- AVRO 基础
- AVRO - 首页
- AVRO - 概述
- AVRO - 序列化
- AVRO - 环境搭建
- AVRO 架构 & API
- AVRO - 架构
- AVRO - 参考 API
- 通过生成类使用 AVRO
- 通过生成类进行序列化
- 通过生成类进行反序列化
- 使用解析器库的 AVRO
- 使用解析器进行序列化
- 使用解析器进行反序列化
- AVRO 有用资源
- AVRO - 快速指南
- AVRO - 有用资源
- AVRO - 讨论
AVRO - 通过生成类进行序列化
可以通过生成与架构相对应的类或使用解析器库来将 Avro 架构读入程序。本章描述了如何通过生成类并使用 Avro序列化数据。
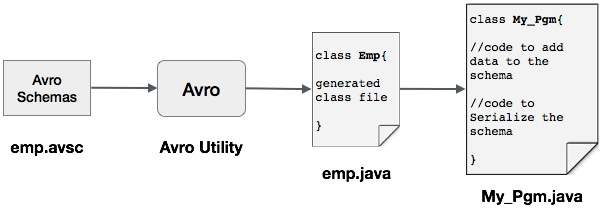
通过生成类进行序列化
要使用 Avro 序列化数据,请按照以下步骤操作:
编写 Avro 架构。
使用 Avro 工具编译架构。您将获得与该架构相对应的 Java 代码。
使用数据填充架构。
使用 Avro 库进行序列化。
定义架构
假设您需要一个包含以下详细信息的架构:
| 字段 | 名称 | id | age | salary | address |
| 类型 | 字符串 | 整数 | 整数 | 整数 | 字符串 |
创建如下所示的 Avro 架构。
将其保存为emp.avsc。
{
"namespace": "tutorialspoint.com",
"type": "record",
"name": "emp",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}
编译架构
创建 Avro 架构后,需要使用 Avro 工具编译创建的架构。avro-tools-1.7.7.jar 是包含这些工具的 jar 文件。
编译 Avro 架构的语法
java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>
在主文件夹中打开终端。
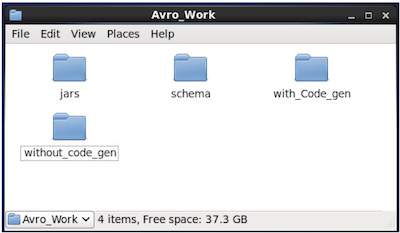
创建一个新的目录来使用 Avro,如下所示:
$ mkdir Avro_Work
在新创建的目录中,创建三个子目录:
第一个名为schema,用于放置架构。
第二个名为with_code_gen,用于放置生成的代码。
第三个名为jars,用于放置 jar 文件。
$ mkdir schema $ mkdir with_code_gen $ mkdir jars
以下屏幕截图显示了创建所有目录后Avro_work文件夹的外观。
现在/home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar 是您下载 avro-tools-1.7.7.jar 文件的目录的路径。
/home/Hadoop/Avro_work/schema/ 是存储架构文件 emp.avsc 的目录的路径。
/home/Hadoop/Avro_work/with_code_gen 是您希望将生成的类文件存储到的目录。
现在编译架构,如下所示:
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_gen
编译后,将在目标目录中根据架构的命名空间创建一个包。在此包中,将创建具有架构名称的 Java 源代码。此生成的源代码是给定架构的 Java 代码,可以直接在应用程序中使用。
例如,在此实例中,将创建一个名为tutorialspoint的包/文件夹,其中包含另一个名为 com 的文件夹(因为命名空间是 tutorialspoint.com),在其中,您可以观察到生成的emp.java文件。以下快照显示了emp.java:
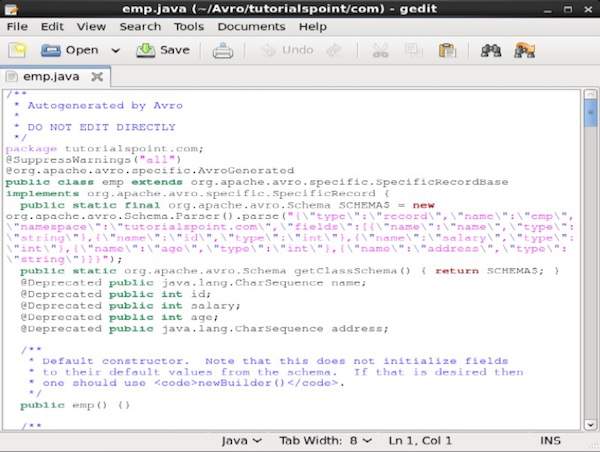
此类可用于根据架构创建数据。
生成的类包含:
- 默认构造函数和参数化构造函数,它们接受架构的所有变量。
- 架构中所有变量的 setter 和 getter 方法。
- 返回架构的 Get() 方法。
- 构建器方法。
创建和序列化数据
首先,将本项目中使用的生成 Java 文件复制到当前目录,或从其所在位置导入。
现在,我们可以编写一个新的 Java 文件并在生成的emp文件(类)中实例化该类,以将员工数据添加到架构中。
让我们看看使用 Apache Avro 根据架构创建数据的过程。
步骤 1
实例化生成的emp类。
emp e1=new emp( );
步骤 2
使用 setter 方法插入第一个员工的数据。例如,我们创建了名为 Omar 的员工的详细信息。
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
同样,使用 setter 方法填写所有员工的详细信息。
步骤 3
使用SpecificDatumWriter类创建DatumWriter接口的对象。这会将 Java 对象转换为内存中的序列化格式。以下示例为emp类实例化SpecificDatumWriter类对象。
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
步骤 4
为emp类实例化DataFileWriter。此类在文件中写入符合架构的数据的序列化记录序列,以及架构本身。此类需要DatumWriter对象作为构造函数的参数。
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
步骤 5
使用create()方法打开一个新文件以存储与给定架构匹配的数据。此方法需要架构和数据要存储到的文件的路径作为参数。
在以下示例中,使用getSchema()方法传递架构,并将数据文件存储在路径/home/Hadoop/Avro/serialized_file/emp.avro中。
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));
步骤 6
使用append()方法将所有创建的记录添加到文件中,如下所示:
empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3);
示例 - 通过生成类进行序列化
以下完整程序演示了如何使用 Apache Avro 将数据序列化到文件中:
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
public class Serialize {
public static void main(String args[]) throws IOException{
//Instantiating generated emp class
emp e1=new emp();
//Creating values according the schema
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
emp e2=new emp();
e2.setName("ram");
e2.setAge(30);
e2.setSalary(40000);
e2.setAddress("Hyderabad");
e2.setId(002);
emp e3=new emp();
e3.setName("robbin");
e3.setAge(25);
e3.setSalary(35000);
e3.setAddress("Hyderabad");
e3.setId(003);
//Instantiate DatumWriter class
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro"));
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);
empFileWriter.close();
System.out.println("data successfully serialized");
}
}
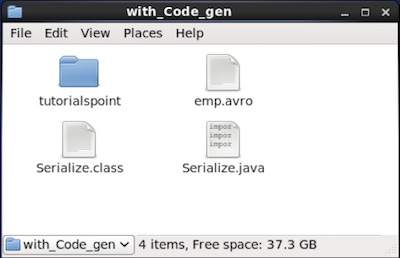
浏览放置生成代码的目录。在本例中,位于home/Hadoop/Avro_work/with_code_gen。
在终端中:
$ cd home/Hadoop/Avro_work/with_code_gen/
在 GUI 中:
现在复制并将上述程序保存到名为Serialize.java的文件中。
编译并执行它,如下所示:
$ javac Serialize.java $ java Serialize
输出
data successfully serialized
如果您验证程序中给定的路径,则可以找到如下所示的生成的序列化文件。