- CatBoost 教程
- CatBoost - 首页
- CatBoost - 概述
- CatBoost - 架构
- CatBoost - 安装
- CatBoost - 特性
- CatBoost - 决策树
- CatBoost - Boosting 过程
- CatBoost - 核心参数
- CatBoost - 数据预处理
- CatBoost - 处理类别特征
- CatBoost - 处理缺失值
- CatBoost - 分类器
- CatBoost - 回归器
- CatBoost - 排序器
- CatBoost - 模型训练
- CatBoost - 模型评估指标
- CatBoost - 分类指标
- CatBoost - 过拟合检测
- CatBoost 与其他 Boosting 算法的比较
- CatBoost 有用资源
- CatBoost - 有用资源
- CatBoost - 讨论
CatBoost - 架构
CatBoost 是一种机器学习程序,可以生成数据驱动的预测。 “CatBoost”这个名称来自两个词:“categorical”(类别)和“boosting”(提升)。
- 类别数据是可以分成不同类别的的数据,例如颜色(红色、蓝色、绿色)或动物类型(猫、狗、鸟)。
- 提升是一种机器学习技术,它结合多个简单的模型来生成更强大、更准确的模型。
CatBoost 的架构
CatBoost 架构指的是 CatBoost 工具生成数据驱动预测的能力。CatBoost 基于一种称为决策树的机器学习系统。
决策树的工作原理类似于流程图,根据接收到的信息做出决策。树的每个“分支”代表一个决策,每个“叶子”表示结果。
CatBoost 使用一种称为“提升”的独特方法,将多个小的决策树组合成一个强大的模型。每棵新树都会纠正之前树的错误,随着时间的推移提高模型的准确性。
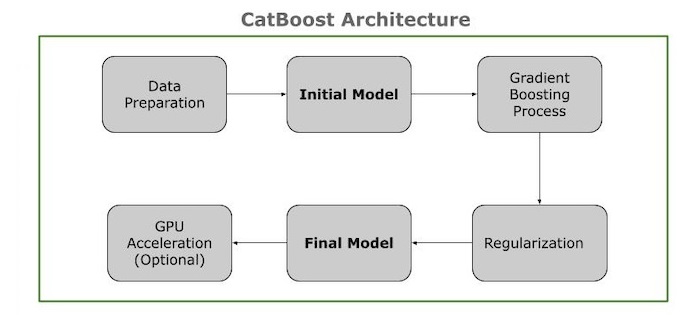
关键组件
CatBoost 架构展示了其主要组件和互连关系。以下是架构组件的概述:
数据准备 包含类别和数值特征,以及目标值。处理缺失值、数据标准化等。将类别特征转换为基于目标的编码。
初始模型 然后,您需要计算一个初始预测,这通常是目标值的平均值。
梯度提升过程 接下来,您需要计算实际值和预测值之间的差异。并仅使用过去的数据(有序提升)进行训练以生成一致的划分(对称树)。然后将树插入模型,调整残差,并重复此过程,直到性能稳定或达到树的数量。
正则化 在此过程中,您需要添加惩罚以防止过拟合并降低模型复杂度。
最终模型 在此阶段,您需要将所有决策树组合起来形成最终模型。并使用完成的模型来预测新数据的效应。
GPU 加速 使用 GPU 加速计算,尤其是在大型数据集上。
数学表示
CatBoost 需要一个函数 F(x) 来预测给定 N 个样本和 M 个特征的训练数据集的目标变量 y。每个样本表示为 (xi, yi),其中 xi 是 M 个特征的向量,yi 是相应的目标变量。
CatBoost 生成各种决策树。每棵树都会生成一个预测,并且将估计值合并以提高准确性。
F(x) = F0(x) + ∑Mm=1 fm(x)
这里:
F(x) 是最终预测。
F0(x) 是初始猜测。
∑Mm=1 fm(x) 是每棵树的预测之和。
树 fm(x) 预测数据集中的所有样本。例如,单个树可能知道一个人购买产品的可能性。
总结
总而言之,CatBoost 是一款功能强大且用户友好的梯度提升工具包,非常适合各种应用。无论您是初学者寻找一种简单的机器学习方法,还是经验丰富的从业者寻求最佳性能,CatBoost 都是您工具箱中一个宝贵的工具。但与任何工具一样,其成功取决于具体问题和数据集,因此始终建议进行实验并将其与其他方法进行比较。