
 数据结构
数据结构 网络
网络 RDBMS
RDBMS 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP解释 Git 协作工作流程
版本控制系统分为两种类型 - 集中式和分布式。在集中式系统中,将有一个由所有团队成员共享的单个存储库。此系统的问题是,如果中央存储库离线,则所有依赖于中央存储库的人员都将受到影响。
在 Git 中,每个人都有一个存储库,这意味着他们不依赖于中央服务器。他们可以使用此模型离线工作。但是,我们如何使用此模型进行协作呢?与存储库的每个用户同步需要时间,但我们可以拥有一个更好的工作流程,称为集中式工作流程。

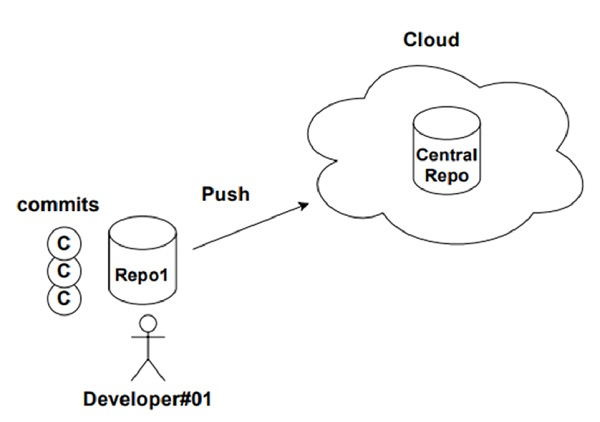
在集中式工作流程中,每个人都将拥有集中式存储库的单独副本,如图表所示。这是大多数私有团队和闭源项目中使用的架构。

让我们看看这如何优于像 Subversion 这样的集中式版本控制系统。这里没有单点故障。如果我们的中央存储库离线,如果需要,我们也可以在存储库之间单独同步。在组织中我们把中央存储库放在哪里?大多数情况下,放在公司私有网络或内部基础设施上的私有服务器上。其他用户使用 Git 托管服务,例如 GitHub、GitLab、Bitbucket 等。所有这些提供商都提供创建私有存储库的选项,这些存储库只能由团队成员访问。
让我们看一个集中式工作流程的示例。

开发人员#01 将存储库克隆到他的本地机器,通过执行多个提交来处理项目,并将更改通过推送更改到中央存储库来共享,如下所示。
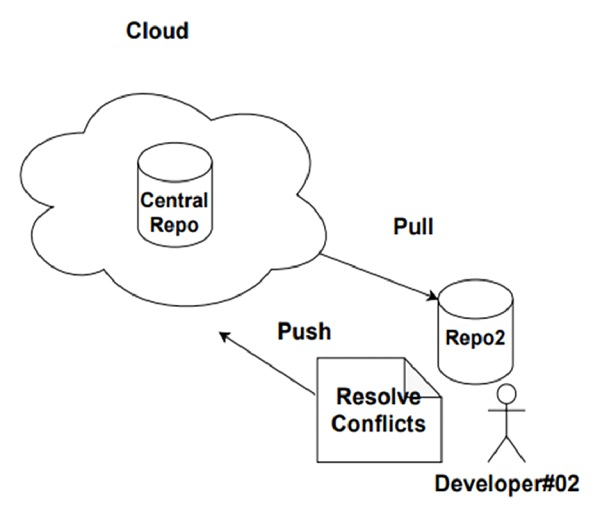
当开发人员#02 需要查看开发人员#01 所做的更改时,他将从中央存储库拉取更改,解决任何现有的冲突并将更改推回中央存储库。
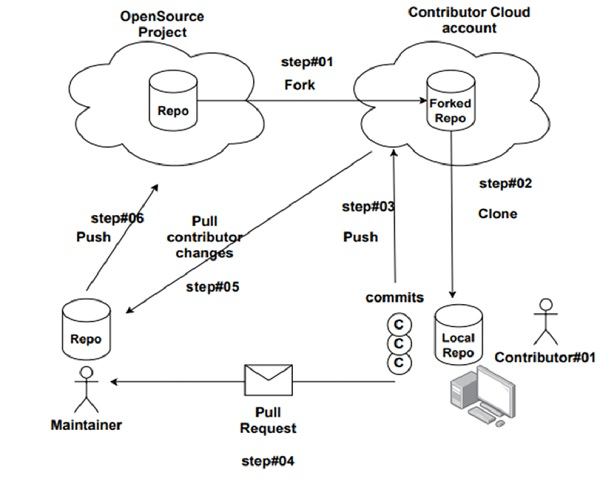
大多数开源项目使用称为集成管理器工作流程的工作流程。让我们看看它是如何工作的。在开源项目中,我们将拥有一个或多个维护者和许多贡献者。
这里的问题是,由于有很多贡献者,我们不能信任他们所有人。我们不能授予所有贡献者对存储库的推送或写入权限。只有项目的维护者应该拥有写入权限。
因此,如果您想让其他用户为开源项目做出贡献,请按照以下步骤操作:
分叉中央存储库,以便贡献者获得中央存储库的副本。
克隆此存储库以在贡献者的机器上获取本地副本,进行更改并执行提交。
准备好共享您的工作后,将更改推回贡献者的中央存储库或分叉存储库。
向项目的维护者发送拉取请求。维护者将收到指示拉取请求的通知。
维护者将拉取贡献者的更改,并审查贡献者所做的更改。
审查后,如果维护者对贡献者的更改感到满意,他将在其本地存储库中合并更改,最后将其推送到中央存储库。
这称为集成管理器工作流程,因为维护者负责项目集成。

260 次浏览
