- PySpark 教程
- PySpark - 首页
- PySpark - 简介
- PySpark - 环境搭建
- PySpark - SparkContext
- PySpark - RDD
- PySpark - 广播变量 & 累加器
- PySpark - SparkConf
- PySpark - SparkFiles
- PySpark - StorageLevel
- PySpark - MLlib
- PySpark - 序列化器
- PySpark 有用资源
- PySpark 快速指南
- PySpark - 有用资源
- PySpark - 讨论
PySpark 快速指南
PySpark – 简介
本章我们将了解 Apache Spark 是什么以及 PySpark 是如何开发的。
Spark – 概述
Apache Spark 是一个闪电般快速的实时处理框架。它进行内存计算以实时分析数据。它的出现是因为 **Apache Hadoop MapReduce** 仅执行批处理,缺乏实时处理功能。因此,引入了 Apache Spark,因为它可以执行实时流处理,也可以处理批处理。
除了实时和批处理之外,Apache Spark 还支持交互式查询和迭代算法。Apache Spark 拥有自己的集群管理器,可以在其中托管其应用程序。它利用 Apache Hadoop 进行存储和处理。它使用 **HDFS**(Hadoop 分布式文件系统)进行存储,也可以在 **YARN** 上运行 Spark 应用程序。
PySpark – 概述
Apache Spark 使用 **Scala 编程语言**编写。为了支持 Spark 使用 Python,Apache Spark 社区发布了一个工具 PySpark。使用 PySpark,你也可以在 Python 编程语言中使用 **RDD**。这是因为一个名为 **Py4j** 的库,它们才能实现这一点。
PySpark 提供了 **PySpark Shell**,它将 Python API 链接到 Spark Core 并初始化 Spark Context。今天,大多数数据科学家和分析专家都使用 Python,因为它拥有丰富的库集。将 Python 与 Spark 集成对他们来说是一个福音。
PySpark - 环境搭建
本章我们将了解 PySpark 的环境搭建。
**注意** − 这是假设你的计算机上已安装 Java 和 Scala。
现在让我们按照以下步骤下载并设置 PySpark。
**步骤 1** − 前往 Apache Spark 官方 下载 页面并下载最新的 Apache Spark 版本。在本教程中,我们使用的是 **spark-2.1.0-bin-hadoop2.7**。
**步骤 2** − 现在,解压下载的 Spark tar 文件。默认情况下,它将下载到 Downloads 目录。
# tar -xvf Downloads/spark-2.1.0-bin-hadoop2.7.tgz
它将创建一个目录 **spark-2.1.0-bin-hadoop2.7**。在启动 PySpark 之前,你需要设置以下环境来设置 Spark 路径和 **Py4j 路径**。
export SPARK_HOME = /home/hadoop/spark-2.1.0-bin-hadoop2.7 export PATH = $PATH:/home/hadoop/spark-2.1.0-bin-hadoop2.7/bin export PYTHONPATH = $SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH export PATH = $SPARK_HOME/python:$PATH
或者,要全局设置上述环境,请将它们放入 **.bashrc 文件**中。然后运行以下命令使环境生效。
# source .bashrc
现在我们已经设置了所有环境,让我们进入 Spark 目录并通过运行以下命令调用 PySpark shell:
# ./bin/pyspark
这将启动你的 PySpark shell。
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
Using Python version 2.7.12 (default, Nov 19 2016 06:48:10)
SparkSession available as 'spark'.
<<<
PySpark - SparkContext
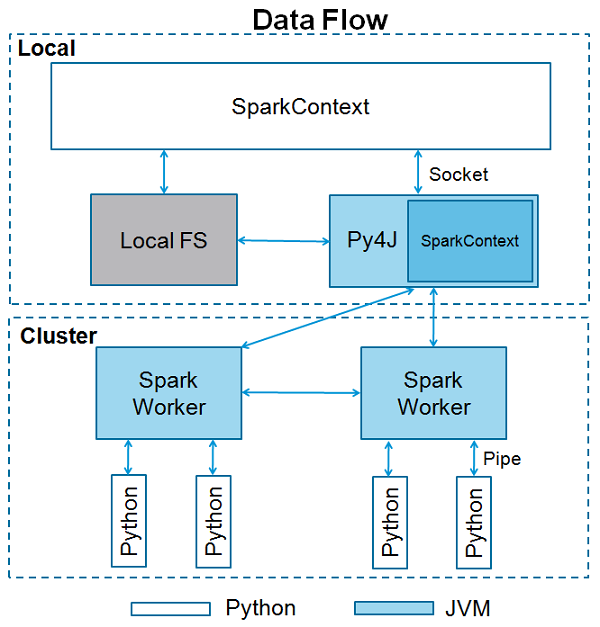
SparkContext 是任何 Spark 功能的入口点。当我们运行任何 Spark 应用程序时,会启动一个驱动程序,其中包含主函数,你的 SparkContext 在此处启动。然后,驱动程序在工作节点上的执行程序上运行操作。
SparkContext 使用 Py4J 启动一个 **JVM** 并创建一个 **JavaSparkContext**。默认情况下,PySpark 提供了名为 **‘sc’** 的 SparkContext,因此创建新的 SparkContext 将不起作用。
以下代码块包含 PySpark 类和 SparkContext 可以接受的参数的详细信息。
class pyspark.SparkContext ( master = None, appName = None, sparkHome = None, pyFiles = None, environment = None, batchSize = 0, serializer = PickleSerializer(), conf = None, gateway = None, jsc = None, profiler_cls = <class 'pyspark.profiler.BasicProfiler'> )
参数
以下是 SparkContext 的参数。
**Master** − 它是要连接到的集群的 URL。
**appName** − 你的作业的名称。
**sparkHome** − Spark 安装目录。
**pyFiles** − 要发送到集群并添加到 PYTHONPATH 的 .zip 或 .py 文件。
**Environment** − 工作节点的环境变量。
**batchSize** − 表示单个 Java 对象的 Python 对象的数量。设置为 1 可禁用批处理,设置为 0 可根据对象大小自动选择批处理大小,设置为 -1 可使用无限批处理大小。
**Serializer** − RDD 序列化器。
**Conf** − 一个 L{SparkConf} 对象,用于设置所有 Spark 属性。
**Gateway** − 使用现有网关和 JVM,否则初始化新的 JVM。
**JSC** − JavaSparkContext 实例。
**profiler_cls** − 用于执行分析的自定义 Profiler 类(默认为 pyspark.profiler.BasicProfiler)。
在上述参数中,**master** 和 **appname** 最常用。任何 PySpark 程序的前两行如下所示:
from pyspark import SparkContext
sc = SparkContext("local", "First App")
SparkContext 示例 – PySpark Shell
现在你已经足够了解 SparkContext,让我们在 PySpark shell 上运行一个简单的示例。在这个示例中,我们将计算 **README.md** 文件中包含字符 'a' 或 'b' 的行数。例如,如果文件中共有 5 行,其中 3 行包含字符 'a',则输出将为 → **包含 a 的行:3**。字符 ‘b’ 也将进行同样的操作。
**注意** − 在下面的示例中,我们没有创建任何 SparkContext 对象,因为默认情况下,当 PySpark shell 启动时,Spark 会自动创建名为 sc 的 SparkContext 对象。如果你尝试创建另一个 SparkContext 对象,你将收到以下错误 – **“ValueError: Cannot run multiple SparkContexts at once”。**
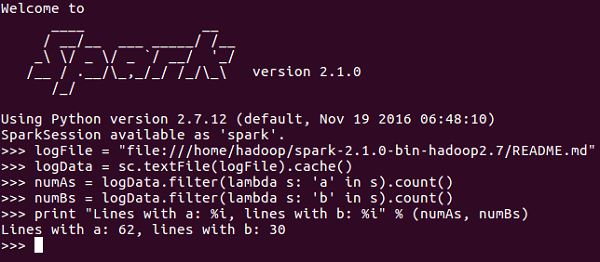
<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md" <<< logData = sc.textFile(logFile).cache() <<< numAs = logData.filter(lambda s: 'a' in s).count() <<< numBs = logData.filter(lambda s: 'b' in s).count() <<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs) Lines with a: 62, lines with b: 30
SparkContext 示例 - Python 程序
让我们使用 Python 程序运行相同的示例。创建一个名为 **firstapp.py** 的 Python 文件,并在该文件中输入以下代码。
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
----------------------------------------firstapp.py---------------------------------------
然后,我们将在终端中执行以下命令来运行此 Python 文件。我们将获得与上面相同的输出。
$SPARK_HOME/bin/spark-submit firstapp.py Output: Lines with a: 62, lines with b: 30
PySpark - RDD
现在我们已经在系统上安装并配置了 PySpark,我们可以在 Apache Spark 上使用 Python 进行编程。但是,在此之前,让我们了解 Spark 中的一个基本概念 - RDD。
RDD 代表 **弹性分布式数据集**,这些是在多个节点上运行和操作以对集群进行并行处理的元素。RDD 是不可变的元素,这意味着一旦你创建了 RDD,就无法更改它。RDD 也是容错的,因此在发生任何故障的情况下,它们会自动恢复。你可以在这些 RDD 上应用多个操作来完成特定任务。
要对这些 RDD 应用操作,有两种方法:
- 转换和
- 行动
让我们详细了解这两种方法。
**转换** − 这些是在 RDD 上应用以创建新 RDD 的操作。Filter、groupBy 和 map 是转换的示例。
**行动** − 这些是在 RDD 上应用的操作,它指示 Spark 执行计算并将结果发送回驱动程序。
要在 PySpark 中应用任何操作,我们首先需要创建一个 **PySpark RDD**。以下代码块包含 PySpark RDD 类的详细信息:
class pyspark.RDD ( jrdd, ctx, jrdd_deserializer = AutoBatchedSerializer(PickleSerializer()) )
让我们看看如何使用 PySpark 运行一些基本操作。Python 文件中的以下代码创建了 RDD words,它存储一组提到的单词。
words = sc.parallelize ( ["scala", "java", "hadoop", "spark", "akka", "spark vs hadoop", "pyspark", "pyspark and spark"] )
现在,我们将对 words 执行一些操作。
count()
返回 RDD 中的元素数量。
----------------------------------------count.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
counts = words.count()
print "Number of elements in RDD -> %i" % (counts)
----------------------------------------count.py---------------------------------------
**命令** − count() 的命令为:
$SPARK_HOME/bin/spark-submit count.py
**输出** − 上述命令的输出为:
Number of elements in RDD → 8
collect()
返回 RDD 中的所有元素。
----------------------------------------collect.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Collect app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
coll = words.collect()
print "Elements in RDD -> %s" % (coll)
----------------------------------------collect.py---------------------------------------
**命令** − collect() 的命令为:
$SPARK_HOME/bin/spark-submit collect.py
**输出** − 上述命令的输出为:
Elements in RDD -> [ 'scala', 'java', 'hadoop', 'spark', 'akka', 'spark vs hadoop', 'pyspark', 'pyspark and spark' ]
foreach(f)
仅返回满足 foreach 内函数条件的元素。在下面的示例中,我们在 foreach 中调用打印函数,该函数打印 RDD 中的所有元素。
----------------------------------------foreach.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "ForEach app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
def f(x): print(x)
fore = words.foreach(f)
----------------------------------------foreach.py---------------------------------------
**命令** − foreach(f) 的命令为:
$SPARK_HOME/bin/spark-submit foreach.py
**输出** − 上述命令的输出为:
scala java hadoop spark akka spark vs hadoop pyspark pyspark and spark
filter(f)
返回一个新的 RDD,其中包含满足 filter 内函数的元素。在下面的示例中,我们过滤掉包含“spark”的字符串。
----------------------------------------filter.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Filter app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_filter = words.filter(lambda x: 'spark' in x)
filtered = words_filter.collect()
print "Fitered RDD -> %s" % (filtered)
----------------------------------------filter.py----------------------------------------
**命令** − filter(f) 的命令为:
$SPARK_HOME/bin/spark-submit filter.py
**输出** − 上述命令的输出为:
Fitered RDD -> [ 'spark', 'spark vs hadoop', 'pyspark', 'pyspark and spark' ]
map(f, preservesPartitioning = False)
通过对 RDD 中的每个元素应用函数来返回一个新的 RDD。在下面的示例中,我们形成一个键值对并将每个字符串映射到值为 1。
----------------------------------------map.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Map app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_map = words.map(lambda x: (x, 1))
mapping = words_map.collect()
print "Key value pair -> %s" % (mapping)
----------------------------------------map.py---------------------------------------
**命令** − map(f, preservesPartitioning=False) 的命令为:
$SPARK_HOME/bin/spark-submit map.py
**输出** − 上述命令的输出为:
Key value pair -> [
('scala', 1),
('java', 1),
('hadoop', 1),
('spark', 1),
('akka', 1),
('spark vs hadoop', 1),
('pyspark', 1),
('pyspark and spark', 1)
]
reduce(f)
执行指定的交换和关联二元运算后,返回 RDD 中的元素。在下面的示例中,我们从 operator 导入 add 包并将其应用于 'num' 以执行简单的加法运算。
----------------------------------------reduce.py---------------------------------------
from pyspark import SparkContext
from operator import add
sc = SparkContext("local", "Reduce app")
nums = sc.parallelize([1, 2, 3, 4, 5])
adding = nums.reduce(add)
print "Adding all the elements -> %i" % (adding)
----------------------------------------reduce.py---------------------------------------
**命令** − reduce(f) 的命令为:
$SPARK_HOME/bin/spark-submit reduce.py
**输出** − 上述命令的输出为:
Adding all the elements -> 15
join(other, numPartitions = None)
它返回一个 RDD,其中包含具有匹配键的元素对以及该特定键的所有值。在下面的示例中,两个不同的 RDD 中有两个元素对。连接这两个 RDD 后,我们得到一个 RDD,其中包含具有匹配键及其值的元素。
----------------------------------------join.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Join app")
x = sc.parallelize([("spark", 1), ("hadoop", 4)])
y = sc.parallelize([("spark", 2), ("hadoop", 5)])
joined = x.join(y)
final = joined.collect()
print "Join RDD -> %s" % (final)
----------------------------------------join.py---------------------------------------
**命令** − join(other, numPartitions = None) 的命令为:
$SPARK_HOME/bin/spark-submit join.py
**输出** − 上述命令的输出为:
Join RDD -> [
('spark', (1, 2)),
('hadoop', (4, 5))
]
cache()
使用默认存储级别 (MEMORY_ONLY) 持久化此 RDD。你还可以检查 RDD 是否已缓存。
----------------------------------------cache.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Cache app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words.cache()
caching = words.persist().is_cached
print "Words got chached > %s" % (caching)
----------------------------------------cache.py---------------------------------------
**命令** − cache() 的命令为:
$SPARK_HOME/bin/spark-submit cache.py
**输出** − 上述程序的输出为:
Words got cached -> True
这些是在 PySpark RDD 上执行的一些最重要的操作。
PySpark - 广播变量 & 累加器
对于并行处理,Apache Spark 使用共享变量。当驱动程序将任务发送到集群上的执行程序时,共享变量的副本会进入集群的每个节点,以便它可以用于执行任务。
Apache Spark 支持两种类型的共享变量:
- 广播变量
- 累加器
让我们详细了解它们。
广播变量
广播变量用于在所有节点上保存数据的副本。此变量缓存在所有机器上,不会发送到具有任务的机器上。以下代码块包含 PySpark 广播类的详细信息。
class pyspark.Broadcast ( sc = None, value = None, pickle_registry = None, path = None )
以下示例显示了如何使用广播变量。广播变量具有一个名为 value 的属性,该属性存储数据并用于返回广播的值。
----------------------------------------broadcast.py--------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Broadcast app")
words_new = sc.broadcast(["scala", "java", "hadoop", "spark", "akka"])
data = words_new.value
print "Stored data -> %s" % (data)
elem = words_new.value[2]
print "Printing a particular element in RDD -> %s" % (elem)
----------------------------------------broadcast.py--------------------------------------
**命令** − 广播变量的命令如下:
$SPARK_HOME/bin/spark-submit broadcast.py
**输出** − 以下命令的输出如下所示。
Stored data -> [ 'scala', 'java', 'hadoop', 'spark', 'akka' ] Printing a particular element in RDD -> hadoop
累加器
累加器变量用于通过关联和交换运算聚合信息。例如,你可以将累加器用于求和运算或计数器(在 MapReduce 中)。以下代码块包含 PySpark 累加器类的详细信息。
class pyspark.Accumulator(aid, value, accum_param)
以下示例显示了如何使用累加器变量。累加器变量具有一个名为 value 的属性,类似于广播变量。它存储数据并用于返回累加器的值,但仅可在驱动程序程序中使用。
在此示例中,累加器变量由多个工作程序使用并返回累积值。
----------------------------------------accumulator.py------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Accumulator app")
num = sc.accumulator(10)
def f(x):
global num
num+=x
rdd = sc.parallelize([20,30,40,50])
rdd.foreach(f)
final = num.value
print "Accumulated value is -> %i" % (final)
----------------------------------------accumulator.py------------------------------------
**命令** − 累加器变量的命令如下:
$SPARK_HOME/bin/spark-submit accumulator.py
**输出** − 上述命令的输出如下所示。
Accumulated value is -> 150
PySpark - SparkConf
要在本地/集群上运行 Spark 应用程序,你需要设置一些配置和参数,这就是 SparkConf 提供帮助的地方。它提供运行 Spark 应用程序的配置。以下代码块包含 PySpark SparkConf 类的详细信息。
class pyspark.SparkConf ( loadDefaults = True, _jvm = None, _jconf = None )
首先,我们将使用 SparkConf() 创建一个 SparkConf 对象,它还将加载来自 **spark.*** Java 系统属性的值。现在你可以使用 SparkConf 对象设置不同的参数,它们的优先级将高于系统属性。
在 SparkConf 类中,存在支持链式调用的 setter 方法。例如,您可以编写 **conf.setAppName("PySpark App").setMaster("local")**。一旦我们将 SparkConf 对象传递给 Apache Spark,任何用户都无法修改它。
以下是 SparkConf 的一些最常用的属性:
**set(key, value)** - 设置配置属性。
**setMaster(value)** - 设置主 URL。
**setAppName(value)** - 设置应用程序名称。
**get(key, defaultValue=None)** - 获取键的配置值。
**setSparkHome(value)** - 设置工作节点上的 Spark 安装路径。
让我们考虑一下在 PySpark 程序中使用 SparkConf 的以下示例。在这个示例中,我们将 spark 应用程序名称设置为 **PySpark App**,并将 spark 应用程序的主 URL 设置为 → **spark://master:7077**。
以下代码块包含这些行,当它们添加到 Python 文件中时,它将设置运行 PySpark 应用程序的基本配置。
---------------------------------------------------------------------------------------
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("PySpark App").setMaster("spark://master:7077")
sc = SparkContext(conf=conf)
---------------------------------------------------------------------------------------
PySpark - SparkFiles
在 Apache Spark 中,您可以使用 **sc.addFile**(sc 是您的默认 SparkContext)上传文件,并使用 **SparkFiles.get** 获取工作节点上的路径。因此,SparkFiles 将路径解析为通过 **SparkContext.addFile()** 添加的文件。
SparkFiles 包含以下类方法:
- get(filename)
- getrootdirectory()
让我们详细了解它们。
get(filename)
它指定通过 SparkContext.addFile() 添加的文件的路径。
getrootdirectory()
它指定包含通过 SparkContext.addFile() 添加的文件的根目录的路径。
----------------------------------------sparkfile.py------------------------------------
from pyspark import SparkContext
from pyspark import SparkFiles
finddistance = "/home/hadoop/examples_pyspark/finddistance.R"
finddistancename = "finddistance.R"
sc = SparkContext("local", "SparkFile App")
sc.addFile(finddistance)
print "Absolute Path -> %s" % SparkFiles.get(finddistancename)
----------------------------------------sparkfile.py------------------------------------
**命令** - 命令如下:
$SPARK_HOME/bin/spark-submit sparkfiles.py
**输出** − 上述命令的输出为:
Absolute Path -> /tmp/spark-f1170149-af01-4620-9805-f61c85fecee4/userFiles-641dfd0f-240b-4264-a650-4e06e7a57839/finddistance.R
PySpark - StorageLevel
StorageLevel 决定了 RDD 如何存储。在 Apache Spark 中,StorageLevel 决定 RDD 是否应存储在内存中,还是应存储在磁盘上,或者两者兼而有之。它还决定是否序列化 RDD 以及是否复制 RDD 分区。
以下代码块包含 StorageLevel 的类定义:
class pyspark.StorageLevel(useDisk, useMemory, useOffHeap, deserialized, replication = 1)
现在,要决定 RDD 的存储方式,有不同的存储级别,如下所示:
**DISK_ONLY** = StorageLevel(True, False, False, False, 1)
**DISK_ONLY_2** = StorageLevel(True, False, False, False, 2)
**MEMORY_AND_DISK** = StorageLevel(True, True, False, False, 1)
**MEMORY_AND_DISK_2** = StorageLevel(True, True, False, False, 2)
**MEMORY_AND_DISK_SER** = StorageLevel(True, True, False, False, 1)
**MEMORY_AND_DISK_SER_2** = StorageLevel(True, True, False, False, 2)
**MEMORY_ONLY** = StorageLevel(False, True, False, False, 1)
**MEMORY_ONLY_2** = StorageLevel(False, True, False, False, 2)
**MEMORY_ONLY_SER** = StorageLevel(False, True, False, False, 1)
**MEMORY_ONLY_SER_2** = StorageLevel(False, True, False, False, 2)
**OFF_HEAP** = StorageLevel(True, True, True, False, 1)
让我们考虑一下 StorageLevel 的以下示例,其中我们使用存储级别 **MEMORY_AND_DISK_2**,这意味着 RDD 分区将具有 2 个副本。
------------------------------------storagelevel.py------------------------------------- from pyspark import SparkContext import pyspark sc = SparkContext ( "local", "storagelevel app" ) rdd1 = sc.parallelize([1,2]) rdd1.persist( pyspark.StorageLevel.MEMORY_AND_DISK_2 ) rdd1.getStorageLevel() print(rdd1.getStorageLevel()) ------------------------------------storagelevel.py-------------------------------------
**命令** - 命令如下:
$SPARK_HOME/bin/spark-submit storagelevel.py
**输出** - 以上命令的输出如下所示:
Disk Memory Serialized 2x Replicated
PySpark - MLlib
Apache Spark 提供了一个名为 **MLlib** 的机器学习 API。PySpark 也在 Python 中提供了这个机器学习 API。它支持不同类型的算法,如下所述:
**mllib.classification** - **spark.mllib** 包支持各种二元分类、多类分类和回归分析方法。分类中一些最流行的算法是 **随机森林、朴素贝叶斯、决策树** 等。
**mllib.clustering** - 聚类是一个无监督学习问题,您旨在根据某种相似性概念将实体的子集相互分组。
**mllib.fpm** - 频繁模式匹配是挖掘频繁项、项集、子序列或其他子结构,这些通常是分析大规模数据集的第一步。这多年来一直是数据挖掘领域的一个活跃研究课题。
**mllib.linalg** - MLlib 用于线性代数的实用程序。
**mllib.recommendation** - 协同过滤通常用于推荐系统。这些技术旨在填充用户项目关联矩阵中的缺失条目。
**spark.mllib** - 它目前支持基于模型的协同过滤,其中用户和产品由一小组潜在因素来描述,这些因素可用于预测缺失的条目。spark.mllib 使用交替最小二乘法 (ALS) 算法来学习这些潜在因素。
**mllib.regression** - 线性回归属于回归算法家族。回归的目标是找到变量之间的关系和依赖性。用于处理线性回归模型和模型摘要的接口与逻辑回归的情况类似。
mllib 包中还有其他算法、类和函数。目前,让我们了解一下 **pyspark.mllib** 的演示。
以下示例使用 ALS 算法进行协同过滤,以构建推荐模型并在训练数据上对其进行评估。
**使用的数据集** - test.data
1,1,5.0 1,2,1.0 1,3,5.0 1,4,1.0 2,1,5.0 2,2,1.0 2,3,5.0 2,4,1.0 3,1,1.0 3,2,5.0 3,3,1.0 3,4,5.0 4,1,1.0 4,2,5.0 4,3,1.0 4,4,5.0
--------------------------------------recommend.py----------------------------------------
from __future__ import print_function
from pyspark import SparkContext
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
if __name__ == "__main__":
sc = SparkContext(appName="Pspark mllib Example")
data = sc.textFile("test.data")
ratings = data.map(lambda l: l.split(','))\
.map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2])))
# Build the recommendation model using Alternating Least Squares
rank = 10
numIterations = 10
model = ALS.train(ratings, rank, numIterations)
# Evaluate the model on training data
testdata = ratings.map(lambda p: (p[0], p[1]))
predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
ratesAndPreds = ratings.map(lambda r: ((r[0], r[1]), r[2])).join(predictions)
MSE = ratesAndPreds.map(lambda r: (r[1][0] - r[1][1])**2).mean()
print("Mean Squared Error = " + str(MSE))
# Save and load model
model.save(sc, "target/tmp/myCollaborativeFilter")
sameModel = MatrixFactorizationModel.load(sc, "target/tmp/myCollaborativeFilter")
--------------------------------------recommend.py----------------------------------------
**命令** - 命令如下:
$SPARK_HOME/bin/spark-submit recommend.py
**输出** - 以上命令的输出将为:
Mean Squared Error = 1.20536041839e-05
PySpark - 序列化器
序列化用于 Apache Spark 的性能调优。所有通过网络发送、写入磁盘或持久化到内存中的数据都应被序列化。序列化在代价高昂的操作中扮演着重要角色。
PySpark 支持自定义序列化器以进行性能调整。PySpark 支持以下两个序列化器:
MarshalSerializer
使用 Python 的 Marshal 序列化器序列化对象。此序列化器比 PickleSerializer 更快,但支持的数据类型更少。
class pyspark.MarshalSerializer
PickleSerializer
使用 Python 的 Pickle 序列化器序列化对象。此序列化器几乎支持任何 Python 对象,但可能不如更专业的序列化器快。
class pyspark.PickleSerializer
让我们看看 PySpark 序列化的一个示例。在这里,我们使用 MarshalSerializer 序列化数据。
--------------------------------------serializing.py-------------------------------------
from pyspark.context import SparkContext
from pyspark.serializers import MarshalSerializer
sc = SparkContext("local", "serialization app", serializer = MarshalSerializer())
print(sc.parallelize(list(range(1000))).map(lambda x: 2 * x).take(10))
sc.stop()
--------------------------------------serializing.py-------------------------------------
**命令** - 命令如下:
$SPARK_HOME/bin/spark-submit serializing.py
**输出** − 上述命令的输出为:
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]