
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何在 Pandas DataFrame 中连接列值?
Pandas 是一个功能强大的 Python 数据处理和分析库。它提供各种用于处理和转换数据的函数和工具,包括连接 Pandas DataFrame 中列值的功能。
在 Pandas DataFrame 中,列表示数据的变量或特征。连接列值涉及将两列或多列的值组合成一列。这对于创建新变量、合并来自不同来源的数据或格式化用于分析的数据很有用。
要连接 Pandas DataFrame 中的列值,可以使用 pd.Series.str.cat() 方法。此方法沿特定轴使用指定的间隔符连接两个或多个序列。str.cat() 方法可以与 apply() 函数一起使用,将其应用于 DataFrame 的每一行。
Pandas 中还有其他几种方法和函数可用于连接列值,包括 pd.concat() 函数、pd.Series.str.join() 方法以及使用不同分隔符或字符串的 pd.Series.str.cat() 方法。每种方法都有其自身的优缺点,具体取决于具体的用例。
在本教程中,我们将探讨 Pandas 中可用于连接 DataFrame 中列值的各种方法和函数。我们将为每种方法提供分步说明和代码示例,以及对每种方法的优缺点进行讨论。在本教程结束时,您将全面了解如何在 Pandas DataFrame 中连接列值,以及哪种方法最适合您的特定用例。
现在让我们考虑两种可以在 Panda 数据框中连接列值的方法。
使用 pd.Series.str.cat() 方法连接列值
在您的 DataFrame 中创建一个新列来存储连接的值。
使用 pd.Series.str.cat() 方法连接要组合的列的值。
使用“sep”参数指定要在连接的值之间使用的分隔符。
使用 apply() 方法将连接函数应用于 DataFrame 的每一行。
现在我们已经用要点讨论了这种方法,让我们在代码中使用它。
示例
请考虑以下所示的代码。
import pandas as pd
from tabulate import tabulate
# Create a sample DataFrame
df = pd.DataFrame({
'Name': ['John', 'Jane', 'Bob'],
'Age': [25, 30, 35],
'Country': ['USA', 'Canada', 'Mexico']
})
# Create a new column for concatenated values
df['Name_Age_Country'] = ''
# Define a function to concatenate the columns
def concatenate_columns(row):
"""
Concatenate the values in the 'Name', 'Age',
and 'Country' columns with a separator of '|'.
"""
return row['Name'] + '|' + str(row['Age']) + '|' + row['Country']
# Apply the function to each row of the DataFrame
df['Name_Age_Country'] = df.apply(concatenate_columns, axis=1)
# Print the original DataFrame and the concatenated DataFrame
print('Original DataFrame:\n')
print(tabulate(df[['Name', 'Age', 'Country']], headers='keys', tablefmt='psql'))
print('\nConcatenated DataFrame:\n')
print(tabulate(df[['Name_Age_Country']], headers='keys', tablefmt='psql'))
输出
执行此代码后,您将获得以下输出 -
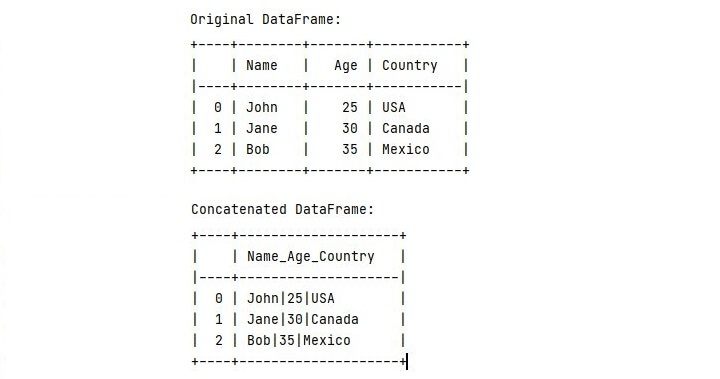
观察原始数据框以及我们连接列后的外观。现在让我们考虑第二种方法。
使用 pd.concat() 方法连接列值
首先创建一个要连接的列列表。
使用 pd.concat() 函数沿您选择的轴(即列或行)连接列。
使用 sep 参数指定要在连接的值之间使用的分隔符。
使用 rename() 方法重命名新的连接列。
使用 drop() 方法删除最初连接的列。
示例
请考虑以下所示的代码。
import pandas as pd
from tabulate import tabulate
# Create a sample DataFrame
df = pd.DataFrame({
'Name': ['John', 'Jane', 'Bob'],
'Age': [25, 30, 35],
'Country': ['USA', 'Canada', 'Mexico']
})
print("\nOriginal Dataframe:")
print(tabulate(df, headers='keys', tablefmt='psql'))
# Concatenate the columns using the pd.concat() function
concatenated_cols = pd.concat(
[df['Name'], df['Age'], df['Country']],
axis=1, keys=['Name', 'Age', 'Country']
)
concatenated_cols['Name_Age_Country'] = concatenated_cols['Name'] + '|' + concatenated_cols['Age'].astype(str) + '|' + concatenated_cols['Country']
# Rename the concatenated column and drop the original columns
df = pd.concat([df, concatenated_cols['Name_Age_Country']], axis=1)
df = df.rename(columns={'Name_Age_Country': 'Name|Age|Country'})
df = df.drop(columns=['Name', 'Age', 'Country'])
# Print the original DataFrame and the concatenated DataFrame
print('\nConcatenated Dataframe:')
print(tabulate(df, headers='keys', tablefmt='psql'))
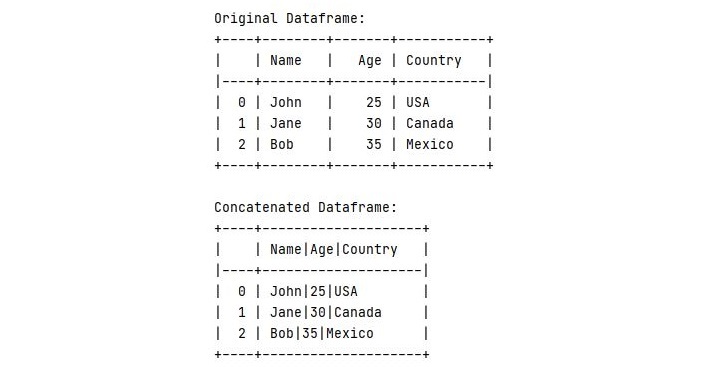
输出
执行此代码后,您将获得以下输出 -
结论
总之,Pandas 提供了几种连接 DataFrame 中列值的方法。在本教程中讨论了两种方法:使用 pd.Series.str.cat() 方法和使用 pd.concat() 函数。
根据您的具体用例,其中一种方法可能比另一种方法更合适。通过利用 Pandas 的灵活性和强大功能,您可以轻松地操作和转换数据以满足您的需求。

6K+ 次查看
