- HCatalog CLI 命令
- HCatalog - 创建表
- HCatalog - 修改表
- HCatalog - 查看
- HCatalog - 显示表
- HCatalog - 显示分区
- HCatalog - 索引
- HCatalog API
- HCatalog - 读写器
- HCatalog - 输入输出格式
- HCatalog - 加载器和存储器
- HCatalog 有用资源
- HCatalog 快速指南
- HCatalog - 有用资源
- HCatalog - 讨论
HCatalog 快速指南
HCatalog - 简介
什么是 HCatalog?
HCatalog 是 Hadoop 的表存储管理工具。它将 Hive 元存储的表格数据暴露给其他 Hadoop 应用程序。它使用户能够使用不同的数据处理工具(Pig、MapReduce)轻松地将数据写入网格。它确保用户不必担心数据存储的位置或格式。
HCatalog 作为 Hive 的关键组件,使用户能够以任何格式和任何结构存储数据。
为什么选择 HCatalog?
为合适的任务启用合适的工具
Hadoop 生态系统包含不同的数据处理工具,例如 Hive、Pig 和 MapReduce。尽管这些工具不需要元数据,但当元数据存在时,它们仍然可以从中受益。共享元数据存储还使用户能够更轻松地在工具之间共享数据。使用 MapReduce 或 Pig 加载和规范化数据,然后通过 Hive 进行分析的工作流程非常常见。如果所有这些工具都共享一个元存储,那么每个工具的用户都可以立即访问使用另一个工具创建的数据。不需要加载或传输步骤。
捕获处理状态以启用共享
HCatalog 可以发布您的分析结果。因此,其他程序员可以通过“REST”访问您的分析平台。您发布的模式对其他数据科学家也很有用。其他数据科学家可以使用您的发现作为后续发现的输入。
将 Hadoop 与所有内容集成
Hadoop 作为处理和存储环境为企业带来了许多机会;但是,为了促进采用,它必须与现有工具协同工作并增强现有工具。Hadoop 应作为您分析平台的输入,或与您的运营数据存储和 Web 应用程序集成。组织应该享受 Hadoop 的价值,而不必学习一套全新的工具。REST 服务通过熟悉的 API 和类似 SQL 的语言向企业开放平台。企业数据管理系统使用 HCatalog 与 Hadoop 平台更深入地集成。
HCatalog 架构
下图显示了 HCatalog 的整体架构。
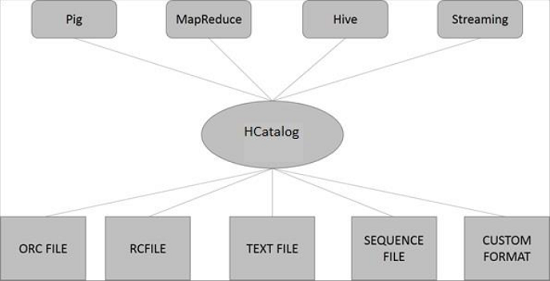
HCatalog 支持读取和写入任何格式的文件,只要可以编写 **SerDe**(序列化器-反序列化器)即可。默认情况下,HCatalog 支持 RCFile、CSV、JSON、SequenceFile 和 ORC 文件格式。要使用自定义格式,必须提供 InputFormat、OutputFormat 和 SerDe。
HCatalog 建立在 Hive 元存储之上,并包含 Hive 的 DDL。HCatalog 为 Pig 和 MapReduce 提供读写接口,并使用 Hive 的命令行界面来发出数据定义和元数据探索命令。
HCatalog - 安装
所有 Hadoop 子项目(如 Hive、Pig 和 HBase)都支持 Linux 操作系统。因此,您需要在系统上安装 Linux 版本。HCatalog 于 2013 年 3 月 26 日与 Hive 安装合并。从 Hive-0.11.0 版本开始,HCatalog 与 Hive 安装一起提供。因此,请按照以下步骤安装 Hive,这将自动在您的系统上安装 HCatalog。
步骤 1:验证 JAVA 安装
安装 Hive 之前,必须在系统上安装 Java。可以使用以下命令检查系统上是否已安装 Java:
$ java –version
如果系统上已安装 Java,则会看到以下响应:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果系统上未安装 Java,则需要按照以下步骤操作。
步骤 2:安装 Java
访问以下链接下载 Java(JDK <最新版本> - X64.tar.gz):http://www.oracle.com/
然后将下载 **jdk-7u71-linux-x64.tar.gz** 到您的系统。
通常,您会在“下载”文件夹中找到下载的 Java 文件。验证并使用以下命令解压缩 **jdk-7u71-linux-x64.gz** 文件。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
要使所有用户都能使用 Java,必须将其移动到“/usr/local/”位置。打开 root 权限,然后键入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
要设置 **PATH** 和 **JAVA_HOME** 变量,请将以下命令添加到 **~/.bashrc** 文件中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin
现在,使用终端中如上所述的命令 **java -version** 验证安装。
步骤 3:验证 Hadoop 安装
安装 Hive 之前,必须在系统上安装 Hadoop。让我们使用以下命令验证 Hadoop 安装:
$ hadoop version
如果系统上已安装 Hadoop,则会看到以下响应:
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
如果系统上未安装 Hadoop,则继续执行以下步骤:
步骤 4:下载 Hadoop
使用以下命令从 Apache 软件基金会下载并解压缩 Hadoop 2.4.1。
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
步骤 5:以伪分布式模式安装 Hadoop
以下步骤用于以伪分布式模式安装 **Hadoop 2.4.1**。
设置 Hadoop
您可以通过将以下命令添加到 **~/.bashrc** 文件中来设置 Hadoop 环境变量。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
现在将所有更改应用到当前正在运行的系统。
$ source ~/.bashrc
Hadoop 配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置文件。您需要根据您的 Hadoop 基础架构对这些配置文件进行适当的更改。
$ cd $HADOOP_HOME/etc/hadoop
为了使用 Java 开发 Hadoop 程序,您必须通过将 **JAVA_HOME** 值替换为系统中 Java 的位置来重置 **hadoop-env.sh** 文件中的 Java 环境变量。
export JAVA_HOME=/usr/local/jdk1.7.0_71
以下是您必须编辑以配置 Hadoop 的文件列表。
core-site.xml
**core-site.xml** 文件包含诸如 Hadoop 实例使用的端口号、为文件系统分配的内存、存储数据的内存限制以及读/写缓冲区的大小等信息。
打开 core-site.xml 并将以下属性添加到 <configuration> 和 </configuration> 标记之间。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://:9000</value>
</property>
</configuration>
hdfs-site.xml
**hdfs-site.xml** 文件包含诸如复制数据的值、namenode 路径和本地文件系统的 datanode 路径等信息。这意味着您要存储 Hadoop 基础架构的位置。
让我们假设以下数据。
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
打开此文件,并将以下属性添加到此文件中的 <configuration>、</configuration> 标记之间。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
**注意** - 在上面的文件中,所有属性值都是用户定义的,您可以根据您的 Hadoop 基础架构进行更改。
yarn-site.xml
此文件用于将 yarn 配置到 Hadoop 中。打开 yarn-site.xml 文件,并将以下属性添加到此文件中的 <configuration>、</configuration> 标记之间。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此文件用于指定我们正在使用哪个 MapReduce 框架。默认情况下,Hadoop 包含 yarn-site.xml 的模板。首先,您需要使用以下命令将文件从 **mapred-site,xml.template** 复制到 **mapred-site.xml** 文件:
$ cp mapred-site.xml.template mapred-site.xml
打开 mapred-site.xml 文件,并将以下属性添加到此文件中的 <configuration>、</configuration> 标记之间。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
步骤 6:验证 Hadoop 安装
以下步骤用于验证 Hadoop 安装。
Namenode 设置
使用命令“hdfs namenode -format”设置 namenode,如下所示:
$ cd ~ $ hdfs namenode -format
预期结果如下:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
验证 Hadoop DFS
以下命令用于启动 DFS。执行此命令将启动您的 Hadoop 文件系统。
$ start-dfs.sh
预期输出如下:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
验证 Yarn 脚本
以下命令用于启动 Yarn 脚本。执行此命令将启动您的 Yarn 守护程序。
$ start-yarn.sh
预期输出如下:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/ yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
在浏览器上访问 Hadoop
访问 Hadoop 的默认端口号为 50070。使用以下 URL 在浏览器上获取 Hadoop 服务。
https://:50070/
验证集群的所有应用程序
访问集群所有应用程序的默认端口号为 8088。使用以下网址访问此服务。
https://:8088/
完成 Hadoop 的安装后,继续执行下一步,在您的系统上安装 Hive。
步骤 7:下载 Hive
本教程中我们使用 hive-0.14.0。您可以访问以下链接下载它:**http://apache.petsads.us/hive/hive-0.14.0/**。让我们假设它下载到 **/Downloads** 目录。在这里,我们为本教程下载名为“**apache-hive-0.14.0-bin.tar.gz**”的 Hive 存档。以下命令用于验证下载:
$ cd Downloads $ ls
下载成功后,您将看到以下响应:
apache-hive-0.14.0-bin.tar.gz
步骤 8:安装 Hive
以下步骤是安装 Hive 到您的系统中所需的步骤。让我们假设 Hive 存档下载到 **/Downloads** 目录。
解压缩和验证 Hive 存档
以下命令用于验证下载并解压缩 Hive 存档:
$ tar zxvf apache-hive-0.14.0-bin.tar.gz $ ls
下载成功后,您将看到以下响应:
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gz
将文件复制到 /usr/local/hive 目录
我们需要从超级用户“su -”复制文件。以下命令用于将文件从解压缩的目录复制到“/usr/local/hive”目录。
$ su - passwd: # cd /home/user/Download # mv apache-hive-0.14.0-bin /usr/local/hive # exit
设置 Hive 的环境
您可以通过将以下几行添加到 **~/.bashrc** 文件中来设置 Hive 环境:
export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:. export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
以下命令用于执行 ~/.bashrc 文件。
$ source ~/.bashrc
步骤 9:配置 Hive
要将 Hive 与 Hadoop 配置,您需要编辑 **hive-env.sh** 文件,该文件位于 **$HIVE_HOME/conf** 目录中。以下命令重定向到 Hive **config** 文件夹并复制模板文件:
$ cd $HIVE_HOME/conf $ cp hive-env.sh.template hive-env.sh
通过添加以下行来编辑 **hive-env.sh** 文件:
export HADOOP_HOME=/usr/local/hadoop
至此,Hive 安装完成。现在您需要一个外部数据库服务器来配置元存储。我们使用 Apache Derby 数据库。
步骤 10:下载和安装 Apache Derby
按照以下步骤下载并安装 Apache Derby:
下载 Apache Derby
使用以下命令下载 Apache Derby。下载需要一些时间。
$ cd ~ $ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz
使用以下命令验证下载:
$ ls
下载成功后,您将看到以下响应:
db-derby-10.4.2.0-bin.tar.gz
解压并验证 Derby 归档文件
使用以下命令解压并验证 Derby 归档文件:
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz $ ls
下载成功后,您将看到以下响应:
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gz
将文件复制到 /usr/local/derby 目录
我们需要以超级用户身份“su -”进行复制。使用以下命令将文件从解压后的目录复制到 **`/usr/local/derby`** 目录:
$ su - passwd: # cd /home/user # mv db-derby-10.4.2.0-bin /usr/local/derby # exit
设置 Derby 环境
您可以通过将以下几行添加到 **`~/.bashrc`** 文件中来设置 Derby 环境:
export DERBY_HOME=/usr/local/derby export PATH=$PATH:$DERBY_HOME/bin export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar
使用以下命令执行 **`~/.bashrc`** 文件:
$ source ~/.bashrc
创建元数据存储目录
在 $DERBY_HOME 目录中创建一个名为 **`data`** 的目录来存储元数据存储数据。
$ mkdir $DERBY_HOME/data
Derby 安装和环境设置已完成。
步骤 11:配置 Hive 元数据存储
配置元数据存储意味着指定 Hive 存储数据库的位置。您可以通过编辑 **`hive-site.xml`** 文件来实现,该文件位于 **`$HIVE_HOME/conf`** 目录中。首先,使用以下命令复制模板文件:
$ cd $HIVE_HOME/conf $ cp hive-default.xml.template hive-site.xml
编辑 **`hive-site.xml`** 文件,并在 `
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby://:1527/metastore_db;create = true</value> <description>JDBC connect string for a JDBC metastore</description> </property>
创建一个名为 **`jpox.properties`** 的文件,并在其中添加以下几行:
javax.jdo.PersistenceManagerFactoryClass = org.jpox.PersistenceManagerFactoryImpl org.jpox.autoCreateSchema = false org.jpox.validateTables = false org.jpox.validateColumns = false org.jpox.validateConstraints = false org.jpox.storeManagerType = rdbms org.jpox.autoCreateSchema = true org.jpox.autoStartMechanismMode = checked org.jpox.transactionIsolation = read_committed javax.jdo.option.DetachAllOnCommit = true javax.jdo.option.NontransactionalRead = true javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true javax.jdo.option.ConnectionUserName = APP javax.jdo.option.ConnectionPassword = mine
步骤 12:验证 Hive 安装
在运行 Hive 之前,您需要在 HDFS 中创建 **`/tmp`** 文件夹和一个单独的 Hive 文件夹。这里我们使用 **`/user/hive/warehouse`** 文件夹。您需要为这些新创建的文件夹设置写入权限,如下所示:
chmod g+w
现在在验证 Hive 之前在 HDFS 中设置它们。使用以下命令:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
使用以下命令验证 Hive 安装:
$ cd $HIVE_HOME $ bin/hive
如果 Hive 安装成功,您将看到以下响应:
Logging initialized using configuration in jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/ hive-log4j.properties Hive history =/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt …………………. hive>
您可以执行以下示例命令来显示所有表:
hive> show tables; OK Time taken: 2.798 seconds hive>
步骤 13:验证 HCatalog 安装
使用以下命令设置 HCatalog 主目录的系统变量 **`HCAT_HOME`**:
export HCAT_HOME = $HiVE_HOME/HCatalog
使用以下命令验证 HCatalog 安装。
cd $HCAT_HOME/bin ./hcat
如果安装成功,您将看到以下输出:
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statement
HCatalog - 命令行界面 (CLI)
HCatalog 命令行界面 (CLI) 可以从命令 **`$HIVE_HOME/HCatalog/bin/hcat`** 调用,其中 $HIVE_HOME 是 Hive 的主目录。**`hcat`** 是用于初始化 HCatalog 服务器的命令。
使用以下命令初始化 HCatalog 命令行。
cd $HCAT_HOME/bin ./hcat
如果安装正确,您将获得以下输出:
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statement
HCatalog CLI 支持以下命令行选项:
| 序号 | 选项 | 示例及说明 |
|---|---|---|
| 1 | -g | hcat -g mygroup ... 要创建的表必须具有组“mygroup”。 |
| 2 | -p | hcat -p rwxr-xr-x ... 要创建的表必须具有读、写和执行权限。 |
| 3 | -f | hcat -f myscript.HCatalog ... myscript.HCatalog 是包含要执行的 DDL 命令的脚本文件。 |
| 4 | -e | hcat -e 'create table mytable(a int);' ... 将以下字符串视为 DDL 命令并执行。 |
| 5 | -D | hcat -Dkey = value ... 将键值对作为 Java 系统属性传递给 HCatalog。 |
| 6 | - | hcat 打印用法信息。 |
注意:
**`-g`** 和 **`-p`** 选项不是必需的。
一次只能提供 **`-e`** 或 **`-f`** 选项,不能同时提供。
选项的顺序无关紧要;您可以按任何顺序指定选项。
| 序号 | DDL 命令及说明 |
|---|---|
| 1 | CREATE TABLE 使用 HCatalog 创建表。如果使用 CLUSTERED BY 子句创建表,则无法使用 Pig 或 MapReduce 向其写入数据。 |
| 2 | ALTER TABLE 支持,但 REBUILD 和 CONCATENATE 选项除外。其行为与 Hive 中相同。 |
| 3 | DROP TABLE 支持。行为与 Hive 相同(删除完整的表和结构)。 |
| 4 | CREATE/ALTER/DROP VIEW 支持。行为与 Hive 相同。 **注意**:Pig 和 MapReduce 无法读取或写入视图。 |
| 5 | SHOW TABLES 显示表列表。 |
| 6 | SHOW PARTITIONS 显示分区列表。 |
| 7 | 创建/删除索引 支持 CREATE 和 DROP FUNCTION 操作,但创建的函数仍必须在 Pig 中注册并放置在 MapReduce 的 CLASSPATH 中。 |
| 8 | DESCRIBE 支持。行为与 Hive 相同。描述结构。 |
后续章节将解释上表中的一些命令。
HCatalog - 创建表
本章解释如何创建表以及如何向表中插入数据。在 HCatalog 中创建表的约定与使用 Hive 创建表非常相似。
创建表语句
Create Table 是一个用于使用 HCatalog 在 Hive 元数据存储中创建表的语句。其语法和示例如下:
语法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format]
示例
假设您需要使用 **`CREATE TABLE`** 语句创建一个名为 **`employee`** 的表。下表列出了 **`employee`** 表中的字段及其数据类型:
| 序号 | 字段名称 | 数据类型 |
|---|---|---|
| 1 | Eid | int |
| 2 | Name | String |
| 3 | Salary | Float |
| 4 | Designation | string |
以下数据定义了受支持的字段,例如 **`Comment`**,行格式化字段,例如 **`Field terminator`**、**`Lines terminator`** 和 **`Stored File type`**。
COMMENT ‘Employee details’ FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED IN TEXT FILE
以下查询使用上述数据创建一个名为 **`employee`** 的表。
./hcat –e "CREATE TABLE IF NOT EXISTS employee ( eid int, name String, salary String, destination String) \ COMMENT 'Employee details' \ ROW FORMAT DELIMITED \ FIELDS TERMINATED BY ‘\t’ \ LINES TERMINATED BY ‘\n’ \ STORED AS TEXTFILE;"
如果添加 **`IF NOT EXISTS`** 选项,则如果表已存在,HCatalog 将忽略该语句。
成功创建表后,您将看到以下响应:
OK Time taken: 5.905 seconds
加载数据语句
通常,在 SQL 中创建表后,我们可以使用 Insert 语句插入数据。但在 HCatalog 中,我们使用 LOAD DATA 语句插入数据。
向 HCatalog 中插入数据时,最好使用 LOAD DATA 来存储批量记录。加载数据有两种方式:一种是从 **本地文件系统**,另一种是从 **Hadoop 文件系统**。
语法
LOAD DATA 的语法如下:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
- LOCAL 是指定本地路径的标识符。它是可选的。
- OVERWRITE 是可选的,用于覆盖表中的数据。
- PARTITION 是可选的。
示例
我们将以下数据插入表中。它是一个名为 **`sample.txt`** 的文本文件,位于 **`/home/user`** 目录中。
1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op Admin
以下查询将给定的文本加载到表中。
./hcat –e "LOAD DATA LOCAL INPATH '/home/user/sample.txt' OVERWRITE INTO TABLE employee;"
下载成功后,您将看到以下响应:
OK Time taken: 15.905 seconds
HCatalog - 修改表
本章解释如何更改表的属性,例如更改表名、更改列名、添加列以及删除或替换列。
更改表语句
您可以使用 ALTER TABLE 语句来更改 Hive 中的表。
语法
根据我们希望修改表中的哪些属性,该语句采用以下任何语法。
ALTER TABLE name RENAME TO new_name ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...]) ALTER TABLE name DROP [COLUMN] column_name ALTER TABLE name CHANGE column_name new_name new_type ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
下面解释了一些场景。
重命名为…语句
以下查询将表名从 **`employee`** 重命名为 **`emp`**。
./hcat –e "ALTER TABLE employee RENAME TO emp;"
更改语句
下表包含 **`employee`** 表的字段,并显示要更改的字段(以粗体显示)。
| 字段名称 | 从数据类型转换 | 更改字段名称 | 转换为数据类型 |
|---|---|---|---|
| eid | int | eid | int |
| name | String | ename | String |
| salary | Float | salary | Double |
| designation | String | designation | String |
以下查询使用上述数据重命名列名和列数据类型:
./hcat –e "ALTER TABLE employee CHANGE name ename String;" ./hcat –e "ALTER TABLE employee CHANGE salary salary Double;"
添加列语句
以下查询将名为 **`dept`** 的列添加到 **`employee`** 表。
./hcat –e "ALTER TABLE employee ADD COLUMNS (dept STRING COMMENT 'Department name');"
替换语句
以下查询删除 **`employee`** 表中的所有列,并将其替换为 **`emp`** 和 **`name`** 列:
./hcat – e "ALTER TABLE employee REPLACE COLUMNS ( eid INT empid Int, ename STRING name String);"
删除表语句
本章介绍如何在 HCatalog 中删除表。当您从元数据存储中删除表时,它会删除表/列数据及其元数据。它可以是普通表(存储在元数据存储中)或外部表(存储在本地文件系统中);HCatalog 对两者都以相同的方式处理,无论其类型如何。
语法如下:
DROP TABLE [IF EXISTS] table_name;
以下查询删除名为 **`employee`** 的表:
./hcat –e "DROP TABLE IF EXISTS employee;"
成功执行查询后,您将看到以下响应:
OK Time taken: 5.3 seconds
HCatalog - 查看
本章介绍如何在 HCatalog 中创建和管理 **视图**。数据库视图使用 **`CREATE VIEW`** 语句创建。视图可以从单个表、多个表或另一个视图创建。
要创建视图,用户必须根据具体的实现拥有适当的系统权限。
创建视图语句
**`CREATE VIEW`** 创建具有给定名称的视图。如果已存在具有相同名称的表或视图,则会引发错误。您可以使用 **`IF NOT EXISTS`** 来跳过错误。
如果没有提供列名,则视图列的名称将自动从 **定义的 SELECT 表达式** 中派生。
**注意**:如果 SELECT 包含未指定别名的标量表达式(例如 x+y),则生成的视图列名将以 _C0、_C1 等形式生成。
重命名列时,还可以提供列注释。注释不会自动从底层列继承。
如果视图的 **定义的 SELECT 表达式** 无效,则 CREATE VIEW 语句将失败。
语法
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], ...) ] [COMMENT view_comment] [TBLPROPERTIES (property_name = property_value, ...)] AS SELECT ...;
示例
以下是 employee 表数据。现在让我们看看如何创建一个名为 **`Emp_Deg_View`** 的视图,其中包含薪水超过 35,000 的员工的 id、name、Designation 和 salary 字段。
+------+-------------+--------+-------------------+-------+ | ID | Name | Salary | Designation | Dept | +------+-------------+--------+-------------------+-------+ | 1201 | Gopal | 45000 | Technical manager | TP | | 1202 | Manisha | 45000 | Proofreader | PR | | 1203 | Masthanvali | 30000 | Technical writer | TP | | 1204 | Kiran | 40000 | Hr Admin | HR | | 1205 | Kranthi | 30000 | Op Admin | Admin | +------+-------------+--------+-------------------+-------+
以下是如何根据上述数据创建视图的命令。
./hcat –e "CREATE VIEW Emp_Deg_View (salary COMMENT ' salary more than 35,000') AS SELECT id, name, salary, designation FROM employee WHERE salary ≥ 35000;"
输出
OK Time taken: 5.3 seconds
删除视图语句
DROP VIEW 删除指定视图的元数据。删除其他视图引用的视图时,不会给出警告(依赖视图将保留为无效,必须由用户删除或重新创建)。
语法
DROP VIEW [IF EXISTS] view_name;
示例
以下命令用于删除名为 **`Emp_Deg_View`** 的视图。
DROP VIEW Emp_Deg_View;
HCatalog - 显示表
您通常希望列出数据库中的所有表或列出表中的所有列。显然,每个数据库都有自己的语法来列出表和列。
**`Show Tables`** 语句显示所有表的名称。默认情况下,它列出当前数据库中的表,或者使用 **`IN`** 子句,在指定的数据库中。
本章介绍如何在 HCatalog 中列出当前数据库中的所有表。
显示表语句
SHOW TABLES 的语法如下:
SHOW TABLES [IN database_name] ['identifier_with_wildcards'];
以下查询显示表列表:
./hcat –e "Show tables;"
成功执行查询后,您将看到以下响应:
OK emp employee Time taken: 5.3 seconds
HCatalog - 显示分区
分区是表格数据的条件,用于创建单独的表或视图。SHOW PARTITIONS 列出给定基表的所有现有分区。分区按字母顺序列出。在 Hive 0.6 之后,也可以指定分区规范的部分内容来过滤结果列表。
您可以使用 SHOW PARTITIONS 命令查看特定表中存在的分区。本章介绍如何在 HCatalog 中列出特定表的分区。
显示分区语句
语法如下:
SHOW PARTITIONS table_name;
以下查询删除名为 **`employee`** 的表:
./hcat –e "Show partitions employee;"
成功执行查询后,您将看到以下响应:
OK Designation = IT Time taken: 5.3 seconds
动态分区
HCatalog 将表组织成分区。这是一种根据分区列的值(例如日期、城市和部门)将表划分为相关部分的方法。使用分区,可以轻松查询数据的一部分。
例如,名为 **`Tab1`** 的表包含员工数据,例如 id、name、dept 和 yoj(即加入年份)。假设您需要检索 2012 年加入的所有员工的详细信息。查询会搜索整个表以查找所需信息。但是,如果按年份对员工数据进行分区并将其存储在单独的文件中,则会缩短查询处理时间。以下示例显示如何分区文件及其数据:
以下文件包含 **`employeedata`** 表。
/tab1/employeedata/file1
id, name, dept, yoj 1, gopal, TP, 2012 2, kiran, HR, 2012 3, kaleel, SC, 2013 4, Prasanth, SC, 2013
上述数据使用年份划分为两个文件。
/tab1/employeedata/2012/file2
1, gopal, TP, 2012 2, kiran, HR, 2012
/tab1/employeedata/2013/file3
3, kaleel, SC, 2013 4, Prasanth, SC, 2013
添加分区
我们可以通过修改表来向表中添加分区。假设我们有一个名为employee的表,其字段包括Id、Name、Salary、Designation、Dept和yoj。
语法
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...; partition_spec: : (p_column = p_col_value, p_column = p_col_value, ...)
以下查询用于向employee表添加分区。
./hcat –e "ALTER TABLE employee ADD PARTITION (year = '2013') location '/2012/part2012';"
重命名分区
您可以使用RENAME-TO命令重命名分区。其语法如下:
./hact –e "ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;"
以下查询用于重命名分区:
./hcat –e "ALTER TABLE employee PARTITION (year=’1203’) RENAME TO PARTITION (Yoj='1203');"
删除分区
用于删除分区的命令语法如下:
./hcat –e "ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec,. PARTITION partition_spec,...;"
以下查询用于删除分区:
./hcat –e "ALTER TABLE employee DROP [IF EXISTS] PARTITION (year=’1203’);"
HCatalog - 索引
创建索引
索引只不过是指向表中特定列的指针。创建索引意味着在表的特定列上创建一个指针。其语法如下:
CREATE INDEX index_name ON TABLE base_table_name (col_name, ...) AS 'index.handler.class.name' [WITH DEFERRED REBUILD] [IDXPROPERTIES (property_name = property_value, ...)] [IN TABLE index_table_name] [PARTITIONED BY (col_name, ...)][ [ ROW FORMAT ...] STORED AS ... | STORED BY ... ] [LOCATION hdfs_path] [TBLPROPERTIES (...)]
示例
让我们来看一个例子来理解索引的概念。使用我们之前用过的同一个employee表,字段包括Id、Name、Salary、Designation和Dept。在employee表的salary列上创建一个名为index_salary的索引。
以下查询创建索引:
./hcat –e "CREATE INDEX inedx_salary ON TABLE employee(salary) AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler';"
它指向salary列。如果修改了该列,则使用索引值存储更改。
删除索引
以下语法用于删除索引:
DROP INDEX <index_name> ON <table_name>
以下查询删除索引index_salary:
./hcat –e "DROP INDEX index_salary ON employee;"
HCatalog - 读写器
HCatalog包含一个数据传输API,用于在不使用MapReduce的情况下进行并行输入和输出。此API使用表和行的基本存储抽象来读取Hadoop集群中的数据并向其中写入数据。
数据传输API主要包含三个类,它们是:
HCatReader - 从Hadoop集群读取数据。
HCatWriter - 将数据写入Hadoop集群。
DataTransferFactory - 生成reader和writer实例。
此API适用于主从节点设置。让我们更详细地讨论HCatReader和HCatWriter。
HCatReader
HCatReader是HCatalog内部的一个抽象类,它将底层系统(从中检索记录)的复杂性抽象出来。
| 序号 | 方法名称及描述 |
|---|---|
| 1 | Public abstract ReaderContext prepareRead() throws HCatException 这应该在主节点上调用以获取ReaderContext,然后将其序列化并发送到从节点。 |
| 2 | Public abstract Iterator <HCatRecorder> read() throws HCaException 这应该在从节点上调用以读取HCatRecords。 |
| 3 | Public Configuration getConf() 它将返回配置类对象。 |
HCatReader类用于从HDFS读取数据。读取是一个两步过程,第一步发生在外部系统的master节点上。第二步在多个slave节点上并行执行。
读取在ReadEntity上进行。在开始读取之前,需要定义一个要从中读取的ReadEntity。这可以通过ReadEntity.Builder完成。您可以指定数据库名称、表名、分区和过滤器字符串。例如:
ReadEntity.Builder builder = new ReadEntity.Builder();
ReadEntity entity = builder.withDatabase("mydb").withTable("mytbl").build(); 10.
上面的代码片段定义了一个ReadEntity对象(“entity”),包含名为mydb的数据库中名为mytbl的表,可用于读取该表的所有行。请注意,此表必须在该操作开始之前存在于HCatalog中。
定义ReadEntity后,使用ReadEntity和集群配置获取HCatReader实例:
HCatReader reader = DataTransferFactory.getHCatReader(entity, config);
下一步是从reader获取ReaderContext,如下所示:
ReaderContext cntxt = reader.prepareRead();
HCatWriter
此抽象类位于HCatalog内部。这是为了便于从外部系统写入HCatalog。不要尝试直接实例化它。而是使用DataTransferFactory。
| 序号 | 方法名称及描述 |
|---|---|
| 1 | Public abstract WriterContext prepareRead() throws HCatException 外部系统应该从主节点精确调用一次此方法。它返回一个WriterContext。这应该被序列化并发送到从节点以在那里构造HCatWriter。 |
| 2 | Public abstract void write(Iterator<HCatRecord> recordItr) throws HCaException 此方法应在从节点上使用以执行写入操作。recordItr是一个迭代器对象,其中包含要写入HCatalog的记录集合。 |
| 3 | Public abstract void abort(WriterContext cntxt) throws HCatException 此方法应该在主节点上调用。此方法的主要目的是在发生故障时进行清理。 |
| 4 | public abstract void commit(WriterContext cntxt) throws HCatException 此方法应该在主节点上调用。此方法的目的是执行元数据提交。 |
与读取类似,写入也是一个两步过程,第一步发生在主节点上。随后,第二步在从节点上并行发生。
写入在WriteEntity上进行,其构造方式类似于读取:
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withDatabase("mydb").withTable("mytbl").build();
上面的代码创建一个WriteEntity对象entity,可用于写入名为mydb的数据库中名为mytbl的表。
创建WriteEntity后,下一步是获取WriterContext:
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config); WriterContext info = writer.prepareWrite();
所有上述步骤都在主节点上发生。主节点然后序列化WriterContext对象,并使其可用于所有从节点。
在从节点上,需要使用WriterContext获取HCatWriter,如下所示:
HCatWriter writer = DataTransferFactory.getHCatWriter(context);
然后,writer将迭代器作为write方法的参数。
writer.write(hCatRecordItr);
然后,writer循环调用此迭代器的getNext()并写出附加到迭代器的所有记录。
TestReaderWriter.java文件用于测试HCatreader和HCatWriter类。以下程序演示了如何使用HCatReader和HCatWriter API从源文件读取数据,然后将其写入目标文件。
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.metastore.api.MetaException;
import org.apache.hadoop.hive.ql.CommandNeedRetryException;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hive.HCatalog.common.HCatException;
import org.apache.hive.HCatalog.data.transfer.DataTransferFactory;
import org.apache.hive.HCatalog.data.transfer.HCatReader;
import org.apache.hive.HCatalog.data.transfer.HCatWriter;
import org.apache.hive.HCatalog.data.transfer.ReadEntity;
import org.apache.hive.HCatalog.data.transfer.ReaderContext;
import org.apache.hive.HCatalog.data.transfer.WriteEntity;
import org.apache.hive.HCatalog.data.transfer.WriterContext;
import org.apache.hive.HCatalog.mapreduce.HCatBaseTest;
import org.junit.Assert;
import org.junit.Test;
public class TestReaderWriter extends HCatBaseTest {
@Test
public void test() throws MetaException, CommandNeedRetryException,
IOException, ClassNotFoundException {
driver.run("drop table mytbl");
driver.run("create table mytbl (a string, b int)");
Iterator<Entry<String, String>> itr = hiveConf.iterator();
Map<String, String> map = new HashMap<String, String>();
while (itr.hasNext()) {
Entry<String, String> kv = itr.next();
map.put(kv.getKey(), kv.getValue());
}
WriterContext cntxt = runsInMaster(map);
File writeCntxtFile = File.createTempFile("hcat-write", "temp");
writeCntxtFile.deleteOnExit();
// Serialize context.
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(writeCntxtFile));
oos.writeObject(cntxt);
oos.flush();
oos.close();
// Now, deserialize it.
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(writeCntxtFile));
cntxt = (WriterContext) ois.readObject();
ois.close();
runsInSlave(cntxt);
commit(map, true, cntxt);
ReaderContext readCntxt = runsInMaster(map, false);
File readCntxtFile = File.createTempFile("hcat-read", "temp");
readCntxtFile.deleteOnExit();
oos = new ObjectOutputStream(new FileOutputStream(readCntxtFile));
oos.writeObject(readCntxt);
oos.flush();
oos.close();
ois = new ObjectInputStream(new FileInputStream(readCntxtFile));
readCntxt = (ReaderContext) ois.readObject();
ois.close();
for (int i = 0; i < readCntxt.numSplits(); i++) {
runsInSlave(readCntxt, i);
}
}
private WriterContext runsInMaster(Map<String, String> config) throws HCatException {
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withTable("mytbl").build();
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
WriterContext info = writer.prepareWrite();
return info;
}
private ReaderContext runsInMaster(Map<String, String> config,
boolean bogus) throws HCatException {
ReadEntity entity = new ReadEntity.Builder().withTable("mytbl").build();
HCatReader reader = DataTransferFactory.getHCatReader(entity, config);
ReaderContext cntxt = reader.prepareRead();
return cntxt;
}
private void runsInSlave(ReaderContext cntxt, int slaveNum) throws HCatException {
HCatReader reader = DataTransferFactory.getHCatReader(cntxt, slaveNum);
Iterator<HCatRecord> itr = reader.read();
int i = 1;
while (itr.hasNext()) {
HCatRecord read = itr.next();
HCatRecord written = getRecord(i++);
// Argh, HCatRecord doesnt implement equals()
Assert.assertTrue("Read: " + read.get(0) + "Written: " + written.get(0),
written.get(0).equals(read.get(0)));
Assert.assertTrue("Read: " + read.get(1) + "Written: " + written.get(1),
written.get(1).equals(read.get(1)));
Assert.assertEquals(2, read.size());
}
//Assert.assertFalse(itr.hasNext());
}
private void runsInSlave(WriterContext context) throws HCatException {
HCatWriter writer = DataTransferFactory.getHCatWriter(context);
writer.write(new HCatRecordItr());
}
private void commit(Map<String, String> config, boolean status,
WriterContext context) throws IOException {
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withTable("mytbl").build();
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
if (status) {
writer.commit(context);
} else {
writer.abort(context);
}
}
private static HCatRecord getRecord(int i) {
List<Object> list = new ArrayList<Object>(2);
list.add("Row #: " + i);
list.add(i);
return new DefaultHCatRecord(list);
}
private static class HCatRecordItr implements Iterator<HCatRecord> {
int i = 0;
@Override
public boolean hasNext() {
return i++ < 100 ? true : false;
}
@Override
public HCatRecord next() {
return getRecord(i);
}
@Override
public void remove() {
throw new RuntimeException();
}
}
}
上述程序以记录的形式从HDFS读取数据,并将记录数据写入mytable
HCatalog - 输入输出格式
HCatInputFormat和HCatOutputFormat接口用于从HDFS读取数据,并在处理后使用MapReduce作业将结果数据写入HDFS。让我们详细说明输入和输出格式接口。
HCatInputFormat
HCatInputFormat用于MapReduce作业从HCatalog管理的表读取数据。HCatInputFormat公开了一个Hadoop 0.20 MapReduce API,用于读取数据,就好像它已发布到表中一样。
| 序号 | 方法名称及描述 |
|---|---|
| 1 | public static HCatInputFormat setInput(Job job, String dbName, String tableName)throws IOException 设置作业要使用的输入。它使用给定的输入规范查询元存储,并将匹配的分区序列化到MapReduce任务的作业配置中。 |
| 2 | public static HCatInputFormat setInput(Configuration conf, String dbName, String tableName) throws IOException 设置作业要使用的输入。它使用给定的输入规范查询元存储,并将匹配的分区序列化到MapReduce任务的作业配置中。 |
| 3 | public HCatInputFormat setFilter(String filter)throws IOException 在输入表上设置过滤器。 |
| 4 | public HCatInputFormat setProperties(Properties properties) throws IOException 设置输入格式的属性。 |
HCatInputFormat API包含以下方法:
- setInput
- setOutputSchema
- getTableSchema
要使用HCatInputFormat读取数据,首先使用要读取的表中的必要信息实例化一个InputJobInfo,然后使用InputJobInfo调用setInput。
您可以使用setOutputSchema方法包含一个投影模式,以指定输出字段。如果没有指定模式,则将返回表中的所有列。您可以使用getTableSchema方法确定指定输入表的表模式。
HCatOutputFormat
HCatOutputFormat用于MapReduce作业将数据写入HCatalog管理的表。HCatOutputFormat公开了一个Hadoop 0.20 MapReduce API,用于将数据写入表。当MapReduce作业使用HCatOutputFormat写入输出时,将使用为表配置的默认OutputFormat,并且作业完成后将新的分区发布到表中。
| 序号 | 方法名称及描述 |
|---|---|
| 1 | public static void setOutput (Configuration conf, Credentials credentials, OutputJobInfo outputJobInfo) throws IOException 设置有关作业要写入的输出的信息。它查询元数据服务器以查找要用于表的StorageHandler。如果分区已发布,则会引发错误。 |
| 2 | public static void setSchema (Configuration conf, HCatSchema schema) throws IOException 设置写入分区的数据模式。如果未调用此方法,则默认使用表模式。 |
| 3 | public RecordWriter <WritableComparable<?>, HCatRecord > getRecordWriter (TaskAttemptContext context)throws IOException, InterruptedException 获取作业的记录写入器。它使用StorageHandler的默认OutputFormat来获取记录写入器。 |
| 4 | public OutputCommitter getOutputCommitter (TaskAttemptContext context) throws IOException, InterruptedException 获取此输出格式的输出提交器。它确保正确提交输出。 |
HCatOutputFormat API包含以下方法:
- setOutput
- setSchema
- getTableSchema
对HCatOutputFormat的第一次调用必须是setOutput;任何其他调用都会引发异常,提示输出格式未初始化。
要写入的数据模式由setSchema方法指定。您必须调用此方法,提供您正在写入的数据模式。如果您的数据与表模式具有相同的模式,则可以使用HCatOutputFormat.getTableSchema()获取表模式,然后将其传递给setSchema()。
示例
以下MapReduce程序从一个表读取数据(假设该表在第二列(“column 1”)中有一个整数),并计算它找到的每个不同值的实例数。也就是说,它执行等效于“select col1, count(*) from $table group by col1;”的操作。
例如,如果第二列中的值为{1, 1, 1, 3, 3, 5},则程序将生成以下值和计数输出:
1, 3 3, 2 5, 1
现在让我们看一下程序代码:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.HCatalog.common.HCatConstants;
import org.apache.HCatalog.data.DefaultHCatRecord;
import org.apache.HCatalog.data.HCatRecord;
import org.apache.HCatalog.data.schema.HCatSchema;
import org.apache.HCatalog.mapreduce.HCatInputFormat;
import org.apache.HCatalog.mapreduce.HCatOutputFormat;
import org.apache.HCatalog.mapreduce.InputJobInfo;
import org.apache.HCatalog.mapreduce.OutputJobInfo;
public class GroupByAge extends Configured implements Tool {
public static class Map extends Mapper<WritableComparable,
HCatRecord, IntWritable, IntWritable> {
int age;
@Override
protected void map(
WritableComparable key, HCatRecord value,
org.apache.hadoop.mapreduce.Mapper<WritableComparable,
HCatRecord, IntWritable, IntWritable>.Context context
)throws IOException, InterruptedException {
age = (Integer) value.get(1);
context.write(new IntWritable(age), new IntWritable(1));
}
}
public static class Reduce extends Reducer<IntWritable, IntWritable,
WritableComparable, HCatRecord> {
@Override
protected void reduce(
IntWritable key, java.lang.Iterable<IntWritable> values,
org.apache.hadoop.mapreduce.Reducer<IntWritable, IntWritable,
WritableComparable, HCatRecord>.Context context
)throws IOException ,InterruptedException {
int sum = 0;
Iterator<IntWritable> iter = values.iterator();
while (iter.hasNext()) {
sum++;
iter.next();
}
HCatRecord record = new DefaultHCatRecord(2);
record.set(0, key.get());
record.set(1, sum);
context.write(null, record);
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
args = new GenericOptionsParser(conf, args).getRemainingArgs();
String serverUri = args[0];
String inputTableName = args[1];
String outputTableName = args[2];
String dbName = null;
String principalID = System
.getProperty(HCatConstants.HCAT_METASTORE_PRINCIPAL);
if (principalID != null)
conf.set(HCatConstants.HCAT_METASTORE_PRINCIPAL, principalID);
Job job = new Job(conf, "GroupByAge");
HCatInputFormat.setInput(job, InputJobInfo.create(dbName, inputTableName, null));
// initialize HCatOutputFormat
job.setInputFormatClass(HCatInputFormat.class);
job.setJarByClass(GroupByAge.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(WritableComparable.class);
job.setOutputValueClass(DefaultHCatRecord.class);
HCatOutputFormat.setOutput(job, OutputJobInfo.create(dbName, outputTableName, null));
HCatSchema s = HCatOutputFormat.getTableSchema(job);
System.err.println("INFO: output schema explicitly set for writing:" + s);
HCatOutputFormat.setSchema(job, s);
job.setOutputFormatClass(HCatOutputFormat.class);
return (job.waitForCompletion(true) ? 0 : 1);
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new GroupByAge(), args);
System.exit(exitCode);
}
}
在编译上述程序之前,您必须下载一些jar文件并将其添加到此应用程序的classpath中。您需要下载所有Hive jar文件和HCatalog jar文件(HCatalog-core-0.5.0.jar、hive-metastore-0.10.0.jar、libthrift-0.7.0.jar、hive-exec-0.10.0.jar、libfb303-0.7.0.jar、jdo2-api-2.3-ec.jar、slf4j-api-1.6.1.jar)。
使用以下命令将这些jar文件从本地复制到HDFS,并将其添加到classpath中。
bin/hadoop fs -copyFromLocal $HCAT_HOME/share/HCatalog/HCatalog-core-0.5.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/hive-metastore-0.10.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/libthrift-0.7.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/hive-exec-0.10.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/libfb303-0.7.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/jdo2-api-2.3-ec.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/slf4j-api-1.6.1.jar /tmp export LIB_JARS=hdfs:///tmp/HCatalog-core-0.5.0.jar, hdfs:///tmp/hive-metastore-0.10.0.jar, hdfs:///tmp/libthrift-0.7.0.jar, hdfs:///tmp/hive-exec-0.10.0.jar, hdfs:///tmp/libfb303-0.7.0.jar, hdfs:///tmp/jdo2-api-2.3-ec.jar, hdfs:///tmp/slf4j-api-1.6.1.jar
使用以下命令编译并执行给定程序。
$HADOOP_HOME/bin/hadoop jar GroupByAge tmp/hive
现在,检查您的输出目录(hdfs: user/tmp/hive)以查看输出(part_0000、part_0001)。
HCatalog - Loader & Storer
HCatLoader和HCatStorer API与Pig脚本一起使用,用于读取和写入HCatalog管理的表中的数据。这些接口不需要任何HCatalog特定的设置。
最好了解一些Apache Pig脚本才能更好地理解本章内容。有关更多参考,请阅读我们的Apache Pig教程。
HCatloader
HCatLoader用于Pig脚本从HCatalog管理的表读取数据。使用以下语法使用HCatloader将数据加载到HDFS中。
A = LOAD 'tablename' USING org.apache.HCatalog.pig.HCatLoader();
您必须用单引号指定表名:LOAD 'tablename'。如果您使用的是非默认数据库,则必须将输入指定为'dbname.tablename'。
Hive元存储允许您在不指定数据库的情况下创建表。如果您以这种方式创建表,则数据库名称为'default',在为HCatLoader指定表时不需要。
下表包含HCatloader类的重要方法和描述。
| 序号 | 方法名称及描述 |
|---|---|
| 1 | public InputFormat<?,?> getInputFormat()throws IOException 使用HCatloader类读取加载数据的输入格式。 |
| 2 | public String relativeToAbsolutePath(String location, Path curDir) throws IOException 它返回绝对路径的字符串格式。 |
| 3 | public void setLocation(String location, Job job) throws IOException 它设置作业可以执行的位置。 |
| 4 | public Tuple getNext() throws IOException 返回循环中的当前元组(键和值)。 |
HCatStorer
HCatStorer用于Pig脚本将数据写入HCatalog管理的表。使用以下语法进行存储操作。
A = LOAD ... B = FOREACH A ... ... ... my_processed_data = ... STORE my_processed_data INTO 'tablename' USING org.apache.HCatalog.pig.HCatStorer();
必须使用单引号指定表名:LOAD 'tablename'。数据库和表都必须在运行 Pig 脚本之前创建。如果使用非默认数据库,则必须将输入指定为'dbname.tablename'。
Hive 元存储允许您在不指定数据库的情况下创建表。如果以这种方式创建表,则数据库名为'default',您不需要在store语句中指定数据库名。
对于USING子句,您可以使用一个字符串参数来表示键值对分区。当写入分区表且分区列不在输出列中时,这是一个必需的参数。分区键的值**不应**加引号。
下表包含 HCatStorer 类的重要方法和描述。
| 序号 | 方法名称及描述 |
|---|---|
| 1 | public OutputFormat getOutputFormat() throws IOException 使用 HCatStorer 类读取存储数据的输出格式。 |
| 2 | public void setStoreLocation (String location, Job job) throws IOException 设置执行此store应用程序的位置。 |
| 3 | public void storeSchema (ResourceSchema schema, String arg1, Job job) throws IOException 存储模式。 |
| 4 | public void prepareToWrite (RecordWriter writer) throws IOException 它有助于使用 RecordWriter 将数据写入特定文件。 |
| 5 | public void putNext (Tuple tuple) throws IOException 将元组数据写入文件。 |
使用 HCatalog 运行 Pig
Pig 不会自动加载 HCatalog jar 包。要引入必要的 jar 包,您可以使用 Pig 命令中的标志,或者设置环境变量PIG_CLASSPATH和PIG_OPTS,如下所述。
要引入用于与 HCatalog 一起工作的适当 jar 包,只需包含以下标志:
pig –useHCatalog <Sample pig scripts file>
设置执行的 CLASSPATH
使用以下 CLASSPATH 设置将 HCatalog 与 Apache Pig 同步。
export HADOOP_HOME = <path_to_hadoop_install> export HIVE_HOME = <path_to_hive_install> export HCAT_HOME = <path_to_hcat_install> export PIG_CLASSPATH = $HCAT_HOME/share/HCatalog/HCatalog-core*.jar:\ $HCAT_HOME/share/HCatalog/HCatalog-pig-adapter*.jar:\ $HIVE_HOME/lib/hive-metastore-*.jar:$HIVE_HOME/lib/libthrift-*.jar:\ $HIVE_HOME/lib/hive-exec-*.jar:$HIVE_HOME/lib/libfb303-*.jar:\ $HIVE_HOME/lib/jdo2-api-*-ec.jar:$HIVE_HOME/conf:$HADOOP_HOME/conf:\ $HIVE_HOME/lib/slf4j-api-*.jar
示例
假设我们在 HDFS 中有一个名为student_details.txt的文件,内容如下所示。
student_details.txt
001, Rajiv, Reddy, 21, 9848022337, Hyderabad 002, siddarth, Battacharya, 22, 9848022338, Kolkata 003, Rajesh, Khanna, 22, 9848022339, Delhi 004, Preethi, Agarwal, 21, 9848022330, Pune 005, Trupthi, Mohanthy, 23, 9848022336, Bhuwaneshwar 006, Archana, Mishra, 23, 9848022335, Chennai 007, Komal, Nayak, 24, 9848022334, trivendram 008, Bharathi, Nambiayar, 24, 9848022333, Chennai
我们还在同一个 HDFS 目录中有一个名为sample_script.pig的示例脚本。此文件包含对student关系执行操作和转换的语句,如下所示。
student = LOAD 'hdfs://:9000/pig_data/student_details.txt' USING
PigStorage(',') as (id:int, firstname:chararray, lastname:chararray,
phone:chararray, city:chararray);
student_order = ORDER student BY age DESC;
STORE student_order INTO 'student_order_table' USING org.apache.HCatalog.pig.HCatStorer();
student_limit = LIMIT student_order 4;
Dump student_limit;
脚本的第一条语句将名为student_details.txt的文件中的数据加载为名为student的关系。
脚本的第二条语句将根据年龄以降序排列关系的元组,并将其存储为student_order。
第三条语句将处理后的数据student_order结果存储在名为student_order_table的单独表中。
脚本的第四条语句将student_order的前四个元组存储为student_limit。
最后,第五条语句将转储关系student_limit的内容。
现在让我们执行sample_script.pig,如下所示。
$./pig -useHCatalog hdfs://:9000/pig_data/sample_script.pig
现在,检查您的输出目录(hdfs: user/tmp/hive)以查看输出(part_0000、part_0001)。