
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用 TensorFlow 对 Auto MPG 数据集进行预测?
Tensorflow 是 Google 提供的一个机器学习框架。它是一个开源框架,与 Python 结合使用以实现算法、深度学习应用程序等等。它用于研究和生产目的。
张量是 TensorFlow 中使用的数据结构。它有助于连接流图中的边。此流图称为“数据流图”。张量只不过是多维数组或列表。它们可以通过三个主要属性来识别
秩 - 它告诉张量的维数。可以理解为张量的阶数或已定义的张量中的维数。
类型 - 它告诉张量元素关联的数据类型。它可以是一维、二维或 n 维张量。
形状 - 它是行数和列数的总和。
回归问题的目的是预测连续或离散变量的输出,例如价格、概率、是否会下雨等等。
我们使用的数据集称为“Auto MPG”数据集。它包含 1970 年代和 1980 年代汽车的燃油效率。它包括重量、马力、排量等属性。有了这些,我们需要预测特定车辆的燃油效率。
我们使用 Google Colaboratory 来运行以下代码。Google Colab 或 Colaboratory 帮助在浏览器上运行 Python 代码,无需任何配置,并且可以免费访问 GPU(图形处理单元)。Colaboratory 建立在 Jupyter Notebook 之上。以下是代码片段 -
示例
print("Predictions being viewed as a function of input variable")
x = tf.linspace(0.0, 250, 251)
y = hrspwr_model.predict(x)
def plot_horsepower(x, y):
plt.scatter(train_features['Horsepower'], train_labels, label='Actual Values')
plt.plot(x, y, color='g', label='Prediction')
plt.xlabel('Horsepower')
plt.ylabel('MPG')
plt.legend()
plot_horsepower(x,y)代码来源 - https://tensorflowcn.cn/tutorials/keras/regression
输出
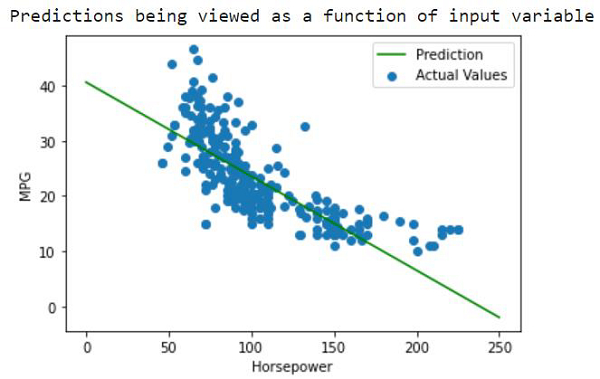
解释
对“MPG”进行预测。
使用“matplotlib”绘制实际值和预测值。
将模型的预测视为输入数据的函数。

更新于: 2021年1月20日
105 次查看

广告