
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP基于情感的音乐播放器:一个机器学习的 Python 项目
介绍
音乐是一种世界共通的语言。尽管文化和语言不同,它都能连接情感,并将人们联系在一起。如今,您可以根据自己的情绪、情感和偏好个性化您的音乐。
本文将教我们如何构建基于情感的音乐播放器。其理念很简单,即识别用户的感情并提供个性化的播放列表。为此,我们需要一些机器学习算法。这些算法将识别情感模式和用户的喜好,以推荐与他们情绪完美匹配的歌曲。
科技与音乐拥有巨大的潜力,能够通过音乐的力量来治愈情感。
本项目将提供一个基于情感的音乐系统。该系统将筛选出适合您心情的歌曲,您无需再搜索歌曲。基于情感的音乐播放器将帮助您管理精神压力,也有助于您管理情绪。
选择数据集
使用机器学习算法训练模型时,数据集至关重要。在本项目中,数据集必不可少。它包含诸如情感状态和各种歌曲信息等数据。
创建的数据集包含各种情绪,例如快乐、平静、愤怒、悲伤、孤独等。该数据集可以帮助训练模型理解和预测用户的情绪状态。然后,模型将对情绪进行分类并推荐合适的歌曲。
数据集将帮助模型推荐带有积极歌词和乐观、欢快的歌曲。同样,音调低、平静且节奏缓慢的歌曲被认为是忧郁的。这类歌曲描述了悲伤、孤独或空虚。
在这里,我们将使用两个数据集:
用于检测面部表情的情感识别数据集 (FER 2013)
Spotify歌曲数据集
https://www.kaggle.com/datasets/musicblogger/spotify-music-data-to-identify-themoods
数据预处理
训练机器学习模型需要音频和情感数据。您需要一位具备一定音乐理论和信号处理知识的人员。
在音频数据中,您需要诸如节奏、音高和韵律等信息。这将有助于模型理解音乐数据。提取这些数据是一项具有挑战性的任务。可能需要更准确的数据来保持模型的准确性。
加载数据集
img_shape = 48 batch_size = 64 train_data_path = '/Users/someswarpal/Downloads/archive-2/train/' test_data_path = '/Users/someswarpal/Downloads/archive-2/test/'
数据预处理
示例
train_preprocessor = ImageDataGenerator( rescale = 1 / 255., # Data Augmentation rotation_range=10, zoom_range=0.2, width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True, fill_mode='nearest', ) test_preprocessor = ImageDataGenerator( rescale = 1 / 255., ) train_data = train_preprocessor.flow_from_directory( train_data_path, class_mode="categorical", target_size=(img_shape,img_shape), color_mode='rgb', shuffle=True, batch_size=batch_size, subset='training', ) test_data = test_preprocessor.flow_from_directory( test_data_path, class_mode="categorical", target_size=(img_shape,img_shape), color_mode="rgb", shuffle=False, batch_size=batch_size, )
输出
Found 28709 images belonging to 7 classes. Found 7178 images belonging to 7 classes.
机器学习模型
基于情感的音乐播放器项目的机器学习模型使用监督学习。它涉及使用预先标记的数据训练模型。标记的数据包括人们的心理状态以及与这些情绪相符的歌曲。
决策树方法通过基于某些规则将信息分解成越来越小的组来对信息进行分类。分支决策允许模型根据获得的信息进行一系列选择,并猜测用户的感受。
创建 CNN 模型
def Create_CNN_Model(): model = Sequential() #CNN1 model.add(Conv2D(32, (3,3), activation='relu', input_shape=(img_shape, img_shape, 3))) model.add(BatchNormalization()) model.add(Conv2D(64,(3,3), activation='relu', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2,2), padding='same')) model.add(Dropout(0.25)) #CNN2 model.add(Conv2D(64, (3,3), activation='relu', )) model.add(BatchNormalization()) model.add(Conv2D(128,(3,3), activation='relu', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2,2), padding='same')) model.add(Dropout(0.25)) #CNN3 model.add(Conv2D(128, (3,3), activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(256,(3,3), activation='relu', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2,2), padding='same')) model.add(Dropout(0.25)) #Output model.add(Flatten()) model.add(Dense(1024, activation='relu')) model.add(BatchNormalization()) model.add(Dropout(0.25)) model.add(Dense(512, activation='relu')) model.add(BatchNormalization()) model.add(Dropout(0.25)) model.add(Dense(256, activation='relu')) model.add(BatchNormalization()) model.add(Dropout(0.25)) model.add(Dense(128, activation='relu')) model.add(BatchNormalization()) model.add(Dropout(0.25)) model.add(Dense(64, activation='relu')) model.add(BatchNormalization()) model.add(Dropout(0.25)) model.add(Dense(32, activation='relu')) model.add(BatchNormalization()) model.add(Dropout(0.25)) model.add(Dense(7,activation='softmax')) return model
编译 CNN 模型
CNN_Model = Create_CNN_Model() CNN_Model.compile(optimizer="adam", loss='categorical_crossentropy', metrics=['accuracy'])
训练模型
CNN_history = CNN_Model.fit( train_data , validation_data= test_data , epochs=50, batch_size= batch_size, callbacks=callbacks, steps_per_epoch= steps_per_epoch, validation_steps=validation_steps)
准确性和图表
示例
CNN_Score = CNN_Model.evaluate(test_data)
print(" Test Loss: {:.5f}".format(CNN_Score[0]))
print("Test Accuracy: {:.2f}%".format(CNN_Score[1] * 100))
def plot_curves(history):
loss = history.history["loss"]
val_loss = history.history["val_loss"]
accuracy = history.history["accuracy"]
val_accuracy = history.history["val_accuracy"]
epochs = range(len(history.history["loss"]))
plt.figure(figsize=(15,5))
#plot loss
plt.subplot(1, 2, 1)
plt.plot(epochs, loss, label = "training_loss")
plt.plot(epochs, val_loss, label = "val_loss")
plt.title("Loss")
plt.xlabel("epochs")
plt.legend()
#plot accuracy
plt.subplot(1, 2, 2)
plt.plot(epochs, accuracy, label = "training_accuracy")
plt.plot(epochs, val_accuracy, label = "val_accuracy")
plt.title("Accuracy")
plt.xlabel("epochs")
plt.legend()
plot_curves(CNN_history)
#plt.tight_layout()
输出
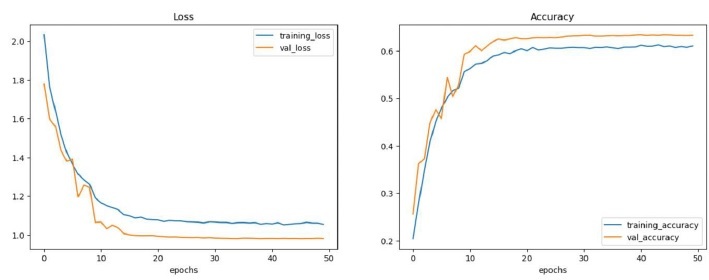
训练测试情绪
CNN_Predictions = CNN_Model.predict(test_data) # Choosing highest probalbilty class in every prediction CNN_Predictions = np.argmax(CNN_Predictions, axis=1)
在随机数据集上测试
示例
test_preprocessor = ImageDataGenerator(
rescale = 1 / 255.,
)
test_generator = test_preprocessor.flow_from_directory(
test_data_path,
class_mode="categorical",
target_size=(img_shape,img_shape),
color_mode="rgb",
shuffle=True,
batch_size=batch_size,
)
Random_batch = np.random.randint(0, len(test_generator) - 1)
Random_Img_Index = np.random.randint(0, batch_size - 1 , 10)
fig, axes = plt.subplots(
nrows=2, ncols=5, figsize=(25, 10),
subplot_kw={'xticks': [], 'yticks': []}
)
for i, ax in enumerate(axes.flat):
Random_Img = test_generator[Random_batch][0][Random_Img_Index[i]]
Random_Img_Label = np.argmax(test_generator[Random_batch][1][Random_Img_Index[i]])
Model_Prediction = np.argmax(CNN_Model.predict( tf.expand_dims(Random_Img,
axis=0) , verbose=0))
ax.imshow(Random_Img)
if Emotion_Classes[Random_Img_Label] == Emotion_Classes[Model_Prediction]:
color = "green"
else:
color = "red"
ax.set_title(f"True: {Emotion_Classes[Random_Img_Label]}\nPredicted:
{Emotion_Classes[Model_Prediction]}", color=color)
plt.show()
plt.tight_layout()
输出

情感检测
情感检测是基于情感的音乐播放器系统的主要部分。适当的情感检测有助于准确预测用户的情感。
可以使用网络摄像头或自拍相机捕捉情绪。这将提供用户的实时情绪。
Python 有一个库 OpenCV,用于通过图片或视频处理情绪。OpenCV 有助于分析面部表情的变化。这是通过跟踪用户的眉毛、眼睛和嘴巴形状的运动来实现的。
映射实时面部表情将根据用户的情绪准确提供个性化推荐。
加载情绪数据集
Music_Player = pd.read_csv("/Users/someswarpal/Downloads/data_moods.csv")
Music_Player = Music_Player[['name','artist','mood','popularity']]
Music_Player.head()
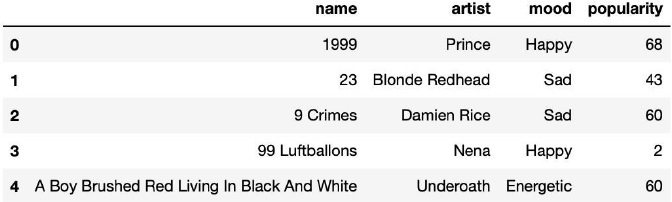
显示数据集的内容
Play = Music_Player[Music_Player['mood'] == 'Happy' ] Play = Play.sort_values(by="popularity", ascending=False) Play = Play[:5].reset_index(drop=True) display(Play)
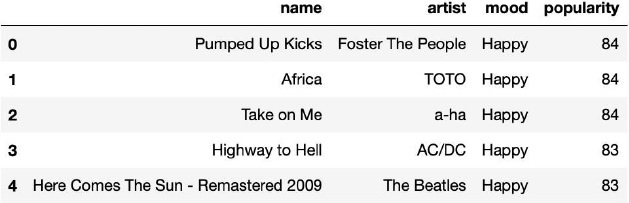
流派检测
流派检测对于本项目也很重要。它允许模型学习用户的音乐偏好。通过使用流派检测,模型可以向用户推荐类似流派的歌曲。它有助于用户扩展他们的音乐品味。
推荐音乐
ML 模型预测用户的情绪并根据情绪推荐歌曲。
训练良好的 ML 模型确保根据用户的心情和情绪选择合适的歌曲。它确保推荐的歌曲适合用户的心情和情绪。
# Making Songs Recommendations Based on Predicted Class
def Recommend_Songs(pred_class):
if( pred_class=='Disgust' ):
Play = Music_Player[Music_Player['mood'] =='Sad' ]
Play = Play.sort_values(by="popularity", ascending=False)
Play = Play[:5].reset_index(drop=True)
display(Play)
if( pred_class=='Happy' or pred_class=='Sad' ):
Play = Music_Player[Music_Player['mood'] =='Happy' ]
Play = Play.sort_values(by="popularity", ascending=False)
Play = Play[:5].reset_index(drop=True)
display(Play)
if( pred_class=='Fear' or pred_class=='Angry' ):
Play = Music_Player[Music_Player['mood'] =='Calm' ]
Play = Play.sort_values(by="popularity", ascending=False)
Play = Play[:5].reset_index(drop=True)
display(Play)
if( pred_class=='Surprise' or pred_class=='Neutral' ):
Play = Music_Player[Music_Player['mood'] =='Energetic' ]
Play = Play.sort_values(by="popularity", ascending=False)
Play = Play[:5].reset_index(drop=True)
display(Play)
打印情绪列表并要求用户选择一个
print("Select a mood by entering a number:\n1. Disgust\n2. Happy/Sad\n3. Fear/Angry\n4.
Surprise/Neutral")
selected_mood = int(input("Enter a number for the mood you want to select: "))
# Display recommended songs based on selected mood
if selected_mood == 1:
Recommend_Songs('Disgust')
elif selected_mood == 2:
Recommend_Songs('Happy')
elif selected_mood == 3:
Recommend_Songs('Fear')
elif selected_mood == 4:
Recommend_Songs('Surprise')
else:
print("Invalid input. Please enter a number between 1 and 4.")
发现新歌
歌曲查找对于基于情感的音乐播放器项目至关重要。它允许用户发现符合他们品味的歌曲。机器学习模型根据用户的收听历史提供新的或鲜为人知的歌曲。
推荐新歌可以改善用户的收听体验并鼓励音乐探索。歌曲发现还可以帮助发现具有相同流派和情绪的其他语言的歌曲。
添加附加功能
音乐系统的基本功能包括情绪检测、流派检测和歌曲推荐。您可以通过添加其他一些功能来更新您的音乐系统,例如:
根据情绪检测搜索歌曲。
根据情绪对歌曲进行评分。
添加建议以更好地训练模型。
与他人分享您基于情感的播放列表或将其公开。
保存或下载歌曲以备将来使用。(可以是高级版本)
结论
基于情感的音乐播放器完美地结合了情感、技术和音乐。它根据用户的感觉和音乐品味提供独特的音乐体验。该模型使用 ML 技术来推荐最符合用户情绪的歌曲。
训练良好的模型确保其推荐的歌曲与用户的感觉相符。音乐系统最重要的部分是情感检测、流派识别和歌曲推荐。
但是,您可以根据自己的感受搜索歌曲、对其进行评分、分享播放列表以及保存或下载音乐。基于情感的音乐播放器可以帮助您平静下来并应对精神焦虑。

1000+ 次浏览
