
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP适合初学者的十大机器学习算法
引言
在一个几乎所有手工操作都机械化的世界里,手工操作的定义正在不断发展。如今,有许多不同类型的机器学习算法可用,其中一些可以帮助计算机学习、变得更聪明,并且更像人类。由于现在的技术发展迅速,可以通过观察计算机随时间的变化来预测未来。
在这些极具活力的时代,已经开发出许多不同的机器学习算法来帮助解决复杂的现实世界问题。自动的、自我修正的ML算法会随着时间的推移而改进。在介绍每个人都应该熟悉的十大机器学习算法之前,让我们先看看各种类型的机器学习算法及其分类。
机器学习算法分为四种类型:
监督学习
无监督学习
半监督学习
强化学习
这四种ML算法类型又细分为其他类别。
适合初学者的十大机器学习算法
线性回归
逻辑回归
决策树
K近邻分类 (KNN)
循环神经网络 (RNN)
支持向量机 (SVM)
随机森林
K均值聚类
朴素贝叶斯定理
人工神经网络
1. 线性回归
该算法最初是在统计学中开发的,用于研究输入变量和数值变量之间的关系,后来被机器学习社区采用,用于基于线性回归方程进行预测。
线性回归的数学定义是一个线性方程,它结合一组特定的输入数据 (x) 来预测该组输入值的输出值 (y)。线性方程为每一组输入值赋予一个因子。这些因子称为系数,用希腊字母 Beta (β) 表示。
具有两组输入值 x1 和 x2 的线性回归模型由以下方程表示。线性方程的系数为 0、1 和 2,y 表示模型的输出。
y = β0 + β1x1 + β2x2
当只有一个输入变量时,线性方程表示一条直线。为简化起见,假设 x2 对线性回归模型的结果没有影响,并且 β2 等于零。在这种情况下,线性回归将显示为一条直线,其方程如下所示。
y = β0 + β1x1
以下是线性回归方程模型的图表。(此处应插入图表)

可以使用线性回归来发现股票随时间的整体价格趋势。这有助于确定价格变化是持续上涨还是下跌。
2. 逻辑回归
逻辑回归用于根据一组自变量估计离散值(通常是二元值,如 0/1)。它通过将数据转换为 logit 函数来帮助预测事件的可能性,有时也称为 logit 回归。
以下技术通常用于改进逻辑回归模型:
加入交互项
移除特征
使用非线性模型
正则化方法
以下方程产生 sigmoid/逻辑函数。
y = 1 / (1+ e-x)
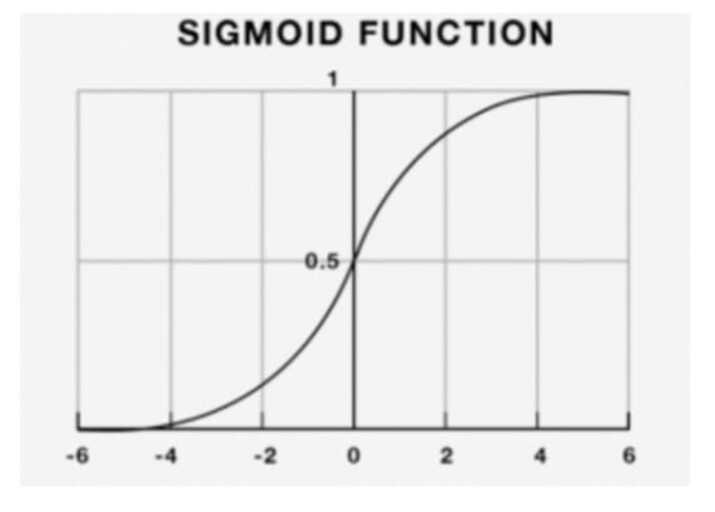
简单来说,逻辑回归可以用来预测市场的走向。
3. 决策树
决策树本质上是一个类似树状的辅助工具,可以用来表示一个原因及其影响。它可以有效地对离散和连续的因变量进行分类。这种方法根据最重要的特征或自变量将总体划分为两个或多个同质集合。
由于其固有的结构系统,决策树具有容易过拟合的缺点。
4. K近邻分类 (KNN)
这种方法可以解决分类和回归问题。在数据科学领域,似乎更常用于解决分类问题。这是一个简单的算法,通过至少获得k个邻居的同意来对新实例进行分类,然后保存所有现有案例。然后将该案例分配给与其最相似的类别。这使用距离函数来计算。
与现实相比,KNN很容易理解。例如,如果我们想更多地了解某人,与该人的朋友和同事交谈是有道理的。
在使用K近邻算法之前,请考虑以下因素:
为了避免算法偏差,应该对范围较大的变量进行归一化。
仍然需要数据预处理。
KNN的计算成本很高。
5. 循环神经网络 (RNN)
RNN是一种特殊类型的神经网络,每个节点都附加一个内存,它简化了顺序数据的处理,其中每个数据单元都依赖于其前面的单元。RNN优于普通神经网络的好处可以用这样一个事实来解释:一个单词需要逐字处理。在一个普通的神经网络中,当它到达字母“d”时,一个节点会忘记单词“trade”中的字母“t”,但是在一个循环神经网络中,一个节点会记住这个字母,因为它有自己的内存。
6. 支持向量机 (SVM)
SVM方法可以通过将原始数据表示为n维空间中的点来对数据进行分类(其中n是特征的数量)。然后,在将每个特征的值连接到特定坐标后,可以轻松地对数据进行分类。分类线可以用来将数据分成组并在图表上绘制它们。
SVM算法会产生一个超平面,作为类别之间的分界线。SVM算法会评估一个新的数据点,并根据它出现在哪一边进行分类。
7. 随机森林
为了解决决策树的一些缺点,创建了随机森林算法。
随机森林包括决策树,它们是表达其行动过程或统计概率的决策图。这些多棵树用于形成分类和回归 (CART) 模型,这是一个单棵树。每棵树都会分配一个分类,称为该类别的“投票”,以便根据其属性对项目进行分类。然后,森林会选择获得最多票数的分类。回归会考虑来自不同树的结果的平均值。
根据以下内容,随机森林的工作原理:
假设共有 N 个案例。训练集被选择为这 N 个示例的子集。
假设有 M 个输入变量,则选择 m,使得 m ≤ M。使用 m 和 M 之间的最佳分割来分割节点。随着树木的增大,m 的数量保持不变。
最大化每棵树的大小。
通过组合 n 棵树的预测来预测新数据(即,分类的多数投票,回归的平均值)。
8. K均值聚类
这是一种无监督学习方法,用于处理聚类问题。将数据集划分为预定数量的聚类(例如,K),以确保每个聚类中的数据点是同质的,并且与其他聚类中的数据点分开。
9. 朴素贝叶斯定理
朴素贝叶斯分类器的核心思想是,一个特征在一个类中的存在不会影响任何其他特征的存在。
朴素贝叶斯分类器在确定特定结果的概率时,会分别考虑每个属性,即使这些特征彼此相关。对于大型数据集,朴素贝叶斯模型有效且易于构建。尽管简单,但它已被证明甚至优于最复杂的分类方法。
10. 人工神经网络
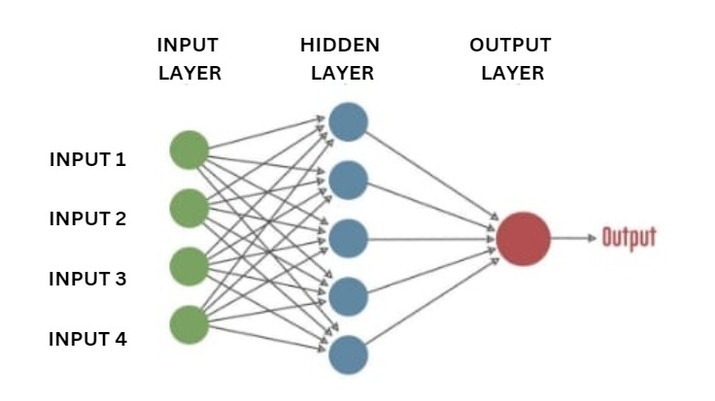
我们的一个重大成就就是人工神经网络。如图所示,我们建立了许多相互连接的节点,以代表我们大脑中的神经元。简单来说,每个神经元接收来自另一个神经元的信息,对其进行处理,然后将结果作为输出发送到另一个神经元。
每个圆形节点代表一个人工神经元,一个神经元的输出与另一个神经元的输入之间的连接由箭头表示。
结论
以上列出了任何数据科学家都必须熟悉的十种机器学习算法。选择哪种数据科学算法是一个非常常见的问题,尤其对于该领域的初学者。此组件的正确选择完全取决于一些关键因素,例如数据的大小、质量水平、类型、可用的处理时间、工作优先级以及数据的预期用途。
为了获得最佳结果,请选择上述任何一种算法,无论您在数据科学领域的技能水平如何。

243 次浏览
