
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP计算机体系结构中的缓存内存是什么?
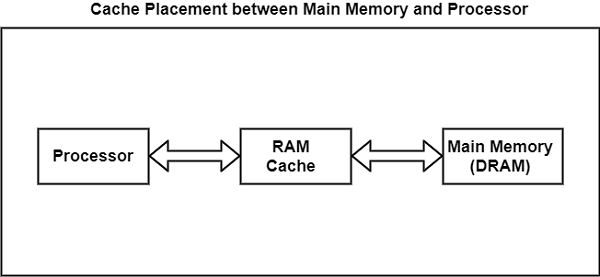
通常由 CPU 使用的主存储器的数据或内容保存在缓存内存中,以便处理器能够更快地访问这些信息。每当 CPU 需要访问内存时,它首先会检查缓存内存。如果数据不在缓存内存中,则 CPU 会转到主存储器访问。
缓存内存位于 CPU 和主存储器之间。缓存内存的框图可以表示为:
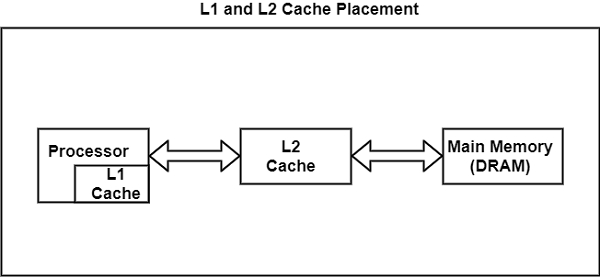
通过在缓存和处理器之间放置一个更小的 SRAM 来优化减少内存大小的概念,从而创建两级缓存。这个新的缓存通常包含在处理器内部。由于新的缓存放置在处理器内部,因此连接这两者的线变得非常短,并且接口电路与处理器的接口电路更加紧密地集成在一起。
这两个条件以及更小的解码器电路有助于更快地访问数据。当存在两个缓存时,处理器内的缓存称为一级缓存或 L1 缓存。L1 缓存和内存之间的缓存称为二级缓存或 L2 缓存。
该图显示了 L1 和 L2 缓存在内存中的位置。
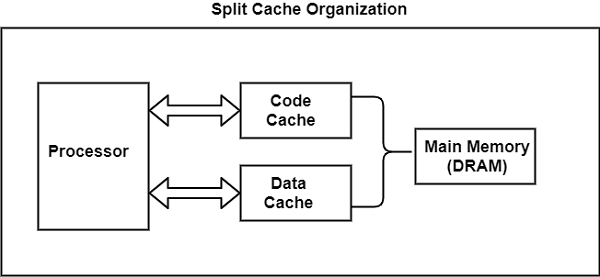
图中显示了另一种缓存组织方式:分割缓存。分割缓存需要两个缓存。在这种情况下,处理器使用一个缓存存储代码/指令,使用另一个缓存存储数据。
这种缓存组织通常用于支持高级类型的处理器架构,例如流水线。在这里,处理器用于处理代码的机制与用于数据的机制如此不同,以至于将这两种类型的信息都放在同一个缓存中没有意义。
缓存的成功依赖于局部性原理。该原理认为,当一个数据项被加载到缓存中时,内存中靠近它的项也应该被加载。
如果程序进入循环,则循环中大部分指令会被执行多次。因此,当循环的第一条指令被加载到缓存时,它会同时加载其相邻的指令以节省时间。这样,处理器就不必等待主存储器提供后续指令。
因此,缓存的组织方式是,当加载一段数据或代码时,也会加载其相邻项的块。加载到缓存中的每个块都用一个称为标签的编号标识。
此标签可用于查找主存储器中数据的原始地址。因此,当处理器搜索一段数据或代码(以下称为字)时,它只需要检查标签以查看该字是否包含在缓存中。

4K+ 次查看
