Python中的逻辑回归 - 快速指南
Python中的逻辑回归 - 介绍
逻辑回归是一种对物体进行分类的统计方法。本章将通过一些例子介绍逻辑回归。
分类
要理解逻辑回归,你应该知道分类是什么意思。让我们考虑以下例子来更好地理解这一点:
- 医生将肿瘤分类为恶性或良性。
- 银行交易可能是欺诈性的或真实的。
多年来,人类一直在执行这些任务——尽管它们容易出错。问题是我们能否训练机器来为我们完成这些任务,并获得更高的准确率?
机器进行分类的一个例子是你机器上的邮件**客户端**,它将每封传入邮件分类为“垃圾邮件”或“非垃圾邮件”,并且它能够以相当高的准确率完成这项工作。逻辑回归的统计技术已成功应用于邮件客户端。在这种情况下,我们已经训练了我们的机器来解决一个分类问题。
逻辑回归只是机器学习中用于解决这种二元分类问题的一部分。已经有几种其他的机器学习技术被开发出来,并用于解决其他类型的问题。
如果你已经注意到,在所有上述例子中,预测的结果只有两个值——是或否。我们将这些称为类别——也就是说,我们说我们的分类器将对象分类为两类。从技术角度来说,我们可以说结果或目标变量本质上是二分的。
还有其他分类问题,其输出可能被分类为两类以上。例如,给定一个装满水果的篮子,你被要求将不同种类的水果分开。现在,篮子里可能包含橙子、苹果、芒果等等。因此,当你将水果分开时,你会将它们分成两类以上。这是一个多元分类问题。
Python中的逻辑回归 - 案例研究
假设一家银行找到你,要求你开发一个机器学习应用程序,帮助他们识别可能在他们那里开定期存款(一些银行也称之为定期存款)的潜在客户。银行定期通过电话或网络表格进行调查,以收集有关潜在客户的信息。调查的性质比较普遍,面向非常广泛的受众,其中许多人可能根本不愿意与这家银行打交道。在剩下的客户中,只有一小部分可能对开定期存款感兴趣。其他人可能对银行提供的其他服务感兴趣。因此,调查并非一定是为了识别开定期存款的客户。你的任务是从银行将与你分享的海量调查数据中,识别所有那些有很高概率开定期存款的客户。
幸运的是,对于那些渴望开发机器学习模型的人来说,有一种这样的数据是公开可用的。这些数据是由加州大学欧文分校的一些学生在外部资金的支持下准备的。该数据库作为**UCI机器学习资源库**的一部分提供,并被世界各地的学生、教育工作者和研究人员广泛使用。数据可以从这里下载。
在接下来的章节中,让我们使用相同的数据来执行应用程序开发。
项目设置
在本章中,我们将详细了解在Python中进行逻辑回归的项目设置过程。
安装Jupyter
我们将使用Jupyter——最广泛使用的机器学习平台之一。如果你的机器上没有安装Jupyter,请从这里下载。对于安装,你可以按照网站上的说明安装平台。正如网站所建议的,你可能更喜欢使用**Anaconda Distribution**,它包含Python和许多常用的用于科学计算和数据科学的Python包。这将避免单独安装这些包的需要。
Jupyter成功安装后,启动一个新项目,此时你的屏幕将如下所示,准备接受你的代码。
现在,通过单击标题名称并进行编辑,将项目名称从**Untitled1更改为“Logistic Regression”**。
首先,我们将导入代码中需要的几个Python包。
导入Python包
为此,请在代码编辑器中键入或复制粘贴以下代码:
In [1]: # import statements import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import preprocessing from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split
在此阶段,你的**Notebook**应该如下所示:
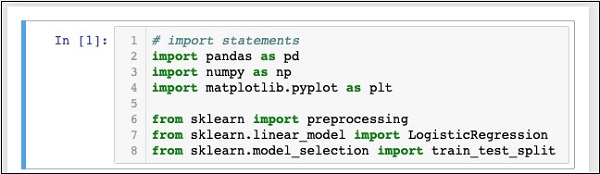
通过单击**运行**按钮运行代码。如果没有生成错误,则表示你已成功安装Jupyter,并且现在可以进行其余的开发。
前三个import语句将pandas、numpy和matplotlib.pyplot包导入到我们的项目中。接下来的三个语句从sklearn导入指定的模块。
我们的下一个任务是下载项目所需的数据。我们将在下一章学习这一点。
Python中的逻辑回归 - 获取数据
本章详细讨论了在Python中进行逻辑回归的数据获取步骤。
下载数据集
如果你还没有下载前面提到的UCI数据集,请现在从这里下载。单击“Data Folder”。你将看到以下屏幕:

通过单击给定的链接下载bank.zip文件。zip文件包含以下文件:

我们将使用bank.csv文件进行模型开发。bank-names.txt文件包含你稍后需要使用的数据库描述。bank-full.csv包含一个更大的数据集,你可以将其用于更高级的开发。
在这里,我们在可下载的源代码zip文件中包含了bank.csv文件。此文件包含逗号分隔的字段。我们还对文件进行了一些修改。建议你使用项目源代码zip文件中包含的文件进行学习。
加载数据
要加载刚刚复制的csv文件中的数据,请键入以下语句并运行代码。
In [2]: df = pd.read_csv('bank.csv', header=0)
你还可以通过运行以下代码语句来检查加载的数据:
IN [3]: df.head()
一旦命令运行,你将看到以下输出:
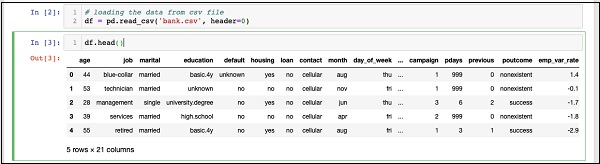
基本上,它打印了加载数据的头五行。检查存在的21列。我们将仅使用其中几列进行模型开发。
接下来,我们需要清理数据。数据可能包含一些包含**NaN**的行。要消除这些行,请使用以下命令:
IN [4]: df = df.dropna()
幸运的是,bank.csv不包含任何包含NaN的行,因此在我们的案例中,此步骤实际上并非必需。但是,通常很难在一个巨大的数据库中发现这样的行。因此,运行上述语句来清理数据始终是比较安全的。
**注意**——你可以随时使用以下语句轻松检查数据大小:
IN [5]: print (df.shape) (41188, 21)
行数和列数将如上面的第二行所示打印在输出中。
接下来要做的就是检查每一列对我们试图构建的模型的适用性。
Python中的逻辑回归 - 数据重构
每当任何组织进行调查时,他们都会尝试从客户那里收集尽可能多的信息,其想法是这些信息将在以后以某种方式对组织有用。为了解决当前问题,我们必须挑选与我们问题直接相关的信息。
显示所有字段
现在,让我们看看如何选择对我们有用的数据字段。在代码编辑器中运行以下语句。
In [6]: print(list(df.columns))
你将看到以下输出:
['age', 'job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'day_of_week', 'duration', 'campaign', 'pdays', 'previous', 'poutcome', 'emp_var_rate', 'cons_price_idx', 'cons_conf_idx', 'euribor3m', 'nr_employed', 'y']
输出显示数据库中所有列的名称。最后一列“y”是一个布尔值,指示该客户是否在银行拥有定期存款。此字段的值为“y”或“n”。你可以在作为数据一部分下载的banks-name.txt文件中阅读每一列的描述和用途。
消除不需要的字段
检查列名,你将知道某些字段与当前问题无关。例如,诸如**月份、星期几**、活动等字段对我们没有用处。我们将从我们的数据库中删除这些字段。要删除列,我们使用如下所示的drop命令:
In [8]: #drop columns which are not needed. df.drop(df.columns[[0, 3, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19]], axis = 1, inplace = True)
该命令表示删除列号0、3、7、8等等。为了确保正确选择索引,请使用以下语句:
In [7]: df.columns[9] Out[7]: 'day_of_week'
这将打印给定索引的列名。
删除不需要的列后,使用head语句检查数据。屏幕输出如下所示:
In [9]: df.head()
Out[9]:
job marital default housing loan poutcome y
0 blue-collar married unknown yes no nonexistent 0
1 technician married no no no nonexistent 0
2 management single no yes no success 1
3 services married no no no nonexistent 0
4 retired married no yes no success 1
现在,我们只有我们认为对我们的数据分析和预测很重要的字段。**数据科学家**的重要性在此步骤中体现出来。数据科学家必须选择合适的列来构建模型。
例如,虽然工作类型乍一看可能无法说服所有人将其纳入数据库,但它将是一个非常有用的字段。并非所有类型的客户都会开设定期存款。低收入人群可能不会开设定期存款,而高收入人群通常会将多余的钱存入定期存款。因此,在这种情况下,工作类型变得非常重要。同样,仔细选择您认为与您的分析相关的列。
在下一章中,我们将准备数据以构建模型。
Python中的逻辑回归 - 数据准备
为了创建分类器,我们必须以分类器构建模块所需的形式准备数据。我们通过进行独热编码来准备数据。
数据编码
我们将简要讨论数据编码的含义。首先,让我们运行代码。在代码窗口中运行以下命令。
In [10]: # creating one hot encoding of the categorical columns. data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])
如注释所示,上述语句将创建数据的独热编码。让我们看看它创建了什么?通过打印数据库中的头部记录来检查名为“data”的已创建数据。
In [11]: data.head()
你将看到以下输出:
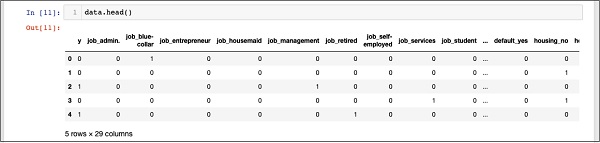
为了理解上述数据,我们将通过运行data.columns命令列出列名,如下所示:
In [12]: data.columns Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'job_unknown', 'marital_divorced', 'marital_married', 'marital_single', 'marital_unknown', 'default_no', 'default_unknown', 'default_yes', 'housing_no', 'housing_unknown', 'housing_yes', 'loan_no', 'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'], dtype='object')
现在,我们将解释get_dummies命令如何进行独热编码。新生成的数据库中的第一列是“y”字段,它指示该客户是否订阅了定期存款。现在,让我们看看经过编码的列。第一列编码列是“job”。在数据库中,您会发现“job”列有很多可能的值,例如“admin”、“blue-collar”、“entrepreneur”等等。对于每个可能的值,我们在数据库中创建一个新列,并将列名作为前缀附加。
因此,我们有名为“job_admin”、“job_blue-collar”等等的列。对于我们原始数据库中的每个编码字段,您会发现已在创建的数据库中添加了一系列列,其中包含该列在原始数据库中采用所有可能的值。仔细检查列列表以了解数据如何映射到新数据库。
理解数据映射
为了理解生成的数据,让我们使用data命令打印出所有数据。运行命令后的部分输出如下所示。
In [13]: data
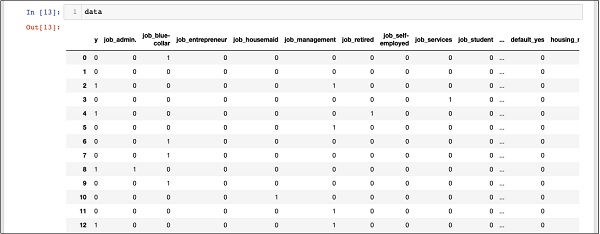
上面的屏幕显示了前十二行。如果您向下滚动,您会看到所有行的映射都已完成。
为了方便参考,此处显示数据库中更下方的部分屏幕输出。
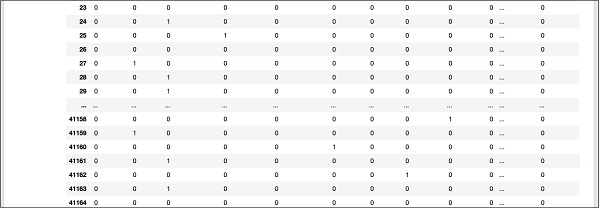
为了理解映射的数据,让我们检查第一行。

它表示此客户未订阅定期存款,如“y”字段中的值所示。它还表明此客户是“蓝领”客户。水平向下滚动,它会告诉您他拥有“住房”并且没有贷款。
在此独热编码之后,我们需要更多的数据处理才能开始构建我们的模型。
删除“unknown”
如果我们检查映射数据库中的列,您会发现存在一些以“unknown”结尾的列。例如,使用屏幕截图中显示的以下命令检查索引为 12 的列:
In [14]: data.columns[12] Out[14]: 'job_unknown'
这表明指定客户的工作未知。显然,在我们的分析和模型构建中包含此类列毫无意义。因此,应删除所有具有“unknown”值的列。这是通过以下命令完成的:
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)
确保您指定了正确的列号。如有疑问,您可以随时通过在columns命令中指定其索引来检查列名,如前所述。
删除不需要的列后,您可以检查最终的列列表,如下面的输出所示:
In [16]: data.columns Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'marital_divorced', 'marital_married', 'marital_single', 'default_no', 'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'], dtype='object')
此时,我们的数据已准备好进行模型构建。
Python中的逻辑回归 - 数据分割
我们大约有四万多条记录。如果我们使用所有数据进行模型构建,我们将没有任何数据用于测试。因此,通常我们将整个数据集分成两部分,例如 70/30 的比例。我们使用 70% 的数据进行模型构建,其余数据用于测试我们创建的模型的预测准确性。您可以根据需要使用不同的分割比例。
创建特征数组
在分割数据之前,我们将数据分成两个数组 X 和 Y。X 数组包含我们要分析的所有特征(数据列),而 Y 数组是一个一维布尔值数组,它是预测的输出。为了理解这一点,让我们运行一些代码。
首先,执行以下 Python 语句以创建 X 数组:
In [17]: X = data.iloc[:,1:]
要检查X的内容,请使用head打印一些初始记录。以下屏幕显示了 X 数组的内容。
In [18]: X.head ()
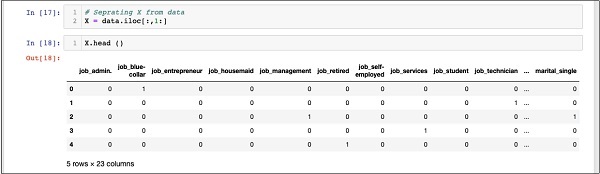
该数组有多行和 23 列。
接下来,我们将创建一个包含“y”值的输出数组。
创建输出数组
要为预测值列创建一个数组,请使用以下 Python 语句:
In [19]: Y = data.iloc[:,0]
通过调用head检查其内容。下面的屏幕输出显示了结果:
In [20]: Y.head() Out[20]: 0 0 1 0 2 1 3 0 4 1 Name: y, dtype: int64
现在,使用以下命令分割数据:
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)
这将创建四个名为X_train、Y_train、X_test 和 Y_test的数组。和以前一样,您可以使用 head 命令检查这些数组的内容。我们将使用 X_train 和 Y_train 数组来训练我们的模型,使用 X_test 和 Y_test 数组来进行测试和验证。
现在,我们准备构建我们的分类器。我们将在下一章中对此进行探讨。
Python中的逻辑回归 - 构建分类器
不需要您必须从头开始构建分类器。构建分类器很复杂,需要掌握统计学、概率论、优化技术等多个领域的知识。市场上有多个预构建的库,这些库具有经过充分测试且非常高效的这些分类器的实现。我们将使用sklearn中的一个这样的预构建模型。
sklearn 分类器
从sklearn工具包创建逻辑回归分类器很简单,只需一个程序语句即可完成,如下所示:
In [22]: classifier = LogisticRegression(solver='lbfgs',random_state=0)
创建分类器后,您将把训练数据馈送到分类器中,以便它可以调整其内部参数并准备好对未来的数据进行预测。为了调整分类器,我们运行以下语句:
In [23]: classifier.fit(X_train, Y_train)
分类器现在已准备好进行测试。以下代码是上述两个语句执行的输出:
Out[23]: LogisticRegression(C = 1.0, class_weight = None, dual = False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='warn', n_jobs=None, penalty='l2', random_state=0, solver='lbfgs', tol=0.0001, verbose=0, warm_start=False))
现在,我们准备测试创建的分类器。我们将在下一章中处理这个问题。
Python中的逻辑回归 - 测试
在我们投入生产使用之前,我们需要测试上述创建的分类器。如果测试表明模型未达到所需的精度,我们将不得不回到上述流程中,选择另一组特征(数据字段),重新构建模型并进行测试。这将是一个迭代步骤,直到分类器满足您所需的精度要求。因此,让我们测试我们的分类器。
预测测试数据
为了测试分类器,我们使用在早期阶段生成的测试数据。我们在创建的对象上调用predict方法,并将测试数据的X数组作为参数传递,如下面的命令所示:
In [24]: predicted_y = classifier.predict(X_test)
这将为整个训练数据集生成一个一维数组,给出 X 数组中每一行的预测。您可以使用以下命令检查此数组:
In [25]: predicted_y
执行上述两个命令后的输出如下:
Out[25]: array([0, 0, 0, ..., 0, 0, 0])
输出表明,前三位和最后三位客户并非定期存款的潜在候选人。您可以检查整个数组以筛选出潜在客户。为此,请使用以下 Python 代码片段:
In [26]: for x in range(len(predicted_y)):
if (predicted_y[x] == 1):
print(x, end="\t")
运行上述代码的输出如下所示:

输出显示了所有可能订阅定期存款的客户的行索引。您现在可以将此输出提供给银行的营销团队,他们将收集所选行中每个客户的联系信息并继续他们的工作。
在我们使此模型投入生产之前,我们需要验证预测的准确性。
验证准确性
要测试模型的准确性,请在分类器上使用 score 方法,如下所示:
In [27]: print('Accuracy: {:.2f}'.format(classifier.score(X_test, Y_test)))
运行此命令的屏幕输出如下所示:
Accuracy: 0.90
它表明我们模型的准确率为 90%,这在大多数应用程序中都被认为非常好。因此,无需进一步调整。现在,我们的客户已准备好启动下一轮营销活动,获取潜在客户列表并促使他们开设定期存款,并可能获得较高的成功率。
Python中的逻辑回归 - 限制
正如您从上面的示例中看到的,将逻辑回归应用于机器学习并非一项困难的任务。但是,它也有其自身的局限性。逻辑回归将无法处理大量分类特征。在我们迄今为止讨论的示例中,我们已经将特征的数量大大减少了。
但是,如果这些特征在我们预测中很重要,我们将被迫包含它们,但随后逻辑回归将无法给我们提供良好的准确性。逻辑回归也容易过度拟合。它不能应用于非线性问题。对于与目标不相关且彼此相关的自变量,它的性能会很差。因此,您必须仔细评估逻辑回归对您尝试解决的问题的适用性。
机器学习的许多领域都指定了其他技术。仅举几例,我们有 k 近邻 (kNN)、线性回归、支持向量机 (SVM)、决策树、朴素贝叶斯等算法。在确定特定模型之前,您必须评估这些各种技术对我们试图解决的问题的适用性。
Python中的逻辑回归 - 总结
逻辑回归是一种二元分类的统计技术。在本教程中,您学习了如何训练机器使用逻辑回归。创建机器学习模型,最重要的要求是数据的可用性。如果没有充分且相关的数据,您就无法简单地让机器学习。
拥有数据后,你的下一个主要任务是数据清洗,消除不需要的行和字段,并为你的模型开发选择合适的字段。完成此操作后,你需要将数据映射到分类器训练所需的格式。因此,数据准备是任何机器学习应用程序中的一个主要任务。准备好数据后,你可以选择特定类型的分类器。
在本教程中,你学习了如何使用sklearn库中提供的逻辑回归分类器。为了训练分类器,我们使用大约70%的数据来训练模型。我们使用其余的数据进行测试。我们测试模型的准确性。如果精度不在可接受的范围内,我们将返回选择新的特征集。
再次重复整个过程:准备数据、训练模型并测试它,直到你对它的准确性满意为止。在开始任何机器学习项目之前,你必须学习并接触到迄今为止已经开发出来并在业界成功应用的各种技术。