
 数据结构
数据结构 网络
网络 关系型数据库管理系统 (RDBMS)
关系型数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP在Pandas DataFrame中突出显示负值为红色,正值为黑色
数据分析是任何数据科学或分析任务的基本方面,数据探索过程中一个常见的要求是快速识别Pandas DataFrame中的负值和正值,以便有效地进行解释。
在本文中,我们将探讨一种使用Python中的Pandas库的强大技术,以便在DataFrame中直观地突出显示负值为红色,正值为黑色。通过采用这种方法,数据分析师和研究人员可以有效地区分正负趋势,从而有助于深入的数据解释和决策。
如何在Pandas DataFrame中突出显示负值为红色,正值为黑色?
有几种方法可以突出显示Pandas DataFrame中负值为红色,正值为黑色。以下是三种常用的技术
方法一:使用Styler和Styler.applymap()
Pandas中的Styler类允许我们对DataFrame元素应用格式化。我们可以定义一个格式化函数,该函数检查每个值的符号并返回相应的CSS样式。然后,我们可以使用Styler.applymap()方法将此函数应用于DataFrame的每个元素。
方法二:使用Styler和Styler.background_gradient()
Styler.background_gradient()方法根据值对DataFrame应用渐变颜色映射。我们可以指定颜色范围,例如从红色到黑色,并将中点设置为零。此方法将自动分配颜色,负值显示为红色,正值显示为黑色。
方法三:使用numpy.where()
我们可以使用numpy.where()函数创建一个新的DataFrame,其中值根据其符号替换为颜色代码。我们可以为负值分配红色,为正值分配黑色。然后,我们可以以所需的颜色格式显示DataFrame。
我们将使用程序示例来理解这些方法,但首先,让我们看看我们将遵循的步骤
导入必要的库:
导入Pandas用于处理DataFrame。
导入numpy用于处理数值计算。
定义格式化函数:
highlight_values函数以一个值作为输入,并返回用于格式化的CSS样式属性。它检查值是否小于零,如果小于零则返回'color: red',否则返回'color: black'。
gradient_color函数以数据序列作为输入,并使用序列的绝对值计算最大值(norm)。然后,它为序列中的每个元素返回一个CSS背景颜色样式列表,为负值分配“红色”,为正值分配“黑色”。
where_color函数使用numpy.where()创建一个新的DataFrame,其中值根据其符号替换为颜色代码。它为负值分配'color: red',为正值分配'color: black'。
创建一个示例DataFrame:
程序创建一个包含一些数值的示例DataFrame df。
应用格式化方法:
方法一:使用Styler和Styler.applymap():
使用df.style.对DataFrame df进行样式设置。
将applymap()方法应用于样式化的DataFrame,并将highlight_values函数作为参数传递。
将生成的样式化DataFrame保存为名为highlighted_values_method1.xlsx的Excel文件。
方法二:使用Styler和Styler.background_gradient():
使用df.style.对DataFrame df进行样式设置。
将apply()方法应用于样式化的DataFrame,并将gradient_color函数作为参数传递。
将生成的样式化DataFrame保存为名为highlighted_values_method2.xlsx的Excel文件。
方法三:使用numpy.where():
使用df.style.对DataFrame df进行样式设置。
将apply()方法应用于样式化的DataFrame,并将where_color函数作为参数传递。
将生成的样式化DataFrame保存为名为highlighted_values_method3.xlsx的Excel文件。
示例
import pandas as pd
import numpy as np
# Method 1: Using Styler and Styler.applymap()
def highlight_values(x):
if x < 0:
return 'color: red'
else:
return 'color: black'
# Method 2: Using Styler and Styler.background_gradient()
def gradient_color(data):
norm = abs(data.values).max()
return ['background-color: {0}'.format('red' if x < 0 else 'black') for x in data]
# Method 3: Using numpy.where()
def where_color(df):
return np.where(df < 0, 'color: red', 'color: black')
# Create a sample DataFrame
data = {'A': [-2, 4, -1, 5, 0],
'B': [3, -6, 2, 7, -4],
'C': [-3, -2, 1, 6, -5]}
df = pd.DataFrame(data)
# Method 1: Using Styler and Styler.applymap()
styled_df = df.style.applymap(highlight_values)
styled_df.to_excel('highlighted_values_method1.xlsx', engine='openpyxl', index=False)
# Method 2: Using Styler and Styler.background_gradient()
styled_df = df.style.apply(gradient_color)
styled_df.to_excel('highlighted_values_method2.xlsx', engine='openpyxl', index=False)
# Method 3: Using numpy.where()
styled_df = df.style.apply(where_color)
styled_df.to_excel('highlighted_values_method3.xlsx', engine='openpyxl', index=False)
输出
highlighted_values_method1.xlsx:
A B C -2 3 -3 4 -6 -2 -1 2 1 5 7 6 0 -4 -5
highlighted_values_method2.xlsx:
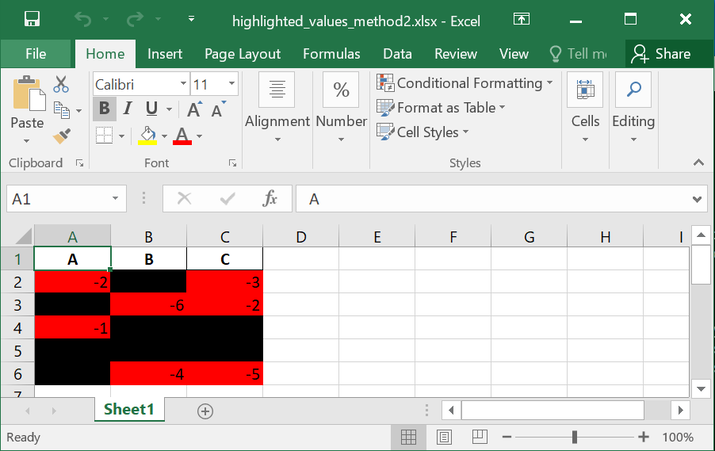
highlighted_values_method3.xlsx:
A B C -2 3 -3 4 -6 -2 -1 2 1 5 7 6 0 -4 -5
结论
总之,使用Pandas中的各种技术,例如Styler类和numpy.where(),我们可以轻松地突出显示DataFrame中负值为红色,正值为黑色。这些方法提供了一种有效的方法来直观地解释数据并识别趋势或异常。

875 次浏览
