- Cassandra 教程
- Cassandra 首页
- Cassandra 简介
- Cassandra 架构
- Cassandra 数据模型
- Cassandra 安装
- Cassandra 参考 API
- Cassandra Cqlsh
- Cassandra Shell 命令
- Cassandra Keyspace 操作
- Cassandra 创建 Keyspace
- Cassandra 修改 Keyspace
- Cassandra 删除 Keyspace
- Cassandra 表操作
- Cassandra 创建表
- Cassandra 修改表
- Cassandra 删除表
- Cassandra 清空表
- Cassandra 创建索引
- Cassandra 删除索引
- Cassandra 批处理
- Cassandra CURD 操作
- Cassandra 创建数据
- Cassandra 更新数据
- Cassandra 读取数据
- Cassandra 删除数据
- Cassandra CQL 类型
- Cassandra CQL 数据类型
- Cassandra CQL 集合
- CQL 用户自定义数据类型
- Cassandra 有用资源
- Cassandra 快速指南
- Cassandra 有用资源
- Cassandra 讨论
Cassandra 架构
Cassandra 的设计目标是在多个节点上处理大数据工作负载,而没有任何单点故障。Cassandra 在其节点之间具有点对点分布式系统,数据分布在集群中的所有节点之间。
集群中的所有节点都扮演相同的角色。每个节点都是独立的,同时又与其他节点互连。
集群中的每个节点都可以接受读写请求,无论数据实际位于集群中的哪个位置。
当一个节点宕机时,可以从网络中的其他节点提供读/写请求服务。
Cassandra 中的数据复制
在 Cassandra 中,集群中的一个或多个节点充当给定数据片段的副本。如果检测到某些节点返回了过期值,Cassandra 将向客户端返回最新值。返回最新值后,Cassandra会在后台执行**读取修复**以更新过时值。
下图显示了 Cassandra 如何在集群中的节点之间使用数据复制来确保没有单点故障的示意图。
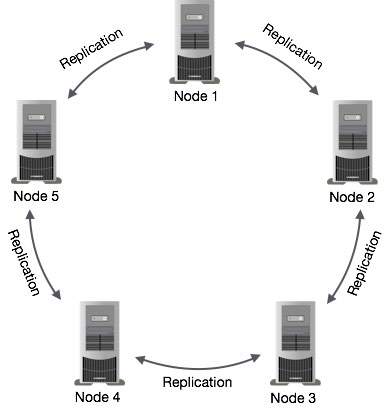
**注意** - Cassandra 在后台使用**Gossip 协议**,允许节点彼此通信并检测集群中的任何故障节点。
Cassandra 的组成部分
Cassandra 的关键组成部分如下:
**节点** - 它是存储数据的地方。
**数据中心** - 它是相关节点的集合。
**集群** - 集群是一个包含一个或多个数据中心的组件。
**提交日志** - 提交日志是 Cassandra 中的崩溃恢复机制。每个写入操作都写入提交日志。
**Memtable** - Memtable 是一个内存驻留数据结构。提交日志之后,数据将写入 Memtable。有时,对于单个列族,将存在多个 Memtable。
**SSTable** - 当 Memtable 的内容达到阈值时,数据将从 Memtable 刷新到磁盘文件 SSTable。
**布隆过滤器** - 这只不过是快速、非确定性的算法,用于测试元素是否为集合的成员。它是一种特殊的缓存。每次查询后都会访问布隆过滤器。
Cassandra 查询语言
用户可以使用 Cassandra 查询语言 (CQL) 通过其节点访问 Cassandra。CQL 将数据库(**Keyspace**)视为表的容器。程序员使用**cqlsh:** 一个提示符来使用 CQL 或单独的应用程序语言驱动程序。
客户端联系任何节点进行读写操作。该节点(协调器)充当客户端和持有数据的节点之间的代理。
写入操作
节点的每个写入活动都由写入节点的**提交日志**捕获。稍后,数据将被捕获并存储在**Memtable**中。每当 Memtable 满了,数据将写入**SSTable**数据文件。所有写入都将自动分区并在整个集群中复制。Cassandra 定期合并 SSTable,丢弃不必要的数据。
读取操作
在读取操作期间,Cassandra 从 Memtable 获取值并检查布隆过滤器以查找保存所需数据的相应 SSTable。