- HSQLDB 教程
- HSQLDB - 首页
- HSQLDB - 简介
- HSQLDB - 安装
- HSQLDB - 连接
- HSQLDB - 数据类型
- HSQLDB - 创建表
- HSQLDB - 删除表
- HSQLDB - 插入查询
- HSQLDB - 选择查询
- HSQLDB - WHERE 子句
- HSQLDB - 更新查询
- HSQLDB - DELETE 子句
- HSQLDB - LIKE 子句
- HSQLDB - 排序结果
- HSQLDB - 连接
- HSQLDB - 空值
- HSQLDB - 正则表达式
- HSQLDB - 事务
- HSQLDB - ALTER 命令
- HSQLDB - 索引
- HSQLDB 有用资源
- HSQLDB 快速指南
- HSQLDB - 有用资源
- HSQLDB - 讨论
HSQLDB 快速指南
HSQLDB - 简介
HyperSQL 数据库 (HSQLDB) 是一款现代的关系数据库管理系统,严格遵循 SQL:2011 标准和 JDBC 4 规范。它支持所有核心功能和 RDBMS。HSQLDB 用于数据库应用程序的开发、测试和部署。
HSQLDB 的主要和独特功能是标准合规性。它可以在用户应用程序进程内、应用程序服务器内或作为单独的服务器进程提供数据库访问。
HSQLDB 的特性
HSQLDB 使用内存结构来对 DB 服务器进行快速操作。它根据用户灵活性的要求使用磁盘持久性,并具有可靠的崩溃恢复功能。
HSQLDB 也适用于商业智能、ETL 和处理大型数据集的其他应用程序。
HSQLDB 拥有广泛的企业部署选项,例如 XA 事务、连接池数据源和远程身份验证。
HSQLDB 使用 Java 编程语言编写,并在 Java 虚拟机 (JVM) 中运行。它支持 JDBC 接口进行数据库访问。
HSQLDB 的组件
HSQLDB jar 包中有三个不同的组件。
HyperSQL RDBMS 引擎 (HSQLDB)
HyperSQL JDBC 驱动程序
数据库管理器(带 Swing 和 AWT 版本的 GUI 数据库访问工具)
HyperSQL RDBMS 和 JDBC 驱动程序提供核心功能。数据库管理器是通用数据库访问工具,可用于任何具有 JDBC 驱动程序的数据库引擎。
一个名为 sqltool.jar 的附加 jar 包含 Sql 工具,这是一个命令行数据库访问工具。这是一个通用的命令。行数据库访问工具,也可用于其他数据库引擎。
HSQlDB - 安装
HSQLDB 是一个用纯 Java 实现的关系数据库管理系统。您可以使用 JDBC 将此数据库轻松嵌入到您的应用程序中。或者您可以单独使用这些操作。
先决条件
请按照 HSQLDB 的先决条件软件安装步骤进行操作。
验证 Java 安装
由于 HSQLDB 是一个用纯 Java 实现的关系数据库管理系统,因此在安装 HSQLDB 之前必须安装 JDK(Java 开发工具包)软件。如果您的系统中已安装 JDK,请尝试使用以下命令验证 Java 版本。
java –version
如果 JDK 成功安装在您的系统中,您将获得以下输出。
java version "1.8.0_91" Java(TM) SE Runtime Environment (build 1.8.0_91-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
如果您的系统中未安装 JDK,请访问以下链接以 安装 JDK。
HSQLDB 安装
以下是安装 HSQLDB 的步骤。
步骤 1 - 下载 HSQLDB 捆绑包
从以下链接下载最新版本的 HSQLDB 数据库 https://sourceforge.net/projects/hsqldb/files/. 单击链接后,您将看到以下屏幕截图。
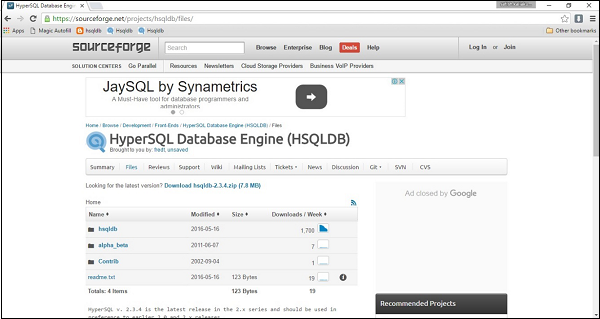
单击 HSQLDB,下载将立即开始。最后,您将获得名为 hsqldb-2.3.4.zip 的 zip 文件。
步骤 2 - 解压缩 HSQLDB zip 文件
解压缩 zip 文件并将其放置到 C:\ 目录中。解压缩后,您将获得以下屏幕截图所示的文件结构。
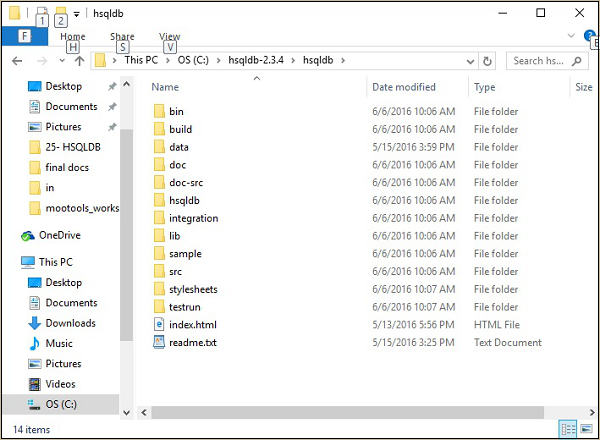
步骤 3 - 创建默认数据库
HSQLDB 没有默认数据库,因此您需要为 HSQLDB 创建一个数据库。让我们创建一个名为 server.properties 的属性文件,该文件定义一个名为 demodb 的新数据库。请查看以下数据库服务器属性。
server.database.0 = file:hsqldb/demodb server.dbname.0 = testdb
将此 server.properties 文件放置到 HSQLDB 主目录中,即 C:\hsqldb- 2.3.4\hsqldb\。
现在在命令提示符下执行以下命令。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server
执行上述命令后,您将收到以下屏幕截图所示的服务器状态。
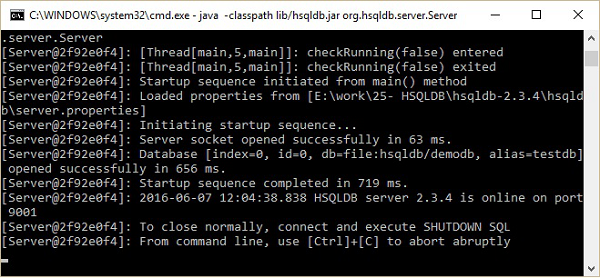
稍后,您将在 HSQLDB 主目录(即 C:\hsqldb-2.3.4\hsqldb)中找到 hsqldb 目录的以下文件夹结构。这些文件是 HSQLDB 数据库服务器创建的 demodb 数据库的临时文件、lck 文件、日志文件、属性文件和脚本文件。
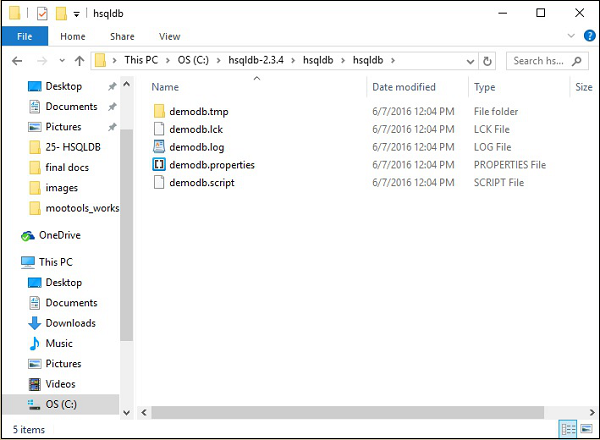
步骤 4 - 启动数据库服务器
创建数据库后,必须使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
执行上述命令后,您将获得以下状态。
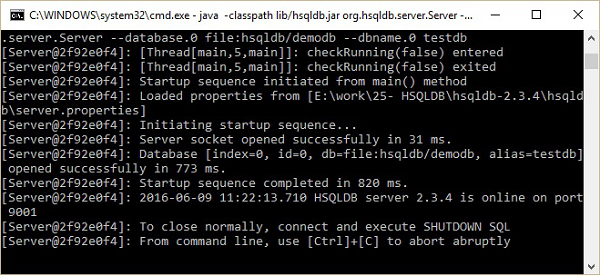
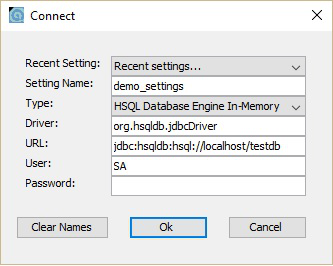
现在,您可以打开数据库主屏幕,即 C:\hsqldb-2.3.4\hsqldb\bin 位置中的 runManagerSwing.bat。此 bat 文件将打开 HSQLDB 数据库的 GUI 文件。在此之前,它将通过对话框询问您数据库设置。请查看以下屏幕截图。在此对话框中,输入设置名称,URL 如上所示,然后单击确定。
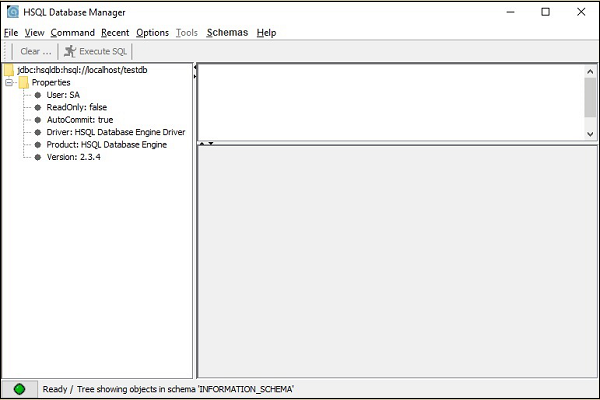
您将获得 HSQLDB 数据库的 GUI 屏幕,如以下屏幕截图所示。
HSQlDB - 连接
在安装章节中,我们讨论了如何手动连接数据库。在本节中,我们将讨论如何以编程方式(使用 Java 编程)连接数据库。
请查看以下程序,它将启动服务器并在 Java 应用程序和数据库之间建立连接。
示例
import java.sql.Connection;
import java.sql.DriverManager;
public class ConnectDatabase {
public static void main(String[] args) {
Connection con = null;
try {
//Registering the HSQLDB JDBC driver
Class.forName("org.hsqldb.jdbc.JDBCDriver");
//Creating the connection with HSQLDB
con = DriverManager.getConnection("jdbc:hsqldb:hsql:///testdb", "SA", "");
if (con!= null){
System.out.println("Connection created successfully");
}else{
System.out.println("Problem with creating connection");
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
将此代码保存到 ConnectDatabase.java 文件中。您将必须使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
您可以使用以下命令编译和执行代码。
\>javac ConnectDatabase.java \>java ConnectDatabase
执行上述命令后,您将收到以下输出 -
Connection created successfully
HSQLDB - 数据类型
本章介绍了 HSQLDB 的不同数据类型。HSQLDB 服务器提供了六类数据类型。
精确数值数据类型
| 数据类型 | 从 | 到 |
|---|---|---|
| bigint | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
| int | -2,147,483,648 | 2,147,483,647 |
| smallint | -32,768 | 32,767 |
| tinyint | 0 | 255 |
| bit | 0 | 1 |
| decimal | -10^38 +1 | 10^38 -1 |
| numeric | -10^38 +1 | 10^38 -1 |
| money | -922,337,203,685,477.5808 | +922,337,203,685,477.5807 |
| smallmoney | -214,748.3648 | +214,748.3647 |
近似数值数据类型
| 数据类型 | 从 | 到 |
|---|---|---|
| float | -1.79E + 308 | 1.79E + 308 |
| real | -3.40E + 38 | 3.40E + 38 |
日期和时间数据类型
| 数据类型 | 从 | 到 |
|---|---|---|
| datetime | 1753 年 1 月 1 日 | 9999 年 12 月 31 日 |
| smalldatetime | 1900 年 1 月 1 日 | 2079 年 6 月 6 日 |
| date | 存储日期,例如 1991 年 6 月 30 日 | |
| time | 存储一天中的时间,例如下午 12:30。 | |
注意 - 在这里,datetime 的精度为 3.33 毫秒,而 small datetime 的精度为 1 分钟。
字符字符串数据类型
| 数据类型 | 描述 |
|---|---|
| char | 最大长度为 8,000 个字符(固定长度非 Unicode 字符) |
| varchar | 最大 8,000 个字符(可变长度非 Unicode 数据) |
| varchar(max) | 最大长度为 231 个字符,可变长度非 Unicode 数据(仅限 SQL Server 2005) |
| text | 可变长度非 Unicode 数据,最大长度为 2,147,483,647 个字符 |
Unicode 字符串数据类型
| 数据类型 | 描述 |
|---|---|
| nchar | 最大长度为 4,000 个字符(固定长度 Unicode) |
| nvarchar | 最大长度为 4,000 个字符(可变长度 Unicode) |
| nvarchar(max) | 最大长度为 231 个字符(仅限 SQL Server 2005),(可变长度 Unicode) |
| ntext | 最大长度为 1,073,741,823 个字符(可变长度 Unicode) |
二进制数据类型
| 数据类型 | 描述 |
|---|---|
| binary | 最大长度为 8,000 字节(固定长度二进制数据) |
| varbinary | 最大长度为 8,000 字节(可变长度二进制数据) |
| varbinary(max) | 最大长度为 231 字节(仅限 SQL Server 2005),(可变长度二进制数据) |
| image | 最大长度为 2,147,483,647 字节(可变长度二进制数据) |
其他数据类型
| 数据类型 | 描述 |
|---|---|
| sql_variant | 存储各种 SQL Server 支持的数据类型的值,除了 text、ntext 和 timestamp |
| timestamp | 存储数据库范围内的唯一编号,每次更新行时都会更新 |
| uniqueidentifier | 存储全局唯一标识符 (GUID) |
| xml | 存储 XML 数据。您可以将 xml 实例存储在列或变量中(仅限 SQL Server 2005) |
| cursor | 对游标对象的引用 |
| table | 存储结果集以供以后处理 |
HSQLDB - 创建表
创建表的必要基本要求是表名、字段名以及这些字段的数据类型。可以选择地,您还可以为表提供键约束。
语法
请查看以下语法。
CREATE TABLE table_name (column_name column_type);
示例
让我们创建一个名为 tutorials_tbl 的表,其字段名称为 id、title、author 和 submission_date。请查看以下查询。
CREATE TABLE tutorials_tbl ( id INT NOT NULL, title VARCHAR(50) NOT NULL, author VARCHAR(20) NOT NULL, submission_date DATE, PRIMARY KEY (id) );
执行上述查询后,您将收到以下输出 -
(0) rows effected
HSQLDB – JDBC 程序
以下是用于在 HSQLDB 数据库中创建名为 tutorials_tbl 的表的 JDBC 程序。将程序保存到 CreateTable.java 文件中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class CreateTable {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection("jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("CREATE TABLE tutorials_tbl (
id INT NOT NULL, title VARCHAR(50) NOT NULL,
author VARCHAR(20) NOT NULL, submission_date DATE,
PRIMARY KEY (id));
");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println("Table created successfully");
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac CreateTable.java \>java CreateTable
执行上述命令后,您将收到以下输出 -
Table created successfully
HSQLDB - 删除表
删除现有的 HSQLDB 表非常容易。但是,在删除任何现有表时,您需要非常小心,因为删除表后,任何丢失的数据都将无法恢复。
语法
以下是删除 HSQLDB 表的通用 SQL 语法。
DROP TABLE table_name;
示例
让我们考虑一个从 HSQLDB 服务器删除名为 employee 的表的示例。以下是删除名为 employee 的表的查询。
DROP TABLE employee;
执行上述查询后,您将收到以下输出 -
(0) rows effected
HSQLDB – JDBC 程序
以下是用于从 HSQLDB 服务器删除 employee 表的 JDBC 程序。
将以下代码保存到 DropTable.java 文件中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DropTable {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection("jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("DROP TABLE employee");
}catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println("Table dropped successfully");
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac DropTable.java \>java DropTable
执行上述命令后,您将收到以下输出 -
Table dropped successfully
HSQLDB - 插入查询
您可以通过使用 INSERT INTO 命令在 HSQLDB 中实现 Insert 查询语句。您必须按照表中列字段的顺序提供用户定义的数据。
语法
以下是INSERT 查询的通用语法。
INSERT INTO table_name (field1, field2,...fieldN) VALUES (value1, value2,...valueN );
要将字符串类型数据插入表中,您必须使用双引号或单引号在插入查询语句中提供字符串值。
示例
让我们考虑一个将记录插入名为 tutorials_tbl 的表的示例,其值为 id = 100、title = Learn PHP、Author = John Poul,提交日期为当前日期。
以下是给定示例的查询。
INSERT INTO tutorials_tbl VALUES (100,'Learn PHP', 'John Poul', NOW());
执行上述查询后,您将收到以下输出 -
1 row effected
HSQLDB – JDBC 程序
这是一个使用 JDBC 程序将记录插入到表中的示例,给定的值包括:id=100,title=Learn PHP,Author=John Poul,提交日期为当前日期。请查看以下程序,并将代码保存到InserQuery.java文件中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class InsertQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("INSERT INTO tutorials_tbl
VALUES (100,'Learn PHP', 'John Poul', NOW())");
con.commit();
}catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" rows effected");
System.out.println("Rows inserted successfully");
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac InsertQuery.java \>java InsertQuery
执行上述命令后,您将收到以下输出 -
1 rows effected Rows inserted successfully
尝试使用INSERT INTO命令将以下记录插入到tutorials_tbl表中。
| Id | 标题 | 作者 | 提交日期 |
|---|---|---|---|
| 101 | Learn C | Yaswanth | Now() |
| 102 | Learn MySQL | Abdul S | Now() |
| 103 | Learn Excell | Bavya kanna | Now() |
| 104 | Learn JDB | Ajith kumar | Now() |
| 105 | Learn Junit | Sathya Murthi | Now() |
HSQLDB - 选择查询
SELECT 命令用于从 HSQLDB 数据库中获取记录数据。在这里,您需要在 Select 语句中指定所需的字段列表。
语法
以下是 Select 查询的通用语法。
SELECT field1, field2,...fieldN table_name1, table_name2... [WHERE Clause] [OFFSET M ][LIMIT N]
您可以在单个 SELECT 命令中获取一个或多个字段。
您可以使用星号 (*) 代替字段。在这种情况下,SELECT 将返回所有字段。
您可以使用 WHERE 子句指定任何条件。
您可以使用 OFFSET 指定 SELECT 从哪里开始返回记录的偏移量。默认情况下,偏移量为零。
您可以使用 LIMIT 属性限制返回的数量。
示例
以下是一个从tutorials_tbl表中获取所有记录的 id、title 和 author 字段的示例。我们可以使用 SELECT 语句实现这一点。以下是该示例的查询。
SELECT id, title, author FROM tutorials_tbl
执行上述查询后,您将收到以下输出。
+------+----------------+-----------------+ | id | title | author | +------+----------------+-----------------+ | 100 | Learn PHP | John Poul | | 101 | Learn C | Yaswanth | | 102 | Learn MySQL | Abdul S | | 103 | Learn Excell | Bavya kanna | | 104 | Learn JDB | Ajith kumar | | 105 | Learn Junit | Sathya Murthi | +------+----------------+-----------------+
HSQLDB – JDBC 程序
以下是一个 JDBC 程序,它将从tutorials_tbl表中获取所有记录的 id、title 和 author 字段。将以下代码保存到SelectQuery.java文件中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class SelectQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author FROM tutorials_tbl");
while(result.next()){
System.out.println(result.getInt("id")+" | "+
result.getString("title")+" | "+
result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述代码。
\>javac SelectQuery.java \>java SelectQuery
执行上述命令后,您将收到以下输出 -
100 | Learn PHP | John Poul 101 | Learn C | Yaswanth 102 | Learn MySQL | Abdul S 103 | Learn Excell | Bavya Kanna 104 | Learn JDB | Ajith kumar 105 | Learn Junit | Sathya Murthi
HSQLDB - WHERE 子句
通常,我们使用 SELECT 命令从 HSQLDB 表中获取数据。我们可以使用 WHERE 条件子句过滤结果数据。使用 WHERE,我们可以指定选择条件来从表中选择所需的记录。
语法
以下是使用 SELECT 命令 WHERE 子句从 HSQLDB 表中获取数据的语法。
SELECT field1, field2,...fieldN table_name1, table_name2... [WHERE condition1 [AND [OR]] condition2.....
您可以使用逗号分隔一个或多个表,以使用 WHERE 子句包含各种条件,但 WHERE 子句是 SELECT 命令的可选部分。
您可以使用 WHERE 子句指定任何条件。
您可以使用 AND 或 OR 运算符指定多个条件。
WHERE 子句也可以与 DELETE 或 UPDATE SQL 命令一起使用以指定条件。
我们可以使用条件过滤记录数据。我们在条件 WHERE 子句中使用不同的运算符。以下是可与 WHERE 子句一起使用的运算符列表。
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 检查两个操作数的值是否相等,如果相等,则条件为真。 | (A = B) 不为真 |
| != | 检查两个操作数的值是否相等,如果值不相等,则条件为真。 | (A != B) 为真 |
| > | 检查左操作数的值是否大于右操作数的值,如果大于,则条件为真。 | (A > B) 不为真 |
| < | 检查左操作数的值是否小于右操作数的值,如果小于,则条件为真。 | (A < B) 为真 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果大于或等于,则条件为真。 | (A >= B) 不为真 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果小于或等于,则条件为真。 | (A <= B) 为真 |
示例
以下是一个检索书籍标题为“Learn C”的详细信息(例如 id、title 和 author)的示例。这可以通过在 SELECT 命令中使用 WHERE 子句来实现。以下是相同的查询。
SELECT id, title, author FROM tutorials_tbl WHERE title = 'Learn C';
执行上述查询后,您将收到以下输出。
+------+----------------+-----------------+ | id | title | author | +------+----------------+-----------------+ | 101 | Learn C | Yaswanth | +------+----------------+-----------------+
HSQLDB – JDBC 程序
以下是一个 JDBC 程序,它从名为 tutorials_tbl 的表中检索标题为Learn C的记录数据。将以下代码保存到WhereClause.java中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class WhereClause {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author FROM tutorials_tbl
WHERE title = 'Learn C'");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述代码。
\>javac WhereClause.java \>java WhereClause
执行上述命令后,您将收到以下输出。
101 | Learn C | Yaswanth
HSQLDB - 更新查询
每当您想要修改表的的值时,都可以使用 UPDATE 命令。这将修改任何 HSQLDB 表中的任何字段值。
语法
以下是 UPDATE 命令的通用语法。
UPDATE table_name SET field1 = new-value1, field2 = new-value2 [WHERE Clause]
- 您可以同时更新一个或多个字段。
- 您可以使用 WHERE 子句指定任何条件。
- 您可以一次更新单个表中的值。
示例
让我们考虑一个将教程的标题从“Learn C”更新为“C and Data Structures”且 id 为“101”的示例。以下是更新查询。
UPDATE tutorials_tbl SET title = 'C and Data Structures' WHERE id = 101;
执行上述查询后,您将收到以下输出。
(1) Rows effected
HSQLDB – JDBC 程序
以下是一个 JDBC 程序,它将 id 为101的教程标题从Learn C更新为C and Data Structures。将以下程序保存到UpdateQuery.java文件中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class UpdateQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate(
"UPDATE tutorials_tbl SET title = 'C and Data Structures' WHERE id = 101");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" Rows effected");
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac UpdateQuery.java \>java UpdateQuery
执行上述命令后,您将收到以下输出 -
1 Rows effected
HSQLDB - DELETE 子句
每当您想要从任何 HSQLDB 表中删除记录时,都可以使用 DELETE FROM 命令。
语法
以下是用于从 HSQLDB 表中删除数据的 DELETE 命令的通用语法。
DELETE FROM table_name [WHERE Clause]
如果未指定 WHERE 子句,则将从给定的 MySQL 表中删除所有记录。
您可以使用 WHERE 子句指定任何条件。
您可以一次删除单个表中的记录。
示例
让我们考虑一个从名为tutorials_tbl的表中删除 id 为105的记录数据的示例。以下是实现给定示例的查询。
DELETE FROM tutorials_tbl WHERE id = 105;
执行上述查询后,您将收到以下输出 -
(1) rows effected
HSQLDB – JDBC 程序
以下是一个实现给定示例的 JDBC 程序。将以下程序保存到DeleteQuery.java中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DeleteQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate(
"DELETE FROM tutorials_tbl WHERE id=105");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" Rows effected");
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac DeleteQuery.java \>java DeleteQuery
执行上述命令后,您将收到以下输出 -
1 Rows effected
HSQLDB - LIKE 子句
RDBMS 结构中有一个 WHERE 子句。您可以将 WHERE 子句与等号 (=) 一起使用,在需要进行精确匹配时使用。但可能存在需要过滤所有作者姓名包含“john”的结果的情况。这可以使用 SQL LIKE 子句以及 WHERE 子句来处理。
如果 SQL LIKE 子句与 % 字符一起使用,那么它在列出命令提示符下所有文件或目录时将类似于 UNIX 中的通配符 (*)。
语法
以下是 LIKE 子句的通用 SQL 语法。
SELECT field1, field2,...fieldN table_name1, table_name2... WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue'
您可以使用 WHERE 子句指定任何条件。
您可以将 LIKE 子句与 WHERE 子句一起使用。
您可以将 LIKE 子句替换为等号。
当 LIKE 子句与 % 符号一起使用时,它将类似于元字符搜索。
您可以使用 AND 或 OR 运算符指定多个条件。
WHERE...LIKE 子句可以与 DELETE 或 UPDATE SQL 命令一起使用以指定条件。
示例
让我们考虑一个检索作者姓名以John开头的教程数据列表的示例。以下是给定示例的 HSQLDB 查询。
SELECT * from tutorials_tbl WHERE author LIKE 'John%';
执行上述查询后,您将收到以下输出。
+-----+----------------+-----------+-----------------+ | id | title | author | submission_date | +-----+----------------+-----------+-----------------+ | 100 | Learn PHP | John Poul | 2016-06-20 | +-----+----------------+-----------+-----------------+
HSQLDB – JDBC 程序
以下是一个 JDBC 程序,它检索作者姓名以John开头的教程数据列表。将代码保存到LikeClause.java中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class LikeClause {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT * from tutorials_tbl WHERE author LIKE 'John%';");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author")+" |
"+result.getDate("submission_date"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述代码。
\>javac LikeClause.java \>java LikeClause
执行以下命令后,您将收到以下输出。
100 | Learn PHP | John Poul | 2016-06-20
HSQLDB - 排序结果
每当需要按照特定顺序检索和显示记录时,SQL SELECT 命令都会从 HSQLDB 表中获取数据。在这种情况下,我们可以使用ORDER BY子句。
语法
以下是使用 ORDER BY 子句对 HSQLDB 中的数据进行排序的 SELECT 命令的语法。
SELECT field1, field2,...fieldN table_name1, table_name2... ORDER BY field1, [field2...] [ASC [DESC]]
您可以对返回的结果中的任何字段进行排序,前提是该字段已列出。
您可以对多个字段进行排序。
您可以使用关键字 ASC 或 DESC 以升序或降序获取结果。默认情况下,它是升序。
您可以像往常一样使用 WHERE...LIKE 子句来设置条件。
示例
让我们考虑一个获取并对tutorials_tbl表中的记录进行排序的示例,方法是按升序对作者姓名进行排序。以下是相同的查询。
SELECT id, title, author from tutorials_tbl ORDER BY author ASC;
执行上述查询后,您将收到以下输出。
+------+----------------+-----------------+ | id | title | author | +------+----------------+-----------------+ | 102 | Learn MySQL | Abdul S | | 104 | Learn JDB | Ajith kumar | | 103 | Learn Excell | Bavya kanna | | 100 | Learn PHP | John Poul | | 105 | Learn Junit | Sathya Murthi | | 101 | Learn C | Yaswanth | +------+----------------+-----------------+
HSQLDB – JDBC 程序
以下是一个 JDBC 程序,它获取并对tutorials_tbl表中的记录进行排序,方法是按升序对作者姓名进行排序。将以下程序保存到OrderBy.java中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class OrderBy {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author from tutorials_tbl
ORDER BY author ASC");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac OrderBy.java \>java OrderBy
执行上述命令后,您将收到以下输出。
102 | Learn MySQL | Abdul S 104 | Learn JDB | Ajith kumar 103 | Learn Excell | Bavya Kanna 100 | Learn PHP | John Poul 105 | Learn Junit | Sathya Murthi 101 | C and Data Structures | Yaswanth
HSQLDB - 连接
每当需要使用单个查询从多个表中检索数据时,您可以使用 RDBMS 中的连接。您可以在单个 SQL 查询中使用多个表。HSQLDB 中的连接行为是指将两个或多个表合并成一个表。
请考虑以下 Customers 和 Orders 表。
Customer: +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+ Orders: +-----+---------------------+-------------+--------+ |OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
现在,让我们尝试检索客户的数据以及相应客户下的订单金额。这意味着我们正在从 Customers 和 Orders 表中检索记录数据。我们可以通过在 HSQLDB 中使用连接的概念来实现这一点。以下是相同的连接查询。
SELECT ID, NAME, AGE, AMOUNT FROM CUSTOMERS, ORDERS WHERE CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
执行上述查询后,您将收到以下输出。
+----+----------+-----+--------+ | ID | NAME | AGE | AMOUNT | +----+----------+-----+--------+ | 3 | kaushik | 23 | 3000 | | 3 | kaushik | 23 | 1500 | | 2 | Khilan | 25 | 1560 | | 4 | Chaitali | 25 | 2060 | +----+----------+-----+--------+
连接类型
HSQLDB 中有不同类型的连接可用。
INNER JOIN − 当两个表中都存在匹配项时返回行。
LEFT JOIN − 返回左侧表中的所有行,即使右侧表中不存在匹配项。
RIGHT JOIN − 返回右侧表中的所有行,即使左侧表中不存在匹配项。
FULL JOIN − 当其中一个表中存在匹配项时返回行。
SELF JOIN − 用于将表自身连接起来,就像该表是两个表一样,在 SQL 语句中至少临时重命名一个表。
内部连接
连接中最常用和最重要的连接是 INNER JOIN。它也称为 EQUIJOIN。
INNER JOIN 通过根据连接谓词组合两个表(table1 和 table2)的列值来创建一个新的结果表。查询将 table1 的每一行与 table2 的每一行进行比较,以查找满足连接谓词的所有行对。当连接谓词满足时,每个匹配的行对 A 和 B 的列值将组合到结果行中。
语法
INNER JOIN 的基本语法如下所示。
SELECT table1.column1, table2.column2... FROM table1 INNER JOIN table2 ON table1.common_field = table2.common_field;
示例
请考虑以下两个表,一个名为 CUSTOMERS 表,另一个名为 ORDERS 表,如下所示 -
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
现在,让我们使用 INNER JOIN 查询连接这两个表,如下所示 -
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS INNER JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
执行上述查询后,您将收到以下输出。
+----+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +----+----------+--------+---------------------+ | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +----+----------+--------+---------------------+
左连接
HSQLDB LEFT JOIN 返回左侧表中的所有行,即使右侧表中不存在匹配项。这意味着,如果 ON 子句在右侧表中匹配 0(零)条记录,则连接仍将在结果中返回一行,但在右侧表中的每一列中都为 NULL。
这意味着左连接返回左侧表中的所有值,加上右侧表中的匹配值,或者在没有匹配连接谓词的情况下返回 NULL。
语法
LEFT JOIN 的基本语法如下所示 -
SELECT table1.column1, table2.column2... FROM table1 LEFT JOIN table2 ON table1.common_field = table2.common_field;
这里给定的条件可以是基于您的需求的任何给定表达式。
示例
请考虑以下两个表,一个名为 CUSTOMERS 表,另一个名为 ORDERS 表,如下所示 -
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
现在,让我们使用 LEFT JOIN 查询连接这两个表,如下所示 -
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS LEFT JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
执行上述查询后,您将收到以下输出 -
+----+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +----+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | +----+----------+--------+---------------------+
右连接
HSQLDB RIGHT JOIN 返回右侧表中的所有行,即使左侧表中不存在匹配项。这意味着,如果 ON 子句在左侧表中匹配 0(零)条记录,则连接仍将在结果中返回一行,但在左侧表中的每一列中都为 NULL。
这意味着右连接返回右侧表中的所有值,加上左侧表中的匹配值,或者在没有匹配连接谓词的情况下返回 NULL。
语法
RIGHT JOIN 的基本语法如下所示 -
SELECT table1.column1, table2.column2... FROM table1 RIGHT JOIN table2 ON table1.common_field = table2.common_field;
示例
请考虑以下两个表,一个名为 CUSTOMERS 表,另一个名为 ORDERS 表,如下所示 -
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
现在,让我们使用 RIGHT JOIN 查询连接这两个表,如下所示 -
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS RIGHT JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
执行上述查询后,您将收到以下结果。
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
全连接
HSQLDB FULL JOIN 组合了左右外连接的结果。
连接的表将包含两个表中的所有记录,并在任一侧的缺失匹配项中填充 NULL。
语法
FULL JOIN 的基本语法如下所示 -
SELECT table1.column1, table2.column2... FROM table1 FULL JOIN table2 ON table1.common_field = table2.common_field;
这里给定的条件可以是基于您的需求的任何给定表达式。
示例
请考虑以下两个表,一个名为 CUSTOMERS 表,另一个名为 ORDERS 表,如下所示 -
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
现在,让我们使用以下 FULL JOIN 查询将这两个表连接起来:
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS FULL JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
执行上述查询后,您将收到以下结果。
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
自连接
SQL 自连接用于将表自身连接起来,就好像该表是两个表一样,在 SQL 语句中至少临时重命名一个表。
语法
自连接的基本语法如下:
SELECT a.column_name, b.column_name... FROM table1 a, table1 b WHERE a.common_field = b.common_field;
这里,WHERE 子句可以是根据您的要求给出的任何表达式。
示例
请考虑以下两个表,一个名为 CUSTOMERS 表,另一个名为 ORDERS 表,如下所示 -
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
现在,让我们使用以下 SELF JOIN 查询将此表连接起来:
SELECT a.ID, b.NAME, a.SALARY FROM CUSTOMERS a, CUSTOMERS b WHERE a.SALARY > b.SALARY;
执行上述查询后,您将收到以下输出 -
+----+----------+---------+ | ID | NAME | SALARY | +----+----------+---------+ | 2 | Ramesh | 1500.00 | | 2 | kaushik | 1500.00 | | 1 | Chaitali | 2000.00 | | 2 | Chaitali | 1500.00 | | 3 | Chaitali | 2000.00 | | 6 | Chaitali | 4500.00 | | 1 | Hardik | 2000.00 | | 2 | Hardik | 1500.00 | | 3 | Hardik | 2000.00 | | 4 | Hardik | 6500.00 | | 6 | Hardik | 4500.00 | | 1 | Komal | 2000.00 | | 2 | Komal | 1500.00 | | 3 | Komal | 2000.00 | | 1 | Muffy | 2000.00 | | 2 | Muffy | 1500.00 | | 3 | Muffy | 2000.00 | | 4 | Muffy | 6500.00 | | 5 | Muffy | 8500.00 | | 6 | Muffy | 4500.00 | +----+----------+---------+
HsqlDB - 空值
SQL NULL 是一个用于表示缺失值的术语。表中的 NULL 值是指字段中看起来为空的值。每当我们尝试给出比较字段或列值与 NULL 的条件时,它都不能正常工作。
我们可以使用以下三种方法处理 NULL 值。
IS NULL - 如果列值为 NULL,则该运算符返回 true。
IS NOT NULL - 如果列值不为 NULL,则该运算符返回 true。
<=> - 该运算符比较值,即使对于两个 NULL 值,它也返回 true(与 = 运算符不同)。
要查找为 NULL 或不为 NULL 的列,请分别使用 IS NULL 或 IS NOT NULL。
示例
让我们考虑一个示例,其中有一个名为 tcount_tbl 的表,其中包含两列,作者和教程计数。我们可以为教程计数提供 NULL 值,表示作者甚至没有发布一篇教程。因此,相应作者的教程计数值为 NULL。
执行以下查询。
create table tcount_tbl(author varchar(40) NOT NULL, tutorial_count INT);
INSERT INTO tcount_tbl values ('Abdul S', 20);
INSERT INTO tcount_tbl values ('Ajith kumar', 5);
INSERT INTO tcount_tbl values ('Jen', NULL);
INSERT INTO tcount_tbl values ('Bavya kanna', 8);
INSERT INTO tcount_tbl values ('mahran', NULL);
INSERT INTO tcount_tbl values ('John Poul', 10);
INSERT INTO tcount_tbl values ('Sathya Murthi', 6);
使用以下命令显示 tcount_tbl 表中的所有记录。
select * from tcount_tbl;
执行上述命令后,您将收到以下输出。
+-----------------+----------------+ | author | tutorial_count | +-----------------+----------------+ | Abdul S | 20 | | Ajith kumar | 5 | | Jen | NULL | | Bavya kanna | 8 | | mahran | NULL | | John Poul | 10 | | Sathya Murthi | 6 | +-----------------+----------------+
要查找教程计数列为 NULL 的记录,以下是查询。
SELECT * FROM tcount_tbl WHERE tutorial_count IS NULL;
查询执行后,您将收到以下输出。
+-----------------+----------------+ | author | tutorial_count | +-----------------+----------------+ | Jen | NULL | | mahran | NULL | +-----------------+----------------+
要查找教程计数列不为 NULL 的记录,以下是查询。
SELECT * FROM tcount_tbl WHERE tutorial_count IS NOT NULL;
查询执行后,您将收到以下输出。
+-----------------+----------------+ | author | tutorial_count | +-----------------+----------------+ | Abdul S | 20 | | Ajith kumar | 5 | | Bavya kanna | 8 | | John Poul | 10 | | Sathya Murthi | 6 | +-----------------+----------------+
HSQLDB – JDBC 程序
这是一个 JDBC 程序,它分别从 tcount_tbl 表中检索记录,其中教程计数为 NULL 和教程计数不为 NULL。将以下程序保存到 NullValues.java 中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class NullValues {
public static void main(String[] args) {
Connection con = null;
Statement stmt_is_null = null;
Statement stmt_is_not_null = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt_is_null = con.createStatement();
stmt_is_not_null = con.createStatement();
result = stmt_is_null.executeQuery(
"SELECT * FROM tcount_tbl WHERE tutorial_count IS NULL;");
System.out.println("Records where the tutorial_count is NULL");
while(result.next()){
System.out.println(result.getString("author")+" |
"+result.getInt("tutorial_count"));
}
result = stmt_is_not_null.executeQuery(
"SELECT * FROM tcount_tbl WHERE tutorial_count IS NOT NULL;");
System.out.println("Records where the tutorial_count is NOT NULL");
while(result.next()){
System.out.println(result.getString("author")+" |
"+result.getInt("tutorial_count"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
使用以下命令编译并执行上述程序。
\>javac NullValues.java \>Java NullValues
执行上述命令后,您将收到以下输出。
Records where the tutorial_count is NULL Jen | 0 mahran | 0 Records where the tutorial_count is NOT NULL Abdul S | 20 Ajith kumar | 5 Bavya kanna | 8 John Poul | 10 Sathya Murthi | 6
HSQLDB - 正则表达式
HSQLDB 支持一些基于正则表达式的模式匹配操作的特殊符号和 REGEXP 运算符。
以下是模式表,可与 REGEXP 运算符一起使用。
| 模式 | 模式匹配的内容 |
|---|---|
| ^ | 字符串的开头 |
| $ | 字符串的结尾 |
| . | 任何单个字符 |
| [...] | 方括号之间列出的任何字符 |
| [^...] | 方括号之间未列出的任何字符 |
| p1|p2|p3 | 替换;匹配模式 p1、p2 或 p3 中的任何一个 |
| * | 前一个元素的零个或多个实例 |
| + | 前一个元素的一个或多个实例 |
| {n} | 前一个元素的 n 个实例 |
| {m,n} | 前一个元素的 m 到 n 个实例 |
示例
让我们尝试不同的示例查询以满足我们的需求。请查看以下给定的查询。
尝试此查询以查找所有以 '^A' 开头的作者姓名。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'^A.*');
执行上述查询后,您将收到以下输出。
+-----------------+ | author | +-----------------+ | Abdul S | | Ajith kumar | +-----------------+
尝试此查询以查找所有以 'ul$' 结尾的作者姓名。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'.*ul$');
执行上述查询后,您将收到以下输出。
+-----------------+ | author | +-----------------+ | John Poul | +-----------------+
尝试此查询以查找所有作者姓名中包含 'th' 的作者。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'.*th.*');
执行上述查询后,您将收到以下输出。
+-----------------+ | author | +-----------------+ | Ajith kumar | | Abdul S | +-----------------+
尝试此查询以查找所有作者姓名以元音(a、e、i、o、u)开头的作者。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'^[AEIOU].*');
执行上述查询后,您将收到以下输出。
+-----------------+ | author | +-----------------+ | Abdul S | | Ajith kumar | +-----------------+
HSQLDB - 事务
事务是一组按顺序执行的数据库操作,这些操作被视为一个工作单元。换句话说,只有在所有操作都成功执行后,整个事务才算完成。如果事务中的任何操作失败,则整个事务将失败。
事务的属性
基本上,事务支持 4 个标准属性。它们可以被称为 ACID 属性。
原子性 - 事务中的所有操作都成功执行,否则事务将在失败点中止,并且之前的操作将回滚到其先前的位置。
一致性 - 数据库在成功提交的事务后会正确更改状态。
隔离性 - 它使事务能够独立于彼此并对其透明地运行。
持久性 - 提交的事务的结果或影响在系统故障的情况下仍然存在。
提交、回滚和保存点
这些关键字主要用于 HSQLDB 事务。
提交 - 成功的事务应始终通过执行 COMMIT 命令来完成。
回滚 - 如果事务中发生错误,则应执行 ROLLBACK 命令以将事务中引用的每个表返回到其先前状态。
保存点 - 在事务组中创建一个要回滚到的点。
示例
以下示例解释了事务概念以及提交、回滚和保存点。让我们考虑一个名为 Customers 的表,其中包含 id、name、age、address 和 salary 列。
| Id | 姓名 | 年龄 | 地址 | 薪资 |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Karun | 25 | Delhi | 1500.00 |
| 3 | Kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitanya | 25 | Mumbai | 6500.00 |
| 5 | Harish | 27 | Bhopal | 8500.00 |
| 6 | Kamesh | 22 | MP | 1500.00 |
| 7 | Murali | 24 | Indore | 10000.00 |
使用以下命令创建客户表,并遵循上述数据。
CREATE TABLE Customer (id INT NOT NULL, name VARCHAR(100) NOT NULL, age INT NOT NULL, address VARCHAR(20), Salary INT, PRIMARY KEY (id)); Insert into Customer values (1, "Ramesh", 32, "Ahmedabad", 2000); Insert into Customer values (2, "Karun", 25, "Delhi", 1500); Insert into Customer values (3, "Kaushik", 23, "Kota", 2000); Insert into Customer values (4, "Chaitanya", 25, "Mumbai", 6500); Insert into Customer values (5, "Harish", 27, "Bhopal", 8500); Insert into Customer values (6, "Kamesh", 22, "MP", 1500); Insert into Customer values (7, "Murali", 24, "Indore", 10000);
COMMIT 示例
以下查询从表中删除年龄为 25 的行,并使用 COMMIT 命令将这些更改应用到数据库中。
DELETE FROM CUSTOMERS WHERE AGE = 25; COMMIT;
执行上述查询后,您将收到以下输出。
2 rows effected
成功执行上述命令后,通过执行以下命令检查客户表的记录。
Select * from Customer;
执行上述查询后,您将收到以下输出。
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000 | | 3 | kaushik | 23 | Kota | 2000 | | 5 | Harish | 27 | Bhopal | 8500 | | 6 | Kamesh | 22 | MP | 4500 | | 7 | Murali | 24 | Indore | 10000 | +----+----------+-----+-----------+----------+
回滚示例
让我们考虑将相同的 Customer 表作为输入。
| Id | 姓名 | 年龄 | 地址 | 薪资 |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Karun | 25 | Delhi | 1500.00 |
| 3 | Kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitanya | 25 | Mumbai | 6500.00 |
| 5 | Harish | 27 | Bhopal | 8500.00 |
| 6 | Kamesh | 22 | MP | 1500.00 |
| 7 | Murali | 24 | Indore | 10000.00 |
这是一个示例查询,它解释了通过从表中删除年龄为 25 的记录,然后回滚数据库中的更改来解释回滚功能。
DELETE FROM CUSTOMERS WHERE AGE = 25; ROLLBACK;
成功执行上述两个查询后,您可以使用以下命令查看 Customer 表中的记录数据。
Select * from Customer;
执行上述命令后,您将收到以下输出。
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000 | | 2 | Karun | 25 | Delhi | 1500 | | 3 | Kaushik | 23 | Kota | 2000 | | 4 | Chaitanya| 25 | Mumbai | 6500 | | 5 | Harish | 27 | Bhopal | 8500 | | 6 | Kamesh | 22 | MP | 4500 | | 7 | Murali | 24 | Indore | 10000 | +----+----------+-----+-----------+----------+
delete 查询删除了年龄为 25 的客户的记录数据。Rollback 命令将这些更改回滚到 Customer 表上。
保存点示例
保存点是在事务中可以将事务回滚到某个点而不回滚整个事务的点。
让我们考虑将相同的 Customer 表作为输入。
| Id | 姓名 | 年龄 | 地址 | 薪资 |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Karun | 25 | Delhi | 1500.00 |
| 3 | Kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitanya | 25 | Mumbai | 6500.00 |
| 5 | Harish | 27 | Bhopal | 8500.00 |
| 6 | Kamesh | 22 | MP | 1500.00 |
| 7 | Murali | 24 | Indore | 10000.00 |
让我们考虑在这个例子中,您计划从 Customers 表中删除三个不同的记录。您希望在每次删除之前创建一个保存点,以便您可以随时回滚到任何保存点以将适当的数据返回到其原始状态。
这是一系列操作。
SAVEPOINT SP1; DELETE FROM CUSTOMERS WHERE ID = 1; SAVEPOINT SP2; DELETE FROM CUSTOMERS WHERE ID = 2; SAVEPOINT SP3; DELETE FROM CUSTOMERS WHERE ID = 3;
现在,您已创建了三个保存点并删除了三个记录。在这种情况下,如果您想回滚 ID 为 2 和 3 的记录,请使用以下回滚命令。
ROLLBACK TO SP2;
请注意,由于您已回滚到 SP2,因此仅执行了第一次删除。使用以下查询显示客户的所有记录。
Select * from Customer;
执行上述查询后,您将收到以下输出。
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 2 | Karun | 25 | Delhi | 1500 | | 3 | Kaushik | 23 | Kota | 2000 | | 4 | Chaitanya| 25 | Mumbai | 6500 | | 5 | Harish | 27 | Bhopal | 8500 | | 6 | Kamesh | 22 | MP | 4500 | | 7 | Murali | 24 | Indore | 10000 | +----+----------+-----+-----------+----------+
释放保存点
我们可以使用 RELEASE 命令释放保存点。以下是通用语法。
RELEASE SAVEPOINT SAVEPOINT_NAME;
HsqlDB - ALTER 命令
每当需要更改表或字段的名称、更改字段的顺序、更改字段的数据类型或任何表结构时,您都可以使用 ALTER 命令来实现。
示例
让我们考虑一个使用不同场景解释 ALTER 命令的示例。
使用以下查询创建一个名为 testalter_tbl 的表,其中包含字段 id 和 name。
//below given query is to create a table testalter_tbl table. create table testalter_tbl(id INT, name VARCHAR(10)); //below given query is to verify the table structure testalter_tbl. Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
执行上述查询后,您将收到以下输出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 | +------------+-------------+------------+-----------+-----------+------------+
删除或添加列
每当您想从 HSQLDB 表中删除现有列时,您可以将 DROP 子句与 ALTER 命令一起使用。
使用以下查询从 testalter_tbl 表中删除列 (name)。
ALTER TABLE testalter_tbl DROP name;
成功执行上述查询后,您可以使用以下命令了解 name 字段是否已从 testalter_tbl 表中删除。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
执行上述命令后,您将收到以下输出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 | +------------+-------------+------------+-----------+-----------+------------+
每当您想向 HSQLDB 表中添加任何列时,您可以将 ADD 子句与 ALTER 命令一起使用。
使用以下查询向 testalter_tbl 表添加一个名为 NAME 的列。
ALTER TABLE testalter_tbl ADD name VARCHAR(10);
成功执行上述查询后,您可以使用以下命令了解 name 字段是否已添加到 testalter_tbl 表中。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
执行上述查询后,您将收到以下输出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 | +------------+-------------+------------+-----------+-----------+------------+
更改列定义或名称
每当需要更改列定义时,请将 MODIFY 或 CHANGE 子句与 ALTER 命令一起使用。
让我们考虑一个示例,它将说明如何使用 CHANGE 子句。testalter_tbl 表包含两个字段 - id 和 name - 它们的数据类型分别为 int 和 varchar。现在让我们尝试将 id 的数据类型从 INT 更改为 BIGINT。以下是进行更改的查询。
ALTER TABLE testalter_tbl CHANGE id id BIGINT;
成功执行上述查询后,可以使用以下命令验证表结构。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
执行上述命令后,您将收到以下输出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | BIGINT | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 | +------------+-------------+------------+-----------+-----------+------------+
现在让我们尝试将 testalter_tbl 表中列 NAME 的大小从 10 增加到 20。以下是使用 MODIFY 子句以及 ALTER 命令实现此目的的查询。
ALTER TABLE testalter_tbl MODIFY name VARCHAR(20);
成功执行上述查询后,可以使用以下命令验证表结构。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
执行上述命令后,您将收到以下输出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | BIGINT | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 20 | +------------+-------------+------------+-----------+-----------+------------+
HSQLDB - 索引
数据库索引是一种数据结构,可以提高表中操作的速度。可以使用一个或多个列创建索引,为快速随机查找和有效排序对记录的访问提供基础。
创建索引时,应考虑哪些列将用于执行 SQL 查询,并在这些列上创建一个或多个索引。
实际上,索引也是一种类型的表,它保存主键或索引字段以及指向实际表中每个记录的指针。
用户无法看到索引。它们仅用于加快查询速度,并将由数据库搜索引擎用于快速定位记录。
在具有索引的表上,INSERT 和 UPDATE 语句需要更多时间,而 SELECT 语句在这些表上运行速度更快。原因是在插入或更新时,数据库也需要插入或更新索引值。
简单索引和唯一索引
您可以在表上创建唯一索引。唯一索引表示两行不能具有相同的索引值。以下是创建表索引的语法。
CREATE UNIQUE INDEX index_name ON table_name (column1, column2,...);
您可以使用一个或多个列来创建索引。例如,使用 tutorial_author 在 tutorials_tbl 上创建索引。
CREATE UNIQUE INDEX AUTHOR_INDEX ON tutorials_tbl (tutorial_author)
您可以在表上创建简单索引。只需从查询中省略 UNIQUE 关键字即可创建简单索引。简单索引允许表中存在重复值。
如果要以降序排列列中的值,可以在列名后添加保留字 DESC。
CREATE UNIQUE INDEX AUTHOR_INDEX ON tutorials_tbl (tutorial_author DESC)
ALTER 命令添加和删除索引
有四种类型的语句用于向表中添加索引:
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) - 此语句添加主键,这意味着索引值必须唯一且不能为 NULL。
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list) - 此语句创建一个索引,该索引的值必须唯一(除了 NULL 值,它可以多次出现)。
ALTER TABLE tbl_name ADD INDEX index_name (column_list) - 这将在其中任何值都可能出现多次的情况下添加普通索引。
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list) - 这将创建一个用于文本搜索目的的特殊 FULLTEXT 索引。
以下是向现有表中添加索引的查询。
ALTER TABLE testalter_tbl ADD INDEX (c);
您可以使用 DROP 子句以及 ALTER 命令删除任何索引。以下是删除上述创建的索引的查询。
ALTER TABLE testalter_tbl DROP INDEX (c);
显示索引信息
您可以使用 SHOW INDEX 命令列出与表关联的所有索引。对于此语句,垂直格式输出(由 \G 指定)通常很有用,以避免长行换行。
以下是显示表索引信息的通用语法。
SHOW INDEX FROM table_name\G