
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 语言编程
C 语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP在 Keras 中训练神经网络的最优轮数
简介
训练神经网络包括找到欠拟合和过拟合之间的适当平衡。在本文中,我们将学习“轮数”的概念,并深入探讨如何确定轮数,这是一个众所周知的深度学习库。通过了解欠拟合和过拟合之间的权衡,利用诸如提前停止和交叉验证等方法,并考虑学习曲线,我们可以成功地确定最佳轮数。
了解轮数
轮数指的是整个训练数据集通过神经网络的一次完整传递。在每个轮数中,网络从训练数据中学习并更新其内部参数(例如权重和偏差),以提高其性能。训练神经网络的目的是最小化损失函数,该函数评估网络预测与实际目标之间的一致性。
权衡:欠拟合和过拟合
在深入探讨最佳轮数之前,让我们了解一下欠拟合和过拟合之间的权衡。
欠拟合:当模型无法捕捉训练数据中的基本模式时,就会发生这种情况。它会导致训练误差高,并且泛化到未见数据的能力差。当模型过于简单或训练轮数不足时,可能会发生欠拟合。
过拟合:另一方面,过拟合发生在模型过于专门化于训练数据并且无法很好地泛化到新数据时。过拟合的特点是训练误差低,但验证误差高。当模型过于复杂或训练轮数过多时,就会发生这种情况。
最优轮数的实现代码
算法
步骤 1:导入必要的库,即 TensorFlow 和 Keras。
步骤 2:定义输入数据和神经网络模型。
步骤 3:使用合适的函数、优化器和指标编译代码。
步骤 4:使用回调函数设置提前停止条件,以监控验证损失。
步骤 5:使用提前停止回调训练模型,以便在验证损失不再改进时停止训练。
步骤 6:检索提前停止训练时的最佳轮数,代表模型的最佳点。
示例
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import EarlyStopping
X_train = np.random.random((1000, 10))
y_train = np.random.randint(2, size=(1000,))
X_val = np.random.random((200, 10))
y_val = np.random.randint(2, size=(200,))
num_classes = 2
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(10,)))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss', patience=5, verbose=1, restore_best_weights=True)
history = model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=100, batch_size=32, callbacks=[early_stopping])
optimal_epochs = early_stopping.stopped_epoch + 1
print("Optimal number of epochs:", optimal_epochs)
输出
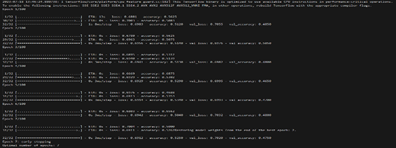
学习曲线
它们是显示性能的图表,包括训练和验证输入作为轮数的函数。它们以可视化的方式展现了模型随时间推移的学习情况,并且对于确定最佳轮数很有价值。
欠拟合:在欠拟合的情况下,学习曲线逐渐趋于平缓,即使增加轮数,训练和验证误差仍然很高。这表明模型需要更大的容量或更多的训练数据来捕捉基本模式。
过拟合:当模型开始过拟合时,学习曲线会发生偏差,训练误差减少而验证误差增加。当模型过度学习训练数据时,就会发生这种情况,导致泛化能力差。
最佳点:最佳轮数位于学习曲线稳定且验证误差最低的点。此时,模型已经学习了数据中的基本模式,而不会出现过拟合。
结论
总之,确定在 Keras 中训练神经网络的最优轮数是实现良好模型性能的关键步骤。通过平衡欠拟合和过拟合之间的权衡,利用诸如提前停止和观察学习曲线等方法,并考虑交叉验证,您可以找到适合您问题的最佳轮数。请记住,超参数调整和经验实验对于优化神经网络的性能至关重要。

258 次浏览
