- ZooKeeper 教程
- ZooKeeper – 首页
- ZooKeeper – 概述
- ZooKeeper - 基础知识
- ZooKeeper – 工作流程
- ZooKeeper – Leader 选举
- ZooKeeper – 安装
- ZooKeeper – CLI
- ZooKeeper – API
- ZooKeeper – 应用
- ZooKeeper 有用资源
- ZooKeeper – 快速指南
- ZooKeeper – 有用资源
- ZooKeeper – 讨论
ZooKeeper 快速指南
ZooKeeper - 概述
ZooKeeper 是一种分布式协调服务,用于管理大量主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper 通过其简单的架构和 API 解决了这个问题。ZooKeeper 允许开发人员专注于核心应用程序逻辑,而无需担心应用程序的分布式特性。
ZooKeeper 框架最初是在“雅虎!”构建的,用于以简单而可靠的方式访问其应用程序。后来,Apache ZooKeeper 成为 Hadoop、HBase 和其他分布式框架使用的标准化服务。例如,Apache HBase 使用 ZooKeeper 来跟踪分布式数据的状态。
在继续之前,了解一些关于分布式应用程序的信息非常重要。因此,让我们从分布式应用程序的快速概述开始讨论。
分布式应用程序
分布式应用程序可以在网络中的多个系统上同时运行,通过相互协调以快速有效的方式完成特定任务。通常,复杂且耗时的任务(非分布式应用程序(在单个系统中运行)可能需要数小时才能完成)可以通过分布式应用程序在几分钟内完成,因为它利用了所有参与系统的计算能力。
通过将分布式应用程序配置为在更多系统上运行,可以进一步减少完成任务的时间。运行分布式应用程序的一组系统称为**集群**,集群中运行的每台机器称为**节点**。
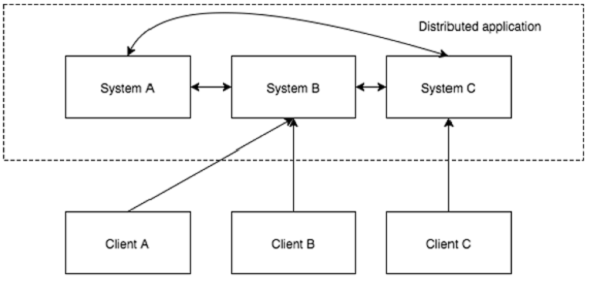
分布式应用程序有两个部分:**服务器**和**客户端**应用程序。服务器应用程序实际上是分布式的,并且具有公共接口,以便客户端可以连接到集群中的任何服务器并获得相同的结果。客户端应用程序是与分布式应用程序交互的工具。
分布式应用程序的优势
**可靠性** - 单个或少数几个系统的故障不会导致整个系统故障。
**可扩展性** - 可以根据需要通过添加更多机器来提高性能,只需对应用程序进行少量配置更改,并且无需停机。
**透明性** - 隐藏系统的复杂性,并显示为单个实体/应用程序。
分布式应用程序的挑战
**竞争条件** - 两台或多台机器尝试执行特定任务,而该任务实际上在任何给定时间只能由一台机器执行。例如,共享资源在任何给定时间只能由一台机器修改。
**死锁** - 两台或多台操作无限期地等待彼此完成。
**不一致性** - 数据的部分故障。
Apache ZooKeeper 的用途是什么?
Apache ZooKeeper 是一种由集群(节点组)使用的服务,用于在它们之间进行协调并使用强大的同步技术维护共享数据。ZooKeeper 本身就是一个分布式应用程序,提供编写分布式应用程序的服务。
ZooKeeper 提供的常见服务如下:
**命名服务** - 通过名称识别集群中的节点。它类似于 DNS,但用于节点。
**配置管理** - 为加入的节点提供系统最新和最新的配置信息。
**集群管理** - 节点加入/离开集群以及实时节点状态。
**Leader 选举** - 选举一个节点作为协调目的的领导者。
**锁定和同步服务** - 在修改数据时锁定数据。此机制有助于在连接其他分布式应用程序(如 Apache HBase)时实现自动故障恢复。
**高可靠性数据注册表** - 即使一个或几个节点出现故障,也能保证数据的可用性。
分布式应用程序提供了许多好处,但也带来了一些复杂且难以解决的挑战。ZooKeeper 框架提供了一种完整的机制来克服所有这些挑战。竞争条件和死锁使用**故障安全同步方法**处理。另一个主要缺点是不一致的数据,ZooKeeper 通过**原子性**解决了这个问题。
ZooKeeper 的优势
以下是使用 ZooKeeper 的优势:
简单的分布式协调过程
**同步** - 服务器进程之间的互斥和协作。此过程有助于 Apache HBase 进行配置管理。
有序消息
**序列化** - 根据特定规则编码数据。确保您的应用程序一致运行。此方法可用于 MapReduce 协调队列以执行正在运行的线程。
可靠性
**原子性** - 数据传输要么完全成功,要么完全失败,但没有部分事务。
ZooKeeper - 基础知识
在深入研究 ZooKeeper 的工作原理之前,让我们先了解一下 ZooKeeper 的基本概念。我们将在本章中讨论以下主题:
- 架构
- 分层命名空间
- 会话
- 监视器
ZooKeeper 的架构
请查看下图。它描述了 ZooKeeper 的“客户端-服务器架构”。
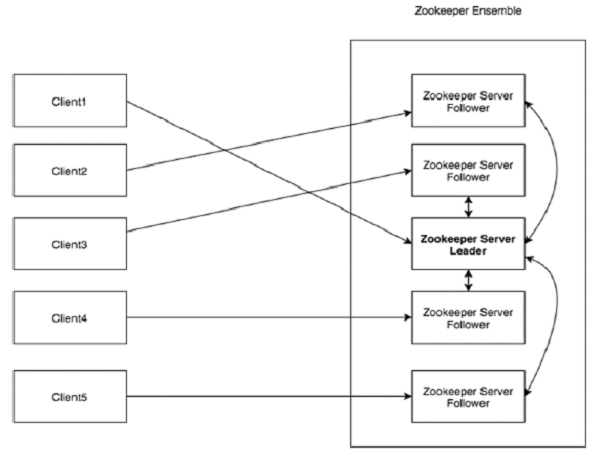
ZooKeeper 架构中每个组件都在下表中进行了说明。
| 部分 | 描述 |
|---|---|
| 客户端 | 客户端(我们分布式应用程序集群中的节点之一)从服务器访问信息。在特定时间间隔内,每个客户端都会向服务器发送一条消息,以告知服务器客户端处于活动状态。 同样,服务器在客户端连接时会发送确认。如果从连接的服务器没有响应,客户端会自动将消息重定向到另一个服务器。 |
| 服务器 | 服务器(我们 ZooKeeper 集群中的节点之一)为客户端提供所有服务。向客户端发送确认以告知服务器处于活动状态。 |
| 集群 | ZooKeeper 服务器组。形成集群所需的最小节点数为 3。 |
| 领导者 | 服务器节点,如果任何连接的节点发生故障,则执行自动恢复。领导者在服务启动时选举产生。 |
| 跟随者 | 遵循领导者指令的服务器节点。 |
分层命名空间
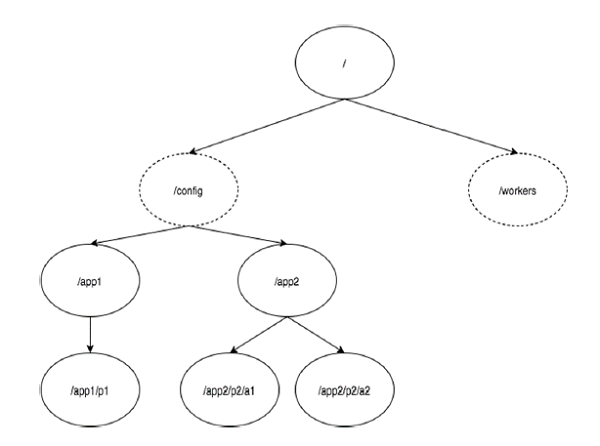
下图描述了用于内存表示的 ZooKeeper 文件系统的树结构。ZooKeeper 节点称为**znode**。每个 znode 都由一个名称标识,并由路径序列(/)分隔。
在图中,首先有一个根**znode**,由“/”分隔。在根目录下,有两个逻辑命名空间**config**和**workers**。
**config**命名空间用于集中式配置管理,而**workers**命名空间用于命名。
在**config**命名空间下,每个 znode 可以存储最多 1MB 的数据。这类似于 UNIX 文件系统,只是父 znode 也可以存储数据。此结构的主要目的是存储同步数据并描述 znode 的元数据。此结构称为**ZooKeeper 数据模型**。
ZooKeeper 数据模型中的每个 znode 都维护一个**stat**结构。stat 简单地提供 znode 的**元数据**。它包括*版本号、访问控制列表 (ACL)、时间戳和数据长度*。
**版本号** - 每个 znode 都有一个版本号,这意味着每次与 znode 关联的数据发生更改时,其相应的版本号也会增加。当多个 Zookeeper 客户端尝试对同一个 znode 执行操作时,版本号的使用非常重要。
**访问控制列表 (ACL)** - ACL 基本上是访问 znode 的身份验证机制。它控制所有 znode 的读写操作。
**时间戳** - 时间戳表示从 znode 创建和修改开始经过的时间。通常以毫秒表示。ZooKeeper 通过“事务 ID”(zxid)识别对 znode 的每次更改。**Zxid** 是唯一的,并为每个事务维护时间,以便您可以轻松识别从一个请求到另一个请求经过的时间。
**数据长度** - 存储在 znode 中的数据总量就是数据长度。您可以存储最多 1MB 的数据。
Znode 的类型
Znode 分为持久性、顺序和临时性。
**持久性 znode** - 即使创建该特定 znode 的客户端断开连接,持久性 znode 也仍然存在。默认情况下,所有 znode 都是持久性的,除非另有指定。
**临时 znode** - 临时 znode 在客户端处于活动状态时处于活动状态。当客户端与 ZooKeeper 集群断开连接时,临时 znode 会自动删除。因此,仅临时 znode 不允许有子节点。如果临时 znode 被删除,则下一个合适的节点将填充其位置。临时 znode 在 Leader 选举中起着重要作用。
**顺序 znode** - 顺序 znode 可以是持久性的或临时性的。当创建一个新的 znode 作为顺序 znode 时,ZooKeeper 会通过在原始名称后附加一个 10 位序列号来设置 znode 的路径。例如,如果一个路径为** /myapp**的 znode 被创建为顺序 znode,ZooKeeper 将路径更改为** /myapp0000000001**并将下一个序列号设置为 0000000002。如果同时创建两个顺序 znode,则 ZooKeeper 永远不会对每个 znode 使用相同的数字。顺序 znode 在锁定和同步中起着重要作用。
会话
会话对于 ZooKeeper 的操作非常重要。会话中的请求按 FIFO 顺序执行。客户端连接到服务器后,将建立会话并为客户端分配一个**会话 ID**。
客户端以特定时间间隔发送**心跳**以保持会话有效。如果 ZooKeeper 集群在服务启动时指定的时间段(会话超时)内未收到客户端的心跳,则它会认为客户端已死。
会话超时通常以毫秒表示。无论出于何种原因,会话结束时,在该会话期间创建的临时 znode 也会被删除。
监视器
监视器是客户端获取 ZooKeeper 集群更改通知的简单机制。客户端在读取特定 znode 时可以设置监视器。监视器会为任何 znode(客户端在其中注册)更改向注册的客户端发送通知。
Znode 的更改是指与 znode 关联的数据的修改或 znode 子节点的更改。Watch 只触发一次。如果客户端想要再次收到通知,则必须通过另一个读取操作来实现。当连接会话过期时,客户端将与服务器断开连接,并且关联的 watch 也会被移除。
Zookeeper - 工作流程
ZooKeeper 集群启动后,将等待客户端连接。客户端将连接到 ZooKeeper 集群中的一个节点。它可能是一个领导者节点或一个跟随者节点。客户端连接后,节点会为该特定客户端分配一个会话 ID 并向客户端发送确认消息。如果客户端没有收到确认消息,它会简单地尝试连接 ZooKeeper 集群中的另一个节点。连接到节点后,客户端将以固定的时间间隔向节点发送心跳,以确保连接不会丢失。
如果客户端想要读取特定的 znode,它会向节点发送一个包含 znode 路径的读取请求,节点会从自己的数据库中获取请求的 znode 并将其返回。因此,ZooKeeper 集群中的读取操作非常快。
如果客户端想要将数据存储到 ZooKeeper 集群中,它会将 znode 路径和数据发送到服务器。连接的服务器会将请求转发到领导者节点,然后领导者节点会向所有跟随者节点重新发布写入请求。只有当大多数节点成功响应时,写入请求才会成功,并且会向客户端发送成功返回代码。否则,写入请求将失败。节点的严格多数被称为Quorum(仲裁)。
ZooKeeper 集群中的节点
让我们分析一下在 ZooKeeper 集群中使用不同数量的节点的影响。
如果我们只有一个节点,那么当该节点发生故障时,ZooKeeper 集群就会失效。这会导致“单点故障”,在生产环境中不建议使用。
如果我们有两个节点,并且一个节点发生故障,我们也没有多数,因为两个节点中只有一个节点不足以构成多数。
如果我们有三个节点,并且一个节点发生故障,我们仍然有多数,因此这是最低要求。在实际生产环境中,ZooKeeper 集群必须至少有三个节点。
如果我们有四个节点,并且两个节点发生故障,它也会失效,这与只有三个节点的情况类似。额外的节点没有任何作用,因此最好以奇数添加节点,例如 3、5、7。
我们知道,在 ZooKeeper 集群中,写入过程比读取过程开销更大,因为所有节点都需要将其数据库中的数据写入相同的数据。因此,为了保持环境的平衡,最好使用较少的节点(3、5 或 7),而不是使用大量的节点。
下图描述了 ZooKeeper 的工作流程,后续表格解释了其不同的组件。
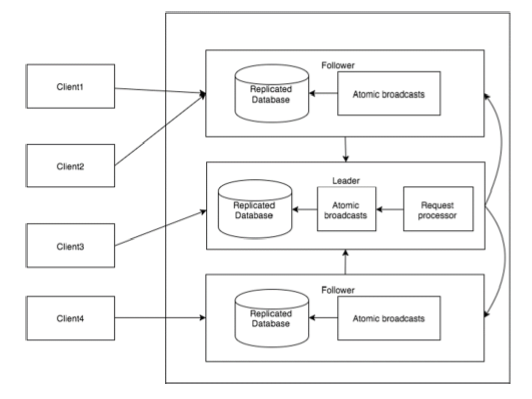
| 组件 | 描述 |
|---|---|
| 写入 | 写入过程由领导者节点处理。领导者节点将写入请求转发到所有 znode 并等待来自 znode 的响应。如果一半的 znode 回复,则写入过程完成。 |
| 读取 | 读取操作由特定的连接 znode 内部执行,因此无需与集群交互。 |
| 复制数据库 | 它用于在 Zookeeper 中存储数据。每个 znode 都有自己的数据库,并且在一致性的帮助下,每个 znode 在任何时间都具有相同的数据。 |
| 领导者 | 领导者是负责处理写入请求的 Znode。 |
| 跟随者 | 跟随者从客户端接收写入请求并将其转发到领导者 znode。 |
| 请求处理器 | 仅存在于领导者节点中。它管理来自跟随者节点的写入请求。 |
| 原子广播 | 负责将更改从领导者节点广播到跟随者节点。 |
Zookeeper - 领导者选举
让我们分析一下如何在 ZooKeeper 集群中选举领导者节点。假设集群中有N个节点。领导者选举过程如下:
所有节点都创建一个具有相同路径的顺序、短暂的 znode,/app/leader_election/guid_。
ZooKeeper 集群会将 10 位序列号附加到路径中,创建的 znode 将是/app/leader_election/guid_0000000001、/app/leader_election/guid_0000000002等。
对于给定的实例,在 znode 中创建最小数字的节点成为领导者,所有其他节点都是跟随者。
每个跟随者节点都监视具有下一个最小数字的 znode。例如,创建 znode /app/leader_election/guid_0000000008 的节点将监视 znode /app/leader_election/guid_0000000007,而创建 znode /app/leader_election/guid_0000000007 的节点将监视 znode /app/leader_election/guid_0000000006。
如果领导者节点宕机,则其对应的 znode /app/leader_electionN 将被删除。
排在后面的跟随者节点将通过监视器收到关于领导者移除的通知。
排在后面的跟随者节点将检查是否还有其他 znode 具有最小数字。如果没有,则它将承担领导者的角色。否则,它会找到创建具有最小数字的 znode 的节点作为领导者。
类似地,所有其他跟随者节点都会选举创建具有最小数字的 znode 的节点作为领导者。
从头开始进行领导者选举是一个复杂的过程。但是 ZooKeeper 服务使它变得非常简单。在下一章中,我们将继续介绍 ZooKeeper 的安装,以便用于开发目的。
Zookeeper - 安装
在安装 ZooKeeper 之前,请确保您的系统正在运行以下任何操作系统:
任何 Linux 操作系统 - 支持开发和部署。它适合于演示应用程序。
Windows 操作系统 - 只支持开发。
Mac OS - 只支持开发。
ZooKeeper 服务器是用 Java 创建的,它运行在 JVM 上。您需要使用 JDK 6 或更高版本。
现在,请按照以下步骤在您的机器上安装 ZooKeeper 框架。
步骤 1:验证 Java 安装
我们相信您已经在系统上安装了 Java 环境。只需使用以下命令验证它即可。
$ java -version
如果您的机器上安装了 Java,则可以看到已安装 Java 的版本。否则,请按照以下简单步骤安装最新版本的 Java。
步骤 1.1:下载 JDK
访问以下链接下载最新版本的 JDK,并下载最新版本。Java
最新版本(编写本教程时)是 JDK 8u 60,文件名为“jdk-8u60-linuxx64.tar.gz”。请将文件下载到您的机器上。
步骤 1.2:解压缩文件
通常,文件会被下载到downloads文件夹中。验证它并使用以下命令解压缩 tar 设置。
$ cd /go/to/download/path $ tar -zxf jdk-8u60-linux-x64.gz
步骤 1.3:移动到 opt 目录
为了使所有用户都能使用 Java,请将解压缩的 Java 内容移动到“/usr/local/java”文件夹。
$ su password: (type password of root user) $ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/
步骤 1.4:设置路径
要设置路径和 JAVA_HOME 变量,请将以下命令添加到 ~/.bashrc 文件中。
export JAVA_HOME = /usr/jdk/jdk-1.8.0_60 export PATH=$PATH:$JAVA_HOME/bin
现在,将所有更改应用到当前正在运行的系统中。
$ source ~/.bashrc
步骤 1.5:Java 备选方案
使用以下命令更改 Java 备选方案。
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100
步骤 1.6
使用步骤 1 中说明的验证命令(java -version)验证 Java 安装。
步骤 2:ZooKeeper 框架安装
步骤 2.1:下载 ZooKeeper
要在您的机器上安装 ZooKeeper 框架,请访问以下链接并下载最新版本的 ZooKeeper。https://zookeeper.net.cn/releases.html
截至目前,ZooKeeper 的最新版本是 3.4.6 (ZooKeeper-3.4.6.tar.gz)。
步骤 2.2:解压缩 tar 文件
使用以下命令解压缩 tar 文件:
$ cd opt/ $ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6 $ mkdir data
步骤 2.3:创建配置文件
使用命令vi conf/zoo.cfg打开名为conf/zoo.cfg的配置文件,并将所有以下参数设置为起点。
$ vi conf/zoo.cfg tickTime = 2000 dataDir = /path/to/zookeeper/data clientPort = 2181 initLimit = 5 syncLimit = 2
配置文件保存成功后,再次返回终端。现在可以启动 Zookeeper 服务器了。
步骤 2.4:启动 ZooKeeper 服务器
执行以下命令:
$ bin/zkServer.sh start
执行此命令后,您将收到如下响应:
$ JMX enabled by default $ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTED
步骤 2.5:启动 CLI
键入以下命令:
$ bin/zkCli.sh
键入上述命令后,您将连接到 ZooKeeper 服务器,并且应该收到以下响应。
Connecting to localhost:2181 ................ ................ ................ Welcome to ZooKeeper! ................ ................ WATCHER:: WatchedEvent state:SyncConnected type: None path:null [zk: localhost:2181(CONNECTED) 0]
停止 ZooKeeper 服务器
连接服务器并执行所有操作后,可以使用以下命令停止 Zookeeper 服务器。
$ bin/zkServer.sh stop
Zookeeper - CLI
ZooKeeper 命令行界面 (CLI) 用于与 ZooKeeper 集群交互以进行开发。它有助于调试和处理不同的选项。
要执行 ZooKeeper CLI 操作,首先打开 ZooKeeper 服务器(“bin/zkServer.sh start”),然后打开 ZooKeeper 客户端(“bin/zkCli.sh”)。客户端启动后,您可以执行以下操作:
- 创建 znode
- 获取数据
- 监视 znode 的更改
- 设置数据
- 创建 znode 的子节点
- 列出 znode 的子节点
- 检查状态
- 移除/删除 znode
现在让我们逐一查看以上命令并举例说明。
创建 Znode
使用给定的路径创建一个 znode。flag参数指定创建的 znode 是否是短暂的、持久的或顺序的。默认情况下,所有 znode 都是持久的。
短暂的 znode(flag:e)会在会话过期或客户端断开连接时自动删除。
顺序的 znode保证 znode 路径是唯一的。
ZooKeeper 集群会在 znode 路径后面添加序列号,并使用 10 位数字进行填充。例如,znode 路径/myapp 会转换为 /myapp0000000001,下一个序列号将是/myapp0000000002。如果未指定任何标志,则 znode 被视为持久性的。
语法
create /path /data
示例
create /FirstZnode “Myfirstzookeeper-app”
输出
[zk: localhost:2181(CONNECTED) 0] create /FirstZnode “Myfirstzookeeper-app” Created /FirstZnode
要创建顺序 znode,请添加-s 标志,如下所示。
语法
create -s /path /data
示例
create -s /FirstZnode second-data
输出
[zk: localhost:2181(CONNECTED) 2] create -s /FirstZnode “second-data” Created /FirstZnode0000000023
要创建临时 Znode,请添加-e 标志,如下所示。
语法
create -e /path /data
示例
create -e /SecondZnode “Ephemeral-data”
输出
[zk: localhost:2181(CONNECTED) 2] create -e /SecondZnode “Ephemeral-data” Created /SecondZnode
请记住,当客户端连接丢失时,临时 znode 将被删除。您可以尝试退出 ZooKeeper CLI,然后重新打开 CLI。
获取数据
它返回 znode 的关联数据和指定 znode 的元数据。您将获得有关数据上次修改时间、修改位置以及数据信息等信息。此 CLI 也用于分配监视器以显示有关数据的通知。
语法
get /path
示例
get /FirstZnode
输出
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode “Myfirstzookeeper-app” cZxid = 0x7f ctime = Tue Sep 29 16:15:47 IST 2015 mZxid = 0x7f mtime = Tue Sep 29 16:15:47 IST 2015 pZxid = 0x7f cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 22 numChildren = 0
要访问顺序 znode,您必须输入 znode 的完整路径。
示例
get /FirstZnode0000000023
输出
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode0000000023 “Second-data” cZxid = 0x80 ctime = Tue Sep 29 16:25:47 IST 2015 mZxid = 0x80 mtime = Tue Sep 29 16:25:47 IST 2015 pZxid = 0x80 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 13 numChildren = 0
监视
监视在指定 znode 或 znode 的子节点数据更改时显示通知。您只能在get命令中设置监视。
语法
get /path [watch] 1
示例
get /FirstZnode 1
输出
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode 1 “Myfirstzookeeper-app” cZxid = 0x7f ctime = Tue Sep 29 16:15:47 IST 2015 mZxid = 0x7f mtime = Tue Sep 29 16:15:47 IST 2015 pZxid = 0x7f cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 22 numChildren = 0
输出类似于普通的get命令,但它将在后台等待 znode 更改。<从这里开始>
设置数据
设置指定 znode 的数据。完成此设置操作后,您可以使用get CLI 命令检查数据。
语法
set /path /data
示例
set /SecondZnode Data-updated
输出
[zk: localhost:2181(CONNECTED) 1] get /SecondZnode “Data-updated” cZxid = 0x82 ctime = Tue Sep 29 16:29:50 IST 2015 mZxid = 0x83 mtime = Tue Sep 29 16:29:50 IST 2015 pZxid = 0x82 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x15018b47db00000 dataLength = 14 numChildren = 0
如果您在get命令中分配了监视选项(如上一个命令),则输出将类似于以下所示:
输出
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode “Mysecondzookeeper-app” WATCHER: : WatchedEvent state:SyncConnected type:NodeDataChanged path:/FirstZnode cZxid = 0x7f ctime = Tue Sep 29 16:15:47 IST 2015 mZxid = 0x84 mtime = Tue Sep 29 17:14:47 IST 2015 pZxid = 0x7f cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 23 numChildren = 0
创建子节点/子 znode
创建子节点类似于创建新的 znode。唯一的区别是子 znode 的路径也将包含父路径。
语法
create /parent/path/subnode/path /data
示例
create /FirstZnode/Child1 firstchildren
输出
[zk: localhost:2181(CONNECTED) 16] create /FirstZnode/Child1 “firstchildren” created /FirstZnode/Child1 [zk: localhost:2181(CONNECTED) 17] create /FirstZnode/Child2 “secondchildren” created /FirstZnode/Child2
列出子节点
此命令用于列出和显示 znode 的子节点。
语法
ls /path
示例
ls /MyFirstZnode
输出
[zk: localhost:2181(CONNECTED) 2] ls /MyFirstZnode [mysecondsubnode, myfirstsubnode]
检查状态
状态描述指定 znode 的元数据。它包含时间戳、版本号、ACL、数据长度和子 znode 等详细信息。
语法
stat /path
示例
stat /FirstZnode
输出
[zk: localhost:2181(CONNECTED) 1] stat /FirstZnode cZxid = 0x7f ctime = Tue Sep 29 16:15:47 IST 2015 mZxid = 0x7f mtime = Tue Sep 29 17:14:24 IST 2015 pZxid = 0x7f cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 23 numChildren = 0
删除 Znode
删除指定的 znode 及其所有子节点(递归)。只有在存在此类 znode 时才会发生这种情况。
语法
rmr /path
示例
rmr /FirstZnode
输出
[zk: localhost:2181(CONNECTED) 10] rmr /FirstZnode [zk: localhost:2181(CONNECTED) 11] get /FirstZnode Node does not exist: /FirstZnode
delete /path 命令类似于remove命令,不同之处在于它仅适用于没有子节点的 znode。
Zookeeper - API
ZooKeeper 具有针对 Java 和 C 的官方 API 绑定。ZooKeeper 社区为大多数语言(.NET、python 等)提供了非官方 API。使用 ZooKeeper API,应用程序可以连接、交互、操作数据、协调,最后断开与 ZooKeeper 集群的连接。
ZooKeeper API 具有丰富的功能集,可以以简单安全的方式获取 ZooKeeper 集群的所有功能。ZooKeeper API 提供同步和异步方法。
ZooKeeper 集群和 ZooKeeper API 在各个方面完全互补,这对开发人员非常有利。在本章中,我们将讨论 Java 绑定。
ZooKeeper API 基础
与 ZooKeeper 集群交互的应用程序称为ZooKeeper 客户端或简称为客户端。
Znode 是 ZooKeeper 集群的核心组件,ZooKeeper API 提供了一小组方法来操作 znode 与 ZooKeeper 集群的所有详细信息。
客户端应遵循以下步骤,以便与 ZooKeeper 集群进行清晰干净的交互。
连接到 ZooKeeper 集群。ZooKeeper 集群为客户端分配一个会话 ID。
定期向服务器发送心跳。否则,ZooKeeper 集群将使会话 ID 过期,客户端需要重新连接。
只要会话 ID 有效,就可以获取/设置 znode。
完成所有任务后,断开与 ZooKeeper 集群的连接。如果客户端长时间处于非活动状态,则 ZooKeeper 集群将自动断开客户端的连接。
Java 绑定
让我们在本章中了解 ZooKeeper API 中最重要的一组 API。ZooKeeper API 的核心部分是ZooKeeper 类。它提供在构造函数中连接 ZooKeeper 集群的选项,并具有以下方法:
connect - 连接到 ZooKeeper 集群
create - 创建 znode
exists - 检查 znode 是否存在及其信息
getData - 从特定 znode 获取数据
setData - 在特定 znode 中设置数据
getChildren - 获取特定 znode 中可用的所有子节点
delete - 获取特定 znode 及其所有子节点
close - 关闭连接
连接到 ZooKeeper 集群
ZooKeeper 类通过其构造函数提供连接功能。构造函数的签名如下:
ZooKeeper(String connectionString, int sessionTimeout, Watcher watcher)
其中,
connectionString - ZooKeeper 集群主机。
sessionTimeout - 会话超时(毫秒)。
watcher - 实现“Watcher”接口的对象。ZooKeeper 集群通过 watcher 对象返回连接状态。
让我们创建一个新的辅助类ZooKeeperConnection并添加一个方法connect。connect方法创建一个 ZooKeeper 对象,连接到 ZooKeeper 集群,然后返回该对象。
这里CountDownLatch用于停止(等待)主进程,直到客户端与 ZooKeeper 集群连接。
ZooKeeper 集群通过Watcher 回调回复连接状态。一旦客户端与 ZooKeeper 集群连接,Watcher 回调将被调用,并且 Watcher 回调调用CountDownLatch的countDown方法来释放锁,主进程中的await。
以下是连接 ZooKeeper 集群的完整代码。
编码:ZooKeeperConnection.java
// import java classes
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
// import zookeeper classes
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.AsyncCallback.StatCallback;
import org.apache.zookeeper.KeeperException.Code;
import org.apache.zookeeper.data.Stat;
public class ZooKeeperConnection {
// declare zookeeper instance to access ZooKeeper ensemble
private ZooKeeper zoo;
final CountDownLatch connectedSignal = new CountDownLatch(1);
// Method to connect zookeeper ensemble.
public ZooKeeper connect(String host) throws IOException,InterruptedException {
zoo = new ZooKeeper(host,5000,new Watcher() {
public void process(WatchedEvent we) {
if (we.getState() == KeeperState.SyncConnected) {
connectedSignal.countDown();
}
}
});
connectedSignal.await();
return zoo;
}
// Method to disconnect from zookeeper server
public void close() throws InterruptedException {
zoo.close();
}
}
保存上述代码,它将在下一节中用于连接 ZooKeeper 集群。
创建 Znode
ZooKeeper 类提供create 方法在 ZooKeeper 集群中创建新的 znode。create方法的签名如下:
create(String path, byte[] data, List<ACL> acl, CreateMode createMode)
其中,
path - Znode 路径。例如,/myapp1、/myapp2、/myapp1/mydata1、myapp2/mydata1/myanothersubdata
data - 要存储在指定 znode 路径中的数据
acl - 要创建的节点的访问控制列表。ZooKeeper API 提供了一个静态接口ZooDefs.Ids来获取一些基本的 acl 列表。例如,ZooDefs.Ids.OPEN_ACL_UNSAFE 返回开放 znode 的 acl 列表。
createMode - 节点类型,可以是临时、顺序或两者兼而有之。这是一个枚举。
让我们创建一个新的 Java 应用程序来检查 ZooKeeper API 的create功能。创建一个文件ZKCreate.java。在 main 方法中,创建一个类型为ZooKeeperConnection的对象并调用connect方法连接到 ZooKeeper 集群。
connect 方法将返回 ZooKeeper 对象zk。现在,使用自定义path和data调用zk对象的create方法。
创建 znode 的完整程序代码如下:
编码:ZKCreate.java
import java.io.IOException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
public class ZKCreate {
// create static instance for zookeeper class.
private static ZooKeeper zk;
// create static instance for ZooKeeperConnection class.
private static ZooKeeperConnection conn;
// Method to create znode in zookeeper ensemble
public static void create(String path, byte[] data) throws
KeeperException,InterruptedException {
zk.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
public static void main(String[] args) {
// znode path
String path = "/MyFirstZnode"; // Assign path to znode
// data in byte array
byte[] data = "My first zookeeper app”.getBytes(); // Declare data
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
create(path, data); // Create the data to the specified path
conn.close();
} catch (Exception e) {
System.out.println(e.getMessage()); //Catch error message
}
}
}
应用程序编译并执行后,将在 ZooKeeper 集群中创建具有指定数据的 znode。您可以使用 ZooKeeper CLI zkCli.sh进行检查。
cd /path/to/zookeeper bin/zkCli.sh >>> get /MyFirstZnode
Exists – 检查 Znode 的存在性
ZooKeeper 类提供exists 方法来检查 znode 的存在性。如果指定的 znode 存在,则返回 znode 的元数据。exists方法的签名如下:
exists(String path, boolean watcher)
其中,
path - Znode 路径
watcher - 布尔值,用于指定是否监视指定的 znode
让我们创建一个新的 Java 应用程序来检查 ZooKeeper API 的“exists”功能。创建一个文件“ZKExists.java”。在 main 方法中,使用“ZooKeeperConnection”对象创建 ZooKeeper 对象“zk”。然后,使用自定义“path”调用“zk”对象的“exists”方法。完整的列表如下:
编码:ZKExists.java
import java.io.IOException;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKExists {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path, true);
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; // Assign znode to the specified path
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path); // Stat checks the path of the znode
if(stat != null) {
System.out.println("Node exists and the node version is " +
stat.getVersion());
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage()); // Catches error messages
}
}
}
应用程序编译并执行后,您将获得以下输出。
Node exists and the node version is 1.
getData 方法
ZooKeeper 类提供getData方法来获取附加在指定 znode 中的数据及其状态。getData方法的签名如下:
getData(String path, Watcher watcher, Stat stat)
其中,
path - Znode 路径。
watcher - 类型为Watcher的回调函数。当指定 znode 的数据发生变化时,ZooKeeper 集群将通过 Watcher 回调进行通知。这是一次性通知。
stat - 返回 znode 的元数据。
让我们创建一个新的 Java 应用程序来了解 ZooKeeper API 的getData功能。创建一个文件ZKGetData.java。在 main 方法中,使用ZooKeeperConnection对象创建一个 ZooKeeper 对象zk。然后,使用自定义路径调用zk对象的getData方法。
以下是从指定节点获取数据的完整程序代码:
编码:ZKGetData.java
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKGetData {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path,true);
}
public static void main(String[] args) throws InterruptedException, KeeperException {
String path = "/MyFirstZnode";
final CountDownLatch connectedSignal = new CountDownLatch(1);
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path);
if(stat != null) {
byte[] b = zk.getData(path, new Watcher() {
public void process(WatchedEvent we) {
if (we.getType() == Event.EventType.None) {
switch(we.getState()) {
case Expired:
connectedSignal.countDown();
break;
}
} else {
String path = "/MyFirstZnode";
try {
byte[] bn = zk.getData(path,
false, null);
String data = new String(bn,
"UTF-8");
System.out.println(data);
connectedSignal.countDown();
} catch(Exception ex) {
System.out.println(ex.getMessage());
}
}
}
}, null);
String data = new String(b, "UTF-8");
System.out.println(data);
connectedSignal.await();
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}
应用程序编译并执行后,您将获得以下输出
My first zookeeper app
并且应用程序将等待 ZooKeeper 集群的进一步通知。使用 ZooKeeper CLI zkCli.sh更改指定 znode 的数据。
cd /path/to/zookeeper bin/zkCli.sh >>> set /MyFirstZnode Hello
现在,应用程序将打印以下输出并退出。
Hello
setData 方法
ZooKeeper 类提供setData方法来修改附加在指定 znode 中的数据。setData方法的签名如下:
setData(String path, byte[] data, int version)
其中,
path - Znode 路径
data - 要存储在指定 znode 路径中的数据。
version - znode 的当前版本。每当数据发生更改时,ZooKeeper 都会更新 znode 的版本号。
现在让我们创建一个新的 Java 应用程序来了解 ZooKeeper API 的setData功能。创建一个文件ZKSetData.java。在 main 方法中,使用ZooKeeperConnection对象创建一个 ZooKeeper 对象zk。然后,使用指定的路径、新数据和节点版本调用zk对象的setData方法。
以下是修改附加在指定 znode 中的数据的完整程序代码。
代码:ZKSetData.java
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import java.io.IOException;
public class ZKSetData {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to update the data in a znode. Similar to getData but without watcher.
public static void update(String path, byte[] data) throws
KeeperException,InterruptedException {
zk.setData(path, data, zk.exists(path,true).getVersion());
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path= "/MyFirstZnode";
byte[] data = "Success".getBytes(); //Assign data which is to be updated.
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
update(path, data); // Update znode data to the specified path
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}
应用程序编译并执行后,指定 znode 的数据将被更改,可以使用 ZooKeeper CLI zkCli.sh进行检查。
cd /path/to/zookeeper bin/zkCli.sh >>> get /MyFirstZnode
getChildrenMethod
ZooKeeper 类提供getChildren方法来获取特定 znode 的所有子节点。getChildren方法的签名如下:
getChildren(String path, Watcher watcher)
其中,
path - Znode 路径。
watcher - 类型为“Watcher”的回调函数。当指定的 znode 被删除或 znode 下的子节点被创建/删除时,ZooKeeper 集群将发出通知。这是一次性通知。
编码:ZKGetChildren.java
import java.io.IOException;
import java.util.*;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKGetChildren {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path,true);
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; // Assign path to the znode
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path); // Stat checks the path
if(stat!= null) {
//“getChildren” method- get all the children of znode.It has two
args, path and watch
List <String> children = zk.getChildren(path, false);
for(int i = 0; i < children.size(); i++)
System.out.println(children.get(i)); //Print children's
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}
在运行程序之前,让我们使用 ZooKeeper CLI zkCli.sh为/MyFirstZnode创建两个子节点。
cd /path/to/zookeeper bin/zkCli.sh >>> create /MyFirstZnode/myfirstsubnode Hi >>> create /MyFirstZnode/mysecondsubmode Hi
现在,编译并运行程序将输出上面创建的 znode。
myfirstsubnode mysecondsubnode
删除 Znode
ZooKeeper 类提供delete方法来删除指定的 znode。delete方法的签名如下:
delete(String path, int version)
其中,
path - Znode 路径。
version - znode 的当前版本。
让我们创建一个新的 Java 应用程序来了解 ZooKeeper API 的delete功能。创建一个文件ZKDelete.java。在 main 方法中,使用ZooKeeperConnection对象创建一个 ZooKeeper 对象zk。然后,使用指定的path和节点版本调用zk对象的delete方法。
删除 znode 的完整程序代码如下:
编码:ZKDelete.java
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
public class ZKDelete {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static void delete(String path) throws KeeperException,InterruptedException {
zk.delete(path,zk.exists(path,true).getVersion());
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; //Assign path to the znode
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
delete(path); //delete the node with the specified path
} catch(Exception e) {
System.out.println(e.getMessage()); // catches error messages
}
}
}
Zookeeper - 应用
Zookeeper 为分布式环境提供灵活的协调基础架构。ZooKeeper 框架支持当今许多最佳的工业应用。我们将在本章中讨论 ZooKeeper 的一些最著名的应用。
雅虎!
ZooKeeper 框架最初由“雅虎”开发。一个设计良好的分布式应用程序需要满足诸如数据透明性、更好的性能、鲁棒性、集中式配置和协调等需求。因此,他们设计了 ZooKeeper 框架来满足这些需求。
Apache Hadoop
Apache Hadoop 是大数据行业发展背后的驱动力。Hadoop 依靠 ZooKeeper 进行配置管理和协调。让我们通过一个场景来理解 ZooKeeper 在 Hadoop 中的作用。
假设一个**Hadoop 集群**连接了**100 台或更多商品服务器**。因此,需要协调和命名服务。由于涉及大量节点的计算,每个节点都需要彼此同步,知道在哪里访问服务,以及如何配置它们。此时,Hadoop 集群需要跨节点服务。ZooKeeper 提供了**跨节点同步**的功能,并确保 Hadoop 项目中的任务被序列化和同步。
多个 ZooKeeper 服务器支持大型 Hadoop 集群。每个客户端机器都与其中一个 ZooKeeper 服务器通信,以检索和更新其同步信息。一些实时示例如下:
**人类基因组计划** - 人类基因组计划包含数TB的数据。Hadoop MapReduce 框架可用于分析数据集并发现人类发展方面的重要信息。
**医疗保健** - 医院可以存储、检索和分析大量的患者医疗记录,这些记录通常以TB为单位。
Apache HBase
Apache HBase 是一个开源的、分布式的、NoSQL 数据库,用于对大型数据集进行实时读/写访问,并且运行在 HDFS 之上。HBase 遵循**主从架构**,其中 HBase Master 控制所有从节点。从节点被称为**区域服务器**。
HBase 分布式应用程序的安装依赖于正在运行的 ZooKeeper 集群。Apache HBase 使用 ZooKeeper 通过**集中式配置管理**和**分布式互斥**机制来跟踪主节点和区域服务器之间分布式数据的状态。以下是 HBase 的一些用例:
**电信** - 电信行业存储数十亿条移动通话记录(大约 30TB/月),并且实时访问这些通话记录成为一项巨大的任务。HBase 可用于轻松高效地实时处理所有记录。
**社交网络** - 与电信行业类似,Twitter、LinkedIn 和 Facebook 等网站通过用户创建的帖子接收大量数据。HBase 可用于查找最新趋势和其他有趣的信息。
Apache Solr
Apache Solr 是一个用 Java 编写的快速开源搜索平台。它是一个闪电般快速、容错的分布式搜索引擎。它建立在**Lucene**之上,是一个高性能、功能齐全的全文搜索引擎。
Solr 广泛使用 ZooKeeper 的每个功能,例如配置管理、领导者选举、节点管理、数据锁定和同步。
Solr 有两个不同的部分,**索引**和**搜索**。索引是将数据存储在适当格式的过程,以便以后可以搜索。Solr 使用 ZooKeeper 来实现多个节点上的数据索引和多个节点上的搜索。ZooKeeper 提供以下功能:
根据需要添加/删除节点
节点之间的数据复制,从而最大程度地减少数据丢失
多个节点之间共享数据,从而从多个节点搜索以获得更快的搜索结果
Apache Solr 的一些用例包括电子商务、职位搜索等。