
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Python 分析人口普查数据
人口普查是指以系统的方式记录特定人群的信息。捕获的数据包括各种类别的信息,例如人口统计、经济和居住情况等。这最终有助于政府了解当前情况以及未来的规划。在本文中,我们将了解如何利用 Python 分析印度人口普查数据。我们将研究各种人口统计和经济方面。然后绘制图表,以图形方式展示分析结果。数据来源来自 Kaggle,位于 此处。
组织数据
在下面的程序中,我们首先使用一个简短的 Python 程序获取数据。它只是将数据加载到 Pandas 数据框中以供进一步分析。输出显示了一些字段以进行更简单的表示。
示例
import pandas as pd
datainput = pd.read_csv('E:\india-districts-census-2011.csv')
#https://www.kaggle.com/danofer/india-census#india-districts-census-2011.csv
print(datainput)输出
运行以上代码将得到以下结果:
District code ... Total_Power_Parity 0 1 ... 1119 1 2 ... 1066 2 3 ... 242 3 4 ... 214 4 5 ... 629 .. ... ... ... 635 636 ... 10027 636 637 ... 4890 637 638 ... 3151 638 639 ... 3151 639 640 ... 5782 [640 rows x 118 columns]
分析两个州之间的相似性
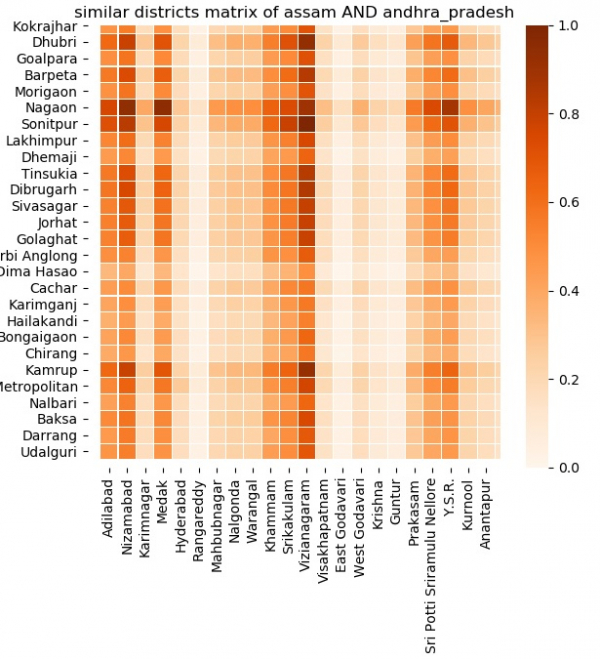
现在我们已经收集了数据,我们可以继续分析两个州在各个方面的相似性。相似性可以基于年龄组、电脑拥有率、住房可用性、教育水平等。在下面的示例中,我们选取了阿萨姆邦和安得拉邦这两个州。然后我们使用 similarity_matrix 比较这两个州。比较了来自这两个州每个可能的区对的所有数据字段。生成的热图表明这两个州的相关程度。阴影越深,相关性越强。
示例
import pandas as pd
import matplotlib.pyplot as plot
from matplotlib.colors import Normalize
import seaborn as sns
import math
datainput = pd.read_csv('E:\india-districts-census-2011.csv')
df_ASSAM = datainput.loc[datainput['State name'] == 'ASSAM']
df_ANDHRA_PRADESH = datainput.loc[datainput['State name'] == 'ANDHRA PRADESH']
def segment(x1, x2):
# Set indices for both the data frames
x1.set_index('District code')
x2.set_index('District code')
# The similarity matrix of size len(x1) X len(x2)
similarity_matrix = []
# Iterate through rows of df1
for r1 in x1.iterrows():
# Create list to hold similarity score of row1 with other rows of x2
y = []
# Iterate through rows of x2
for r2 in x2.iterrows():
# Calculate sum of squared differences
n = 0
for c in list(datainput)[3:]:
maximum_c = max(datainput[c])
minimum_c = min(datainput[c])
n += pow((r1[1][c] - r2[1][c]) / (maximum_c - minimum_c), 2)
# Take sqrt and inverse the result
y.append(1 / math.sqrt(n))
# Append similarity scores
similarity_matrix.append(y)
p = 0
q = 0
r = 0
for m in range(len(similarity_matrix)):
for n in range(len(similarity_matrix[m])):
if (similarity_matrix[m][n] > p):
p = similarity_matrix[m][n]
q = m
r = n
print("%s from ASSAM and %s from ANDHRA PRADESH are most similar" % (x1['District name'].iloc[q],x2['District name'].iloc[r]))
return similarity_matrix
m = segment(df_ASSAM, df_ANDHRA_PRADESH)
normalization=Normalize()
s = plot.axes()
sns.heatmap(normalization(m), xticklabels=df_ANDHRA_PRADESH['District name'],yticklabels=df_ASSAM['District name'],linewidths=0.05,cmap='Oranges').set_title("similar districts matrix of assam AND andhra_pradesh")
plot.rcParams['figure.figsize'] = (20,20)
plot.show()输出
运行以上代码将得到以下结果:
比较特定参数
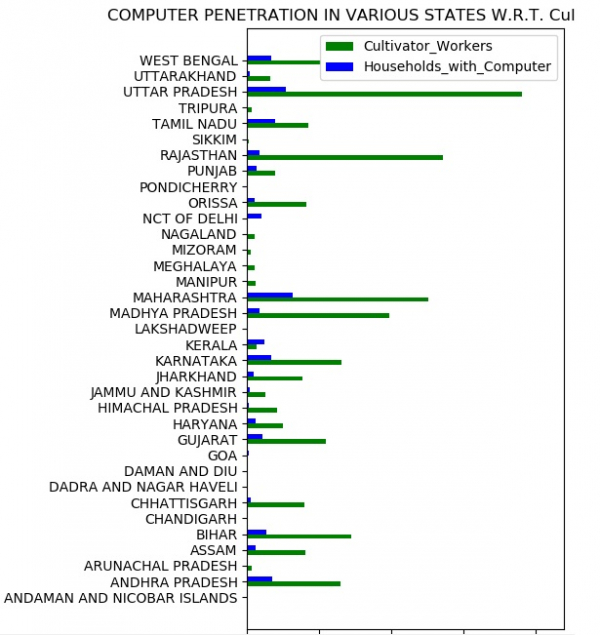
现在我们还可以根据特定参数比较地点。在下面的示例中,我们比较了耕作者使用的家庭电脑的可用性。我们生成图表,显示了这两个参数在每个州的比较情况。
示例
import pandas as pd
import matplotlib.pyplot as plot
from numpy import *
datainput = pd.read_csv('E:\india-districts-census-2011.csv')
z = datainput.groupby(by="State name")
m = []
w = []
for k, g in z:
t = 0
t1 = 0
for r in g.iterrows():
t += r[1][36]
t1 += r[1][21]
m.append((k, t))
w.append((k, t1))
mp= pd.DataFrame({
'state': [x[0] for x in m],
'Households_with_Computer': [x[1] for x in m],
'Cultivator_Workers': [x[1] for x in w]})
d = arange(35)
wi = 0.3
fig, f = plot.subplots()
plot.xlim(0, 22000000)
r1 = f.barh(d, mp['Cultivator_Workers'], wi, color='g', align='center')
r2 = f.barh(d + wi, mp['Households_with_Computer'], wi, color='b', align='center')
f.set_xlabel('Population')
f.set_title('COMPUTER PENETRATION IN VARIOUS STATES W.R.T. Cultivator_Workers')
f.set_yticks(d + wi / 2)
f.set_yticklabels((x for x in mp['state']))
f.legend((r1[0], r2[0]), ('Cultivator_Workers', 'Households_with_Computer'))
plot.rcParams.update({'font.size': 15})
plot.rcParams['figure.figsize'] = (15, 15)
plot.show()输出
运行以上代码将得到以下结果:

更新时间: 2020年2月4日
618 次查看

广告