
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP分支处理的微体系结构实现是什么?
分支处理包括基本任务,例如指令获取、解码和 BTA 计算,以及可能的其他专用任务以加快分支处理速度。这些专用任务可能是早期分支检测、分支预测或访问目标路径的高级方案。
通常,专用任务使用专用硬件执行,例如 BTAC、BTIC 或 BHT。基本任务有两种方法。所有早期的流水线处理器和许多最近的处理器都通过利用可用于通用指令处理的流水线阶段来执行分支,如图所示 -
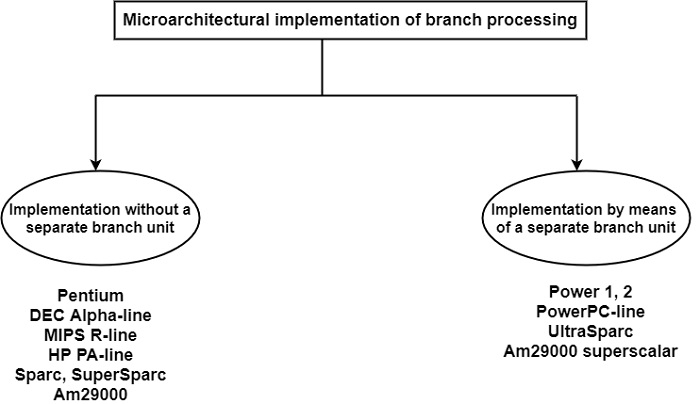
相比之下,一些最近的处理器提供了一个单独的单元,通常称为**分支单元**,来执行分支处理的基本任务。这种方法将分支处理与一般数据操作解耦,并导致微体系结构结构更加对称。此外,这种方法也有助于提高性能,因为其他单元从分支处理的基本子任务(例如地址计算)中释放出来。
因此,分支可以与数据操作并行处理。如图所示,它显示了 Power1、Power2 和 PowerPC 模型遵循此方法。例如 UltraSparc 和 Am29000 超标量处理器。
使用预测的处理器的分支惩罚
有一种有效的技术可以大幅减少或避免对正确预测的分支的惩罚,例如 I 缓存方案中的 BTAC 或后继索引。使用这些方案,甚至可以实现零周期分支,如表所示。此表包含最近使用真正的静态或动态预测的处理器中的分支惩罚数据。
采用静态或动态预测的处理器中的分支惩罚
| 处理器类型 | 正确预测分支的惩罚(周期) | 错误预测分支的惩罚(周期) |
|---|---|---|
| MC 88110(1993) | 0 | 2 |
| MC 68060(1993) | Z | 7 |
| 奔腾(1993) | 0 | 3-4 |
| Gmicro/500(1993) | z/21 | n.a. |
| PA 7200(1995) | n.a. | 0-1 |
| PA 8000(1996) | z/22,3 | 5 |
| R 8000(1994) | n.a. | 3 |
| R 10000(1996) | 13 | 1−46 |
| α21164(1995) | 0 | 5 |
| PowerPC 604(1995) | $\frac{0^1}{1}$ −22 | 3 |
| PowerPC 620(1996) | $\frac{0^1}{1^3}$ | 2 |
| Nx586(1995) | Z | 54−195 |
如果分支地址提示 BTAC。
如果分支地址未命中 BTAC。
如果解码队列中有足够的指令,则此延迟可能会部分或全部隐藏。
如果保留站队列为空。
如果保留站队列已满(14 个条目)。
R10000 最多允许 4 个嵌入式挂起预测。错误预测惩罚的实际值取决于错误预测的深度。
Z 表示零周期分支。
如表所示,它表明尽管这些技术大大减少了错误预测的惩罚,但大多数最近的处理器至少需要两到三个周期才能恢复。PA7200 和 R10000 在某些情况下只有一个甚至没有惩罚周期。
但是,错误预测惩罚对有效分支惩罚的贡献在很大程度上取决于预测精度。预测精度越高,错误预测惩罚对处理器性能的阻碍就越小。例如,对于 90% 的预测精度,两个周期的错误预测惩罚只会导致平均分支惩罚增加 0.1*2=0.2 个周期。

195 次查看
