- MuleSoft 教程
- MuleSoft - 首页
- MuleSoft - Mule ESB 简介
- MuleSoft - Mule 项目
- MuleSoft - Mule 在我们的机器中
- MuleSoft - Anypoint Studio
- MuleSoft - 探索 Anypoint Studio
- 创建第一个 Mule 应用
- MuleSoft - DataWeave 语言
- 消息处理器和脚本组件
- 核心组件及其配置
- MuleSoft - 端点
- 流程控制和转换器
- 使用 Anypoint Studio 的 Web 服务
- MuleSoft - Mule 错误处理
- MuleSoft - Mule 异常处理
- MuleSoft - 使用 MUnit 进行测试
- MuleSoft 有用资源
- MuleSoft 快速指南
- MuleSoft - 有用资源
- MuleSoft - 讨论
MuleSoft 快速指南
MuleSoft - Mule ESB 简介
ESB 代表企业服务总线 (Enterprise Service Bus),它基本上是一个用于通过总线式基础架构集成各种应用程序的中间件工具。从根本上说,它是一种旨在提供统一方法来在集成应用程序之间移动工作的架构。通过这种方式,借助 ESB 架构,我们可以通过通信总线连接不同的应用程序,并使它们能够在不依赖彼此的情况下进行通信。
ESB 的实现
ESB 架构的主要焦点是从彼此解耦系统,并允许它们以稳定和可控的方式进行通信。ESB 的实现可以通过以下方式使用“总线”和“适配器”来完成:
“总线”的概念是通过像 JMS 或 AMQP 这样的消息服务器实现的,用于将不同的应用程序彼此解耦。
“适配器”的概念负责与后端应用程序通信并将数据从应用程序格式转换为总线格式,用于应用程序和总线之间。
通过总线从一个应用程序到另一个应用程序的数据或消息传递采用规范格式,这意味着将存在一种一致的消息格式。
适配器还可以执行其他活动,例如安全、监控、错误处理和消息路由管理。
ESB 的指导原则
我们可以将这些原则称为核心集成原则。它们如下:
编排 - 集成两个或多个服务以实现数据和流程之间的同步。
转换 - 将数据从规范格式转换为特定于应用程序的格式。
传输 - 处理不同格式之间的协议协商,例如 FTP、HTTP、JMS 等。
中介 - 提供多个接口以支持服务的多个版本。
非功能一致性 - 还提供用于管理事务和安全的机制。
ESB 的需求
ESB 架构使我们能够集成不同的应用程序,每个应用程序都可以通过它进行通信。以下是一些关于何时使用 ESB 的指导原则:
集成两个或多个应用程序 - 当需要集成两个或多个服务或应用程序时,使用 ESB 架构是有益的。
将来集成更多应用程序 - 如果我们想将来添加更多服务或应用程序,那么可以使用 ESB 架构轻松完成。
使用多种协议 - 如果我们需要使用多种协议,例如 HTTP、FTP、JMS 等,ESB 是正确的选择。
消息路由 - 如果我们需要基于消息内容和其他类似参数进行消息路由,则可以使用 ESB。
组合和使用 - 如果我们需要发布服务以进行组合和使用,则可以使用 ESB。
点对点集成与 ESB 集成
随着应用程序数量的增加,开发人员面前的一个大问题是如何连接不同的应用程序?这种情况是通过手工编码各种应用程序之间的连接来处理的。这称为点对点集成。
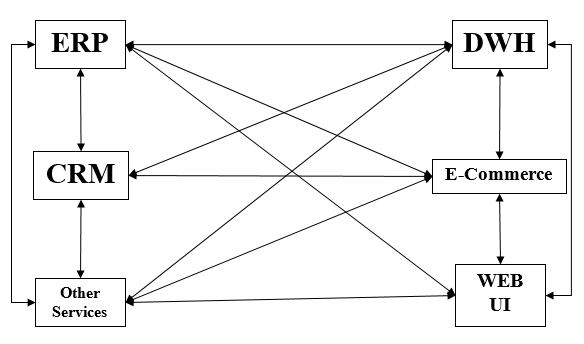
僵化是点对点集成的最明显的缺点。随着连接和接口数量的增加,复杂性也会增加。P-2-P 集成的缺点导致我们转向 ESB 集成。
ESB 是一种更灵活的应用程序集成方法。它将每个应用程序的功能封装并公开为一组离散的可重用功能。没有应用程序直接与其他应用程序集成,而是它们通过 ESB 集成,如下所示:
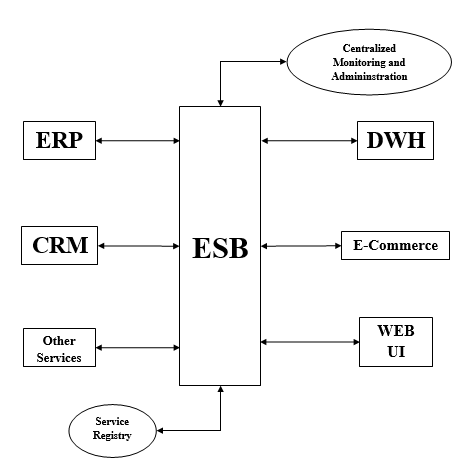
为了管理集成,ESB 具有以下两个组件:
服务注册表 - Mule ESB 具有服务注册表/存储库,所有公开到 ESB 的服务都在此处发布和注册。它充当发现点,从中可以消费其他应用程序的服务和功能。
集中式管理 - 顾名思义,它提供 ESB 内部发生的交互的交易流和性能视图。
ESB 功能 - 通常使用 VETRO 首字母缩写来总结 ESB 的功能。它如下:
V(验证) - 顾名思义,它验证模式验证。它需要一个验证解析器和最新的模式。一个例子是符合最新模式的 XML 文档。
E(丰富) - 它向消息添加附加数据。目的是使消息对目标服务更有意义和更有用。
T(转换) - 它将数据结构转换为规范格式或从规范格式转换。示例包括日期/时间、货币等的转换。
R(路由) - 它将路由消息并充当服务端点的看门人。
O(操作) - 此功能的主要工作是调用目标服务或与目标应用程序交互。它们在后端运行。
VETRO 模式为集成提供了整体灵活性,并确保只有一致且经过验证的数据才能在整个 ESB 中路由。
什么是 Mule ESB?
Mule ESB 是 MuleSoft 提供的基于 Java 的轻量级且高度可扩展的企业服务总线 (ESB) 和集成平台。Mule ESB 允许开发人员轻松快速地连接应用程序。无论应用程序使用什么技术,Mule ESB 都能轻松集成应用程序,使它们能够交换数据。Mule ESB 具有以下两个版本:
- 社区版
- 企业版
Mule ESB 的一个优点是我们可以轻松地从 Mule ESB 社区版升级到 Mule ESB 企业版,因为这两个版本都是基于相同的代码库构建的。
Mule ESB 的特性和功能
Mule ESB 具有以下特性:
- 它具有简单的拖放式图形设计。
- Mule ESB 能够进行可视化数据映射和转换。
- 用户可以使用数百个预构建的经过认证的连接器。
- 集中式监控和管理。
- 它提供强大的企业安全执行功能。
- 它提供 API 管理功能。
- 它有安全的云/本地连接数据网关。
- 它提供服务注册表,所有公开到 ESB 的服务都在此处发布和注册。
- 用户可以通过基于 Web 的管理控制台进行控制。
- 可以使用服务流分析器进行快速调试。
MuleSoft - Mule 项目
Mule 项目背后的动机是:
使程序员的工作更简单,
需要轻量级且模块化的解决方案,该解决方案可以从应用程序级消息传递框架扩展到企业范围的高度可分布式框架。
Mule ESB 被设计为事件驱动型和程序化框架。它是事件驱动的,因为它与消息的统一表示相结合,并且可以通过可插入模块进行扩展。它是程序化的,因为程序员可以轻松地植入一些额外的行为,例如特定的消息处理或自定义数据转换。
历史
Mule 项目的历史视角如下:
SourceForge 项目
Mule 项目于 2003 年 4 月作为 SourceForge 项目启动,两年后发布了第一个版本并迁移到 CodeHaus。通用消息对象 (UMO) API 是其架构的核心。UMO API 背后的想法是在保持它们与底层传输隔离的同时统一逻辑。
1.0 版本
它于 2005 年 4 月发布,包含许多传输。其后许多其他版本的重点是调试和添加新功能。
2.0 版本(采用 Spring 2)
Mule 2 采用了 Spring 2 作为配置和接线框架,但由于所需 XML 配置缺乏表达性,这被证明是一次重大改动。当 Spring 2 中引入了基于 XML Schema 的配置后,这个问题得到了解决。
使用 Maven 构建
简化 Mule 使用(在开发和部署时)的最大改进是使用 Maven。从 1.3 版本开始,它开始使用 Maven 构建。
MuleSource
2006 年,MuleSource 公司成立,“以帮助支持和启用快速发展的社区,在关键任务型企业应用程序中使用 Mule”。这被证明是 Mule 项目的关键里程碑。
Mule ESB 的竞争对手
以下是 Mule ESB 的一些主要竞争对手:
- WSO2 ESB
- Oracle Service Bus
- WebSphere Message Broker
- Aurea CX Platform
- Fiorano ESB
- WebSphere DataPower Gateway
- Workday Business Process Framework
- Talend Enterprise Service Bus
- JBoss Enterprise Service Bus
- iWay Service Manager
Mule 的核心概念
如上所述,Mule ESB 是一个基于 Java 的轻量级且高度可扩展的企业服务总线 (ESB) 和集成平台。无论应用程序使用什么技术,Mule ESB 都能轻松集成应用程序,使它们能够交换数据。在本节中,我们将讨论 Mule 的核心概念,这些概念使这种集成成为可能。
为此,我们需要了解其架构以及构建块。
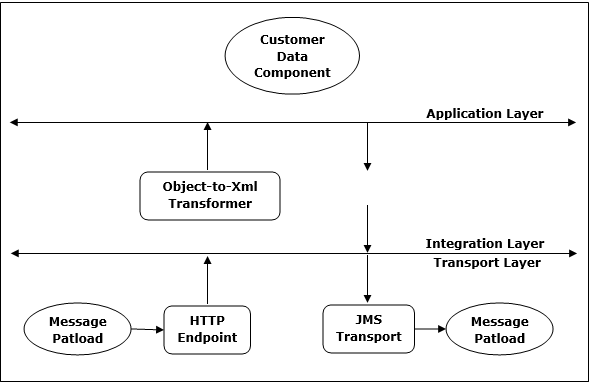
架构
Mule ESB 的架构具有三个层,即传输层、集成层和应用程序层,如下图所示:
通常,可以执行以下三种类型的任务来配置和自定义 Mule 部署:
服务组件开发
此任务涉及开发或重用现有的 POJO 或 Spring Bean。POJO 是一个带有属性的类,它生成 get 和 set 方法,云连接器。另一方面,Spring Bean 包含用于丰富消息的业务逻辑。
服务编排
此任务基本上提供了服务中介,其中涉及配置消息处理器、路由器、转换器和过滤器。
集成
Mule ESB 的最重要任务是集成各种应用程序,而不管它们使用的协议如何。为此,Mule 提供了允许在各种协议连接器上接收和调度消息的传输方法。Mule 支持许多现有的传输方法,或者我们也可以使用自定义传输方法。
构建块
Mule 配置具有以下构建块:
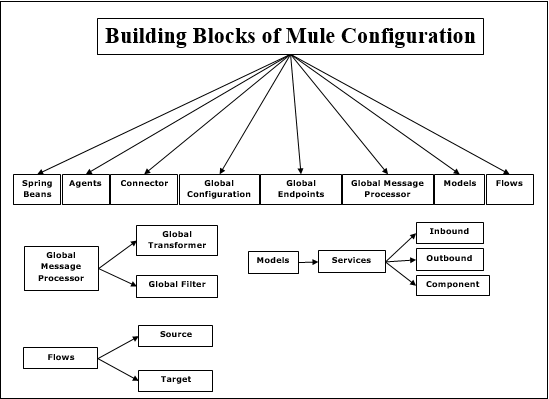
Spring bean
Spring Bean 的主要用途是构建服务组件。构建 Spring 服务组件后,可以通过配置文件定义它,如果没有配置文件,也可以手动定义。
代理 (Agents)
它本质上是在 Anypoint Studio(Mule Studio 之前的版本)中创建的服务。代理在启动服务器时创建,并在停止服务器时销毁。
连接器 (Connector)
它是一个软件组件,配置了特定于协议的参数。主要用于控制协议的使用。例如,JMS 连接器配置了连接,此连接器将在负责实际通信的各种实体之间共享。
全局配置 (Global Configuration)
顾名思义,此构建块用于设置全局属性和设置。
全局端点 (Global Endpoints)
它可以在“全局元素”选项卡中使用,可以在流程中多次使用。
全局消息处理器 (Global Message Processor)
顾名思义,它观察或修改消息或消息流。转换器和过滤器是全局消息处理器的示例。
转换器 (Transformers) − 转换器的主要工作是将数据从一种格式转换为另一种格式。它可以在全局定义,并可以在多个流程中使用。
过滤器 (Filters) − 它是一个过滤器,用于决定应处理哪个 Mule 消息。过滤器基本上指定了必须满足才能处理消息并将其路由到服务的条件。
模型 (Models)
与代理相反,它是 studio 中创建的服务的逻辑分组。我们可以自由地启动和停止特定模型内的所有服务。
服务 (Services) − 服务是封装我们的业务逻辑或组件的服务。它还专门为该服务配置路由器、端点、转换器和过滤器。
端点 (Endpoints) − 可以将其定义为服务将传入(接收)和传出(发送)消息的对象。服务通过端点连接。
流程 (Flow)
消息处理器使用流程来定义源和目标之间的消息流。
Mule 消息结构 (Mule Message Structure)
Mule 消息完全封装在 Mule 消息对象中,它是通过 Mule 流程传递应用程序的数据。Mule 消息的结构如下图所示:
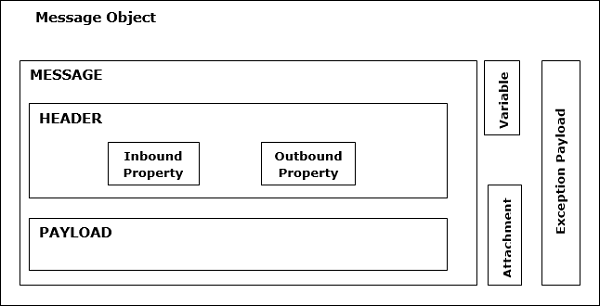
如上图所示,Mule 消息主要包含两部分:
报头 (Header)
它只是消息的元数据,由以下两个属性进一步表示:
输入属性 (Inbound Properties) − 这些是由消息源自动设置的属性。用户无法操作或设置它们。本质上,输入属性是不可变的。
输出属性 (Outbound Properties) − 这些属性包含类似于输入属性的元数据,可以在流程过程中设置。它们可以由 Mule 自动设置,也可以由用户手动设置。本质上,输出属性是可变的。
当消息通过传输从一个流程的输出端点传递到另一个流程的输入端点时,输出属性将变为输入属性。
当消息通过 flow-ref 而不是连接器传递到新流程时,输出属性将保持为输出属性。
有效负载 (Payload)
消息对象携带的实际业务消息称为有效负载。
变量 (Variables)
可以将其定义为关于消息的用户定义元数据。基本上,变量是处理消息的应用程序使用的关于消息的临时信息片段。它并非旨在与消息一起传递到其目的地。它有以下三种类型:
流程变量 (Flow variables) − 这些变量仅适用于它们所在的流程。
会话变量 (Session variables) − 这些变量适用于同一应用程序中的所有流程。
记录变量 (Record variables) − 这些变量仅适用于作为批处理一部分处理的记录。
附件和额外有效负载 (Attachments and Extra Payload)
这些是关于消息有效负载的一些额外元数据,并不一定每次都出现在消息对象中。
MuleSoft - Mule 在我们的机器中
在前面的章节中,我们学习了 Mule ESB 的基础知识。在本节中,让我们学习如何安装和配置它。
先决条件 (Prerequisites)
在计算机上安装 Mule 之前,我们需要满足以下先决条件:
Java 开发工具包 (JDK)
在安装 MULE 之前,请验证系统中是否有受支持版本的 Java。建议使用 JDK 1.8.0 来成功安装 Mule。
操作系统 (Operating System)
Mule 支持以下操作系统:
- MacOS 10.11.x
- HP-UX 11iV3
- AIX 7.2
- Windows 2016 Server
- Windows 2012 R2 Server
- Windows 10
- Windows 8.1
- Solaris 11.3
- RHEL 7
- Ubuntu Server 18.04
- Linux 内核 3.13+
数据库 (Database)
不需要应用程序服务器或数据库,因为 Mule Runtime 作为独立服务器运行。但是,如果我们需要访问数据存储或想要使用应用程序服务器,可以使用以下受支持的应用程序服务器或数据库:
- Oracle 11g
- Oracle 12c
- MySQL 5.5+
- IBM DB2 10
- PostgreSQL 9
- Derby 10
- Microsoft SQL Server 2014
系统要求 (System Requirements)
在系统上安装 Mule 之前,它必须满足以下系统要求:
- 至少 2 GHz CPU 或虚拟化环境中的 1 个虚拟 CPU
- 至少 1 GB RAM
- 至少 4 GB 存储空间
下载 Mule (Download Mule)
要下载 Mule 4 二进制文件,请单击链接 https://www.mulesoft.com/lp/dl/mule-esb-enterprise,它将引导您进入 MuleSoft 的官方网页:
提供必要的详细信息后,您可以获得 Zip 格式的 Mule 4 二进制文件。
安装和运行 Mule (Install and Run Mule)
现在下载 Mule 4 二进制文件后,将其解压缩并为解压缩文件夹内的 Mule 目录设置名为MULE_HOME的环境变量。
例如,在 Windows 和 Linux/Unix 环境中,可以为 Downloads 目录中的 4.1.5 版本设置环境变量,如下所示:
Windows 环境
$ env:MULE_HOME=C:\Downloads\mule-enterprise-standalone-4.1.5\
Unix/Linux 环境
$ export MULE_HOME=~/Downloads/mule-enterprise-standalone-4.1.5/
现在,要测试 Mule 是否在系统中无错误地运行,请使用以下命令:
Windows 环境
$ $MULE_HOME\bin\mule.bat
Unix/Linux 环境
$ $MULE_HOME/bin/mule
以上命令将在前台模式下运行 Mule。如果 Mule 正在运行,则无法在终端上发出任何其他命令。按终端中的ctrl-c命令将停止 Mule。
启动 Mule 服务 (Start Mule Services)
我们可以将 Mule 作为 Windows 服务和 Linux/Unix 守护程序启动。
Mule 作为 Windows 服务
要将 Mule 作为 Windows 服务运行,我们需要按照以下步骤操作:
步骤 1 − 首先,使用以下命令安装它:
$ $MULE_HOME\bin\mule.bat install
步骤 2 − 安装后,我们可以使用以下命令将 mule 作为 Windows 服务运行
$ $MULE_HOME\bin\mule.bat start
Mule 作为 Linux/Unix 守护程序
要将 Mule 作为 Linux/Unix 守护程序运行,我们需要按照以下步骤操作:
步骤 1 − 使用以下命令安装它:
$ $MULE_HOME/bin/mule install
步骤 2 − 安装后,我们可以使用以下命令将 mule 作为 Windows 服务运行:
$ $MULE_HOME/bin/mule start
示例 (Example)
以下示例将 Mule 作为 Unix 守护程序启动:
$ $MULE_HOME/bin/mule start MULE_HOME is set to ~/Downloads/mule-enterprise-standalone-4.1.5 MULE_BASE is set to ~/Downloads/mule-enterprise-standalone-4.1.5 Starting Mule Enterprise Edition... Waiting for Mule Enterprise Edition................. running: PID:87329
部署 Mule 应用程序 (Deploy Mule Apps)
我们可以通过以下步骤部署 Mule 应用程序:
步骤 1 − 首先,启动 Mule。
步骤 2 − Mule 启动后,我们可以通过将 JAR 包文件移动到$MULE_HOME中的apps目录来部署 Mule 应用程序。
停止 Mule 服务 (Stop Mule Services)
我们可以使用stop命令停止 Mule。例如,以下示例将 Mule 作为 Unix 守护程序启动:
$ $MULE_HOME/bin/mule stop MULE_HOME is set to /Applications/mule-enterprise-standalone-4.1.5 MULE_BASE is set to /Applications/mule-enterprise-standalone-4.1.5 Stopping Mule Enterprise Edition... Stopped Mule Enterprise Edition.
我们还可以使用remove命令从系统中删除 Mule 服务或守护程序。以下示例删除作为 Unix 守护程序的 Mule:
$ $MULE_HOME/bin/mule remove MULE_HOME is set to /Applications/mule-enterprise-standalone-4.1.5 MULE_BASE is set to /Applications/mule-enterprise-standalone-4.1.5 Detected Mac OSX: Mule Enterprise Edition is not running. Removing Mule Enterprise Edition daemon...
MuleSoft - Anypoint Studio
MuleSoft 的 Anypoint Studio 是一个用户友好的IDE(集成开发环境),用于设计和测试 Mule 应用程序。它是一个基于 Eclipse 的 IDE。我们可以轻松地从 Mule 调色板中拖动连接器。换句话说,Anypoint Studio 是一个基于 Eclipse 的 IDE,用于开发流程等。
先决条件 (Prerequisites)
在所有操作系统(即 Windows、Mac 和 Linux/Unix)上安装 Mule 之前,我们需要满足以下先决条件。
Java 开发工具包 (JDK) − 在安装 Mule 之前,请验证系统中是否有受支持版本的 Java。建议使用 JDK 1.8.0 来成功安装 Anypoint。
下载和安装 Anypoint Studio (Downloading and Installing Anypoint Studio)
在不同的操作系统上下载和安装 Anypoint Studio 的过程可能会有所不同。接下来,以下是下载和安装 Anypoint Studio 的步骤:
在 Windows 上
要在 Windows 上下载和安装 Anypoint Studio,我们需要按照以下步骤操作:
步骤 1 − 首先,单击链接 https://www.mulesoft.com/lp/dl/studio,并从下拉列表中选择 Windows 操作系统以下载 studio。
步骤 2 − 现在,将其解压缩到‘C:\’根文件夹。
步骤 3 − 打开解压缩的 Anypoint Studio。
步骤 4 − 要接受默认工作区,请单击“确定”。首次加载时,您将收到欢迎消息。
步骤 5 − 现在,单击“开始使用”按钮以使用 Anypoint Studio。
在 OS X 上
要在 OS X 上下载和安装 Anypoint Studio,我们需要按照以下步骤操作:
步骤 1 − 首先,单击链接https://www.mulesoft.com/lp/dl/studio 并下载 studio。
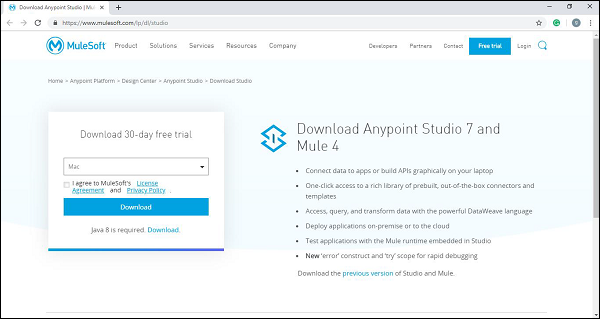
步骤 2 − 现在,将其解压缩。如果您使用的是 OS Sierra 版本,请确保在启动之前将解压缩的应用程序移动到/Applications 文件夹。
步骤 3 − 打开解压缩的 Anypoint Studio。
步骤 4 − 要接受默认工作区,请单击“确定”。首次加载时,您将收到欢迎消息。
步骤 5 − 现在,单击开始使用按钮以使用 Anypoint Studio。
如果您要将自定义路径用于您的工作区,请注意 Anypoint Studio 不会扩展 Linux/Unix 系统中使用的 ~ 波浪号。因此,建议在定义工作区时使用绝对路径。
在 Linux 上
要在 Linux 上下载和安装 Anypoint Studio,我们需要按照以下步骤操作:
步骤 1 − 首先,单击链接 https://www.mulesoft.com/lp/dl/studio,并从下拉列表中选择 Linux 操作系统以下载 studio。
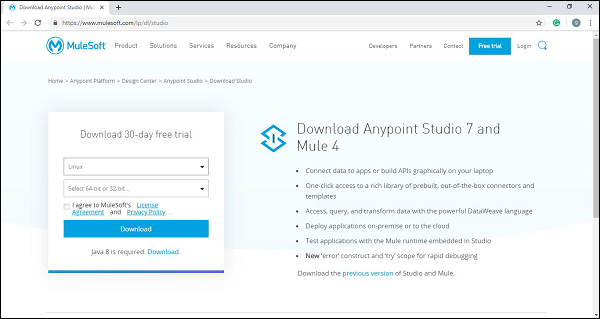
步骤 2 − 现在,将其解压缩。
步骤 3 − 接下来,打开解压缩的 Anypoint Studio。
步骤 4 − 要接受默认工作区,请单击“确定”。首次加载时,您将收到欢迎消息。
步骤 5 − 现在,单击“开始使用”按钮以使用 Anypoint Studio。
如果您要将自定义路径用于您的工作区,请注意 Anypoint Studio 不会扩展 Linux/Unix 系统中使用的 ~ 波浪号。因此,建议在定义工作区时使用绝对路径。
还建议安装 GTK 版本 2 以在 Linux 中使用完整的 Studio 主题。
Anypoint Studio 的功能 (Features of Anypoint Studio)
以下是 Anypoint studio 的一些功能,可在构建 Mule 应用程序时提高生产力:
它可以在本地运行时内立即运行 Mule 应用程序。
Anypoint studio 为我们提供了用于配置 API 定义文件和 Mule 域的可视化编辑器。
它内嵌了单元测试框架,提高了生产力。
Anypoint Studio 提供了内置支持,可以直接部署到 CloudHub。
它可以与 Exchange 集成,用于从其他 Anypoint Platform 组织导入模板、示例、定义和其他资源。
MuleSoft - 探索 Anypoint Studio
Anypoint Studio 编辑器帮助我们设计应用程序、API、属性和配置文件。除了设计之外,它还帮助我们编辑它们。为此,我们有 Mule 配置文件编辑器。要打开此编辑器,请双击 **`/src/main/mule`** 中的应用程序 XML 文件。
要使用我们的应用程序,Mule 配置文件编辑器下有以下三个选项卡。
消息流选项卡
此选项卡以可视化方式显示工作流程。它基本上包含一个画布,帮助我们可视化地检查流程。如果要将 Mule 调色板中的事件处理器添加到画布中,只需拖放即可,它将反映在画布中。
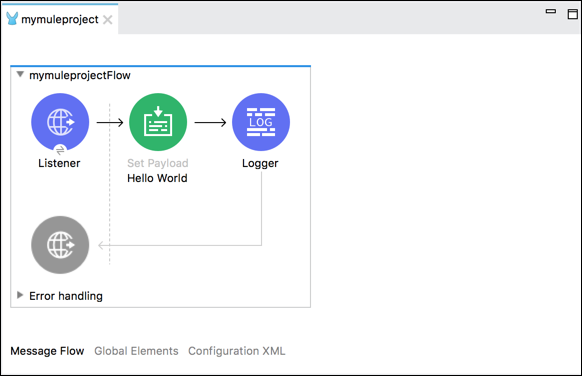
单击事件处理器,即可获取包含所选处理程序属性的 Mule 属性视图。我们也可以编辑它们。
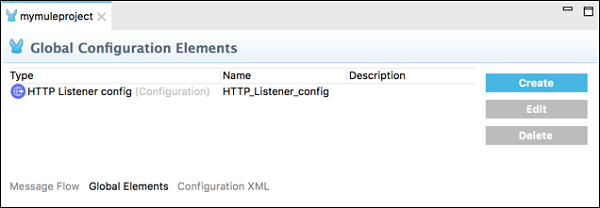
全局元素选项卡
此选项卡包含模块的全局 Mule 配置元素。在此选项卡下,我们可以创建、编辑或删除配置文件。
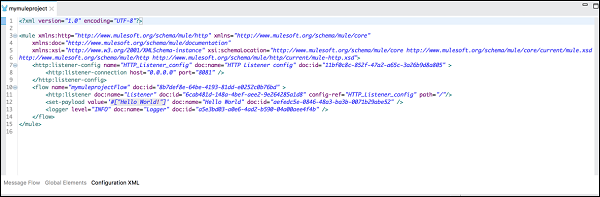
配置 XML 选项卡
顾名思义,它包含定义 Mule 应用程序的 XML。在此处进行的所有更改都将反映在画布以及消息流选项卡下事件处理器的属性视图中。
视图
对于活动编辑器,Anypoint Studio 通过视图帮助我们以图形方式显示项目元数据和属性。用户可以移动、关闭以及在 Mule 项目中添加视图。以下是 Anypoint Studio 中的一些默认视图:
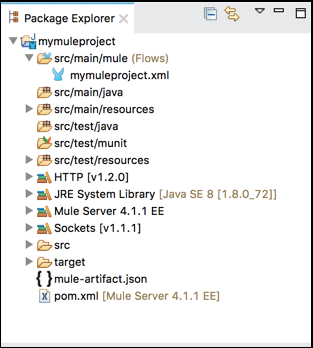
包资源管理器
包资源管理器视图的主要任务是显示 Mule 项目中包含的项目文件夹和文件。我们可以通过单击项目旁边的箭头来展开或折叠 Mule 项目文件夹。可以通过双击打开文件夹或文件。请查看其截图:
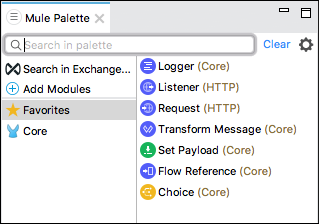
Mule 调色板
Mule 调色板视图显示事件处理器(例如作用域、过滤器和流控制路由器)以及模块及其相关操作。Mule 调色板视图的主要任务如下:
- 此视图帮助我们管理项目中的模块和连接器。
- 我们还可以从 Exchange 添加新元素。
请查看其截图:
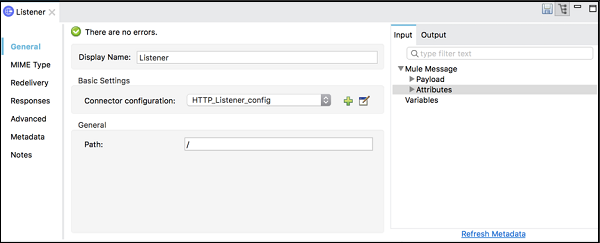
Mule 属性
顾名思义,它允许我们编辑当前在画布中选择的模块的属性。Mule 属性视图包括以下内容:
DataSense 资源管理器,提供有关有效负载数据结构的实时信息。
如有可用,则为输入和输出属性或变量。
以下是截图:
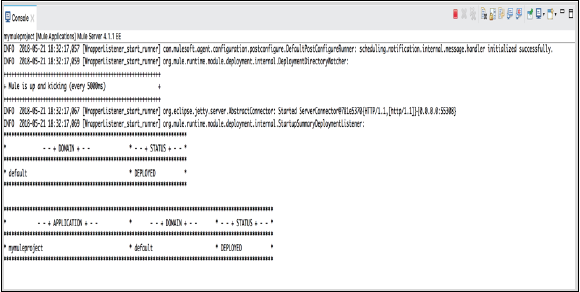
控制台
每当我们创建或运行 Mule 应用程序时,嵌入式 Mule 服务器都会显示 Studio 报告的事件和问题列表(如果有)。控制台视图包含该嵌入式 Mule 服务器的控制台。请查看其截图:
问题视图
在处理 Mule 项目时,我们可能会遇到许多问题。所有这些问题都显示在问题视图中。以下是截图:

透视图
在 Anypoint Studio 中,它是在特定排列中的一组视图和编辑器。Anypoint Studio 中有两种类型的透视图:
**Mule 设计透视图** - 这是我们在 Studio 中获得的默认透视图。
**Mule 调试透视图** - Anypoint Studio 提供的另一个透视图是 Mule 调试透视图。
另一方面,我们还可以创建自己的透视图,并可以添加或删除任何默认视图。
MuleSoft - 创建第一个 Mule 应用程序
在本章中,我们将使用 MuleSoft 的 Anypoint Studio 创建第一个 Mule 应用程序。要创建它,首先我们需要启动 Anypoint Studio。
启动 Anypoint Studio
单击 Anypoint Studio 启动它。如果这是第一次启动,您将看到以下窗口:
Anypoint Studio 的用户界面
单击“转到工作区”按钮后,您将进入 Anypoint Studio 的用户界面,如下所示:
创建 Mule 应用程序的步骤
要创建 Mule 应用程序,请按照以下步骤操作:
创建新项目
创建 Mule 应用程序的第一步是创建一个新项目。这可以通过按照路径 **文件 → 新建 → Mule 项目** 来完成,如下所示:
命名项目
如上所述,单击新的 Mule 项目后,将打开一个新窗口,要求输入项目名称和其他规范。为项目命名为“**TestAPP1**”,然后单击“完成”按钮。
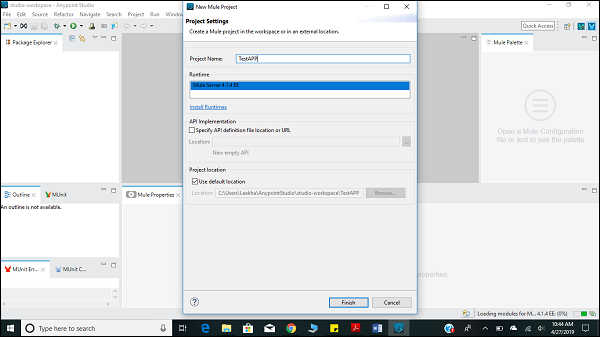
单击“完成”按钮后,将打开为您的 Mule 项目(即“**TestAPP1**”)构建的工作区。您可以看到上一章中描述的所有**编辑器**和**视图**。
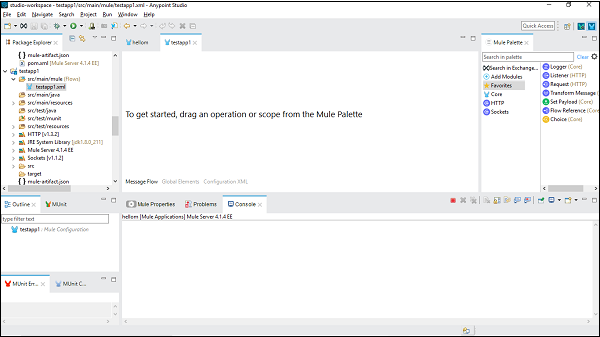
配置连接器
在这里,我们将为 HTTP 侦听器构建一个简单的 Mule 应用程序。为此,我们需要将 HTTP 侦听器连接器从 Mule 调色板拖放到工作区中,如下所示:
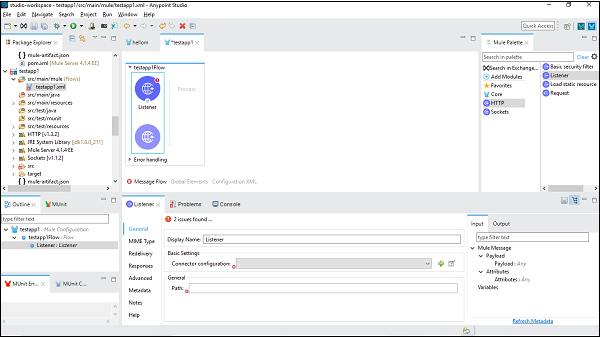
现在,我们需要配置它。单击基本设置下的连接器配置后的绿色“+”号,如上所示。
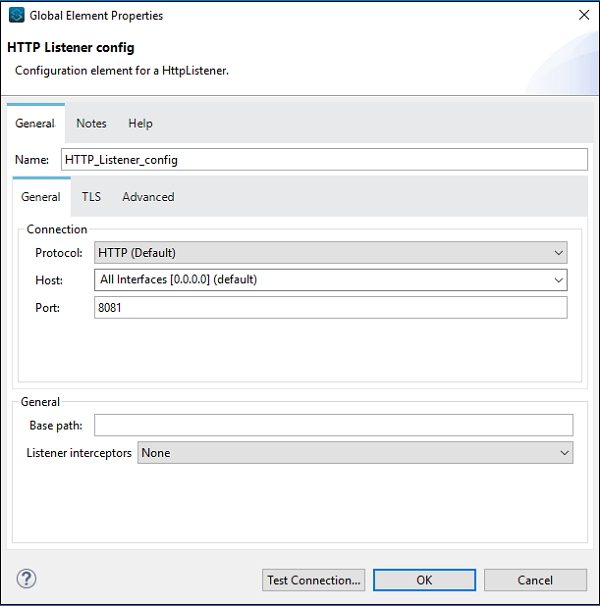
单击“确定”后,它将带您返回 HTTP 侦听器属性页面。现在我们需要在“常规”选项卡下提供路径。在此特定示例中,我们提供了“** /FirstAPP**”作为路径名称。
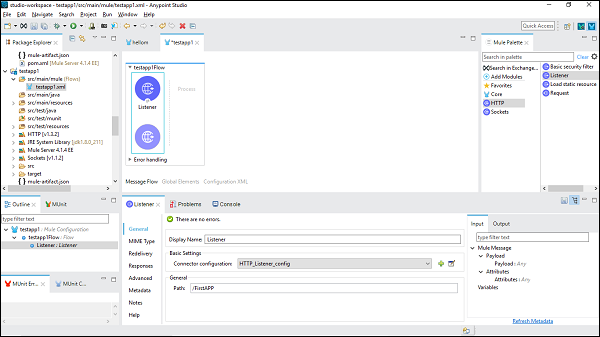
配置设置有效负载连接器
现在,我们需要使用“设置有效负载”连接器。我们还需要在“设置”选项卡下提供其值,如下所示:
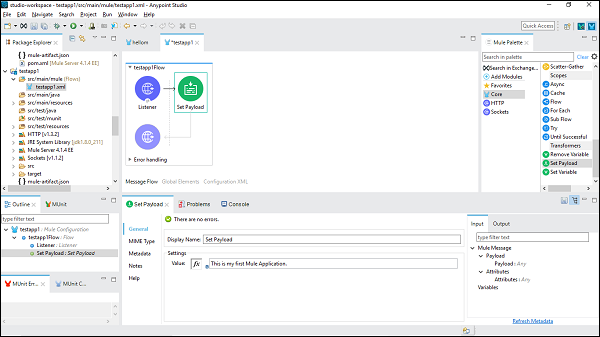
在此示例中提供的名称是“**这是一个我的第一个 Mule 应用程序**”。
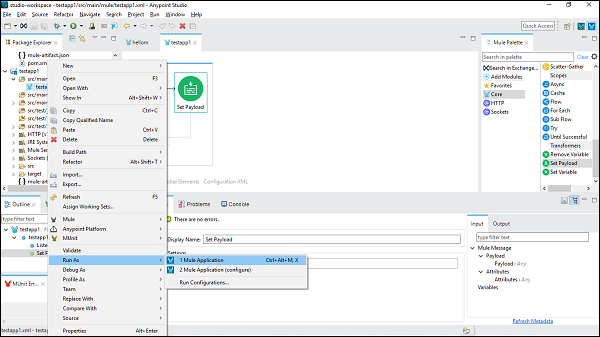
运行 Mule 应用程序
现在,保存它并单击“作为 Mule 应用程序运行”,如下所示:
我们可以在控制台中检查它,它会部署应用程序,如下所示:
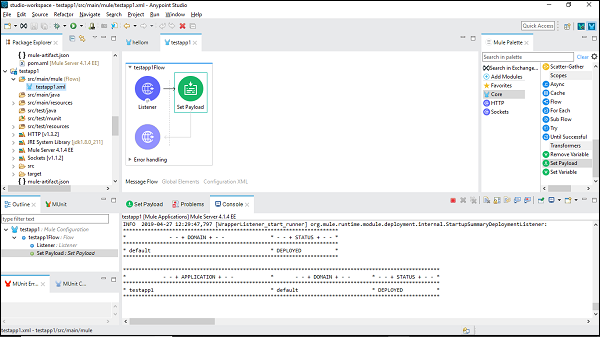
这表明您已成功构建了第一个 Mule 应用程序。
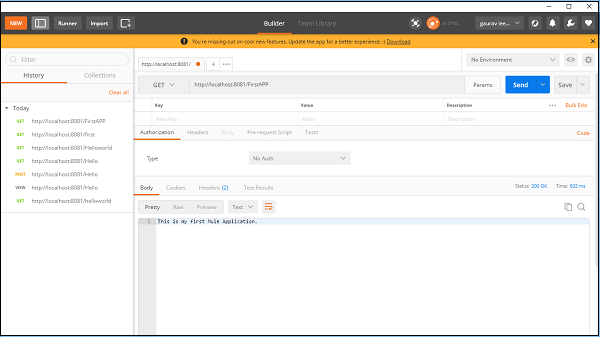
验证 Mule 应用程序
现在,我们需要测试我们的应用程序是否正在运行。**转到 POSTMAN**(一个 Chrome 应用程序),输入 URL:**http:/localhost:8081**。它显示了我们在构建 Mule 应用程序时提供的消息,如下所示:
MuleSoft - DataWeave 语言
DataWeave 本质上是一种 MuleSoft 表达式语言。它主要用于访问和转换通过 Mule 应用程序接收的数据。Mule 运行时负责运行我们 Mule 应用程序中的脚本和表达式,DataWeave 与 Mule 运行时紧密集成。
DataWeave 语言的特性
以下是 DataWeave 语言的一些重要特性:
数据可以很容易地从一种格式转换为另一种格式。例如,我们可以将 application/json 转换为 application/xml。输入有效负载如下:
{
"title": "MuleSoft",
"author": " tutorialspoint.com ",
"year": 2019
}
以下是 DataWeave 的转换代码:
%dw 2.0
output application/xml
---
{
order: {
'type': 'Tutorial',
'title': payload.title,
'author': upper(payload.author),
'year': payload.year
}
}
接下来,**输出**有效负载如下:
<?xml version = '1.0' encoding = 'UTF-8'?> <order> <type>Tutorial</type> <title>MuleSoft</title> <author>tutorialspoint.com</author> <year>2019</year> </order>
转换组件可用于创建执行简单和复杂数据转换的脚本。
我们可以访问和使用我们需要的大多数 Mule 消息处理器支持 DataWeave 表达式,从而在 Mule 事件的部分上使用核心 DataWeave 函数。
先决条件 (Prerequisites)
在我们的计算机上使用 DataWeave 脚本之前,我们需要满足以下先决条件:
需要 Anypoint Studio 7 来使用 DataWeave 脚本。
安装 Anypoint Studio 后,我们需要设置一个包含转换消息组件的项目才能使用 DataWeave 脚本。
使用 DataWeave 脚本(带示例)的步骤
要使用 DataWeave 脚本,我们需要按照以下步骤操作:
步骤 1
首先,我们需要像上一章那样,使用**文件 → 新建 → Mule 项目**设置一个新项目。
步骤 2
接下来,我们需要提供项目的名称。对于此示例,我们将其命名为“**Mule_test_script**”。
步骤 3
现在,我们需要将**转换消息组件**从**Mule 调色板选项卡**拖到**画布**中。如下所示:
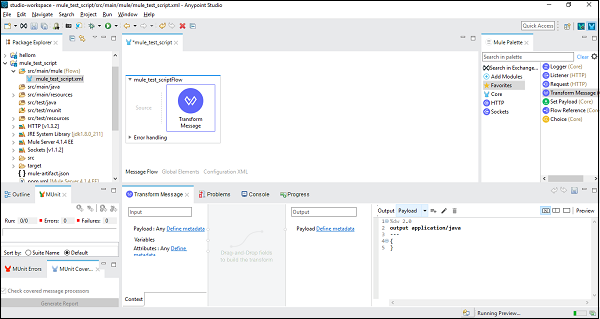
步骤 4
接下来,在**转换消息组件**选项卡中,单击“预览”以打开“预览”窗格。我们可以通过单击“预览”旁边的空矩形来展开源代码区域。
步骤 5
现在,我们可以开始使用 DataWeave 语言编写脚本了。
示例 (Example)
以下是将两个字符串连接成一个字符串的简单示例:
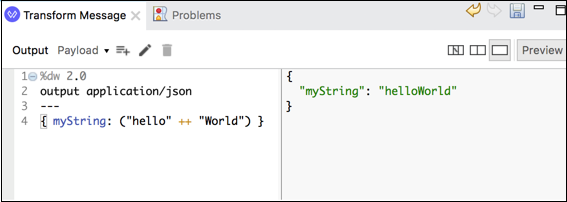
上述 DataWeave 脚本具有键值对**({ myString: ("hello" ++ "World") })**,它将把两个字符串连接成一个字符串。
MuleSoft - 消息处理器和脚本组件
脚本模块使用户能够在 Mule 中使用脚本语言。简单来说,脚本模块可以交换用脚本语言编写的自定义逻辑。脚本可以用作实现或转换器。它们可用于表达式计算,即用于控制消息路由。
Mule 支持以下脚本语言:
- Groovy
- Python
- JavaScript
- Ruby
如何安装脚本模块?
实际上,Anypoint Studio 自带脚本模块。如果在 Mule 调色板中找不到该模块,则可以使用“+ 添加模块”来添加它。添加后,我们可以在 Mule 应用程序中使用脚本模块操作。
实现示例
如前所述,我们需要将模块拖放到画布中以创建工作区并在我们的应用程序中使用它。以下是一个示例:
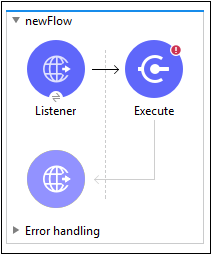
我们已经知道如何配置 HTTP 侦听器组件;因此,我们将讨论如何配置脚本模块。我们需要按照以下步骤配置脚本模块:
步骤 1
从 Mule 调色板搜索脚本模块,并将脚本模块的**EXECUTE**操作拖到您的流中,如上所示。
步骤 2
现在,通过双击打开“执行”配置选项卡。
步骤 3
在**常规**选项卡下,我们需要在**代码文本窗口**中提供代码,如下所示:
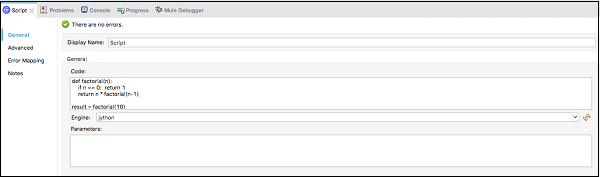
步骤 4
最后,我们需要从执行组件中选择**引擎**。引擎列表如下:
- Groovy
- Nashorn(javaScript)
- jython(Python)
- jRuby(Ruby)
以上执行示例在配置XML编辑器中的XML如下:
<scripting:execute engine="jython" doc:name = "Script">
<scripting:code>
def factorial(n):
if n == 0: return 1
return n * factorial(n-1)
result = factorial(10)
</scripting:code>
</scripting:execute>
消息来源
Mule 4 的消息模型比 Mule 3 简化,使跨连接器以一致的方式处理数据更容易,而不会覆盖信息。在 Mule 4 消息模型中,每个 Mule 事件包含两部分:**一条消息及其关联的变量**。
Mule 消息包含有效负载及其属性,其中属性主要是元数据,例如文件大小。
变量保存任意用户信息,例如操作结果、辅助值等。
输入
Mule 3 中的输入属性在 Mule 4 中变为属性。我们知道输入属性存储通过消息源获得的有效负载的附加信息,但在 Mule 4 中,这是借助属性完成的。属性具有以下优点:
借助属性,我们可以轻松查看哪些数据可用,因为属性是强类型的。
我们可以轻松访问属性中包含的信息。
以下是 Mule 4 中典型消息的示例:
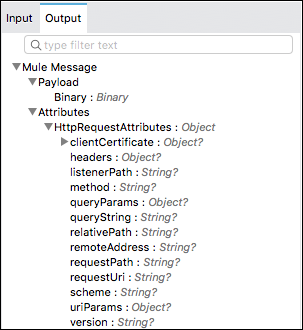
输出
Mule 3 中的输出属性必须由 Mule 连接器和传输显式指定才能发送附加数据。但在 Mule 4 中,可以使用 DataWeave 表达式分别设置每个属性。它不会对主流程产生任何副作用。
例如,下面的 DataWeave 表达式将执行 HTTP 请求并生成标头和查询参数,而无需设置消息属性。这在下面的代码中显示:
<http:request path = "M_issue" config-ref="http" method = "GET">
<http:headers>#[{'path':'input/issues-list.json'}]</http:headers>
<http:query-params>#[{'provider':'memory-provider'}]</http:query-params>
</http:request>
消息处理器
Mule 从消息源接收消息后,消息处理器的处理开始。Mule 使用一个或多个消息处理器通过流程处理消息。消息处理器的主要任务是在消息通过 Mule 流程时转换、过滤、丰富和处理消息。
Mule 处理器的分类
以下是基于功能的 Mule 处理器类别:
**连接器** - 这些消息处理器发送和接收数据。它们还通过标准协议或第三方 API 将数据插入外部数据源。
**组件** - 这些消息处理器本质上很灵活,并且执行以各种语言(如 Java、JavaScript、Groovy、Python 或 Ruby)实现的业务逻辑。
**过滤器** - 它们过滤消息,并仅允许基于特定条件继续在流程中处理特定消息。
**路由器** - 此消息处理器用于控制消息流的路由、重新排序或拆分。
**作用域** - 它们基本上包装代码片段,用于定义流程内的细粒度行为。
**转换器** - 转换器的作用是转换消息有效负载类型和数据格式,以促进系统之间的通信。
**业务事件** - 它们基本上捕获与关键绩效指标相关的数据。
**异常策略** - 这些消息处理器处理消息处理期间发生的任何类型的错误。
MuleSoft - 核心组件和配置
Mule 最重要的能力之一是它可以使用组件执行路由、转换和处理,因此结合各种元素的 Mule 应用程序的配置文件大小非常大。
以下是 Mule 提供的配置模式类型:
- 简单服务模式
- 桥接
- 验证器
- HTTP 代理
- WS 代理
配置组件
在 Anypoint Studio 中,我们可以按照以下步骤配置组件:
步骤 1
我们需要将我们希望在 Mule 应用程序中使用的组件拖动到应用程序中。例如,这里我们使用 HTTP 监听器组件,如下所示:
步骤 2
接下来,双击组件以获取配置窗口。对于 HTTP 监听器,它如下所示:
步骤 3
我们可以根据项目的需要配置组件。例如,我们为 HTTP 监听器组件进行了配置:
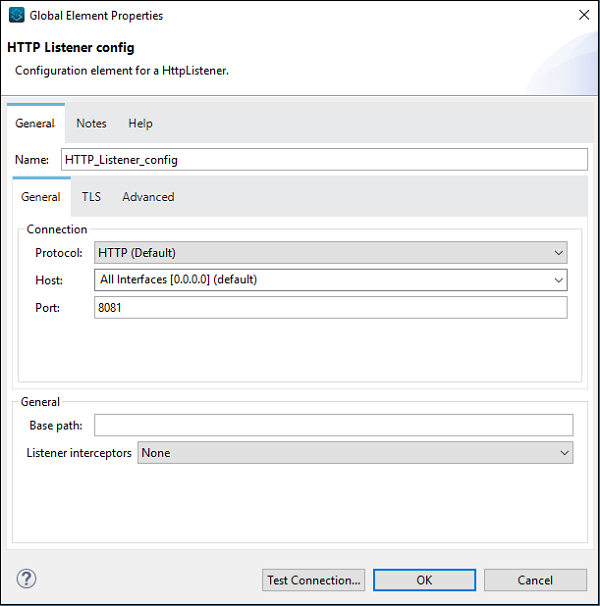
核心组件是 Mule 应用程序中工作流的重要构建块之一。这些核心组件提供了处理 Mule 事件的逻辑。在 Anypoint Studio 中,要访问这些核心组件,您可以从 Mule 调色板中单击“核心”,如下所示:
以下是**Mule 4 中各种核心组件及其工作方式**:
自定义业务事件
此核心组件用于收集有关处理 Mule 应用程序中业务事务的流程以及消息处理器的信息。换句话说,我们可以使用自定义业务事件组件在我们的工作流程中添加以下内容:
- 元数据
- 关键绩效指标 (KPI)
如何添加 KPI?
以下是将 KPI 添加到 Mule 应用程序流程中的步骤:
**步骤 1** - 按照 Mule **调色板→核心→组件→自定义业务事件**,将自定义业务事件组件添加到 Mule 应用程序的工作流程中。
**步骤 2** - 单击组件以打开它。
**步骤 3** - 现在,我们需要为显示名称和事件名称提供值。
**步骤 4** - 要从消息有效负载中捕获信息,请按如下方式添加 KPI:
为 KPI(*tracking: meta-data* 元素)提供一个名称(键)和一个值。该名称将用于运行时管理器的搜索界面。
提供一个值,该值可以是任何 Mule 表达式。
示例 (Example)
下表包含 KPI 列表及其名称和值:
| 名称 | 表达式/值 |
|---|---|
| 学生学号 | #[payload[‘RollNo’]] |
| 学生姓名 | #[payload[‘Name’]] |
动态评估
此核心组件用于动态选择 Mule 应用程序中的脚本。我们也可以通过转换消息组件使用硬编码脚本,但使用动态评估组件是更好的方法。此核心组件的工作原理如下:
- 首先,它评估一个表达式,该表达式应产生另一个脚本。
- 然后它评估该脚本以获得最终结果。
这样,它允许我们动态选择脚本,而不是对其进行硬编码。
示例 (Example)
以下是如何通过 Id 查询参数从数据库中选择脚本并将该脚本存储在名为 *MyScript* 的变量中的示例。现在,动态评估组件将访问该变量以调用脚本,以便它可以从 **UName** 查询参数中添加名称变量。
流程的 XML 配置如下:
<flow name = "DynamicE-example-flow">
<http:listener config-ref = "HTTP_Listener_Configuration" path = "/"/>
<db:select config-ref = "dbConfig" target = "myScript">
<db:sql>#["SELECT script FROM SCRIPTS WHERE ID =
$(attributes.queryParams.Id)"]
</db:sql>
</db:select>
<ee:dynamic-evaluate expression = "#[vars.myScript]">
<ee:parameters>#[{name: attributes.queryParams.UName}]</ee:parameters>
</ee:dynamic-evaluate>
</flow>
脚本可以使用消息、有效负载、vars 或属性等上下文变量。但是,如果要添加自定义上下文变量,则需要提供一组键值对。
配置动态评估
下表提供了一种配置动态评估组件的方法:
| 字段 | 值 | 描述 | 示例 (Example) |
|---|---|---|---|
| 表达式 | DataWeave 表达式 | 它指定要评估为最终脚本的表达式。 | expression="#[vars.generateOrderScript]" |
| 参数 | DataWeave 表达式 | 它指定键值对。 | #[{joiner: ' and ', id: payload.user.id}] |
流程引用组件
如果要将 Mule 事件路由到同一个 Mule 应用程序中的另一个流程或子流程并返回,则流程引用组件是正确的选择。
特性
以下是此核心组件的特性:
此核心组件允许我们将整个引用流程视为当前流程中的单个组件。
它将 Mule 应用程序分解成离散且可重用的单元。例如,一个流程定期列出文件。它可能会引用另一个处理列表操作输出的流程。
这样,我们可以附加指向处理流程的流程引用,而不是附加整个处理步骤。下面的屏幕截图显示流程引用核心组件指向名为 **ProcessFiles** 的子流程。
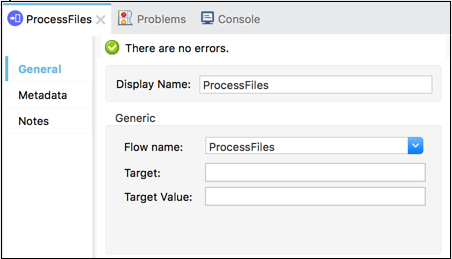
工作原理
可以通过下图了解流程引用组件的工作原理:
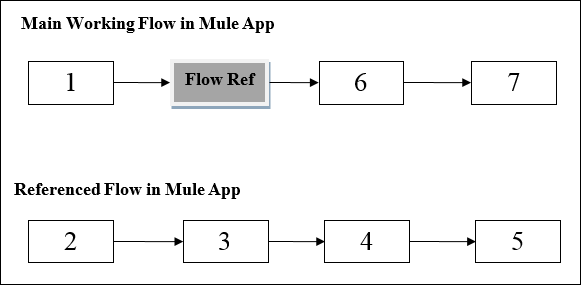
该图显示了当一个流程引用同一个应用程序中的另一个流程时 Mule 应用程序中的处理顺序。当 Mule 应用程序中的主要工作流程触发时,Mule 事件会贯穿整个流程并执行该流程,直到 Mule 事件到达流程引用。
到达流程引用后,Mule 事件将从头到尾执行引用的流程。Mule 事件完成执行引用流程后,它将返回到主流程。
示例 (Example)
为了更好地理解,**让我们在 Anypoint Studio 中使用此组件**。在此示例中,我们使用 HTTP 监听器来获取消息,就像我们在上一章中所做的那样。因此,我们可以拖放组件并进行配置。但对于此示例,我们需要添加一个子流程组件,并在其下设置有效负载组件,如下所示:
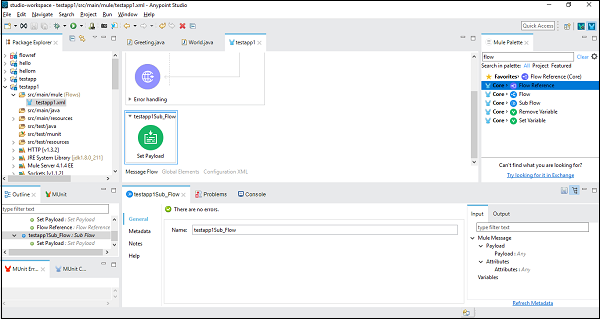
接下来,我们需要通过双击来配置**设置有效负载**。这里我们提供值“已执行子流程”,如下所示:
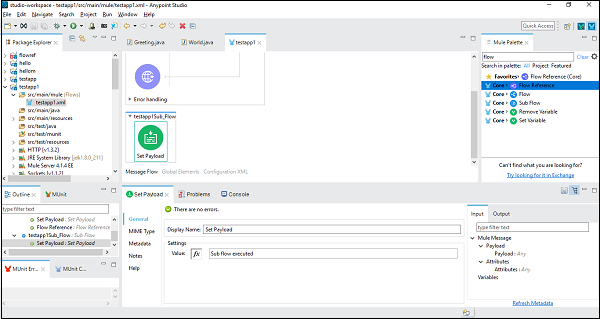
成功配置子流程组件后,我们需要在主流程的“设置有效负载”之后设置流程引用组件,我们可以从 Mule 调色板中将其拖放,如下所示:
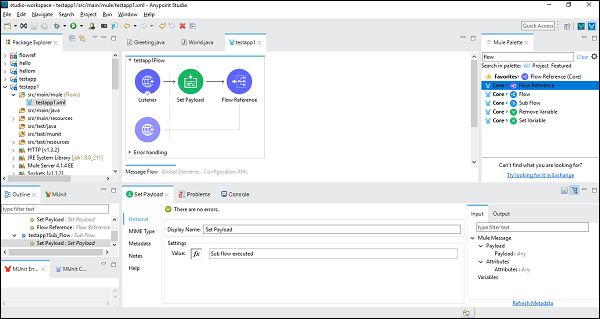
接下来,在配置流程引用组件时,我们需要在“通用”选项卡下选择流程名称,如下所示:
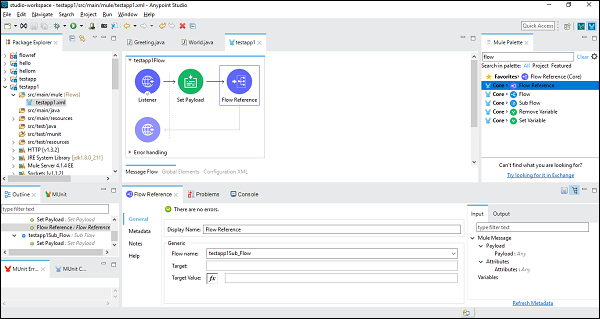
现在,保存并运行此应用程序。要测试此功能,请转到 POSTMAN,并在 URL 栏中键入 **http:/localhost:8181/FirstAPP**,您将收到消息“已执行子流程”。
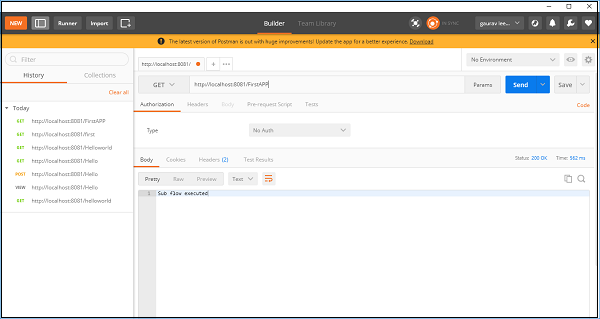
日志记录组件
名为日志记录器的核心组件通过记录重要信息(如错误消息、状态通知、有效负载等)来帮助我们监控和调试 Mule 应用程序。在 AnyPoint Studio 中,它们显示在**控制台**中。
优势
以下是日志记录组件的一些优势:
- 我们可以在工作流程中的任何位置添加此核心组件。
- 我们可以将其配置为记录我们指定的字符串。
- 我们可以将其配置为我们编写的 DataWeave 表达式的输出。
- 我们还可以将其配置为字符串和表达式的任意组合。
示例 (Example)
下面的示例在浏览器中显示“Hello World”消息,并在设置有效负载的同时记录该消息。
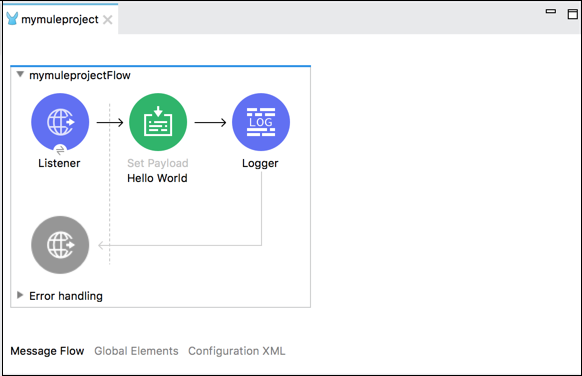
以下是上述示例中流程的 XML 配置:
<http:listener-config name = "HTTP_Listener_Configuration" host = "localhost" port = "8081"/> <flow name = "mymuleprojectFlow"> <http:listener config-ref="HTTP_Listener_Configuration" path="/"/> <set-payload value="Hello World"/> <logger message = "#[payload]" level = "INFO"/> </flow>
消息转换组件
消息转换组件,也称为转换组件,允许我们将输入数据转换为新的输出格式。
构建转换的方法
我们可以通过以下两种方法构建转换:
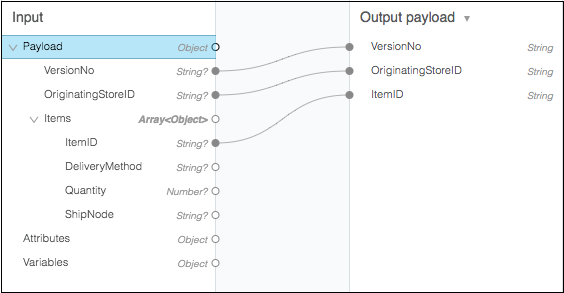
拖放编辑器(图形视图) - 这是构建转换的首选和最常用的方法。在这种方法中,我们可以使用此组件的可视化映射器来拖放传入数据结构的元素。例如,在下图中,两个树视图显示了输入和输出的预期元数据结构。连接输入到输出字段的线表示两个树视图之间的映射。
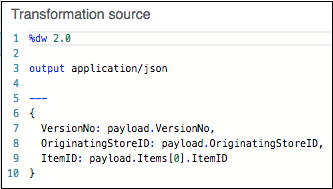
脚本视图 - 转换的可视化映射也可以借助 DataWeave(Mule 代码语言)来表示。我们可以对一些高级转换进行编码,例如聚合、规范化、分组、连接、分区、透视和过滤。示例如下:
此核心组件基本上接受变量、属性或消息有效负载的输入和输出元数据。我们可以为以下内容提供特定于格式的资源:
- CSV
- 模式
- 平面文件模式
- JSON
- 对象类
- 简单类型
- XML 模式
- Excel 列名和类型
- 固定宽度列名和类型
MuleSoft - 端点
端点基本上包括那些触发或启动 Mule 应用程序工作流程中处理的组件。它们在 Anypoint Studio 中称为源,在 Mule 的设计中心中称为触发器。Mule 4 中一个重要的端点是调度程序组件。
调度程序端点
此组件基于时间条件工作,这意味着它使我们能够在满足基于时间的条件时触发流程。例如,调度程序可以触发一个事件,以每隔 10 秒启动一个 Mule 工作流程。我们还可以使用灵活的 Cron 表达式来触发调度程序端点。
关于调度程序的重要提示
使用调度程序事件时,需要注意以下几点:
调度程序端点遵循 Mule 运行时运行的机器的时区。
假设 Mule 应用程序在 CloudHub 上运行,则调度程序将遵循 CloudHub 工作程序运行的区域的时区。
在任何给定时间,只有一个由调度程序端点触发的流程可以处于活动状态。
在 Mule 运行时集群中,调度程序端点仅在主节点上运行或触发。
配置调度程序的方法
如上所述,我们可以将调度程序端点配置为以固定间隔触发,也可以提供 Cron 表达式。
配置调度程序的参数(对于固定间隔)
以下是将调度程序设置为定期触发流程的参数:
频率 - 它基本上描述了调度程序端点将触发 Mule 流程的频率。此时间单位可以从时间单位字段中选择。如果您没有为此提供任何值,它将使用默认值 1000。另一方面,如果您提供 0 或负值,它也将使用默认值。
启动延迟 - 这是应用程序启动后第一次触发 Mule 流程之前必须等待的时间量。启动延迟的值以与频率相同的时间单位表示。其默认值为 0。
时间单位 - 它描述了频率和启动延迟的时间单位。时间单位的可能值为毫秒、秒、分钟、小时、天。默认值为毫秒。
配置调度程序的参数(对于 Cron 表达式)
实际上,Cron 是用于描述时间和日期信息的标准。如果您使用灵活的 Cron 表达式来使调度程序触发,则调度程序端点会跟踪每一秒,并在 Quartz Cron 表达式与时间日期设置匹配时创建一个 Mule 事件。使用 Cron 表达式,事件可以只触发一次或定期触发。
下表给出了六个必需设置的日期时间表达式:
| 属性 | 值 |
|---|---|
| 秒 | 0-59 |
| 分钟 | 0-59 |
| 小时 | 0-23 |
| 月份中的某一天 | 1-31 |
| 月份 | 1-12 或 JAN-DEC |
| 星期几 | 1-7 或 SUN-SAT |
以下是一些调度程序端点支持的 Quartz Cron 表达式的示例:
½ * * * * ? - 表示调度程序每天每 2 秒运行一次。
0 0/5 16 ** ? - 表示调度程序从下午 4 点开始,每 5 分钟运行一次,直到下午 4:55,每天如此。
1 1 1 1, 5 * ? - 表示调度程序每年的一月一日和四月一日运行。
示例 (Example)
以下代码每秒记录一次“hi”消息:
<flow name = "cronFlow" doc:id = "ae257a5d-6b4f-4006-80c8-e7c76d2f67a0">
<doc:name = "Scheduler" doc:id = "e7b6scheduler8ccb-c6d8-4567-87af-aa7904a50359">
<scheduling-strategy>
<cron expression = "* * * * * ?" timeZone = "America/Los_Angeles"/>
</scheduling-strategy>
</scheduler>
<logger level = "INFO" doc:name = "Logger"
doc:id = "e2626dbb-54a9-4791-8ffa-b7c9a23e88a1" message = '"hi"'/>
</flow>
MuleSoft - 流程控制和转换器
流程控制(路由器)
流程控制组件的主要任务是获取输入 Mule 事件并将其路由到一个或多个单独的组件序列。它基本上是将输入 Mule 事件路由到其他组件序列。因此,它也称为路由器。选择和散射-收集路由器是流程控制组件中最常用的路由器。
选择路由器
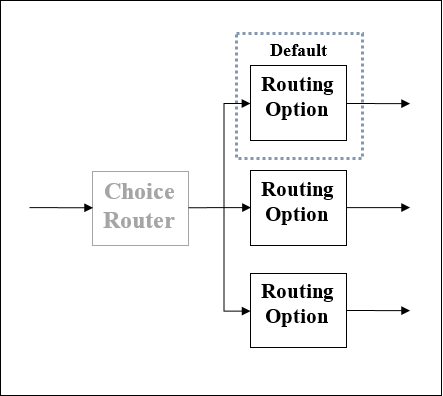
顾名思义,此路由器应用 DataWeave 逻辑来选择两条或多条路由中的一条。如前所述,每条路由都是 Mule 事件处理程序的一个单独序列。我们可以将选择路由器定义为根据用于评估消息内容的一组 DataWeave 表达式动态地通过流程路由消息的路由器。
选择路由器的示意图
使用选择路由器的效果就像在流程中添加条件处理或在大多数编程语言中添加if/then/else代码块一样。以下是具有三个选项的选择路由器的示意图。其中一个是默认路由器。
散射-收集路由器
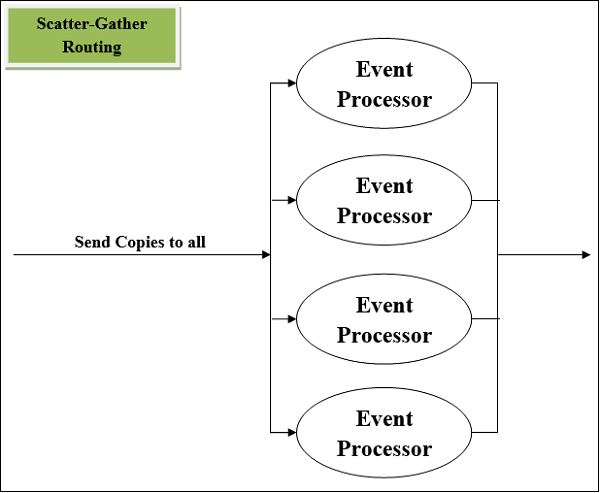
另一个最常用的路由事件处理器是散射-收集组件。顾名思义,它基于散射(复制)和收集(合并)的基本原理。我们可以通过以下两点来了解其工作原理:
首先,此路由器将 Mule 事件复制(散射)到两条或多条并行路由。条件是每条路由必须是一条或多条事件处理程序的序列,这就像一个子流程。在这种情况下,每条路由都将使用单独的线程创建 Mule 事件。每个 Mule 事件都将拥有自己的有效负载、属性和变量。
接下来,此路由器从每条路由收集创建的 Mule 事件,然后将它们合并到一个新的 Mule 事件中。之后,它将此合并的 Mule 事件传递给下一个事件处理器。这里的条件是,只有当每条路由都成功完成时,S-G 路由器才会将合并的 Mule 事件传递给下一个事件处理器。
散射-收集路由器的示意图
以下是具有四个事件处理器的散射-收集路由器的示意图。它并行执行每条路由,而不是顺序执行。
散射-收集路由器的错误处理
首先,我们必须了解散射-收集组件中可能生成的错误类型。事件处理器中可能生成任何错误,导致散射-收集组件抛出类型为Mule: COMPOSITE_ERROR的错误。此错误仅在每条路由失败或完成之后才会由 S-G 组件抛出。
为了处理此错误类型,可以在散射-收集组件的每条路由中使用try 范围。如果try 范围成功处理了错误,则路由肯定能够生成 Mule 事件。
转换器
假设我们想要设置或删除任何 Mule 事件的一部分,转换器组件是最佳选择。转换器组件的类型如下:
删除变量转换器
顾名思义,此组件获取变量名并从 Mule 事件中删除该变量。
配置删除变量转换器
下表显示了配置删除变量转换器时需要考虑的字段名称及其说明:
| 序号 | 字段和说明 |
|---|---|
| 1 |
显示名称 (doc:name) 我们可以自定义它以在我们的 Mule 工作流程中显示此组件的唯一名称。 |
| 2 | 名称 (variableName) 它表示要删除的变量的名称。 |
设置有效负载转换器
借助set-payload组件,我们可以更新有效负载(可以是文字字符串或 DataWeave 表达式)的消息。不建议将此组件用于复杂的表达式或转换。它可以用于简单的选择。
下表显示了配置设置有效负载转换器时需要考虑的字段名称及其说明:
| 字段 | 用法 | 说明 |
|---|---|---|
| 值 (value) | 必需 | 值字段是设置有效负载所必需的。它将接受文字字符串或 DataWeave 表达式,用于定义如何设置有效负载。示例例如“some string”。 |
| MIME 类型 (mimeType) | 可选 | 它是可选的,但表示分配给消息有效负载的值的 MIME 类型。示例例如 text/plain。 |
| 编码 (encoding) | 可选 | 它也是可选的,但表示分配给消息有效负载的值的编码。示例例如 UTF-8。 |
我们可以通过 XML 配置代码设置有效负载:
使用静态内容 - 以下 XML 配置代码将使用静态内容设置有效负载:
<set-payload value = "{ 'name' : 'Gaurav', 'Id' : '2510' }"
mimeType = "application/json" encoding = "UTF-8"/>
使用表达式内容 - 以下 XML 配置代码将使用表达式内容设置有效负载:
<set-payload value = "#['Hi' ++ ' Today is ' ++ now()]"/>
上述示例将今天的日期附加到消息有效负载“Hi”。
设置变量转换器
借助set variable组件,我们可以创建或更新变量以存储值,这些值可以是简单的文字值(如字符串、消息有效负载或属性对象),以便在 Mule 应用程序的流程中使用。不建议将此组件用于复杂的表达式或转换。它可以用于简单的选择。
配置设置变量转换器
下表显示了配置设置有效负载转换器时需要考虑的字段名称及其说明:
| 字段 | 用法 | 说明 |
|---|---|---|
| 变量名称 (variableName) | 必需 | 这是必需字段,它表示变量的名称。在给出名称时,请遵循命名约定,例如它必须包含数字、字符和下划线。 |
| 值 (value) | 必需 | 值字段是设置变量所必需的。它将接受文字字符串或 DataWeave 表达式。 |
| MIME 类型 (mimeType) | 可选 | 它是可选的,但表示变量的 MIME 类型。示例例如 text/plain。 |
| 编码 (encoding) | 可选 | 它也是可选的,但表示变量的编码。示例例如 ISO 10646/Unicode(UTF-8)。 |
示例 (Example)
以下示例将变量设置为消息有效负载:
Variable Name = msg_var Value = payload in Design center and #[payload] in Anypoint Studio
同样,以下示例将变量设置为消息有效负载:
Variable Name = msg_var Value = attributes in Design center and #[attributes] in Anypoint Studio.
MuleSoft - 使用 Anypoint Studio 的 Web 服务
REST Web 服务
REST 的全称是表述性状态转移,它与 HTTP 绑定。因此,如果您想要设计一个专门在 Web 上使用的应用程序,REST 是最佳选择。
使用 RESTful Web 服务
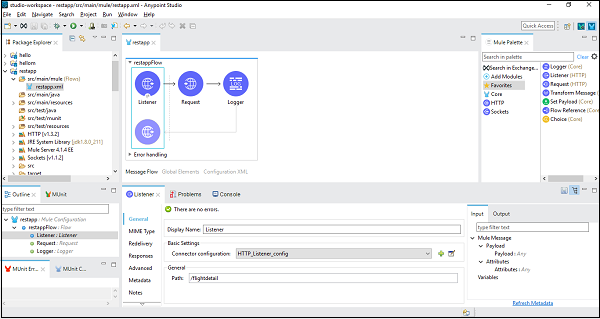
在下面的示例中,我们将使用 REST 组件和 MuleSoft 提供的一个公共 RESTful 服务,称为美国航班详细信息。它包含各种详细信息,但我们将使用 GET:http://training-american-ws.cloudhub.io/api/flights ,它将返回所有航班详细信息。如前所述,REST 与 HTTP 绑定,因此此应用程序也需要两个 HTTP 组件——一个是侦听器,另一个是请求。下面的屏幕截图显示了 HTTP 侦听器的配置:
配置和传递参数
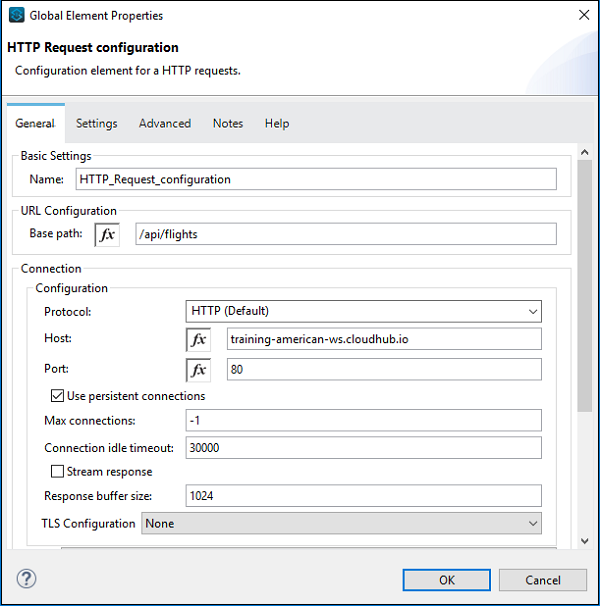
HTTP 请求的配置如下:
现在,根据我们的工作区流程,我们使用了日志记录器,因此可以将其配置如下:
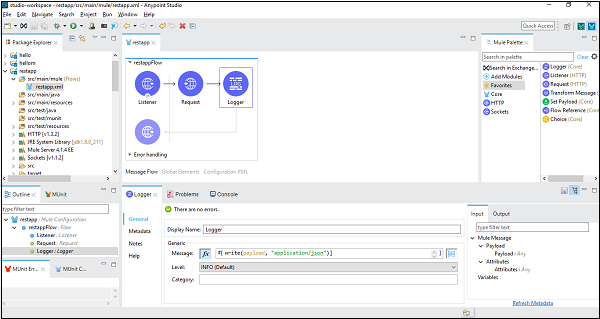
在消息标签中,我们编写代码将有效负载转换为字符串。
应用程序测试
现在,保存并运行应用程序,然后转到POSTMAN检查最终输出,如下所示:
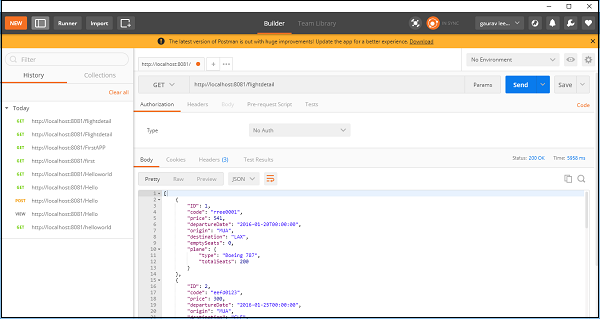
您可以看到它使用REST组件提供航班详细信息。
SOAP组件
SOAP的全称是**简单对象访问协议**(Simple Object Access Protocol)。它基本上是一个消息协议规范,用于在Web服务的实现中交换信息。接下来,我们将使用Anypoint Studio中的SOAP API通过Web服务访问信息。
使用基于SOAP的Web服务
在此示例中,我们将使用名为“国家信息服务”(Country Info Service)的公共SOAP服务,该服务保留与国家信息相关的服务。其WSDL地址为:http://www.oorsprong.org/websamples.countryinfo/countryinfoservice.wso?WSDL
首先,我们需要从Mule Palette中将SOAP使用者拖到画布上,如下所示:
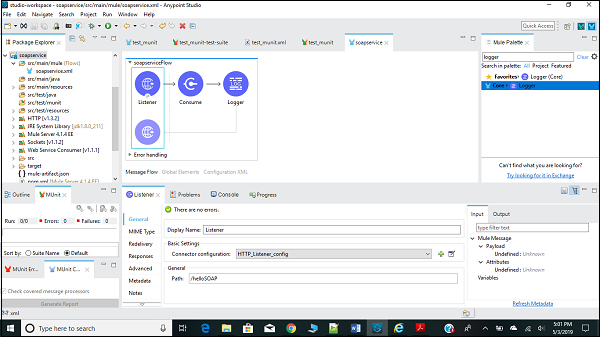
配置和传递参数
接下来,我们需要像上面的示例一样配置HTTP请求,如下所示:
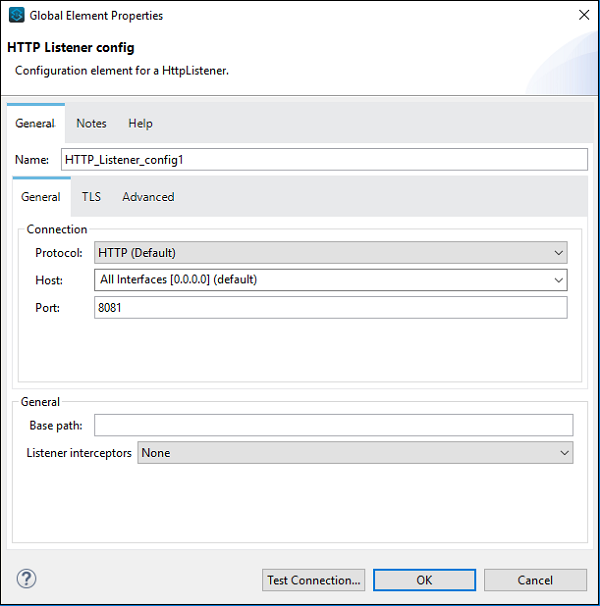
现在,我们还需要配置Web服务使用者,如下所示:
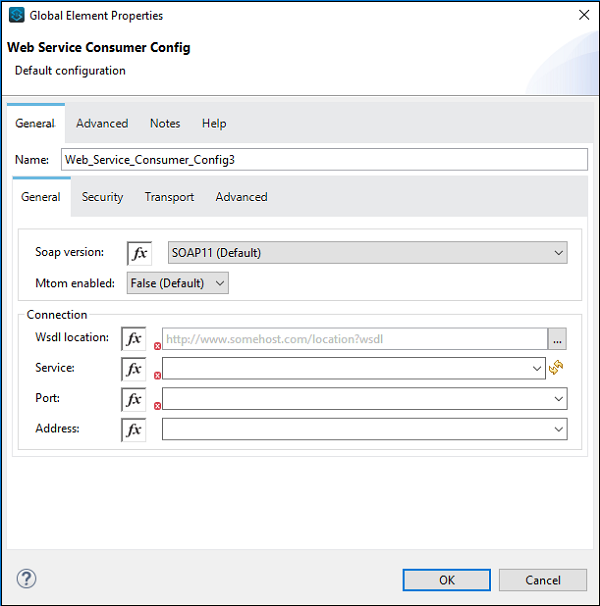
在WSDL位置处,我们需要提供上面提供的WSDL的Web地址(对于此示例)。提供Web地址后,Studio将自行搜索服务、端口和地址。您无需手动提供。
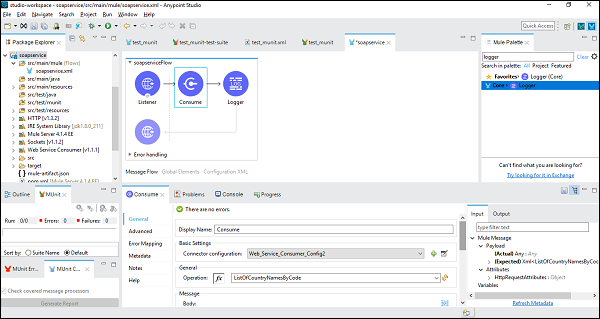
从Web服务传输响应
为此,我们需要在Mule流中添加一个日志记录器并将其配置为提供有效负载,如下所示:
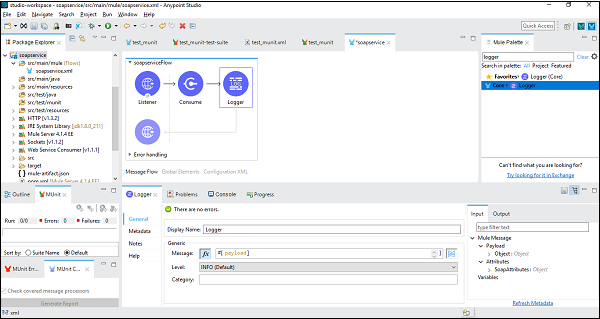
应用程序测试
保存并运行应用程序,然后转到Google Chrome检查最终输出。键入**http://localhist:8081/helloSOAP**(此示例) ,它将按代码显示国家名称,如下面的屏幕截图所示:

MuleSoft - Mule 错误处理
新的Mule错误处理是Mule 4中最大和最重要的更改之一。新的错误处理可能看起来很复杂,但它更好且更高效。在本章中,我们将讨论Mule错误的组件、错误类型、Mule错误的类别以及处理Mule错误的组件。
Mule错误的组件
Mule错误是Mule异常失败的结果,具有以下组件:
描述
这是Mule错误的一个重要组成部分,它将提供关于问题的描述。其表达式如下:
#[error.description]
类型
Mule错误的“类型”组件用于描述问题。它还允许在错误处理程序内进行路由。其表达式如下:
#[error.errorType]
原因
Mule错误的“原因”组件提供了导致失败的底层Java可抛出对象。其表达式如下:
#[error.cause]
消息
Mule错误的消息组件显示有关错误的可选消息。其表达式如下:
#[error.errorMessage]
子错误
Mule错误的子错误组件提供内部错误的可选集合。这些内部错误主要由诸如Scatter-Gather之类的元素用于提供聚合的路由错误。其表达式如下:
#[error.childErrors]
示例 (Example)
如果HTTP请求以401状态码失败,则Mule错误如下:
Description: HTTP GET on resource ‘https://127.0.0.1:8181/TestApp’
failed: unauthorized (401)
Type: HTTP:UNAUTHORIZED
Cause: a ResponseValidatorTypedException instance
Error Message: { "message" : "Could not authorize the user." }
| 序号 | 错误类型和描述 |
|---|---|
| 1 | 转换(TRANSFORMATION) 此错误类型表示在转换值时发生错误。转换是Mule运行时内部转换,而不是DataWeave转换。 |
| 2 | 表达式(EXPRESSION) 此错误类型表示在计算表达式时发生错误。 |
| 3 | 验证(VALIDATION) 此错误类型表示发生验证错误。 |
| 4 | 重复消息(DUPLICATE_MESSAGE) 一种验证错误,当消息被处理两次时发生。 |
| 5 | 重试耗尽(REDELIVERY_EXHAUSTED) 当从源重处理消息的最大尝试次数已用尽时,会发生此错误类型。 |
| 6 | 连接(CONNECTIVITY) 此错误类型表示在建立连接时出现问题。 |
| 7 | 路由(ROUTING) 此错误类型表示在路由消息时发生错误。 |
| 8 | 安全(SECURITY) 此错误类型表示发生安全错误。例如,收到无效的凭据。 |
| 9 | 流最大大小超出(STREAM_MAXIMUM_SIZE_EXCEEDED) 当流允许的最大大小用尽时,会发生此错误类型。 |
| 10 | 超时(TIMEOUT) 它表示在处理消息时超时。 |
| 11 | 未知(UNKNOWN) 此错误类型表示发生意外错误。 |
| 12 | 源(SOURCE) 它表示在流的源中发生错误。 |
| 13 | 源响应(SOURCE_RESPONSE) 它表示在流的源中处理成功响应时发生错误。 |
在上面的示例中,您可以看到mule错误的消息组件。
错误类型
让我们借助其特征来了解错误类型:
Mule错误类型的第一个特征是它包含**命名空间和标识符**。这使我们能够根据其域区分类型。在上面的示例中,错误类型是**HTTP: UNAUTHORIZED**。
第二个重要特征是错误类型可能具有父类型。例如,错误类型**HTTP: UNAUTHORIZED**具有**MULE:CLIENT_SECURITY**作为父类型,而**MULE:CLIENT_SECURITY**又具有名为**MULE:SECURITY**的父类型。此特征将错误类型确立为更全局项目的规范。
错误类型的种类
以下是所有错误所属的类别:
任何(ANY)
此类别下的错误是在流中可能发生的错误。它们并不严重,可以轻松处理。
严重(CRITICAL)
此类别下的错误是无法处理的严重错误。以下是此类别下的错误类型列表:
| 序号 | 错误类型和描述 |
|---|---|
| 1 | 过载(OVERLOAD) 此错误类型表示由于过载问题而发生错误。在这种情况下,将拒绝执行。 |
| 2 | 致命JVM错误(FATAL_JVM_ERROR) 此错误类型表示发生致命错误。例如,堆栈溢出。 |
自定义错误类型(CUSTOM Error Type)
自定义错误类型是我们定义的错误。在映射或引发错误时可以定义它们。我们必须为这些错误类型提供特定的自定义命名空间,以便将它们与Mule应用程序中的其他现有错误类型区分开来。例如,在使用HTTP的Mule应用程序中,我们不能使用HTTP作为自定义错误类型。
Mule错误的类别
广义地说,Mule中的错误可以分为两类,即**消息错误和系统错误**。
消息错误
此类Mule错误与Mule流有关。每当Mule流中出现问题时,Mule都会抛出消息错误。我们可以在错误处理程序组件内部设置出错时(On Error)组件来处理这些Mule错误。
系统错误
系统错误表示在系统级别发生的异常。如果没有Mule事件,则系统错误由系统错误处理程序处理。系统错误处理程序处理以下类型的异常:
- 应用程序启动期间发生的异常。
- 连接到外部系统失败时发生的异常。
如果发生系统错误,Mule会向注册的侦听器发送错误通知。它还会记录错误。另一方面,如果错误是由连接故障引起的,Mule将执行重新连接策略。
处理Mule错误
Mule有以下两个错误处理程序来处理错误:
出错时错误处理程序(On-Error Error Handlers)
第一个Mule错误处理程序是“出错时”(On-Error)组件,它定义了可以处理的错误类型。如前所述,我们可以在类似作用域的错误处理程序组件内部配置“出错时”组件。每个Mule流只包含一个错误处理程序,但是此错误处理程序可以包含任意数量的“出错时”作用域。
首先,每当Mule流引发错误时,正常的流执行都会停止。
接下来,流程将转移到已经具有“出错时”组件以匹配错误类型和表达式的错误处理程序组件。
最后,错误处理程序组件将错误路由到匹配错误的第一个“出错时”作用域。
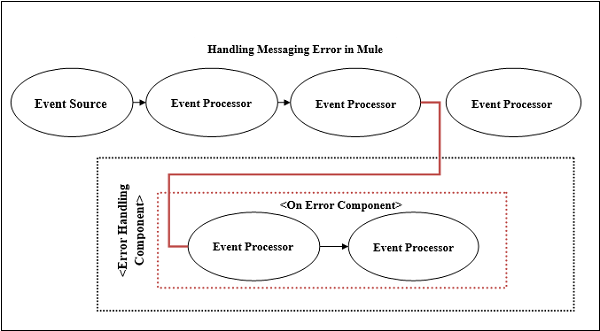
以下是Mule支持的两种类型的“出错时”组件:
出错时传播(On-Error Propagate)
“出错时传播”组件执行但会将错误传播到下一级并中断所有者的执行。如果由“出错时传播”组件处理,则事务将回滚。
出错时继续(On-Error Continue)
与“出错时传播”组件类似,“出错时继续”组件也执行事务。唯一的条件是,如果所有者已成功完成执行,则此组件将使用执行的结果作为其所有者的结果。如果由“出错时继续”组件处理,则事务将提交。
尝试作用域组件(Try Scope Component)
“尝试作用域”是Mule 4中提供的众多新功能之一。它的工作方式类似于JAVA的try块,我们习惯于将可能出现异常的代码括起来,以便在不中断整个代码的情况下进行处理。
我们可以将一个或多个Mule事件处理器包装在“尝试作用域”中,然后,“尝试作用域”将捕获并处理这些事件处理器抛出的任何异常。“尝试作用域”的主要工作原理围绕其自身的错误处理策略,该策略支持在其内部组件而不是整个流上进行错误处理。这就是为什么我们不需要将流提取到单独的流中的原因。
示例 (Example)
以下是“尝试作用域”使用示例:
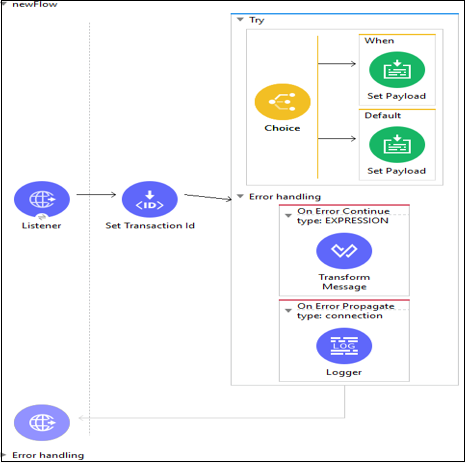
配置“尝试作用域”以处理事务
众所周知,事务是一系列不应部分执行的操作。事务范围内的所有操作都在同一线程中执行,如果发生错误,则应导致回滚或提交。我们可以按以下方式配置“尝试作用域”,以便它将子操作视为事务。
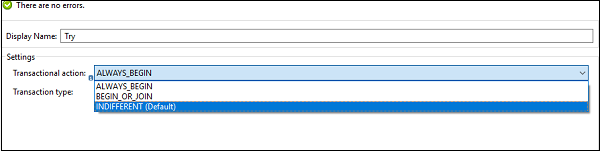
无关紧要 [默认] − 如果我们在try块上选择此配置,则子操作将不被视为事务。在这种情况下,错误既不会导致回滚也不会导致提交。
始终开始(ALWAYS_BEGIN) − 它表示每次执行作用域时都将启动一个新事务。
开始或加入(BEGIN_OR_JOIN) − 它表示如果流的当前处理已启动事务,则加入它。否则,启动一个新的事务。
MuleSoft - Mule异常处理
对于每个项目而言,异常的发生是不可避免的。因此,捕获、分类和处理异常非常重要,以防止系统/应用程序处于不一致的状态。Mule应用程序隐式地应用了一种默认的异常处理策略,该策略会自动回滚所有挂起的交易。
Mule中的异常
在深入探讨异常处理之前,我们应该了解可能发生的异常类型,以及开发人员在设计异常处理程序时必须考虑的三个基本问题。
哪个传输很重要?
在设计异常处理程序之前,这个问题非常重要,因为并非所有传输都支持事务。
文件或HTTP不支持事务。因此,如果在这些情况下发生异常,我们必须手动处理它。
数据库支持事务。在这种情况下设计异常处理程序时,我们必须记住数据库事务可以自动回滚(如果需要)。
对于REST API,我们应该记住它们应该返回正确的HTTP状态码。例如,找不到资源时返回404。
要使用哪个消息交换模式?
在设计异常处理程序时,我们必须注意消息交换模式。可以是同步(请求-回复)或异步(fire-forget)消息模式。
同步消息模式基于请求-回复格式,这意味着此模式将期望一个响应,并将被阻塞,直到返回响应或超时。
异步消息模式基于fire-forget格式,这意味着此模式假定请求最终将被处理。
这是什么类型的异常?
一个非常简单的规则是,您将根据异常的类型来处理它。知道异常是由系统/技术问题还是业务问题引起非常重要。
由系统/技术问题(例如网络中断)引起的异常应通过重试机制自动处理。
另一方面,由业务问题(例如无效数据)引起的异常不应通过应用重试机制来解决,因为在不解决根本原因的情况下重试是没有意义的。
为什么要对异常进行分类?
众所周知,并非所有异常都是相同的,对异常进行分类非常重要。在高级别,异常可以分为以下两种类型:
业务异常
业务异常发生的主要原因是数据错误或流程错误。这类异常通常不可重试,因此不建议配置回滚。即使应用重试机制也没有意义,因为在不解决根本原因的情况下重试是没有用的。为了处理此类异常,处理应该立即停止,并将异常作为响应发送到死信队列。还应该向运维人员发送通知。
非业务异常
非业务异常发生的主要原因是系统问题或技术问题。这类异常是可重试的,因此最好配置重试机制来解决这些异常。
异常处理策略
Mule具有以下五种异常处理策略:
默认异常策略
Mule将此策略隐式应用于Mule流程。它可以处理流程中的所有异常,但也可以通过添加catch、Choice或Rollback异常策略来覆盖。此异常策略将回滚任何挂起的交易并记录异常。此异常策略的一个重要特性是,即使没有事务,它也会记录异常。
作为默认策略,Mule在流程中发生任何错误时都会实现它。我们无法在AnyPoint Studio中配置它。
回滚异常策略
假设如果无法找到纠正错误的解决方案,该怎么办?一个解决方案是使用回滚异常策略,它将回滚事务,并向父流程的入站连接器发送消息以重新处理消息。当我们想要重新处理消息时,此策略也非常有用。
示例 (Example)
此策略可以应用于银行交易,其中资金存入支票/储蓄账户。我们可以在此处配置回滚异常策略,因为如果事务过程中发生错误,此策略会将消息回滚到流程的开头以重新尝试处理。
捕获异常策略
此策略捕获在其父流程中抛出的所有异常。它通过处理父流程抛出的所有异常来覆盖Mule的默认异常策略。我们可以使用捕获异常策略来避免将异常传播到入站连接器和父流程。
此策略还确保当发生异常时,流程处理的事务不会回滚。
示例 (Example)
此策略可以应用于航班预订系统,在这个系统中,我们有一个流程用于处理来自队列的消息。消息增强器在消息上添加一个属性来分配座位,然后将消息发送到另一个队列。
现在,如果此流程中发生任何错误,则消息将抛出异常。在这里,我们的捕获异常策略可以添加一个带有适当消息的标头,并将该消息从流程推送到下一个队列。
选择异常策略
如果您想根据消息内容处理异常,那么选择异常策略将是最佳选择。此异常策略的工作原理如下:
- 首先,它捕获父流程中抛出的所有异常。
- 接下来,它检查消息内容和异常类型。
- 最后,它将消息路由到相应的异常策略。
在选择异常策略中,将定义多个异常策略,例如Catch或Rollback。如果没有在此异常策略下定义策略,则它将消息路由到默认异常策略。它从不执行任何提交、回滚或使用活动。
引用异常策略
这指的是在单独的配置文件中定义的通用异常策略。当消息抛出异常时,此异常策略将引用在全局catch、rollback或choice异常策略中定义的错误处理参数。与选择异常策略一样,它也不执行任何提交、回滚或使用活动。
MuleSoft - 使用 MUnit 进行测试
我们知道单元测试是一种可以测试源代码的各个单元以确定它们是否适合使用的的方法。Java程序员可以使用Junit框架编写测试用例。同样,MuleSoft也有一个名为MUnit的框架,允许我们为我们的API和集成编写自动化测试用例。它非常适合持续集成/部署环境。MUnit框架的最大优势之一是我们可以将其与Maven和Surefire集成。
MUnit的特性
以下是Mule MUnit测试框架的一些非常有用的特性:
在MUnit框架中,我们可以使用Mule代码和Java代码创建Mule测试。
我们可以在Anypoint Studio中以图形方式或XML方式设计和测试我们的Mule应用程序和API。
MUnit允许我们轻松地将测试集成到现有的CI/CD流程中。
它提供自动生成的测试和覆盖率报告;因此,人工工作最少。
我们还可以使用本地数据库/FTP/邮件服务器,通过CI流程使测试更易于移植。
它允许我们启用或禁用测试。
我们还可以使用插件扩展MUnit框架。
它允许我们验证消息处理器调用。
借助MUnit测试框架,我们还可以禁用端点连接器以及流程入站端点。
我们可以使用Mule堆栈跟踪检查错误报告。
Mule MUnit测试框架的最新版本
MUnit 2.1.4是Mule MUnit测试框架的最新版本。它需要以下硬件和软件要求:
- MS Windows 8+
- Apple Mac OS X 10.10+
- Linux
- Java 8
- Maven 3.3.3、3.3.9、3.5.4、3.6.0
它与Mule 4.1.4和Anypoint Studio 7.3.0兼容。
MUnit和Anypoint Studio
如前所述,MUnit完全集成在Anypoint Studio中,我们可以在Anypoint Studio中以图形方式或XML方式设计和测试我们的Mule应用程序和API。换句话说,我们可以使用Anypoint Studio的图形界面执行以下操作:
- 创建和设计MUnit测试
- 运行我们的测试
- 查看测试结果以及覆盖率报告
- 调试测试
因此,让我们开始逐一讨论每个任务。
创建和设计MUnit测试
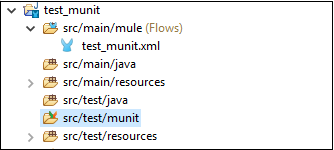
启动新项目后,它会自动向我们的项目添加一个名为src/test/munit的新文件夹。例如,我们启动了一个名为test_munit的新Mule项目,您可以在下图中看到,它在我们的项目下添加了上述文件夹。
现在,启动新项目后,有两种基本方法可以在Anypoint Studio中创建新的MUnit测试:
右键单击流程 - 在此方法中,我们需要右键单击特定的流程并从下拉菜单中选择MUnit。
使用向导 - 在此方法中,我们需要使用向导创建测试。它允许我们为工作区中的任何流程创建测试。
我们将使用“右键单击流程”方法为特定流程创建测试。
首先,我们需要在工作区中创建流程,如下所示:
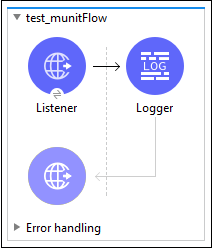
现在,右键单击此流程并选择MUnit以为此流程创建测试,如下所示:
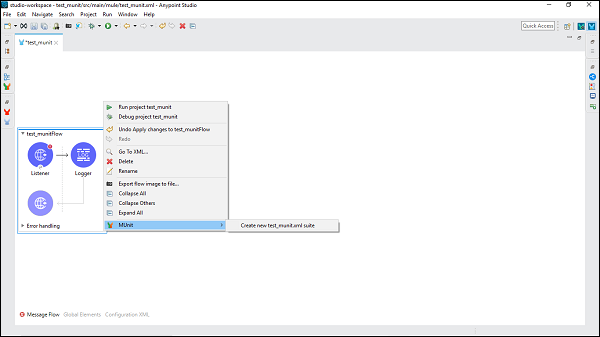
它将创建一个新的测试套件,其名称与包含流程的XML文件相同。在本例中,test_munit-test-suite是新的测试套件的名称,如下所示:
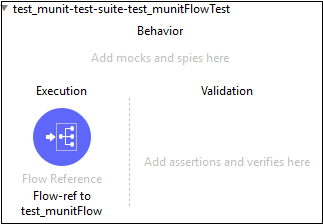
以下是上述消息流程的XML编辑器:
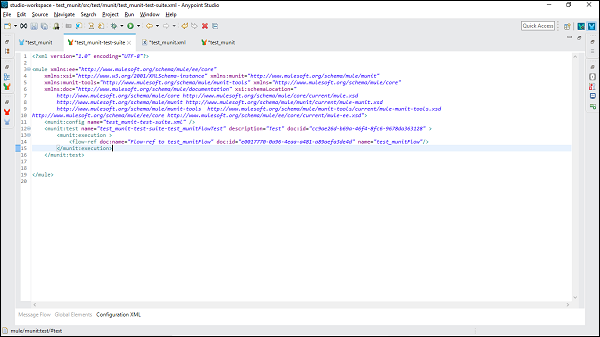
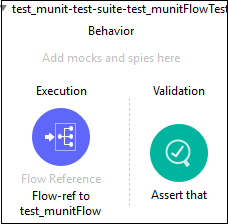
现在,我们可以通过将其从Mule调色板拖动到测试套件中添加MUnit消息处理器。
如果您想通过向导创建测试,则按照文件→新建→MUnit操作,它将引导您进入以下MUnit测试套件:
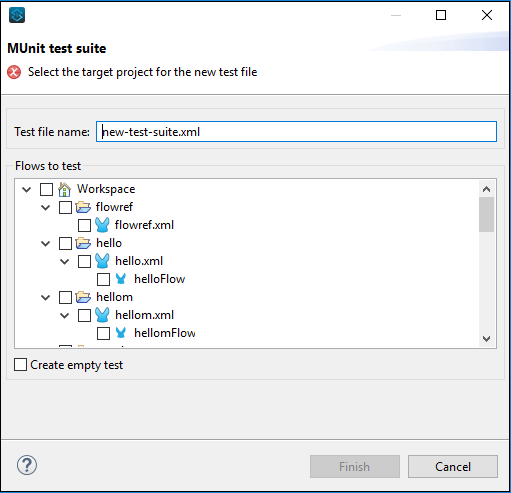
配置测试
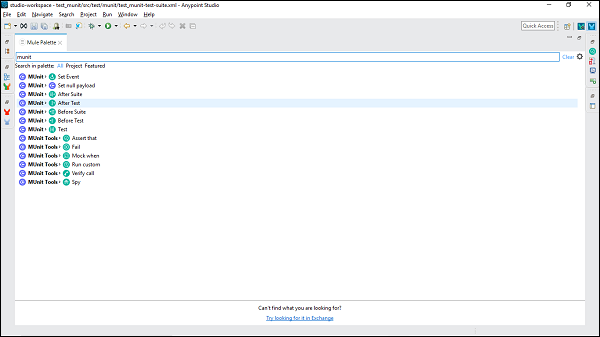
在Mule 4中,我们有两个新的部分,即MUnit和MUnit工具,它们共同拥有所有MUnit消息处理器。您可以将任何消息处理器拖到您的MUnit测试区域。如下面的屏幕截图所示:
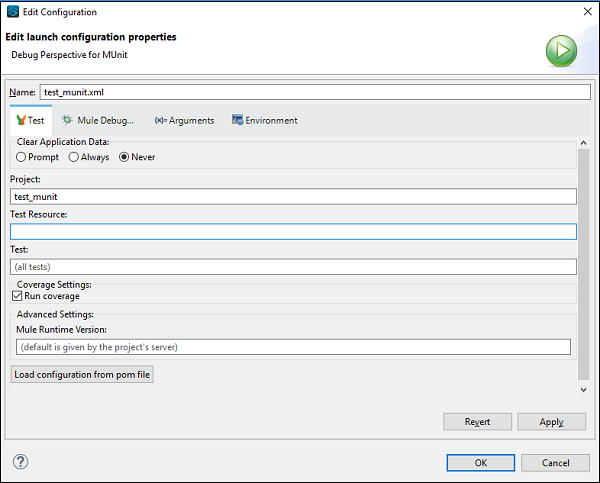
现在,如果您想在Anypoint Studio中编辑套件或测试的配置,则需要按照以下步骤操作:
步骤 1
转到包资源管理器,右键单击套件或测试的.xml文件。然后,选择属性。
步骤 2
现在,在“属性”窗口中,我们需要点击运行/调试设置。之后点击新建。
步骤 3
在最后一步,在选择配置类型窗口下点击MUnit,然后点击确定。
运行测试
我们可以运行测试套件以及单个测试。首先,我们将了解如何运行测试套件。
运行测试套件
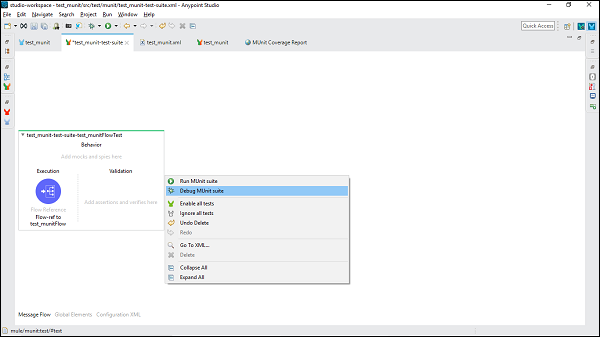
要运行测试套件,右键单击包含测试套件的Mule画布的空白部分。这将打开一个下拉菜单。现在,点击运行MUnit套件,如下所示:
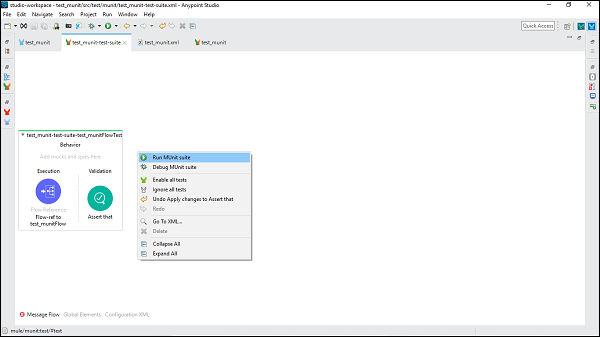
稍后,我们可以在控制台中看到输出。
运行测试
要运行特定的测试,我们需要选择特定的测试并右键单击它。我们将获得与运行测试套件时相同的下拉菜单。现在,点击运行MUnit测试选项,如下所示:
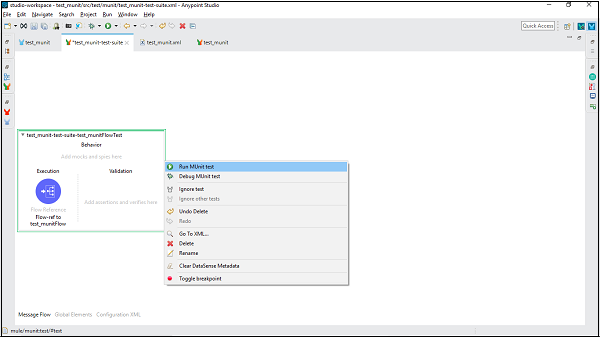
之后,可以在控制台中看到输出。
查看和分析测试结果
Anypoint Studio在左侧资源管理器窗格的MUnit选项卡中显示MUnit测试结果。您可以找到绿色显示的成功测试和红色显示的失败测试,如下所示:
我们可以通过查看覆盖率报告来分析测试结果。覆盖率报告的主要功能是提供一个指标,说明MUnit测试已成功执行了多少Mule应用程序。MUnit覆盖率基本上基于已执行的MUnit消息处理器的数量。MUnit覆盖率报告提供以下指标:
- 应用程序整体覆盖率
- 资源覆盖率
- 流程覆盖率
要获取覆盖率报告,我们需要在MUnit选项卡下点击“生成报告”,如下所示:
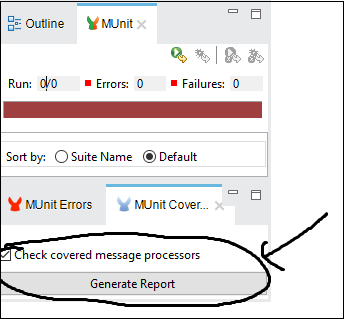
调试测试
我们可以调试测试套件以及单个测试。首先,我们将了解如何调试测试套件。
调试测试套件
要调试测试套件,右键单击包含测试套件的Mule画布的空白部分。这将打开一个下拉菜单。现在,点击调试MUnit套件,如下图所示:
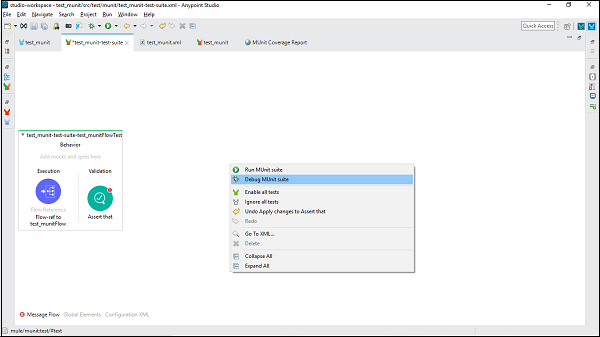
然后,我们可以在控制台中看到输出。
调试测试
要调试特定的测试,我们需要选择特定的测试并右键单击它。我们将获得与调试测试套件时相同的下拉菜单。现在,点击调试MUnit测试选项。它显示在下面的屏幕截图中。