- Apache Tajo 教程
- Apache Tajo - 首页
- Apache Tajo - 简介
- Apache Tajo - 架构
- Apache Tajo - 安装
- Apache Tajo - 配置设置
- Apache Tajo - Shell 命令
- Apache Tajo - 数据类型
- Apache Tajo - 运算符
- Apache Tajo - SQL 函数
- Apache Tajo - 数学函数
- Apache Tajo - 字符串函数
- Apache Tajo - 日期时间函数
- Apache Tajo - JSON 函数
- Apache Tajo - 数据库创建
- Apache Tajo - 表管理
- Apache Tajo - SQL 语句
- 聚合与窗口函数
- Apache Tajo - SQL 查询
- Apache Tajo - 存储插件
- 与 HBase 集成
- Apache Tajo - 与 Hive 集成
- OpenStack Swift 集成
- Apache Tajo - JDBC 接口
- Apache Tajo - 自定义函数
- Apache Tajo 有用资源
- Apache Tajo - 快速指南
- Apache Tajo - 有用资源
- Apache Tajo - 讨论
Apache Tajo - 架构
下图描述了 Apache Tajo 的架构。
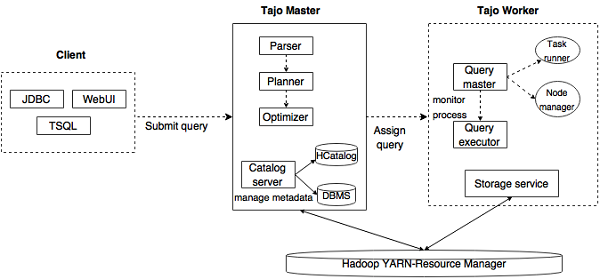
下表详细描述了每个组件。
| 序号 | 组件及描述 |
|---|---|
| 1 | 客户端 客户端向 Tajo Master 提交 SQL 语句以获取结果。 |
| 2 | Master Master 是主守护进程。它负责查询规划,并且是 worker 的协调器。 |
| 3 | 元数据服务器 维护表和索引描述。它嵌入在 Master 守护进程中。元数据服务器使用 Apache Derby 作为存储层,并通过 JDBC 客户端连接。 |
| 4 | Worker Master 节点将任务分配给 worker 节点。TajoWorker 处理数据。随着 TajoWorker 数量的增加,处理能力也线性增加。 |
| 5 | 查询 Master Tajo master 将查询分配给 Query Master。Query Master 负责控制分布式执行计划。它启动 TaskRunner 并将任务调度到 TaskRunner。Query Master 的主要作用是监控正在运行的任务并将其报告给 Master 节点。 |
| 6 | 节点管理器 管理 worker 节点的资源。它决定如何将请求分配给节点。 |
| 7 | TaskRunner 充当本地查询执行引擎。它用于运行和监控查询进程。TaskRunner 一次处理一个任务。 它具有以下三个主要属性:
|
| 8 | 查询执行器 它用于执行查询。 |
| 9 | 存储服务 将底层数据存储连接到 Tajo。 |
工作流程
Tajo 使用 Hadoop 分布式文件系统 (HDFS) 作为存储层,并拥有自己的查询执行引擎,而不是 MapReduce 框架。Tajo 集群由一个 master 节点和跨集群节点的多个 worker 组成。
master 主要负责查询规划和 worker 的协调。master 将查询划分为小的任务并分配给 worker。每个 worker 都有一个本地查询引擎,该引擎执行物理运算符的有向无环图。
此外,Tajo 可以比 MapReduce 更灵活地控制分布式数据流,并支持索引技术。
Tajo 的基于 Web 的界面具有以下功能:
- 查找提交的查询如何规划的选项
- 查找查询如何在节点之间分布的选项
- 检查集群和节点状态的选项