- PL/SQL 教程
- PL/SQL - 首页
- PL/SQL - 概述
- PL/SQL - 环境
- PL/SQL - 基本语法
- PL/SQL - 数据类型
- PL/SQL - 变量
- PL/SQL - 常量和字面量
- PL/SQL - 运算符
- PL/SQL - 条件语句
- PL/SQL - 循环语句
- PL/SQL - 字符串
- PL/SQL - 数组
- PL/SQL - 过程
- PL/SQL - 函数
- PL/SQL - 游标
- PL/SQL - 记录
- PL/SQL - 异常处理
- PL/SQL - 触发器
- PL/SQL - 包
- PL/SQL - 集合
- PL/SQL - 事务
- PL/SQL - 日期和时间
- PL/SQL - DBMS 输出
- PL/SQL - 面向对象
- PL/SQL 有用资源
- PL/SQL - 常见问题解答
- PL/SQL 快速指南
- PL/SQL - 有用资源
- PL/SQL - 讨论
PL/SQL 快速指南
PL/SQL - 概述
PL/SQL编程语言是由Oracle公司在20世纪80年代后期开发的,它是SQL和Oracle关系数据库的过程扩展语言。以下是关于PL/SQL的一些值得注意的事实:
PL/SQL是一种完全可移植的、高性能的事务处理语言。
PL/SQL提供了一个内置的、解释型的、与操作系统无关的编程环境。
PL/SQL也可以直接从命令行**SQL*Plus界面**调用。
也可以从外部编程语言调用数据库。
PL/SQL的通用语法基于ADA和Pascal编程语言。
除了Oracle之外,PL/SQL还在**TimesTen内存数据库**和**IBM DB2**中可用。
PL/SQL 的特性
PL/SQL具有以下特性:
- PL/SQL与SQL紧密集成。
- 它提供了广泛的错误检查。
- 它提供了许多数据类型。
- 它提供了各种编程结构。
- 它通过函数和过程支持结构化编程。
- 它支持面向对象编程。
- 它支持Web应用程序和服务器页面的开发。
PL/SQL 的优点
PL/SQL具有以下优点:
SQL是标准的数据库语言,PL/SQL与SQL紧密集成。PL/SQL支持静态SQL和动态SQL。静态SQL支持来自PL/SQL块的DML操作和事务控制。在动态SQL中,SQL允许在PL/SQL块中嵌入DDL语句。
PL/SQL允许一次将整个语句块发送到数据库。这减少了网络流量,并为应用程序提供了高性能。
PL/SQL可以提高程序员的生产力,因为它可以查询、转换和更新数据库中的数据。
PL/SQL通过强大的功能(例如异常处理、封装、数据隐藏和面向对象数据类型)节省了设计和调试时间。
用PL/SQL编写的应用程序是完全可移植的。
PL/SQL提供高安全级别。
PL/SQL可以访问预定义的SQL包。
PL/SQL支持面向对象编程。
PL/SQL支持开发Web应用程序和服务器页面。
PL/SQL - 环境设置
本章将讨论PL/SQL的环境设置。PL/SQL不是一种独立的编程语言;它是Oracle编程环境中的一个工具。**SQL*Plus**是一个交互式工具,允许您在命令提示符下键入SQL和PL/SQL语句。然后将这些命令发送到数据库进行处理。语句处理完成后,结果将被发送回并显示在屏幕上。
要运行PL/SQL程序,您的计算机上应安装Oracle RDBMS服务器。这将负责执行SQL命令。最新的Oracle RDBMS版本是11g。您可以从以下链接下载Oracle 11g的试用版:
您需要根据您的操作系统下载32位或64位版本的安装程序。通常有两个文件。我们下载了64位版本。您也可以在您的操作系统上使用类似的步骤,无论它是Linux还是Solaris。
win64_11gR2_database_1of2.zip
win64_11gR2_database_2of2.zip
下载上述两个文件后,您需要将它们解压到单个目录**database**中,并在该目录下找到以下子目录:
步骤 1
现在让我们使用安装文件启动Oracle数据库安装程序。以下是第一个屏幕。您可以提供您的电子邮件ID并选中复选框,如下面的屏幕截图所示。单击**下一步**按钮。
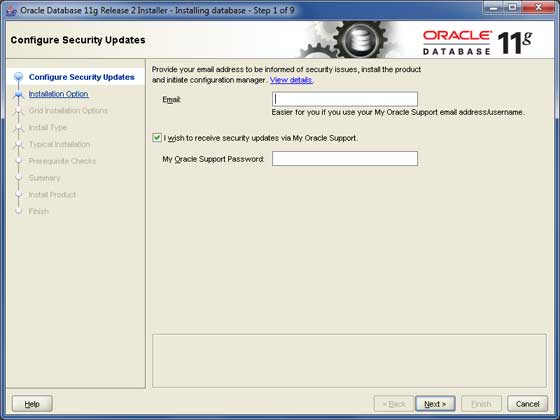
步骤 2
您将被定向到以下屏幕;取消选中复选框并单击**继续**按钮继续。
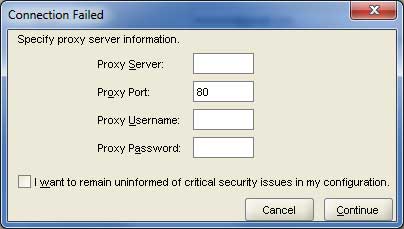
步骤 3
只需选择第一个选项**创建和配置数据库**,然后单击**下一步**按钮继续。
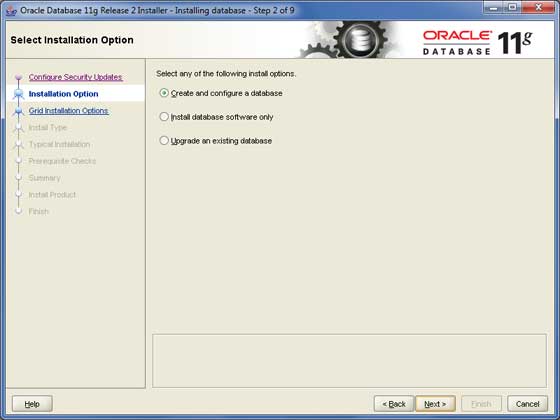
步骤 4
我们假设您安装Oracle是为了学习基本目的,并且您将其安装在您的PC或笔记本电脑上。因此,选择**桌面级**选项,然后单击**下一步**按钮继续。
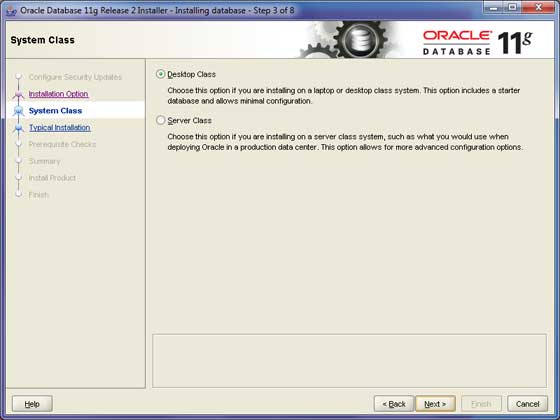
步骤 5
提供一个安装Oracle服务器的位置。只需修改**Oracle Base**,其他位置将自动设置。您还必须提供密码;系统DBA将使用此密码。提供所需信息后,单击**下一步**按钮继续。
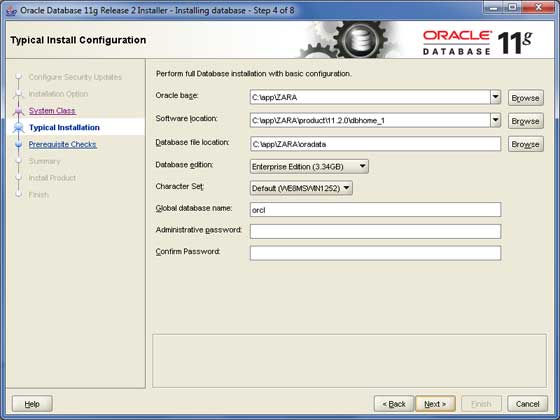
步骤 6
再次单击**下一步**按钮继续。
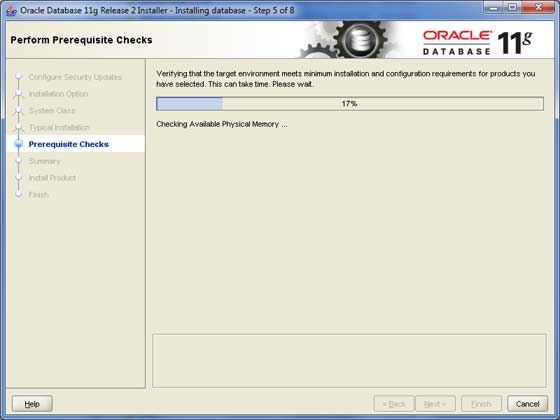
步骤 7
单击**完成**按钮继续;这将启动实际的服务器安装。
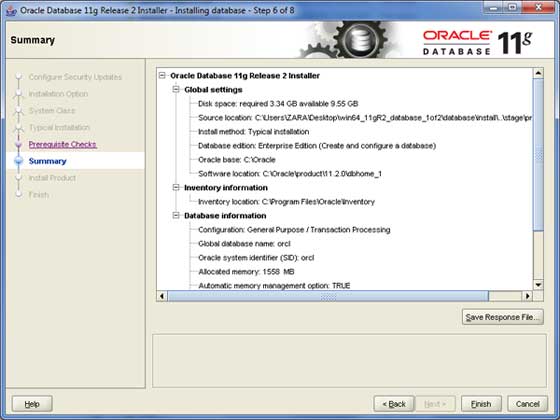
步骤 8
这将需要一些时间,直到Oracle开始执行所需的配置。
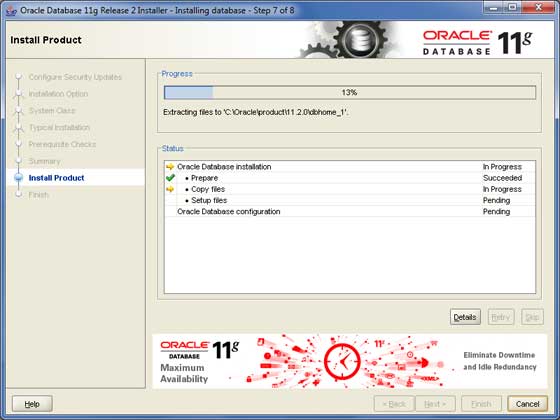
步骤 9
在这里,Oracle安装将复制所需的配置文件。这应该需要一些时间:
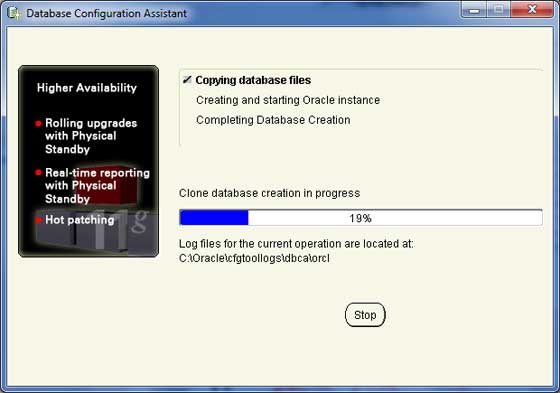
步骤 10
复制数据库文件后,您将看到以下对话框。只需单击**确定**按钮并退出。
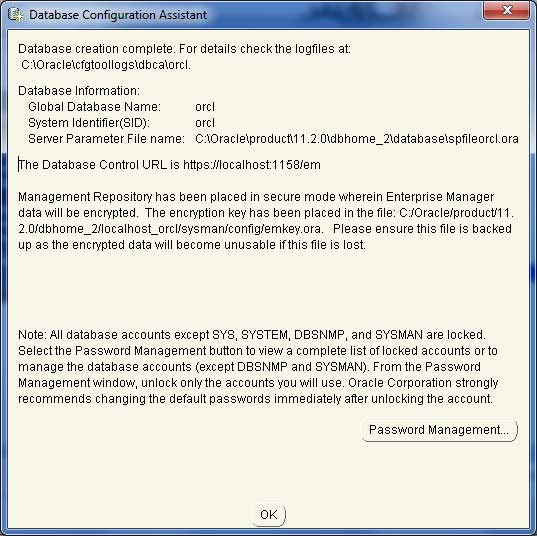
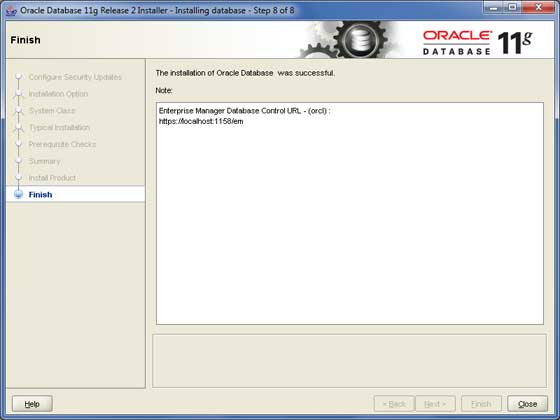
步骤 11
安装后,您将看到以下最终窗口。
最后一步
现在是验证您的安装的时候了。如果您使用的是Windows,请在命令提示符下使用以下命令:
sqlplus "/ as sysdba"
您应该会看到SQL提示符,您可以在其中编写PL/SQL命令和脚本:
文本编辑器
从命令提示符运行大型程序可能会导致您无意中丢失一些工作。始终建议使用命令文件。要使用命令文件:
在文本编辑器(如**记事本、Notepad+**或**EditPlus**等)中键入您的代码。
将文件保存为**.sql**扩展名,并保存在主目录中。
从创建PL/SQL文件的目录启动**SQL*Plus命令提示符**。
在SQL*Plus命令提示符下键入**@file_name**以执行您的程序。
如果您不使用文件来执行PL/SQL脚本,则只需复制您的PL/SQL代码,然后右键单击显示SQL提示符的黑色窗口;使用**粘贴**选项将完整代码粘贴到命令提示符中。最后,只需按**Enter**键执行代码(如果尚未执行)。
PL/SQL - 基本语法
本章将讨论PL/SQL的基本语法,它是一种**块结构**语言;这意味着PL/SQL程序被划分为逻辑代码块。每个块都包含三个子部分:
| 序号 | 部分及描述 |
|---|---|
| 1 |
声明部分 此部分以关键字**DECLARE**开头。它是可选部分,定义程序中将使用的所有变量、游标、子程序和其他元素。 |
| 2 |
可执行命令 此部分包含在关键字**BEGIN**和**END**之间,它是必填部分。它包含程序的可执行PL/SQL语句。它应该至少有一行可执行代码,这可能只是一条**NULL命令**,表示不执行任何操作。 |
| 3 | 异常处理 此部分以关键字**EXCEPTION**开头。此可选部分包含处理程序中错误的**异常**。 |
每个PL/SQL语句都以分号(;)结尾。PL/SQL块可以使用**BEGIN**和**END**嵌套在其他PL/SQL块中。以下是PL/SQL块的基本结构:
DECLARE <declarations section> BEGIN <executable command(s)> EXCEPTION <exception handling> END;
“Hello World”示例
DECLARE message varchar2(20):= 'Hello, World!'; BEGIN dbms_output.put_line(message); END; /
**end;**行表示PL/SQL块的结尾。要从SQL命令行运行代码,您可能需要在代码最后一行后的第一行空白行开头键入/。当上述代码在SQL提示符下执行时,它会产生以下结果:
Hello World PL/SQL procedure successfully completed.
PL/SQL标识符
PL/SQL标识符是常量、变量、异常、过程、游标和保留字。标识符由一个字母组成,后面可以选择跟更多字母、数字、美元符号、下划线和数字符号,并且不应超过30个字符。
默认情况下,**标识符不区分大小写**。因此,您可以使用**integer**或**INTEGER**来表示数值。您不能使用保留关键字作为标识符。
PL/SQL分隔符
分隔符是一个具有特殊含义的符号。以下是PL/SQL中分隔符的列表:
| 分隔符 | 描述 |
|---|---|
| +, -, *, / | 加法、减法/负号、乘法、除法 |
| % | 属性指示符 |
| ' | 字符字符串分隔符 |
| . | 组件选择器 |
| (,) | 表达式或列表分隔符 |
| : | 主机变量指示符 |
| , | 项目分隔符 |
| " | 带引号的标识符分隔符 |
| = | 关系运算符 |
| @ | 远程访问指示符 |
| ; | 语句终止符 |
| := | 赋值运算符 |
| => | 关联运算符 |
| || | 连接运算符 |
| ** | 求幂运算符 |
| <<, >> | 标签分隔符(begin 和 end) |
| /*, */ | 多行注释分隔符(begin 和 end) |
| -- | 单行注释指示符 |
| .. | 范围运算符 |
| <, >, <=, >= | 关系运算符 |
| <>, '=, ~=, ^= | 不同版本的NOT EQUAL |
PL/SQL注释
程序注释是可以包含在您编写的PL/SQL代码中的解释性语句,可以帮助任何阅读其源代码的人。所有编程语言都允许某种形式的注释。
PL/SQL支持单行和多行注释。PL/SQL编译器会忽略任何注释中包含的所有字符。PL/SQL单行注释以分隔符--(双连字符)开头,多行注释用/*和*/括起来。
DECLARE -- variable declaration message varchar2(20):= 'Hello, World!'; BEGIN /* * PL/SQL executable statement(s) */ dbms_output.put_line(message); END; /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Hello World PL/SQL procedure successfully completed.
PL/SQL程序单元
PL/SQL单元可以是以下任何一个:
- PL/SQL块
- 函数
- 包
- 包体
- 过程
- 触发器
- 类型
- 类型体
这些单元中的每一个都将在后续章节中讨论。
PL/SQL - 数据类型
本章将讨论PL/SQL中的数据类型。PL/SQL变量、常量和参数必须具有有效的数据类型,该类型指定存储格式、约束和有效值范围。本章将重点介绍**标量**和**LOB**数据类型。其他两种数据类型将在其他章节中介绍。
| 序号 | 类别及描述 |
|---|---|
| 1 | 标量 没有内部组件的单值,例如数字、日期或布尔值。 |
| 2 | 大型对象 (LOB) 指向存储在其他数据项之外的大型对象的指针,例如文本、图形图像、视频剪辑和声音波形。 |
| 3 | 复合类型 具有可单独访问的内部组件的数据项。例如,集合和记录。 |
| 4 | 引用 指向其他数据项的指针。 |
PL/SQL 标量数据类型和子类型
PL/SQL 标量数据类型和子类型属于以下类别:
| 序号 | 数据类型和描述 |
|---|---|
| 1 | 数值型 执行算术运算的数值。 |
| 2 | 字符型 表示单个字符或字符字符串的字母数字值。 |
| 3 | 布尔型 执行逻辑运算的逻辑值。 |
| 4 | 日期时间型 日期和时间。 |
PL/SQL 提供数据类型的子类型。例如,数据类型 NUMBER 具有名为 INTEGER 的子类型。您可以在 PL/SQL 程序中使用子类型,以使数据类型与其他程序中的数据类型兼容,同时将 PL/SQL 代码嵌入到另一个程序中,例如 Java 程序。
PL/SQL 数值数据类型和子类型
下表列出了 PL/SQL 预定义的数值数据类型及其子类型:
| 序号 | 数据类型和描述 |
|---|---|
| 1 | PLS_INTEGER 范围为 -2,147,483,648 到 2,147,483,647 的带符号整数,用 32 位表示 |
| 2 | BINARY_INTEGER 范围为 -2,147,483,648 到 2,147,483,647 的带符号整数,用 32 位表示 |
| 3 | BINARY_FLOAT 单精度 IEEE 754 格式浮点数 |
| 4 | BINARY_DOUBLE 双精度 IEEE 754 格式浮点数 |
| 5 | NUMBER(prec, scale) 定点或浮点数,绝对值范围为 1E-130 到(但不包括)1.0E126。NUMBER 变量也可以表示 0 |
| 6 | DEC(prec, scale) ANSI 特定的定点类型,最大精度为 38 位小数 |
| 7 | DECIMAL(prec, scale) IBM 特定的定点类型,最大精度为 38 位小数 |
| 8 | NUMERIC(pre, secale) 最大精度为 38 位小数的浮点类型 |
| 9 | DOUBLE PRECISION ANSI 特定的浮点类型,最大精度为 126 位二进制数字(大约 38 位小数) |
| 10 | FLOAT ANSI 和 IBM 特定的浮点类型,最大精度为 126 位二进制数字(大约 38 位小数) |
| 11 | INT ANSI 特定的整数类型,最大精度为 38 位小数 |
| 12 | INTEGER ANSI 和 IBM 特定的整数类型,最大精度为 38 位小数 |
| 13 | SMALLINT ANSI 和 IBM 特定的整数类型,最大精度为 38 位小数 |
| 14 | REAL 浮点类型,最大精度为 63 位二进制数字(大约 18 位小数) |
以下是一个有效的声明:
DECLARE num1 INTEGER; num2 REAL; num3 DOUBLE PRECISION; BEGIN null; END; /
编译并执行上述代码后,将产生以下结果:
PL/SQL procedure successfully completed
PL/SQL 字符数据类型和子类型
以下是 PL/SQL 预定义的字符数据类型及其子类型的详细信息:
| 序号 | 数据类型和描述 |
|---|---|
| 1 | CHAR 最大大小为 32,767 字节的固定长度字符字符串 |
| 2 | VARCHAR2 最大大小为 32,767 字节的可变长度字符字符串 |
| 3 | RAW 最大大小为 32,767 字节的可变长度二进制或字节字符串,PL/SQL 不解释 |
| 4 | NCHAR 最大大小为 32,767 字节的固定长度国家字符字符串 |
| 5 | NVARCHAR2 最大大小为 32,767 字节的可变长度国家字符字符串 |
| 6 | LONG 最大大小为 32,760 字节的可变长度字符字符串 |
| 7 | LONG RAW 最大大小为 32,760 字节的可变长度二进制或字节字符串,PL/SQL 不解释 |
| 8 | ROWID 物理行标识符,普通表中行的地址 |
| 9 | UROWID 通用行标识符(物理、逻辑或外部行标识符) |
PL/SQL 布尔数据类型
BOOLEAN 数据类型存储用于逻辑运算的逻辑值。逻辑值是布尔值 TRUE 和 FALSE 以及值 NULL。
但是,SQL 没有与 BOOLEAN 等效的数据类型。因此,布尔值不能用于:
- SQL 语句
- 内置 SQL 函数(例如 TO_CHAR)
- 从 SQL 语句调用的 PL/SQL 函数
PL/SQL 日期时间和区间类型
DATE 数据类型用于存储固定长度的日期时间,其中包括自午夜以来的秒数。有效日期范围从公元前 4712 年 1 月 1 日到公元 9999 年 12 月 31 日。
默认日期格式由 Oracle 初始化参数 NLS_DATE_FORMAT 设置。例如,默认值可能是 'DD-MON-YY',其中包括月份的两位数字、月份名称的缩写和年份的后两位数字。例如,01-OCT-12。
每个 DATE 包括世纪、年份、月份、日期、小时、分钟和秒。下表显示每个字段的有效值:
| 字段名称 | 有效日期时间值 | 有效区间值 |
|---|---|---|
| YEAR | -4712 到 9999(不包括年份 0) | 任何非零整数 |
| MONTH | 01 到 12 | 0 到 11 |
| DAY | 01 到 31(根据区域设置日历规则,受 MONTH 和 YEAR 值的限制) | 任何非零整数 |
| HOUR | 00 到 23 | 0 到 23 |
| MINUTE | 00 到 59 | 0 到 59 |
| SECOND | 00 到 59.9(n),其中 9(n) 是时间小数秒的精度 | 0 到 59.9(n),其中 9(n) 是区间小数秒的精度 |
| TIMEZONE_HOUR | -12 到 14(范围适应夏令时变化) | 不适用 |
| TIMEZONE_MINUTE | 00 到 59 | 不适用 |
| TIMEZONE_REGION | 在动态性能视图 V$TIMEZONE_NAMES 中找到 | 不适用 |
| TIMEZONE_ABBR | 在动态性能视图 V$TIMEZONE_NAMES 中找到 | 不适用 |
PL/SQL 大型对象 (LOB) 数据类型
大型对象 (LOB) 数据类型指的是大型数据项,例如文本、图形图像、视频剪辑和声音波形。LOB 数据类型允许对这些数据进行高效的、随机的、分段的访问。以下是预定义的 PL/SQL LOB 数据类型:
| 数据类型 | 描述 | 大小 |
|---|---|---|
| BFILE | 用于在数据库外部的操作系统文件中存储大型二进制对象。 | 系统相关。不能超过 4 千兆字节 (GB)。 |
| BLOB | 用于在数据库中存储大型二进制对象。 | 8 到 128 太字节 (TB) |
| CLOB | 用于在数据库中存储大型字符数据块。 | 8 到 128 TB |
| NCLOB | 用于在数据库中存储大型 NCHAR 数据块。 | 8 到 128 TB |
PL/SQL 用户定义的子类型
子类型是另一种数据类型的子集,称为其基类型。子类型与其基类型具有相同的有效操作,但只有其有效值的子集。
PL/SQL 在包 STANDARD 中预定义了几个子类型。例如,PL/SQL 预定义了子类型 CHARACTER 和 INTEGER,如下所示:
SUBTYPE CHARACTER IS CHAR; SUBTYPE INTEGER IS NUMBER(38,0);
您可以定义和使用您自己的子类型。以下程序说明了定义和使用用户定义的子类型:
DECLARE
SUBTYPE name IS char(20);
SUBTYPE message IS varchar2(100);
salutation name;
greetings message;
BEGIN
salutation := 'Reader ';
greetings := 'Welcome to the World of PL/SQL';
dbms_output.put_line('Hello ' || salutation || greetings);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Hello Reader Welcome to the World of PL/SQL PL/SQL procedure successfully completed.
PL/SQL 中的 NULL 值
PL/SQL NULL 值表示缺失或未知数据,它们不是整数、字符或任何其他特定数据类型。请注意,NULL 与空数据字符串或空字符值 '\0' 不相同。可以赋值 NULL,但不能将其与任何东西等同,包括自身。
PL/SQL - 变量
在本章中,我们将讨论 Pl/SQL 中的变量。变量只不过是程序可以操作的存储区域的名称。PL/SQL 中的每个变量都具有特定的数据类型,这决定了变量内存的大小和布局;可以存储在该内存中的值的范围以及可以应用于该变量的操作集。
PL/SQL 变量的名称由一个字母组成,后面可以选择跟多个字母、数字、美元符号、下划线和数字符号,并且不应超过 30 个字符。默认情况下,变量名称不区分大小写。您不能使用保留的 PL/SQL 关键字作为变量名。
PL/SQL 编程语言允许定义各种类型的变量,例如日期时间数据类型、记录、集合等,我们将在后续章节中介绍。对于本章,让我们只学习基本的变量类型。
PL/SQL 中的变量声明
必须在声明部分或包中作为全局变量声明 PL/SQL 变量。声明变量时,PL/SQL 会为变量的值分配内存,并且存储位置由变量名标识。
声明变量的语法如下:
variable_name [CONSTANT] datatype [NOT NULL] [:= | DEFAULT initial_value]
其中,variable_name 是 PL/SQL 中的有效标识符,datatype 必须是有效的 PL/SQL 数据类型或任何我们已经在上一章中讨论过的用户定义的数据类型。一些有效的变量声明及其定义如下所示:
sales number(10, 2); pi CONSTANT double precision := 3.1415; name varchar2(25); address varchar2(100);
当您为数据类型提供大小、比例或精度限制时,这称为受约束声明。受约束声明比不受约束声明需要更少的内存。例如:
sales number(10, 2); name varchar2(25); address varchar2(100);
在 PL/SQL 中初始化变量
每当您声明一个变量时,PL/SQL 都会为其分配 NULL 的默认值。如果要使用非 NULL 值初始化变量,可以在声明期间使用以下任一方法:
DEFAULT 关键字
赋值运算符
例如:
counter binary_integer := 0; greetings varchar2(20) DEFAULT 'Have a Good Day';
您还可以使用 NOT NULL 约束指定变量不应具有 NULL 值。如果使用 NOT NULL 约束,则必须为该变量显式分配初始值。
正确初始化变量是一种良好的编程习惯,否则,有时程序会产生意外的结果。尝试以下示例,该示例使用了各种类型的变量:
DECLARE
a integer := 10;
b integer := 20;
c integer;
f real;
BEGIN
c := a + b;
dbms_output.put_line('Value of c: ' || c);
f := 70.0/3.0;
dbms_output.put_line('Value of f: ' || f);
END;
/
执行上述代码后,将产生以下结果:
Value of c: 30 Value of f: 23.333333333333333333 PL/SQL procedure successfully completed.
PL/SQL 中的变量作用域
PL/SQL 允许嵌套块,即每个程序块可能包含另一个内部块。如果在内部块中声明了一个变量,则外部块无法访问它。但是,如果在外部块中声明并可以访问一个变量,则所有嵌套的内部块也可以访问它。有两种类型的变量作用域:
局部变量 - 在内部块中声明的变量,外部块无法访问。
全局变量 - 在最外层块或包中声明的变量。
下面的例子以简单的方式展示了局部和全局变量的用法:
DECLARE
-- Global variables
num1 number := 95;
num2 number := 85;
BEGIN
dbms_output.put_line('Outer Variable num1: ' || num1);
dbms_output.put_line('Outer Variable num2: ' || num2);
DECLARE
-- Local variables
num1 number := 195;
num2 number := 185;
BEGIN
dbms_output.put_line('Inner Variable num1: ' || num1);
dbms_output.put_line('Inner Variable num2: ' || num2);
END;
END;
/
执行上述代码后,将产生以下结果:
Outer Variable num1: 95 Outer Variable num2: 85 Inner Variable num1: 195 Inner Variable num2: 185 PL/SQL procedure successfully completed.
将SQL查询结果赋值给PL/SQL变量
您可以使用SQL的SELECT INTO语句将值赋给PL/SQL变量。对于SELECT列表中的每个项目,都必须在INTO列表中有一个类型兼容的对应变量。下面的例子说明了这个概念。让我们创建一个名为CUSTOMERS的表:
(关于SQL语句,请参考SQL教程)
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) ); Table Created
现在让我们向表中插入一些值:
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'kaushik', 23, 'Kota', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (6, 'Komal', 22, 'MP', 4500.00 );
下面的程序使用SQL的SELECT INTO子句将上述表中的值赋给PL/SQL变量:
DECLARE
c_id customers.id%type := 1;
c_name customers.name%type;
c_addr customers.address%type;
c_sal customers.salary%type;
BEGIN
SELECT name, address, salary INTO c_name, c_addr, c_sal
FROM customers
WHERE id = c_id;
dbms_output.put_line
('Customer ' ||c_name || ' from ' || c_addr || ' earns ' || c_sal);
END;
/
执行上述代码后,将产生以下结果:
Customer Ramesh from Ahmedabad earns 2000 PL/SQL procedure completed successfully
PL/SQL - 常量和字面量
本章将讨论PL/SQL中的常量和字面量。常量保存一个值,一旦声明,程序中就不会改变。常量声明指定其名称、数据类型和值,并为其分配存储空间。声明还可以施加NOT NULL约束。
声明常量
常量使用CONSTANT关键字声明。它需要一个初始值,并且不允许更改该值。例如:
PI CONSTANT NUMBER := 3.141592654;
DECLARE
-- constant declaration
pi constant number := 3.141592654;
-- other declarations
radius number(5,2);
dia number(5,2);
circumference number(7, 2);
area number (10, 2);
BEGIN
-- processing
radius := 9.5;
dia := radius * 2;
circumference := 2.0 * pi * radius;
area := pi * radius * radius;
-- output
dbms_output.put_line('Radius: ' || radius);
dbms_output.put_line('Diameter: ' || dia);
dbms_output.put_line('Circumference: ' || circumference);
dbms_output.put_line('Area: ' || area);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Radius: 9.5 Diameter: 19 Circumference: 59.69 Area: 283.53 Pl/SQL procedure successfully completed.
PL/SQL字面量
字面量是显式的数字、字符、字符串或布尔值,不以标识符表示。例如,TRUE、786、NULL、'tutorialspoint'都是布尔型、数字型或字符串型的字面量。PL/SQL字面量区分大小写。PL/SQL支持以下类型的字面量:
- 数字字面量
- 字符字面量
- 字符串字面量
- 布尔字面量
- 日期和时间字面量
下表提供了所有这些类别字面值的示例。
| 序号 | 字面量类型 & 示例 |
|---|---|
| 1 | 数字字面量 050 78 -14 0 +32767 6.6667 0.0 -12.0 3.14159 +7800.00 6E5 1.0E-8 3.14159e0 -1E38 -9.5e-3 |
| 2 | 字符字面量 'A' '%' '9' ' ' 'z' '(' |
| 3 | 字符串字面量 'Hello, world!' 'Tutorials Point' '19-NOV-12' |
| 4 | 布尔字面量 TRUE、FALSE和NULL。 |
| 5 | 日期和时间字面量 DATE '1978-12-25'; TIMESTAMP '2012-10-29 12:01:01'; |
要在字符串字面量中嵌入单引号,请将两个单引号并排放置,如下程序所示:
DECLARE message varchar2(30):= 'That''s tutorialspoint.com!'; BEGIN dbms_output.put_line(message); END; /
当上述代码在SQL提示符下执行时,它会产生以下结果:
That's tutorialspoint.com! PL/SQL procedure successfully completed.
PL/SQL - 运算符
本章将讨论PL/SQL中的运算符。运算符是一个符号,它告诉编译器执行特定的数学或逻辑操作。PL/SQL语言富含内置运算符,并提供以下类型的运算符:
- 算术运算符
- 关系运算符
- 比较运算符
- 逻辑运算符
- 字符串运算符
在这里,我们将逐一了解算术、关系、比较和逻辑运算符。字符串运算符将在后面的章节中讨论:PL/SQL - 字符串。
算术运算符
下表显示了PL/SQL支持的所有算术运算符。假设变量A值为10,变量B值为5,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| + | 将两个操作数相加 | A + B 将得到 15 |
| - | 从第一个操作数中减去第二个操作数 | A - B 将得到 5 |
| * | 将两个操作数相乘 | A * B 将得到 50 |
| / | 将分子除以分母 | A / B 将得到 2 |
| ** | 指数运算符,将一个操作数提高到另一个操作数的幂 | A ** B 将得到 100000 |
关系运算符
关系运算符比较两个表达式或值,并返回布尔结果。下表显示了PL/SQL支持的所有关系运算符。假设变量A值为10,变量B值为20,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 检查两个操作数的值是否相等,如果相等则条件为真。 | (A = B) 为假。 |
!= <> ~= |
检查两个操作数的值是否不相等,如果不相等则条件为真。 | (A != B) 为真。 |
| > | 检查左边操作数的值是否大于右边操作数的值,如果是则条件为真。 | (A > B) 为假。 |
| < | 检查左边操作数的值是否小于右边操作数的值,如果是则条件为真。 | (A < B) 为真。 |
| >= | 检查左边操作数的值是否大于或等于右边操作数的值,如果是则条件为真。 | (A >= B) 为假。 |
| <= | 检查左边操作数的值是否小于或等于右边操作数的值,如果是则条件为真。 | (A <= B) 为真 |
比较运算符
比较运算符用于比较一个表达式与另一个表达式。结果始终为TRUE、FALSE或NULL。
| 运算符 | 描述 | 示例 |
|---|---|---|
| LIKE | LIKE运算符将字符、字符串或CLOB值与模式进行比较,如果值与模式匹配则返回TRUE,如果不匹配则返回FALSE。 | 如果 'Zara Ali' like 'Z% A_i' 返回布尔值true,而 'Nuha Ali' like 'Z% A_i' 返回布尔值false。 |
| BETWEEN | BETWEEN运算符测试值是否在指定范围内。x BETWEEN a AND b表示x >= a且x <= b。 | 如果x = 10,则x between 5 and 20返回true,x between 5 and 10返回true,但x between 11 and 20返回false。 |
| IN | IN运算符测试集合成员资格。x IN (set)表示x等于集合的任何成员。 | 如果x = 'm',则x in ('a', 'b', 'c')返回布尔值false,但x in ('m', 'n', 'o')返回布尔值true。 |
| IS NULL | IS NULL运算符如果其操作数为NULL则返回布尔值TRUE,如果不为NULL则返回FALSE。涉及NULL值的比较始终产生NULL。 | 如果x = 'm',则'x is null'返回布尔值false。 |
逻辑运算符
下表显示了PL/SQL支持的逻辑运算符。所有这些运算符都作用于布尔操作数并产生布尔结果。假设变量A值为true,变量B值为false,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| and | 称为逻辑AND运算符。如果两个操作数都为真,则条件为真。 | (A and B) 为假。 |
| or | 称为逻辑OR运算符。如果两个操作数中的任何一个为真,则条件为真。 | (A or B) 为真。 |
| not | 称为逻辑NOT运算符。用于反转其操作数的逻辑状态。如果条件为真,则逻辑NOT运算符将使其为假。 | not (A and B) 为真。 |
PL/SQL运算符优先级
运算符优先级决定了表达式中项的分组。这会影响表达式的计算方式。某些运算符的优先级高于其他运算符;例如,乘法运算符的优先级高于加法运算符。
例如,x = 7 + 3 * 2;这里,x被赋值为13,而不是20,因为运算符*的优先级高于+,所以它先与3*2相乘,然后加到7中。
这里,优先级最高的运算符出现在表的最上面,优先级最低的出现在表的最下面。在一个表达式中,优先级较高的运算符将首先被计算。
运算符的优先级如下:=,<,>,<=,>=,<>,!=,~=,^=,IS NULL,LIKE,BETWEEN,IN。
| 运算符 | 操作 |
|---|---|
| ** | 指数 |
| +, - | 恒等式,否定 |
| *, / | 乘法,除法 |
| +, -, || | 加法,减法,连接 |
| 比较 | |
| NOT | 逻辑否定 |
| AND | 连接 |
| OR | 包含 |
PL/SQL - 条件语句
本章将讨论PL/SQL中的条件。决策结构要求程序员指定一个或多个要由程序评估或测试的条件,以及如果确定条件为真则要执行的语句或语句,以及可选地,如果确定条件为假则要执行的其他语句。
以下是大多数编程语言中常见的条件(即决策)结构的一般形式:
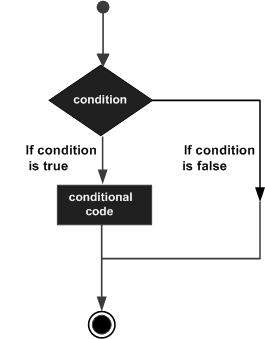
PL/SQL编程语言提供以下类型的决策语句。点击下面的链接查看它们的详细信息。
| 序号 | 语句 & 描述 |
|---|---|
| 1 | IF - THEN语句
IF语句将一个条件与由关键字THEN和END IF括起来的语句序列关联起来。如果条件为真,则语句被执行;如果条件为假或NULL,则IF语句什么也不做。 |
| 2 | IF-THEN-ELSE语句
IF语句添加关键字ELSE,后跟一个备选语句序列。如果条件为假或NULL,则只执行备选语句序列。它确保执行语句序列中的一个。 |
| 3 | IF-THEN-ELSIF语句
它允许您在多个备选方案之间进行选择。 |
| 4 | Case语句
与IF语句一样,CASE语句选择一个语句序列来执行。 但是,为了选择序列,CASE语句使用选择器而不是多个布尔表达式。选择器是一个表达式,其值用于选择多个备选方案中的一个。 |
| 5 | Searched CASE语句
Searched CASE语句没有选择器,其WHEN子句包含产生布尔值的搜索条件。 |
| 6 | 嵌套IF-THEN-ELSE
您可以将一个IF-THEN或IF-THEN-ELSIF语句放在另一个IF-THEN或IF-THEN-ELSIF语句内。 |
PL/SQL - 循环语句
本章将讨论PL/SQL中的循环。可能会有这样的情况,您需要多次执行一段代码。一般来说,语句是顺序执行的:函数中的第一个语句首先执行,然后是第二个语句,依此类推。
编程语言提供各种控制结构,允许更复杂的执行路径。
循环语句允许我们多次执行一个语句或一组语句,以下是大多数编程语言中循环语句的一般形式:
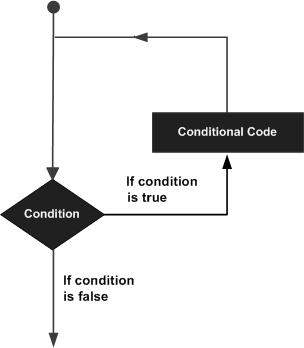
PL/SQL 提供以下几种循环类型来处理循环需求。点击以下链接查看详情。
| 序号 | 循环类型和描述 |
|---|---|
| 1 | PL/SQL 基本 LOOP 循环
在这种循环结构中,语句序列包含在 LOOP 和 END LOOP 语句之间。每次迭代,都会执行语句序列,然后控制返回到循环的顶部。 |
| 2 | PL/SQL WHILE 循环
当给定条件为真时,重复执行一条语句或一组语句。它在执行循环体之前测试条件。 |
| 3 | PL/SQL FOR 循环
多次执行一系列语句,并简化管理循环变量的代码。 |
| 4 | PL/SQL 中的嵌套循环
可以在任何其他基本循环、while 循环或 for 循环内使用一个或多个循环。 |
PL/SQL 循环的标注
PL/SQL 循环可以加标签。标签应包含在双尖括号(<< 和 >>)中,并出现在 LOOP 语句的开头。标签名称也可以出现在 LOOP 语句的结尾。可以在 EXIT 语句中使用标签来退出循环。
下面的程序演示了这个概念:
DECLARE
i number(1);
j number(1);
BEGIN
<< outer_loop >>
FOR i IN 1..3 LOOP
<< inner_loop >>
FOR j IN 1..3 LOOP
dbms_output.put_line('i is: '|| i || ' and j is: ' || j);
END loop inner_loop;
END loop outer_loop;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
i is: 1 and j is: 1 i is: 1 and j is: 2 i is: 1 and j is: 3 i is: 2 and j is: 1 i is: 2 and j is: 2 i is: 2 and j is: 3 i is: 3 and j is: 1 i is: 3 and j is: 2 i is: 3 and j is: 3 PL/SQL procedure successfully completed.
循环控制语句
循环控制语句改变执行的正常顺序。当执行离开作用域时,在该作用域中创建的所有自动对象都会被销毁。
PL/SQL 支持以下控制语句。为循环添加标签也有助于控制退出循环。点击以下链接查看详情。
| 序号 | 控制语句和描述 |
|---|---|
| 1 | EXIT 语句
EXIT 语句完成循环,控制转移到 END LOOP 后面的语句。 |
| 2 | CONTINUE 语句
使循环跳过其主体其余部分,并在立即重新测试其条件之前重新迭代。 |
| 3 | GOTO 语句
将控制转移到带标签的语句。虽然不建议在程序中使用 GOTO 语句。 |
PL/SQL - 字符串
PL/SQL 中的字符串实际上是一系列字符,带有一个可选的长度规范。字符可以是数字、字母、空格、特殊字符或所有字符的组合。PL/SQL 提供三种类型的字符串:
定长字符串 - 在此类字符串中,程序员在声明字符串时指定长度。字符串用空格向右填充到指定的长度。
变长字符串 - 在此类字符串中,指定字符串的最大长度(最多 32,767),并且不进行填充。
字符大对象 (CLOB) - 这些是变长字符串,最大可达 128 TB。
PL/SQL 字符串可以是变量或字面量。字符串字面量用引号括起来。例如:
'This is a string literal.' Or 'hello world'
要在字符串字面量中包含单引号,需要键入两个相邻的单引号。例如:
'this isn''t what it looks like'
声明字符串变量
Oracle 数据库提供了许多字符串数据类型,例如 CHAR、NCHAR、VARCHAR2、NVARCHAR2、CLOB 和 NCLOB。以'N'为前缀的数据类型是'国家字符集'数据类型,用于存储 Unicode 字符数据。
如果需要声明变长字符串,必须提供该字符串的最大长度。例如,VARCHAR2 数据类型。下面的示例演示了声明和使用一些字符串变量:
DECLARE
name varchar2(20);
company varchar2(30);
introduction clob;
choice char(1);
BEGIN
name := 'John Smith';
company := 'Infotech';
introduction := ' Hello! I''m John Smith from Infotech.';
choice := 'y';
IF choice = 'y' THEN
dbms_output.put_line(name);
dbms_output.put_line(company);
dbms_output.put_line(introduction);
END IF;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
John Smith Infotech Hello! I'm John Smith from Infotech. PL/SQL procedure successfully completed
要声明定长字符串,请使用 CHAR 数据类型。这里不需要为定长变量指定最大长度。如果省略长度约束,Oracle 数据库会自动使用所需的最大长度。以下两个声明是相同的:
red_flag CHAR(1) := 'Y'; red_flag CHAR := 'Y';
PL/SQL 字符串函数和运算符
PL/SQL 提供连接运算符(||)用于连接两个字符串。下表提供了 PL/SQL 提供的字符串函数:
| 序号 | 函数和用途 |
|---|---|
| 1 | ASCII(x); 返回字符 x 的 ASCII 值。 |
| 2 | CHR(x); 返回 ASCII 值为 x 的字符。 |
| 3 | CONCAT(x, y); 连接字符串 x 和 y 并返回追加的字符串。 |
| 4 | INITCAP(x); 将 x 中每个单词的首字母转换为大写并返回该字符串。 |
| 5 | INSTR(x, find_string [, start] [, occurrence]); 在 x 中搜索find_string 并返回其出现的位置。 |
| 6 | INSTRB(x); 返回一个字符串在另一个字符串中的位置,但以字节为单位返回该值。 |
| 7 | LENGTH(x); 返回 x 中的字符数。 |
| 8 | LENGTHB(x); 对于单字节字符集,返回字符字符串的长度(以字节为单位)。 |
| 9 | LOWER(x); 将 x 中的字母转换为小写并返回该字符串。 |
| 10 | LPAD(x, width [, pad_string]) ; 在x的左侧用空格填充,使字符串的总长度达到 width 个字符。 |
| 11 | LTRIM(x [, trim_string]); 从x的左侧修剪字符。 |
| 12 | NANVL(x, value); 如果 x 与 NaN 特殊值(非数字)匹配,则返回 value;否则返回x。 |
| 13 | NLS_INITCAP(x); 与 INITCAP 函数相同,但它可以使用 NLSSORT 指定的不同排序方法。 |
| 14 | NLS_LOWER(x) ; 与 LOWER 函数相同,但它可以使用 NLSSORT 指定的不同排序方法。 |
| 15 | NLS_UPPER(x); 与 UPPER 函数相同,但它可以使用 NLSSORT 指定的不同排序方法。 |
| 16 | NLSSORT(x); 更改字符的排序方法。必须在任何 NLS 函数之前指定;否则,将使用默认排序。 |
| 17 | NVL(x, value); 如果x为 null,则返回 value;否则返回 x。 |
| 18 | NVL2(x, value1, value2); 如果 x 不为 null,则返回 value1;如果 x 为 null,则返回 value2。 |
| 19 | REPLACE(x, search_string, replace_string); 在x中搜索 search_string 并将其替换为 replace_string。 |
| 20 | RPAD(x, width [, pad_string]); 在x的右侧填充。 |
| 21 | RTRIM(x [, trim_string]); 从x的右侧修剪。 |
| 22 | SOUNDEX(x) ; 返回包含x的语音表示的字符串。 |
| 23 | SUBSTR(x, start [, length]); 返回x的子字符串,该子字符串从 start 指定的位置开始。可以提供子字符串的可选长度。 |
| 24 | SUBSTRB(x); 与 SUBSTR 相同,只是对于单字节字符系统,参数以字节而不是字符表示。 |
| 25 | TRIM([trim_char FROM) x); 从x的左侧和右侧修剪字符。 |
| 26 | UPPER(x); 将 x 中的字母转换为大写并返回该字符串。 |
现在让我们通过一些示例来理解这个概念:
示例 1
DECLARE
greetings varchar2(11) := 'hello world';
BEGIN
dbms_output.put_line(UPPER(greetings));
dbms_output.put_line(LOWER(greetings));
dbms_output.put_line(INITCAP(greetings));
/* retrieve the first character in the string */
dbms_output.put_line ( SUBSTR (greetings, 1, 1));
/* retrieve the last character in the string */
dbms_output.put_line ( SUBSTR (greetings, -1, 1));
/* retrieve five characters,
starting from the seventh position. */
dbms_output.put_line ( SUBSTR (greetings, 7, 5));
/* retrieve the remainder of the string,
starting from the second position. */
dbms_output.put_line ( SUBSTR (greetings, 2));
/* find the location of the first "e" */
dbms_output.put_line ( INSTR (greetings, 'e'));
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
HELLO WORLD hello world Hello World h d World ello World 2 PL/SQL procedure successfully completed.
示例 2
DECLARE greetings varchar2(30) := '......Hello World.....'; BEGIN dbms_output.put_line(RTRIM(greetings,'.')); dbms_output.put_line(LTRIM(greetings, '.')); dbms_output.put_line(TRIM( '.' from greetings)); END; /
当上述代码在SQL提示符下执行时,它会产生以下结果:
......Hello World Hello World..... Hello World PL/SQL procedure successfully completed.
PL/SQL - 数组
在本章中,我们将讨论 PL/SQL 中的数组。PL/SQL 编程语言提供了一种称为VARRAY的数据结构,它可以存储相同类型元素的固定大小的顺序集合。可以使用 varray 存储有序的数据集合,但是通常最好将数组视为相同类型变量的集合。
所有 varray 都由连续的内存位置组成。最低地址对应于第一个元素,最高地址对应于最后一个元素。

数组是集合类型数据的一部分,它代表可变大小的数组。我们将在后面的章节'PL/SQL 集合'中学习其他集合类型。
varray中的每个元素都与一个索引相关联。它还有一个可以动态更改的最大大小。
创建 Varray 类型
使用CREATE TYPE语句创建 varray 类型。必须指定 varray 中存储元素的最大大小和类型。
在模式级别创建 VARRAY 类型的基本语法如下:
CREATE OR REPLACE TYPE varray_type_name IS VARRAY(n) of <element_type>
其中:
- varray_type_name 是有效的属性名称,
- n 是 varray 中元素的数量(最大值),
- element_type 是数组元素的数据类型。
可以使用ALTER TYPE语句更改 varray 的最大大小。
例如:
CREATE Or REPLACE TYPE namearray AS VARRAY(3) OF VARCHAR2(10); / Type created.
在 PL/SQL 块中创建 VARRAY 类型的基本语法如下:
TYPE varray_type_name IS VARRAY(n) of <element_type>
例如:
TYPE namearray IS VARRAY(5) OF VARCHAR2(10); Type grades IS VARRAY(5) OF INTEGER;
现在让我们通过一些示例来理解这个概念:
示例 1
下面的程序演示了 varray 的用法:
DECLARE
type namesarray IS VARRAY(5) OF VARCHAR2(10);
type grades IS VARRAY(5) OF INTEGER;
names namesarray;
marks grades;
total integer;
BEGIN
names := namesarray('Kavita', 'Pritam', 'Ayan', 'Rishav', 'Aziz');
marks:= grades(98, 97, 78, 87, 92);
total := names.count;
dbms_output.put_line('Total '|| total || ' Students');
FOR i in 1 .. total LOOP
dbms_output.put_line('Student: ' || names(i) || '
Marks: ' || marks(i));
END LOOP;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Total 5 Students Student: Kavita Marks: 98 Student: Pritam Marks: 97 Student: Ayan Marks: 78 Student: Rishav Marks: 87 Student: Aziz Marks: 92 PL/SQL procedure successfully completed.
请注意:
在 Oracle 环境中,varrays 的起始索引始终为 1。
可以使用 varray 类型的构造函数方法初始化 varray 元素,该方法与 varray 的名称相同。
Varrays 是一维数组。
声明 varray 时,它自动为 NULL,并且必须在引用其元素之前对其进行初始化。
示例 2
varray 的元素也可以是任何数据库表的 %ROWTYPE 或任何数据库表字段的 %TYPE。以下示例说明了这个概念。
我们将使用存储在我们数据库中的 CUSTOMERS 表,如下所示:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
以下示例使用了游标,您将在单独的章节中详细学习。
DECLARE
CURSOR c_customers is
SELECT name FROM customers;
type c_list is varray (6) of customers.name%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter + 1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter ||'):'||name_list(counter));
END LOOP;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Customer(1): Ramesh Customer(2): Khilan Customer(3): kaushik Customer(4): Chaitali Customer(5): Hardik Customer(6): Komal PL/SQL procedure successfully completed.
PL/SQL - 过程
在本章中,我们将讨论 PL/SQL 中的过程。子程序是一个执行特定任务的程序单元/模块。这些子程序组合起来形成更大的程序。这基本上称为“模块化设计”。子程序可以由另一个子程序或程序调用,该子程序或程序称为调用程序。
可以创建子程序:
- 在模式级别
- 在包内
- 在 PL/SQL 块内
在模式级别,子程序是独立子程序。它使用 CREATE PROCEDURE 或 CREATE FUNCTION 语句创建。它存储在数据库中,可以使用 DROP PROCEDURE 或 DROP FUNCTION 语句删除。
在包内创建的子程序是打包子程序。它存储在数据库中,只有在使用 DROP PACKAGE 语句删除包时才能删除。我们将在章节'PL/SQL - 包'中讨论包。
PL/SQL 子程序是命名的 PL/SQL 块,可以使用一组参数调用。PL/SQL 提供两种子程序:
函数 - 这些子程序返回单个值;主要用于计算和返回值。
过程 - 这些子程序不直接返回值;主要用于执行操作。
本章将介绍PL/SQL 过程的重要方面。我们将在下一章讨论PL/SQL 函数。
PL/SQL 子程序的组成部分
每个 PL/SQL 子程序都有一个名称,并且可能还有一个参数列表。与匿名 PL/SQL 块一样,命名块也包含以下三个部分:
| 序号 | 部分和描述 |
|---|---|
| 1 | 声明部分 这是一个可选部分。但是,子程序的声明部分不是以 DECLARE 关键字开头。它包含类型、游标、常量、变量、异常和嵌套子程序的声明。这些项目对子程序是局部的,并且在子程序完成执行时将不复存在。 |
| 2 | 可执行部分 这是必须的部分,包含执行指定操作的语句。 |
| 3 | 异常处理 这又是一个可选部分。它包含处理运行时错误的代码。 |
创建过程
使用CREATE OR REPLACE PROCEDURE语句创建过程。CREATE OR REPLACE PROCEDURE 语句的简化语法如下:
CREATE [OR REPLACE] PROCEDURE procedure_name
[(parameter_name [IN | OUT | IN OUT] type [, ...])]
{IS | AS}
BEGIN
< procedure_body >
END procedure_name;
其中:
过程名指定过程的名称。
[OR REPLACE] 选项允许修改现有过程。
可选参数列表包含参数的名称、模式和类型。IN 代表从外部传入的值,OUT 代表用于将值返回到过程外部的参数。
过程体包含可执行部分。
对于创建独立过程,使用 AS 关键字代替 IS 关键字。
示例
以下示例创建一个简单的过程,在执行时在屏幕上显示字符串“Hello World!”。
CREATE OR REPLACE PROCEDURE greetings
AS
BEGIN
dbms_output.put_line('Hello World!');
END;
/
使用 SQL 提示符执行上述代码时,将产生以下结果:
Procedure created.
执行独立过程
可以两种方式调用独立过程:
使用EXECUTE关键字
从 PL/SQL 块调用过程名称
上述名为'greetings'的过程可以用 EXECUTE 关键字调用,如下所示:
EXECUTE greetings;
上述调用将显示:
Hello World PL/SQL procedure successfully completed.
也可以从另一个 PL/SQL 块调用该过程:
BEGIN greetings; END; /
上述调用将显示:
Hello World PL/SQL procedure successfully completed.
删除独立过程
使用DROP PROCEDURE语句删除独立过程。删除过程的语法如下:
DROP PROCEDURE procedure-name;
可以使用以下语句删除 greetings 过程:
DROP PROCEDURE greetings;
PL/SQL 子程序中的参数模式
下表列出了 PL/SQL 子程序中的参数模式:
| 序号 | 参数模式 & 说明 |
|---|---|
| 1 | IN IN 参数允许您向子程序传递值。它是一个只读参数。在子程序内部,IN 参数的作用类似于常量。不能为其赋值。您可以将常量、文字、已初始化的变量或表达式作为 IN 参数传递。您还可以将其初始化为默认值;但是,在这种情况下,它将从子程序调用中省略。它是参数传递的默认模式。参数通过引用传递。 |
| 2 | OUT OUT 参数将值返回给调用程序。在子程序内部,OUT 参数的作用类似于变量。您可以更改其值并在赋值后引用该值。实际参数必须是变量,并且是按值传递的。 |
| 3 | IN OUT IN OUT 参数将初始值传递给子程序,并将更新后的值返回给调用者。可以为其赋值,也可以读取其值。 与 IN OUT 形式参数对应的实际参数必须是变量,而不是常量或表达式。形式参数必须赋值。实际参数按值传递。 |
IN & OUT 模式示例 1
此程序查找两个值的最小值。在这里,过程使用 IN 模式获取两个数字,并使用 OUT 参数返回它们的最小值。
DECLARE
a number;
b number;
c number;
PROCEDURE findMin(x IN number, y IN number, z OUT number) IS
BEGIN
IF x < y THEN
z:= x;
ELSE
z:= y;
END IF;
END;
BEGIN
a:= 23;
b:= 45;
findMin(a, b, c);
dbms_output.put_line(' Minimum of (23, 45) : ' || c);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Minimum of (23, 45) : 23 PL/SQL procedure successfully completed.
IN & OUT 模式示例 2
此过程计算传递值的平方。此示例显示如何使用相同的参数来接受一个值,然后返回另一个结果。
DECLARE
a number;
PROCEDURE squareNum(x IN OUT number) IS
BEGIN
x := x * x;
END;
BEGIN
a:= 23;
squareNum(a);
dbms_output.put_line(' Square of (23): ' || a);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Square of (23): 529 PL/SQL procedure successfully completed.
传递参数的方法
实际参数可以通过三种方式传递:
- 位置表示法
- 命名表示法
- 混合表示法
位置表示法
在位置表示法中,您可以按如下方式调用过程:
findMin(a, b, c, d);
在位置表示法中,第一个实际参数将替换第一个形式参数;第二个实际参数将替换第二个形式参数,依此类推。因此,a 将替换 x,b 将替换 y,c 将替换 z,d 将替换 m。
命名表示法
在命名表示法中,使用箭头符号 (=>)将实际参数与形式参数关联。过程调用将如下所示:
findMin(x => a, y => b, z => c, m => d);
混合表示法
在混合表示法中,您可以在过程调用中混合两种表示法;但是,位置表示法应该在命名表示法之前。
以下调用是合法的:
findMin(a, b, c, m => d);
但是,这是非法的
findMin(x => a, b, c, d);
PL/SQL - 函数
在本章中,我们将讨论 PL/SQL 中的函数。函数与过程相同,只是它返回一个值。因此,前一章的所有讨论也适用于函数。
创建函数
使用CREATE FUNCTION语句创建独立函数。CREATE OR REPLACE PROCEDURE语句的简化语法如下:
CREATE [OR REPLACE] FUNCTION function_name
[(parameter_name [IN | OUT | IN OUT] type [, ...])]
RETURN return_datatype
{IS | AS}
BEGIN
< function_body >
END [function_name];
其中:
函数名指定函数的名称。
[OR REPLACE] 选项允许修改现有函数。
可选参数列表包含参数的名称、模式和类型。IN 代表从外部传入的值,OUT 代表用于将值返回到过程外部的参数。
函数必须包含return语句。
RETURN子句指定您将从函数返回的数据类型。
函数体包含可执行部分。
对于创建独立函数,使用 AS 关键字代替 IS 关键字。
示例
以下示例说明如何创建和调用独立函数。此函数返回 customers 表中 CUSTOMERS 的总数。
我们将使用 CUSTOMERS 表,我们在PL/SQL 变量章节中创建并使用了该表:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
CREATE OR REPLACE FUNCTION totalCustomers
RETURN number IS
total number(2) := 0;
BEGIN
SELECT count(*) into total
FROM customers;
RETURN total;
END;
/
使用 SQL 提示符执行上述代码时,将产生以下结果:
Function created.
调用函数
在创建函数时,您会给出函数必须执行的操作的定义。要使用函数,您必须调用该函数以执行定义的任务。当程序调用函数时,程序控制将转移到被调用的函数。
被调用的函数执行定义的任务,当执行其 return 语句或到达最后一个 end 语句时,它将程序控制返回到主程序。
要调用函数,您只需将所需的参数与函数名称一起传递,如果函数返回值,则可以存储返回值。以下程序从匿名块调用函数totalCustomers:
DECLARE
c number(2);
BEGIN
c := totalCustomers();
dbms_output.put_line('Total no. of Customers: ' || c);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Total no. of Customers: 6 PL/SQL procedure successfully completed.
示例
以下示例演示声明、定义和调用一个简单的 PL/SQL 函数,该函数计算并返回两个值的较大值。
DECLARE
a number;
b number;
c number;
FUNCTION findMax(x IN number, y IN number)
RETURN number
IS
z number;
BEGIN
IF x > y THEN
z:= x;
ELSE
Z:= y;
END IF;
RETURN z;
END;
BEGIN
a:= 23;
b:= 45;
c := findMax(a, b);
dbms_output.put_line(' Maximum of (23,45): ' || c);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Maximum of (23,45): 45 PL/SQL procedure successfully completed.
PL/SQL 递归函数
我们已经看到,程序或子程序可以调用另一个子程序。当子程序调用自身时,称为递归调用,该过程称为递归。
为了说明这个概念,让我们计算一个数字的阶乘。数字 n 的阶乘定义为:
n! = n*(n-1)!
= n*(n-1)*(n-2)!
...
= n*(n-1)*(n-2)*(n-3)... 1
以下程序通过递归调用自身来计算给定数字的阶乘:
DECLARE
num number;
factorial number;
FUNCTION fact(x number)
RETURN number
IS
f number;
BEGIN
IF x=0 THEN
f := 1;
ELSE
f := x * fact(x-1);
END IF;
RETURN f;
END;
BEGIN
num:= 6;
factorial := fact(num);
dbms_output.put_line(' Factorial '|| num || ' is ' || factorial);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Factorial 6 is 720 PL/SQL procedure successfully completed.
PL/SQL - 游标
在本章中,我们将讨论 PL/SQL 中的游标。Oracle 创建一个称为上下文区域的内存区域用于处理 SQL 语句,其中包含处理语句所需的所有信息;例如,处理的行数等。
游标是指向此上下文区域的指针。PL/SQL 通过游标控制上下文区域。游标包含 SQL 语句返回的行(一行或多行)。游标保存的行集称为活动集。
您可以命名游标,以便可以在程序中引用它来逐一提取和处理 SQL 语句返回的行。有两种类型的游标:
- 隐式游标
- 显式游标
隐式游标
每当执行 SQL 语句时,如果没有语句的显式游标,Oracle 就会自动创建隐式游标。程序员无法控制隐式游标及其中的信息。
每当发出 DML 语句(INSERT、UPDATE 和 DELETE)时,都会将隐式游标与该语句关联。对于 INSERT 操作,游标包含需要插入的数据。对于 UPDATE 和 DELETE 操作,游标标识将受影响的行。
在 PL/SQL 中,您可以将最新的隐式游标称为SQL 游标,它始终具有属性,例如%FOUND、%ISOPEN、%NOTFOUND和%ROWCOUNT。SQL 游标具有附加属性%BULK_ROWCOUNT和%BULK_EXCEPTIONS,专为与FORALL语句一起使用而设计。下表提供了最常用属性的描述:
| 序号 | 属性 & 说明 |
|---|---|
| 1 | %FOUND 如果 INSERT、UPDATE 或 DELETE 语句影响了一行或多行,或者 SELECT INTO 语句返回了一行或多行,则返回 TRUE。否则,返回 FALSE。 |
| 2 | %NOTFOUND %FOUND 的逻辑反义词。如果 INSERT、UPDATE 或 DELETE 语句没有影响任何行,或者 SELECT INTO 语句没有返回任何行,则返回 TRUE。否则,返回 FALSE。 |
| 3 | %ISOPEN 对于隐式游标始终返回 FALSE,因为 Oracle 在执行其关联的 SQL 语句后会自动关闭 SQL 游标。 |
| 4 | %ROWCOUNT 返回 INSERT、UPDATE 或 DELETE 语句影响的行数,或者 SELECT INTO 语句返回的行数。 |
任何 SQL 游标属性都将作为sql%attribute_name访问,如下例所示。
示例
我们将使用我们在前几章中创建和使用的 CUSTOMERS 表。
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
以下程序将更新表并将每个客户的工资增加 500,并使用SQL%ROWCOUNT属性确定受影响的行数:
DECLARE
total_rows number(2);
BEGIN
UPDATE customers
SET salary = salary + 500;
IF sql%notfound THEN
dbms_output.put_line('no customers selected');
ELSIF sql%found THEN
total_rows := sql%rowcount;
dbms_output.put_line( total_rows || ' customers selected ');
END IF;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
6 customers selected PL/SQL procedure successfully completed.
如果您检查 customers 表中的记录,您会发现行已被更新:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2500.00 | | 2 | Khilan | 25 | Delhi | 2000.00 | | 3 | kaushik | 23 | Kota | 2500.00 | | 4 | Chaitali | 25 | Mumbai | 7000.00 | | 5 | Hardik | 27 | Bhopal | 9000.00 | | 6 | Komal | 22 | MP | 5000.00 | +----+----------+-----+-----------+----------+
显式游标
显式游标是程序员定义的游标,用于更好地控制上下文区域。显式游标应在 PL/SQL 块的声明部分定义。它是在返回多行的 SELECT 语句上创建的。
创建显式游标的语法为:
CURSOR cursor_name IS select_statement;
使用显式游标包括以下步骤:
- 声明游标以初始化内存
- 打开游标以分配内存
- 提取游标以检索数据
- 关闭游标以释放已分配的内存
声明游标
声明游标使用名称和关联的 SELECT 语句定义游标。例如:
CURSOR c_customers IS SELECT id, name, address FROM customers;
打开游标
打开游标会为游标分配内存,并使其准备好将 SQL 语句返回的行提取到其中。例如,我们将打开上述定义的游标,如下所示:
OPEN c_customers;
提取游标
提取游标涉及一次访问一行。例如,我们将从上述打开的游标中提取行,如下所示:
FETCH c_customers INTO c_id, c_name, c_addr;
关闭游标
关闭游标意味着释放已分配的内存。例如,我们将关闭上述打开的游标,如下所示:
CLOSE c_customers;
示例
下面是一个完整的例子,用于说明显式游标的概念。
DECLARE
c_id customers.id%type;
c_name customer.name%type;
c_addr customers.address%type;
CURSOR c_customers is
SELECT id, name, address FROM customers;
BEGIN
OPEN c_customers;
LOOP
FETCH c_customers into c_id, c_name, c_addr;
EXIT WHEN c_customers%notfound;
dbms_output.put_line(c_id || ' ' || c_name || ' ' || c_addr);
END LOOP;
CLOSE c_customers;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
1 Ramesh Ahmedabad 2 Khilan Delhi 3 kaushik Kota 4 Chaitali Mumbai 5 Hardik Bhopal 6 Komal MP PL/SQL procedure successfully completed.
PL/SQL - 记录
在本章中,我们将讨论PL/SQL中的记录。一个记录是一个数据结构,可以保存不同类型的数据项。记录由不同的字段组成,类似于数据库表的一行。
例如,你想跟踪图书馆里的书籍。你可能想跟踪每本书的以下属性,例如标题、作者、主题、图书ID。一个包含每个项目字段的记录允许将BOOK视为一个逻辑单元,并允许你更好地组织和表示其信息。
PL/SQL可以处理以下类型的记录:
- 基于表的记录
- 基于游标的记录
- 用户定义的记录
基于表的记录
%ROWTYPE属性使程序员能够创建基于表和基于游标的记录。
下面的例子说明了基于表记录的概念。我们将使用我们在前面章节中创建和使用的CUSTOMERS表:
DECLARE
customer_rec customers%rowtype;
BEGIN
SELECT * into customer_rec
FROM customers
WHERE id = 5;
dbms_output.put_line('Customer ID: ' || customer_rec.id);
dbms_output.put_line('Customer Name: ' || customer_rec.name);
dbms_output.put_line('Customer Address: ' || customer_rec.address);
dbms_output.put_line('Customer Salary: ' || customer_rec.salary);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Customer ID: 5 Customer Name: Hardik Customer Address: Bhopal Customer Salary: 9000 PL/SQL procedure successfully completed.
基于游标的记录
下面的例子说明了基于游标记录的概念。我们将使用我们在前面章节中创建和使用的CUSTOMERS表:
DECLARE
CURSOR customer_cur is
SELECT id, name, address
FROM customers;
customer_rec customer_cur%rowtype;
BEGIN
OPEN customer_cur;
LOOP
FETCH customer_cur into customer_rec;
EXIT WHEN customer_cur%notfound;
DBMS_OUTPUT.put_line(customer_rec.id || ' ' || customer_rec.name);
END LOOP;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
1 Ramesh 2 Khilan 3 kaushik 4 Chaitali 5 Hardik 6 Komal PL/SQL procedure successfully completed.
用户定义的记录
PL/SQL提供了一种用户定义的记录类型,允许你定义不同的记录结构。这些记录由不同的字段组成。假设你想跟踪图书馆里的书籍。你可能想跟踪每本书的以下属性:
- 标题
- 作者
- 主题
- 图书ID
定义记录
记录类型定义如下:
TYPE type_name IS RECORD ( field_name1 datatype1 [NOT NULL] [:= DEFAULT EXPRESSION], field_name2 datatype2 [NOT NULL] [:= DEFAULT EXPRESSION], ... field_nameN datatypeN [NOT NULL] [:= DEFAULT EXPRESSION); record-name type_name;
Book记录的声明方式如下:
DECLARE TYPE books IS RECORD (title varchar(50), author varchar(50), subject varchar(100), book_id number); book1 books; book2 books;
访问字段
要访问记录的任何字段,我们使用点(.)运算符。成员访问运算符被编码为记录变量名和我们想要访问的字段之间的句点。以下是一个解释记录用法的例子:
DECLARE
type books is record
(title varchar(50),
author varchar(50),
subject varchar(100),
book_id number);
book1 books;
book2 books;
BEGIN
-- Book 1 specification
book1.title := 'C Programming';
book1.author := 'Nuha Ali ';
book1.subject := 'C Programming Tutorial';
book1.book_id := 6495407;
-- Book 2 specification
book2.title := 'Telecom Billing';
book2.author := 'Zara Ali';
book2.subject := 'Telecom Billing Tutorial';
book2.book_id := 6495700;
-- Print book 1 record
dbms_output.put_line('Book 1 title : '|| book1.title);
dbms_output.put_line('Book 1 author : '|| book1.author);
dbms_output.put_line('Book 1 subject : '|| book1.subject);
dbms_output.put_line('Book 1 book_id : ' || book1.book_id);
-- Print book 2 record
dbms_output.put_line('Book 2 title : '|| book2.title);
dbms_output.put_line('Book 2 author : '|| book2.author);
dbms_output.put_line('Book 2 subject : '|| book2.subject);
dbms_output.put_line('Book 2 book_id : '|| book2.book_id);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Book 1 title : C Programming Book 1 author : Nuha Ali Book 1 subject : C Programming Tutorial Book 1 book_id : 6495407 Book 2 title : Telecom Billing Book 2 author : Zara Ali Book 2 subject : Telecom Billing Tutorial Book 2 book_id : 6495700 PL/SQL procedure successfully completed.
记录作为子程序参数
你可以像传递任何其他变量一样传递记录作为子程序参数。你也可以像在上面的例子中一样访问记录字段:
DECLARE
type books is record
(title varchar(50),
author varchar(50),
subject varchar(100),
book_id number);
book1 books;
book2 books;
PROCEDURE printbook (book books) IS
BEGIN
dbms_output.put_line ('Book title : ' || book.title);
dbms_output.put_line('Book author : ' || book.author);
dbms_output.put_line( 'Book subject : ' || book.subject);
dbms_output.put_line( 'Book book_id : ' || book.book_id);
END;
BEGIN
-- Book 1 specification
book1.title := 'C Programming';
book1.author := 'Nuha Ali ';
book1.subject := 'C Programming Tutorial';
book1.book_id := 6495407;
-- Book 2 specification
book2.title := 'Telecom Billing';
book2.author := 'Zara Ali';
book2.subject := 'Telecom Billing Tutorial';
book2.book_id := 6495700;
-- Use procedure to print book info
printbook(book1);
printbook(book2);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Book title : C Programming Book author : Nuha Ali Book subject : C Programming Tutorial Book book_id : 6495407 Book title : Telecom Billing Book author : Zara Ali Book subject : Telecom Billing Tutorial Book book_id : 6495700 PL/SQL procedure successfully completed.
PL/SQL - 异常处理
在本章中,我们将讨论PL/SQL中的异常。异常是在程序执行期间发生的错误条件。PL/SQL支持程序员使用程序中的EXCEPTION块捕获此类条件,并对错误条件采取适当的措施。异常有两种类型:
- 系统定义的异常
- 用户定义的异常
异常处理语法
异常处理的通用语法如下。在这里,你可以列出尽可能多的你可以处理的异常。默认异常将使用WHEN others THEN处理:
DECLARE
<declarations section>
BEGIN
<executable command(s)>
EXCEPTION
<exception handling goes here >
WHEN exception1 THEN
exception1-handling-statements
WHEN exception2 THEN
exception2-handling-statements
WHEN exception3 THEN
exception3-handling-statements
........
WHEN others THEN
exception3-handling-statements
END;
示例
让我们编写一个代码来说明这个概念。我们将使用我们在前面章节中创建和使用的CUSTOMERS表:
DECLARE
c_id customers.id%type := 8;
c_name customerS.Name%type;
c_addr customers.address%type;
BEGIN
SELECT name, address INTO c_name, c_addr
FROM customers
WHERE id = c_id;
DBMS_OUTPUT.PUT_LINE ('Name: '|| c_name);
DBMS_OUTPUT.PUT_LINE ('Address: ' || c_addr);
EXCEPTION
WHEN no_data_found THEN
dbms_output.put_line('No such customer!');
WHEN others THEN
dbms_output.put_line('Error!');
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
No such customer! PL/SQL procedure successfully completed.
上面的程序显示了ID已知的客户的姓名和地址。由于我们的数据库中没有ID值为8的客户,程序引发了运行时异常NO_DATA_FOUND,该异常在EXCEPTION块中被捕获。
引发异常
每当发生任何内部数据库错误时,异常都会由数据库服务器自动引发,但是程序员可以使用RAISE命令显式引发异常。以下是引发异常的简单语法:
DECLARE
exception_name EXCEPTION;
BEGIN
IF condition THEN
RAISE exception_name;
END IF;
EXCEPTION
WHEN exception_name THEN
statement;
END;
你可以使用上面的语法来引发Oracle标准异常或任何用户定义的异常。在下一节中,我们将提供一个关于引发用户定义异常的例子。你可以以类似的方式引发Oracle标准异常。
用户定义的异常
PL/SQL允许你根据程序的需要定义自己的异常。用户定义的异常必须声明,然后使用RAISE语句或过程DBMS_STANDARD.RAISE_APPLICATION_ERROR显式引发。
声明异常的语法是:
DECLARE my-exception EXCEPTION;
示例
下面的例子说明了这个概念。该程序请求客户ID,当用户输入无效ID时,将引发异常invalid_id。
DECLARE
c_id customers.id%type := &cc_id;
c_name customerS.Name%type;
c_addr customers.address%type;
-- user defined exception
ex_invalid_id EXCEPTION;
BEGIN
IF c_id <= 0 THEN
RAISE ex_invalid_id;
ELSE
SELECT name, address INTO c_name, c_addr
FROM customers
WHERE id = c_id;
DBMS_OUTPUT.PUT_LINE ('Name: '|| c_name);
DBMS_OUTPUT.PUT_LINE ('Address: ' || c_addr);
END IF;
EXCEPTION
WHEN ex_invalid_id THEN
dbms_output.put_line('ID must be greater than zero!');
WHEN no_data_found THEN
dbms_output.put_line('No such customer!');
WHEN others THEN
dbms_output.put_line('Error!');
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Enter value for cc_id: -6 (let's enter a value -6) old 2: c_id customers.id%type := &cc_id; new 2: c_id customers.id%type := -6; ID must be greater than zero! PL/SQL procedure successfully completed.
预定义异常
PL/SQL提供了许多预定义的异常,当程序违反任何数据库规则时,这些异常就会被执行。例如,当SELECT INTO语句不返回任何行时,将引发预定义异常NO_DATA_FOUND。下表列出了一些重要的预定义异常:
| 异常 | Oracle错误 | SQLCODE | 描述 |
|---|---|---|---|
| ACCESS_INTO_NULL | 06530 | -6530 | 当空对象自动赋值时引发。 |
| CASE_NOT_FOUND | 06592 | -6592 | 当CASE语句的WHEN子句中没有选择任何选项,并且没有ELSE子句时引发。 |
| COLLECTION_IS_NULL | 06531 | -6531 | 当程序尝试对未初始化的嵌套表或varray应用EXISTS以外的集合方法,或者程序尝试为未初始化的嵌套表或varray的元素赋值时引发。 |
| DUP_VAL_ON_INDEX | 00001 | -1 | 当尝试将重复值存储到具有唯一索引的列中时引发。 |
| INVALID_CURSOR | 01001 | -1001 | 当尝试进行不允许的游标操作时引发,例如关闭未打开的游标。 |
| INVALID_NUMBER | 01722 | -1722 | 当字符字符串转换为数字失败时引发,因为该字符串不代表有效的数字。 |
| LOGIN_DENIED | 01017 | -1017 | 当程序尝试使用无效用户名或密码登录数据库时引发。 |
| NO_DATA_FOUND | 01403 | +100 | 当SELECT INTO语句不返回任何行时引发。 |
| NOT_LOGGED_ON | 01012 | -1012 | 当在未连接到数据库的情况下发出数据库调用时引发。 |
| PROGRAM_ERROR | 06501 | -6501 | 当PL/SQL出现内部问题时引发。 |
| ROWTYPE_MISMATCH | 06504 | -6504 | 当游标在具有不兼容数据类型的变量中获取值时引发。 |
| SELF_IS_NULL | 30625 | -30625 | 当调用成员方法但未初始化对象类型的实例时引发。 |
| STORAGE_ERROR | 06500 | -6500 | 当PL/SQL内存不足或内存损坏时引发。 |
| TOO_MANY_ROWS | 01422 | -1422 | 当SELECT INTO语句返回多于一行时引发。 |
| VALUE_ERROR | 06502 | -6502 | 当发生算术、转换、截断或大小约束错误时引发。 |
| ZERO_DIVIDE | 01476 | 1476 | 当尝试将数字除以零时引发。 |
PL/SQL - 触发器
在本章中,我们将讨论PL/SQL中的触发器。触发器是存储的程序,当发生某些事件时会自动执行或触发。触发器实际上是编写来响应以下任何事件执行的:
数据库操作(DML)语句(DELETE、INSERT或UPDATE)
数据库定义(DDL)语句(CREATE、ALTER或DROP)。
数据库操作(SERVERERROR、LOGON、LOGOFF、STARTUP或SHUTDOWN)。
触发器可以在表、视图、模式或与事件关联的数据库上定义。
触发器的优点
触发器可以用于以下目的:
- 自动生成一些派生列值
- 强制参照完整性
- 事件日志记录和存储表访问信息
- 审计
- 表的同步复制
- 实施安全授权
- 防止无效事务
创建触发器
创建触发器的语法是:
CREATE [OR REPLACE ] TRIGGER trigger_name
{BEFORE | AFTER | INSTEAD OF }
{INSERT [OR] | UPDATE [OR] | DELETE}
[OF col_name]
ON table_name
[REFERENCING OLD AS o NEW AS n]
[FOR EACH ROW]
WHEN (condition)
DECLARE
Declaration-statements
BEGIN
Executable-statements
EXCEPTION
Exception-handling-statements
END;
其中:
CREATE [OR REPLACE] TRIGGER trigger_name - 创建或替换现有触发器,触发器名为 *trigger_name*。
{BEFORE | AFTER | INSTEAD OF} - 指定触发器何时执行。INSTEAD OF子句用于在视图上创建触发器。
{INSERT [OR] | UPDATE [OR] | DELETE} - 指定DML操作。
[OF col_name] - 指定将更新的列名。
[ON table_name] - 指定与触发器关联的表名。
[REFERENCING OLD AS o NEW AS n] - 允许你引用各种DML语句(如INSERT、UPDATE和DELETE)的新旧值。
[FOR EACH ROW] - 指定行级触发器,即触发器将针对每个受影响的行执行。否则,触发器只会在执行SQL语句时执行一次,这称为表级触发器。
WHEN (condition) - 为触发器将触发的行提供条件。此子句仅对行级触发器有效。
示例
首先,我们将使用我们在前面章节中创建和使用的CUSTOMERS表:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
以下程序为customers表创建了一个行级触发器,该触发器将在对CUSTOMERS表执行INSERT、UPDATE或DELETE操作时触发。此触发器将显示旧值和新值之间的薪资差异:
CREATE OR REPLACE TRIGGER display_salary_changes
BEFORE DELETE OR INSERT OR UPDATE ON customers
FOR EACH ROW
WHEN (NEW.ID > 0)
DECLARE
sal_diff number;
BEGIN
sal_diff := :NEW.salary - :OLD.salary;
dbms_output.put_line('Old salary: ' || :OLD.salary);
dbms_output.put_line('New salary: ' || :NEW.salary);
dbms_output.put_line('Salary difference: ' || sal_diff);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Trigger created.
这里需要注意以下几点:
OLD和NEW引用不适用于表级触发器,而你可以将它们用于记录级触发器。
如果你想在同一个触发器中查询表,那么你应该使用AFTER关键字,因为触发器只有在应用初始更改并且表恢复到一致状态后才能查询表或再次更改它。
上面的触发器是这样编写的,它将在表上执行任何DELETE、INSERT或UPDATE操作之前触发,但是你可以在单个或多个操作上编写触发器,例如BEFORE DELETE,它将在每次使用DELETE操作在表上删除记录时触发。
触发触发器
让我们对CUSTOMERS表执行一些DML操作。这是一个INSERT语句,它将在表中创建一个新记录:
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (7, 'Kriti', 22, 'HP', 7500.00 );
当在CUSTOMERS表中创建记录时,上面的创建触发器display_salary_changes将被触发,并将显示以下结果:
Old salary: New salary: 7500 Salary difference:
因为这是一个新记录,所以旧工资不可用,上面的结果为null。现在让我们对CUSTOMERS表执行另一个DML操作。UPDATE语句将更新表中的现有记录:
UPDATE customers SET salary = salary + 500 WHERE id = 2;
当在CUSTOMERS表中更新记录时,上面的创建触发器display_salary_changes将被触发,并将显示以下结果:
Old salary: 1500 New salary: 2000 Salary difference: 500
PL/SQL - 包
在本章中,我们将讨论PL/SQL中的包。包是模式对象,它将逻辑相关的PL/SQL类型、变量和子程序分组。
一个包将有两个必须的部分:
- 包规范
- 包体或定义
包规范
规范是包的接口。它只声明可以从包外部引用的类型、变量、常量、异常、游标和子程序。换句话说,它包含关于包内容的所有信息,但不包括子程序的代码。
放在规范中的所有对象都称为公共对象。不在包规范中但在包体中编码的任何子程序都称为私有对象。
以下代码片段显示了一个包含单个过程的包规范。你可以在包中定义许多全局变量和多个过程或函数。
CREATE PACKAGE cust_sal AS PROCEDURE find_sal(c_id customers.id%type); END cust_sal; /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Package created.
包体
包体包含包规范中声明的各种方法的代码以及其他私有声明,这些声明对包外部的代码隐藏。
CREATE PACKAGE BODY语句用于创建包体。以下代码片段显示了上面创建的cust_sal包的包体声明。我假设我们已经在我们的数据库中创建了CUSTOMERS表,如PL/SQL - 变量章节所述。
CREATE OR REPLACE PACKAGE BODY cust_sal AS
PROCEDURE find_sal(c_id customers.id%TYPE) IS
c_sal customers.salary%TYPE;
BEGIN
SELECT salary INTO c_sal
FROM customers
WHERE id = c_id;
dbms_output.put_line('Salary: '|| c_sal);
END find_sal;
END cust_sal;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Package body created.
使用包元素
包元素(变量、过程或函数)使用以下语法访问:
package_name.element_name;
假设我们已经在我们的数据库模式中创建了上面的包,以下程序使用cust_sal包的find_sal方法:
DECLARE code customers.id%type := &cc_id; BEGIN cust_sal.find_sal(code); END; /
在 SQL 提示符下执行上述代码时,系统会提示输入客户 ID,输入 ID 后,将显示相应的工资,如下所示:
Enter value for cc_id: 1 Salary: 3000 PL/SQL procedure successfully completed.
示例
下面的程序提供了一个更完整的包。我们将使用存储在数据库中的 CUSTOMERS 表,其中包含以下记录:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 3000.00 | | 2 | Khilan | 25 | Delhi | 3000.00 | | 3 | kaushik | 23 | Kota | 3000.00 | | 4 | Chaitali | 25 | Mumbai | 7500.00 | | 5 | Hardik | 27 | Bhopal | 9500.00 | | 6 | Komal | 22 | MP | 5500.00 | +----+----------+-----+-----------+----------+
包规范
CREATE OR REPLACE PACKAGE c_package AS -- Adds a customer PROCEDURE addCustomer(c_id customers.id%type, c_name customers.Name%type, c_age customers.age%type, c_addr customers.address%type, c_sal customers.salary%type); -- Removes a customer PROCEDURE delCustomer(c_id customers.id%TYPE); --Lists all customers PROCEDURE listCustomer; END c_package; /
在 SQL 提示符下执行上述代码时,它将创建上述包并显示以下结果:
Package created.
创建包体
CREATE OR REPLACE PACKAGE BODY c_package AS
PROCEDURE addCustomer(c_id customers.id%type,
c_name customers.Name%type,
c_age customers.age%type,
c_addr customers.address%type,
c_sal customers.salary%type)
IS
BEGIN
INSERT INTO customers (id,name,age,address,salary)
VALUES(c_id, c_name, c_age, c_addr, c_sal);
END addCustomer;
PROCEDURE delCustomer(c_id customers.id%type) IS
BEGIN
DELETE FROM customers
WHERE id = c_id;
END delCustomer;
PROCEDURE listCustomer IS
CURSOR c_customers is
SELECT name FROM customers;
TYPE c_list is TABLE OF customers.Name%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer(' ||counter|| ')'||name_list(counter));
END LOOP;
END listCustomer;
END c_package;
/
上面的例子使用了**嵌套表**。我们将在下一章讨论嵌套表的概念。
当上述代码在SQL提示符下执行时,它会产生以下结果:
Package body created.
使用包
下面的程序使用在包 *c_package* 中声明和定义的方法。
DECLARE code customers.id%type:= 8; BEGIN c_package.addcustomer(7, 'Rajnish', 25, 'Chennai', 3500); c_package.addcustomer(8, 'Subham', 32, 'Delhi', 7500); c_package.listcustomer; c_package.delcustomer(code); c_package.listcustomer; END; /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Customer(1): Ramesh Customer(2): Khilan Customer(3): kaushik Customer(4): Chaitali Customer(5): Hardik Customer(6): Komal Customer(7): Rajnish Customer(8): Subham Customer(1): Ramesh Customer(2): Khilan Customer(3): kaushik Customer(4): Chaitali Customer(5): Hardik Customer(6): Komal Customer(7): Rajnish PL/SQL procedure successfully completed
PL/SQL - 集合
在本章中,我们将讨论 PL/SQL 中的集合。集合是具有相同数据类型的一组有序元素。每个元素都由一个唯一的下标标识,该下标表示其在集合中的位置。
PL/SQL 提供三种集合类型:
- 按索引表或关联数组
- 嵌套表
- 变长数组或 Varray
Oracle 文档为每种类型的集合提供了以下特性:
| 集合类型 | 元素数量 | 下标类型 | 密集型或稀疏型 | 创建位置 | 可以是对象类型属性 |
|---|---|---|---|---|---|
| 关联数组(或按索引表) | 无界 | 字符串或整数 | 两者皆可 | 仅在 PL/SQL 块中 | 否 |
| 嵌套表 | 无界 | 整数 | 初始为密集型,可以变为稀疏型 | 在 PL/SQL 块中或在模式级别 | 是 |
| 变长数组 (Varray) | 有界 | 整数 | 始终密集型 | 在 PL/SQL 块中或在模式级别 | 是 |
我们已经在**“PL/SQL 数组”**一章中讨论了 varray。在本章中,我们将讨论 PL/SQL 表。
两种 PL/SQL 表(即按索引表和嵌套表)具有相同的结构,并且它们的行的访问使用下标表示法。但是,这两种类型的表在一个方面有所不同;嵌套表可以存储在数据库列中,而按索引表则不能。
按索引表
**按索引**表(也称为**关联数组**)是一组**键值**对。每个键都是唯一的,用于定位对应的值。键可以是整数或字符串。
按索引表使用以下语法创建。在这里,我们正在创建一个名为**table_name**的**按索引**表,其键将为 `subscript_type` 类型,关联值将为 `element_type` 类型。
TYPE type_name IS TABLE OF element_type [NOT NULL] INDEX BY subscript_type; table_name type_name;
示例
下面的示例演示如何创建一个表来存储整数及其名称,然后打印相同的名称列表。
DECLARE
TYPE salary IS TABLE OF NUMBER INDEX BY VARCHAR2(20);
salary_list salary;
name VARCHAR2(20);
BEGIN
-- adding elements to the table
salary_list('Rajnish') := 62000;
salary_list('Minakshi') := 75000;
salary_list('Martin') := 100000;
salary_list('James') := 78000;
-- printing the table
name := salary_list.FIRST;
WHILE name IS NOT null LOOP
dbms_output.put_line
('Salary of ' || name || ' is ' || TO_CHAR(salary_list(name)));
name := salary_list.NEXT(name);
END LOOP;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Salary of James is 78000 Salary of Martin is 100000 Salary of Minakshi is 75000 Salary of Rajnish is 62000 PL/SQL procedure successfully completed.
示例
按索引表的元素也可以是任何数据库表的**%ROWTYPE** 或任何数据库表字段的**%TYPE**。以下示例说明了这个概念。我们将使用存储在数据库中的**CUSTOMERS** 表,如下所示:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
DECLARE
CURSOR c_customers is
select name from customers;
TYPE c_list IS TABLE of customers.Name%type INDEX BY binary_integer;
name_list c_list;
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter||'):'||name_lis t(counter));
END LOOP;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Customer(1): Ramesh Customer(2): Khilan Customer(3): kaushik Customer(4): Chaitali Customer(5): Hardik Customer(6): Komal PL/SQL procedure successfully completed
嵌套表
**嵌套表**类似于具有任意数量元素的一维数组。但是,嵌套表在以下方面与数组不同:
数组具有声明的元素数量,但嵌套表没有。嵌套表的大小可以动态增加。
数组始终是密集型的,即始终具有连续的下标。嵌套数组最初是密集型的,但是当从中删除元素时,它可能会变为稀疏型。
嵌套表使用以下语法创建:
TYPE type_name IS TABLE OF element_type [NOT NULL]; table_name type_name;
此声明类似于**按索引**表的声明,但是没有**INDEX BY** 子句。
嵌套表可以存储在数据库列中。它可以进一步用于简化 SQL 操作,在这些操作中,您将单列表与更大的表连接。关联数组不能存储在数据库中。
示例
以下示例说明了嵌套表的使用:
DECLARE
TYPE names_table IS TABLE OF VARCHAR2(10);
TYPE grades IS TABLE OF INTEGER;
names names_table;
marks grades;
total integer;
BEGIN
names := names_table('Kavita', 'Pritam', 'Ayan', 'Rishav', 'Aziz');
marks:= grades(98, 97, 78, 87, 92);
total := names.count;
dbms_output.put_line('Total '|| total || ' Students');
FOR i IN 1 .. total LOOP
dbms_output.put_line('Student:'||names(i)||', Marks:' || marks(i));
end loop;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Total 5 Students Student:Kavita, Marks:98 Student:Pritam, Marks:97 Student:Ayan, Marks:78 Student:Rishav, Marks:87 Student:Aziz, Marks:92 PL/SQL procedure successfully completed.
示例
**嵌套表**的元素也可以是任何数据库表的**%ROWTYPE** 或任何数据库表字段的 %TYPE。以下示例说明了这个概念。我们将使用存储在数据库中的 CUSTOMERS 表,如下所示:
Select * from customers; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | +----+----------+-----+-----------+----------+
DECLARE
CURSOR c_customers is
SELECT name FROM customers;
TYPE c_list IS TABLE of customerS.No.ame%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter||'):'||name_list(counter));
END LOOP;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Customer(1): Ramesh Customer(2): Khilan Customer(3): kaushik Customer(4): Chaitali Customer(5): Hardik Customer(6): Komal PL/SQL procedure successfully completed.
集合方法
PL/SQL 提供内置集合方法,使集合更易于使用。下表列出了这些方法及其用途:
| 序号 | 方法名称和用途 |
|---|---|
| 1 | EXISTS(n) 如果集合中存在第 n 个元素,则返回 TRUE;否则返回 FALSE。 |
| 2 | COUNT 返回集合当前包含的元素数量。 |
| 3 | LIMIT 检查集合的最大大小。 |
| 4 | FIRST 返回使用整数下标的集合中的第一个(最小)索引号。 |
| 5 | LAST 返回使用整数下标的集合中的最后一个(最大)索引号。 |
| 6 | PRIOR(n) 返回集合中位于索引 n 之前的索引号。 |
| 7 | NEXT(n) 返回集合中位于索引 n 之后的索引号。 |
| 8 | EXTEND 将一个空元素附加到集合。 |
| 9 | EXTEND(n) 将 n 个空元素附加到集合。 |
| 10 | EXTEND(n,i) 将第 i 个元素的 n 个副本附加到集合。 |
| 11 | TRIM 从集合末尾删除一个元素。 |
| 12 | TRIM(n) 从集合末尾删除 n 个元素。 |
| 13 | DELETE 删除集合中的所有元素,并将 COUNT 设置为 0。 |
| 14 | DELETE(n) 从具有数字键的关联数组或嵌套表中删除第 **n** 个元素。如果关联数组具有字符串键,则删除对应于键值的元素。如果 **n** 为空,则 **DELETE(n)** 不执行任何操作。 |
| 15 | DELETE(m,n) 从关联数组或嵌套表中删除范围 **m..n** 内的所有元素。如果 **m** 大于 **n** 或 **m** 或 **n** 为空,则 **DELETE(m,n)** 不执行任何操作。 |
集合异常
下表提供了集合异常及其引发的时间:
| 集合异常 | 引发情况 |
|---|---|
| COLLECTION_IS_NULL | 尝试对原子空集合进行操作。 |
| NO_DATA_FOUND | 下标指定已删除的元素,或关联数组中不存在的元素。 |
| SUBSCRIPT_BEYOND_COUNT | 下标超过集合中的元素数量。 |
| SUBSCRIPT_OUTSIDE_LIMIT | 下标超出允许的范围。 |
| VALUE_ERROR | 下标为空或无法转换为键类型。如果键定义为 **PLS_INTEGER** 范围,并且下标在此范围之外,则可能会发生此异常。 |
PL/SQL - 事务
在本章中,我们将讨论 PL/SQL 中的事务。数据库**事务**是可能包含一个或多个相关 SQL 语句的原子工作单元。它被称为原子,因为构成事务的 SQL 语句带来的数据库修改可以集体地提交(即永久保存到数据库)或回滚(从数据库撤消)。
成功执行的 SQL 语句和提交的事务并不相同。即使成功执行了 SQL 语句,除非包含该语句的事务已提交,否则它可以回滚,并且该语句所做的所有更改都可以撤消。
启动和结束事务
事务有**开始**和**结束**。当发生以下事件之一时,事务开始:
连接到数据库后执行第一个 SQL 语句。
在事务完成后发出的每个新的 SQL 语句。
当发生以下事件之一时,事务结束:
发出 **COMMIT** 或 **ROLLBACK** 语句。
发出 **DDL** 语句(例如 **CREATE TABLE** 语句);因为在这种情况下会自动执行 COMMIT。
发出 **DCL** 语句(例如 **GRANT** 语句);因为在这种情况下会自动执行 COMMIT。
用户与数据库断开连接。
用户通过发出 **EXIT** 命令退出 **SQL*PLUS**,将自动执行 COMMIT。
SQL*Plus 异常终止,将自动执行 **ROLLBACK**。
**DML** 语句失败;在这种情况下,将自动执行 ROLLBACK 以撤消该 DML 语句。
提交事务
通过发出 SQL 命令 COMMIT 来使事务永久化。COMMIT 命令的通用语法为:
COMMIT;
例如:
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'kaushik', 23, 'Kota', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (6, 'Komal', 22, 'MP', 4500.00 ); COMMIT;
回滚事务
未提交的数据库更改可以使用 ROLLBACK 命令撤消。
ROLLBACK 命令的通用语法为:
ROLLBACK [TO SAVEPOINT < savepoint_name>];
当事务由于某些意外情况(例如系统故障)而中止时,自提交以来整个事务将自动回滚。如果您没有使用**保存点**,则只需使用以下语句即可回滚所有更改:
ROLLBACK;
保存点
保存点是某种标记,通过设置一些检查点来帮助将长事务分割成更小的单元。通过在长事务中设置保存点,如果需要,您可以回滚到检查点。这是通过发出 **SAVEPOINT** 命令来完成的。
SAVEPOINT 命令的通用语法为:
SAVEPOINT < savepoint_name >;
例如
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (7, 'Rajnish', 27, 'HP', 9500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (8, 'Riddhi', 21, 'WB', 4500.00 ); SAVEPOINT sav1; UPDATE CUSTOMERS SET SALARY = SALARY + 1000; ROLLBACK TO sav1; UPDATE CUSTOMERS SET SALARY = SALARY + 1000 WHERE ID = 7; UPDATE CUSTOMERS SET SALARY = SALARY + 1000 WHERE ID = 8; COMMIT;
**ROLLBACK TO sav1** - 此语句将回滚所有更改,直到您标记保存点 sav1 的位置。
之后,您所做的更改将开始。
自动事务控制
要每当执行 **INSERT、UPDATE** 或 **DELETE** 命令时自动执行 **COMMIT**,您可以设置 **AUTOCOMMIT** 环境变量,如下所示:
SET AUTOCOMMIT ON;
您可以使用以下命令关闭自动提交模式:
SET AUTOCOMMIT OFF;
PL/SQL - 日期和时间
在本章中,我们将讨论 PL/SQL 中的日期和时间。PL/SQL 中有两类与日期和时间相关的数据类型:
- 日期时间数据类型
- 间隔数据类型
日期时间数据类型为:
- DATE
- TIMESTAMP
- TIMESTAMP WITH TIME ZONE
- TIMESTAMP WITH LOCAL TIME ZONE
间隔数据类型为:
- INTERVAL YEAR TO MONTH
- INTERVAL DAY TO SECOND
日期时间和间隔数据类型的字段值
**日期时间**和**间隔**数据类型都包含**字段**。这些字段的值决定了数据类型的的值。下表列出了日期时间和间隔的字段及其可能的值。
| 字段名称 | 有效日期时间值 | 有效区间值 |
|---|---|---|
| YEAR | -4712 到 9999(不包括年份 0) | 任何非零整数 |
| MONTH | 01 到 12 | 0 到 11 |
| DAY | 01 到 31(根据区域设置日历规则,受 MONTH 和 YEAR 值的限制) | 任何非零整数 |
| HOUR | 00 到 23 | 0 到 23 |
| MINUTE | 00 到 59 | 0 到 59 |
| SECOND | 00 到 59.9(n),其中 9(n) 是时间小数秒的精度 9(n) 部分不适用于 DATE。 |
0 到 59.9(n),其中 9(n) 是区间小数秒的精度 |
| TIMEZONE_HOUR | -12 到 14(范围适应夏令时变化) 不适用于 DATE 或 TIMESTAMP。 |
不适用 |
| TIMEZONE_MINUTE | 00 到 59 不适用于 DATE 或 TIMESTAMP。 |
不适用 |
| TIMEZONE_REGION | 不适用于 DATE 或 TIMESTAMP。 | 不适用 |
| TIMEZONE_ABBR | 不适用于 DATE 或 TIMESTAMP。 | 不适用 |
日期时间数据类型和函数
以下是日期时间数据类型:
DATE
它以字符和数字数据类型存储日期和时间信息。它包含有关世纪、年份、月份、日期、小时、分钟和秒的信息。它被指定为:
TIMESTAMP
它是DATE数据类型的一个扩展。它存储DATE数据类型的年份、月份和日期,以及小时、分钟和秒的值。它用于存储精确的时间值。
TIMESTAMP WITH TIME ZONE
它是TIMESTAMP的一个变体,在其值中包含时区区域名称或时区偏移量。时区偏移量是当地时间与UTC之间的差值(以小时和分钟表示)。此数据类型对于跨地理区域收集和评估日期信息非常有用。
TIMESTAMP WITH LOCAL TIME ZONE
它是TIMESTAMP的另一个变体,在其值中包含时区偏移量。
下表提供了日期时间函数(其中,x 具有日期时间值):
| 序号 | 函数名称及描述 |
|---|---|
| 1 | ADD_MONTHS(x, y); 将y个月添加到x。 |
| 2 | LAST_DAY(x); 返回该月的最后一天。 |
| 3 | MONTHS_BETWEEN(x, y); 返回x和y之间的月数。 |
| 4 | NEXT_DAY(x, day); 返回x之后下一个day的日期时间。 |
| 5 | NEW_TIME; 返回用户指定的时区的时间/日期值。 |
| 6 | ROUND(x [, unit]); 对x进行四舍五入。 |
| 7 | SYSDATE(); 返回当前日期时间。 |
| 8 | TRUNC(x [, unit]); 截断x。 |
时间戳函数(其中,x 具有时间戳值):
| 序号 | 函数名称及描述 |
|---|---|
| 1 | CURRENT_TIMESTAMP(); 返回一个包含当前会话时间以及会话时区的TIMESTAMP WITH TIME ZONE。 |
| 2 | EXTRACT({ YEAR | MONTH | DAY | HOUR | MINUTE | SECOND } | { TIMEZONE_HOUR | TIMEZONE_MINUTE } | { TIMEZONE_REGION | } TIMEZONE_ABBR ) FROM x) 提取并返回来自x的年份、月份、日期、小时、分钟、秒或时区。 |
| 3 | FROM_TZ(x, time_zone); 将TIMESTAMP x 和time_zone指定的时区转换为TIMESTAMP WITH TIMEZONE。 |
| 4 | LOCALTIMESTAMP(); 返回一个包含会话时区中本地时间的TIMESTAMP。 |
| 5 | SYSTIMESTAMP(); 返回一个包含当前数据库时间以及数据库时区的TIMESTAMP WITH TIME ZONE。 |
| 6 | SYS_EXTRACT_UTC(x); 将TIMESTAMP WITH TIMEZONE x 转换为包含UTC中日期和时间的TIMESTAMP。 |
| 7 | TO_TIMESTAMP(x, [format]); 将字符串x转换为TIMESTAMP。 |
| 8 | TO_TIMESTAMP_TZ(x, [format]); 将字符串x转换为TIMESTAMP WITH TIMEZONE。 |
示例
以下代码片段说明了上述函数的用法:
示例 1
SELECT SYSDATE FROM DUAL;
输出:
08/31/2012 5:25:34 PM
示例 2
SELECT TO_CHAR(CURRENT_DATE, 'DD-MM-YYYY HH:MI:SS') FROM DUAL;
输出:
31-08-2012 05:26:14
示例3
SELECT ADD_MONTHS(SYSDATE, 5) FROM DUAL;
输出:
01/31/2013 5:26:31 PM
示例4
SELECT LOCALTIMESTAMP FROM DUAL;
输出:
8/31/2012 5:26:55.347000 PM
区间数据类型和函数
以下是区间数据类型:
IINTERVAL YEAR TO MONTH — 它使用YEAR和MONTH日期时间字段存储一段时间。
INTERVAL DAY TO SECOND — 它以天、小时、分钟和秒为单位存储一段时间。
区间函数
| 序号 | 函数名称及描述 |
|---|---|
| 1 | NUMTODSINTERVAL(x, interval_unit); 将数字x转换为INTERVAL DAY TO SECOND。 |
| 2 | NUMTOYMINTERVAL(x, interval_unit); 将数字x转换为INTERVAL YEAR TO MONTH。 |
| 3 | TO_DSINTERVAL(x); 将字符串x转换为INTERVAL DAY TO SECOND。 |
| 4 | TO_YMINTERVAL(x); 将字符串x转换为INTERVAL YEAR TO MONTH。 |
PL/SQL - DBMS 输出
本章将讨论PL/SQL中的DBMS输出。DBMS_OUTPUT是一个内置包,它允许您显示输出、调试信息以及从PL/SQL块、子程序、包和触发器发送消息。在我们的教程中,我们已经多次使用过此包。
让我们来看一个小代码片段,它将显示数据库中所有用户表。请在您的数据库中尝试它以列出所有表名:
BEGIN
dbms_output.put_line (user || ' Tables in the database:');
FOR t IN (SELECT table_name FROM user_tables)
LOOP
dbms_output.put_line(t.table_name);
END LOOP;
END;
/
DBMS_OUTPUT子程序
DBMS_OUTPUT包具有以下子程序:
| 序号 | 子程序及用途 | |
|---|---|---|
| 1 | DBMS_OUTPUT.DISABLE; 禁用消息输出。 |
|
| 2 | DBMS_OUTPUT.ENABLE(buffer_size IN INTEGER DEFAULT 20000); 启用消息输出。buffer_size的NULL值表示缓冲区大小不限。 |
|
| 3 | DBMS_OUTPUT.GET_LINE (line OUT VARCHAR2, status OUT INTEGER); 检索缓冲区中的一行信息。 |
|
| 4 | DBMS_OUTPUT.GET_LINES (lines OUT CHARARR, numlines IN OUT INTEGER); 从缓冲区检索一系列行。 |
|
| 5 | DBMS_OUTPUT.NEW_LINE; 放置一个行尾标记。 |
|
| 6 | DBMS_OUTPUT.PUT(item IN VARCHAR2); 将部分行放入缓冲区。 |
|
| 7 | DBMS_OUTPUT.PUT_LINE(item IN VARCHAR2); 将一行放入缓冲区。 |
示例
DECLARE
lines dbms_output.chararr;
num_lines number;
BEGIN
-- enable the buffer with default size 20000
dbms_output.enable;
dbms_output.put_line('Hello Reader!');
dbms_output.put_line('Hope you have enjoyed the tutorials!');
dbms_output.put_line('Have a great time exploring pl/sql!');
num_lines := 3;
dbms_output.get_lines(lines, num_lines);
FOR i IN 1..num_lines LOOP
dbms_output.put_line(lines(i));
END LOOP;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Hello Reader! Hope you have enjoyed the tutorials! Have a great time exploring pl/sql! PL/SQL procedure successfully completed.
PL/SQL - 面向对象
本章将讨论面向对象的PL/SQL。PL/SQL允许定义对象类型,这有助于在Oracle中设计面向对象的数据库。对象类型允许您创建复合类型。使用对象允许您实现具有特定数据结构和操作方法的现实世界对象。对象具有属性和方法。属性是对象的属性,用于存储对象的状态;方法用于模拟其行为。
使用CREATE [OR REPLACE] TYPE语句创建对象。以下是如何创建一个包含少量属性的简单address对象的示例:
CREATE OR REPLACE TYPE address AS OBJECT (house_no varchar2(10), street varchar2(30), city varchar2(20), state varchar2(10), pincode varchar2(10) ); /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type created.
让我们再创建一个customer对象,我们将属性和方法组合在一起,以获得面向对象的感觉:
CREATE OR REPLACE TYPE customer AS OBJECT (code number(5), name varchar2(30), contact_no varchar2(12), addr address, member procedure display ); /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type created.
实例化对象
定义对象类型提供对象的蓝图。要使用此对象,您需要创建此对象的实例。您可以使用实例名称和访问运算符 (.)访问对象的属性和方法,如下所示:
DECLARE
residence address;
BEGIN
residence := address('103A', 'M.G.Road', 'Jaipur', 'Rajasthan','201301');
dbms_output.put_line('House No: '|| residence.house_no);
dbms_output.put_line('Street: '|| residence.street);
dbms_output.put_line('City: '|| residence.city);
dbms_output.put_line('State: '|| residence.state);
dbms_output.put_line('Pincode: '|| residence.pincode);
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
House No: 103A Street: M.G.Road City: Jaipur State: Rajasthan Pincode: 201301 PL/SQL procedure successfully completed.
成员方法
成员方法用于操作对象的属性。在声明对象类型时,您提供成员方法的声明。对象主体定义成员方法的代码。对象主体使用CREATE TYPE BODY语句创建。
构造函数是返回新对象作为其值的函数。每个对象都有一个系统定义的构造函数方法。构造函数的名称与对象类型相同。例如:
residence := address('103A', 'M.G.Road', 'Jaipur', 'Rajasthan','201301');
比较方法用于比较对象。比较对象有两种方法:
Map方法
Map方法是一个以这种方式实现的函数,其值取决于属性的值。例如,对于客户对象,如果两个客户的客户代码相同,则这两个客户可能相同。因此,这两个对象之间的关系将取决于代码的值。
Order方法
Order方法实现了一些用于比较两个对象的内部逻辑。例如,对于矩形对象,如果矩形的两边都更大,则一个矩形大于另一个矩形。
使用Map方法
让我们使用以下矩形对象来理解上述概念:
CREATE OR REPLACE TYPE rectangle AS OBJECT (length number, width number, member function enlarge( inc number) return rectangle, member procedure display, map member function measure return number ); /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type created.
创建类型主体:
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER FUNCTION enlarge(inc number) return rectangle IS
BEGIN
return rectangle(self.length + inc, self.width + inc);
END enlarge;
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
MAP MEMBER FUNCTION measure return number IS
BEGIN
return (sqrt(length*length + width*width));
END measure;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type body created.
现在使用矩形对象及其成员函数:
DECLARE
r1 rectangle;
r2 rectangle;
r3 rectangle;
inc_factor number := 5;
BEGIN
r1 := rectangle(3, 4);
r2 := rectangle(5, 7);
r3 := r1.enlarge(inc_factor);
r3.display;
IF (r1 > r2) THEN -- calling measure function
r1.display;
ELSE
r2.display;
END IF;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Length: 8 Width: 9 Length: 5 Width: 7 PL/SQL procedure successfully completed.
使用Order方法
现在,可以使用order方法实现相同的效果。让我们使用order方法重新创建矩形对象:
CREATE OR REPLACE TYPE rectangle AS OBJECT (length number, width number, member procedure display, order member function measure(r rectangle) return number ); /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type created.
创建类型主体:
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
ORDER MEMBER FUNCTION measure(r rectangle) return number IS
BEGIN
IF(sqrt(self.length*self.length + self.width*self.width)>
sqrt(r.length*r.length + r.width*r.width)) then
return(1);
ELSE
return(-1);
END IF;
END measure;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type body created.
使用矩形对象及其成员函数:
DECLARE
r1 rectangle;
r2 rectangle;
BEGIN
r1 := rectangle(23, 44);
r2 := rectangle(15, 17);
r1.display;
r2.display;
IF (r1 > r2) THEN -- calling measure function
r1.display;
ELSE
r2.display;
END IF;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Length: 23 Width: 44 Length: 15 Width: 17 Length: 23 Width: 44 PL/SQL procedure successfully completed.
PL/SQL对象的继承
PL/SQL允许从现有的基对象创建对象。要实现继承,基对象应声明为NOT FINAL。默认值为FINAL。
以下程序说明了PL/SQL对象中的继承。让我们创建另一个名为TableTop的对象,它继承自Rectangle对象。为此,我们需要创建基rectangle对象:
CREATE OR REPLACE TYPE rectangle AS OBJECT (length number, width number, member function enlarge( inc number) return rectangle, NOT FINAL member procedure display) NOT FINAL /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type created.
创建基类型主体:
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER FUNCTION enlarge(inc number) return rectangle IS
BEGIN
return rectangle(self.length + inc, self.width + inc);
END enlarge;
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
END;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type body created.
创建子对象tabletop:
CREATE OR REPLACE TYPE tabletop UNDER rectangle ( material varchar2(20), OVERRIDING member procedure display ) /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type created.
创建子对象tabletop的类型主体
CREATE OR REPLACE TYPE BODY tabletop AS
OVERRIDING MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
dbms_output.put_line('Material: '|| material);
END display;
/
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type body created.
使用tabletop对象及其成员函数:
DECLARE t1 tabletop; t2 tabletop; BEGIN t1:= tabletop(20, 10, 'Wood'); t2 := tabletop(50, 30, 'Steel'); t1.display; t2.display; END; /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Length: 20 Width: 10 Material: Wood Length: 50 Width: 30 Material: Steel PL/SQL procedure successfully completed.
PL/SQL中的抽象对象
NOT INSTANTIABLE子句允许您声明抽象对象。您不能按原样使用抽象对象;您必须创建此类对象的子类型或子类型才能使用其功能。
例如:
CREATE OR REPLACE TYPE rectangle AS OBJECT (length number, width number, NOT INSTANTIABLE NOT FINAL MEMBER PROCEDURE display) NOT INSTANTIABLE NOT FINAL /
当上述代码在SQL提示符下执行时,它会产生以下结果:
Type created.