- Apache Tajo 教程
- Apache Tajo - 首页
- Apache Tajo - 简介
- Apache Tajo - 架构
- Apache Tajo - 安装
- Apache Tajo - 配置设置
- Apache Tajo - Shell 命令
- Apache Tajo - 数据类型
- Apache Tajo - 运算符
- Apache Tajo - SQL 函数
- Apache Tajo - 数学函数
- Apache Tajo - 字符串函数
- Apache Tajo - 日期时间函数
- Apache Tajo - JSON 函数
- Apache Tajo - 数据库创建
- Apache Tajo - 表管理
- Apache Tajo - SQL 语句
- 聚合与窗口函数
- Apache Tajo - SQL 查询
- Apache Tajo - 存储插件
- 与 HBase 集成
- Apache Tajo - 与 Hive 集成
- OpenStack Swift 集成
- Apache Tajo - JDBC 接口
- Apache Tajo - 自定义函数
- Apache Tajo 有用资源
- Apache Tajo 快速指南
- Apache Tajo - 有用资源
- Apache Tajo - 讨论
Apache Tajo 快速指南
Apache Tajo - 简介
分布式数据仓库系统
数据仓库是一个关系型数据库,其设计用于查询和分析,而不是事务处理。它是一个面向主题的、集成的、随时间变化的、非易失性的数据集合。这些数据帮助分析师在组织中做出明智的决策,但关系型数据的数量日益增加。
为了克服这些挑战,分布式数据仓库系统跨多个数据存储库共享数据,用于联机分析处理 (OLAP)。每个数据仓库可能属于一个或多个组织。它执行负载平衡和可扩展性。元数据被复制和集中分发。
Apache Tajo 是一个分布式数据仓库系统,它使用 Hadoop 分布式文件系统 (HDFS) 作为存储层,并拥有自己的查询执行引擎,而不是 MapReduce 框架。
Hadoop 上 SQL 的概述
Hadoop 是一个开源框架,允许在分布式环境中存储和处理大数据。它极其快速和强大。但是,Hadoop 的查询能力有限,因此借助 Hadoop 上的 SQL 可以使其性能得到进一步提升。这允许用户通过简单的 SQL 命令与 Hadoop 进行交互。
Hadoop 上 SQL 应用的一些示例包括 Hive、Impala、Drill、Presto、Spark、HAWQ 和 Apache Tajo。
什么是 Apache Tajo
Apache Tajo 是一个关系型分布式数据处理框架。它旨在实现低延迟和可扩展的 ad-hoc 查询分析。
Tajo 支持标准 SQL 和各种数据格式。大多数 Tajo 查询无需任何修改即可执行。
Tajo 通过用于失败任务的重启机制和可扩展的查询重写引擎具有**容错性**。
Tajo 执行必要的**ETL(提取、转换和加载过程)**操作以汇总存储在 HDFS 上的大型数据集。它是 Hive/Pig 的替代选择。
最新版本的 Tajo 具有与 Java 程序和 Oracle 和 PostGreSQL 等第三方数据库更好的连接性。
Apache Tajo 的特性
Apache Tajo 具有以下特性:
- 卓越的可扩展性和优化的性能
- 低延迟
- 用户定义函数
- 行/列存储处理框架。
- 与 HiveQL 和 Hive MetaStore 兼容
- 简单的数据流和易于维护。
Apache Tajo 的优势
Apache Tajo 提供以下优势:
- 易于使用
- 简化的架构
- 基于成本的查询优化
- 矢量化查询执行计划
- 快速交付
- 简单的 I/O 机制并支持各种类型的存储。
- 容错性
Apache Tajo 的用例
以下是 Apache Tajo 的一些用例:
数据仓库和分析
韩国 SK 电讯公司针对 1.7 TB 的数据运行 Tajo,发现它可以比 Hive 或 Impala 更快地完成查询。
数据发现
韩国音乐流媒体服务 Melon 使用 Tajo 进行分析处理。Tajo 执行 ETL(提取-转换-加载过程)作业的速度比 Hive 快 1.5 到 10 倍。
日志分析
韩国公司 Bluehole Studio 开发了 TERA——一款奇幻多人在线游戏。该公司使用 Tajo 进行游戏日志分析,并查找服务质量中断的主要原因。
存储和数据格式
Apache Tajo 支持以下数据格式:
- JSON
- 文本文件 (CSV)
- Parquet
- Sequence File
- AVRO
- Protocol Buffer
- Apache Orc
Tajo 支持以下存储格式:
- HDFS
- JDBC
- Amazon S3
- Apache HBase
- Elasticsearch
Apache Tajo - 架构
下图描述了 Apache Tajo 的架构。
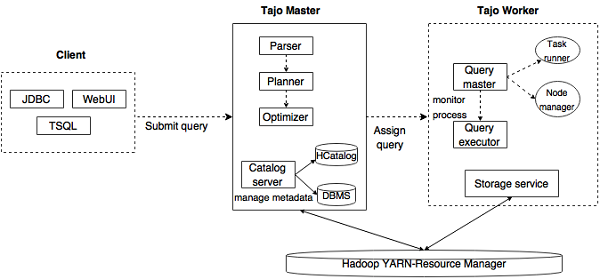
下表详细描述了每个组件。
| 序号 | 组件与描述 |
|---|---|
| 1 | 客户端 **客户端**将 SQL 语句提交到 Tajo Master 以获取结果。 |
| 2 | 主节点 (Master) 主节点是主守护进程。它负责查询规划,并且是工作节点的协调器。 |
| 3 | 目录服务器 维护表和索引描述。它嵌入在 Master 守护进程中。目录服务器使用 Apache Derby 作为存储层,并通过 JDBC 客户端连接。 |
| 4 | 工作节点 (Worker) 主节点将任务分配给工作节点。TajoWorker 处理数据。随着 TajoWorker 数量的增加,处理能力也线性增加。 |
| 5 | 查询主节点 (Query Master) Tajo 主节点将查询分配给查询主节点。查询主节点负责控制分布式执行计划。它启动 TaskRunner 并将任务调度到 TaskRunner。查询主节点的主要作用是监控正在运行的任务并将它们报告给主节点。 |
| 6 | 节点管理器 (Node Managers) 管理工作节点的资源。它决定将请求分配给哪个节点。 |
| 7 | 任务运行器 (TaskRunner) 充当本地查询执行引擎。它用于运行和监控查询过程。TaskRunner 一次处理一个任务。 它具有以下三个主要属性:
|
| 8 | 查询执行器 它用于执行查询。 |
| 9 | 存储服务 将底层数据存储连接到 Tajo。 |
工作流程
Tajo 使用 Hadoop 分布式文件系统 (HDFS) 作为存储层,并拥有自己的查询执行引擎,而不是 MapReduce 框架。Tajo 集群由一个主节点和跨集群节点的多个工作节点组成。
主节点主要负责查询规划和工作节点的协调。主节点将查询划分为小的任务并分配给工作节点。每个工作节点都有一个本地查询引擎,用于执行物理运算符的有向无环图。
此外,Tajo 可以比 MapReduce 更灵活地控制分布式数据流,并支持索引技术。
Tajo 的基于 Web 的界面具有以下功能:
- 查找提交的查询是如何规划的选项
- 查找查询如何在节点之间分布的选项
- 检查集群和节点状态的选项
Apache Tajo - 安装
要安装 Apache Tajo,您的系统上必须安装以下软件:
- Hadoop 2.3 或更高版本
- Java 1.7 或更高版本
- Linux 或 Mac OS
现在让我们继续执行以下步骤来安装 Tajo。
验证 Java 安装
希望您已经在机器上安装了 Java 8 版本。现在,您只需通过验证它来继续。
要验证,请使用以下命令:
$ java -version
如果 Java 已成功安装在您的机器上,您可以看到已安装 Java 的当前版本。如果 Java 未安装,请按照以下步骤在您的机器上安装 Java 8。
下载 JDK
访问以下链接下载最新版本的 JDK,然后下载最新版本。
最新版本为**JDK 8u 92**,文件名为**“jdk-8u92-linux-x64.tar.gz”**。请将文件下载到您的机器上。接下来,解压文件并将它们移动到特定目录。现在,设置 Java 备选方案。最后,Java 已安装在您的机器上。
验证 Hadoop 安装
您已在系统上安装了**Hadoop**。现在,使用以下命令验证它:
$ hadoop version
如果您的设置一切正常,那么您可以看到 Hadoop 的版本。如果 Hadoop 未安装,请访问以下链接下载并安装 Hadoop:https://apache.org
Apache Tajo 安装
Apache Tajo 提供两种执行模式——本地模式和完全分布式模式。验证 Java 和 Hadoop 安装后,请按照以下步骤在您的机器上安装 Tajo 集群。本地模式 Tajo 实例需要非常简单的配置。
访问以下链接下载最新版本的 Tajo:https://apache.org/dyn/closer.cgi/tajo
现在您可以从您的机器下载文件**“tajo-0.11.3.tar.gz”**。
解压 Tar 文件
使用以下命令解压 tar 文件:
$ cd opt/ $ tar tajo-0.11.3.tar.gz $ cd tajo-0.11.3
设置环境变量
将以下更改添加到**“conf/tajo-env.sh”**文件中
$ cd tajo-0.11.3 $ vi conf/tajo-env.sh # Hadoop home. Required export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2 # The java implementation to use. Required. export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/
在这里,您必须将 Hadoop 和 Java 路径指定到**“tajo-env.sh”**文件中。完成更改后,保存文件并退出终端。
启动 Tajo 服务器
要启动 Tajo 服务器,请执行以下命令:
$ bin/start-tajo.sh
您将收到类似于以下的响应:
Starting single TajoMaster starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../ localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/ Tajo master web UI: http://local:26080 Tajo Client Service: local:26002
现在,输入命令“jps”查看正在运行的守护进程。
$ jps 1010 TajoWorker 1140 Jps 933 TajoMaster
启动 Tajo Shell (Tsql)
要启动 Tajo shell 客户端,请使用以下命令:
$ bin/tsql
您将收到以下输出:
welcome to _____ ___ _____ ___ /_ _/ _ |/_ _/ / / // /_| |_/ // / / /_//_/ /_/___/ \__/ 0.11.3 Try \? for help.
退出 Tajo Shell
执行以下命令以退出 Tsql:
default> \q bye!
这里,默认指的是 Tajo 中的目录。
Web UI
输入以下 URL 启动 Tajo Web UI:https://:26080/
您现在将看到以下屏幕,它类似于 ExecuteQuery 选项。
停止 Tajo
要停止 Tajo 服务器,请使用以下命令:
$ bin/stop-tajo.sh
您将收到以下响应:
localhost: stopping worker stopping master
Apache Tajo - 配置设置
Tajo 的配置基于 Hadoop 的配置系统。本章详细解释 Tajo 配置设置。
基本设置
Tajo 使用以下两个配置文件:
- catalog-site.xml - 目录服务器的配置。
- tajo-site.xml - 其他 Tajo 模块的配置。
分布式模式配置
分布式模式设置运行在 Hadoop 分布式文件系统 (HDFS) 上。让我们按照以下步骤配置 Tajo 分布式模式设置。
tajo-site.xml
此文件位于 /path/to/tajo/conf 目录下,充当其他 Tajo 模块的配置。要在分布式模式下访问 Tajo,请对 “tajo-site.xml” 应用以下更改。
<property> <name>tajo.rootdir</name> <value>hdfs://hostname:port/tajo</value> </property> <property> <name>tajo.master.umbilical-rpc.address</name> <value>hostname:26001</value> </property> <property> <name>tajo.master.client-rpc.address</name> <value>hostname:26002</value> </property> <property> <name>tajo.catalog.client-rpc.address</name> <value>hostname:26005</value> </property>
主节点配置
Tajo 使用 HDFS 作为主要存储类型。配置如下,应添加到 “tajo-site.xml” 中。
<property> <name>tajo.rootdir</name> <value>hdfs://namenode_hostname:port/path</value> </property>
目录配置
如果要自定义目录服务,请将 $path/to/Tajo/conf/catalogsite.xml.template 复制到 $path/to/Tajo/conf/catalog-site.xml 并根据需要添加以下任何配置。
例如,如果使用 “Hive 目录存储” 访问 Tajo,则配置应如下所示:
<property> <name>tajo.catalog.store.class</name> <value>org.apache.tajo.catalog.store.HCatalogStore</value> </property>
如果需要存储 MySQL 目录,请应用以下更改:
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>
同样,您可以注册配置文件中其他 Tajo 支持的目录。
工作节点配置
默认情况下,TajoWorker 将临时数据存储在本地文件系统中。它在“tajo-site.xml”文件中定义如下:
<property> <name>tajo.worker.tmpdir.locations</name> <value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value> </property>
要增加每个工作节点资源运行任务的容量,请选择以下配置:
<property> <name>tajo.worker.resource.cpu-cores</name> <value>12</value> </property> <property> <name>tajo.task.resource.min.memory-mb</name> <value>2000</value> </property> <property> <name>tajo.worker.resource.disks</name> <value>4</value> </property>
要使 Tajo 工作节点在专用模式下运行,请选择以下配置:
<property> <name>tajo.worker.resource.dedicated</name> <value>true</value> </property>
Apache Tajo - Shell 命令
本章将详细了解 Tajo Shell 命令。
要执行 Tajo shell 命令,需要使用以下命令启动 Tajo 服务器和 Tajo shell:
启动服务器
$ bin/start-tajo.sh
启动 Shell
$ bin/tsql
上述命令现在可以执行了。
元命令
现在让我们讨论一下 元命令。Tsql 元命令以反斜杠 (‘\’) 开头。
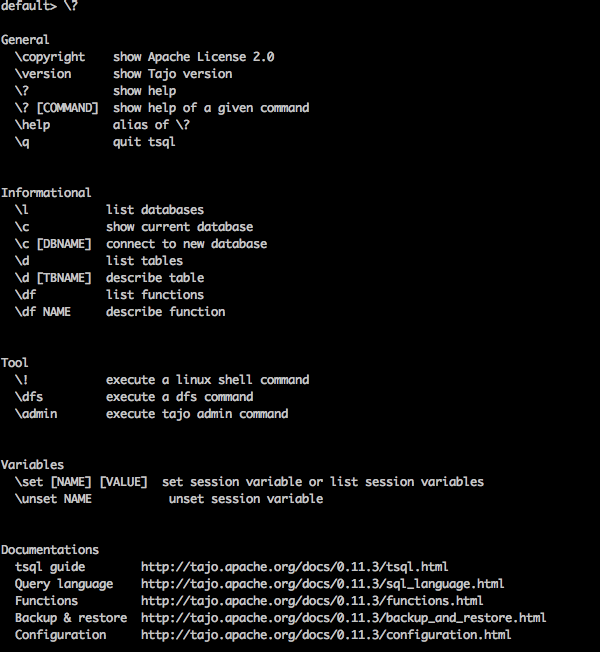
帮助命令
“\?” 命令用于显示帮助选项。
查询
default> \?
结果
上述 \? 命令列出了 Tajo 中所有基本使用方法选项。您将收到以下输出:
列出数据库
要列出 Tajo 中的所有数据库,请使用以下命令:
查询
default> \l
结果
您将收到以下输出:
information_schema default
目前,我们还没有创建任何数据库,因此它显示了两个内置的 Tajo 数据库。
当前数据库
\c 选项用于显示当前数据库名称。
查询
default> \c
结果
您现在已以用户“username”连接到数据库“default”。
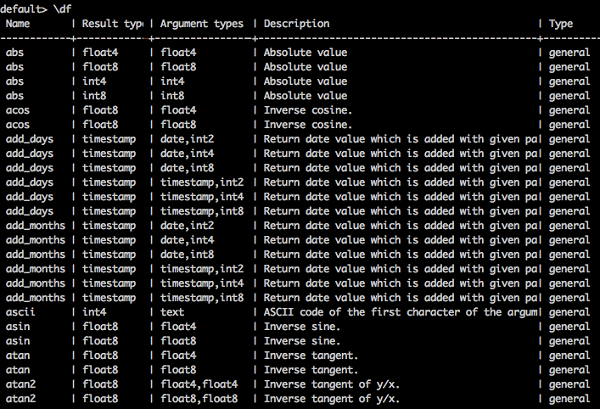
列出内置函数
要列出所有内置函数,请键入如下查询:
查询
default> \df
结果
您将收到以下输出:
描述函数
\df 函数名 - 此查询返回给定函数的完整描述。
查询
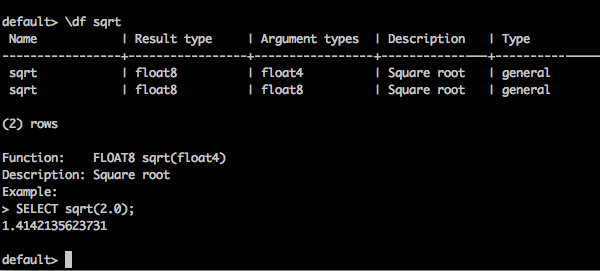
default> \df sqrt
结果
您将收到以下输出:
退出终端
要退出终端,请键入以下查询:
查询
default> \q
结果
您将收到以下输出:
bye!
管理员命令
Tajo shell 提供 \admin 选项以列出所有管理员功能。
查询
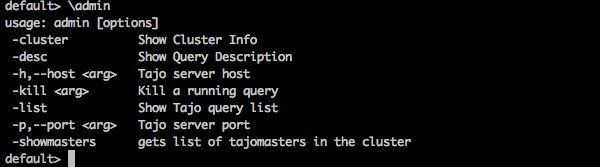
default> \admin
结果
您将收到以下输出:
集群信息
要显示 Tajo 中的集群信息,请使用以下查询
查询
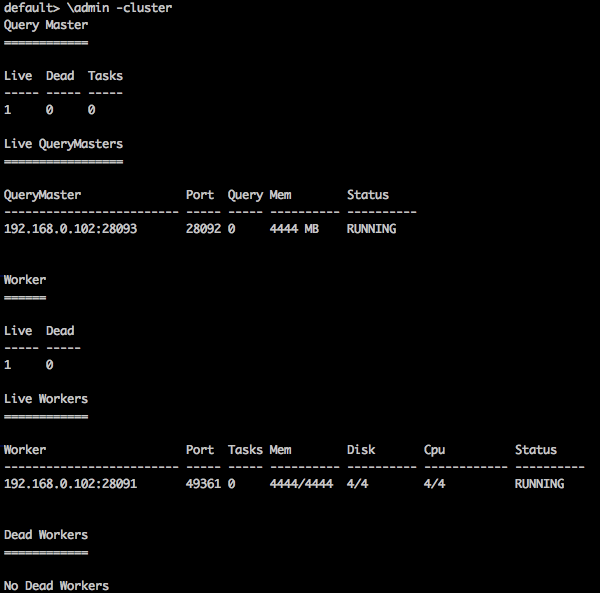
default> \admin -cluster
结果
您将收到以下输出:
显示主节点
以下查询显示当前主节点信息。
查询
default> \admin -showmasters
结果
localhost
同样,您可以尝试其他管理员命令。
会话变量
Tajo 客户端通过唯一的会话 ID 连接到主节点。会话在客户端断开连接或过期之前一直处于活动状态。
以下命令用于列出所有会话变量。
查询
default> \set
结果
'SESSION_LAST_ACCESS_TIME' = '1470206387146' 'CURRENT_DATABASE' = 'default' ‘USERNAME’ = 'user' 'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c' 'TIMEZONE' = 'Asia/Kolkata' 'FETCH_ROWNUM' = '200' ‘COMPRESSED_RESULT_TRANSFER' = 'false'
\set key val 将使用值 val 设置名为 key 的会话变量。例如,
查询
default> \set ‘current_database’='default'
结果
usage: \set [[NAME] VALUE]
在这里,您可以在 \set 命令中分配键和值。如果需要恢复更改,请使用 \unset 命令。
Apache Tajo - 数据类型
要在 Tajo shell 中执行查询,请打开终端并移动到已安装 Tajo 的目录,然后键入以下命令:
$ bin/tsql
您现在将看到如下程序所示的响应:
default>
您现在可以执行您的查询。或者,您可以通过 Web 控制台应用程序运行您的查询,访问以下 URL:https://:26080/
基本数据类型
Apache Tajo 支持以下基本数据类型列表:
| 序号 | 数据类型 & 描述 |
|---|---|
| 1 | integer 用于存储整数,占用 4 个字节。 |
| 2 | tinyint 微型整数,占用 1 个字节。 |
| 3 | smallint 用于存储小型整数,占用 2 个字节。 |
| 4 | bigint 大范围整数,占用 8 个字节。 |
| 5 | boolean 返回 true/false。 |
| 6 | real 用于存储实数,大小为 4 个字节。 |
| 7 | float 浮点精度值,占用 4 或 8 个字节存储空间。 |
| 8 | double 双精度值,存储在 8 个字节中。 |
| 9 | char[(n)] 字符值。 |
| 10 | varchar[(n)] 可变长度非 Unicode 数据。 |
| 11 | number 十进制值。 |
| 12 | binary 二进制值。 |
| 13 | date 日历日期(年、月、日)。 示例 - DATE '2016-08-22' |
| 14 | time 一天中的时间(小时、分钟、秒、毫秒),没有时区。此类型的值在会话时区中进行解析和呈现。 |
| 15 | timezone 一天中的时间(小时、分钟、秒、毫秒),带有时区。此类型的值使用值中的时区进行呈现。 示例 - TIME '01:02:03.456 Asia/kolkata' |
| 16 | timestamp 包含日期和时间(没有时区)的瞬间时间。 示例 - TIMESTAMP '2016-08-22 03:04:05.321' |
| 17 | text 可变长度 Unicode 文本。 |
Apache Tajo - 运算符
以下运算符用于在 Tajo 中执行所需的运算。
| 序号 | 运算符 & 描述 |
|---|---|
| 1 | 算术运算符
Presto 支持算术运算符,例如 +、-、*、/、%。 |
| 2 | 关系运算符
<, >, <=, >=, =, <> |
| 3 | 逻辑运算符
AND、OR、NOT |
| 4 | 字符串运算符
‘||’ 运算符执行字符串连接。 |
| 5 | 范围运算符
范围运算符用于测试特定范围内的值。Tajo 支持 BETWEEN、IS NULL、IS NOT NULL 运算符。 |
Apache Tajo - SQL 函数
目前,您已经了解如何在 Tajo 上运行简单的基本查询。在接下来的几章中,我们将讨论以下 SQL 函数:
Apache Tajo - 数学函数
数学函数对数学公式进行运算。下表详细描述了函数列表。
| 序号 | 函数 & 描述 |
|---|---|
| 1 | abs(x)
返回 x 的绝对值。 |
| 2 | cbrt(x)
返回 x 的立方根。 |
| 3 | ceil(x)
返回向上舍入到最接近整数的 x 值。 |
| 4 | floor(x)
返回向下舍入到最接近整数的 x 值。 |
| 5 | pi()
返回 pi 值。结果将作为双精度值返回。 |
| 6 | radians(x)
将角度 x 从度转换为弧度。 |
| 7 | degrees(x)
返回 x 的度数值。 |
| 8 | pow(x,p)
返回值 ‘p’ 的 x 次幂。 |
| 9 | div(x,y)
返回给定的两个整数 x,y 的除法结果。 |
| 10 | exp(x)
返回欧拉数 e 的 x 次幂。 |
| 11 | sqrt(x)
返回 x 的平方根。 |
| 12 | sign(x)
返回 x 的符号函数,即:
|
| 13 | mod(n,m)
返回 n 除以 m 的模(余数)。 |
| 14 | round(x)
返回 x 的四舍五入值。 |
| 15 | cos(x)
返回余弦值(x)。 |
| 16 | asin(x)
返回反正弦值(x)。 |
| 17 | acos(x)
返回反余弦值(x)。 |
| 18 | atan(x)
返回反正切值(x)。 |
| 19 | atan2(y,x)
返回反正切值(y/x)。 |
数据类型函数
下表列出了 Apache Tajo 中可用的数据类型函数。
| 序号 | 函数 & 描述 |
|---|---|
| 1 | to_bin(x)
返回整数的二进制表示。 |
| 2 | to_char(int,text)
将整数转换为字符串。 |
| 3 | to_hex(x)
将 x 值转换为十六进制。 |
Apache Tajo - 字符串函数
下表列出了 Tajo 中的字符串函数。
| 序号 | 函数 & 描述 |
|---|---|
| 1 | concat(string1, ..., stringN)
连接给定的字符串。 |
| 2 | length(string)
返回给定字符串的长度。 |
| 3 | lower(string)
返回字符串的小写格式。 |
| 4 | upper(string)
返回给定字符串的大写格式。 |
| 5 | ascii(string text)
返回文本第一个字符的 ASCII 码。 |
| 6 | bit_length(string text)
返回字符串中的位数。 |
| 7 | char_length(string text)
返回字符串中的字符数。 |
| 8 | octet_length(string text)
返回字符串中的字节数。 |
| 9 | digest(input text, method text)
计算字符串的 Digest 哈希值。这里,第二个参数 method 指的是哈希方法。 |
| 10 | initcap(string text)
将每个单词的第一个字母转换为大写。 |
| 11 | md5(string text)
计算字符串的 MD5 哈希值。 |
| 12 | left(string text, int size)
返回字符串中的前 n 个字符。 |
| 13 | right(string text, int size)
返回字符串中的最后 n 个字符。 |
| 14 | locate(source text, target text, start_index)
返回指定子字符串的位置。 |
| 15 | strposb(source text, target text)
返回指定子字符串的二进制位置。 |
| 16 | substr(source text, start index, length)
返回指定长度的子字符串。 |
| 17 | trim(string text[, characters text])
删除字符串开头/结尾/两端 的字符(默认为空格)。 |
| 18 | split_part(string text, delimiter text, field int)
按分隔符分割字符串,并返回给定的字段(从 1 开始计数)。 |
| 19 | regexp_replace(string text, pattern text, replacement text)
替换与给定正则表达式模式匹配的子字符串。 |
| 20 | reverse(string)
对字符串执行反转操作。 |
Apache Tajo - 日期时间函数
Apache Tajo 支持以下日期时间函数。
Apache Tajo - JSON 函数
JSON 函数列在下面的表格中:
| 序号 | 函数 & 描述 |
|---|---|
| 1 | json_extract_path_text(json text, json_path text)
根据指定的 json 路径从 JSON 字符串中提取 JSON 字符串。 |
| 2 | json_array_get(json_array text, index int4)
返回 JSON 数组中指定索引处的元素。 |
| 3 | json_array_contains(json_array text, value any)
确定给定值是否存在于 JSON 数组中。 |
| 4 | json_array_length(json_array text)
返回 JSON 数组的长度。 |
Apache Tajo - 数据库创建
本节解释 Tajo DDL 命令。Tajo 有一个名为 **default** 的内置数据库。
创建数据库语句
**创建数据库** 用于在 Tajo 中创建数据库。此语句的语法如下:
CREATE DATABASE [IF NOT EXISTS] <database_name>
查询
default> default> create database if not exists test;
结果
上述查询将生成以下结果。
OK
数据库是 Tajo 中的命名空间。一个数据库可以包含多个具有唯一名称的表。
显示当前数据库
要检查当前数据库名称,请发出以下命令:
查询
default> \c
结果
上述查询将生成以下结果。
You are now connected to database "default" as user “user1". default>
连接到数据库
目前,您已经创建了一个名为“test”的数据库。以下语法用于连接“test”数据库。
\c <database name>
查询
default> \c test
结果
上述查询将生成以下结果。
You are now connected to database "test" as user “user1”. test>
您现在可以看到提示符从 default 数据库更改为 test 数据库。
删除数据库
要删除数据库,请使用以下语法:
DROP DATABASE <database-name>
查询
test> \c default You are now connected to database "default" as user “user1". default> drop database test;
结果
上述查询将生成以下结果。
OK
Apache Tajo - 表管理
表是一个数据源的逻辑视图。它包含逻辑模式、分区、URL 和各种属性。Tajo 表可以是 HDFS 中的目录、单个文件、一个 HBase 表或一个 RDBMS 表。
Tajo 支持以下两种类型的表:
- 外部表
- 内部表
外部表
创建外部表时需要 location 属性。例如,如果您的数据已经存在为 Text/JSON 文件或 HBase 表,您可以将其注册为 Tajo 外部表。
以下查询是外部表创建的示例。
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';
这里,
**External 关键字** - 用于创建外部表。这有助于在指定位置创建表。
Sample 指的是表名。
**Location** - 它是 HDFS、Amazon S3、HBase 或本地文件系统的目录。要为目录分配 location 属性,请使用以下 URI 示例:
**HDFS** - hdfs://:port/path/to/table
**Amazon S3** - s3://bucket-name/table
**本地文件系统** - file:///path/to/table
**Openstack Swift** - swift://bucket-name/table
表属性
外部表具有以下属性:
**TimeZone** - 用户可以指定读取或写入表的时区。
**压缩格式** - 用于使数据大小更紧凑。例如,text/json 文件使用 **compression.codec** 属性。
内部表
内部表也称为 **托管表**。它是在称为表空间的预定义物理位置创建的。
语法
create table table1(col1 int,col2 text);
默认情况下,Tajo 使用位于“conf/tajo-site.xml”中的“tajo.warehouse.directory”。要为表分配新位置,可以使用表空间配置。
表空间
表空间用于定义存储系统中的位置。仅内部表支持它。您可以通过表空间名称访问表空间。每个表空间可以使用不同的存储类型。如果您没有指定表空间,则 Tajo 使用根目录中的默认表空间。
表空间配置
您在 Tajo 中有 **“conf/tajo-site.xml.template”**。复制该文件并将其重命名为 **“storagesite.json”**。此文件将充当表空间的配置。Tajo 数据格式使用以下配置:
HDFS 配置
$ vi conf/storage-site.json {
"spaces": {
"${tablespace_name}": {
"uri": “hdfs://:9000/path/to/Tajo"
}
}
}
HBase 配置
$ vi conf/storage-site.json {
"spaces": {
"${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}
文本文件配置
$ vi conf/storage-site.json {
"spaces": {
"${tablespace_name}": {
“uri”: “hdfs://:9000/path/to/Tajo”
}
}
}
表空间创建
Tajo 的内部表记录只能从另一个表访问。您可以使用表空间对其进行配置。
语法
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name] [using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]
这里,
**IF NOT EXISTS** - 如果尚未创建相同的表,则可以避免错误。
**TABLESPACE** - 此子句用于分配表空间名称。
**存储类型** - Tajo 数据支持 text、JSON、HBase、Parquet、Sequencefile 和 ORC 等格式。
**AS select 语句** - 从另一个表中选择记录。
配置表空间
启动您的 Hadoop 服务并打开文件 **“conf/storage-site.json”**,然后添加以下更改:
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://:9000/path/to/Tajo"
}
}
}
在这里,Tajo 将引用来自 HDFS 位置的数据,并且 **space1** 是表空间名称。如果您没有启动 Hadoop 服务,则无法注册表空间。
查询
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;
上述查询创建一个名为“table1”的表,而“space1”指的是表空间名称。
数据格式
Tajo 支持数据格式。让我们逐一详细了解每种格式。
文本
字符分隔值纯文本文件表示由行和列组成的表格数据集。每一行都是一个纯文本行。
创建表
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;
这里,**“customers.csv”** 文件指的是位于 Tajo 安装目录中的逗号分隔值文件。
要使用文本格式创建内部表,请使用以下查询:
default> create table customer(id int,name text,address text,age int) using text;
在上述查询中,您没有分配任何表空间,因此它将采用 Tajo 的默认表空间。
属性
文本文件格式具有以下属性:
**text.delimiter** - 这是一个分隔符字符。默认为 '|'。
**compression.codec** - 这是一个压缩格式。默认情况下,它是禁用的。您可以使用指定的算法更改设置。
**timezone** - 用于读取或写入的表。
**text.error-tolerance.max-num** - 最大容错级别数。
**text.skip.headerlines** - 每行跳过的标题行数。
**text.serde** - 这是序列化属性。
JSON
Apache Tajo 支持 JSON 格式用于查询数据。Tajo 将 JSON 对象视为 SQL 记录。一个对象等于 Tajo 表中的一行。让我们考虑如下所示的“array.json”:
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}
创建此文件后,切换到 Tajo shell 并键入以下查询以使用 JSON 格式创建表。
查询
default> create external table sample (num1 int,num2 text,num3 float) using json location ‘json/array.json’;
请始终记住,文件数据必须与表模式匹配。否则,您可以省略列名并使用 *,它不需要列列表。
要创建内部表,请使用以下查询:
default> create table sample (num1 int,num2 text,num3 float) using json;
Parquet
Parquet 是一种列式存储格式。Tajo 使用 Parquet 格式来实现轻松、快速和高效的访问。
表创建
以下查询是表创建的示例:
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;
Parquet 文件格式具有以下属性:
**parquet.block.size** - 缓冲在内存中的行组的大小。
**parquet.page.size** - 页面大小用于压缩。
**parquet.compression** - 用于压缩页面的压缩算法。
**parquet.enable.dictionary** - 布尔值用于启用/禁用字典编码。
RCFile
RCFile 是记录列式文件。它由二进制键/值对组成。
表创建
以下查询是表创建的示例:
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;
RCFile 具有以下属性:
**rcfile.serde** - 自定义反序列化类。
**compression.codec** - 压缩算法。
**rcfile.null** - NULL 字符。
SequenceFile
SequenceFile 是 Hadoop 中的一种基本文件格式,它由键/值对组成。
表创建
以下查询是表创建的示例:
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;
此序列文件具有 Hive 兼容性。这可以在 Hive 中编写为:
CREATE TABLE table1 (id int, name string, score float, type string) STORED AS sequencefile;
ORC
ORC(Optimized Row Columnar)是来自 Hive 的列式存储格式。
表创建
以下查询是表创建的示例:
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;
ORC 格式具有以下属性:
**orc.max.merge.distance** - 读取 ORC 文件时,当距离较低时会合并。
**orc.stripe.size** - 这是每个条带的大小。
**orc.buffer.size** - 默认值为 256KB。
**orc.rowindex.stride** - 这是 ORC 索引跨度(以行数表示)。
Apache Tajo - SQL 语句
在上一章中,您了解了如何在 Tajo 中创建表。本章解释 Tajo 中的 SQL 语句。
创建表语句
在创建表之前,请在 Tajo 安装目录路径中创建一个名为“students.csv”的文本文件,如下所示:
students.csv
| Id | 姓名 | 地址 | 年龄 | 分数 |
|---|---|---|---|---|
| 1 | Adam | 23 New Street | 21 | 90 |
| 2 | Amit | 12 Old Street | 13 | 95 |
| 3 | Bob | 10 Cross Street | 12 | 80 |
| 4 | David | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 North Street | 12 | 55 |
| 7 | Jack | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 South Street | 12 | 70 |
| 9 | Mary | 5 West Street | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
文件创建后,移动到终端并逐一启动 Tajo 服务器和 shell。
创建数据库
使用以下命令创建一个新数据库:
查询
default> create database sampledb; OK
连接到现在已创建的数据库“sampledb”。
default> \c sampledb You are now connected to database "sampledb" as user “user1”.
然后,在“sampledb”中创建一个表,如下所示:
查询
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;
结果
上述查询将生成以下结果。
OK
这里,创建了外部表。现在,您只需输入文件位置即可。如果您必须从 hdfs 分配表,请使用 hdfs 而不是 file。
接下来,**“students.csv”** 文件包含逗号分隔的值。**text.delimiter** 字段分配了 ','。
您现在已在“sampledb”中成功创建了“mytable”。
显示表
要在 Tajo 中显示表,请使用以下查询。
查询
sampledb> \d mytable sampledb> \d mytable
结果
上述查询将生成以下结果。
table name: sampledb.mytable table uri: file:/Users/workspace/Tajo/students.csv store type: TEXT number of rows: unknown volume: 261 B Options: 'timezone' = 'Asia/Kolkata' 'text.null' = '\\N' 'text.delimiter' = ',' schema: id INT4 name TEXT address TEXT age INT4 mark INT4
列出表
要获取表中的所有记录,请键入以下查询:
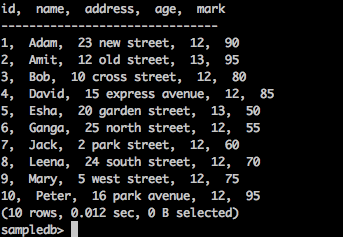
查询
sampledb> select * from mytable;
结果
上述查询将生成以下结果。
插入表语句
Tajo 使用以下语法将记录插入表中。
语法
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;
Tajo 的 insert 语句类似于 SQL 的 **INSERT INTO SELECT** 语句。
查询
让我们创建一个表来覆盖现有表的表数据。
sampledb> create table test(sno int,name text,addr text,age int,mark int); OK sampledb> \d
结果
上述查询将生成以下结果。
mytable test
插入记录
要将记录插入“test”表,请键入以下查询。
查询
sampledb> insert overwrite into test select * from mytable;
结果
上述查询将生成以下结果。
Progress: 100%, response time: 0.518 sec
这里,“mytable”记录覆盖了“test”表。如果您不想创建“test”表,则可以直接分配物理路径位置,如插入查询的替代选项中所述。
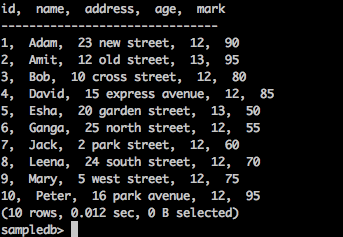
提取记录
使用以下查询列出“test”表中的所有记录:
查询
sampledb> select * from test;
结果
上述查询将生成以下结果。
此语句用于添加、删除或修改现有表的列。
要重命名表,请使用以下语法:
Alter table table1 RENAME TO table2;
查询
sampledb> alter table test rename to students;
结果
上述查询将生成以下结果。
OK
要检查更改后的表名,请使用以下查询。
sampledb> \d mytable students
现在表“test”已更改为“students”表。
添加列
要在“students”表中插入新列,请键入以下语法:
Alter table <table_name> ADD COLUMN <column_name> <data_type>
查询
sampledb> alter table students add column grade text;
结果
上述查询将生成以下结果。
OK
设置属性
此属性用于更改表的属性。
查询
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD', 'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ; OK
这里,分配了压缩类型和编解码器属性。
要更改文本分隔符属性,请使用以下命令:
查询
ALTER TABLE students SET PROPERTY ‘text.delimiter'=','; OK
结果
上述查询将生成以下结果。
sampledb> \d students table name: sampledb.students table uri: file:/tmp/tajo-user1/warehouse/sampledb/students store type: TEXT number of rows: 10 volume: 228 B Options: 'compression.type' = 'RECORD' 'timezone' = 'Asia/Kolkata' 'text.null' = '\\N' 'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec' 'text.delimiter' = ',' schema: id INT4 name TEXT addr TEXT age INT4 mark INT4 grade TEXT
上述结果显示使用“SET”属性更改了表的属性。
选择语句
SELECT 语句用于从数据库中选择数据。
Select 语句的语法如下:
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...] [FROM <table reference> [[AS] <table alias name>] [, ...]] [WHERE <condition>] [GROUP BY <expression> [, ...]] [HAVING <condition>] [ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]
Where 子句
Where 子句用于从表中筛选记录。
查询
sampledb> select * from mytable where id > 5;
结果
上述查询将生成以下结果。
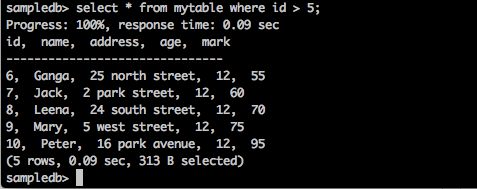
查询返回 id 大于 5 的学生的记录。
查询
sampledb> select * from mytable where name = ‘Peter’;
结果
上述查询将生成以下结果。
Progress: 100%, response time: 0.117 sec id, name, address, age ------------------------------- 10, Peter, 16 park avenue , 12
结果仅筛选 Peter 的记录。
Distinct 子句
表列可能包含重复值。“DISTINCT”关键字可以用来只返回不同的值。
语法
SELECT DISTINCT column1,column2 FROM table_name;
查询
sampledb> select distinct age from mytable;
结果
上述查询将生成以下结果。
Progress: 100%, response time: 0.216 sec age ------------------------------- 13 12
查询返回来自**mytable**表中学生年龄的唯一值。
GROUP BY 子句
GROUP BY 子句与 SELECT 语句一起使用,用于将相同的数据整理成组。
语法
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;
查询
select age,sum(mark) as sumofmarks from mytable group by age;
结果
上述查询将生成以下结果。
age, sumofmarks ------------------------------- 13, 145 12, 610
这里,“mytable”列包含两种年龄——12岁和13岁。现在,查询按年龄对记录进行分组,并计算对应年龄学生的成绩总和。
HAVING 子句
HAVING 子句允许您指定条件,以过滤最终结果中显示的组结果。WHERE 子句对选定的列施加条件,而 HAVING 子句对 GROUP BY 子句创建的组施加条件。
语法
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]
查询
sampledb> select age from mytable group by age having sum(mark) > 200;
结果
上述查询将生成以下结果。
age ------------------------------- 12
查询按年龄对记录分组,并在满足条件sum(mark) > 200时返回年龄。
ORDER BY 子句
ORDER BY 子句用于根据一个或多个列对数据进行升序或降序排序。Tajo 数据库默认按升序排序查询结果。
语法
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
查询
sampledb> select * from mytable where mark > 60 order by name desc;
结果
上述查询将生成以下结果。
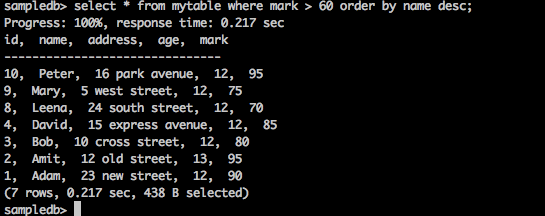
查询按降序返回成绩大于 60 的学生的姓名。
创建索引语句
CREATE INDEX 语句用于在表中创建索引。索引用于快速检索数据。当前版本仅支持对存储在 HDFS 上的纯文本格式进行索引。
语法
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }
查询
create index student_index on mytable(id);
结果
上述查询将生成以下结果。
id ———————————————
要查看为列分配的索引,请键入以下查询。
default> \d mytable table name: default.mytable table uri: file:/Users/deiva/workspace/Tajo/students.csv store type: TEXT number of rows: unknown volume: 307 B Options: 'timezone' = 'Asia/Kolkata' 'text.null' = '\\N' 'text.delimiter' = ',' schema: id INT4 name TEXT address TEXT age INT4 mark INT4 Indexes: "student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )
这里,Tajo 默认使用 TWO_LEVEL_BIN_TREE 方法。
删除表语句
删除表语句用于从数据库中删除表。
语法
drop table table name;
查询
sampledb> drop table mytable;
要检查表是否已从表中删除,请键入以下查询。
sampledb> \d mytable;
结果
上述查询将生成以下结果。
ERROR: relation 'mytable' does not exist
您也可以使用“\d”命令检查查询,列出可用的 Tajo 表。
聚合与窗口函数
本章详细解释了聚合函数和窗口函数。
聚合函数
聚合函数根据一组输入值生成单个结果。下表详细描述了聚合函数的列表。
| 序号 | 函数 & 描述 |
|---|---|
| 1 | AVG(exp)
计算数据源中所有记录的列的平均值。 |
| 2 | CORR(expression1, expression2)
返回一组数字对之间的相关系数。 |
| 3 | COUNT()
返回行数。 |
| 4 | MAX(expression)
返回所选列的最大值。 |
| 5 | MIN(expression)
返回所选列的最小值。 |
| 6 | SUM(expression)
返回给定列的总和。 |
| 7 | LAST_VALUE(expression)
返回给定列的最后一个值。 |
窗口函数
窗口函数作用于一组行,并为查询中的每一行返回单个值。“窗口”一词表示函数的行集。
在查询中,窗口函数使用 OVER() 子句定义窗口。
**OVER()** 子句具有以下功能:
- 定义窗口分区以形成行组。(PARTITION BY 子句)
- 对分区内的行进行排序。(ORDER BY 子句)
下表详细描述了窗口函数。
| 函数 | 返回类型 | 描述 |
|---|---|---|
| rank() | int | 返回当前行的排名,带有间隙。 |
| row_num() | int | 返回当前行在其分区中的排名,从 1 开始计数。 |
| lead(value[, offset integer[, default any]]) | 与输入类型相同 | 返回在分区内当前行之后偏移行数处计算的值。如果没有这样的行,则返回默认值。 |
| lag(value[, offset integer[, default any]]) | 与输入类型相同 | 返回在分区内当前行之前偏移行数处计算的值。 |
| first_value(value) | 与输入类型相同 | 返回输入行的第一个值。 |
| last_value(value) | 与输入类型相同 | 返回输入行的最后一个值。 |
Apache Tajo - SQL 查询
本章解释了以下重要的查询。
- 谓词
- 解释
- 连接
让我们继续执行查询。
谓词
谓词是一个表达式,用于评估真/假值和 UNKNOWN。谓词用于 WHERE 子句和 HAVING 子句以及其他需要布尔值的结构的搜索条件中。
IN 谓词
确定要测试的表达式的值是否与子查询或列表中的任何值匹配。子查询是一个普通的 SELECT 语句,它有一个包含一列和多行的结果集。此列或列表中的所有表达式必须与要测试的表达式具有相同的数据类型。
语法
IN::= <expression to test> [NOT] IN (<subquery>) | (<expression1>,...)
查询
select id,name,address from mytable where id in(2,3,4);
结果
上述查询将生成以下结果。
id, name, address ------------------------------- 2, Amit, 12 old street 3, Bob, 10 cross street 4, David, 15 express avenue
查询返回**mytable**表中学生 ID 为 2、3 和 4 的记录。
查询
select id,name,address from mytable where id not in(2,3,4);
结果
上述查询将生成以下结果。
id, name, address ------------------------------- 1, Adam, 23 new street 5, Esha, 20 garden street 6, Ganga, 25 north street 7, Jack, 2 park street 8, Leena, 24 south street 9, Mary, 5 west street 10, Peter, 16 park avenue
上述查询返回**mytable**表中studentId 不在 2、3 和 4 中的记录。
LIKE 谓词
LIKE 谓词比较第一个表达式中指定的字符串(作为要测试的值)与第二个表达式中定义的模式。
模式可以包含任何通配符组合,例如:
下划线符号 (_) ,可以代替要测试值中的任何单个字符。
百分号 (%) ,可以代替要测试值中零个或多个字符的任何字符串。
语法
LIKE::= <expression for calculating the string value> [NOT] LIKE <expression for calculating the string value> [ESCAPE <symbol>]
查询
select * from mytable where name like ‘A%';
结果
上述查询将生成以下结果。
id, name, address, age, mark ------------------------------- 1, Adam, 23 new street, 12, 90 2, Amit, 12 old street, 13, 95
查询返回mytable表中姓名以“A”开头的学生的记录。
查询
select * from mytable where name like ‘_a%';
结果
上述查询将生成以下结果。
id, name, address, age, mark ——————————————————————————————————————- 4, David, 15 express avenue, 12, 85 6, Ganga, 25 north street, 12, 55 7, Jack, 2 park street, 12, 60 9, Mary, 5 west street, 12, 75
查询返回**mytable**表中姓名第二个字符为“a”的学生的记录。
在搜索条件中使用 NULL 值
现在让我们了解如何在搜索条件中使用 NULL 值。
语法
Predicate IS [NOT] NULL
查询
select name from mytable where name is not null;
结果
上述查询将生成以下结果。
name ------------------------------- Adam Amit Bob David Esha Ganga Jack Leena Mary Peter (10 rows, 0.076 sec, 163 B selected)
这里,结果为真,因此它返回表中的所有名称。
查询
现在让我们检查带有 NULL 条件的查询。
default> select name from mytable where name is null;
结果
上述查询将生成以下结果。
name ------------------------------- (0 rows, 0.068 sec, 0 B selected)
解释
**EXPLAIN** 用于获取查询执行计划。它显示语句的逻辑和全局计划执行。
逻辑计划查询
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
结果
上述查询将生成以下结果。

查询结果显示给定表的逻辑计划格式。逻辑计划返回以下三个结果:
- 目标列表
- 输出模式
- 输入模式
全局计划查询
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)
结果
上述查询将生成以下结果。
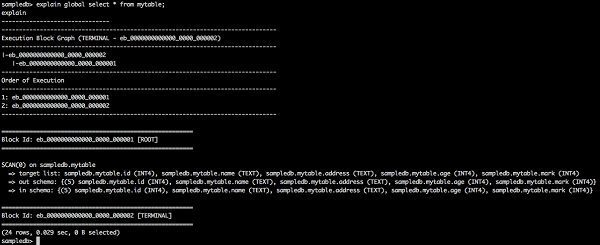
这里,全局计划显示执行块 ID、执行顺序及其信息。
连接
SQL 连接用于组合来自两个或多个表的行。以下是不同类型的 SQL 连接:
- 内连接
- { LEFT | RIGHT | FULL } OUTER JOIN
- 交叉连接
- 自连接
- 自然连接
考虑以下两个表来执行连接操作。
表1 - 客户
| Id | 姓名 | 地址 | 年龄 |
|---|---|---|---|
| 1 | 客户1 | 23 老街 | 21 |
| 2 | 客户2 | 12 新街 | 23 |
| 3 | 客户3 | 10 快车大道 | 22 |
| 4 | 客户4 | 15 Express Avenue | 22 |
| 5 | 客户5 | 20 Garden Street | 33 |
| 6 | 客户6 | 21 北街 | 25 |
表2 - 客户订单
| Id | 订单 ID | 员工 ID |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
让我们继续在上述两个表上执行 SQL 连接操作。
内连接
内连接在两个表中的列之间匹配时,选择两个表中的所有行。
语法
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
查询
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;
结果
上述查询将生成以下结果。
age, empid ------------------------------- 21, 101 23, 102 22, 103 22, 104 33, 105
查询匹配来自两个表的五行。因此,它返回来自第一个表匹配行的年龄。
左外连接
左外连接保留“左”表的所有行,无论是否有与“右”表匹配的行。
查询
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;
结果
上述查询将生成以下结果。
name, empid ------------------------------- customer1, 101 customer2, 102 customer3, 103 customer4, 104 customer5, 105 customer6,
这里,左外连接返回来自客户(左)表的 name 列行和来自客户订单(右)表匹配的 empid 列行。
右外连接
右外连接保留“右”表的所有行,无论是否有与“左”表匹配的行。
查询
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;
结果
上述查询将生成以下结果。
name, empid ------------------------------- customer1, 101 customer2, 102 customer3, 103 customer4, 104 customer5, 105
这里,右外连接返回来自客户订单(右)表的 empid 行和来自客户表的 name 列匹配行。
全外连接
全外连接保留左表和右表的所有行。
查询
select * from customers c full outer join customer_order c1 on c.id = c1.id;
结果
上述查询将生成以下结果。
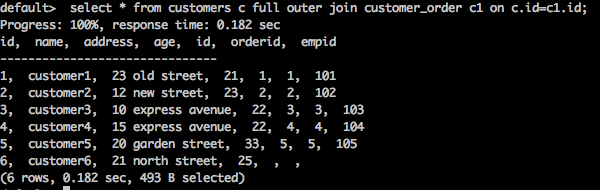
查询返回客户表和客户订单表中的所有匹配行和不匹配行。
交叉连接
这返回来自两个或多个连接表的记录集的笛卡尔积。
语法
SELECT * FROM table1 CROSS JOIN table2;
查询
select orderid,name,address from customers,customer_order;
结果
上述查询将生成以下结果。
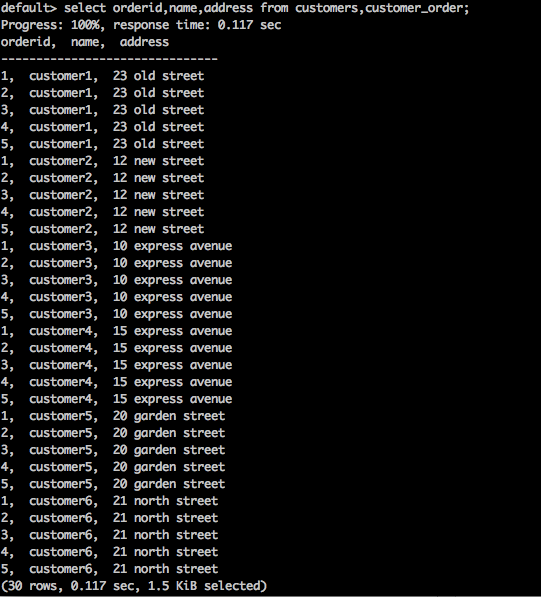
上述查询返回表的笛卡尔积。
自然连接
自然连接不使用任何比较运算符。它不会像笛卡尔积那样进行连接。只有当两个关系之间存在至少一个公共属性时,我们才能执行自然连接。
语法
SELECT * FROM table1 NATURAL JOIN table2;
查询
select * from customers natural join customer_order;
结果
上述查询将生成以下结果。
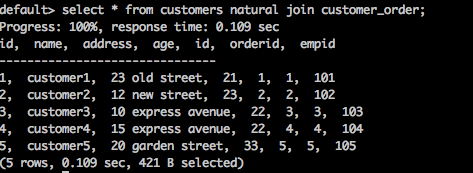
这里,两个表之间存在一个公共列 id。使用该公共列,**自然连接**连接这两个表。
自连接
SQL 自连接用于将表本身连接起来,就好像表是两个表一样,在 SQL 语句中临时重命名至少一个表。
语法
SELECT a.column_name, b.column_name... FROM table1 a, table1 b WHERE a.common_filed = b.common_field
查询
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;
结果
上述查询将生成以下结果。
id, name ------------------------------- 1, customer1 2, customer2 3, customer3 4, customer4 5, customer5 6, customer6
查询将客户表本身连接起来。
Apache Tajo - 存储插件
Tajo 支持各种存储格式。要注册存储插件配置,应将更改添加到配置文件“storage-site.json”。
storage-site.json
结构定义如下:
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}
每个存储实例都由 URI 标识。
PostgreSQL 存储处理程序
Tajo 支持 PostgreSQL 存储处理程序。它使用户查询能够访问 PostgreSQL 中的数据库对象。它是 Tajo 中的默认存储处理程序,因此您可以轻松配置它。
配置
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}
这里,**“database1”** 指的是映射到 Tajo 中数据库 **“sampledb”** 的 **postgreSQL** 数据库。
Apache Tajo - 与 HBase 集成
Apache Tajo 支持 HBase 集成。这使我们能够在 Tajo 中访问 HBase 表。HBase 是一个构建在 Hadoop 文件系统之上的分布式列式数据库。它是 Hadoop 生态系统的一部分,它为 Hadoop 文件系统中的数据提供随机的实时读/写访问。配置 HBase 集成需要执行以下步骤。
设置环境变量
将以下更改添加到“conf/tajo-env.sh”文件。
$ vi conf/tajo-env.sh # HBase home directory. It is opitional but is required mandatorily to use HBase. # export HBASE_HOME = path/to/HBase
包含HBase路径后,Tajo会将HBase库文件设置到classpath。
创建外部表
使用以下语法创建外部表:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;
要访问HBase表,必须配置表空间位置。
这里,
表 (Table) − 设置HBase原始表名。如果要创建外部表,则该表必须存在于HBase中。
列 (Columns) − Key 指的是HBase行键。列的个数必须等于Tajo表列的个数。
hbase.zookeeper.quorum − 设置ZooKeeper集群地址。
hbase.zookeeper.property.clientPort − 设置ZooKeeper客户端端口。
查询
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';
此处,“位置路径”字段设置ZooKeeper客户端端口ID。如果未设置端口,Tajo将引用hbase-site.xml文件的属性。
在HBase中创建表
可以使用“hbase shell”命令启动HBase交互式shell,如下所示。
查询
/bin/hbase shell
结果
上述查询将生成以下结果。
hbase(main):001:0>
查询HBase的步骤
要查询HBase,应完成以下步骤:
步骤1 − 将以下命令管道传输到HBase shell以创建“tutorial”表。
查询
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'
步骤2 − 现在,在hbase shell中发出以下命令以将数据加载到表中。
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shell
步骤3 − 现在,返回到Tajo shell并执行以下命令以查看表的元数据:
default> \d students; table name: default.students table path: store type: HBASE number of rows: unknown volume: 0 B Options: 'columns' = ':key,info:id,content:name' 'table' = 'students' schema: rowkey TEXT id INT4 name TEXT
步骤4 − 要从表中获取结果,请使用以下查询:
查询
default> select * from students
结果
以上查询将获取以下结果:
rowkey, id, name ------------------------------- row-01, 001, Adam row-02, 002, Amit row-03 003, Bob
Apache Tajo - 与 Hive 集成
Tajo支持HiveCatalogStore来与Apache Hive集成。此集成允许Tajo访问Apache Hive中的表。
设置环境变量
将以下更改添加到“conf/tajo-env.sh”文件。
$ vi conf/tajo-env.sh export HIVE_HOME = /path/to/hive
包含Hive路径后,Tajo会将Hive库文件设置到classpath。
目录配置
在“conf/catalog-site.xml”文件中添加以下更改。
$ vi conf/catalog-site.xml <property> <name>tajo.catalog.store.class</name> <value>org.apache.tajo.catalog.store.HiveCatalogStore</value> </property>
配置HiveCatalogStore后,就可以在Tajo中访问Hive的表了。
Apache Tajo - OpenStack Swift集成
Swift是一个分布式且一致的对象/Blob存储。Swift提供云存储软件,以便您可以使用简单的API存储和检索大量数据。Tajo支持Swift集成。
以下是Swift集成的先决条件:
- Swift
- Hadoop
core-site.xml
在Hadoop的“core-site.xml”文件中添加以下更改:
<property> <name>fs.swift.impl</name> <value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value> <description>File system implementation for Swift</description> </property> <property> <name>fs.swift.blocksize</name> <value>131072</value> <description>Split size in KB</description> </property>
这将用于Hadoop访问Swift对象。完成所有更改后,移动到Tajo目录以设置Swift环境变量。
conf/tajo-env.sh
打开Tajo配置文件并添加设置环境变量,如下所示:
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jar
现在,Tajo将能够使用Swift查询数据。
创建表
让我们创建一个外部表来访问Tajo中的Swift对象,如下所示:
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';
创建表后,您可以运行SQL查询。
Apache Tajo - JDBC 接口
Apache Tajo提供JDBC接口来连接和执行查询。我们可以使用相同的JDBC接口从基于Java的应用程序连接Tajo。在本节中,让我们了解如何使用JDBC接口在本示例Java应用程序中连接Tajo并执行命令。
下载JDBC驱动程序
访问以下链接下载JDBC驱动程序:https://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar。
现在,“tajo-jdbc-0.11.3.jar”文件已下载到您的计算机上。
设置类路径
要在程序中使用JDBC驱动程序,请按如下方式设置类路径:
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATH
连接到Tajo
Apache Tajo提供JDBC驱动程序作为一个jar文件,它位于@ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar。
连接Apache Tajo的连接字符串格式如下:
jdbc:tajo://host/ jdbc:tajo://host/database jdbc:tajo://host:port/ jdbc:tajo://host:port/database
这里,
host − TajoMaster的主机名。
port − 服务器侦听的端口号。默认端口号为26002。
database − 数据库名称。默认数据库名称为default。
Java应用程序
让我们了解一下Java应用程序。
编码
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo:///default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}
可以使用以下命令编译和运行应用程序。
编译
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.java
执行
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample
结果
以上命令将生成以下结果:
ID: 1; Name: Adam ID: 2; Name: Amit ID: 3; Name: Bob ID: 4; Name: David ID: 5; Name: Esha ID: 6; Name: Ganga ID: 7; Name: Jack ID: 8; Name: Leena ID: 9; Name: Mary ID: 10; Name: Peter
Apache Tajo - 自定义函数
Apache Tajo支持自定义/用户定义函数 (UDF)。自定义函数可以在Python中创建。
自定义函数只是带有装饰器“@output_type(<tajo sql datatype>)”的普通Python函数,如下所示:
@ouput_type(“integer”) def sum_py(a, b): return a + b;
可以通过在“tajosite.xml”中添加以下配置来注册包含UDF的Python脚本。
<property> <name>tajo.function.python.code-dir</name> <value>file:///path/to/script1.py,file:///path/to/script2.py</value> </property>
注册脚本后,重新启动集群,UDF将在SQL查询中可用,如下所示:
select sum_py(10, 10) as pyfn;
Apache Tajo也支持用户定义的聚合函数,但不支持用户定义的窗口函数。