- Peewee 教程
- Peewee - 首页
- Peewee - 概述
- Peewee - 数据库类
- Peewee - 模型
- Peewee - 字段类
- Peewee - 插入新记录
- Peewee - 选择记录
- Peewee - 过滤器
- Peewee - 主键和复合键
- Peewee - 更新现有记录
- Peewee - 删除记录
- Peewee - 创建索引
- Peewee - 约束
- Peewee - 使用 MySQL
- Peewee - 使用 PostgreSQL
- Peewee - 动态定义数据库
- Peewee - 连接管理
- Peewee - 关系和联接
- Peewee - 子查询
- Peewee - 排序
- Peewee - 计数和聚合
- Peewee - SQL 函数
- Peewee - 获取行元组/字典
- Peewee - 用户自定义运算符
- Peewee - 原子事务
- Peewee - 数据库错误
- Peewee - 查询构建器
- Peewee - 与 Web 框架集成
- Peewee - SQLite 扩展
- Peewee - PostgreSQL 和 MySQL 扩展
- Peewee - 使用 CockroachDB
- Peewee 有用资源
- Peewee - 快速指南
- Peewee - 有用资源
- Peewee - 讨论
Peewee - 快速指南
Peewee - 概述
Peewee 是一个 Python 对象关系映射 (ORM) 库,由美国软件工程师Charles Leifer于 2010 年 10 月开发。其最新版本为3.13.3。Peewee 支持 SQLite、MySQL、PostgreSQL 和 Cockroach 数据库。
对象关系映射是一种编程技术,用于在面向对象编程语言中转换不兼容类型系统之间的数据。
在 Python 等面向对象 (OO) 编程语言中定义的类被认为是非标量的。它不能表示为基本类型,例如整数和字符串。
另一方面,像 Oracle、MySQL、SQLite 等数据库只能存储和操作标量值,例如组织在表中的整数和字符串。
程序员必须将对象值转换为标量数据类型的组以存储在数据库中,或者在检索时将其转换回来,或者仅在程序中使用简单的标量值。
在 ORM 系统中,每个类都映射到底层数据库中的一个表。ORM处理了这些问题,而不是让您自己编写乏味的数据库接口代码,而您可以专注于系统逻辑的编程。
环境设置
要安装托管在 PyPI(Python 包索引)上的最新版本的 Peewee,请使用 pip 安装程序。
pip3 install peewee
Peewee 工作没有其他依赖项。它与 SQLite 一起使用,无需安装任何其他软件包,因为 sqlite3 模块与标准库捆绑在一起。
但是,要使用 MySQL 和 PostgreSQL,您可能需要分别安装与 DB-API 兼容的驱动程序模块 pymysql 和 pyscopg2。Cockroach 数据库通过默认与 Peewee 一起安装的 playhouse 扩展进行处理。
Peewee 是一个开源项目,托管在https://github.com/coleifer/peewee 存储库中。因此,可以使用 git 从这里安装。
git clone https://github.com/coleifer/peewee.git cd peewee python setup.py install
Peewee - 数据库类
Peewee 包中 Database 类的对象表示与数据库的连接。Peewee 通过 Database 类的相应子类为 SQLite、PostgreSQL 和 MySQL 数据库提供了开箱即用的支持。
Database 类实例包含打开与数据库引擎连接所需的所有信息,并用于执行查询、管理事务和执行表的内省、列等。
Database 类具有SqliteDatabase、PostgresqlDatabase 和MySQLDatabase 子类。虽然 Python 标准库中包含 sqlite3 模块形式的 SQLite 的 DB-API 驱动程序,但必须首先安装psycopg2 和pymysql 模块才能将 PostgreSql 和 MySQL 数据库与 Peewee 一起使用。
使用 Sqlite 数据库
Python 以 sqlite3 模块的形式内置支持 SQLite 数据库。因此,连接非常容易。Peewee 中 SqliteDatabase 类的对象表示连接对象。
con=SqliteDatabase(name, pragmas, timeout)
这里,pragma 是 SQLite 扩展,用于修改 SQLite 库的操作。此参数可以是字典或包含 pragma 键和值的 2 元组列表,每次打开连接时都会设置。
超时参数以秒为单位指定,以设置 SQLite 驱动程序的繁忙超时。这两个参数都是可选的。
以下语句使用新的 SQLite 数据库(如果尚不存在)创建连接。
>>> db = peewee.SqliteDatabase('mydatabase.db')
Pragma 参数通常用于新的数据库连接。pragmase 字典中提到的典型属性是journal_mode、cache_size、locking_mode、foreign-keys 等。
>>> db = peewee.SqliteDatabase(
'test.db', pragmas={'journal_mode': 'wal', 'cache_size': 10000,'foreign_keys': 1}
)
以下 pragma 设置是理想的指定内容:
| Pragma 属性 | 推荐值 | 含义 |
|---|---|---|
| journal_mode | wal | 允许读者和作者共存 |
| cache_size | -1 * data_size_kb | 以 KiB 为单位设置页面缓存大小 |
| foreign_keys | 1 | 强制执行外键约束 |
| ignore_check_constraints | 0 | 强制执行 CHECK 约束 |
| Synchronous | 0 | 让操作系统处理 fsync |
Peewee 还有另一个 Python SQLite 包装器 (apsw),一个高级 sqlite 驱动程序。它提供了高级功能,例如虚拟表和文件系统以及共享连接。APSW 比标准库 sqlite3 模块更快。
Peewee - 模型
Peewee API 中 Model 子类的对象对应于已建立连接的数据库中的表。它允许在 Model 类中定义的方法的帮助下执行数据库表操作。
用户定义的模型具有一到多个类属性,每个属性都是 Field 类的对象。Peewee 有许多用于保存不同类型数据的子类。例如 TextField、DatetimeField 等。它们对应于数据库表中的字段或列。关联数据库和表的引用以及模型配置在 Meta 类中提及。以下属性用于指定配置:
Meta 类属性
Meta 类属性解释如下:
| 序号 | 属性和描述 |
|---|---|
| 1 | 数据库 模型的数据库。 |
| 2 | db_table 存储数据的表名。默认情况下,它是模型类名。 |
| 3 | 索引 要索引的字段列表。 |
| 4 | primary_key 复合键实例。 |
| 5 | 约束 表约束列表。 |
| 6 | 模式 模型的数据库模式。 |
| 7 | 临时 指示临时表。 |
| 8 | depends_on 指示此表依赖于另一个表进行创建。 |
| 9 | without_rowid 指示表不应具有 rowid(仅限 SQLite)。 |
以下代码定义了 mydatabase.db 中 User 表的 Model 类:
from peewee import *
db = SqliteDatabase('mydatabase.db')
class User (Model):
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
User.create_table()
create_table() 方法是 Model 类的类方法,执行等效的 CREATE TABLE 查询。另一个实例方法save()添加对应于对象的行。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class User (Model):
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
User.create_table()
rec1=User(name="Rajesh", age=21)
rec1.save()
Model 类中的方法
Model 类中的其他方法如下:
| 序号 | Model 类和描述 |
|---|---|
| 1 | 类方法 alias() 为模型类创建别名。它允许在查询中多次引用同一模型。 |
| 2 | 类方法 select() 执行 SELECT 查询操作。如果未显式提供字段作为参数,则查询默认将执行等效于 SELECT * 的操作。 |
| 3 | 类方法 update() 执行 UPDATE 查询函数。 |
| 4 | 类方法 insert() 在映射到模型的底层表中插入新行。 |
| 5 | 类方法 delete() 执行删除查询,通常与 where 子句的过滤器相关联。 |
| 6 | 类方法 get() 从映射表中检索与给定过滤器匹配的单个行。 |
| 7 | get_id() 实例方法返回行的主键。 |
| 8 | save() 将对象的数据保存为新行。如果主键值已存在,则会导致执行 UPDATE 查询。 |
| 9 | 类方法 bind() 将模型绑定到给定的数据库。 |
Peewee - 字段类
Model 类包含一个或多个属性,这些属性是 Peewee 中 Field 类的对象。不会直接实例化 Base Field 类。Peewee 为等效的 SQL 数据类型定义了不同的子类。
Field 类的构造函数具有以下参数:
| 序号 | 构造函数和描述 |
|---|---|
| 1 | column_name (str) 指定字段的列名。 |
| 2 | primary_key (bool) 字段是主键。 |
| 3 | constraints (list) 要应用于列的约束列表 |
| 4 | choices (list) 一个 2 元组的可迭代对象,用于将列值映射到显示标签。 |
| 5 | null (bool) 字段允许 NULL。 |
| 6 | index (bool) 在字段上创建索引。 |
| 7 | unique (bool) 在字段上创建唯一索引。 |
| 8 | 默认 默认值。 |
| 9 | collation (str) 字段的排序规则名称。 |
| 10 | help_text (str) 字段的帮助文本,用于元数据目的。 |
| 11 | verbose_name (str) 字段的详细名称,用于元数据目的。 |
Field 类的子类映射到各个数据库中对应的数据库类型,即 SQLite、PostgreSQL、MySQL 等。
数字字段类
Peewee 中的数字字段类如下所示:
| 序号 | 字段类和描述 |
|---|---|
| 1 | IntegerField 用于存储整数的字段类。 |
| 2 | BigIntegerField 用于存储大整数的字段类(分别映射到 SQLite、PostgreSQL 和 MySQL 中的 integer、bigint 和 bigint 类型)。 |
| 3 | SmallIntegerField 用于存储小整数的字段类(如果数据库支持)。 |
| 4 | FloatField 用于存储浮点数的字段类,对应于 real 数据类型。 |
| 5 | DoubleField 用于存储双精度浮点数的字段类,映射到相应 SQL 数据库中的等效数据类型。 |
| 6 | DecimalField 用于存储十进制数的字段类。参数如下所示:
|
文本字段
Peewee 中可用的文本字段如下所示:
| 序号 | 字段和描述 |
|---|---|
| 1 | CharField 用于存储字符串的字段类。最大 255 个字符。等效的 SQL 数据类型为 varchar。 |
| 2 | FixedCharField 用于存储固定长度字符串的字段类。 |
| 3 | TextField 用于存储文本的字段类。映射到 SQLite 和 PostgreSQL 中的 TEXT 数据类型,以及 MySQL 中的 longtext。 |
二进制字段
Peewee 中的二进制字段解释如下:
| 序号 | 字段和描述 |
|---|---|
| 1 | BlobField 用于存储二进制数据的字段类。 |
| 2 | BitField 用于在 64 位整数列中存储选项的字段类。 |
| 3 | BigBitField 用于在二进制大对象 (BLOB) 中存储任意大小的位图的字段类。该字段将根据需要扩展底层缓冲区。 |
| 4 | UUIDField 用于存储通用唯一标识符 (UUID) 对象的字段类。映射到 Postgres 中的 UUID 类型。SQLite 和 MySQL 没有 UUID 类型,它存储为 VARCHAR。 |
日期和时间字段
Peewee 中的日期和时间字段如下所示:
| 序号 | 字段和描述 |
|---|---|
| 1 | DateTimeField 用于存储 datetime.datetime 对象的字段类。接受一个特殊参数字符串格式,可以使用该格式对日期时间进行编码。 |
| 2 | DateField 用于存储 datetime.date 对象的字段类。接受一个特殊参数字符串格式来编码日期。 |
| 3 | TimeField 用于存储 datetime.time 对象的字段类。接受一个特殊参数格式来显示编码时间。 |
由于 SQLite 没有 DateTime 数据类型,因此此字段映射为字符串。
ForeignKeyField
此类用于在两个模型中建立外键关系,因此,在数据库中建立相应的表。此类使用以下参数实例化:
| 序号 | 字段和描述 |
|---|---|
| 1 | model (Model) 要引用的模型。如果设置为“self”,则为自引用外键。 |
| 2 | field (Field) 要引用的模型字段(默认为主键)。 |
| 3 | backref (str) 反向引用的访问器名称。“+”禁用反向引用访问器。 |
| 4 | on_delete (str) ON DELETE 操作。 |
| 5 | on_update (str) ON UPDATE 操作。 |
| 6 | lazy_load (bool) 访问外键字段属性时获取相关对象。如果为 FALSE,则访问外键字段将返回存储在外键列中的值。 |
示例
以下是 ForeignKeyField 的示例。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class Customer(Model):
id=IntegerField(primary_key=True)
name = TextField()
address = TextField()
phone = IntegerField()
class Meta:
database=db
db_table='Customers'
class Invoice(Model):
id=IntegerField(primary_key=True)
invno=IntegerField()
amount=IntegerField()
custid=ForeignKeyField(Customer, backref='Invoices')
class Meta:
database=db
db_table='Invoices'
db.create_tables([Customer, Invoice])
执行上述脚本时,将运行以下 SQL 查询:
CREATE TABLE Customers (
id INTEGER NOT NULL
PRIMARY KEY,
name TEXT NOT NULL,
address TEXT NOT NULL,
phone INTEGER NOT NULL
);
CREATE TABLE Invoices (
id INTEGER NOT NULL
PRIMARY KEY,
invno INTEGER NOT NULL,
amount INTEGER NOT NULL,
custid_id INTEGER NOT NULL,
FOREIGN KEY (
custid_id
)
REFERENCES Customers (id)
);
在 SQLiteStuidio GUI 工具中进行验证时,表结构如下所示:
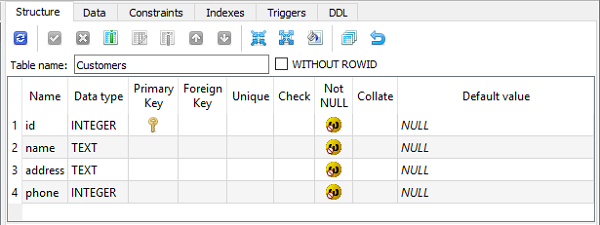
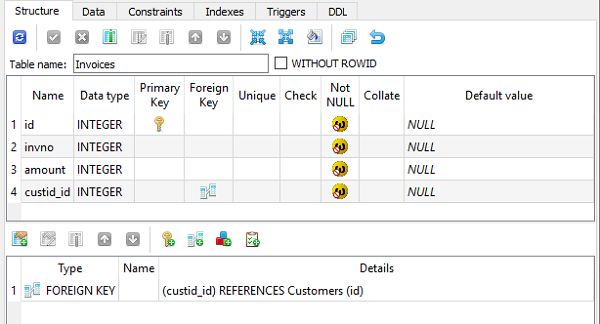
其他字段类型
Peewee 中的其他字段类型包括:
| 序号 | 字段和描述 |
|---|---|
| 1 | IPField 用于有效存储 IPv4 地址(作为整数)的字段类。 |
| 2 | BooleanField 用于存储布尔值的字段类。 |
| 3 | AutoField 用于存储自动递增主键的字段类。 |
| 4 | IdentityField 用于使用新的 Postgres 10 IDENTITY字段类存储自动递增主键的字段类,使用新的 Postgres 10 IDENTITY 列类型。列类型。 |
Peewee - 插入新记录
在 Peewee 中,有多个命令可以向表中添加新记录。我们已经使用了 Model 实例的 save() 方法。
rec1=User(name="Rajesh", age=21) rec1.save()
Peewee.Model 类还有一个 create() 方法,该方法创建一个新实例并将它的数据添加到表中。
User.create(name="Kiran", age=19)
此外,Model 还具有 insert() 作为类方法,该方法构造 SQL insert 查询对象。Query 对象的 execute() 方法执行在底层表中添加一行。
q = User.insert(name='Lata', age=20) q.execute()
查询对象是一个等效的 INSERT 查询。q.sql() 返回查询字符串。
print (q.sql())
('INSERT INTO "User" ("name", "age") VALUES (?, ?)', ['Lata', 20])
以下是演示上述插入记录方法的完整代码。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class User (Model):
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
db.create_tables([User])
rec1=User(name="Rajesh", age=21)
rec1.save()
a=User(name="Amar", age=20)
a.save()
User.create(name="Kiran", age=19)
q = User.insert(name='Lata', age=20)
q.execute()
db.close()
我们可以在 SQLiteStudio GUI 中验证结果。
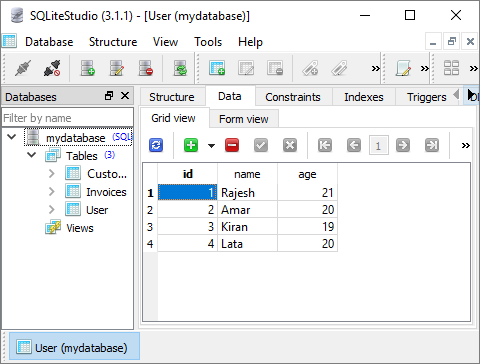
批量插入
为了在表中一次使用多行,Peewee 提供了两种方法:bulk_create 和 insert_many。
insert_many()
insert_many() 方法使用字典对象的列表生成等效的 INSERT 查询,每个字典对象都包含一个对象的字段值对。
rows=[{"name":"Rajesh", "age":21}, {"name":"Amar", "age":20}]
q=User.insert_many(rows)
q.execute()
同样,q.sql() 返回的 INSERT 查询字符串如下所示:
print (q.sql())
('INSERT INTO "User" ("name", "age") VALUES (?, ?), (?, ?)', ['Rajesh', 21, 'Amar', 20])
bulk_create()
此方法采用一个列表参数,该参数包含一个或多个映射到表的模型的未保存实例。
a=User(name="Kiran", age=19) b=User(name='Lata', age=20) User.bulk_create([a,b])
以下代码使用这两种方法执行批量插入操作。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class User (Model):
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
db.create_tables([User])
rows=[{"name":"Rajesh", "age":21}, {"name":"Amar", "age":20}]
q=User.insert_many(rows)
q.execute()
a=User(name="Kiran", age=19)
b=User(name='Lata', age=20)
User.bulk_create([a,b])
db.close()
Peewee - 选择记录
检索表中数据最简单和最明显的方法是调用相应模型的 select() 方法。在 select() 方法中,我们可以指定一个或多个字段属性。但是,如果未指定任何属性,则会选择所有列。
Model.select() 返回一个与行对应的模型实例列表。这类似于 SELECT 查询返回的结果集,可以通过 for 循环遍历。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class User (Model):
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
rows=User.select()
print (rows.sql())
for row in rows:
print ("name: {} age: {}".format(row.name, row.age))
db.close()
上述脚本显示以下输出:
('SELECT "t1"."id", "t1"."name", "t1"."age" FROM "User" AS "t1"', [])
name: Rajesh age: 21
name: Amar age : 20
name: Kiran age : 19
name: Lata age : 20
Peewee - 过滤器
可以使用 where 子句从 SQLite 表中检索数据。Peewee 支持以下逻辑运算符列表。
| == | x 等于 y |
| < | x 小于 y |
| <= | x 小于或等于 y |
| > | x 大于 y |
| >= | x 大于或等于 y |
| != | x 不等于 y |
| << | x IN y,其中 y 是列表或查询 |
| >> | x IS y,其中 y 为 None/NULL |
| % | x LIKE y,其中 y 可能包含通配符 |
| ** | x ILIKE y,其中 y 可能包含通配符 |
| ^ | x XOR y |
| ~ | 一元否定(例如,NOT x) |
以下代码显示年龄>=20的姓名:
rows=User.select().where (User.age>=20)
for row in rows:
print ("name: {} age: {}".format(row.name, row.age))
以下代码仅显示 names 列表中存在的姓名。
names=['Anil', 'Amar', 'Kiran', 'Bala']
rows=User.select().where (User.name << names)
for row in rows:
print ("name: {} age: {}".format(row.name, row.age))
因此,Peewee 生成的 SELECT 查询将为:
('SELECT "t1"."id", "t1"."name", "t1"."age" FROM "User" AS "t1" WHERE
("t1"."name" IN (?, ?, ?, ?))', ['Anil', 'Amar', 'Kiran', 'Bala'])
结果输出如下所示:
name: Amar age: 20 name: Kiran age: 19
过滤方法
除了上面在核心 Python 中定义的逻辑运算符之外,Peewee 还提供以下方法进行过滤:
| 序号 | 方法和描述 |
|---|---|
| 1 | .in_(value) IN 查找(与 << 相同)。 |
| 2 | .not_in(value) NOT IN 查找。 |
| 3 | .is_null(is_null) IS NULL 或 IS NOT NULL。接受布尔参数。 |
| 4 | .contains(substr) 子字符串的通配符搜索。 |
| 5 | .startswith(prefix) 搜索以 prefix 开头的值。 |
| 6 | .endswith(suffix) 搜索以 suffix 结尾的值。 |
| 7 | .between(low, high) 搜索介于 low 和 high 之间的值。 |
| 8 | .regexp(exp) 正则表达式匹配(区分大小写)。 |
| 9 | .iregexp(exp) 正则表达式匹配(不区分大小写)。 |
| 10 | .bin_and(value) 二进制 AND。 |
| 11 | .bin_or(value) 二进制 OR。 |
| 12 | .concat(other) 使用 || 连接两个字符串或对象。 |
| 13 | .distinct() 标记用于 DISTINCT 选择的列。 |
| 14 | .collate(collation) 使用给定的排序规则指定列。 |
| 15 | .cast(type) 将列的值转换为给定的类型。 |
例如,请查看以下代码。它检索以“R”开头或以“r”结尾的姓名。
rows=User.select().where (User.name.startswith('R') | User.name.endswith('r'))
等效的 SQL SELECT 查询为
('SELECT "t1"."id", "t1"."name", "t1"."age" FROM "User" AS "t1" WHERE
(("t1"."name" LIKE ?) OR ("t1"."name" LIKE ?))', ['R%', '%r'])
替代方案
Python 的内置运算符 in、not in、and、or 等将不起作用。请改用 Peewee 替代方案。
您可以使用:
.in_() 和 .not_in() 方法代替 in 和 not in 运算符。
& 代替 and。
| 代替 or。
~ 代替 not。
.is_null() 代替 is。
None 或 == None。
Peewee - 主键和复合主键
建议关系数据库中的表应该将其中一列应用于主键约束。相应地,Peewee Model 类也可以指定将 primary-key 参数设置为 True 的字段属性。但是,如果模型类没有任何主键,则 Peewee 会自动创建一个名为“id”的主键。请注意,上面定义的 User 模型没有任何字段被明确定义为主键。因此,我们数据库中映射的 User 表有一个 id 字段。
要定义自动递增整数主键,请在模型中使用 AutoField 对象作为其中一个属性。
class User (Model):
user_id=AutoField()
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
这将转换为以下 CREATE TABLE 查询:
CREATE TABLE User ( user_id INTEGER NOT NULL PRIMARY KEY, name TEXT NOT NULL, age INTEGER NOT NULL );
您还可以将任何非整数字段指定为主键,方法是将 primary_key 参数设置为 True。假设我们要将某个字母数字值存储为 user_id。
class User (Model):
user_id=TextField(primary_key=True)
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
但是,当模型包含非整数字段作为主键时,模型实例的 save() 方法不会导致数据库驱动程序自动生成新 ID,因此我们需要传递 force_insert=True 参数。但是,请注意,create() 方法隐式指定了 force_insert 参数。
User.create(user_id='A001',name="Rajesh", age=21) b=User(user_id='A002',name="Amar", age=20) b.save(force_insert=True)
save() 方法还会更新表中的现有行,此时,force_insert 主键不是必需的,因为具有唯一主键的 ID 已经存在。
Peewee 允许定义复合主键的功能。CompositeKey 类的对象在 Meta 类中定义为主键。在以下示例中,由 User 模型的 name 和 city 字段组成的复合键已分配为复合键。
class User (Model):
name=TextField()
city=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
primary_key=CompositeKey('name', 'city')
此模型转换为以下 CREATE TABLE 查询。
CREATE TABLE User (
name TEXT NOT NULL,
city TEXT NOT NULL,
age INTEGER NOT NULL,
PRIMARY KEY (
name,
city
)
);
如果需要,表不应该有主键,则在模型的 Meta 类中指定 primary_key=False。
Peewee - 更新现有记录
可以通过在模型实例上调用 save() 方法以及使用 update() 类方法来修改现有数据。
以下示例使用 get() 方法从 User 表中获取一行,并通过更改 age 字段的值来更新它。
row=User.get(User.name=="Amar")
print ("name: {} age: {}".format(row.name, row.age))
row.age=25
row.save()
Method 类的 update() 方法生成 UPDATE 查询。然后调用查询对象的 execute() 方法。
以下示例使用 update() 方法更改 age 列的值大于 20 的行。
qry=User.update({User.age:25}).where(User.age>20)
print (qry.sql())
qry.execute()
update() 方法呈现的 SQL 查询如下所示:
('UPDATE "User" SET "age" = ? WHERE ("User"."age" > ?)', [25, 20])
Peewee 还具有 bulk_update() 方法,可以帮助在单个查询操作中更新多个模型实例。该方法需要更新模型对象以及要更新的字段列表。
以下示例使用新值更新指定行的 age 字段。
rows=User.select() rows[0].age=25 rows[2].age=23 User.bulk_update([rows[0], rows[2]], fields=[User.age])
Peewee - 删除记录
在模型实例上运行 delete_instance() 方法将从映射的表中删除相应的行。
obj=User.get(User.name=="Amar") obj.delete_instance()
另一方面,delete() 是在模型类中定义的类方法,它生成 DELETE 查询。执行它会有效地从表中删除行。
db.create_tables([User]) qry=User.delete().where (User.age==25) qry.execute()
数据库中的相关表显示 DELETE 查询的效果如下所示:
('DELETE FROM "User" WHERE ("User"."age" = ?)', [25])
Peewee - 创建索引
通过使用 Peewee ORM,可以定义一个模型,该模型将创建一个在单个列以及多个列上创建索引的表。
根据 Field 属性定义,将 unique 约束设置为 True 将在映射的字段上创建索引。类似地,将 index=True 参数传递给字段构造函数也会在指定的字段上创建索引。
在以下示例中,MyUser 模型中有两个字段,username 字段的 unique 参数设置为 True,email 字段的 index=True。
class MyUser(Model):
username = CharField(unique=True)
email = CharField(index=True)
class Meta:
database=db
db_table='MyUser'
结果,SQLiteStudio 图形用户界面 (GUI) 显示创建的索引如下所示:
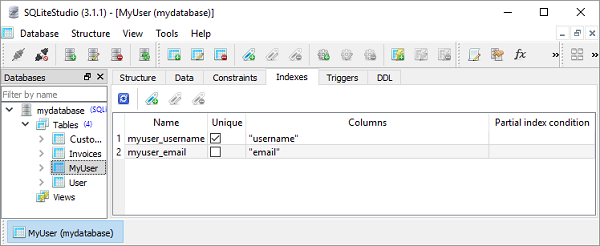
要定义多列索引,我们需要在模型类定义内的 Meta 类中添加 indexes 属性。它是一个 2 元素元组的元组,每个元组表示一个索引定义。在每个 2 元素元组中,第一部分是字段名称的元组,第二部分设置为 True 以使其唯一,否则为 False。
我们定义 MyUser 模型,带有一个两列唯一索引,如下所示:
class MyUser (Model):
name=TextField()
city=TextField()
age=IntegerField()
class Meta:
database=db
db_table='MyUser'
indexes=(
(('name', 'city'), True),
)
相应地,SQLiteStudio 显示索引定义如下面的图所示:
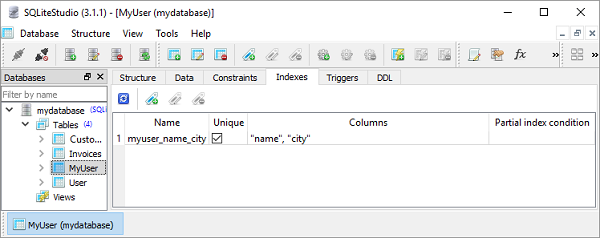
索引也可以在模型定义之外构建。
您还可以通过手动将 SQL 帮助器语句作为参数提供给 add_index() 方法来创建索引。
MyUser.add_index(SQL('CREATE INDEX idx on MyUser(name);'))
在使用 SQLite 时,尤其需要上述方法。对于 MySQL 和 PostgreSQL,我们可以获取 Index 对象并将其与 add_index() 方法一起使用。
ind=MyUser.index(MyUser.name) MyUser.add_index(ind)
Peewee - 约束
约束是对字段中可以输入的可能值的限制。其中一种约束是主键。当在字段定义中指定primary_key=True时,每一行只能存储唯一值——同一字段的值不能在另一行中重复。
如果一个字段不是主键,它仍然可以被约束为在表中存储唯一的值。字段构造函数也有constraints参数。
以下示例对age字段应用CHECK约束。
class MyUser (Model):
name=TextField()
city=TextField()
age=IntegerField(constraints=[Check('name<10')])
class Meta:
database=db
db_table='MyUser'
这将生成以下数据定义语言 (DDL) 表达式:
CREATE TABLE MyUser ( id INTEGER NOT NULL PRIMARY KEY, name TEXT NOT NULL, city TEXT NOT NULL, age INTEGER NOT NULL CHECK (name < 10) );
因此,如果新行中age<10将导致错误。
MyUser.create(name="Rajesh", city="Mumbai",age=9) peewee.IntegrityError: CHECK constraint failed: MyUser
在字段定义中,我们还可以使用DEFAULT约束,如下所示的city字段定义。
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
因此,模型对象可以在有或没有city的显式值的情况下构造。如果未使用,city字段将填充默认值——孟买。
Peewee - 使用 MySQL
如前所述,Peewee通过MySQLDatabase类支持MySQL数据库。但是,与SQLite数据库不同,Peewee无法创建MySql数据库。您需要手动创建它或使用兼容DB-API的模块(如pymysql)的功能。
首先,您应该在您的机器上安装MySQL服务器。它可以是从https://dev.mysqlserver.cn/downloads/installer/.安装的独立MySQL服务器。
您也可以使用捆绑了MySQL的Apache(例如从https://www.apachefriends.org/download.html下载和安装的XAMPP)。
接下来,我们安装pymysql模块,这是一个与DB-API兼容的Python驱动程序。
pip install pymysql
然后创建一个名为mydatabase的新数据库。我们将使用XAMPP中提供的phpmyadmin界面。
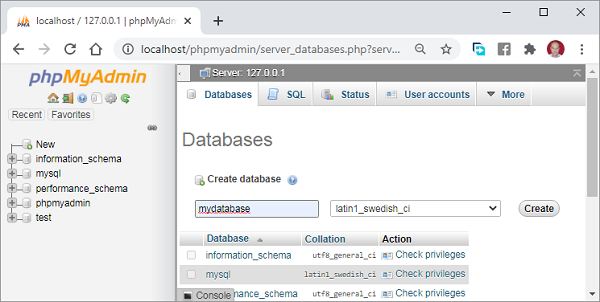
如果您选择以编程方式创建数据库,请使用以下Python脚本:
import pymysql
conn = pymysql.connect(host='localhost', user='root', password='')
conn.cursor().execute('CREATE DATABASE mydatabase')
conn.close()
一旦在服务器上创建了数据库,我们现在就可以声明一个模型,从而在其中创建一个映射表。
MySQLDatabase对象需要服务器凭据,例如主机、端口、用户名和密码。
from peewee import *
db = MySQLDatabase('mydatabase', host='localhost', port=3306, user='root', password='')
class MyUser (Model):
name=TextField()
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
age=IntegerField()
class Meta:
database=db
db_table='MyUser'
db.connect()
db.create_tables([MyUser])
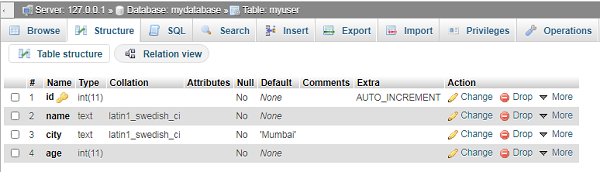
Phpmyadmin Web界面现在显示已创建的myuser表。
Peewee - 使用 PostgreSQL
Peewee也支持PostgreSQL数据库。它为此目的提供了PostgresqlDatabase类。在本章中,我们将了解如何使用Peewee模型连接到Postgres数据库并在其中创建表。
与MySQL一样,无法使用Peewee的功能在Postgres服务器上创建数据库。必须使用Postgres shell或PgAdmin工具手动创建数据库。
首先,我们需要安装Postgres服务器。对于Windows操作系统,我们可以下载https://get.enterprisedb.com/postgresql/postgresql-13.1-1-windows-x64.exe并安装。
接下来,使用pip安装程序安装Postgres的Python驱动程序——Psycopg2包。
pip install psycopg2
然后启动服务器,可以通过PgAdmin工具或psql shell启动。我们现在可以创建数据库了。运行以下Python脚本在Postgres服务器上创建mydatabase。
import psycopg2
conn = psycopg2.connect(host='localhost', user='postgres', password='postgres')
conn.cursor().execute('CREATE DATABASE mydatabase')
conn.close()
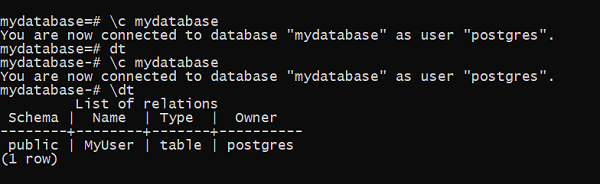
检查数据库是否已创建。在psql shell中,可以使用\l命令进行验证:

要声明MyUser模型并在上述数据库中创建同名表,请运行以下Python代码:
from peewee import *
db = PostgresqlDatabase('mydatabase', host='localhost', port=5432, user='postgres', password='postgres')
class MyUser (Model):
name=TextField()
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
age=IntegerField()
class Meta:
database=db
db_table='MyUser'
db.connect()
db.create_tables([MyUser])
我们可以验证表是否已创建。在shell中,连接到mydatabase并获取其中的表列表。
要检查新创建的MyUser数据库的结构,请在shell中运行以下查询:
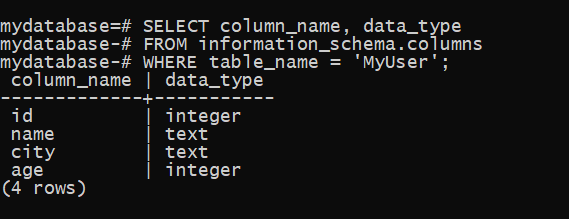
Peewee - 动态定义数据库
如果您的数据库计划在运行时发生变化,请使用DatabaseProxy帮助程序更好地控制如何初始化它。DatabaseProxy对象是一个占位符,可以使用它在运行时选择数据库。
在以下示例中,根据应用程序的配置设置选择合适的数据库。
from peewee import *
db_proxy = DatabaseProxy() # Create a proxy for our db.
class MyUser (Model):
name=TextField()
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
age=IntegerField()
class Meta:
database=db_proxy
db_table='MyUser'
# Based on configuration, use a different database.
if app.config['TESTING']:
db = SqliteDatabase(':memory:')
elif app.config['DEBUG']:
db = SqliteDatabase('mydatabase.db')
else:
db = PostgresqlDatabase(
'mydatabase', host='localhost', port=5432, user='postgres', password='postgres'
)
# Configure our proxy to use the db we specified in config.
db_proxy.initialize(db)
db.connect()
db.create_tables([MyUser])
您还可以使用数据库类和模型类中声明的bind()方法在运行时将模型关联到任何数据库对象。
以下示例在数据库类中使用bind()方法。
from peewee import *
class MyUser (Model):
name=TextField()
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
age=IntegerField()
db = MySQLDatabase('mydatabase', host='localhost', port=3306, user='root', password='')
db.connect()
db.bind([MyUser])
db.create_tables([MyUser])
相同的bind()方法也在Model类中定义。
from peewee import *
class MyUser (Model):
name=TextField()
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
age=IntegerField()
db = MySQLDatabase('mydatabase', host='localhost', port=3306, user='root', password='')
db.connect()
MyUser.bind(db)
db.create_tables([MyUser])
Peewee - 连接管理
默认情况下,Database对象创建时autoconnect参数设置为True。相反,要以编程方式管理数据库连接,最初将其设置为False。
db=SqliteDatabase("mydatabase", autoconnect=False)
数据库类具有connect()方法,该方法建立与服务器上存在的数据库的连接。
db.connect()
始终建议在执行完操作后关闭连接。
db.close()
如果您尝试打开一个已经打开的连接,Peewee将引发OperationError。
>>> db.connect()
True
>>> db.connect()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "c:\peewee\lib\site-packages\peewee.py", line 3031, in connect
raise OperationalError('Connection already opened.')
peewee.OperationalError: Connection already opened.
要避免此错误,请使用reuse_if_open=True作为connect()方法的参数。
>>> db.connect(reuse_if_open=True) False
对已关闭的连接调用close()不会导致错误。但是,您可以使用is_closed()方法检查连接是否已关闭。
>>> if db.is_closed()==True: db.connect() True >>>
除了在最后显式调用db.close()之外,还可以将数据库对象用作context_manager。
from peewee import *
db = SqliteDatabase('mydatabase.db', autoconnect=False)
class User (Model):
user_id=TextField(primary_key=True)
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
with db:
db.connect()
db.create_tables([User])
Peewee - 关系和连接
Peewee支持实现不同类型的SQL JOIN查询。它的Model类有一个join()方法,该方法返回一个Join实例。
M1.joint(m2, join_type, on)
连接表将M1模型映射到m2模型,并返回Join类实例。on参数默认为None,是用于连接谓词的表达式。
连接类型
Peewee支持以下连接类型(默认值为INNER)。
JOIN.INNER
JOIN.LEFT_OUTER
JOIN.RIGHT_OUTER
JOIN.FULL
JOIN.FULL_OUTER
JOIN.CROSS
为了展示join()方法的使用,我们首先声明以下模型:
db = SqliteDatabase('mydatabase.db')
class BaseModel(Model):
class Meta:
database = db
class Item(BaseModel):
itemname = TextField()
price = IntegerField()
class Brand(BaseModel):
brandname = TextField()
item = ForeignKeyField(Item, backref='brands')
class Bill(BaseModel):
item = ForeignKeyField(Item, backref='bills')
brand = ForeignKeyField(Brand, backref='bills')
qty = DecimalField()
db.create_tables([Item, Brand, Bill])
表
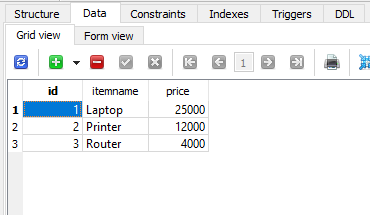
接下来,我们使用以下测试数据填充这些表:
Item表
Item表如下所示:
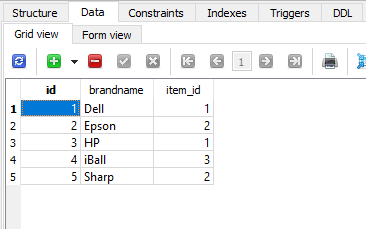
Brand表
以下是Brand表:
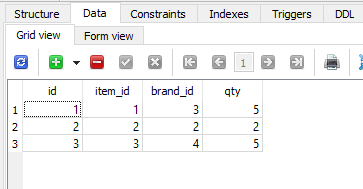
Bill表
Bill表如下所示:
要执行Brand和Item表之间的简单连接操作,请执行以下代码:
qs=Brand.select().join(Item)
for q in qs:
print ("Brand ID:{} Item Name: {} Price: {}".format(q.id, q.brandname, q.item.price))
结果输出如下所示:
Brand ID:1 Item Name: Dell Price: 25000 Brand ID:2 Item Name: Epson Price: 12000 Brand ID:3 Item Name: HP Price: 25000 Brand ID:4 Item Name: iBall Price: 4000 Brand ID:5 Item Name: Sharp Price: 12000
连接多个表
我们有一个Bill模型,它与item和brand模型具有两个外键关系。要从所有三个表中获取数据,请使用以下代码:
qs=Bill.select().join(Brand).join(Item)
for q in qs:
print ("BillNo:{} Brand:{} Item:{} price:{} Quantity:{}".format(q.id, \
q.brand.brandname, q.item.itemname, q.item.price, q.qty))
根据我们的测试数据,将显示以下输出:
BillNo:1 Brand:HP Item:Laptop price:25000 Quantity:5 BillNo:2 Brand:Epson Item:Printer price:12000 Quantity:2 BillNo:3 Brand:iBall Item:Router price:4000 Quantity:5
Peewee - 子查询
在SQL中,子查询是另一个查询的WHERE子句中的嵌入查询。我们可以将子查询实现为model.select()作为外部model.select()语句的where属性内的参数。
为了演示Peewee中子查询的使用,让我们使用以下定义的模型:
from peewee import *
db = SqliteDatabase('mydatabase.db')
class BaseModel(Model):
class Meta:
database = db
class Contacts(BaseModel):
RollNo = IntegerField()
Name = TextField()
City = TextField()
class Branches(BaseModel):
RollNo = IntegerField()
Faculty = TextField()
db.create_tables([Contacts, Branches])
创建表后,将使用以下示例数据填充它们:
Contacts表
Contacts表如下所示:
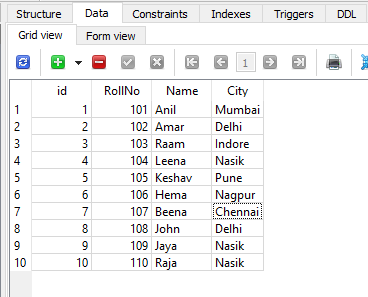
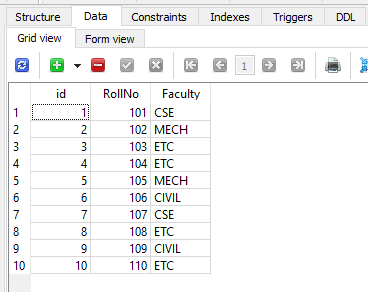
为了仅显示Contact表中注册为ETC教师的RollNo的姓名和城市,以下代码生成一个SELECT查询,并在其WHERE子句中包含另一个SELECT查询。
#this query is used as subquery
faculty=Branches.select(Branches.RollNo).where(Branches.Faculty=="ETC")
names=Contacts.select().where (Contacts.RollNo .in_(faculty))
print ("RollNo and City for Faculty='ETC'")
for name in names:
print ("RollNo:{} City:{}".format(name.RollNo, name.City))
db.close()
以上代码将显示以下结果
RollNo and City for Faculty='ETC' RollNo:103 City:Indore RollNo:104 City:Nasik RollNo:108 City:Delhi RollNo:110 City:Nasik
Peewee - 排序
可以使用order_by子句以及模型的select()方法从表中选择记录。此外,通过将desc()附加到要对其执行排序的字段属性,记录将按降序收集。
示例
以下代码按城市名称升序显示Contact表中的记录。
rows=Contacts.select().order_by(Contacts.City)
print ("Contact list in order of city")
for row in rows:
print ("RollNo:{} Name: {} City:{}".format(row.RollNo,row.Name, row.City))
输出
这是一个根据城市名称升序排列的排序列表。
Contact list in order of city RollNo:107 Name: Beena City:Chennai RollNo:102 Name: Amar City:Delhi RollNo:108 Name: John City:Delhi RollNo:103 Name: Raam City:Indore RollNo:101 Name: Anil City:Mumbai RollNo:106 Name: Hema City:Nagpur RollNo:104 Name: Leena City:Nasik RollNo:109 Name: Jaya City:Nasik RollNo:110 Name: Raja City:Nasik RollNo:105 Name: Keshav City:Pune
示例
以下代码按Name字段降序显示列表。
rows=Contacts.select().order_by(Contacts.Name.desc())
print ("Contact list in descending order of Name")
for row in rows:
print ("RollNo:{} Name: {} City:{}".format(row.RollNo,row.Name, row.City))
输出
输出如下所示:
Contact list in descending order of Name RollNo:110 Name: Raja City:Nasik RollNo:103 Name: Raam City:Indore RollNo:104 Name: Leena City:Nasik RollNo:105 Name: Keshav City:Pune RollNo:108 Name: John City:Delhi RollNo:109 Name: Jaya City:Nasik RollNo:106 Name: Hema City:Nagpur RollNo:107 Name: Beena City:Chennai RollNo:101 Name: Anil City:Mumbai RollNo:102 Name: Amar City:Delhi
Peewee - 计数和聚合
我们可以通过附加count()方法来查找任何SELECT查询中报告的记录数。例如,以下语句返回City='Nasik'的Contacts表中的行数。
qry=Contacts.select().where (Contacts.City=='Nasik').count() print (qry)
示例
SQL在SELECT查询中具有GROUP BY子句。Peewee以group_by()方法的形式支持它。以下代码返回Contacts表中按城市划分的姓名计数。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class Contacts(BaseModel):
RollNo = IntegerField()
Name = TextField()
City = TextField()
class Meta:
database = db
db.create_tables([Contacts])
qry=Contacts.select(Contacts.City, fn.Count(Contacts.City).alias('count')).group_by(Contacts.City)
print (qry.sql())
for q in qry:
print (q.City, q.count)
Peewee发出的SELECT查询如下所示:
('SELECT "t1"."City", Count("t1"."City") AS "count" FROM "contacts" AS "t1" GROUP BY "t1"."City"', [])
输出
根据Contacts表中的示例数据,将显示以下输出:
Chennai 1 Delhi 2 Indore 1 Mumbai 1 Nagpur 1 Nasik 3 Pune 1
Peewee - SQL 函数
美国国家标准学会 (ANSI) 结构化查询语言 (SQL) 标准定义了许多SQL函数。
以下聚合函数在Peewee中很有用。
AVG() - 返回平均值。
COUNT() - 返回行数。
FIRST() - 返回第一个值。
LAST() - 返回最后一个值。
MAX() - 返回最大值。
MIN() - 返回最小值。
SUM() - 返回总和。
为了实现这些SQL函数,Peewee有一个SQL帮助函数fn()。在上面的示例中,我们使用它来查找每个城市的记录数。
以下示例构建一个使用SUM()函数的SELECT查询。
使用前面定义的模型中的Bill和Item表,我们将显示Bill表中输入的每个项目的数量总和。
Item表
包含数据的Item表如下所示:
| Id | Item Name | Price |
|---|---|---|
| 1 | Laptop | 25000 |
| 2 | Printer | 12000 |
| 3 | Router | 4000 |
Bill表
Bill表如下所示:
| Id | Item_id | Brand_id | Quantity |
|---|---|---|---|
| 1 | 1 | 3 | 5 |
| 2 | 2 | 2 | 2 |
| 3 | 3 | 4 | 5 |
| 4 | 2 | 2 | 6 |
| 5 | 3 | 4 | 3 |
| 6 | 1 | 3 | 1 |
示例
我们在Bill和Item表之间创建一个连接,从Item表中选择项目名称,从Bill表中选择数量总和。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class BaseModel(Model):
class Meta:
database = db
class Item(BaseModel):
itemname = TextField()
price = IntegerField()
class Brand(BaseModel):
brandname = TextField()
item = ForeignKeyField(Item, backref='brands')
class Bill(BaseModel):
item = ForeignKeyField(Item, backref='bills')
brand = ForeignKeyField(Brand, backref='bills')
qty = DecimalField()
db.create_tables([Item, Brand, Bill])
qs=Bill.select(Item.itemname, fn.SUM(Bill.qty).alias('Sum'))
.join(Item).group_by(Item.itemname)
print (qs)
for q in qs:
print ("Item: {} sum: {}".format(q.item.itemname, q.Sum))
db.close()
以上脚本执行以下SELECT查询:
SELECT "t1"."itemname", SUM("t2"."qty") AS "Sum" FROM "bill" AS "t2"
INNER JOIN "item" AS "t1" ON ("t2"."item_id" = "t1"."id") GROUP BY "t1"."itemname"
输出
因此,输出如下所示:
Item: Laptop sum: 6 Item: Printer sum: 8 Item: Router sum: 8
Peewee - 获取行元组/字典
可以迭代结果集而无需创建模型实例。这可以通过使用以下方法来实现:
tuples()方法。
dicts()方法。
示例
要将SELECT查询中的字段数据作为元组集合返回,请使用tuples()方法。
qry=Contacts.select(Contacts.City, fn.Count(Contacts.City).alias('count'))
.group_by(Contacts.City).tuples()
lst=[]
for q in qry:
lst.append(q)
print (lst)
输出
输出如下所示:
[
('Chennai', 1),
('Delhi', 2),
('Indore', 1),
('Mumbai', 1),
('Nagpur', 1),
('Nasik', 3),
('Pune', 1)
]
示例
要获取字典对象的集合:
qs=Brand.select().join(Item).dicts() lst=[] for q in qs: lst.append(q) print (lst)
输出
输出如下所示:
[
{'id': 1, 'brandname': 'Dell', 'item': 1},
{'id': 2, 'brandname': 'Epson', 'item': 2},
{'id': 3, 'brandname': 'HP', 'item': 1},
{'id': 4, 'brandname': 'iBall', 'item': 3},
{'id': 5, 'brandname': 'Sharp', 'item': 2}
]
Peewee - 用户自定义运算符
Peewee有一个Expression类,借助它,我们可以在Peewee的操作符列表中添加任何自定义操作符。Expression的构造函数需要三个参数,左操作数、操作符和右操作数。
op=Expression(left, operator, right)
使用Expression类,我们定义了一个mod()函数,它接受左操作数和右操作数以及'%'作为操作符的参数。
from peewee import Expression # the building block for expressions def mod(lhs, rhs): return Expression(lhs, '%', rhs)
示例
我们可以在SELECT查询中使用它来获取Contacts表中id为偶数的记录列表。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class BaseModel(Model):
class Meta:
database = db
class Contacts(BaseModel):
RollNo = IntegerField()
Name = TextField()
City = TextField()
db.create_tables([Contacts])
from peewee import Expression # the building block for expressions
def mod(lhs, rhs):
return Expression(lhs,'%', rhs)
qry=Contacts.select().where (mod(Contacts.id,2)==0)
print (qry.sql())
for q in qry:
print (q.id, q.Name, q.City)
此代码将发出以下由字符串表示的SQL查询:
('SELECT "t1"."id", "t1"."RollNo", "t1"."Name", "t1"."City" FROM "contacts" AS "t1" WHERE (("t1"."id" % ?) = ?)', [2, 0])
输出
因此,输出如下所示:
2 Amar Delhi 4 Leena Nasik 6 Hema Nagpur 8 John Delhi 10 Raja Nasik
Peewee - 原子事务
Peewee的数据库类具有atomic()方法,该方法创建一个上下文管理器。它启动一个新的事务。在上下文块内,可以根据事务是否已成功完成或遇到异常来提交或回滚事务。
with db.atomic() as transaction:
try:
User.create(name='Amar', age=20)
transaction.commit()
except DatabaseError:
transaction.rollback()
atomic()也可以用作装饰器。
@db.atomic()
def create_user(nm,n):
return User.create(name=nm, age=n)
create_user('Amar', 20)
多个原子事务块也可以嵌套。
with db.atomic() as txn1:
User.create('name'='Amar', age=20)
with db.atomic() as txn2:
User.get(name='Amar')
Peewee - 数据库错误
Python的DB-API标准(PEP 249推荐)指定了任何符合DB-API的模块(例如pymysql、pyscopg2等)要定义的异常类类型。
Peewee API为这些异常提供了易于使用的包装器。PeeweeException是基类,以下异常类已在Peewee API中定义:
DatabaseError
DataError
IntegrityError
InterfaceError
InternalError
NotSupportedError
OperationalError
编程错误
我们可以使用Peewee提供的异常,而不是尝试使用特定于DB-API的异常。
Peewee - 查询构建器
Peewee还提供了一个非ORM API来访问数据库。我们可以将数据库表和列绑定到Peewee中定义的Table和Column对象,而不是定义模型和字段,并通过它们执行查询。
首先,声明一个与数据库中表对应的Table对象。您必须指定表名和列列表。可选地,还可以提供主键。
Contacts=Table('Contacts', ('id', 'RollNo', 'Name', 'City'))
此表对象使用bind()方法绑定到数据库。
Contacts=Contacts.bind(db)
示例
现在,我们可以使用select()方法在此表对象上设置一个SELECT查询,并如下迭代结果集:
names=Contacts.select() for name in names: print (name)
输出
默认情况下,行以字典的形式返回。
{'id': 1, 'RollNo': 101, 'Name': 'Anil', 'City': 'Mumbai'}
{'id': 2, 'RollNo': 102, 'Name': 'Amar', 'City': 'Delhi'}
{'id': 3, 'RollNo': 103, 'Name': 'Raam', 'City': 'Indore'}
{'id': 4, 'RollNo': 104, 'Name': 'Leena', 'City': 'Nasik'}
{'id': 5, 'RollNo': 105, 'Name': 'Keshav', 'City': 'Pune'}
{'id': 6, 'RollNo': 106, 'Name': 'Hema', 'City': 'Nagpur'}
{'id': 7, 'RollNo': 107, 'Name': 'Beena', 'City': 'Chennai'}
{'id': 8, 'RollNo': 108, 'Name': 'John', 'City': 'Delhi'}
{'id': 9, 'RollNo': 109, 'Name': 'Jaya', 'City': 'Nasik'}
{'id': 10, 'RollNo': 110, 'Name': 'Raja', 'City': 'Nasik'}
如果需要,可以将其作为元组、命名元组或对象获取。
元组
程序如下所示:
示例
names=Contacts.select().tuples() for name in names: print (name)
输出
输出如下所示:
(1, 101, 'Anil', 'Mumbai') (2, 102, 'Amar', 'Delhi') (3, 103, 'Raam', 'Indore') (4, 104, 'Leena', 'Nasik') (5, 105, 'Keshav', 'Pune') (6, 106, 'Hema', 'Nagpur') (7, 107, 'Beena', 'Chennai') (8, 108, 'John', 'Delhi') (9, 109, 'Jaya', 'Nasik') (10, 110, 'Raja', 'Nasik')
命名元组
程序如下所示:
示例
names=Contacts.select().namedtuples() for name in names: print (name)
输出
输出如下所示:
Row(id=1, RollNo=101, Name='Anil', City='Mumbai') Row(id=2, RollNo=102, Name='Amar', City='Delhi') Row(id=3, RollNo=103, Name='Raam', City='Indore') Row(id=4, RollNo=104, Name='Leena', City='Nasik') Row(id=5, RollNo=105, Name='Keshav', City='Pune') Row(id=6, RollNo=106, Name='Hema', City='Nagpur') Row(id=7, RollNo=107, Name='Beena', City='Chennai') Row(id=8, RollNo=108, Name='John', City='Delhi') Row(id=9, RollNo=109, Name='Jaya', City='Nasik') Row(id=10, RollNo=110, Name='Raja', City='Nasik')
要插入新记录,INSERT查询构造如下:
id = Contacts.insert(RollNo=111, Name='Abdul', City='Surat').execute()
如果要添加的记录列表存储为字典列表或元组列表,则可以批量添加它们。
Records=[{‘RollNo’:112, ‘Name’:’Ajay’, ‘City’:’Mysore’},
{‘RollNo’:113, ‘Name’:’Majid’,’City’:’Delhi’}}
Or
Records=[(112, ‘Ajay’,’Mysore’), (113, ‘Majid’, ‘Delhi’)}
INSERT查询如下所示:
Contacts.insert(Records).execute()
Peewee的Table对象具有update()方法来实现SQL UPDATE查询。要更改所有来自Nasik到Nagar的记录的City,我们使用以下查询。
Contacts.update(City='Nagar').where((Contacts.City=='Nasik')).execute()
最后,Peewee中的Table类还具有delete()方法来实现SQL中的DELETE查询。
Contacts.delete().where(Contacts.Name=='Abdul').execute()
Peewee - 与 Web 框架集成
Peewee可以与大多数Python Web框架API无缝协作。每当Web服务器网关接口(WSGI)服务器从客户端接收连接请求时,都会建立与数据库的连接,然后在传递响应后关闭连接。
在基于Flask的Web应用程序中使用时,连接会影响@app.before_request装饰器,并在@app.teardown_request上断开连接。
from flask import Flask
from peewee import *
db = SqliteDatabase('mydatabase.db')
app = Flask(__name__)
@app.before_request
def _db_connect():
db.connect()
@app.teardown_request
def _db_close(exc):
if not db.is_closed():
db.close()
Peewee API也可以在Django中使用。为此,在Django应用程序中添加一个中间件。
def PeeweeConnectionMiddleware(get_response):
def middleware(request):
db.connect()
try:
response = get_response(request)
finally:
if not db.is_closed():
db.close()
return response
return middleware
中间件添加到Django的settings模块中。
# settings.py MIDDLEWARE_CLASSES = ( # Our custom middleware appears first in the list. 'my_blog.middleware.PeeweeConnectionMiddleware', #followed by default middleware list. .. )
Peewee可以方便地与其他框架(如Bottle、Pyramid和Tornado等)一起使用。
Peewee - SQLite 扩展
Peewee带有一个Playhouse命名空间。它是一组各种扩展模块的集合。其中之一是playhouse.sqlite_ext模块。它主要定义了SqliteExtDatabase类,该类继承了SqliteDatabase类,支持以下附加功能:
SQLite扩展的功能
Peewee支持的SQLite扩展功能如下:
全文搜索。
JavaScript对象表示法(JSON)扩展集成。
闭包表扩展支持。
LSM1扩展支持。
用户定义的表函数。
支持使用备份API:backup_to_file()进行在线备份。
BLOB API支持,用于高效的二进制数据存储。
如果将特殊的JSONField声明为字段属性之一,则可以存储JSON数据。
class MyModel(Model): json_data = JSONField(json_dumps=my_json_dumps)
要激活全文搜索,模型可以具有DocIdField来定义主键。
class NoteIndex(FTSModel):
docid = DocIDField()
content = SearchField()
class Meta:
database = db
FTSModel是VirtualModel的子类,可在https://peewee.org.cn/en/latest/peewee/sqlite_ext.html#VirtualModel中使用,用于FTS3和FTS4全文搜索扩展。Sqlite会将所有列类型视为TEXT(尽管您可以存储其他数据类型,Sqlite会将其视为文本)。
SearchField是一个字段类,用于表示全文搜索虚拟表的模型上的列。
SqliteDatabase支持AutoField来增加主键。但是,SqliteExtDatabase支持AutoIncrementField以确保主键始终单调递增,而不管行是否被删除。
playhouse命名空间(playhouse.sqliteq)中的SqliteQ模块定义了SqliteExeDatabase的子类,以处理对SQlite数据库的序列化并发写入。
另一方面,playhouse.apsw模块支持apsw sqlite驱动程序。另一个Python SQLite包装器(APSW)速度很快,并且可以处理嵌套事务,这些事务由您的代码显式管理。
from apsw_ext import *
db = APSWDatabase('testdb')
class BaseModel(Model):
class Meta:
database = db
class MyModel(BaseModel):
field1 = CharField()
field2 = DateTimeField()
Peewee - PostgreSQL和MySQL扩展
playhouse.postgres_ext模块中定义的帮助程序启用了其他PostgreSQL功能。此模块定义了PostgresqlExtDatabase类,并提供了以下其他字段类型,这些类型专门用于声明要映射到PostgreSQL数据库表的模型。
PostgreSQL扩展的功能
Peewee支持的PostgreSQL扩展功能如下:
ArrayField字段类型,用于存储数组。
HStoreField字段类型,用于存储键值对。
IntervalField字段类型,用于存储timedelta对象。
JSONField字段类型,用于存储JSON数据。
BinaryJSONField字段类型用于jsonb JSON数据类型。
TSVectorField字段类型,用于存储全文搜索数据。
DateTimeTZField字段类型,一个时区感知的日期时间字段。
此模块中的其他特定于Postgres的功能旨在提供。
hstore支持。
服务器端游标。
全文搜索。
Postgres hstore是一个键值存储,可以作为HStoreField类型字段之一嵌入到表中。要启用hstore支持,请使用register_hstore=True参数创建数据库实例。
db = PostgresqlExtDatabase('mydatabase', register_hstore=True)
使用一个HStoreField定义一个模型。
class Vehicles(BaseExtModel): type = CharField() features = HStoreField()
如下创建模型实例:
v=Vechicle.create(type='Car', specs:{'mfg':'Maruti', 'Fuel':'Petrol', 'model':'Alto'})
访问hstore值:
obj=Vehicle.get(Vehicle.id=v.id) print (obj.features)
MySQL扩展
playhouse.mysql_ext模块中定义的MySQLConnectorDatabase提供了MysqlDatabase类的替代实现。它使用Python的DB-API兼容的官方mysql/python connector。
from playhouse.mysql_ext import MySQLConnectorDatabase
db = MySQLConnectorDatabase('mydatabase', host='localhost', user='root', password='')
Peewee - 使用 CockroachDB
CockroachDB或Cockroach数据库(CRDB)由计算机软件公司Cockroach Labs开发。它是一个可扩展的、一致复制的事务性数据存储,旨在将数据的副本存储在多个位置,以提供快速的访问。
Peewee通过playhouse.cockroachdb扩展模块中定义的CockroachDatabase类为该数据库提供支持。该模块包含CockroachDatabase的定义,它是核心模块中PostgresqlDatabase类的子类。
此外,还有一个run_transaction()方法,它在事务内运行一个函数,并提供自动的客户端端重试逻辑。
字段类
该扩展还具有一些特殊的字段类,用作与CRDB兼容的模型中的属性。
UUIDKeyField - 一个主键字段,使用CRDB的UUID类型以及默认的随机生成的UUID。
RowIDField - 一个主键字段,使用CRDB的INT类型以及默认的unique_rowid()。
JSONField - 与Postgres BinaryJSONField相同。
ArrayField - 与Postgres扩展相同,但不支持多维数组。