Weka 快速指南
Weka - 简介
任何机器学习应用程序的基础都是数据 - 不仅仅是一点点数据,而是一大批数据,在当前术语中被称为大数据。
为了训练机器分析大数据,您需要对数据进行一些考虑 -
- 数据必须是干净的。
- 它不应该包含空值。
此外,数据表中的并非所有列都对您尝试实现的分析类型有用。在将数据馈送到机器学习算法之前,必须删除不相关的列或机器学习术语中的“特征”。
简而言之,您的海量数据在用于机器学习之前需要大量预处理。数据准备就绪后,您将应用各种机器学习算法(如分类、回归、聚类等)来解决您最终的问题。
您应用的算法类型很大程度上取决于您的领域知识。即使在同一类型中,例如分类,也有多种算法可用。您可能希望测试同一类别下的不同算法以构建有效的机器学习模型。在此过程中,您会更喜欢可视化处理后的数据,因此您还需要可视化工具。
在接下来的章节中,您将学习 Weka,一个能够轻松完成所有上述操作并让您舒适地处理大数据的软件。
什么是 Weka?
WEKA - 一个开源软件,提供数据预处理、多种机器学习算法的实现以及可视化工具,以便您可以开发机器学习技术并将它们应用于现实世界的数据挖掘问题。WEKA 提供的功能在下面的图表中进行了总结 -
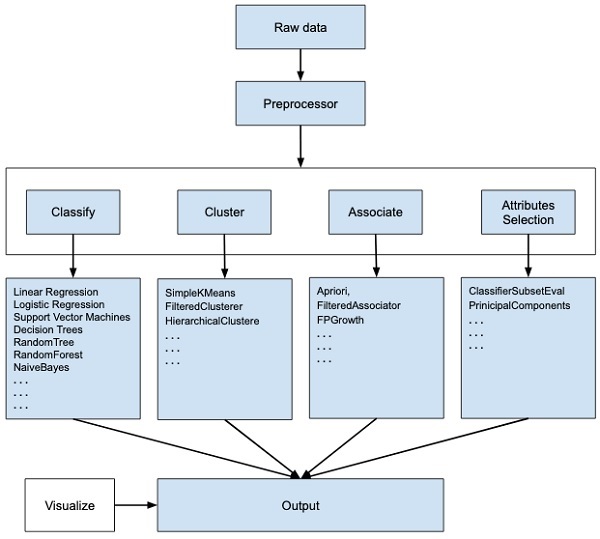
如果您观察图像流程的开始,您就会明白,处理大数据以使其适合机器学习有很多步骤 -
首先,您将从现场收集的原始数据开始。此数据可能包含多个空值和不相关的字段。您使用 WEKA 中提供的数据预处理工具来清理数据。
然后,您将预处理后的数据保存到本地存储中以应用 ML 算法。
接下来,根据您尝试开发的 ML 模型类型,您将选择其中一个选项,例如分类、聚类或关联。属性选择允许自动选择特征以创建缩减的数据集。
请注意,在每个类别下,WEKA 都提供了多种算法的实现。您可以选择您选择的算法,设置所需的参数并在数据集上运行它。
然后,WEKA 将为您提供模型处理的统计输出。它为您提供了一个可视化工具来检查数据。
各种模型可以应用于相同的数据集。然后,您可以比较不同模型的输出并选择最符合您目的的模型。
因此,使用 WEKA 可以更快地开发整个机器学习模型。
现在我们已经了解了 WEKA 是什么以及它做什么,在下一章中,让我们学习如何在本地计算机上安装 WEKA。
Weka - 安装
要在您的机器上安装 WEKA,请访问WEKA 的官方网站并下载安装文件。WEKA 支持在 Windows、Mac OS X 和 Linux 上安装。您只需要按照此页面上的说明为您的操作系统安装 WEKA 即可。
在 Mac 上安装的步骤如下 -
- 下载 Mac 安装文件。
- 双击下载的weka-3-8-3-corretto-jvm.dmg 文件。
成功安装后,您将看到以下屏幕。
- 单击weak-3-8-3-corretto-jvm图标以启动 Weka。
- 您也可以从命令行启动它 -
java -jar weka.jar
WEKA GUI 选择器应用程序将启动,您将看到以下屏幕 -
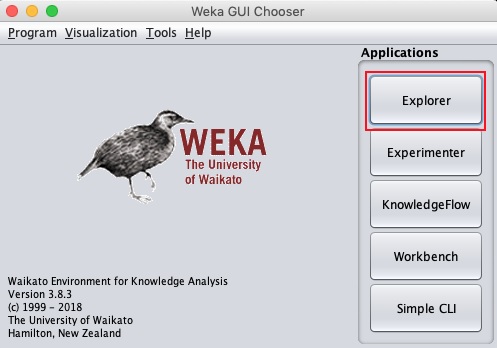
GUI 选择器应用程序允许您运行五种不同类型的应用程序,如下所示 -
- Explorer
- Experimenter
- KnowledgeFlow
- Workbench
- Simple CLI
在本教程中,我们将使用Explorer。
Weka - 启动 Explorer
在本章中,让我们深入了解 Explorer 为处理大数据提供的各种功能。
当您单击应用程序选择器中的Explorer按钮时,它将打开以下屏幕 -
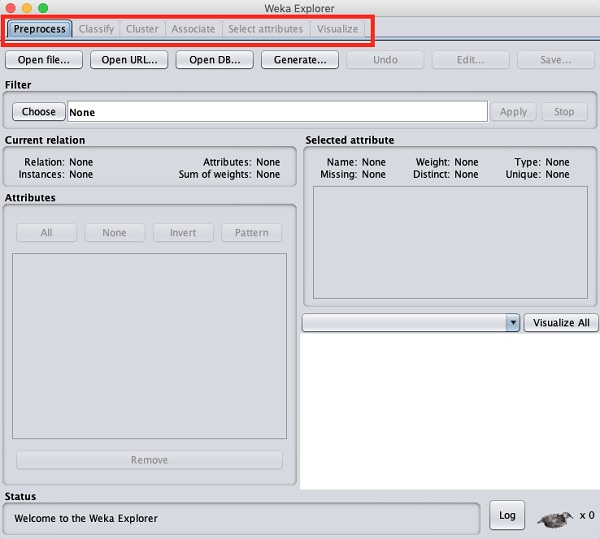
在顶部,您将看到几个选项卡,如下所示 -
- 预处理
- 分类
- 聚类
- 关联
- 选择属性
- 可视化
在这些选项卡下,有几个预先实现的机器学习算法。现在让我们详细了解一下每个算法。
预处理选项卡
最初,当您打开 Explorer 时,只有预处理选项卡可用。机器学习的第一步是对数据进行预处理。因此,在预处理选项中,您将选择数据文件,对其进行处理并使其适合应用各种机器学习算法。
分类选项卡
分类选项卡为您提供了用于对数据进行分类的多种机器学习算法。举几个例子,您可以应用线性回归、逻辑回归、支持向量机、决策树、随机树、随机森林、朴素贝叶斯等算法。该列表非常详尽,提供了监督和无监督的机器学习算法。
聚类选项卡
在聚类选项卡下,提供了多种聚类算法,例如 SimpleKMeans、FilteredClusterer、HierarchicalClusterer 等。
关联选项卡
在关联选项卡下,您会找到 Apriori、FilteredAssociator 和 FPGrowth。
选择属性选项卡
选择属性允许您基于多种算法(如 ClassifierSubsetEval、PrinicipalComponents 等)进行特征选择。
可视化选项卡
最后,可视化选项允许您可视化处理后的数据以进行分析。
正如您所注意到的,WEKA 提供了多种现成的算法来测试和构建您的机器学习应用程序。要有效地使用 WEKA,您必须具备这些算法的扎实知识,了解它们的工作原理,在什么情况下选择哪一个,在它们的处理输出中寻找什么,等等。简而言之,您必须拥有机器学习的坚实基础才能有效地使用 WEKA 构建您的应用程序。
在接下来的章节中,您将深入研究 Explorer 中的每个选项卡。
Weka - 加载数据
在本章中,我们从第一个选项卡开始,用于预处理数据。这对于您应用于数据以构建模型的所有算法都是通用的,并且是 WEKA 中所有后续操作的常见步骤。
为了使机器学习算法获得可接受的准确性,必须首先清理数据。这是因为从现场收集的原始数据可能包含空值、不相关的列等等。
在本章中,您将学习如何预处理原始数据并为进一步使用创建干净、有意义的数据集。
首先,您将学习如何将数据文件加载到 WEKA Explorer 中。数据可以从以下来源加载 -
- 本地文件系统
- 网络
- 数据库
在本章中,我们将详细了解这三种加载数据的方式。
从本地文件系统加载数据
在上一课中学习的机器学习选项卡下方,您会找到以下三个按钮 -
- 打开文件…
- 打开 URL…
- 打开 DB…
单击打开文件…按钮。将打开一个目录导航器窗口,如下面的屏幕截图所示 -
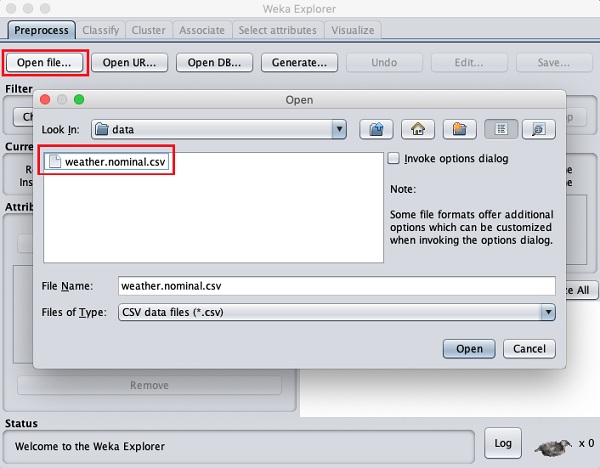
现在,导航到存储数据文件的文件夹。WEKA 安装附带了许多示例数据库,供您进行实验。它们位于 WEKA 安装的data文件夹中。
为了学习目的,从该文件夹中选择任何数据文件。文件内容将加载到 WEKA 环境中。我们很快就会学习如何检查和处理这些加载的数据。在此之前,让我们看看如何从 Web 加载数据文件。
从 Web 加载数据
单击打开 URL…按钮后,您会看到一个窗口,如下所示 -
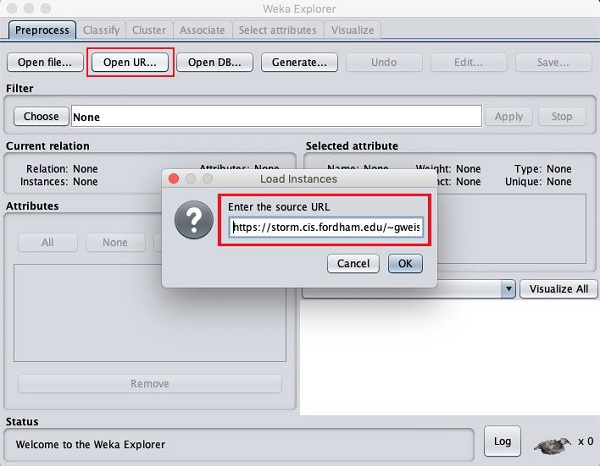
我们将从公共 URL 打开文件。在弹出框中输入以下 URL -
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
您可以指定存储数据的任何其他 URL。Explorer将从远程站点加载数据到其环境中。
从 DB 加载数据
单击打开 DB…按钮后,您会看到一个窗口,如下所示 -
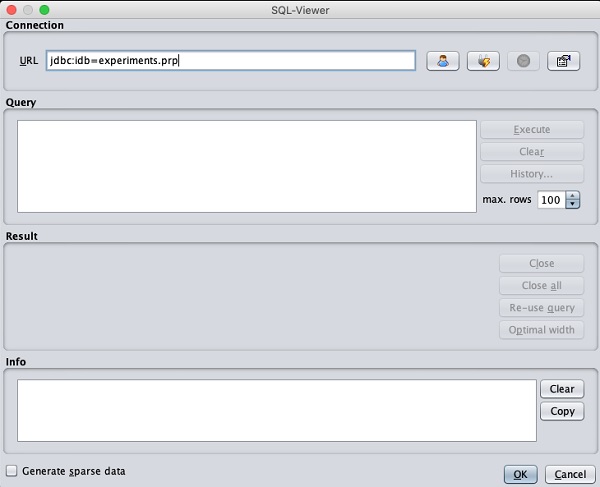
将连接字符串设置为您的数据库,设置数据选择查询,处理查询并将选定的记录加载到 WEKA 中。
Weka - 文件格式
WEKA 支持大量数据文件格式。以下是完整列表 -
- arff
- arff.gz
- bsi
- csv
- dat
- data
- json
- json.gz
- libsvm
- m
- names
- xrff
- xrff.gz
它支持的文件类型列在屏幕底部的下拉列表框中。这在下面给出的屏幕截图中显示。
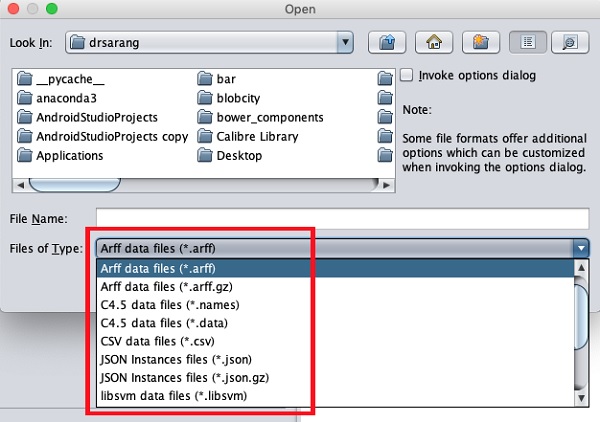
正如您所注意到的,它支持多种格式,包括 CSV 和 JSON。默认文件类型为 Arff。
Arff 格式
Arff文件包含两个部分 - 标题和数据。
- 标题描述了属性类型。
- 数据部分包含一个逗号分隔的数据列表。
作为 Arff 格式的示例,从 WEKA 示例数据库加载的天气数据文件如下所示 -

从屏幕截图中,您可以推断出以下几点 -
@relation 标记定义了数据库的名称。
@attribute 标记定义了属性。
@data 标记开始数据行的列表,每个数据行包含逗号分隔的字段。
属性可以采用名义值,如这里所示的 outlook -
@attribute outlook (sunny, overcast, rainy)
属性可以采用实数值,在本例中 -
@attribute temperature real
您还可以设置目标或称为 play 的类变量,如这里所示 -
@attribute play (yes, no)
目标采用两个名义值 yes 或 no。
其他格式
Explorer 可以加载前面提到的任何格式的数据。由于 arff 是 WEKA 中的首选格式,因此您可以从任何格式加载数据并将其保存为 arff 格式以供以后使用。在预处理数据后,只需将其保存为 arff 格式以供进一步分析。
既然您已经学习了如何将数据加载到 WEKA 中,那么在下一章中,您将学习如何预处理数据。
Weka - 数据预处理
从现场收集的数据包含许多不需要的东西,这会导致错误的分析。例如,数据可能包含空字段,可能包含与当前分析无关的列,等等。因此,必须对数据进行预处理,以满足您正在寻求的分析类型的要求。这在预处理模块中完成。
为了演示预处理中可用的功能,我们将使用安装中提供的Weather数据库。
使用Preprocess标签下的Open file ...选项选择weather-nominal.arff文件。
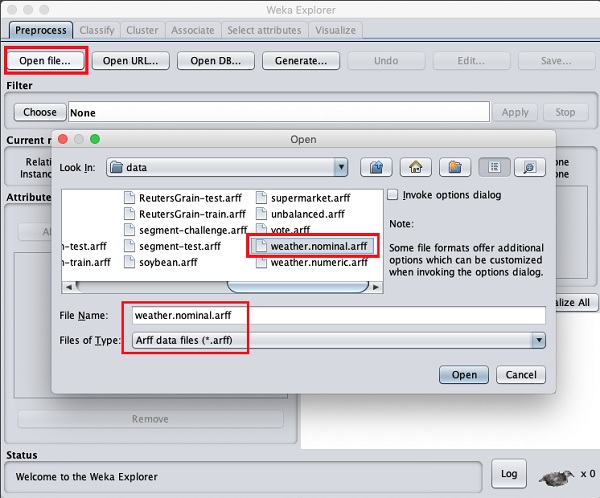
打开文件后,您的屏幕将如下所示:
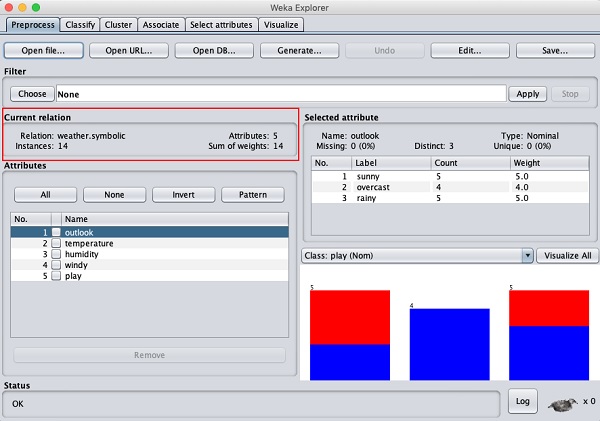
此屏幕告诉我们有关加载数据的几件事,这些内容将在本章中进一步讨论。
理解数据
让我们首先查看突出显示的Current relation子窗口。它显示当前加载的数据库的名称。您可以从此子窗口推断出两点:
有14个实例 - 表格中的行数。
该表包含5个属性 - 字段,将在接下来的部分中讨论。
在左侧,请注意Attributes子窗口,它显示数据库中的各个字段。
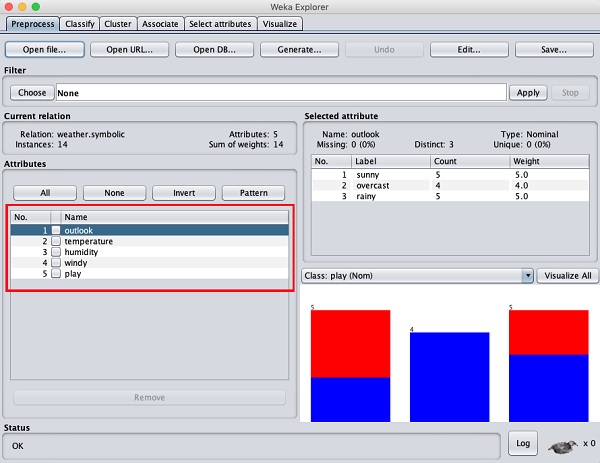
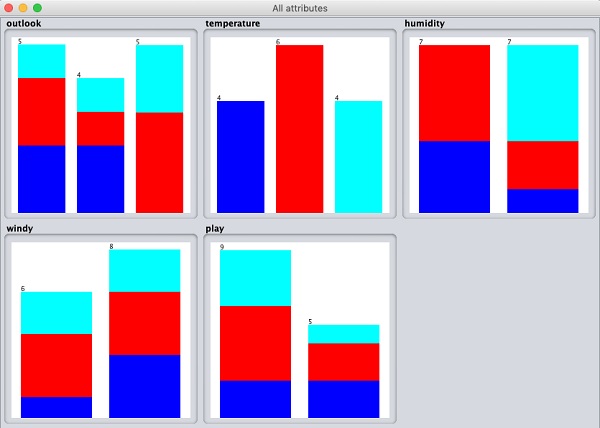
weather数据库包含五个字段 - outlook、temperature、humidity、windy和play。当您通过单击从该列表中选择一个属性时,属性本身的更多详细信息将显示在右侧。
让我们首先选择temperature属性。当您单击它时,您将看到以下屏幕:
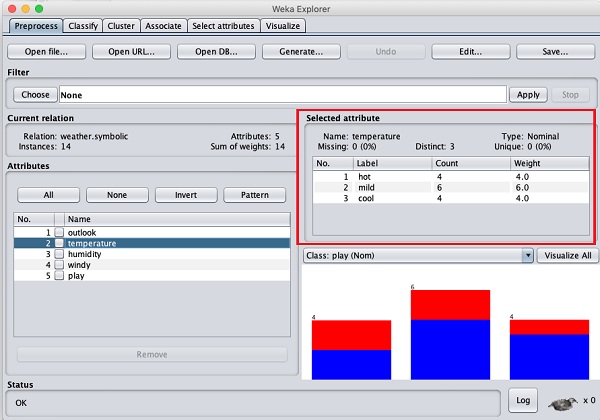
在Selected Attribute子窗口中,您可以观察到以下内容:
显示了属性的名称和类型。
temperature属性的类型为Nominal。
Missing值的数目为零。
有三个不同的值,没有唯一的值。
此信息下方的表格显示了此字段的标称值为hot、mild和cold。
它还显示了每个标称值的计数和权重(百分比)。
在窗口底部,您可以看到class值的视觉表示。
如果您单击Visualize All按钮,您将能够在一个窗口中看到所有功能,如下所示:
移除属性
很多时候,您想要用于模型构建的数据会附带许多不相关的字段。例如,客户数据库可能包含他的手机号码,这与分析他的信用评级相关。
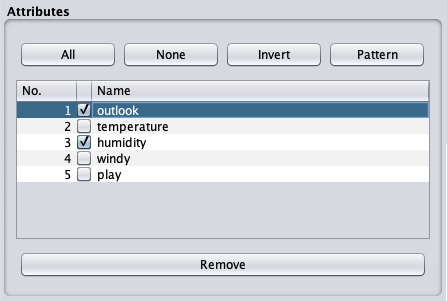
要移除属性,请选择它们并单击底部的Remove按钮。
选定的属性将从数据库中移除。在您完全预处理数据后,您可以将其保存以进行模型构建。
接下来,您将学习通过对这些数据应用过滤器来预处理数据。
应用过滤器
一些机器学习技术(如关联规则挖掘)需要分类数据。为了说明过滤器的使用,我们将使用包含两个numeric属性(temperature和humidity)的weather-numeric.arff数据库。
我们将通过对原始数据应用过滤器将其转换为nominal。单击Filter子窗口中的Choose按钮,然后选择以下过滤器:
weka→filters→supervised→attribute→Discretize
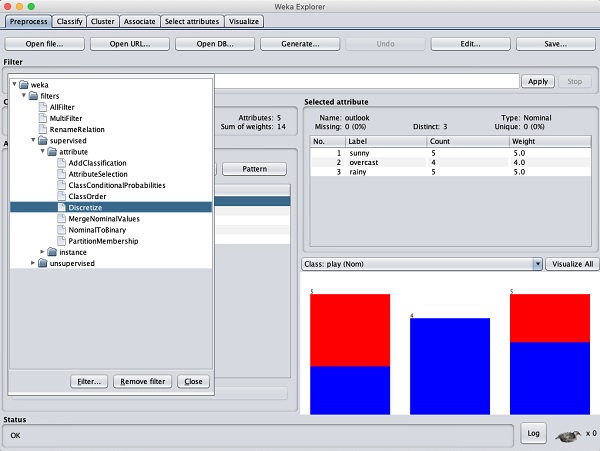
单击Apply按钮并检查temperature和/或humidity属性。您会注意到它们已从数字类型更改为标称类型。
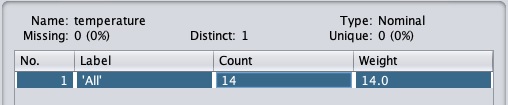
现在让我们看看另一个过滤器。假设您想选择决定play的最佳属性。选择并应用以下过滤器:
weka→filters→supervised→attribute→AttributeSelection
您会注意到它从数据库中移除了temperature和humidity属性。
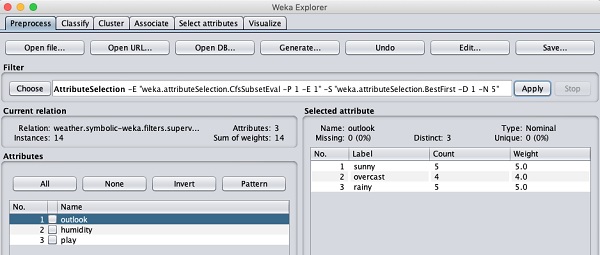
在您对数据的预处理感到满意后,通过单击Save ...按钮保存数据。您将使用此保存的文件进行模型构建。
在下一章中,我们将探讨使用几个预定义的ML算法进行模型构建。
Weka - 分类器
许多机器学习应用程序都与分类相关。例如,您可能希望将肿瘤分类为恶性或良性。您可能希望根据天气状况决定是否进行户外游戏。通常,此决定取决于天气的几个特征/条件。因此,您可能更喜欢使用树分类器来决定是否玩游戏。
在本章中,我们将学习如何在天气数据上构建这样的树分类器来决定比赛条件。
设置测试数据
我们将使用上一课中预处理的天气数据文件。使用Preprocess选项卡下的Open file ...选项打开保存的文件,单击Classify选项卡,您将看到以下屏幕:
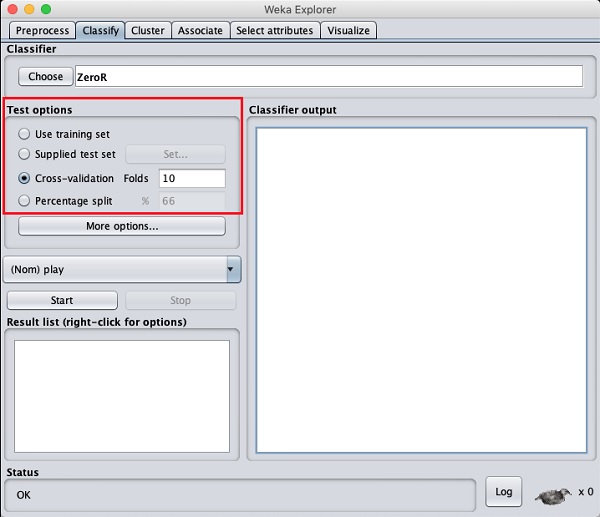
在您了解可用分类器之前,让我们检查一下测试选项。您会注意到如下所示的四个测试选项:
- 训练集
- 提供的测试集
- 交叉验证
- 百分比分割
除非您有自己的训练集或客户提供的测试集,否则您将使用交叉验证或百分比分割选项。在交叉验证下,您可以设置整个数据将被分割并用于每次训练迭代的折叠数。在百分比分割中,您将使用设置的分割百分比将数据分割为训练和测试。
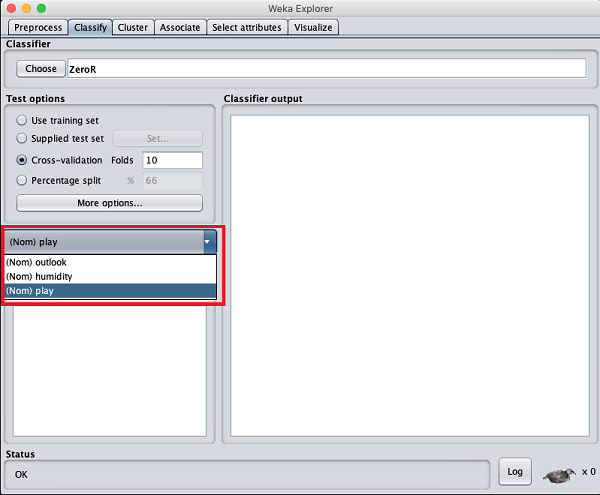
现在,将默认的play选项保留为输出类:
接下来,您将选择分类器。
选择分类器
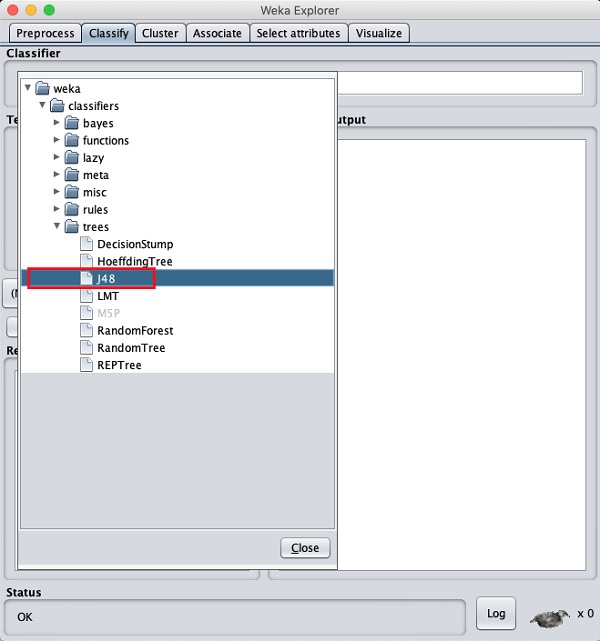
单击Choose按钮,然后选择以下分类器:
weka→classifiers>trees>J48
这在下面的屏幕截图中显示:
单击Start按钮开始分类过程。一段时间后,分类结果将显示在您的屏幕上,如下所示:
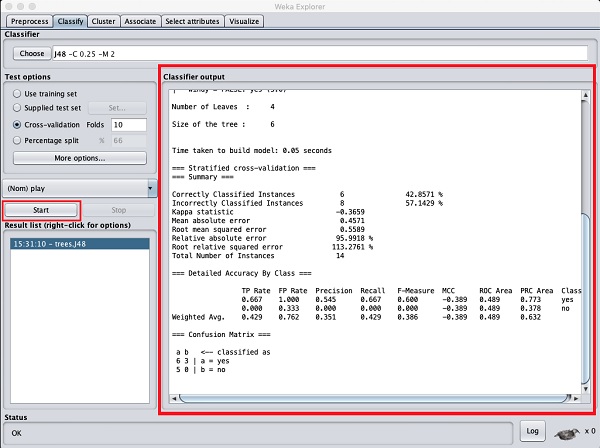
让我们检查一下屏幕右侧显示的输出。
它说树的大小为6。您很快就会看到树的可视化表示。在摘要中,它说正确分类的实例为2,错误分类的实例为3,它还说相对绝对误差为110%。它还显示了混淆矩阵。深入分析这些结果超出了本教程的范围。但是,您可以很容易地从这些结果中看出分类不可接受,并且您需要更多数据进行分析,以改进您的特征选择,重建模型,依此类推,直到您对模型的准确性感到满意为止。无论如何,这就是WEKA的全部意义所在。它允许您快速测试您的想法。
可视化结果
要查看结果的可视化表示,请右键单击Result list框中的结果。屏幕上将弹出几个选项,如下所示:
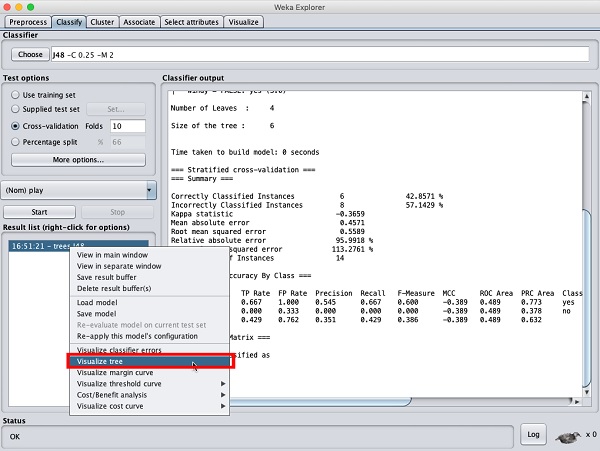
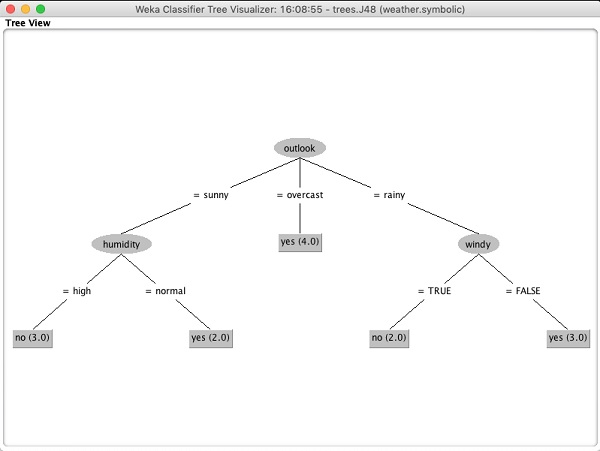
选择Visualize tree以获得遍历树的可视化表示,如下面的屏幕截图所示:
选择Visualize classifier errors将绘制分类结果,如下所示:
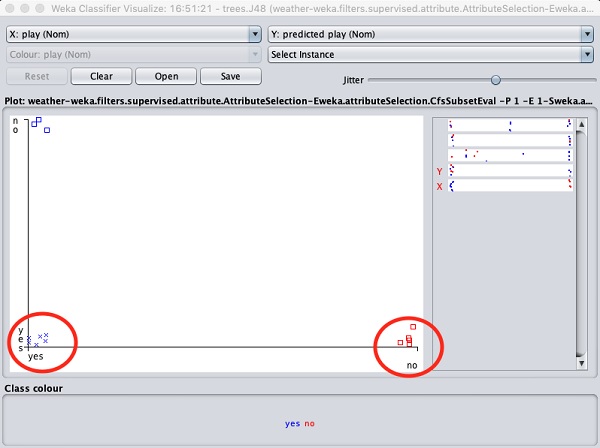
十字表示正确分类的实例,而正方形表示错误分类的实例。在图的左下角,您会看到一个十字,表示如果outlook为sunny,则play游戏。因此,这是一个正确分类的实例。要定位实例,您可以通过滑动jitter滑块在其上引入一些抖动。
当前图是outlook与play的关系。它们由屏幕顶部的两个下拉列表框指示。
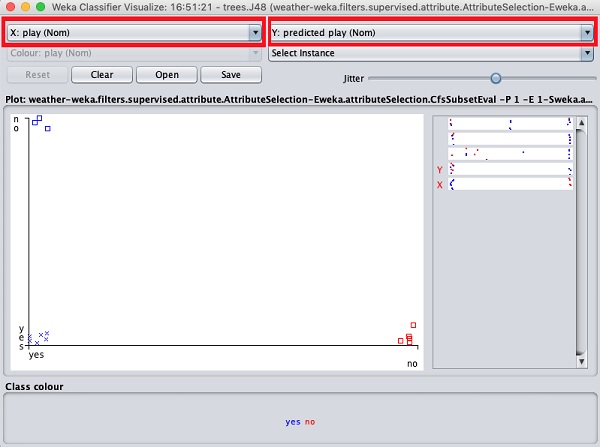
现在,尝试在每个框中进行不同的选择,并注意X和Y轴如何变化。可以通过使用图右侧的水平条来实现相同的效果。每个条带代表一个属性。左键单击条带将在X轴上设置选定的属性,而右键单击将在Y轴上设置它。
为了更深入的分析,还提供了其他几个图。明智地使用它们来微调您的模型。下面显示了一个成本/收益分析图,供您快速参考。
解释这些图表中的分析超出了本教程的范围。鼓励读者复习他们对机器学习算法分析的知识。
在下一章中,我们将学习下一组机器学习算法,即聚类。
Weka - 聚类
聚类算法在整个数据集中查找相似实例的组。WEKA支持多种聚类算法,例如EM、FilteredClusterer、HierarchicalClusterer、SimpleKMeans等等。您应该完全理解这些算法,以充分利用WEKA的功能。
与分类一样,WEKA允许您以图形方式可视化检测到的聚类。为了演示聚类,我们将使用提供的iris数据库。数据集包含三个类别,每个类别包含50个实例。每个类别都指一种鸢尾花植物。
加载数据
在WEKA资源管理器中,选择Preprocess选项卡。单击Open file ...选项,并在文件选择对话框中选择iris.arff文件。加载数据后,屏幕将如下所示:
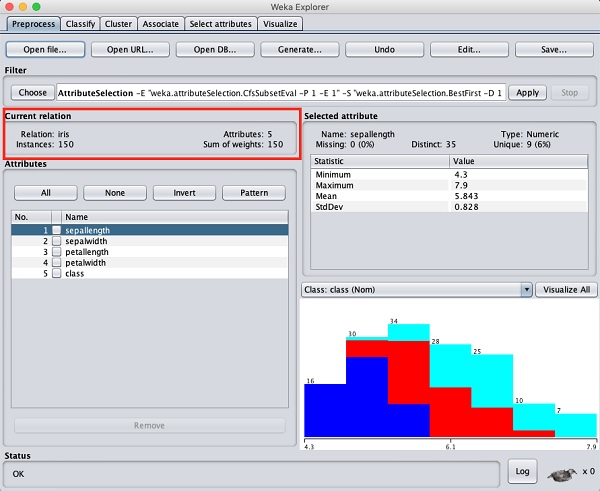
您可以观察到有150个实例和5个属性。属性的名称列为sepallength、sepalwidth、petallength、petalwidth和class。前四个属性为数字类型,而class为标称类型,具有3个不同的值。检查每个属性以了解数据库的功能。我们不会对此数据进行任何预处理,而是直接进行模型构建。
聚类
单击Cluster选项卡以将聚类算法应用于我们加载的数据。单击Choose按钮。您将看到以下屏幕:
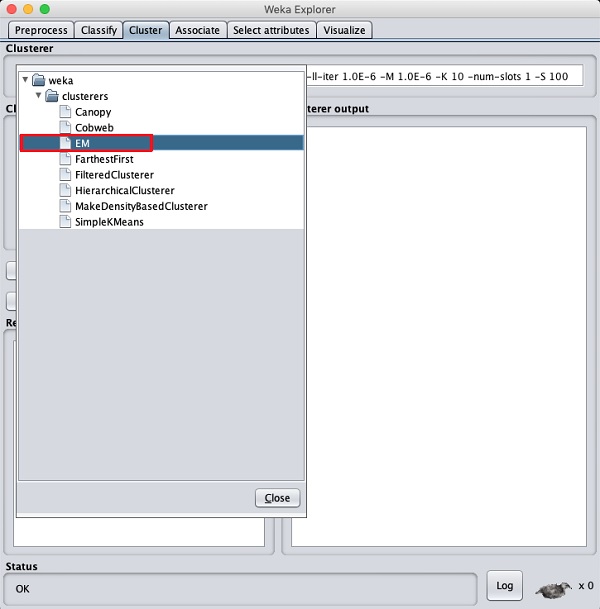
现在,选择EM作为聚类算法。在Cluster mode子窗口中,选择Classes to clusters evaluation选项,如下面的屏幕截图所示:
单击Start按钮处理数据。一段时间后,结果将显示在屏幕上。
接下来,让我们研究一下结果。
检查输出
数据处理的输出显示在下面的屏幕中:
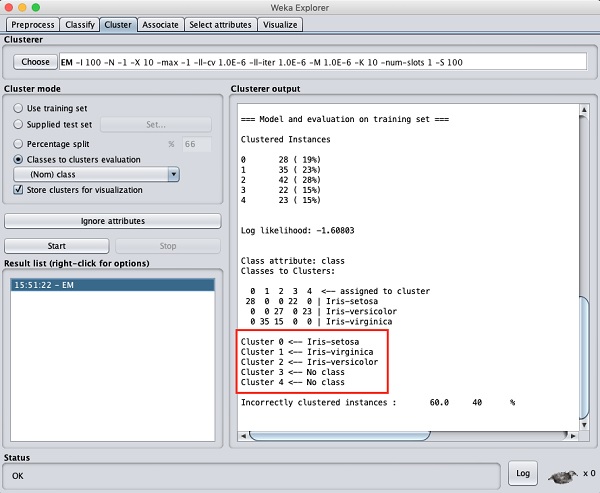
从输出屏幕中,您可以观察到:
在数据库中检测到5个聚类实例。
Cluster 0表示setosa,Cluster 1表示virginica,Cluster 2表示versicolor,而最后两个聚类没有任何与之关联的类。
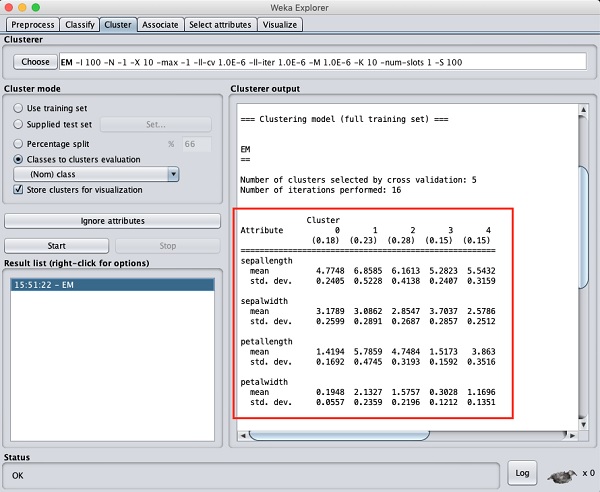
如果您向上滚动输出窗口,您还将看到一些统计信息,这些信息提供了各个检测到的聚类中每个属性的均值和标准差。这在下面给出的屏幕截图中显示:
接下来,我们将查看聚类的可视化表示。
可视化聚类
要可视化聚类,请右键单击Result list中的EM结果。您将看到以下选项:
选择Visualize cluster assignments。您将看到以下输出:
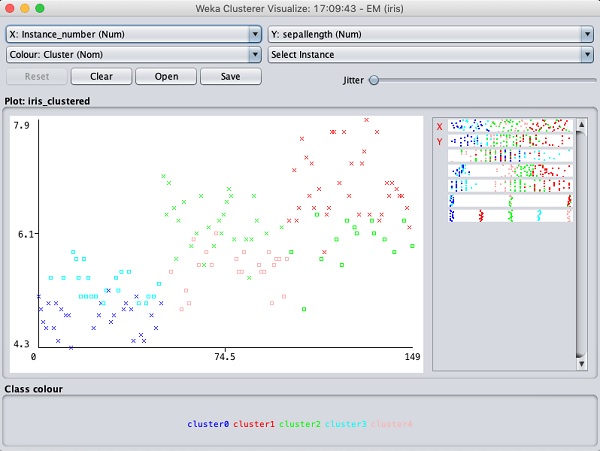
与分类的情况类似,您会注意到正确识别和错误识别的实例之间的区别。您可以通过更改 X 轴和 Y 轴来分析结果。您可以像分类情况下那样使用抖动来找出正确识别实例的集中情况。可视化图中的操作与您在分类案例中学习的操作类似。
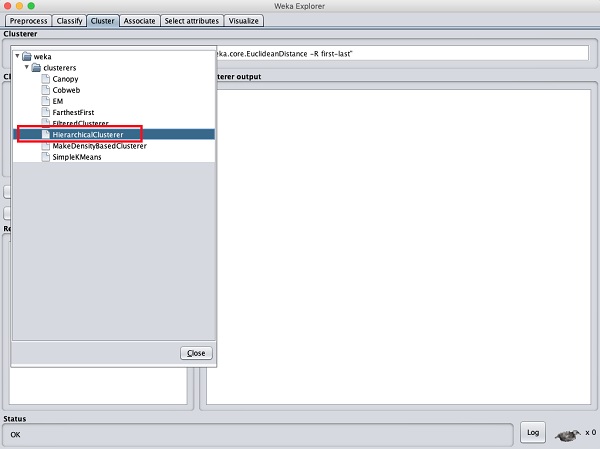
应用层次聚类
为了演示 WEKA 的强大功能,让我们现在看看另一种聚类算法的应用。在 WEKA 浏览器中,选择HierarchicalClusterer作为您的机器学习算法,如下面的屏幕截图所示:
选择聚类模式为类到聚类评估,然后单击开始按钮。您将看到以下输出:
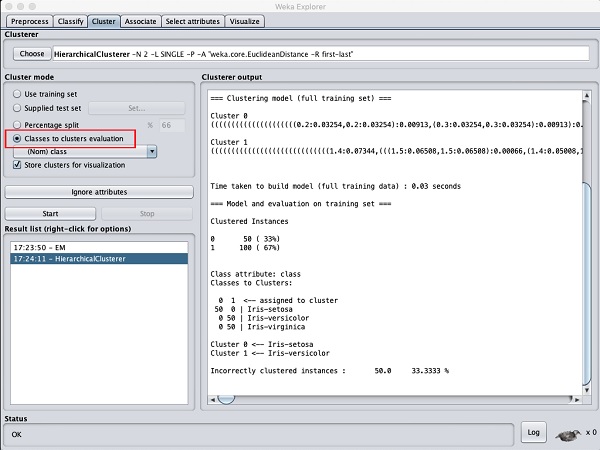
请注意,在结果列表中,列出了两个结果:第一个是 EM 结果,第二个是当前的层次结果。同样,您可以将多种机器学习算法应用于相同的数据集,并快速比较其结果。
如果您检查此算法生成的树,您将看到以下输出:
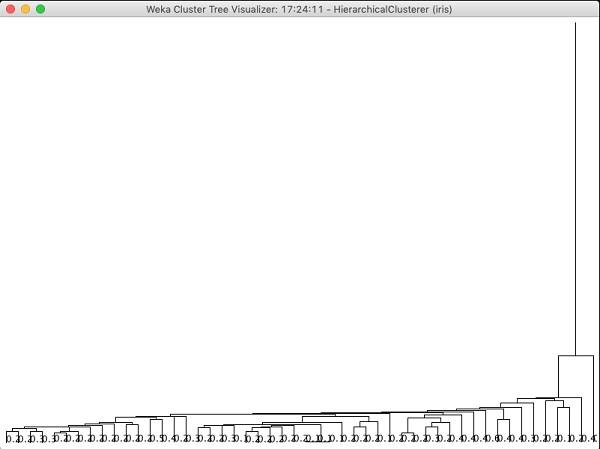
在下一章中,您将学习关联类型的机器学习算法。
Weka - 关联规则
据观察,购买啤酒的人也同时购买尿布。也就是说,在购买啤酒和尿布之间存在关联。虽然这似乎不太令人信服,但此关联规则是从超市的大型数据库中挖掘出来的。类似地,花生酱和面包之间也可能存在关联。
发现这种关联对于超市至关重要,因为它们会将尿布存放在啤酒旁边,以便顾客可以轻松找到两种商品,从而增加超市的销量。
Apriori算法就是这样一种机器学习算法,它可以找出可能的关联并创建关联规则。WEKA 提供了 Apriori 算法的实现。在计算这些规则时,您可以定义最小支持度和可接受的置信度水平。您将把Apriori算法应用于 WEKA 安装中提供的超市数据。
加载数据
在 WEKA 浏览器中,打开预处理选项卡,单击打开文件...按钮,并从安装文件夹中选择supermarket.arff数据库。数据加载后,您将看到以下屏幕:
该数据库包含 4627 个实例和 217 个属性。您可以轻松理解检测如此大量属性之间的关联有多么困难。幸运的是,借助 Apriori 算法,这项任务可以自动化。
关联器
单击关联选项卡,然后单击选择按钮。选择Apriori关联,如屏幕截图所示:
要设置 Apriori 算法的参数,请单击其名称,将弹出一个窗口,如下所示,允许您设置参数:
设置参数后,单击开始按钮。过一段时间后,您将看到如下面的屏幕截图所示的结果:
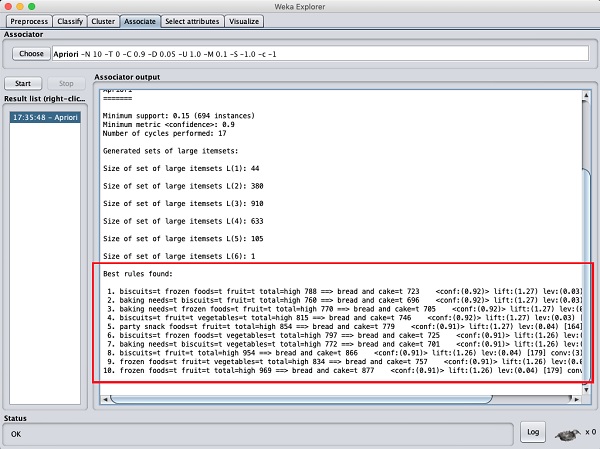
在底部,您将找到检测到的最佳关联规则。这将有助于超市将其产品存放在合适的货架上。
Weka - 特征选择
当数据库包含大量属性时,将有一些属性在您当前正在寻求的分析中变得不重要。因此,从数据集中删除不需要的属性成为开发良好机器学习模型的重要任务。
您可以直观地检查整个数据集,并确定不相关的属性。对于包含大量属性(例如您在上一课中看到的超市案例)的数据库来说,这可能是一项巨大的任务。幸运的是,WEKA 提供了一个自动化的特征选择工具。
本章将在此数据库上演示此功能,该数据库包含大量属性。
加载数据
在 WEKA 浏览器的预处理标签中,选择labor.arff文件以加载到系统中。加载数据后,您将看到以下屏幕:
请注意,有 17 个属性。我们的任务是通过消除与我们的分析无关的一些属性来创建缩减后的数据集。
特征提取
单击选择属性选项卡。您将看到以下屏幕:
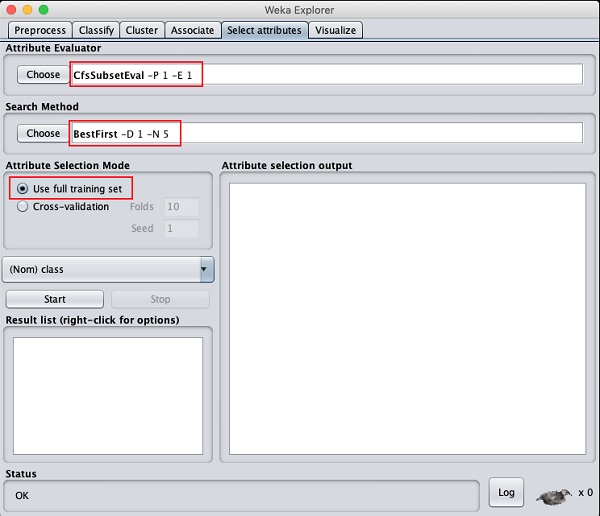
在属性评估器和搜索方法下,您会找到多个选项。我们在这里只使用默认值。在属性选择模式中,使用完整训练集选项。
单击开始按钮以处理数据集。您将看到以下输出:
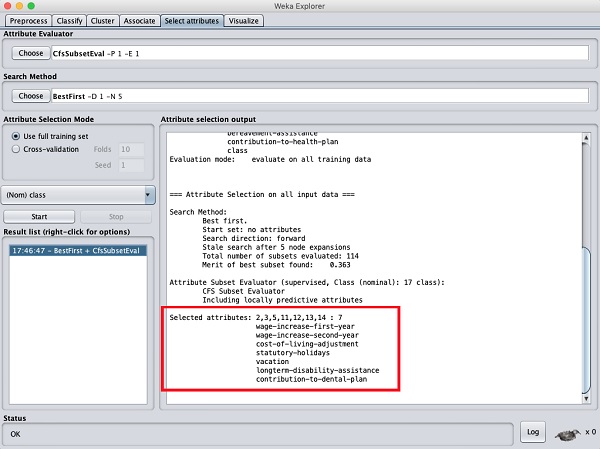
在结果窗口底部,您将获得已选择属性的列表。要获得可视化表示,请右键单击结果列表中的结果。
输出显示在以下屏幕截图中:
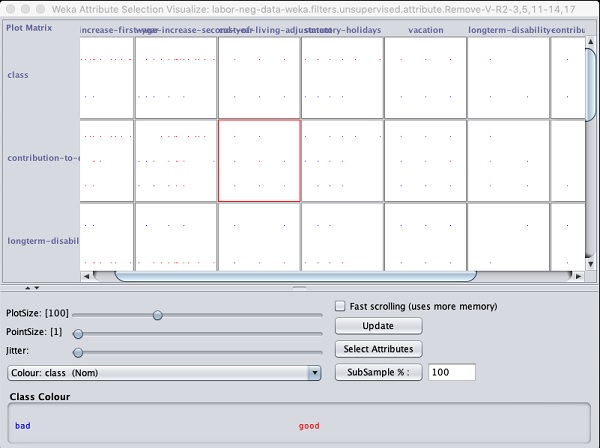
单击任意正方形将为您提供数据图,以供您进一步分析。一个典型的数据图如下所示:
这类似于我们在前面章节中看到的那些。尝试使用不同的可用选项来分析结果。
下一步是什么?
到目前为止,您已经看到了 WEKA 在快速开发机器学习模型方面的强大功能。我们使用的是一个名为Explorer的图形工具来开发这些模型。WEKA 还提供了一个命令行界面,它为您提供了比浏览器中提供的更多功能。
在GUI 选择器应用程序中单击简单 CLI按钮将启动此命令行界面,如下面的屏幕截图所示:
在底部的输入框中键入您的命令。您将能够完成到目前为止在浏览器中完成的所有操作,以及更多操作。有关更多详细信息,请参阅 WEKA 文档 (https://www.cs.waikato.ac.nz/ml/weka/documentation.html)。
最后,WEKA 是用 Java 开发的,并为其 API 提供了一个接口。因此,如果您是 Java 开发人员并且热衷于将 WEKA 机器学习实现包含在您自己的 Java 项目中,您可以轻松做到这一点。
结论
WEKA 是一个用于开发机器学习模型的强大工具。它提供了多种最广泛使用的机器学习算法的实现。在将这些算法应用于您的数据集之前,它还允许您预处理数据。支持的算法类型分为分类、聚类、关联和选择属性。处理各个阶段的结果可以通过美观且强大的可视化表示来显示。这使得数据科学家更容易在其数据集上快速应用各种机器学习技术,比较结果并为最终用途创建最佳模型。