- XML 教程
- XML - 首页
- XML - 概述
- XML - 语法
- XML - 文档
- XML - 声明
- XML - 标签
- XML - 元素
- XML - 属性
- XML - 注释
- XML - 字符实体
- XML - CDATA 节
- XML - 空格
- XML - 处理
- XML - 编码
- XML - 验证
- XML 有用资源
- XML 快速指南
- XML - 有用资源
XML 快速指南
XML - 概述
XML 代表可扩展标记语言 (Extensible Markup Language)。它是一种基于文本的标记语言,源自标准通用标记语言 (SGML)。
XML 标签标识数据,用于存储和组织数据,而不是像 HTML 标签那样指定如何显示数据(HTML 标签用于显示数据)。XML 在不久的将来不会取代 HTML,但它通过采用 HTML 的许多成功特性引入了新的可能性。
XML 有三个重要的特性使其在各种系统和解决方案中都非常有用:
XML 是可扩展的 - XML 允许您创建适合您应用程序的自己的自描述标签或语言。
XML 传输数据,不呈现数据 - XML 允许您存储数据,而不管它将如何呈现。
XML 是公共标准 - XML 由万维网联盟 (W3C) 开发,是一个开放标准。
XML 用途
XML 用途简要列表如下:
XML 可以幕后工作,简化大型网站 HTML 文档的创建。
XML 可用于在组织和系统之间交换信息。
XML 可用于数据库的卸载和重新加载。
XML 可用于存储和组织数据,可以定制您的数据处理需求。
XML 可以轻松与样式表合并,以创建几乎任何所需的输出。
实际上,任何类型的数据都可以表示为 XML 文档。
什么是标记?
XML 是一种标记语言,它定义了一组规则,用于以既可人读又可机器读的格式编码文档。那么什么是标记语言呢?标记是添加到文档中的信息,它以某种方式增强了文档的含义,因为它标识了文档的各个部分以及它们之间的关系。更具体地说,标记语言是一组符号,可以放置在文档的文本中以划分和标记该文档的各个部分。
以下示例显示了嵌入在文本中的 XML 标记的外观:
<message> <text>Hello, world!</text> </message>
此代码片段包含标记符号或标签,例如 <message>...</message> 和 <text>... </text>。标签 <message> 和 </message> 标记 XML 代码片段的开始和结束。标签 <text> 和 </text> 包含文本 Hello, world!。
XML 是一种编程语言吗?
编程语言由语法规则和自己的词汇表组成,用于创建计算机程序。这些程序指示计算机执行特定任务。XML 不符合编程语言的资格,因为它不执行任何计算或算法。它通常存储在简单的文本文件中,并由能够解释 XML 的专用软件处理。
XML - 语法
在本节中,我们将讨论编写 XML 文档的简单语法规则。以下是完整的 XML 文档:
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
您会注意到上面的示例中有两种信息:
标记,如 <contact-info>
文本或字符数据,Tutorials Point 和 (040) 123-4567。
下图描述了在 XML 文档中编写不同类型标记和文本的语法规则。
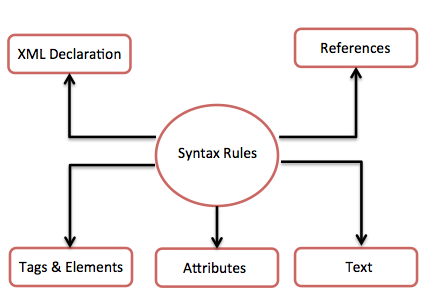
让我们详细了解上图的每个组件。
XML 声明
XML 文档可以选择包含 XML 声明。它写成如下:
<?xml version = "1.0" encoding = "UTF-8"?>
其中version 是 XML 版本,encoding 指定文档中使用的字符编码。
XML 声明的语法规则
XML 声明区分大小写,必须以“<?xml>”开头,其中“xml”小写。
如果文档包含 XML 声明,则它必须严格作为 XML 文档的第一个语句。
XML 声明必须严格作为 XML 文档中的第一个语句。
HTTP 协议可以覆盖您在 XML 声明中设置的encoding 值。
标签和元素
XML 文件由多个 XML 元素构成,也称为 XML 节点或 XML 标签。XML 元素的名称用三角括号 < > 括起来,如下所示:
<element>
标签和元素的语法规则
元素语法 - 每个 XML 元素都需要用开始元素或结束元素关闭,如下所示:
<element>....</element>
或者在简单情况下,只需这样:
<element/>
元素嵌套 - XML 元素可以包含多个 XML 元素作为其子元素,但子元素不能重叠。即,元素的结束标签必须与最近的不匹配的开始标签具有相同的名称。
以下示例显示了嵌套标签不正确:
<?xml version = "1.0"?> <contact-info> <company>TutorialsPoint </contact-info> </company>
以下示例显示了嵌套标签正确:
<?xml version = "1.0"?> <contact-info> <company>TutorialsPoint</company> <contact-info>
根元素 - XML 文档只能有一个根元素。例如,以下不是正确的 XML 文档,因为x 和y 元素都出现在顶级,没有根元素:
<x>...</x> <y>...</y>
以下示例显示了一个格式正确的 XML 文档:
<root> <x>...</x> <y>...</y> </root>
大小写敏感性 - XML 元素的名称区分大小写。这意味着开始元素和结束元素的名称必须完全相同。
例如,<contact-info> 与 <Contact-Info> 不同
XML 属性
属性使用名称/值对指定元素的单个属性。XML 元素可以有一个或多个属性。例如:
<a href = "https://tutorialspoint.com/">Tutorialspoint!</a>
这里href 是属性名称,https://tutorialspoint.com/ 是属性值。
XML 属性的语法规则
XML 中的属性名称(与 HTML 不同)区分大小写。也就是说,HREF 和 href 被认为是两个不同的 XML 属性。
同一属性在一个语法中不能有两个值。以下示例显示了不正确的语法,因为属性b 被指定了两次
—
<a b = "x" c = "y" b = "z">....</a>
属性名称无需用引号定义,而属性值必须始终用引号括起来。以下示例演示了不正确的 xml 语法
—
<a b = x>....</a>
在上例语法中,属性值没有用引号定义。
XML 引用
引用通常允许您在 XML 文档中添加或包含其他文本或标记。引用始终以符号"&"(这是一个保留字符)开头,并以符号";" 结尾。XML 有两种类型的引用:
实体引用 - 实体引用包含开始和结束分隔符之间的名称。例如&,其中amp 是name。name 指的是预定义的文本和/或标记字符串。
字符引用 - 这些包含引用,例如A,包含一个井号 (“#”),后跟一个数字。该数字始终指字符的 Unicode 代码。在这种情况下,65 指字母“A”。
XML 文本
XML 元素和 XML 属性的名称区分大小写,这意味着开始元素和结束元素的名称需要使用相同的大小写。为了避免字符编码问题,所有 XML 文件都应保存为 Unicode UTF-8 或 UTF-16 文件。
XML 元素之间和 XML 属性之间的空格字符(如空格、制表符和换行符)将被忽略。
某些字符被 XML 语法本身保留。因此,不能直接使用它们。要使用它们,可以使用一些替代实体,如下所示:
| 不允许使用的字符 | 替代实体 | 字符描述 |
|---|---|---|
| < | < | 小于 |
| > | > | 大于 |
| & | & | 和号 |
| ' | ' | 撇号 |
| " | " | 引号 |
XML - 文档
XML 文档是由元素和其他标记组成的有序包中的 XML 信息的基本单元。XML 文档可以包含各种各样的数据。例如,数字数据库、表示分子结构的数字或数学方程式。
XML 文档示例
以下示例显示了一个简单的文档:
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
下图描述了 XML 文档的各个部分。

文档序言部分
文档序言位于文档的顶部,位于根元素之前。本节包含:
- XML 声明
- 文档类型声明
您可以在本章中了解有关 XML 声明的更多信息:XML 声明
文档元素部分
文档元素是 XML 的构建块。它们将文档划分为一个层次结构的部分,每个部分都具有特定的用途。您可以将文档分成多个部分,以便可以以不同的方式呈现它们,或被搜索引擎使用。元素可以是容器,包含文本和其他元素的组合。
您可以在本章中了解有关 XML 元素的更多信息:XML 元素
XML - 声明
本章详细介绍了 XML 声明。XML 声明包含准备 XML 处理器解析 XML 文档的详细信息。它是可选的,但如果使用,则必须出现在 XML 文档的第一行。
语法
以下语法显示 XML 声明:
<?xml version = "version_number" encoding = "encoding_declaration" standalone = "standalone_status" ?>
每个参数都包含一个参数名称、一个等号 (=) 和一个带引号的参数值。下表详细显示了上述语法:
| 参数 | 参数值 | 参数描述 |
|---|---|---|
| 版本 | 1.0 | 指定使用的 XML 标准版本。 |
| 编码 | UTF-8、UTF-16、ISO-10646-UCS-2、ISO-10646-UCS-4、ISO-8859-1 到 ISO-8859-9、ISO-2022-JP、Shift_JIS、EUC-JP | 它定义文档中使用的字符编码。UTF-8 是使用的默认编码。 |
| 独立 | yes 或 no | 它通知解析器文档是否依赖于外部源(例如外部文档类型定义 (DTD))的信息来获取其内容。默认值为no。将其设置为yes 将告诉处理器解析文档不需要任何外部声明。 |
规则
XML 声明应遵守以下规则:
如果 XML 中存在 XML 声明,则必须将其放置在 XML 文档的第一行。
如果包含 XML 声明,则必须包含版本号属性。
参数名称和值区分大小写。
名称始终小写。
参数放置的顺序很重要。正确的顺序是:version、encoding 和 standalone。
可以使用单引号或双引号。
XML 声明没有结束标签,即</?xml>
XML 声明示例
以下是 XML 声明的一些示例:
没有参数的 XML 声明:
<?xml >
带有版本定义的 XML 声明:
<?xml version = "1.0">
定义了所有参数的 XML 声明:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
使用单引号定义所有参数的XML声明 -
<?xml version = '1.0' encoding = 'iso-8859-1' standalone = 'no' ?>
XML - 标签
让我们学习XML最重要的部分之一:XML标签。XML标签构成了XML的基础。它们定义了XML中元素的范围。它们还可以用于插入注释,声明解析环境所需的设置以及插入特殊指令。
我们可以将XML标签大致分为以下几类:
开始标签
每个非空XML元素的开头都用开始标签标记。以下是开始标签的示例:
<address>
结束标签
每个具有开始标签的元素都应该以结束标签结尾。以下是结束标签的示例:
</address>
请注意,结束标签在元素名称之前包含一个斜杠("/")。
空标签
出现在开始标签和结束标签之间的文本称为内容。没有内容的元素称为空元素。空元素可以用以下两种方式表示:
开始标签紧跟结束标签,如下所示:
<hr></hr>
完整的空元素标签如下所示:
<hr />
空元素标签可以用于任何没有内容的元素。
XML标签规则
以下是使用XML标签时需要遵循的规则:
规则1
XML标签区分大小写。以下代码行是错误语法`
`的示例,因为两个标签的大小写不同,这在XML中被视为错误语法。<address>This is wrong syntax</Address>
以下代码显示了正确的方法,我们使用相同的大小写来命名开始和结束标签。
<address>This is correct syntax</address>
规则2
必须按正确的顺序关闭XML标签,即,在另一个元素内部打开的XML标签必须在外部元素关闭之前关闭。例如:
<outer_element>
<internal_element>
This tag is closed before the outer_element
</internal_element>
</outer_element>
XML - 元素
XML元素可以定义为XML的构建块。元素可以作为容器来容纳文本、元素、属性、媒体对象或所有这些。
每个XML文档包含一个或多个元素,其范围由开始和结束标签分隔,或者对于空元素,由空元素标签分隔。
语法
以下是编写XML元素的语法:
<element-name attribute1 attribute2> ....content </element-name>
其中:
element-name是元素的名称。其名称在开始和结束标签中的大小写必须匹配。
attribute1, attribute2是元素的属性,用空格分隔。属性定义了元素的属性。它将名称与值相关联,值是字符字符串。属性的写法如下:
name = "value"
name后跟一个=号和一个用双引号(" ")或单引号(' ')括起来的字符串value。
空元素
空元素(没有内容的元素)具有以下语法:
<name attribute1 attribute2.../>
以下是用各种XML元素编写的XML文档示例:
<?xml version = "1.0"?>
<contact-info>
<address category = "residence">
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>
</contact-info>
XML元素规则
XML元素需要遵循以下规则:
元素名称可以包含任何字母数字字符。名称中唯一允许的标点符号是连字符 (-)、下划线 (_) 和句点 (.)。
名称区分大小写。例如,Address、address和ADDRESS是不同的名称。
元素的开始和结束标签必须相同。
元素作为容器,可以包含文本或元素,如上例所示。
XML - 属性
本章描述了XML属性。属性是XML元素的一部分。一个元素可以有多个唯一的属性。属性提供了关于XML元素的更多信息。更准确地说,它们定义了元素的属性。XML属性始终是名称-值对。
语法
XML属性具有以下语法:
<element-name attribute1 attribute2 > ....content.. < /element-name>
其中attribute1和attribute2具有以下形式:
name = "value"
value必须用双引号(" ")或单引号(' ')括起来。这里,attribute1和attribute2是唯一的属性标签。
属性用于为元素添加唯一的标签,将标签放在类别中,添加布尔标志,或将其与某些数据字符串关联。以下示例演示了属性的使用:
<?xml version = "1.0" encoding = "UTF-8"?> <!DOCTYPE garden [ <!ELEMENT garden (plants)*> <!ELEMENT plants (#PCDATA)> <!ATTLIST plants category CDATA #REQUIRED> ]> <garden> <plants category = "flowers" /> <plants category = "shrubs"> </plants> </garden>
当您不想为每种情况创建一个新元素时,属性用于区分同名元素。因此,使用属性可以更详细地区分两个或多个相似的元素。
在上例中,我们通过包含属性category并为每个元素分配不同的值来对植物进行分类。因此,我们有两个类别plants,一个flowers,另一个shrubs。因此,我们有两个具有不同属性的plant元素。
您还可以观察到,我们在XML开头声明了此属性。
属性类型
下表列出了属性类型:
| 属性类型 | 描述 |
|---|---|
| StringType | 它接受任何文字字符串作为值。CDATA是StringType。CDATA是字符数据。这意味着,任何非标记字符的字符串都是属性的合法部分。 |
| TokenizedType | 这是一个更受限制的类型。在属性值被规范化后,将应用语法中提到的有效性约束。TokenizedType属性如下:
|
| EnumeratedType | 在其声明中有一组预定义的值。从中,它必须分配一个值。有两种枚举属性:
|
元素属性规则
以下是属性需要遵循的规则:
属性名称在同一个开始标签或空元素标签中不能出现多次。
必须使用属性列表声明在文档类型定义 (DTD) 中声明属性。
属性值不能包含对外部实体的直接或间接实体引用。
属性值中直接或间接引用的任何实体的替换文本不能包含小于号 (<)
XML - 注释
本章解释了XML注释在XML文档中的工作原理。XML注释类似于HTML注释。注释作为笔记或行添加,以了解XML代码的目的。
注释可用于包含相关链接、信息和术语。它们仅在源代码中可见;不在XML代码中。注释可以出现在XML代码中的任何位置。
语法
XML注释具有以下语法:
<!--Your comment-->
注释以<!--开头,以-->结尾。您可以在字符之间添加文本注释作为注释。您不能将一个注释嵌套在另一个注释内。
示例
以下示例演示了在XML文档中使用注释:
<?xml version = "1.0" encoding = "UTF-8" ?>
<!--Students grades are uploaded by months-->
<class_list>
<student>
<name>Tanmay</name>
<grade>A</grade>
</student>
</class_list>
<!--和-->字符之间的任何文本都被视为注释。
XML注释规则
XML注释应遵循以下规则:
- 注释不能出现在XML声明之前。
- 注释可以出现在文档中的任何位置。
- 注释不能出现在属性值中。
- 注释不能嵌套在其他注释内。
XML - 字符实体
本章描述了XML字符实体。在了解字符实体之前,让我们首先了解什么是XML实体。
正如W3 Consortium所述,实体的定义如下:
“文档实体作为实体树的根和XML处理器的起点”。
这意味着,实体是XML中的占位符。这些可以在文档序言或DTD中声明。有不同类型的实体,本章将讨论字符实体。
HTML和XML都有一些保留用于其自身的符号,这些符号不能用作XML代码中的内容。例如,<和>符号用于打开和关闭XML标签。要显示这些特殊字符,可以使用字符实体。
有一些特殊字符或符号无法直接从键盘输入。字符实体也可以用于显示这些符号/特殊字符。
字符实体类型
有三种类型的字符实体:
- 预定义字符实体
- 编号字符实体
- 命名字符实体
预定义字符实体
引入它们是为了避免使用某些符号时出现的歧义。例如,当小于 (<) 或大于 (>) 符号与角标签 (<>) 一起使用时,会观察到歧义。字符实体基本上用于分隔XML中的标签。以下是XML规范中预定义字符实体的列表。这些可以用来表达字符而不会产生歧义。
与号 - &
单引号 - '
大于 - >
小于 - <
双引号 - "
数字字符实体
数字引用用于引用字符实体。数字引用可以是十进制或十六进制格式。由于有数千个可用的数字引用,这些引用有点难以记住。数字引用通过其在Unicode字符集中的编号来引用字符。
十进制数字引用的通用语法为:
&# decimal number ;
十六进制数字引用的通用语法为:
&#x Hexadecimal number ;
下表列出了一些预定义的字符实体及其数值:
| 实体名称 | 字符 | 十进制引用 | 十六进制引用 |
|---|---|---|---|
| quot | " | " | " |
| amp | & | & | & |
| apos | ' | ' | ' |
| lt | < | < | < |
| gt | > | > | > |
命名字符实体
由于难以记住数字字符,因此最常用的字符实体类型是命名字符实体。在这里,每个实体都用一个名称标识。
例如:
'Aacute' 代表带有重音符的大写
 字符。
字符。'ugrave' 代表带有重音符的小写
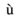 。
。
XML - CDATA 节
本章将讨论XML CDATA 部分。CDATA表示字符数据。CDATA定义为不被解析器解析的文本块,但会被识别为标记。
预定义实体,如<、>和&,需要输入,并且通常难以在标记中阅读。在这种情况下,可以使用CDATA部分。通过使用CDATA部分,您可以命令解析器文档的特定部分不包含标记,应将其视为常规文本。
语法
以下是CDATA部分的语法:
<![CDATA[ characters with markup ]]>
上述语法由三个部分组成:
CDATA 开始部分 - CDATA 以九个字符的分隔符<![CDATA[开头
CDATA 结束部分 - CDATA 部分以]]>分隔符结尾。
CDATA 部分 - 这两个括号之间的字符被解释为字符,而不是标记。此部分可能包含标记字符 (<、> 和 &),但XML处理器会忽略它们。
示例
以下标记代码显示了CDATA的示例。这里,CDATA部分中编写的每个字符都被解析器忽略。
<script>
<![CDATA[
<message> Welcome to TutorialsPoint </message>
]] >
</script >
在上文的语法中,`
CDATA 规则
对于 XML CDATA,必须遵循以下规则:
- CDATA 在 XML 文档中的任何位置都不能包含字符串“]]>”。
- CDATA 区段不允许嵌套。
XML - 空格
本章将讨论 XML 文档中的空格处理。空格是空格、制表符和换行符的集合。它们通常用于使文档更易于阅读。
XML 文档包含两种类型的空格——有效空格和无效空格。下面将通过示例对两者进行解释。
有效空格
有效空格出现在包含文本和标记同时存在的元素中。例如:
<name>TanmayPatil</name>
和
<name>Tanmay Patil</name>
由于Tanmay 和 Patil 之间的空格,以上两个元素有所不同。读取 XML 文件中此元素的任何程序都必须保持这种区别。
无效空格
无效空格是指只允许元素内容的空格。例如:
<address.category = "residence">或
<address....category = "..residence">
以上示例相同。此处,空格由点 (.) 表示。在上例中,`address` 和 `category` 之间的空格是无效的。
可以为元素附加一个名为xml:space 的特殊属性。这表示应用程序不应删除该元素的空格。可以将此属性设置为default 或preserve,如下例所示:
<!ATTLIST address xml:space (default|preserve) 'preserve'>
其中:
值default 表示应用程序的默认空格处理模式对于此元素是可以接受的。
值preserve 表示应用程序应保留所有空格。
XML - 处理
本章介绍处理指令 (PI)。根据 XML 1.0 建议的定义:
“处理指令 (PI) 允许文档包含应用程序的指令。PI 不是文档字符数据的一部分,但必须传递给应用程序。”
处理指令 (PI) 可用于将信息传递给应用程序。PI 可以出现在文档中标记之外的任何位置。它们可以出现在序言中(包括文档类型定义 (DTD))、文本内容中或文档之后。
语法
以下是 PI 的语法:
<?target instructions?>
其中
target - 指明指令的目标应用程序。
instruction - 描述应用程序要处理的信息的字符。
PI 以特殊标记<? 开头,以?> 结尾。字符串?> 出现后,内容处理立即结束。
示例
PI 很少使用。它们主要用于将 XML 文档链接到样式表。以下是一个示例:
<?xml-stylesheet href = "tutorialspointstyle.css" type = "text/css"?>
此处,target 为xml-stylesheet。href="tutorialspointstyle.css" 和 type="text/css" 是data 或instructions,目标应用程序将在处理给定的 XML 文档时使用这些数据或指令。
在这种情况下,浏览器通过指示应在显示之前转换 XML 来识别目标;第一个属性声明转换的类型为 XSL,第二个属性指向其位置。
处理指令规则
PI 可以包含任何数据,但?> 组合除外,该组合被解释为结束分隔符。以下是两个有效 PI 的示例:
<?welcome to pg = 10 of tutorials point?> <?welcome?>
XML - 编码
编码是将 Unicode 字符转换为其等效二进制表示的过程。当 XML 处理器读取 XML 文档时,它会根据编码类型对文档进行编码。因此,我们需要在 XML 声明中指定编码类型。
编码类型
主要有两种编码类型:
- UTF-8
- UTF-16
UTF 代表UCS 变换格式,UCS 本身代表通用字符集。8 或 16 指的是表示字符所用的位数。它们是 8 位(1 到 4 个字节)或 16 位(2 或 4 个字节)。对于没有编码信息的文档,默认情况下设置为 UTF-8。
语法
编码类型包含在 XML 文档的序言部分中。UTF-8 编码的语法如下:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
UTF-16 编码的语法如下:
<?xml version = "1.0" encoding = "UTF-16" standalone = "no" ?>
示例
以下示例显示了编码的声明:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
在上例中,encoding="UTF-8" 指定使用 8 位来表示字符。要表示 16 位字符,可以使用UTF-16 编码。
使用 UTF-8 编码的 XML 文件的大小往往小于使用 UTF-16 格式编码的文件。
XML - 验证
验证是一个验证 XML 文档的过程。如果 XML 文档的内容与元素、属性和相关的文档类型声明 (DTD) 匹配,并且文档符合其中表达的约束,则该文档被称为有效。XML 解析器通过两种方式处理验证。它们是:
- 格式良好的 XML 文档
- 有效的 XML 文档
格式良好的 XML 文档
如果 XML 文档符合以下规则,则称其为格式良好:
非 DTD XML 文件必须使用预定义的字符实体来表示amp(&)、apos(单引号)、gt(>)、lt(<)、quot(双引号)。
它必须遵循标记的顺序,即必须在关闭外部标记之前关闭内部标记。
它的每个开始标记都必须有一个结束标记,或者它必须是一个自结束标记。(`
`....` - 技术教程 ` 或 ``)。 它在一个开始标记中只能有一个属性,该属性需要用引号括起来。
必须声明除amp(&)、apos(单引号)、gt(>)、lt(<)、quot(双引号) 以外的其他实体。
示例
以下是一个格式良好的 XML 文档示例:
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?> <!DOCTYPE address [ <!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)> ]> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
以上示例被称为格式良好,因为:
它定义了文档的类型。此处,文档类型为element 类型。
它包含一个名为address 的根元素。
name、company 和 phone 之间的每个子元素都包含在其自解释标记中。
保持标记的顺序。
有效的 XML 文档
如果 XML 文档格式良好且具有关联的文档类型声明 (DTD),则称其为有效的 XML 文档。我们将在章节XML - DTDs中详细学习 DTD。
XML - DTDs
XML 文档类型声明,通常称为 DTD,是一种精确描述 XML 语言的方法。DTD 根据相应 XML 语言的语法规则检查 XML 文档的词汇和结构的有效性。
XML DTD 可以指定在文档内,也可以保存在单独的文档中,然后单独链接。
语法
DTD 的基本语法如下:
<!DOCTYPE element DTD identifier [ declaration1 declaration2 ........ ]>
在上文的语法中:
DTD 以`
element 告诉解析器从指定的根元素解析文档。
DTD 标识符是文档类型定义的标识符,它可能是系统上文件的路径或互联网上文件的 URL。如果 DTD 指向外部路径,则称为外部子集。
方括号 [ ] 包含一个可选的实体声明列表,称为内部子集。
内部 DTD
如果在 XML 文件中声明元素,则 DTD 称为内部 DTD。要将其称为内部 DTD,XML 声明中的`standalone` 属性必须设置为yes。这意味着声明独立于外部源工作。
语法
以下是内部 DTD 的语法:
<!DOCTYPE root-element [element-declarations]>
其中root-element 是根元素的名称,element-declarations 是声明元素的地方。
示例
以下是一个内部 DTD 的简单示例:
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?> <!DOCTYPE address [ <!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)> ]> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
让我们来看一下上面的代码:
开始声明- 使用以下语句开始 XML 声明。
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?>
DTD - 在 XML 头之后,紧跟着文档类型声明,通常称为 DOCTYPE -
<!DOCTYPE address [
DOCTYPE 声明的元素名称开头有一个感叹号 (!) 。DOCTYPE 通知解析器此 XML 文档与 DTD 相关联。
DTD 主体 - DOCTYPE 声明之后是 DTD 的主体,您可以在其中声明元素、属性、实体和符号。
<!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone_no (#PCDATA)>
此处声明了几个构成`
结束声明 - 最后,使用右括号和右尖括号 (]>) 关闭 DTD 的声明部分。这有效地结束了定义,此后,XML 文档紧随其后。
规则
文档类型声明必须出现在文档的开头(仅在 XML 头之前)——不允许出现在文档中的其他任何位置。
与 DOCTYPE 声明类似,元素声明必须以感叹号开头。
文档类型声明中的名称必须与根元素的元素类型匹配。
外部 DTD
在外部 DTD 中,元素在 XML 文件之外声明。通过指定系统属性来访问它们,系统属性可以是合法的.dtd 文件或有效的 URL。要将其称为外部 DTD,XML 声明中的`standalone` 属性必须设置为no。这意味着声明包含来自外部源的信息。
语法
以下是外部 DTD 的语法:
<!DOCTYPE root-element SYSTEM "file-name">
其中file-name 是具有.dtd 扩展名的文件。
示例
以下示例显示了外部 DTD 的用法:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?> <!DOCTYPE address SYSTEM "address.dtd"> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
DTD 文件address.dtd 的内容如下所示:
<!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)>
类型
您可以使用系统标识符或公共标识符引用外部 DTD。
系统标识符
系统标识符使您可以指定包含 DTD 声明的外部文件的位置。语法如下:
<!DOCTYPE name SYSTEM "address.dtd" [...]>
如您所见,它包含关键字 SYSTEM 和指向文档位置的 URI 引用。
公共标识符
公共标识符提供了一种查找 DTD 资源的机制,其写法如下:
<!DOCTYPE name PUBLIC "-//Beginning XML//DTD Address Example//EN">
如你所见,它以关键字 PUBLIC 开头,后面跟着一个特殊的标识符。公共标识符用于识别目录中的条目。公共标识符可以遵循任何格式,但是,一种常用的格式称为正式公共标识符 (Formal Public Identifiers, 或 FPI)。
XML - 模式
XML Schema 通常被称为XML 模式定义 (XML Schema Definition, XSD)。它用于描述和验证 XML 数据的结构和内容。XML 模式定义元素、属性和数据类型。模式元素支持命名空间。它类似于描述数据库中数据的数据库模式。
语法
您需要在 XML 文档中声明一个模式,如下所示:
示例
以下示例显示了如何使用模式:
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema">
<xs:element name = "contact">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
<xs:element name = "phone" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
XML 模式背后的基本思想是它们描述了 XML 文档可以采用的合法格式。
元素
正如我们在XML - 元素章节中看到的,元素是 XML 文档的构建块。元素可以在 XSD 中定义如下:
<xs:element name = "x" type = "y"/>
定义类型
您可以通过以下方式定义 XML 模式元素:
简单类型
简单类型元素仅在文本上下文中使用。一些预定义的简单类型包括:xs:integer、xs:boolean、xs:string、xs:date。例如:
<xs:element name = "phone_number" type = "xs:int" />
复杂类型
复杂类型是其他元素定义的容器。这允许您指定元素可以包含哪些子元素,并在 XML 文档中提供一些结构。例如:
<xs:element name = "Address">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
<xs:element name = "phone" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
在上面的例子中,Address 元素包含子元素。这是一个用于其他<xs:element>定义的容器,允许在 XML 文档中构建简单的元素层次结构。
全局类型
使用全局类型,您可以在文档中定义单个类型,所有其他引用都可以使用该类型。例如,假设您想为公司的不同地址概括person和company。在这种情况下,您可以定义一个通用类型,如下所示:
<xs:element name = "AddressType">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
现在让我们在我们的示例中使用此类型,如下所示:
<xs:element name = "Address1">
<xs:complexType>
<xs:sequence>
<xs:element name = "address" type = "AddressType" />
<xs:element name = "phone1" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name = "Address2">
<xs:complexType>
<xs:sequence>
<xs:element name = "address" type = "AddressType" />
<xs:element name = "phone2" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
无需两次定义名称和公司(一次用于Address1,一次用于Address2),我们现在只有一个定义。这使得维护更简单,即,如果您决定向地址添加“邮政编码”元素,您只需要在一个地方添加它们。
属性
XSD 中的属性在元素内提供额外信息。属性具有如下所示的name和type属性:
<xs:attribute name = "x" type = "y"/>
XML - 树状结构
XML 文档始终具有描述性。树状结构通常被称为XML 树,它在轻松描述任何 XML 文档方面起着重要作用。
树状结构包含根(父)元素、子元素等等。通过使用树状结构,您可以从根开始了解所有后续分支和子分支。解析从根开始,然后向下移动到第一个分支的元素,从那里取第一个分支,依此类推,直到叶子节点。
示例
以下示例演示了简单的 XML 树结构:
<?xml version = "1.0"?>
<Company>
<Employee>
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
<Address>
<City>Bangalore</City>
<State>Karnataka</State>
<Zip>560212</Zip>
</Address>
</Employee>
</Company>
以下树结构表示上述 XML 文档:
在上图中,有一个名为<company>的根元素。在里面,还有一个元素<Employee>。在 employee 元素内,有五个分支,名为<FirstName>、<LastName>、<ContactNo>、<Email>和<Address>。在<Address>元素内,有三个子分支,名为<City> <State>和<Zip>。
XML - DOM
文档对象模型 (Document Object Model, DOM)是 XML 的基础。XML 文档具有称为节点的信息单元的层次结构;DOM 是一种描述这些节点及其之间关系的方法。
DOM 文档是按层次结构组织的节点或信息片段的集合。这种层次结构允许开发人员遍历树来查找特定信息。由于它基于信息的层次结构,因此 DOM 被称为基于树的。
另一方面,XML DOM 还提供了一个 API,允许开发人员在树中的任何点添加、编辑、移动或删除节点,以创建应用程序。
示例
以下示例 (sample.htm) 将 XML 文档 (“address.xml”) 解析为 XML DOM 对象,然后使用 JavaScript 从中提取一些信息:
<!DOCTYPE html>
<html>
<body>
<h1>TutorialsPoint DOM example </h1>
<div>
<b>Name:</b> <span id = "name"></span><br>
<b>Company:</b> <span id = "company"></span><br>
<b>Phone:</b> <span id = "phone"></span>
</div>
<script>
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/xml/address.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("name").innerHTML=
xmlDoc.getElementsByTagName("name")[0].childNodes[0].nodeValue;
document.getElementById("company").innerHTML=
xmlDoc.getElementsByTagName("company")[0].childNodes[0].nodeValue;
document.getElementById("phone").innerHTML=
xmlDoc.getElementsByTagName("phone")[0].childNodes[0].nodeValue;
</script>
</body>
</html>
address.xml的内容如下:
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
现在让我们将这两个文件sample.htm和address.xml放在同一个目录/xml中,并通过在任何浏览器中打开它来执行sample.htm文件。这应该产生以下输出。

在这里,您可以看到如何提取每个子节点以显示其值。
XML - 命名空间
命名空间是一组唯一的名称。命名空间是一种机制,通过它可以将元素和属性名称分配给一个组。命名空间由 URI(统一资源标识符)标识。
命名空间声明
命名空间使用保留属性声明。这样的属性名称必须是xmlns或以xmlns:开头,如下所示:
<element xmlns:name = "URL">
语法
命名空间以关键字xmlns开头。
单词name是命名空间前缀。
URL是命名空间标识符。
示例
命名空间只影响文档中的有限区域。包含声明的元素及其所有后代都在命名空间的范围内。以下是一个简单的 XML 命名空间示例:
<?xml version = "1.0" encoding = "UTF-8"?> <cont:contact xmlns:cont = "www.tutorialspoint.com/profile"> <cont:name>Tanmay Patil</cont:name> <cont:company>TutorialsPoint</cont:company> <cont:phone>(011) 123-4567</cont:phone> </cont:contact>
这里,命名空间前缀是cont,命名空间标识符 (URI) 为www.tutorialspoint.com/profile。这意味着,带有cont前缀的元素名称和属性名称(包括 contact 元素),都属于www.tutorialspoint.com/profile命名空间。
XML - 数据库
XML 数据库用于以 XML 格式存储大量信息。随着 XML 在各个领域的应用越来越广泛,需要一个安全的地方来存储 XML 文档。数据库中存储的数据可以使用XQuery查询、序列化并导出为所需的格式。
XML 数据库类型
XML 数据库主要有两种类型:
- 支持 XML 的
- 原生 XML (NXD)
支持 XML 的数据库
支持 XML 的数据库只不过是为转换 XML 文档而提供的扩展。这是一个关系数据库,其中数据存储在由行和列组成的表中。表包含一组记录,这些记录又包含字段。
原生 XML 数据库
原生 XML 数据库基于容器而不是表格式。它可以存储大量的 XML 文档和数据。原生 XML 数据库由XPath表达式查询。
原生 XML 数据库优于支持 XML 的数据库。与支持 XML 的数据库相比,它在存储、查询和维护 XML 文档方面具有更高的能力。
示例
以下示例演示了 XML 数据库:
<?xml version = "1.0"?>
<contact-info>
<contact1>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact1>
<contact2>
<name>Manisha Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 789-4567</phone>
</contact2>
</contact-info>
在这里,创建了一个联系人表,其中包含联系人的记录(contact1 和 contact2),这些记录又包含三个实体:name、company和phone。
XML - 查看器
本章介绍了查看 XML 文档的各种方法。可以使用简单的文本编辑器或任何浏览器来查看 XML 文档。大多数主要的浏览器都支持 XML。可以通过双击 XML 文档(如果它是本地文件)或在地址栏中键入 URL 路径(如果文件位于服务器上)在浏览器中打开 XML 文件,就像我们在浏览器中打开其他文件一样。XML 文件以“.xml”扩展名保存。
让我们探索可以查看 XML 文件的各种方法。以下示例 (sample.xml) 用于查看本章的所有部分。
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
文本编辑器
任何简单的文本编辑器,如记事本、TextPad 或 TextEdit,都可以用来创建或查看 XML 文档,如下所示:
Firefox 浏览器
通过双击文件在 Chrome 中打开上述 XML 代码。XML 代码以彩色显示编码,使代码更易于阅读。它在 XML 元素左侧显示加号 (+) 或减号 (-)。当我们单击减号 (-) 时,代码会隐藏。当我们单击加号 (+) 时,代码行会展开。Firefox 中的输出如下所示:

Chrome 浏览器
在 Chrome 浏览器中打开上述 XML 代码。代码显示如下:

XML 文档中的错误
如果您的 XML 代码缺少某些标记,则浏览器中会显示一条消息。让我们尝试在 Chrome 中打开以下 XML 文件:
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
在上面的代码中,起始标记和结束标记不匹配(参考 contact_info 标记),因此浏览器会显示错误消息,如下所示:
XML - 编辑器
XML 编辑器是一种标记语言编辑器。可以使用现有的编辑器(例如记事本、WordPad 或任何类似的文本编辑器)来编辑或创建 XML 文档。您还可以在线或下载专业 XML 编辑器,它具有更强大的编辑功能,例如:
- 它会自动关闭未关闭的标记。
- 它严格检查语法。
- 它以彩色突出显示 XML 语法,以提高可读性。
- 它可以帮助您编写有效的 XML 代码。
- 它提供针对 DTD 和模式的 XML 文档的自动验证。
开源 XML 编辑器
以下是一些开源 XML 编辑器:
在线 XML 编辑器 - 这是一款轻量级的 XML 编辑器,您可以在线使用。
Xerlin - Xerlin 是一个针对 Java 2 平台的开源 XML 编辑器,在 Apache 许可下发布。它是一个基于 Java 的 XML 建模应用程序,可以轻松创建和编辑 XML 文件。
CAM - 内容组装机制 (CAM - Content Assembly Mechanism) - CAM XML 编辑器工具带有 Oracle 赞助的 XML+JSON+SQL Open-XDX。
XML - 解析器
XML 解析器是一个软件库或包,它为客户端应用程序提供与 XML 文档交互的接口。它检查 XML 文档的格式是否正确,也可能验证 XML 文档。现代浏览器具有内置的 XML 解析器。
下图显示了 XML 解析器如何与 XML 文档交互:
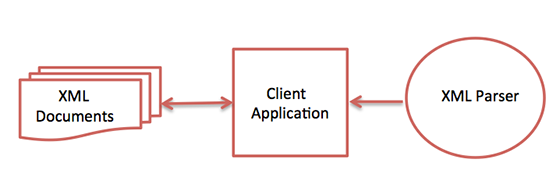
解析器的目标是将 XML 转换为可读的代码。
为了简化解析过程,有一些商业产品可以促进 XML 文档的分解并产生更可靠的结果。
一些常用的解析器如下所示:
MSXML (Microsoft Core XML Services) - 这是 Microsoft 提供的一套标准 XML 工具,其中包括一个解析器。
System.Xml.XmlDocument - 此类是 .NET 库的一部分,其中包含许多与使用 XML 相关的不同类。
Java 内置解析器 - Java 库有自己的解析器。该库的设计使得您可以用外部实现(例如 Apache 的 Xerces 或 Saxon)替换内置解析器。
Saxon - Saxon 提供用于解析、转换和查询 XML 的工具。
Xerces - Xerces 使用 Java 实现,由著名的开源 Apache 软件基金会开发。
XML - 处理器
当软件程序读取 XML 文档并相应地采取行动时,这称为处理XML。任何可以读取和处理 XML 文档的程序都称为XML 处理器。XML 处理器读取 XML 文件并将其转换为内存中的结构,程序的其余部分可以访问这些结构。
最基本的 XML 处理器读取 XML 文档并将其转换为内部表示,供其他程序或子程序使用。这称为解析器,它是每个 XML 处理程序的重要组成部分。
处理器涉及处理指令,这可以在处理指令章节中学习。
类型
XML 处理器分为验证型或非验证型,这取决于它们是否检查 XML 文档的有效性。发现有效性错误的处理器必须能够报告它,但可以继续进行正常的处理。
一些验证解析器包括 − xml4c(IBM,C++编写),xml4j(IBM,Java编写),MSXML(微软,Java编写),TclXML(TCL),xmlproc(Python),XML::Parser(Perl),Java Project X(Sun,Java编写)。
一些非验证解析器包括 − OpenXML(Java),Lark(Java),xp(Java),AElfred(Java),expat(C),XParse(JavaScript),xmllib(Python)。