Python 并发编程 - 快速指南
Python 并发编程 - 简介
本章我们将了解 Python 中并发的概念,并学习不同的线程和进程。
什么是并发?
简单来说,并发是指两个或多个事件同时发生。并发是一种自然现象,因为在任何给定时间,许多事件会同时发生。
在编程方面,并发是指两个任务在执行上重叠。通过并发编程,可以提高应用程序和软件系统的性能,因为我们可以并发处理请求,而不是等待上一个请求完成。
并发的历史回顾
以下几点将简要回顾并发的历史:
从铁路的概念出发
并发与铁路的概念密切相关。有了铁路,就需要以一种方式处理同一铁路系统上的多列火车,确保每列火车都能安全到达目的地。
学术界中的并发计算
对计算机科学并发的兴趣始于 Edsger W. Dijkstra 在 1965 年发表的研究论文。在这篇论文中,他识别并解决了互斥问题,这是并发控制的一个特性。
高级并发原语
近年来,由于引入了高级并发原语,程序员们获得了改进的并发解决方案。
编程语言改进的并发性
诸如 Google 的 Golang、Rust 和 Python 等编程语言在帮助我们获得更好的并发解决方案的领域取得了令人难以置信的发展。
什么是线程和多线程?
线程是操作系统中可以执行的最小执行单元。它本身不是一个程序,而是在程序中运行。换句话说,线程彼此不独立。每个线程与其他线程共享代码段、数据段等。它们也被称为轻量级进程。
线程包含以下组件:
程序计数器,包含下一个可执行指令的地址
堆栈
寄存器集
一个唯一的 ID
另一方面,多线程是指 CPU 管理操作系统使用情况的能力,通过并发执行多个线程来实现。多线程的主要思想是通过将一个进程分成多个线程来实现并行性。可以通过以下示例理解多线程的概念。
示例
假设我们正在运行一个特定的进程,其中我们打开 MS Word 在其中键入内容。一个线程将被分配来打开 MS Word,另一个线程将需要在其中键入内容。现在,如果我们想编辑现有的内容,则需要另一个线程来执行编辑任务,依此类推。
什么是进程和多进程?
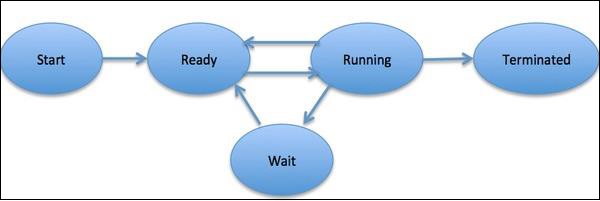
进程被定义为一个实体,它表示要在系统中实现的基本工作单元。简单来说,我们将计算机程序写在文本文件中,当我们执行此程序时,它就变成了一个执行程序中提到的所有任务的进程。在进程生命周期中,它会经历不同的阶段——开始、就绪、运行、等待和终止。
下图显示了进程的不同阶段:
一个进程可以只有一个线程(称为主线程),也可以有多个线程,每个线程都有自己的一组寄存器、程序计数器和堆栈。下图将显示它们的差异:
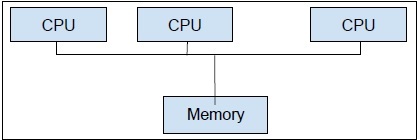
另一方面,多进程是在单个计算机系统中使用两个或多个 CPU 单元。我们的主要目标是从我们的硬件中获得全部潜力。为了实现这一点,我们需要利用计算机系统中可用的全部 CPU 内核数量。多进程是实现此目标的最佳方法。
Python是最流行的编程语言之一。以下是一些使其适合并发应用程序的原因:
语法糖
语法糖是在编程语言中设计的语法,旨在使代码更易于阅读或表达。它使语言对人类使用更“友好”:可以更清晰、更简洁地表达事物,或者根据偏好采用替代风格。Python 带有魔术方法,可以定义为作用于对象。这些魔术方法用作语法糖,并绑定到更容易理解的关键字。
大型社区
Python 语言在人工智能、机器学习、深度学习和定量分析领域工作的众多数据科学家和数学家中获得了广泛的采用率。
用于并发编程的有用 API
Python 2 和 3 拥有大量专用于并行/并发编程的 API。其中最流行的是threading、concurrent.futures、multiprocessing、asyncio、gevent 和 greenlets等。
Python 在实现并发应用程序方面的局限性
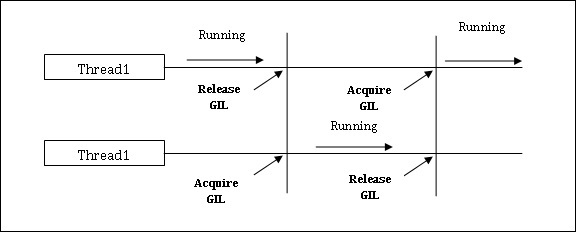
Python 在并发应用程序方面存在一个限制。这个限制被称为GIL(全局解释器锁)存在于 Python 中。GIL 从不允许我们利用 CPU 的多个核心,因此我们可以说 Python 中没有真正的线程。我们可以如下理解 GIL 的概念:
GIL(全局解释器锁)
这是 Python 世界中备受争议的话题之一。在 CPython 中,GIL 是互斥锁——互斥锁,它使事物线程安全。换句话说,我们可以说 GIL 阻止多个线程并行执行 Python 代码。一次只能由一个线程持有该锁,如果我们想要执行一个线程,则它必须首先获取该锁。下图将帮助你了解 GIL 的工作原理。
但是,Python 中有一些库和实现,例如Numpy、Jpython和IronPytbhon。这些库无需与 GIL 交互即可工作。
并发与并行
并发和并行都用于与多线程程序相关,但对它们之间相似性和差异的理解存在很多混淆。这方面的一个大问题是:并发是不是并行?虽然这两个术语看起来非常相似,但上述问题的答案是否定的,并发和并行并不相同。现在,如果它们不相同,那么它们之间有什么根本区别呢?
简单来说,并发处理的是从不同线程管理对共享状态的访问,而并行处理的是利用多个 CPU 或其核心来提高硬件性能。
并发详解
并发是指两个任务在执行上重叠。这可能是一种情况,即应用程序同时在多个任务上取得进展。我们可以用图表来理解它;多个任务同时取得进展,如下所示:
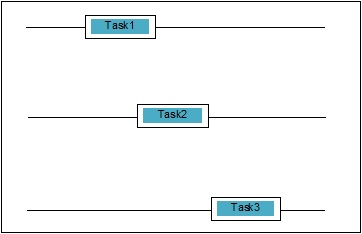
并发级别
在本节中,我们将讨论编程方面并发性的三个重要级别:
低级并发
在此并发级别中,显式使用原子操作。我们不能将这种并发用于应用程序构建,因为它很容易出错并且难以调试。即使 Python 也不支持这种并发。
中级并发
在此并发中,不使用显式原子操作。它使用显式锁。Python 和其他编程语言支持这种并发。大多数应用程序程序员都使用这种并发。
高级并发
在此并发中,既不使用显式原子操作也不使用显式锁。Python 有concurrent.futures模块来支持这种并发。
并发系统的属性
为了使程序或并发系统正确,它必须满足某些属性。与系统终止相关的属性如下:
正确性属性
正确性属性意味着程序或系统必须提供所需的正确答案。为了简单起见,我们可以说系统必须正确地将起始程序状态映射到最终状态。
安全性属性
安全性属性意味着程序或系统必须保持在“良好”或“安全”状态,并且永远不会做任何“坏”事。
活性属性
此属性意味着程序或系统必须“取得进展”并且它将达到某个理想状态。
并发系统的参与者
这是并发系统的一个共同属性,其中可以有多个进程和线程同时运行以在自己的任务上取得进展。这些进程和线程被称为并发系统的参与者。
并发系统的资源
参与者必须利用内存、磁盘、打印机等资源才能执行其任务。
某些规则集
每个并发系统都必须拥有一组规则来定义参与者要执行的任务类型以及每个任务的时间安排。任务可能是获取锁、共享内存、修改状态等。
并发系统的障碍
在实现并发系统时,程序员必须考虑以下两个重要问题,它们可能是并发系统的障碍:数据共享
在实现并发系统时,一个重要的问题是在多个线程或进程之间共享数据。实际上,程序员必须确保锁保护共享数据,以便对它的所有访问都是串行的,并且一次只有一个线程或进程可以访问共享数据。如果多个线程或进程都试图访问相同的共享数据,则并非所有线程或进程都会被阻塞并保持空闲状态。换句话说,当锁生效时,我们一次只能使用一个进程或线程。有一些简单的解决方案可以消除上述障碍:
数据共享限制
最简单的解决方案是不共享任何可变数据。在这种情况下,我们不需要使用显式锁,由于互斥数据造成的并发障碍也会得到解决。
数据结构辅助
很多时候,并发进程需要同时访问相同的数据。除了使用显式锁之外,另一个解决方案是使用支持并发访问的数据结构。例如,我们可以使用queue模块,它提供线程安全的队列。我们还可以使用multiprocessing.JoinableQueue类进行基于多处理的并发。
不可变数据传输
有时,我们正在使用的数据结构(例如并发队列)不合适,那么我们可以传递不可变数据而无需锁定它。
可变数据传输
延续上述解决方案,假设需要传递仅可变数据而不是不可变数据,那么我们可以传递只读的可变数据。
I/O资源共享
在实现并发系统时,另一个重要问题是线程或进程使用I/O资源。当一个线程或进程长时间使用I/O而其他进程处于空闲状态时,就会出现问题。在处理I/O密集型应用程序时,我们可以看到这种类型的障碍。可以用一个例子来理解,例如从Web浏览器请求页面。这是一个重量级应用程序。在这里,如果请求数据的速率慢于消耗数据的速率,那么我们的并发系统中就会出现I/O障碍。
以下Python脚本用于请求网页并获取网络获取请求页面的时间:
import urllib.request
import time
ts = time.time()
req = urllib.request.urlopen('https://tutorialspoint.com')
pageHtml = req.read()
te = time.time()
print("Page Fetching Time : {} Seconds".format (te-ts))
执行上述脚本后,我们可以得到如下所示的页面获取时间。
输出
Page Fetching Time: 1.0991398811340332 Seconds
我们可以看到获取页面的时间超过一秒。现在,如果我们要获取数千个不同的网页,您可以理解我们的网络将需要多少时间。
什么是并行性?
并行性可以定义为将任务分解成可以同时处理的子任务的艺术。它与上面讨论的并发性相反,并发性是指两个或多个事件同时发生。我们可以通过图表来理解它;一个任务被分解成许多可以并行处理的子任务,如下所示:
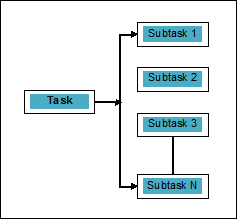
为了更好地理解并发和并行之间的区别,请考虑以下几点:
并发但不并行
一个应用程序可以是并发但不并行的,这意味着它同时处理多个任务,但这些任务没有被分解成子任务。
并行但不并发
一个应用程序可以是并行但不并发的,这意味着它一次只处理一个任务,并且可以并行处理将任务分解成的子任务。
既不并行也不并发
一个应用程序可以既不并行也不并发。这意味着它一次只处理一个任务,并且任务从未被分解成子任务。
既并行又并发
一个应用程序可以既并行又并发,这意味着它既可以同时处理多个任务,又可以将任务分解成子任务以并行执行它们。
并行性的必要性
我们可以通过将子任务分配到单个CPU的不同内核或连接到网络中的多台计算机上来实现并行性。
请考虑以下要点,以了解为什么需要实现并行性:
高效的代码执行
借助并行性,我们可以高效地运行代码。这将节省我们的时间,因为代码的各个部分是并行运行的。
比顺序计算快
顺序计算受到物理和实际因素的约束,因此无法获得更快的计算结果。另一方面,这个问题通过并行计算得到解决,并且比顺序计算给我们更快的计算结果。
更短的执行时间
并行处理减少了程序代码的执行时间。
如果我们谈论并行性的现实例子,我们计算机的显卡就是一个突显并行处理真正能力的例子,因为它拥有数百个独立工作的独立处理核心,可以同时执行。由于这个原因,我们能够运行高端应用程序和游戏。
理解处理器以进行实现
我们了解并发、并行以及它们之间的区别,但是关于要在其上实现的系统呢?了解我们将要实现的系统非常必要,因为它使我们在设计软件时能够做出明智的决策。我们有以下两种类型的处理器:
单核处理器
单核处理器能够在任何给定时间执行一个线程。这些处理器使用上下文切换来存储特定时间线程的所有必要信息,然后稍后恢复信息。上下文切换机制帮助我们在给定的一秒钟内在许多线程上取得进展,看起来系统正在处理多件事情。
单核处理器有很多优点。这些处理器功耗更低,多个内核之间没有复杂的通信协议。另一方面,单核处理器的速度有限,不适合大型应用程序。
多核处理器
多核处理器具有多个独立的处理单元,也称为内核。
此类处理器不需要上下文切换机制,因为每个内核都包含执行一系列存储指令所需的一切。
取指令-解码-执行周期
多核处理器的内核遵循一个执行周期。这个周期称为取指令-解码-执行周期。它包括以下步骤:
取指令
这是周期的第一步,它涉及从程序内存中获取指令。
解码
最近获取的指令将转换为一系列信号,这些信号将触发CPU的其他部分。
执行
这是最后一步,其中获取和解码的指令将被执行。执行结果将存储在CPU寄存器中。
一个优点是多核处理器的执行速度比单核处理器快。它适合大型应用程序。另一方面,多个内核之间的复杂通信协议是一个问题。多个内核比单核处理器需要更多的功耗。
系统和内存架构
在设计程序或并发系统时,需要考虑不同的系统和内存架构样式。这是非常必要的,因为一种系统和内存样式可能适合一项任务,但可能对另一项任务容易出错。
支持并发的计算机系统架构
Michael Flynn在1972年提出了对不同类型的计算机系统架构进行分类的分类法。该分类法定义了四种不同的样式,如下所示:
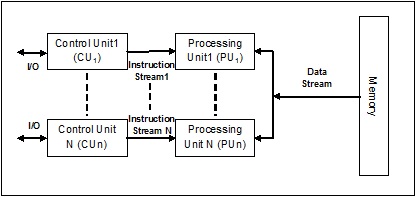
- 单指令流,单数据流 (SISD)
- 单指令流,多数据流 (SIMD)
- 多指令流,单数据流 (MISD)
- 多指令流,多数据流 (MIMD)。
单指令流,单数据流 (SISD)
顾名思义,这种系统将拥有一个顺序的输入数据流和一个执行数据流的单个处理单元。它们就像具有并行计算架构的单处理器系统。以下是SISD的架构:
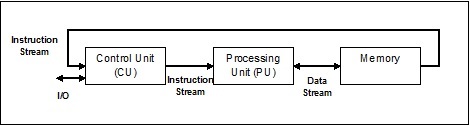
SISD的优点
SISD架构的优点如下:
- 功耗更低。
- 多个内核之间没有复杂的通信协议问题。
SISD的缺点
SISD架构的缺点如下:
- SISD架构的速度与单核处理器一样有限。
- 它不适合大型应用程序。
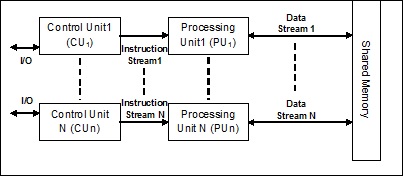
单指令流,多数据流 (SIMD)
顾名思义,这种系统将拥有多个输入数据流和多个处理单元,这些处理单元可以在任何给定时间对单个指令进行操作。它们就像具有并行计算架构的多处理器系统。以下是SIMD的架构:
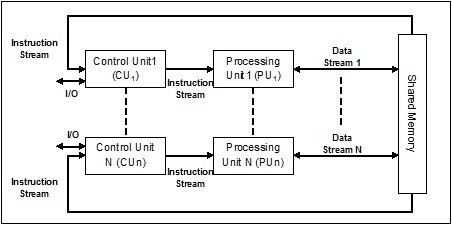
SIMD的最佳示例是显卡。这些卡具有数百个独立的处理单元。如果我们谈论SISD和SIMD之间的计算差异,那么对于添加数组[5, 15, 20]和[15, 25, 10],SISD架构必须执行三个不同的加法运算。另一方面,使用SIMD架构,我们可以在单个加法运算中添加它们。
SIMD的优点
SIMD架构的优点如下:
只需一条指令即可对多个元素执行相同的操作。
通过增加处理器的内核数量,可以提高系统的吞吐量。
处理速度高于SISD架构。
SIMD的缺点
SIMD架构的缺点如下:
- 处理器内核之间存在复杂的通信。
- 成本高于SISD架构。
多指令单数据 (MISD) 流
具有MISD流的系统具有多个处理单元,通过对相同数据集执行不同的指令来执行不同的操作。以下是MISD的架构:
MISD架构的代表尚未在商业上存在。
多指令多数据 (MIMD) 流
在使用MIMD架构的系统中,多处理器系统中的每个处理器都可以独立地对不同数据集的不同指令集进行并行执行。它与SIMD架构相反,在SIMD架构中,对多个数据集执行单个操作。以下是MIMD的架构:
普通的多分处理器使用MIMD架构。这些架构基本上应用于许多领域,例如计算机辅助设计/计算机辅助制造、仿真、建模、通信交换机等。
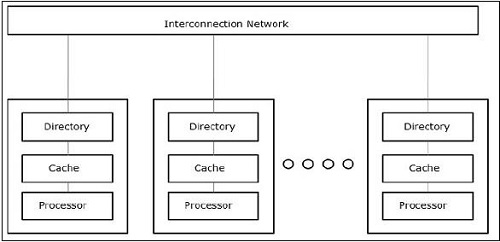
支持并发的内存架构
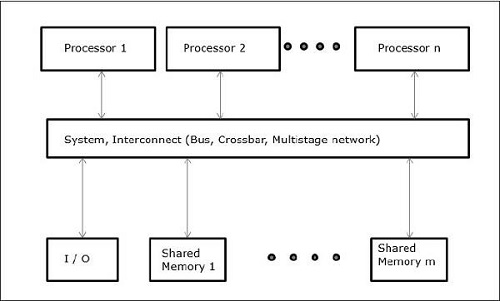
在处理并发和并行等概念时,总是需要加快程序速度。计算机设计师找到的一种解决方案是创建共享内存多计算机,即具有单个物理地址空间的计算机,该地址空间由处理器的所有内核访问。在这种情况下,可能存在许多不同的架构风格,但以下三种架构风格非常重要:
UMA(统一内存访问)
在这个模型中,所有处理器都统一共享物理内存。所有处理器对所有内存字的访问时间相同。每个处理器可能都有一个私有缓存内存。外围设备遵循一组规则。
当所有处理器都能平等地访问所有外围设备时,系统被称为对称多处理器。当只有一个或少数处理器可以访问外围设备时,系统被称为非对称多处理器。
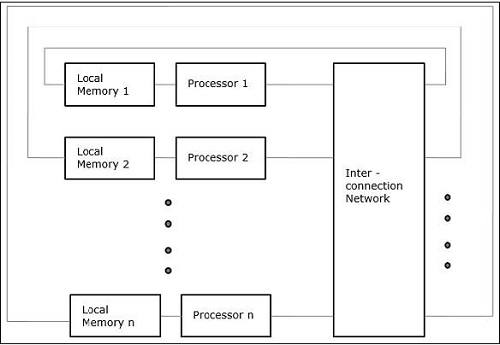
非统一内存访问 (NUMA)
在 NUMA 多处理器模型中,访问时间随内存字的位置而变化。在这里,共享内存物理上分布在所有处理器之间,称为本地内存。所有本地内存的集合构成一个全局地址空间,所有处理器都可以访问。
仅缓存内存架构 (COMA)
COMA 模型是 NUMA 模型的一个特殊版本。在这里,所有分布式主内存都被转换为缓存内存。
Python 中的并发 - 线程
一般来说,我们知道线程是一根非常细的扭曲的线,通常由棉或丝织物制成,用于缝制衣服等。术语“线程”也用于计算机编程领域。现在,我们如何将用于缝制衣服的线程与用于计算机编程的线程联系起来呢?两者执行的角色在这里是相似的。在衣服中,线将布料缝合在一起;在计算机编程中,线程将计算机程序连接在一起,并允许程序一次执行顺序操作或许多操作。
线程是操作系统中最小的执行单元。它本身并不是一个程序,而是在程序内运行。换句话说,线程彼此不独立,并与其他线程共享代码段、数据段等。这些线程也称为轻量级进程。
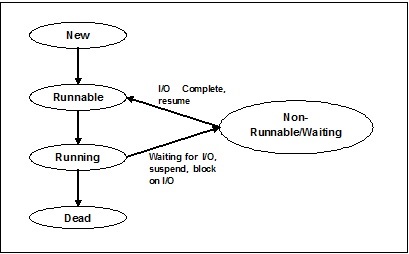
线程的状态
为了深入了解线程的功能,我们需要了解线程的生命周期或不同的线程状态。通常,线程可以存在于五个不同的状态。不同的状态如下所示:
新建线程
一个新线程从新建状态开始其生命周期。但是,在这个阶段,它尚未启动,也没有分配任何资源。可以说它只是一个对象的实例。
可运行
当新创建的线程启动时,线程变为可运行状态,即等待运行。在此状态下,它拥有所有资源,但任务调度程序尚未安排它运行。
运行
在此状态下,线程取得进展并执行任务调度程序选择运行的任务。现在,线程可以进入死亡状态或不可运行/等待状态。
不可运行/等待
在此状态下,线程暂停,因为它正在等待某些 I/O 请求的响应或等待其他线程执行完成。
死亡
当可运行线程完成其任务或以其他方式终止时,它进入终止状态。
下图显示了线程的完整生命周期:
线程的类型
在本节中,我们将了解不同类型的线程。这些类型描述如下:
用户级线程
这些是用户管理的线程。
在这种情况下,线程管理内核不知道线程的存在。线程库包含用于创建和销毁线程、在线程之间传递消息和数据、调度线程执行以及保存和恢复线程上下文的代码。应用程序从单个线程开始。
用户级线程的示例包括:
- Java 线程
- POSIX 线程
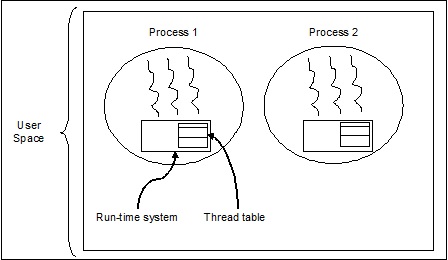
用户级线程的优点
以下是用户级线程的不同优点:
- 线程切换不需要内核模式权限。
- 用户级线程可以在任何操作系统上运行。
- 用户级线程的调度可以是特定于应用程序的。
- 用户级线程创建和管理速度快。
用户级线程的缺点
以下是用户级线程的不同缺点:
- 在典型的操作系统中,大多数系统调用都是阻塞的。
- 多线程应用程序无法利用多处理。
内核级线程
操作系统管理的线程作用于内核,内核是操作系统核心。
在这种情况下,内核进行线程管理。应用程序区域中没有线程管理代码。内核线程直接由操作系统支持。任何应用程序都可以编程为多线程的。应用程序中的所有线程都支持在一个进程中。
内核维护整个进程以及进程中各个线程的上下文信息。内核按线程进行调度。内核在内核空间中执行线程创建、调度和管理。内核线程的创建和管理通常比用户线程慢。内核级线程的示例包括 Windows 和 Solaris。
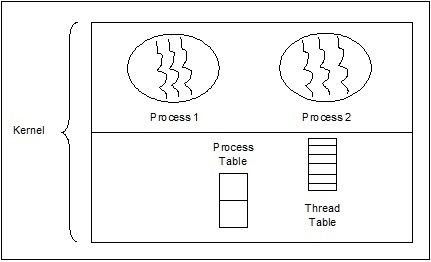
内核级线程的优点
以下是内核级线程的不同优点:
内核可以同时在多个进程上调度来自同一进程的多个线程。
如果进程中的一个线程被阻塞,内核可以调度同一进程的另一个线程。
内核例程本身可以是多线程的。
内核级线程的缺点
内核线程的创建和管理通常比用户线程慢。
从同一进程中的一个线程到另一个线程的控制转移需要模式切换到内核。
线程控制块 - TCB
线程控制块 (TCB) 可以定义为操作系统内核中的数据结构,该结构主要包含有关线程的信息。存储在 TCB 中的特定于线程的信息将突出显示有关每个进程的一些重要信息。
考虑与 TCB 中包含的线程相关的以下几点:
线程标识 - 这是分配给每个新线程的唯一线程 ID (tid)。
线程状态 - 它包含与线程状态(运行、可运行、不可运行、死亡)相关的信息。
程序计数器 (PC) - 它指向线程的当前程序指令。
寄存器集 - 它包含分配给线程进行计算的寄存器值。
堆栈指针 - 它指向进程中线程的堆栈。它包含线程作用域内的局部变量。
指向 PCB 的指针 - 它包含指向创建该线程的进程的指针。

进程与线程之间的关系
在多线程中,进程和线程是两个非常密切相关的术语,它们具有相同的目标:使计算机能够同时执行多项任务。一个进程可以包含一个或多个线程,但相反,线程不能包含一个进程。但是,它们仍然是两个基本的执行单元。执行一系列指令的程序会同时启动进程和线程。
下表显示了进程和线程之间的比较:
| 进程 | 线程 |
|---|---|
| 进程是重量级的或资源密集型的。 | 线程是轻量级的,它比进程消耗更少的资源。 |
| 进程切换需要与操作系统交互。 | 线程切换不需要与操作系统交互。 |
| 在多处理环境中,每个进程执行相同的代码,但拥有自己的内存和文件资源。 | 所有线程都可以共享同一组打开的文件、子进程。 |
| 如果一个进程被阻塞,则在第一个进程被解除阻塞之前,任何其他进程都不能执行。 | 当一个线程被阻塞并等待时,同一任务中的第二个线程可以运行。 |
| 不使用线程的多个进程使用更多资源。 | 多个线程进程使用更少的资源。 |
| 在多个进程中,每个进程独立于其他进程运行。 | 一个线程可以读取、写入或更改另一个线程的数据。 |
| 如果父进程发生任何更改,则不会影响子进程。 | 如果主线程发生任何更改,则可能会影响该进程中其他线程的行为。 |
| 要与兄弟进程通信,进程必须使用进程间通信。 | 线程可以直接与该进程的其他线程通信。 |
多线程的概念
正如我们前面讨论的那样,多线程是 CPU 管理操作系统使用方式的能力,通过同时执行多个线程来实现。多线程的主要思想是通过将进程划分为多个线程来实现并行性。更简单地说,多线程是使用线程概念实现多任务处理的一种方式。
可以通过以下示例了解多线程的概念。
示例
假设我们正在运行一个进程。该进程可能是为了打开 MS Word 来编写一些内容。在此过程中,一个线程将被分配来打开 MS Word,另一个线程将被要求进行编写。现在,假设如果我们想编辑某些内容,则需要另一个线程来执行编辑任务,依此类推。
下图有助于我们理解多个线程如何在内存中存在:
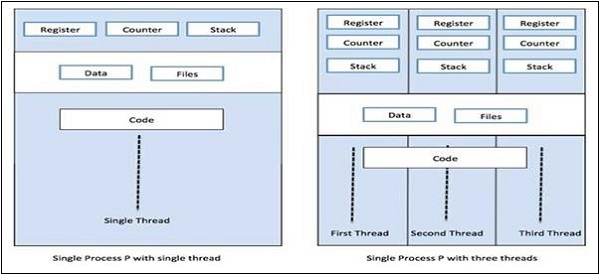
我们可以在上图中看到,在一个进程中可以存在多个线程,其中每个线程都包含它自己的寄存器集和局部变量。除此之外,进程中的所有线程共享全局变量。
多线程的优点
现在让我们看看多线程的一些优点。优点如下:
通信速度 - 多线程提高了计算速度,因为每个核心或处理器同时处理单独的线程。
程序保持响应 - 它允许程序保持响应,因为一个线程等待输入,而另一个线程同时运行 GUI。
访问全局变量 - 在多线程中,特定进程的所有线程都可以访问全局变量,如果全局变量发生任何更改,则其他线程也能看到。
资源利用率 - 在每个程序中运行多个线程可以更好地利用 CPU,并且 CPU 的空闲时间减少。
数据共享 - 每个线程不需要额外的空间,因为程序中的线程可以共享相同的数据。
多线程的缺点
现在让我们看看多线程的一些缺点。缺点如下:
不适用于单处理器系统 − 与多处理器系统相比,多线程在单处理器系统上难以在计算速度方面实现性能提升。
安全问题 − 众所周知,程序中的所有线程共享相同的数据,因此始终存在安全问题,因为任何未知线程都可能更改数据。
复杂性增加 − 多线程会增加程序的复杂性,从而使调试变得困难。
导致死锁状态 − 多线程可能导致程序面临达到死锁状态的潜在风险。
需要同步 − 需要同步来避免互斥。这会导致更多的内存和 CPU 利用率。
线程的实现
本章,我们将学习如何在 Python 中实现线程。
Python 线程实现模块
Python 线程有时被称为轻量级进程,因为线程比进程占用更少的内存。线程允许同时执行多个任务。在 Python 中,我们有以下两个模块用于在程序中实现线程:
<_thread> 模块
<threading> 模块
这两个模块的主要区别在于,<_thread> 模块将线程视为一个函数,而 <threading> 模块将每个线程视为一个对象并以面向对象的方式实现它。此外,<_thread> 模块在低级线程中有效,并且功能少于 <threading> 模块。
<_thread> 模块
在早期版本的 Python 中,我们有 <thread> 模块,但它已被认为是“已弃用”很长时间了。鼓励用户改用 <threading> 模块。因此,在 Python 3 中,“thread”模块不再可用。为了 Python 3 的向后兼容性,它已被重命名为“<_thread>”。
要借助 <_thread> 模块生成新线程,我们需要调用其 start_new_thread 方法。可以通过以下语法了解此方法的工作原理:
_thread.start_new_thread ( function, args[, kwargs] )
这里:
args 是一个参数元组
kwargs 是一个可选的关键字参数字典
如果我们想在不传递参数的情况下调用函数,则需要在 args 中使用空的参数元组。
此方法调用立即返回,子线程启动,并使用传递的 args 列表(如果有)调用函数。线程在函数返回时终止。
示例
以下是使用 <_thread> 模块生成新线程的示例。我们在这里使用 start_new_thread() 方法。
import _thread
import time
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: unable to start thread")
while 1:
pass
输出
以下输出将帮助我们理解借助 <_thread> 模块生成新线程。
Thread-1: Mon Apr 23 10:03:33 2018 Thread-2: Mon Apr 23 10:03:35 2018 Thread-1: Mon Apr 23 10:03:35 2018 Thread-1: Mon Apr 23 10:03:37 2018 Thread-2: Mon Apr 23 10:03:39 2018 Thread-1: Mon Apr 23 10:03:39 2018 Thread-1: Mon Apr 23 10:03:41 2018 Thread-2: Mon Apr 23 10:03:43 2018 Thread-2: Mon Apr 23 10:03:47 2018 Thread-2: Mon Apr 23 10:03:51 2018
<threading> 模块
<threading> 模块以面向对象的方式实现,并将每个线程视为一个对象。因此,它比 <_thread> 模块提供了更强大、更高级别的线程支持。此模块包含在 Python 2.4 中。
<threading> 模块中的附加方法
<threading> 模块包含 <_thread> 模块的所有方法,但它也提供其他方法。附加方法如下:
threading.activeCount() − 此方法返回活动线程对象的数目
threading.currentThread() − 此方法返回调用方线程控制中的线程对象数目。
threading.enumerate() − 此方法返回当前活动的所有线程对象的列表。
run() − run() 方法是线程的入口点。
start() − start() 方法通过调用 run 方法启动线程。
join([time]) − join() 等待线程终止。
isAlive() − isAlive() 方法检查线程是否仍在执行。
getName() − getName() 方法返回线程的名称。
setName() − setName() 方法设置线程的名称。
为了实现线程,<threading> 模块具有 Thread 类,它提供以下方法:
如何使用 <threading> 模块创建线程?
在本节中,我们将学习如何使用 <threading> 模块创建线程。请按照以下步骤使用 <threading> 模块创建新线程:
步骤 1 − 在此步骤中,我们需要定义 Thread 类的新的子类。
步骤 2 − 然后为了添加附加参数,我们需要重写 __init__(self [,args]) 方法。
步骤 3 − 在此步骤中,我们需要重写 run(self [,args]) 方法来实现线程启动时应执行的操作。
现在,在创建新的 Thread 子类之后,我们可以创建它的实例,然后通过调用 start() 启动新线程,这反过来会调用 run() 方法。
示例
请考虑此示例以了解如何使用 <threading> 模块生成新线程。
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Starting " + self.name)
print_time(self.name, self.counter, 5)
print ("Exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("Exiting Main Thread")
Starting Thread-1
Starting Thread-2
输出
现在,请考虑以下输出:
Thread-1: Mon Apr 23 10:52:09 2018 Thread-1: Mon Apr 23 10:52:10 2018 Thread-2: Mon Apr 23 10:52:10 2018 Thread-1: Mon Apr 23 10:52:11 2018 Thread-1: Mon Apr 23 10:52:12 2018 Thread-2: Mon Apr 23 10:52:12 2018 Thread-1: Mon Apr 23 10:52:13 2018 Exiting Thread-1 Thread-2: Mon Apr 23 10:52:14 2018 Thread-2: Mon Apr 23 10:52:16 2018 Thread-2: Mon Apr 23 10:52:18 2018 Exiting Thread-2 Exiting Main Thread
Python 程序用于各种线程状态
线程有五种状态——新建、可运行、运行、等待和死亡。在这五种状态中,我们将主要关注三种状态——运行、等待和死亡。线程在其运行状态下获取其资源,在其等待状态下等待资源;如果执行并获取,则在死亡状态下最终释放资源。
以下 Python 程序借助 start()、sleep() 和 join() 方法将显示线程如何分别进入运行、等待和死亡状态。
步骤 1 − 导入必要的模块,<threading> 和 <time>
import threading import time
步骤 2 − 定义一个函数,该函数将在创建线程时调用。
def thread_states():
print("Thread entered in running state")
步骤 3 − 我们使用 time 模块的 sleep() 方法使我们的线程等待例如 2 秒。
time.sleep(2)
步骤 4 − 现在,我们正在创建一个名为 T1 的线程,它接受上面定义的函数的参数。
T1 = threading.Thread(target=thread_states)
步骤 5 − 现在,借助 start() 函数,我们可以启动我们的线程。它将生成我们定义函数时设置的消息。
T1.start() Thread entered in running state
步骤 6 − 现在,最后,我们可以在线程完成执行后使用 join() 方法终止线程。
T1.join()
在 Python 中启动线程
在 Python 中,我们可以通过不同的方式启动新线程,但其中最简单的一种方法是将其定义为单个函数。定义函数后,我们可以将其作为新 threading.Thread 对象的目标,依此类推。执行以下 Python 代码以了解函数的工作原理:
import threading
import time
import random
def Thread_execution(i):
print("Execution of Thread {} started\n".format(i))
sleepTime = random.randint(1,4)
time.sleep(sleepTime)
print("Execution of Thread {} finished".format(i))
for i in range(4):
thread = threading.Thread(target=Thread_execution, args=(i,))
thread.start()
print("Active Threads:" , threading.enumerate())
输出
Execution of Thread 0 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>]
Execution of Thread 1 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>]
Execution of Thread 2 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>]
Execution of Thread 3 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>,
<Thread(Thread-3579, started 4520)>]
Execution of Thread 0 finished
Execution of Thread 1 finished
Execution of Thread 2 finished
Execution of Thread 3 finished
Python 中的守护线程
在 Python 中实现守护线程之前,我们需要了解守护线程及其用途。在计算方面,守护程序是一个后台进程,它处理各种服务的请求,例如数据发送、文件传输等。如果不再需要它,它将处于休眠状态。也可以借助非守护线程完成相同的任务。但是,在这种情况下,主线程必须手动跟踪非守护线程。另一方面,如果我们使用守护线程,则主线程可以完全忘记这一点,并且在主线程退出时它将被终止。关于守护线程的另一个重要点是,我们可以选择仅将它们用于非必需任务,如果这些任务未完成或中途被终止,则不会影响我们。以下是 Python 中守护线程的实现:
import threading
import time
def nondaemonThread():
print("starting my thread")
time.sleep(8)
print("ending my thread")
def daemonThread():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonThread = threading.Thread(target = nondaemonThread)
daemonThread = threading.Thread(target = daemonThread)
daemonThread.setDaemon(True)
daemonThread.start()
nondaemonThread.start()
在上面的代码中,有两个函数,即 >nondaemonThread() 和 >daemonThread()。第一个函数打印其状态并在 8 秒后休眠,而 deamonThread() 函数每 2 秒无限期地打印 Hello。我们可以借助以下输出了解非守护线程和守护线程之间的区别:
Hello starting my thread Hello Hello Hello Hello ending my thread Hello Hello Hello Hello Hello
线程同步
线程同步可以定义为一种方法,借助该方法,我们可以确保两个或多个并发线程不会同时访问称为临界区的程序段。另一方面,众所周知,临界区是访问共享资源的程序部分。因此,我们可以说同步是确保两个或多个线程不会通过同时访问资源来相互干扰的过程。下图显示了四个线程试图同时访问程序的临界区。
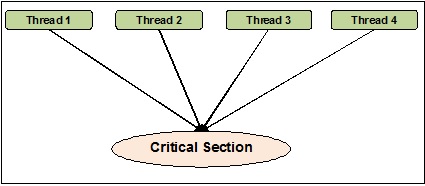
为了更清楚地说明,假设两个或多个线程试图同时在列表中添加对象。此操作无法成功结束,因为它要么会丢弃一个或所有对象,要么会完全破坏列表的状态。这里的同步作用是,一次只有一个线程可以访问列表。
线程同步中的问题
在实现并发编程或应用同步原语时,我们可能会遇到问题。在本节中,我们将讨论两个主要问题。问题是:
- 死锁
- 竞争条件
竞争条件
这是并发编程中的一个主要问题。对共享资源的并发访问可能导致竞争条件。竞争条件可以定义为当两个或多个线程可以访问共享数据,然后尝试同时更改其值时发生的条件。因此,变量的值可能不可预测,并且会根据进程上下文切换的时机而变化。
示例
请考虑此示例以了解竞争条件的概念:
步骤 1 − 在此步骤中,我们需要导入 threading 模块:
import threading
步骤 2 − 现在,定义一个全局变量,例如 x,其值为 0:
x = 0
步骤 3 − 现在,我们需要定义 increment_global() 函数,它将在这个全局函数 x 中递增 1:
def increment_global(): global x x += 1
步骤 4 − 在此步骤中,我们将定义 taskofThread() 函数,它将调用 increment_global() 函数指定次数;对于我们的示例,它是 50000 次:
def taskofThread():
for _ in range(50000):
increment_global()
步骤 5 − 现在,定义 main() 函数,其中创建线程 t1 和 t2。两者都将借助 start() 函数启动,并借助 join() 函数等待它们完成其工作。
def main(): global x x = 0 t1 = threading.Thread(target= taskofThread) t2 = threading.Thread(target= taskofThread) t1.start() t2.start() t1.join() t2.join()
步骤 6 − 现在,我们需要指定范围,即我们希望调用 main() 函数的迭代次数。这里,我们调用它 5 次。
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))
在下面显示的输出中,我们可以看到竞争条件的影响,因为每次迭代后 x 的值预期为 100000。但是,值存在很大的差异。这是由于线程并发访问共享全局变量 x 造成的。
输出
x = 100000 after Iteration 0 x = 54034 after Iteration 1 x = 80230 after Iteration 2 x = 93602 after Iteration 3 x = 93289 after Iteration 4
使用锁处理竞争条件
正如我们在上述程序中看到的竞争条件的影响一样,我们需要一个同步工具来处理多个线程之间的竞争条件。在 Python 中,<threading> 模块提供 Lock 类来处理竞争条件。此外,Lock 类提供不同的方法,我们可以用这些方法来处理多个线程之间的竞争条件。这些方法描述如下:
acquire() 方法
此方法用于获取,即阻塞锁。锁可以是阻塞的或非阻塞的,这取决于以下真或假值:
值为 True − 如果以 True 调用 acquire() 方法(这是默认参数),则线程执行将被阻塞,直到锁被解锁。
值为 False − 如果以 False 调用 acquire() 方法(这不是默认参数),则线程执行不会被阻塞,直到它被设置为 true,即直到它被锁定。
release() 方法
此方法用于释放锁。以下是与此方法相关的几个重要任务:
如果锁已锁定,则release() 方法将解锁它。它的作用是允许恰好一个线程继续执行,如果多个线程被阻塞并等待锁被解锁。
如果锁已解锁,它将引发ThreadError。
现在,我们可以使用 lock 类及其方法重写上述程序以避免竞争条件。我们需要用 lock 参数定义 taskofThread() 方法,然后需要使用 acquire() 和 release() 方法来阻塞和非阻塞锁,以避免竞争条件。
示例
以下是 Python 程序示例,用于理解用于处理竞争条件的锁的概念:
import threading
x = 0
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target = taskofThread, args = (lock,))
t2 = threading.Thread(target = taskofThread, args = (lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))
下面的输出显示竞争条件的影响被忽略了;因为每次迭代后 x 的值现在都是 100000,这符合该程序的预期。
输出
x = 100000 after Iteration 0 x = 100000 after Iteration 1 x = 100000 after Iteration 2 x = 100000 after Iteration 3 x = 100000 after Iteration 4
死锁 - 哲学家就餐问题
死锁是设计并发系统时可能遇到的一个棘手问题。我们可以用哲学家就餐问题来说明这个问题,如下所示:
Edsger Dijkstra 最初提出了哲学家就餐问题,这是并发系统最大问题之一的著名例证,称为死锁。
在这个问题中,有五个著名的哲学家坐在圆桌旁,从他们的碗里吃东西。有五把叉子可以被五个哲学家用来吃饭。但是,哲学家决定同时使用两把叉子吃饭。
现在,哲学家有两个主要条件。首先,每个哲学家都可以处于吃饭或思考状态;其次,他们必须首先获得两把叉子,即左边和右边。当五个哲学家都设法同时拿起左边的叉子时,问题就出现了。现在他们都在等待右边的叉子空闲,但他们永远不会放弃自己的叉子,直到他们吃完饭,而右边的叉子永远不会可用。因此,餐桌上会出现死锁状态。
并发系统中的死锁
现在如果我们看到,同样的问题也可能出现在我们的并发系统中。上面例子中的叉子将是系统资源,每个哲学家可以代表一个进程,该进程正在竞争获取资源。
Python 程序的解决方案
这个问题的解决方案可以通过将哲学家分成两种类型来找到——贪婪的哲学家和慷慨的哲学家。主要是一个贪婪的哲学家会试图拿起左边的叉子,并等待它出现。然后,他将等待右边的叉子出现,拿起它,吃东西,然后放下它。另一方面,一个慷慨的哲学家会试图拿起左边的叉子,如果它不存在,他会等待一段时间后再尝试。如果他们拿到左边的叉子,他们就会试图拿到右边的叉子。如果他们也拿到右边的叉子,他们就会吃东西并释放两个叉子。但是,如果他们没有拿到右边的叉子,他们就会释放左边的叉子。
示例
下面的 Python 程序将帮助我们找到哲学家就餐问题的解决方案:
import threading
import random
import time
class DiningPhilosopher(threading.Thread):
running = True
def __init__(self, xname, Leftfork, Rightfork):
threading.Thread.__init__(self)
self.name = xname
self.Leftfork = Leftfork
self.Rightfork = Rightfork
def run(self):
while(self.running):
time.sleep( random.uniform(3,13))
print ('%s is hungry.' % self.name)
self.dine()
def dine(self):
fork1, fork2 = self.Leftfork, self.Rightfork
while self.running:
fork1.acquire(True)
locked = fork2.acquire(False)
if locked: break
fork1.release()
print ('%s swaps forks' % self.name)
fork1, fork2 = fork2, fork1
else:
return
self.dining()
fork2.release()
fork1.release()
def dining(self):
print ('%s starts eating '% self.name)
time.sleep(random.uniform(1,10))
print ('%s finishes eating and now thinking.' % self.name)
def Dining_Philosophers():
forks = [threading.Lock() for n in range(5)]
philosopherNames = ('1st','2nd','3rd','4th', '5th')
philosophers= [DiningPhilosopher(philosopherNames[i], forks[i%5], forks[(i+1)%5]) \
for i in range(5)]
random.seed()
DiningPhilosopher.running = True
for p in philosophers: p.start()
time.sleep(30)
DiningPhilosopher.running = False
print (" It is finishing.")
Dining_Philosophers()
上面的程序使用了贪婪和慷慨的哲学家的概念。该程序还使用了<threading> 模块的Lock 类的acquire() 和release() 方法。我们可以在下面的输出中看到解决方案:
输出
4th is hungry. 4th starts eating 1st is hungry. 1st starts eating 2nd is hungry. 5th is hungry. 3rd is hungry. 1st finishes eating and now thinking.3rd swaps forks 2nd starts eating 4th finishes eating and now thinking. 3rd swaps forks5th starts eating 5th finishes eating and now thinking. 4th is hungry. 4th starts eating 2nd finishes eating and now thinking. 3rd swaps forks 1st is hungry. 1st starts eating 4th finishes eating and now thinking. 3rd starts eating 5th is hungry. 5th swaps forks 1st finishes eating and now thinking. 5th starts eating 2nd is hungry. 2nd swaps forks 4th is hungry. 5th finishes eating and now thinking. 3rd finishes eating and now thinking. 2nd starts eating 4th starts eating It is finishing.
线程间通信
在现实生活中,如果一个团队的人正在从事一项共同的任务,那么他们之间应该进行沟通才能正确完成任务。同样的类比也适用于线程。在编程中,为了减少处理器的空闲时间,我们创建多个线程并将不同的子任务分配给每个线程。因此,必须有一个通信机制,并且它们应该相互交互以同步的方式完成工作。
考虑与线程间通信相关的以下重要事项:
没有性能提升 − 如果我们无法实现线程和进程之间的正确通信,那么并发和并行带来的性能提升就毫无用处。
正确完成任务 − 如果没有线程之间的正确通信机制,则无法正确完成分配的任务。
比进程间通信更高效 − 线程间通信比进程间通信更高效且更容易使用,因为一个进程中的所有线程共享相同的地址空间,它们不需要使用共享内存。
用于线程安全通信的 Python 数据结构
多线程代码带来了一个问题,即从一个线程传递信息到另一个线程。标准通信原语无法解决此问题。因此,我们需要实现我们自己的复合对象,以便在线程之间共享对象以使通信线程安全。以下是一些数据结构,它们在进行一些更改后提供线程安全通信:
集合
为了以线程安全的方式使用集合数据结构,我们需要扩展集合类以实现我们自己的锁定机制。
示例
这是一个扩展类的 Python 示例:
class extend_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(extend_class, self).__init__(*args, **kwargs)
def add(self, elem):
self._lock.acquire()
try:
super(extend_class, self).add(elem)
finally:
self._lock.release()
def delete(self, elem):
self._lock.acquire()
try:
super(extend_class, self).delete(elem)
finally:
self._lock.release()
在上面的例子中,定义了一个名为extend_class的类对象,它进一步继承自 Python 的set 类。在这个类的构造函数中创建了一个锁对象。现在,有两个函数 - add() 和 delete()。这些函数已定义且是线程安全的。它们都依赖于super类的功能,但有一个关键例外。
装饰器
这是另一种用于线程安全通信的关键方法,即使用装饰器。
示例
考虑一个 Python 示例,它展示了如何使用装饰器:
def lock_decorator(method):
def new_deco_method(self, *args, **kwargs):
with self._lock:
return method(self, *args, **kwargs)
return new_deco_method
class Decorator_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(Decorator_class, self).__init__(*args, **kwargs)
@lock_decorator
def add(self, *args, **kwargs):
return super(Decorator_class, self).add(elem)
@lock_decorator
def delete(self, *args, **kwargs):
return super(Decorator_class, self).delete(elem)
在上面的例子中,定义了一个名为 lock_decorator 的装饰器方法,它进一步继承自 Python 方法类。然后在这个类的构造函数中创建了一个锁对象。现在,有两个函数 - add() 和 delete()。这些函数已定义且是线程安全的。它们都依赖于super类的功能,但有一个关键例外。
列表
列表数据结构是线程安全的,对于临时内存存储来说既快速又容易。在 CPython 中,GIL 可以防止并发访问它们。正如我们所知,列表是线程安全的,但是它们中的数据呢?实际上,列表的数据不受保护。例如,L.append(x) 不能保证在另一个线程尝试执行相同操作时返回预期结果。这是因为,虽然append()是一个原子操作且线程安全,但另一个线程正在尝试并发地修改列表的数据,因此我们可以在输出中看到竞争条件的副作用。
为了解决这类问题并安全地修改数据,我们必须实现一个适当的锁定机制,这进一步确保多个线程不会潜在遇到竞争条件。为了实现适当的锁定机制,我们可以像在前面的示例中那样扩展类。
列表上的一些其他原子操作如下:
L.append(x) L1.extend(L2) x = L[i] x = L.pop() L1[i:j] = L2 L.sort() x = y x.field = y D[x] = y D1.update(D2) D.keys()
这里:
- L、L1、L2 都是列表
- D、D1、D2 是字典
- x、y 是对象
- i、j 是整数
队列
如果列表的数据不受保护,我们可能不得不面对后果。我们可能会获取或删除错误的数据项,或者出现竞争条件。这就是建议使用队列数据结构的原因。队列的现实世界例子可以是一个单车道单行道,车辆先进入,先退出。在售票窗口和公交车站可以看到更多现实世界的例子。
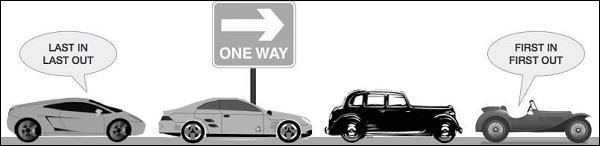
队列默认是线程安全的的数据结构,我们不必担心实现复杂的锁定机制。Python 为我们提供了
队列类型
在本节中,我们将了解不同类型的队列。Python 提供了三个队列选项,可从<queue> 模块中使用:
- 普通队列 (FIFO,先进先出)
- LIFO,后进先出
- 优先级
我们将在后续章节中学习不同的队列。
普通队列 (FIFO,先进先出)
这是 Python 提供的最常用的队列实现。在这种排队机制中,谁先来,谁先得到服务。FIFO 也称为普通队列。FIFO 队列可以表示如下:

FIFO 队列的 Python 实现
在 Python 中,FIFO 队列可以使用单线程和多线程实现。
单线程 FIFO 队列
为了使用单线程实现 FIFO 队列,Queue 类将实现一个基本的先进先出容器。将使用put()将元素添加到序列的“一端”,并使用get()从另一端移除元素。
示例
以下是使用单线程实现 FIFO 队列的 Python 程序:
import queue
q = queue.Queue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end = " ")
输出
item-0 item-1 item-2 item-3 item-4 item-5 item-6 item-7
输出显示上面的程序使用单个线程来说明元素以插入它们的相同顺序从队列中移除。
多线程 FIFO 队列
为了实现多线程FIFO队列,我们需要定义myqueue()函数,该函数扩展自queue模块。get()和put()方法的工作原理与上面讨论的单线程FIFO队列实现相同。然后,为了使其支持多线程,我们需要声明和实例化线程。这些线程将以FIFO方式消费队列。
示例
下面是一个使用多线程实现FIFO队列的Python程序
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.Queue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
输出
<Thread(Thread-3654, started 5044)> removed 0 from the queue <Thread(Thread-3655, started 3144)> removed 1 from the queue <Thread(Thread-3656, started 6996)> removed 2 from the queue <Thread(Thread-3657, started 2672)> removed 3 from the queue <Thread(Thread-3654, started 5044)> removed 4 from the queue
LIFO队列(后进先出队列)
此队列与FIFO(先进先出)队列的逻辑完全相反。在此排队机制中,最后到达的将最先获得服务。这类似于实现栈数据结构。LIFO队列在实现人工智能的深度优先搜索等算法时非常有用。
LIFO队列的Python实现
在Python中,LIFO队列可以使用单线程和多线程实现。
单线程LIFO队列
为了实现单线程LIFO队列,**Queue**类将使用**Queue.LifoQueue**结构实现一个基本的先进后出容器。现在,调用**put()**时,元素添加到容器的头部,使用**get()**时也从头部移除。
示例
下面是一个使用单线程实现LIFO队列的Python程序:
import queue
q = queue.LifoQueue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end=" ")
Output:
item-7 item-6 item-5 item-4 item-3 item-2 item-1 item-0
输出显示上述程序使用单线程来说明元素以与插入顺序相反的顺序从队列中移除。
多线程LIFO队列
实现方法与我们使用多线程实现FIFO队列的方法类似。唯一的区别是我们需要使用**Queue**类,它将使用**Queue.LifoQueue**结构实现一个基本的先进后出容器。
示例
下面是一个使用多线程实现LIFO队列的Python程序:
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.LifoQueue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
输出
<Thread(Thread-3882, started 4928)> removed 4 from the queue <Thread(Thread-3883, started 4364)> removed 3 from the queue <Thread(Thread-3884, started 6908)> removed 2 from the queue <Thread(Thread-3885, started 3584)> removed 1 from the queue <Thread(Thread-3882, started 4928)> removed 0 from the queue
优先级队列
在FIFO和LIFO队列中,项目的顺序与插入顺序相关。但是,在许多情况下,优先级比插入顺序更重要。让我们考虑一个现实世界的例子。假设机场安检正在检查不同类别的乘客。VVIP、航空公司员工、海关官员等类别的乘客可能会优先检查,而不是像普通乘客那样按到达顺序检查。
优先级队列需要考虑的另一个重要方面是如何开发任务调度程序。一种常见的方案是基于优先级服务队列中最紧急的任务。此数据结构可用于根据项目的优先级值从队列中提取项目。
优先级队列的Python实现
在Python中,优先级队列可以使用单线程和多线程实现。
单线程优先级队列
为了实现单线程优先级队列,**Queue**类将使用**Queue.PriorityQueue**结构实现一个基于优先级的任务容器。现在,调用**put()**时,元素将添加一个值,其中值越小优先级越高,因此将首先使用**get()**检索。
示例
考虑以下使用单线程实现优先级队列的Python程序:
import queue as Q
p_queue = Q.PriorityQueue()
p_queue.put((2, 'Urgent'))
p_queue.put((1, 'Most Urgent'))
p_queue.put((10, 'Nothing important'))
prio_queue.put((5, 'Important'))
while not p_queue.empty():
item = p_queue.get()
print('%s - %s' % item)
输出
1 – Most Urgent 2 - Urgent 5 - Important 10 – Nothing important
在上面的输出中,我们可以看到队列根据优先级存储了项目——值越小,优先级越高。
多线程优先级队列
实现方法与使用多线程实现FIFO和LIFO队列的方法类似。唯一的区别是我们需要使用**Queue**类来使用**Queue.PriorityQueue**结构初始化优先级。另一个区别在于队列的生成方式。在下面给出的示例中,它将使用两个相同的数据集生成。
示例
下面的Python程序有助于使用多线程实现优先级队列:
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(1)
q = queue.PriorityQueue()
for i in range(5):
q.put(i,1)
for i in range(5):
q.put(i,1)
threads = []
for i in range(2):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
输出
<Thread(Thread-4939, started 2420)> removed 0 from the queue <Thread(Thread-4940, started 3284)> removed 0 from the queue <Thread(Thread-4939, started 2420)> removed 1 from the queue <Thread(Thread-4940, started 3284)> removed 1 from the queue <Thread(Thread-4939, started 2420)> removed 2 from the queue <Thread(Thread-4940, started 3284)> removed 2 from the queue <Thread(Thread-4939, started 2420)> removed 3 from the queue <Thread(Thread-4940, started 3284)> removed 3 from the queue <Thread(Thread-4939, started 2420)> removed 4 from the queue <Thread(Thread-4940, started 3284)> removed 4 from the queue
线程应用测试
在本章中,我们将学习线程应用程序的测试。我们还将学习测试的重要性。
为什么要测试?
在我们深入讨论测试的重要性之前,我们需要知道什么是测试。一般来说,测试是一种找出某事物工作情况有多好的技术。另一方面,如果我们具体谈论计算机程序或软件,那么测试就是访问软件程序功能的技术。
在本节中,我们将讨论软件测试的重要性。在软件开发中,在向客户发布软件之前必须进行二次检查。这就是为什么由经验丰富的测试团队测试软件非常重要的原因。请考虑以下几点,以了解软件测试的重要性:
提高软件质量
当然,没有公司想交付低质量的软件,也没有客户想购买低质量的软件。测试通过查找和修复其中的错误来提高软件质量。
客户满意度
任何业务最重要的部分是客户的满意度。通过提供无错误且高质量的软件,公司可以实现客户满意度。
减少新功能的影响
假设我们已经制作了一个10000行的软件系统,我们需要添加一个新功能,那么开发团队会担心这个新功能对整个软件的影响。在这里,测试也起着至关重要的作用,因为如果测试团队创建了一套良好的测试,那么它可以使我们免受任何潜在的灾难性故障。
用户体验
任何业务的另一个最重要的部分是该产品用户的体验。只有测试才能确保最终用户发现该产品简单易用。
降低成本
测试可以通过在开发阶段查找和修复错误来降低软件的总成本,而不是在交付后修复它。如果软件交付后存在重大错误,则会增加其有形成本(例如支出)和无形成本(例如客户不满、公司负面声誉等)。
测试什么?
始终建议对要测试的内容有适当的了解。在本节中,我们首先将了解测试任何软件时测试人员的首要动机。在测试时,应避免代码覆盖率,即我们的测试套件命中了多少行代码。这是因为,在测试时,只关注代码行数不会为我们的系统增加任何实际价值。即使在部署后,也可能仍然存在一些错误,这些错误会在稍后的阶段反映出来。
考虑以下与测试内容相关的要点:
我们需要关注测试代码的功能,而不是代码覆盖率。
我们需要首先测试代码中最重要的部分,然后转向代码中不太重要的部分。这肯定会节省时间。
测试人员必须进行多种不同的测试,这些测试可以将软件推到其极限。
并发软件程序的测试方法
由于能够利用多核架构的真正能力,并发软件系统正在取代顺序系统。近年来,并发系统程序已用于从手机到洗衣机,从汽车到飞机等一切事物。我们需要更加小心地测试并发软件程序,因为如果我们向已经存在错误的单线程应用程序添加了多个线程,那么最终会产生多个错误。
并发软件程序的测试技术主要集中在选择交错,以揭示潜在的有害模式,例如竞争条件、死锁和原子性违规。以下是两种并发软件程序测试方法:
系统探索
这种方法旨在尽可能广泛地探索交错空间。此类方法可以采用蛮力技术,其他方法采用部分顺序约简技术或启发式技术来探索交错空间。
属性驱动
属性驱动的方法依赖于这样的观察:并发错误更有可能发生在揭示特定属性(例如可疑内存访问模式)的交错下。不同的属性驱动方法针对不同的错误,例如竞争条件、死锁和原子性违规,这进一步取决于一个或另一个特定属性。
测试策略
测试策略也称为测试方法。该策略定义了如何进行测试。测试方法有两种技术:
主动式
一种方法,其中测试设计过程尽早启动,以便在创建构建之前查找和修复缺陷。
被动式
一种方法,其中测试直到开发过程完成后才开始。
在将任何测试策略或方法应用于Python程序之前,我们必须对软件程序可能存在的错误类型有一个基本的了解。错误如下:
语法错误
在程序开发过程中,可能会出现许多小错误。这些错误大多是由于打字错误造成的。例如,缺少冒号或关键字拼写错误等。此类错误是由于程序语法中的错误造成的,而不是逻辑错误。因此,这些错误称为语法错误。
语义错误
语义错误也称为逻辑错误。如果软件程序中存在逻辑或语义错误,则该语句将正确编译和运行,但它不会给出预期的输出,因为逻辑不正确。
单元测试
这是用于测试Python程序最常用的测试策略之一。此策略用于测试代码的单元或组件。就单元或组件而言,我们的意思是代码的类或函数。单元测试通过测试“小型”单元来简化大型编程系统的测试。借助上述概念,单元测试可以定义为一种方法,其中测试单个源代码单元以确定它们是否返回所需的输出。
在我们接下来的章节中,我们将学习用于单元测试的不同Python模块。
unittest模块
第一个用于单元测试的模块是unittest模块。它受JUnit启发,默认包含在Python 3.6中。它支持测试自动化、共享测试的设置和拆卸代码、将测试聚合到集合中以及测试与报告框架的独立性。
以下是unittest模块支持的一些重要概念
测试装置
它用于设置测试,以便在开始测试之前运行它,并在测试结束后拆除。这可能包括在开始测试之前创建所需的临时数据库、目录等。
测试用例
测试用例检查特定输入集是否产生所需响应。unittest模块包含一个名为TestCase的基类,可用于创建新的测试用例。它默认包含两种方法:
**setUp()** - 一个挂钩方法,用于在执行测试装置之前设置它。这在调用已实现的测试方法之前调用。
**tearDown()** - 一个挂钩方法,用于在运行类中所有测试后解构类测试装置。
测试套件
它是测试套件、测试用例或两者的集合。
测试运行器
它控制测试用例或套件的运行,并将结果提供给用户。它可以使用GUI或简单的文本界面来提供结果。
示例
下面的Python程序使用unittest模块来测试名为Fibonacci的模块。该程序有助于计算数字的斐波那契数列。在这个例子中,我们创建了一个名为Fibo_test的类,使用不同的方法定义测试用例。这些方法继承自unittest.TestCase。我们默认使用了两个方法——setUp()和tearDown()。我们还定义了testfibocal方法。测试名称必须以字母test开头。在最后的块中,unittest.main()为测试脚本提供了一个命令行界面。
import unittest
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return a
class Fibo_Test(unittest.TestCase):
def setUp(self):
print("This is run before our tests would be executed")
def tearDown(self):
print("This is run after the completion of execution of our tests")
def testfibocal(self):
self.assertEqual(fib(0), 0)
self.assertEqual(fib(1), 1)
self.assertEqual(fib(5), 5)
self.assertEqual(fib(10), 55)
self.assertEqual(fib(20), 6765)
if __name__ == "__main__":
unittest.main()
从命令行运行时,上述脚本生成的输出如下所示:
输出
This runs before our tests would be executed. This runs after the completion of execution of our tests. . ---------------------------------------------------------------------- Ran 1 test in 0.006s OK
现在,为了更清晰起见,我们修改了帮助定义Fibonacci模块的代码。
以下代码块为例:
def fibonacci(n): a, b = 0, 1 for i in range(n): a, b = b, a + b return a
对代码块进行了一些更改,如下所示:
def fibonacci(n): a, b = 1, 1 for i in range(n): a, b = b, a + b return a
现在,使用修改后的代码运行脚本后,我们将得到以下输出:
This runs before our tests would be executed. This runs after the completion of execution of our tests. F ====================================================================== FAIL: testCalculation (__main__.Fibo_Test) ---------------------------------------------------------------------- Traceback (most recent call last): File "unitg.py", line 15, in testCalculation self.assertEqual(fib(0), 0) AssertionError: 1 != 0 ---------------------------------------------------------------------- Ran 1 test in 0.007s FAILED (failures = 1)
上述输出表明该模块未能给出期望的输出。
doctest模块
doctest模块也有助于单元测试。它也预先打包在python中。它比unittest模块更容易使用。unittest模块更适合复杂的测试。要使用doctest模块,我们需要导入它。相应函数的文档字符串必须包含交互式python会话及其输出。
如果我们的代码一切正常,那么doctest模块将不会输出任何内容;否则,它将提供输出。
示例
以下Python示例使用doctest模块测试名为Fibonacci的模块,该模块有助于计算数字的斐波那契数列。
import doctest
def fibonacci(n):
"""
Calculates the Fibonacci number
>>> fibonacci(0)
0
>>> fibonacci(1)
1
>>> fibonacci(10)
55
>>> fibonacci(20)
6765
>>>
"""
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return a
if __name__ == "__main__":
doctest.testmod()
我们可以看到,名为fib的相应函数的文档字符串包含交互式python会话及其输出。如果我们的代码正常,则doctest模块不会输出任何内容。但是为了了解其工作原理,我们可以使用-v选项运行它。
(base) D:\ProgramData>python dock_test.py -v Trying: fibonacci(0) Expecting: 0 ok Trying: fibonacci(1) Expecting: 1 ok Trying: fibonacci(10) Expecting: 55 ok Trying: fibonacci(20) Expecting: 6765 ok 1 items had no tests: __main__ 1 items passed all tests: 4 tests in __main__.fibonacci 4 tests in 2 items. 4 passed and 0 failed. Test passed.
现在,我们将更改帮助定义Fibonacci模块的代码
以下代码块为例:
def fibonacci(n): a, b = 0, 1 for i in range(n): a, b = b, a + b return a
以下代码块有助于进行更改:
def fibonacci(n): a, b = 1, 1 for i in range(n): a, b = b, a + b return a
即使没有使用-v选项,使用更改后的代码运行脚本后,我们将得到如下所示的输出。
输出
(base) D:\ProgramData>python dock_test.py ********************************************************************** File "unitg.py", line 6, in __main__.fibonacci Failed example: fibonacci(0) Expected: 0 Got: 1 ********************************************************************** File "unitg.py", line 10, in __main__.fibonacci Failed example: fibonacci(10) Expected: 55 Got: 89 ********************************************************************** File "unitg.py", line 12, in __main__.fibonacci Failed example: fibonacci(20) Expected: 6765 Got: 10946 ********************************************************************** 1 items had failures: 3 of 4 in __main__.fibonacci ***Test Failed*** 3 failures.
我们可以看到上面的输出显示三个测试失败了。
线程应用调试
在本章中,我们将学习如何调试线程应用程序。我们还将学习调试的重要性。
什么是调试?
在计算机编程中,调试是查找并删除计算机程序中错误、异常和异常的过程。这个过程从代码编写之初就开始,并在后续阶段持续进行,因为代码与其他编程单元组合在一起形成软件产品。调试是软件测试过程的一部分,也是整个软件开发生命周期中不可或缺的一部分。
Python调试器
Python调试器或pdb是Python标准库的一部分。它是一个很好的后备工具,用于追踪难以查找的错误,并允许我们快速可靠地修复有故障的代码。以下是pdp调试器的两个最重要的任务:
- 它允许我们在运行时检查变量的值。
- 我们还可以逐步执行代码并设置断点。
我们可以通过以下两种方式使用pdb:
- 通过命令行;这也被称为事后调试。
- 通过交互式运行pdb。
使用pdb
要使用Python调试器,我们需要在想要进入调试器的 位置使用以下代码:
import pdb; pdb.set_trace()
考虑使用以下命令通过命令行使用pdb。
- h(help)
- d(down)
- u(up)
- b(break)
- cl(clear)
- l(list)
- n(next)
- c(continue)
- s(step)
- r(return)
- b(break)
以下是Python调试器h(help)命令的演示:
import pdb pdb.set_trace() --Call-- >d:\programdata\lib\site-packages\ipython\core\displayhook.py(247)__call__() -> def __call__(self, result = None): (Pdb) h Documented commands (type help <topic>): ======================================== EOF c d h list q rv undisplay a cl debug help ll quit s unt alias clear disable ignore longlist r source until args commands display interact n restart step up b condition down j next return tbreak w break cont enable jump p retval u whatis bt continue exit l pp run unalias where Miscellaneous help topics: ========================== exec pdb
示例
在使用Python调试器时,我们可以使用以下几行代码在脚本中的任何位置设置断点:
import pdb; pdb.set_trace()
设置断点后,我们可以正常运行脚本。脚本将执行到某个点;直到设置了断点的行。以下示例中,我们将使用上述几行代码在脚本中的各个位置运行脚本:
import pdb; a = "aaa" pdb.set_trace() b = "bbb" c = "ccc" final = a + b + c print (final)
运行上述脚本时,它将执行程序直到a = “aaa”,我们可以在以下输出中检查这一点。
输出
--Return-- > <ipython-input-7-8a7d1b5cc854>(3)<module>()->None -> pdb.set_trace() (Pdb) p a 'aaa' (Pdb) p b *** NameError: name 'b' is not defined (Pdb) p c *** NameError: name 'c' is not defined
在pdb中使用命令‘p(print)’后,此脚本只打印‘aaa’。之后出现错误,因为我们已将断点设置到a = "aaa"。
同样,我们可以通过更改断点来运行脚本并查看输出差异:
import pdb a = "aaa" b = "bbb" c = "ccc" pdb.set_trace() final = a + b + c print (final)
输出
--Return-- > <ipython-input-9-a59ef5caf723>(5)<module>()->None -> pdb.set_trace() (Pdb) p a 'aaa' (Pdb) p b 'bbb' (Pdb) p c 'ccc' (Pdb) p final *** NameError: name 'final' is not defined (Pdb) exit
在以下脚本中,我们在程序的最后一行设置断点:
import pdb a = "aaa" b = "bbb" c = "ccc" final = a + b + c pdb.set_trace() print (final)
输出如下:
--Return-- > <ipython-input-11-8019b029997d>(6)<module>()->None -> pdb.set_trace() (Pdb) p a 'aaa' (Pdb) p b 'bbb' (Pdb) p c 'ccc' (Pdb) p final 'aaabbbccc' (Pdb)
基准测试和性能分析
在本章中,我们将学习基准测试和性能分析如何帮助解决性能问题。
假设我们编写了一个代码,它也给出了期望的结果,但是如果我们想让这个代码运行得更快一些,因为需求发生了变化呢?在这种情况下,我们需要找出代码的哪些部分正在减慢整个程序的运行速度。在这种情况下,基准测试和性能分析可能会有用。
什么是基准测试?
基准测试旨在通过与标准进行比较来评估某些东西。但是,这里出现的问题是基准测试是什么,以及在软件编程的情况下为什么需要它。对代码进行基准测试意味着代码的执行速度以及瓶颈在哪里。基准测试的一个主要原因是它可以优化代码。
基准测试是如何工作的?
如果我们谈论基准测试的工作原理,我们需要从将整个程序作为一个当前状态进行基准测试开始,然后我们可以组合微基准测试,然后将程序分解成更小的程序。为了找到程序中的瓶颈并对其进行优化。换句话说,我们可以将其理解为将大型难题分解成一系列较小且更容易解决的问题,以便对其进行优化。
Python基准测试模块
在Python中,我们有一个默认的基准测试模块,称为timeit。借助timeit模块,我们可以在主程序中测量一小段Python代码的性能。
示例
在下面的Python脚本中,我们导入了timeit模块,该模块进一步测量执行两个函数——functionA和functionB——所需的时间:
import timeit
import time
def functionA():
print("Function A starts the execution:")
print("Function A completes the execution:")
def functionB():
print("Function B starts the execution")
print("Function B completes the execution")
start_time = timeit.default_timer()
functionA()
print(timeit.default_timer() - start_time)
start_time = timeit.default_timer()
functionB()
print(timeit.default_timer() - start_time)
运行上述脚本后,我们将得到两个函数的执行时间,如下所示。
输出
Function A starts the execution: Function A completes the execution: 0.0014599495514175942 Function B starts the execution Function B completes the execution 0.0017024724827479076
使用装饰器函数编写我们自己的计时器
在Python中,我们可以创建我们自己的计时器,它的作用就像timeit模块一样。这可以通过装饰器函数来实现。以下是一个自定义计时器的示例:
import random
import time
def timer_func(func):
def function_timer(*args, **kwargs):
start = time.time()
value = func(*args, **kwargs)
end = time.time()
runtime = end - start
msg = "{func} took {time} seconds to complete its execution."
print(msg.format(func = func.__name__,time = runtime))
return value
return function_timer
@timer_func
def Myfunction():
for x in range(5):
sleep_time = random.choice(range(1,3))
time.sleep(sleep_time)
if __name__ == '__main__':
Myfunction()
上面的python脚本有助于导入随机时间模块。我们创建了timer_func()装饰器函数。它内部包含function_timer()函数。现在,嵌套函数将在调用传入的函数之前获取时间。然后它等待函数返回并获取结束时间。通过这种方式,我们最终可以使python脚本打印执行时间。脚本将生成如下所示的输出。
输出
Myfunction took 8.000457763671875 seconds to complete its execution.
什么是性能分析?
有时程序员希望测量程序的一些属性,例如内存使用情况、时间复杂度或特定指令的使用情况,以衡量该程序的实际能力。对程序进行这种测量称为性能分析。性能分析使用动态程序分析进行这种测量。
在接下来的部分中,我们将学习关于不同Python性能分析模块的内容。
cProfile – 内置模块
cProfile是Python内置的性能分析模块。该模块是一个C扩展,开销合理,使其适合于分析长时间运行的程序。运行后,它会记录所有函数和执行时间。它非常强大,但有时有点难以解释和处理。在下面的示例中,我们对下面的代码使用cProfile:
示例
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target=taskofThread, args=(lock,))
t2 = threading.Thread(target= taskofThread, args=(lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))
上述代码保存在thread_increment.py文件中。现在,在命令行上使用cProfile执行代码,如下所示:
(base) D:\ProgramData>python -m cProfile thread_increment.py
x = 100000 after Iteration 0
x = 100000 after Iteration 1
x = 100000 after Iteration 2
x = 100000 after Iteration 3
x = 100000 after Iteration 4
3577 function calls (3522 primitive calls) in 1.688 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:103(release)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:143(__init__)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:147(__enter__)
… … … …
从上面的输出可以看出,cProfile打印出所有调用的3577个函数,以及每个函数花费的时间以及它们被调用的次数。以下是我们在输出中获得的列:
ncalls – 这是调用的次数。
tottime – 这是在给定函数中花费的总时间。
percall – 它指的是tottime除以ncalls的商。
cumtime – 这是在此函数和所有子函数中花费的累积时间。对于递归函数来说,它甚至更准确。
percall – 它是cumtime除以原始调用的商。
filename:lineno(function) – 它基本上提供了每个函数的相应数据。
Python中的并发 - 线程池
假设我们必须为我们的多线程任务创建大量线程。由于可能存在许多性能问题,因此在计算上将是最昂贵的,因为过多的线程可能会导致吞吐量受限。我们可以通过创建线程池来解决这个问题。线程池可以定义为一组预实例化和空闲的线程,它们随时准备接收工作。当我们需要执行大量任务时,创建线程池比为每个任务实例化新线程更可取。线程池可以管理大量线程的并发执行,如下所示:
如果线程池中的一个线程完成了执行,则可以重用该线程。
如果线程终止,将创建另一个线程来替换该线程。
Python模块 – concurrent.futures
Python标准库包含concurrent.futures模块。此模块添加到Python 3.2中,为开发人员提供了一个高级接口来启动异步任务。它是在Python的threading和multiprocessing模块顶部的抽象层,用于提供使用线程池或进程运行任务的接口。
在接下来的部分中,我们将学习关于concurrent.futures模块的不同类的内容。
Executor类
Executor是concurrent.futures Python模块的抽象类。不能直接使用它,我们需要使用以下具体子类之一:
- ThreadPoolExecutor
- ProcessPoolExecutor
ThreadPoolExecutor – 一个具体的子类
它是Executor类的具体子类之一。该子类使用多线程,我们得到一个线程池来提交任务。此池将任务分配给可用的线程并安排它们运行。
如何创建一个ThreadPoolExecutor?
借助于**concurrent.futures**模块及其具体的子类**Executor**,我们可以轻松地创建一个线程池。为此,我们需要用想要在池中创建的线程数来构造一个**ThreadPoolExecutor**。默认情况下,线程数为5。然后我们可以向线程池提交任务。当我们**submit()**一个任务时,我们会得到一个**Future**对象。Future对象有一个名为**done()**的方法,它指示future是否已完成。这意味着为该特定的future对象设置了一个值。当任务完成后,线程池执行器会将值设置到future对象。
示例
from concurrent.futures import ThreadPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ThreadPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()
输出
False True Completed
在上面的例子中,已经构造了一个包含5个线程的**ThreadPoolExecutor**。然后将一个任务提交到线程池执行器,该任务将在发出消息之前等待2秒。从输出中可以看到,任务直到2秒后才完成,因此第一次调用**done()**将返回False。2秒后,任务完成,我们通过调用其上的**result()**方法获得future的结果。
实例化ThreadPoolExecutor – 上下文管理器
实例化**ThreadPoolExecutor**的另一种方法是借助上下文管理器。它的工作方式类似于上面示例中使用的方法。使用上下文管理器的主要优点是它在语法上看起来更好。可以使用以下代码进行实例化:
with ThreadPoolExecutor(max_workers = 5) as executor
示例
下面的例子取自Python文档。在这个例子中,首先需要导入**concurrent.futures**模块。然后创建一个名为**load_url()**的函数,该函数将加载请求的URL。然后该函数创建**ThreadPoolExecutor**,池中有5个线程。**ThreadPoolExecutor**被用作上下文管理器。我们可以通过调用其上的**result()**方法获得future的结果。
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
with concurrent.futures.ThreadPoolExecutor(max_workers = 5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
输出
以下是上面Python脚本的输出:
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed> 'http://www.foxnews.com/' page is 229313 bytes 'http://www.cnn.com/' page is 168933 bytes 'http://www.bbc.co.uk/' page is 283893 bytes 'http://europe.wsj.com/' page is 938109 bytes
Executor.map()函数的使用
Python的**map()**函数广泛用于许多任务中。其中一项任务是将某个函数应用于迭代对象中的每个元素。类似地,我们可以将迭代器的所有元素映射到一个函数,并将这些元素作为独立的作业提交到我们的**ThreadPoolExecutor**。考虑以下Python脚本示例,以了解该函数的工作原理。
示例
在下面的例子中,map函数用于将**square()**函数应用于values数组中的每个值。
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ThreadPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()
输出
上面的Python脚本生成以下输出:
4 9 16 25
Python中的并发 - 进程池
进程池的创建和使用方式与我们创建和使用线程池的方式相同。进程池可以定义为一组预先实例化且处于空闲状态的进程,它们随时准备接收工作。当我们需要执行大量任务时,创建进程池比为每个任务实例化新进程更可取。
Python模块 – concurrent.futures
Python标准库有一个名为**concurrent.futures**的模块。此模块是在Python 3.2中添加的,为开发人员提供了一个用于启动异步任务的高级接口。它是Python的threading和multiprocessing模块之上的一个抽象层,用于提供使用线程池或进程池运行任务的接口。
在接下来的章节中,我们将了解concurrent.futures模块的不同子类。
Executor类
**Executor**是**concurrent.futures** Python模块的抽象类。它不能直接使用,我们需要使用以下具体的子类之一:
- ThreadPoolExecutor
- ProcessPoolExecutor
ProcessPoolExecutor – 一个具体的子类
它是Executor类的具体子类之一。它使用多进程,我们得到一个用于提交任务的进程池。该池将任务分配给可用的进程并安排它们运行。
如何创建一个ProcessPoolExecutor?
借助于**concurrent.futures**模块及其具体的子类**Executor**,我们可以轻松地创建一个进程池。为此,我们需要用想要在池中创建的进程数来构造一个**ProcessPoolExecutor**。默认情况下,进程数为5。之后将任务提交到进程池。
示例
我们现在考虑与创建线程池时使用的相同示例,唯一的区别是现在我们将使用**ProcessPoolExecutor**而不是**ThreadPoolExecutor**。
from concurrent.futures import ProcessPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ProcessPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()
输出
False False Completed
在上面的例子中,已经构造了一个包含5个进程的Process**PoolExecutor**。然后将一个任务提交到进程池执行器,该任务将在发出消息之前等待2秒。从输出中可以看到,任务直到2秒后才完成,因此第一次调用**done()**将返回False。2秒后,任务完成,我们通过调用其上的**result()**方法获得future的结果。
实例化ProcessPoolExecutor – 上下文管理器
实例化ProcessPoolExecutor的另一种方法是借助上下文管理器。它的工作方式类似于上面示例中使用的方法。使用上下文管理器的主要优点是它在语法上看起来更好。可以使用以下代码进行实例化:
with ProcessPoolExecutor(max_workers = 5) as executor
示例
为了更好地理解,我们使用与创建线程池时相同的示例。在这个例子中,我们需要首先导入**concurrent.futures**模块。然后创建一个名为**load_url()**的函数,该函数将加载请求的URL。然后创建**ProcessPoolExecutor**,池中有5个线程。Process**PoolExecutor**被用作上下文管理器。我们可以通过调用其上的**result()**方法获得future的结果。
import concurrent.futures
from concurrent.futures import ProcessPoolExecutor
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
def main():
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
if __name__ == '__main__':
main()
输出
上面的Python脚本将生成以下输出:
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed> 'http://www.foxnews.com/' page is 229476 bytes 'http://www.cnn.com/' page is 165323 bytes 'http://www.bbc.co.uk/' page is 284981 bytes 'http://europe.wsj.com/' page is 967575 bytes
Executor.map()函数的使用
Python的**map()**函数广泛用于执行许多任务。其中一项任务是将某个函数应用于迭代对象中的每个元素。类似地,我们可以将迭代器的所有元素映射到一个函数,并将这些元素作为独立的作业提交到**ProcessPoolExecutor**。考虑以下Python脚本示例以了解这一点。
示例
我们将考虑与使用**Executor.map()**函数创建线程池时相同的示例。在下面的示例中,map函数用于将**square()**函数应用于values数组中的每个值。
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ProcessPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()
输出
上面的Python脚本将生成以下输出
4 9 16 25
何时使用ProcessPoolExecutor和ThreadPoolExecutor?
现在我们已经学习了两个Executor类——ThreadPoolExecutor和ProcessPoolExecutor,我们需要知道何时使用哪个执行器。对于CPU密集型工作负载,我们需要选择ProcessPoolExecutor;对于I/O密集型工作负载,我们需要选择ThreadPoolExecutor。
如果我们使用**ProcessPoolExecutor**,那么我们不需要担心GIL,因为它使用多进程。此外,与**ThreadPoolExecution**相比,执行时间将更短。考虑以下Python脚本示例以了解这一点。
示例
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()
输出
Start: 8000000 Time taken: 1.5509998798370361
Start: 7000000 Time taken: 1.3259999752044678
Total time taken: 2.0840001106262207
Example- Python script with ThreadPoolExecutor:
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()
输出
Start: 8000000 Time taken: 3.8420000076293945 Start: 7000000 Time taken: 3.6010000705718994 Total time taken: 3.8480000495910645
从上面两个程序的输出中,我们可以看到使用**ProcessPoolExecutor**和**ThreadPoolExecutor**时的执行时间差异。
Python中的并发 - 多进程
在本章中,我们将更侧重于多进程和多线程之间的比较。
多进程
它是在单个计算机系统中使用两个或多个CPU单元。这是充分发挥硬件潜力的最佳方法,因为它可以利用计算机系统中可用的所有CPU核心。
多线程
它指的是CPU能够通过并发执行多个线程来管理操作系统的使用。多线程的主要思想是通过将进程分成多个线程来实现并行性。
下表显示了它们之间的一些重要区别:
| 多进程 | 多程序设计 |
|---|---|
| 多进程是指多个CPU同时处理多个进程。 | 多程序设计同时将多个程序保留在主内存中,并利用单个CPU并发执行它们。 |
| 它利用多个CPU。 | 它利用单个CPU。 |
| 它允许并行处理。 | 发生上下文切换。 |
| 处理作业所需时间更少。 | 处理作业所需时间更多。 |
| 它有助于更有效地利用计算机系统的设备。 | 效率低于多进程。 |
| 通常更昂贵。 | 此类系统成本较低。 |
消除全局解释器锁 (GIL) 的影响
在使用并发应用程序时,Python中存在一个名为**GIL(全局解释器锁)**的限制。GIL不允许我们利用CPU的多个核心,因此我们可以说Python中没有真正的线程。GIL是互斥锁,它使事物线程安全。换句话说,我们可以说GIL阻止多个线程并行执行Python代码。一次只能由一个线程持有锁,如果我们想要执行一个线程,则它必须首先获取锁。
通过使用多进程,我们可以有效地绕过GIL造成的限制:
通过使用多进程,我们正在利用多个进程的能力,因此我们正在利用GIL的多个实例。
因此,在任何时候都没有限制在一个程序中执行一个线程的字节码。
在Python中启动进程
可以使用以下三种方法在multiprocessing模块中启动Python中的进程:
- fork
- spawn
- forkserver
使用fork创建进程
fork命令是UNIX中找到的标准命令。它用于创建称为子进程的新进程。此子进程与称为父进程的进程并发运行。这些子进程与其父进程也相同,并继承父进程可用的所有资源。在使用fork创建进程时,使用以下系统调用:
**fork()** – 它通常在内核中实现的系统调用。它用于创建进程的副本。
**getpid()** – 此系统调用返回调用进程的进程ID (PID)。
示例
以下Python脚本示例将帮助您了解如何创建新的子进程并获取子进程和父进程的PID:
import os
def child():
n = os.fork()
if n > 0:
print("PID of Parent process is : ", os.getpid())
else:
print("PID of Child process is : ", os.getpid())
child()
输出
PID of Parent process is : 25989 PID of Child process is : 25990
使用spawn创建进程
spawn意为启动新的事物。因此,生成进程意味着父进程创建新的进程。父进程继续异步执行或等待子进程结束执行。按照以下步骤生成进程:
导入multiprocessing模块。
创建进程对象。
通过调用**start()**方法启动进程活动。
等待进程完成其工作并通过调用**join()**方法退出。
示例
以下Python脚本示例有助于生成三个进程
import multiprocessing
def spawn_process(i):
print ('This is process: %s' %i)
return
if __name__ == '__main__':
Process_jobs = []
for i in range(3):
p = multiprocessing.Process(target = spawn_process, args = (i,))
Process_jobs.append(p)
p.start()
p.join()
输出
This is process: 0 This is process: 1 This is process: 2
使用forkserver创建进程
forkserver机制仅适用于支持通过Unix管道传递文件描述符的某些选定的UNIX平台。考虑以下几点,以了解forkserver机制的工作原理:
使用forkserver机制启动新进程时,会实例化一个服务器。
然后,服务器接收命令并处理所有创建新进程的请求。
为了创建新进程,我们的Python程序将向Forkserver发送请求,它将为我们创建一个进程。
最后,我们可以在程序中使用这个新创建的进程。
Python中的守护进程
Python的multiprocessing模块允许我们通过其daemonic选项拥有守护进程。守护进程或在后台运行的进程遵循与守护线程类似的概念。要在后台执行进程,我们需要将daemonic标志设置为true。守护进程将在主进程执行期间继续运行,并在完成其执行或主程序被终止后终止。
示例
这里,我们使用与守护线程中相同的示例。唯一的区别是将模块从multithreading更改为multiprocessing并将daemonic标志设置为true。但是,输出会有所不同,如下所示:
import multiprocessing
import time
def nondaemonProcess():
print("starting my Process")
time.sleep(8)
print("ending my Process")
def daemonProcess():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonProcess = multiprocessing.Process(target = nondaemonProcess)
daemonProcess = multiprocessing.Process(target = daemonProcess)
daemonProcess.daemon = True
nondaemonProcess.daemon = False
daemonProcess.start()
nondaemonProcess.start()
输出
starting my Process ending my Process
与守护线程生成的输出相比,输出有所不同,因为非守护模式下的进程有输出。因此,守护进程在主程序结束后会自动结束,以避免运行进程的持久性。
终止Python中的进程
我们可以使用terminate()方法立即终止进程。我们将使用此方法立即终止在函数帮助下创建的子进程,该子进程在完成其执行之前。
示例
import multiprocessing
import time
def Child_process():
print ('Starting function')
time.sleep(5)
print ('Finished function')
P = multiprocessing.Process(target = Child_process)
P.start()
print("My Process has terminated, terminating main thread")
print("Terminating Child Process")
P.terminate()
print("Child Process successfully terminated")
输出
My Process has terminated, terminating main thread Terminating Child Process Child Process successfully terminated
输出显示程序在创建子进程(借助Child_process()函数创建)执行之前终止。这意味着子进程已成功终止。
识别Python中的当前进程
操作系统中的每个进程都有一个称为PID的进程标识。在Python中,我们可以借助以下命令找出当前进程的PID:
import multiprocessing print(multiprocessing.current_process().pid)
示例
以下Python脚本示例有助于找出主进程的PID以及子进程的PID:
import multiprocessing
import time
def Child_process():
print("PID of Child Process is: {}".format(multiprocessing.current_process().pid))
print("PID of Main process is: {}".format(multiprocessing.current_process().pid))
P = multiprocessing.Process(target=Child_process)
P.start()
P.join()
输出
PID of Main process is: 9401 PID of Child Process is: 9402
在子类中使用进程
我们可以通过子类化threading.Thread类来创建线程。此外,我们还可以通过子类化multiprocessing.Process类来创建进程。要在子类中使用进程,我们需要考虑以下几点:
我们需要定义Process类的新子类。
我们需要重写_init_(self [,args] )类。
我们需要重写run(self [,args] )方法来实现Process的功能。
我们需要通过调用start()方法来启动进程。
示例
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
print ('called run method in process: %s' %self.name)
return
if __name__ == '__main__':
jobs = []
for i in range(5):
P = MyProcess()
jobs.append(P)
P.start()
P.join()
输出
called run method in process: MyProcess-1 called run method in process: MyProcess-2 called run method in process: MyProcess-3 called run method in process: MyProcess-4 called run method in process: MyProcess-5
Python多进程模块 – Pool类
如果我们在Python应用程序中讨论简单的并行处理任务,那么multiprocessing模块为我们提供了Pool类。Pool类的以下方法可用于在我们主程序中启动多个子进程。
apply()方法
此方法类似于.ThreadPoolExecutor的.submit()方法。它会阻塞,直到结果准备好。
apply_async()方法
当我们需要并行执行任务时,我们需要使用apply_async()方法将任务提交到池中。这是一个异步操作,在所有子进程执行完毕之前不会锁定主线程。
map()方法
与apply()方法一样,它也会阻塞,直到结果准备好。它等效于内置的map()函数,该函数将可迭代数据分成多个块,并将其作为单独的任务提交给进程池。
map_async()方法
它是map()方法的变体,就像apply_async()之于apply()方法一样。它返回一个结果对象。当结果准备好时,会将一个可调用对象应用于它。可调用对象必须立即完成;否则,处理结果的线程将被阻塞。
示例
以下示例将帮助您实现一个进程池来执行并行执行。通过multiprocessing.Pool方法应用square()函数,已经执行了简单的数字平方计算。然后使用pool.map()提交了5个数字(输入是从0到4的整数列表)。结果将存储在p_outputs中并打印出来。
def square(n):
result = n*n
return result
if __name__ == '__main__':
inputs = list(range(5))
p = multiprocessing.Pool(processes = 4)
p_outputs = pool.map(function_square, inputs)
p.close()
p.join()
print ('Pool :', p_outputs)
输出
Pool : [0, 1, 4, 9, 16]
进程间通信
进程间通信是指进程之间的数据交换。为了开发并行应用程序,需要在进程之间交换数据。下图显示了多个子进程之间同步的各种通信机制:
各种通信机制
在本节中,我们将学习各种通信机制。这些机制描述如下:
队列
队列可以与多进程程序一起使用。multiprocessing模块的Queue类类似于Queue.Queue类。因此,可以使用相同的API。Multiprocessing.Queue为我们在进程之间提供了一种线程和进程安全的FIFO(先进先出)通信机制。
示例
以下是从python官方文档中获取的一个关于multiprocessing的简单示例,用于理解multiprocessing的Queue类的概念。
from multiprocessing import Process, Queue import queue import random def f(q): q.put([42, None, 'hello']) def main(): q = Queue() p = Process(target = f, args = (q,)) p.start() print (q.get()) if __name__ == '__main__': main()
输出
[42, None, 'hello']
管道
它是一种数据结构,用于在多进程程序中的进程之间进行通信。Pipe()函数返回一对由管道连接的连接对象,默认情况下是双工(双向)的。它的工作方式如下:
它返回一对连接对象,它们表示管道的两端。
每个对象都有两个方法——send()和recv(),用于进程间通信。
示例
以下是从python官方文档中获取的一个关于multiprocessing的简单示例,用于理解multiprocessing的Pipe()函数的概念。
from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, 'hello']) conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() p = Process(target = f, args = (child_conn,)) p.start() print (parent_conn.recv()) p.join()
输出
[42, None, 'hello']
管理器
Manager是multiprocessing模块的一个类,它提供了一种协调所有用户之间共享信息的方法。管理器对象控制一个服务器进程,该进程管理共享对象并允许其他进程操作它们。换句话说,管理器提供了一种创建可以在不同进程之间共享的数据的方法。以下是管理器对象的不同的属性:
管理器的主要属性是控制一个服务器进程,该进程管理共享对象。
另一个重要的属性是在任何进程修改共享对象时更新所有共享对象。
示例
以下是一个示例,它使用管理器对象在服务器进程中创建列表记录,然后在该列表中添加新记录。
import multiprocessing
def print_records(records):
for record in records:
print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
def insert_record(record, records):
records.append(record)
print("A New record is added\n")
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
records = manager.list([('Computers', 1), ('Histoty', 5), ('Hindi',9)])
new_record = ('English', 3)
p1 = multiprocessing.Process(target = insert_record, args = (new_record, records))
p2 = multiprocessing.Process(target = print_records, args = (records,))
p1.start()
p1.join()
p2.start()
p2.join()
输出
A New record is added Name: Computers Score: 1 Name: Histoty Score: 5 Name: Hindi Score: 9 Name: English Score: 3
管理器中的命名空间概念
Manager类带有命名空间的概念,这是一种在多个进程之间共享多个属性的快速方法。命名空间没有任何可以调用的公共方法,但它们具有可写属性。
示例
以下Python脚本示例帮助我们利用命名空间在主进程和子进程之间共享数据:
import multiprocessing
def Mng_NaSp(using_ns):
using_ns.x +=5
using_ns.y *= 10
if __name__ == '__main__':
manager = multiprocessing.Manager()
using_ns = manager.Namespace()
using_ns.x = 1
using_ns.y = 1
print ('before', using_ns)
p = multiprocessing.Process(target = Mng_NaSp, args = (using_ns,))
p.start()
p.join()
print ('after', using_ns)
输出
before Namespace(x = 1, y = 1) after Namespace(x = 6, y = 10)
Ctypes-Array和Value
Multiprocessing模块提供Array和Value对象用于在共享内存映射中存储数据。Array是从共享内存分配的ctypes数组,Value是从共享内存分配的ctypes对象。
首先,从multiprocessing导入Process、Value、Array。
示例
以下Python脚本是从python文档中获取的一个示例,用于利用Ctypes Array和Value在进程之间共享一些数据。
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target = f, args = (num, arr))
p.start()
p.join()
print (num.value)
print (arr[:])
输出
3.1415927 [0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
通信顺序进程 (CSP)
CSP用于说明系统与具有并发模型的其他系统的交互。CSP是一个编写并发程序或通过消息传递进行编程的框架,因此它对于描述并发性非常有效。
Python库 – PyCSP
为了实现CSP中发现的核心原语,Python有一个名为PyCSP的库。它使实现非常简短易读,因此很容易理解。以下是PyCSP的基本进程网络:
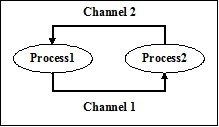
在上面的PyCSP进程网络中,有两个进程——Process1和Process 2。这些进程通过两个通道——通道1和通道2——传递消息进行通信。
安装PyCSP
借助以下命令,我们可以安装Python库PyCSP:
pip install PyCSP
示例
以下Python脚本是一个简单的示例,用于并行运行两个进程。这是借助PyCSP python库完成的:
from pycsp.parallel import *
import time
@process
def P1():
time.sleep(1)
print('P1 exiting')
@process
def P2():
time.sleep(1)
print('P2 exiting')
def main():
Parallel(P1(), P2())
print('Terminating')
if __name__ == '__main__':
main()
在上面的脚本中,创建了两个函数,即P1和P2,然后用@process装饰器将它们转换为进程。
输出
P2 exiting P1 exiting Terminating
事件驱动编程
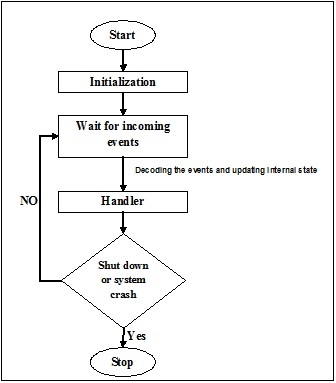
事件驱动编程关注事件。最终,程序的流程取决于事件。到目前为止,我们一直在处理顺序或并行执行模型,但是具有事件驱动编程概念的模型称为异步模型。事件驱动编程依赖于一个始终在监听新传入事件的事件循环。事件驱动编程的工作取决于事件。一旦事件循环运行,事件就决定执行什么以及按什么顺序执行。以下流程图将帮助您理解其工作原理:
Python模块 – Asyncio
Asyncio模块添加到Python 3.4中,它提供编写使用协程的单线程并发代码的基础设施。以下是Asyncio模块使用的不同概念:
事件循环
事件循环是一种处理计算代码中所有事件的功能。在整个程序执行期间,它以循环方式运行,并跟踪传入事件和事件的执行。Asyncio模块允许每个进程只有一个事件循环。以下是Asyncio模块提供的一些用于管理事件循环的方法:
loop = get_event_loop() − 此方法将提供当前上下文的事件循环。
loop.call_later(time_delay,callback,argument) − 此方法安排在给定的time_delay秒后调用的回调。
loop.call_soon(callback,argument) − 此方法安排尽快调用的回调。回调在call_soon()返回并且控制返回到事件循环后调用。
loop.time() − 此方法用于根据事件循环的内部时钟返回当前时间。
asyncio.set_event_loop() − 此方法将当前上下文的事件循环设置为loop。
asyncio.new_event_loop() − 此方法将创建并返回一个新的事件循环对象。
loop.run_forever() − 此方法将运行,直到调用stop()方法。
示例
以下事件循环示例使用get_event_loop()方法打印hello world。此示例取自Python官方文档。
import asyncio
def hello_world(loop):
print('Hello World')
loop.stop()
loop = asyncio.get_event_loop()
loop.call_soon(hello_world, loop)
loop.run_forever()
loop.close()
输出
Hello World
期物 (Futures)
这与concurrent.futures.Future类兼容,该类表示尚未完成的计算。asyncio.futures.Future和concurrent.futures.Future之间存在以下区别:
result()和exception()方法不带超时参数,并在期物尚未完成时引发异常。
使用add_done_callback()注册的回调始终通过事件循环的call_soon()调用。
asyncio.futures.Future类与concurrent.futures包中的wait()和as_completed()函数不兼容。
示例
以下是一个示例,将帮助您了解如何使用asyncio.futures.future类。
import asyncio
async def Myoperation(future):
await asyncio.sleep(2)
future.set_result('Future Completed')
loop = asyncio.get_event_loop()
future = asyncio.Future()
asyncio.ensure_future(Myoperation(future))
try:
loop.run_until_complete(future)
print(future.result())
finally:
loop.close()
输出
Future Completed
协程
Asyncio 中的协程概念类似于 threading 模块下标准 Thread 对象的概念。这是子例程概念的泛化。协程可以在执行期间暂停,以便等待外部处理,并在外部处理完成时从其停止的位置返回。以下两种方法可以帮助我们实现协程:
async def function()
这是在 Asyncio 模块下实现协程的一种方法。下面是一个 Python 脚本:
import asyncio
async def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()
输出
First Coroutine
@asyncio.coroutine 装饰器
实现协程的另一种方法是使用带有 @asyncio.coroutine 装饰器的生成器。下面是一个 Python 脚本:
import asyncio
@asyncio.coroutine
def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()
输出
First Coroutine
任务 (Tasks)
Asyncio 模块的这个子类负责以并行方式在事件循环中执行协程。下面的 Python 脚本是一个并行处理一些任务的示例。
import asyncio
import time
async def Task_ex(n):
time.sleep(1)
print("Processing {}".format(n))
async def Generator_task():
for i in range(10):
asyncio.ensure_future(Task_ex(i))
int("Tasks Completed")
asyncio.sleep(2)
loop = asyncio.get_event_loop()
loop.run_until_complete(Generator_task())
loop.close()
输出
Tasks Completed Processing 0 Processing 1 Processing 2 Processing 3 Processing 4 Processing 5 Processing 6 Processing 7 Processing 8 Processing 9
传输 (Transports)
Asyncio 模块提供传输类来实现各种类型的通信。这些类不是线程安全的,并且在建立通信通道后始终与协议实例配对。
以下是继承自 BaseTransport 的不同类型的传输:
ReadTransport - 这是一个只读传输的接口。
WriteTransport - 这是一个只写传输的接口。
DatagramTransport - 这是一个用于发送数据的接口。
BaseSubprocessTransport - 类似于 BaseTransport 类。
以下是 BaseTransport 类的五个不同的方法,这些方法随后在四种传输类型中都是瞬态的:
close() - 它关闭传输。
is_closing() - 如果传输正在关闭或已经关闭,此方法将返回 true。
get_extra_info(name, default = none) - 这将给我们一些关于传输的额外信息。
get_protocol() - 此方法将返回当前协议。
协议 (Protocols)
Asyncio 模块提供基类,您可以对其进行子类化以实现您的网络协议。这些类与传输一起使用;协议解析传入数据并请求写入传出数据,而传输负责实际的 I/O 和缓冲。以下是协议的三个类:
Protocol - 这是用于实现与 TCP 和 SSL 传输一起使用的流协议的基类。
DatagramProtocol - 这是用于实现与 UDP 传输一起使用的数据报协议的基类。
SubprocessProtocol - 这是用于实现通过一组单向管道与子进程通信的协议的基类。
响应式编程
响应式编程是一种处理数据流和更改传播的编程范例。这意味着当一个组件发出数据流时,更改将通过响应式编程库传播到其他组件。更改的传播将持续到到达最终接收器为止。事件驱动编程和响应式编程的区别在于,事件驱动编程围绕事件展开,而响应式编程围绕数据展开。
ReactiveX 或 RX 用于响应式编程
ReactiveX 或 Reactive Extension 是响应式编程最著名的实现。ReactiveX 的工作依赖于以下两个类:
Observable 类
此类是数据流或事件的来源,它打包传入数据,以便数据可以从一个线程传递到另一个线程。在某些观察者订阅它之前,它不会提供数据。
Observer 类
此类使用Observable发出的数据流。可以有多个观察者使用 Observable,每个观察者将接收发出的每个数据项。观察者可以通过订阅 Observable 来接收三种类型的事件:
on_next() 事件 - 这意味着数据流中有一个元素。
on_completed() 事件 - 这意味着发射结束,不再有项目。
on_error() 事件 - 这也意味着发射结束,但在Observable抛出错误的情况下。
RxPY – 用于响应式编程的 Python 模块
RxPY 是一个可用于响应式编程的 Python 模块。我们需要确保安装了该模块。可以使用以下命令安装 RxPY 模块:
pip install RxPY
示例
下面是一个 Python 脚本,它使用RxPY模块及其类Observable和Observe进行响应式编程。基本上有两个类:
get_strings() - 用于从观察者获取字符串。
PrintObserver() - 用于从观察者打印字符串。它使用观察者类的所有三个事件。它还使用 subscribe() 类。
from rx import Observable, Observer
def get_strings(observer):
observer.on_next("Ram")
observer.on_next("Mohan")
observer.on_next("Shyam")
observer.on_completed()
class PrintObserver(Observer):
def on_next(self, value):
print("Received {0}".format(value))
def on_completed(self):
print("Finished")
def on_error(self, error):
print("Error: {0}".format(error))
source = Observable.create(get_strings)
source.subscribe(PrintObserver())
输出
Received Ram Received Mohan Received Shyam Finished
用于响应式编程的 PyFunctional 库
PyFunctional是另一个可用于响应式编程的 Python 库。它使我们能够使用 Python 编程语言创建函数式程序。它很有用,因为它允许我们使用链式函数运算符创建数据管道。
RxPY 和 PyFunctional 之间的区别
这两个库都用于响应式编程,并以类似的方式处理流,但它们之间的主要区别取决于数据的处理方式。RxPY处理系统中的数据和事件,而PyFunctional专注于使用函数式编程范例转换数据。
安装 PyFunctional 模块
在使用此模块之前,我们需要安装它。可以使用 pip 命令安装它,如下所示:
pip install pyfunctional
示例
以下示例使用PyFunctional模块及其seq类,该类充当流对象,我们可以使用它来迭代和操作。在这个程序中,它使用 lambda 函数将序列映射为每个值的双倍,然后过滤 x 大于 4 的值,最后将序列简化为所有剩余值的总和。
from functional import seq
result = seq(1,2,3).map(lambda x: x*2).filter(lambda x: x > 4).reduce(lambda x, y: x + y)
print ("Result: {}".format(result))
输出
Result: 6