
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP什么是 LR 解析表的实现?
LR 解析表是一个二维数组,其中每个条目表示一个动作或 goto 条目。一个具有大量产生式的编程语言语法具有大量状态或项目,即 I0、I1 … … In。
因此,由于状态过多,将填充更多动作和 goto 条目,这需要大量内存。因此,二维数组不足以存储如此多的动作条目,因为每个条目至少需要 8 位来编码。
因此,我们必须使用比二维数组更有效的编码来编码动作和 goto 字段。
例如,考虑语法。
E → E + T
E → T
T → T * F
T → (F)
F → (E)
F → id
其解析表将是
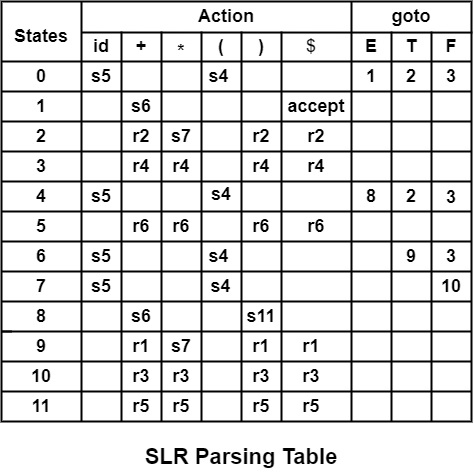
编码动作字段
动作表的一些行是相同的,即它们具有相同的动作条目。因此,它可以通过为每个状态生成一个指向一维数组的指针来存储多个空间。
要从数组访问条目,我们可以为每个终结符分配从 0 到 n-1 的顺序编号。此整数可以用作访问特定终结符的偏移量。可以通过创建对列表来管理空间效率。
在给定的解析表中,状态 0、4、6、7 具有相同的动作条目。它们可以表示为
| 符号 | 动作 |
|---|---|
| Id | s5 |
| ( | s4 |
| 任何 | 错误 |
**状态 1** 具有列表。
| 符号 | 动作 |
|---|---|
| + | s6 |
| $ | 接受 |
| 任何 | 错误 |
在**状态 2** 中,如果它可以用 r2 替换错误条目。因此,r2 将出现在除 * 之外的所有条目上。
| 符号 | 动作 |
|---|---|
| * | s7 |
| 任何 | r2 |
**状态 3** - 它只有 r4 条目和错误条目。如果它也可以用 r4 替换错误条目,则所有条目都将由 r4 表示。
| 符号 | 动作 |
|---|---|
| 任何 | r4 |
**状态 5、10、11** 可以类似地解决。
状态 8
| 符号 | 动作 |
|---|---|
| + | s6 |
| ) | s11 |
| 任何 | 错误 |
状态 9
| 符号 | 动作 |
|---|---|
| * | s7 |
| 任何 | r1 |
编码 goto 字段
goto 表也可以由列表编码。列表包含一对 (当前状态,下一个状态)
∴ Goto [当前状态,A] = 下一个状态
**列 F** - 列 F 对状态 7 具有 10,所有其他条目均为 3 或错误。我们可以用 3 替换错误。
| 当前状态 | 下一个状态 |
|---|---|
| 7 | 10 |
| 任何 | 3 |
列 T
| 当前状态 | 下一个状态 |
|---|---|
| 6 | 9 |
| 任何 | 2 |
在**列 E** 中,我们可以选择 1 或 8 作为默认值。
| 当前状态 | 下一个状态 |
|---|---|
| 4 | 8 |
| 任何 | 1 |
因此,维护这些列表显然会节省一些空间,即占用比之前少大约 10% 的空间。这些列表占用少量内存。但列表表示比矩阵表示慢。

2K+ 次查看
