- Prolog 教程
- Prolog - 首页
- Prolog - 简介
- Prolog - 环境设置
- Prolog - Hello World
- Prolog - 基础知识
- Prolog - 关系
- Prolog - 数据对象
- Prolog - 运算符
- 循环与决策
- 合取与析取
- Prolog - 列表
- 递归和结构
- Prolog - 回溯
- Prolog - 不同与非
- Prolog - 输入和输出
- Prolog - 内置谓词
- 树形数据结构(案例研究)
- Prolog - 例子
- Prolog - 基本程序
- Prolog - cut 的例子
- 汉诺塔问题
- Prolog - 链表
- 猴子和香蕉问题
- Prolog 有用资源
- Prolog 快速指南
- Prolog - 有用资源
- Prolog - 讨论
Prolog 快速指南
Prolog - 简介
Prolog,顾名思义,是**LOG**ical **PRO**gramming 的缩写。它是一种逻辑和声明式编程语言。在深入探讨 Prolog 的概念之前,让我们首先了解逻辑编程究竟是什么。
逻辑编程是计算机编程范式的一种,其中程序语句表达了系统中形式逻辑内不同问题的 facts 和 rules。这里的规则以逻辑子句的形式编写,其中包含头部和体部。例如,H 是头部,B1、B2、B3 是体部的元素。现在,如果我们声明“当 B1、B2、B3 全都为真时,H 为真”,这就是一个规则。另一方面,事实就像规则,但没有体部。因此,“H 为真”就是一个事实的例子。
一些逻辑编程语言,如 Datalog 或 ASP(Answer Set Programming),被称为纯粹的声明式语言。这些语言允许关于程序应该完成什么的语句。没有关于如何逐步执行任务的说明。然而,像 Prolog 这样的其他语言既具有声明式特性,也具有命令式特性。这可能还包括程序性语句,例如“要解决问题 H,执行 B1、B2 和 B3”。
下面列出了一些逻辑编程语言:
ALF(代数逻辑函数式编程语言)
ASP(Answer Set Programming)
CycL
Datalog
FuzzyCLIPS
Janus
Parlog
Prolog
Prolog++
ROOP
逻辑编程和函数式编程
我们将讨论逻辑编程和传统的函数式编程语言之间的区别。我们可以使用下图来说明这两者:
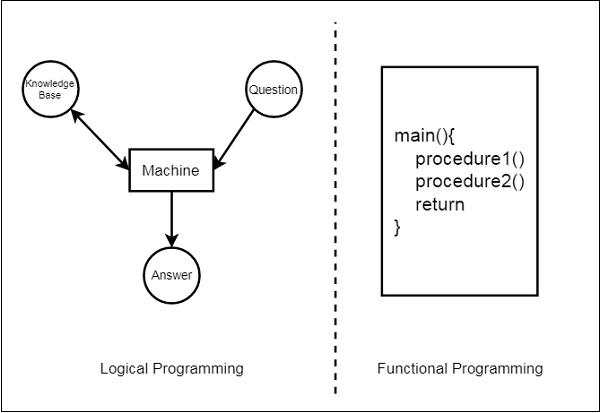
从这个图示中,我们可以看到,在函数式编程中,我们必须定义过程和过程的工作方式。这些过程一步一步地解决基于算法的特定问题。另一方面,对于逻辑编程,我们将提供知识库。使用这个知识库,机器可以找到给定问题的答案,这与函数式编程完全不同。
在函数式编程中,我们必须提到如何解决一个问题,但在逻辑编程中,我们必须指定我们实际上想要解决哪个问题。然后逻辑编程会自动找到一个合适的解决方案来帮助我们解决那个特定问题。
现在让我们看看下面更多区别:
| 函数式编程 | 逻辑编程 |
|---|---|
| 函数式编程遵循冯·诺依曼架构,或使用顺序步骤。 | 逻辑编程使用抽象模型,或处理对象及其关系。 |
| 语法实际上是语句的序列,例如 (a, s, I)。 | 语法基本上是逻辑公式(Horn 子句)。 |
| 计算通过顺序执行语句来进行。 | 它通过演绎子句来计算。 |
| 逻辑和控制混合在一起。 | 逻辑和控制可以分开。 |
什么是 Prolog?
Prolog 或 **PRO**gramming in **LOG**ics 是一种逻辑和声明式编程语言。它是支持声明式编程范式的第四代语言的一个主要例子。这尤其适用于涉及**符号**或**非数值计算**的程序。这是在**人工智能**中使用 Prolog 作为编程语言的主要原因,其中**符号操作**和**推理操作**是基本任务。
在 Prolog 中,我们不需要提及如何解决一个问题,我们只需要提及问题是什么,这样 Prolog 就会自动解决它。但是,在 Prolog 中,我们应该给出作为**解决方案方法**的线索。
Prolog 语言基本上有三个不同的元素:
**事实** - 事实是为真的谓词,例如,如果我们说“Tom 是 Jack 的儿子”,那么这是一个事实。
**规则** - 规则是包含条件子句的事实的扩展。为了满足规则,这些条件应该得到满足。例如,如果我们定义一个规则为:
grandfather(X, Y) :- father(X, Z), parent(Z, Y)
这意味着,对于 X 来说是 Y 的祖父,Z 应该是 Y 的父母,而 X 应该是 Z 的父亲。
**问题** - 为了运行 Prolog 程序,我们需要一些问题,而这些问题可以通过给定的 facts 和 rules 来回答。
Prolog 的历史
Prolog 的起源包括对定理证明器和其他一些在 1960 年代和 1970 年代开发的自动化演绎系统的研究。Prolog 的推理机制基于 Robinson 在 1965 年提出的 Resolution Principle,以及 Green (1968) 提出的答案提取机制。这些想法随着线性分辨率程序的出现而强有力地结合在一起。
明确的目标导向线性分辨率程序推动了通用逻辑编程系统的开发。**第一个**Prolog 是**Marseille Prolog**,基于**Colmerauer**在 1970 年的工作。这个 Marseille Prolog 解释器的说明书 (Roussel, 1975) 是 Prolog 语言的第一个详细描述。
Prolog 也被认为是支持声明式编程范式的第四代编程语言。1981 年宣布的著名的日本第五代计算机项目采用了 Prolog 作为开发语言,从而引起了人们对这种语言及其能力的广泛关注。
Prolog 的一些应用
Prolog 用于各个领域。它在自动化系统中发挥着至关重要的作用。以下是 Prolog 使用的其他一些重要领域:
智能数据库检索
自然语言理解
规范语言
机器学习
机器人规划
自动化系统
问题解决
Prolog - 环境设置
在本章中,我们将讨论如何在我们的系统中安装 Prolog。
Prolog 版本
在本教程中,我们使用的是 GNU Prolog,版本:1.4.5
官方网站
这是 GNU Prolog 的官方网站,我们可以在那里看到关于 GNU Prolog 的所有必要细节,并获得下载链接。
直接下载链接
以下是 Windows 系统 GNU Prolog 的直接下载链接。对于其他操作系统(如 Mac 或 Linux),您可以访问官方网站(链接如上所示)获取下载链接:
http://www.gprolog.org/#download(32 位系统)
安装指南
下载 exe 文件并运行它。
您将看到如下所示的窗口,然后单击**下一步**:
选择要安装软件的正确**目录**,否则将其安装在默认目录中。然后点击**下一步**。
您将看到以下屏幕,只需转到**下一步**。
您可以验证以下屏幕,并**选中/取消选中**相应的复选框,否则您可以将其保留为默认设置。然后点击**下一步**。
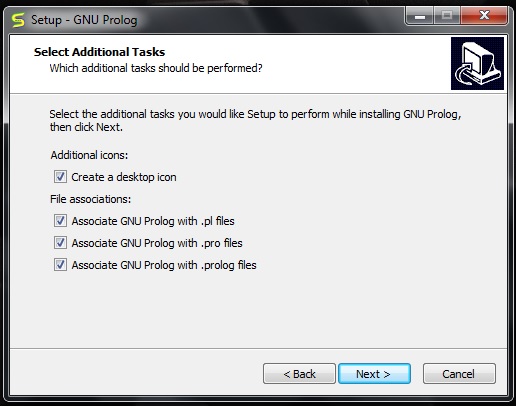
在下一步中,您将看到以下屏幕,然后单击**安装**。
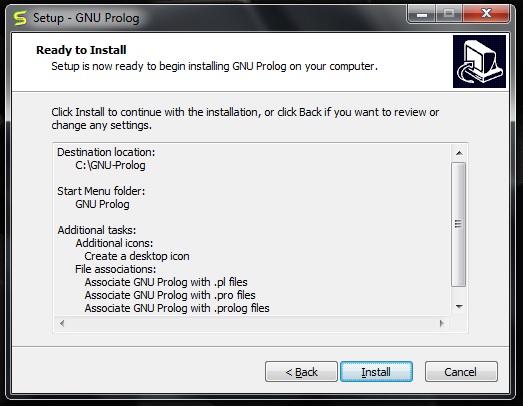
然后等待安装过程完成。
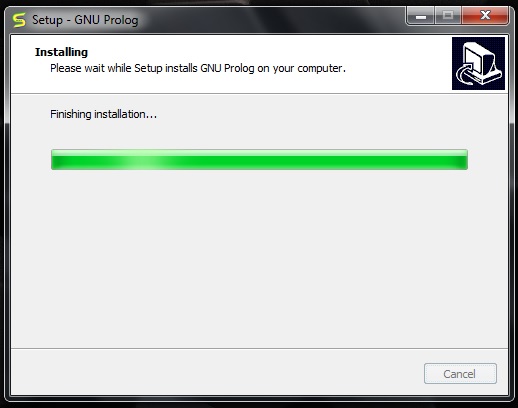
最后单击**完成**以启动 GNU Prolog。
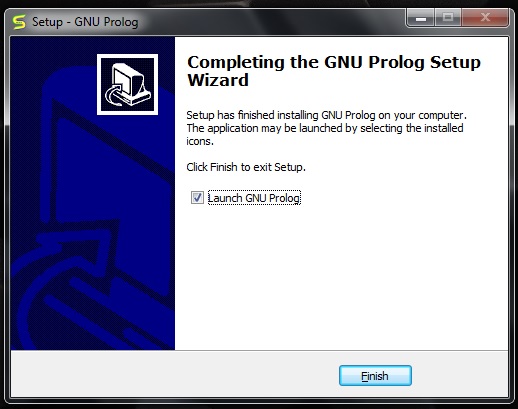
GNU prolog 成功安装,如下所示:
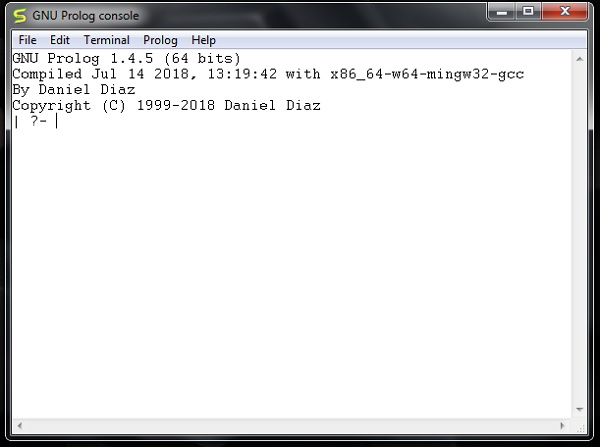
Prolog - Hello World
在上一节中,我们已经看到了如何安装 GNU Prolog。现在,我们将了解如何在我们的 Prolog 环境中编写一个简单的**Hello World**程序。
Hello World 程序
运行 GNU prolog 后,我们可以直接从控制台编写 hello world 程序。为此,我们必须编写如下命令:
write('Hello World').
**注意** - 每行之后,都必须使用一个句点 (.) 符号来表示该行已结束。
相应的输出将如下所示:
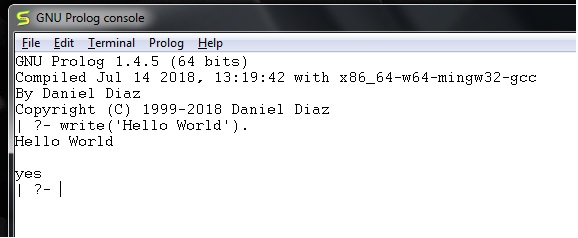
现在让我们看看如何将 Prolog 脚本文件(扩展名为 *.pl)运行到 Prolog 控制台中。
在运行 *.pl 文件之前,我们必须将文件存储到 GNU prolog 控制台指向的目录中,否则只需按照以下步骤更改目录:
**步骤 1** - 在 prolog 控制台中,转到文件 > 更改目录,然后单击该菜单。
**步骤 2** - 选择正确的文件夹并按**确定**。
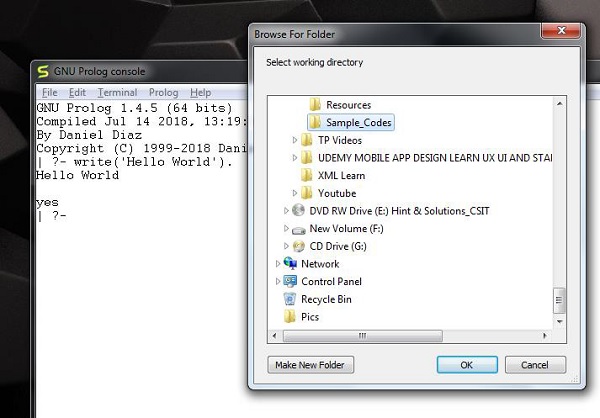
现在,我们可以在 prolog 控制台中看到,它显示我们已成功更改目录。
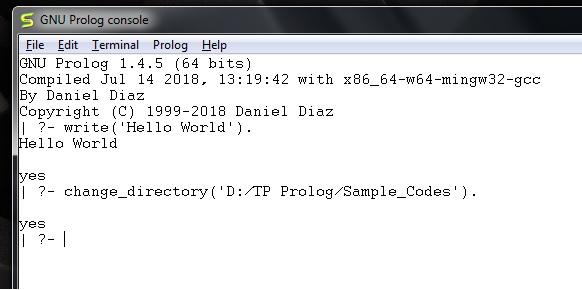
**步骤 3** - 现在创建一个文件(扩展名为 *.pl)并编写如下代码:
main :- write('This is sample Prolog program'),
write(' This program is written into hello_world.pl file').
现在让我们运行代码。要运行它,我们必须编写文件名如下:
[hello_world]
输出如下:
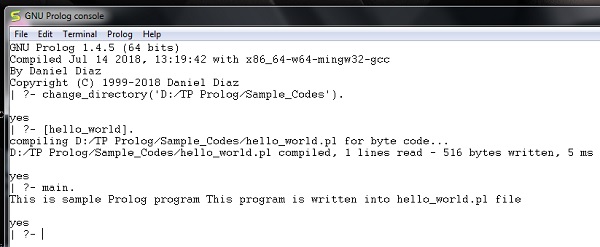
Prolog - 基础知识
在本章中,我们将了解一些关于 Prolog 的基本知识。因此,我们将继续进行 Prolog 编程的第一步。
本章将涵盖的不同主题包括:
**知识库** - 这是逻辑编程的基本部分之一。我们将详细了解知识库以及它如何帮助逻辑编程。
**事实、规则和查询** - 这些是逻辑编程的构建块。我们将获得关于事实和规则的一些详细知识,并了解一些将在逻辑编程中使用的查询。
在这里,我们将讨论逻辑编程的基本构建块。这些构建块是**事实、规则和查询**。
事实
我们可以将事实定义为对象之间以及对象可能具有的属性之间的显式关系。因此,事实本质上是无条件为真的。假设我们有一些如下所示的事实:
Tom 是一只猫
Kunal 喜欢吃意大利面
头发是黑色的
Nawaz 喜欢玩游戏
Pratyusha 很懒。
所以这些是一些无条件为真的事实。这些实际上是我们必须认为是正确的陈述。
以下是编写事实的一些指导原则:
属性/关系的名称以小写字母开头。
关系名称显示为第一个术语。
对象显示为括号内用逗号分隔的参数。
句点“.”必须结束一个事实。
对象也以小写字母开头。它们也可以以数字开头(如 1234),并且可以是用引号括起来的字符字符串,例如 color(penink, ‘red’)。
phoneno(agnibha, 1122334455)。也称为谓词或子句。
语法
事实的语法如下:
relation(object1,object2...).
例子
以下是上述概念的一个例子:
cat(tom). loves_to_eat(kunal,pasta). of_color(hair,black). loves_to_play_games(nawaz). lazy(pratyusha).
规则
我们可以将规则定义为对象之间的隐式关系。因此,事实是有条件为真的。因此,当一个关联条件为真时,谓词也为真。假设我们有一些如下所示的规则:
如果 Lili 跳舞,她就会快乐。
如果 Tom 正在寻找食物,他就饿了。
如果 Jack 和 Bili 都喜欢打板球,那么他们是朋友。
如果学校放假,而且他空闲,他就会去玩。
这些规则是条件性成立的,即当右侧为真时,左侧也为真。
这里符号 (:- ) 读作“如果”或“由…蕴含”。它也称为箭头符号,符号左侧称为头部 (Head),右侧称为体 (Body)。这里可以使用逗号 (,),它表示合取;也可以使用分号 (;),它表示析取。
语法
rule_name(object1, object2, ...) :- fact/rule(object1, object2, ...) Suppose a clause is like : P :- Q;R. This can also be written as P :- Q. P :- R. If one clause is like : P :- Q,R;S,T,U. Is understood as P :- (Q,R);(S,T,U). Or can also be written as: P :- Q,R. P :- S,T,U.
例子
happy(lili) :- dances(lili). hungry(tom) :- search_for_food(tom). friends(jack, bili) :- lovesCricket(jack), lovesCricket(bili). goToPlay(ryan) :- isClosed(school), free(ryan).
查询
查询是对对象和对象属性之间关系的一些提问。问题可以是任何内容,例如:
Tom 是否是一只猫?
Kunal 是否喜欢吃意大利面?
Lili 是否快乐?
Ryan 会去玩吗?
根据这些查询,逻辑编程语言可以找到答案并返回它们。
逻辑编程中的知识库
在本节中,我们将了解逻辑编程中的知识库是什么。
众所周知,逻辑编程中有三个主要组成部分:事实、规则和查询。如果将这三个部分中的事实和规则作为一个整体收集起来,则构成一个知识库。因此,可以说知识库是事实和规则的集合。
现在,我们将了解如何编写一些知识库。假设我们有第一个知识库,称为 KB1。在 KB1 中,我们有一些事实。事实用于陈述对感兴趣的领域无条件为真的事情。
知识库 1
假设我们知道 Priya、Tiyasha 和 Jaya 是三个女孩,其中 Priya 会做饭。让我们尝试以更通用的方式编写这些事实,如下所示:
girl(priya). girl(tiyasha). girl(jaya). can_cook(priya).
注意 - 这里我们将名称写成小写字母,因为在 Prolog 中,以大写字母开头的字符串表示变量。
现在,我们可以通过提出一些查询来使用这个知识库。“Priya 是女孩吗?”,它将回答“是”;“Jamini 是女孩吗?”,它将回答“否”,因为它不知道 Jamini 是谁。我们的下一个问题是“Priya 会做饭吗?”,它会说“是”,但如果我们对 Jaya 提问相同的问题,它会说“否”。
输出
GNU Prolog 1.4.5 (64 bits)
Compiled Jul 14 2018, 13:19:42 with x86_64-w64-mingw32-gcc
By Daniel Diaz
Copyright (C) 1999-2018 Daniel Diaz
| ?- change_directory('D:/TP Prolog/Sample_Codes').
yes
| ?- [kb1]
.
compiling D:/TP Prolog/Sample_Codes/kb1.pl for byte code...
D:/TP Prolog/Sample_Codes/kb1.pl compiled, 3 lines read - 489 bytes written, 10 ms
yes
| ?- girl(priya)
.
yes
| ?- girl(jamini).
no
| ?- can_cook(priya).
yes
| ?- can_cook(jaya).
no
| ?-
让我们看看另一个知识库,其中我们有一些规则。规则包含一些关于感兴趣的领域条件为真的信息。假设我们的知识库如下所示:
sing_a_song(ananya). listens_to_music(rohit). listens_to_music(ananya) :- sing_a_song(ananya). happy(ananya) :- sing_a_song(ananya). happy(rohit) :- listens_to_music(rohit). playes_guitar(rohit) :- listens_to_music(rohit).
上面给出了一些事实和规则。前两个是事实,但其余的是规则。我们知道 Ananya 会唱歌,这意味着她也会听音乐。因此,如果我们问“Ananya 听音乐吗?”,答案将为真。同样,“Rohit 快乐吗?”,这也将为真,因为他听音乐。但如果我们的问题是“Ananya 弹吉他吗?”,那么根据知识库,它将说“否”。这些是基于此知识库的一些查询示例。
输出
| ?- [kb2]. compiling D:/TP Prolog/Sample_Codes/kb2.pl for byte code... D:/TP Prolog/Sample_Codes/kb2.pl compiled, 6 lines read - 1066 bytes written, 15 ms yes | ?- happy(rohit). yes | ?- sing_a_song(rohit). no | ?- sing_a_song(ananya). yes | ?- playes_guitar(rohit). yes | ?- playes_guitar(ananya). no | ?- listens_to_music(ananya). yes | ?-
知识库 3
知识库 3 的事实和规则如下:
can_cook(priya). can_cook(jaya). can_cook(tiyasha). likes(priya,jaya) :- can_cook(jaya). likes(priya,tiyasha) :- can_cook(tiyasha).
如果我们想查看会做饭的成员,可以在查询中使用一个变量。变量应以大写字母开头。结果将逐一显示。如果按 Enter 键,则会退出;否则,如果按分号 (;),则会显示下一个结果。
让我们看看一个实际演示输出,以了解其工作原理。
输出
| ?- [kb3].
compiling D:/TP Prolog/Sample_Codes/kb3.pl for byte code...
D:/TP Prolog/Sample_Codes/kb3.pl compiled, 5 lines read - 737 bytes written, 22 ms
warning: D:/TP Prolog/Sample_Codes/kb3.pl:1: redefining procedure can_cook/1
D:/TP Prolog/Sample_Codes/kb1.pl:4: previous definition
yes
| ?- can_cook(X).
X = priya ? ;
X = jaya ? ;
X = tiyasha
yes
| ?- likes(priya,X).
X = jaya ? ;
X = tiyasha
yes
| ?-
Prolog - 关系
关系是我们在 Prolog 中必须正确提及的主要特征之一。这些关系可以表示为事实和规则。之后,我们将了解家庭关系,如何在 Prolog 中表达基于家庭的关系,以及查看家庭的递归关系。
我们将通过创建事实和规则来创建知识库,并在其上运行查询。
Prolog 中的关系
在 Prolog 程序中,它指定了对象及其属性之间的关系。
例如,有一句话:“Amit 有一辆自行车”,我们实际上是在声明两个对象之间的所有权关系——一个是 Amit,另一个是自行车。
如果我们问一个问题:“Amit 是否拥有自行车?”,我们实际上是在试图了解一种关系。
有各种各样的关系,其中一些也可以是规则。即使关系没有明确定义为事实,规则也可以找出关系。
我们可以定义兄弟关系如下:
两个人是兄弟,如果:
他们都是男性。
他们有相同的父母。
现在考虑我们有以下短语:
parent(sudip, piyus).
parent(sudip, raj).
male(piyus).
male(raj).
brother(X,Y) :- parent(Z,X), parent(Z,Y),male(X), male(Y)
这些子句可以给出 Piyus 和 Raj 是兄弟的答案,但在这里我们将得到三对输出。它们是:(piyus, piyus), (piyus, raj), (raj, raj)。对于这些对,给定条件为真,但对于 (piyus, piyus), (raj, raj) 这两对,他们实际上不是兄弟,他们是同一个人。因此,我们必须正确创建子句以形成关系。
修改后的关系可以如下所示:
A 和 B 是兄弟,如果:
A 和 B 都是男性
他们有相同的父亲
他们有相同的母亲
A 和 B 不是同一个人
Prolog 中的家庭关系
在这里,我们将看到家庭关系。这是一个使用 Prolog 可以形成的复杂关系的示例。我们想要制作一个家谱,并将该家谱映射到事实和规则中,然后我们可以对其运行一些查询。
假设家谱如下所示:
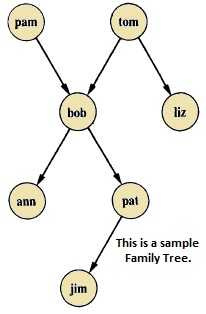
从这棵树中,我们可以了解到有一些关系。Bob 是 Pam 和 Tom 的孩子,Bob 也有两个孩子——Ann 和 Pat。Bob 还有一个兄弟 Liz,其父母也是 Tom。因此,我们希望制作如下谓词:
谓词
parent(pam, bob).
parent(tom, bob).
parent(tom, liz).
parent(bob, ann).
parent(bob, pat).
parent(pat, jim).
parent(bob, peter).
parent(peter, jim).
从我们的示例中,它有助于说明一些要点:
我们根据家谱中给出的信息,通过声明基于对象的 n 元组来定义父关系。
用户可以轻松地查询 Prolog 系统关于程序中定义的关系。
Prolog 程序由以句点结尾的子句组成。
关系的参数可以(除其他外)是:具体对象或常量(例如 pat 和 jim),或通用对象,例如 X 和 Y。程序中第一类对象称为原子。第二类对象称为变量。
对系统的问题包含一个或多个目标。
有些事实可以用两种不同的方式编写,例如家庭成员的性别可以用以下两种形式中的任何一种编写:
female(pam).
male(tom).
male(bob).
female(liz).
female(pat).
female(ann).
male(jim).
或以下形式:
sex( pam, feminine).
sex( tom, masculine).
sex( bob, masculine).
……等等。
现在,如果我们想建立母亲和姐妹的关系,我们可以按如下方式编写:
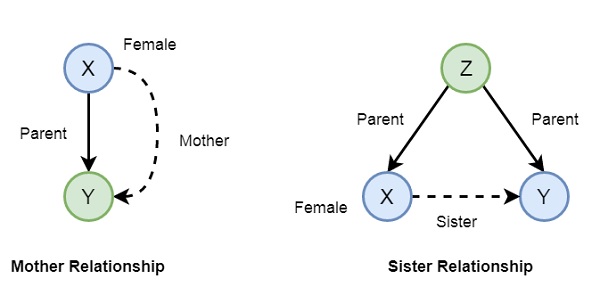
在 Prolog 语法中,我们可以编写:
mother(X,Y) :- parent(X,Y), female(X).
sister(X,Y) :- parent(Z,X), parent(Z,Y), female(X), X \== Y.
现在让我们看看实际演示:
知识库 (family.pl)
female(pam). female(liz). female(pat). female(ann). male(jim). male(bob). male(tom). male(peter). parent(pam,bob). parent(tom,bob). parent(tom,liz). parent(bob,ann). parent(bob,pat). parent(pat,jim). parent(bob,peter). parent(peter,jim). mother(X,Y):- parent(X,Y),female(X). father(X,Y):- parent(X,Y),male(X). haschild(X):- parent(X,_). sister(X,Y):- parent(Z,X),parent(Z,Y),female(X),X\==Y. brother(X,Y):-parent(Z,X),parent(Z,Y),male(X),X\==Y.
输出
| ?- [family]. compiling D:/TP Prolog/Sample_Codes/family.pl for byte code... D:/TP Prolog/Sample_Codes/family.pl compiled, 23 lines read - 3088 bytes written, 9 ms yes | ?- parent(X,jim). X = pat ? ; X = peter yes | ?- mother(X,Y). X = pam Y = bob ? ; X = pat Y = jim ? ; no | ?- haschild(X). X = pam ? ; X = tom ? ; X = tom ? ; X = bob ? ; X = bob ? ; X = pat ? ; X = bob ? ; X = peter yes | ?- sister(X,Y). X = liz Y = bob ? ; X = ann Y = pat ? ; X = ann Y = peter ? ; X = pat Y = ann ? ; X = pat Y = peter ? ; (16 ms) no | ?-
现在让我们看看从先前家庭关系中可以建立的一些更多关系。因此,如果我们想要建立祖父母关系,则可以如下形成:
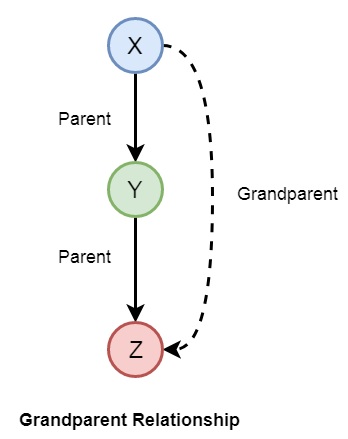
我们还可以创建其他一些关系,例如妻子、叔叔等。我们可以按如下方式编写关系:
grandparent(X,Y) :- parent(X,Z), parent(Z,Y).
grandmother(X,Z) :- mother(X,Y), parent(Y,Z).
grandfather(X,Z) :- father(X,Y), parent(Y,Z).
wife(X,Y) :- parent(X,Z),parent(Y,Z), female(X),male(Y).
uncle(X,Z) :- brother(X,Y), parent(Y,Z).
因此,让我们编写一个 Prolog 程序来实际查看这一点。在这里,我们还将看到跟踪以跟踪执行过程。
知识库 (family_ext.pl)
female(pam). female(liz). female(pat). female(ann). male(jim). male(bob). male(tom). male(peter). parent(pam,bob). parent(tom,bob). parent(tom,liz). parent(bob,ann). parent(bob,pat). parent(pat,jim). parent(bob,peter). parent(peter,jim). mother(X,Y):- parent(X,Y),female(X). father(X,Y):-parent(X,Y),male(X). sister(X,Y):-parent(Z,X),parent(Z,Y),female(X),X\==Y. brother(X,Y):-parent(Z,X),parent(Z,Y),male(X),X\==Y. grandparent(X,Y):-parent(X,Z),parent(Z,Y). grandmother(X,Z):-mother(X,Y),parent(Y,Z). grandfather(X,Z):-father(X,Y),parent(Y,Z). wife(X,Y):-parent(X,Z),parent(Y,Z),female(X),male(Y). uncle(X,Z):-brother(X,Y),parent(Y,Z).
输出
| ?- [family_ext]. compiling D:/TP Prolog/Sample_Codes/family_ext.pl for byte code... D:/TP Prolog/Sample_Codes/family_ext.pl compiled, 27 lines read - 4646 bytes written, 10 ms | ?- uncle(X,Y). X = peter Y = jim ? ; no | ?- grandparent(X,Y). X = pam Y = ann ? ; X = pam Y = pat ? ; X = pam Y = peter ? ; X = tom Y = ann ? ; X = tom Y = pat ? ; X = tom Y = peter ? ; X = bob Y = jim ? ; X = bob Y = jim ? ; no | ?- wife(X,Y). X = pam Y = tom ? ; X = pat Y = peter ? ; (15 ms) no | ?-
跟踪输出
在 Prolog 中,我们可以跟踪执行过程。要跟踪输出,必须通过键入“trace.”进入跟踪模式。然后从输出中我们可以看到我们只是在跟踪“Pam 是谁的母亲?”。通过将 X=pam 和 Y 作为变量来查看跟踪输出,则 Y 的答案将是 bob。要退出跟踪模式,请按“notrace.”。
程序
| ?- [family_ext].
compiling D:/TP Prolog/Sample_Codes/family_ext.pl for byte code...
D:/TP Prolog/Sample_Codes/family_ext.pl compiled, 27 lines read - 4646 bytes written, 10 ms
(16 ms) yes
| ?- mother(X,Y).
X = pam
Y = bob ? ;
X = pat
Y = jim ? ;
no
| ?- trace.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- mother(pam,Y).
1 1 Call: mother(pam,_23) ?
2 2 Call: parent(pam,_23) ?
2 2 Exit: parent(pam,bob) ?
3 2 Call: female(pam) ?
3 2 Exit: female(pam) ?
1 1 Exit: mother(pam,bob) ?
Y = bob
(16 ms) yes
{trace}
| ?- notrace.
The debugger is switched off
yes
| ?-
家庭关系中的递归
在上一节中,我们已经看到我们可以定义一些家庭关系。这些关系本质上是静态的。我们还可以创建一些递归关系,这些关系可以从以下图示中表达:
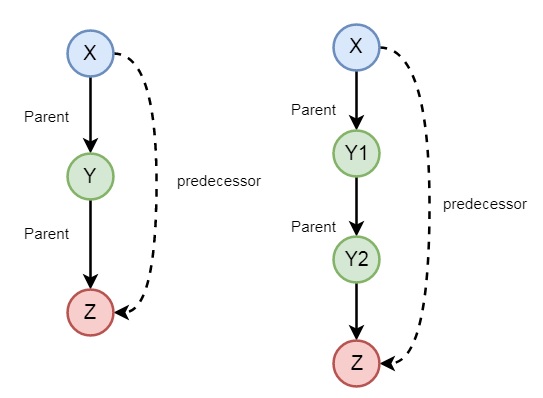
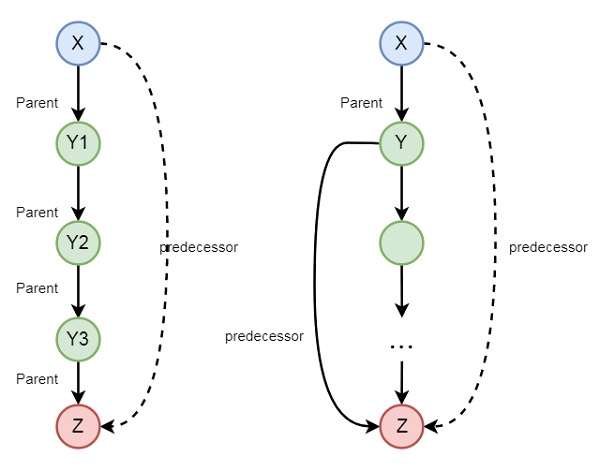
因此,我们可以理解先行关系是递归的。我们可以使用以下语法表达这种关系:
predecessor(X, Z) :- parent(X, Z). predecessor(X, Z) :- parent(X, Y),predecessor(Y, Z).
现在让我们看看实际演示。
知识库 (family_rec.pl)
female(pam). female(liz). female(pat). female(ann). male(jim). male(bob). male(tom). male(peter). parent(pam,bob). parent(tom,bob). parent(tom,liz). parent(bob,ann). parent(bob,pat). parent(pat,jim). parent(bob,peter). parent(peter,jim). predecessor(X, Z) :- parent(X, Z). predecessor(X, Z) :- parent(X, Y),predecessor(Y, Z).
输出
| ?- [family_rec].
compiling D:/TP Prolog/Sample_Codes/family_rec.pl for byte code...
D:/TP Prolog/Sample_Codes/family_rec.pl compiled, 21 lines read - 1851 bytes written, 14 ms
yes
| ?- predecessor(peter,X).
X = jim ? ;
no
| ?- trace.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- predecessor(bob,X).
1 1 Call: predecessor(bob,_23) ?
2 2 Call: parent(bob,_23) ?
2 2 Exit: parent(bob,ann) ?
1 1 Exit: predecessor(bob,ann) ?
X = ann ? ;
1 1 Redo: predecessor(bob,ann) ?
2 2 Redo: parent(bob,ann) ?
2 2 Exit: parent(bob,pat) ?
1 1 Exit: predecessor(bob,pat) ?
X = pat ? ;
1 1 Redo: predecessor(bob,pat) ?
2 2 Redo: parent(bob,pat) ?
2 2 Exit: parent(bob,peter) ?
1 1 Exit: predecessor(bob,peter) ?
X = peter ? ;
1 1 Redo: predecessor(bob,peter) ?
2 2 Call: parent(bob,_92) ?
2 2 Exit: parent(bob,ann) ?
3 2 Call: predecessor(ann,_23) ?
4 3 Call: parent(ann,_23) ?
4 3 Fail: parent(ann,_23) ?
4 3 Call: parent(ann,_141) ?
4 3 Fail: parent(ann,_129) ?
3 2 Fail: predecessor(ann,_23) ?
2 2 Redo: parent(bob,ann) ?
2 2 Exit: parent(bob,pat) ?
3 2 Call: predecessor(pat,_23) ?
4 3 Call: parent(pat,_23) ?
4 3 Exit: parent(pat,jim) ?
3 2 Exit: predecessor(pat,jim) ?
1 1 Exit: predecessor(bob,jim) ?
X = jim ? ;
1 1 Redo: predecessor(bob,jim) ?
3 2 Redo: predecessor(pat,jim) ?
4 3 Call: parent(pat,_141) ?
4 3 Exit: parent(pat,jim) ?
5 3 Call: predecessor(jim,_23) ?
6 4 Call: parent(jim,_23) ?
6 4 Fail: parent(jim,_23) ?
6 4 Call: parent(jim,_190) ?
6 4 Fail: parent(jim,_178) ?
5 3 Fail: predecessor(jim,_23) ?
3 2 Fail: predecessor(pat,_23) ?
2 2 Redo: parent(bob,pat) ?
2 2 Exit: parent(bob,peter) ?
3 2 Call: predecessor(peter,_23) ?
4 3 Call: parent(peter,_23) ?
4 3 Exit: parent(peter,jim) ?
3 2 Exit: predecessor(peter,jim) ?
1 1 Exit: predecessor(bob,jim) ?
X = jim ?
(78 ms) yes
{trace}
| ?-
Prolog - 数据对象
在本章中,我们将学习 Prolog 中的数据对象。它们可以分为以下几类:
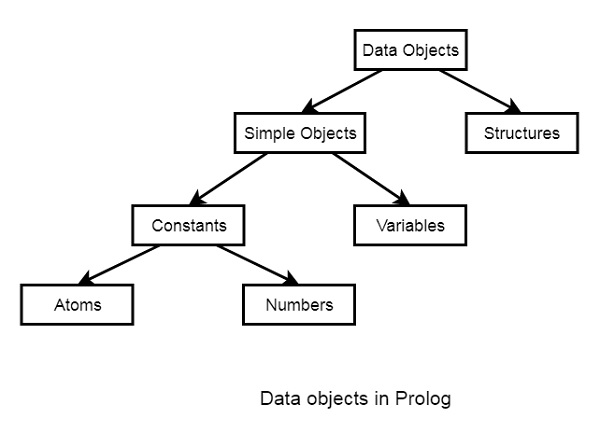
以下是各种数据对象的示例:
原子 - tom、pat、x100、x_45
数字 - 100、1235、2000.45
变量 - X、Y、Xval、_X
结构 - day(9, jun, 2017)、point(10, 25)
原子和变量
在本节中,我们将讨论 Prolog 的原子、数字和变量。
原子
原子是常量的一种变体。它们可以是任何名称或对象。在尝试使用原子时,应遵循以下一些规则:
以小写字母开头的字母、数字和下划线字符“_”的字符串。例如:
azahar
b59
b_59
b_59AB
b_x25
antara_sarkar
特殊字符的字符串
我们必须记住,当使用这种形式的原子时,需要小心,因为某些特殊字符的字符串已经具有预定义的含义;例如 ':-'。
<--->
=======>
...
.:.
::=
用单引号括起来的字符字符串。
如果我们想要一个以大写字母开头的原子,这将非常有用。通过将其括在引号中,我们可以使其与变量区分开来:
‘Rubai’
‘Arindam_Chatterjee’
‘Sumit Mitra’
数字
常量的另一个变体是数字。因此,整数可以表示为 100、4、-81、1202。在 Prolog 中,整数的正常范围是从 -16383 到 16383。
Prolog 还支持实数,但通常在 Prolog 程序中很少使用浮点数,因为 Prolog 用于符号而非数值计算。实数的处理取决于 Prolog 的实现。实数的示例是 3.14159、-0.00062、450.18 等。
变量属于简单对象部分。变量可以在我们之前看到的 Prolog 程序中的许多情况下使用。因此,在 Prolog 中定义变量有一些规则。
我们可以定义 Prolog 变量,使得变量是字母、数字和下划线字符的字符串。它们以大写字母或下划线字符开头。一些变量示例如下:
X
Sum
Memer_name
Student_list
Shoppinglist
_a50
_15
Prolog 中的匿名变量
匿名变量没有名称。Prolog 中的匿名变量由单个下划线字符“_”表示。重要的一点是,每个单独的匿名变量都被视为不同的。它们并不相同。
现在的问题是,我们应该在哪里使用这些匿名变量?
假设在我们的知识库中有一些事实——“jim讨厌tom”、“pat讨厌bob”。所以如果tom想知道谁讨厌他,他可以使用变量。但是,如果他想检查是否有人讨厌他,我们可以使用匿名变量。所以当我们想使用变量,但不想透露变量的值时,我们可以使用匿名变量。
让我们看看它的实际实现:
知识库 (var_anonymous.pl)
hates(jim,tom). hates(pat,bob). hates(dog,fox). hates(peter,tom).
输出
| ?- [var_anonymous]. compiling D:/TP Prolog/Sample_Codes/var_anonymous.pl for byte code... D:/TP Prolog/Sample_Codes/var_anonymous.pl compiled, 3 lines read - 536 bytes written, 16 ms yes | ?- hates(X,tom). X = jim ? ; X = peter yes | ?- hates(_,tom). true ? ; (16 ms) yes | ?- hates(_,pat). no | ?- hates(_,fox). true ? ; no | ?-
Prolog - 运算符
在接下来的部分中,我们将了解Prolog中不同类型的运算符。比较运算符和算术运算符的类型。
我们还将了解这些运算符与任何其他高级语言运算符的不同之处,它们的语法差异以及它们的工作方式差异。我们还将看到一些实际演示,以了解不同运算符的使用。
比较运算符
比较运算符用于比较两个等式或状态。以下是不同的比较运算符:
| 运算符 | 含义 |
|---|---|
| X > Y | X 大于 Y |
| X < Y | X 小于 Y |
| X >= Y | X 大于或等于 Y |
| X =< Y | X 小于或等于 Y |
| X =:= Y | X 和 Y 的值相等 |
| X =\= Y | X 和 Y 的值不相等 |
您可以看到,'=<' 运算符、'=:= '运算符和'=\='运算符在语法上与其他语言不同。让我们来看一些实际演示。
例子
| ?- 1+2=:=2+1. yes | ?- 1+2=2+1. no | ?- 1+A=B+2. A = 2 B = 1 yes | ?- 5<10. yes | ?- 5>10. no | ?- 10=\=100. yes
在这里我们可以看到 1+2=:=2+1 返回 true,但 1+2=2+1 返回 false。这是因为,在第一种情况下,它检查 1 + 2 的值是否与 2 + 1 相同,而另一种情况则检查两个模式 '1+2' 和 '2+1' 是否相同。由于它们不相同,它返回 no (false)。在 1+A=B+2 的情况下,A 和 B 是两个变量,它们会自动赋值为一些与模式匹配的值。
Prolog中的算术运算符
算术运算符用于执行算术运算。有几种不同类型的算术运算符,如下所示:
| 运算符 | 含义 |
|---|---|
| + | 加法 |
| - | 减法 |
| * | 乘法 |
| / | 除法 |
| ** | 乘方 |
| // | 整数除法 |
| 模运算 | 取模 |
让我们看一个实际代码来了解这些运算符的使用。
程序
calc :- X is 100 + 200,write('100 + 200 is '),write(X),nl,
Y is 400 - 150,write('400 - 150 is '),write(Y),nl,
Z is 10 * 300,write('10 * 300 is '),write(Z),nl,
A is 100 / 30,write('100 / 30 is '),write(A),nl,
B is 100 // 30,write('100 // 30 is '),write(B),nl,
C is 100 ** 2,write('100 ** 2 is '),write(C),nl,
D is 100 mod 30,write('100 mod 30 is '),write(D),nl.
注意 - nl 用于创建新行。
输出
| ?- change_directory('D:/TP Prolog/Sample_Codes').
yes
| ?- [op_arith].
compiling D:/TP Prolog/Sample_Codes/op_arith.pl for byte code...
D:/TP Prolog/Sample_Codes/op_arith.pl compiled, 6 lines read - 2390 bytes written, 11 ms
yes
| ?- calc.
100 + 200 is 300
400 - 150 is 250
10 * 300 is 3000
100 / 30 is 3.3333333333333335
100 // 30 is 3
100 ** 2 is 10000.0
100 mod 30 is 10
yes
| ?-
Prolog - 循环和决策
在本章中,我们将讨论Prolog中的循环和决策。
循环
循环语句用于多次执行代码块。通常,for、while、do-while 是编程语言(如 Java、C、C++)中的循环结构。
使用递归谓词逻辑多次执行代码块。某些其他语言中没有直接循环,但我们可以使用几种不同的技术来模拟循环。
程序
count_to_10(10) :- write(10),nl. count_to_10(X) :- write(X),nl, Y is X + 1, count_to_10(Y).
输出
| ?- [loop]. compiling D:/TP Prolog/Sample_Codes/loop.pl for byte code... D:/TP Prolog/Sample_Codes/loop.pl compiled, 4 lines read - 751 bytes written, 16 ms (16 ms) yes | ?- count_to_10(3). 3 4 5 6 7 8 9 10 true ? yes | ?-
现在创建一个循环,该循环取最小值和最大值。因此,我们可以使用 between() 来模拟循环。
程序
让我们看一个示例程序:
count_down(L, H) :- between(L, H, Y), Z is H - Y, write(Z), nl. count_up(L, H) :- between(L, H, Y), Z is L + Y, write(Z), nl.
输出
| ?- [loop]. compiling D:/TP Prolog/Sample_Codes/loop.pl for byte code... D:/TP Prolog/Sample_Codes/loop.pl compiled, 14 lines read - 1700 bytes written, 16 ms yes | ?- count_down(12,17). 5 true ? ; 4 true ? ; 3 true ? ; 2 true ? ; 1 true ? ; 0 yes | ?- count_up(5,12). 10 true ? ; 11 true ? ; 12 true ? ; 13 true ? ; 14 true ? ; 15 true ? ; 16 true ? ; 17 yes | ?-
决策
决策语句是 If-Then-Else 语句。因此,当我们尝试匹配某些条件并执行某些任务时,我们将使用决策语句。基本用法如下:
If <condition> is true, Then <do this>, Else
在一些不同的编程语言中,有 If-Else 语句,但在 Prolog 中,我们必须以其他方式定义我们的语句。以下是 Prolog 中决策的一个示例。
程序
% If-Then-Else statement
gt(X,Y) :- X >= Y,write('X is greater or equal').
gt(X,Y) :- X < Y,write('X is smaller').
% If-Elif-Else statement
gte(X,Y) :- X > Y,write('X is greater').
gte(X,Y) :- X =:= Y,write('X and Y are same').
gte(X,Y) :- X < Y,write('X is smaller').
输出
| ?- [test]. compiling D:/TP Prolog/Sample_Codes/test.pl for byte code... D:/TP Prolog/Sample_Codes/test.pl compiled, 3 lines read - 529 bytes written, 15 ms yes | ?- gt(10,100). X is smaller yes | ?- gt(150,100). X is greater or equal true ? yes | ?- gte(10,20). X is smaller (15 ms) yes | ?- gte(100,20). X is greater true ? yes | ?- gte(100,100). X and Y are same true ? yes | ?-
Prolog - 连接词和析取词
在本章中,我们将讨论连接词和析取词属性。这些属性在其他编程语言中使用 AND 和 OR 逻辑。Prolog 也在其语法中使用相同的逻辑。
连接词
连接词 (AND 逻辑) 可以使用逗号 (,) 运算符实现。因此,用逗号分隔的两个谓词与 AND 语句连接在一起。假设我们有一个谓词,parent(jhon, bob),这意味着“Jhon 是 Bob 的父母”,另一个谓词,male(jhon),这意味着“Jhon 是男性”。所以我们可以创建另一个谓词 father(jhon,bob),这意味着“Jhon 是 Bob 的父亲”。当他是父母 **AND** 他是男性时,我们可以定义谓词 **father**。
析取词
析取词 (OR 逻辑) 可以使用分号 (;) 运算符实现。因此,用分号分隔的两个谓词与 OR 语句连接在一起。假设我们有一个谓词,father(jhon, bob)。这表示“Jhon 是 Bob 的父亲”,另一个谓词,mother(lili,bob),这表示“lili 是 bob 的母亲”。如果我们创建另一个谓词为 child(),则当 father(jhon, bob) 为真 **OR** mother(lili,bob) 为真时,它将为真。
程序
parent(jhon,bob). parent(lili,bob). male(jhon). female(lili). % Conjunction Logic father(X,Y) :- parent(X,Y),male(X). mother(X,Y) :- parent(X,Y),female(X). % Disjunction Logic child_of(X,Y) :- father(X,Y);mother(X,Y).
输出
| ?- [conj_disj]. compiling D:/TP Prolog/Sample_Codes/conj_disj.pl for byte code... D:/TP Prolog/Sample_Codes/conj_disj.pl compiled, 11 lines read - 1513 bytes written, 24 ms yes | ?- father(jhon,bob). yes | ?- child_of(jhon,bob). true ? yes | ?- child_of(lili,bob). yes | ?-
Prolog - 列表
在本章中,我们将讨论 Prolog 中的一个重要概念:列表。它是一种数据结构,可用于非数值编程的不同情况下。列表用于将原子存储为集合。
在后续章节中,我们将讨论以下主题:
Prolog 中列表的表示
Prolog 的基本操作,例如插入、删除、更新、追加。
重新定位运算符,例如排列、组合等。
集合运算,例如集合并集、集合交集等。
列表的表示
列表是一种简单的数据结构,广泛用于非数值编程。列表包含任意数量的项目,例如 red、green、blue、white、dark。它将表示为 [red, green, blue, white, dark]。元素列表将用 **方括号** 括起来。
列表可以是 **空** 的或 **非空** 的。在第一种情况下,列表简单地写为 Prolog 原子,[]。在第二种情况下,列表包含如下所示的两部分:
第一项,称为列表的 **头部**;
列表的其余部分,称为 **尾部**。
假设我们有一个列表: [red, green, blue, white, dark]。这里头部是 red,尾部是 [green, blue, white, dark]。因此尾部是另一个列表。
现在,让我们考虑我们有一个列表,L = [a, b, c]。如果我们写 Tail = [b, c],那么我们也可以将列表 L 写为 L = [ a | Tail]。这里竖线 (|) 分隔头部和尾部。
因此,以下列表表示也是有效的:
[a, b, c] = [x | [b, c] ]
[a, b, c] = [a, b | [c] ]
[a, b, c] = [a, b, c | [ ] ]
对于这些属性,我们可以将列表定义为:
一种数据结构,或者是空的,或者由两部分组成:头部和尾部。尾部本身必须是一个列表。
列表的基本操作
下表包含 Prolog 列表的各种操作:
| 操作 | 定义 |
|---|---|
| 成员资格检查 | 在此操作期间,我们可以验证给定元素是否是指定列表的成员? |
| 长度计算 | 通过此操作,我们可以找到列表的长度。 |
| 连接 | 连接是一个用于连接/添加两个列表的操作。 |
| 删除项目 | 此操作将从列表中删除指定的元素。 |
| 追加项目 | 追加操作将一个列表添加到另一个列表中(作为一项)。 |
| 插入项目 | 此操作将给定项目插入到列表中。 |
成员资格操作
在此操作期间,我们可以检查成员 X 是否存在于列表 L 中?那么如何检查呢?好吧,我们必须定义一个谓词来做到这一点。假设谓词名称为 list_member(X,L)。此谓词的目标是检查 X 是否存在于 L 中。
要设计此谓词,我们可以遵循以下观察结果。如果 X 是 L 的成员,则:
X 是 L 的头部,或者
X 是 L 的尾部的成员
程序
list_member(X,[X|_]). list_member(X,[_|TAIL]) :- list_member(X,TAIL).
输出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 1 lines read - 467 bytes written, 13 ms yes | ?- list_member(b,[a,b,c]). true ? yes | ?- list_member(b,[a,[b,c]]). no | ?- list_member([b,c],[a,[b,c]]). true ? yes | ?- list_member(d,[a,b,c]). no | ?- list_member(d,[a,b,c]).
长度计算
这用于查找列表 L 的长度。我们将定义一个谓词来执行此任务。假设谓词名称为 list_length(L,N)。它将 L 和 N 作为输入参数。这将计算列表 L 中的元素并将 N 实例化为它们的个数。与我们之前涉及列表的关系一样,考虑两种情况很有用:
如果列表为空,则长度为 0。
如果列表不为空,则 L = [Head|Tail],则其长度为 1 + 尾部的长度。
程序
list_length([],0). list_length([_|TAIL],N) :- list_length(TAIL,N1), N is N1 + 1.
输出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 4 lines read - 985 bytes written, 23 ms yes | ?- list_length([a,b,c,d,e,f,g,h,i,j],Len). Len = 10 yes | ?- list_length([],Len). Len = 0 yes | ?- list_length([[a,b],[c,d],[e,f]],Len). Len = 3 yes | ?-
连接
两个列表的连接意味着在第一个列表之后添加第二个列表的列表项。因此,如果两个列表是 [a,b,c] 和 [1,2],则最终列表将是 [a,b,c,1,2]。因此,要执行此任务,我们将创建一个名为 list_concat() 的谓词,它将第一个列表 L1、第二个列表 L2 和 L3 作为结果列表。这里有两个观察结果。
如果第一个列表为空,而第二个列表是 L,则结果列表将是 L。
如果第一个列表不为空,则将其写为 [Head|Tail],递归地将 Tail 与 L2 连接起来,并以 [Head|New List] 的形式将其存储到新列表中。
程序
list_concat([],L,L). list_concat([X1|L1],L2,[X1|L3]) :- list_concat(L1,L2,L3).
输出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 7 lines read - 1367 bytes written, 19 ms yes | ?- list_concat([1,2],[a,b,c],NewList). NewList = [1,2,a,b,c] yes | ?- list_concat([],[a,b,c],NewList). NewList = [a,b,c] yes | ?- list_concat([[1,2,3],[p,q,r]],[a,b,c],NewList). NewList = [[1,2,3],[p,q,r],a,b,c] yes | ?-
从列表中删除
假设我们有一个列表 L 和一个元素 X,我们必须从 L 中删除 X。因此有三种情况:
如果 X 是唯一的元素,则删除它后,它将返回空列表。
如果 X 是 L 的头部,则结果列表将是尾部。
如果 X 存在于尾部,则从那里递归删除。
程序
list_delete(X, [X], []). list_delete(X,[X|L1], L1). list_delete(X, [Y|L2], [Y|L1]) :- list_delete(X,L2,L1).
输出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 11 lines read - 1923 bytes written, 25 ms yes | ?- list_delete(a,[a,e,i,o,u],NewList). NewList = [e,i,o,u] ? yes | ?- list_delete(a,[a],NewList). NewList = [] ? yes | ?- list_delete(X,[a,e,i,o,u],[a,e,o,u]). X = i ? ; no | ?-
追加到列表
追加两个列表意味着将两个列表加在一起,或者将一个列表添加为一项。现在,如果该项存在于列表中,则追加函数将不起作用。因此,我们将创建一个名为 list_append(L1, L2, L3) 的谓词。以下是一些观察结果:
令 A 为一个元素,L1 为一个列表,当 L1 已经包含 A 时,输出也将是 L1。
否则,新列表将是 L2 = [A|L1]。
程序
list_member(X,[X|_]). list_member(X,[_|TAIL]) :- list_member(X,TAIL). list_append(A,T,T) :- list_member(A,T),!. list_append(A,T,[A|T]).
在这种情况下,我们使用了 (!) 符号,它被称为剪切。因此,当第一行成功执行时,我们将对其进行剪切,因此它将不会执行下一个操作。
输出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 14 lines read - 2334 bytes written, 25 ms (16 ms) yes | ?- list_append(a,[e,i,o,u],NewList). NewList = [a,e,i,o,u] yes | ?- list_append(e,[e,i,o,u],NewList). NewList = [e,i,o,u] yes | ?- list_append([a,b],[e,i,o,u],NewList). NewList = [[a,b],e,i,o,u] yes | ?-
插入到列表
此方法用于将项目 X 插入到列表 L 中,结果列表将是 R。因此,谓词将采用此形式 list_insert(X, L, R)。因此,这可以将 X 插入到 L 的所有可能位置。如果我们仔细观察,则会有一些观察结果。
如果我们执行 list_insert(X,L,R),我们可以使用 list_delete(X,R,L),因此从 R 中删除 X 并创建新的列表 L。
程序
list_delete(X, [X], []). list_delete(X,[X|L1], L1). list_delete(X, [Y|L2], [Y|L1]) :- list_delete(X,L2,L1). list_insert(X,L,R) :- list_delete(X,R,L).
输出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 16 lines read - 2558 bytes written, 22 ms (16 ms) yes | ?- list_insert(a,[e,i,o,u],NewList). NewList = [a,e,i,o,u] ? a NewList = [e,a,i,o,u] NewList = [e,i,a,o,u] NewList = [e,i,o,a,u] NewList = [e,i,o,u,a] NewList = [e,i,o,u,a] (15 ms) no | ?-
列表项的重新定位操作
以下是重新定位操作:
| 重新定位操作 | 定义 |
|---|---|
| 排列 | 此操作将更改列表项的位置并生成所有可能的结果。 |
| 反转项目 | 此操作将列表的项目按反向顺序排列。 |
| 移位项目 | 此操作将列表中的一个元素向左循环移动。 |
| 顺序项 | 此操作验证给定列表是否已排序。 |
排列操作
此操作将更改列表项的位置并生成所有可能的结果。因此,我们将创建一个谓词 list_perm(L1,L2),这将生成 L1 的所有排列,并将它们存储到 L2 中。为此,我们需要 list_delete() 子句来帮助。
为了设计这个谓词,我们可以遵循以下一些观察结果:
如果 X 是 L 的成员,则:
如果第一个列表为空,则第二个列表也必须为空。
如果第一个列表不为空,则它具有形式 [X | L],并且可以如下构造此类列表的排列:首先排列 L 得到 L1,然后将 X 插入到 L1 的任何位置。
程序
list_delete(X,[X|L1], L1). list_delete(X, [Y|L2], [Y|L1]) :- list_delete(X,L2,L1). list_perm([],[]). list_perm(L,[X|P]) :- list_delete(X,L,L1),list_perm(L1,P).
输出
| ?- [list_repos]. compiling D:/TP Prolog/Sample_Codes/list_repos.pl for byte code... D:/TP Prolog/Sample_Codes/list_repos.pl compiled, 4 lines read - 1060 bytes written, 17 ms (15 ms) yes | ?- list_perm([a,b,c,d],X). X = [a,b,c,d] ? a X = [a,b,d,c] X = [a,c,b,d] X = [a,c,d,b] X = [a,d,b,c] X = [a,d,c,b] X = [b,a,c,d] X = [b,a,d,c] X = [b,c,a,d] X = [b,c,d,a] X = [b,d,a,c] X = [b,d,c,a] X = [c,a,b,d] X = [c,a,d,b] X = [c,b,a,d] X = [c,b,d,a] X = [c,d,a,b] X = [c,d,b,a] X = [d,a,b,c] X = [d,a,c,b] X = [d,b,a,c] X = [d,b,c,a] X = [d,c,a,b] X = [d,c,b,a] (31 ms) no | ?-
反转操作
假设我们有一个列表 L = [a,b,c,d,e],我们想要反转元素,则输出将为 [e,d,c,b,a]。为此,我们将创建一个子句 list_reverse(List, ReversedList)。以下是一些观察结果:
如果列表为空,则结果列表也将为空。
否则,将列表项命名为 [Head|Tail],递归反转 Tail 项,并与 Head 连接。
否则,将列表项命名为 [Head|Tail],递归反转 Tail 项,并与 Head 连接。
程序
list_concat([],L,L). list_concat([X1|L1],L2,[X1|L3]) :- list_concat(L1,L2,L3). list_rev([],[]). list_rev([Head|Tail],Reversed) :- list_rev(Tail, RevTail),list_concat(RevTail, [Head],Reversed).
输出
| ?- [list_repos]. compiling D:/TP Prolog/Sample_Codes/list_repos.pl for byte code... D:/TP Prolog/Sample_Codes/list_repos.pl compiled, 10 lines read - 1977 bytes written, 19 ms yes | ?- list_rev([a,b,c,d,e],NewList). NewList = [e,d,c,b,a] yes | ?- list_rev([a,b,c,d,e],[e,d,c,b,a]). yes | ?-
移位操作
使用移位操作,我们可以将列表的一个元素向左循环移动。因此,如果列表项为 [a,b,c,d],则移位后将为 [b,c,d,a]。因此,我们将创建一个子句 list_shift(L1, L2)。
我们将列表表示为 [Head|Tail],然后递归地将 Head 连接到 Tail 之后,因此我们可以感觉到元素被移动了。
这也可以用来检查两个列表是否在一个位置移位。
程序
list_concat([],L,L). list_concat([X1|L1],L2,[X1|L3]) :- list_concat(L1,L2,L3). list_shift([Head|Tail],Shifted) :- list_concat(Tail, [Head],Shifted).
输出
| ?- [list_repos]. compiling D:/TP Prolog/Sample_Codes/list_repos.pl for byte code... D:/TP Prolog/Sample_Codes/list_repos.pl compiled, 12 lines read - 2287 bytes written, 10 ms yes | ?- list_shift([a,b,c,d,e],L2). L2 = [b,c,d,e,a] (16 ms) yes | ?- list_shift([a,b,c,d,e],[b,c,d,e,a]). yes | ?-
排序操作
在这里,我们将定义一个谓词 list_order(L),它检查 L 是否已排序。因此,如果 L = [1,2,3,4,5,6],则结果为真。
如果只有一个元素,则该元素已排序。
否则,将前两个元素 X 和 Y 作为 Head,其余作为 Tail。如果 X <= Y,则再次调用该子句,参数为 [Y|Tail],因此这将递归地从下一个元素开始检查。
程序
list_order([X, Y | Tail]) :- X =< Y, list_order([Y|Tail]). list_order([X]).
输出
| ?- [list_repos]. compiling D:/TP Prolog/Sample_Codes/list_repos.pl for byte code... D:/TP Prolog/Sample_Codes/list_repos.pl:15: warning: singleton variables [X] for list_order/1 D:/TP Prolog/Sample_Codes/list_repos.pl compiled, 15 lines read - 2805 bytes written, 18 ms yes | ?- list_order([1,2,3,4,5,6,6,7,7,8]). true ? yes | ?- list_order([1,4,2,3,6,5]). no | ?-
列表上的集合操作
我们将尝试编写一个子句,该子句将获取给定集合的所有可能的子集。因此,如果集合是 [a,b],则结果将为 [],[a],[b],[a,b]。为此,我们将创建一个子句 list_subset(L, X)。它将获取 L 并将每个子集返回到 X 中。因此,我们将按以下方式进行:
如果列表为空,则子集也为空。
通过保留 Head 递归地查找子集,并且
进行另一个递归调用,我们将删除 Head。
程序
list_subset([],[]). list_subset([Head|Tail],[Head|Subset]) :- list_subset(Tail,Subset). list_subset([Head|Tail],Subset) :- list_subset(Tail,Subset).
输出
| ?- [list_set]. compiling D:/TP Prolog/Sample_Codes/list_set.pl for byte code... D:/TP Prolog/Sample_Codes/list_set.pl:3: warning: singleton variables [Head] for list_subset/2 D:/TP Prolog/Sample_Codes/list_set.pl compiled, 2 lines read - 653 bytes written, 7 ms yes | ?- list_subset([a,b],X). X = [a,b] ? ; X = [a] ? ; X = [b] ? ; X = [] (15 ms) yes | ?- list_subset([x,y,z],X). X = [x,y,z] ? a X = [x,y] X = [x,z] X = [x] X = [y,z] X = [y] X = [z] X = [] yes | ?-
并集操作
让我们定义一个名为 list_union(L1,L2,L3) 的子句,因此这将获取 L1 和 L2,并对它们执行并集,并将结果存储到 L3 中。正如您所知,如果两个列表具有相同的元素两次,则并集后将只有一个。因此,我们需要另一个辅助子句来检查成员资格。
程序
list_member(X,[X|_]). list_member(X,[_|TAIL]) :- list_member(X,TAIL). list_union([X|Y],Z,W) :- list_member(X,Z),list_union(Y,Z,W). list_union([X|Y],Z,[X|W]) :- \+ list_member(X,Z), list_union(Y,Z,W). list_union([],Z,Z).
注意 - 在程序中,我们使用了 (\+) 运算符,此运算符用于表示非。
输出
| ?- [list_set]. compiling D:/TP Prolog/Sample_Codes/list_set.pl for byte code... D:/TP Prolog/Sample_Codes/list_set.pl:6: warning: singleton variables [Head] for list_subset/2 D:/TP Prolog/Sample_Codes/list_set.pl compiled, 9 lines read - 2004 bytes written, 18 ms yes | ?- list_union([a,b,c,d,e],[a,e,i,o,u],L3). L3 = [b,c,d,a,e,i,o,u] ? (16 ms) yes | ?- list_union([a,b,c,d,e],[1,2],L3). L3 = [a,b,c,d,e,1,2] yes
交集操作
让我们定义一个名为 list_intersection(L1,L2,L3) 的子句,因此这将获取 L1 和 L2,并执行交集运算,并将结果存储到 L3 中。交集将返回同时存在于两个列表中的元素。因此,如果 L1 = [a,b,c,d,e],L2 = [a,e,i,o,u],则 L3 = [a,e]。在这里,我们将使用 list_member() 子句来检查一个元素是否存在于列表中。
程序
list_member(X,[X|_]). list_member(X,[_|TAIL]) :- list_member(X,TAIL). list_intersect([X|Y],Z,[X|W]) :- list_member(X,Z), list_intersect(Y,Z,W). list_intersect([X|Y],Z,W) :- \+ list_member(X,Z), list_intersect(Y,Z,W). list_intersect([],Z,[]).
输出
| ?- [list_set]. compiling D:/TP Prolog/Sample_Codes/list_set.pl for byte code... D:/TP Prolog/Sample_Codes/list_set.pl compiled, 13 lines read - 3054 bytes written, 9 ms (15 ms) yes | ?- list_intersect([a,b,c,d,e],[a,e,i,o,u],L3). L3 = [a,e] ? yes | ?- list_intersect([a,b,c,d,e],[],L3). L3 = [] yes | ?-
列表上的杂项操作
以下是可以在列表上执行的一些杂项操作:
| 杂项操作 | 定义 |
|---|---|
| 查找奇数和偶数长度 | 验证列表是否具有奇数或偶数个元素。 |
| 划分 | 将列表分成两个列表,并且这些列表的长度大致相同。 |
| 最大值 | 从给定列表中检索具有最大值的元素。 |
| Sum | 返回给定列表中元素的总和。 |
| 归并排序 | 按顺序排列给定列表的元素(使用归并排序算法)。 |
奇数和偶数长度操作
在这个例子中,我们将看到两个操作,我们可以使用它们来检查列表是否具有奇数个元素或偶数个元素。我们将定义谓词 list_even_len(L) 和 list_odd_len(L)。
如果列表没有元素,则它是偶数长度的列表。
否则,我们将它视为 [Head|Tail],如果 Tail 的长度为奇数,则整个列表是偶数长度的字符串。
同样,如果列表只有一个元素,则它是奇数长度的列表。
将其视为 [Head|Tail],如果 Tail 是偶数长度的字符串,则整个列表是奇数长度的列表。
程序
list_even_len([]). list_even_len([Head|Tail]) :- list_odd_len(Tail). list_odd_len([_]). list_odd_len([Head|Tail]) :- list_even_len(Tail).
输出
| ?- [list_misc]. compiling D:/TP Prolog/Sample_Codes/list_misc.pl for byte code... D:/TP Prolog/Sample_Codes/list_misc.pl:2: warning: singleton variables [Head] for list_even_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl:5: warning: singleton variables [Head] for list_odd_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl compiled, 4 lines read - 726 bytes written, 20 ms yes | ?- list_odd_len([a,2,b,3,c]). true ? yes | ?- list_odd_len([a,2,b,3]). no | ?- list_even_len([a,2,b,3]). true ? yes | ?- list_even_len([a,2,b,3,c]). no | ?-
划分列表操作
此操作将列表分成两个列表,并且这些列表的长度大致相同。因此,如果给定列表为 [a,b,c,d,e],则结果将为 [a,c,e],[b,d]。这会将所有奇数位置的元素放入一个列表中,并将所有偶数位置的元素放入另一个列表中。我们将定义谓词 list_divide(L1,L2,L3) 来解决此任务。
如果给定列表为空,则它将返回空列表。
如果只有一个元素,则第一个列表将是包含该元素的列表,而第二个列表将为空。
假设 X、Y 是来自头部(Head)的两个元素,其余为 Tail,所以创建两个列表 [X|List1],[Y|List2],这些 List1 和 List2 通过划分 Tail 分隔。
程序
list_divide([],[],[]). list_divide([X],[X],[]). list_divide([X,Y|Tail], [X|List1],[Y|List2]) :- list_divide(Tail,List1,List2).
输出
| ?- [list_misc]. compiling D:/TP Prolog/Sample_Codes/list_misc.pl for byte code... D:/TP Prolog/Sample_Codes/list_misc.pl:2: warning: singleton variables [Head] for list_even_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl:5: warning: singleton variables [Head] for list_odd_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl compiled, 8 lines read - 1432 bytes written, 8 ms yes | ?- list_divide([a,1,b,2,c,3,d,5,e],L1,L2). L1 = [a,b,c,d,e] L2 = [1,2,3,5] ? yes | ?- list_divide([a,b,c,d],L1,L2). L1 = [a,c] L2 = [b,d] yes | ?-
最大项操作
此操作用于从列表中查找最大元素。我们将定义一个谓词 list_max_elem(List, Max),然后这将从列表中查找 Max 元素并返回。
如果只有一个元素,则它将是最大元素。
将列表划分为 [X,Y|Tail]。现在递归地查找 [Y|Tail] 的最大值并将其存储到 MaxRest 中,并将 X 和 MaxRest 的最大值存储,然后将其存储到 Max 中。
程序
max_of_two(X,Y,X) :- X >= Y. max_of_two(X,Y,Y) :- X < Y. list_max_elem([X],X). list_max_elem([X,Y|Rest],Max) :- list_max_elem([Y|Rest],MaxRest), max_of_two(X,MaxRest,Max).
输出
| ?- [list_misc]. compiling D:/TP Prolog/Sample_Codes/list_misc.pl for byte code... D:/TP Prolog/Sample_Codes/list_misc.pl:2: warning: singleton variables [Head] for list_even_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl:5: warning: singleton variables [Head] for list_odd_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl compiled, 16 lines read - 2385 bytes written, 16 ms yes | ?- list_max_elem([8,5,3,4,7,9,6,1],Max). Max = 9 ? yes | ?- list_max_elem([5,12,69,112,48,4],Max). Max = 112 ? yes | ?-
列表求和操作
在这个例子中,我们将定义一个子句 list_sum(List, Sum),这将返回列表中元素的总和。
如果列表为空,则总和为 0。
将列表表示为 [Head|Tail],递归查找尾部的总和并将其存储到 SumTemp 中,然后设置 Sum = Head + SumTemp。
程序
list_sum([],0). list_sum([Head|Tail], Sum) :- list_sum(Tail,SumTemp), Sum is Head + SumTemp.
输出
yes | ?- [list_misc]. compiling D:/TP Prolog/Sample_Codes/list_misc.pl for byte code... D:/TP Prolog/Sample_Codes/list_misc.pl:2: warning: singleton variables [Head] for list_even_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl:5: warning: singleton variables [Head] for list_odd_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl compiled, 21 lines read - 2897 bytes written, 21 ms (32 ms) yes | ?- list_sum([5,12,69,112,48,4],Sum). Sum = 250 yes | ?- list_sum([8,5,3,4,7,9,6,1],Sum). Sum = 43 yes | ?-
列表归并排序
如果列表是 [4,5,3,7,8,1,2],则结果将是 [1,2,3,4,5,7,8]。执行归并排序的步骤如下:
获取列表并将其拆分为两个子列表。此拆分将递归执行。
以排序顺序合并每个拆分。
因此,整个列表将被排序。
我们将定义一个名为 mergesort(L, SL) 的谓词,它将获取 L 并将结果返回到 SL 中。
程序
mergesort([],[]). /* covers special case */ mergesort([A],[A]). mergesort([A,B|R],S) :- split([A,B|R],L1,L2), mergesort(L1,S1), mergesort(L2,S2), merge(S1,S2,S). split([],[],[]). split([A],[A],[]). split([A,B|R],[A|Ra],[B|Rb]) :- split(R,Ra,Rb). merge(A,[],A). merge([],B,B). merge([A|Ra],[B|Rb],[A|M]) :- A =< B, merge(Ra,[B|Rb],M). merge([A|Ra],[B|Rb],[B|M]) :- A > B, merge([A|Ra],Rb,M).
输出
| ?- [merge_sort]. compiling D:/TP Prolog/Sample_Codes/merge_sort.pl for byte code... D:/TP Prolog/Sample_Codes/merge_sort.pl compiled, 17 lines read - 3048 bytes written, 19 ms yes | ?- mergesort([4,5,3,7,8,1,2],L). L = [1,2,3,4,5,7,8] ? yes | ?- mergesort([8,5,3,4,7,9,6,1],L). L = [1,3,4,5,6,7,8,9] ? yes | ?-
Prolog - 递归和结构
本章涵盖递归和结构。
递归
递归是一种技术,其中一个谓词使用自身(可能与其他一些谓词一起)来查找真值。
让我们通过一个例子来理解这个定义:
is_digesting(X,Y) :- just_ate(X,Y).
is_digesting(X,Y) :-just_ate(X,Z),is_digesting(Z,Y).
因此,这个谓词本质上是递归的。假设我们说 *just_ate(deer, grass)*,这意味着 *is_digesting(deer, grass)* 为真。现在如果我们说 *is_digesting(tiger, grass)*,如果 *is_digesting(tiger, grass)* :- *just_ate(tiger, deer), is_digesting(deer, grass)*,则语句 *is_digesting(tiger, grass)* 也为真。
可能还有一些其他的例子,所以让我们来看一个家庭的例子。如果我们想表达前驱逻辑,可以使用以下图表来表达:
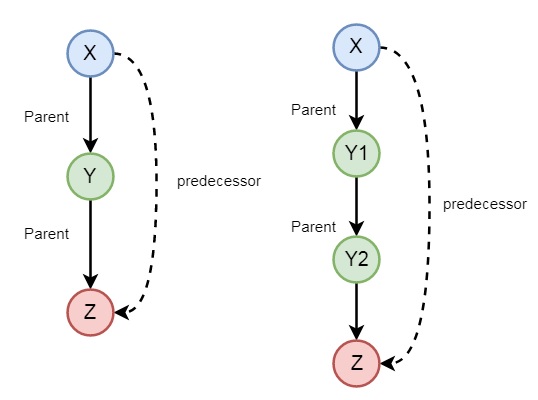
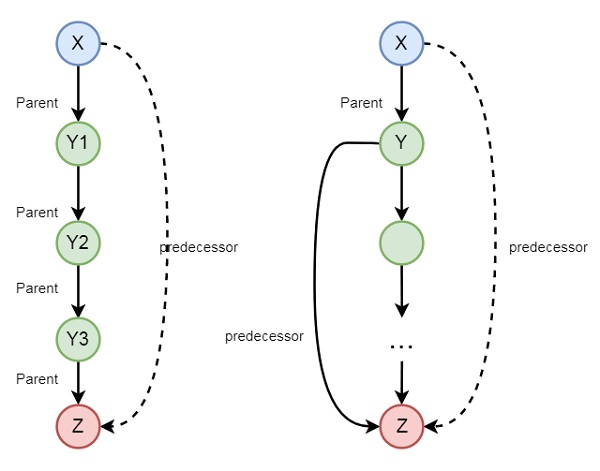
所以我们可以理解前驱关系是递归的。我们可以使用以下语法表达这种关系:
predecessor(X, Z) :- parent(X, Z).
predecessor(X, Z) :- parent(X, Y),predecessor(Y, Z).
结构
结构是包含多个组件的数据对象。
例如,日期可以看作是一个具有三个组件的结构——日、月和年。那么 2020 年 4 月 9 日可以写成:date(9, apr, 2020)。
注意 - 结构本身可以包含另一个结构作为其组件。
因此,我们可以将视图视为树形结构和Prolog 函数符。
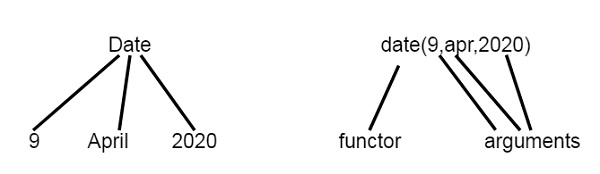
现在让我们来看一个 Prolog 中结构的例子。我们将定义点、线段和三角形作为结构的结构。
为了用 Prolog 中的结构表示点、线段和三角形,我们可以考虑以下语句:
p1 - point(1, 1)
p2 - point(2,3)
S - seg( Pl, P2): seg( point(1,1), point(2,3))
T - triangle( point(4,Z), point(6,4), point(7,1) )
注意 - 结构可以自然地描绘成树。Prolog 可以被视为一种用于处理树的语言。
Prolog 中的匹配
匹配用于检查两个给定项是否相同(相同)或者两个项中的变量在被实例化后是否可以具有相同的对象。让我们来看一个例子。
假设日期结构定义为 date(D,M,2020) = date(D1,apr, Y1),这表示 D = D1,M = feb 并且 Y1 = 2020。
以下规则用于检查两个项 S 和 T 是否匹配:
如果 S 和 T 是常量,如果两者是相同的对象,则 S=T。
如果 S 是变量,而 T 是任何东西,则 T=S。
如果 T 是变量,而 S 是任何东西,则 S=T。
如果 S 和 T 是结构,则 S=T 如果:
S 和 T 具有相同的函数符。
所有对应的参数组件都必须匹配。
二叉树
以下是使用递归结构的二叉树结构:
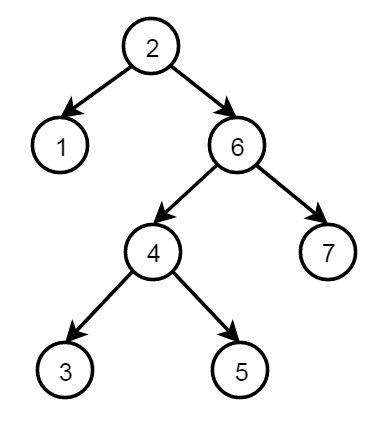
结构的定义如下:
node(2, node(1,nil,nil), node(6, node(4,node(3,nil,nil), node(5,nil,nil)), node(7,nil,nil))
每个节点都有三个字段,数据和两个节点。一个没有子节点(叶节点)的节点结构写为 node(value, nil, nil),只有一个左子节点的节点写为 node(value, left_node, nil),只有一个右子节点的节点写为 node(value, nil; right_node),并且具有两个子节点的节点具有 node(value, left_node, right_node)。
Prolog - 回溯
在本章中,我们将讨论 Prolog 中的回溯。回溯是一个过程,其中 Prolog 通过检查谓词是否正确来搜索不同谓词的真值。回溯这个术语在算法设计和不同的编程环境中非常常见。在 Prolog 中,直到到达正确的目的地,它才会尝试回溯。找到目的地后,它会停止。
让我们看看使用树状结构回溯是如何发生的:
假设 A 到 G 是某些规则和事实。我们从 A 开始,想到达 G。正确的路径将是 A-C-G,但首先,它将从 A 到 B,然后从 B 到 D。当它发现 D 不是目的地时,它回溯到 B,然后到 E,然后再次回溯到 B,因为 B 没有其他子节点,然后它回溯到 A,因此它搜索 G,最终在路径 A-C-G 中找到 G。(虚线表示回溯。)所以当它找到 G 时,它就停止了。
回溯是如何工作的?
现在我们知道了 Prolog 中的回溯是什么。让我们来看一个例子,
注意 - 当我们运行一些 Prolog 代码时,在回溯过程中可能会有多个答案,我们可以按分号(;)来一个一个地获取下一个答案,这有助于回溯。否则,当我们得到一个结果时,它将停止。
现在,考虑一种情况,两个人 X 和 Y 可以互相支付,但条件是一个男孩可以支付给一个女孩,所以 X 将是一个男孩,而 Y 将是一个女孩。因此,我们为此定义了一些事实和规则:
知识库
boy(tom). boy(bob). girl(alice). girl(lili). pay(X,Y) :- boy(X), girl(Y).
以下是上述场景的图示:
由于 X 将是一个男孩,所以有两个选择,对于每个男孩,都有两个选择 alice 和 lili。现在让我们看看输出,回溯是如何工作的。
输出
| ?- [backtrack].
compiling D:/TP Prolog/Sample_Codes/backtrack.pl for byte code...
D:/TP Prolog/Sample_Codes/backtrack.pl compiled, 5 lines read - 703 bytes written, 22 ms
yes
| ?- pay(X,Y).
X = tom
Y = alice ?
(15 ms) yes
| ?- pay(X,Y).
X = tom
Y = alice ? ;
X = tom
Y = lili ? ;
X = bob
Y = alice ? ;
X = bob
Y = lili
yes
| ?- trace.
The debugger will first creep -- showing everything (trace)
(16 ms) yes
{trace}
| ?- pay(X,Y).
1 1 Call: pay(_23,_24) ?
2 2 Call: boy(_23) ?
2 2 Exit: boy(tom) ?
3 2 Call: girl(_24) ?
3 2 Exit: girl(alice) ?
1 1 Exit: pay(tom,alice) ?
X = tom
Y = alice ? ;
1 1 Redo: pay(tom,alice) ?
3 2 Redo: girl(alice) ?
3 2 Exit: girl(lili) ?
1 1 Exit: pay(tom,lili) ?
X = tom
Y = lili ? ;
1 1 Redo: pay(tom,lili) ?
2 2 Redo: boy(tom) ?
2 2 Exit: boy(bob) ?
3 2 Call: girl(_24) ?
3 2 Exit: girl(alice) ?
1 1 Exit: pay(bob,alice) ?
X = bob
Y = alice ? ;
1 1 Redo: pay(bob,alice) ?
3 2 Redo: girl(alice) ?
3 2 Exit: girl(lili) ?
1 1 Exit: pay(bob,lili) ?
X = bob
Y = lili
yes
{trace}
| ?-
防止回溯
到目前为止,我们已经了解了一些回溯的概念。现在让我们看看回溯的一些缺点。有时,当我们的程序需要时,我们会多次编写相同的谓词,例如编写递归规则或制作一些决策系统。在这种情况下,不受控制的回溯可能会导致程序效率低下。为了解决这个问题,我们将使用Prolog中的剪枝。
假设我们有一些如下所示的规则:
双步函数
规则 1 &minnus; 如果 X < 3,则 Y = 0
规则 2 &minnus; 如果 3 <= X 且 X < 6,则 Y = 2
规则 3 &minnus; 如果 6 <= X,则 Y = 4
在Prolog语法中,我们可以这样写:
f(X,0) :- X < 3. % 规则 1
f(X,2) :- 3 =< X, X < 6. % 规则 2
f(X,4) :- 6 =< X. % 规则 3
现在,如果我们提出一个问题,例如 f(1,Y), 2 < Y。
第一个目标 f(1,Y) 将 Y 实例化为 0。第二个目标变为 2 < 0,这将失败。Prolog 通过回溯尝试了两个无结果的替代方案(规则 2 和规则 3)。如果我们仔细观察,我们可以发现:
这三个规则是互斥的,最多只有一个会成功。
一旦其中一个成功,就没有必要尝试使用其他的,因为它们注定会失败。
所以我们可以使用剪枝来解决这个问题。剪枝可以用感叹号表示。Prolog语法如下:
f(X,0) :- X < 3, !. % 规则 1
f(X,2) :- 3 =< X, X < 6, !. % 规则 2
f(X,4) :- 6 =< X. % 规则 3
现在,如果我们使用相同的问题,?- f(1,Y), 2 < Y。Prolog 选择规则 1,因为 1 < 3,并且目标 2 < Y 失败。Prolog 将尝试回溯,但不会超出程序中标记为 ! 的点,规则 2 和规则 3 将不会被生成。
让我们在下面的执行中看到这一点:
程序
f(X,0) :- X < 3. % Rule 1 f(X,2) :- 3 =< X, X < 6. % Rule 2 f(X,4) :- 6 =< X. % Rule 3
输出
| ?- [backtrack].
compiling D:/TP Prolog/Sample_Codes/backtrack.pl for byte code...
D:/TP Prolog/Sample_Codes/backtrack.pl compiled, 10 lines read - 1224 bytes written, 17 ms
yes
| ?- f(1,Y), 2<Y.
no
| ?- trace
.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- f(1,Y), 2<Y.
1 1 Call: f(1,_23) ?
2 2 Call: 1<3 ?
2 2 Exit: 1<3 ?
1 1 Exit: f(1,0) ?
3 1 Call: 2<0 ?
3 1 Fail: 2<0 ?
1 1 Redo: f(1,0) ?
2 2 Call: 3=<1 ?
2 2 Fail: 3=<1 ?
2 2 Call: 6=<1 ?
2 2 Fail: 6=<1 ?
1 1 Fail: f(1,_23) ?
(46 ms) no
{trace}
| ?-
让我们看看使用剪枝的相同情况。
程序
f(X,0) :- X < 3,!. % Rule 1 f(X,2) :- 3 =< X, X < 6,!. % Rule 2 f(X,4) :- 6 =< X. % Rule 3
输出
| ?- [backtrack].
1 1 Call: [backtrack] ?
compiling D:/TP Prolog/Sample_Codes/backtrack.pl for byte code...
D:/TP Prolog/Sample_Codes/backtrack.pl compiled, 10 lines read - 1373 bytes written, 15 ms
1 1 Exit: [backtrack] ?
(16 ms) yes
{trace}
| ?- f(1,Y), 2<Y.
1 1 Call: f(1,_23) ?
2 2 Call: 1<3 ?
2 2 Exit: 1<3 ?
1 1 Exit: f(1,0) ?
3 1 Call: 2<0 ?
3 1 Fail: 2<0 ?
no
{trace}
| ?-
失败即否定
在这里,当条件不满足时,我们将执行失败。假设我们有一句话:“玛丽喜欢所有动物,除了蛇”,我们将用Prolog来表达这句话。
如果语句是“玛丽喜欢所有动物”,那就很容易直接表达了。在这种情况下,我们可以写“如果X是动物,玛丽喜欢X”。在Prolog中,我们可以将此语句写成:likes(mary, X) := animal(X)。
我们的实际语句可以表达为:
如果X是蛇,“玛丽喜欢X”为假
否则,如果X是动物,则玛丽喜欢X。
在Prolog中,我们可以这样写:
likes(mary,X) :- snake(X), !, fail.
likes(mary, X) :- animal(X).
‘fail’语句会导致失败。现在让我们看看它如何在Prolog中工作。
程序
animal(dog). animal(cat). animal(elephant). animal(tiger). animal(cobra). animal(python). snake(cobra). snake(python). likes(mary, X) :- snake(X), !, fail. likes(mary, X) :- animal(X).
输出
| ?- [negate_fail].
compiling D:/TP Prolog/Sample_Codes/negate_fail.pl for byte code...
D:/TP Prolog/Sample_Codes/negate_fail.pl compiled, 11 lines read - 1118 bytes written, 17 ms
yes
| ?- likes(mary,elephant).
yes
| ?- likes(mary,tiger).
yes
| ?- likes(mary,python).
no
| ?- likes(mary,cobra).
no
| ?- trace
.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- likes(mary,dog).
1 1 Call: likes(mary,dog) ?
2 2 Call: snake(dog) ?
2 2 Fail: snake(dog) ?
2 2 Call: animal(dog) ?
2 2 Exit: animal(dog) ?
1 1 Exit: likes(mary,dog) ?
yes
{trace}
| ?- likes(mary,python).
1 1 Call: likes(mary,python) ?
2 2 Call: snake(python) ?
2 2 Exit: snake(python) ?
3 2 Call: fail ?
3 2 Fail: fail ?
1 1 Fail: likes(mary,python) ?
no
{trace}
| ?-
Prolog - 不同与非
在这里,我们将定义两个谓词——different和not。different谓词将检查两个给定的参数是否相同。如果它们相同,它将返回false,否则它将返回true。not谓词用于否定某个语句,这意味着,当一个语句为真时,not(statement)为假,否则如果语句为假,则not(statement)为真。
因此,“different”可以用三种不同的方式表达,如下所示:
X和Y不是字面上的相同
X和Y不匹配
算术表达式X和Y的值不相等
所以在Prolog中,我们将尝试将语句表达如下:
如果X和Y匹配,则different(X,Y)失败;
否则different(X,Y)成功。
相应的Prolog语法如下:
different(X, X) :- !, fail.
different(X, Y).
我们也可以使用析取子句来表达它,如下所示:
different(X, Y) :- X = Y, !, fail ; true. % true是一个总是成功的目标
程序
下面的例子展示了如何在Prolog中做到这一点:
different(X, X) :- !, fail. different(X, Y).
输出
| ?- [diff_rel]. compiling D:/TP Prolog/Sample_Codes/diff_rel.pl for byte code... D:/TP Prolog/Sample_Codes/diff_rel.pl:2: warning: singleton variables [X,Y] for different/2 D:/TP Prolog/Sample_Codes/diff_rel.pl compiled, 2 lines read - 327 bytes written, 11 ms yes | ?- different(100,200). yes | ?- different(100,100). no | ?- different(abc,def). yes | ?- different(abc,abc). no | ?-
让我们看看一个使用析取子句的程序:
程序
different(X, Y) :- X = Y, !, fail ; true.
输出
| ?- [diff_rel]. compiling D:/TP Prolog/Sample_Codes/diff_rel.pl for byte code... D:/TP Prolog/Sample_Codes/diff_rel.pl compiled, 0 lines read - 556 bytes written, 17 ms yes | ?- different(100,200). yes | ?- different(100,100). no | ?- different(abc,def). yes | ?- different(abc,abc). no | ?-
Prolog中的否定关系
not关系在不同的情况下非常有用。在我们传统的编程语言中,我们也使用逻辑非运算来否定某个语句。这意味着,当一个语句为真时,not(statement)为假,否则如果语句为假,则not(statement)为真。
在Prolog中,我们可以定义如下:
not(P) :- P, !, fail ; true.
所以如果P为真,则剪枝并失败,这将返回false,否则将返回true。现在让我们看一段简单的代码来理解这个概念。
程序
not(P) :- P, !, fail ; true.
输出
| ?- [not_rel]. compiling D:/TP Prolog/Sample_Codes/not_rel.pl for byte code... D:/TP Prolog/Sample_Codes/not_rel.pl compiled, 0 lines read - 630 bytes written, 17 ms yes | ?- not(true). no | ?- not(fail). yes | ?-
Prolog - 输入和输出
在本章中,我们将了解一些通过Prolog处理输入和输出的技术。我们将使用一些内置谓词来完成这些任务,并将看到文件处理技术。
我们将详细讨论以下主题:
处理输入和输出
使用Prolog进行文件处理
使用一些外部文件来读取行和项
用于输入和输出的字符操作
构造和分解原子
将Prolog文件导入其他Prolog程序的技术。
处理输入和输出
到目前为止,我们已经看到我们可以编写一个程序和控制台上的查询来执行。在某些情况下,我们在控制台上打印一些内容,这些内容写在我们的Prolog代码中。所以在这里我们将更详细地看到Prolog中读写任务。这将是输入和输出处理技术。
write()谓词
要写入输出,我们可以使用write()谓词。此谓词将参数作为输入,并默认将内容写入控制台。write()也可以写入文件。让我们看看write()函数的一些例子。
程序
| ?- write(56).
56
yes
| ?- write('hello').
hello
yes
| ?- write('hello'),nl,write('world').
hello
world
yes
| ?- write("ABCDE")
.
[65,66,67,68,69]
yes
从上面的例子可以看出,write()谓词可以将内容写入控制台。我们可以使用'nl'来创建新行。从这个例子可以看出,如果我们想在控制台上打印一些字符串,我们必须使用单引号('string')。但是如果我们使用双引号("string"),它将返回ASCII值的列表。
read()谓词
read()谓词用于从控制台读取。用户可以在控制台中写入一些内容,这些内容可以作为输入并进行处理。read()通常用于从控制台读取,但也可以用于从文件读取。现在让我们看一个例子来了解read()是如何工作的。
程序
cube :-
write('Write a number: '),
read(Number),
process(Number).
process(stop) :- !.
process(Number) :-
C is Number * Number * Number,
write('Cube of '),write(Number),write(': '),write(C),nl, cube.
输出
| ?- [read_write]. compiling D:/TP Prolog/Sample_Codes/read_write.pl for byte code... D:/TP Prolog/Sample_Codes/read_write.pl compiled, 9 lines read - 1226 bytes written, 12 ms (15 ms) yes | ?- cube. Write a number: 2. Cube of 2: 8 Write a number: 10. Cube of 10: 1000 Write a number: 12. Cube of 12: 1728 Write a number: 8. Cube of 8: 512 Write a number: stop . (31 ms) yes | ?-
tab()谓词
tab()是可以使用的另一个谓词,当我们写一些东西时,它可以添加一些空格。它将一个数字作为参数,并打印那么多空格。
程序
| ?- write('hello'),tab(15),write('world').
hello world
yes
| ?- write('We'),tab(5),write('will'),tab(5),write('use'),tab(5),write('tabs').
We will use tabs
yes
| ?-
读取/写入文件
在本节中,我们将了解如何使用文件进行读取和写入。有一些内置谓词可以用于从文件读取和写入文件。
tell和told
如果我们想写入文件而不是控制台,我们可以写入tell()谓词。此tell()谓词将文件名作为参数。如果该文件不存在,则创建一个新文件并写入其中。该文件将打开,直到我们写入told命令。我们可以使用tell()打开多个文件。当调用told时,所有文件都将关闭。
Prolog命令
| ?- told('myFile.txt').
uncaught exception: error(existence_error(procedure,told/1),top_level/0)
| ?- told("myFile.txt").
uncaught exception: error(existence_error(procedure,told/1),top_level/0)
| ?- tell('myFile.txt').
yes
| ?- tell('myFile.txt').
yes
| ?- write('Hello World').
yes
| ?- write(' Writing into a file'),tab(5),write('myFile.txt'),nl.
yes
| ?- write("Write some ASCII values").
yes
| ?- told.
yes
| ?-
输出 (myFile.txt)
Hello World Writing into a file myFile.txt [87,114,105,116,101,32,115,111,109,101,32,65,83,67,73,73,32,118,97,108,117,101,115]
同样,我们也可以从文件读取。让我们看一些从文件读取的例子。
see和seen
当我们想从文件而不是键盘读取时,我们必须更改当前输入流。所以我们可以使用see()谓词。这将接收文件名作为输入。当读取操作完成后,我们将使用seen命令。
示例文件 (sample_predicate.txt)
likes(lili, cat). likes(jhon,dog).
输出
| ?- see('sample_predicate.txt'),
read(X),
read(Y),
seen,
read(Z).
the_end.
X = end_of_file
Y = end_of_file
Z = the_end
yes
| ?-
所以从这个例子可以看出,使用see()谓词我们可以从文件中读取。现在在使用seen命令后,控制权再次转移到控制台。所以最后它从控制台接收输入。
处理术语文件
我们已经了解了如何读取文件的特定内容(几行)。现在,如果我们想读取/处理文件的全部内容,我们需要编写一个子句来处理文件(process_file),直到到达文件的末尾。
程序
process_file :- read(Line), Line \== end_of_file, % when Line is not not end of file, call process. process(Line). process_file :- !. % use cut to stop backtracking process(Line):- %this will print the line into the console write(Line),nl, process_file.
示例文件 (sample_predicate.txt)
likes(lili, cat). likes(jhon,dog). domestic(dog). domestic(cat).
输出
| ?- [process_file].
compiling D:/TP Prolog/Sample_Codes/process_file.pl for byte code...
D:/TP Prolog/Sample_Codes/process_file.pl compiled, 9 lines read - 774 bytes written, 23 ms
yes
| ?- see('sample_predicate.txt'), process_file, seen.
likes(lili,cat)
likes(jhon,dog)
domestic(dog)
domestic(cat)
true ?
(15 ms) yes
| ?-
操作字符
使用read()和write(),我们可以读取或写入原子、谓词、字符串等的值。在本节中,我们将了解如何将单个字符写入当前输出流,或如何从当前输入流读取。因此,有一些预定义的谓词可以执行这些任务。
put(C)和put_char(C)谓词
我们可以使用put(C)一次一个字符地将字符写入当前输出流。输出流可以是文件或控制台。在像SWI Prolog这样的其他版本的Prolog中,C可以是字符或ASCII码,但在GNU Prolog中,它只支持ASCII值。要使用字符而不是ASCII,我们可以使用put_char(C)。
程序
| ?- put(97),put(98),put(99),put(100),put(101).
abcde
yes
| ?- put(97),put(66),put(99),put(100),put(101).
aBcde
(15 ms) yes
| ?- put(65),put(66),put(99),put(100),put(101).
ABcde
yes
| ?-put_char('h'),put_char('e'),put_char('l'),put_char('l'),put_char('o').
hello
yes
| ?-
get_char(C)和get_code(C)谓词
要从当前输入流读取单个字符,我们可以使用get_char(C)谓词。这将获取字符。如果我们想要ASCII码,我们可以使用get_code(C)。
程序
| ?- get_char(X).
A.
X = 'A'
yes
uncaught exception: error(syntax_error('user_input:6 (char:689) expression expected'),read_term/3)
| ?- get_code(X).
A.
X = 65
yes
uncaught exception: error(syntax_error('user_input:7 (char:14) expression expected'),read_term/3)
| ?-
构造原子
原子构造是指从字符列表中,我们可以创建一个原子,或者从ASCII值列表中也可以创建原子。为此,我们必须使用atom_chars()和atom_codes()谓词。在这两种情况下,第一个参数将是一个变量,第二个参数将是一个列表。所以atom_chars()从字符构造原子,而atom_codes()从ASCII序列构造原子。
例子
| ?- atom_chars(X, ['t','i','g','e','r']). X = tiger yes | ?- atom_chars(A, ['t','o','m']). A = tom yes | ?- atom_codes(X, [97,98,99,100,101]). X = abcde yes | ?- atom_codes(A, [97,98,99]). A = abc yes | ?-
分解原子
原子分解是指从一个原子中,我们可以得到一个字符序列或一个ASCII码序列。为此,我们必须使用相同的atom_chars()和atom_codes()谓词。但不同之处在于,在这两种情况下,第一个参数将是一个原子,第二个参数将是一个变量。所以atom_chars()将原子分解为字符,而atom_codes()将原子分解为ASCII序列。
例子
| ?- atom_chars(tiger,X). X = [t,i,g,e,r] yes | ?- atom_chars(tom,A). A = [t,o,m] yes | ?- atom_codes(tiger,X). X = [116,105,103,101,114] yes | ?- atom_codes(tom,A). A = [116,111,109] (16 ms) yes | ?-
Prolog中的consult
咨询是一种技术,用于合并来自不同文件的谓词。我们可以使用 consult() 谓词,并传递文件名来附加谓词。让我们看一个示例程序来理解这个概念。
假设我们有两个文件,分别是 prog1.pl 和 prog2.pl。
程序 (prog1.pl)
likes(mary,cat). likes(joy,rabbit). likes(tim,duck).
程序 (prog2.pl)
likes(suman,mouse). likes(angshu,deer).
输出
| ?- [prog1].
compiling D:/TP Prolog/Sample_Codes/prog1.pl for byte code...
D:/TP Prolog/Sample_Codes/prog1.pl compiled, 2 lines read - 443 bytes written, 23 ms
yes
| ?- likes(joy,rabbit).
yes
| ?- likes(suman,mouse).
no
| ?- consult('prog2.pl').
compiling D:/TP Prolog/Sample_Codes/prog2.pl for byte code...
D:/TP Prolog/Sample_Codes/prog2.pl compiled, 1 lines read - 366 bytes written, 20 ms
warning: D:/TP Prolog/Sample_Codes/prog2.pl:1: redefining procedure likes/2
D:/TP Prolog/Sample_Codes/prog1.pl:1: previous definition
yes
| ?- likes(suman,mouse).
yes
| ?- likes(joy,rabbit).
no
| ?-
从这个输出中我们可以理解,这不像看起来那么简单。如果两个文件具有**完全不同的子句**,那么它将正常工作。但是,如果存在相同的谓词,那么当我们尝试咨询该文件时,它将检查第二个文件中的谓词,当它找到一些匹配项时,它会简单地删除本地数据库中相同谓词的所有条目,然后从第二个文件中再次加载它们。
Prolog - 内置谓词
在 Prolog 中,我们已经看到在大多数情况下都是用户定义的谓词,但也有一些内置谓词。内置谓词分为以下三种类型:
标识项
分解结构
收集所有解决方案
所以这是一个属于标识项组的一些谓词的列表:
| 谓词 | 描述 |
|---|---|
| var(X) | 如果 X 当前是一个未实例化的变量,则成功。 |
| novar(X) | 如果 X 不是变量,或者已经实例化,则成功。 |
| atom(X) | 如果 X 当前代表一个原子,则为真。 |
| number(X) | 如果 X 当前代表一个数字,则为真。 |
| integer(X) | 如果 X 当前代表一个整数,则为真。 |
| float(X) | 如果 X 当前代表一个实数,则为真。 |
| atomic(X) | 如果 X 当前代表一个数字或一个原子,则为真。 |
| compound(X) | 如果 X 当前代表一个结构,则为真。 |
| ground(X) | 如果 X 不包含任何未实例化的变量,则成功。 |
var(X) 谓词
当 X 未初始化时,它将显示 true,否则为 false。让我们来看一个例子。
例子
| ?- var(X). yes | ?- X = 5, var(X). no | ?- var([X]). no | ?-
novar(X) 谓词
当 X 未初始化时,它将显示 false,否则为 true。让我们来看一个例子。
例子
| ?- nonvar(X). no | ?- X = 5,nonvar(X). X = 5 yes | ?- nonvar([X]). yes | ?-
atom(X) 谓词
当传递给 X 的是非变量项,且参数为 0 且不是数字项时,这将返回 true,否则为 false。
例子
| ?- atom(paul). yes | ?- X = paul,atom(X). X = paul yes | ?- atom([]). yes | ?- atom([a,b]). no | ?-
number(X) 谓词
如果 X 代表任何数字,则返回 true,否则为 false。
例子
| ?- number(X). no | ?- X=5,number(X). X = 5 yes | ?- number(5.46). yes | ?-
integer(X) 谓词
如果 X 是正整数或负整数,则返回 true,否则为 false。
例子
| ?- integer(5). yes | ?- integer(5.46). no | ?-
float(X) 谓词
如果 X 是浮点数,则返回 true,否则为 false。
例子
| ?- float(5). no | ?- float(5.46). yes | ?-
atomic(X) 谓词
我们有 atom(X),它过于具体,对于数值数据返回 false,atomic(X) 与 atom(X) 类似,但它接受数字。
例子
| ?- atom(5). no | ?- atomic(5). yes | ?-
compound(X) 谓词
如果 atomic(X) 失败,则项要么是一个未实例化的变量(可以使用 var(X) 测试),要么是一个复合项。当我们传递一些复合结构时,Compound 将为 true。
例子
| ?- compound([]). no | ?- compound([a]). yes | ?- compound(b(a)). yes | ?-
ground(X) 谓词
如果 X 不包含任何未实例化的变量,则返回 true。这也检查复合项内部,否则返回 false。
例子
| ?- ground(X). no | ?- ground(a(b,X)). no | ?- ground(a). yes | ?- ground([a,b,c]). yes | ?-
分解结构
现在我们将看到另一组内置谓词,即分解结构。我们之前已经看到过标识项。因此,当我们使用复合结构时,我们不能使用变量来检查或创建函子。它将返回错误。因此,函子名称不能由变量表示。
错误
X = tree, Y = X(maple). Syntax error Y=X<>(maple)
现在,让我们看看属于分解结构组的一些内置谓词。
functor(T,F,N) 谓词
如果 F 是 T 的主函子,并且 N 是 F 的元数,则返回 true。
**注意** - 元数表示属性的数量。
例子
| ?- functor(t(f(X),a,T),Func,N). Func = t N = 3 (15 ms) yes | ?-
arg(N,Term,A) 谓词
如果 A 是 Term 中的第 N 个参数,则返回 true。否则返回 false。
例子
| ?- arg(1,t(t(X),[]),A). A = t(X) yes | ?- arg(2,t(t(X),[]),A). A = [] yes | ?-
现在,让我们看另一个例子。在这个例子中,我们检查 D 的第一个参数将是 12,第二个参数将是 apr,第三个参数将是 2020。
例子
| ?- functor(D,date,3), arg(1,D,12), arg(2,D,apr), arg(3,D,2020). D = date(12,apr,2020) yes | ?-
../2 谓词
这是另一个表示为双点 (..) 的谓词。它接受 2 个参数,所以写为“/2”。所以 Term = .. L,如果 L 是一个列表,其中包含 Term 的函子及其参数,则为真。
例子
| ?- f(a,b) =.. L. L = [f,a,b] yes | ?- T =.. [is_blue,sam,today]. T = is_blue(sam,today) yes | ?-
通过将结构的组件表示为列表,可以在不知道函子名称的情况下递归地处理它们。让我们看另一个例子:
例子
| ?- f(2,3)=..[F,N|Y], N1 is N*3, L=..[F,N1|Y]. F = f L = f(6,3) N = 2 N1 = 6 Y = [3] yes | ?-
收集所有解决方案
现在让我们看看第三类,称为收集所有解决方案,它属于 Prolog 中的内置谓词。
我们已经看到,可以使用提示符中的分号来生成给定目标的所有给定解决方案。这是一个例子:
例子
| ?- member(X, [1,2,3,4]). X = 1 ? ; X = 2 ? ; X = 3 ? ; X = 4 yes
有时,我们需要在某些 AI 相关应用程序中生成某个目标的所有解决方案。因此,有三个内置谓词可以帮助我们获得结果。这些谓词如下:
findall/3
setoff/3
bagof/3
这三个谓词接受三个参数,因此我们在谓词名称后写了“/3”。
这些也被称为**元谓词**。它们用于操纵 Prolog 的证明策略。
语法
findall(X,P,L). setof(X,P,L) bagof(X,P,L)
这三个谓词列出了所有对象 X,只要目标 P 满足(例如:age(X,Age))。它们都重复调用目标 P,通过在 P 中实例化变量 X 并将其添加到列表 L 中。当没有更多解决方案时,这将停止。
Findall/3、Setof/3 和 Bagof/3
在这里,我们将看到三个不同的内置谓词 findall/3、setof/3 和 bagof/3,它们属于**收集所有解决方案**类别。
findall/3 谓词
此谓词用于从谓词 P 中创建所有解决方案 X 的列表。返回的列表将是 L。因此,我们将读取此内容为“查找所有 Xs,这样 X 是谓词 P 的解决方案,并将结果列表放入 L 中”。在这里,此谓词按 Prolog 找到它们的顺序存储结果。如果存在重复的解决方案,则所有解决方案都将进入结果列表,如果存在无限的解决方案,则该过程将永远不会终止。
现在我们也可以对它们进行一些改进。第二个参数,即目标,可能是一个复合目标。那么语法将是**findall(X, (Predicate on X, other goal), L)**
而且第一个参数可以是任何复杂度的项。让我们看看这几个规则的例子,并检查输出。
例子
| ?- findall(X, member(X, [1,2,3,4]), Results). Results = [1,2,3,4] yes | ?- findall(X, (member(X, [1,2,3,4]), X > 2), Results). Results = [3,4] yes | ?- findall(X/Y, (member(X,[1,2,3,4]), Y is X * X), Results). Results = [1/1,2/4,3/9,4/16] yes | ?-
setof/3 谓词
setof/3 也类似于 findall/3,但它在这里删除所有重复的输出,答案将被排序。
如果在目标中使用任何变量,则该变量不会出现在第一个参数中,setof/3 将为该变量的每个可能的实例化返回一个单独的结果。
让我们看一个例子来理解这个 setof/3。假设我们有一个如下所示的知识库:
age(peter, 7). age(ann, 5). age(pat, 8). age(tom, 5). age(ann, 5).
在这里我们可以看到 age(ann, 5) 在知识库中有两个条目。在这种情况下,年龄未排序,名称未按字典顺序排序。现在让我们看一个 setof/3 用法的例子。
例子
| ?- setof(Child, age(Child,Age),Results). Age = 5 Results = [ann,tom] ? ; Age = 7 Results = [peter] ? ; Age = 8 Results = [pat] (16 ms) yes | ?-
在这里,我们可以看到年龄和名称都是排序的。对于年龄 5,有两个条目,因此谓词创建了一个包含两个元素的与年龄值对应的列表。并且重复的条目只出现一次。
我们可以使用 setof/3 的嵌套调用来收集各个结果。我们将看到另一个例子,其中第一个参数将是 Age/Children。作为第二个参数,它将像之前一样接受另一个 setof。因此,这将返回一个 (age/Children) 对列表。让我们在 Prolog 执行中查看:
例子
| ?- setof(Age/Children, setof(Child,age(Child,Age), Children), AllResults). AllResults = [5/[ann,tom],7/[peter],8/[pat]] yes | ?-
现在,如果我们不关心第一个参数中未出现的变量,则可以使用以下示例:
例子
| ?- setof(Child, Age^age(Child,Age), Results). Results = [ann,pat,peter,tom] yes | ?-
在这里,我们使用上标符号 (^),这表示 Age 不在第一个参数中。因此,我们将读取此内容为,“查找所有孩子的集合,这样孩子有年龄(无论是什么),并将结果放入 Results 中”。
bagof/3 谓词
bagof/3 类似于 setof/3,但它不删除重复的输出,答案可能未排序。
让我们看一个例子来理解这个 bagof/3。假设我们有一个如下所示的知识库:
知识库
age(peter, 7). age(ann, 5). age(pat, 8). age(tom, 5). age(ann, 5).
例子
| ?- bagof(Child, age(Child,Age),Results). Age = 5 Results = [ann,tom,ann] ? ; Age = 7 Results = [peter] ? ; Age = 8 Results = [pat] (15 ms) yes | ?-
在这里,对于 Age 值 5,结果是 [ann, tom, ann]。因此答案未排序,并且未删除重复的条目,因此我们得到了两个“ann”值。
bagof/3 与 findall/3 不同,因为它为目标中所有未出现在第一个参数中的变量生成单独的结果。我们将在下面的示例中看到这一点:
例子
| ?- findall(Child, age(Child,Age),Results). Results = [peter,ann,pat,tom,ann] yes | ?-
数学谓词
以下是数学谓词:
| 谓词 | 描述 |
|---|---|
| random(L,H,X)。 | 获取 L 和 H 之间的随机值 |
| between(L,H,X)。 | 获取 L 和 H 之间的所有值 |
| succ(X,Y)。 | 加 1 并将其赋值给 X |
| abs(X)。 | 获取 X 的绝对值 |
| max(X,Y)。 | 获取 X 和 Y 之间的最大值 |
| min(X,Y)。 | 获取 X 和 Y 之间的最小值 |
| round(X)。 | 四舍五入到接近 X 的值 |
| truncate(X)。 | 将浮点数转换为整数,删除小数部分 |
| floor(X)。 | 向下取整 |
| ceiling(X)。 | 向上取整 |
| sqrt(X)。 | 平方根 |
除此之外,还有一些其他谓词,例如 sin、cos、tan、asin、acos、atan、atan2、sinh、cosh、tanh、asinh、acosh、atanh、log、log10、exp、pi 等。
现在让我们使用 Prolog 程序看看这些函数的实际作用。
例子
| ?- random(0,10,X). X = 0 yes | ?- random(0,10,X). X = 5 yes | ?- random(0,10,X). X = 1 yes | ?- between(0,10,X). X = 0 ? a X = 1 X = 2 X = 3 X = 4 X = 5 X = 6 X = 7 X = 8 X = 9 X = 10 (31 ms) yes | ?- succ(2,X). X = 3 yes | ?- X is abs(-8). X = 8 yes | ?- X is max(10,5). X = 10 yes | ?- X is min(10,5). X = 5 yes | ?- X is round(10.56). X = 11 yes | ?- X is truncate(10.56). X = 10 yes | ?- X is floor(10.56). X = 10 yes | ?- X is ceiling(10.56). X = 11 yes | ?- X is sqrt(144). X = 12.0 yes | ?-
树形数据结构(案例研究)
到目前为止,我们已经了解了Prolog中逻辑编程的不同概念。现在,我们将研究一个Prolog的案例研究。我们将学习如何使用Prolog实现树形数据结构,并创建我们自己的运算符。让我们开始规划。
假设我们有如下所示的树:
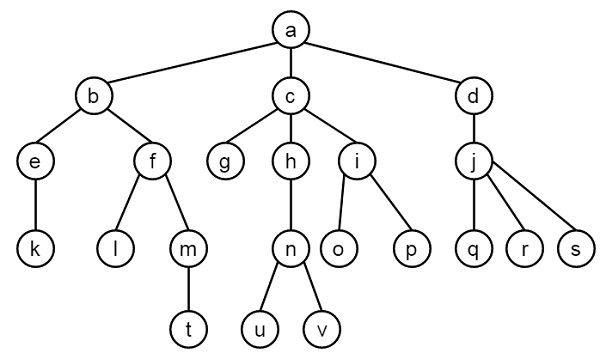
我们必须使用Prolog实现这棵树。我们有一些操作如下:
op(500, xfx, ‘is_parent’).
op(500, xfx, ‘is_sibling_of’).
op(500, xfx, ‘is_at_same_level’).
还有一个谓词,即leaf_node(Node)
在这些运算符中,你看到了一些参数,例如(500, xfx, <operator_name>)。第一个参数(此处为500)是该运算符的优先级。'xfx'表示这是一个二元运算符,而<operator_name>是运算符的名称。
这些运算符可以用来定义树数据库。我们可以如下使用这些运算符:
a is_parent b,或 is_parent(a, b)。 这表示节点a是节点b的父节点。
X is_sibling_of Y 或 is_sibling_of(X,Y)。 这表示X是节点Y的兄弟节点。规则是,如果另一个节点Z是X的父节点,并且Z也是Y的父节点,并且X和Y不同,那么X和Y就是兄弟节点。
leaf_node(Node)。 如果一个节点(Node)没有子节点,则称该节点为叶子节点。
X is_at_same_level Y,或 is_at_same_level(X,Y)。 这将检查X和Y是否在同一层级。条件是:如果X和Y相同,则返回true;否则,W是X的父节点,Z是Y的父节点,并且W和Z在同一层级。
如上所示,其他规则在代码中定义。让我们看看程序以获得更好的了解。
程序
/* The tree database */
:- op(500,xfx,'is_parent').
a is_parent b. c is_parent g. f is_parent l. j is_parent q.
a is_parent c. c is_parent h. f is_parent m. j is_parent r.
a is_parent d. c is_parent i. h is_parent n. j is_parent s.
b is_parent e. d is_parent j. i is_parent o. m is_parent t.
b is_parent f. e is_parent k. i is_parent p. n is_parent u.
n
is_parent v.
/* X and Y are siblings i.e. child from the same parent */
:- op(500,xfx,'is_sibling_of').
X is_sibling_of Y :- Z is_parent X,
Z is_parent Y,
X \== Y.
leaf_node(Node) :- \+ is_parent(Node,Child). % Node grounded
/* X and Y are on the same level in the tree. */
:-op(500,xfx,'is_at_same_level').
X is_at_same_level X .
X is_at_same_level Y :- W is_parent X,
Z is_parent Y,
W is_at_same_level Z.
输出
| ?- [case_tree]. compiling D:/TP Prolog/Sample_Codes/case_tree.pl for byte code... D:/TP Prolog/Sample_Codes/case_tree.pl:20: warning: singleton variables [Child] for leaf_node/1 D:/TP Prolog/Sample_Codes/case_tree.pl compiled, 28 lines read - 3244 bytes written, 7 ms yes | ?- i is_parent p. yes | ?- i is_parent s. no | ?- is_parent(i,p). yes | ?- e is_sibling_of f. true ? yes | ?- is_sibling_of(e,g). no | ?- leaf_node(v). yes | ?- leaf_node(a). no | ?- is_at_same_level(l,s). true ? yes | ?- l is_at_same_level v. no | ?-
更多关于树形数据结构
这里,我们将看到一些更多将对上述给定的树形数据结构执行的操作。
让我们在这里考虑同一棵树:
我们将定义其他操作:
path(Node)
locate(Node)
由于我们已经创建了最后一个数据库,我们将创建一个新的程序来保存这些操作,然后查询新文件以便在现有的程序上使用这些操作。
让我们看看这些运算符的目的:
path(Node) - 这将显示从根节点到给定节点的路径。为了解决这个问题,假设X是Node的父节点,那么找到path(X),然后写入X。当到达根节点'a'时,它将停止。
locate(Node) - 这将从树的根部定位一个节点(Node)。在这种情况下,我们将调用path(Node)并写入Node。
程序
让我们看看程序的执行:
path(a). /* Can start at a. */
path(Node) :- Mother is_parent Node, /* Choose parent, */
path(Mother), /* find path and then */
write(Mother),
write(' --> ').
/* Locate node by finding a path from root down to the node */
locate(Node) :- path(Node),
write(Node),
nl.
输出
| ?- consult('case_tree_more.pl').
compiling D:/TP Prolog/Sample_Codes/case_tree_more.pl for byte code...
D:/TP Prolog/Sample_Codes/case_tree_more.pl compiled, 9 lines read - 866 bytes written, 6 ms
yes
| ?- path(n).
a --> c --> h -->
true ?
yes
| ?- path(s).
a --> d --> j -->
true ?
yes
| ?- path(w).
no
| ?- locate(n).
a --> c --> h --> n
true ?
yes
| ?- locate(s).
a --> d --> j --> s
true ?
yes
| ?- locate(w).
no
| ?-
树形数据结构的改进
现在让我们在相同的树形数据结构上定义一些高级操作。
在这里,我们将学习如何使用Prolog内置谓词setof/3查找节点的高度,即从该节点到最长路径的长度。此谓词采用(Template, Goal, Set)。这将Set绑定到满足目标Goal的所有Template实例的列表。
我们之前已经定义了树,因此我们将查询当前代码以执行这些操作集,而无需再次重新定义树数据库。
我们将创建一些谓词,如下所示:
ht(Node,H)。 这查找高度。它还会检查节点是否是叶子节点,如果是,则将高度H设置为0,否则递归查找Node子节点的高度,并为它们加1。
max([X|R], M,A)。 这从列表和值M中计算最大元素。如果M是最大值,则返回M,否则返回列表中大于M的最大元素。为了解决这个问题,如果给定的列表为空,则返回M作为最大元素,否则检查Head是否大于M,如果是,则使用尾部和值X调用max(),否则使用尾部和值M调用max()。
height(N,H)。 这使用setof/3谓词。这将使用目标ht(N,Z)为模板Z查找结果集,并存储到称为Set的列表类型变量中。现在找到Set的最大值和值0,并将结果存储到H中。
现在让我们看看程序的执行:
程序
height(N,H) :- setof(Z,ht(N,Z),Set),
max(Set,0,H).
ht(Node,0) :- leaf_node(Node),!.
ht(Node,H) :- Node is_parent Child,
ht(Child,H1),
H is H1 + 1.
max([],M,M).
max([X|R],M,A) :- (X > M -> max(R,X,A) ; max(R,M,A)).
输出
| ?- consult('case_tree_adv.pl').
compiling D:/TP Prolog/Sample_Codes/case_tree_adv.pl for byte code...
D:/TP Prolog/Sample_Codes/case_tree_adv.pl compiled, 9 lines read - 2060 bytes written, 9 ms
yes
| ?- ht(c,H).
H = 1 ? a
H = 3
H = 3
H = 2
H = 2
yes
| ?- max([1,5,3,4,2],10,Max).
Max = 10
yes
| ?- max([1,5,3,40,2],10,Max).
Max = 40
yes
| ?- setof(H, ht(c,H),Set).
Set = [1,2,3]
yes
| ?- max([1,2,3],0,H).
H = 3
yes
| ?- height(c,H).
H = 3
yes
| ?- height(a,H).
H = 4
yes
| ?-
Prolog - 基本程序
在下一章中,我们将讨论基本的Prolog示例,以:
查找两个数字的最小值和最大值
查找电阻电路的等效电阻
验证线段是水平的、垂直的还是倾斜的
两个数字的最大值和最小值
在这里,我们将看到一个Prolog程序,它可以找到两个数字的最小值和最大值。首先,我们将创建两个谓词,find_max(X,Y,Max)。这将采用X和Y值,并将最大值存储到Max中。类似地,find_min(X,Y,Min)将采用X和Y值,并将最小值存储到Min变量中。
程序
find_max(X, Y, X) :- X >= Y, !. find_max(X, Y, Y) :- X < Y. find_min(X, Y, X) :- X =< Y, !. find_min(X, Y, Y) :- X > Y.
输出
| ?- find_max(100,200,Max). Max = 200 yes | ?- find_max(40,10,Max). Max = 40 yes | ?- find_min(40,10,Min). Min = 10 yes | ?- find_min(100,200,Min). Min = 100 yes | ?-
电阻和电阻电路
在本节中,我们将学习如何编写一个Prolog程序,帮助我们找到电阻电路的等效电阻。
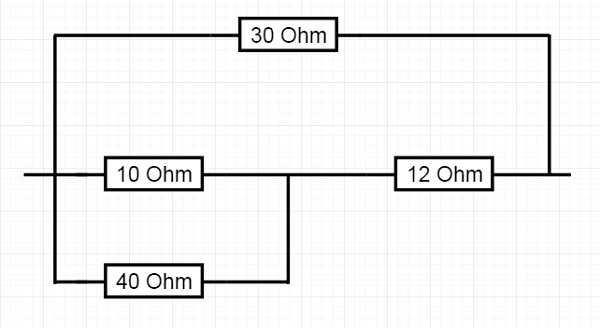
让我们考虑以下电路来理解这个概念:
我们必须找到这个网络的等效电阻。首先,我们将尝试手动获得结果,然后尝试查看结果是否与Prolog输出匹配。
我们知道有两条规则:
如果R1和R2串联,则等效电阻Re = R1 + R2。
如果R1和R2并联,则等效电阻Re = (R1 * R2)/(R1 + R2)。
这里10欧姆和40欧姆电阻并联,然后与12欧姆串联,下半部分的等效电阻与30欧姆并联。所以让我们尝试计算等效电阻。
R3 = (10 * 40)/(10 + 40) = 400/50 = 8欧姆
R4 = R3 + 12 = 8 + 12 = 20欧姆
R5 = (20 * 30)/(20 + 30) = 12欧姆
程序
series(R1,R2,Re) :- Re is R1 + R2. parallel(R1,R2,Re) :- Re is ((R1 * R2) / (R1 + R2)).
输出
| ?- [resistance]. compiling D:/TP Prolog/Sample_Codes/resistance.pl for byte code... D:/TP Prolog/Sample_Codes/resistance.pl compiled, 1 lines read - 804 bytes written, 14 ms yes | ?- parallel(10,40,R3). R3 = 8.0 yes | ?- series(8,12,R4). R4 = 20 yes | ?- parallel(20,30,R5). R5 = 12.0 yes | ?- parallel(10,40,R3),series(R3,12,R4),parallel(R4,30,R5). R3 = 8.0 R4 = 20.0 R5 = 12.0 yes | ?-
水平和垂直线段
线段有三种类型:水平、垂直或倾斜。此示例验证线段是水平的、垂直的还是倾斜的。
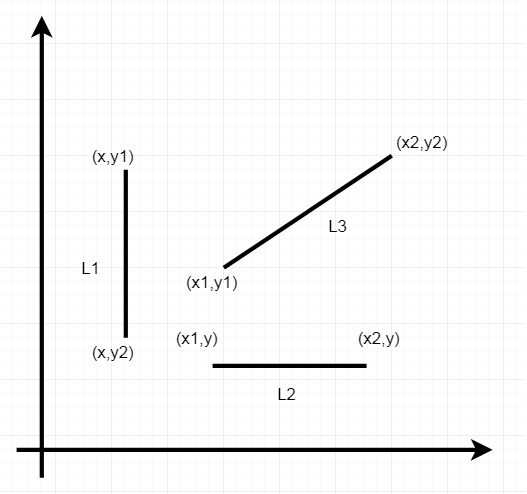
从该图我们可以理解:
对于水平线,两个端点的y坐标值相同。
对于垂直线,两个端点的x坐标值相同。
对于倾斜线,两个端点的(x,y)坐标不同。
现在让我们看看如何编写程序来检查这个。
程序
vertical(seg(point(X,_),point(X,_))).
horizontal(seg(point(_,Y),point(_,Y))).
oblique(seg(point(X1,Y1),point(X2,Y2)))
:-X1 \== X2,
Y1 \== Y2.
输出
| ?- [line_seg]. compiling D:/TP Prolog/Sample_Codes/line_seg.pl for byte code... D:/TP Prolog/Sample_Codes/line_seg.pl compiled, 6 lines read - 1276 bytes written, 26 ms yes | ?- vertical(seg(point(10,20), point(10,30))). yes | ?- vertical(seg(point(10,20), point(15,30))). no | ?- oblique(seg(point(10,20), point(15,30))). yes | ?- oblique(seg(point(10,20), point(15,20))). no | ?- horizontal(seg(point(10,20), point(15,20))). yes | ?-
Prolog - cut 的例子
在本节中,我们将看到一些Prolog中cut的示例。让我们考虑一下,我们想找到两个元素的最大值。所以我们将检查这两个条件。
如果X > Y,则Max := X
如果X <= Y,则Max := Y
现在从这两行,我们可以理解这两条语句是互斥的,所以当一个为真时,另一个一定为假。在这种情况下,我们可以使用cut。所以让我们看看程序。
我们还可以定义一个谓词,其中我们使用析取(OR逻辑)的两种情况。所以当第一个满足时,它不会检查第二个,否则,它将检查第二个语句。
程序
max(X,Y,X) :- X >= Y,!. max(X,Y,Y) :- X < Y. max_find(X,Y,Max) :- X >= Y,!, Max = X; Max = Y.
输出
| ?- [cut_example].
1 1 Call: [cut_example] ?
compiling D:/TP Prolog/Sample_Codes/cut_example.pl for byte code...
D:/TP Prolog/Sample_Codes/cut_example.pl compiled, 3 lines read - 1195 bytes written, 43 ms
1 1 Exit: [cut_example] ?
yes
{trace}
| ?- max(10,20,Max).
1 1 Call: max(10,20,_23) ?
2 2 Call: 10>=20 ?
2 2 Fail: 10>=20 ?
2 2 Call: 10<20 ?
2 2 Exit: 10<20 ?
1 1 Exit: max(10,20,20) ?
Max = 20
yes
{trace}
| ?- max_find(20,10,Max).
1 1 Call: max_find(20,10,_23) ?
2 2 Call: 20>=10 ?
2 2 Exit: 20>=10 ?
1 1 Exit: max_find(20,10,20) ?
Max = 20
yes
{trace}
| ?-
程序
让我们看另一个例子,我们将使用列表。在这个程序中,我们将尝试将一个元素插入到列表中,如果它之前不在列表中。如果列表之前有该元素,我们将简单地将其cut掉。对于成员资格检查,如果该项位于头部,我们不应该进一步检查,因此将其cut掉,否则检查尾部。
list_member(X,[X|_]) :- !. list_member(X,[_|TAIL]) :- list_member(X,TAIL). list_append(A,T,T) :- list_member(A,T),!. list_append(A,T,[A|T]).
输出
| ?- [cut_example].
compiling D:/TP Prolog/Sample_Codes/cut_example.pl for byte code...
D:/TP Prolog/Sample_Codes/cut_example.pl compiled, 9 lines read - 1954 bytes written, 15 ms
yes
| ?- trace.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- list_append(a,[a,b,c,d,e], L).
1 1 Call: list_append(a,[a,b,c,d,e],_33) ?
2 2 Call: list_member(a,[a,b,c,d,e]) ?
2 2 Exit: list_member(a,[a,b,c,d,e]) ?
1 1 Exit: list_append(a,[a,b,c,d,e],[a,b,c,d,e]) ?
L = [a,b,c,d,e]
yes
{trace}
| ?- list_append(k,[a,b,c,d,e], L).
1 1 Call: list_append(k,[a,b,c,d,e],_33) ?
2 2 Call: list_member(k,[a,b,c,d,e]) ?
3 3 Call: list_member(k,[b,c,d,e]) ?
4 4 Call: list_member(k,[c,d,e]) ?
5 5 Call: list_member(k,[d,e]) ?
6 6 Call: list_member(k,[e]) ?
7 7 Call: list_member(k,[]) ?
7 7 Fail: list_member(k,[]) ?
6 6 Fail: list_member(k,[e]) ?
5 5 Fail: list_member(k,[d,e]) ?
4 4 Fail: list_member(k,[c,d,e]) ?
3 3 Fail: list_member(k,[b,c,d,e]) ?
2 2 Fail: list_member(k,[a,b,c,d,e]) ?
1 1 Exit: list_append(k,[a,b,c,d,e],[k,a,b,c,d,e]) ?
L = [k,a,b,c,d,e]
(16 ms) yes
{trace}
| ?-
Prolog - 汉诺塔问题
汉诺塔问题是一个著名的难题,它使用中间桩作为辅助支撑桩,将N个圆盘从源桩/塔移动到目标桩/塔。解决这个问题时必须遵循两个条件:
较大的圆盘不能放在较小的圆盘上。
一次只能移动一个圆盘。
下图描绘了N=3个圆盘的起始设置。
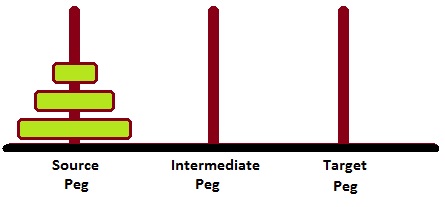
为了解决这个问题,我们必须编写一个过程move(N, Source, Target, auxiliary)。这里必须将N个圆盘从Source桩移到Target桩,并将Auxiliary桩作为中间桩。
例如 - move(3, source, target, auxiliary)。
将顶部圆盘从源移动到目标
将顶部圆盘从源移动到辅助
将顶部圆盘从目标移动到辅助
将顶部圆盘从源移动到目标
将顶部圆盘从辅助移动到源
将顶部圆盘从辅助移动到目标
将顶部圆盘从源移动到目标
程序
move(1,X,Y,_) :-
write('Move top disk from '), write(X), write(' to '), write(Y), nl.
move(N,X,Y,Z) :-
N>1,
M is N-1,
move(M,X,Z,Y),
move(1,X,Y,_),
move(M,Z,Y,X).
输出
| ?- [towersofhanoi]. compiling D:/TP Prolog/Sample_Codes/towersofhanoi.pl for byte code... D:/TP Prolog/Sample_Codes/towersofhanoi.pl compiled, 8 lines read - 1409 bytes written, 15 ms yes | ?- move(4,source,target,auxiliary). Move top disk from source to auxiliary Move top disk from source to target Move top disk from auxiliary to target Move top disk from source to auxiliary Move top disk from target to source Move top disk from target to auxiliary Move top disk from source to auxiliary Move top disk from source to target Move top disk from auxiliary to target Move top disk from auxiliary to source Move top disk from target to source Move top disk from auxiliary to target Move top disk from source to auxiliary Move top disk from source to target Move top disk from auxiliary to target true ? (31 ms) yes
Prolog - 链表
后面的章节描述如何使用递归结构生成/创建链表。
链表有两个组成部分:整数部分和链接部分。链接部分将保存另一个节点。列表的末尾将在链接部分中包含nil。

在Prolog中,我们可以使用node(2, node(5, node(6, nil)))来表达这一点。
注意 - 最小的列表是nil,其他每个列表都将包含nil作为末尾节点的“next”。在列表术语中,第一个元素通常被称为列表的头部,列表的其余部分被称为尾部。因此,上述列表的头部是2,其尾部是列表node(5, node(6, nil))。
我们还可以将元素插入到前面和后面:
程序
add_front(L,E,NList) :- NList = node(E,L). add_back(nil, E, NList) :- NList = node(E,nil). add_back(node(Head,Tail), E, NList) :- add_back(Tail, E, NewTail), NList = node(Head,NewTail).
输出
| ?- [linked_list]. compiling D:/TP Prolog/Sample_Codes/linked_list.pl for byte code... D:/TP Prolog/Sample_Codes/linked_list.pl compiled, 7 lines read - 966 bytes written, 14 ms (15 ms) yes | ?- add_front(nil, 6, L1), add_front(L1, 5, L2), add_front(L2, 2, L3). L1 = node(6,nil) L2 = node(5,node(6,nil)) L3 = node(2,node(5,node(6,nil))) yes | ?- add_back(nil, 6, L1), add_back(L1, 5, L2), add_back(L2, 2, L3). L1 = node(6,nil) L2 = node(6,node(5,nil)) L3 = node(6,node(5,node(2,nil))) yes | ?- add_front(nil, 6, L1), add_front(L1, 5, L2), add_back(L2, 2, L3). L1 = node(6,nil) L2 = node(5,node(6,nil)) L3 = node(5,node(6,node(2,nil))) yes | ?-
Prolog - 猴子和香蕉问题
在这个Prolog示例中,我们将看到一个非常有趣且著名的难题:猴子和香蕉问题。
问题陈述
假设问题如下:
一只饥饿的猴子在一个房间里,它靠近门。
猴子在地板上。
香蕉挂在房间天花板的中央。
房间窗户附近有一个木块(或椅子)。
猴子想要香蕉,但够不着。
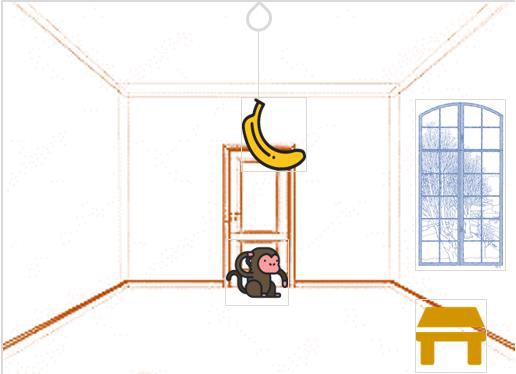
那么猴子怎么能得到香蕉呢?
所以如果猴子足够聪明,它可以走到木块旁,将木块拖到中央,爬上去,拿到香蕉。以下是这种情况的一些观察结果:
如果猴子和木块都在同一层,猴子就能够到木块。从上图可以看出,猴子和木块都在地板上。
如果木块的位置不在中央,猴子可以将其拖到中央。
如果猴子和木块都在地板上,并且木块在中央,那么猴子就可以爬上木块。因此猴子的垂直位置将改变。
当猴子在木块上,并且木块在中央时,猴子就可以拿到香蕉。
现在,让我们看看如何使用Prolog来解决这个问题。我们将创建一些谓词,如下所示:
我们有一些谓词,通过执行动作从一个状态移动到另一个状态。
当木块在中间,猴子在木块顶部,并且猴子没有香蕉(即has not状态)时,使用grasp动作,它将从has not状态变为have状态。
从地板上,它可以通过执行动作climb移动到木块的顶部(即on top状态)。
push或drag操作将木块从一个位置移动到另一个位置。
猴子可以使用walk或move子句从一个位置移动到另一个位置。
另一个谓词将是canget()。这里我们传递一个状态,所以这将使用不同的动作执行从一个状态到另一个状态的移动谓词,然后在状态2上执行canget()。当我们到达状态“has>”时,这表示“有香蕉”。我们将停止执行。
程序
move(state(middle,onbox,middle,hasnot), grasp, state(middle,onbox,middle,has)). move(state(P,onfloor,P,H), climb, state(P,onbox,P,H)). move(state(P1,onfloor,P1,H), drag(P1,P2), state(P2,onfloor,P2,H)). move(state(P1,onfloor,B,H), walk(P1,P2), state(P2,onfloor,B,H)). canget(state(_,_,_,has)). canget(State1) :- move(State1,_,State2), canget(State2).
输出
| ?- [monkey_banana].
compiling D:/TP Prolog/Sample_Codes/monkey_banana.pl for byte code...
D:/TP Prolog/Sample_Codes/monkey_banana.pl compiled, 17 lines read - 2167 bytes written, 19 ms
(31 ms) yes
| ?- canget(state(atdoor, onfloor, atwindow, hasnot)).
true ?
yes
| ?- trace
.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- canget(state(atdoor, onfloor, atwindow, hasnot)).
1 1 Call: canget(state(atdoor,onfloor,atwindow,hasnot)) ?
2 2 Call: move(state(atdoor,onfloor,atwindow,hasnot),_52,_92) ?
2 2 Exit:move(state(atdoor,onfloor,atwindow,hasnot),walk(atdoor,_80),state(_80,onfloor,atwindow,hasnot)) ?
3 2 Call: canget(state(_80,onfloor,atwindow,hasnot)) ?
4 3 Call: move(state(_80,onfloor,atwindow,hasnot),_110,_150) ?
4 3 Exit: move(state(atwindow,onfloor,atwindow,hasnot),climb,state(atwindow,onbox,atwindow,hasnot)) ?
5 3 Call: canget(state(atwindow,onbox,atwindow,hasnot)) ?
6 4 Call: move(state(atwindow,onbox,atwindow,hasnot),_165,_205) ?
6 4 Fail: move(state(atwindow,onbox,atwindow,hasnot),_165,_193) ?
5 3 Fail: canget(state(atwindow,onbox,atwindow,hasnot)) ?
4 3 Redo: move(state(atwindow,onfloor,atwindow,hasnot),climb,state(atwindow,onbox,atwindow,hasnot)) ?
4 3 Exit: move(state(atwindow,onfloor,atwindow,hasnot),drag(atwindow,_138),state(_138,onfloor,_138,hasnot)) ?
5 3 Call: canget(state(_138,onfloor,_138,hasnot)) ?
6 4 Call: move(state(_138,onfloor,_138,hasnot),_168,_208) ?
6 4 Exit: move(state(_138,onfloor,_138,hasnot),climb,state(_138,onbox,_138,hasnot)) ?
7 4 Call: canget(state(_138,onbox,_138,hasnot)) ?
8 5 Call: move(state(_138,onbox,_138,hasnot),_223,_263) ?
8 5 Exit: move(state(middle,onbox,middle,hasnot),grasp,state(middle,onbox,middle,has)) ?
9 5 Call: canget(state(middle,onbox,middle,has)) ?
9 5 Exit: canget(state(middle,onbox,middle,has)) ?
7 4 Exit: canget(state(middle,onbox,middle,hasnot)) ?
5 3 Exit: canget(state(middle,onfloor,middle,hasnot)) ?
3 2 Exit: canget(state(atwindow,onfloor,atwindow,hasnot)) ?
1 1 Exit: canget(state(atdoor,onfloor,atwindow,hasnot)) ?
true ?
(78 ms) yes