各种格式的 OpenNLP 库的源文件和二进制文件。下载源文件和二进制文件,apache-opennlp-1.6.0-bin.zip 和 apache-opennlp1.6.0-src.zip(适用于 Windows)。
设置类路径
下载 OpenNLP 库后,您需要将其路径设置为bin目录。假设您已将 OpenNLP 库下载到系统的 E 盘。
现在,按照以下步骤操作:
步骤 1 - 右键单击“我的电脑”并选择“属性”。
步骤 2 - 在“高级”选项卡下点击“环境变量”按钮。
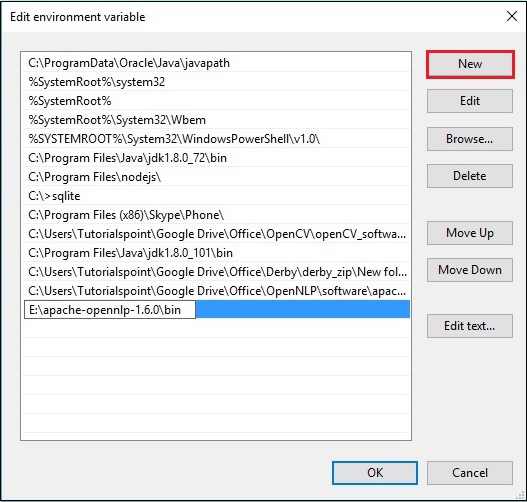
步骤 3 - 选择path变量并点击编辑按钮,如下图所示。
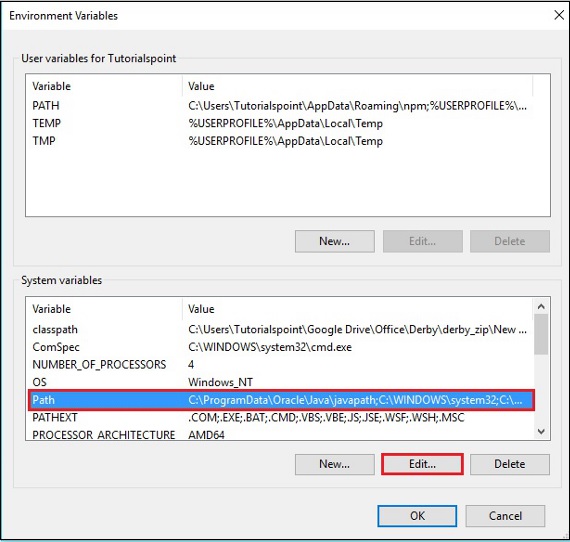
步骤 4 - 在“编辑环境变量”窗口中,点击新建按钮并添加 OpenNLP 目录的路径E:\apache-opennlp-1.6.0\bin,然后点击确定按钮,如下图所示。
Eclipse 安装
您可以通过将构建路径设置为 JAR 文件或使用pom.xml来设置 OpenNLP 库的 Eclipse 环境。
将构建路径设置为 JAR 文件
按照以下步骤在 Eclipse 中安装 OpenNLP:
步骤 1 - 确保您的系统中已安装 Eclipse 环境。
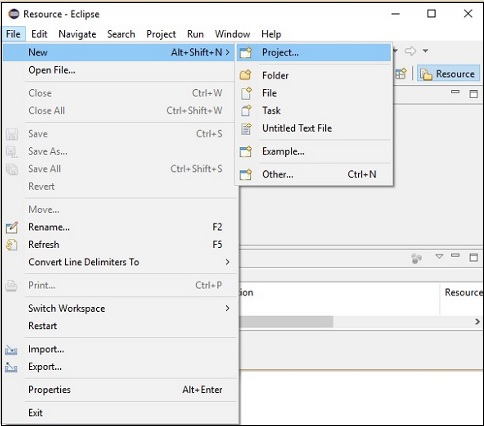
步骤 2 - 打开 Eclipse。点击文件 → 新建 → 打开一个新项目,如下所示。
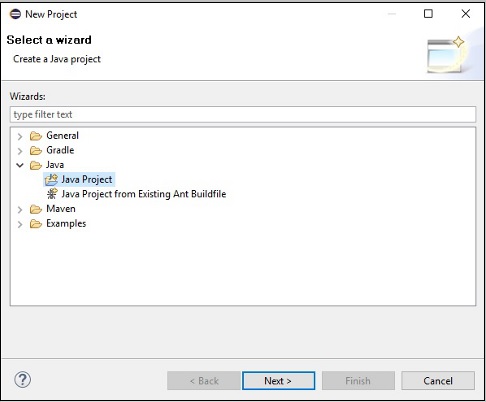
步骤 3 - 您将获得新建项目向导。在此向导中,选择 Java 项目,然后点击下一步按钮继续。
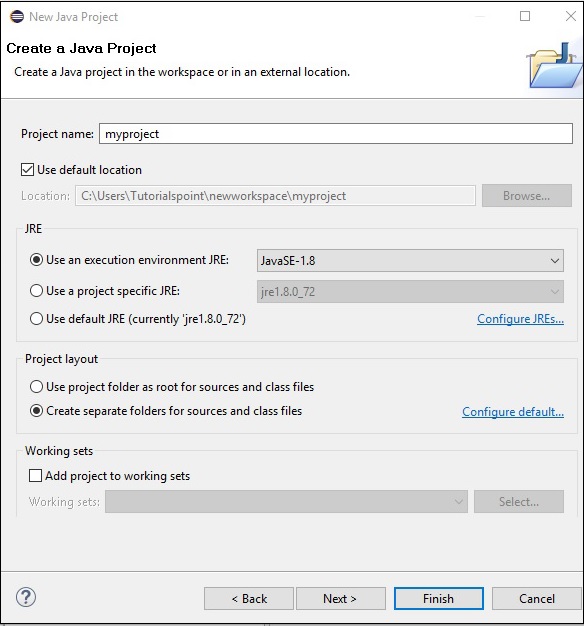
步骤 4 - 接下来,您将获得新建 Java 项目向导。在这里,您需要创建一个新项目并点击下一步按钮,如下所示。
步骤 5 - 创建新项目后,右键单击它,选择构建路径,然后点击配置构建路径。
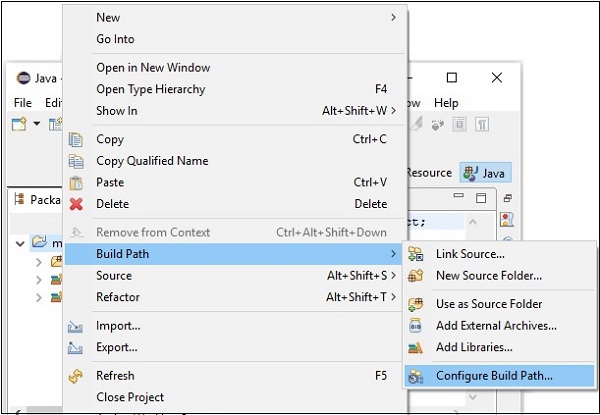
步骤 6 - 接下来,您将获得Java 构建路径向导。在这里,点击添加外部 JARs按钮,如下所示。
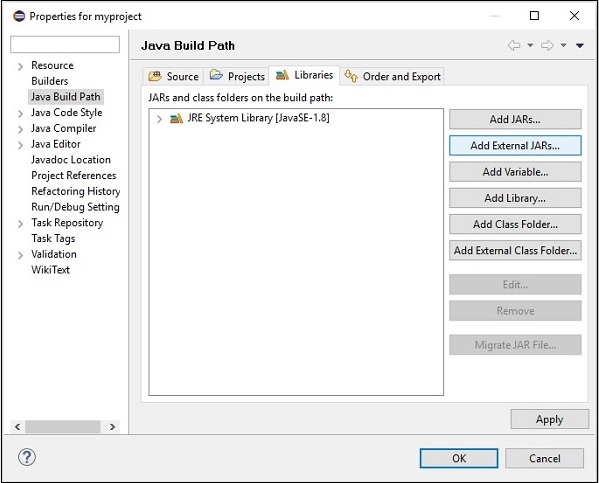
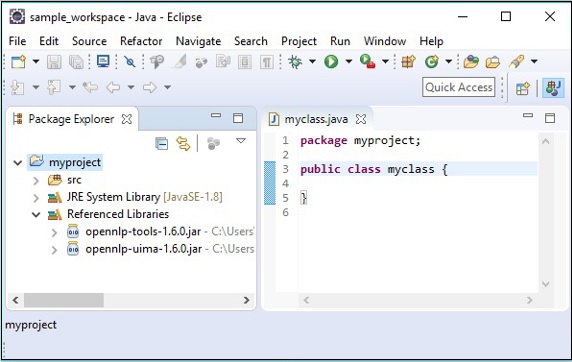
步骤 7 - 选择位于apache-opennlp-1.6.0文件夹的lib文件夹中的 jar 文件opennlp-tools-1.6.0.jar和opennlp-uima-1.6.0.jar。
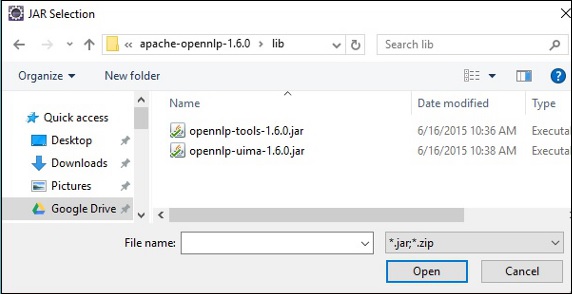
在上面屏幕中点击打开按钮,所选文件将添加到您的库中。
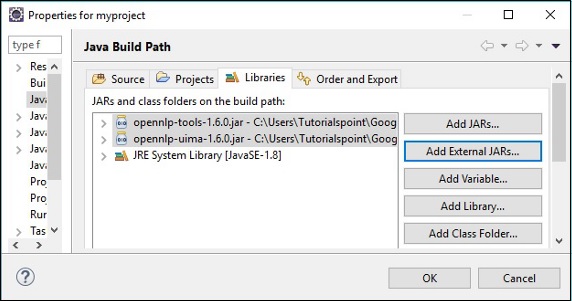
点击确定,您将成功地将所需的 JAR 文件添加到当前项目中,您可以通过展开“引用库”来验证这些已添加的库,如下所示。
使用 pom.xml
将项目转换为 Maven 项目并将以下代码添加到其pom.xml中。
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>myproject</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-uima</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>
OpenNLP - 参考 API
在本节中,我们将讨论在本教程后续章节中将使用的类和方法。
句子检测
SentenceModel 类
此类表示用于检测给定原始文本中句子的预定义模型。此类属于包opennlp.tools.sentdetect。
此类的构造函数接受句子检测模型文件 (en-sent.bin) 的InputStream对象。
SentenceDetectorME 类
此类属于包opennlp.tools.sentdetect,它包含用于将原始文本分割成句子 的方法。此类使用最大熵模型来评估字符串中的句子结束字符,以确定它们是否表示句子的结尾。
以下是此类的重要方法。
| 序号 | 方法和说明 |
|---|---|
| 1 |
sentDetect() 此方法用于检测传递给它的原始文本中的句子。它接受一个 String 变量作为参数,并返回一个 String 数组,其中包含给定原始文本中的句子。 |
| 2 |
sentPosDetect() 此方法用于检测给定文本中句子的位置。此方法接受一个表示句子的字符串变量,并返回一个类型为Span的对象数组。 名为Span的opennlp.tools.util包中的类用于存储集合的开始和结束整数。 |
| 3 |
getSentenceProbabilities() 此方法返回与最近对sentDetect()方法的调用相关的概率。 |
分词
TokenizerModel 类
此类表示用于对给定句子进行分词的预定义模型。此类属于包opennlp.tools.tokenizer。
此类的构造函数接受分词模型文件 (entoken.bin) 的InputStream对象。
类
为了执行分词,OpenNLP 库提供了三个主要的类。所有这三个类都实现了名为Tokenizer的接口。
| 序号 | 类和说明 |
|---|---|
| 1 |
SimpleTokenizer 此类使用字符类对给定的原始文本进行分词。 |
| 2 |
WhitespaceTokenizer 此类使用空格对给定的文本进行分词。 |
| 3 |
TokenizerME 此类将原始文本转换为单独的标记。它使用最大熵来做出决定。 |
这些类包含以下方法。
| 序号 | 方法和说明 |
|---|---|
| 1 |
tokenize() 此方法用于对原始文本进行分词。此方法接受一个 String 变量作为参数,并返回一个 String 数组(标记)。 |
| 2 |
sentPosDetect() 此方法用于获取标记的位置或跨度。它以字符串形式接受句子(或)原始文本,并返回一个类型为Span的对象数组。 |
除了上述两种方法外,TokenizerME类还具有getTokenProbabilities()方法。
| 序号 | 方法和说明 |
|---|---|
| 1 |
getTokenProbabilities() 此方法用于获取与最近对tokenizePos()方法的调用相关的概率。 |
命名实体识别
TokenNameFinderModel 类
此类表示用于查找给定句子中命名实体的预定义模型。此类属于包opennlp.tools.namefind。
此类的构造函数接受名称查找模型文件 (enner-person.bin) 的InputStream对象。
NameFinderME 类
该类属于包opennlp.tools.namefind,包含执行命名实体识别 (NER) 任务的方法。此类使用最大熵模型来查找给定原始文本中的命名实体。
| 序号 | 方法和说明 |
|---|---|
| 1 |
find() 此方法用于检测原始文本中的命名实体。它接受一个表示原始文本的字符串变量作为参数,并返回一个Span类型对象的数组。 |
| 2 |
probs() 此方法用于获取最后解码序列的概率。 |
词性标注
POSModel 类
此类表示预定义模型,用于标注给定句子的词性。此类属于包opennlp.tools.postag。
此类的构造函数接受词性标注模型文件 (enpos-maxent.bin) 的InputStream对象。
POSTaggerME 类
此类属于包opennlp.tools.postag,用于预测给定原始文本的词性。它使用最大熵模型进行决策。
| 序号 | 方法和说明 |
|---|---|
| 1 |
tag() 此方法用于为句子的标记分配词性标签。此方法接受一个标记(字符串)数组作为参数,并返回一个标签数组。 |
| 2 |
getSentenceProbabilities() 此方法用于获取最近标注句子的每个标签的概率。 |
句子解析
ParserModel 类
此类表示预定义模型,用于解析给定句子。此类属于包opennlp.tools.parser。
此类的构造函数接受解析器模型文件 (en-parserchunking.bin) 的InputStream对象。
Parser Factory 类
此类属于包opennlp.tools.parser,用于创建解析器。
| 序号 | 方法和说明 |
|---|---|
| 1 |
create() 这是一个静态方法,用于创建解析器对象。此方法接受解析器模型文件的Filestream对象。 |
ParserTool 类
此类属于opennlp.tools.cmdline.parser包,用于解析内容。
| 序号 | 方法和说明 |
|---|---|
| 1 |
parseLine() ParserTool类的此方法用于在OpenNLP中解析原始文本。此方法接受:
|
分块
ChunkerModel 类
此类表示预定义模型,用于将句子分成较小的块。此类属于包opennlp.tools.chunker。
此类的构造函数接受分块模型文件 (enchunker.bin) 的InputStream对象。
ChunkerME 类
此类属于名为opennlp.tools.chunker的包,用于将给定句子分成较小的块。
| 序号 | 方法和说明 |
|---|---|
| 1 |
chunk() 此方法用于将给定句子分成较小的块。它接受句子的标记和词性标签作为参数。 |
| 2 |
probs() 此方法返回最后解码序列的概率。 |
OpenNLP - 句子检测
在处理自然语言时,确定句子的开始和结束是一个需要解决的问题。此过程称为句子边界消歧 (SBD) 或简单的句子分割。
我们用于检测给定文本中句子的技术取决于文本的语言。
使用Java进行句子检测
我们可以使用正则表达式和一组简单的规则在Java中检测给定文本中的句子。
例如,让我们假设句点、问号或感叹号在给定文本中表示句子的结尾,那么我们可以使用String类的split()方法分割句子。在这里,我们必须以字符串格式传递正则表达式。
以下是使用Java正则表达式(split方法)确定给定文本中句子的程序。将此程序保存到名为SentenceDetection_RE.java的文件中。
public class SentenceDetection_RE {
public static void main(String args[]){
String sentence = " Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
String simple = "[.?!]";
String[] splitString = (sentence.split(simple));
for (String string : splitString)
System.out.println(string);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件。
javac SentenceDetection_RE.java java SentenceDetection_RE
执行后,上述程序将创建一个PDF文档,显示以下消息。
Hi How are you Welcome to Tutorialspoint We provide free tutorials on various technologies
使用OpenNLP进行句子检测
为了检测句子,OpenNLP使用一个预定义模型,一个名为en-sent.bin的文件。此预定义模型经过训练,可以检测给定原始文本中的句子。
opennlp.tools.sentdetect包包含用于执行句子检测任务的类和接口。
要使用OpenNLP库检测句子,您需要:
使用SentenceModel类加载en-sent.bin模型
实例化SentenceDetectorME类。
使用此类的sentDetect()方法检测句子。
以下是编写检测给定原始文本中句子的程序需要遵循的步骤。
步骤1:加载模型
句子检测模型由名为SentenceModel的类表示,该类属于opennlp.tools.sentdetect包。
要加载句子检测模型:
创建模型的InputStream对象(实例化FileInputStream并将模型路径以字符串格式传递给其构造函数)。
实例化SentenceModel类,并将模型的InputStream(对象)作为参数传递给其构造函数,如下面的代码块所示:
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/ensent.bin");
SentenceModel model = new SentenceModel(inputStream);
步骤2:实例化SentenceDetectorME类
opennlp.tools.sentdetect包中的SentenceDetectorME类包含将原始文本分割成句子方法。此类使用最大熵模型来评估字符串中的句子结束字符,以确定它们是否表示句子的结尾。
实例化此类,并将上一步中创建的模型对象作为参数传递,如下所示。
//Instantiating the SentenceDetectorME class SentenceDetectorME detector = new SentenceDetectorME(model);
步骤3:检测句子
SentenceDetectorME类的sentDetect()方法用于检测传递给它的原始文本中的句子。此方法接受一个字符串变量作为参数。
通过将句子的字符串格式传递给此方法来调用此方法。
//Detecting the sentence String sentences[] = detector.sentDetect(sentence);
示例
以下是检测给定原始文本中句子的程序。将此程序保存到名为SentenceDetectionME.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionME {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac SentenceDetectorME.java java SentenceDetectorME
执行后,上述程序读取给定的字符串并检测其中的句子,并显示以下输出。
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
检测句子的位置
我们还可以使用SentenceDetectorME类的sentPosDetect()方法检测句子的位置。
以下是编写检测给定原始文本中句子位置的程序需要遵循的步骤。
步骤1:加载模型
句子检测模型由名为SentenceModel的类表示,该类属于opennlp.tools.sentdetect包。
要加载句子检测模型:
创建模型的InputStream对象(实例化FileInputStream并将模型路径以字符串格式传递给其构造函数)。
实例化SentenceModel类,并将模型的InputStream(对象)作为参数传递给其构造函数,如下面的代码块所示。
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
步骤2:实例化SentenceDetectorME类
opennlp.tools.sentdetect包中的SentenceDetectorME类包含将原始文本分割成句子方法。此类使用最大熵模型来评估字符串中的句子结束字符,以确定它们是否表示句子的结尾。
实例化此类,并将上一步中创建的模型对象作为参数传递。
//Instantiating the SentenceDetectorME class SentenceDetectorME detector = new SentenceDetectorME(model);
步骤3:检测句子的位置
SentenceDetectorME类的sentPosDetect()方法用于检测传递给它的原始文本中句子的位置。此方法接受一个字符串变量作为参数。
通过将句子的字符串格式作为参数传递给此方法来调用此方法。
//Detecting the position of the sentences in the paragraph Span[] spans = detector.sentPosDetect(sentence);
步骤4:打印句子的范围
SentenceDetectorME类的sentPosDetect()方法返回一个Span类型对象的数组。opennlp.tools.util包中名为Span的类用于存储集合的开始和结束整数。
您可以将sentPosDetect()方法返回的范围存储在Span数组中并打印它们,如下面的代码块所示。
//Printing the sentences and their spans of a sentence for (Span span : spans) System.out.println(paragraph.substring(span);
示例
以下是检测给定原始文本中句子的程序。将此程序保存到名为SentenceDetectionME.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencePosDetection {
public static void main(String args[]) throws Exception {
String paragraph = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the raw text
Span spans[] = detector.sentPosDetect(paragraph);
//Printing the spans of the sentences in the paragraph
for (Span span : spans)
System.out.println(span);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac SentencePosDetection.java java SentencePosDetection
执行后,上述程序读取给定的字符串并检测其中的句子,并显示以下输出。
[0..16) [17..43) [44..93)
句子及其位置
String类的substring()方法接受开始和结束偏移量并返回相应的字符串。我们可以使用此方法来一起打印句子及其范围(位置),如下面的代码块所示。
for (Span span : spans) System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
以下是检测给定原始文本中的句子并显示它们及其位置的程序。将此程序保存到名为SentencesAndPosDetection.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencesAndPosDetection {
public static void main(String args[]) throws Exception {
String sen = "Hi. How are you? Welcome to Tutorialspoint."
+ " We provide free tutorials on various technologies";
//Loading a sentence model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sen);
//Printing the sentences and their spans of a paragraph
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac SentencesAndPosDetection.java java SentencesAndPosDetection
执行后,上述程序读取给定的字符串并检测句子及其位置,并显示以下输出。
Hi. How are you? [0..16) Welcome to Tutorialspoint. [17..43) We provide free tutorials on various technologies [44..93)
句子概率检测
SentenceDetectorME类的getSentenceProbabilities()方法返回与最近对sentDetect()方法的调用的关联概率。
//Getting the probabilities of the last decoded sequence double[] probs = detector.getSentenceProbabilities();
以下是打印与对sentDetect()方法的调用相关的概率的程序。将此程序保存到名为SentenceDetectionMEProbs.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionMEProbs {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac SentenceDetectionMEProbs.java java SentenceDetectionMEProbs
执行后,上述程序读取给定的字符串并检测句子并打印它们。此外,它还返回与最近对sentDetect()方法调用的关联概率,如下所示。
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies 0.9240246995179983 0.9957680129995953 1.0
OpenNLP - 分词
将给定句子分解成较小的部分(标记)的过程称为分词。通常,给定的原始文本是基于一组分隔符(主要是空格)进行分词的。
分词用于拼写检查、处理搜索、识别词性、句子检测、文档分类等任务。
使用OpenNLP进行分词
opennlp.tools.tokenize包包含用于执行分词的类和接口。
为了将给定的句子分解成更简单的片段,OpenNLP库提供了三个不同的类:
SimpleTokenizer - 此类使用字符类对给定的原始文本进行分词。
WhitespaceTokenizer - 此类使用空格对给定的文本进行分词。
TokenizerME - 此类将原始文本转换成单独的标记。它使用最大熵模型进行决策。
SimpleTokenizer
要使用SimpleTokenizer类对句子进行分词,您需要:
创建一个相应类的对象。
使用tokenize()方法对句子进行分词。
打印分词结果。
以下是编写程序对给定原始文本进行分词的步骤。
步骤 1 − 实例化相应类
在这两个类中,都没有可用的构造函数来实例化它们。因此,我们需要使用静态变量INSTANCE来创建这些类的对象。
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;
步骤 2 − 对句子进行分词
这两个类都包含一个名为tokenize()的方法。此方法接受字符串格式的原始文本。调用此方法时,它会对给定的字符串进行分词,并返回一个字符串数组(分词结果)。
使用tokenizer()方法对句子进行分词,如下所示。
//Tokenizing the given sentence String tokens[] = tokenizer.tokenize(sentence);
步骤 3 − 打印分词结果
对句子进行分词后,您可以使用for循环打印分词结果,如下所示。
//Printing the tokens for(String token : tokens) System.out.println(token);
示例
以下是使用SimpleTokenizer类对给定句子进行分词的程序。将此程序保存到名为SimpleTokenizerExample.java的文件中。
import opennlp.tools.tokenize.SimpleTokenizer;
public class SimpleTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Tokenizing the given sentence
String tokens[] = simpleTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens) {
System.out.println(token);
}
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac SimpleTokenizerExample.java java SimpleTokenizerExample
执行上述程序后,程序会读取给定的字符串(原始文本),对其进行分词,并显示以下输出:
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologies
WhitespaceTokenizer
要使用WhitespaceTokenizer类对句子进行分词,您需要:
创建一个相应类的对象。
使用tokenize()方法对句子进行分词。
打印分词结果。
以下是编写程序对给定原始文本进行分词的步骤。
步骤 1 − 实例化相应类
在这两个类中,都没有可用的构造函数来实例化它们。因此,我们需要使用静态变量INSTANCE来创建这些类的对象。
WhitespaceTokenizer tokenizer = WhitespaceTokenizer.INSTANCE;
步骤 2 − 对句子进行分词
这两个类都包含一个名为tokenize()的方法。此方法接受字符串格式的原始文本。调用此方法时,它会对给定的字符串进行分词,并返回一个字符串数组(分词结果)。
使用tokenizer()方法对句子进行分词,如下所示。
//Tokenizing the given sentence String tokens[] = tokenizer.tokenize(sentence);
步骤 3 − 打印分词结果
对句子进行分词后,您可以使用for循环打印分词结果,如下所示。
//Printing the tokens for(String token : tokens) System.out.println(token);
示例
以下是使用WhitespaceTokenizer类对给定句子进行分词的程序。将此程序保存到名为WhitespaceTokenizerExample.java的文件中。
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class WhitespaceTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating whitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Tokenizing the given paragraph
String tokens[] = whitespaceTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens)
System.out.println(token);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac WhitespaceTokenizerExample.java java WhitespaceTokenizerExample
执行上述程序后,程序会读取给定的字符串(原始文本),对其进行分词,并显示以下输出。
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
TokenizerME类
OpenNLP也使用预定义模型(名为de-token.bin的文件)对句子进行分词。它经过训练,可以对给定原始文本中的句子进行分词。
opennlp.tools.tokenizer包的TokenizerME类用于加载此模型,并使用OpenNLP库对给定的原始文本进行分词。为此,您需要:
使用TokenizerModel类加载en-token.bin模型。
实例化TokenizerME类。
使用此类的tokenize()方法对句子进行分词。
以下是使用TokenizerME类对给定原始文本中的句子进行分词的程序步骤。
步骤 1 − 加载模型
分词模型由名为TokenizerModel的类表示,该类属于opennlp.tools.tokenize包。
要加载分词模型:
创建模型的InputStream对象(实例化FileInputStream并将模型路径以字符串格式传递给其构造函数)。
实例化TokenizerModel类,并将模型的InputStream(对象)作为参数传递给其构造函数,如下面的代码块所示。
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
步骤 2 − 实例化TokenizerME类
opennlp.tools.tokenize包的TokenizerME类包含将原始文本分割成较小部分(分词)的方法。它使用最大熵来做出决策。
实例化此类,并将上一步中创建的模型对象作为参数传递,如下所示。
//Instantiating the TokenizerME class TokenizerME tokenizer = new TokenizerME(tokenModel);
步骤 3 − 对句子进行分词
TokenizerME类的tokenize()方法用于对传递给它的原始文本进行分词。此方法接受一个字符串变量作为参数,并返回一个字符串数组(分词结果)。
通过将句子的字符串格式传递给此方法来调用此方法,如下所示。
//Tokenizing the given raw text String tokens[] = tokenizer.tokenize(paragraph);
示例
以下是对给定原始文本进行分词的程序。将此程序保存到名为TokenizerMEExample.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
public class TokenizerMEExample {
public static void main(String args[]) throws Exception{
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(sentence);
//Printing the tokens
for (String a : tokens)
System.out.println(a);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac TokenizerMEExample.java java TokenizerMEExample
执行上述程序后,程序会读取给定的字符串,检测其中的句子,并显示以下输出:
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologie
检索分词的位置
我们还可以使用tokenizePos()方法获取分词的位置或范围。这是opennlp.tools.tokenize包中Tokenizer接口的方法。由于所有(三个)Tokenizer类都实现了此接口,因此您可以在所有类中找到此方法。
此方法接受字符串形式的句子或原始文本,并返回一个类型为Span的对象数组。
您可以使用tokenizePos()方法获取分词的位置,如下所示:
//Retrieving the tokens tokenizer.tokenizePos(sentence);
打印位置(范围)
名为Span的opennlp.tools.util包中的类用于存储集合的开始和结束整数。
您可以将tokenizePos()方法返回的范围存储在Span数组中并打印它们,如下面的代码块所示。
//Retrieving the tokens Span[] tokens = tokenizer.tokenizePos(sentence); //Printing the spans of tokens for( Span token : tokens) System.out.println(token);
一起打印分词及其位置
String类的substring()方法接受起始和结束偏移量,并返回相应的字符串。我们可以使用此方法一起打印分词及其范围(位置),如下面的代码块所示。
//Printing the spans of tokens for(Span token : tokens) System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
示例(SimpleTokenizer)
以下是使用SimpleTokenizer类检索原始文本的分词范围的程序。它还会打印分词及其位置。将此程序保存到名为SimpleTokenizerSpans.java的文件中。
import opennlp.tools.tokenize.SimpleTokenizer;
import opennlp.tools.util.Span;
public class SimpleTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Retrieving the boundaries of the tokens
Span[] tokens = simpleTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac SimpleTokenizerSpans.java java SimpleTokenizerSpans
执行上述程序后,程序会读取给定的字符串(原始文本),对其进行分词,并显示以下输出:
[0..2) Hi [2..3) . [4..7) How [8..11) are [12..15) you [15..16) ? [17..24) Welcome [25..27) to [28..42) Tutorialspoint [42..43) . [44..46) We [47..54) provide [55..59) free [60..69) tutorials [70..72) on [73..80) various [81..93) technologies
示例(WhitespaceTokenizer)
以下是使用WhitespaceTokenizer类检索原始文本的分词范围的程序。它还会打印分词及其位置。将此程序保存到名为WhitespaceTokenizerSpans.java的文件中。
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class WhitespaceTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Retrieving the tokens
Span[] tokens = whitespaceTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
}
}
使用以下命令从命令提示符编译并执行保存的java文件
javac WhitespaceTokenizerSpans.java java WhitespaceTokenizerSpans
执行上述程序后,程序会读取给定的字符串(原始文本),对其进行分词,并显示以下输出。
[0..3) Hi. [4..7) How [8..11) are [12..16) you? [17..24) Welcome [25..27) to [28..43) Tutorialspoint. [44..46) We [47..54) provide [55..59) free [60..69) tutorials [70..72) on [73..80) various [81..93) technologies
示例(TokenizerME)
以下是使用TokenizerME类检索原始文本的分词范围的程序。它还会打印分词及其位置。将此程序保存到名为TokenizerMESpans.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMESpans {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac TokenizerMESpans.java java TokenizerMESpans
执行上述程序后,程序会读取给定的字符串(原始文本),对其进行分词,并显示以下输出:
[0..5) Hello [6..10) John [11..14) how [15..18) are [19..22) you [23..30) welcome [31..33) to [34..48) Tutorialspoint
分词概率
TokenizerME类的getTokenProbabilities()方法用于获取与最近对tokenizePos()方法的调用的关联概率。
//Getting the probabilities of the recent calls to tokenizePos() method double[] probs = detector.getSentenceProbabilities();
以下是打印与tokenizePos()方法调用相关的概率的程序。将此程序保存到名为TokenizerMEProbs.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac TokenizerMEProbs.java java TokenizerMEProbs
执行上述程序后,程序会读取给定的字符串,对句子进行分词并打印它们。此外,它还会返回与最近对tokenizerPos()方法的调用的关联概率。
[0..5) Hello [6..10) John [11..14) how [15..18) are [19..22) you [23..30) welcome [31..33) to [34..48) Tutorialspoint 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
OpenNLP - 命名实体识别
从给定文本中查找名称、人物、地点和其他实体的过程称为命名实体识别 (NER)。本章将讨论如何使用OpenNLP库通过Java程序执行NER。
使用OpenNLP进行命名实体识别
为了执行各种NER任务,OpenNLP使用不同的预定义模型,例如en-ner-date.bin、en-ner-location.bin、en-ner-organization.bin、en-ner-person.bin和en-ner-time.bin。所有这些文件都是预定义模型,经过训练可以检测给定原始文本中的相应实体。
opennlp.tools.namefind包包含用于执行NER任务的类和接口。要使用OpenNLP库执行NER任务,您需要:
使用TokenNameFinderModel类加载相应的模型。
实例化NameFinder类。
查找名称并打印它们。
以下是编写程序从给定原始文本中检测命名实体的步骤。
步骤1:加载模型
句子检测模型由名为TokenNameFinderModel的类表示,该类属于opennlp.tools.namefind包。
要加载NER模型:
创建模型的InputStream对象(实例化FileInputStream并将相应NER模型的路径(字符串格式)传递给其构造函数)。
实例化TokenNameFinderModel类,并将模型的InputStream(对象)作为参数传递给其构造函数,如下面的代码块所示。
//Loading the NER-person model
InputStream inputStreamNameFinder = new FileInputStream(".../en-nerperson.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
步骤 2:实例化NameFinderME类
opennlp.tools.namefind包的NameFinderME类包含执行NER任务的方法。此类使用最大熵模型在给定的原始文本中查找命名实体。
实例化此类,并将上一步中创建的模型对象作为参数传递,如下所示:
//Instantiating the NameFinderME class NameFinderME nameFinder = new NameFinderME(model);
步骤 3:查找句子中的名称
NameFinderME类的find()方法用于检测传递给它的原始文本中的名称。此方法接受一个字符串变量作为参数。
通过将句子的字符串格式传递给此方法来调用此方法。
//Finding the names in the sentence Span nameSpans[] = nameFinder.find(sentence);
步骤 4:打印句子中名称的范围
NameFinderME类的find()方法返回一个类型为Span的对象数组。opennlp.tools.util包中的Span类用于存储整数集合的起始和结束位置。
您可以将find()方法返回的范围存储在Span数组中并打印它们,如下面的代码块所示。
//Printing the sentences and their spans of a sentence for (Span span : spans) System.out.println(paragraph.substring(span);
NER示例
以下是读取给定句子并识别其中人名范围的程序。将此程序保存到名为NameFinderME_Example.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.util.Span;
public class NameFinderME_Example {
public static void main(String args[]) throws Exception{
/Loading the NER - Person model InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStream);
//Instantiating the NameFinder class
NameFinderME nameFinder = new NameFinderME(model);
//Getting the sentence in the form of String array
String [] sentence = new String[]{
"Mike",
"and",
"Smith",
"are",
"good",
"friends"
};
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);
//Printing the spans of the names in the sentence
for(Span s: nameSpans)
System.out.println(s.toString());
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac NameFinderME_Example.java java NameFinderME_Example
执行上述程序后,程序会读取给定的字符串(原始文本),检测其中的人名,并显示它们的位置(范围),如下所示。
[0..1) person [2..3) person
名称及其位置
String类的substring()方法接受起始和结束偏移量,并返回相应的字符串。我们可以使用此方法一起打印名称及其范围(位置),如下面的代码块所示。
for(Span s: nameSpans) System.out.println(s.toString()+" "+tokens[s.getStart()]);
以下是检测给定原始文本中的名称并将其与其位置一起显示的程序。将此程序保存到名为NameFinderSentences.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class NameFinderSentences {
public static void main(String args[]) throws Exception{
//Loading the tokenizer model
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the sentence in to a string array
String sentence = "Mike is senior programming
manager and Rama is a clerk both are working at
Tutorialspoint";
String tokens[] = tokenizer.tokenize(sentence);
//Loading the NER-person model
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/enner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(tokens);
//Printing the names and their spans in a sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac NameFinderSentences.java java NameFinderSentences
执行上述程序后,程序会读取给定的字符串(原始文本),检测其中的人名,并显示它们的位置(范围),如下所示。
[0..1) person Mike
查找地点名称
通过加载各种模型,您可以检测各种命名实体。以下是一个Java程序,它加载en-ner-location.bin模型并检测给定句子中的地点名称。将此程序保存到名为LocationFinder.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class LocationFinder {
public static void main(String args[]) throws Exception{
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//String paragraph = "Mike and Smith are classmates";
String paragraph = "Tutorialspoint is located in Hyderabad";
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
String tokens[] = tokenizer.tokenize(paragraph);
//Loading the NER-location moodel
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/en- ner-location.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names of a location
Span nameSpans[] = nameFinder.find(tokens);
//Printing the spans of the locations in the sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac LocationFinder.java java LocationFinder
执行上述程序后,程序会读取给定的字符串(原始文本),检测其中的人名,并显示它们的位置(范围),如下所示。
[4..5) location Hyderabad
NameFinder概率
NameFinderME类的probs()方法用于获取最后解码序列的概率。
double[] probs = nameFinder.probs();
以下是打印概率的程序。将此程序保存到名为TokenizerMEProbs.java的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac TokenizerMEProbs.java java TokenizerMEProbs
执行上述程序后,程序会读取给定的字符串,对句子进行分词并打印它们。此外,它还会返回最后解码序列的概率,如下所示。
[0..5) Hello [6..10) John [11..14) how [15..18) are [19..22) you [23..30) welcome [31..33) to [34..48) Tutorialspoint 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
OpenNLP - 词性标注
使用OpenNLP,您还可以检测给定句子的词性并打印它们。OpenNLP不使用词性的全称,而是使用每个词性的缩写。下表显示了OpenNLP检测到的各种词性及其含义。
| 词性 | 词性含义 |
|---|---|
| NN | 名词,单数或不可数 |
| DT | 限定词 |
| VB | 动词,基本形式 |
| VBD | 动词,过去时 |
| VBZ | 动词,第三人称单数现在时 |
| IN | 介词或从属连词 |
| NNP | 专有名词,单数 |
| TO | to |
| JJ | 形容词 |
词性标注
为了标注句子的词性,OpenNLP 使用一个模型,名为 en-posmaxent.bin 的文件。这是一个预定义的模型,经过训练可以标注给定原始文本的词性。
opennlp.tools.postag 包中的 POSTaggerME 类用于加载此模型,并使用 OpenNLP 库标注给定原始文本的词性。为此,您需要:
使用 POSModel 类加载 en-pos-maxent.bin 模型。
实例化 POSTaggerME 类。
分词句子。
使用 tag() 方法生成标签。
使用 POSSample 类打印标记和标签。
以下是使用 POSTaggerME 类编写程序来标注给定原始文本中词性的步骤。
步骤 1:加载模型
词性标注模型由名为 POSModel 的类表示,该类属于 opennlp.tools.postag 包。
要加载分词模型:
创建模型的InputStream对象(实例化FileInputStream并将模型路径以字符串格式传递给其构造函数)。
实例化 POSModel 类并将模型的 InputStream(对象)作为参数传递给其构造函数,如下面的代码块所示:
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
步骤 2:实例化 POSTaggerME 类
opennlp.tools.postag 包中的 POSTaggerME 类用于预测给定原始文本的词性。它使用最大熵来做出决策。
实例化此类并将上一步创建的模型对象作为参数传递,如下所示:
//Instantiating POSTaggerME class POSTaggerME tagger = new POSTaggerME(model);
步骤 3:分词句子
whitespaceTokenizer 类的 tokenize() 方法用于对传递给它的原始文本进行分词。此方法接受一个字符串变量作为参数,并返回一个字符串数组(标记)。
实例化 whitespaceTokenizer 类,并通过将句子的字符串格式传递给此方法来调用此方法。
//Tokenizing the sentence using WhitespaceTokenizer class WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE; String[] tokens = whitespaceTokenizer.tokenize(sentence);
步骤 4:生成标签
whitespaceTokenizer 类的 tag() 方法为标记的句子分配词性标签。此方法接受一个标记(字符串)数组作为参数并返回标签(数组)。
通过将上一步生成的标记传递给它来调用 tag() 方法。
//Generating tags String[] tags = tagger.tag(tokens);
步骤 5:打印标记和标签
POSSample 类表示词性标注的句子。要实例化此类,我们需要一个文本标记数组和一个标签数组。
此类的 toString() 方法返回标注后的句子。通过传递上一步创建的标记和标签数组来实例化此类,并调用其 toString() 方法,如下面的代码块所示。
//Instantiating the POSSample class POSSample sample = new POSSample(tokens, tags); System.out.println(sample.toString());
示例
以下是标注给定原始文本中词性的程序。将此程序保存到名为 PosTaggerExample.java 的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerExample {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
String sentence = "Hi welcome to Tutorialspoint";
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac PosTaggerExample.java java PosTaggerExample
执行后,上述程序将读取给定的文本并检测这些句子的词性,然后显示它们,如下所示。
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
词性标注器性能
以下是标注给定原始文本词性的程序。它还会监控性能并显示标注器的性能。将此程序保存到名为 PosTagger_Performance.java 的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTagger_Performance {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Monitoring the performance of POS tagger
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
perfMon.start();
perfMon.incrementCounter();
perfMon.stopAndPrintFinalResult();
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac PosTaggerExample.java java PosTaggerExample
执行后,上述程序将读取给定的文本,标注这些句子的词性并显示它们。此外,它还会监控词性标注器的性能并显示它。
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB Average: 0.0 sent/s Total: 1 sent Runtime: 0.0s
词性标注器概率
POSTaggerME 类的 probs() 方法用于查找最近标注句子的每个标签的概率。
//Getting the probabilities of the recent calls to tokenizePos() method double[] probs = detector.getSentenceProbabilities();
以下是显示最后标注句子的每个标签的概率的程序。将此程序保存到名为 PosTaggerProbs.java 的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerProbs {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_mdl/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Probabilities for each tag of the last tagged sentence.
double [] probs = tagger.probs();
System.out.println(" ");
//Printing the probabilities
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac TokenizerMEProbs.java java TokenizerMEProbs
执行后,上述程序将读取给定的原始文本,标注其中每个标记的词性,并显示它们。此外,它还会显示给定句子中每个词性的概率,如下所示。
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB 0.6416834779738033 0.42983612874819177 0.8584513635863117 0.4394784478206072
OpenNLP - 句子解析
使用 OpenNLP API,您可以解析给定的句子。在本章中,我们将讨论如何使用 OpenNLP API 解析原始文本。
使用 OpenNLP 库解析原始文本
为了检测句子,OpenNLP 使用一个预定义的模型,名为 en-parserchunking.bin 的文件。这是一个预定义的模型,经过训练可以解析给定的原始文本。
opennlp.tools.Parser 包中的 Parser 类用于保存解析成分,而 opennlp.tools.cmdline.parser 包中的 ParserTool 类用于解析内容。
以下是使用 ParserTool 类编写程序来解析给定原始文本的步骤。
步骤1:加载模型
文本解析模型由名为 ParserModel 的类表示,该类属于 opennlp.tools.parser 包。
要加载分词模型:
创建模型的InputStream对象(实例化FileInputStream并将模型路径以字符串格式传递给其构造函数)。
实例化 ParserModel 类并将模型的 InputStream(对象)作为参数传递给其构造函数,如下面的代码块所示。
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
步骤 2:创建 Parser 类的对象
opennlp.tools.parser 包中的 Parser 类表示用于保存解析成分的数据结构。您可以使用 ParserFactory 类的静态 create() 方法创建此类的对象。
通过传递上一步创建的模型对象来调用 ParserFactory 的 create() 方法,如下所示:
//Creating a parser Parser parser = ParserFactory.create(model);
步骤 3:解析句子
ParserTool 类的 parseLine() 方法用于在 OpenNLP 中解析原始文本。此方法接受:
表示要解析的文本的字符串变量。
一个解析器对象。
一个整数,表示要执行的解析次数。
通过将句子、上一步创建的解析对象和一个整数(表示要执行的所需解析次数)作为参数来调用此方法。
//Parsing the sentence String sentence = "Tutorialspoint is the largest tutorial library."; Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
示例
以下是解析给定原始文本的程序。将此程序保存到名为 ParserExample.java 的文件中。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.parser.ParserTool;
import opennlp.tools.parser.Parse;
import opennlp.tools.parser.Parser;
import opennlp.tools.parser.ParserFactory;
import opennlp.tools.parser.ParserModel;
public class ParserExample {
public static void main(String args[]) throws Exception{
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
//Creating a parser
Parser parser = ParserFactory.create(model);
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
for (Parse p : topParses)
p.show();
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac ParserExample.java java ParserExample
执行后,上述程序将读取给定的原始文本,对其进行解析,并显示以下输出:
(TOP (S (NP (NN Tutorialspoint)) (VP (VBZ is) (NP (DT the) (JJS largest) (NN tutorial) (NN library.)))))
OpenNLP - 句子组块
句子分块是指将句子分解/划分成单词部分,例如词组和动词组。
使用 OpenNLP 进行句子分块
为了检测句子,OpenNLP 使用一个模型,名为 en-chunker.bin 的文件。这是一个预定义的模型,经过训练可以对给定原始文本中的句子进行分块。
opennlp.tools.chunker 包包含用于查找非递归句法注释(例如名词短语块)的类和接口。
您可以使用 ChunkerME 类的 chunk() 方法对句子进行分块。此方法接受句子的标记和词性标签作为参数。因此,在开始分块过程之前,首先需要对句子进行分词并生成其词性标签。
要使用 OpenNLP 库对句子进行分块,您需要:
分词句子。
为其生成词性标签。
使用 ChunkerModel 类加载 en-chunker.bin 模型
实例化 ChunkerME 类。
使用此类的 chunk() 方法对句子进行分块。
以下是编写程序从给定原始文本中分块句子的步骤。
步骤 1:分词句子
使用 whitespaceTokenizer 类的 tokenize() 方法对句子进行分词,如下面的代码块所示。
//Tokenizing the sentence String sentence = "Hi welcome to Tutorialspoint"; WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE; String[] tokens = whitespaceTokenizer.tokenize(sentence);
步骤 2:生成词性标签
使用 POSTaggerME 类的 tag() 方法生成句子的词性标签,如下面的代码块所示。
//Generating the POS tags
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
步骤 3:加载模型
句子分块模型由名为 ChunkerModel 的类表示,该类属于 opennlp.tools.chunker 包。
要加载句子检测模型:
创建模型的InputStream对象(实例化FileInputStream并将模型路径以字符串格式传递给其构造函数)。
实例化 ChunkerModel 类并将模型的 InputStream(对象)作为参数传递给其构造函数,如下面的代码块所示:
//Loading the chunker model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
步骤 4:实例化 chunkerME 类
opennlp.tools.chunker 包中的 chunkerME 类包含用于分块句子的方法。这是一个基于最大熵的分块器。
实例化此类,并将上一步中创建的模型对象作为参数传递。
//Instantiate the ChunkerME class ChunkerME chunkerME = new ChunkerME(chunkerModel);
步骤 5:分块句子
ChunkerME 类的 chunk() 方法用于对传递给它的原始文本中的句子进行分块。此方法接受两个字符串数组作为参数,分别表示标记和标签。
通过将上一步创建的标记数组和标签数组作为参数来调用此方法。
//Generating the chunks String result[] = chunkerME.chunk(tokens, tags);
示例
以下是分块给定原始文本中句子的程序。将此程序保存到名为 ChunkerExample.java 的文件中。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerExample{
public static void main(String args[]) throws IOException {
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating the POS tags
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);
for (String s : result)
System.out.println(s);
}
}
使用以下命令从命令提示符编译并执行保存的 Java 文件:
javac ChunkerExample.java java ChunkerExample
执行后,上述程序将读取给定的字符串,对其进行句子分块,并显示如下所示的结果:
Loading POS Tagger model ... done (1.040s) B-NP I-NP B-VP I-VP
检测标记的位置
我们还可以使用 ChunkerME 类的 chunkAsSpans() 方法检测块的位置或跨度。此方法返回一个 Span 类型的对象数组。opennlp.tools.util 包中的 Span 类用于存储集合的 start 和 end 整数。
您可以将 chunkAsSpans() 方法返回的跨度存储在 Span 数组中并打印它们,如下面的代码块所示。
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
示例
以下是检测给定原始文本中句子的程序。将此程序保存到名为 ChunkerSpansEample.java 的文件中。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class ChunkerSpansEample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac ChunkerSpansEample.java java ChunkerSpansEample
执行后,上述程序将读取给定的字符串,并显示其块的跨度,显示以下输出:
Loading POS Tagger model ... done (1.059s) [0..2) NP [2..4) VP
分块器概率检测
ChunkerME 类的 probs() 方法返回最后解码序列的概率。
//Getting the probabilities of the last decoded sequence double[] probs = chunkerME.probs();
以下是打印 chunker 最后解码序列的概率的程序。将此程序保存到名为 ChunkerProbsExample.java 的文件中。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerProbsExample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel cModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(cModel);
//Generating the chunk tags
chunkerME.chunk(tokens, tags);
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
使用以下命令从命令提示符编译并执行保存的Java文件:
javac ChunkerProbsExample.java java ChunkerProbsExample
执行后,上述程序将读取给定的字符串,对其进行分块,并打印最后解码序列的概率。
0.9592746040797778 0.6883933131241501 0.8830563473996004 0.8951150529746051
OpenNLP - 命令行界面
OpenNLP 提供了一个命令行界面 (CLI) 用于通过命令行执行不同的操作。在本章中,我们将通过一些示例来演示如何使用 OpenNLP 命令行界面。
分词
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
语法
> opennlp TokenizerME path_for_models../en-token.bin <inputfile..> outputfile..
命令
C:\> opennlp TokenizerME C:\OpenNLP_models/en-token.bin <input.txt >output.txt
输出
Loading Tokenizer model ... done (0.207s) Average: 214.3 sent/s Total: 3 sent Runtime: 0.014s
output.txt
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologies
句子检测
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
语法
> opennlp SentenceDetector path_for_models../en-token.bin <inputfile..> outputfile..
命令
C:\> opennlp SentenceDetector C:\OpenNLP_models/en-sent.bin <input.txt > output_sendet.txt
输出
Loading Sentence Detector model ... done (0.067s) Average: 750.0 sent/s Total: 3 sent Runtime: 0.004s
Output_sendet.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
命名实体识别
input.txt
<START:person> <START:person> Mike <END> <END> is senior programming manager and <START:person> Rama <END> is a clerk both are working at Tutorialspoint
语法
> opennlp TokenNameFinder path_for_models../en-token.bin <inputfile..
命令
C:\>opennlp TokenNameFinder C:\OpenNLP_models\en-ner-person.bin <input_namefinder.txt
输出
Loading Token Name Finder model ... done (0.730s) <START:person> <START:person> Mike <END> <END> is senior programming manager and <START:person> Rama <END> is a clerk both are working at Tutorialspoint Average: 55.6 sent/s Total: 1 sent Runtime: 0.018s
词性标注
Input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
语法
> opennlp POSTagger path_for_models../en-token.bin <inputfile..
命令
C:\>opennlp POSTagger C:\OpenNLP_models/en-pos-maxent.bin < input.txt
输出
Loading POS Tagger model ... done (1.315s) Hi._NNP How_WRB are_VBP you?_JJ Welcome_NNP to_TO Tutorialspoint._NNP We_PRP provide_VBP free_JJ tutorials_NNS on_IN various_JJ technologies_NNS Average: 66.7 sent/s Total: 1 sent Runtime: 0.015s