- Euphoria 教程
- Euphoria - 首页
- Euphoria - 概述
- Euphoria - 环境
- Euphoria - 基本语法
- Euphoria - 变量
- Euphoria - 常量
- Euphoria - 数据类型
- Euphoria - 运算符
- Euphoria - 分支
- Euphoria - 循环类型
- Euphoria - 流程控制
- Euphoria - 短路
- Euphoria - 序列
- Euphoria - 日期和时间
- Euphoria - 过程
- Euphoria - 函数
- Euphoria - 文件 I/O
- Euphoria 有用资源
- Euphoria 快速指南
- Euphoria - 库例程
- Euphoria - 有用资源
- Euphoria - 讨论
Euphoria 快速指南
Euphoria - 概述
Euphoria 代表 **E**nd-**U**ser **P**rogramming with **H**ierarchical **O**bjects for **R**obust **I**nterpreted **A**pplications。Euphoria 的第一个版本由 Robert Craig 在 Atari Mega-ST 上创建,并于 1993 年首次发布。现在由 Rapid Deployment Software 维护。
它是一种免费、简单、灵活、易于学习的解释型语言,但速度极快,是一种用于 DOS、Windows、Linux、FreeBSD 等的 32 位高级编程语言。
Euphoria 用于开发 Windows GUI 程序、高速 DOS 游戏和 Linux/FreeBSD X Windows 程序。Euphoria 也可以用于 CGI(基于 Web)编程。
Euphoria 特性
以下是 Euphoria 主要特性的列表:
它是一种简单、灵活、强大的语言定义,易于学习和使用。
它支持动态存储分配,这意味着变量可以增长或缩小,而程序员无需担心分配和释放内存。它会自动进行垃圾回收。
它比 Perl 和 Python 等传统解释器快得多。
Euphoria 程序可在 Linux、FreeBSD、32 位 Windows 和任何 DOS 环境下运行。
Euphoria 程序不受任何 640K 内存限制。
它提供一个优化的 Euphoria 到 C 翻译器,您可以使用它将 Euphoria 程序转换为 C,然后使用 C 编译器编译它以获得可执行文件(.exe)。这可以将程序速度提高 2 到 5 倍。
底层硬件完全隐藏,这意味着程序不知道字长、值的底层位级表示、字节序等。
Euphoria 安装程序附带全屏幕源代码调试器、执行分析器和全屏幕多文件编辑器。
它支持运行时错误处理、下标和类型检查。
它是一种开源语言,完全免费。
平台要求
Euphoria 可在 Windows、Linux、FreeBSD 和 OSX 上使用。以下是各个平台所需的最低版本:
**WIN32 版本** - 您需要 Windows 95 或更高版本的 Windows。它在 XP 和 Vista 上运行良好。
**Linux 版本** - 您需要任何相当新的 Linux 发行版,该发行版具有 libc6 或更高版本。例如,Red Hat 5.2 或更高版本可以正常工作。
**FreeBSD 版本** - 您需要任何相当新的 FreeBSD 发行版。
**Mac OS X 版本** - 您需要任何相当新的基于 Intel 的 Mac。
Euphoria 限制
以下是 Euphoria 的一些主要限制:
尽管 Euphoria 对程序员来说足够简单、快速和灵活;但它并不支持许多重要功能的调用。例如,网络编程。
Euphoria 发明于 1993 年,至今仍然没有关于这种语言的书籍。该语言的文档也不多。
但是现在,这门语言正在迅速流行起来,您可以希望很快就能获得不错的实用程序和书籍。
Euphoria 许可
本产品是免费且开源的,并受益于许多人的贡献。您拥有完全免版税的权利来分发您开发的任何 Euphoria 程序。
图标文件,例如 euphoria.ico 和 euphoria\bin 中提供的二进制文件,可以随您的更改一起分发,也可以不随您的更改一起分发。
您可以 **隐藏** 或 **绑定** 您的程序并免版税地分发生成的 文件。当您使用 Euphoria 到 C 翻译器时,可能适用一些额外的第三方法律限制。
慷慨的 **开源许可证** 允许 Euphoria 用于个人和商业目的。与许多其他开源许可证不同,您的更改不必开源。
Euphoria - 环境
本章介绍如何在各种平台上安装 Euphoria。您可以按照步骤在 Linux、FreeBSD 和 32 位 Windows 上安装 Euphoria。因此,您可以根据您的工作环境选择步骤。
Linux、Free BSD 安装
官方网站提供 **.tar.gz** 文件,用于在您的 Linux 或 BSD 操作系统上安装 Euphoria。您可以从其官方网站下载最新版本的 Euphoria:下载 Euphoria。
获得 .tar.gz 文件后,以下是三个简单的步骤,用于在 Linux 或 Free BSD 机器上安装 Euphoria:
**步骤 1** - 安装文件
将下载的文件 **euphoria-4.0b2.tar.gz** 解压缩到您要安装 Euphoria 的目录中。如果您想将其安装到 /home 目录,则:
$cp euphoria-4.0b2.tar.gz /home $cd /home $gunzip euphoria-4.0b2.tar.gz $tar -xvf euphoria-4.0b2.tar
这将在 ** /home/euphoria-4.0b2** 目录内创建如下所示的目录层次结构:
$ls -l -rw-r--r-- 1 1001 1001 2485 Aug 17 06:15 Jamfile -rw-r--r-- 1 1001 1001 5172 Aug 20 12:37 Jamrules -rw-r--r-- 1 1001 1001 1185 Aug 13 06:21 License.txt drwxr-xr-x 2 1001 1001 4096 Aug 31 10:07 bin drwxr-xr-x 7 1001 1001 4096 Aug 31 10:07 demo -rw-r--r-- 1 1001 1001 366 Mar 18 09:02 file_id.diz drwxr-xr-x 4 1001 1001 4096 Aug 31 10:07 include -rw-r--r-- 1 1001 1001 1161 Mar 18 09:02 installu.doc drwxr-xr-x 4 1001 1001 4096 Aug 31 10:07 source drwxr-xr-x 19 1001 1001 4096 Sep 7 12:09 tests drwxr-xr-x 2 1001 1001 4096 Aug 31 10:07 tutorial
**注意** - 文件名 euphoria-4.0b2.tar.gz 取决于可用的最新版本。本教程使用 4.0b2 版本的语言。
**步骤 2** - 设置路径
安装 Euphoria 后,您需要设置正确的路径,以便您的 shell 可以找到所需的 Euphoria 二进制文件和实用程序。在继续之前,您需要设置以下三个重要的环境变量:
将 PATH 环境变量设置为指向 /home/euphoria-4.0b2/bin 目录。
将 EUDIR 环境变量设置为指向 /home/euphoria-4.0b2。
将 EUINC 环境变量设置为指向 /home/euphoria-4.0b2/include。
这些变量可以按如下方式设置:
$export PATH=$PATH:/home/euphoria-4.0b2/bin $export EUDIR=/home/euphoria-4.0b2 $export EUINC=/home/euphoria-4.0b2/include
**注意** - 用于设置环境变量的上述命令可能因您的 Shell 而异。我们使用 *bash* shell 执行这些命令来设置变量。
**步骤 3** - 确认安装
确认您是否已成功安装 Euphoria。
执行以下命令:
$eui -version
如果您得到以下结果,则表示您已成功安装 Euphoria;否则,您必须返回并再次检查所有步骤。
$eui -version Euphoria Interpreter 4.0.0 beta 2 (r2670) for Linux Using System Memory $
就是这样,Euphoria 编程环境已准备好用于您的 UNIX 机器,您可以开始轻松地编写复杂的程序。
WIN32 和 DOS 安装
官方网站提供 **.exe** 文件,用于在您的 WIN32 或 DOS 操作系统上安装 Euphoria。您可以从其官方网站下载最新版本的 Euphoria:下载 Euphoria。
获得 .exe 文件后,以下是三个简单的步骤,用于在 WIN32 或 DOS 机器上安装 Euphoria 编程语言:
**步骤 1** - 安装文件
双击下载的 **.exe** 安装程序以安装所有文件。我们下载了 euphoria-40b2.exe 文件进行安装。
文件名 euphoria-40b2.exe 取决于可用的最新版本。我们使用 4 beta 2 版本的语言。
默认情况下,Euphoria 将安装在 C:\ *euphoria-40b2* 目录中,但您也可以选择所需的位置。
**步骤 2** - 重启机器
重新启动您的机器以完成安装。
**步骤 3** - 确认安装
确认您是否已成功安装 Euphoria。
执行以下命令:
c:\>eui -version
如果您得到以下结果,则表示您已成功安装 Euphoria;否则,您必须返回并再次检查所有步骤。
c:\>eui -version Euphoria Interpreter 4.0.0 beta 2 (r2670) for Windows Using Managed Memory c:\>
就是这样,Euphoria 编程环境已准备好用于您的 WIN32 机器,您可以开始轻松地编写复杂的程序。
Euphoria 解释器
根据您使用的平台,Euphoria 具有多个解释器:
主解释器是 **eui**。
在 Windows 平台上,您有两种选择。如果您运行 **eui**,则会创建一个控制台窗口。如果您运行 **euiw**,则不会创建控制台,使其适合 GUI 应用程序。
Euphoria 不关心您选择的文件扩展名。但是按照约定;基于控制台的应用程序带有 **.ex** 扩展名。
基于 GUI 的应用程序具有 **.exw** 扩展名,包含文件具有 **.e** 扩展名。
Euphoria - 基本语法
Euphoria 语言与 Perl、C 和 Java 有很多相似之处。但是,这些语言之间也存在一些明显的差异。本章旨在快速让您了解 Euphoria 中预期的语法。
本教程假设您使用的是 Linux,并且所有示例都在 Linux 平台上编写。但是据观察,Linux 和 WIN32 的程序语法没有任何明显的区别。因此,您可以在 WIN32 上遵循相同的步骤。
第一个 Euphoria 程序
让我们在一个脚本中编写一个简单的 Euphoria 程序。在 test.ex 文件中键入以下源代码并保存它。
#!/home/euphoria-4.0b2/bin/eui puts(1, "Hello, Euphoria!\n")
假设 Euphoria 解释器位于 * /home/euphoria-4.0b2/bin/* 目录中。现在按如下方式运行此程序:
$ chmod +x test.ex # This is to make file executable $ ./test.ex
这将产生以下结果:
Hello, Euphoria!
此脚本使用了内置函数 **puts()**,它接受两个参数。第一个参数指示文件名或设备号,第二个参数指示要打印的字符串。这里 1 指示 STDOUT 设备。
Euphoria 标识符
Euphoria 标识符是用于标识变量、函数、类、模块或其他对象的名称。标识符以字母 A 到 Z 或 a 到 z 开头,然后后跟字母、数字或下划线。
Euphoria 不允许在标识符中使用诸如 @、$ 和 % 之类的标点符号。
Euphoria 是一种区分大小写的编程语言。因此,**Manpower** 和 **manpower** 在 Euphoria 中是两个不同的标识符。例如,有效的标识符是:
- n
- color26
- ShellSort
- quick_sort
- a_very_long_indentifier
保留字
以下列表显示了 Euphoria 中的保留字。这些保留字不能用作常量或变量或任何其他标识符名称。Euphoria 关键字仅包含小写字母。
| and | exit | override |
| as | export | procedure |
| break | fallthru | public |
| by | for | retry |
| case | function | return |
| constant | global | routine |
| continue | goto | switch |
| do | if | then |
| else | ifdef | to |
| elsedef | include | type |
| elsif | label | until |
| elsifdef | loop | while |
| end | namespace | with |
| entry | not | without |
| enum | or | xor |
表达式
Euphoria 允许您通过形成表达式来计算结果。但是,在 Euphoria 中,您可以使用一个表达式对整个数据序列执行计算。
您可以像处理单个数字一样处理序列。它可以被复制、传递给子例程或作为单元进行计算。例如:
{1,2,3} + 5
这是一个表达式,它将序列 {1, 2, 3} 和原子 5 相加,得到结果序列 {6, 7, 8}。您将在后续章节中学习序列。
代码块
学习 Euphoria 时程序员遇到的第一个警告之一是,没有大括号来指示过程和函数定义或流程控制的代码块。代码块由关联的关键字表示。
以下示例显示了 **if...then...end if** 块:
if condition then code block comes here end if
多行语句
Euphoria 中的语句通常以换行符结尾。但是,Euphoria 允许将单个语句写入多行。例如:
total = item_one + item_two + item_three
转义字符
可以使用反斜杠输入转义字符。例如:
下表列出了可以使用反斜杠表示法表示的转义字符或不可打印字符。
| 反斜杠表示法 | 描述 |
|---|---|
| 换行符 | |
| 回车符 | 回车 |
| 制表符 | 制表符 |
| \\ | 反斜杠 |
| \" | 双引号 |
| \' | 单引号 |
Euphoria中的注释
所有注释都被编译器忽略,不会影响执行速度。建议在程序中使用更多注释以提高可读性。
注释有三种形式:
注释以两个连字符开始,一直延续到当前行的结尾。
多行格式注释包含在/*...*/内,即使跨行。
您可以在程序的第一行使用以“#! ”开头的特殊注释。
示例
#!/home/euphoria-4.0b2/bin/eui -- First comment puts(1, "Hello, Euphoria!\n") -- second comment /* This is a comment which extends over a number of text lines and has no impact on the program */
这将产生以下结果:
Hello, Euphoria!
注意 - 您可以使用以“#! ”开头的特殊注释。这会通知Linux shell您的文件应该由Euphoria解释器执行。
Euphoria - 变量
变量只不过是保留的内存位置,用于存储值。这意味着当您创建变量时,您会在内存中保留一些空间。
根据变量的数据类型,解释器会分配内存并决定可以在保留的内存中存储什么内容。因此,通过为变量分配不同的数据类型,您可以将整数、小数或字符存储在这些变量中。Euphoria数据类型在不同的章节中解释。
这些内存位置称为变量,因为它们的值在其生命周期内可以更改。
变量声明
Euphoria变量必须显式声明以保留内存空间。因此,在为变量赋值之前,必须声明变量。
变量声明包含一个类型名称,后跟要声明的变量列表。例如:
integer x, y, z sequence a, b, x
当您声明变量时,您会命名变量,并定义在程序执行期间可以合法地分配给变量的值的类型。
仅仅声明变量不会为其分配任何值。如果您在为其分配任何值之前尝试读取它,Euphoria 将发出运行时错误,例如“变量 xyz 从未被赋值”。
赋值
等号 (=) 用于为变量赋值。可以按以下方式赋值:
变量名 = 变量值
例如:
#!/home/euphoria/bin/eui
-- Here is the declaration of the variables.
integer counter
integer miles
sequence name
counter = 100 -- An integer assignment
miles = 1000.0 -- A floating point
name = "John" -- A string ( sequence )
printf(1, "Value of counter %d\n", counter )
printf(1, "Value of miles %f\n", miles )
printf(1, "Value of name %s\n", {name} )
这里,100、1000.0 和 "John" 分别是赋值给 *counter*、*miles* 和 *name* 变量的值。此程序产生以下结果:
Value of counter 100 Value of miles 1000.000000 Value of name John
为了防止忘记初始化变量,并且因为它可以使代码更清晰易读,您可以组合声明和赋值:
integer n = 5
这等效于以下内容:
integer n n = 5
标识符作用域
标识符的作用域描述了哪些代码可以访问它。在标识符相同作用域内的代码可以访问该标识符,不在相同作用域内的代码则无法访问它。
变量的作用域取决于其声明的位置和方式。
如果它在 **for、while 循环** 或 **switch** 中声明,则其作用域从声明开始,到相应的 **end** 语句结束。
在 **if** 语句中,作用域从声明开始,到下一个 **else、elsif** 或 **end if** 语句结束。
如果变量在例程内声明,则变量的作用域从声明开始,到例程的 end 语句结束。这称为私有变量。
如果变量在例程外部声明,则其作用域从声明开始,到其声明所在文件的结尾。这称为模块变量。
没有作用域修饰符的 **常量** 的作用域从声明开始,到其声明所在文件的结尾。
没有作用域修饰符的 **枚举** 的作用域从声明开始,到其声明所在文件的结尾。
所有没有作用域修饰符的 **过程、函数** 和 **类型** 的作用域从其声明的源文件开头开始,到源文件结尾结束。
没有作用域修饰符的常量、枚举、模块变量、过程、函数和类型被称为 **局部变量**。但是,这些标识符可以在其声明之前具有作用域修饰符,这会导致它们的作用域扩展到其声明的文件之外。
如果关键字 **global** 在声明之前,则这些标识符的作用域扩展到整个应用程序。应用程序文件中的任何代码都可以访问它们。
如果关键字 **public** 在声明之前,则作用域扩展到显式包含声明标识符的文件的任何文件,或包含反过来 *public* 包含包含 *public* 声明的文件的任何文件。
如果关键字 **export** 在声明之前,则作用域仅扩展到直接包含声明标识符的文件的任何文件。
当您在另一个文件中 **include** Euphoria 文件时,只有使用作用域修饰符声明的标识符才能被进行 *include* 操作的文件访问。包含文件中的其他声明对进行 *include* 操作的文件不可见。
Euphoria - 常量
常量也是变量,它们被赋予一个初始值,在程序的生命周期中永远不会改变。Euphoria 允许使用 constant 关键字定义常量,如下所示:
constant MAX = 100
constant Upper = MAX - 10, Lower = 5
constant name_list = {"Fred", "George", "Larry"}
任何表达式的结果都可以赋值给常量,甚至包括对先前定义的函数的调用,但是一旦赋值完成,常量变量的值就会“锁定”。
常量不能在子程序内声明。没有作用域修饰符的 **常量** 的作用域从声明开始,到其声明所在文件的结尾。
示例
#!/home/euphoria-4.0b2/bin/eui constant MAX = 100 constant Upper = MAX - 10, Lower = 5 printf(1, "Value of MAX %d\n", MAX ) printf(1, "Value of Upper %d\n", Upper ) printf(1, "Value of Lower %d\n", Lower ) MAX = MAX + 1 printf(1, "Value of MAX %d\n", MAX )
这将产生以下错误:
./test.ex:10 <0110>:: may not change the value of a constant MAX = MAX + 1 ^ Press Enter
如果您从示例中删除最后两行,则会产生以下结果:
Value of MAX 100 Value of Upper 90 Value of Lower 5
枚举
枚举值是一种特殊的常量类型,其中第一个值默认为数字 1,之后的每个项目都递增 1。枚举只能取数值。
枚举不能在子程序内声明。没有作用域修饰符的 **枚举** 的作用域从声明开始,到其声明所在文件的结尾。
示例
#!/home/euphoria-4.0b2/bin/eui enum ONE, TWO, THREE, FOUR printf(1, "Value of ONE %d\n", ONE ) printf(1, "Value of TWO %d\n", TWO ) printf(1, "Value of THREE %d\n", THREE ) printf(1, "Value of FOUR %d\n", FOUR )
这将产生以下结果:
Value of ONE 1 Value of TWO 2 Value of THREE 3 Value of FOUR 4
您可以通过为任何一个项目赋值一个数值来更改其值。后续值始终是前一个值加一,除非它们也被赋予默认值。
#!/home/euphoria-4.0b2/bin/eui enum ONE, TWO, THREE, ABC=10, XYZ printf(1, "Value of ONE %d\n", ONE ) printf(1, "Value of TWO %d\n", TWO ) printf(1, "Value of THREE %d\n", THREE ) printf(1, "Value of ABC %d\n", ABC ) printf(1, "Value of XYZ %d\n", XYZ )
这将产生以下结果:
Value of ONE 1 Value of TWO 2 Value of THREE 3 Value of ABC 10 Value of XYZ 11
序列使用整数索引,但使用枚举,您可以编写如下代码:
enum X, Y
sequence point = { 0,0 }
point[X] = 3
point[Y] = 4
Euphoria - 数据类型
存储在内存中的数据可以是多种类型。例如,一个人的年龄存储为数值,而他的地址存储为字母数字字符。
Euphoria 有一些标准类型,用于定义对它们的可能操作以及每种类型的存储方法。
Euphoria 有以下四种标准数据类型:
- 整数
- 原子
- 序列
- 对象
理解原子和序列是理解 Euphoria 的关键。
整数
Euphoria 整数数据类型存储数值。它们声明和定义如下:
integer var1, var2 var1 = 1 var2 = 100
用 integer 类型声明的变量必须是具有从 -1073741824 到 +1073741823(含)的 **整数** 值的原子。您可以对更大的整数(最多约 15 位十进制数字)执行精确计算,但将其声明为原子,而不是整数。
原子
Euphoria 中的所有数据对象都是原子或序列。原子是单个数值。原子可以具有任何整数或双精度浮点数。Euphoria 原子声明和定义如下:
atom var1, var2, var3 var1 = 1000 var2 = 198.6121324234 var3 = 'E'
原子的范围大约从 -1e300 到 +1e300,精度为 15 位十进制数字。单个字符是一个 **原子**,必须使用单引号输入。例如,以下所有语句都是合法的:
-- Following is equivalent to the atom 66 - the ASCII code for B
char = 'B'
-- Following is equivalent to the sequence {66}
sentence = "B"
序列
序列是可以通过其索引访问的数值集合。Euphoria 中的所有数据对象都是原子或序列。
序列索引从 1 开始,这与其他编程语言中数组索引从 0 开始不同。Euphoria 序列声明和定义如下:
sequence var1, var2, var3, var4
var1 = {2, 3, 5, 7, 11, 13, 17, 19}
var2 = {1, 2, {3, 3, 3}, 4, {5, {6}}}
var3 = {{"zara", "ali"}, 52389, 97.25}
var4 = {} -- the 0 element sequence
字符字符串只是一个 **序列** 字符,可以使用双引号输入。例如,以下所有语句都是合法的:
word = 'word' sentence = "ABCDEFG"
字符字符串可以像任何其他序列一样进行操作和处理。例如,上述字符串与序列完全等效:
sentence = {65, 66, 67, 68, 69, 70, 71}
您将在 Euphoria - 序列 中学习更多关于序列的知识。
对象
这是 Euphoria 中的一种超级数据类型,它可以采用任何值,包括原子、序列或整数。Euphoria 对象声明和定义如下:
object var1, var2, var3
var1 = {2, 3, 5, 7, 11, 13, 17, 19}
var2 = 100
var3 = 'E'
对象可以具有以下值之一:
序列
原子
整数
用作文件号的整数
字符串序列或单字符原子
Euphoria - 运算符
Euphoria 提供了一套丰富的运算符来操作变量。我们可以将所有 Euphoria 运算符分为以下几组:
- 算术运算符
- 关系运算符
- 逻辑运算符
- 赋值运算符
- 其他运算符
算术运算符
算术运算符在数学表达式中的使用方法与在代数中相同。下表列出了算术运算符。假设整数变量 A 为 10,变量 B 为 20,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| + | 加法 - 将运算符两侧的值相加 | A + B 将得到 30 |
| - | 减法 - 从左操作数减去右操作数 | A - B 将得到 -10 |
| * | 乘法 - 将运算符两侧的值相乘 | A * B 将得到 200 |
| / | 除法 - 将左操作数除以右操作数 | B / A 将得到 2 |
| + | 一元加 - 这对变量值没有影响。 | +B 得到 20 |
| - | 一元减 - 这会创建给定变量的负值。 | -B 得到 -20 |
关系运算符
Euphoria 语言支持以下关系运算符。假设变量 A 为 10,变量 B 为 20,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 检查两个操作数的值是否相等,如果相等,则条件为真。 | (A = B) 为假。 |
| != | 检查两个操作数的值是否相等,如果不相等,则条件为真。 | (A != B) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是,则条件为真。 | (A > B) 为假。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是,则条件为真。 | (A < B) 为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件为真。 | (A >= B) 为假。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件为真。 | (A <= B) 为真。 |
逻辑运算符
下表列出了逻辑运算符。假设布尔变量 A 为 1,变量 B 为 0,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| and | 称为逻辑与运算符。如果两个操作数均非零,则条件为真。 | (A and B) 为假。 |
| or | 称为逻辑或运算符。如果两个操作数中任何一个非零,则条件为真。 | (A or B) 为真。 |
| xor | 称为逻辑异或运算符。如果只有一个操作数为真,则条件为真;如果两个操作数都为真或都为假,则条件为假。 | (A xor B) 为真。 |
| not | 称为逻辑非运算符,它否定结果。使用此运算符,真变为假,假变为真。 | not(B) 为真。 |
您还可以将这些运算符应用于 1 或 0 之外的数字。约定是:零表示假,非零表示真。
赋值运算符
Euphoria 语言支持以下赋值运算符:
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 简单赋值运算符,将右侧操作数的值赋给左侧操作数。 | C = A + B 将 A + B 的值赋给 C。 |
| += | 加法赋值运算符,它将右侧操作数添加到左侧操作数,并将结果赋给左侧操作数。 | C += A 等效于 C = C + A。 |
| -= | 减法赋值运算符,它从左侧操作数中减去右侧操作数,并将结果赋给左侧操作数。 | C -= A 等效于 C = C - A。 |
| *= | 乘法赋值运算符,它将右侧操作数乘以左侧操作数,并将结果赋给左侧操作数。 | C *= A 等效于 C = C * A。 |
| /= | 除法赋值运算符,它将左侧操作数除以右侧操作数,并将结果赋给左侧操作数。 | C /= A 等效于 C = C / A。 |
| &= | 连接运算符 | C &= {2} 等效于 C = {C} & {2}。 |
注意 - 赋值语句中使用的等号 '=' 不是运算符,它只是语法的一部分。
其他运算符
Euphoria 语言还支持其他一些运算符。
& 运算符
可以使用“&”运算符连接任意两个对象。结果是一个序列,其长度等于被连接对象的长度之和。
例如:
#!/home/euphoria-4.0b2/bin/eui
sequence a, b, c
a = {1, 2, 3}
b = {4}
c = {1, 2, 3} & {4}
printf(1, "Value of c[1] %d\n", c[1] )
printf(1, "Value of c[2] %d\n", c[2] )
printf(1, "Value of c[3] %d\n", c[3] )
printf(1, "Value of c[4] %d\n", c[4] )
这将产生以下结果:
Value of c[1] 1 Value of c[2] 2 Value of c[3] 3 Value of c[4] 4
Euphoria 运算符的优先级
运算符优先级决定了表达式中项的分组方式。这会影响表达式的求值方式。某些运算符的优先级高于其他运算符;例如,乘法运算符的优先级高于加法运算符。
例如,x = 7 + 3 * 2
这里,x 被赋值为 13,而不是 20,因为运算符 * 的优先级高于 +。
因此,它首先计算 3*2,然后加到 7 中。
这里,优先级最高的运算符出现在表的顶部,优先级最低的运算符出现在底部。在表达式中,优先级较高的运算符先被求值。
| 类别 | 运算符 | 结合性 |
|---|---|---|
| 后缀 | 函数/类型调用 | |
| 一元 | + - ! not | 从右到左 |
| 乘法 | * / | 从左到右 |
| 加法 | + - | 从左到右 |
| 连接 | & | 从左到右 |
| 关系 | > >= < <= | 从左到右 |
| 相等 | = != | 从左到右 |
| 逻辑与 | and | 从左到右 |
| 逻辑或 | or | 从左到右 |
| 逻辑异或 | xor | 从左到右 |
| 逗号 | , | 从左到右 |
Euphoria - 分支
分支是任何编程语言最重要的方面之一。编写程序时,您可能会遇到需要做出决策或从给定的多个选项中选择一个选项的情况。
下图显示了一个简单的场景,其中程序需要根据给定的条件选择两条路径之一。
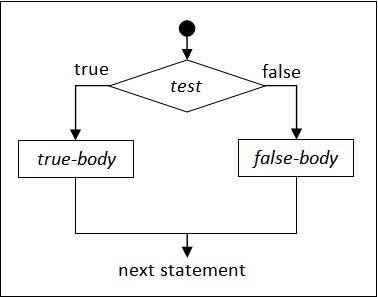
Euphoria 提供以下三种类型的决策(分支或条件)语句:
让我们详细了解这些语句:
Euphoria - 循环类型
循环是任何编程语言的另一个最重要的方面。编写程序时,您可能会遇到需要多次执行相同语句的情况,有时甚至可能是无限次。
有多种方法可以指定进程应持续多长时间,以及如何停止或更改它。迭代块可以非正式地称为循环,循环中代码的每次执行都称为循环的一次迭代。
下图显示了循环的简单逻辑流程:
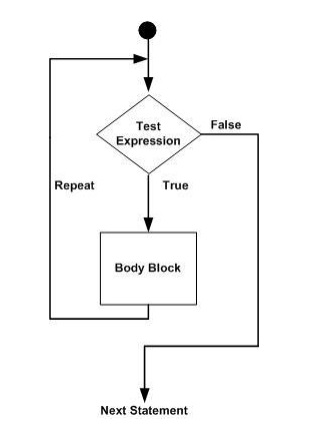
Euphoria 提供以下三种类型的循环语句:
以上所有语句都根据不同的情况为您提供灵活性和易用性。让我们逐一详细了解它们:
Euphoria - 流程控制
程序执行流程是指程序语句执行的顺序。默认情况下,语句一个接一个地执行。
但是,很多时候需要更改执行顺序以完成任务。
Euphoria 有许多流程控制语句,您可以使用它们来安排语句的执行顺序。
exit 语句
使用关键字exit退出循环。这会导致流程立即离开当前循环,并在循环结束后的第一条语句处重新开始。
语法
exit 语句的语法如下:
exit [ "Label Name" ] [Number]
exit语句终止最新的和最内层的循环,除非指定了可选的标签名称或编号。
exit N的一种特殊形式是exit 0。这将离开所有级别的循环,无论深度如何。控制将在最外层循环块之后继续。同样,exit -1 退出第二外层循环,以此类推。
示例
#!/home/euphoria-4.0b2/bin/eui
integer b
for a = 1 to 16 do
printf(1, "value of a %d\n", a)
if a = 10 then
b = a
exit
end if
end for
printf(1, "value of b %d\n", b)
这将产生以下结果:
value of a 1 value of a 2 value of a 3 value of a 4 value of a 5 value of a 6 value of a 7 value of a 8 value of a 9 value of a 10 value of b 10
break 语句
break语句的工作方式与exit语句完全相同,但适用于if语句或switch语句,而不是任何类型的循环语句。
语法
break 语句的语法如下:
break [ "Label Name" ] [Number]
break语句终止最新的和最内层的if或switch块,除非指定了可选的标签名称或编号。
break N的一种特殊形式是break 0。这将离开最外层的if或switch块,无论深度如何。控制将在最外层块之后继续。同样,break -1 将中断第二个最外层的if或switch块,以此类推。
示例
#!/home/euphoria-4.0b2/bin/eui
integer a, b
sequence s = {'E','u', 'p'}
if s[1] = 'E' then
a = 3
if s[2] = 'u' then
b = 1
if s[3] = 'p' then
break 0 -- leave topmost if block
end if
a = 2
else
b = 4
end if
else
a = 0
b = 0
end if
printf(1, "value of a %d\n", a)
printf(1, "value of b %d\n", b)
这将产生以下结果:
value of a 3 value of b 1
continue 语句
continue语句通过转到下一次迭代并跳过其余迭代来继续执行它所应用的循环。
转到下一次迭代意味着测试条件变量索引并检查它是否仍在范围内。
语法
continue 语句的语法如下:
continue [ "Label Name" ] [Number]
continue语句将重新迭代最新的和最内层的循环,除非指定了可选的标签名称或编号。
continue N的一种特殊形式是continue 0。这将重新迭代最外层的循环,无论深度如何。同样,continue -1 从第二个最外层的循环开始,以此类推。
示例
#!/home/euphoria-4.0b2/bin/eui
for a = 3 to 6 do
printf(1, "value of a %d\n", a)
if a = 4 then
puts(1,"(2)\n")
continue
end if
printf(1, "value of a %d\n", a*a)
end for
This would produce following result:
value of a 3
value of a 9
value of a 4
(2)
value of a 5
value of a 25
value of a 6
value of a 36
retry 语句
retry语句通过转到下一次迭代并跳过其余迭代来继续执行它所应用的循环。
语法
retry 语句的语法如下:
retry [ "Label Name" ] [Number]
retry语句重试执行它所应用的循环的当前迭代。该语句跳转到指定循环的第一条语句,既不测试任何内容也不递增for循环索引。
retry N的一种特殊形式是retry 0。这将重试执行最外层的循环,无论深度如何。同样,retry -1 重试第二个最外层的循环,以此类推。
通常,包含retry语句的子块还包含另一个流程控制关键字,如exit、continue或break。否则,迭代将无限期地执行。
示例
#!/home/euphoria-4.0b2/bin/eui
integer errors = 0
integer files_to_open = 10
for i = 1 to length(files_to_open) do
fh = open(files_to_open[i], "rb")
if fh = -1 then
if errors > 5 then
exit
else
errors += 1
retry
end if
end if
file_handles[i] = fh
end for
由于retry不会更改i的值并尝试再次打开同一个文件,因此必须有一种方法可以从循环中跳出,exit语句提供了这种方法。
goto 语句
goto语句指示计算机在标记的位置恢复代码执行。
恢复执行的位置称为语句的目标。它仅限于位于当前例程中,或者如果位于任何例程之外,则位于当前文件中。
语法
goto 语句的语法如下:
goto "Label Name"
goto语句的目标可以是任何可访问的标签语句:
label "Label Name"
标签名称必须是双引号括起来的常量字符串。由于它是常规字符串,因此 Euphoria 标识符中非法的字符可能会出现在标签名称中。
示例
#!/home/euphoria-4.0b2/bin/eui integer a = 0 label "FIRST" printf(1, "value of a %d\n", a) a += 10 if a < 50 then goto "FIRST" end if printf(1, "Final value of a %d\n", a)
这将产生以下结果:
value of a 0 value of a 10 value of a 20 value of a 30 value of a 40 Final value of a 50
Euphoria - 短路求值
当使用and或or运算符通过if、elsif、until或while测试条件时,将使用短路求值。例如:
if a < 0 and b > 0 then -- block of code end if
如果 a < 0 为假,则 Euphoria 不理会测试 b 是否大于 0。它知道无论如何整体结果都是假的。同样:
if a < 0 or b > 0 then -- block of code end if
如果 a < 0 为真,则 Euphoria 立即决定结果为真,而不测试 b 的值,因为此测试的结果无关紧要。
一般来说,当您有以下形式的条件时:
A and B
其中 A 和 B 可以是任意两个表达式,当 A 为假时,Euphoria 会走捷径并立即将整体结果设为假,甚至不查看表达式 B。
同样,当您有以下形式的条件时:
A or B
其中 A 为真,Euphoria 将跳过表达式 B 的求值,并声明结果为真。
短路求值仅适用于 if、elsif、until 和 while 条件。它不用于其他上下文。例如:
x = 1 or {1,2,3,4,5} -- x should be set to {1,1,1,1,1}
如果在这里使用短路,您将把 x 设置为 1,甚至不查看 {1,2,3,4,5},这是错误的。
因此,短路可以用于 if、elsif、until 或 while 条件,因为您只需要关心结果是真还是假,并且需要条件产生原子作为结果。
Euphoria - 序列
序列由大括号 { } 中用逗号分隔的对象列表表示。序列可以包含原子和其他序列。例如:
{2, 3, 5, 7, 11, 13, 17, 19}
{1, 2, {3, 3, 3}, 4, {5, {6}}}
{{"Zara", "Ayan"}, 52389, 97.25}
{} -- the 0-element sequence
可以通过给出方括号中的元素编号来选择序列的单个元素。元素编号从 1 开始。
例如,如果 x 包含 {5, 7.2, 9, 0.5, 13},则 x[2] 为 7.2。
假设 x[2] 包含 {11,22,33},现在如果您请求 x[2],您将得到 {11,22,33};如果您请求 x[2][3],您将得到原子 33。
示例
#!/home/euphoria-4.0b2/bin/eui
sequence x
x = {1, 2, 3, 4}
for a = 1 to length(x) do
printf(1, "value of x[%d] = %d\n", {a, x[a]})
end for
这里,length() 是内置函数,它返回序列的长度。上面的例子产生以下结果:
value of x[1] = 1 value of x[2] = 2 value of x[3] = 3 value of x[4] = 4
字符字符串
字符字符串只是一个字符序列。它可以通过以下两种方式之一输入:
(a) 使用双引号:
"ABCDEFG"
(b) 使用原始字符串表示法:
-- Using back-quotes `ABCDEFG` or -- Using three double-quotes """ABCDEFG"""
您可以尝试以下示例来理解这个概念:
#!/home/euphoria-4.0b2/bin/eui
sequence x
x = "ABCD"
for a = 1 to length(x) do
printf(1, "value of x[%d] = %s\n", {a, x[a]})
end for
这将产生以下结果:
value of x[1] = A value of x[2] = B value of x[3] = C value of x[4] = D
字符串数组
可以使用序列如下实现字符串数组:
#!/home/euphoria-4.0b2/bin/eui
sequence x = {"Hello", "World", "Euphoria", "", "Last One"}
for a = 1 to length(x) do
printf(1, "value of x[%d] = %s\n", {a, x[a]})
end for
这将产生以下结果:
value of x[1] = Hello value of x[2] = World value of x[3] = Euphoria value of x[4] = value of x[5] = Last One
Euphoria 结构
可以使用序列实现结构,如下所示:
#!/home/euphoria-4.0b2/bin/eui
sequence employee = {
{"John","Smith"},
45000,
27,
185.5
}
printf(1, "First Name = %s, Last Name = %s\n", {employee[1][1],employee[1][2]} )
这将产生以下结果:
First Name = John, Last Name = Smith
可以直接对序列执行各种操作。让我们详细了解一下:
一元运算
当应用于序列时,一元运算符实际上应用于序列中的每个元素,以产生相同长度的结果序列。
#!/home/euphoria-4.0b2/bin/eui
sequence x
x = -{1, 2, 3, 4}
for a = 1 to length(x) do
printf(1, "value of x[%d] = %d\n", {a, x[a]})
end for
这将产生以下结果:
value of x[1] = -1 value of x[2] = -2 value of x[3] = -3 value of x[4] = -4
算术运算
几乎所有算术运算都可以如下对序列执行:
#!/home/euphoria-4.0b2/bin/eui
sequence x, y, a, b, c
x = {1, 2, 3}
y = {10, 20, 30}
a = x + y
puts(1, "Value of a = {")
for i = 1 to length(a) do
printf(1, "%d,", a[i])
end for
puts(1, "}\n")
b = x - y
puts(1, "Value of b = {")
for i = 1 to length(a) do
printf(1, "%d,", b[i])
end for
puts(1, "}\n")
c = x * 3
puts(1, "Value of c = {")
for i = 1 to length(c) do
printf(1, "%d,", c[i])
end for
puts(1, "}\n")
这将产生以下结果:
Value of a = {11,22,33,}
Value of b = {-9,-18,-27,}
Value of c = {3,6,9,}
命令行选项
用户可以将命令行选项传递给 Euphoria 脚本,并且可以使用command_line()函数将其作为序列访问,如下所示:
#!/home/euphoria-4.0b2/bin/eui
sequence x
x = command_line()
printf(1, "Interpeter Name: %s\n", {x[1]} )
printf(1, "Script Name: %s\n", {x[2]} )
printf(1, "First Argument: %s\n", {x[3]})
printf(1, "Second Argument: %s\n", {x[4]})
这里printf()是 Euphoria 的内置函数。现在,如果运行此脚本,则如下所示:
$eui test.ex "one" "two"
这将产生以下结果:
Interpeter Name: /home/euphoria-4.0b2/bin/eui Script Name: test.ex First Argument: one Second Argument: two
Euphoria - 日期和时间
Euphoria 有一个库例程,可以将日期和时间返回给您的程序。
date() 方法
date() 方法返回一个由八个原子元素组成的序列值。以下示例详细解释了它:
#!/home/euphoria-4.0b2/bin/eui
integer curr_year, curr_day, curr_day_of_year, curr_hour, curr_minute, curr_second
sequence system_date, word_week, word_month, notation,
curr_day_of_week, curr_month
word_week = {"Sunday",
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday",
"Saturday"}
word_month = {"January", "February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December"}
-- Get current system date.
system_date = date()
-- Now take individual elements
curr_year = system_date[1] + 1900
curr_month = word_month[system_date[2]]
curr_day = system_date[3]
curr_hour = system_date[4]
curr_minute = system_date[5]
curr_second = system_date[6]
curr_day_of_week = word_week[system_date[7]]
curr_day_of_year = system_date[8]
if curr_hour >= 12 then
notation = "p.m."
else
notation = "a.m."
end if
if curr_hour > 12 then
curr_hour = curr_hour - 12
end if
if curr_hour = 0 then
curr_hour = 12
end if
puts(1, "\nHello Euphoria!\n\n")
printf(1, "Today is %s, %s %d, %d.\n", {curr_day_of_week,
curr_month, curr_day, curr_year})
printf(1, "The time is %.2d:%.2d:%.2d %s\n", {curr_hour,
curr_minute, curr_second, notation})
printf(1, "It is %3d days into the current year.\n", {curr_day_of_year})
这会在您的标准屏幕上产生以下结果:
Hello Euphoria! Today is Friday, January 22, 2010. The time is 02:54:58 p.m. It is 22 days into the current year.
time() 方法
time() 方法返回一个原子值,表示自某个固定时间点以来经过的秒数。以下示例详细解释了它:
#!/home/euphoria-4.0b2/bin/eui
constant ITERATIONS = 100000000
integer p
atom t0, t1, loop_overhead
t0 = time()
for i = 1 to ITERATIONS do
-- time an empty loop
end for
loop_overhead = time() - t0
printf(1, "Loop overhead:%d\n", loop_overhead)
t0 = time()
for i = 1 to ITERATIONS do
p = power(2, 20)
end for
t1 = (time() - (t0 + loop_overhead))/ITERATIONS
printf(1, "Time (in seconds) for one call to power:%d\n", t1)
这将产生以下结果:
Loop overhead:1 Time (in seconds) for one call to power:0
日期和时间相关方法
Euphoria 提供了一系列方法,可帮助您操作日期和时间。这些方法列在Euphoria 库例程中。
Euphoria - 过程
过程是一组可重用的代码,可以从程序中的任何位置调用。这消除了重复编写相同代码的需要。这有助于程序员编写模块化代码。
与任何其他高级编程语言一样,Euphoria 也支持使用过程编写模块化代码所需的所有功能。
您一定在前面的章节中看到过诸如printf()和length()之类的过程。我们反复使用这些过程,但它们只在 Euphoria 核心代码中编写过一次。
Euphoria 也允许您编写自己的过程。本节解释如何在 Euphoria 中编写自己的过程。
过程定义
在使用过程之前,需要定义它。在 Euphoria 中定义过程最常用的方法是使用procedure关键字,后跟唯一的过程名称、参数列表(可能为空)和以end procedure语句结尾的语句块。基本语法如下所示:
procedure procedurename(parameter-list) statements .......... end procedure
示例
这里定义了一个名为 sayHello 的简单过程,它不带参数:
procedure sayHello() puts(1, "Hello there") end procedure
调用过程
要在脚本后面的某个位置调用过程,只需编写该过程的名称,如下所示:
#!/home/euphoria-4.0b2/bin/eui procedure sayHello() puts(1, "Hello there") end procedure -- Call above defined procedure. sayHello()
这将产生以下结果:
Hello there
过程参数
到目前为止,您已经看到了不带参数的过程。但是,在调用过程时,可以传递不同的参数。这些传递的参数可以在过程中捕获,并且可以对这些参数进行任何操作。
过程可以带有多个参数,参数之间用逗号分隔。
示例
让我们对我们的sayHello过程进行一些修改。这次它接受两个参数:
#!/home/euphoria-4.0b2/bin/eui
procedure sayHello(sequence name,atom age)
printf(1, "%s is %d years old.", {name, age})
end procedure
-- Call above defined procedure.
sayHello("zara", 8)
这将产生以下结果:
zara is 8 years old.
Euphoria - 函数
Euphoria 函数就像过程一样,但它们返回值,并且可以用于表达式。本章解释如何在 Euphoria 中编写您自己的函数。
函数定义
在使用函数之前,需要定义它。在 Euphoria 中定义函数最常用的方法是使用function关键字,后跟唯一的函数名称、参数列表(可能为空)和以end function语句结尾的语句块。此处显示基本语法:
function functionname(parameter-list) statements .......... return [Euphoria Object] end function
示例
这里定义了一个名为 sayHello 的简单函数,它不带参数:
function sayHello() puts(1, "Hello there") return 1 end function
调用函数
要在脚本后面的某个位置调用函数,只需编写该函数的名称,如下所示:
#!/home/euphoria-4.0b2/bin/eui function sayHello() puts(1, "Hello there") return 1 end function -- Call above defined function. sayHello()
这将产生以下结果:
Hello there
函数参数
到目前为止,我们已经看到了不带参数的函数。但是,在调用函数时,可以传递不同的参数。这些传递的参数可以在函数中捕获,并且可以对这些参数进行任何操作。
函数可以带有多个参数,参数之间用逗号分隔。
示例
让我们对我们的sayHello函数进行一些修改。这次它接受两个参数:
#!/home/euphoria-4.0b2/bin/eui
function sayHello(sequence name,atom age)
printf(1, "%s is %d years old.", {name, age})
return 1
end function
-- Call above defined function.
sayHello("zara", 8)
这将产生以下结果:
zara is 8 years old.
return 语句
Euphoria 函数必须在结束语句end function之前包含return语句。可以返回任何 Euphoria 对象。实际上,您可以通过返回对象的序列来拥有多个返回值。例如:
return {x_pos, y_pos}
如果没有要返回的内容,则只需返回 1 或 0。返回值 1 表示成功,0 表示失败。
Euphoria - 文件 I/O
使用 Euphoria 编程语言,您可以编写读取和更改软盘驱动器或硬盘驱动器上的文件数据,或创建新文件作为输出形式的程序。您甚至可以访问计算机上的设备,例如打印机和调制解调器。
本章介绍了 Euphoria 中提供的所有基本 I/O 函数。有关更多函数的信息,请参阅标准 Euphoria 文档。
在屏幕上显示
最简单的输出方法是使用puts()语句,您可以在其中传递任何要在屏幕上显示的字符串。还有一种方法printf(),如果您必须使用动态值格式化字符串,则可以使用该方法。
这些方法将您传递给它们的表达式转换为字符串,并将结果写入标准输出,如下所示:
#!/home/euphoria-4.0b2/bin/eui puts(1, "Euphoria is really a great language, isn't it?" )
这会在您的标准屏幕上产生以下结果:
Euphoria is really a great language, isn't it?
打开和关闭文件
Euphoria 默认情况下提供操作文件所需的基本方法。您可以使用以下方法执行大部分文件操作:
- open()
- close()
- printf()
- gets()
- getc()
open 方法
在读取或写入文件之前,必须使用 Euphoria 的内置open()方法打开它。此函数创建一个文件描述符,用于调用与其关联的其他支持方法。
语法
integer file_num = open(file_name, access_mode)
如果打开给定文件名时出错,则上述方法返回 -1。以下是参数:
file_name - file_name 参数是一个字符串值,其中包含要访问的文件的名称。
access_mode - access_mode 确定打开文件的模式。例如,读取、写入追加等。下表列出了文件打开模式的完整可能的取值列表:
| 序号 | 模式和描述 |
|---|---|
| 1 | r 只读方式打开文本文件。文件指针置于文件的开头。 |
| 2 | rb 以二进制格式只读方式打开文件。文件指针置于文件的开头。 |
| 3 | w 只写方式打开文本文件。如果文件存在,则覆盖该文件。如果文件不存在,则创建一个新文件进行写入。 |
| 4 | wb 以二进制格式只写方式打开文件。如果文件存在,则覆盖该文件。如果文件不存在,则创建一个新文件进行写入。 |
| 5 | u 打开一个文件进行读写。文件指针设置在文件的开头。 |
| 6 | ub 以二进制格式打开一个文件进行读写。文件指针置于文件的开头。 |
| 7 | a 打开一个文件进行追加。如果文件存在(追加模式),则文件指针位于文件的末尾。如果文件不存在,则创建一个新文件进行写入。 |
| 8 | ab 以二进制格式打开一个文件进行追加。如果文件存在(追加模式),则文件指针位于文件的末尾。如果文件不存在,则创建一个新文件进行写入。 |
示例
以下示例在 Linux 系统的当前目录中创建一个新的文本文件:
#!/home/euphoria-4.0b2/bin/eui
integer file_num
constant ERROR = 2
constant STDOUT = 1
file_num = open("myfile,txt", "w")
if file_num = -1 then
puts(ERROR, "couldn't open myfile\n")
else
puts(STDOUT, "File opend successfully\n")
end if
如果文件成功打开,则会在您的当前目录中创建“myfile.txt”,并产生以下结果:
File opend successfully
close() 方法
close() 方法刷新任何未写入的信息并关闭文件,之后不能再对文件进行读取或写入。
当文件的引用对象重新分配给另一个文件时,Euphoria 会自动关闭该文件。最好使用 close() 方法关闭文件。
语法
close( file_num );
此处将打开文件时接收到的文件描述符作为参数传递。
示例
以下示例创建文件(如上所示),然后在程序退出之前关闭它:
#!/home/euphoria-4.0b2/bin/eui
integer file_num
constant ERROR = 2
constant STDOUT = 1
file_num = open("myfile.txt", "w")
if file_num = -1 then
puts(ERROR, "couldn't open myfile\n")
else
puts(STDOUT, "File opend successfully\n")
end if
if file_num = -1 then
puts(ERROR, "No need to close the file\n")
else
close( file_num )
puts(STDOUT, "File closed successfully\n")
end if
这将产生以下结果:
File opend successfully File closed successfully
读取和写入文件
Euphoria 提供了一组访问方法,使我们在读取或写入文本模式或二进制模式下的文件时更容易。让我们看看如何使用printf()和gets()方法读取和写入文件。
printf() 方法
printf()方法将任何字符串写入打开的文件。
语法
printf(fn, st, x)
以下是参数:
fn - 从 open() 方法接收到的文件描述符。
st - 格式字符串,其中十进制或原子使用 %d 格式化,字符串或序列使用 %s 格式化。
x - 如果 x 是一个序列,则 st 中的格式说明符与 x 的相应元素匹配。如果 x 是一个原子,则 st 通常只包含一个格式说明符,并将其应用于 x。但是;如果 st 包含多个格式说明符,则每个说明符都应用于相同的值 x。
示例
以下示例打开一个文件,并将一个人的姓名和年龄写入此文件中:
#!/home/euphoria-4.0b2/bin/eui
integer file_num
constant ERROR = 2
constant STDOUT = 1
file_num = open("myfile.txt", "w")
if file_num = -1 then
puts(ERROR, "couldn't open myfile\n")
else
puts(STDOUT, "File opend successfully\n")
end if
printf(file_num, "My name is %s and age is %d\n", {"Zara", 8})
if file_num = -1 then
puts(ERROR, "No need to close the file\n")
else
close( file_num )
puts(STDOUT, "File closed successfully\n")
end if
上面的例子创建了myfile.txt文件。它将给定的内容写入该文件,最后关闭。如果您打开此文件,它将包含以下内容:
My name is Zara and age is 8
gets() 方法
gets()方法从打开的文件中读取字符串。
语法
gets(file_num)
此处传递的参数是opend()方法返回的文件描述符。此方法从文件的开头开始逐行读取。字符的值范围为 0 到 255。在文件末尾返回原子 -1。
示例
让我们以一个已经创建的myfile.txt文件为例。
#!/home/euphoria-4.0b2/bin/eui
integer file_num
object line
constant ERROR = 2
constant STDOUT = 1
file_num = open("myfile.txt", "r")
if file_num = -1 then
puts(ERROR, "couldn't open myfile\n")
else
puts(STDOUT, "File opend successfully\n")
end if
line = gets(file_num)
printf( STDOUT, "Read content : %s\n", {line})
if file_num = -1 then
puts(ERROR, "No need to close the file\n")
else
close( file_num )
puts(STDOUT, "File closed successfully\n")
end if
这将产生以下结果:
File opend successfully Read content : My name is Zara and age is 8 File closed successfully
Euphoria 提供了一系列方法,可帮助您操作文件。这些方法列在Euphoria 库例程中。