
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 语言编程
C 语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP早期数据库模型
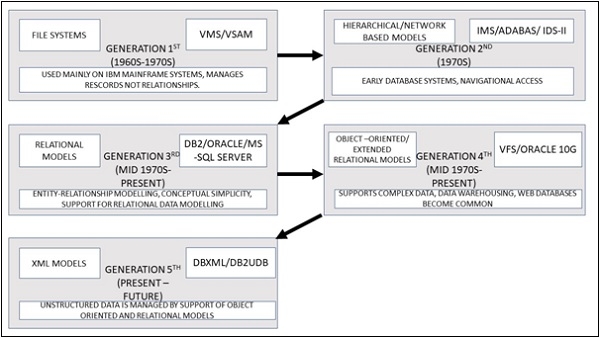
数据库模型决定了数据库的逻辑结构,并确定了在基础层面如何存储、组织和操作数据的方式。在数据库被设计出来之前,唯一存储数据的方式是文件存储,这增加了复杂性,因为程序员必须费尽心思地提取数据,并且他们的程序必须执行复杂的解析和关联操作。
有一些语言,比如 Perl,由于其强大的正则表达式,可以更轻松地处理文本。但是,从文件中访问数据仍然是一项复杂的任务。由于没有标准的方式来访问数据,因此系统更容易出错、开发速度更慢,并且更难维护。还存在数据冗余(数据被不必要地复制)和数据完整性差(数据未在所有位置更改,导致提供错误或过时数据)的问题。
为了解决这些问题,开发了数据库管理系统 (DBMS),它提供了一种标准且可靠的方式来访问和更新数据。在应用程序和数据之间有一个中间层,程序员可以专注于开发应用程序,而不必担心数据访问问题。
因此,我们可以将数据库模型定义为一个逻辑模型,它关注数据是如何表示的。数据库设计人员关注更高、更概念化的层面,而不是担心数据的物理存储,从而减少了正在开发的应用程序的现实世界问题与技术实现之间的差距。
数据模型用于组织数据元素并标准化数据元素之间的关系。由于数据元素用于记录现实生活中的人、地点和事物以及它们之间的事件,因此它代表了现实,例如,一座建筑物有很多窗户,或者一条狗有两只眼睛。模型有助于构建数据,同时它还定义了一组可以对数据执行的操作。给定的 DBMS 可能提供多个模型。最佳结构取决于应用程序数据的自然组织以及相关应用程序的需求,一些不同的因素包括:
- 事务速率(速度),
- 可靠性,
- 可维护性,
- 可扩展性,
- 成本。
**平面(或表格)模型**是最传统和简单的数据库模型,它由一个单一的二维数据元素数组组成,其中给定列的所有成员表示相似的值,并且行的所有成员表示彼此之间的关系。例如,列用于名称和密码,它们是系统安全数据库的一部分。每一行都包含与特定用户关联的特定密码。表的列包含一个类型,该类型定义字符数据、日期或时间信息、整数或浮点数。
现在我们可以说平面文件数据库是一个存储普通非结构化文件(也称为“平面文件”)的数据库。该文件完全存储到计算机内存中,以便轻松访问数据结构并在计算机系统上进行操作。数据库操作完成后,该文件将退出计算机系统并传输到主机的文件系统。这种存储模式被称为“平面”,因为它没有索引结构,并且记录之间通常没有结构化关系。
这种平面模型最适合小型简单的数据库。随着数据量的增长,内存访问变得困难,需要更复杂的数据库。用手写的姓名、联系电话、地址、城市列表就是一个平面文件数据库,如果将相同的信息记录到电子表格中,则可以联机使用以提高搜索能力。还可以使用平面文件数据库模型传输数据。
示例数据库
以下示例说明了平面文件数据库的基本元素。它由一系列组织成表的列和行组成。
这些列包括名称(一个人的姓名,第二列);团队(此人支持的运动队的名称,第三列);以及一个数字唯一 ID(用于唯一标识记录,第一列)。
以下类型的数据表示对于平面文件数据库来说非常标准:
| ID | 姓名 | 团队 |
|---|---|---|
| 101 | Abhinav | Blues |
| 102 | Aditya | Blues |
| 103 | Anjali | Pink |
| 104 | Bhavna | Pink |
| 105 | Charu | Pink |
| 106 | Divy | Blues |
| 107 | Disha | Pink |
| 108 | Eashan | Blues |
| 109 | Gauri | Pink |

222 次查看
