- Avro 基础
- Avro - 首页
- Avro - 概述
- Avro - 序列化
- Avro - 环境设置
- Avro Schema & API
- Avro - Schema
- Avro - 参考 API
- 通过生成类使用 Avro
- 通过生成类进行序列化
- 通过生成类进行反序列化
- 使用解析器库使用 Avro
- 使用解析器进行序列化
- 使用解析器进行反序列化
- Avro 有用资源
- Avro 快速指南
- Avro - 有用资源
- Avro - 讨论
Avro 快速指南
Avro - 概述
为了在网络上传输数据或将其持久存储,您需要序列化数据。在 Java 和 Hadoop 提供的序列化 API 之前,我们有一个特殊的实用程序,称为Avro,这是一种基于模式的序列化技术。
本教程将教您如何使用 Avro 序列化和反序列化数据。Avro 为各种编程语言提供了库。在本教程中,我们将使用 Java 库演示示例。
什么是 Avro?
Apache Avro 是一种与语言无关的数据序列化系统。它由 Hadoop 之父 Doug Cutting 开发。由于 Hadoop 可写类缺乏语言可移植性,因此 Avro 变得非常有用,因为它处理可以由多种语言处理的数据格式。Avro 是在 Hadoop 中序列化数据的首选工具。
Avro 具有基于模式的系统。与语言无关的模式与其读写操作相关联。Avro 序列化具有内置模式的数据。Avro 将数据序列化为紧凑的二进制格式,任何应用程序都可以对其进行反序列化。
Avro 使用 JSON 格式声明数据结构。目前,它支持 Java、C、C++、C#、Python 和 Ruby 等语言。
Avro Schema
Avro 严重依赖其Schema。它允许在没有先验 Schema 知识的情况下写入所有数据。它序列化速度快,并且生成的序列化数据大小更小。Schema 与 Avro 数据一起存储在文件中,以便进一步处理。
在 RPC 中,客户端和服务器在连接期间交换 Schema。此交换有助于在同名字段、缺少字段、额外字段等之间进行通信。
Avro Schema 使用 JSON 定义,这简化了在具有 JSON 库的语言中的实现。
与 Avro 一样,Hadoop 中还有其他序列化机制,例如顺序文件、协议缓冲区和Thrift。
与 Thrift 和 Protocol Buffers 的比较
Thrift 和Protocol Buffers 是 Avro 最有竞争力的库。Avro 在以下方面与这些框架不同:
Avro 根据需要支持动态类型和静态类型。Protocol Buffers 和 Thrift 使用接口定义语言 (IDL) 来指定 Schema 及其类型。这些 IDL 用于生成序列化和反序列化的代码。
Avro 内置于 Hadoop 生态系统中。Thrift 和 Protocol Buffers 未内置于 Hadoop 生态系统中。
与 Thrift 和 Protocol Buffer 不同,Avro 的 Schema 定义使用 JSON,而不是任何专有的 IDL。
| 属性 | Avro | Thrift & Protocol Buffer |
|---|---|---|
| 动态 Schema | 是 | 否 |
| 内置于 Hadoop | 是 | 否 |
| Schema 使用 JSON | 是 | 否 |
| 无需编译 | 是 | 否 |
| 无需声明 ID | 是 | 否 |
| 前沿技术 | 是 | 否 |
Avro 的特性
下面列出了一些 Avro 的主要特性:
Avro 是一种与语言无关的数据序列化系统。
它可以被多种语言处理(目前包括 C、C++、C#、Java、Python 和 Ruby)。
Avro 创建二进制结构化格式,该格式既可压缩又可分割。因此,它可以有效地用作 Hadoop MapReduce 作业的输入。
Avro 提供丰富的 数据结构。例如,您可以创建一个包含数组、枚举类型和子记录的记录。这些数据类型可以在任何语言中创建,可以在 Hadoop 中处理,并且结果可以馈送到第三种语言。
Avro Schema 使用JSON 定义,这便于在已具有 JSON 库的语言中实现。
Avro 创建一个名为Avro 数据文件的自描述文件,其中它将数据及其 Schema 存储在元数据部分。
Avro 也用于远程过程调用 (RPC)。在 RPC 期间,客户端和服务器在连接握手期间交换 Schema。
Avro 的一般工作原理
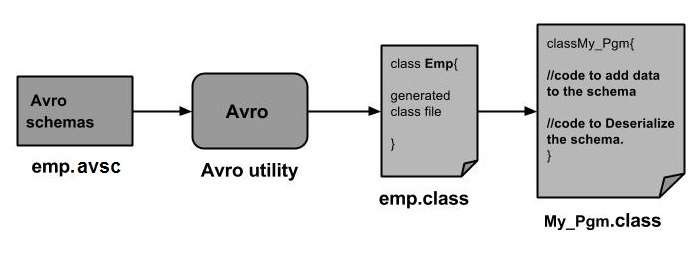
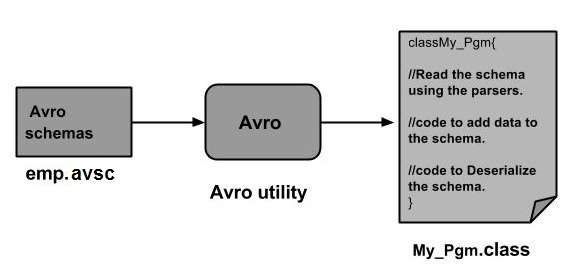
要使用 Avro,您需要遵循以下工作流程:
步骤 1 - 创建 Schema。在这里,您需要根据您的数据设计 Avro Schema。
步骤 2 - 将 Schema 读取到您的程序中。这可以通过两种方式完成:
通过生成与 Schema 对应的类 - 使用 Avro 编译 Schema。这将生成与 Schema 对应的类文件
通过使用解析器库 - 您可以使用解析器库直接读取 Schema。
步骤 3 - 使用 Avro 提供的序列化 API 序列化数据,该 API 位于包 org.apache.avro.specific 中。
步骤 4 - 使用 Avro 提供的反序列化 API 反序列化数据,该 API 位于包 org.apache.avro.specific 中。
Avro - 序列化
数据序列化有两个目的:
用于持久存储
在网络上传输数据
什么是序列化?
序列化是将数据结构或对象状态转换为二进制或文本形式以在网络上传输数据或存储在某些持久存储中的过程。一旦数据通过网络传输或从持久存储中检索,就需要再次对其进行反序列化。序列化称为封送,反序列化称为解封送。
Java 中的序列化
Java 提供了一种称为对象序列化的机制,其中对象可以表示为字节序列,其中包括对象的数据以及有关对象类型和存储在对象中的数据类型的信息。
将序列化后的对象写入文件后,可以从文件中读取并反序列化。也就是说,表示对象及其数据类型信息和字节可用于在内存中重新创建对象。
ObjectInputStream 和ObjectOutputStream 类分别用于在 Java 中序列化和反序列化对象。
Hadoop 中的序列化
通常在像 Hadoop 这样的分布式系统中,序列化的概念用于进程间通信和持久存储。
进程间通信
为了建立连接到网络中的节点之间的进程间通信,使用了 RPC 技术。
RPC 使用内部序列化在将消息发送到远程节点之前将其转换为二进制格式。在另一端,远程系统将二进制流反序列化为原始消息。
RPC 序列化格式需要如下所示:
紧凑 - 以最佳方式利用网络带宽,这是数据中心中最稀缺的资源。
快速 - 由于节点之间的通信在分布式系统中至关重要,因此序列化和反序列化过程应快速,产生较少的开销。
可扩展 - 协议会随着时间的推移而发生变化以满足新的需求,因此应该能够以受控的方式轻松地发展客户端和服务器的协议。
互操作性 - 消息格式应支持用不同语言编写的节点。
持久存储
持久存储是一种数字存储设施,不会因电源供应中断而丢失数据。文件、文件夹、数据库是持久存储的示例。
Writable 接口
这是 Hadoop 中提供序列化和反序列化方法的接口。下表描述了这些方法:
| 序号 | 方法和描述 |
|---|---|
| 1 | void readFields(DataInput in) 此方法用于反序列化给定对象的字段。 |
| 2 | void write(DataOutput out) 此方法用于序列化给定对象的字段。 |
Writable Comparable 接口
它是Writable 和Comparable 接口的组合。此接口继承了 Hadoop 的Writable 接口以及 Java 的Comparable 接口。因此,它提供了数据序列化、反序列化和比较的方法。
| 序号 | 方法和描述 |
|---|---|
| 1 | int compareTo(class obj) 此方法将当前对象与给定对象 obj 进行比较。 |
除了这些类之外,Hadoop 还支持许多实现 WritableComparable 接口的包装类。每个类都包装了一个 Java 基本类型。Hadoop 序列化的类层次结构如下所示:
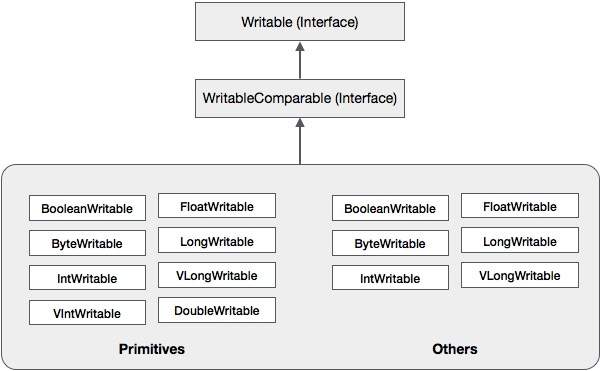
这些类可用于在 Hadoop 中序列化各种类型的数据。例如,让我们考虑IntWritable 类。让我们看看如何使用此类在 Hadoop 中序列化和反序列化数据。
IntWritable 类
此类实现了Writable、Comparable 和WritableComparable 接口。它在其内部包装了一个整数数据类型。此类提供用于序列化和反序列化整数类型数据的方法。
构造函数
| 序号 | 摘要 |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
方法
| 序号 | 摘要 |
|---|---|
| 1 | int get() 使用此方法,您可以获取当前对象中存在的整数值。 |
| 2 | void readFields(DataInput in) 此方法用于反序列化给定DataInput 对象中的数据。 |
| 3 | void set(int value) 此方法用于设置当前IntWritable 对象的值。 |
| 4 | void write(DataOutput out) 此方法用于将当前对象中的数据序列化到给定的DataOutput 对象。 |
在 Hadoop 中序列化数据
下面讨论了序列化整数类型数据的过程。
通过在其内部包装一个整数值来实例化IntWritable 类。
实例化ByteArrayOutputStream 类。
实例化DataOutputStream 类并将ByteArrayOutputStream 类的对象传递给它。
使用write() 方法序列化 IntWritable 对象中的整数值。此方法需要一个 DataOutputStream 类的对象。
序列化后的数据将存储在作为参数传递给DataOutputStream 类(在实例化时)的字节数组对象中。将对象中的数据转换为字节数组。
示例
以下示例显示了如何在 Hadoop 中序列化整数类型的数据:
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}
在 Hadoop 中反序列化数据
下面讨论了反序列化整数类型数据的过程:
通过在其内部包装一个整数值来实例化IntWritable 类。
实例化ByteArrayOutputStream 类。
实例化DataOutputStream 类并将ByteArrayOutputStream 类的对象传递给它。
使用 IntWritable 类的readFields() 方法反序列化DataInputStream 对象中的数据。
反序列化后的数据将存储在 IntWritable 类的对象中。您可以使用此类的get() 方法检索此数据。
示例
以下示例显示了如何在 Hadoop 中反序列化整数类型的数据:
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}
Hadoop 相对于 Java 序列化的优势
Hadoop 基于 Writable 的序列化能够通过重用 Writable 对象来减少对象创建开销,这在 Java 的原生序列化框架中是不可能的。
Hadoop 序列化的缺点
要序列化 Hadoop 数据,有两种方法:
您可以使用 Hadoop 原生库提供的Writable 类。
您还可以使用顺序文件,这些文件以二进制格式存储数据。
这两种机制的主要缺点是Writable 和顺序文件仅具有 Java API,并且无法用任何其他语言编写或读取。
因此,使用上述两种机制在 Hadoop 中创建的任何文件都无法被任何其他第三方语言读取,这使得 Hadoop 成为一个有限的盒子。为了解决此缺点,Doug Cutting 创建了Avro,这是一种与语言无关的数据结构。
Avro - 环境设置
Apache 软件基金会为 Avro 提供了各种版本。您可以从 Apache 镜像下载所需的版本。让我们看看如何设置环境以使用 Avro -
下载 Avro
要下载 Apache Avro,请执行以下操作 -
打开网页 Apache.org。您将看到 Apache Avro 的主页,如下所示 -
点击 project → releases。您将获得一个版本列表。
选择最新版本,这将引导您到一个下载链接。
mirror.nexcess 是您可以找到 Avro 支持的所有不同语言库列表的链接之一,如下所示 -
您可以选择并下载任何提供的语言的库。在本教程中,我们使用 Java。因此,下载 jar 文件 avro-1.7.7.jar 和 avro-tools-1.7.7.jar。
使用 Eclipse 的 Avro
要在 Eclipse 环境中使用 Avro,您需要按照以下步骤操作 -
步骤 1. 打开 Eclipse。
步骤 2. 创建一个项目。
步骤 3. 右键单击项目名称。您将获得一个快捷菜单。
步骤 4. 点击Build Path。它将引导您到另一个快捷菜单。
步骤 5. 点击Configure Build Path... 您可以看到项目的属性窗口,如下所示 -
步骤 6. 在库选项卡下,点击ADD EXternal JARs... 按钮。
步骤 7. 选择您下载的 jar 文件 avro-1.77.jar。
步骤 8. 点击OK。
使用 Maven 的 Avro
您也可以使用 Maven 将 Avro 库引入您的项目。以下是 Avro 的 pom.xml 文件。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Test</groupId>
<artifactId>Test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-tools</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.0-beta9</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.0-beta9</version>
</dependency>
</dependencies>
</project>
设置类路径
要在 Linux 环境中使用 Avro,请下载以下 jar 文件 -
- avro-1.77.jar
- avro-tools-1.77.jar
- log4j-api-2.0-beta9.jar
- log4j-core-2.0.beta9.jar。
将这些文件复制到一个文件夹中,并在 ./bashrc 文件中将类路径设置为该文件夹,如下所示。
#class path for Avro export CLASSPATH=$CLASSPATH://home/Hadoop/Avro_Work/jars/*
Avro - Schema
Avro 作为一种基于模式的序列化实用程序,接受模式作为输入。尽管有各种模式可用,但 Avro 遵循其自身的模式定义标准。这些模式描述以下详细信息 -
- 文件类型(默认为记录)
- 记录的位置
- 记录的名称
- 记录中的字段及其对应的数据类型
使用这些模式,您可以使用更少的空间以二进制格式存储序列化值。这些值存储时没有任何元数据。
创建 Avro 模式
Avro 模式以 JavaScript 对象表示法 (JSON) 文档格式创建,这是一种轻量级的基于文本的数据交换格式。它可以通过以下几种方式创建 -
- JSON 字符串
- JSON 对象
- JSON 数组
示例 - 下面的示例显示了一个模式,该模式在名称空间 Tutorialspoint 下定义了一个文档,名称为 Employee,具有 name 和 age 字段。
{
"type" : "record",
"namespace" : "Tutorialspoint",
"name" : "Employee",
"fields" : [
{ "name" : "Name" , "type" : "string" },
{ "name" : "Age" , "type" : "int" }
]
}
在此示例中,您可以观察到每个记录有四个字段 -
type - 此字段位于文档下以及名为 fields 的字段下。
在文档的情况下,它显示文档的类型,通常是记录,因为有多个字段。
当它是字段时,type 描述数据类型。
namespace - 此字段描述对象所在的名称空间的名称。
name - 此字段位于文档下以及名为 fields 的字段下。
在文档的情况下,它描述模式名称。此模式名称与名称空间一起唯一标识存储中的模式(Namespace.schema name)。在上面的示例中,模式的全名将是 Tutorialspoint.Employee。
在字段的情况下,它描述字段的名称。
Avro 的基本数据类型
Avro 模式具有基本数据类型和复杂数据类型。下表描述了 Avro 的基本数据类型 -
| 数据类型 | 描述 |
|---|---|
| null | Null 是一种没有值的类型。 |
| int | 32 位有符号整数。 |
| long | 64 位有符号整数。 |
| float | 单精度 (32 位) IEEE 754 浮点数。 |
| double | 双精度 (64 位) IEEE 754 浮点数。 |
| bytes | 8 位无符号字节序列。 |
| string | Unicode 字符序列。 |
Avro 的复杂数据类型
除了基本数据类型之外,Avro 还提供了六种复杂数据类型,即记录、枚举、数组、映射、联合和固定。
记录
Avro 中的记录数据类型是多个属性的集合。它支持以下属性 -
name - 此字段的值保存记录的名称。
namespace - 此字段的值保存对象存储的名称空间的名称。
type - 此属性的值保存文档(记录)的类型或模式中字段的数据类型。
fields - 此字段保存一个 JSON 数组,其中包含模式中所有字段的列表,每个字段都具有 name 和 type 属性。
示例
下面是记录的示例。
{
" type " : "record",
" namespace " : "Tutorialspoint",
" name " : "Employee",
" fields " : [
{ "name" : " Name" , "type" : "string" },
{ "name" : "age" , "type" : "int" }
]
}
枚举
枚举是集合中项目的列表,Avro 枚举支持以下属性 -
name - 此字段的值保存枚举的名称。
namespace - 此字段的值包含限定枚举名称的字符串。
symbols - 此字段的值保存枚举的符号,作为名称数组。
示例
下面是枚举的示例。
{
"type" : "enum",
"name" : "Numbers",
"namespace": "data",
"symbols" : [ "ONE", "TWO", "THREE", "FOUR" ]
}
数组
此数据类型定义了一个数组字段,该字段具有单个属性 items。此 items 属性指定数组中项目的类型。
示例
{ " type " : " array ", " items " : " int " }
映射
映射数据类型是键值对的数组,它将数据组织为键值对。Avro 映射的键必须是字符串。映射的值保存映射内容的数据类型。
示例
{"type" : "map", "values" : "int"}
联合
当字段具有一个或多个数据类型时,使用联合数据类型。它们表示为 JSON 数组。例如,如果一个字段可以是 int 或 null,则联合表示为 ["int", "null"]。
示例
下面是使用联合的示例文档 -
{
"type" : "record",
"namespace" : "tutorialspoint",
"name" : "empdetails ",
"fields" :
[
{ "name" : "experience", "type": ["int", "null"] }, { "name" : "age", "type": "int" }
]
}
固定
此数据类型用于声明一个固定大小的字段,该字段可用于存储二进制数据。它具有字段名称和数据作为属性。Name 保存字段的名称,size 保存字段的大小。
示例
{ "type" : "fixed" , "name" : "bdata", "size" : 1048576}
Avro - 参考 API
在上一章中,我们描述了 Avro 的输入类型,即 Avro 模式。在本章中,我们将解释 Avro 模式序列化和反序列化中使用的类和方法。
SpecificDatumWriter 类
此类属于包 org.apache.avro.specific。它实现了 DatumWriter 接口,该接口将 Java 对象转换为内存中的序列化格式。
构造函数
| 序号 | 描述 |
|---|---|
| 1 | SpecificDatumWriter(Schema schema) |
方法
| 序号 | 描述 |
|---|---|
| 1 | SpecificData getSpecificData() 返回此写入器使用的 SpecificData 实现。 |
SpecificDatumReader 类
此类属于包 org.apache.avro.specific。它实现了 DatumReader 接口,该接口读取模式的数据并确定内存中的数据表示。SpecificDatumReader 是支持生成的 Java 类的类。
构造函数
| 序号 | 描述 |
|---|---|
| 1 | SpecificDatumReader(Schema schema) 写入器和读取器的模式相同的构造。 |
方法
| 序号 | 描述 |
|---|---|
| 1 | SpecificData getSpecificData() 返回包含的 SpecificData。 |
| 2 | void setSchema(Schema actual) 此方法用于设置写入器的模式。 |
DataFileWriter
为emp 类实例化DataFileWrite。此类将符合模式的数据的序列化记录序列以及模式写入文件。
构造函数
| 序号 | 描述 |
|---|---|
| 1 | DataFileWriter(DatumWriter<D> dout) |
方法
| 序号 | 描述 |
|---|---|
| 1 | void append(D datum) 将数据追加到文件。 |
| 2 | DataFileWriter<D> appendTo(File file) 此方法用于打开一个追加到现有文件的写入器。 |
Data FileReader
此类提供对使用DataFileWriter写入的文件的随机访问。它继承了类DataFileStream。
构造函数
| 序号 | 描述 |
|---|---|
| 1 | DataFileReader(File file, DatumReader<D> reader)) |
方法
| 序号 | 描述 |
|---|---|
| 1 | next() 读取文件中下一个数据。 |
| 2 | Boolean hasNext() 如果此文件中还有更多条目,则返回 true。 |
Class Schema.parser
此类是 JSON 格式模式的解析器。它包含解析模式的方法。它属于org.apache.avro包。
构造函数
| 序号 | 描述 |
|---|---|
| 1 | Schema.Parser() |
方法
| 序号 | 描述 |
|---|---|
| 1 | parse (File file) 解析给定file中提供的模式。 |
| 2 | parse (InputStream in) 解析给定InputStream中提供的模式。 |
| 3 | parse (String s) 解析给定String中提供的模式。 |
接口 GenricRecord
此接口提供通过名称和索引访问字段的方法。
方法
| 序号 | 描述 |
|---|---|
| 1 | Object get(String key) 返回给定字段的值。 |
| 2 | void put(String key, Object v) 设置给定名称的字段的值。 |
Class GenericData.Record
构造函数
| 序号 | 描述 |
|---|---|
| 1 | GenericData.Record(Schema schema) |
方法
| 序号 | 描述 |
|---|---|
| 1 | Object get(String key) 返回给定名称的字段的值。 |
| 2 | Schema getSchema() 返回此实例的模式。 |
| 3 | void put(int i, Object v) 设置给定模式中位置的字段的值。 |
| 4 | void put(String key, Object value) 设置给定名称的字段的值。 |
AVRO - 通过生成类进行序列化
可以通过生成与模式对应的类或使用解析器库将 Avro 模式读入程序。本章介绍如何通过生成类并序列化数据来读取模式。
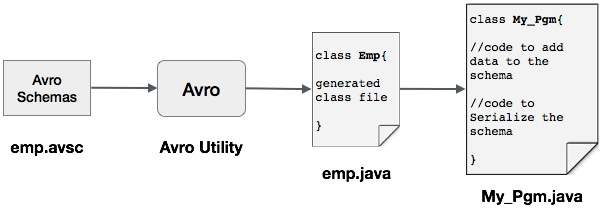
通过生成类进行序列化
要使用 Avro 序列化数据,请按照以下步骤操作 -
编写 Avro 模式。
使用 Avro 实用程序编译模式。您将获得与该模式对应的 Java 代码。
使用数据填充模式。
使用 Avro 库对其进行序列化。
定义模式
假设您想要一个具有以下详细信息的模式 -
| 字段 | 名称 | id | age | salary | address |
| 类型 | String | int | int | int | string |
创建 Avro 模式,如下所示。
将其保存为emp.avsc。
{
"namespace": "tutorialspoint.com",
"type": "record",
"name": "emp",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}
编译模式
创建 Avro 模式后,您需要使用 Avro 工具编译创建的模式。avro-tools-1.7.7.jar 是包含工具的 jar 文件。
编译 Avro 模式的语法
java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>
在主文件夹中打开终端。
创建一个新目录以使用 Avro,如下所示 -
$ mkdir Avro_Work
在新创建的目录中,创建三个子目录 -
第一个名为schema,用于放置模式。
第二个名为with_code_gen,用于放置生成的代码。
第三个名为jars,用于放置 jar 文件。
$ mkdir schema $ mkdir with_code_gen $ mkdir jars
以下屏幕截图显示了创建所有目录后您的Avro_work文件夹应如何显示。
现在/home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar 是您下载 avro-tools-1.7.7.jar 文件的目录的路径。
/home/Hadoop/Avro_work/schema/ 是存储模式文件 emp.avsc 的目录的路径。
/home/Hadoop/Avro_work/with_code_gen 是您希望将生成的类文件存储到的目录。
现在编译模式,如下所示 -
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_gen
编译完成后,将在目标目录中根据架构名称空间创建一个包。在此包中,将创建具有架构名称的 Java 源代码。此生成的源代码是给定架构的 Java 代码,可直接在应用程序中使用。
例如,在此示例中,创建了一个名为tutorialspoint的包/文件夹,其中包含另一个名为 com 的文件夹(因为名称空间是 tutorialspoint.com),并且在其中,您可以看到生成的emp.java文件。以下快照显示了emp.java -
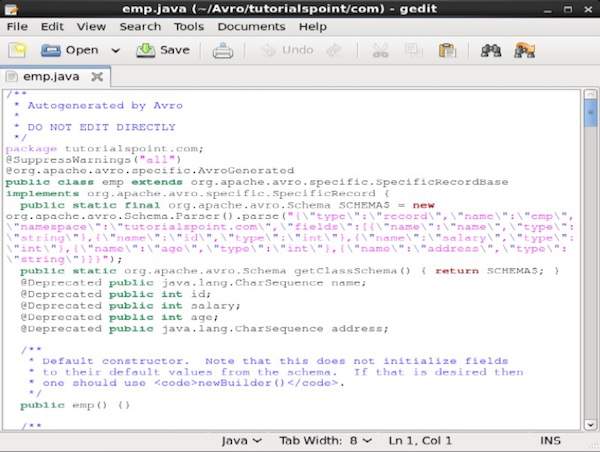
此类用于根据架构创建数据。
生成的类包含 -
- 默认构造函数和参数化构造函数,接受架构的所有变量。
- 架构中所有变量的 setter 和 getter 方法。
- 返回架构的 Get() 方法。
- 构建器方法。
创建和序列化数据
首先,将此项目中使用的生成的 java 文件复制到当前目录或从其所在位置导入。
现在,我们可以编写一个新的 Java 文件并在生成的 emp 文件中实例化类,以将员工数据添加到架构中。
让我们看看使用 apache Avro 根据架构创建数据的过程。
步骤 1
实例化生成的 emp 类。
emp e1=new emp( );
步骤 2
使用 setter 方法插入第一个员工的数据。例如,我们创建了名为 Omar 的员工的详细信息。
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
类似地,使用 setter 方法填写所有员工详细信息。
步骤 3
使用 SpecificDatumWriter 类创建 DatumWriter 接口的对象。这将 Java 对象转换为内存中的序列化格式。以下示例为 emp 类实例化 SpecificDatumWriter 类对象。
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
步骤 4
为 emp 类实例化 DataFileWriter。此类将符合架构的一系列序列化数据记录(以及架构本身)写入文件。此类需要 DatumWriter 对象作为构造函数的参数。
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
步骤 5
使用 create() 方法打开一个新文件以存储与给定架构匹配的数据。此方法需要架构和存储数据的文件路径作为参数。
在以下示例中,使用 getSchema() 方法传递架构,并将数据文件存储在路径 /home/Hadoop/Avro/serialized_file/emp.avro 中。
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));
步骤 6
使用 append() 方法将所有创建的记录添加到文件中,如下所示 -
empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3);
示例 – 通过生成类进行序列化
以下完整程序演示了如何使用 Apache Avro 将数据序列化到文件中 -
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
public class Serialize {
public static void main(String args[]) throws IOException{
//Instantiating generated emp class
emp e1=new emp();
//Creating values according the schema
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
emp e2=new emp();
e2.setName("ram");
e2.setAge(30);
e2.setSalary(40000);
e2.setAddress("Hyderabad");
e2.setId(002);
emp e3=new emp();
e3.setName("robbin");
e3.setAge(25);
e3.setSalary(35000);
e3.setAddress("Hyderabad");
e3.setId(003);
//Instantiate DatumWriter class
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro"));
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);
empFileWriter.close();
System.out.println("data successfully serialized");
}
}
浏览放置生成代码的目录。在本例中,位于home/Hadoop/Avro_work/with_code_gen。
在终端中 -
$ cd home/Hadoop/Avro_work/with_code_gen/
在 GUI 中 -
现在将上述程序复制并保存到名为 Serialize.java 的文件中
编译并执行它,如下所示 -
$ javac Serialize.java $ java Serialize
输出
data successfully serialized
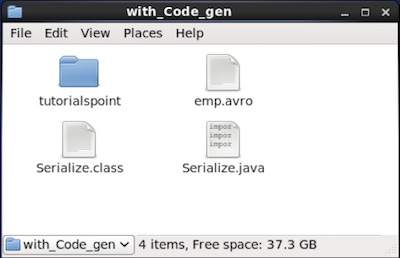
如果您验证程序中给定的路径,您会发现生成的序列化文件,如下所示。
AVRO - 通过生成类进行反序列化
如前所述,可以通过生成与架构对应的类或使用解析器库将 Avro 架构读入程序。本章介绍如何通过生成类读取架构并使用 Avro反序列化数据。
通过生成类进行反序列化
序列化数据存储在文件 emp.avro 中。您可以使用 Avro 反序列化并读取它。
请按照以下步骤从文件中反序列化序列化数据。
步骤 1
使用 SpecificDatumReader 类创建 DatumReader 接口的对象。
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);
步骤 2
为 emp 类实例化 DataFileReader。此类从文件中读取序列化数据。它需要 Dataumeader 对象和存在序列化数据的文件的路径作为构造函数的参数。
DataFileReader<emp> dataFileReader = new DataFileReader(new File("/path/to/emp.avro"), empDatumReader);
步骤 3
使用 DataFileReader 的方法打印反序列化的数据。
如果 Reader 中有任何元素,hasNext() 方法将返回一个布尔值。
DataFileReader 的 next() 方法返回 Reader 中的数据。
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
示例 – 通过生成类进行反序列化
以下完整程序演示了如何使用 Avro 反序列化文件中的数据。
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.io.DatumReader;
import org.apache.avro.specific.SpecificDatumReader;
public class Deserialize {
public static void main(String args[]) throws IOException{
//DeSerializing the objects
DatumReader<emp> empDatumReader = new SpecificDatumReader<emp>(emp.class);
//Instantiating DataFileReader
DataFileReader<emp> dataFileReader = new DataFileReader<emp>(new
File("/home/Hadoop/Avro_Work/with_code_genfile/emp.avro"), empDatumReader);
emp em=null;
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
}
}
浏览放置生成代码的目录。在本例中,位于home/Hadoop/Avro_work/with_code_gen。
$ cd home/Hadoop/Avro_work/with_code_gen/
现在,将上述程序复制并保存到名为 DeSerialize.java 的文件中。编译并执行它,如下所示 -
$ javac Deserialize.java $ java Deserialize
输出
{"name": "omar", "id": 1, "salary": 30000, "age": 21, "address": "Hyderabad"}
{"name": "ram", "id": 2, "salary": 40000, "age": 30, "address": "Hyderabad"}
{"name": "robbin", "id": 3, "salary": 35000, "age": 25, "address": "Hyderabad"}
AVRO - 使用解析器进行序列化
可以通过生成与架构对应的类或使用解析器库将 Avro 架构读入程序。在 Avro 中,数据始终与其对应的架构一起存储。因此,我们始终可以在没有代码生成的情况下读取架构。
本章介绍如何使用解析器库读取架构并使用 Avro序列化数据。
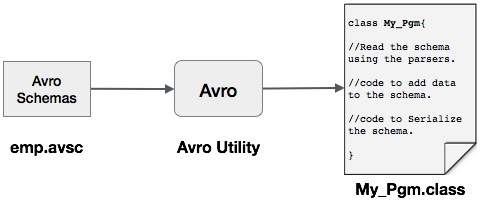
使用解析器库进行序列化
要序列化数据,我们需要读取架构,根据架构创建数据,并使用 Avro API 序列化架构。以下过程在不生成任何代码的情况下序列化数据 -
步骤 1
首先,从文件中读取架构。为此,请使用 Schema.Parser 类。此类提供方法以不同格式解析架构。
通过传递存储架构的文件路径来实例化 Schema.Parser 类。
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));
步骤 2
通过实例化 GenericData.Record 类来创建 GenericRecord 接口的对象,如下所示。将上面创建的架构对象传递给它的构造函数。
GenericRecord e1 = new GenericData.Record(schema);
步骤 3
使用 GenericData 类的 put() 方法在架构中插入值。
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chennai");
步骤 4
使用 SpecificDatumWriter 类创建 DatumWriter 接口的对象。它将 Java 对象转换为内存中的序列化格式。以下示例为 emp 类实例化 SpecificDatumWriter 类对象 -
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
步骤 5
为 emp 类实例化 DataFileWriter。此类将符合架构的一系列序列化数据记录(以及架构本身)写入文件。此类需要 DatumWriter 对象作为构造函数的参数。
DataFileWriter<emp> dataFileWriter = new DataFileWriter<emp>(empDatumWriter);
步骤 6
使用 create() 方法打开一个新文件以存储与给定架构匹配的数据。此方法需要架构和存储数据的文件路径作为参数。
在下面给出的示例中,使用 getSchema() 方法传递架构,并将数据文件存储在路径
/home/Hadoop/Avro/serialized_file/emp.avro 中。
empFileWriter.create(e1.getSchema(), new
File("/home/Hadoop/Avro/serialized_file/emp.avro"));
步骤 7
使用 append( ) 方法将所有创建的记录添加到文件中,如下所示。
empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3);
示例 – 使用解析器进行序列化
以下完整程序演示了如何使用解析器序列化数据 -
import java.io.File;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
public class Seriali {
public static void main(String args[]) throws IOException{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
//Instantiating the GenericRecord class.
GenericRecord e1 = new GenericData.Record(schema);
//Insert data according to schema
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chenni");
GenericRecord e2 = new GenericData.Record(schema);
e2.put("name", "rahman");
e2.put("id", 002);
e2.put("salary", 35000);
e2.put("age", 30);
e2.put("address", "Delhi");
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, new File("/home/Hadoop/Avro_work/without_code_gen/mydata.txt"));
dataFileWriter.append(e1);
dataFileWriter.append(e2);
dataFileWriter.close();
System.out.println(“data successfully serialized”);
}
}
浏览放置生成代码的目录。在本例中,位于home/Hadoop/Avro_work/without_code_gen。
$ cd home/Hadoop/Avro_work/without_code_gen/
现在将上述程序复制并保存到名为 Serialize.java 的文件中。编译并执行它,如下所示 -
$ javac Serialize.java $ java Serialize
输出
data successfully serialized
如果您验证程序中给定的路径,您会发现生成的序列化文件,如下所示。
AVRO - 使用解析器进行反序列化
如前所述,可以通过生成与架构对应的类或使用解析器库将 Avro 架构读入程序。在 Avro 中,数据始终与其对应的架构一起存储。因此,我们始终可以在没有代码生成的情况下读取序列化项。
本章介绍如何使用解析器库读取架构并使用 Avro反序列化数据。
使用解析器库进行反序列化
序列化数据存储在文件 mydata.txt 中。您可以使用 Avro 反序列化并读取它。
请按照以下步骤从文件中反序列化序列化数据。
步骤 1
首先,从文件中读取架构。为此,请使用 Schema.Parser 类。此类提供方法以不同格式解析架构。
通过传递存储架构的文件路径来实例化 Schema.Parser 类。
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));
步骤 2
使用 SpecificDatumReader 类创建 DatumReader 接口的对象。
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);
步骤 3
实例化 DataFileReader 类。此类从文件中读取序列化数据。它需要 DatumReader 对象和存在序列化数据的文件的路径作为构造函数的参数。
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/path/to/mydata.txt"), datumReader);
步骤 4
使用 DataFileReader 的方法打印反序列化的数据。
如果 Reader 中有任何元素,hasNext() 方法将返回一个布尔值。
DataFileReader 的 next() 方法返回 Reader 中的数据。
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
示例 – 使用解析器库进行反序列化
以下完整程序演示了如何使用解析器库反序列化序列化数据 -
public class Deserialize {
public static void main(String args[]) throws Exception{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/home/Hadoop/Avro_Work/without_code_gen/mydata.txt"), datumReader);
GenericRecord emp = null;
while (dataFileReader.hasNext()) {
emp = dataFileReader.next(emp);
System.out.println(emp);
}
System.out.println("hello");
}
}
浏览放置生成代码的目录。在本例中,位于home/Hadoop/Avro_work/without_code_gen。
$ cd home/Hadoop/Avro_work/without_code_gen/
现在将上述程序复制并保存到名为 DeSerialize.java 的文件中。编译并执行它,如下所示 -
$ javac Deserialize.java $ java Deserialize
输出
{"name": "ramu", "id": 1, "salary": 30000, "age": 25, "address": "chennai"}
{"name": "rahman", "id": 2, "salary": 35000, "age": 30, "address": "Delhi"}