缓存一致性和同步
本章将讨论用于应对多缓存不一致问题的缓存一致性协议。
缓存一致性问题
在多处理器系统中,数据不一致可能发生在相邻级别之间或内存层次结构的同一级别内。例如,缓存和主内存可能具有同一对象的副本不一致。
由于多个处理器并行且独立地运行,多个缓存可能拥有同一内存块的不同副本,这会产生缓存一致性问题。缓存一致性方案通过维护每个缓存数据块的统一状态来帮助避免此问题。
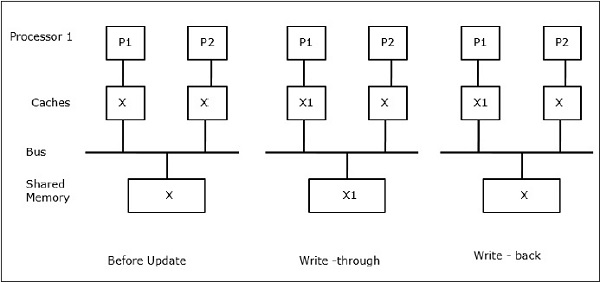
设X为共享数据的元素,已被两个处理器P1和P2引用。开始时,X的三个副本是一致的。如果处理器P1使用直写策略将新的数据X1写入缓存,则相同的副本将立即写入共享内存。在这种情况下,缓存内存和主内存之间会发生不一致。当使用写回策略时,当缓存中修改的数据被替换或失效时,主内存将被更新。
一般来说,存在三个不一致问题来源:
- 共享可写数据
- 进程迁移
- I/O活动
窥探总线协议
窥探协议通过基于总线的内存系统实现缓存内存和共享内存之间的数据一致性。写失效和写更新策略用于维护缓存一致性。
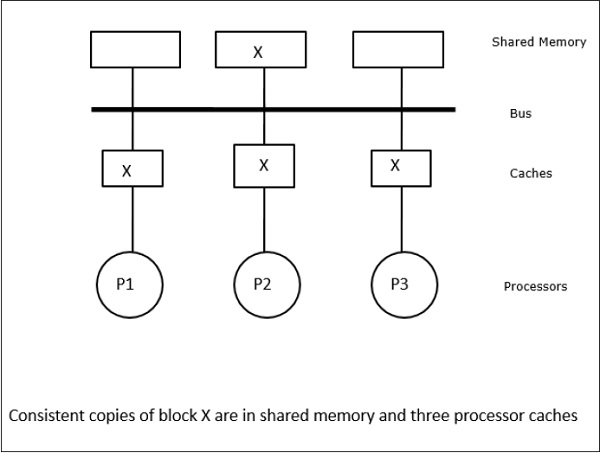
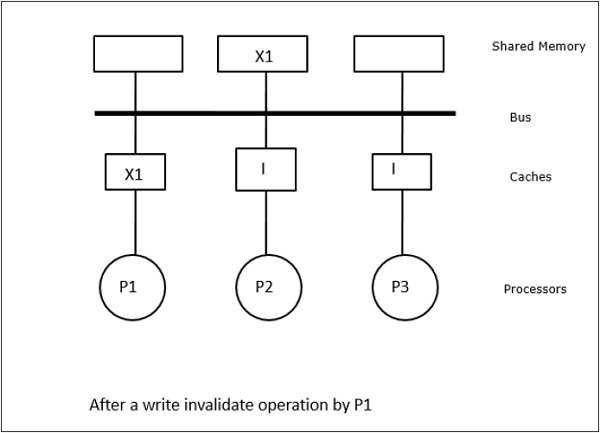
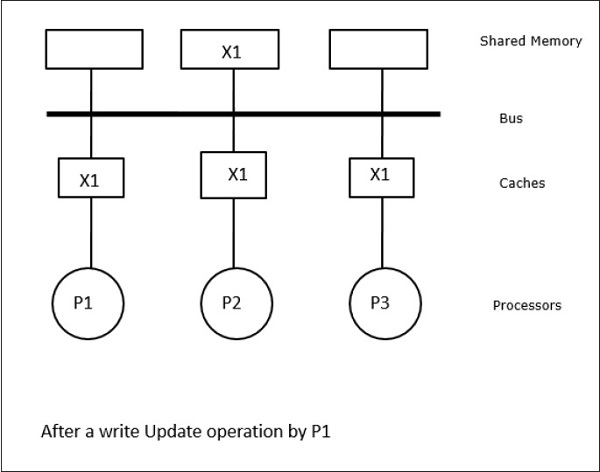
在这种情况下,我们有三个处理器P1、P2和P3,它们的本地缓存内存和共享内存中都具有数据元素“X”的一致副本(图a)。处理器P1使用写失效协议将其缓存内存中的X写入X1。因此,所有其他副本都通过总线失效。它用“I”表示(图b)。失效的块也称为脏块,即它们不应使用。写更新协议通过总线更新所有缓存副本。使用写回缓存,内存副本也会更新(图c)。
缓存事件和操作
执行内存访问和失效命令时会发生以下事件和操作:
读失效 - 当处理器想要读取一个块而它不在缓存中时,就会发生读失效。这将启动总线读取操作。如果不存在脏副本,则具有一致副本的主内存会向请求缓存内存提供副本。如果在远程缓存内存中存在脏副本,则该缓存将限制主内存并向请求缓存内存发送副本。在这两种情况下,缓存副本在读失效后都将进入有效状态。
写命中 - 如果副本处于脏或保留状态,则在本地执行写入,新状态为脏。如果新状态有效,则将写失效命令广播到所有缓存,使它们的副本失效。当共享内存被直写时,在此第一次写入之后,结果状态将被保留。
写失效 - 如果处理器无法写入本地缓存内存,则副本必须来自主内存或具有脏块的远程缓存内存。这是通过发送读失效命令完成的,该命令将使所有缓存副本失效。然后,本地副本将更新为脏状态。
读命中 - 读命中始终在本地缓存内存中执行,而不会导致状态转换或使用窥探总线进行失效。
块替换 - 当副本脏时,它将通过块替换方法写回到主内存。但是,当副本处于有效、保留或无效状态时,不会发生替换。
基于目录的协议
通过使用多级网络构建具有数百个处理器的较大多处理器,需要修改窥探缓存协议以适应网络功能。由于在多级网络中执行广播非常昂贵,因此一致性命令仅发送给保留块副本的那些缓存。这就是为网络连接的多处理器开发基于目录的协议的原因。
在基于目录的协议系统中,要共享的数据放置在一个公共目录中,该目录维护缓存之间的一致性。在这里,目录充当过滤器,处理器请求允许将其条目从主内存加载到其缓存内存中。如果条目更改,目录会更新它或使具有该条目的其他缓存失效。
硬件同步机制
同步是一种特殊的通信形式,其中不是数据控制,而是驻留在相同或不同处理器中的通信进程之间交换信息。
多处理器系统使用硬件机制来实现低级同步操作。大多数多处理器都有硬件机制来强制执行原子操作,例如内存读、写或读-修改-写操作,以实现一些同步原语。除了原子内存操作外,还有一些处理器间中断用于同步目的。
共享内存机器中的缓存一致性
当处理器包含本地缓存内存时,维护缓存一致性是多处理器系统中的一个问题。在此系统中,不同缓存之间的数据不一致很容易发生。
主要关注领域是:
- 共享可写数据
- 进程迁移
- I/O活动
共享可写数据
当两个处理器(P1和P2)在其本地缓存中具有相同的数据元素(X),并且一个进程(P1)写入数据元素(X)时,由于P1的缓存是直写本地缓存,主内存也会更新。现在,当P2尝试读取数据元素(X)时,它找不到X,因为P2缓存中的数据元素已过期。
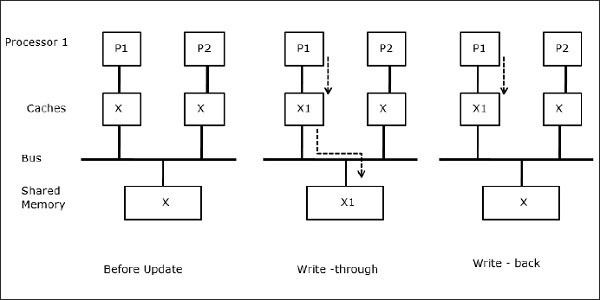
进程迁移
在第一阶段,P1的缓存具有数据元素X,而P2没有任何数据。P2上的一个进程首先写入X,然后迁移到P1。现在,进程开始读取数据元素X,但是由于处理器P1具有过时的数据,因此进程无法读取它。因此,P1上的一个进程写入数据元素X,然后迁移到P2。迁移后,P2上的一个进程开始读取数据元素X,但它在主内存中找到X的过时版本。
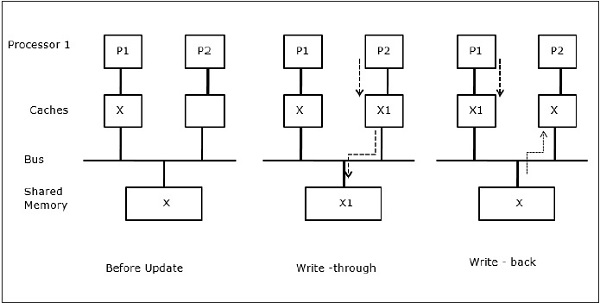
I/O活动
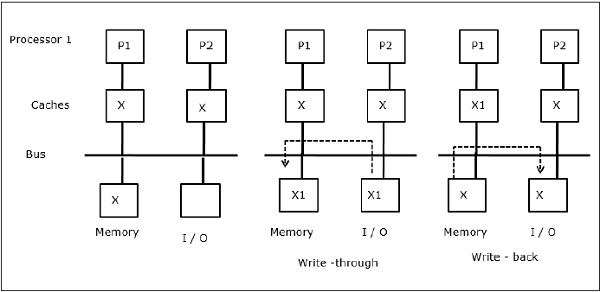
如图所示,I/O设备添加到双处理器多处理器体系结构中的总线上。开始时,两个缓存都包含数据元素X。当I/O设备接收新的元素X时,它直接将新元素存储到主内存中。现在,当P1或P2(假设为P1)尝试读取元素X时,它会获得过时的副本。因此,P1写入元素X。现在,如果I/O设备尝试传输X,它会获得过时的副本。
统一内存访问(UMA)
统一内存访问(UMA)体系结构意味着共享内存对于系统中的所有处理器都是相同的。常用的UMA机器类别(用于(文件)服务器)是所谓的对称多处理器(SMP)。在SMP中,所有系统资源(如内存、磁盘、其他I/O设备等)都可以由处理器以统一的方式访问。
非统一内存访问(NUMA)
在NUMA体系结构中,有多个具有内部间接/共享网络的SMP集群,它们连接在可扩展的消息传递网络中。因此,NUMA体系结构在逻辑上是共享的,在物理上是分布式内存体系结构。
在NUMA机器中,处理器的缓存控制器确定内存引用是本地于SMP的内存还是远程的。为了减少远程内存访问的数量,NUMA体系结构通常应用可以缓存远程数据的缓存处理器。但是当涉及缓存时,需要维护缓存一致性。因此,这些系统也称为CC-NUMA(缓存一致性NUMA)。
仅缓存内存体系结构(COMA)
COMA机器类似于NUMA机器,唯一的区别是COMA机器的主内存充当直接映射或组相联缓存。数据块根据其地址散列到DRAM缓存中的位置。远程获取的数据实际上存储在本地主内存中。此外,数据块没有固定的存储位置,它们可以自由地在系统中移动。
COMA体系结构大多具有分层的消息传递网络。此类树中的交换机包含一个目录,其数据元素作为其子树。由于数据没有存储位置,因此必须显式地搜索它。这意味着远程访问需要沿着树中的交换机进行遍历以搜索其目录中所需的数据。因此,如果网络中的交换机从其子树接收到对同一数据的多个请求,它会将它们组合成单个请求,然后将其发送到交换机的父节点。当请求的数据返回时,交换机会将其多个副本发送到其子树。
COMA与CC-NUMA
以下是COMA和CC-NUMA的区别。
COMA往往比CC-NUMA更灵活,因为COMA无需操作系统即可透明地支持数据的迁移和复制。
COMA机器的构建成本高且复杂,因为它们需要非标准的内存管理硬件,并且一致性协议更难实现。
COMA中的远程访问通常比CC-NUMA中的远程访问慢,因为需要遍历树网络才能找到数据。