
 数据结构
数据结构 网络
网络 关系型数据库管理系统 (RDBMS)
关系型数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPSeaborn能否用于执行数据的计算,例如均值或标准差?
Seaborn主要是一个数据可视化库,它不提供直接执行数据计算的方法,例如计算均值或标准差。但是,Seaborn可以与pandas库无缝协作,pandas是Python中一个强大的数据处理库。您可以使用pandas对数据进行计算,然后使用Seaborn可视化计算结果。
均值是一种统计度量,表示一组数字的平均值。它是通过将集合中的所有数字加起来,然后将总和除以数字的总数来计算的。
标准差是一种统计度量,用于量化一组值中的离散度或可变性。
通过结合pandas的数据处理功能来对数据进行计算,以及Seaborn的可视化功能,我们可以从数据中获得见解,并通过可视化有效地传达我们的发现。
以下是关于如何结合使用Seaborn和pandas对数据进行计算的详细说明。
导入必要的库
首先,在Python环境中导入所有必需的库,例如seaborn和pandas。
import seaborn as sns import pandas as pd
将数据加载到pandas DataFrame中
接下来,我们必须使用pandas库中的read_csv()函数加载数据集。
df = pd.read_csv("https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv")
使用pandas执行计算
Pandas提供了各种方法和函数来对数据执行计算。以下是一些我们可以使用pandas执行的常见计算示例
计算列的均值
要计算特定列的均值,pandas库中具有mean()函数。
示例
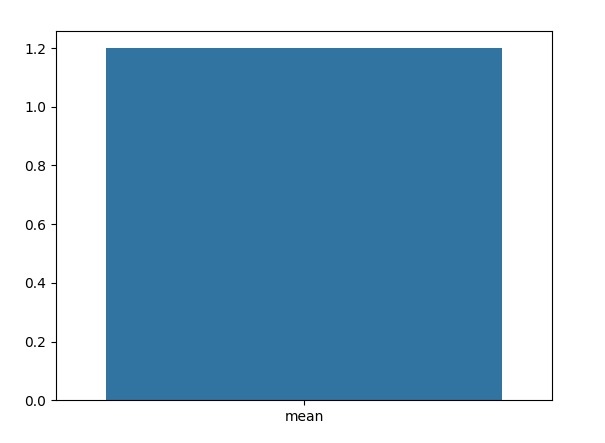
mean_value = df['petal.width'].mean()
print("The mean of the petal.width column:",mean_value)
输出
The mean of the petal.width column: 1.199333333333334
计算列的标准差
要计算列的标准差,pandas库中有一个名为std()的函数。
示例
std_value = df['petal.width'].std()
print("The standard deviation of the petal.width column:",std_value)
输出
The standard deviation of the petal.width column: 0.7622376689603465
计算列的总和
pandas中有一个名为sum()的函数,用于计算列的总和。
sum_value = df['petal.width'].sum()
print("The sum of the petal.width column:",sum_value)
以上只是一些示例,pandas提供了广泛的方法来执行计算,包括聚合、统计函数等等。
使用Seaborn可视化计算结果
使用pandas对数据进行计算后,我们可以使用Seaborn可视化计算结果。Seaborn提供了各种绘图函数,这些函数接受pandas Series或DataFrame对象作为输入。
我们可以使用各种其他的Seaborn绘图函数来可视化我们的计算结果,例如箱线图、小提琴图、点图等等。Seaborn提供了许多自定义选项来增强我们数据的视觉表示。
示例
在这个例子中,我们使用Seaborn的'barplot()'函数来创建均值的条形图。'x'参数表示x轴标签,'y'参数表示计算出的均值。
#Create a bar plot of the mean values sns.barplot(x=['mean'], y=[mean_value])
输出
注意
虽然Seaborn本身不提供直接的计算方法,但它利用了pandas强大的数据处理和计算能力。因此,在使用Seaborn可视化数据之前,了解pandas及其功能来对数据执行高级计算非常重要。

浏览量:330
