- Unix/Linux 初学者指南
- Unix/Linux - 首页
- Unix/Linux - 什么是Linux?
- Unix/Linux - 入门指南
- Unix/Linux - 文件管理
- Unix/Linux - 目录
- Unix/Linux - 文件权限
- Unix/Linux - 环境
- Unix/Linux - 基本实用程序
- Unix/Linux - 管道和过滤器
- Unix/Linux - 进程
- Unix/Linux - 通信
- Unix/Linux - vi 编辑器
- Unix/Linux Shell 编程
- Unix/Linux - Shell 脚本
- Unix/Linux - 什么是 Shell?
- Unix/Linux - 使用变量
- Unix/Linux - 特殊变量
- Unix/Linux - 使用数组
- Unix/Linux - 基本运算符
- Unix/Linux - 决策
- Unix/Linux - Shell 循环
- Unix/Linux - 循环控制
- Unix/Linux - Shell 替换
- Unix/Linux - 引号机制
- Unix/Linux - I/O 重定向
- Unix/Linux - Shell 函数
- Unix/Linux - 手册页帮助
- 高级 Unix/Linux
- Unix/Linux - 标准 I/O 流
- Unix/Linux - 文件链接
- Unix/Linux - 正则表达式
- Unix/Linux - 文件系统基础
- Unix/Linux - 用户管理
- Unix/Linux - 系统性能
- Unix/Linux - 系统日志
- Unix/Linux - 信号和陷阱
Unix/Linux 快速指南
Unix - 入门指南
什么是 Unix?
Unix 操作系统是一组程序,充当计算机和用户之间的桥梁。
分配系统资源并协调计算机内部所有细节的计算机程序称为操作系统或内核。
用户通过一个称为shell的程序与内核通信。Shell 是一个命令行解释器;它翻译用户输入的命令,并将它们转换为内核能够理解的语言。
Unix 最初由贝尔实验室的 AT&T 员工 Ken Thompson、Dennis Ritchie、Douglas McIlroy 和 Joe Ossanna 于 1969 年开发。
市场上有各种 Unix 变体。Solaris Unix、AIX、HP Unix 和 BSD 是一些例子。Linux 也是一种免费提供的 Unix 变体。
多个人可以同时使用一台 Unix 计算机;因此,Unix 被称为多用户系统。
用户还可以同时运行多个程序;因此,Unix 是一个多任务环境。
Unix 架构
以下是 Unix 系统的基本框图:
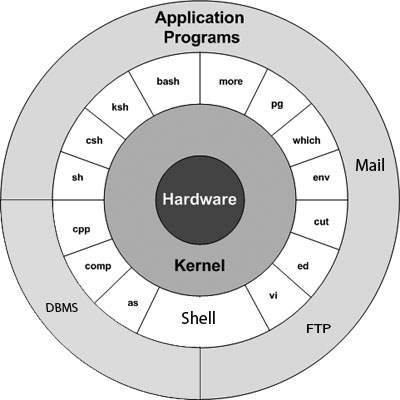
统一所有 Unix 版本的主要概念是以下四个基础:
内核 - 内核是操作系统的核心。它与硬件交互,并执行大多数任务,例如内存管理、任务调度和文件管理。
Shell - Shell 是处理您请求的实用程序。当您在终端输入命令时,Shell 会解释该命令并调用您想要的程序。Shell 对所有命令使用标准语法。C Shell、Bourne Shell 和 Korn Shell 是最著名的 Shell,大多数 Unix 变体都提供这些 Shell。
命令和实用程序 - 您可以使用各种命令和实用程序来完成日常活动。cp、mv、cat 和 grep 等是命令和实用程序的一些示例。除了 250 多个标准命令之外,第三方软件还提供了许多其他命令。所有命令都附带各种选项。
文件和目录 - Unix 的所有数据都组织成文件。所有文件都组织成目录。这些目录进一步组织成一个称为文件系统的树状结构。
系统启动
如果您有一台安装了 Unix 操作系统的计算机,则只需打开系统即可使其运行。
打开系统后,它就开始启动,最后提示您登录系统,这是一种登录系统并将其用于日常活动的活动。
登录 Unix
首次连接到 Unix 系统时,通常会看到如下所示的提示:
login:
登录
准备好您的用户 ID(用户标识)和密码。如果您还没有这些信息,请联系您的系统管理员。
在登录提示符处键入您的用户 ID,然后按ENTER。您的用户 ID区分大小写,因此请确保您完全按照系统管理员的指示键入。
在密码提示符处键入您的密码,然后按ENTER。您的密码也区分大小写。
如果您提供了正确的用户 ID 和密码,则允许您进入系统。阅读屏幕上显示的信息和消息,如下所示。
login : amrood amrood's password: Last login: Sun Jun 14 09:32:32 2009 from 62.61.164.73 $
系统将为您提供命令提示符(有时称为$提示符),您可以在其中键入所有命令。例如,要查看日历,您需要键入cal命令,如下所示:
$ cal
June 2009
Su Mo Tu We Th Fr Sa
1 2 3 4 5 6
7 8 9 10 11 12 13
14 15 16 17 18 19 20
21 22 23 24 25 26 27
28 29 30
$
更改密码
所有 Unix 系统都需要密码,以帮助确保您的文件和数据仍然属于您,并且系统本身免受黑客和破解者的攻击。以下是更改密码的步骤:
步骤 1 - 首先,在命令提示符处键入 password,如下所示。
步骤 2 - 输入您的旧密码,即您当前使用的密码。
步骤 3 - 输入您的新密码。始终使您的密码足够复杂,以防止任何人猜测。但请确保您记住它。
步骤 4 - 您必须通过再次键入密码来验证它。
$ passwd Changing password for amrood (current) Unix password:****** New UNIX password:******* Retype new UNIX password:******* passwd: all authentication tokens updated successfully $
注意 - 我们在这里添加了星号 (*) 只是为了显示您需要输入当前和新密码的位置,否则在您的系统上,它不会显示您键入的任何字符。
列出目录和文件
Unix 中的所有数据都组织成文件。所有文件都组织成目录。这些目录组织成一个称为文件系统的树状结构。
您可以使用ls命令列出目录中所有可用的文件或目录。以下是使用ls命令和-l选项的示例。
$ ls -l total 19621 drwxrwxr-x 2 amrood amrood 4096 Dec 25 09:59 uml -rw-rw-r-- 1 amrood amrood 5341 Dec 25 08:38 uml.jpg drwxr-xr-x 2 amrood amrood 4096 Feb 15 2006 univ drwxr-xr-x 2 root root 4096 Dec 9 2007 urlspedia -rw-r--r-- 1 root root 276480 Dec 9 2007 urlspedia.tar drwxr-xr-x 8 root root 4096 Nov 25 2007 usr -rwxr-xr-x 1 root root 3192 Nov 25 2007 webthumb.php -rw-rw-r-- 1 amrood amrood 20480 Nov 25 2007 webthumb.tar -rw-rw-r-- 1 amrood amrood 5654 Aug 9 2007 yourfile.mid -rw-rw-r-- 1 amrood amrood 166255 Aug 9 2007 yourfile.swf $
此处以d.....开头的条目表示目录。例如,uml、univ 和 urlspedia 是目录,其余条目是文件。
您是谁?
在您登录系统时,您可能想知道:我 是 谁?
查找“您是谁”的最简单方法是输入whoami命令:
$ whoami amrood $
在您的系统上试一试。此命令列出与当前登录关联的帐户名。您也可以尝试who am i命令来获取有关您自己的信息。
谁已登录?
有时您可能想知道同时谁登录到计算机。
有三个命令可用于获取此信息,具体取决于您希望了解其他用户的信息量:users、who 和 w。
$ users amrood bablu qadir $ who amrood ttyp0 Oct 8 14:10 (limbo) bablu ttyp2 Oct 4 09:08 (calliope) qadir ttyp4 Oct 8 12:09 (dent) $
在您的系统上尝试w命令以检查输出。这将列出与登录到系统中的用户关联的信息。
注销
完成会话后,您需要注销系统。这样做是为了确保没有人访问您的文件。
注销
只需在命令提示符处键入logout命令,系统就会清理所有内容并断开连接。
系统关机
通过命令行正确关闭 Unix 系统最一致的方法是使用以下命令之一:
| 序号 | 命令和说明 |
|---|---|
| 1 |
halt 立即关闭系统 |
| 2 |
init 0 使用预定义脚本关闭系统,以在关闭之前同步和清理系统 |
| 3 |
init 6 通过完全关闭系统然后重新启动系统来重新启动系统 |
| 4 |
poweroff 通过关闭电源关闭系统 |
| 5 |
reboot 重新启动系统 |
| 6 |
shutdown 关闭系统 |
您通常需要是超级用户或 root(Unix 系统上权限最高的帐户)才能关闭系统。但是,在某些独立或个人拥有的 Unix 计算机上,管理员用户有时甚至普通用户也可以这样做。
Unix - 文件管理
在本章中,我们将详细讨论 Unix 中的文件管理。Unix 中的所有数据都组织成文件。所有文件都组织成目录。这些目录组织成一个称为文件系统的树状结构。
在使用 Unix 时,您或多或少会花费大部分时间处理文件。本教程将帮助您了解如何创建和删除文件、复制和重命名文件、创建指向它们的链接等。
在 Unix 中,有三种基本类型的文件:
普通文件 - 普通文件是系统上的文件,其中包含数据、文本或程序指令。在本教程中,您将了解如何处理普通文件。
目录 - 目录存储特殊文件和普通文件。对于熟悉 Windows 或 Mac OS 的用户,Unix 目录等效于文件夹。
特殊文件 - 一些特殊文件提供对硬件的访问,例如硬盘驱动器、CD-ROM 驱动器、调制解调器和以太网适配器。其他特殊文件类似于别名或快捷方式,使您可以使用不同的名称访问单个文件。
列出文件
要列出当前目录中存储的文件和目录,请使用以下命令:
$ls
以下是上述命令的示例输出:
$ls bin hosts lib res.03 ch07 hw1 pub test_results ch07.bak hw2 res.01 users docs hw3 res.02 work
ls命令支持-l选项,这将帮助您获取有关已列出文件的更多信息:
$ls -l total 1962188 drwxrwxr-x 2 amrood amrood 4096 Dec 25 09:59 uml -rw-rw-r-- 1 amrood amrood 5341 Dec 25 08:38 uml.jpg drwxr-xr-x 2 amrood amrood 4096 Feb 15 2006 univ drwxr-xr-x 2 root root 4096 Dec 9 2007 urlspedia -rw-r--r-- 1 root root 276480 Dec 9 2007 urlspedia.tar drwxr-xr-x 8 root root 4096 Nov 25 2007 usr drwxr-xr-x 2 200 300 4096 Nov 25 2007 webthumb-1.01 -rwxr-xr-x 1 root root 3192 Nov 25 2007 webthumb.php -rw-rw-r-- 1 amrood amrood 20480 Nov 25 2007 webthumb.tar -rw-rw-r-- 1 amrood amrood 5654 Aug 9 2007 yourfile.mid -rw-rw-r-- 1 amrood amrood 166255 Aug 9 2007 yourfile.swf drwxr-xr-x 11 amrood amrood 4096 May 29 2007 zlib-1.2.3 $
以下是所有已列出列的信息:
第一列 − 表示文件类型和文件赋予的权限。以下是所有文件类型的描述。
第二列 − 表示文件或目录占用的内存块数量。
第三列 − 表示文件的拥有者。这是创建此文件的 Unix 用户。
第四列 − 表示拥有者的组。每个 Unix 用户都将有一个关联的组。
第五列 − 表示文件大小(以字节为单位)。
第六列 − 表示此文件创建或最后修改的日期和时间。
第七列 − 表示文件或目录名称。
在 ls -l 列表示例中,每行文件都以 d、- 或 l 开头。这些字符指示所列文件类型。
| 序号 | 前缀 & 描述 |
|---|---|
| 1 |
- 普通文件,例如 ASCII 文本文件、二进制可执行文件或硬链接。 |
| 2 |
b 块特殊文件。块输入/输出设备文件,例如物理硬盘。 |
| 3 |
c 字符特殊文件。原始输入/输出设备文件,例如物理硬盘。 |
| 4 |
d 目录文件,包含其他文件和目录的列表。 |
| 5 |
l 符号链接文件。任何普通文件的链接。 |
| 6 |
p 命名管道。进程间通信的机制。 |
| 7 |
s 用于进程间通信的套接字。 |
元字符
元字符在 Unix 中具有特殊含义。例如,* 和 ? 是元字符。我们使用 * 匹配 0 个或多个字符,问号 (?) 匹配单个字符。
例如 −
$ls ch*.doc
显示所有以 ch 开头并以 .doc 结尾的文件名 −
ch01-1.doc ch010.doc ch02.doc ch03-2.doc ch04-1.doc ch040.doc ch05.doc ch06-2.doc ch01-2.doc ch02-1.doc c
这里,* 用作元字符,匹配任何字符。如果要显示所有以 .doc 结尾的文件,则可以使用以下命令 −
$ls *.doc
隐藏文件
隐藏文件是指第一个字符为点或句点字符 (.) 的文件。Unix 程序(包括 shell)使用大多数这些文件来存储配置信息。
一些常见的隐藏文件示例包括以下文件 −
.profile − Bourne shell (sh) 初始化脚本
.kshrc − Korn shell (ksh) 初始化脚本
.cshrc − C shell (csh) 初始化脚本
.rhosts − 远程 shell 配置文件
要列出隐藏文件,请为 ls 指定 -a 选项 −
$ ls -a . .profile docs lib test_results .. .rhosts hosts pub users .emacs bin hw1 res.01 work .exrc ch07 hw2 res.02 .kshrc ch07.bak hw3 res.03 $
单点 (.) − 表示当前目录。
双点 (..) − 表示父目录。
创建文件
您可以使用 vi 编辑器在任何 Unix 系统上创建普通文件。您只需执行以下命令 −
$ vi filename
上述命令将打开一个具有给定文件名的文件。现在,按 i 键进入编辑模式。进入编辑模式后,您可以在文件中开始编写内容,如下面的程序所示 −
This is unix file....I created it for the first time..... I'm going to save this content in this file.
完成程序后,请执行以下步骤 −
按 esc 键退出编辑模式。
同时按下 Shift + ZZ 两个键以完全退出文件。
您现在将在当前目录中创建一个名为 filename 的文件。
$ vi filename $
编辑文件
您可以使用 vi 编辑器编辑现有文件。我们将简要讨论如何打开现有文件 −
$ vi filename
文件打开后,您可以通过按 i 键进入编辑模式,然后继续编辑文件。如果要在此文件中四处移动,则首先需要通过按 Esc 键退出编辑模式。之后,您可以使用以下键在文件中移动 −
l 键向右移动。
h 键向左移动。
k 键向上移动文件。
j 键向下移动文件。
因此,使用上述键,您可以将光标定位在要编辑的任何位置。定位后,您可以使用 i 键进入编辑模式。完成文件编辑后,按 Esc,最后同时按下 Shift + ZZ 两个键以完全退出文件。
显示文件内容
您可以使用 cat 命令查看文件的内容。以下是一个简单的示例,用于查看上面创建的文件的内容 −
$ cat filename This is unix file....I created it for the first time..... I'm going to save this content in this file. $
您可以通过使用 -b 选项以及 cat 命令来显示行号,如下所示 −
$ cat -b filename 1 This is unix file....I created it for the first time..... 2 I'm going to save this content in this file. $
计算文件中的单词
您可以使用 wc 命令获取文件中包含的行、单词和字符的总数。以下是一个简单的示例,用于查看上面创建的文件的信息 −
$ wc filename 2 19 103 filename $
以下是所有四列的详细信息 −
第一列 − 表示文件中行的总数。
第二列 − 表示文件中单词的总数。
第三列 − 表示文件中字节的总数。这是文件的实际大小。
第四列 − 表示文件名。
您可以提供多个文件,并一次获取有关这些文件的信息。以下是一个简单的语法 −
$ wc filename1 filename2 filename3
复制文件
要复制文件,请使用 cp 命令。该命令的基本语法如下 −
$ cp source_file destination_file
以下是如何创建现有文件 filename 副本的示例。
$ cp filename copyfile $
您现在将在当前目录中找到另一个文件 copyfile。此文件将与原始文件 filename 完全相同。
重命名文件
要更改文件名,请使用 mv 命令。以下为基本语法 −
$ mv old_file new_file
以下程序将现有文件 filename 重命名为 newfile。
$ mv filename newfile $
mv 命令将完全将现有文件移动到新文件。在这种情况下,您将在当前目录中仅找到 newfile。
删除文件
要删除现有文件,请使用 rm 命令。以下为基本语法 −
$ rm filename
注意 − 文件可能包含有用的信息。在使用此 删除 命令时,始终建议谨慎操作。最好将 -i 选项与 rm 命令一起使用。
以下示例显示了如何完全删除现有文件 filename。
$ rm filename $
您可以使用以下命令一次删除多个文件 −
$ rm filename1 filename2 filename3 $
标准 Unix 流
在正常情况下,每个 Unix 程序在启动时都会为其打开三个流(文件)−
stdin − 这称为 标准输入,关联的文件描述符为 0。这也表示为 STDIN。Unix 程序将从 STDIN 读取默认输入。
stdout − 这称为 标准输出,关联的文件描述符为 1。这也表示为 STDOUT。Unix 程序将在 STDOUT 写入默认输出
stderr − 这称为 标准错误,关联的文件描述符为 2。这也表示为 STDERR。Unix 程序将在 STDERR 写入所有错误消息。
Unix - 目录管理
在本章中,我们将详细讨论 Unix 中的目录管理。
目录是一个文件,其唯一工作是存储文件名和相关信息。所有文件,无论是普通文件、特殊文件还是目录文件,都包含在目录中。
Unix 使用分层结构来组织文件和目录。这种结构通常称为目录树。树有一个根节点,即斜杠字符 (/),所有其他目录都包含在其下方。
主目录
您第一次登录时所在的目录称为您的主目录。
您将在主目录和您将创建的子目录中完成大部分工作,以组织您的文件。
您可以随时使用以下命令进入您的主目录 −
$cd ~ $
这里 ~ 表示主目录。假设您必须进入任何其他用户的主目录,请使用以下命令 −
$cd ~username $
要进入您的上一个目录,您可以使用以下命令 −
$cd - $
绝对/相对路径名
目录以根 (/) 为顶层进行分层排列。文件在层次结构中的位置由其路径名描述。
路径名的元素由 / 分隔。如果路径名相对于根进行描述,则该路径名为绝对路径名,因此绝对路径名始终以 / 开头。
以下是一些绝对文件名的示例。
/etc/passwd /users/sjones/chem/notes /dev/rdsk/Os3
路径名也可以相对于您当前的工作目录。相对路径名永远不会以 / 开头。相对于用户 amrood 的主目录,一些路径名可能如下所示 −
chem/notes personal/res
要随时确定您在文件系统层次结构中的位置,请输入 pwd 命令以打印当前工作目录 −
$pwd /user0/home/amrood $
列出目录
要列出目录中的文件,您可以使用以下语法 −
$ls dirname
以下是如何列出 /usr/local 目录中所有文件的示例 −
$ls /usr/local X11 bin gimp jikes sbin ace doc include lib share atalk etc info man ami
创建目录
我们现在将了解如何创建目录。目录由以下命令创建 −
$mkdir dirname
这里,directory 是要创建的目录的绝对或相对路径名。例如,命令 −
$mkdir mydir $
在当前目录中创建目录 mydir。以下为另一个示例 −
$mkdir /tmp/test-dir $
此命令在 /tmp 目录中创建目录 test-dir。如果 mkdir 成功创建了请求的目录,则不会产生任何输出。
如果在命令行上提供多个目录,则 mkdir 将创建每个目录。例如,−
$mkdir docs pub $
在当前目录下创建目录 docs 和 pub。
创建父目录
我们现在将了解如何创建父目录。有时,当您要创建目录时,其父目录或目录可能不存在。在这种情况下,mkdir 会发出以下错误消息 −
$mkdir /tmp/amrood/test mkdir: Failed to make directory "/tmp/amrood/test"; No such file or directory $
在这种情况下,您可以为 mkdir 命令指定 -p 选项。它为您创建所有必要的目录。例如 −
$mkdir -p /tmp/amrood/test $
上述命令创建所有必需的父目录。
删除目录
可以使用以下 rmdir 命令删除目录 −
$rmdir dirname $
注意 − 要删除目录,请确保它为空,这意味着此目录中不应有任何文件或子目录。
您可以一次删除多个目录,如下所示 −
$rmdir dirname1 dirname2 dirname3 $
如果上述目录为空,则上述命令将删除目录 dirname1、dirname2 和 dirname3。如果 rmdir 命令成功,则不会产生任何输出。
更改目录
您可以使用 cd 命令执行的操作不仅仅是更改为主目录。您可以使用它通过指定有效的绝对或相对路径来更改到任何目录。语法如下所示 −
$cd dirname $
这里,dirname 是要更改到的目录的名称。例如,命令 −
$cd /usr/local/bin $
对目录/usr/local/bin的更改。从此目录,您可以使用以下相对路径cd到目录/usr/home/amrood:
$cd ../../home/amrood $
重命名目录
mv(移动)命令也可以用于重命名目录。语法如下:
$mv olddir newdir $
您可以将目录mydir重命名为yourdir,方法如下:
$mv mydir yourdir $
目录 .(点)和 ..(点点)
文件名 .(点)表示当前工作目录;文件名 ..(点点)表示当前工作目录上一级目录,通常称为父目录。
如果我们输入显示当前工作目录/文件的列表的命令,并使用-a 选项列出所有文件以及-l 选项提供长列表,我们将收到以下结果。
$ls -la drwxrwxr-x 4 teacher class 2048 Jul 16 17.56 . drwxr-xr-x 60 root 1536 Jul 13 14:18 .. ---------- 1 teacher class 4210 May 1 08:27 .profile -rwxr-xr-x 1 teacher class 1948 May 12 13:42 memo $
Unix - 文件权限/访问模式
在本章中,我们将详细讨论 Unix 中的文件权限和访问模式。文件所有权是 Unix 中的一个重要组成部分,它提供了一种安全的文件存储方法。Unix 中的每个文件都具有以下属性:
所有者权限 - 所有者的权限决定了文件的所有者可以对文件执行哪些操作。
组权限 - 组的权限决定了属于该文件所属组的用户可以对文件执行哪些操作。
其他(世界)权限 - 其他用户的权限指示所有其他用户可以对文件执行哪些操作。
权限指示符
使用ls -l命令时,它会显示与文件权限相关的各种信息,如下所示:
$ls -l /home/amrood -rwxr-xr-- 1 amrood users 1024 Nov 2 00:10 myfile drwxr-xr--- 1 amrood users 1024 Nov 2 00:10 mydir
这里,第一列表示不同的访问模式,即与文件或目录关联的权限。
权限被分成三组,每组中的每个位置都表示特定的权限,顺序为:读(r)、写(w)、执行(x) -
前三个字符(2-4)表示文件所有者的权限。例如,-rwxr-xr--表示所有者具有读(r)、写(w)和执行(x)权限。
第二组三个字符(5-7)由文件所属组的权限组成。例如,-rwxr-xr--表示该组具有读(r)和执行(x)权限,但没有写权限。
最后一组三个字符(8-10)表示其他所有人的权限。例如,-rwxr-xr--表示只有读(r)权限。
文件访问模式
文件的权限是 Unix 系统安全的第一道防线。Unix 权限的基本构建块是读、写和执行权限,这些权限已在下面进行了描述:
读取
授予读取功能,即查看文件内容。
写入
授予修改或删除文件内容的功能。
执行
具有执行权限的用户可以将文件作为程序运行。
目录访问模式
目录访问模式与任何其他文件一样列出和组织。需要提到一些差异:
读取
访问目录意味着用户可以读取其内容。用户可以查看目录中的文件名。
写入
访问意味着用户可以向目录添加或删除文件。
执行
执行目录实际上没有意义,因此可以将其视为遍历权限。
用户必须对bin目录具有执行权限才能执行ls或cd命令。
更改权限
要更改文件或目录权限,可以使用chmod(更改模式)命令。使用 chmod 有两种方法——符号模式和绝对模式。
在符号模式下使用 chmod
对于初学者来说,修改文件或目录权限最简单的方法是使用符号模式。使用符号权限,您可以通过使用下表中的运算符来添加、删除或指定所需的权限集。
| 序号 | Chmod 运算符 & 描述 |
|---|---|
| 1 |
+ 将指定的权限添加到文件或目录。 |
| 2 |
- 从文件或目录中删除指定的权限。 |
| 3 |
= 设置指定的权限。 |
这是一个使用testfile的示例。对 testfile 运行ls -1显示文件的权限如下:
$ls -l testfile -rwxrwxr-- 1 amrood users 1024 Nov 2 00:10 testfile
然后对 testfile 运行前面表格中的每个示例chmod命令,然后运行ls –l,以便您可以看到权限更改:
$chmod o+wx testfile $ls -l testfile -rwxrwxrwx 1 amrood users 1024 Nov 2 00:10 testfile $chmod u-x testfile $ls -l testfile -rw-rwxrwx 1 amrood users 1024 Nov 2 00:10 testfile $chmod g = rx testfile $ls -l testfile -rw-r-xrwx 1 amrood users 1024 Nov 2 00:10 testfile
以下是如何在一行中组合这些命令:
$chmod o+wx,u-x,g = rx testfile $ls -l testfile -rw-r-xrwx 1 amrood users 1024 Nov 2 00:10 testfile
使用 chmod 和绝对权限
使用 chmod 命令修改权限的第二种方法是使用数字来指定文件的每个权限集。
每个权限都分配了一个值,如下表所示,并且每个权限集的总和为该集提供了一个数字。
| 数字 | 八进制权限表示 | 参考 |
|---|---|---|
| 0 | 无权限 | --- |
| 1 | 执行权限 | --x |
| 2 | 写权限 | -w- |
| 3 | 执行和写权限:1(执行)+ 2(写)= 3 | -wx |
| 4 | 读权限 | r-- |
| 5 | 读和执行权限:4(读)+ 1(执行)= 5 | r-x |
| 6 | 读和写权限:4(读)+ 2(写)= 6 | rw- |
| 7 | 所有权限:4(读)+ 2(写)+ 1(执行)= 7 | rwx |
这是一个使用 testfile 的示例。对 testfile 运行ls -1显示文件的权限如下:
$ls -l testfile -rwxrwxr-- 1 amrood users 1024 Nov 2 00:10 testfile
然后对 testfile 运行前面表格中的每个示例chmod命令,然后运行ls –l,以便您可以看到权限更改:
$ chmod 755 testfile $ls -l testfile -rwxr-xr-x 1 amrood users 1024 Nov 2 00:10 testfile $chmod 743 testfile $ls -l testfile -rwxr---wx 1 amrood users 1024 Nov 2 00:10 testfile $chmod 043 testfile $ls -l testfile ----r---wx 1 amrood users 1024 Nov 2 00:10 testfile
更改所有者和组
在 Unix 上创建帐户时,它会为每个用户分配一个所有者 ID和一个组 ID。上面提到的所有权限也基于所有者和组分配。
有两个命令可用于更改文件的所有者和组:
chown - chown命令代表“更改所有者”,用于更改文件的所有者。
chgrp - chgrp命令代表“更改组”,用于更改文件的组。
更改所有权
chown命令更改文件的所有权。基本语法如下:
$ chown user filelist
用户的值可以是系统上的用户名或系统上用户的用户 ID(uid)。
以下示例将帮助您理解该概念:
$ chown amrood testfile $
将给定文件的所有者更改为用户amrood。
注意 - 超级用户 root 具有更改任何文件所有权的无限制功能,但普通用户只能更改他们拥有的文件的所有权。
更改组所有权
chgrp命令更改文件组的所有权。基本语法如下:
$ chgrp group filelist
组的值可以是系统上的组名或系统上组的组 ID(GID)。
以下示例帮助您理解该概念:
$ chgrp special testfile $
将给定文件的组更改为special组。
SUID 和 SGID 文件权限
通常,当执行命令时,必须以特殊权限执行才能完成其任务。
例如,当您使用passwd命令更改密码时,新密码将存储在文件/etc/shadow中。
出于安全原因,作为普通用户,您没有对该文件的读或写访问权限,但是当您更改密码时,您需要对该文件具有写权限。这意味着passwd程序必须为您提供其他权限,以便您可以写入文件/etc/shadow。
通过称为设置用户 ID(SUID)和设置组 ID(SGID)位的机制为程序提供其他权限。
当您执行启用了 SUID 位的程序时,您将继承该程序所有者的权限。未设置 SUID 位的程序将以启动该程序的用户权限运行。
SGID 也是如此。通常,程序以您的组权限执行,但改为将您的组仅针对此程序更改为程序的组所有者。
如果权限可用,则 SUID 和 SGID 位将显示为字母“s”。SUID“s”位将位于所有者执行权限通常驻留的权限位中。
例如,命令:
$ ls -l /usr/bin/passwd -r-sr-xr-x 1 root bin 19031 Feb 7 13:47 /usr/bin/passwd* $
显示 SUID 位已设置,并且该命令由 root 拥有。执行位置中的大写字母S而不是小写字母s表示未设置执行位。
如果在目录上启用了粘滞位,则只有在您是以下用户之一时才能删除文件:
- 粘滞目录的所有者
- 正在删除的文件的所有者
- 超级用户 root
要为任何目录设置 SUID 和 SGID 位,请尝试以下命令:
$ chmod ug+s dirname $ ls -l drwsr-sr-x 2 root root 4096 Jun 19 06:45 dirname $
Unix - 环境
在本章中,我们将详细讨论 Unix 环境。一个重要的 Unix 概念是环境,它由环境变量定义。有些由系统设置,有些由您设置,还有些由 shell 或任何加载其他程序的程序设置。
变量是一个字符字符串,我们为其分配一个值。分配的值可以是数字、文本、文件名、设备或任何其他类型的数据。
例如,首先我们设置一个变量 TEST,然后我们使用echo命令访问其值:
$TEST="Unix Programming" $echo $TEST
它产生以下结果。
Unix Programming
请注意,环境变量是在不使用$符号的情况下设置的,但在访问它们时,我们使用$符号作为前缀。这些变量会保留其值,直到我们退出 shell。
当您登录到系统时,shell 会经历一个称为初始化的阶段以设置环境。这通常是一个两步过程,涉及 shell 读取以下文件:
- /etc/profile
- profile
过程如下:
shell 检查文件/etc/profile是否存在。
如果存在,shell 会读取它。否则,将跳过此文件。不会显示错误消息。
shell 检查文件.profile是否在您的主目录中存在。您的主目录是您登录后开始所在的目录。
如果存在,shell 会读取它;否则,shell 会跳过它。不会显示错误消息。
这两个文件读取完成后,shell 会显示一个提示:
$
这是您可以输入命令以执行它们的提示。
注意 - 此处详细介绍的 shell 初始化过程适用于所有Bourne类型的 shell,但bash和ksh使用一些其他文件。
.profile 文件
文件/etc/profile由 Unix 机器系统管理员维护,包含系统上所有用户所需的 shell 初始化信息。
文件.profile 由您控制。您可以在此文件中添加任意数量的 Shell 自定义信息。您需要配置的最小信息集包括:
- 您正在使用的终端类型。
- 用于查找命令的目录列表。
- 影响终端外观的一系列变量。
您可以在您的主目录中检查您的.profile。使用 vi 编辑器打开它,并检查为您的环境设置的所有变量。
设置终端类型
通常,您正在使用的终端类型会由login 或getty 程序自动配置。有时,自动配置过程会错误地猜测您的终端。
如果您的终端设置不正确,命令的输出可能看起来很奇怪,或者您可能无法正确与 Shell 交互。
为了确保不会出现这种情况,大多数用户会将其终端设置为以下最低公分母:
$TERM=vt100 $
设置 PATH
当您在命令提示符下键入任何命令时,Shell 必须在执行命令之前找到该命令。
PATH 变量指定 Shell 应在其中查找命令的位置。通常,Path 变量设置为如下:
$PATH=/bin:/usr/bin $
这里,由冒号字符(:) 分隔的每个单独的条目都是目录。如果您请求 Shell 执行命令,并且它在 PATH 变量中给出的任何目录中都找不到它,则会出现类似以下的消息:
$hello hello: not found $
还有一些变量,如 PS1 和 PS2,将在下一节中讨论。
PS1 和 PS2 变量
Shell 显示为命令提示符的字符存储在变量 PS1 中。您可以将此变量更改为您想要的任何内容。一旦您更改它,Shell 从那时起就会使用它。
例如,如果您发出以下命令:
$PS1='=>' => => =>
您的提示符将变为=>。要设置PS1 的值,使其显示工作目录,请发出以下命令:
=>PS1="[\u@\h \w]\$" [root@ip-72-167-112-17 /var/www/tutorialspoint/unix]$ [root@ip-72-167-112-17 /var/www/tutorialspoint/unix]$
此命令的结果是提示符显示用户的用户名、机器的名称(主机名)和工作目录。
有相当多的转义序列可以用作 PS1 的值参数;尝试将自己限制在最关键的那些,以避免提示符用信息淹没您。
| 序号 | 转义序列 & 描述 |
|---|---|
| 1 |
\t 当前时间,表示为 HH:MM:SS |
| 2 |
\d 当前日期,表示为星期几 月份 日期 |
| 3 |
\n 换行符 |
| 4 |
\s 当前 Shell 环境 |
| 5 |
\W 工作目录 |
| 6 |
\w 工作目录的完整路径 |
| 7 |
\u 当前用户的用户名 |
| 8 |
\h 当前机器的主机名 |
| 9 |
\# 当前命令的命令编号。输入新命令时递增 |
| 10 |
\$ 如果有效 UID 为 0(即,如果您以 root 身份登录),则以 # 字符结束提示符;否则,使用 $ 符号 |
您可以在每次登录时自行进行更改,或者也可以通过将其添加到.profile 文件中来自动进行更改。
当您发出一个不完整的命令时,Shell 将显示一个辅助提示符,并等待您完成命令并再次按下Enter。
默认辅助提示符为>(大于号),但可以通过重新定义PS2 Shell 变量来更改:
以下是使用默认辅助提示符的示例:
$ echo "this is a > test" this is a test $
以下示例使用自定义提示符重新定义 PS2:
$ PS2="secondary prompt->" $ echo "this is a secondary prompt->test" this is a test $
环境变量
以下是重要环境变量的部分列表。这些变量的设置和访问方式如下所示:
| 序号 | 变量 & 描述 |
|---|---|
| 1 |
DISPLAY 包含X11 程序默认应使用的显示的标识符。 |
| 2 |
HOME 指示当前用户的家目录:cd内置命令的默认参数。 |
| 3 |
IFS 指示内部字段分隔符,解析器在扩展后用于单词分割。 |
| 4 |
LANG LANG 扩展到默认系统区域设置;LC_ALL 可用于覆盖此设置。例如,如果其值为pt_BR,则语言设置为(巴西)葡萄牙语,区域设置为巴西。 |
| 5 |
LD_LIBRARY_PATH 具有动态链接器的 Unix 系统,包含一个冒号分隔的目录列表,动态链接器在 exec 后构建进程映像时应在其中搜索共享对象,然后在搜索任何其他目录之前。 |
| 6 |
PATH 指示命令的搜索路径。它是一个冒号分隔的目录列表,Shell 在其中查找命令。 |
| 7 |
PWD 指示由 cd 命令设置的当前工作目录。 |
| 8 |
RANDOM 每次引用时都会生成一个介于 0 和 32,767 之间的随机整数。 |
| 9 |
SHLVL 每次启动 bash 实例时递增 1。此变量对于确定内置 exit 命令是否结束当前会话很有用。 |
| 10 |
TERM 指的是显示类型。 |
| 11 |
TZ 指的是时区。它可以取 GMT、AST 等值。 |
| 12 |
UID 扩展到当前用户的数字用户 ID,在 Shell 启动时初始化。 |
以下是一个示例,显示了一些环境变量:
$ echo $HOME /root ]$ echo $DISPLAY $ echo $TERM xterm $ echo $PATH /usr/local/bin:/bin:/usr/bin:/home/amrood/bin:/usr/local/bin $
Unix 基本实用程序 - 打印、电子邮件
在本章中,我们将详细讨论打印和电子邮件作为 Unix 的基本实用程序。到目前为止,我们已经尝试了解 Unix 操作系统及其基本命令的性质。在本章中,我们将学习一些重要的 Unix 实用程序,这些实用程序可用于我们的日常生活中。
打印文件
在 Unix 系统上打印文件之前,您可能希望对其进行重新格式化以调整边距、突出显示某些单词等。大多数文件也可以在不重新格式化的情况下打印,但原始打印输出可能不太吸引人。
许多版本的 Unix 包括两个功能强大的文本格式化程序,nroff 和troff。
pr 命令
pr 命令对终端屏幕或打印机上的文件进行少量格式化。例如,如果文件中有很长的姓名列表,您可以将其在屏幕上格式化为两列或多列。
以下是pr 命令的语法:
pr option(s) filename(s)
pr 仅更改屏幕或打印副本上的文件格式;它不会修改原始文件。下表列出了一些pr 选项:
| 序号 | 选项 & 描述 |
|---|---|
| 1 |
-k 生成k 列输出 |
| 2 |
-d 双倍行距输出(并非所有pr 版本都支持) |
| 3 |
-h "header" 将下一个项目作为报表标题 |
| 4 |
-t 取消打印标题和顶部/底部边距 |
| 5 |
-l PAGE_LENGTH 将页面长度设置为 PAGE_LENGTH(66)行。默认文本行数为 56 |
| 6 |
-o MARGIN 使用 MARGIN(零)个空格缩进每一行 |
| 7 |
-w PAGE_WIDTH 仅针对多文本列输出,将页面宽度设置为 PAGE_WIDTH(72)个字符 |
在使用pr 之前,以下是名为 food 的示例文件的内容。
$cat food Sweet Tooth Bangkok Wok Mandalay Afghani Cuisine Isle of Java Big Apple Deli Sushi and Sashimi Tio Pepe's Peppers ........ $
让我们使用pr 命令创建一个带有标题Restaurants 的两列报表:
$pr -2 -h "Restaurants" food Nov 7 9:58 1997 Restaurants Page 1 Sweet Tooth Isle of Java Bangkok Wok Big Apple Deli Mandalay Sushi and Sashimi Afghani Cuisine Tio Pepe's Peppers ........ $
lp 和 lpr 命令
命令lp 或lpr 将文件打印到纸上而不是屏幕显示。一旦您使用pr 命令完成格式化,就可以使用这些命令中的任何一个将文件打印到连接到计算机的打印机上。
您的系统管理员可能已在您的站点上设置了默认打印机。要将名为food 的文件打印到默认打印机,请使用lp 或lpr 命令,如下例所示:
$lp food request id is laserp-525 (1 file) $
lp 命令显示一个 ID,您可以使用它来取消打印作业或检查其状态。
如果您使用的是lp 命令,则可以使用 -nNum 选项打印 Num 个副本。与lpr 命令一起,您可以使用 -Num 实现相同的功能。
如果有多个打印机连接到共享网络,则可以使用 -dprinter 选项与 lp 命令一起选择打印机,为了达到相同目的,您可以使用 -Pprinter 选项与 lpr 命令一起使用。这里的 printer 是打印机名称。
lpstat 和 lpq 命令
lpstat 命令显示打印机队列中的内容:请求 ID、所有者、文件大小、发送打印作业的时间以及请求的状态。
如果您想查看所有输出请求(而不仅仅是您自己的请求),请使用lpstat -o。请求按打印顺序显示:
$lpstat -o laserp-573 john 128865 Nov 7 11:27 on laserp laserp-574 grace 82744 Nov 7 11:28 laserp-575 john 23347 Nov 7 11:35 $
lpq 提供的信息与lpstat -o 略有不同:
$lpq laserp is ready and printing Rank Owner Job Files Total Size active john 573 report.ps 128865 bytes 1st grace 574 ch03.ps ch04.ps 82744 bytes 2nd john 575 standard input 23347 bytes $
这里第一行显示打印机状态。如果打印机已禁用或纸张用尽,您可能会在第一行看到不同的消息。
cancel 和 lprm 命令
cancel 命令终止lp 命令的打印请求。lprm 命令终止所有lpr 请求。您可以指定请求的 ID(由 lp 或 lpq 显示)或打印机的名称。
$cancel laserp-575 request "laserp-575" cancelled $
要取消当前正在打印的任何请求(无论其 ID 如何),只需输入 cancel 和打印机名称即可:
$cancel laserp request "laserp-573" cancelled $
如果lprm 命令属于您,则它将取消活动作业。否则,您可以将作业编号作为参数提供,或使用破折号 (-) 删除所有作业:
$lprm 575 dfA575diamond dequeued cfA575diamond dequeued $
lprm 命令会告诉您从打印机队列中删除的实际文件名。
发送电子邮件
您可以使用 Unix mail 命令发送和接收邮件。以下是发送电子邮件的语法:
$mail [-s subject] [-c cc-addr] [-b bcc-addr] to-addr
以下是与 mail 命令相关的重要的选项 -s
| 序号 | 选项 & 描述 |
|---|---|
| 1 |
-s 在命令行上指定主题。 |
| 2 |
-c 向用户列表发送抄送。列表应为用逗号分隔的名称列表。 |
| 3 |
-b 向列表发送密件抄送。列表应为用逗号分隔的名称列表。 |
以下是如何向 admin@yahoo.com 发送测试消息的示例。
$mail -s "Test Message" admin@yahoo.com
然后,您需要输入您的消息,然后在一行的开头输入“control-D”。要停止,只需键入点(.),如下所示:
Hi, This is a test . Cc:
您可以使用重定向 < 运算符发送完整的文件,如下所示:
$mail -s "Report 05/06/07" admin@yahoo.com < demo.txt
要在您的 Unix 系统上检查传入的电子邮件,只需键入 email,如下所示:
$mail no email
Unix - 管道和过滤器
在本章中,我们将详细讨论 Unix 中的管道和过滤器。您可以将两个命令连接在一起,以便一个程序的输出成为下一个程序的输入。以这种方式连接的两个或多个命令构成一个管道。
要创建管道,请在命令行上两个命令之间放置一个竖线(|)。
当一个程序从另一个程序获取输入时,它会对该输入执行某些操作,并将结果写入标准输出。它被称为过滤器。
grep 命令
grep 命令搜索文件或多个文件中包含特定模式的行。语法为:
$grep pattern file(s)
名称“grep” 来自 ed(一个 Unix 行编辑器)命令g/re/p,意思是“全局搜索正则表达式并打印所有包含它的行”。
正则表达式可以是一些纯文本(例如一个单词)和/或用于模式匹配的特殊字符。
grep 最简单的用法是查找由单个单词组成的模式。它可以用于管道中,以便仅将输入文件中包含给定字符串的行发送到标准输出。如果您没有给 grep 提供要读取的文件名,它将读取其标准输入;所有过滤器程序都是这样工作的:
$ls -l | grep "Aug" -rw-rw-rw- 1 john doc 11008 Aug 6 14:10 ch02 -rw-rw-rw- 1 john doc 8515 Aug 6 15:30 ch07 -rw-rw-r-- 1 john doc 2488 Aug 15 10:51 intro -rw-rw-r-- 1 carol doc 1605 Aug 23 07:35 macros $
您可以与grep 命令一起使用各种选项:
| 序号 | 选项 & 描述 |
|---|---|
| 1 |
-v 打印所有与模式不匹配的行。 |
| 2 |
-n 打印匹配的行及其行号。 |
| 3 |
-l 仅打印包含匹配行(字母“l”)的文件名。 |
| 4 |
-c 仅打印匹配行的数量。 |
| 5 |
-i 匹配大小写。 |
现在让我们使用一个正则表达式,告诉 grep 查找包含“carol”的行,后跟零个或多个字符(在正则表达式中缩写为“.*”),然后后跟“Aug”。−
这里,我们使用-i选项进行不区分大小写的搜索−
$ls -l | grep -i "carol.*aug" -rw-rw-r-- 1 carol doc 1605 Aug 23 07:35 macros $
sort 命令
sort命令按字母或数字顺序排列文本行。以下示例对food文件中的行进行排序−
$sort food Afghani Cuisine Bangkok Wok Big Apple Deli Isle of Java Mandalay Sushi and Sashimi Sweet Tooth Tio Pepe's Peppers $
sort命令默认按字母顺序排列文本行。有很多选项可以控制排序−
| 序号 | 描述 |
|---|---|
| 1 |
-n 按数字排序(例如:10 将在 2 之后排序),忽略空格和制表符。 |
| 2 |
-r 反转排序顺序。 |
| 3 |
-f 将大小写字母一起排序。 |
| 4 |
+x 在排序时忽略前x个字段。 |
可以将两个以上的命令链接到管道中。以之前使用grep的管道示例为例,我们可以进一步按大小顺序对8月份修改的文件进行排序。
以下管道由ls、grep和sort命令组成−
$ls -l | grep "Aug" | sort +4n -rw-rw-r-- 1 carol doc 1605 Aug 23 07:35 macros -rw-rw-r-- 1 john doc 2488 Aug 15 10:51 intro -rw-rw-rw- 1 john doc 8515 Aug 6 15:30 ch07 -rw-rw-rw- 1 john doc 11008 Aug 6 14:10 ch02 $
此管道按大小顺序对目录中所有在8月份修改的文件进行排序,并在终端屏幕上打印它们。sort选项+4n跳过四个字段(字段由空格分隔),然后按数字顺序对行进行排序。
pg 和 more 命令
长的输出通常可以由您在屏幕上压缩,但是如果您通过more运行文本或使用pg命令作为过滤器;一旦屏幕上充满了文本,显示就会停止。
假设您有一个很长的目录列表。为了更容易阅读排序后的列表,请按如下方式将输出通过管道传递到more−
$ls -l | grep "Aug" | sort +4n | more -rw-rw-r-- 1 carol doc 1605 Aug 23 07:35 macros -rw-rw-r-- 1 john doc 2488 Aug 15 10:51 intro -rw-rw-rw- 1 john doc 8515 Aug 6 15:30 ch07 -rw-rw-r-- 1 john doc 14827 Aug 9 12:40 ch03 . . . -rw-rw-rw- 1 john doc 16867 Aug 6 15:56 ch05 --More--(74%)
一旦屏幕上充满了由文件大小顺序排序的行组成的文本,屏幕就会填满。屏幕底部是more提示符,您可以在其中键入命令以浏览排序后的文本。
完成此屏幕后,您可以使用more程序讨论中列出的任何命令。
Unix - 进程管理
在本章中,我们将详细讨论Unix中的进程管理。当您在Unix系统上执行程序时,系统会为该程序创建一个特殊的环境。此环境包含系统运行程序所需的一切,就像系统上没有其他程序正在运行一样。
每当您在Unix中发出命令时,它都会创建或启动一个新进程。当您尝试使用ls命令列出目录内容时,您启动了一个进程。简单来说,进程是正在运行的程序的一个实例。
操作系统通过一个五位数的ID号跟踪进程,该ID号称为pid或进程ID。系统中的每个进程都有一个唯一的pid。
Pid 最终会重复,因为所有可能的数字都被用完了,下一个pid会滚动或重新开始。在任何时间点,系统中都不存在两个具有相同pid的进程,因为它是Unix用于跟踪每个进程的pid。
启动进程
当您启动进程(运行命令)时,您可以通过两种方式运行它−
- 前台进程
- 后台进程
前台进程
默认情况下,您启动的每个进程都在前台运行。它从键盘获取输入并将输出发送到屏幕。
您可以看到ls命令是如何做到的。如果您希望列出当前目录中的所有文件,可以使用以下命令−
$ls ch*.doc
这将显示所有文件名以ch开头并以.doc结尾的文件−
ch01-1.doc ch010.doc ch02.doc ch03-2.doc ch04-1.doc ch040.doc ch05.doc ch06-2.doc ch01-2.doc ch02-1.doc
该进程在前台运行,输出被定向到我的屏幕,如果ls命令需要任何输入(它不需要),它会等待键盘输入。
当一个程序在前台运行并且耗时时,无法运行其他命令(启动任何其他进程),因为在程序完成处理并退出之前,提示符将不可用。
后台进程
后台进程在不连接到键盘的情况下运行。如果后台进程需要任何键盘输入,它会等待。
在后台运行进程的优点是您可以运行其他命令;您不必等到它完成才能启动另一个!
启动后台进程最简单的方法是在命令末尾添加一个与号(&)。
$ls ch*.doc &
这将显示所有文件名以ch开头并以.doc结尾的文件−
ch01-1.doc ch010.doc ch02.doc ch03-2.doc ch04-1.doc ch040.doc ch05.doc ch06-2.doc ch01-2.doc ch02-1.doc
这里,如果ls命令需要任何输入(它不需要),它会进入停止状态,直到我们将其移动到前台并从键盘提供数据。
第一行包含有关后台进程的信息 - 作业号和进程ID。您需要知道作业号才能在后台和前台之间对其进行操作。
按Enter键,您将看到以下内容−
[1] + Done ls ch*.doc & $
第一行告诉您ls命令后台进程已成功完成。第二个是另一个命令的提示符。
列出正在运行的进程
通过运行ps(进程状态)命令,可以轻松查看您自己的进程,如下所示−
$ps PID TTY TIME CMD 18358 ttyp3 00:00:00 sh 18361 ttyp3 00:01:31 abiword 18789 ttyp3 00:00:00 ps
ps最常用的标志之一是-f(f表示完整)选项,它提供更多信息,如以下示例所示−
$ps -f UID PID PPID C STIME TTY TIME CMD amrood 6738 3662 0 10:23:03 pts/6 0:00 first_one amrood 6739 3662 0 10:22:54 pts/6 0:00 second_one amrood 3662 3657 0 08:10:53 pts/6 0:00 -ksh amrood 6892 3662 4 10:51:50 pts/6 0:00 ps -f
以下是ps -f命令显示的所有字段的描述−
| 序号 | 列 & 描述 |
|---|---|
| 1 |
UID 此进程所属的用户ID(运行它的人) |
| 2 |
PID 进程ID |
| 3 |
PPID 父进程ID(启动它的进程的ID) |
| 4 |
C 进程的CPU利用率 |
| 5 |
STIME 进程启动时间 |
| 6 |
TTY 与进程关联的终端类型 |
| 7 |
TIME 进程占用的CPU时间 |
| 8 |
CMD 启动此进程的命令 |
还有其他选项可以与ps命令一起使用−
| 序号 | 选项 & 描述 |
|---|---|
| 1 |
-a 显示所有用户的信息 |
| 2 |
-x 显示没有终端的进程的信息 |
| 3 |
-u 显示其他信息,如-f选项 |
| 4 |
-e 显示扩展信息 |
停止进程
结束进程可以通过几种不同的方式完成。通常,从基于控制台的命令中,发送CTRL + C键击(默认中断字符)将退出命令。当进程在前景模式下运行时,这适用。
如果进程在后台运行,则应使用ps命令获取其作业ID。之后,您可以使用kill命令杀死进程,如下所示−
$ps -f UID PID PPID C STIME TTY TIME CMD amrood 6738 3662 0 10:23:03 pts/6 0:00 first_one amrood 6739 3662 0 10:22:54 pts/6 0:00 second_one amrood 3662 3657 0 08:10:53 pts/6 0:00 -ksh amrood 6892 3662 4 10:51:50 pts/6 0:00 ps -f $kill 6738 Terminated
这里,kill命令终止first_one进程。如果进程忽略常规kill命令,您可以使用kill -9后跟进程ID,如下所示−
$kill -9 6738 Terminated
父进程和子进程
每个unix进程都有两个分配给它的ID号:进程ID(pid)和父进程ID(ppid)。系统中的每个用户进程都有一个父进程。
您运行的大多数命令都以shell作为其父进程。检查ps -f示例,其中此命令列出了进程ID和父进程ID。
僵尸进程和孤儿进程
通常,当子进程被杀死时,父进程会通过SIGCHLD信号更新。然后父进程可以执行其他任务或根据需要重新启动一个新的子进程。但是,有时父进程会在其子进程被杀死之前被杀死。在这种情况下,“所有进程的父进程”,init进程,成为新的PPID(父进程ID)。在某些情况下,这些进程称为孤儿进程。
当进程被杀死时,ps列表可能仍然显示该进程处于Z状态。这是一个僵尸或失效的进程。该进程已死且未使用。这些进程与孤儿进程不同。它们已完成执行,但仍在进程表中找到条目。
守护进程
守护进程是与系统相关的后台进程,通常以root权限运行并为其他进程提供服务请求。
守护进程没有控制终端。它无法打开/dev/tty。如果您执行"ps -ef"并查看tty字段,所有守护进程的tty都将为?。
准确地说,守护进程是在后台运行的进程,通常等待某些事情发生,它能够处理这些事情。例如,等待打印命令的打印机守护进程。
如果您有一个需要长时间处理的程序,那么将其设为守护进程并在后台运行是值得的。
top 命令
top命令是一个非常有用的工具,可以快速显示按各种标准排序的进程。
它是一个交互式诊断工具,可以频繁更新并显示有关物理和虚拟内存、CPU使用率、负载平均值和繁忙进程的信息。
以下是运行top命令并查看不同进程的CPU利用率统计信息的简单语法−
$top
作业ID与进程ID
后台和挂起进程通常通过作业号(作业ID)进行操作。此编号与进程ID不同,并且使用的原因是它更短。
此外,一个作业可以由多个进程组成,这些进程可以串行或并行运行。使用作业ID比跟踪单个进程更容易。
Unix - 网络通信实用程序
在本章中,我们将详细讨论Unix中的网络通信实用程序。当您在分布式环境中工作时,您需要与远程用户通信,并且还需要访问远程Unix机器。
有几个Unix实用程序可以帮助用户在网络化、分布式环境中进行计算。本章列出了一些实用程序。
ping 实用程序
ping命令向网络上可用的主机发送回显请求。使用此命令,您可以检查远程主机是否响应良好。
ping命令对以下方面很有用−
- 跟踪和隔离硬件和软件问题。
- 确定网络和各种外部主机的状态。
- 测试、测量和管理网络。
语法
以下是使用 ftp 命令的简单语法:
$ping hostname or ip-address
上述命令每秒打印一次响应。要退出命令,您可以按 **Ctrl + C** 键终止它。
示例
以下是一个检查网络上主机可用性的示例:
$ping google.com PING google.com (74.125.67.100) 56(84) bytes of data. 64 bytes from 74.125.67.100: icmp_seq = 1 ttl = 54 time = 39.4 ms 64 bytes from 74.125.67.100: icmp_seq = 2 ttl = 54 time = 39.9 ms 64 bytes from 74.125.67.100: icmp_seq = 3 ttl = 54 time = 39.3 ms 64 bytes from 74.125.67.100: icmp_seq = 4 ttl = 54 time = 39.1 ms 64 bytes from 74.125.67.100: icmp_seq = 5 ttl = 54 time = 38.8 ms --- google.com ping statistics --- 22 packets transmitted, 22 received, 0% packet loss, time 21017ms rtt min/avg/max/mdev = 38.867/39.334/39.900/0.396 ms $
如果主机不存在,您将收到以下输出:
$ping giiiiiigle.com ping: unknown host giiiiigle.com $
ftp 实用程序
这里,**ftp** 代表 **F**ile **T**ransfer **P**rotocol。此实用程序可帮助您将文件从一台计算机上传和下载到另一台计算机。
ftp 实用程序有自己的一套类 Unix 命令。这些命令可帮助您执行以下任务:
连接并登录到远程主机。
导航目录。
列出目录内容。
上传和下载文件。
以 **ascii**、**ebcdic** 或 **binary** 格式传输文件。
语法
以下是使用 ftp 命令的简单语法:
$ftp hostname or ip-address
上述命令将提示您输入登录 ID 和密码。身份验证后,您可以访问登录帐户的主目录,并且可以执行各种命令。
下表列出了一些重要的命令:
| 序号 | 命令和说明 |
|---|---|
| 1 |
put filename 将本地机器上的 filename 上传到远程机器。 |
| 2 |
get filename 将远程机器上的 filename 下载到本地机器。 |
| 3 |
mput file list 将本地机器上的多个文件上传到远程机器。 |
| 4 |
mget file list 将远程机器上的多个文件下载到本地机器。 |
| 5 |
prompt off 关闭提示。默认情况下,您将收到一个提示,提示您使用 **mput** 或 **mget** 命令上传或下载文件。 |
| 6 |
prompt on 打开提示。 |
| 7 |
dir 列出远程机器当前目录中所有可用的文件。 |
| 8 |
cd dirname 将远程机器上的目录更改为 dirname。 |
| 9 |
lcd dirname 将本地机器上的目录更改为 dirname。 |
| 10 |
quit 帮助注销当前登录。 |
需要注意的是,所有文件都将下载或上传到或从当前目录。如果您想将文件上传到特定目录,则需要先更改到该目录,然后上传所需文件。
示例
以下示例显示了一些命令的工作原理:
$ftp amrood.com Connected to amrood.com. 220 amrood.com FTP server (Ver 4.9 Thu Sep 2 20:35:07 CDT 2009) Name (amrood.com:amrood): amrood 331 Password required for amrood. Password: 230 User amrood logged in. ftp> dir 200 PORT command successful. 150 Opening data connection for /bin/ls. total 1464 drwxr-sr-x 3 amrood group 1024 Mar 11 20:04 Mail drwxr-sr-x 2 amrood group 1536 Mar 3 18:07 Misc drwxr-sr-x 5 amrood group 512 Dec 7 10:59 OldStuff drwxr-sr-x 2 amrood group 1024 Mar 11 15:24 bin drwxr-sr-x 5 amrood group 3072 Mar 13 16:10 mpl -rw-r--r-- 1 amrood group 209671 Mar 15 10:57 myfile.out drwxr-sr-x 3 amrood group 512 Jan 5 13:32 public drwxr-sr-x 3 amrood group 512 Feb 10 10:17 pvm3 226 Transfer complete. ftp> cd mpl 250 CWD command successful. ftp> dir 200 PORT command successful. 150 Opening data connection for /bin/ls. total 7320 -rw-r--r-- 1 amrood group 1630 Aug 8 1994 dboard.f -rw-r----- 1 amrood group 4340 Jul 17 1994 vttest.c -rwxr-xr-x 1 amrood group 525574 Feb 15 11:52 wave_shift -rw-r--r-- 1 amrood group 1648 Aug 5 1994 wide.list -rwxr-xr-x 1 amrood group 4019 Feb 14 16:26 fix.c 226 Transfer complete. ftp> get wave_shift 200 PORT command successful. 150 Opening data connection for wave_shift (525574 bytes). 226 Transfer complete. 528454 bytes received in 1.296 seconds (398.1 Kbytes/s) ftp> quit 221 Goodbye. $
telnet 实用程序
有时我们需要连接到远程 Unix 机器并在该机器上远程工作。**Telnet** 是一种实用程序,允许一个站点的一位计算机用户建立连接,登录,然后在另一个站点的计算机上进行工作。
使用 Telnet 登录后,您可以在远程连接的机器上执行所有活动。以下是 Telnet 会话的示例:
C:>telnet amrood.com
Trying...
Connected to amrood.com.
Escape character is '^]'.
login: amrood
amrood's Password:
*****************************************************
* *
* *
* WELCOME TO AMROOD.COM *
* *
* *
*****************************************************
Last unsuccessful login: Fri Mar 3 12:01:09 IST 2009
Last login: Wed Mar 8 18:33:27 IST 2009 on pts/10
{ do your work }
$ logout
Connection closed.
C:>
finger 实用程序
**finger** 命令显示给定主机上用户的信息。主机可以是本地或远程的。
出于安全原因,其他系统上的 Finger 可能已被禁用。
以下是使用 finger 命令的简单语法:
检查本地机器上所有已登录的用户:
$ finger Login Name Tty Idle Login Time Office amrood pts/0 Jun 25 08:03 (62.61.164.115)
获取本地机器上特定用户信息:
$ finger amrood Login: amrood Name: (null) Directory: /home/amrood Shell: /bin/bash On since Thu Jun 25 08:03 (MST) on pts/0 from 62.61.164.115 No mail. No Plan.
检查远程机器上所有已登录的用户:
$ finger @avtar.com Login Name Tty Idle Login Time Office amrood pts/0 Jun 25 08:03 (62.61.164.115)
获取远程机器上特定用户信息:
$ finger amrood@avtar.com Login: amrood Name: (null) Directory: /home/amrood Shell: /bin/bash On since Thu Jun 25 08:03 (MST) on pts/0 from 62.61.164.115 No mail. No Plan.
Unix - vi 编辑器教程
在本章中,我们将了解 vi 编辑器在 Unix 中的工作原理。在 Unix 中,有多种方法可以编辑文件。使用屏幕导向文本编辑器 **vi** 编辑文件是最佳方法之一。此编辑器使您能够在文件中的其他行上下文中编辑行。
vi 编辑器的改进版本,称为 **VIM**,现已可用。这里,VIM 代表 **Vi IM**proved。
vi 通常被认为是 Unix 编辑器的实际标准,因为:
它通常可在所有 Unix 系统版本上使用。
它的实现跨平台非常相似。
它需要的资源很少。
它比其他编辑器(如 **ed** 或 **ex**)更友好。
您可以使用 **vi** 编辑器编辑现有文件或从头创建一个新文件。您还可以使用此编辑器仅读取文本文件。
启动 vi 编辑器
下表列出了使用 vi 编辑器的基本命令:
| 序号 | 命令和说明 |
|---|---|
| 1 |
vi filename 如果文件不存在,则创建一个新文件,否则打开现有文件。 |
| 2 |
vi -R filename 以只读模式打开现有文件。 |
| 3 |
view filename 以只读模式打开现有文件。 |
以下是如何在当前工作目录中创建新文件 **testfile** 的示例(如果该文件不存在):
$vi testfile
上述命令将生成以下输出:
| ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ "testfile" [New File]
您会注意到光标后面每一行都有一个 **波浪线** (~)。波浪线表示未使用的行。如果一行不是以波浪线开头并且看起来是空白的,则表示存在空格、制表符、换行符或其他不可见的字符。
您现在有一个打开的文件可以开始工作。在继续之前,让我们了解一些重要的概念。
操作模式
在使用 vi 编辑器时,我们通常会遇到以下两种模式:
**命令模式** - 此模式使您能够执行管理任务,例如保存文件、执行命令、移动光标、剪切(复制)和粘贴行或单词,以及查找和替换。在此模式下,您键入的任何内容都将被解释为命令。
**插入模式** - 此模式使您能够将文本插入文件。在此模式下键入的所有内容都将被解释为输入并放置在文件中。
vi 始终以 **命令模式** 启动。要输入文本,您必须处于插入模式,只需键入 **i** 即可。要退出插入模式,请按 **Esc** 键,这将带您返回命令模式。
**提示** - 如果您不确定自己处于哪种模式,请按两次 Esc 键;这将带您进入命令模式。您可以使用 vi 编辑器打开文件。开始键入一些字符,然后进入命令模式以了解区别。
退出 vi
退出 vi 的命令是 **:q**。在命令模式下,键入冒号和“q”,然后按回车键。如果您的文件以任何方式被修改,编辑器将警告您这一点,并且不允许您退出。要忽略此消息,退出 vi 而不保存的命令是 **:q!**。这允许您退出 vi 而不保存任何更改。
保存编辑器内容的命令是 **:w**。您可以将上述命令与退出命令结合使用,或使用 **:wq** 并按回车键。
**保存更改并退出 vi** 的最简单方法是使用 ZZ 命令。当您处于命令模式时,键入 **ZZ**。**ZZ** 命令的工作方式与 **:wq** 命令相同。
如果要为文件指定/说明任何特定名称,则可以在 **:w** 后指定它。例如,如果您想将正在处理的文件另存为名为 **filename2** 的其他文件名,则键入 **:w filename2** 并按回车键。
在文件中移动
要在文件中移动而不影响您的文本,您必须处于命令模式(按两次 Esc)。下表列出了一些可用于一次移动一个字符的命令:
| 序号 | 命令和说明 |
|---|---|
| 1 |
k 将光标向上移动一行 |
| 2 |
j 将光标向下移动一行 |
| 3 |
h 将光标向左移动一个字符位置 |
| 4 |
l l |
将光标向右移动一个字符位置
在文件中移动时,需要注意以下几点:
vi 区分大小写。使用命令时,请注意大小写。
大多数 vi 命令都可以以您希望操作发生的次数为前缀。例如,**2j** 将光标向下移动两个光标位置。
| 序号 | 命令和说明 |
|---|---|
| 1 |
以下是用于在文件中移动的命令列表。 0 或 | |
| 2 |
$ 将光标定位在行首 |
| 3 |
$ 将光标定位在行尾 |
| 4 |
b w |
| 5 |
( 将光标定位到下一个单词 |
| 6 |
) b |
| 7 |
将光标定位到上一个单词 1 |
| 8 |
{ 将光标定位到当前句子的开头 |
| 9 |
} ) |
| 10 |
[[ 将光标定位到下一句的开头 |
| 11 |
]] E |
| 12 |
移动到空白分隔单词的末尾 [[ |
| 13 |
向后移动一段 ]] |
| 14 |
向前移动一段 [{ |
| 15 |
向后移动一个节 }] |
| 16 |
向前移动一个节 }] |
| 17 |
n| 移动到当前行的第 **n** 列 |
| 18 |
1G 移动到文件的首行 |
| 19 |
G 移动到文件的最后一行 |
| 20 |
nG 移动到文件的第 **n** 行 |
| 21 |
:n fc |
| 22 |
向前移动到 **c** Fc |
| 23 |
向后移动到 **c** H |
| 24 |
移动到屏幕顶部 nH |
移动到屏幕顶部的第 **n** 行
M
| 序号 | 命令和说明 |
|---|---|
| 1 |
L 移动到屏幕底部 |
| 2 |
nL 移动到屏幕底部的第 **n** 行 |
| 3 |
:x 冒号后跟一个数字将把光标定位在 **x** 表示的行号上 |
| 4 |
控制命令 以下命令可以与 Control 键一起使用,以执行下表中给出的功能: |
| 5 |
以下是控制命令列表。 Ctrl+d |
| 6 |
向前移动 1/2 屏幕 Ctrl+f |
| 7 |
:x 将屏幕向上移动半页 |
| 8 |
L 将屏幕向下移动半页 |
| 9 |
控制命令 将屏幕向上移动一页 |
| 10 |
nL 将屏幕向下移动一页 |
| 11 |
CTRL+I 重绘屏幕 |
编辑文件
要编辑文件,您需要处于插入模式。从命令模式进入插入模式有很多方法:
| 序号 | 命令和说明 |
|---|---|
| 1 |
i 在当前光标位置之前插入文本 |
| 2 |
I 在当前行的开头插入文本 |
| 3 |
a 在当前光标位置之后插入文本 |
| 4 |
A 在当前行的末尾插入文本 |
| 5 |
o 在光标位置下方创建新行以输入文本 |
| 6 |
O 在光标位置上方创建新行以输入文本 |
删除字符
以下是重要命令列表,可用于删除打开文件中的字符和行:
| 序号 | 命令和说明 |
|---|---|
| 1 |
x 删除光标所在位置的字符 |
| 2 |
X 删除光标之前位置的字符 |
| 3 |
dw 从当前光标位置删除到下一个单词 |
| 4 |
d^ 从当前光标位置删除到行首 |
| 5 |
d$ 从当前光标位置删除到行尾 |
| 6 |
D 从光标位置删除到当前行尾 |
| 7 |
dd 删除光标所在的行 |
如上所述,vi 中的大多数命令都可以加上要执行操作的次数作为前缀。例如,**2x** 删除光标所在位置的两个字符,**2dd** 删除光标所在的两行。
建议在继续操作之前练习这些命令。
更改命令
您还可以更改 vi 中的字符、单词或行,而无需删除它们。以下是相关的命令:
| 序号 | 命令和说明 |
|---|---|
| 1 |
cc 删除该行的内容,并使您进入插入模式。 |
| 2 |
cw 更改光标所在的单词,从光标到单词末尾的小写 **w**。 |
| 3 |
r 替换光标下的字符。输入替换内容后,vi 返回到命令模式。 |
| 4 |
R 从当前光标下的字符开始覆盖多个字符。您必须使用 **Esc** 停止覆盖。 |
| 5 |
s 用您键入的字符替换当前字符。之后,您将处于插入模式。 |
| 6 |
S 删除光标所在的行,并用新文本替换它。输入新文本后,vi 保持在插入模式。 |
复制和粘贴命令
您可以使用以下命令将行或单词从一个位置复制到另一个位置:
| 序号 | 命令和说明 |
|---|---|
| 1 |
yy 复制当前行。 |
| 2 |
yw 从光标所在的小写 w 字符复制到单词末尾的当前单词。 |
| 3 |
p p |
| 4 |
将复制的文本放在光标之后。 P |
将复制的文本放在光标之前。
高级命令
| 序号 | 命令和说明 |
|---|---|
| 1 |
以下是高级命令列表。 J |
| 2 |
<< 将当前行与下一行连接。j 命令的计数连接多行。 |
| 3 |
>> 将当前行向左移动一个缩进宽度。 |
| 4 |
~ 将当前行向右移动一个缩进宽度。 |
| 5 |
切换光标下字符的大小写。 ^G |
| 6 |
同时按下 Ctrl 和 G 键以显示当前文件名和状态。 U |
| 7 |
将当前行恢复到光标进入该行之前的状态。 u |
| 8 |
以下是高级命令列表。 这有助于撤消对文件中所做的最后一次更改。再次键入“u”将重做更改。 |
| 9 |
将当前行与下一行连接。计数连接指定行数。 :f |
| 10 |
显示文件中当前位置的百分比和文件名,以及文件的总数。 :f filename |
| 11 |
将当前文件重命名为 filename。 :w filename |
| 12 |
写入文件 filename。 :e filename |
| 13 |
打开另一个名为 filename 的文件。 :cd dirname |
| 14 |
将当前工作目录更改为 dirname。 :e # |
| 15 |
向前移动一个节 在两个打开的文件之间切换。 |
| 16 |
如果您使用 vi 打开多个文件,请使用 **:n** 转到系列中的下一个文件。 :p |
| 17 |
如果您使用 vi 打开多个文件,请使用 **:p** 转到系列中的上一个文件。 :N |
| 18 |
如果您使用 vi 打开多个文件,请使用 **:N** 转到系列中的上一个文件。 :r file |
| 19 |
读取文件并将其插入到当前行的后面。 :nr file |
读取文件并将其插入到第 n 行的后面。
单词和字符搜索
vi 编辑器有两种搜索:**字符串**和**字符**。对于字符串搜索,使用 **/** 和 **?** 命令。当您开始这些命令时,刚刚键入的命令将显示在屏幕的最后一行,您可以在其中键入要查找的特定字符串。
这两个命令仅在搜索发生的方向上有所不同:
**/** 命令在文件中向前(向下)搜索。
**?** 命令在文件中向后(向上)搜索。
| 序号 | **n** 和 **N** 命令分别重复上一个搜索命令,方向相同或相反。某些字符具有特殊含义。这些字符必须以反斜杠(**\**)作为前缀才能作为搜索表达式的一部分包含在内。 |
|---|---|
| 1 |
^ 字符和描述 |
| 2 |
. 在行首搜索(在搜索表达式的开头使用)。 |
| 3 |
* 匹配单个字符。 |
| 4 |
$ 匹配前一个字符零次或多次。 |
| 5 |
[ 行尾(在搜索表达式的末尾使用)。 |
| 6 |
< 开始一组匹配或不匹配的表达式。 |
| 7 |
> 这放在用反斜杠转义的表达式中,以查找单词的结尾或开头。 |
这有助于查看上面“**<**”字符的描述。
字符搜索在同一行内搜索输入命令后输入的字符。**f** 和 **F** 命令仅在当前行中搜索字符。**f** 向前搜索,**F** 向后搜索,光标移动到找到的字符的位置。
**t** 和 **T** 命令仅在当前行中搜索字符,但对于 **t**,光标移动到字符之前的位置,**T** 向后搜索该行到字符之后的位置。
设置命令
| 序号 | 命令和说明 |
|---|---|
| 1 |
您可以使用以下 **:set** 命令更改 vi 屏幕的外观。一旦您处于命令模式,键入 **:set** 后跟以下任何命令。 :set ic |
| 2 |
搜索时忽略大小写 :set ai |
| 3 |
设置自动缩进 :set noai |
| 4 |
取消设置自动缩进 :set nu |
| 5 |
在左侧显示带行号的行 :set sw |
| 6 |
设置软件制表符的宽度。例如,您可以使用此命令将缩进宽度设置为 4 — **:set sw = 4** :set ws |
| 7 |
如果设置了 *wrapscan*,并且在文件底部找不到该单词,它将尝试在开头搜索该单词 :set wm |
| 8 |
如果此选项的值大于零,则编辑器将自动“换行”。例如,要将换行边距设置为两个字符,您可以键入以下内容:**:set wm = 2** :set ro |
| 9 |
将文件类型更改为“只读” :set term |
| 10 |
打印终端类型 :set bf |
丢弃输入中的控制字符
运行命令
vi 能够在编辑器内部运行命令。要运行命令,您只需进入命令模式并键入 **:!** 命令。
例如,如果您想在尝试使用该文件名保存文件之前检查文件是否存在,您可以键入 **:! ls**,您将在屏幕上看到 **ls** 的输出。
您可以按任意键(或命令的转义序列)返回到您的 vi 会话。
替换文本
:s/search/replace/g
替换命令(**:s/**)使您能够快速替换文件中的单词或单词组。以下是替换文本的语法:
**g** 代表全局。此命令的结果是光标所在行上的所有出现都被更改。
需要注意的重要事项
以下几点将有助于您成功使用 vi:
您必须处于命令模式才能使用命令。(随时按两次 Esc 以确保您处于命令模式。)
您必须小心使用命令。这些命令区分大小写。
您必须处于插入模式才能输入文本。
Unix - 什么是 Shell?
**Shell** 为您提供了一个与 Unix 系统交互的界面。它收集您的输入并根据该输入执行程序。当程序执行完毕后,它会显示该程序的输出。
Shell 是一个我们可以运行命令、程序和 Shell 脚本的环境。Shell 有不同的种类,就像操作系统有不同的种类一样。每种 Shell 都有自己的一套可识别的命令和函数。
Shell 提示符
提示符 **$**,称为 **命令提示符**,由 Shell 发出。当提示符显示时,您可以键入命令。
下面是一个date命令的简单示例,它显示当前日期和时间:
$date Thu Jun 25 08:30:19 MST 2009
您可以使用环境变量 PS1 自定义命令提示符,这在环境教程中有所解释。
Shell 类型
在 Unix 中,主要有两种类型的 Shell:
Bourne Shell - 如果你使用的是 Bourne 型 Shell,则$字符是默认提示符。
C Shell - 如果你使用的是 C 型 Shell,则 % 字符是默认提示符。
Bourne Shell 有以下子类别:
- Bourne Shell (sh)
- Korn Shell (ksh)
- Bourne Again Shell (bash)
- POSIX Shell (sh)
不同的 C 型 Shell 如下:
- C Shell (csh)
- TENEX/TOPS C Shell (tcsh)
最初的 Unix Shell 由 Stephen R. Bourne 于 20 世纪 70 年代中期编写,当时他在新泽西州的 AT&T Bell Labs 工作。
Bourne Shell 是第一个出现在 Unix 系统上的 Shell,因此被称为“Shell”。
Bourne Shell 通常安装在大多数 Unix 版本的/bin/sh中。因此,它是编写可在不同 Unix 版本上使用的脚本的首选 Shell。
在本章中,我们将涵盖大多数基于 Borne Shell 的 Shell 概念。
Shell 脚本
Shell 脚本的基本概念是一系列命令,这些命令按执行顺序排列。一个好的 Shell 脚本将包含注释(以#符号开头),描述每个步骤。
它包含条件测试(例如,值 A 大于值 B),循环允许我们遍历大量数据,文件用于读取和存储数据,变量用于读取和存储数据,并且脚本可能包含函数。
我们将在接下来的章节中编写许多脚本。它将是一个简单的文本文件,我们在其中放置所有命令以及其他一些必要的结构,这些结构告诉 Shell 环境做什么以及何时做。
Shell 脚本和函数都是解释执行的。这意味着它们不会被编译。
脚本示例
假设我们创建一个test.sh脚本。请注意,所有脚本都将具有.sh扩展名。在向脚本添加任何其他内容之前,您需要提醒系统正在启动一个 Shell 脚本。这是使用shebang结构完成的。例如:
#!/bin/sh
这告诉系统后续的命令将由 Bourne Shell 执行。它被称为 shebang,因为#符号称为散列,而!符号称为感叹号。
要创建包含这些命令的脚本,请先放置 shebang 行,然后添加命令:
#!/bin/bash pwd ls
Shell 注释
您可以按如下方式在脚本中添加注释:
#!/bin/bash # Author : Zara Ali # Copyright (c) Tutorialspoint.com # Script follows here: pwd ls
保存以上内容并使脚本可执行:
$chmod +x test.sh
Shell 脚本现在已准备好执行:
$./test.sh
执行后,您将收到以下结果:
/home/amrood index.htm unix-basic_utilities.htm unix-directories.htm test.sh unix-communication.htm unix-environment.htm
注意 - 要执行当前目录中可用的程序,请使用./program_name
扩展的 Shell 脚本
Shell 脚本有几个必要的结构,这些结构告诉 Shell 环境做什么以及何时做。当然,大多数脚本都比上面的复杂。
毕竟,Shell 是一种真正的编程语言,包含变量、控制结构等等。无论脚本变得多么复杂,它仍然只是一系列按顺序执行的命令。
以下脚本使用read命令,该命令从键盘获取输入并将其分配为变量 PERSON 的值,最后将其打印到标准输出。
#!/bin/sh # Author : Zara Ali # Copyright (c) Tutorialspoint.com # Script follows here: echo "What is your name?" read PERSON echo "Hello, $PERSON"
以下是脚本的示例运行:
$./test.sh What is your name? Zara Ali Hello, Zara Ali $
Unix - 使用 Shell 变量
在本章中,我们将学习如何在 Unix 中使用 Shell 变量。变量是一个字符字符串,我们为其分配一个值。分配的值可以是数字、文本、文件名、设备或任何其他类型的数据。
变量只不过是指向实际数据的指针。Shell 使您能够创建、分配和删除变量。
变量名称
变量名只能包含字母(a 到 z 或 A 到 Z)、数字(0 到 9)或下划线字符(_)。
按照惯例,Unix Shell 变量的名称将使用大写字母。
以下示例是有效的变量名:
_ALI TOKEN_A VAR_1 VAR_2
以下是无效变量名的示例:
2_VAR -VARIABLE VAR1-VAR2 VAR_A!
您不能使用!、*或-等其他字符的原因是这些字符对 Shell 具有特殊含义。
定义变量
变量定义如下:
variable_name=variable_value
例如:
NAME="Zara Ali"
以上示例定义了变量 NAME 并将其值设置为“Zara Ali”。此类型的变量称为标量变量。标量变量一次只能保存一个值。
Shell 使您能够在变量中存储任何所需的值。例如:
VAR1="Zara Ali" VAR2=100
访问值
要访问存储在变量中的值,请在其名称前加上美元符号 ($):
例如,以下脚本将访问已定义变量 NAME 的值并将其打印到标准输出:
#!/bin/sh NAME="Zara Ali" echo $NAME
以上脚本将产生以下值:
Zara Ali
只读变量
Shell 提供了一种使用只读命令将变量标记为只读的方法。变量被标记为只读后,其值将无法更改。
例如,以下脚本在尝试更改 NAME 的值时会生成错误:
#!/bin/sh NAME="Zara Ali" readonly NAME NAME="Qadiri"
以上脚本将生成以下结果:
/bin/sh: NAME: This variable is read only.
取消设置变量
取消设置或删除变量会指示 Shell 从其跟踪的变量列表中删除该变量。一旦取消设置变量,您将无法访问变量中存储的值。
以下是使用unset命令取消设置已定义变量的语法:
unset variable_name
以上命令取消设置已定义变量的值。这是一个简单的示例,演示了该命令的工作原理:
#!/bin/sh NAME="Zara Ali" unset NAME echo $NAME
以上示例未打印任何内容。您不能使用 unset 命令来取消设置标记为只读的变量。
变量类型
当 Shell 运行时,存在三种主要的变量类型:
局部变量 - 局部变量是在 Shell 的当前实例中存在的变量。它对 Shell 启动的程序不可用。它们是在命令提示符处设置的。
环境变量 - 环境变量可用于 Shell 的任何子进程。某些程序需要环境变量才能正常运行。通常,Shell 脚本仅定义其运行的程序所需的那些环境变量。
Shell 变量 - Shell 变量是一种特殊的变量,由 Shell 设置,并且 Shell 为了正常运行而需要它。其中一些变量是环境变量,而另一些是局部变量。
Unix - 特殊变量
在本章中,我们将详细讨论 Unix 中的特殊变量。在我们之前的章节之一中,我们了解了在使用变量名中的某些非字母数字字符时需要谨慎。这是因为这些字符用于特殊 Unix 变量的名称。这些变量保留用于特定功能。
例如,$字符表示当前 Shell 的进程 ID 号或 PID:
$echo $$
以上命令写入当前 Shell 的 PID:
29949
下表显示了您可以在 Shell 脚本中使用的一些特殊变量:
| 序号 | 变量 & 描述 |
|---|---|
| 1 |
$0 当前脚本的文件名。 |
| 2 |
$n 这些变量对应于调用脚本的参数。这里n是一个正十进制数,对应于参数的位置(第一个参数是 $1,第二个参数是 $2,依此类推)。 |
| 3 |
$# 提供给脚本的参数数量。 |
| 4 |
$* 所有参数都用双引号括起来。如果脚本接收两个参数,则 $* 等效于 $1 $2。 |
| 5 |
$@ 所有参数都分别用双引号括起来。如果脚本接收两个参数,则 $@ 等效于 $1 $2。 |
| 6 |
$? 最后执行的命令的退出状态。 |
| 7 |
$$ 当前 Shell 的进程号。对于 Shell 脚本,这是它们正在执行的进程 ID。 |
| 8 |
$! 最后一个后台命令的进程号。 |
命令行参数
命令行参数 $1、$2、$3、...$9 是位置参数,其中 $0 指向实际的命令、程序、Shell 脚本或函数,而 $1、$2、$3、...$9 作为该命令的参数。
以下脚本使用与命令行相关的各种特殊变量:
#!/bin/sh echo "File Name: $0" echo "First Parameter : $1" echo "Second Parameter : $2" echo "Quoted Values: $@" echo "Quoted Values: $*" echo "Total Number of Parameters : $#"
以下是以上脚本的示例运行:
$./test.sh Zara Ali File Name : ./test.sh First Parameter : Zara Second Parameter : Ali Quoted Values: Zara Ali Quoted Values: Zara Ali Total Number of Parameters : 2
特殊参数 $* 和 $@
有一些特殊参数允许一次访问所有命令行参数。$*和$@都将具有相同的作用,除非它们用双引号""括起来。
这两个参数都指定命令行参数。但是,"$*" 特殊参数将整个列表作为带空格的一个参数,而 "$@" 特殊参数将整个列表作为单独的参数。
我们可以按如下所示编写 Shell 脚本,以使用 $* 或 $@ 特殊参数处理未知数量的命令行参数:
#!/bin/sh for TOKEN in $* do echo $TOKEN done
以下是以上脚本的示例运行:
$./test.sh Zara Ali 10 Years Old Zara Ali 10 Years Old
注意 - 这里do...done是一种循环,将在后续教程中介绍。
退出状态
$?变量表示前一个命令的退出状态。
退出状态是每个命令在完成时返回的一个数值。通常,大多数命令在成功时返回退出状态 0,在失败时返回 1。
某些命令出于特定原因会返回额外的退出状态。例如,某些命令会区分错误类型,并根据特定故障类型返回不同的退出值。
以下是成功命令的示例 -
$./test.sh Zara Ali File Name : ./test.sh First Parameter : Zara Second Parameter : Ali Quoted Values: Zara Ali Quoted Values: Zara Ali Total Number of Parameters : 2 $echo $? 0 $
Unix - 使用 Shell 数组
在本章中,我们将讨论如何在 Unix 中使用 Shell 数组。Shell 变量能够保存单个值。这些变量称为标量变量。
Shell 支持一种称为数组变量的不同类型的变量。它可以同时保存多个值。数组提供了一种对一组变量进行分组的方法。您可以使用存储所有其他变量的单个数组变量,而不是为每个所需的变量创建新的名称。
为 Shell 变量讨论的所有命名规则在命名数组时都适用。
定义数组值
数组变量和标量变量之间的区别可以解释如下。
假设您尝试将各种学生的姓名表示为一组变量。每个单独的变量都是一个标量变量,如下所示 -
NAME01="Zara" NAME02="Qadir" NAME03="Mahnaz" NAME04="Ayan" NAME05="Daisy"
我们可以使用单个数组来存储上面提到的所有名称。以下是创建数组变量的最简单方法。这有助于为其索引之一赋值。
array_name[index]=value
这里array_name是数组的名称,index是您要设置的数组中项目的索引,而value是要为该项目设置的值。
例如,以下命令 -
NAME[0]="Zara" NAME[1]="Qadir" NAME[2]="Mahnaz" NAME[3]="Ayan" NAME[4]="Daisy"
如果您使用的是ksh shell,则以下是数组初始化的语法 -
set -A array_name value1 value2 ... valuen
如果您使用的是bash shell,则以下是数组初始化的语法 -
array_name=(value1 ... valuen)
访问数组值
设置任何数组变量后,您可以按如下方式访问它 -
${array_name[index]}
这里array_name是数组的名称,index是要访问的值的索引。以下是一个示例,用于理解这个概念 -
#!/bin/sh
NAME[0]="Zara"
NAME[1]="Qadir"
NAME[2]="Mahnaz"
NAME[3]="Ayan"
NAME[4]="Daisy"
echo "First Index: ${NAME[0]}"
echo "Second Index: ${NAME[1]}"
以上示例将生成以下结果 -
$./test.sh First Index: Zara Second Index: Qadir
您可以通过以下方式之一访问数组中的所有项目 -
${array_name[*]}
${array_name[@]}
这里array_name是您感兴趣的数组的名称。以下示例将帮助您理解这个概念 -
#!/bin/sh
NAME[0]="Zara"
NAME[1]="Qadir"
NAME[2]="Mahnaz"
NAME[3]="Ayan"
NAME[4]="Daisy"
echo "First Method: ${NAME[*]}"
echo "Second Method: ${NAME[@]}"
以上示例将生成以下结果 -
$./test.sh First Method: Zara Qadir Mahnaz Ayan Daisy Second Method: Zara Qadir Mahnaz Ayan Daisy
Unix - Shell 基本运算符
每个 Shell 都支持各种运算符。我们将在本章中详细讨论 Bourne Shell(默认 Shell)。
我们现在将讨论以下运算符 -
- 算术运算符
- 关系运算符
- 布尔运算符
- 字符串运算符
- 文件测试运算符
Bourne Shell 最初没有执行简单算术运算的机制,但它使用外部程序,即awk或expr。
以下示例显示如何添加两个数字 -
#!/bin/sh val=`expr 2 + 2` echo "Total value : $val"
以上脚本将生成以下结果:
Total value : 4
添加时需要考虑以下几点 -
运算符和表达式之间必须有空格。例如,2+2 不正确;应写成 2 + 2。
整个表达式应包含在‘ ‘之间,称为反引号。
算术运算符
Bourne Shell 支持以下算术运算符。
假设变量a保存 10,变量b保存 20,则 -
| 运算符 | 描述 | 示例 |
|---|---|---|
| +(加法) | 将运算符两侧的值相加 | `expr $a + $b` 将给出 30 |
| -(减法) | 从左操作数中减去右操作数 | `expr $a - $b` 将给出 -10 |
| *(乘法) | 将运算符两侧的值相乘 | `expr $a \* $b` 将给出 200 |
| /(除法) | 将左操作数除以右操作数 | `expr $b / $a` 将给出 2 |
| %(模数) | 将左操作数除以右操作数并返回余数 | `expr $b % $a` 将给出 0 |
| =(赋值) | 将右操作数赋值给左操作数 | a = $b 会将 b 的值赋值给 a |
| ==(相等) | 比较两个数字,如果两者相同则返回真。 | [ $a == $b ] 将返回假。 |
| !=(不相等) | 比较两个数字,如果两者不同则返回真。 | [ $a != $b ] 将返回真。 |
务必理解所有条件表达式都应放在方括号内,并在其周围留有空格,例如[ $a == $b ]是正确的,而[$a==$b]是不正确的。
所有算术计算均使用长整数完成。
关系运算符
Bourne Shell 支持以下特定于数值的关系运算符。除非其值为数字,否则这些运算符不适用于字符串值。
例如,以下运算符将用于检查 10 和 20 之间的关系,以及“10”和“20”之间,但不适用于“ten”和“twenty”之间。
假设变量a保存 10,变量b保存 20,则 -
| 运算符 | 描述 | 示例 |
|---|---|---|
| -eq | 检查两个操作数的值是否相等;如果是,则条件变为真。 | [ $a -eq $b ] 不是真。 |
| -ne | 检查两个操作数的值是否相等;如果值不相等,则条件变为真。 | [ $a -ne $b ] 是真。 |
| -gt | 检查左操作数的值是否大于右操作数的值;如果是,则条件变为真。 | [ $a -gt $b ] 不是真。 |
| -lt | 检查左操作数的值是否小于右操作数的值;如果是,则条件变为真。 | [ $a -lt $b ] 是真。 |
| -ge | 检查左操作数的值是否大于或等于右操作数的值;如果是,则条件变为真。 | [ $a -ge $b ] 不是真。 |
| -le | 检查左操作数的值是否小于或等于右操作数的值;如果是,则条件变为真。 | [ $a -le $b ] 是真。 |
务必理解所有条件表达式都应放在方括号内,并在其周围留有空格。例如,[ $a <= $b ]是正确的,而[$a <= $b]是不正确的。
布尔运算符
Bourne Shell 支持以下布尔运算符。
假设变量a保存 10,变量b保存 20,则 -
| 运算符 | 描述 | 示例 |
|---|---|---|
| ! | 这是逻辑否定。它将真条件反转为假,反之亦然。 | [ ! false ] 是真。 |
| -o | 这是逻辑OR。如果其中一个操作数为真,则条件变为真。 | [ $a -lt 20 -o $b -gt 100 ] 是真。 |
| -a | 这是逻辑AND。如果两个操作数都为真,则条件变为真,否则为假。 | [ $a -lt 20 -a $b -gt 100 ] 是假。 |
字符串运算符
Bourne Shell 支持以下字符串运算符。
假设变量a保存“abc”,变量b保存“efg”,则 -
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 检查两个操作数的值是否相等;如果是,则条件变为真。 | [ $a = $b ] 不是真。 |
| != | 检查两个操作数的值是否相等;如果值不相等,则条件变为真。 | [ $a != $b ] 是真。 |
| -z | 检查给定字符串操作数的大小是否为零;如果长度为零,则返回真。 | [ -z $a ] 不是真。 |
| -n | 检查给定字符串操作数的大小是否不为零;如果长度不为零,则返回真。 | [ -n $a ] 不是假。 |
| str | 检查str是否不是空字符串;如果为空,则返回假。 | [ $a ] 不是假。 |
文件测试运算符
我们有一些运算符可用于测试与 Unix 文件关联的各种属性。
假设变量file保存一个现有的文件名“test”,其大小为 100 字节,并且具有以下权限:read、write和execute -
| 运算符 | 描述 | 示例 |
|---|---|---|
| -b file | 检查文件是否是块特殊文件;如果是,则条件变为真。 | [ -b $file ] 是假。 |
| -c file | 检查文件是否是字符特殊文件;如果是,则条件变为真。 | [ -c $file ] 是假。 |
| -d file | 检查文件是否是目录;如果是,则条件变为真。 | [ -d $file ] 不是真。 |
| -f file | 检查文件是否为普通文件,而不是目录或特殊文件;如果是,则条件变为真。 | [ -f $file ] 是真。 |
| -g file | 检查文件是否设置了其 set group ID (SGID) 位;如果是,则条件变为真。 | [ -g $file ] 是假。 |
| -k file | 检查文件是否设置了其粘滞位;如果是,则条件变为真。 | [ -k $file ] 是假。 |
| -p file | 检查文件是否为命名管道;如果是,则条件变为真。 | [ -p $file ] 是假。 |
| -t file | 检查文件描述符是否已打开并与终端关联;如果是,则条件变为真。 | [ -t $file ] 是假。 |
| -u file | 检查文件是否设置了其 Set User ID (SUID) 位;如果是,则条件变为真。 | [ -u $file ] 是假。 |
| -r file | 检查文件是否可读;如果是,则条件变为真。 | [ -r $file ] 是真。 |
| -w file | 检查文件是否可写;如果是,则条件变为真。 | [ -w $file ] 是真。 |
| -x file | 检查文件是否可执行;如果是,则条件变为真。 | [ -x $file ] 是真。 |
| -s file | 检查文件大小是否大于 0;如果是,则条件变为真。 | [ -s $file ] 是真。 |
| -e file | 检查文件是否存在;即使文件是目录但存在,也为真。 | [ -e $file ] 是真。 |
C Shell 运算符
以下链接将为您提供有关 C Shell 运算符的简要说明 -
Korn Shell 运算符
以下链接可帮助您了解 Korn Shell 运算符 -
Unix - Shell 决策
在本章中,我们将了解 Unix 中的 Shell 决策。在编写 Shell 脚本时,可能需要在给定的两条路径中选择一条路径。因此,您需要使用条件语句,使程序能够做出正确的决策并执行正确的操作。
Unix Shell 支持条件语句,用于根据不同条件执行不同的操作。我们现在将了解这里两种决策语句 -
if...else语句
case...esac语句
if...else 语句
If else 语句是有用的决策语句,可用于从给定的一组选项中选择一个选项。
Unix Shell 支持以下形式的if…else语句 -
大多数if语句使用上一章讨论的关系运算符来检查关系。
case...esac语句
您可以使用多个if...elif语句来执行多路分支。但是,这并不总是最佳解决方案,尤其是在所有分支都依赖于单个变量的值时。
Unix Shell支持case...esac语句,该语句恰好处理这种情况,并且它比重复使用if...elif语句效率更高。
这里只有一种case...esac语句形式,此处已对其进行了详细描述 -
Unix shell中的case...esac语句与我们在其他编程语言(如C或C++和PERL等)中使用的switch...case语句非常相似。
Unix - Shell循环类型
在本章中,我们将讨论Unix中的shell循环。循环是一种强大的编程工具,使您能够重复执行一组命令。在本章中,我们将检查shell程序员可用的以下类型的循环 -
您将根据情况使用不同的循环。例如,while循环执行给定的命令,直到给定的条件保持为真;until循环执行直到给定的条件变为真。
一旦您拥有良好的编程实践,您将获得专业知识,从而开始根据情况使用合适的循环。这里,while和for循环在大多数其他编程语言(如C、C++和PERL等)中都可用。
嵌套循环
所有循环都支持嵌套概念,这意味着您可以将一个循环放在另一个类似的循环或不同的循环内。此嵌套可以根据您的需求无限次进行。
以下是一个嵌套while循环的示例。其他循环可以根据编程需求以类似的方式嵌套 -
嵌套while循环
可以使用while循环作为另一个while循环主体的一部分。
语法
while command1 ; # this is loop1, the outer loop
do
Statement(s) to be executed if command1 is true
while command2 ; # this is loop2, the inner loop
do
Statement(s) to be executed if command2 is true
done
Statement(s) to be executed if command1 is true
done
示例
以下是一个简单的循环嵌套示例。让我们在用于计数到九的循环内添加另一个倒计时循环 -
#!/bin/sh
a=0
while [ "$a" -lt 10 ] # this is loop1
do
b="$a"
while [ "$b" -ge 0 ] # this is loop2
do
echo -n "$b "
b=`expr $b - 1`
done
echo
a=`expr $a + 1`
done
这将产生以下结果。重要的是要注意echo -n在这里是如何工作的。这里-n选项允许echo避免打印换行符。
0 1 0 2 1 0 3 2 1 0 4 3 2 1 0 5 4 3 2 1 0 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0
Unix - Shell循环控制
在本章中,我们将讨论Unix中的shell循环控制。到目前为止,您已经了解了创建循环以及使用循环来完成不同任务。有时您需要停止循环或跳过循环的迭代。
在本章中,我们将学习以下两个用于控制shell循环的语句 -
break语句
continue语句
无限循环
所有循环都有有限的生命周期,一旦条件为假或真,它们就会退出,具体取决于循环。
如果未满足所需条件,循环可能会永远继续。永远执行而不终止的循环会执行无限次。因此,此类循环称为无限循环。
示例
以下是一个简单的示例,它使用while循环显示数字零到九 -
#!/bin/sh a=10 until [ $a -lt 10 ] do echo $a a=`expr $a + 1` done
此循环永远继续,因为a始终大于或等于10,并且永远小于10。
break语句
break语句用于终止整个循环的执行,在完成执行直到break语句的所有代码行后。然后它向下转到循环结束后的代码。
语法
以下break语句用于退出循环 -
break
break命令也可以使用此格式退出嵌套循环 -
break n
这里n指定要退出的第n个封闭循环。
示例
以下是一个简单的示例,它显示循环一旦a变为5就会终止 -
#!/bin/sh
a=0
while [ $a -lt 10 ]
do
echo $a
if [ $a -eq 5 ]
then
break
fi
a=`expr $a + 1`
done
执行后,您将收到以下结果:
0 1 2 3 4 5
以下是一个嵌套for循环的简单示例。如果var1等于2并且var2等于0,则此脚本将退出这两个循环 -
#!/bin/sh
for var1 in 1 2 3
do
for var2 in 0 5
do
if [ $var1 -eq 2 -a $var2 -eq 0 ]
then
break 2
else
echo "$var1 $var2"
fi
done
done
执行后,您将收到以下结果。在内部循环中,您有一个带参数2的break命令。这表示如果满足条件,您应该退出外部循环,最终也退出内部循环。
1 0 1 5
continue语句
continue语句类似于break命令,不同之处在于它会导致当前循环迭代退出,而不是整个循环。
当发生错误但您想尝试执行循环的下一迭代时,此语句很有用。
语法
continue
与break语句一样,可以向continue命令提供一个整数参数以跳过嵌套循环中的命令。
continue n
这里n指定要继续执行的第n个封闭循环。
示例
以下循环使用了continue语句,该语句从continue语句返回并开始处理下一条语句 -
#!/bin/sh
NUMS="1 2 3 4 5 6 7"
for NUM in $NUMS
do
Q=`expr $NUM % 2`
if [ $Q -eq 0 ]
then
echo "Number is an even number!!"
continue
fi
echo "Found odd number"
done
执行后,您将收到以下结果:
Found odd number Number is an even number!! Found odd number Number is an even number!! Found odd number Number is an even number!! Found odd number
Unix - Shell替换
什么是替换?
当shell遇到包含一个或多个特殊字符的表达式时,它会执行替换。
示例
这里,变量的打印值被其值替换。同时,"\n"被换行符替换 -
#!/bin/sh a=10 echo -e "Value of a is $a \n"
您将收到以下结果。这里-e选项启用反斜杠转义的解释。
Value of a is 10
以下是不使用-e选项的结果 -
Value of a is 10\n
以下是可在echo命令中使用的转义序列 -
| 序号 | 转义符 & 描述 |
|---|---|
| 1 |
\\ 反斜杠 |
| 2 |
\a 警报 (BEL) |
| 3 |
\b 退格键 |
| 4 |
\c 抑制尾随换行符 |
| 5 |
\f 换页符 |
| 6 |
\n 换行符 |
| 7 |
\r 回车符 |
| 8 |
\t 水平制表符 |
| 9 |
\v 垂直制表符 |
您可以使用-E选项禁用反斜杠转义的解释(默认值)。
您可以使用-n选项禁用插入换行符。
命令替换
命令替换是shell执行给定命令集然后将其输出替换为命令位置的机制。
语法
当给出以下命令时,会执行命令替换 -
`command`
执行命令替换时,请确保使用反引号,而不是单引号字符。
示例
命令替换通常用于将命令的输出分配给变量。以下每个示例都演示了命令替换 -
#!/bin/sh DATE=`date` echo "Date is $DATE" USERS=`who | wc -l` echo "Logged in user are $USERS" UP=`date ; uptime` echo "Uptime is $UP"
执行后,您将收到以下结果:
Date is Thu Jul 2 03:59:57 MST 2009 Logged in user are 1 Uptime is Thu Jul 2 03:59:57 MST 2009 03:59:57 up 20 days, 14:03, 1 user, load avg: 0.13, 0.07, 0.15
变量替换
变量替换使shell程序员能够根据变量的状态来操作变量的值。
以下是所有可能替换的表格 -
| 序号 | 形式 & 描述 |
|---|---|
| 1 |
${var} 替换var的值。 |
| 2 |
${var:-word} 如果var为空或未设置,则将word替换为var。var的值不会改变。 |
| 3 |
${var:=word} 如果var为空或未设置,则var将设置为word的值。 |
| 4 |
${var:?message} 如果var为空或未设置,则将message打印到标准错误。这检查变量是否正确设置。 |
| 5 |
${var:+word} 如果var已设置,则将word替换为var。var的值不会改变。 |
示例
以下示例显示了上述替换的各种状态 -
#!/bin/sh
echo ${var:-"Variable is not set"}
echo "1 - Value of var is ${var}"
echo ${var:="Variable is not set"}
echo "2 - Value of var is ${var}"
unset var
echo ${var:+"This is default value"}
echo "3 - Value of var is $var"
var="Prefix"
echo ${var:+"This is default value"}
echo "4 - Value of var is $var"
echo ${var:?"Print this message"}
echo "5 - Value of var is ${var}"
执行后,您将收到以下结果:
Variable is not set 1 - Value of var is Variable is not set 2 - Value of var is Variable is not set 3 - Value of var is This is default value 4 - Value of var is Prefix Prefix 5 - Value of var is Prefix
Unix - Shell引用机制
在本章中,我们将详细讨论Shell引用机制。我们将从讨论元字符开始。
元字符
Unix Shell提供各种元字符,这些字符在任何Shell脚本中使用时都具有特殊含义,并导致单词终止,除非被引用。
例如,?在列出目录中的文件时与单个字符匹配,而*与多个字符匹配。以下是大多数shell特殊字符(也称为元字符)的列表 -
* ? [ ] ' " \ $ ; & ( ) | ^ < > new-line space tab
可以通过在其前面加上\来引用字符(即使其代表自身)。
示例
以下示例显示了如何打印*或? -
#!/bin/sh echo Hello; Word
执行后,您将收到以下结果:
Hello ./test.sh: line 2: Word: command not found shell returned 127
现在让我们尝试使用引用的字符 -
#!/bin/sh echo Hello\; Word
执行后,您将收到以下结果:
Hello; Word
$符号是元字符之一,因此必须对其进行引用以避免shell的特殊处理 -
#!/bin/sh echo "I have \$1200"
执行后,您将收到以下结果:
I have $1200
下表列出了四种引用形式 -
| 序号 | 引用 & 描述 |
|---|---|
| 1 |
单引号 这些引号之间的所有特殊字符都将失去其特殊含义。 |
| 2 |
双引号 这些引号之间的大多数特殊字符都将失去其特殊含义,但以下例外 -
|
| 3 |
反斜杠 反斜杠后面的任何字符都将失去其特殊含义。 |
| 4 |
反引号 反引号之间的任何内容都将被视为命令并执行。 |
单引号
考虑一个包含许多特殊shell字符的echo命令 -
echo <-$1500.**>; (update?) [y|n]
在每个特殊字符前面加上反斜杠既繁琐又使行难以阅读 -
echo \<-\$1500.\*\*\>\; \(update\?\) \[y\|n\]
有一种简单的方法可以引用大量字符。在字符串的开头和结尾处加上单引号(') -
echo '<-$1500.**>; (update?) [y|n]'
单引号内的字符就像每个字符前面都有反斜杠一样被引用。这样,echo命令就可以以正确的方式显示。
如果单引号出现在要输出的字符串中,则不应将整个字符串放在单引号中,而应使用反斜杠(\)在其前面,如下所示 -
echo 'It\'s Shell Programming
双引号
尝试执行以下shell脚本。此shell脚本使用了单引号 -
VAR=ZARA echo '$VAR owes <-$1500.**>; [ as of (`date +%m/%d`) ]'
执行后,您将收到以下结果:
$VAR owes <-$1500.**>; [ as of (`date +%m/%d`) ]
这不是必须显示的内容。很明显,单引号阻止了变量替换。如果要替换变量值并使倒引号按预期工作,则需要将命令放在双引号中,如下所示 -
VAR=ZARA echo "$VAR owes <-\$1500.**>; [ as of (`date +%m/%d`) ]"
执行后,您将收到以下结果:
ZARA owes <-$1500.**>; [ as of (07/02) ]
双引号消除了除以下字符之外的所有字符的特殊含义 -
$ 用于参数替换
反引号用于命令替换
\$ 用于启用文字美元符号
\` 用于启用文字反引号
\" 用于启用嵌入式双引号
\\ 用于启用嵌入式反斜杠
所有其他\字符都是文字(不是特殊字符)
单引号内的字符就像每个字符前面都有反斜杠一样被引用。这有助于echo命令正确显示。
如果单引号出现在要输出的字符串中,则不应将整个字符串放在单引号中,而应使用反斜杠(\)在其前面,如下所示 -
echo 'It\'s Shell Programming'
反引号
将任何Shell命令放在反引号之间会执行该命令。
语法
下面是将任何 Shell **命令**放在反引号之间的简单语法。
var=`command`
示例
在下面的示例中,执行了**date**命令,并将产生的结果存储在 DATA 变量中。
DATE=`date` echo "Current Date: $DATE"
执行后,您将收到以下结果:
Current Date: Thu Jul 2 05:28:45 MST 2009
Unix - Shell 输入/输出重定向
在本章中,我们将详细讨论 Shell 输入/输出重定向。大多数 Unix 系统命令从您的终端获取输入,并将结果输出发送回您的终端。命令通常从标准输入读取其输入,默认情况下标准输入恰好是您的终端。类似地,命令通常将其输出写入标准输出,默认情况下标准输出也是您的终端。
输出重定向
通常用于标准输出的命令输出可以轻松地改为重定向到文件。此功能称为输出重定向。
如果符号 > file 附加到任何通常将其输出写入标准输出的命令,则该命令的输出将写入文件而不是您的终端。
检查以下**who**命令,该命令将命令的完整输出重定向到 users 文件中。
$ who > users
请注意,终端上没有显示任何输出。这是因为输出已从默认标准输出设备(终端)重定向到指定的文件。您可以检查 users 文件以获取完整内容 -
$ cat users oko tty01 Sep 12 07:30 ai tty15 Sep 12 13:32 ruth tty21 Sep 12 10:10 pat tty24 Sep 12 13:07 steve tty25 Sep 12 13:03 $
如果命令的输出重定向到文件,并且该文件已包含某些数据,则这些数据将丢失。请考虑以下示例 -
$ echo line 1 > users $ cat users line 1 $
您可以使用 >> 运算符将输出追加到现有文件中,如下所示 -
$ echo line 2 >> users $ cat users line 1 line 2 $
输入重定向
就像命令的输出可以重定向到文件一样,命令的输入也可以重定向到文件。由于**大于号 >**用于输出重定向,因此**小于号 <**用于重定向命令的输入。
通常从标准输入获取输入的命令可以以这种方式从文件重定向其输入。例如,要计算上面生成的 users 文件中的行数,您可以执行以下命令 -
$ wc -l users 2 users $
执行后,您将收到以下输出。您可以通过将**wc**命令的标准输入从 users 文件重定向来计算文件中的行数 -
$ wc -l < users 2 $
请注意,wc 命令的两种形式产生的输出存在差异。在第一种情况下,文件 users 的名称与行数一起列出;在第二种情况下,则没有。
在第一种情况下,wc 知道它正在从文件 users 读取其输入。在第二种情况下,它只知道它正在从标准输入读取其输入,因此它不会显示文件名。
此处文档
**此处文档**用于将输入重定向到交互式 shell 脚本或程序。
我们可以通过为交互式程序或交互式 shell 脚本提供所需的输入,在 shell 脚本中运行交互式程序,而无需用户操作。
**此处**文档的通用形式如下 -
command << delimiter document delimiter
此处,shell 将**<<**运算符解释为读取输入的指令,直到找到包含指定分隔符的行。然后,所有直到包含分隔符的行之前的输入行都将馈送到命令的标准输入。
分隔符告诉 shell **此处**文档已完成。如果没有它,shell 将永远继续读取输入。分隔符必须是一个不包含空格或制表符的单个单词。
以下是 **wc -l** 命令的输入,用于计算总行数 -
$wc -l << EOF This is a simple lookup program for good (and bad) restaurants in Cape Town. EOF 3 $
您可以使用**此处文档**通过您的脚本打印多行,如下所示 -
#!/bin/sh cat << EOF This is a simple lookup program for good (and bad) restaurants in Cape Town. EOF
执行后,您将收到以下结果:
This is a simple lookup program for good (and bad) restaurants in Cape Town.
以下脚本运行与**vi**文本编辑器的会话并将输入保存到文件**test.txt**中。
#!/bin/sh filename=test.txt vi $filename <<EndOfCommands i This file was created automatically from a shell script ^[ ZZ EndOfCommands
如果您运行此脚本,其中 vim 充当 vi,那么您可能会看到如下输出 -
$ sh test.sh Vim: Warning: Input is not from a terminal $
运行脚本后,您应该会看到以下内容添加到文件**test.txt**中 -
$ cat test.txt This file was created automatically from a shell script $
丢弃输出
有时您需要执行命令,但不想在屏幕上显示输出。在这种情况下,您可以通过将其重定向到文件** /dev/null**来丢弃输出 -
$ command > /dev/null
此处 command 是您要执行的命令的名称。文件** /dev/null**是一个特殊文件,会自动丢弃其所有输入。
要丢弃命令的输出及其错误输出,请使用标准重定向将**STDERR**重定向到**STDOUT** -
$ command > /dev/null 2>&1
这里**2**代表**STDERR**,**1**代表**STDOUT**。您可以通过将 STDOUT 重定向到 STDERR 来在 STDERR 上显示消息,如下所示 -
$ echo message 1>&2
重定向命令
以下是您可以用于重定向的完整命令列表 -
| 序号 | 命令和说明 |
|---|---|
| 1 |
pgm > file pgm 的输出重定向到 file |
| 2 |
pgm < file 程序 pgm 从 file 读取其输入 |
| 3 |
pgm >> file pgm 的输出追加到 file |
| 4 |
n > file 具有描述符**n**的流的输出重定向到 file |
| 5 |
n >> file 具有描述符**n**的流的输出追加到 file |
| 6 |
n >& m 将流**n**的输出与流**m**合并 |
| 7 |
n <& m 将流**n**的输入与流**m**合并 |
| 8 |
<< tag 标准输入从此处通过下一行开头的 tag 传入 |
| 9 |
| 获取一个程序或进程的输出,并将其发送到另一个程序或进程 |
请注意,文件描述符**0**通常是标准输入 (STDIN),**1**是标准输出 (STDOUT),**2**是标准错误输出 (STDERR)。
Unix - Shell 函数
在本章中,我们将详细讨论 shell 函数。函数使您能够将脚本的整体功能分解成更小、更逻辑的子部分,然后可以在需要时调用这些子部分来执行其各自的任务。
使用函数执行重复性任务是创建**代码重用**的绝佳方法。这是现代面向对象编程原则的重要组成部分。
Shell 函数类似于其他编程语言中的子例程、过程和函数。
创建函数
要声明函数,只需使用以下语法 -
function_name () {
list of commands
}
您的函数的名称是**function_name**,这就是您将在脚本的其他地方使用它来调用它的方式。函数名称后面必须跟括号,然后是括在大括号中的命令列表。
示例
以下示例显示了函数的使用 -
#!/bin/sh
# Define your function here
Hello () {
echo "Hello World"
}
# Invoke your function
Hello
执行后,您将收到以下输出 -
$./test.sh Hello World
向函数传递参数
您可以定义一个函数,该函数将在调用函数时接受参数。这些参数将由**$1**、**$2**等表示。
以下是一个示例,我们传递两个参数 Zara 和 Ali,然后我们在函数中捕获并打印这些参数。
#!/bin/sh
# Define your function here
Hello () {
echo "Hello World $1 $2"
}
# Invoke your function
Hello Zara Ali
执行后,您将收到以下结果:
$./test.sh Hello World Zara Ali
从函数返回值
如果您从函数内部执行**exit**命令,其效果不仅是终止函数的执行,还会终止调用该函数的 shell 程序的执行。
如果您只想终止函数的执行,则有一种方法可以退出已定义的函数。
根据情况,您可以使用**return**命令从您的函数返回任何值,其语法如下 -
return code
此处**code**可以是您选择的任何内容,但显然您应该选择在整个脚本的上下文中具有意义或有用的内容。
示例
以下函数返回一个值 10 -
#!/bin/sh
# Define your function here
Hello () {
echo "Hello World $1 $2"
return 10
}
# Invoke your function
Hello Zara Ali
# Capture value returnd by last command
ret=$?
echo "Return value is $ret"
执行后,您将收到以下结果:
$./test.sh Hello World Zara Ali Return value is 10
嵌套函数
函数更有趣的特性之一是它们可以调用自身以及其他函数。调用自身的函数称为**递归函数**。
以下示例演示了两个函数的嵌套 -
#!/bin/sh
# Calling one function from another
number_one () {
echo "This is the first function speaking..."
number_two
}
number_two () {
echo "This is now the second function speaking..."
}
# Calling function one.
number_one
执行后,您将收到以下结果:
This is the first function speaking... This is now the second function speaking...
从提示符调用函数
您可以将常用函数的定义放在您的**.profile**中。这些定义将在您登录时可用,您可以在命令提示符下使用它们。
或者,您可以将定义分组到一个文件中,例如**test.sh**,然后通过键入以下内容在当前 shell 中执行该文件 -
$. test.sh
这将导致在**test.sh**中定义的函数被读取并定义到当前 shell 中,如下所示 -
$ number_one This is the first function speaking... This is now the second function speaking... $
要从 shell 中删除函数的定义,请使用带**.f**选项的 unset 命令。此命令也用于从 shell 中删除变量的定义。
$ unset -f function_name
Unix - Shell 手册页帮助
所有 Unix 命令都带有一些可选和必需的选项。忘记这些命令的完整语法非常常见。
因为没有人能记住每个 Unix 命令及其所有选项,所以我们提供了在线帮助来缓解这种情况,从 Unix 开发阶段开始就提供了。
Unix 的**帮助文件**版本称为**手册页**。如果有一个命令名称,您不确定如何使用它,则手册页可以帮助您完成每个步骤。
语法
以下是在使用系统时帮助您获取任何 Unix 命令详细信息的简单命令 -
$man command
示例
假设有一个命令需要您获取帮助;假设您想知道有关**pwd**的信息,那么您只需使用以下命令 -
$man pwd
以上命令帮助您了解有关**pwd**命令的完整信息。在您的命令提示符下亲自尝试一下以获取更多详细信息。
您可以使用以下命令获取有关**man**命令本身的完整详细信息 -
$man man
手册页部分
手册页通常分为几个部分,这些部分通常因手册页作者的偏好而异。下表列出了一些常见的部分 -
| 序号 | 部分 & 描述 |
|---|---|
| 1 |
NAME 命令的名称 |
| 2 |
SYNOPSIS 命令的一般用法参数 |
| 3 |
DESCRIPTION 描述命令的作用 |
| 4 |
OPTIONS 描述命令的所有参数或选项 |
| 5 |
SEE ALSO 列出与手册页中的命令直接相关或与其功能非常相似的其他命令 |
| 6 |
BUGS 解释命令或其输出存在的任何已知问题或错误 |
| 7 |
EXAMPLES 常见的用法示例,让读者了解如何使用该命令 |
| 8 |
AUTHORS 手册页/命令的作者 |
总而言之,手册页是重要的资源,也是在您需要有关 Unix 系统中的命令或文件的信息时进行研究的第一途径。
有用的 Shell 命令
以下链接为您提供最重要的和最常用的 Unix Shell 命令列表。
如果您不知道如何使用任何命令,请使用手册页获取有关该命令的完整详细信息。
以下是Unix Shell - 有用命令的列表
Unix - 使用 SED 的正则表达式
在本章中,我们将详细讨论 Unix 中使用 SED 的正则表达式。
正则表达式是可以用来描述多个字符序列的字符串。正则表达式被几个不同的 Unix 命令使用,包括**ed**、**sed**、**awk**、**grep**,以及在更有限的程度上,**vi**。
这里SED代表stream editor(流编辑器)。这个面向流的编辑器是专门为执行脚本而创建的。因此,您输入的所有内容都会通过它传递到STDOUT,并且它不会更改输入文件。
调用sed
在开始之前,让我们确保我们有一个/etc/passwd文本文件的本地副本,以便与sed一起使用。
如前所述,sed可以通过将数据通过管道发送到它来调用,如下所示:
$ cat /etc/passwd | sed
Usage: sed [OPTION]... {script-other-script} [input-file]...
-n, --quiet, --silent
suppress automatic printing of pattern space
-e script, --expression = script
...............................
cat命令将/etc/passwd的内容通过管道转储到sed,进入sed的模式空间。模式空间是sed在其操作中使用的内部工作缓冲区。
sed通用语法
以下是sed的通用语法:
/pattern/action
这里,pattern是正则表达式,action是下表中给出的命令之一。如果省略pattern,则对每一行执行action,就像我们上面看到的那样。
包围模式的斜杠字符(/)是必需的,因为它们用作分隔符。
| 序号 | 范围和描述 |
|---|---|
| 1 |
p 打印该行 |
| 2 |
d 删除该行 |
| 3 |
s/pattern1/pattern2/ 将pattern1的第一次出现替换为pattern2 |
使用sed删除所有行
现在我们将了解如何使用sed删除所有行。再次调用sed;但现在sed应该使用编辑命令删除行,用单个字母d表示:
$ cat /etc/passwd | sed 'd' $
sed可以通过从文件读取数据来代替通过管道发送文件的方式调用,如下例所示。
以下命令与前面的示例完全相同,无需cat命令:
$ sed -e 'd' /etc/passwd $
sed地址
sed也支持地址。地址要么是文件中的特定位置,要么是应应用特定编辑命令的范围。当sed遇到没有地址时,它会对文件中的每一行执行其操作。
以下命令向您一直在使用的sed命令添加了一个基本地址:
$ cat /etc/passwd | sed '1d' |more daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:65534:sync:/bin:/bin/sync games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/sh $
请注意,数字1是在删除编辑命令之前添加的。这指示sed对文件的第1行执行编辑命令。在此示例中,sed将删除/etc/password的第一行并打印文件的其余部分。
sed地址范围
现在我们将了解如何使用sed地址范围。那么,如果您想从文件中删除多行怎么办?您可以使用sed指定地址范围,如下所示:
$ cat /etc/passwd | sed '1, 5d' |more games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/sh $
以上命令将应用于从1到5的所有行。这将删除前五行。
尝试以下地址范围:
| 序号 | 范围和描述 |
|---|---|
| 1 |
'4,10d' 从第4行到第10行都被删除 |
| 2 |
'10,4d' 仅删除第10行,因为sed不反向工作 |
| 3 |
'4,+5d' 这匹配文件中的第4行,删除该行,继续删除接下来的五行,然后停止删除并打印其余部分 |
| 4 |
'2,5!d' 这将删除除第2行到第5行之外的所有内容 |
| 5 |
'1~3d' 这将删除第一行,跳过接下来的三行,然后删除第四行。sed继续应用此模式,直到文件结束。 |
| 6 |
'2~2d' 这告诉sed删除第二行,跳过下一行,删除下一行,并重复直到文件结束 |
| 7 |
'4,10p' 从第4行到第10行都被打印 |
| 8 |
'4,d' 这会生成语法错误 |
| 9 |
',10d' 这也会生成语法错误 |
注意 - 使用p操作时,应使用-n选项避免重复打印行。检查以下两个命令之间的区别:
$ cat /etc/passwd | sed -n '1,3p' Check the above command without -n as follows − $ cat /etc/passwd | sed '1,3p'
替换命令
替换命令(用s表示)将替换您指定的任何字符串为任何其他您指定的字符串。
要将一个字符串替换为另一个字符串,sed需要知道第一个字符串在哪里结束以及替换字符串在哪里开始的信息。为此,我们继续用正斜杠(/)字符将这两个字符串括起来。
以下命令将该行上root字符串的第一次出现替换为amrood字符串。
$ cat /etc/passwd | sed 's/root/amrood/' amrood:x:0:0:root user:/root:/bin/sh daemon:x:1:1:daemon:/usr/sbin:/bin/sh ..........................
务必注意,sed仅替换一行上的第一次出现。如果字符串root在一行上出现多次,则只替换第一个匹配项。
为了使sed执行全局替换,请在命令末尾添加字母g,如下所示:
$ cat /etc/passwd | sed 's/root/amrood/g' amrood:x:0:0:amrood user:/amrood:/bin/sh daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh ...........................
替换标志
除了g标志之外,还可以传递许多其他有用的标志,并且您可以同时指定多个标志。
| 序号 | 标志和描述 |
|---|---|
| 1 |
g 替换所有匹配项,而不仅仅是第一个匹配项 |
| 2 |
NUMBER 仅替换第NUMBER个匹配项 |
| 3 |
p 如果进行了替换,则打印模式空间 |
| 4 |
w FILENAME 如果进行了替换,则将结果写入FILENAME |
| 5 |
I或i 以不区分大小写的方式匹配 |
| 6 |
M或m 除了特殊正则表达式字符^和$的正常行为之外,此标志还会导致^匹配换行符后的空字符串,$匹配换行符前的空字符串 |
使用替代字符串分隔符
假设您必须对包含正斜杠字符的字符串进行替换。在这种情况下,您可以通过在s之后提供指定的字符来指定不同的分隔符。
$ cat /etc/passwd | sed 's:/root:/amrood:g' amrood:x:0:0:amrood user:/amrood:/bin/sh daemon:x:1:1:daemon:/usr/sbin:/bin/sh
在上面的示例中,我们使用了:作为分隔符而不是斜杠/,因为我们试图搜索/root而不是简单的root。
替换为空格
使用空替换字符串将/etc/passwd文件中的root字符串完全删除:
$ cat /etc/passwd | sed 's/root//g' :x:0:0::/:/bin/sh daemon:x:1:1:daemon:/usr/sbin:/bin/sh
地址替换
如果您只想在第10行上将字符串sh替换为字符串quiet,您可以按如下方式指定:
$ cat /etc/passwd | sed '10s/sh/quiet/g' root:x:0:0:root user:/root:/bin/sh daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:65534:sync:/bin:/bin/sync games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/quiet
类似地,要进行地址范围替换,您可以执行以下操作:
$ cat /etc/passwd | sed '1,5s/sh/quiet/g' root:x:0:0:root user:/root:/bin/quiet daemon:x:1:1:daemon:/usr/sbin:/bin/quiet bin:x:2:2:bin:/bin:/bin/quiet sys:x:3:3:sys:/dev:/bin/quiet sync:x:4:65534:sync:/bin:/bin/sync games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/sh
从输出中可以看到,前五行将字符串sh更改为quiet,但其余行保持不变。
匹配命令
您将使用p选项和-n选项来打印所有匹配的行,如下所示:
$ cat testing | sed -n '/root/p' root:x:0:0:root user:/root:/bin/sh [root@ip-72-167-112-17 amrood]# vi testing root:x:0:0:root user:/root:/bin/sh daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:65534:sync:/bin:/bin/sync games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/sh
使用正则表达式
在匹配模式时,您可以使用正则表达式,它提供了更大的灵活性。
检查以下示例,该示例匹配所有以daemon开头的行,然后删除它们:
$ cat testing | sed '/^daemon/d' root:x:0:0:root user:/root:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:65534:sync:/bin:/bin/sync games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/sh
以下示例删除所有以sh结尾的行:
$ cat testing | sed '/sh$/d' sync:x:4:65534:sync:/bin:/bin/sync
下表列出了正则表达式中非常有用的四个特殊字符。
| 序号 | 字符和描述 |
|---|---|
| 1 |
^ 匹配行的开头 |
| 2 |
$ 匹配行的结尾 |
| 3 |
. 匹配任何单个字符 |
| 4 |
* 匹配前一个字符的零个或多个出现 |
| 5 |
[chars] 匹配chars中给出的任何一个字符,其中chars是字符序列。您可以使用-字符表示字符范围。 |
匹配字符
查看更多表达式以演示元字符的使用。例如,以下模式:
| 序号 | 表达式和描述 |
|---|---|
| 1 |
/a.c/ 匹配包含a+c、a-c、abc、match和a3c等字符串的行 |
| 2 |
/a*c/ 匹配相同的字符串以及ace、yacc和arctic等字符串 |
| 3 |
/[tT]he/ 匹配字符串The和the |
| 4 |
/^$/ 匹配空行 |
| 5 |
/^.*$/ 匹配任何整行 |
| 6 |
/ */ 匹配一个或多个空格 |
| 7 |
/^$/ 匹配空行 |
下表显示了一些常用的字符集:
| 序号 | 集和描述 |
|---|---|
| 1 |
[a-z] 匹配单个小写字母 |
| 2 |
[A-Z] 匹配单个大写字母 |
| 3 |
[a-zA-Z] 匹配单个字母 |
| 4 |
[0-9] 匹配单个数字 |
| 5 |
[a-zA-Z0-9] 匹配单个字母或数字 |
字符类关键字
一些特殊关键字通常可用于regexps,尤其是使用regexps的GNU实用程序。它们对sed正则表达式非常有用,因为它们简化了操作并提高了可读性。
例如,字符a到z和字符A到Z构成一类具有关键字[[:alpha:]]的字符。
使用字母字符类关键字,此命令仅打印/etc/syslog.conf文件中以字母开头的那些行:
$ cat /etc/syslog.conf | sed -n '/^[[:alpha:]]/p' authpriv.* /var/log/secure mail.* -/var/log/maillog cron.* /var/log/cron uucp,news.crit /var/log/spooler local7.* /var/log/boot.log
下表是GNU sed中可用字符类关键字的完整列表。
| 序号 | 字符类和描述 |
|---|---|
| 1 |
[[:alnum:]] 字母数字 [a-z A-Z 0-9] |
| 2 |
[[:alpha:]] 字母 [a-z A-Z] |
| 3 |
[[:blank:]] 空白字符(空格或制表符) |
| 4 |
[[:cntrl:]] 控制字符 |
| 5 |
[[:digit:]] 数字 [0-9] |
| 6 |
[[:graph:]] 任何可见字符(不包括空格) |
| 7 |
[[:lower:]] 小写字母 [a-z] |
| 8 |
[[:print:]] 可打印字符(非控制字符) |
| 9 |
[[:punct:]] 标点符号 |
| 10 |
[[:space:]] 空白字符 |
| 11 |
[[:upper:]] 大写字母 [A-Z] |
| 12 |
[[:xdigit:]] 十六进制数字 [0-9 a-f A-F] |
&符号引用
sed元字符&表示匹配的模式的内容。例如,假设您有一个名为phone.txt的文件,其中包含以下电话号码:
5555551212 5555551213 5555551214 6665551215 6665551216 7775551217
您希望将区号(前三位数字)用括号括起来,以便于阅读。为此,您可以使用&替换字符:
$ sed -e 's/^[[:digit:]][[:digit:]][[:digit:]]/(&)/g' phone.txt (555)5551212 (555)5551213 (555)5551214 (666)5551215 (666)5551216 (777)5551217
这里在模式部分,您匹配前三位数字,然后使用&将这三位数字替换为周围的括号。
使用多个sed命令
您可以在单个sed命令中使用多个sed命令,如下所示:
$ sed -e 'command1' -e 'command2' ... -e 'commandN' files
这里command1到commandN是前面讨论过的类型的sed命令。这些命令应用于files给出的文件列表中的每一行。
使用相同的机制,我们可以将上述电话号码示例编写如下:
$ sed -e 's/^[[:digit:]]\{3\}/(&)/g' \
-e 's/)[[:digit:]]\{3\}/&-/g' phone.txt
(555)555-1212
(555)555-1213
(555)555-1214
(666)555-1215
(666)555-1216
(777)555-1217
注意 - 在上面的示例中,我们没有重复三次字符类关键字[[:digit:]],而是用\{3\}替换它,这意味着前面的正则表达式匹配三次。我们还使用了\来换行,在运行命令之前必须将其删除。
反向引用
&符号元字符很有用,但更实用的是能够在正则表达式中定义特定区域。这些特殊区域可以在替换字符串中用作参考。通过定义正则表达式的特定部分,您可以使用特殊的引用字符来引用这些部分。
要进行反向引用,您必须首先定义一个区域,然后引用该区域。要定义一个区域,您需要在每个感兴趣的区域周围插入反斜杠括号。您用反斜杠括起来的第一个区域由\1引用,第二个区域由\2引用,以此类推。
假设phone.txt包含以下文本:
(555)555-1212 (555)555-1213 (555)555-1214 (666)555-1215 (666)555-1216 (777)555-1217
尝试以下命令:
$ cat phone.txt | sed 's/\(.*)\)\(.*-\)\(.*$\)/Area \ code: \1 Second: \2 Third: \3/' Area code: (555) Second: 555- Third: 1212 Area code: (555) Second: 555- Third: 1213 Area code: (555) Second: 555- Third: 1214 Area code: (666) Second: 555- Third: 1215 Area code: (666) Second: 555- Third: 1216 Area code: (777) Second: 555- Third: 1217
注意 - 在上面的示例中,括号内的每个正则表达式将分别由\1、\2等进行反向引用。我们在这里使用了\来换行。在运行命令之前应将其删除。
Unix - 文件系统基础
文件系统是分区或磁盘上文件的逻辑集合。分区是信息的容器,如果需要,可以跨越整个硬盘驱动器。
您的硬盘驱动器可以有多个分区,这些分区通常只包含一个文件系统,例如一个文件系统容纳/文件系统,另一个文件系统容纳/home文件系统。
每个分区一个文件系统允许对不同的文件系统进行逻辑维护和管理。
在Unix中,所有内容都被视为文件,包括物理设备,例如DVD-ROM、USB设备和软盘驱动器。
目录结构
Unix使用分层文件系统结构,很像一棵倒置的树,根目录(/)位于文件系统的底部,所有其他目录都从那里扩展。
Unix文件系统是文件的集合和目录,具有以下属性:
它有一个根目录(/),其中包含其他文件和目录。
每个文件或目录都由其名称、所在的目录和唯一的标识符(通常称为inode)唯一标识。
按照惯例,根目录的inode编号为2,lost+found目录的inode编号为3。inode编号0和1未使用。可以通过为ls命令指定-i选项查看文件inode编号。
它是自包含的。一个文件系统与另一个文件系统之间没有依赖关系。
这些目录具有特定的用途,并且通常保存相同类型的信息,以便于查找文件。以下是主要版本的Unix上存在的目录:
| 序号 | 目录&描述 |
|---|---|
| 1 |
/ 这是根目录,它应该只包含文件结构顶层所需的目录 |
| 2 |
/bin 这是可执行文件所在的目录。所有用户都可以使用这些文件 |
| 3 |
/dev 这些是设备驱动程序 |
| 4 |
/etc 主管目录命令、配置文件、磁盘配置文件、有效用户列表、组、以太网、主机、将关键消息发送到哪里 |
| 5 |
/lib 包含共享库文件,有时还包含其他与内核相关的文件 |
| 6 |
/boot 包含用于启动系统的文件 |
| 7 |
/home 包含用户和其他帐户的主目录 |
| 8 |
/mnt 用于挂载其他临时文件系统,例如cdrom和floppy,分别用于CD-ROM驱动器和软盘驱动器 |
| 9 |
/proc 包含所有进程,这些进程由进程号或其他对系统动态的信息标记为文件 |
| 10 |
/tmp 保存系统启动之间使用的临时文件 |
| 11 |
/usr 用于各种用途,并且可以被许多用户使用。包括管理命令、共享文件、库文件等 |
| 12 |
/var 通常包含可变长度的文件,例如日志和打印文件,以及可能包含可变数量数据的任何其他类型的文件 |
| 13 |
/sbin 包含二进制(可执行)文件,通常用于系统管理。例如,fdisk和ifconfig实用程序 |
| 14 |
/kernel 包含内核文件 |
导航文件系统
现在您已经了解了文件系统的基础知识,您可以开始导航到您需要的文件。以下命令用于导航系统:
| 序号 | 命令和说明 |
|---|---|
| 1 |
cat filename 显示文件名 |
| 2 |
cd dirname 将您移动到指定的目录 |
| 3 |
cp file1 file2 将一个文件/目录复制到指定位置 |
| 4 |
file filename 识别文件类型(二进制、文本等) |
| 5 |
find filename dir 查找文件/目录 |
| 6 |
head filename 显示文件的开头 |
| 7 |
less filename 从文件末尾或开头浏览文件 |
| 8 |
ls dirname 显示指定目录的内容 |
| 9 |
mkdir dirname 创建指定的目录 |
| 10 |
more filename 从头到尾浏览文件 |
| 11 |
mv file1 file2 移动文件/目录的位置或重命名文件/目录 |
| 12 |
pwd 显示用户所在的当前目录 |
| 13 |
rm filename 删除文件 |
| 14 |
rmdir dirname 删除目录 |
| 15 |
tail filename 显示文件的末尾 |
| 16 |
touch filename 创建一个空白文件或修改现有文件或其属性 |
| 17 |
whereis filename 显示文件的位置 |
| 18 |
which filename 如果文件在您的PATH中,则显示文件的位置 |
您可以使用手册页帮助检查此处提到的每个命令的完整语法。
df命令
管理分区空间的第一种方法是使用df(磁盘空闲)命令。命令df -k(磁盘空闲)显示以千字节为单位的磁盘空间使用情况,如下所示:
$df -k Filesystem 1K-blocks Used Available Use% Mounted on /dev/vzfs 10485760 7836644 2649116 75% / /devices 0 0 0 0% /devices $
某些目录,例如/devices,在kbytes、used和avail列中显示0,容量为0%。这些是特殊的(或虚拟的)文件系统,尽管它们驻留在/下的磁盘上,但它们本身不会占用磁盘空间。
df -k输出在所有Unix系统上通常相同。以下是它通常包含的内容:
| 序号 | 列 & 描述 |
|---|---|
| 1 |
文件系统 物理文件系统名称 |
| 2 |
kbytes 存储介质上可用的总千字节数 |
| 3 |
used 已使用的总千字节数(由文件占用) |
| 4 |
avail 可用于使用的总千字节数 |
| 5 |
capacity 文件使用的总空间百分比 |
| 6 |
挂载点 文件系统挂载到的位置 |
您可以使用-h(人类可读)选项以更容易理解的表示法显示输出。
du命令
du(磁盘使用情况)命令使您能够指定目录以显示特定目录上的磁盘空间使用情况。
如果您想确定特定目录占用了多少空间,此命令很有用。以下命令显示每个目录消耗的块数。单个块可能占用512字节或1千字节,具体取决于您的系统。
$du /etc 10 /etc/cron.d 126 /etc/default 6 /etc/dfs ... $
-h选项使输出更容易理解:
$du -h /etc 5k /etc/cron.d 63k /etc/default 3k /etc/dfs ... $
挂载文件系统
必须挂载文件系统才能被系统使用。要查看当前挂载到系统上的内容(可用),请使用以下命令:
$ mount /dev/vzfs on / type reiserfs (rw,usrquota,grpquota) proc on /proc type proc (rw,nodiratime) devpts on /dev/pts type devpts (rw) $
根据Unix约定,/mnt目录是临时挂载点(例如CDROM驱动器、远程网络驱动器和软盘驱动器)所在的位置。如果您需要挂载文件系统,可以使用mount命令,其语法如下:
mount -t file_system_type device_to_mount directory_to_mount_to
例如,如果您想将CD-ROM挂载到目录/mnt/cdrom,您可以键入:
$ mount -t iso9660 /dev/cdrom /mnt/cdrom
这假设您的CD-ROM设备称为/dev/cdrom,并且您希望将其挂载到/mnt/cdrom。有关更具体的信息,请参阅mount手册页,或在命令行键入mount -h以获取帮助信息。
挂载后,您可以使用cd命令通过刚刚创建的挂载点导航新可用的文件系统。
卸载文件系统
要从系统中卸载(删除)文件系统,请使用umount命令并识别挂载点或设备。
例如,要卸载cdrom,请使用以下命令:
$ umount /dev/cdrom
mount命令使您能够访问文件系统,但在大多数现代Unix系统上,自动挂载功能使此过程对用户不可见,并且不需要任何干预。
用户和组配额
用户和组配额提供了机制,通过这些机制,单个用户或特定组内所有用户使用的空间量可以限制为管理员定义的值。
配额围绕两个限制进行操作,如果空间量或磁盘块数量开始超过管理员定义的限制,则允许用户采取一些措施:
软限制 - 如果用户超过定义的限制,则会有一个宽限期,允许用户释放一些空间。
硬限制 - 当达到硬限制时,无论宽限期如何,都无法再分配任何文件或块。
有一些命令可以管理配额:
| 序号 | 命令和说明 |
|---|---|
| 1 |
quota 显示用户或组的磁盘使用情况和限制 |
| 2 |
edquota 这是一个配额编辑器。可以使用此命令编辑用户或组配额 |
| 3 |
quotacheck 扫描文件系统以获取磁盘使用情况,创建、检查和修复配额文件 |
| 4 |
setquota 这是一个命令行配额编辑器 |
| 5 |
quotaon 这会通知系统在一个或多个文件系统上启用磁盘配额 |
| 6 |
quotaoff 这会通知系统在一个或多个文件系统上禁用磁盘配额 |
| 7 |
repquota 这将打印指定文件系统的磁盘使用情况和配额的摘要 |
您可以使用手册页帮助检查此处提到的每个命令的完整语法。
Unix - 用户管理
本章将详细讨论 Unix 中的用户管理。
Unix 系统上有三种类型的账户:
根账户
这也被称为**超级用户**,拥有对系统的完全和不受限制的控制权。超级用户可以运行任何命令而没有任何限制。此用户应被视为系统管理员。
系统账户
系统账户是系统特定组件操作所需的账户,例如邮件账户和**sshd**账户。这些账户通常是系统上某些特定功能所必需的,对其进行任何修改都可能对系统产生不利影响。
用户账户
用户账户为用户和用户组提供对系统的交互式访问。普通用户通常被分配到这些账户,并且通常对关键系统文件和目录的访问权限有限。
Unix 支持组账户的概念,它在逻辑上将多个账户分组。每个账户都将是另一个组账户的一部分。Unix 组在处理文件权限和进程管理方面发挥着重要作用。
管理用户和组
主要有四个用户管理文件:
/etc/passwd - 保存用户账户和密码信息。此文件保存了 Unix 系统上大部分账户信息。
/etc/shadow - 保存对应账户的加密密码。并非所有系统都支持此文件。
/etc/group - 此文件包含每个账户的组信息。
/etc/gshadow - 此文件包含安全的组账户信息。
使用cat命令检查所有上述文件。
下表列出了大多数 Unix 系统上可用于创建和管理账户和组的命令:
| 序号 | 命令和说明 |
|---|---|
| 1 |
useradd 向系统添加账户 |
| 2 |
usermod 修改账户属性 |
| 3 |
userdel 从系统删除账户 |
| 4 |
groupadd 向系统添加组 |
| 5 |
groupmod 修改组属性 |
| 6 |
groupdel 从系统删除组 |
您可以使用手册页帮助检查此处提到的每个命令的完整语法。
创建组
现在我们将了解如何创建一个组。为此,我们需要在创建任何账户之前先创建组,否则,我们可以使用系统中现有的组。我们在/etc/groups文件中列出了所有组。
所有默认组都是特定于系统账户的组,不建议将其用于普通账户。因此,以下是创建新组账户的语法:
groupadd [-g gid [-o]] [-r] [-f] groupname
下表列出了参数:
| 序号 | 选项 & 描述 |
|---|---|
| 1 |
-g GID 组ID的数值 |
| 2 |
-o 此选项允许添加具有非唯一GID的组 |
| 3 |
-r 此标志指示groupadd添加系统账户 |
| 4 |
-f 如果指定的组已存在,此选项会导致仅以成功状态退出。使用 -g,如果指定的 GID 已存在,则选择其他(唯一)GID |
| 5 |
groupname 要创建的实际组名 |
如果不指定任何参数,则系统使用默认值。
以下示例使用默认值创建了一个名为developers的组,这对于大多数管理员来说都是可以接受的。
$ groupadd developers
修改组
要修改组,请使用groupmod语法:
$ groupmod -n new_modified_group_name old_group_name
要将developers_2组名更改为developer,请键入:
$ groupmod -n developer developer_2
以下是将financial的GID更改为545的方法:
$ groupmod -g 545 developer
删除组
现在我们将了解如何删除组。要删除现有组,您只需要groupdel命令和组名。要删除financial组,命令为:
$ groupdel developer
这仅删除组,不删除与该组关联的文件。文件仍然可以被其所有者访问。
创建账户
让我们看看如何在您的 Unix 系统上创建一个新账户。以下是创建用户账户的语法:
useradd -d homedir -g groupname -m -s shell -u userid accountname
下表列出了参数:
| 序号 | 选项 & 描述 |
|---|---|
| 1 |
-d homedir 指定账户的主目录 |
| 2 |
-g groupname 为该账户指定一个组账户 |
| 3 |
-m 如果不存在,则创建主目录 |
| 4 |
-s shell 指定此账户的默认shell |
| 5 |
-u userid 您可以为该账户指定用户ID |
| 6 |
accountname 要创建的实际账户名 |
如果不指定任何参数,则系统使用默认值。useradd命令修改/etc/passwd、/etc/shadow和/etc/group文件,并创建一个主目录。
以下示例创建了一个名为mcmohd的账户,将其主目录设置为/home/mcmohd,并将组设置为developers。此用户将被分配Korn Shell。
$ useradd -d /home/mcmohd -g developers -s /bin/ksh mcmohd
在发出上述命令之前,请确保您已使用groupadd命令创建了developers组。
创建账户后,您可以使用passwd命令设置其密码,如下所示:
$ passwd mcmohd20 Changing password for user mcmohd20. New UNIX password: Retype new UNIX password: passwd: all authentication tokens updated successfully.
当您键入passwd accountname时,它会为您提供更改密码的选项,前提是您是超级用户。否则,您可以使用相同的命令更改您的密码,但无需指定您的账户名。
修改账户
usermod命令允许您从命令行对现有账户进行更改。它使用与useradd命令相同的参数,以及-l参数,该参数允许您更改账户名。
例如,要将账户名mcmohd更改为mcmohd20并相应地更改主目录,您需要发出以下命令:
$ usermod -d /home/mcmohd20 -m -l mcmohd mcmohd20
删除账户
userdel命令可用于删除现有用户。如果使用不当,这是一个非常危险的命令。
该命令只有一个参数或选项.r,用于删除账户的主目录和邮件文件。
例如,要删除账户mcmohd20,请发出以下命令:
$ userdel -r mcmohd20
如果您想保留主目录以备备份,请省略-r选项。您可以根据需要在以后删除主目录。
Unix - 系统性能
本章将详细讨论 Unix 中的系统性能。
我们将向您介绍一些可用于监控和管理 Unix 系统性能的免费工具。这些工具还提供了有关如何在 Unix 环境中诊断和解决性能问题的指南。
Unix 有以下主要资源类型需要监控和调整:
CPU
内存
磁盘空间
通信线路
I/O时间
网络时间
应用程序
性能组件
下表列出了占用系统时间的五个主要组件:
| 序号 | 组件和描述 |
|---|---|
| 1 |
用户态CPU CPU实际花费在用户态运行用户程序的时间。它包括花费在执行库调用上的时间,但不包括代表其在内核中花费的时间。 |
| 2 |
系统态CPU 这是CPU代表此程序在系统态花费的时间。所有I/O例程都需要内核服务。程序员可以通过阻塞I/O传输来影响此值。 |
| 3 |
I/O时间和网络时间 这是花费在移动数据和服务I/O请求上的时间。 |
| 4 |
虚拟内存性能 这包括上下文切换和交换。 |
| 5 |
应用程序 花费在运行其他程序上的时间 - 当系统未服务此应用程序,因为另一个应用程序当前拥有CPU时。 |
性能工具
Unix 提供以下重要工具来衡量和微调 Unix 系统性能:
| 序号 | 命令和说明 |
|---|---|
| 1 |
nice/renice 以修改后的调度优先级运行程序 |
| 2 |
netstat 打印网络连接、路由表、接口统计信息、伪装连接和多播成员资格 |
| 3 |
time 帮助计时简单的命令或提供资源使用情况 |
| 4 |
uptime 这是系统负载平均值 |
| 5 |
ps 报告当前进程的快照 |
| 6 |
vmstat 报告虚拟内存统计信息 |
| 7 |
gprof 显示调用图配置文件数据 |
| 8 |
prof 促进进程分析 |
| 9 |
top 显示系统任务 |
您可以使用手册页帮助检查此处提到的每个命令的完整语法。
Unix - 系统日志记录
本章将详细讨论 Unix 中的系统日志记录。
Unix 系统具有非常灵活且强大的日志记录系统,它使您能够记录几乎所有您可以想象的内容,然后操纵日志以检索您所需的信息。
许多版本的 Unix 提供了一个名为syslog的通用日志记录工具。需要记录信息的各个程序将信息发送到 syslog。
Unix syslog 是一个可由主机配置的统一系统日志记录工具。系统使用一个集中的系统日志记录进程,该进程运行程序/etc/syslogd或/etc/syslog。
系统记录器的操作非常简单。程序将其日志条目发送到syslogd,syslogd会查阅配置文件/etc/syslogd.conf或/etc/syslog,并在找到匹配项时将日志消息写入所需的日志文件。
有四个基本的 syslog 术语您应该了解:
| 序号 | 术语和描述 |
|---|---|
| 1 |
工具 用于描述提交日志消息的应用程序或进程的标识符。例如,邮件、内核和 ftp。 |
| 2 |
优先级 消息重要性的指示器。级别在 syslog 中定义为指南,从调试信息到关键事件。 |
| 3 |
选择器 一个或多个工具和级别的组合。当传入事件与选择器匹配时,将执行一个操作。 |
| 4 |
操作 对与选择器匹配的传入消息执行的操作 - 操作可以将消息写入日志文件、将消息回显到控制台或其他设备、将消息写入已登录的用户或将消息发送到另一个 syslog 服务器。 |
Syslog 工具
现在我们将了解 syslog 工具。以下是选择器可用的工具。并非所有工具都存在于所有版本的 Unix 上。
| 工具 | 描述 |
|---|---|
| 1 |
auth 与请求名称和密码相关的活动(getty、su、login) |
| 2 |
authpriv 与auth相同,但记录到只能由选定用户读取的文件中 |
| 3 |
console 用于捕获通常定向到系统控制台的消息 |
| 4 |
cron 来自 cron 系统调度程序的消息 |
| 5 |
daemon 系统守护进程通用 |
| 6 |
ftp 与 ftp 守护进程相关的消息 |
| 7 |
kern 内核消息 |
| 8 |
local0.local7 每个站点定义的本地工具 |
| 9 |
lpr 来自行打印系统的消息 |
| 10 |
与邮件系统相关的消息 |
| 11 |
mark 用于在日志文件中生成时间戳的伪事件 |
| 12 |
新闻 与网络新闻协议 (nntp) 相关的消息 |
| 13 |
ntp 与网络时间协议相关的消息 |
| 14 |
用户 常规用户进程 |
| 15 |
uucp UUCP 子系统 |
Syslog 优先级
syslog 优先级在以下表格中进行了总结:
| 序号 | 优先级 & 描述 |
|---|---|
| 1 |
emerg 紧急情况,例如即将发生的系统崩溃,通常广播给所有用户 |
| 2 |
alert 应该立即纠正的情况,例如损坏的系统数据库 |
| 3 |
crit 严重情况,例如硬件错误 |
| 4 |
err 普通错误 |
| 5 |
警告 警告 |
| 6 |
notice 不是错误的情况,但可能应该以特殊方式处理 |
| 7 |
info 信息消息 |
| 8 |
debug 调试程序时使用的消息 |
| 9 |
none 用于指定不记录消息的伪级别 |
设施和级别的组合使您能够明智地选择要记录的内容以及信息存储的位置。
每个程序都尽职地将其消息发送到系统日志记录器,日志记录器根据选择器中定义的级别决定要跟踪哪些内容以及要丢弃哪些内容。
指定级别后,系统将跟踪该级别及其以上的所有内容。
/etc/syslog.conf 文件
/etc/syslog.conf 文件控制消息记录的位置。一个典型的 syslog.conf 文件可能如下所示:
*.err;kern.debug;auth.notice /dev/console daemon,auth.notice /var/log/messages lpr.info /var/log/lpr.log mail.* /var/log/mail.log ftp.* /var/log/ftp.log auth.* @prep.ai.mit.edu auth.* root,amrood netinfo.err /var/log/netinfo.log install.* /var/log/install.log *.emerg * *.alert |program_name mark.* /dev/console
该文件的每一行包含两部分:
一个消息选择器,用于指定要记录的消息类型。例如,内核的所有错误消息或所有调试消息。
一个操作字段,用于说明如何处理该消息。例如,将其放入文件中或将消息发送到用户的终端。
以下是上述配置的要点:
消息选择器有两部分:设施和优先级。例如,kern.debug 选择内核(设施)生成的所有调试消息(优先级)。
消息选择器 kern.debug 选择所有大于调试的优先级。
设施或优先级位置的星号表示“全部”。例如,*.debug 表示所有调试消息,而 kern.* 表示内核生成的所有消息。
您还可以使用逗号指定多个设施。可以使用分号将两个或多个选择器组合在一起。
日志记录操作
操作字段指定以下五种操作之一:
将消息记录到文件或设备。例如,/var/log/lpr.log 或 /dev/console。
将消息发送给用户。您可以通过逗号分隔多个用户名来指定它们;例如,root, amrood。
将消息发送给所有用户。在这种情况下,操作字段由星号组成;例如,*。
将消息传递给程序。在这种情况下,程序在 Unix 管道符号(|)之后指定。
将消息发送到另一台主机上的 syslog。在这种情况下,操作字段由一个主机名组成,前面带有 at 符号;例如,@tutorialspoint.com。
logger 命令
Unix 提供了 logger 命令,这是一个处理系统日志记录的极其有用的命令。logger 命令将日志消息发送到 syslogd 守护进程,从而引发系统日志记录。
这意味着我们可以在任何时候从命令行检查 syslogd 守护进程及其配置。logger 命令提供了一种方法,可以从命令行将单行条目添加到系统日志文件中。
命令格式如下:
logger [-i] [-f file] [-p priority] [-t tag] [message]...
以下是参数的详细信息:
| 序号 | 选项 & 描述 |
|---|---|
| 1 |
-f filename 使用文件 filename 的内容作为要记录的消息。 |
| 2 |
-i 将 logger 进程的进程 ID 与每一行一起记录。 |
| 3 |
-p priority 以指定的优先级(指定的选取器条目)输入消息;消息优先级可以以数字形式指定,也可以以 facility.priority 对的形式指定。默认优先级为 user.notice。 |
| 4 |
-t tag 使用指定的标签标记添加到日志中的每一行。 |
| 5 |
message 其内容按指定的顺序连接在一起的字符串参数,并用空格分隔。 |
您可以使用手册页帮助来检查此命令的完整语法。
日志轮换
日志文件具有增长非常快并消耗大量磁盘空间的倾向。为了启用日志轮换,大多数发行版都使用 newsyslog 或 logrotate 等工具。
应使用 cron 守护进程在频繁的时间间隔内调用这些工具。有关更多详细信息,请查看 newsyslog 或 logrotate 的手册页。
重要的日志位置
所有系统应用程序都在 /var/log 及其子目录中创建其日志文件。以下是几个重要的应用程序及其相应的日志目录:
| 应用程序 | 目录 |
|---|---|
| httpd | /var/log/httpd |
| samba | /var/log/samba |
| cron | /var/log/ |
| /var/log/ | |
| mysql | /var/log/ |
Unix - 信号和陷阱
在本章中,我们将详细讨论 Unix 中的信号和陷阱。
信号是发送到程序的软件中断,用于指示发生了重要事件。事件可以从用户请求到非法内存访问错误不等。某些信号(例如中断信号)指示用户已要求程序执行不属于正常控制流的操作。
下表列出了您可能遇到并希望在程序中使用的常见信号:
| 信号名称 | 信号编号 | 描述 |
|---|---|---|
| SIGHUP | 1 | 在控制终端上检测到挂断或控制进程死亡 |
| SIGINT | 2 | 如果用户发送中断信号 (Ctrl + C),则发出此信号 |
| SIGQUIT | 3 | 如果用户发送退出信号 (Ctrl + D),则发出此信号 |
| SIGFPE | 8 | 如果尝试进行非法数学运算,则发出此信号 |
| SIGKILL | 9 | 如果进程收到此信号,则必须立即退出,并且不会执行任何清理操作 |
| SIGALRM | 14 | 闹钟信号(用于计时器) |
| SIGTERM | 15 | 软件终止信号(默认情况下由 kill 发送) |
信号列表
有一种简单的方法可以列出系统支持的所有信号。只需发出 kill -l 命令,它就会显示所有支持的信号:
$ kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAX
信号的实际列表在 Solaris、HP-UX 和 Linux 之间有所不同。
默认操作
每个信号都与其关联的默认操作。信号的默认操作是脚本或程序在收到信号时执行的操作。
一些可能的默认操作包括:
终止进程。
忽略信号。
转储核心。这会创建一个名为 core 的文件,其中包含进程在收到信号时的内存映像。
停止进程。
继续停止的进程。
发送信号
有多种方法可以将信号传递到程序或脚本。最常见的一种方法是用户在脚本执行期间键入 CONTROL-C 或 INTERRUPT 键。
当您按下 Ctrl+C 键时,会将 SIGINT 发送到脚本,并且根据定义的默认操作,脚本将终止。
传递信号的另一种常见方法是使用 kill 命令,其语法如下:
$ kill -signal pid
此处 signal 是要传递的信号的编号或名称,pid 是要发送信号到的进程 ID。例如:
$ kill -1 1001
上述命令将 HUP 或挂断信号发送到以 进程 ID 1001 运行的程序。要向同一进程发送 kill 信号,请使用以下命令:
$ kill -9 1001
这将杀死以 进程 ID 1001 运行的进程。
捕获信号
当您在 shell 程序执行期间在终端上按下 Ctrl+C 或 Break 键时,通常该程序会立即终止,并且您的命令提示符会返回。这可能并不总是理想的。例如,您最终可能会留下一些不会被清理的临时文件。
捕获这些信号非常容易,并且 trap 命令具有以下语法:
$ trap commands signals
此处 command 可以是任何有效的 Unix 命令,甚至可以是用户定义的函数,而 signal 可以是您要捕获的任意数量的信号的列表。
shell 脚本中 trap 有两种常见用途:
- 清理临时文件
- 忽略信号
清理临时文件
以下示例显示了如何删除一些文件,然后在有人尝试从终端中止程序时退出,以此作为 trap 命令的示例:
$ trap "rm -f $WORKDIR/work1$$ $WORKDIR/dataout$$; exit" 2
从执行此 trap 的 shell 程序中的这一点开始,如果程序收到信号编号 2,则会自动删除 work1$$ 和 dataout$$ 这两个文件。
因此,如果用户在此 trap 执行后中断程序的执行,则可以确保这两个文件将被清理。rm 之后的 exit 命令是必要的,因为如果没有它,执行将在程序中从收到信号时中断的点继续。
信号编号 1 是为 挂断 生成的。要么有人故意挂断线路,要么线路意外断开连接。
您可以修改前面的 trap,以便在这种情况下也删除这两个指定的的,方法是将信号编号 1 添加到信号列表中:
$ trap "rm $WORKDIR/work1$$ $WORKDIR/dataout$$; exit" 1 2
现在,如果线路挂断或按下 Ctrl+C 键,则会删除这些文件。
指定要捕获的命令必须用引号括起来,如果它们包含多个命令。另请注意,shell 在执行 trap 命令时以及收到列出的信号之一时都会扫描命令行。
因此,在前面的示例中,WORKDIR 和 $$ 的值将在执行 trap 命令时替换。如果您希望此替换在收到信号 1 或 2 时发生,则可以将命令放在单引号中:
$ trap 'rm $WORKDIR/work1$$ $WORKDIR/dataout$$; exit' 1 2
忽略信号
如果为 trap 命令列出的命令为空,则在接收到指定信号时将忽略该信号。例如,命令 −
$ trap '' 2
这指定要忽略中断信号。在执行不想被打断的操作时,您可能希望忽略某些信号。您可以按如下方式指定要忽略的多个信号 −
$ trap '' 1 2 3 15
请注意,必须指定第一个参数才能忽略信号,并且它与编写以下内容不相同,后者具有其自身的单独含义 −
$ trap 2
如果您忽略了一个信号,所有子 shell 也都会忽略该信号。但是,如果您指定在收到信号时要采取的操作,所有子 shell 在收到该信号时仍将采取默认操作。
重置陷阱
在您将收到信号时要采取的默认操作更改为其他操作后,您可以使用 trap 再次将其更改回,如果您只是省略第一个参数;所以 −
$ trap 1 2
这将收到信号 1 或 2 时要采取的操作重置为默认值。