- 数据仓库教程
- DWH - 首页
- DWH - 概述
- DWH - 概念
- DWH - 术语
- DWH - 交付流程
- DWH - 系统流程
- DWH - 架构
- DWH - OLAP
- DWH - 关系型 OLAP
- DWH - 多维 OLAP
- DWH - 模式
- DWH - 分区策略
- DWH - 元数据概念
- DWH - 数据市场
- DWH - 系统管理员
- DWH - 流程管理员
- DWH - 安全
- DWH - 备份
- DWH - 调优
- DWH - 测试
- DWH - 未来展望
- DWH - 面试问题
- DWH 有用资源
- DWH - 快速指南
- DWH - 有用资源
- DWH - 讨论
数据仓库 - 分区策略
分区是为了提高性能并简化数据管理。分区还有助于平衡系统的各种需求。它通过将每个事实表划分为多个单独的分区来优化硬件性能并简化数据仓库的管理。在本章中,我们将讨论不同的分区策略。
为什么需要分区?
出于以下原因,分区非常重要:
- 便于管理,
- 协助备份/恢复,
- 提高性能。
便于管理
数据仓库中的事实表的大小可能高达数百 GB。这种巨大的事实表作为单个实体非常难以管理。因此,它需要分区。
协助备份/恢复
如果我们不分区事实表,那么我们必须加载包含所有数据的完整事实表。分区允许我们仅根据需要定期加载数据。它减少了加载时间,并提高了系统性能。
注意 - 为了减少备份大小,除了当前分区之外的所有分区都可以标记为只读。然后,我们可以将这些分区置于无法修改的状态。然后可以备份它们。这意味着只需要备份当前分区。
提高性能
通过将事实表划分为数据集,可以增强查询过程。查询性能得到增强,因为现在查询仅扫描相关的分区。它不必扫描所有数据。
水平分区
事实表有多种分区方式。在水平分区中,我们必须牢记数据仓库的可管理性需求。
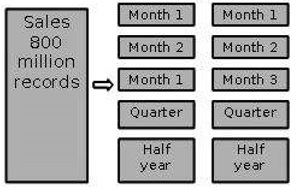
按时间划分为相等段
在这种分区策略中,事实表是根据时间段进行分区的。这里每个时间段代表业务内一个重要的保留期。例如,如果用户查询本月至今的数据,那么将数据划分为月度段是合适的。我们可以通过删除其中的数据来重用分区表。
按时间划分为不同大小的段
这种分区是在很少访问旧数据的情况下进行的。它被实现为一组用于相对当前数据的小分区,以及用于非活动数据的大分区。
注意事项
详细信息可在线获取。
物理表的数量保持相对较小,从而降低了运营成本。
此技术适用于需要混合使用数据深入了解近期历史和数据挖掘整个历史的情况。
此技术不适用于分区配置文件定期更改的情况,因为重新分区会增加数据仓库的运营成本。
按不同维度分区
事实表也可以根据时间以外的其他维度进行分区,例如产品组、区域、供应商或任何其他维度。让我们举个例子。
假设市场职能已构建成不同的区域部门,例如按州划分。如果每个区域都希望查询其区域内捕获的信息,那么将事实表划分为区域分区将被证明更有效。这将导致查询速度加快,因为它不需要扫描不相关的信息。
注意事项
查询不必扫描不相关的数据,从而加快了查询过程。
此技术不适用于维度在未来不太可能发生变化的情况。因此,值得确定维度在未来不会发生变化。
如果维度发生变化,则必须重新分区整个事实表。
注意 - 我们建议仅根据时间维度执行分区,除非您确定建议的维度分组在数据仓库的生命周期内不会发生变化。
按表大小分区
当没有明确的依据可以根据任何维度对事实表进行分区时,我们应该根据其大小对事实表进行分区。我们可以将预设大小设置为临界点。当表超过预设大小时,将创建一个新的表分区。
注意事项
这种分区管理起来很复杂。
它需要元数据来识别每个分区中存储的数据。
分区维度
如果维度包含大量条目,则需要对维度进行分区。在这里,我们必须检查维度的尺寸。
考虑一个随时间变化的大型设计。如果我们需要存储所有变体以便应用比较,则该维度可能非常大。这肯定会影响响应时间。
循环分区
在循环技术中,当需要新分区时,旧分区会被存档。它使用元数据允许用户访问工具引用正确的表分区。
此技术使数据仓库内易于自动化表管理功能。
垂直分区
垂直分区将数据垂直拆分。以下图像描述了如何进行垂直分区。
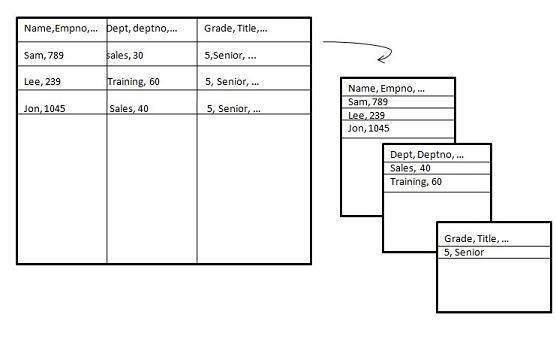
垂直分区可以通过以下两种方式执行:
- 规范化
- 行拆分
规范化
规范化是数据库组织的标准关系方法。在这种方法中,行被折叠成一行,因此它减少了空间。请查看以下显示如何执行规范化的表格。
规范化前的表格
| 产品ID | 数量 | 价值 | 销售日期 | 商店ID | 商店名称 | 位置 | 地区 |
|---|---|---|---|---|---|---|---|
| 30 | 5 | 3.67 | 2013年8月3日 | 16 | 阳光 | 班加罗尔 | S |
| 35 | 4 | 5.33 | 2013年9月3日 | 16 | 阳光 | 班加罗尔 | S |
| 40 | 5 | 2.50 | 2013年9月3日 | 64 | 圣安 | 孟买 | W |
| 45 | 7 | 5.66 | 2013年9月3日 | 16 | 阳光 | 班加罗尔 | S |
规范化后的表格
| 商店ID | 商店名称 | 位置 | 地区 |
|---|---|---|---|
| 16 | 阳光 | 班加罗尔 | W |
| 64 | 圣安 | 孟买 | S |
| 产品ID | 数量 | 价值 | 销售日期 | 商店ID |
|---|---|---|---|---|
| 30 | 5 | 3.67 | 2013年8月3日 | 16 |
| 35 | 4 | 5.33 | 2013年9月3日 | 16 |
| 40 | 5 | 2.50 | 2013年9月3日 | 64 |
| 45 | 7 | 5.66 | 2013年9月3日 | 16 |
行拆分
行拆分倾向于在分区之间保留一对一映射。行拆分的目的是通过减小其大小来加快对大表的访问。
注意 - 使用垂直分区时,请确保不需要在两个分区之间执行主要的联接操作。
确定分区的键
选择正确的分区键非常关键。选择错误的分区键会导致事实表重新组织。让我们举个例子。假设我们要对以下表格进行分区。
Account_Txn_Table transaction_id account_id transaction_type value transaction_date region branch_name
我们可以选择对任何键进行分区。两个可能的键可能是
- 地区
- 交易日期
假设业务组织在 30 个地理区域中,每个区域都有不同数量的分支机构。这将为我们提供 30 个分区,这很合理。这种分区足够好,因为我们的需求捕获表明绝大多数查询仅限于用户自己的业务区域。
如果我们按交易日期而不是按区域进行分区,则来自每个区域的最新交易将位于一个分区中。现在,希望查看其所在区域数据的用户必须跨多个分区进行查询。
因此,值得确定正确的分区键。