
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用列表中的列在 PySpark 中按多列分区
你是否曾经想过数据处理公司如何有效地管理海量数据集?分区是其中一种关键方法。本文将探讨 PySpark 中的分区概念,重点介绍如何使用列表按多列进行分区。我们将逐步分解整个过程,即使是初学者也能理解。
引言
在当今大数据时代,高效处理和管理大型数据集至关重要。Apache Spark,特别是 PySpark(Spark 的 Python API),是管理此类任务的有效解决方案。“分区”是最大化 PySpark 查询速度和数据管理的最佳策略之一。本文将介绍 PySpark 中的分区概念,重点介绍如何按多列(特别是列的列表)进行分区。什么是分区?
分区过程是指将大型数据集分解成更小、更容易管理的片段或“分区”。PySpark 现在可以同时处理多个较小的文件,从而避免处理单个大型文件,节省处理时间。这就像把一个大披萨切成片,这样每个人都能更快地吃!假设您正在处理一个包含全年来自不同地区多个商店的销售数据的数据集。如果您正在查找来自单个存储的信息,分区使您可以更快、更容易地仅获取所需的数据。
为什么要按多列分区?
按多列分区意味着根据多个列划分数据集。例如,如果您有一个包含“班级”和“组别”列的学生数据集,您可以同时按“班级”和“组别”对数据进行分区。这有助于更好地组织数据,并加快某些操作的处理速度。术语解释
在深入研究代码之前,让我们定义一些重要的术语- PySpark:Apache Spark 的 Python API,允许您使用 Spark 的分布式计算功能。
- 分区:数据集的一个小子集,物理上分离到磁盘上的较小文件中,以提高读写性能。
- DataFrame:PySpark 中一种二维的、类似表格的结构,可以容纳带有行和列的数据,类似于电子表格或 SQL 表。
- 列:在表(或 DataFrame)中,列表示特定的数据字段,例如“年龄”或“位置”。
- 列表:以特定顺序存储元素的集合。在 Python 中,列表可以容纳数字或字符串等值,灵活且易于使用。
为什么在 PySpark 中使用分区?
分区有助于以下方面:- 性能提升:当数据被分区后,PySpark 可以跨多个节点并行化数据的读取和处理,从而加快速度。
- 高效的数据检索:PySpark 只会扫描所需的分区,从而节省 I/O 操作,而不是扫描整个数据集。
- 可扩展性:当任务在分区之间拆分时,管理大型数据集变得更容易。
分步指南:在 PySpark 中按多列分区
本节将向您展示如何使用 PySpark 和公共数据集按多列对数据集进行分区。在本例中,我们将使用著名的“鸢尾花”数据集,其中包含有关几种花卉物种及其尺寸的详细信息。步骤 1:安装所需的库
pip install pyspark pandas matplotlib ipywidgets
步骤 2:加载数据集
我们将使用鸢尾花数据集,该数据集可从 UCI 机器学习存储库公开获取。我们可以使用 pandas 直接从 URL 加载它。import pandas as pd
# Load the Iris dataset from a public URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
iris_df = pd.read_csv(url, names=columns)
# Display the first few rows of the dataset
iris_df.head()
步骤 3:设置 PySpark
接下来,我们需要设置 PySpark 并将我们的 pandas DataFrame 转换为 PySpark DataFrame。from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("PartitioningExample").getOrCreate()
# Convert pandas DataFrame to PySpark DataFrame
spark_df = spark.createDataFrame(iris_df)
# Show first few rows of the PySpark DataFrame
spark_df.show(5)
步骤 4:按多列分区
这里的目标是按两个列(species 和 sepal_length)对数据进行分区。让我们将它们定义为我们的分区列。# Specify the columns to partition by
partition_columns = ["species", "sepal_length"]
# Partition the data and save it as Parquet files
output_path = "output/partitioned_iris"
spark_df.write.partitionBy(partition_columns).parquet(output_path)
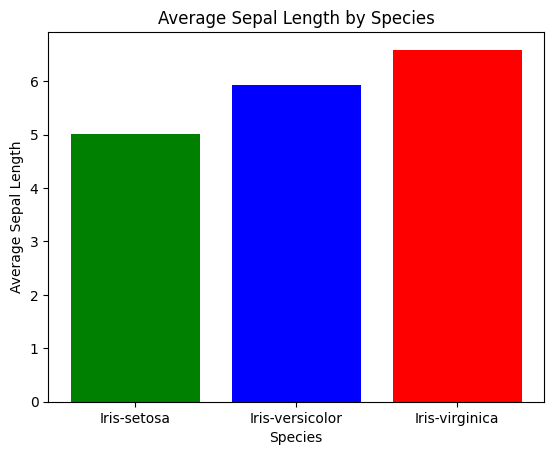
步骤 5:数据可视化
现在,让我们可视化分区的工作原理。我们将绘制不同物种中 sepal_length 的分布,以了解分区如何帮助我们。import matplotlib.pyplot as plt
# Extract relevant data for plotting
iris_grouped = iris_df.groupby('species')['sepal_length'].mean().reset_index()
# Plotting
plt.bar(iris_grouped['species'], iris_grouped['sepal_length'], color=['green', 'blue', 'red'])
plt.xlabel('Species')
plt.ylabel('Average Sepal Length')
plt.title('Average Sepal Length by Species')
plt.show()
输出
分区最佳实践
- 明智地选择列:选择分区列时,请确保每列中唯一值的个数相对较少。如果按其进行分区的列具有过多的唯一值,则会产生大量的小文件,这可能会降低性能。
- 监控分区大小:目标是使分区既不太大也不太小。理想情况下,每个分区的最佳大小应在 100MB 到 1GB 之间。
- 避免过度分区:过度分区会导致产生太多的小文件,从而增加了在分布式系统中处理这些文件的成本。
常见问题解答
问:为什么分区对大数据很重要?
答:分区通过将大型数据集划分为更小、更容易管理的块来提高可扩展性和性能。问:我可以按多于两列分区吗?
答:当然!您可以根据需要使用任意数量的列进行分区,但是避免过度分区,因为这可能会导致效率低下。问:所有数据集都需要分区吗?
答:不需要,当您经常需要对特定数据组执行操作时,分区对于大型数据集很有帮助。结论
分区是一种强大的方法,可以提高 PySpark 中大数据处理的效率。通过学习如何按多列(特别是使用列表)进行分区,您可以显著提高数据操作的性能。只需在选择分区列时小心,并避免创建过多的小文件即可。无论处理的数据集大小如何,了解如何分区数据在大数据分析领域都是至关重要的。**祝您编程愉快!**更新于:2024年9月10日
60 次浏览

广告