
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 语言编程
C 语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPSelenium Python 中的父元素方法
Selenium 是一款强大的工具,能够自动化 Web 浏览器,而 Python 广泛用于测试自动化。Selenium 的一个重要方面是它能够通过多种方法查找网页上的元素,而这可以使用父元素方法轻松实现,该方法是一种非常有价值的技术。
通过识别和操作与特定目标元素关联的父元素,测试人员可以有效地与网页的特定部分进行交互。本文深入探讨了 Selenium Python 中的父元素方法,阐明了其优势和实际实施策略。
什么是 Selenium Python 中的父元素方法?
在我们深入细节之前,让我们先弄清楚我们所说的父元素是什么意思。在 HTML 中,元素嵌套在其他元素中,形成一个层次结构。父元素是指包含您要与其交互的目标元素的直接容器元素。通过识别和操作父元素,我们可以控制其子元素并有效地导航网页的结构。
父元素方法的优势
以下是使用父元素方法的一些优势:
改进的元素定位器 − 仅基于元素的单个属性来定位元素可能具有挑战性,尤其是在复杂的网页上。通过使用父元素方法,您可以建立一种更强大、更可靠的元素定位方法。您可以利用网页的结构而不是依赖于唯一属性,从而使您的定位器不易受到更改的影响。
简化的测试维护 − Web 应用程序是动态的,如果测试严重依赖于特定的元素属性,则页面结构的更新或修改可能会破坏您的测试。通过使用父元素方法,您的测试对更改更具弹性。如果子元素的属性发生更改,您仍然可以使用其父元素可靠地找到它。
有效地与相关元素交互 − 有时,您可能需要与共享公共父元素的一组元素进行交互。例如,考虑一个具有多行多列的表格。通过识别父元素(表格),您可以轻松访问并与子元素(表格单元格或行)进行交互,而无需复杂的定位器。
实现策略
在 Selenium Python 中实现父元素方法涉及以下几个关键步骤:
定位父元素 − 首先确定包含您要与其交互的目标元素的父元素。检查网页的 HTML 结构以找到一个合适的父元素,该元素包含所需的部分。
使用 XPath 或 CSS 选择器 − 确定父元素后,您可以使用 XPath 或 CSS 选择器以编程方式找到它。这两种方法都提供了灵活且强大的方法来导航网页的结构并找到所需的元素。
对子元素执行操作 − 定位父元素后,您可以使用 Selenium 丰富的函数集与子元素进行交互。无论是点击按钮、填写表单还是提取数据,您都可以对父元素中的目标元素执行各种操作。
处理动态元素 − 请记住,网页通常包含动态内容,这些内容会根据用户交互或服务器响应而动态更改。在使用父元素方法时,请确保您的代码可以通过在父元素中实现适当的等待条件或使用动态定位器来处理此类动态元素。
Selenium Python 中父元素方法的程序示例
这是一个使用 Selenium Python 中的父元素方法以及维基百科网站的代码示例:
示例
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Step 1: Initialize the WebDriver
driver = webdriver.Chrome("C:/Users/Tutorialspoint/chromedriver.exe") # Replace with the appropriate path to chromedriver.exe
# Step 2: Navigate to the Wikipedia page
driver.get("https://en.wikipedia.org/wiki/Python_(programming_language)")
# Step 3: Locate the parent element
# Wait for the parent element to be present before interacting with it
parent_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "mw-content-text"))
)
# Step 4: Perform actions on child elements within the parent element
# Locate and perform actions on the child elements within the parent element
child_elements = parent_element.find_elements(By.TAG_NAME, "p")
# Print the text of each child element
for child_element in child_elements:
print(child_element.text)
# Step 5: Close the browser
driver.quit()
输出
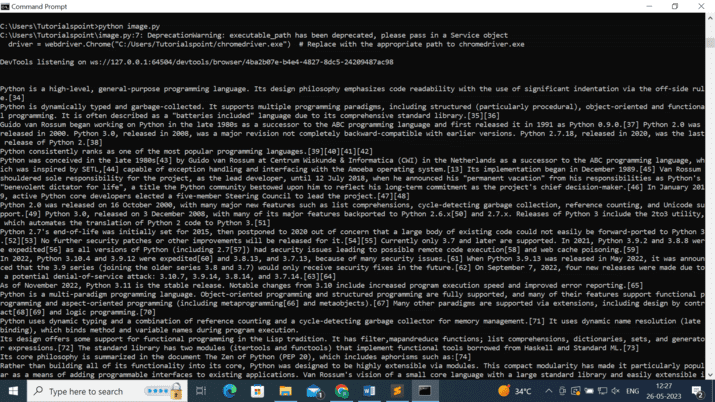
运行程序
确保已安装 Selenium Python 包。如果没有,可以使用 pip 安装:
pip install selenium
下载与 Chrome 浏览器版本兼容的 ChromeDriver 可执行文件,并向 `webdriver.Chrome()` 构造函数提供路径。将 "C:/Users/Tutorialspoint/chromedriver.exe" 替换为您系统上 chromedriver 可执行文件的相应路径。
代码示例设置为导航到 Python 编程语言的维基百科页面。您可以将 URL 替换为任何其他维基百科页面或您想要抓取的任何网页。
该示例使用 ID 为 "mw-content-text" 的父元素。您可以根据需要修改父元素选择器。
然后,代码示例使用 `find_elements()` 方法和标签名称 "p" 查找父元素中的所有子元素(段落)。它打印每个子元素的文本,但您可以修改此部分以对子元素执行任何所需的操作。
运行脚本,它将导航到指定的网页,定位父元素并与子元素(段落)进行交互。
结论
总之,Selenium Python 中的父元素方法是与网页特定部分交互的强大技术。通过定位父元素并访问其子元素,测试人员和开发人员可以有效地提取信息、执行操作和自动化 Web 交互。
凭借处理动态内容和导航复杂 Web 结构的能力,此方法在 Web 抓取、测试和自动化任务中证明了其价值。

2K+ 浏览量
