
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP实现分布式共享内存的算法
共享内存是指可以被多个程序访问的内存块。共享内存的概念用于提供一种通信方式,并提供更少的冗余内存管理。
分布式共享内存,缩写为DSM,是在分布式系统中实现共享内存概念的方法。DSM 系统在松耦合系统中实现了共享内存模型,这些系统在系统中缺乏本地物理共享内存。在这种类型的系统中,分布式共享内存提供了一个虚拟内存空间,所有系统(也称为节点)都可以访问该空间。
在实现 DSM 时,需要牢记一些常见的挑战:
跟踪存储在共享内存中远程数据的数据地址(位置)。
减少与远程数据引用相关的通信延迟和高开销。
控制在 DSM 中共享数据的并发访问。
基于这些挑战,设计了用于实现分布式共享内存的算法。有四种算法:
- 中央服务器算法
- 迁移算法
- 读取复制算法
- 完全复制算法
中央服务器算法
所有共享数据都由中央服务器维护。分布式系统的其他节点向服务器请求读取和写入数据,服务器处理请求并更新或提供对数据的访问以及确认消息。
这些确认消息用于提供服务器是否已处理数据请求的状态。当数据发送到调用函数时,它会确认一个数字,该数字显示数据的访问顺序以维护并发性。如果发生故障,则返回超时。
对于更大的分布式系统,可能存在多个服务器。在这种情况下,服务器是使用其地址或使用映射函数来定位的。

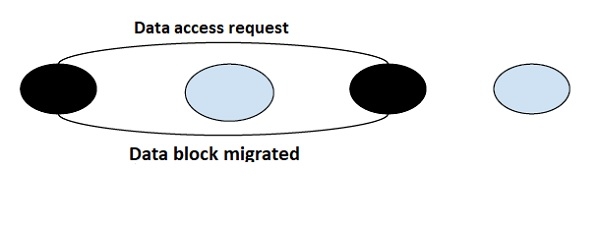
迁移算法
顾名思义,迁移算法的工作是迁移数据元素。与其使用中央服务器处理每个请求,不如将包含系统请求的数据的块迁移到该系统以供进一步访问和处理。它根据请求迁移数据。
尽管此算法在系统多次访问相同数据块并且能够集成虚拟内存概念时效果很好,但它也存在一些需要解决的缺点。
一次只有一个节点能够访问共享数据元素,并且整个块会迁移到该节点。此外,由于根据节点的请求迁移数据项,因此该算法更容易发生抖动。
读取复制算法
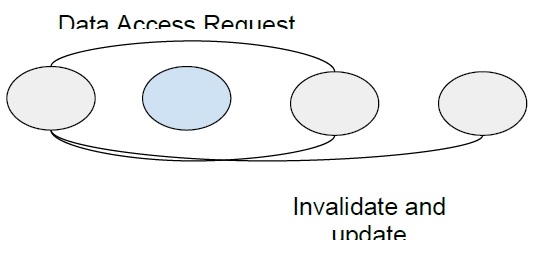
在读取复制算法中,要访问的数据块会被复制,并且在所有副本中只允许读取。如果要执行写操作,则所有读取访问都会暂停,直到所有副本都更新为止。
由于允许并发访问,因此整体系统性能得到提高。但是,由于需要更新所有共享块以维护并发性,因此写操作代价很高。需要跟踪数据元素的所有副本以维护一致性。
完全复制算法
读取复制算法的扩展允许节点在共享块上同时执行读取和写入操作。但是,此节点访问受到控制以维护其一致性。
为了在所有节点的并发访问中维护数据的一致性,会维护顺序,并且在对数据进行任何修改后,都会进行多播,并将修改反映到所有数据副本中。


5K+ 浏览量
