- Talend 教程
- Talend - 首页
- Talend - 简介
- Talend - 系统要求
- Talend - 安装
- Talend Open Studio
- Talend - 数据集成
- Talend - 模型基础
- 数据集成组件
- Talend - 作业设计
- Talend - 元数据
- Talend - 上下文变量
- Talend - 作业管理
- Talend - 处理作业执行
- Talend - 大数据
- Hadoop 分布式文件系统
- Talend - Map Reduce
- Talend - 使用 Pig
- Talend - Hive
- Talend 有用资源
- Talend 快速指南
- Talend - 有用资源
- Talend - 讨论
Talend 快速指南
Talend - 简介
Talend 是一个软件集成平台,提供数据集成、数据质量、数据管理、数据准备和大数据解决方案。拥有 Talend 知识的 ETL 专业人员非常紧缺。此外,它是唯一一个拥有所有插件能够轻松集成到大数据生态系统的 ETL 工具。
根据 Gartner 的说法,Talend 位列数据集成工具领导者象限。
Talend 提供各种商业产品,如下所示:
- Talend 数据质量
- Talend 数据集成
- Talend 数据准备
- Talend 云
- Talend 大数据
- Talend MDM(主数据管理)平台
- Talend 数据服务平台
- Talend 元数据管理器
- Talend 数据织物
Talend 还提供 Open Studio,这是一个广泛用于数据集成和大数据的开源免费工具。
Talend - 系统要求
以下是下载和使用 Talend Open Studio 的系统要求:
推荐操作系统
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13/High Sierra
内存需求
- 内存 - 最低 4 GB,推荐 8 GB
- 存储空间 - 30 GB
此外,你还需要一个运行中的 Hadoop 集群(最好是 Cloudera)。
注意 - 必须安装 Java 8 并已设置环境变量。
Talend - 安装
要下载适用于大数据和数据集成的 Talend Open Studio,请按照以下步骤操作:
步骤 1 - 转到页面:https://www.talend.com/products/big-data/big-data-open-studio/ 并单击下载按钮。您会看到 TOS_BD_xxxxxxx.zip 文件开始下载。
步骤 2 - 下载完成后,解压缩 zip 文件,它将创建一个包含所有 Talend 文件的文件夹。
步骤 3 - 打开 Talend 文件夹并双击可执行文件:TOS_BD-win-x86_64.exe。接受用户许可协议。
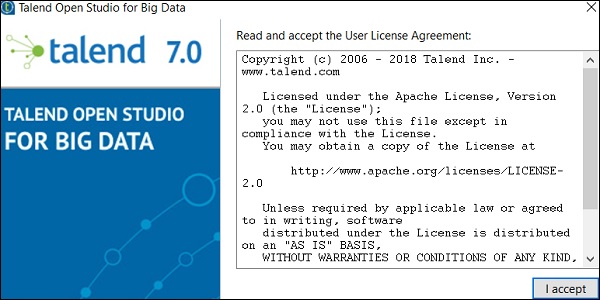
步骤 4 - 创建一个新项目并单击“完成”。
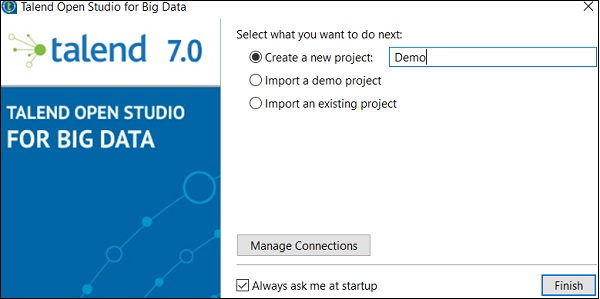
步骤 5 - 如果您收到 Windows 安全警报,请单击“允许访问”。
步骤 6 - 现在,将打开 Talend Open Studio 欢迎页面。
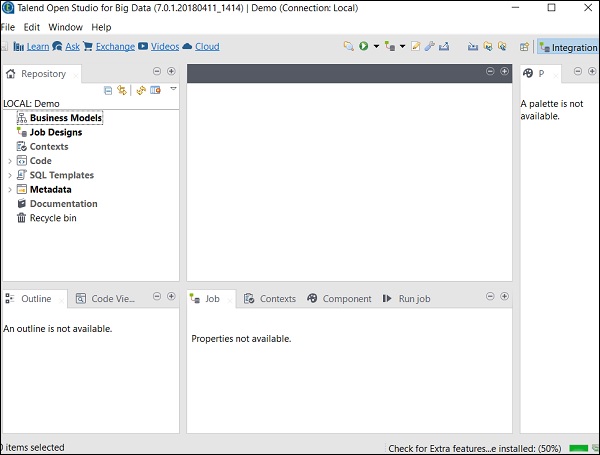
步骤 7 - 单击“完成”以安装所需的第三方库。
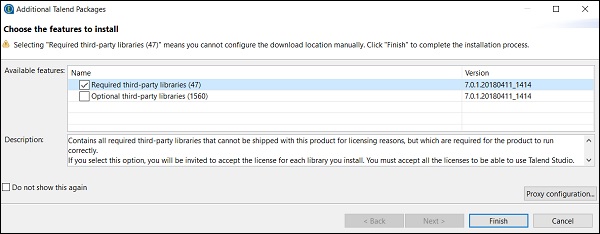
步骤 8 - 接受条款并单击“完成”。
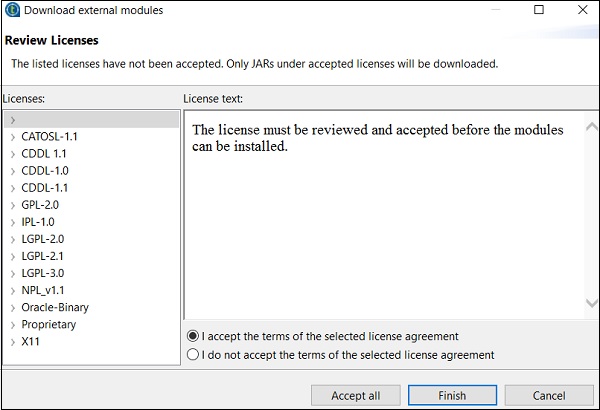
步骤 9 - 单击“是”。
现在,您的 Talend Open Studio 已准备好必要的库。
Talend Open Studio
Talend Open Studio 是一款免费的开源 ETL 工具,用于数据集成和大数据。它是一个基于 Eclipse 的开发工具和作业设计器。您只需拖放组件并连接它们即可创建和运行 ETL 或 ETL 作业。该工具将自动为作业创建 Java 代码,您无需编写任何代码。
有多种选项可以连接到数据源,例如 RDBMS、Excel、SaaS 大数据生态系统以及 SAP、CRM、Dropbox 等应用程序和技术。
Talend Open Studio 提供的一些重要优势如下:
提供数据集成和同步所需的所有功能,包括 900 多个组件、内置连接器、将作业自动转换为 Java 代码等等。
该工具完全免费,因此可以节省大量成本。
在过去的 12 年中,许多大型组织已采用 TOS 进行数据集成,这表明该工具具有很高的信任度。
Talend 的数据集成社区非常活跃。
Talend 不断向这些工具添加新功能,文档结构清晰,易于理解。
Talend - 数据集成
大多数组织从多个地方获取数据并将其分别存储。现在,如果组织需要进行决策,则必须从不同的来源获取数据,将其放入统一视图中,然后对其进行分析以获得结果。此过程称为数据集成。
优势
数据集成提供了许多好处,如下所述:
改善试图访问组织数据的不同团队之间的协作。
节省时间并简化数据分析,因为数据已有效集成。
自动化的数据集成流程同步数据并简化实时和定期报告,否则如果手动完成将非常耗时。
从多个来源集成的的数据会随着时间的推移而成熟和改进,最终有助于提高数据质量。
使用项目
在本节中,让我们了解如何处理 Talend 项目:
创建项目
双击 TOS Big Data 可执行文件,将打开如下所示的窗口。
选择“创建新项目”选项,提及项目名称,然后单击“创建”。
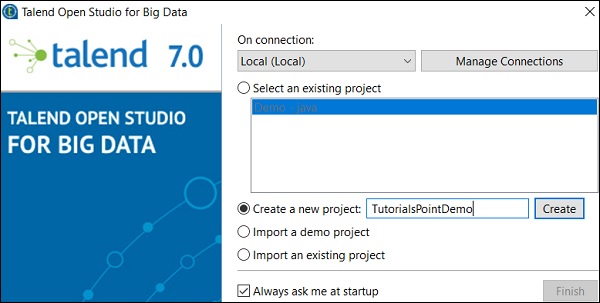
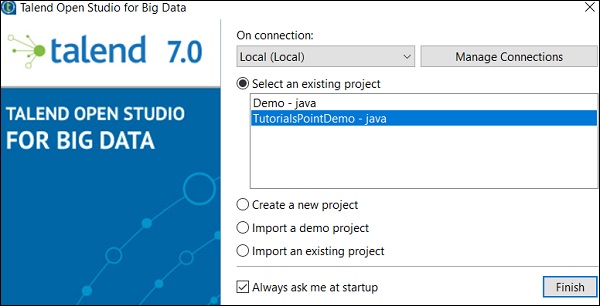
选择您创建的项目,然后单击“完成”。
导入项目
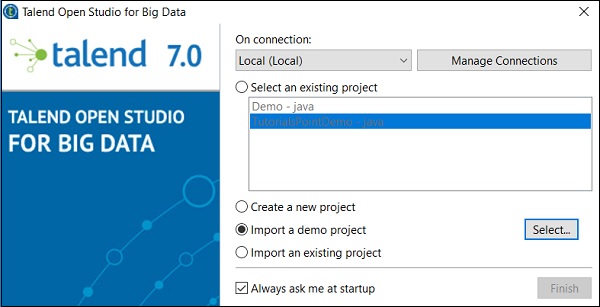
双击 TOS Big Data 可执行文件,您将看到如下所示的窗口。选择“导入演示项目”选项,然后单击“选择”。
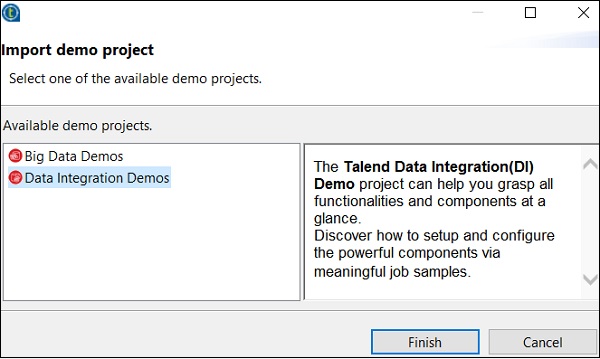
您可以从以下选项中选择。这里我们选择“数据集成演示”。现在,单击“完成”。
现在,输入项目名称和说明。单击“完成”。
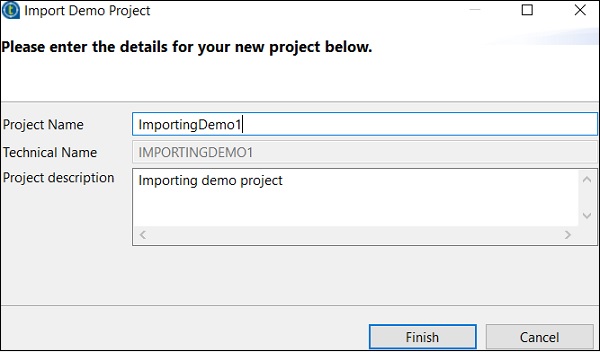
您可以在现有项目列表中看到已导入的项目。
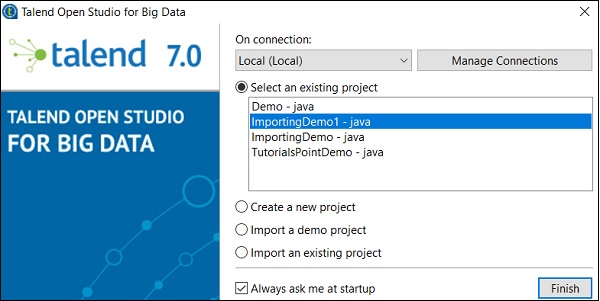
现在,让我们了解如何导入现有的 Talend 项目。
选择“导入现有项目”选项,然后单击“选择”。
输入项目名称并选择“选择根目录”选项。
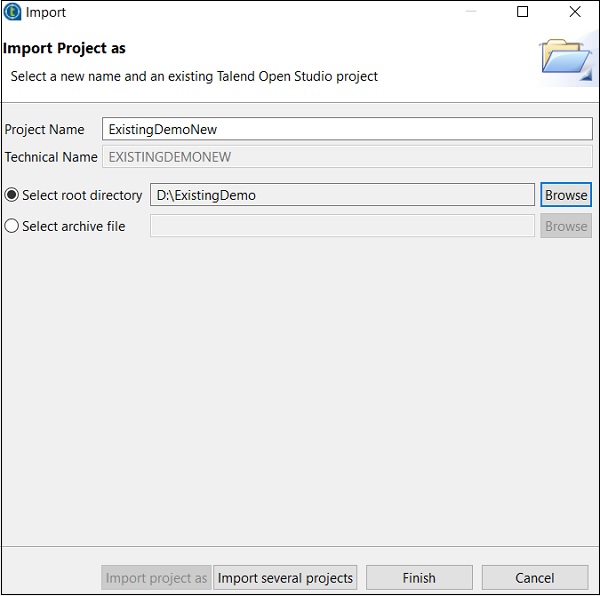
浏览您现有的 Talend 项目主目录,然后单击“完成”。
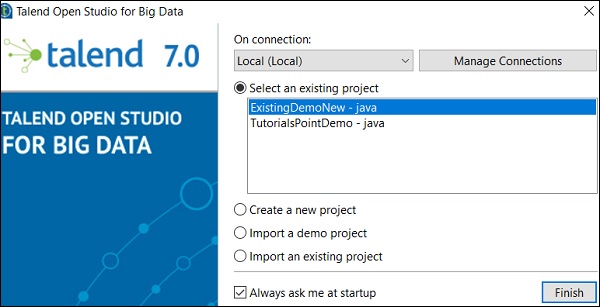
您的现有 Talend 项目将被导入。
打开项目
从现有项目中选择一个项目,然后单击“完成”。这将打开该 Talend 项目。
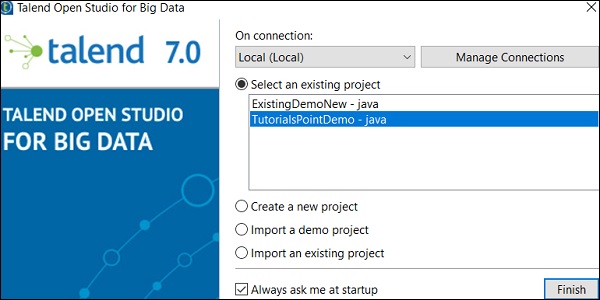
删除项目
要删除项目,请单击“管理连接”。
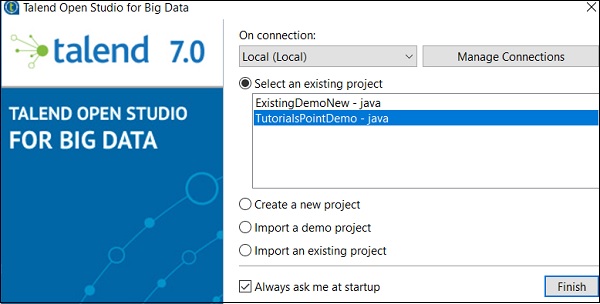
单击“删除现有项目”。
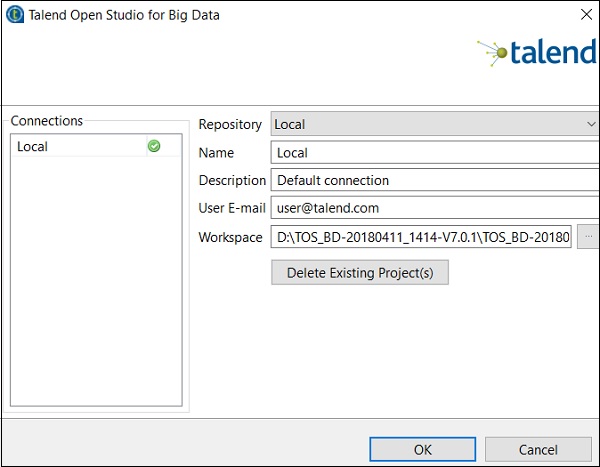
选择要删除的项目,然后单击“确定”。
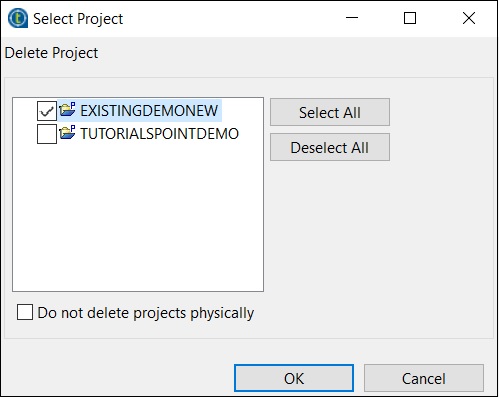
再次单击“确定”。
导出项目
单击“导出项目”选项。
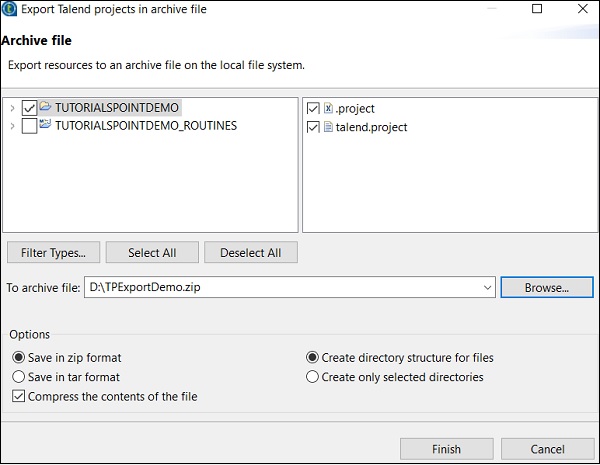
选择要导出的项目,并指定应将其导出到的路径。单击“完成”。
Talend - 模型基础
业务模型是数据集成项目的图形表示。它是业务工作流程的非技术表示。
为什么需要业务模型?
构建业务模型是为了向高层管理人员展示您的工作内容,它还可以让您的团队了解您试图实现的目标。设计业务模型被认为是组织在其数据集成项目开始时采用的最佳实践之一。此外,它有助于降低成本,并能发现和解决项目中的瓶颈。如果需要,可以在项目实施期间和之后修改模型。
在 Talend Open Studio 中创建业务模型
Talend Open Studio 提供多个形状和连接器来创建和设计业务模型。业务模型中的每个模块都可以附加文档。
Talend Open Studio 提供以下形状和连接器选项来创建业务模型:
决策 - 此形状用于在模型中放置 if 条件。
操作 - 此形状用于显示任何转换、翻译或格式化。
终端 - 此形状显示输出终端类型。
数据 - 此形状用于显示数据类型。
文档 - 此形状用于插入文档对象,该对象可用于已处理数据的输入/输出。
输入 - 此形状用于插入输入对象,用户可以使用该对象手动传递数据。
列表 - 此形状包含提取的数据,可以将其定义为仅在列表中保存某种类型的数据。
数据库 - 此形状用于保存输入/输出数据。
参与者 - 此形状象征着参与决策和技术流程的个人。
椭圆 - 插入椭圆形状。
齿轮 - 此形状显示必须由 Talend 作业替换的手动程序。
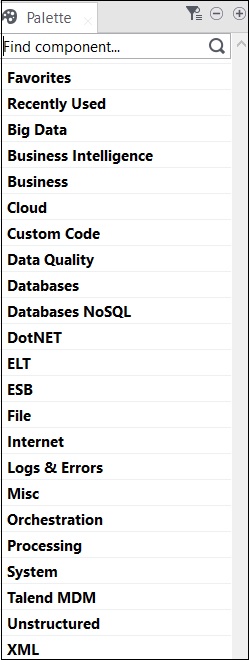
Talend - 数据集成组件
Talend 中的所有操作均由连接器和组件执行。Talend 提供 800 多个连接器和组件来执行多项操作。这些组件存在于调色板中,并且有 21 个主要类别属于这些组件。您可以选择连接器并将其拖放到设计器窗格中,它将自动创建 Java 代码,当您保存 Talend 代码时,该代码将被编译。
包含组件的主要类别如下所示:
以下是 Talend Open Studio 中广泛使用的数据集成连接器和组件的列表:
tMysqlConnection - 连接到组件中定义的 MySQL 数据库。
tMysqlInput - 运行数据库查询以读取数据库并提取字段(表、视图等),具体取决于查询。
tMysqlOutput - 用于写入、更新、修改 MySQL 数据库中的数据。
tFileInputDelimited - 行读入分隔符文件,并将它们分成单独的字段,然后传递到下一个组件。
tFileInputExcel - 行读入excel文件,并将它们分成单独的字段,然后传递到下一个组件。
tFileList - 从给定的文件掩码模式获取所有文件和目录。
tFileArchive - 将一组文件或文件夹压缩到 zip、gzip 或 tar.gz 归档文件中。
tRowGenerator − 提供一个编辑器,您可以在其中编写函数或选择表达式来生成示例数据。
tMsgBox − 返回一个带有指定消息和“确定”按钮的对话框。
tLogRow − 监控正在处理的数据。它在运行控制台中显示数据/输出。
tPreJob − 定义在实际作业开始之前将运行的子作业。
tMap − 充当 Talend Studio 中的插件。它从一个或多个来源获取数据,对其进行转换,然后将转换后的数据发送到一个或多个目标。
tJoin − 通过在主流程和查找流程之间执行内连接和外连接来连接两个表。
tJava − 使您能够在 Talend 程序中使用个性化的 Java 代码。
tRunJob − 通过一个接一个地运行 Talend 作业来管理复杂的作业系统。
Talend - 作业设计
这是业务模型的技术实现/图形表示。在此设计中,一个或多个组件相互连接以运行数据集成过程。因此,当您在设计面板中拖放组件并使用连接器连接它们时,作业设计会将所有内容转换为代码,并创建一个完整的可运行程序,从而形成数据流。
创建作业
在资源库窗口中,右键单击“作业设计”,然后单击“创建作业”。
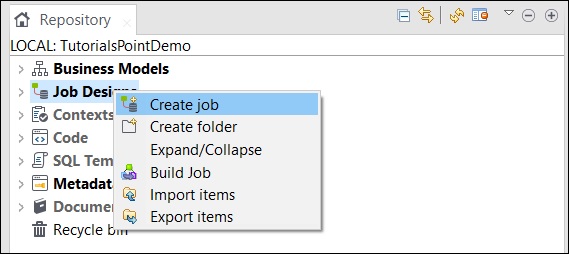
提供作业的名称、用途和说明,然后单击“完成”。
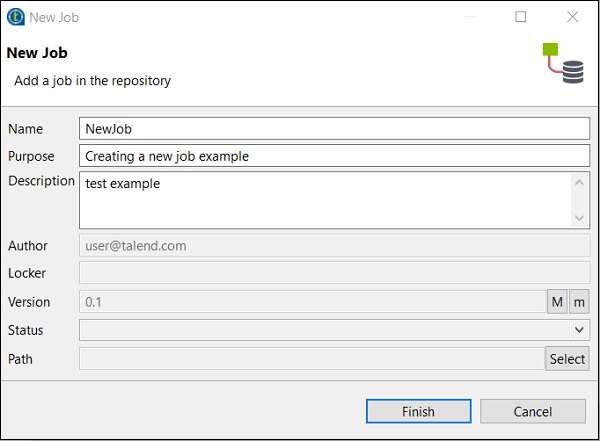
您会看到您的作业已在“作业设计”下创建。
现在,让我们使用此作业添加组件、连接并配置它们。在这里,我们将采用 Excel 文件作为输入,并生成具有相同数据的 Excel 文件作为输出。
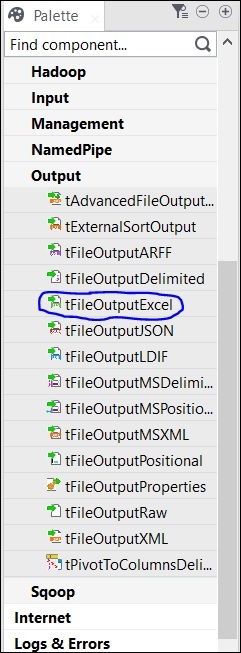
向作业添加组件
调色板中有几个组件可供选择。还有一个搜索选项,您可以在其中输入组件的名称以选择它。
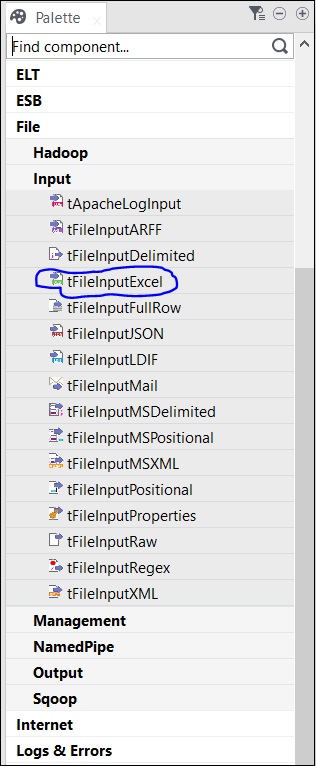
由于此处我们将 Excel 文件作为输入,因此我们将从调色板中将 tFileInputExcel 组件拖放到设计器窗口。

现在,如果您单击设计器窗口中的任何位置,都会出现一个搜索框。找到 tLogRow 并选择它以将其带入设计器窗口。
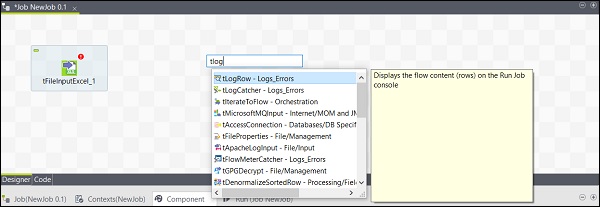
最后,从调色板中选择 tFileOutputExcel 组件,并将其拖放到设计器窗口。
现在,组件的添加已完成。
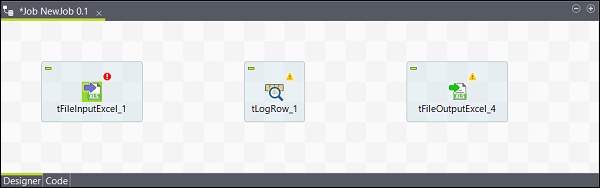
连接组件
添加组件后,必须连接它们。右键单击第一个组件 tFileInputExcel,然后绘制一条主线到 tLogRow,如下所示。
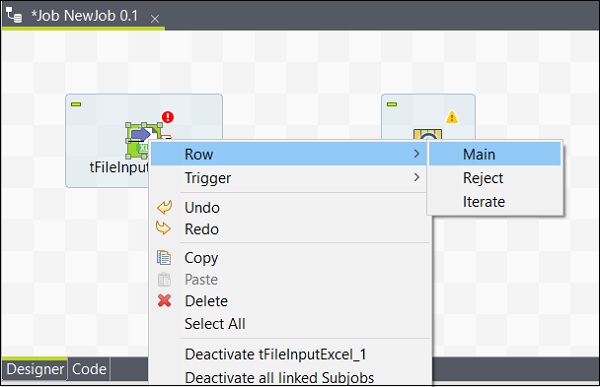
同样,右键单击 tLogRow,然后在 tFileOutputExcel 上绘制一条主线。现在,您的组件已连接。
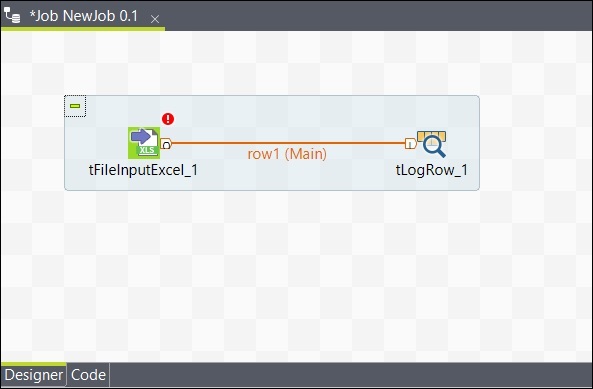
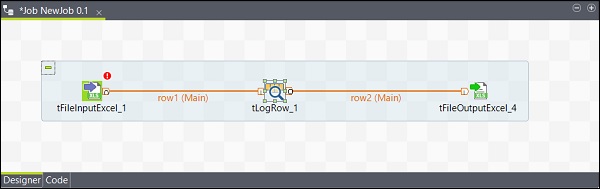
配置组件
在作业中添加和连接组件后,您需要配置它们。为此,双击第一个组件 tFileInputExcel 进行配置。在“文件名/流”中提供输入文件的路径,如下所示。
如果您的 Excel 文件的第 1 行包含列名,请在“标题”选项中输入 1。
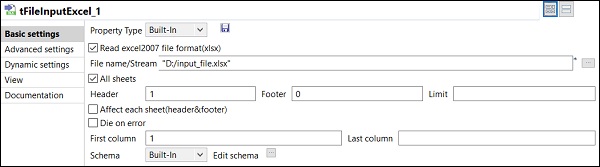
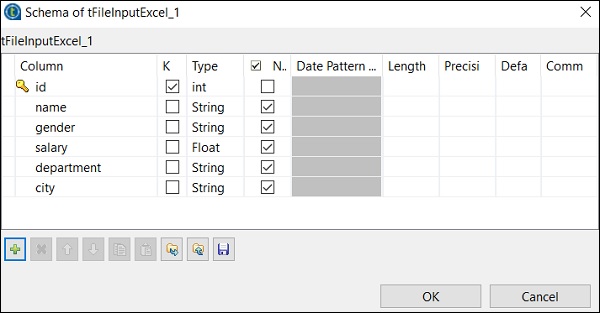
单击“编辑架构”,并根据您的输入 Excel 文件添加列及其类型。添加架构后,单击“确定”。
单击“是”。
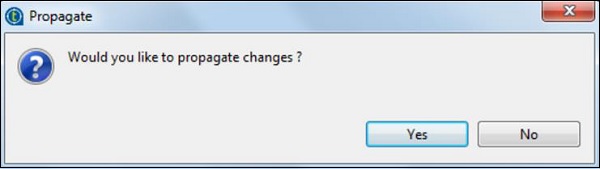
在 tLogRow 组件中,单击“同步列”,并选择要从中生成行的模式。在这里,我们选择了以“,”作为字段分隔符的基本模式。
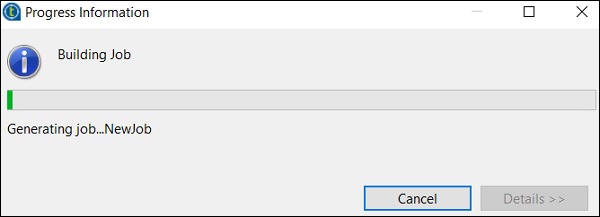
最后,在 tFileOutputExcel 组件中,提供要存储输出 Excel 文件的文件夹路径和文件名。
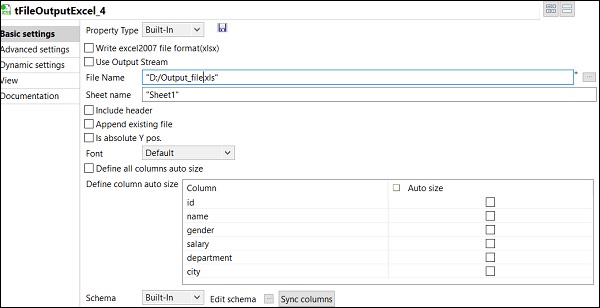
以及工作表名称。单击“同步列”。
执行作业
完成添加、连接和配置组件后,您就可以执行 Talend 作业了。单击“运行”按钮开始执行。

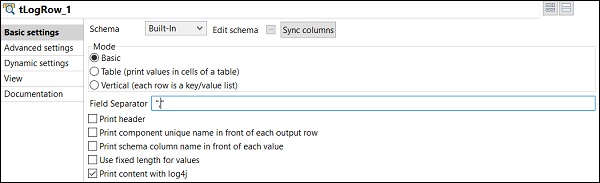
您将在基本模式下看到输出,并以“,”作为分隔符。
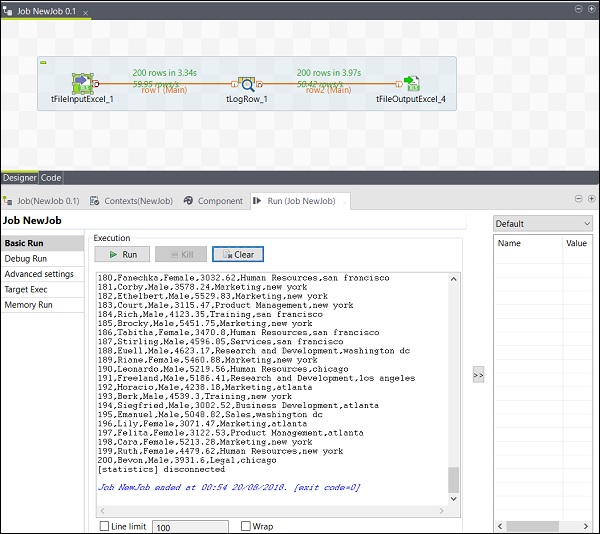
您还可以看到您的输出已保存为 Excel 文件,存储在您指定的输出路径。
Talend - 元数据
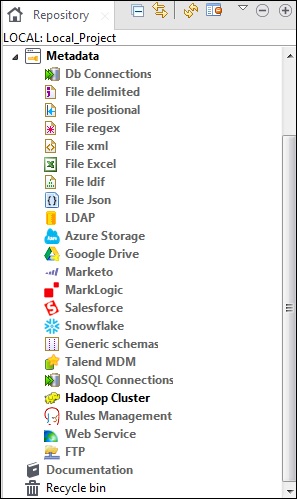
元数据基本上是指关于数据的数据。它说明了数据的什么、何时、为什么、谁、何地、哪个和如何。在 Talend 中,元数据包含 Talend Studio 中存在的数据的全部信息。元数据选项位于 Talend Open Studio 的“资源库”窗格中。
各种来源,例如数据库连接、不同类型的文件、LDAP、Azure、Salesforce、Web 服务 FTP、Hadoop 集群以及许多其他选项都位于 Talend 元数据下。
Talend Open Studio 中元数据的主要用途是,您只需从资源库面板中的元数据中简单地拖放即可在多个作业中使用这些数据源。
Talend - 上下文变量
上下文变量是可以具有不同环境中不同值的变量。您可以创建一个上下文组来保存多个上下文变量。您无需逐个将每个上下文变量添加到作业中,只需将上下文组添加到作业中即可。
这些变量用于使代码准备好投入生产。这意味着通过使用上下文变量,您可以将代码移动到开发、测试或生产环境中,它将在所有环境中运行。
在任何作业中,您都可以转到如下所示的“上下文”选项卡并添加上下文变量。
Talend - 作业管理
在本章中,让我们了解在 Talend 中管理作业以及包含的相应功能。
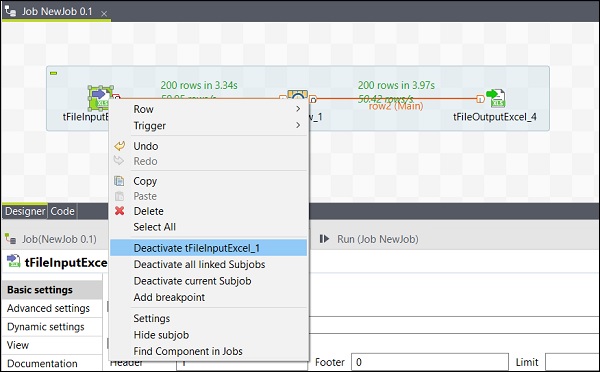
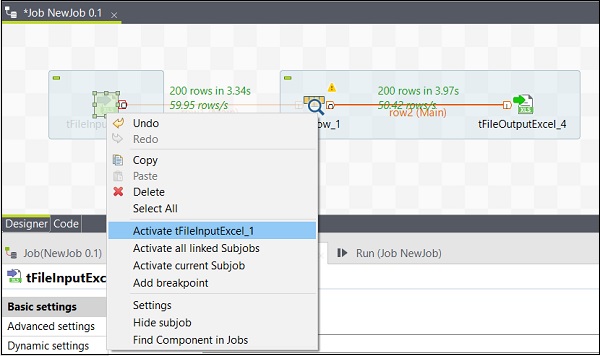
激活/停用组件
激活/停用组件非常简单。您只需要选择组件,右键单击它,然后选择停用或激活该组件选项即可。
导入/导出项目和构建作业
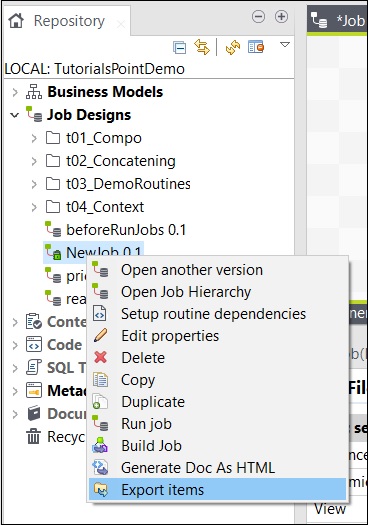
要从作业中导出项目,请右键单击“作业设计”中的作业,然后单击“导出项目”。
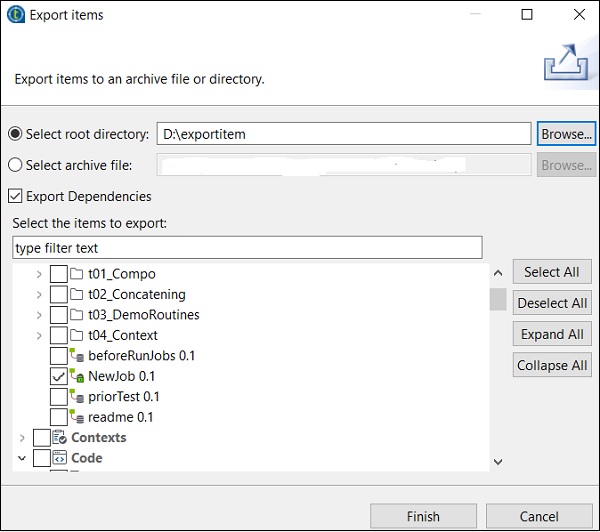
输入要导出项目的路径,然后单击“完成”。
要从作业中导入项目,请右键单击“作业设计”中的作业,然后单击“导入项目”。
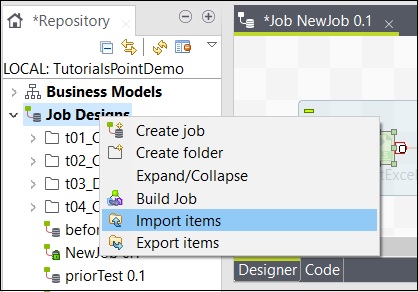
浏览要从中导入项目的根目录。
选择所有复选框,然后单击“完成”。
Talend - 处理作业执行
在本章中,让我们了解在 Talend 中处理作业执行。
要构建作业,请右键单击该作业并选择“构建作业”选项。
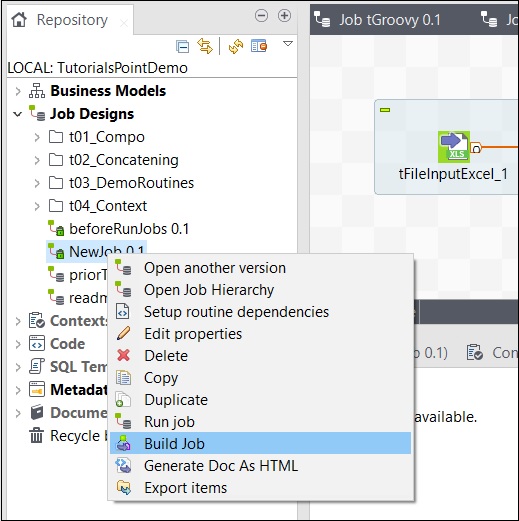
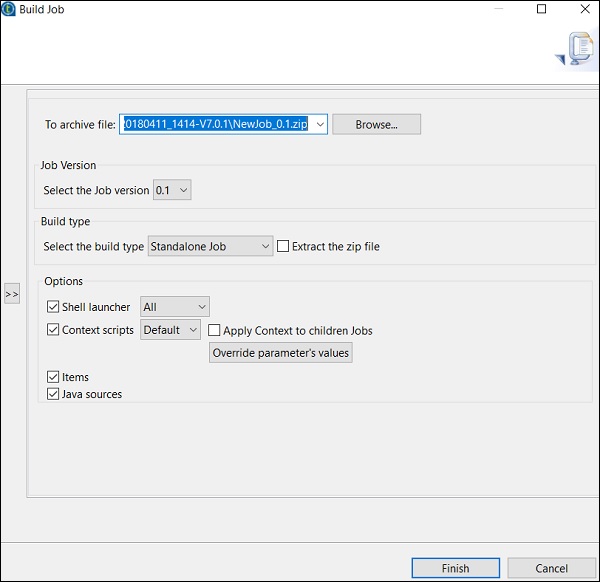
提及要存档作业的路径,选择作业版本和构建类型,然后单击“完成”。
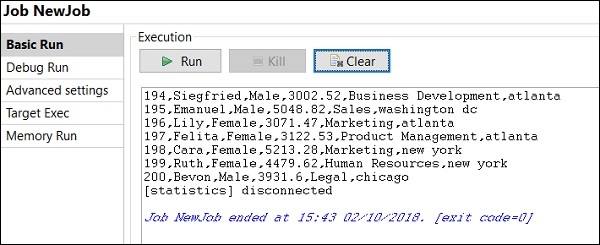
如何在普通模式下运行作业
要在普通节点中运行作业,您需要选择“基本运行”,然后单击“运行”按钮以开始执行。
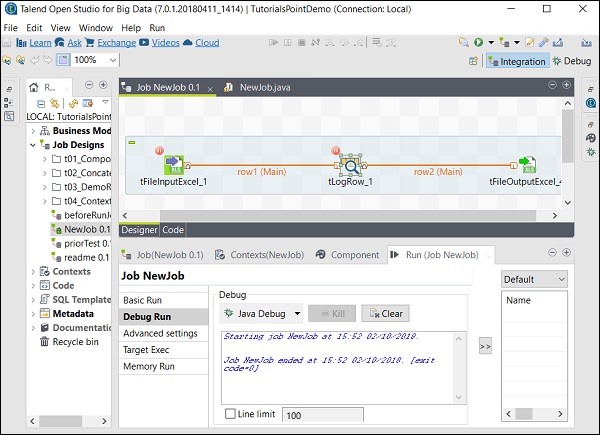
如何在调试模式下运行作业
要在调试模式下运行作业,请在要调试的组件中添加断点。
然后,选择并右键单击组件,单击“添加断点”选项。请注意,此处我们在 tFileInputExcel 和 tLogRow 组件中添加了断点。然后,转到“调试运行”,然后单击“Java 调试”按钮。
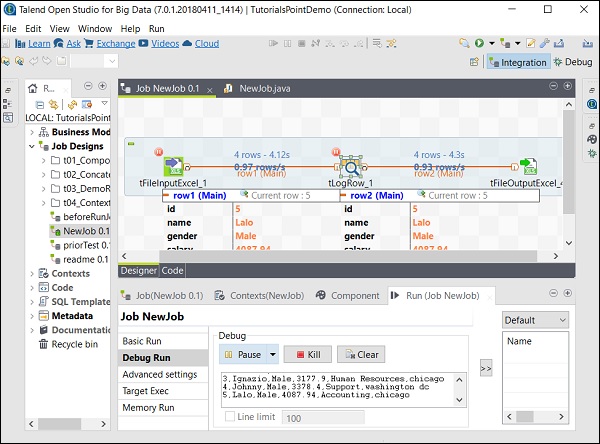
您可以从以下屏幕截图中观察到,作业现在将在调试模式下执行,并根据我们提到的断点进行执行。
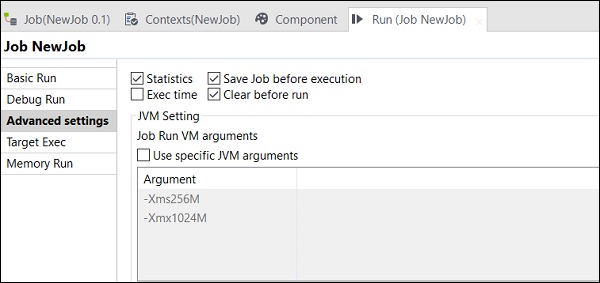
高级设置
在高级设置中,您可以从统计信息、执行时间、执行前保存作业、运行前清除和 JVM 设置中进行选择。此处解释了每个选项的功能:
统计信息 − 显示处理的性能率;
执行时间 − 执行作业所花费的时间。
执行前保存作业 − 在执行开始之前自动保存作业。
运行前清除 − 从输出控制台中删除所有内容。
JVM 设置 − 帮助我们配置自己的 Java 参数。
Talend - 大数据
带有大数据的 Open Studio 的标语是“使用领先的免费开源大数据 ETL 工具简化 ETL 和 ELT”。在本章中,让我们了解 Talend 作为在大数据环境中处理数据的工具的用法。
介绍
Talend Open Studio – Big Data 是一款免费的开源工具,可让您在大数据环境中非常轻松地处理数据。Talend Open Studio 中提供了大量的大数据组件,只需简单地拖放几个 Hadoop 组件,即可创建和运行 Hadoop 作业。
此外,我们无需编写大量 MapReduce 代码;Talend Open Studio Big data 通过其中提供的组件帮助您做到这一点。它会自动为您生成 MapReduce 代码,您只需拖放组件并配置一些参数即可。
它还允许您连接到多个大数据发行版,例如 Cloudera、HortonWorks、MapR、Amazon EMR 甚至 Apache。
用于大数据的 Talend 组件
下面显示了在“大数据”下包含的用于在大数据环境中运行作业的组件类别列表:
下面显示了 Talend Open Studio 中的大数据连接器和组件列表:
tHDFSConnection − 用于连接到 HDFS(Hadoop 分布式文件系统)。
tHDFSInput − 从给定的 hdfs 路径读取数据,将其放入 Talend 架构中,然后将其传递给作业中的下一个组件。
tHDFSList − 检索给定 hdfs 路径中的所有文件和文件夹。
tHDFSPut − 将文件/文件夹从本地文件系统(用户定义)复制到给定路径的 hdfs。
tHDFSGet − 将文件/文件夹从 hdfs 复制到给定路径的本地文件系统(用户定义)。
tHDFSDelete − 从 HDFS 删除文件。
tHDFSExist − 检查文件是否存在于 HDFS 上。
tHDFSOutput − 将数据流写入 HDFS。
tCassandraConnection − 打开与 Cassandra 服务器的连接。
tCassandraRow − 在指定的数据库上运行 CQL(Cassandra 查询语言)查询。
tHBaseConnection − 打开与 HBase 数据库的连接。
tHBaseInput − 从 HBase 数据库读取数据。
tHiveConnection − 打开与 Hive 数据库的连接。
tHiveCreateTable − 在 Hive 数据库中创建一个表。
tHiveInput − 从 Hive 数据库读取数据。
tHiveLoad − 将数据写入 Hive 表或指定的目录。
tHiveRow − 在指定的数据库上运行 HiveQL 查询。
tPigLoad − 将输入数据加载到输出流。
tPigMap − 用于在 Pig 过程中转换和路由数据。
tPigJoin − 基于连接键执行两个文件的连接操作。
tPigCoGroup − 对来自多个输入的数据进行分组和聚合。
tPigSort − 根据一个或多个定义的排序键对给定数据进行排序。
tPigStoreResult − 将 Pig 操作的结果存储在定义的存储空间中。
tPigFilterRow − 筛选指定的列,以便根据给定条件拆分数据。
tPigDistinct − 从关系中删除重复元组。
tSqoopImport − 将数据从关系数据库(如 MySQL、Oracle DB)传输到 HDFS。
tSqoopExport − 将数据从 HDFS 传输到关系数据库(如 MySQL、Oracle DB)。
Talend - Hadoop 分布式文件系统
在本章中,让我们详细了解 Talend 如何与 Hadoop 分布式文件系统协同工作。
设置和先决条件
在我们继续使用 Talend 和 HDFS 之前,我们应该了解为此目的应满足的设置和先决条件。
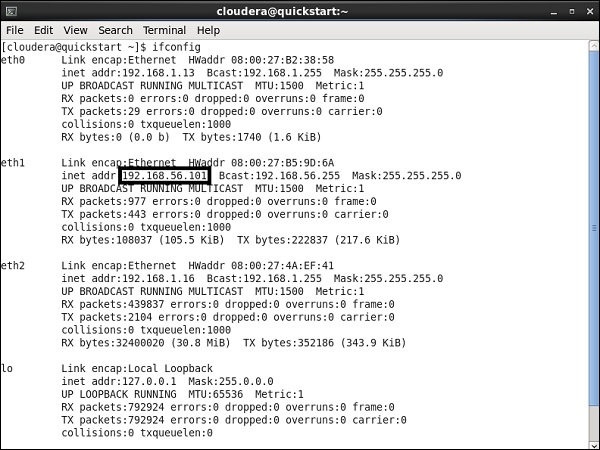
在这里,我们在 VirtualBox 上运行 Cloudera 快速入门 5.10 VM。此 VM 必须使用专用主机网络。
专用主机网络 IP:192.168.56.101
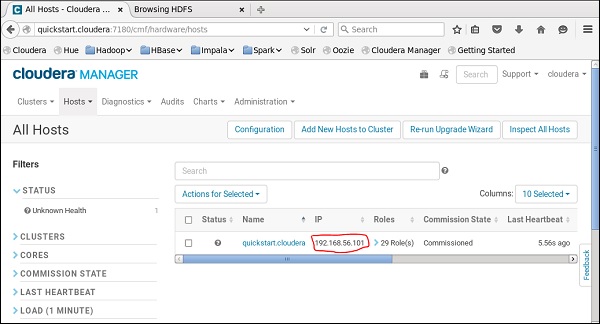
您必须在 Cloudera Manager 上运行相同的 host。
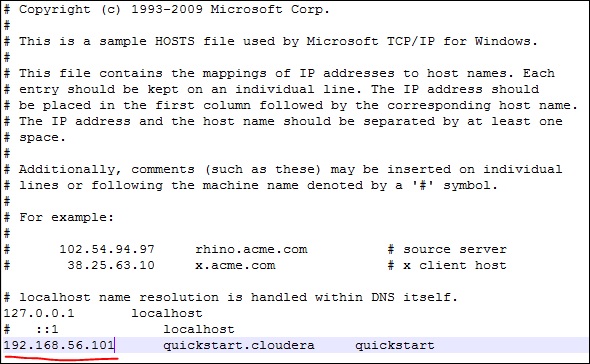
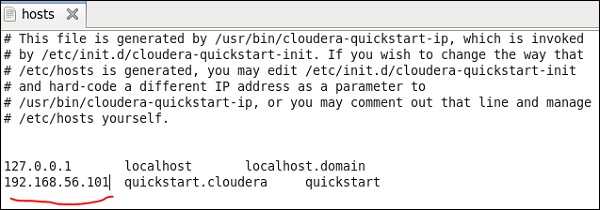
现在,在您的 Windows 系统上,转到 c:\Windows\System32\Drivers\etc\hosts 并使用记事本编辑此文件,如下所示。
同样,在您的 Cloudera 快速入门 VM 上,编辑您的 /etc/hosts 文件,如下所示。
sudo gedit /etc/hosts
设置 Hadoop 连接
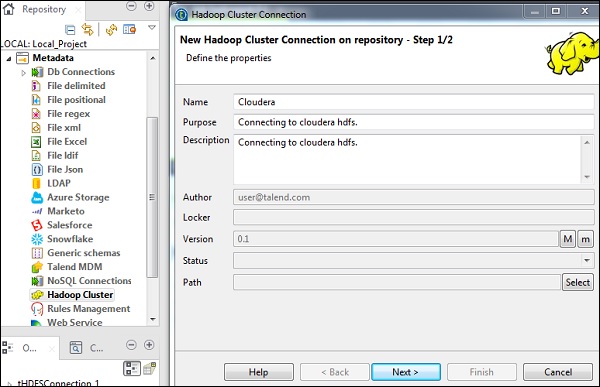
在资源库面板中,转到“元数据”。右键单击“Hadoop 集群”,然后创建一个新的集群。为该 Hadoop 集群连接提供名称、用途和说明。
单击“下一步”。
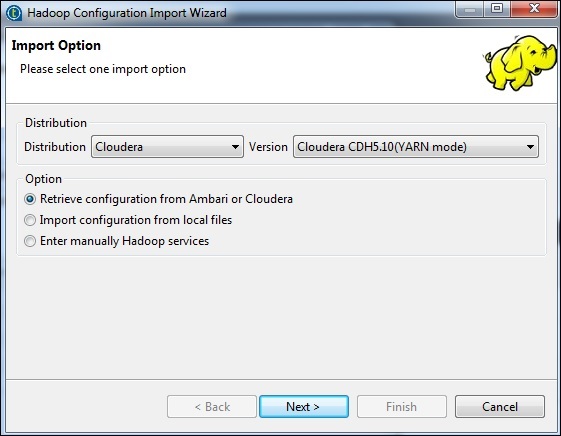
选择发行版为 Cloudera,然后选择您正在使用的版本。选择“检索配置”选项,然后单击“下一步”。
输入管理器凭据(带端口的 URI、用户名、密码),如下所示,然后单击“连接”。如果详细信息正确,您将在已发现的集群下获得 Cloudera QuickStart。
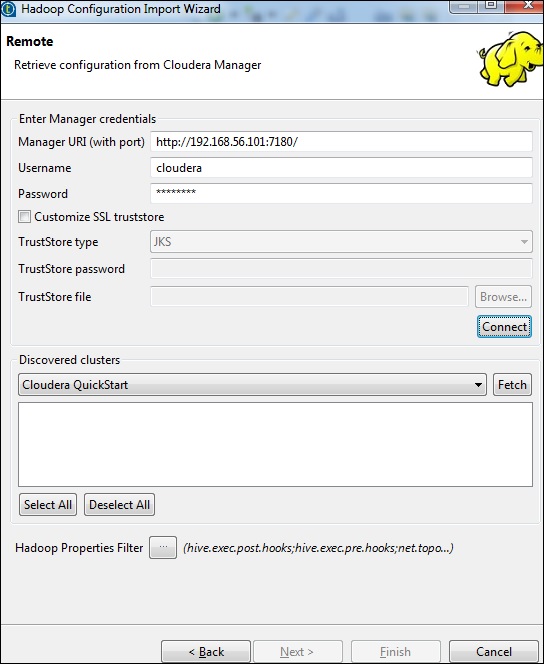
单击“获取”。这将获取 HDFS、YARN、HBASE、HIVE 的所有连接和配置。
选择“全部”,然后单击“完成”。
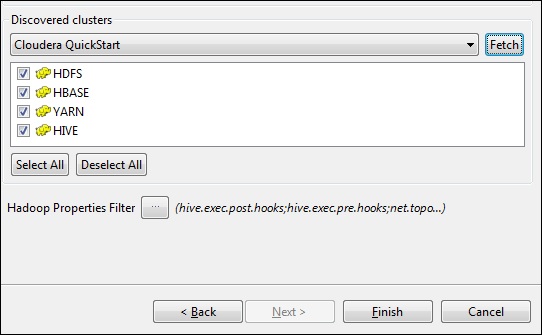
请注意,所有连接参数都将自动填充。在用户名中提及 cloudera,然后单击“完成”。
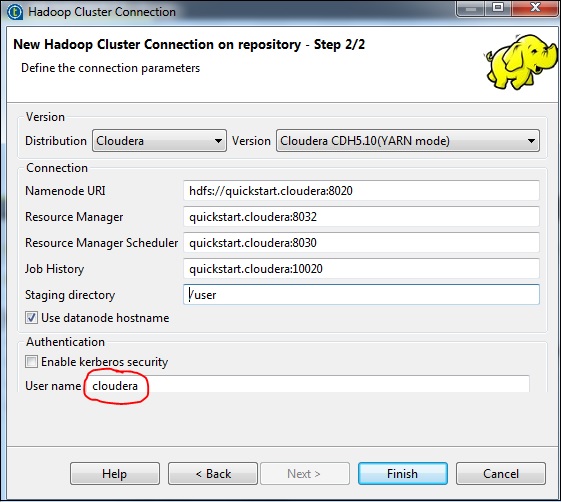
这样,您就成功连接到 Hadoop 集群。

连接到 HDFS
在此作业中,我们将列出 HDFS 上存在的所有目录和文件。
首先,我们将创建一个作业,然后向其中添加 HDFS 组件。右键单击“作业设计”,创建一个新作业 - hadoopjob。
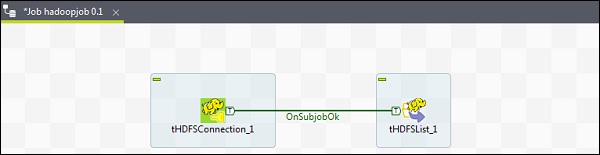
现在从调色板中添加 2 个组件 - tHDFSConnection 和 tHDFSList。右键单击 tHDFSConnection,并使用“OnSubJobOk”触发器连接这两个组件。
现在,配置这两个 Talend hdfs 组件。
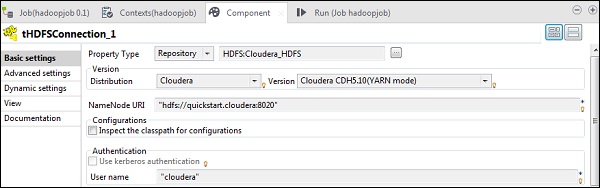
在 tHDFSConnection 中,选择“Repository”作为属性类型,并选择您之前创建的 Hadoop cloudera 集群。它将自动填充此组件所需的所有必要详细信息。
在 tHDFSList 中,选择“使用现有连接”,并在组件列表中选择您配置的 tHDFSConnection。
在“HDFS 目录”选项中提供 HDFS 的主目录路径,然后单击右侧的浏览按钮。
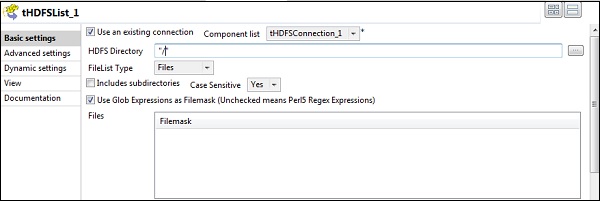
如果您已使用上述配置正确建立连接,您将看到如下所示的窗口。它将列出 HDFS 主目录上存在的所有目录和文件。
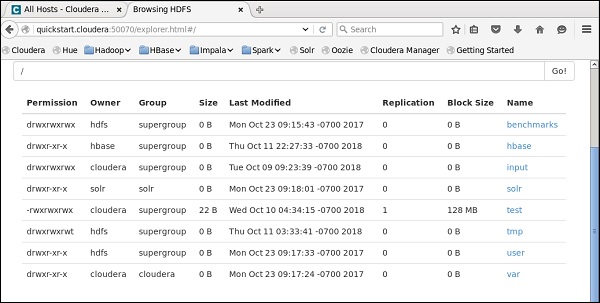
您可以通过检查 Cloudera 上的 HDFS 来验证这一点。
从 HDFS 读取文件
在本节中,让我们了解如何在 Talend 中从 HDFS 读取文件。您可以为此创建一个新作业,但是在这里我们使用现有的作业。
从调色板将 3 个组件 - tHDFSConnection、tHDFSInput 和 tLogRow 拖放到设计器窗口。
右键单击 tHDFSConnection,并使用“OnSubJobOk”触发器连接 tHDFSInput 组件。
右键单击 tHDFSInput,并将主链接拖动到 tLogRow。
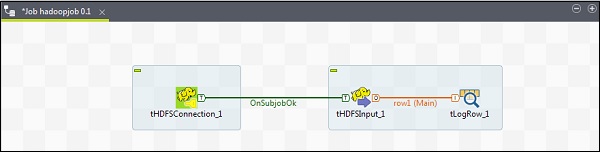
请注意,tHDFSConnection 将具有与之前相同的配置。在 tHDFSInput 中,选择“使用现有连接”,然后从组件列表中选择 tHDFSConnection。
在“文件名”中,提供要读取的文件的 HDFS 路径。这里我们读取一个简单的文本文件,因此我们的文件类型是“文本文件”。类似地,根据您的输入,填写如下所示的行分隔符、字段分隔符和标题详细信息。最后,单击“编辑模式”按钮。
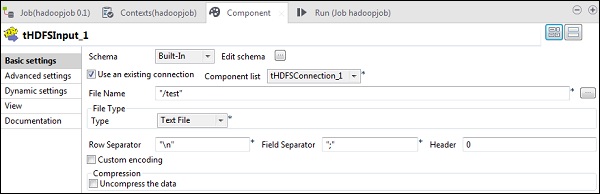
由于我们的文件只有纯文本,我们只添加一列字符串类型。现在,单击“确定”。
注意 - 当您的输入具有多种不同类型的列时,您需要在此处相应地提及模式。
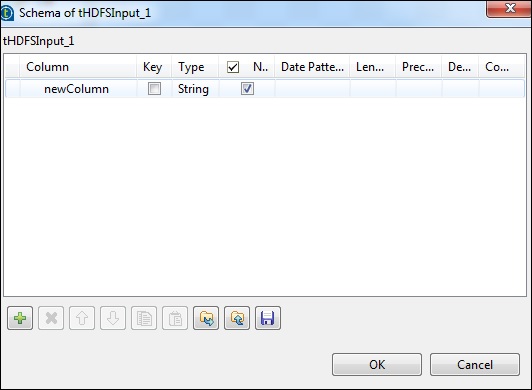
在 tLogRow 组件中,单击“编辑模式”中的“同步列”。
选择您希望输出打印的模式。
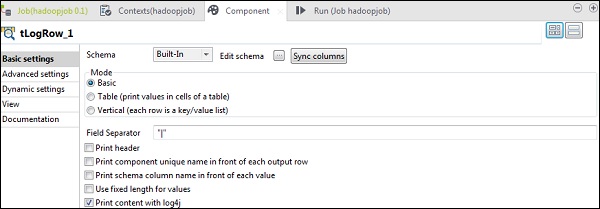
最后,单击“运行”以执行作业。
成功读取 HDFS 文件后,您将看到以下输出。
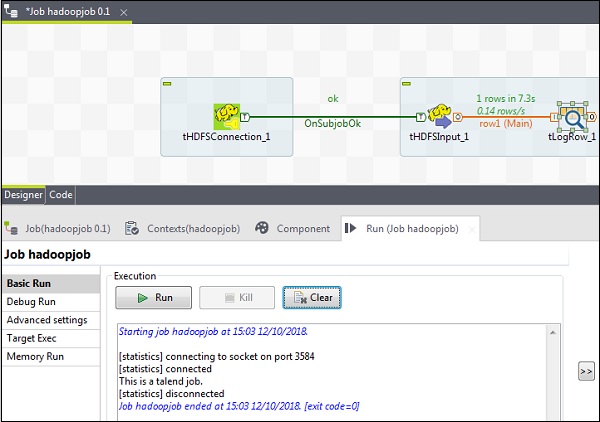
将文件写入 HDFS
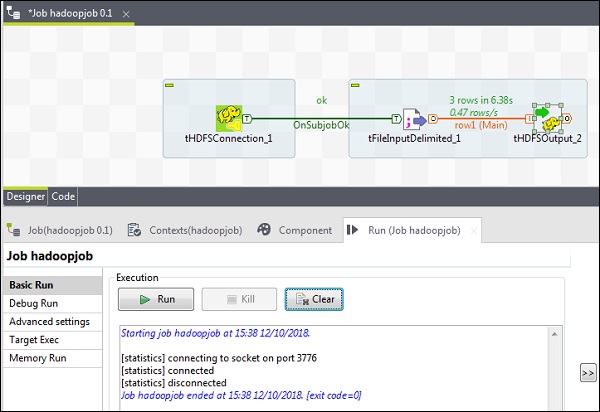
让我们看看如何在 Talend 中将文件写入 HDFS。从调色板将 3 个组件 - tHDFSConnection、tFileInputDelimited 和 tHDFSOutput 拖放到设计器窗口。
右键单击 tHDFSConnection,并使用“OnSubJobOk”触发器连接 tFileInputDelimited 组件。
右键单击 tFileInputDelimited,并将主链接拖动到 tHDFSOutput。
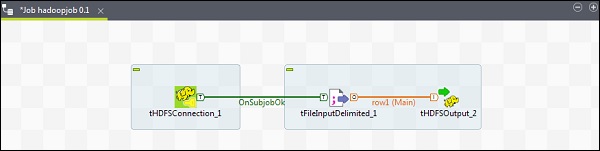
请注意,tHDFSConnection 将具有与之前相同的配置。
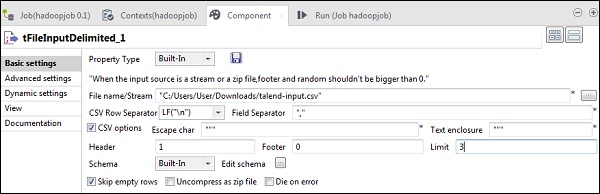
现在,在 tFileInputDelimited 中,在“文件名/流”选项中提供输入文件的路径。这里我们使用 csv 文件作为输入,因此字段分隔符是“,”。
根据您的输入文件选择标题、页脚和限制。请注意,这里我们的标题是 1,因为第 1 行包含列名,限制是 3,因为我们只将前 3 行写入 HDFS。
现在,单击“编辑模式”。
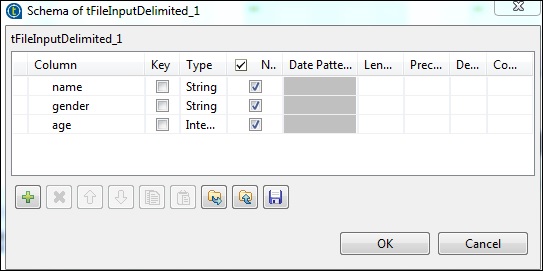
现在,根据我们的输入文件定义模式。我们的输入文件有 3 列,如下所示。
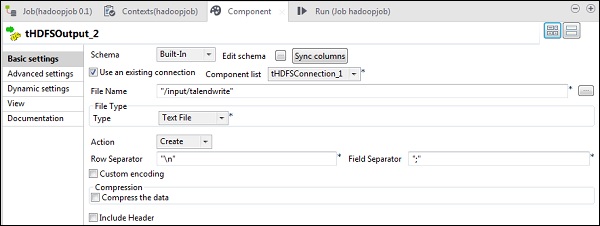
在 tHDFSOutput 组件中,单击“同步列”。然后,在“使用现有连接”中选择 tHDFSConnection。此外,在“文件名”中,提供您要写入文件的 HDFS 路径。
请注意,文件类型将是文本文件,“操作”将是“创建”,“行分隔符”将是“\n”,字段分隔符是“;”。
最后,单击“运行”以执行您的作业。作业成功执行后,检查您的文件是否在 HDFS 上。
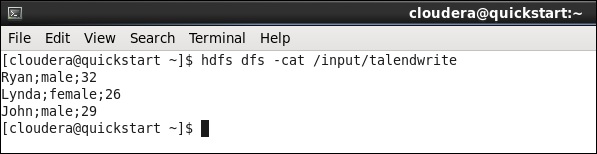
使用您在作业中提到的输出路径运行以下 hdfs 命令。
hdfs dfs -cat /input/talendwrite
如果您成功写入 HDFS,您将看到以下输出。
Talend - Map Reduce
在上一章中,我们了解了 Talend 如何与大数据一起工作。在本章中,让我们了解如何在 Talend 中使用 MapReduce。
创建 Talend MapReduce 作业
让我们学习如何在 Talend 上运行 MapReduce 作业。在这里,我们将运行 MapReduce 单词计数示例。
为此,请右键单击“作业设计”,创建一个新作业 - MapreduceJob。提及作业的详细信息,然后单击“完成”。
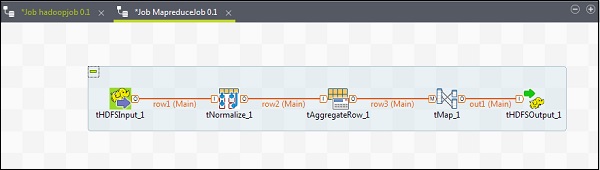
向 MapReduce 作业添加组件
要向 MapReduce 作业添加组件,请将 Talend 的五个组件 - tHDFSInput、tNormalize、tAggregateRow、tMap、tOutput 从调色板拖放到设计器窗口。右键单击 tHDFSInput 并创建到 tNormalize 的主链接。
右键单击 tNormalize 并创建到 tAggregateRow 的主链接。然后,右键单击 tAggregateRow 并创建到 tMap 的主链接。现在,右键单击 tMap 并创建到 tHDFSOutput 的主链接。
配置组件和转换
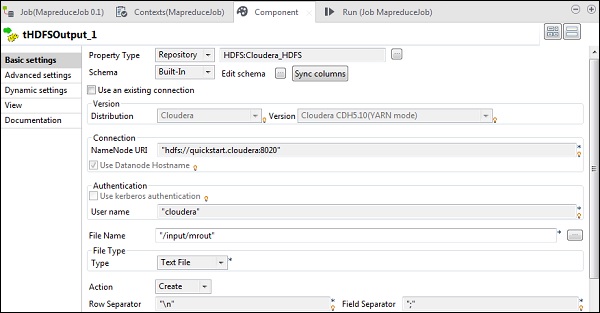
在 tHDFSInput 中,选择分布式 cloudera 及其版本。请注意,NameNode URI 应为“hdfs://quickstart.cloudera:8020”,用户名应为“cloudera”。在文件名选项中,提供输入文件到 MapReduce 作业的路径。确保此输入文件存在于 HDFS 上。
现在,根据您的输入文件选择文件类型、行分隔符、文件分隔符和标题。
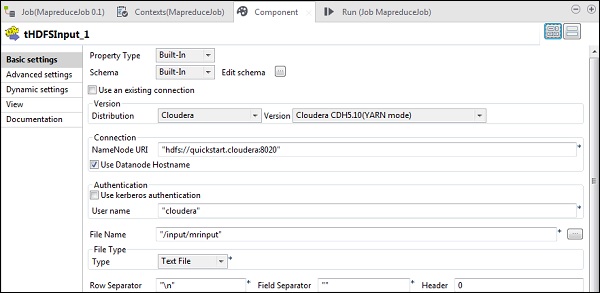
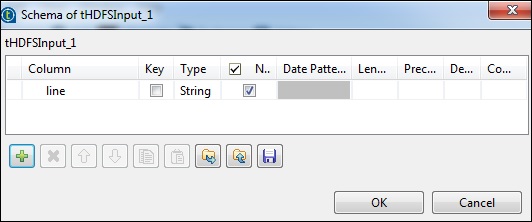
单击“编辑模式”并添加字段“line”作为字符串类型。
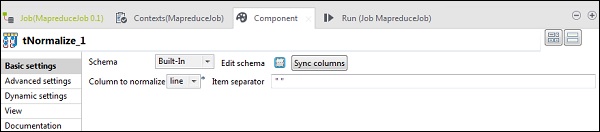
在 tNomalize 中,要规范化的列将是 line,项目分隔符将是空格 - >“ ”。现在,单击“编辑模式”。tNormalize 将具有 line 列,而 tAggregateRow 将具有 2 列 word 和 wordcount,如下所示。
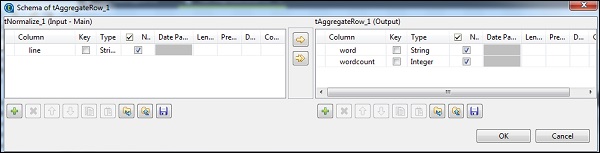
在 tAggregateRow 中,将 word 作为输出列放在“分组依据”选项中。在“操作”中,将 wordcount 作为输出列,函数为 count,输入列位置为 line。
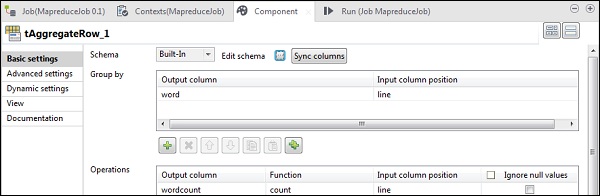
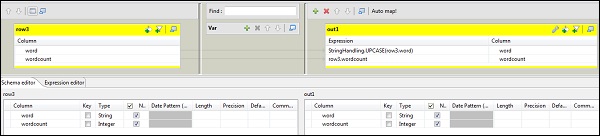
现在双击 tMap 组件以输入映射编辑器并将输入与所需的输出映射。在此示例中,word 映射到 word,wordcount 映射到 wordcount。在表达式列中,单击 […] 以输入表达式构建器。
现在,从类别列表中选择 StringHandling 和 UPCASE 函数。将表达式编辑为“StringHandling.UPCASE(row3.word)”,然后单击“确定”。将 row3.wordcount 保留在与 wordcount 对应的表达式列中,如下所示。
在 tHDFSOutput 中,从属性类型作为存储库连接到我们创建的 Hadoop 集群。观察字段将自动填充。在“文件名”中,提供要存储输出的输出路径。保持操作、行分隔符和字段分隔符如下所示。
执行 MapReduce 作业
配置成功完成后,单击“运行”并执行您的 MapReduce 作业。
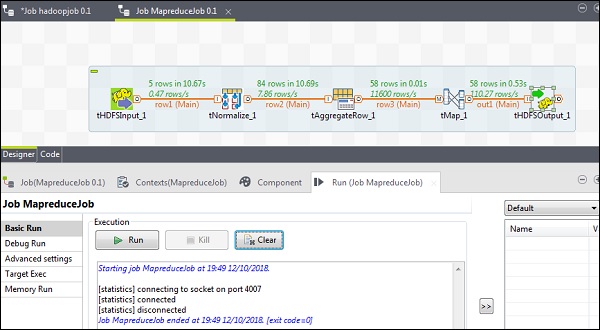
转到您的 HDFS 路径并检查输出。请注意,所有单词都将大写,并带有它们的字数。
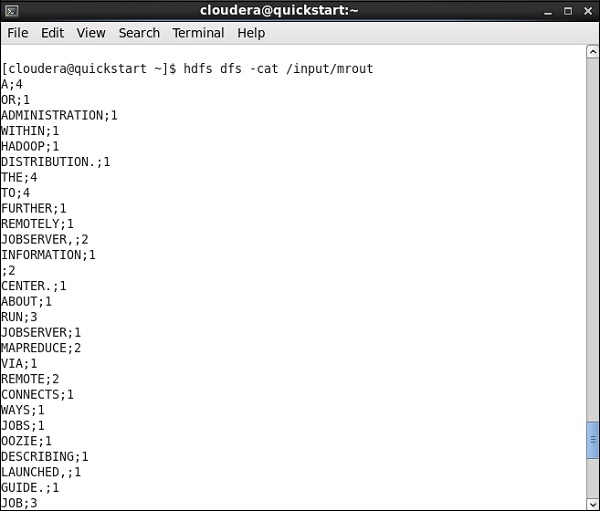
Talend - 使用 Pig
在本章中,让我们学习如何在 Talend 中使用 Pig 作业。
创建 Talend Pig 作业
在本节中,让我们学习如何在 Talend 上运行 Pig 作业。在这里,我们将处理 NYSE 数据以找出 IBM 的平均股票成交量。
为此,请右键单击“作业设计”,创建一个新作业 - pigjob。提及作业的详细信息,然后单击“完成”。
向 Pig 作业添加组件
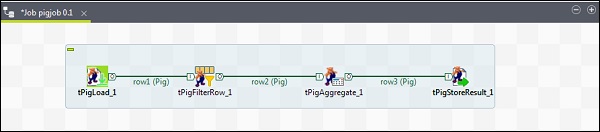
要向 Pig 作业添加组件,请从调色板将四个 Talend 组件:tPigLoad、tPigFilterRow、tPigAggregate、tPigStoreResult 拖放到设计器窗口。
然后,右键单击 tPigLoad 并创建 Pig 组合行到 tPigFilterRow。接下来,右键单击 tPigFilterRow 并创建 Pig 组合行到 tPigAggregate。右键单击 tPigAggregate 并创建 Pig 组合行到 tPigStoreResult。
配置组件和转换
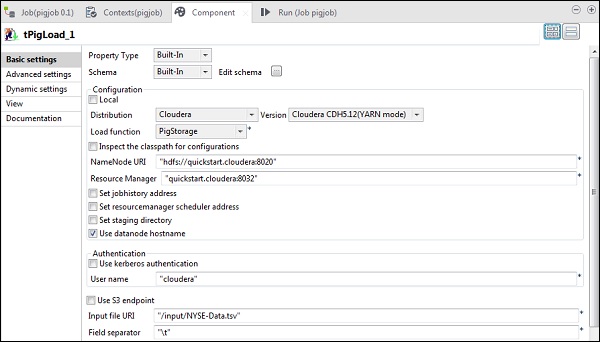
在 tPigLoad 中,将分布式设置为 cloudera 和 cloudera 的版本。请注意,NameNode URI 应为“hdfs://quickstart.cloudera:8020”,资源管理器应为“quickstart.cloudera:8020”。此外,用户名应为“cloudera”。
在输入文件 URI 中,提供您的 NYSE 输入文件到 pig 作业的路径。请注意,此输入文件应存在于 HDFS 上。
单击“编辑模式”,添加列及其类型,如下所示。
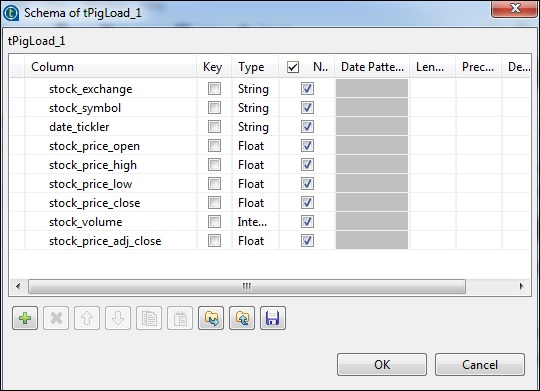
在 tPigFilterRow 中,选择“使用高级过滤器”选项,并在“过滤器”选项中输入“stock_symbol == ‘IBM’”。
在 tAggregateRow 中,单击“编辑模式”并在输出中添加 avg_stock_volume 列,如下所示。
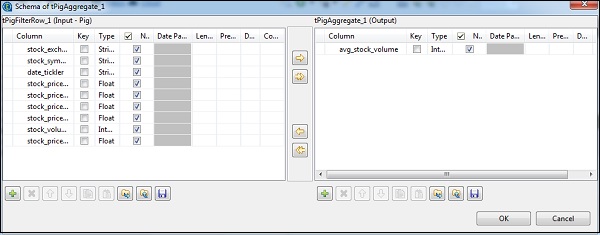
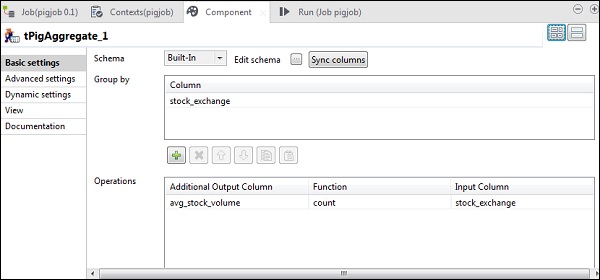
现在,将 stock_exchange 列放在“分组依据”选项中。使用 count 函数和 stock_exchange 作为输入列,在“操作”字段中添加 avg_stock_volume 列。
在 tPigStoreResult 中,在“结果文件夹 URI”中提供要存储 Pig 作业结果的输出路径。选择 store 函数为 PigStorage,字段分隔符(非强制性)为“\t”。
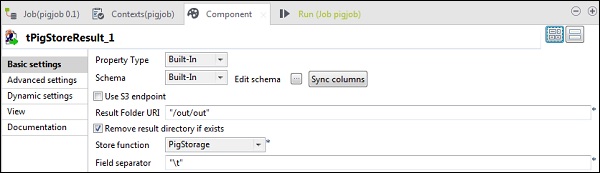
执行 Pig 作业
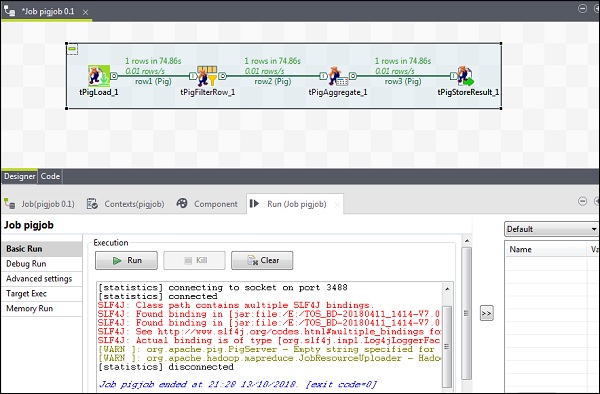
现在单击“运行”以执行您的 Pig 作业。(忽略警告)
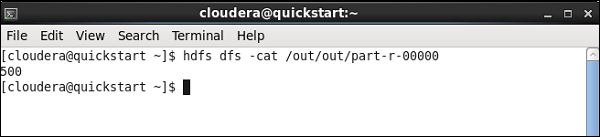
作业完成后,转到您提到的用于存储 pig 作业结果的 HDFS 路径并检查您的输出。IBM 的平均股票成交量为 500。
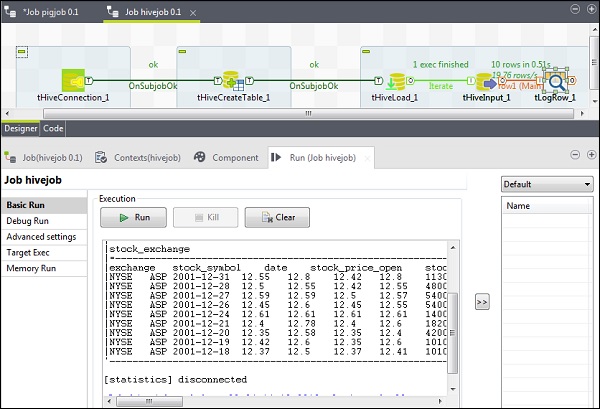
Talend - Hive
在本章中,让我们了解如何在 Talend 中使用 Hive 作业。
创建 Talend Hive 作业
例如,我们将 NYSE 数据加载到 Hive 表中并运行基本的 Hive 查询。右键单击“作业设计”,创建一个新作业 - hivejob。提及作业的详细信息,然后单击“完成”。
向 Hive 作业添加组件
要向 Hive 作业添加组件,请从调色板将五个 Talend 组件 - tHiveConnection、tHiveCreateTable、tHiveLoad、tHiveInput 和 tLogRow 拖放到设计器窗口。然后,右键单击 tHiveConnection 并创建 OnSubjobOk 触发器到 tHiveCreateTable。现在,右键单击 tHiveCreateTable 并创建 OnSubjobOk 触发器到 tHiveLoad。右键单击 tHiveLoad 并创建迭代触发器到 tHiveInput。最后,右键单击 tHiveInput 并创建到 tLogRow 的主线。
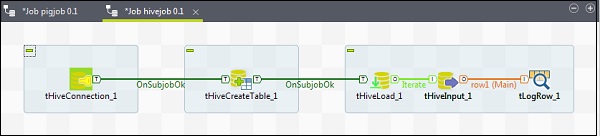
配置组件和转换
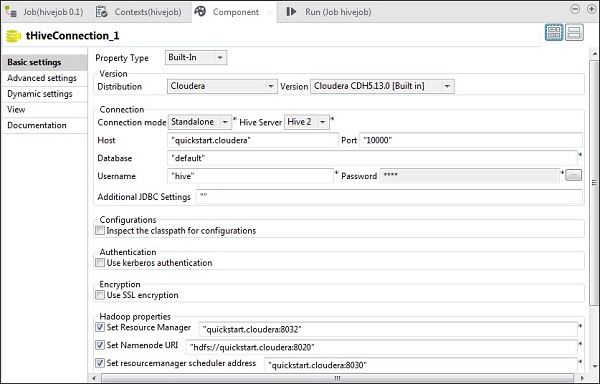
在 tHiveConnection 中,选择分布式为 cloudera 及其正在使用的版本。请注意,连接模式将是独立的,Hive 服务将是 Hive 2。还要检查以下参数是否已相应设置 -
- 主机:“quickstart.cloudera”
- 端口:“10000”
- 数据库:“default”
- 用户名:“hive”
请注意,密码将自动填充,无需编辑。其他Hadoop属性也将预设并默认设置。
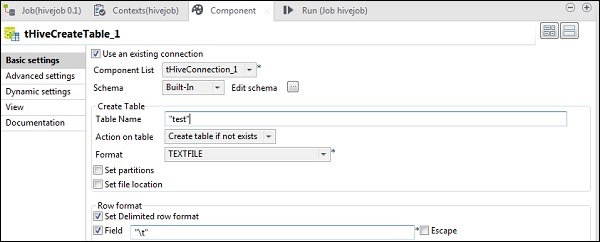
在tHiveCreateTable中,选择“使用现有连接”,并将tHiveConnection放入组件列表。在默认数据库中输入您要创建的表名。保持其他参数如下所示。
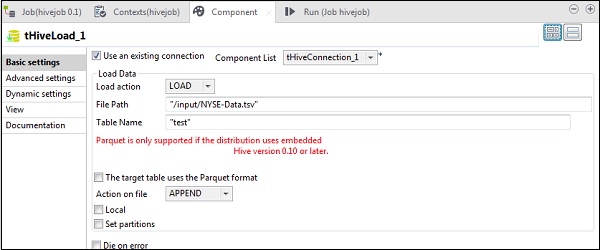
在tHiveLoad中,选择“使用现有连接”,并将tHiveConnection放入组件列表。在加载操作中选择LOAD。在“文件路径”中,输入NYSE输入文件的HDFS路径。在“表名”中指定您要加载输入数据的表。保持其他参数如下所示。
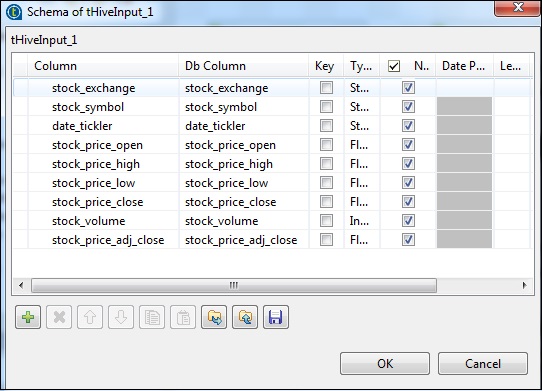
在tHiveInput中,选择“使用现有连接”,并将tHiveConnection放入组件列表。点击编辑模式,添加列及其类型,如下面的模式快照所示。现在输入您在tHiveCreateTable中创建的表名。
在查询选项中输入您想在Hive表上运行的查询。这里我们打印测试Hive表中前10行的所有列。
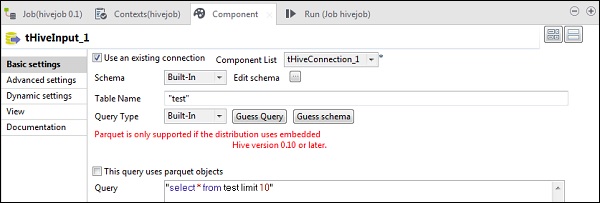
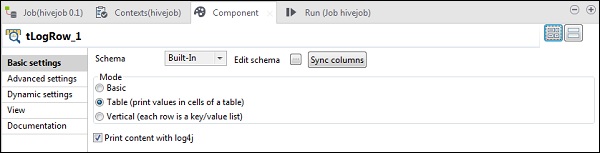
在tLogRow中,点击同步列,并选择表模式以显示输出。
执行Hive作业
点击“运行”开始执行。如果所有连接和参数都设置正确,您将看到如下所示的查询输出。