
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何在Python中执行F检验
统计学家使用F检验来检查两个数据集是否具有相同的方差。F检验以罗纳德·费希尔爵士命名。要使用F检验,我们提出两个假设,一个零假设和一个备择假设。然后,我们选择F检验批准的这两个假设中的任何一个。
方差是数据分布度量,用于说明数据偏离均值的程度。较高的值表示比较低值更大的离散度。
在本文中,您将学习如何在Python编程语言中执行F检验及其用例。
F检验过程
执行F检验的过程如下:
首先,定义零假设和备择假设。
零假设或H0:σ12 = σ22(总体方差相等)
备择假设或H1:σ12 ≠ σ22(总体方差不相等)
选择用于检验的统计量。
计算总体的自由度。例如,如果m和n是总体样本大小,则自由度分别表示为(df1) = m–1 和 (df2) = n – 1。
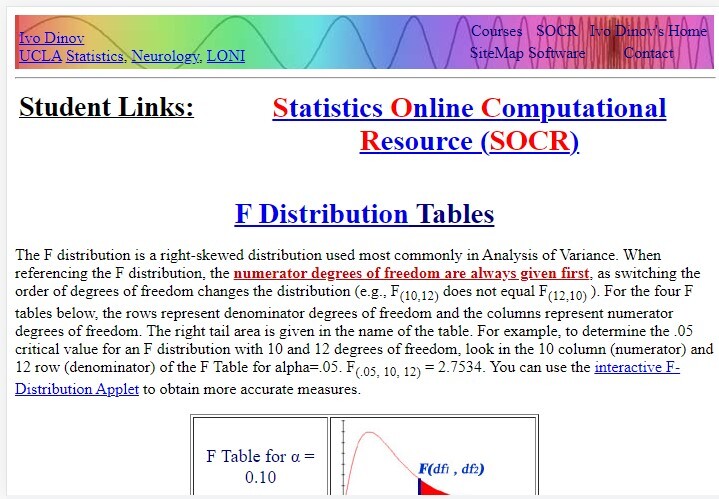
现在从F分布表中查找F值。
最后,将alpha值除以2(用于双尾检验)以计算临界值。
因此,我们使用总体的自由度来定义F值。我们在第一行读取df1,在第一列读取df2。
对于不同类型的自由度,有各种F表。我们将步骤2中计算的F统计量与步骤4中计算的临界值进行比较。如果临界值小于F统计量,则可以拒绝零假设。相反,如果在某个显著性水平下临界值大于F统计量,则可以接受零假设。
假设
在根据数据集执行F检验之前,我们做一些假设。
数据总体服从正态分布,即符合钟形曲线。
样本彼此不相关,即总体中不存在多重共线性。
除了这些假设之外,在执行F检验时,我们还应该考虑以下关键点:
要执行右尾检验,最大方差值应位于分子中。
在双尾检验的情况下,将alpha值除以2后确定临界值。
检查您是否有方差或标准差。
如果F表中没有自由度,则使用最大值作为临界值。
Python中的F检验
语法
scipy stats.f()
参数
x : quantiles q : lower or upper tail probability dfn, dfd shape parameters loc :location parameter scale : scale parameter (default=1) size : random variate shape moments : [‘mvsk’] letters, specifying which moments to compute
解释
在此方法中,用户必须将f值和每个数组的可迭代长度传递到scipy.stats.f.cdf()中,并将其与1相减以执行F检验。
算法
首先,导入NumPy和Scipy.stats库进行操作。
然后创建两个具有两个不同变量名的随机值列表,并将它们转换为NumPy数组,并使用Numpy计算每个数组的方差。
定义一个函数来计算F分数,首先我们将数组的方差除以自由度为1。
然后计算每个数组的可迭代长度,并将f值(方差比)和长度传递给CDF函数,并从1中减去该值以计算p值。
最后,函数返回p值和f值。
示例
import numpy as np import scipy.stats # Create data group1 = [0.28, 0.2, 0.26, 0.28, 0.5] group2 = [0.2, 0.23, 0.26, 0.21, 0.23] # Converting the list to an array x = np.array(group1) y = np.array(group2) # Calculate the variance of each group print(np.var(group1), np.var(group2)) def f_test(group1, group2): f = np.var(group1, ddof=1)/np.var(group2, ddof=1) nun = x.size-1 dun = y.size-1 p_value = 1-scipy.stats.f.cdf(f, nun, dun) return f, p_value # perform F-test f_test(x, y)
输出
Variances: 0.010464 0.00042400000000000017
您可以观察到F检验值为4.38712,相应的p值为0.019127。
由于p值小于.05,我们将放弃零假设。因此,我们可以说这两个总体方差不相等。
结论
阅读本文后,您现在知道了如何使用F检验来检查两个样本是否属于具有相同方差的总体。您学习了F检验的过程、假设和Python实现。让我们总结一下本文的一些要点:
F检验告诉您两个总体方差是否相等。
计算自由度并计算临界值。
从F表中找到F统计量,并将其与上一步中计算的临界值进行比较。
根据临界值和F统计量的比较结果,接受或拒绝零假设。

4K+ 次浏览
