- Puppet 教程
- Puppet - 首页
- Puppet 基础
- Puppet - 概述
- Puppet - 架构
- Puppet - 安装
- Puppet - 配置
- Puppet - 环境配置
- Puppet - Master
- Puppet - Agent 设置
- Puppet - SSL 证书设置
- r10K 的安装与配置
- Puppet - 验证设置
- Puppet - 代码风格
- Puppet - 清单文件
- Puppet - 模块
- Puppet - 文件服务器
- Puppet - Facter & Facts
- 高级 Puppet
- Puppet - 资源
- Puppet - 资源抽象层
- Puppet - 模板
- Puppet - 类
- Puppet - 函数
- Puppet - 自定义函数
- Puppet - 环境
- Puppet - 类型 & 提供程序
- Puppet - RESTful API
- Puppet - 实时项目
- Puppet 有用资源
- Puppet 快速指南
- Puppet - 有用资源
- Puppet - 讨论
Puppet 快速指南
Puppet - 概述
Puppet 是由 Puppet Labs 开发的配置管理工具,用于自动化基础设施管理和配置。Puppet 是一款非常强大的工具,有助于实现基础设施即代码的概念。该工具使用 Ruby DSL 语言编写,有助于将完整的基础设施转换为代码格式,易于管理和配置。
Puppet 遵循客户端-服务器模型,其中集群中的某一台机器充当服务器,称为 Puppet master(主控端),其他机器充当客户端,称为节点上的从属端。Puppet 能够从头开始管理任何系统,从初始配置到任何特定机器的生命周期结束。
Puppet 系统的功能
以下是 Puppet 最重要的功能。
幂等性
Puppet 支持幂等性,这使其独一无二。与 Chef 类似,在 Puppet 中,可以安全地在同一台机器上多次运行相同的配置集。在此流程中,Puppet 会检查目标机器的当前状态,并且只有在配置发生任何特定更改时才会进行更改。
幂等性有助于管理任何特定机器在其整个生命周期中,从机器的创建、机器的配置更改到生命周期结束。Puppet 的幂等性功能非常有助于使机器保持多年的更新,而不是在配置发生任何更改时多次重建同一台机器。
跨平台
在 Puppet 中,借助使用 Puppet 资源的资源抽象层 (RAL),可以针对系统的指定配置,而无需担心实现细节以及配置命令如何在系统内部工作,这些细节在底层配置文件中定义。
Puppet - 工作流程
Puppet 使用以下工作流程将配置应用于系统。
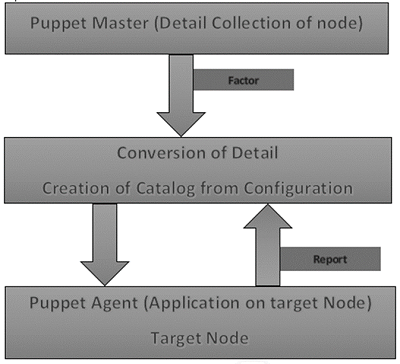
在 Puppet 中,Puppet master 首先要做的是收集目标机器的详细信息。它使用存在于所有 Puppet 节点上的 facter(类似于 Chef 中的 Ohai),获取所有机器级别的配置详细信息。这些详细信息被收集并发送回 Puppet master。
然后,Puppet master 将检索到的配置与已定义的配置详细信息进行比较,并根据已定义的配置创建目录,并将其发送到目标 Puppet agent。
然后,Puppet agent 应用这些配置,使系统达到所需状态。
最后,一旦目标节点处于所需状态,它就会向 Puppet master 发送报告,这有助于 Puppet master 了解系统当前状态(如目录中定义的那样)。
Puppet - 关键组件
以下是 Puppet 的关键组件。
Puppet 资源
Puppet 资源是建模任何特定机器的关键组件。这些资源有其自身的实现模型。Puppet 使用相同的模型来使任何特定资源达到所需状态。
提供程序
提供程序基本上是 Puppet 中使用的任何特定资源的执行者。例如,包类型“apt-get”和“yum”都适用于包管理。有时,在一个特定平台上可以使用多个提供程序。尽管每个平台总是有一个默认提供程序。
清单
清单是资源的集合,这些资源在函数或类中耦合在一起以配置任何目标系统。它们包含一组 Ruby 代码以配置系统。
模块
模块是 Puppet 的关键构建块,可以定义为资源、文件、模板等的集合。它们可以轻松地在不同类型的操作系统之间分发,前提是它们属于相同的类型。由于它们可以轻松分发,因此一个模块可以多次使用相同的配置。
模板
模板使用 Ruby 表达式来定义自定义内容和变量输入。它们用于开发自定义内容。模板在清单中定义,并复制到系统上的某个位置。例如,如果要使用可自定义端口定义 httpd,则可以使用以下表达式。
Listen <% = @httpd_port %>
在这种情况下,httpd_port 变量是在引用此模板的清单中定义的。
静态文件
静态文件可以定义为有时需要执行特定任务的通用文件。它们可以使用 Puppet 从一个位置简单地复制到另一个位置。所有静态文件都位于任何模块的 files 目录中。清单中文件的任何操作都是使用 file 资源完成的。
Puppet - 架构
以下是 Puppet 架构的图示。
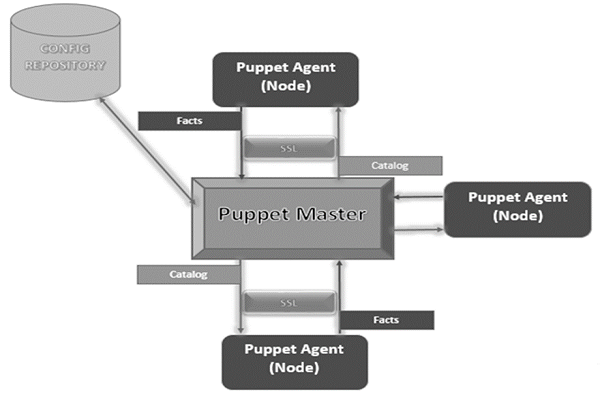
Puppet Master
Puppet Master 是处理所有配置相关事务的关键机制。它使用 Puppet agent 将配置应用于节点。
Puppet Agent
Puppet Agent 是由 Puppet master 管理的实际工作机器。它们在内部运行 Puppet agent 守护程序服务。
配置仓库
这是存储所有节点和服务器相关配置并在需要时提取的仓库。
事实
事实是与节点或主控机器相关的详细信息,主要用于分析任何节点的当前状态。根据事实,对任何目标机器进行更改。Puppet 中有预定义的事实和自定义事实。
目录
所有在 Puppet 中编写的清单文件或配置首先被转换为名为目录的编译格式,然后将这些目录应用于目标机器。
Puppet - 安装
Puppet 基于客户端服务器架构,其中服务器称为 Puppet master,客户端称为 Puppet 节点。此设置是通过在客户端和所有服务器机器上安装 Puppet 来实现的。
对于大多数平台,Puppet 可以通过选择的包管理器安装。但是,对于少数平台,可以通过安装tarball或RubyGems来完成。
先决条件
Factor 是唯一一个不与 Chef 中的Ohai一起提供的先决条件。
标准操作系统库
我们需要具有任何底层操作系统的标准库集。其余所有系统都带有 Ruby 1.8.2+ 版本。以下是操作系统应包含的库项目列表。
- base64
- cgi
- digest/md5
- etc
- fileutils
- ipaddr
- openssl
- strscan
- syslog
- uri
- webrick
- webrick/https
- xmlrpc
Facter 安装
如上所述,facter不包含在 Ruby 的标准版本中。因此,为了在目标系统中获取 facter,需要从源代码手动安装它,因为 facter 库是 Puppet 的先决条件。
此包适用于多个平台,但是为了安全起见,可以使用tarball进行安装,这有助于获取最新版本。
首先,使用wget实用程序从 Puppet 官方网站下载tarball。
$ wget http://puppetlabs.com/downloads/facter/facter-latest.tgz ------: 1
接下来,解压缩 tar 文件。使用 CD 命令进入解压缩的目录。最后,使用facter目录中的install.rb文件安装 facter。
$ gzip -d -c facter-latest.tgz | tar xf - -----: 2 $ cd facter-* ------: 3 $ sudo ruby install.rb # or become root and run install.rb -----:4
从源代码安装 Puppet
首先,使用wget从 Puppet 网站安装 Puppet tarball。然后,将 tarball 解压到目标位置。使用CD命令进入创建的目录。使用install.rb文件,在底层服务器上安装 Puppet。
# get the latest tarball $ wget http://puppetlabs.com/downloads/puppet/puppet-latest.tgz -----: 1 # untar and install it $ gzip -d -c puppet-latest.tgz | tar xf - ----: 2 $ cd puppet-* ------: 3 $ sudo ruby install.rb # or become root and run install.rb -------: 4
使用 Ruby Gem 安装 Puppet 和 Facter
# Installing Facter $ wget http://puppetlabs.com/downloads/gems/facter-1.5.7.gem $ sudo gem install facter-1.5.7.gem # Installing Puppet $ wget http://puppetlabs.com/downloads/gems/puppet-0.25.1.gem $ sudo gem install puppet-0.25.1.gem
Puppet - 配置
在系统上安装 Puppet 后,下一步是配置它以执行某些初始操作。
打开机器上的防火墙端口
为了使 Puppet 服务器集中管理客户端服务器,需要在所有机器上打开指定的端口,即如果在我们要配置的任何机器中未使用8140,则可以使用它。我们需要在所有机器上启用 TCP 和 UDP 通信。
配置文件
Puppet 的主要配置文件是etc/puppet/puppet.conf。所有配置文件都在 Puppet 的基于包的配置中创建。配置 Puppet 所需的大部分配置都保存在这些文件中,一旦 Puppet 运行,它就会自动提取这些配置。但是,对于某些特定任务(例如配置 Web 服务器或外部证书颁发机构 (CA)),Puppet 有单独的配置文件和设置。
服务器配置文件位于也称为 Puppet master 的conf.d目录中。这些文件默认位于/etc/puppetlabs/puppetserver/conf.d路径下。这些配置文件采用 HOCON 格式,它保留了 JSON 的基本结构,但更易于阅读。当 Puppet 启动时,它会从 conf.d 目录中提取所有 .cong 文件,并使用它们进行任何配置更改。只有在服务器重新启动时,这些文件的任何更改才会生效。
文件列表和设置文件
- global.conf
- webserver.conf
- web-routes.conf
- puppetserver.conf
- auth.conf
- master.conf(已弃用)
- ca.conf(已弃用)
Puppet 中有不同的配置文件,这些配置文件特定于 Puppet 中的每个组件。
Puppet.conf
Puppet.conf 文件是 Puppet 的主要配置文件。Puppet 使用相同的配置文件来配置所有必需的 Puppet 命令和服务。所有与 Puppet 相关的设置(例如 Puppet master、Puppet agent、Puppet apply 和证书的定义)都在此文件中定义。Puppet 可以根据需要引用它们。
配置文件类似于标准 ini 文件,其中设置可以进入主部分的特定应用程序部分。
主配置部分
[main] certname = Test1.vipin.com server = TestingSrv environment = production runinterval = 1h
Puppet Master 配置文件
[main] certname = puppetmaster.vipin.com server = MasterSrv environment = production runinterval = 1h strict_variables = true [master] dns_alt_names = MasterSrv,brcleprod01.vipin.com,puppet,puppet.test.com reports = puppetdb storeconfigs_backend = puppetdb storeconfigs = true environment_timeout = unlimited
详细概述
在 Puppet 配置中,将要使用的文件包含多个配置段,每个段都有多种设置。
配置段
Puppet 配置文件主要包含以下配置段。
主(Main) − 这被称为全局段,Puppet 中的所有命令和服务都会使用它。在主段中定义默认值,这些值可以被 puppet.conf 文件中的任何段覆盖。
主控端(Master) − 此段由 Puppet 主控端服务和 Puppet cert 命令引用。
代理端(Agent) − 此段由 Puppet 代理端服务引用。
用户(User) − 它主要由 Puppet apply 命令以及许多不太常用的命令使用。
[main] certname = PuppetTestmaster1.example.com
配置文件的关键组件
以下是配置文件的关键组件。
注释行
在 Puppet 中,任何注释行都以 (#) 符号开头。这前面可以有任意数量的空格。我们也可以在同一行中添加部分注释。
# This is a comment. Testing = true #this is also a comment in same line
设置行
设置行必须包含:
- 任意数量的前导空格(可选)
- 设置的名称
- 一个等号 =,它可以被任意数量的空格包围
- 设置的值
设置变量
在大多数情况下,设置的值将是一个单词,但在某些特殊情况下,有一些特殊值。
路径
在配置文件设置中,会列出一组目录。定义这些目录时,应记住它们应以系统路径分隔符分隔,在 *nix 平台上为 (:),在 Windows 上为分号 (;)。
# *nix version: environmentpath = $codedir/special_environments:$codedir/environments # Windows version: environmentpath = $codedir/environments;C:\ProgramData\PuppetLabs\code\environment
在定义中,首先扫描列出的文件目录,如果找不到,则移至列表中的其他目录。
文件和目录
所有接受单个文件或目录的设置都可以接受可选的权限哈希。服务器启动时,Puppet 将强制执行列表中的这些文件或目录。
ssldir = $vardir/ssl {owner = service, mode = 0771}
在上面的代码中,允许的哈希为所有者、组和模式。所有者和组键只有两个有效值。
Puppet - 环境配置
在 Puppet 中,所有环境都具有environment.conf文件。此文件可以在主控端为任何节点或分配给该特定环境的所有节点提供服务时覆盖多个默认设置。
位置
在 Puppet 中,对于所有已定义的环境,environment.conf 文件位于其主环境的顶层,紧挨着 manifest 和 modules 目录。例如,如果您的环境位于默认目录(Vipin/testing/environment)中,则测试环境的配置文件位于Vipin/testing/environments/test/environment.conf。
示例
# /etc/testingdir/code/environments/test/environment.conf # Puppet Enterprise requires $basemodulepath; see note below under modulepath". modulepath = site:dist:modules:$basemodulepath # Use our custom script to get a git commit for the current state of the code: config_version = get_environment_commit.sh
格式
Puppet 中的所有配置文件都使用相同的 INI 风格格式。environment.conf 文件与其他文件(如 puppet.conf 文件)一样,遵循相同的 INI 风格格式。environment.conf 和puppet.conf之间的唯一区别是 environment.conf 文件不能包含 [main] 段。environment.conf 文件中的所有设置都必须位于任何配置段之外。
值中的相对路径
大多数允许的设置都接受文件路径或路径列表作为值。如果任何路径是相关路径,则它们以不带前导斜杠或驱动器号开头——它们主要相对于该环境的主目录解析。
值中的插值
Environment.conf 设置文件能够使用其他设置的值作为变量。可以将多个有用的变量插入到 environment.conf 文件中。以下是几个重要变量的列表:
$basemodulepath − 用于在 modulepath 设置中包含目录。Puppet Enterprise 用户通常应该包含此 modulepath 值,因为 Puppet 引擎使用basemodulepath中的模块。
$environment − 用作 config_version 脚本的命令行参数。您只能在 config_version 设置中插入此变量。
$codedir − 用于查找文件。
允许的设置
默认情况下,Puppet environment.conf 文件只允许覆盖配置中的四个设置,如下所示。
- Modulepath
- 清单
- Config_version
- Environment_timeout
Modulepath
这是 environment.conf 文件中的关键设置之一。Puppet 默认加载 modulepath 中定义的所有目录。这是 Puppet 加载其模块的路径位置。需要显式设置它。如果没有设置上述设置,则 Puppet 中任何环境的默认 modulepath 将为:
<MODULES DIRECTORY FROM ENVIRONMENT>:$basemodulepath
清单
这用于定义主清单文件,Puppet 主控端将在启动和编译已定义的清单(将用于配置环境)的目录时使用它。在这里,我们可以定义单个文件、文件列表,甚至是包含多个需要按定义的字母顺序评估和编译的清单文件的目录。
需要在 environment.conf 文件中显式定义此设置。如果没有,Puppet 将使用环境默认清单目录作为其主清单。
Config_version
Config_version 可以定义为用于标识目录和事件的明确版本。当 Puppet 默认编译任何清单文件时,它会将配置版本添加到生成的目录以及 Puppet 主控端在 Puppet 节点上应用任何已定义的目录时生成的报告中。Puppet 运行一个脚本来执行所有上述步骤,并将所有生成的输出用作 Config_version。
环境超时 (Environment Timeout)
它用于获取有关 Puppet 应使用多少时间来加载给定环境的数据的详细信息。如果在 puppet.conf 文件中定义了该值,则这些值将覆盖默认超时值。
示例 environment.conf 文件
[master] manifest = $confdir/environments/$environment/manifests/site.pp modulepath = $confdir/environments/$environment/modules
在上面的代码中,$confdir 是环境配置文件所在的目录的路径。$environment 是正在对其进行配置的环境的名称。
生产就绪环境配置文件
# The environment configuration file # The main manifest directory or file where Puppet starts to evaluate code # This is the default value. Works with just a site.pp file or any other manifest = manifests/ # The directories added to the module path, looked in first match first used order: # modules - Directory for external modules, populated by r10k based on Puppetfile # $basemodulepath - As from: puppet config print basemodulepath modulepath = site:modules:$basemodulepath # Set the cache timeout for this environment. # This overrides what is set directly in puppet.conf for the whole Puppet server # environment_timeout = unlimited # With caching you need to flush the cache whenever new Puppet code is deployed # This can also be done manually running: bin/puppet_flush_environment_cache.sh # To disable catalog caching: environment_timeout = 0 # Here we pass to one in the control repo the Puppet environment (and git branch) # to get title and essential info of the last git commit config_version = 'bin/config_script.sh $environment'
Puppet - Master
在 Puppet 中,Puppet 主控端的客户端服务器架构被认为是整个设置的控制机构。Puppet 主控端充当设置中的服务器,并控制所有节点上的所有活动。
对于任何需要充当 Puppet 主控端的服务器,它都应该运行 Puppet 服务器软件。此服务器软件是控制节点上所有活动的关键组件。在此设置中,需要记住的一点是拥有对设置中将使用的所有机器的超级用户访问权限。以下是设置 Puppet 主控端的步骤。
先决条件
私有网络 DNS − 应配置正向和反向解析,其中每个服务器都应具有唯一的主机名。如果没有配置 DNS,则可以使用私有网络与基础设施通信。
防火墙开放端口 − Puppet 主控端应在特定端口上打开,以便它可以在特定端口上侦听传入请求。我们可以使用防火墙上打开的任何端口。
创建 Puppet 主控端服务器
我们将创建的 Puppet 主控端将在使用 Puppet 作为主机名的 CentOS 7 x64 机器上运行。创建 Puppet 主控端的最小系统配置为两个 CPU 内核和 1GB 内存。根据我们将用此主控端管理的节点数量,配置也可能更大。在基础设施中,它大于使用 2GB RAM 配置的。
| 主机名 | 角色 | 私有 FQDN |
|---|---|---|
| Brcleprod001 | Puppet 主控端 | bnrcleprod001.brcl.com |
接下来,需要生成 Puppet 主控端 SSL 证书,并将主控端机器的名称复制到所有节点的配置文件中。
安装 NTP
由于 Puppet 主控端是任何给定设置中代理节点的中心机构,因此 Puppet 主控端的一项关键职责是维护准确的系统时间,以避免可能在向节点颁发代理证书时出现的配置问题。
如果出现时间冲突问题,则如果主控端和节点之间存在时间差异,则证书可能显示已过期。网络时间协议是避免此类问题的关键机制之一。
列出可用的时区
$ timedatectl list-timezones
上述命令将提供所有可用时区的完整列表。它将提供具有时区可用性的区域。
可以使用以下命令在机器上设置所需的时区。
$ sudo timedatectl set-timezone India/Delhi
使用 CentOS 机器上的 yum 实用程序在 Puppet 服务器机器上安装 NTP。
$ sudo yum -y install ntp
将 NTP 与我们在上述命令中设置的系统时间同步。
$ sudo ntpdate pool.ntp.org
在常见做法中,我们将更新 NTP 配置以使用更靠近机器数据中心的公共池。为此,我们需要编辑/etc下的 ntp.conf 文件。
$ sudo vi /etc/ntp.conf
从 NTP 池时区中添加时间服务器。ntp.conf 文件如下所示。
brcleprod001.brcl.pool.ntp.org brcleprod002.brcl.pool.ntp.org brcleprod003.brcl.pool.ntp.org brcleprod004.brcl.pool.ntp.org
保存配置。启动服务器并启用守护进程。
$ sudo systemctl restart ntpd $ sudo systemctl enable ntpd
设置 Puppet 服务器软件
Puppet 服务器软件是在 Puppet 主控端机器上运行的软件。它是将配置推送到运行 Puppet 代理端软件的其他机器的机器。
使用以下命令启用官方 Puppet Labs 集合存储库。
$ sudo rpm -ivh https://yum.puppetlabs.com/puppetlabs-release-pc1-el7.noarch.rpm
安装 puppetserver 包。
$ sudo yum -y install puppetserver
配置 Puppet 服务器上的内存分配
正如我们所讨论的,默认情况下,Puppet 服务器配置在 2GB RAM 机器上。可以根据机器上可用的空闲内存以及服务器将管理多少个节点来自定义设置。
在 vi 模式下编辑 puppet 服务器配置
$ sudo vi /etc/sysconfig/puppetserver Find the JAVA_ARGS and use the –Xms and –Xms options to set the memory allocation. We will allocate 3GB of space JAVA_ARGS="-Xms3g -Xmx3g"
完成后,保存并退出编辑模式。
完成所有上述设置后,我们就可以使用以下命令在主控端机器上启动 Puppet 服务器。
$ sudo systemctl start puppetserver
接下来,我们将进行设置,以便每次主服务器启动时都启动 puppet 服务器。
$ sudo systemctl enable puppetserver
Puppet.conf 主控端段
[master]
autosign = $confdir/autosign.conf { mode = 664 }
reports = foreman
external_nodes = /etc/puppet/node.rb
node_terminus = exec
ca = true
ssldir = /var/lib/puppet/ssl
certname = sat6.example.com
strict_variables = false
manifest =
/etc/puppet/environments/$environment/manifests/site.pp
modulepath = /etc/puppet/environments/$environment/modules
config_version =
Puppet - Agent 设置
Puppet agent 是 Puppet Labs 提供的一个软件应用程序,运行在 Puppet 集群中的任何节点上。如果要使用 Puppet master 管理任何服务器,则需要在该特定服务器上安装 Puppet agent 软件。一般情况下,在任何给定的基础架构上,除了 Puppet master 机器外,所有机器上都会安装 Puppet agent。Puppet agent 软件能够在大多数 Linux、UNIX 和 Windows 机器上运行。在以下示例中,我们使用 CentOS 机器在其上安装 Puppet agent 软件。
步骤 1 - 使用以下命令启用官方 Puppet Labs 集合存储库。
$ sudo rpm -ivh https://yum.puppetlabs.com/puppetlabs-release-pc1-el7.noarch.rpm
步骤 2 - 安装 Puppet agent 软件包。
$ sudo yum -y install puppet-agent
步骤 3 - 安装 Puppet agent 后,使用以下命令启用它。
$ sudo /opt/puppetlabs/bin/puppet resource service puppet ensure=running enable = true
Puppet agent 的一个关键特性是,在 Puppet agent 首次运行时,它会生成一个 SSL 证书并将其发送到将要管理它的 Puppet master 进行签名和批准。一旦 Puppet master 批准 agent 的证书签名请求,它就能够与 agent 节点通信并进行管理。
注意 - 需要在所有需要配置和由给定 Puppet master 管理的节点上重复上述步骤。
Puppet - SSL 证书设置
当 Puppet agent 软件在任何 Puppet 节点上首次运行时,它会生成一个证书并将证书签名请求发送到 Puppet master。在 Puppet 服务器能够与 agent 节点通信和控制它们之前,它必须签署该特定 agent 节点的证书。在以下部分,我们将描述如何签署和检查签名请求。
列出当前证书请求
在 Puppet master 上,运行以下命令查看所有未签名的证书请求。
$ sudo /opt/puppetlabs/bin/puppet cert list
由于我们刚刚设置了一个新的 agent 节点,我们将看到一个待批准的请求。以下是输出。
"Brcleprod004.brcl.com" (SHA259) 15:90:C2:FB:ED:69:A4:F7:B1:87:0B:BF:F7:ll: B5:1C:33:F7:76:67:F3:F6:45:AE:07:4B:F 6:E3:ss:04:11:8d
它开头不包含任何 +(加号),这表示证书尚未签名。
签署请求
为了签署在 Puppet agent 在新节点上运行时生成的新的证书请求,将使用 Puppet cert sign 命令,以及由需要签署的新配置节点生成的证书的主机名。由于我们有 Brcleprod004.brcl.com 的证书,我们将使用以下命令。
$ sudo /opt/puppetlabs/bin/puppet cert sign Brcleprod004.brcl.com
以下是输出。
Notice: Signed certificate request for Brcle004.brcl.com Notice: Removing file Puppet::SSL::CertificateRequest Brcle004.brcl.com at '/etc/puppetlabs/puppet/ssl/ca/requests/Brcle004.brcl.com.pem'
Puppet 服务器现在可以与签署证书的节点通信。
$ sudo /opt/puppetlabs/bin/puppet cert sign --all
撤销 Puppet 设置中的主机
在内核重建配置中,当需要从设置中删除主机并重新添加它时,存在一些条件。这些是 Puppet 本身无法管理的条件。可以使用以下命令完成此操作。
$ sudo /opt/puppetlabs/bin/puppet cert clean hostname
查看所有已签署的请求
以下命令将生成已签署证书的列表,其中包含 +(加号),表示请求已批准。
$ sudo /opt/puppetlabs/bin/puppet cert list --all
以下是其输出。
+ "puppet" (SHA256) 5A:71:E6:06:D8:0F:44:4D:70:F0: BE:51:72:15:97:68:D9:67:16:41:B0:38:9A:F2:B2:6C:B B:33:7E:0F:D4:53 (alt names: "DNS:puppet", "DNS:Brcle004.nyc3.example.com") + "Brcle004.brcl.com" (SHA259) F5:DC:68:24:63:E6:F1:9E:C5:FE:F5: 1A:90:93:DF:19:F2:28:8B:D7:BD:D2:6A:83:07:BA:F E:24:11:24:54:6A + " Brcle004.brcl.com" (SHA259) CB:CB:CA:48:E0:DF:06:6A:7D:75:E6:CB:22:BE:35:5A:9A:B3
完成上述操作后,我们的基础架构已准备就绪,Puppet master 现在能够管理新添加的节点。
Puppet - 安装和配置 r10k
在 Puppet 中,我们有一个名为 r10k 的代码管理工具,它有助于管理与我们在 Puppet 中可以配置的不同类型的环境(例如开发、测试和生产)相关的环境配置。这有助于将与环境相关的配置存储在源代码存储库中。使用源代码控制仓库分支,r10k 在 Puppet master 机器上创建环境,并使用仓库中存在的模块安装和更新环境。
可以使用 Gem 文件在任何机器上安装 r10k,但为了模块化并获得最新版本,我们将使用 rpm 和 rpm 包管理器。以下是相同的示例。
$ urlgrabber -o /etc/yum.repos.d/timhughes-r10k-epel-6.repo https://copr.fedoraproject.org/coprs/timhughes/yum -y install rubygem-r10k
在 /etc/puppet/puppet.conf 中配置环境
[main] environmentpath = $confdir/environments
为 r10k 配置创建配置文件
cat <<EOF >/etc/r10k.yaml # The location to use for storing cached Git repos :cachedir: '/var/cache/r10k' # A list of git repositories to create :sources: # This will clone the git repository and instantiate an environment per # branch in /etc/puppet/environments :opstree: #remote: 'https://github.com/fullstack-puppet/fullstackpuppet-environment.git' remote: '/var/lib/git/fullstackpuppet-environment.git' basedir: '/etc/puppet/environments' EOF
安装 Puppet 清单和模块
r10k deploy environment -pv
由于我们需要每 15 分钟继续更新环境,我们将为此创建一个 cron 作业。
cat << EOF > /etc/cron.d/r10k.conf SHELL = /bin/bash PATH = /sbin:/bin:/usr/sbin:/usr/bin H/15 * * * * root r10k deploy environment -p EOF
测试安装
为了测试一切是否按预期工作,需要编译 Puppet 清单以获取 Puppet 模块。运行以下命令,并将 YAML 输出作为结果。
curl --cert /etc/puppet/ssl/certs/puppet.corp.guest.pem \ --key /etc/puppet/ssl/private_keys/puppet.corp.guest.pem \ --cacert /etc/puppet/ssl/ca/ca_crt.pem \ -H 'Accept: yaml' \ https://puppet.corp.guest:8140/production/catalog/puppet.corp.guest
Puppet - 验证 Puppet 设置
在 Puppet 中,可以在本地测试设置。因此,一旦我们设置了 Puppet master 和节点,就该在本地验证设置了。我们需要在本地安装 Vagrant 和 Vagrant box,这有助于在本地测试设置。
设置虚拟机
由于我们正在本地测试设置,因此实际上不需要运行 Puppet master。这意味着无需在服务器上实际运行 Puppet master,我们只需使用 Puppet 应用 Puppet 设置验证命令即可。Puppet apply 命令将根据配置文件中的虚拟机主机名应用来自local/etc/puppet 的更改。
为了测试设置,我们需要执行的第一步是构建以下Vagrantfile 并启动一台机器并将/etc/puppet 文件夹装载到适当位置。所有必需的文件都将放置在版本控制系统中,并具有以下结构。
目录结构
- manifests \- site.pp - modules \- your modules - test \- update-puppet.sh \- Vagrantfile - puppet.conf
Vagrant 文件
# -*- mode: ruby -*-
# vi: set ft = ruby :
Vagrant.configure("2") do |config|
config.vm.box = "precise32"
config.vm.box_url = "http://files.vagrantup.com/precise64.box"
config.vm.provider :virtualbox do |vb|
vb.customize ["modifyvm", :id, "--memory", 1028, "--cpus", 2]
end
# Mount our repo onto /etc/puppet
config.vm.synced_folder "../", "/etc/puppet"
# Run our Puppet shell script
config.vm.provision "shell" do |s|
s.path = "update-puppet.sh"
end
config.vm.hostname = "localdev.example.com"
end
在上面的代码中,我们使用了 Shell provisioner,我们试图运行名为update-puppet.sh 的 Shell 脚本。该脚本位于与 Vagrant 文件相同的目录中,脚本内容如下所示。
!/bin/bash
echo "Puppet version is $(puppet --version)"
if [ $( puppet --version) != "3.4.1" ]; then
echo "Updating puppet"
apt-get install --yes lsb-release
DISTRIB_CODENAME = $(lsb_release --codename --short)
DEB = "puppetlabs-release-${DISTRIB_CODENAME}.deb"
DEB_PROVIDES="/etc/apt/sources.list.d/puppetlabs.list"
if [ ! -e $DEB_PROVIDES ]
then
wget -q http://apt.puppetlabs.com/$DEB
sudo dpkg -i $DEB
fi
sudo apt-get update
sudo apt-get install -o Dpkg::Options:: = "--force-confold"
--force-yes -y puppet
else
echo "Puppet is up to date!"
fi
进一步处理,用户需要在 Manifests 目录内创建一个名为site.pp 的清单文件,该文件将在 VM 上安装一些软件。
node 'brclelocal03.brcl.com' {
package { ['vim','git'] :
ensure => latest
}
}
echo "Running puppet"
sudo puppet apply /etc/puppet/manifests/site.pp
一旦用户准备好上述脚本以及所需的 Vagrant 文件配置,用户就可以 cd 到测试目录并运行vagrant up 命令。这将启动一个新的 VM,稍后安装 Puppet,然后使用 Shell 脚本运行它。
以下是输出。
Notice: Compiled catalog for localdev.example.com in environment production in 0.09 seconds Notice: /Stage[main]/Main/Node[brclelocal03.brcl.com]/Package[git]/ensure: created Notice: /Stage[main]/Main/Node[brcllocal03.brcl.com]/Package[vim]/ensure: ensure changed 'purged' to 'latest'
验证多台机器配置
如果需要在本地测试多台机器的配置,只需更改 Vagrant 配置文件即可。
新的配置 Vagrant 文件
config.vm.define "brclelocal003" do |brclelocal003| brclelocal03.vm.hostname = "brclelocal003.brcl.com" end config.vm.define "production" do |production| production.vm.hostname = "brcleprod004.brcl.com" end
假设我们有一个新的生产服务器,需要安装 SSL 实用程序。我们只需要使用以下配置扩展旧清单即可。
node 'brcleprod004.brcl.com' inherits 'brcleloacl003.brcl.com' {
package { ['SSL'] :
ensure => latest
}
}
在清单文件中进行配置更改后,我们只需要移动到测试目录并运行基本的 vagrant up 命令,该命令将启动brclelocal003.brcl.com 和brcleprod004.brcl.com 机器。在我们的例子中,我们试图启动生产机器,这可以通过运行vagrant up production 命令来完成。这将在 Vagrant 文件中定义的名为 production 的新机器中创建,并在其中安装 SSL 包。
Puppet - 代码风格
在 Puppet 中,编码风格定义了在尝试将机器配置的基础架构转换为代码时需要遵循的所有标准。Puppet 使用资源执行并执行其所有定义的任务。
Puppet 的语言定义有助于以结构化的方式指定所有资源,这是管理需要管理的任何目标机器所必需的。Puppet 使用 Ruby 作为其编码语言,它具有多种内置功能,可以轻松地通过代码端的简单配置完成任务。
基本单元
Puppet 使用多种易于理解和管理的基本编码风格。以下是一些列表。
资源
在 Puppet 中,资源被称为基本建模单元,用于管理或修改任何目标系统。资源涵盖系统的各个方面,例如文件、服务和包。Puppet 带有内置功能,允许用户或开发人员开发自定义资源,这有助于管理机器的任何特定单元。
在 Puppet 中,所有资源都通过使用“define”或“classes”组合在一起。这些聚合功能有助于组织模块。以下是一个示例资源,它包含多种类型、一个标题和一个属性列表,Puppet 可以支持多个属性。Puppet 中的每个资源都有其自己的默认值,可以在需要时覆盖。
文件的示例 Puppet 资源
在以下命令中,我们试图为特定文件指定权限。
file {
'/etc/passwd':
owner => superuser,
group => superuser,
mode => 644,
}
每当在任何机器上执行上述命令时,它都会验证系统中的 passwd 文件是否按描述进行配置。冒号之前的文件是资源的标题,可以在 Puppet 配置的其他部分将其称为资源。
除了标题之外,还指定本地名称
file { 'sshdconfig':
name => $operaSystem ? {
solaris => '/usr/local/etc/ssh/sshd_config',
default => '/etc/ssh/sshd_config',
},
owner => superuser,
group => superuser,
mode => 644,
}
通过使用始终相同的标题,很容易在配置中引用文件资源,而无需重复与操作系统相关的逻辑。
另一个示例可能是使用依赖于文件的服务。
service { 'sshd':
subscribe => File[sshdconfig],
}
通过此依赖关系,一旦sshdconfig 文件更改,sshd 服务将始终重新启动。这里需要注意的是File[sshdconfig] 是声明,File 为小写,但如果将其更改为FILE[sshdconfig],则它将是一个引用。
声明资源时需要记住的一个基本点是,每个配置文件只能声明一次。重复声明同一个资源多次将导致错误。通过这个基本概念,Puppet 确保配置建模良好。
我们甚至能够管理资源依赖关系,这有助于管理多个关系。
service { 'sshd':
require => File['sshdconfig', 'sshconfig', 'authorized_keys']
}
元参数
元参数在 Puppet 中被称为全局参数。元参数的一个关键特性是,它适用于 Puppet 中任何类型的资源。
资源默认值
当需要定义默认资源属性值时,Puppet 提供了一组使用大写资源规范(没有标题)来存档它的语法。
例如,如果我们想设置所有可执行文件的默认路径,可以使用以下命令完成。
Exec { path => '/usr/bin:/bin:/usr/sbin:/sbin' }
exec { 'echo Testing mataparamaters.': }
在上面的命令中,第一个语句 Exec 将设置 exec 资源的默认值。Exec 资源需要完全限定的路径或类似于可执行文件的路径。通过此,可以为整个配置定义单个默认路径。默认值适用于 Puppet 中的任何资源类型。
默认值不是全局值,但是,它们只影响定义它们的范围或紧随其后的变量。如果要为整个配置定义default,则在下一节中定义default 和类。
资源集合
聚合是将事物组合在一起的方法。Puppet 支持非常强大的聚合概念。在 Puppet 中,聚合用于对资源进行分组,资源是 Puppet 的基本单元。Puppet 中的这种聚合概念是通过使用两种强大的方法实现的,即类和定义。
类和定义
类负责模拟节点的基本方面。它们可以说节点是一个 Web 服务器,而这个特定节点是其中之一。在 Puppet 中,编程类是单例,它们每个节点只能评估一次。
另一方面,定义可以在单个节点上多次使用。它们的工作方式类似于使用该语言创建自己的 Puppet 类型。它们被创建为多次使用,每次使用不同的输入。这意味着可以将变量值传递到定义中。
类和定义之间的区别
类和定义之间唯一的关键区别在于:定义构建结构和分配资源时,类在每个节点上只会被评估一次,而定义在同一个节点上会被使用多次。
类
Puppet 中的类使用 `class` 关键字引入,该类的内容用花括号括起来,如下例所示。
class unix {
file {
'/etc/passwd':
owner => 'superuser',
group => 'superuser',
mode => 644;
'/etc/shadow':
owner => 'vipin',
group => 'vipin',
mode => 440;
}
}
在下面的例子中,我们使用了一些与上面类似的简写。
class unix {
file {
'/etc/passwd':
owner => 'superuser',
group => 'superuser',
mode => 644;
}
file {'/etc/shadow':
owner => 'vipin',
group => 'vipin',
mode => 440;
}
}
Puppet 类中的继承
在 Puppet 中,默认支持 OOP 的继承概念,其中类可以扩展以前的功能,而无需在新创建的类中再次复制粘贴完整的代码段。继承允许子类覆盖在父类中定义的资源设置。使用继承时需要注意的一点是,一个类只能继承自一个父类,不能继承多个父类。
class superclass inherits testsubclass {
File['/etc/passwd'] { group => wheel }
File['/etc/shadow'] { group => wheel }
}
如果需要撤销父类中指定的某些逻辑,可以使用 **`undef` 命令**。
class superclass inherits testsubcalss {
File['/etc/passwd'] { group => undef }
}
使用继承的另一种方法
class tomcat {
service { 'tomcat': require => Package['httpd'] }
}
class open-ssl inherits tomcat {
Service[tomcat] { require +> File['tomcat.pem'] }
}
Puppet 中的嵌套类
Puppet 支持嵌套类的概念,允许使用嵌套类,这意味着在一个类中使用另一个类。这有助于实现模块化和作用域。
class testclass {
class nested {
file {
'/etc/passwd':
owner => 'superuser',
group => 'superuser',
mode => 644;
}
}
}
class anotherclass {
include myclass::nested
}
参数化类
在 Puppet 中,类可以扩展其功能以允许将参数传递到类中。
要在类中传递参数,可以使用以下结构:
class tomcat($version) {
... class contents ...
}
在 Puppet 中需要记住的一点是,带有参数的类不是使用 `include` 函数添加的,而是可以将生成的类添加为定义。
node webserver {
class { tomcat: version => "1.2.12" }
}
类中作为参数的默认值
class tomcat($version = "1.2.12",$home = "/var/www") {
... class contents ...
}
运行阶段
Puppet 支持运行阶段的概念,这意味着用户可以根据需要添加多个阶段来管理任何特定资源或多个资源。当用户想要开发一个复杂的目录时,此功能非常有用。在一个复杂的目录中,有大量的资源需要编译,同时要记住所定义的资源之间的依赖关系不应该受到影响。
运行阶段在管理资源依赖关系方面非常有用。这可以通过在定义的阶段中添加类来完成,其中特定类包含资源集合。使用运行阶段,Puppet 保证定义的阶段每次目录运行并在任何 Puppet 节点上应用时都将按指定的可预测顺序运行。
为了使用它,需要声明除了已经存在的阶段之外的附加阶段,然后可以配置 Puppet 使用相同的资源关系语法在 `require` 之前管理每个阶段的指定顺序 `“->”` 和 `“+>”`。然后,该关系将保证与每个阶段关联的类的顺序。
使用 Puppet 声明式语法声明附加阶段
stage { "first": before => Stage[main] }
stage { "last": require => Stage[main] }
声明阶段后,可以使用 `stage` 将类与主类以外的阶段关联。
class {
"apt-keys": stage => first;
"sendmail": stage => main;
"apache": stage => last;
}
与类 `apt-key` 关联的所有资源将首先运行。`Sendmail` 中的所有资源将是主类,而与 `Apache` 关联的资源将是最后一个阶段。
定义
在 Puppet 中,任何清单文件中的资源集合都是通过类或定义完成的。定义在 Puppet 中非常类似于类,但是它们是用 **`define` 关键字(而不是 `class`)** 引入的,它们支持参数而不是继承。它们可以在同一个系统上多次运行,并使用不同的参数。
例如,如果想要创建一个定义来控制正在尝试在同一系统上创建多个存储库的源代码存储库,则可以使用定义而不是类。
define perforce_repo($path) {
exec {
"/usr/bin/svnadmin create $path/$title":
unless => "/bin/test -d $path",
}
}
svn_repo { puppet_repo: path => '/var/svn_puppet' }
svn_repo { other_repo: path => '/var/svn_other' }
这里需要注意的关键点是如何将变量与定义一起使用。我们使用美元符号变量(**`$`**)。在上面,我们使用了 `$title`。定义可以同时具有 `$title` 和 `$name`,可以用它们来表示名称和标题。默认情况下,`$title` 和 `$name` 设置为相同的值,但是可以设置标题属性并传递不同的名称作为参数。`$title` 和 `$name` 仅在定义中有效,在类或其他资源中无效。
模块
模块可以定义为 Puppet master 用于在任何特定 Puppet 节点(agent)上应用配置更改的所有配置的集合。它们也被称为不同类型配置的可移植集合,这些集合是执行特定任务所需的。例如,一个模块可能包含配置 Postfix 和 Apache 所需的所有资源。
节点
节点是一个非常简单的剩余步骤,即我们如何将我们定义的内容(“这就是 web 服务器的样子”)与选择用于执行这些指令的机器相匹配。
节点定义与类完全相同,包括支持继承,但是它们很特殊,因为当节点(运行 Puppet 客户端的受管理计算机)连接到 Puppet master 守护程序时,它的名称将在定义的节点列表中查找。将评估节点的定义信息,然后节点将发送该配置。
节点名称可以是短主机名或完全限定域名 (FQDN)。
node 'www.vipin.com' {
include common
include apache, squid
}
上述定义创建了一个名为 `www.vipin.com` 的节点,并包含 `common`、`Apache` 和 `Squid` 类。
我们可以通过用逗号分隔每个节点来向不同的节点发送相同的配置。
node 'www.testing.com', 'www.testing2.com', 'www3.testing.com' {
include testing
include tomcat, squid
}
用于匹配节点的正则表达式
node /^www\d+$/ {
include testing
}
节点继承
节点支持有限的继承模型。与类一样,节点只能继承自另一个节点。
node 'www.testing2.com' inherits 'www.testing.com' {
include loadbalancer
}
在上面的代码中,`www.testing2.com` 继承了 `www.testing.com` 的所有功能,此外还有一个额外的 `loadbalancer` 类。
高级支持功能
**引用** - 在大多数情况下,不需要在 Puppet 中引用字符串。任何以字母开头的字母数字字符串都无需引用。但是,对于任何非负值,引用字符串始终是一个最佳实践。
带引号的变量插值
到目前为止,我们已经从定义的角度提到了变量。如果需要将这些变量与字符串一起使用,请使用双引号,而不是单引号。单引号字符串不会进行任何变量插值,双引号字符串会进行。变量可以用 `{}` 括起来,这使得它们更容易一起使用,也更容易理解。
$value = "${one}${two}"
最佳实践是,对于不需要字符串插值的字符串,应该使用单引号。
大写
大写是一个用于引用、继承和设置特定资源的默认属性的过程。基本上有两种使用它的基本方法。
**引用** - 这是引用已创建资源的方法。它主要用于依赖目的,必须大写资源的名称。例如,`require => file[sshdconfig]`
**继承** - 从子类覆盖父类设置时,使用资源名称的大写版本。使用小写版本会导致错误。
**设置默认属性值** - 使用没有标题的大写资源可以设置资源的默认值。
数组
Puppet 允许在多个区域使用数组 `[One, two, three]`。
一些类型成员,例如主机定义中的别名,在其值中接受数组。具有多个别名的主机资源如下所示。
host { 'one.vipin.com':
alias => [ 'satu', 'dua', 'tiga' ],
ip => '192.168.100.1',
ensure => present,
}
上面的代码将主机 `'one.brcletest.com'` 添加到主机列表中,并带有三个别名 `'satu' 'dua' 'tiga'`。如果想要将多个资源添加到一个资源,可以按照下面的示例进行操作。
resource { 'baz':
require => [ Package['rpm'], File['testfile'] ],
}
变量
Puppet 支持多种变量,就像大多数其他编程语言一样。Puppet 变量用 **`$`** 表示。
$content = 'some content\n'
file { '/tmp/testing': content => $content }
如前所述,Puppet 是一种声明式语言,这意味着它的作用域和赋值规则与命令式语言不同。主要区别在于,不能在一个作用域内更改变量,因为它们依赖于文件中的顺序来确定变量的值。顺序在声明式语言中无关紧要。
$user = root
file {
'/etc/passwd':
owner => $user,
}
$user = bin
file {
'/bin':
owner => $user,
recurse => true,
}
变量作用域
变量作用域定义所有定义的变量是否有效。随着最新功能的出现,Puppet 当前是动态作用域的,在 Puppet 术语中,这意味着所有定义的变量都根据其作用域而不是其定义位置进行评估。
$test = 'top'
class Testclass {
exec { "/bin/echo $test": logoutput => true }
}
class Secondtestclass {
$test = 'other'
include myclass
}
include Secondtestclass
限定变量
Puppet 支持在类或定义内使用限定变量。当用户希望在已定义或将要定义的其他类中使用相同的变量时,这非常有用。
class testclass {
$test = 'content'
}
class secondtestclass {
$other = $myclass::test
}
在上面的代码中,`$other` 变量的值评估内容。
条件语句
条件是在用户希望在满足定义的条件或所需条件时执行一组语句或代码的情况。Puppet 支持两种类型的条件。
选择器条件只能在定义的资源内使用,以选择机器的正确值。
语句条件在清单中更广泛地使用,这有助于包含用户希望在同一清单文件中包含的其他类。在类中定义一组不同的资源,或做出其他结构性决策。
选择器
当用户希望根据事实或其他变量指定与默认值不同的资源属性和变量时,选择器非常有用。在 Puppet 中,选择器索引就像一个多值三元运算符。选择器还可以定义在清单中定义且匹配条件的无值中的自定义默认值。
$owner = $Sysoperenv ? {
sunos => 'adm',
redhat => 'bin',
default => undef,
}
在 Puppet 0.25.0 的后续版本中,选择器可以用作正则表达式。
$owner = $Sysoperenv ? {
/(Linux|Ubuntu)/ => 'bin',
default => undef,
}
在上面的示例中,如果选择器 `$Sysoperenv` 值匹配 Linux 或 Ubuntu,则 `bin` 将是所选结果,否则用户将设置为未定义。
语句条件
语句条件是 Puppet 中的另一种条件语句,它与 Shell 脚本中的 switch case 条件非常相似。在此,定义了多组 case 语句,并将给定的输入值与每个条件进行匹配。
与给定输入条件匹配的 case 语句将被执行。此 case 语句条件没有任何返回值。在 Puppet 中,条件语句的一个非常常见的用例是根据底层操作系统运行一组代码段。
case $ Sysoperenv {
sunos: { include solaris }
redhat: { include redhat }
default: { include generic}
}
Case 语句还可以通过逗号分隔来指定多个条件。
case $Sysoperenv {
development,testing: { include development } testing,production: { include production }
default: { include generic }
}
If-Else 语句
Puppet 支持基于条件的操作的概念。为了实现它,If/else 语句根据条件的返回值提供分支选项。如下例所示:
if $Filename {
file { '/some/file': ensure => present }
} else {
file { '/some/other/file': ensure => present }
}
最新版本的 Puppet 支持变量表达式,其中 if 语句还可以根据表达式的值进行分支。
if $machine == 'production' {
include ssl
} else {
include nginx
}
为了在代码中实现更多多样性并执行复杂的条件操作,Puppet 支持嵌套 if/else 语句,如下面的代码所示。
if $ machine == 'production' {
include ssl
} elsif $ machine == 'testing' {
include nginx
} else {
include openssl
}
虚拟资源
虚拟资源是指除非实现,否则不会发送到客户端的资源。
以下是 Puppet 中使用虚拟资源的语法。
@user { vipin: ensure => present }
在上面的例子中,用户 `vipin` 是虚拟定义的,要实现该定义,可以使用它来进行集合。
User <| title == vipin |>
注释
注释用于在任何代码片段中添加关于几行代码及其功能的额外说明。在 Puppet 中,目前支持两种类型的注释。
- Unix shell 风格注释。它们可以位于单独一行或下一行。
- 多行 C 风格注释。
以下是一个 shell 风格注释的示例。
# this is a comment
以下是一个多行注释的示例。
/* This is a comment */
运算符优先级
Puppet 的运算符优先级符合大多数系统中的标准优先级,从高到低。
以下是表达式列表
- ! = 非
- / = 乘法和除法
- - + = 减法,加法
- << >> = 左移和右移
- == != = 不等于,等于
- >= <= > < = 大于等于,小于等于,大于,小于
比较表达式
当用户希望在满足给定条件时执行一组语句时,使用比较表达式。比较表达式包括使用 == 表达式进行相等性测试。
if $environment == 'development' {
include openssl
} else {
include ssl
}
不相等示例
if $environment != 'development' {
$otherenvironment = 'testing'
} else {
$otherenvironment = 'production'
}
算术表达式
$one = 1 $one_thirty = 1.30 $two = 2.034e-2 $result = ((( $two + 2) / $one_thirty) + 4 * 5.45) - (6 << ($two + 4)) + (0×800 + -9)
布尔表达式
可以使用 or、and、& not 来实现布尔表达式。
$one = 1 $two = 2 $var = ( $one < $two ) and ( $one + 1 == $two )
正则表达式
Puppet 使用 =~(匹配)和 !~(不匹配)支持正则表达式匹配。
if $website =~ /^www(\d+)\./ {
notice('Welcome web server #$1')
}
像 case 和 selector 正则表达式匹配一样,为每个正则表达式创建有限范围的变量。
exec { "Test":
command => "/bin/echo now we don’t have openssl installed on machine > /tmp/test.txt",
unless => "/bin/which php"
}
同样,我们可以使用 unless,unless 始终执行命令,除非 unless 下的命令成功退出。
exec { "Test":
command => "/bin/echo now we don’t have openssl installed on machine > /tmp/test.txt",
unless => "/bin/which php"
}
使用模板
当希望拥有一个预定义的结构,该结构将在 Puppet 中的多个模块中使用,并且这些模块将分发到多台机器上时,可以使用模板。使用模板的第一步是创建一个使用模板方法呈现模板内容的模板。
file { "/etc/tomcat/sites-available/default.conf":
ensure => "present",
content => template("tomcat/vhost.erb")
}
为了强制执行组织性和模块化,Puppet 在处理本地文件时做了一些假设。Puppet 在 modules 目录内的 apache/templates 文件夹内查找 vhost.erb 模板。
定义和触发服务
在 Puppet 中,它有一个名为 service 的资源,能够管理在任何特定机器或环境上运行的所有服务的生命周期。Service 资源用于确保服务已初始化并启用。它们也用于服务重启。
例如,在我们之前设置 apache 虚拟主机的 tomcat 模板中。如果希望确保在虚拟主机更改后重新启动 apache,我们需要使用以下命令为 apache 服务创建一个 service 资源。
service { 'tomcat':
ensure => running,
enable => true
}
在定义资源时,我们需要包含 notify 选项才能触发重启。
file { "/etc/tomcat/sites-available/default.conf":
ensure => "present",
content => template("vhost.erb"),
notify => Service['tomcat']
}
Puppet - 清单文件
在 Puppet 中,所有使用 Ruby 编程语言编写并以 **.pp** 扩展名保存的程序都称为 **清单**。一般来说,所有旨在创建或管理任何目标主机机的 Puppet 程序都称为清单。所有用 Puppet 编写的程序都遵循 Puppet 编码风格。
Puppet 的核心是资源的声明方式以及这些资源如何表示其状态。在任何清单中,用户都可以拥有各种资源的集合,这些资源使用类和定义组合在一起。
在某些情况下,Puppet 清单甚至可以包含条件语句以实现所需的状态。但是,最终都归结为确保所有资源都以正确的方式定义和使用,并且在应用后转换为目录的已定义清单能够执行其设计目的的任务。
清单文件工作流程
Puppet 清单包含以下组件:
**文件**(这些是普通文件,Puppet 与它们无关,只是将它们提取并放置到目标位置)
资源
**模板**(这些可用于在节点上构建配置文件)
**节点**(此处定义与客户端节点相关的所有定义)
类
注意事项
在 Puppet 中,所有清单文件都使用 Ruby 作为其编码语言,并以 **.pp** 扩展名保存。
许多清单中的“import”语句用于在 Puppet 启动时加载文件。
为了导入目录中包含的所有文件,您可以以另一种方式使用 import 语句,例如 import 'clients/*'。这将导入该目录内所有 **.pp** 文件。
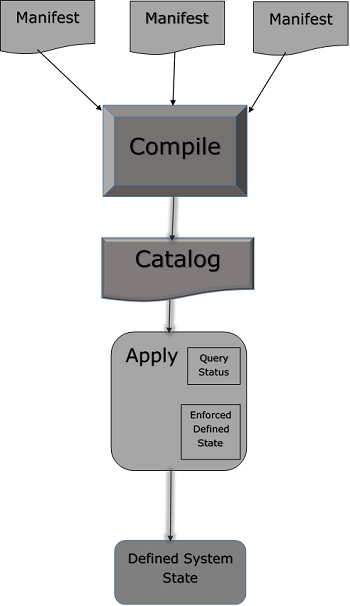
编写清单
使用变量
在编写清单时,用户可以在清单中的任何位置定义新变量或使用现有变量。Puppet 支持不同类型的变量,但其中一些经常使用,例如字符串和字符串数组。除此之外,还支持其他格式。
字符串变量示例
$package = "vim"
package { $package:
ensure => "installed"
}
使用循环
当希望对同一组代码进行多次迭代直到满足定义的条件时,可以使用循环。它们还用于使用不同的值执行重复性任务。为 10 件不同的事情创建 10 个任务。可以创建一个单一任务,并使用循环重复该任务,并使用想要安装的不同软件包。
最常见的是使用数组来使用不同的值重复测试。
$packages = ['vim', 'git', 'curl']
package { $packages:
ensure => "installed"
}
使用条件语句
Puppet 支持可以在传统编程语言中找到的大多数条件结构。条件可用于动态定义是否执行特定任务或应执行一组代码。例如 if/else 和 case 语句。此外,像 execute 这样的条件还将支持像条件一样工作的属性,但仅接受命令输出作为条件。
if $OperatingSystem != 'Linux' {
warning('This manifest is not supported on this other OS apart from linux.')
} else {
notify { 'the OS is Linux. We are good to go!': }
}
Puppet - 模块
在 Puppet 中,模块可以定义为资源、类、文件、定义和模板的集合。Puppet 支持轻松重新分发模块,这对于代码的模块化非常有用,因为可以编写指定的通用模块,并且只需很少的代码更改即可多次使用它。例如,这将在 /etc/puppet 下启用默认站点配置,Puppet 自身提供的模块位于 /etc/share/puppet。
模块配置
在任何 Puppet 模块中,我们都有两个分区,它们有助于定义代码结构和控制分母。
模块的搜索路径是使用 **puppetmasterd** 或 **masterd** 中的冒号分隔的目录列表进行配置的,这是 Puppet 主配置文件的后面部分,使用 **modulepath** 参数。
[puppetmasterd] ... modulepath = /var/lib/puppet/modules:/data/puppet/modules
fileserver.conf 中的文件服务器模块的访问控制设置,该模块的路径配置始终被忽略,指定路径将产生警告。
可以通过设置 PUPPETLAB 环境变量在运行时添加搜索路径,该变量也必须是冒号分隔的变量列表。
模块来源
Puppet 支持不同的模块存储位置。任何模块都可以存储在任何特定机器的不同文件系统中。但是,必须在称为 **modulepath** 的配置变量中指定所有存储模块的路径,该变量通常是一个路径变量,Puppet 在启动时扫描所有模块目录并加载它们。
可以配置一个合理的默认路径为:
/etc/puppet/modules:/usr/share/puppet:/var/lib/modules.
或者,可以将 /etc/puppet 目录建立为一个特殊的匿名模块,该模块始终首先搜索。
模块命名
Puppet 遵循特定模块的相同命名标准,其中模块名称必须是普通单词,匹配 [-\\w+](字母、单词、数字、下划线和破折号),并且不包含命名空间分隔符:或 /。虽然在模块层次结构方面可能是允许的,但对于新模块,它不能嵌套。
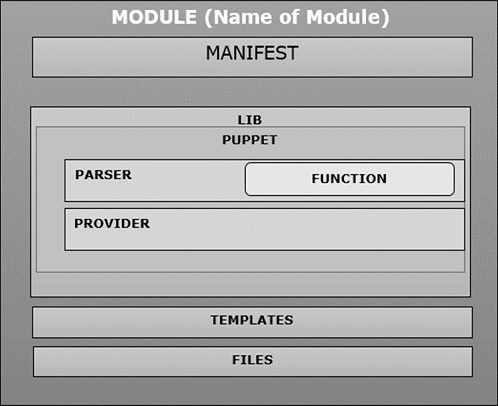
模块内部组织
当用户在 Puppet 中创建新模块时,它遵循相同的结构,并包含以特定目录结构排列的清单、分布式文件、插件和模板,如下面的代码所示。
MODULE_PATH/
downcased_module_name/
files/
manifests/
init.pp
lib/
puppet/
parser/
functions
provider/
type/
facter/
templates/
README
每当创建模块时,它都会在 manifests 目录内的指定固定位置包含 **init.pp** 清单文件。此清单文件是首先在任何特定模块中执行的默认文件,并且包含与该特定模块关联的所有类的集合。可以将其他 **.pp** 文件直接添加到 manifests 文件夹下。如果添加其他 .pp 文件,则应以类名命名。
使用模块实现的关键特性之一是代码共享。模块本质上应该是自包含的,这意味着应该能够从任何地方包含任何模块,并将其放入模块路径中,在 Puppet 启动时加载。借助模块,可以在 Puppet 基础设施编码中实现模块化。
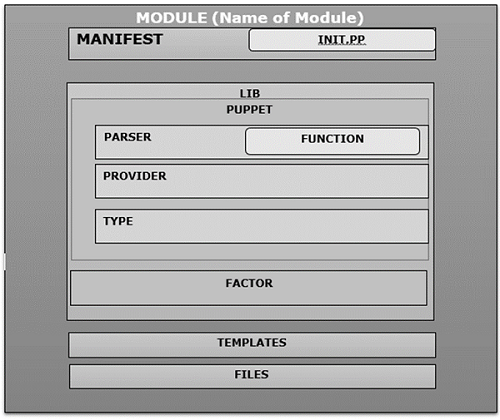
示例
考虑一个安装固定 auto.homes 映射并从模板生成 auto.master 的 autofs 模块。
class autofs {
package { autofs: ensure => latest }
service { autofs: ensure => running }
file { "/etc/auto.homes":
source => "puppet://$servername/modules/autofs/auto.homes"
}
file { "/etc/auto.master":
content => template("autofs/auto.master.erb")
}
}
文件系统将包含以下文件。
MODULE_PATH/ autofs/ manifests/ init.pp files/ auto.homes templates/ auto.master.erb
模块查找
Puppet 遵循预定义的结构,其中包含以定义结构排列的多个目录和子目录。这些目录包含模块执行某些操作所需的不同类型的文件。一些幕后操作可确保将正确的文件与正确的上下文关联起来。所有模块搜索都在 modulepath 内进行,modulepath 是一个冒号分隔的目录列表。
对于文件服务器上的文件引用,使用类似的引用,以便对 puppet: //$servername/modules/autofs/auto.homes 的引用解析为模块路径中的 autofs/files/auto.homes 文件。
为了使模块可用于命令行客户端和 puppet master,可以使用 puppet:///path 格式的 URL。即没有显式服务器名称的 URL。此类 URL 由 **Puppet** 和 **puppetd** 处理方式略有不同。Puppet 在本地文件系统中搜索无服务器 URL。
模板文件的搜索方式类似于清单和文件:提及模板(“autofs/auto.master.erb”)将使 puppetmaster 首先在 **$templatedir/autofs/auto.master.erb** 中查找文件,然后在模块路径上的 **autofs/templates/auto.master.erb** 中查找。使用 Puppet 版本的所有内容都可以在 Puppet 下使用。这称为模块自动加载。Puppet 将尝试自动加载模块中的类和定义。
Puppet - 文件服务器
Puppet 遵循客户端和服务器的概念,其中一个设置中的机器充当服务器机器,在其上运行 Puppet 服务器软件,其余机器充当客户端,在其上运行 Puppet 代理软件。文件服务器的此功能有助于在多台机器之间复制文件。Puppet 中的文件服务功能作为中央 Puppet 守护程序的一部分提供。Puppetmasterd 和客户端功能在将文件对象作为文件属性来源方面起着关键作用。
class { 'java':
package => 'jdk-8u25-linux-x64',
java_alternative => 'jdk1.8.0_25',
java_alternative_path => '/usr/java/jdk1.8.0_25/jre/bin/java'
}
如上面的代码片段所示,Puppet 的文件服务功能通过支持文件服务模块来抽象本地文件系统拓扑。我们将以以下方式指定文件服务模块。
“puppet://server/modules/module_name/sudoers”
文件格式
在 Puppet 目录结构中,默认情况下,文件服务器配置位于 ** /etc/puppet/fileserver.config** 目录下,如果用户希望更改此默认配置文件路径,可以使用新的 config 标志来完成 **puppetmasterd**。配置文件类似于 INI 文件,但并不完全相同。
[module] path /path/to/files allow *.domain.com deny *.wireless.domain.com
如上代码片段所示,所有三个选项都在配置文件中表示。模块名称用括号括起来。路径是唯一必需的选项。默认安全选项是拒绝所有访问,因此,如果没有指定允许行,则配置的模块将对任何人可用。
路径可以包含任何或所有 %d、%h 和 %H,这些参数会动态替换为其域名、主机名和完全限定主机名。所有这些都取自客户端的 SSL 证书(因此,如果主机名和证书名称不匹配,请小心)。这在创建每个客户端的文件完全分开保存的模块时非常有用。例如,用于私有主机密钥。
[private] path /data/private/%h allow *
在上面的代码片段中,代码尝试从客户端 **client1.vipin.com** 搜索文件 /private/file.txt。它将在 /data/private/client1/file.txt 中查找它,而针对 client2.vipin.com 的相同请求将尝试在文件服务器上检索文件 /data/private/client2/file.txt。
安全性
Puppet 支持在 Puppet 文件服务器上保护文件的两个基本概念。这是通过允许访问特定文件并拒绝访问不需要的文件来实现的。默认情况下,Puppet 不允许访问任何文件。需要显式定义。可以在文件中使用 IP 地址、名称或全局允许来允许或拒绝访问。
如果客户端没有直接连接到 Puppet 文件服务器,例如使用反向代理和 Mongrel,则文件服务器将看到所有连接都来自代理服务器,而不是 Puppet 客户端。在上述情况下,基于主机名限制主机名是最佳实践。
定义文件结构时需要注意一个关键点,所有 deny 语句都在 allow 语句之前解析。因此,如果任何 deny 语句匹配主机,则该主机将被拒绝,并且如果后续文件中没有写入任何 allow 语句,则该主机将被拒绝。此功能有助于设置特定站点的优先级。
主机名
在任何文件服务器配置中,文件主机名可以通过两种方式指定:使用完整主机名或使用 * 通配符指定整个域名,如下例所示。
[export] path /usr allow brcleprod001.brcl.com allow *.brcl.com deny brcleprod002.brcl.com
IP 地址
在任何文件服务器配置中,文件地址的指定方式与主机名类似,可以使用完整 IP 地址或通配符地址。也可以使用 CIDR 系统表示法。
[export] path /usr allow 127.0.0.1 allow 172.223.30.* allow 172.223.30.0/24
全局允许
当用户希望每个人都可以访问特定模块时,使用全局允许。为此,单个通配符有助于让每个人都可以访问该模块。
[export] path /export allow *
Puppet - Facter & Facts
Puppet 支持将多个值作为环境变量保存。Puppet 通过使用 **facter** 支持此功能。在 Puppet 中,facter 是一个独立的工具,它保存环境级变量。它可以被认为类似于 Bash 或 Linux 的 env 变量。有时,存储在事实中的信息与机器的环境变量之间可能存在重叠。在 Puppet 中,键值对被称为“事实”。每个资源都有自己的事实,在 Puppet 中,用户可以利用它来构建自己的自定义事实。
# facter
**Facter 命令** 可用于列出所有不同的环境变量及其关联的值。这些事实集合随 facter 开箱即用,称为核心事实。可以向集合中添加自定义事实。
如果只想查看一个变量,可以使用以下命令。
# facter {Variable Name}
Example
[root@puppetmaster ~]# facter virtual
virtualbox
facter 对 Puppet 很重要的原因是 facter 和事实在整个 Puppet 代码中都可用作 **“全局变量”**,这意味着它可以在代码的任何时间点使用,而无需任何其他引用。
测试示例
[root@puppetmaster modules]# tree brcle_account
brcle_account
└── manifests └── init.pp [root@puppetmaster modules]# cat brcle_account/manifests/init.pp
class brcle_account {
user { 'G01063908':
ensure => 'present',
uid => '121',
shell => '/bin/bash',
home => '/home/G01063908',
}
file {'/tmp/userfile.txt':
ensure => file,
content => "the value for the 'OperatingSystem' fact is: $OperatingSystem \n",
}
}
测试它
[root@puppetmaster modules]# puppet agent --test Notice: /Stage[main]/Activemq::Service/Service[activemq]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Activemq::Service/Service[activemq]: Unscheduling refresh on Service[activemq] Notice: Finished catalog run in 4.09 seconds [root@puppetmaster modules]# cat /tmp/testfile.txt the value for the 'OperatingSystem' fact is: Linux [root@puppetmaster modules]# facter OperatingSystem Linux
正如我们在上面的代码片段中注意到的那样,我们没有定义 **OperatingSystem**。我们只是用软编码值 **$OperatingSystem** 作为普通变量替换了该值。
在 Puppet 中,可以使用和定义三种类型的 fact:
- 核心事实
- 自定义事实
- 外部事实
核心事实是在顶层定义的,在代码的任何位置都可供所有人访问。
Puppet 事实
在代理向主服务器请求目录之前,代理首先会编译一个完整的列表,其中包含其自身以键值对形式提供的所有信息。代理上的信息由名为 facter 的工具收集,每个键值对都被称为事实。以下是代理上事实的常见输出。
[root@puppetagent1 ~]# facter
architecture => x86_64
augeasversion => 1.0.0
bios_release_date => 13/09/2012
bios_vendor => innotek GmbH
bios_version => VirtualBox
blockdevice_sda_model => VBOX HARDDISK
blockdevice_sda_size => 22020587520
blockdevice_sda_vendor => ATA
blockdevice_sr0_model => CD-ROM
blockdevice_sr0_size => 1073741312
blockdevice_sr0_vendor => VBOX
blockdevices => sda,sr0
boardmanufacturer => Oracle Corporation
boardproductname => VirtualBox
boardserialnumber => 0
domain => codingbee.dyndns.org
facterversion => 2.1.0
filesystems => ext4,iso9660
fqdn => puppetagent1.codingbee.dyndns.org
hardwareisa => x86_64
hardwaremodel => x86_64
hostname => puppetagent1
id => root
interfaces => eth0,lo
ipaddress => 172.228.24.01
ipaddress_eth0 => 172.228.24.01
ipaddress_lo => 127.0.0.1
is_virtual => true
kernel => Linux
kernelmajversion => 2.6
kernelrelease => 2.6.32-431.23.3.el6.x86_64
kernelversion => 2.6.32
lsbdistcodename => Final
lsbdistdescription => CentOS release 6.5 (Final)
lsbdistid => CentOS
lsbdistrelease => 6.5
lsbmajdistrelease => 6
lsbrelease => :base-4.0-amd64:base-4.0-noarch:core-4.0-amd64:core-4.0noarch:graphics-4.0-amd64:
graphics-4.0-noarch:printing-4.0-amd64:printing-4.0noarch
macaddress => 05:00:22:47:H9:77
macaddress_eth0 => 05:00:22:47:H9:77
manufacturer => innotek GmbH
memoryfree => 125.86 GB
memoryfree_mb => 805.86
memorysize => 500 GB
memorysize_mb => 996.14
mtu_eth0 => 1500
mtu_lo => 16436
netmask => 255.255.255.0
netmask_eth0 => 255.255.255.0
network_lo => 127.0.0.0
operatingsystem => CentOS
operatingsystemmajrelease => 6
operatingsystemrelease => 6.5
osfamily => RedHat
partitions => {"sda1"=>{
"uuid"=>"d74a4fa8-0883-4873-8db0-b09d91e2ee8d", "size" =>"1024000",
"mount" => "/boot", "filesystem" => "ext4"}, "sda2"=>{"size" => "41981952",
"filesystem" => "LVM2_member"}
}
path => /usr/lib64/qt3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
physicalprocessorcount => 1
processor0 => Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz
processor1 => Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz
processor2 => Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz
processorcount => 3
productname => VirtualBox
ps => ps -ef
puppetversion => 3.6.2
rubysitedir => /usr/lib/ruby/site_ruby/1.8
rubyversion => 1.8.7
selinux => true
selinux_config_mode => enforcing
selinux_config_policy => targeted
selinux_current_mode => enforcing
selinux_enforced => true
selinux_policyversion => 24
serialnumber => 0
sshdsakey => AAAAB3NzaC1kc3MAAACBAK5fYwRM3UtOs8zBCtRTjuHLw56p94X/E0UZBZwFR3q7
WH0x5+MNsjfmdCxKvpY/WlIIUcFJzvlfjXm4qDaTYalbzSZJMT266njNbw5WwLJcJ74KdW92ds76pjgm
CsjAh+R9YnyKCEE35GsYjGH7whw0gl/rZVrjvWYKQDOmJA2dAAAAFQCoYABgjpv3EkTWgjLIMnxA0Gfud
QAAAIBM4U6/nerfn6Qvt43FC2iybvwVo8ufixJl5YSEhs92uzsW6jiw68aaZ32q095/gEqYzeF7a2knr
OpASgO9xXqStYKg8ExWQVaVGFTR1NwqhZvz0oRSbrN3h3tHgknoKETRAg/imZQ2P6tppAoQZ8wpuLrXU
CyhgJGZ04Phv8hinAAAAIBN4xaycuK0mdH/YdcgcLiSn8cjgtiETVzDYa+jF
swapfree => 3.55 GB
swapfree_mb => 2015.99
swapsize => 3.55 GB
swapsize_mb => 2015.99
timezone => GMT
type => Other
uniqueid => a8c0af01
uptime => 45:012 hours
uptime_days => 0
uptime_hours => 6
uptime_seconds => 21865
uuid => BD8B9D85-1BFD-4015-A633-BF71D9A6A741
virtual => virtualbox
在上面的代码中,我们可以看到一些数据与 bash “env” 变量中提供的一些信息重叠。Puppet 不直接使用这些数据,而是使用 facter 数据,Facter 数据被视为全局变量。
然后,这些事实将作为顶层变量可用,Puppet 主服务器可以使用它们为请求代理编译 Puppet 目录。Facter 在清单中作为带有 $ 前缀的普通变量调用。
示例
if ($OperatingSystem == "Linux") {
$message = "This machine OS is of the type $OperatingSystem \n"
} else {
$message = "This machine is unknown \n"
}
file { "/tmp/machineOperatingSystem.txt":
ensure => file,
content => "$message"
}
上面的清单文件只关心一个名为 **machineOperatingSystem.txt** 的文件,该文件的内容由名为 **OperatingSystem** 的事实推断得出。
[root@puppetagent1 /]# facter OperatingSystem
Linux
[root@puppetagent1 /]# puppet apply /tmp/ostype.pp
Notice: Compiled catalog for puppetagent1.codingbee.dyndns.org
in environment production in 0.07 seconds
Notice: /Stage[main]/Main/File[/tmp/machineOperatingSystem.txt]/ensure:
defined content as '{md5}f59dc5797d5402b1122c28c6da54d073'
Notice: Finished catalog run in 0.04 seconds
[root@puppetagent1 /]# cat /tmp/machinetype.txt
This machine OS is of the type Linux
自定义事实
我们看到的所有上述事实都是机器的核心事实。可以通过以下方式将此自定义事实添加到节点中:
- 使用“export FACTER … 语法”
- 使用 $LOAD_PATH 设置
- FACTERLIB
- Pluginsync
使用“export FACTER”语法
可以使用 export FACTER_{fact’s name} 语法手动添加事实。
示例
[root@puppetagent1 facter]# export FACTER_tallest_mountain="Everest" [root@puppetagent1 facter]# facter tallest_mountain Everest
使用 $LOAD_PATH 设置
在 Ruby 中,$LOAD_PATH 等效于 Bash 特殊参数。虽然它类似于 bash $PATH 变量,但在实际事实中,$LOAD_PATH 不是环境变量,而是一个预定义的变量。
$LOAD_PATH 有一个同义词“$:”。此变量是一个用于搜索和加载值的数组。
[root@puppetagent1 ~]# ruby -e 'puts $LOAD_PATH' # note you have to use single quotes. /usr/lib/ruby/site_ruby/1.6 /usr/lib64/ruby/site_ruby/1.6 /usr/lib64/ruby/site_ruby/1.6/x86_64-linux /usr/lib/ruby/site_ruby /usr/lib64/ruby/site_ruby /usr/lib64/site_ruby/1.6 /usr/lib64/site_ruby/1.6/x86_64-linux /usr/lib64/site_ruby /usr/lib/ruby/1.6 /usr/lib64/ruby/1.6 /usr/lib64/ruby/1.6/x86_64-linux
让我们以创建一个 facter 目录并添加一个 **.pp** 文件并将内容附加到其中的示例为例。
[root@puppetagent1 ~]# cd /usr/lib/ruby/site_ruby/ [root@puppetagent1 site_ruby]# mkdir facter [root@puppetagent1 site_ruby]# cd facter/ [root@puppetagent1 facter]# ls [root@puppetagent1 facter]# touch newadded_facts.rb
将以下内容添加到 custom_facts.rb 文件中。
[root@puppetagent1 facter]# cat newadded_facts.rb
Facter.add('tallest_mountain') do
setcode "echo Everest"
end
Facter 的工作方法是扫描 $LOAD_PATH 中列出的所有文件夹,并查找名为 facter 的目录。一旦找到该特定文件夹,它就会将它们加载到文件夹结构中的任何位置。如果找到此文件夹,则它会查找 facter 文件夹中的任何 Ruby 文件,并将有关任何特定配置的所有已定义事实加载到内存中。
使用 FACTERLIB
在 Puppet 中,FACTERLIB 的工作方式与 $LOAD_PATH 非常相似,但只有一个关键区别,即它是一个操作系统级环境参数,而不是 Ruby 特殊变量。默认情况下,可能未设置环境变量。
[root@puppetagent1 facter]# env | grep "FACTERLIB" [root@puppetagent1 facter]#
要测试 FACTERLIB,需要执行以下步骤。
创建名为 test_facts 的文件夹,其结构如下。
[root@puppetagent1 tmp]# tree /tmp/test_facts/ /tmp/some_facts/ ├── vipin │ └── longest_river.rb └── testing └── longest_wall.rb
将以下内容添加到 .rb 文件中。
[root@puppetagent1 vipin]# cat longest_river.rb
Facter.add('longest_river') do
setcode "echo Nile"
end
[root@puppetagent1 testing]# cat longest_wall.rb
Facter.add('longest_wall') do
setcode "echo 'China Wall'"
end
使用 export 语句。
[root@puppetagent1 /]# export FACTERLIB = "/tmp/some_facts/river:/tmp/some_facts/wall" [root@puppetagent1 /]# env | grep "FACTERLIB" FACTERLIB = /tmp/some_facts/river:/tmp/some_facts/wall
测试新的 facter。
[root@puppetagent1 /]# facter longest_river Nile [root@puppetagent1 /]# facter longest_wall China Wall
外部事实
当用户希望应用在配置时间创建的一些新事实时,外部事实非常有用。外部事实是在其配置阶段(例如,使用 vSphere、OpenStack、AWS 等)将元数据应用于 VM 的关键方法之一。
创建的所有元数据及其详细信息都可以由 Puppet 用于确定目录中应存在哪些详细信息,这些详细信息将被应用。
创建外部事实
在代理机器上,需要创建如下所示的目录。
$ mkdir -p /etc/facter/facts.d
在目录中创建一个 Shell 脚本,内容如下。
$ ls -l /etc/facter/facts.d total 4 -rwxrwxrwx. 1 root root 65 Sep 18 13:11 external-factstest.sh $ cat /etc/facter/facts.d/external-factstest.sh #!/bin/bash echo "hostgroup = dev" echo "environment = development"
更改脚本文件的权限。
$ chmod u+x /etc/facter/facts.d/external-facts.sh
完成后,我们现在可以看到带有键/值对的变量。
$ facter hostgroup dev $ facter environment development
可以在 Puppet 中编写自定义事实。作为参考,请使用 Puppet 站点上的以下链接。
https://docs.puppet.com/facter/latest/fact_overview.html#writing-structured-facts
Puppet - 资源
资源是 Puppet 的关键基本单元之一,用于设计和构建任何特定的基础设施或机器。它们主要用于建模和维护系统配置。Puppet 有多种类型的资源,可用于定义系统架构,或者用户可以利用它们来构建和定义新的资源。
清单文件或任何其他文件中的 Puppet 代码块称为资源声明。代码块是用一种名为声明性建模语言 (DML) 的语言编写的。以下是如何显示它的示例。
user { 'vipin':
ensure => present,
uid => '552',
shell => '/bin/bash',
home => '/home/vipin',
}
在 Puppet 中,任何特定资源类型的资源声明都在代码块中完成。在下面的示例中,用户主要由四个预定义的参数组成。
**资源类型** - 在上面的代码片段中,它是用户。
**资源参数** - 在上面的代码片段中,它是 Vipin。
**属性** - 在上面的代码片段中,它是 ensure、uid、shell、home。
**值** - 这些是与每个属性对应的值。
每种资源类型都有自己的定义和参数定义方式,用户有权选择他希望自己的资源看起来像什么。
资源类型
Puppet 中提供了不同类型的资源,它们具有自己的功能方式。可以使用“describe”命令以及“-list”选项查看这些资源类型。
[root@puppetmaster ~]# puppet describe --list These are the types known to puppet: augeas - Apply a change or an array of changes to the ... computer - Computer object management using DirectorySer ... cron - Installs and manages cron jobs exec - Executes external commands file - Manages files, including their content, owner ... filebucket - A repository for storing and retrieving file ... group - Manage groups host - Installs and manages host entries interface - This represents a router or switch interface k5login - Manage the ‘.k5login’ file for a user macauthorization - Manage the Mac OS X authorization database mailalias - .. no documentation .. maillist - Manage email lists mcx - MCX object management using DirectoryService ... mount - Manages mounted filesystems, including puttin ... nagios_command - The Nagios type command nagios_contact - The Nagios type contact nagios_contactgroup - The Nagios type contactgroup nagios_host - The Nagios type host nagios_hostdependency - The Nagios type hostdependency nagios_hostescalation - The Nagios type hostescalation nagios_hostextinfo - The Nagios type hostextinfo nagios_hostgroup - The Nagios type hostgroup nagios_service - The Nagios type service nagios_servicedependency - The Nagios type servicedependency nagios_serviceescalation - The Nagios type serviceescalation nagios_serviceextinfo - The Nagios type serviceextinfo nagios_servicegroup - The Nagios type servicegroup nagios_timeperiod - The Nagios type timeperiod notify - .. no documentation .. package - Manage packages resources - This is a metatype that can manage other reso ... router - .. no documentation .. schedule - Define schedules for Puppet scheduled_task - Installs and manages Windows Scheduled Tasks selboolean - Manages SELinux booleans on systems with SELi ... service - Manage running services ssh_authorized_key - Manages SSH authorized keys sshkey - Installs and manages ssh host keys stage - A resource type for creating new run stages tidy - Remove unwanted files based on specific crite ... user - Manage users vlan - .. no documentation .. whit - Whits are internal artifacts of Puppet's curr ... yumrepo - The client-side description of a yum reposito ... zfs - Manage zfs zone - Manages Solaris zones zpool - Manage zpools
资源标题
在上面的代码片段中,我们的资源标题是 vipin,它在代码的同一文件中使用的每个资源中都是唯一的。这是此用户资源类型的唯一标题。我们不能拥有同名的资源,因为这会导致冲突。
可以使用 Resource 命令来查看使用类型 user 的所有资源的列表。
[root@puppetmaster ~]# puppet resource user
user { 'abrt':
ensure => 'present',
gid => '173',
home => '/etc/abrt',
password => '!!',
password_max_age => '-1',
password_min_age => '-1',
shell => '/sbin/nologin',
uid => '173',
}
user { 'admin':
ensure => 'present',
comment => 'admin',
gid => '444',
groups => ['sys', 'admin'],
home => '/var/admin',
password => '*',
password_max_age => '99999',
password_min_age => '0',
shell => '/sbin/nologin',
uid => '55',
}
user { 'tomcat':
ensure => 'present',
comment => 'tomcat',
gid => '100',
home => '/var/www',
password => '!!',
password_max_age => '-1',
password_min_age => '-1',
shell => '/sbin/nologin',
uid => '100',
}
列出特定用户的资源
[root@puppetmaster ~]# puppet resource user tomcat
user { 'apache':
ensure => 'present',
comment => 'tomcat',
gid => '100',
home => '/var/www',
password => '!!',
password_max_age => '-1',
password_min_age => '-1',
shell => '/sbin/nologin',
uid => '100’,
}
属性和值
任何资源的主体都是由属性-值对的集合组成的。在这里,可以为给定资源的属性指定值。每种资源类型都有自己的一组属性,可以使用键值对进行配置。
描述可以用来获取有关特定资源属性的更多详细信息的子命令。在下面的示例中,我们有关于用户资源及其所有可配置属性的详细信息。
[root@puppetmaster ~]# puppet describe user
user
====
Manage users. This type is mostly built to manage system users,
so it is lacking some features useful for managing normal users.
This resource type uses the prescribed native tools for creating groups
and generally uses POSIX APIs for retrieving information about them.
It does not directly modify ‘/etc/passwd’ or anything.
**Autorequires:** If Puppet is managing the user's primary group
(as provided in the ‘gid’ attribute),
the user resource will autorequire that group.
If Puppet is managing any role accounts corresponding to the user's roles,
the user resource will autorequire those role accounts.
Parameters
----------
- **allowdupe**
Whether to allow duplicate UIDs. Defaults to ‘false’.
Valid values are ‘true’, ‘false’, ‘yes’, ‘no’.
- **attribute_membership**
Whether specified attribute value pairs should be treated as the
**complete list** (‘inclusive’) or the **minimum list** (‘minimum’) of
attribute/value pairs for the user. Defaults to ‘minimum’.
Valid values are ‘inclusive’, ‘minimum’.
- **auths**
The auths the user has. Multiple auths should be
specified as an array.
Requires features manages_solaris_rbac.
- **comment**
A description of the user. Generally the user's full name.
- **ensure**
The basic state that the object should be in.
Valid values are ‘present’, ‘absent’, ‘role’.
- **expiry**
The expiry date for this user. Must be provided in
a zero-padded YYYY-MM-DD format --- e.g. 2010-02-19.
If you want to make sure the user account does never
expire, you can pass the special value ‘absent’.
Valid values are ‘absent’. Values can match ‘/^\d{4}-\d{2}-\d{2}$/’.
Requires features manages_expiry.
- **forcelocal**
Forces the mangement of local accounts when accounts are also
being managed by some other NSS
- **gid**
The user's primary group. Can be specified numerically or by name.
This attribute is not supported on Windows systems; use the ‘groups’
attribute instead. (On Windows, designating a primary group is only
meaningful for domain accounts, which Puppet does not currently manage.)
- **groups**
The groups to which the user belongs. The primary group should
not be listed, and groups should be identified by name rather than by
GID. Multiple groups should be specified as an array.
- **home**
The home directory of the user. The directory must be created
separately and is not currently checked for existence.
- **ia_load_module**
The name of the I&A module to use to manage this user.
Requires features manages_aix_lam.
- **iterations**
This is the number of iterations of a chained computation of the
password hash (http://en.wikipedia.org/wiki/PBKDF2). This parameter
is used in OS X. This field is required for managing passwords on OS X
>= 10.8.
Requires features manages_password_salt.
- **key_membership**
- **managehome**
Whether to manage the home directory when managing the user.
This will create the home directory when ‘ensure => present’, and
delete the home directory when ‘ensure => absent’. Defaults to ‘false’.
Valid values are ‘true’, ‘false’, ‘yes’, ‘no’.
- **membership**
Whether specified groups should be considered the **complete list**
(‘inclusive’) or the **minimum list** (‘minimum’) of groups to which
the user belongs. Defaults to ‘minimum’.
Valid values are ‘inclusive’, ‘minimum’.
- **name**
The user name. While naming limitations vary by operating system,
it is advisable to restrict names to the lowest common denominator,
which is a maximum of 8 characters beginning with a letter.
Note that Puppet considers user names to be case-sensitive, regardless
of the platform's own rules; be sure to always use the same case when
referring to a given user.
- **password**
The user's password, in whatever encrypted format the local
system requires.
* Most modern Unix-like systems use salted SHA1 password hashes. You can use
Puppet's built-in ‘sha1’ function to generate a hash from a password.
* Mac OS X 10.5 and 10.6 also use salted SHA1 hashes.
Windows API
for setting the password hash.
[stdlib]: https://github.com/puppetlabs/puppetlabs-stdlib/
Be sure to enclose any value that includes a dollar sign ($) in single
quotes (') to avoid accidental variable interpolation.
Requires features manages_passwords.
- **password_max_age**
The maximum number of days a password may be used before it must be changed.
Requires features manages_password_age.
- **password_min_age**
The minimum number of days a password must be used before it may be changed.
Requires features manages_password_age.
- **profile_membership**
Whether specified roles should be treated as the **complete list**
(‘inclusive’) or the **minimum list** (‘minimum’) of roles
of which the user is a member. Defaults to ‘minimum’.
Valid values are ‘inclusive’, ‘minimum’.
- **profiles**
The profiles the user has. Multiple profiles should be
specified as an array.
Requires features manages_solaris_rbac.
- **project**
The name of the project associated with a user.
Requires features manages_solaris_rbac.
- **uid**
The user ID; must be specified numerically. If no user ID is
specified when creating a new user, then one will be chosen
automatically. This will likely result in the same user having
different UIDs on different systems, which is not recommended. This is
especially noteworthy when managing the same user on both Darwin and
other platforms, since Puppet does UID generation on Darwin, but
the underlying tools do so on other platforms.
On Windows, this property is read-only and will return the user's
security identifier (SID).
Puppet - 资源抽象层
在Puppet中,资源抽象层 (RAL) 可被认为是整个基础架构和Puppet设置的核心概念模型。在RAL中,每个字母都有其自身的特定含义,定义如下。
资源 [R]
资源可以被认为是用于在Puppet中建模任何配置的所有资源。它们基本上是Puppet中默认存在的内置资源。它们可以被认为是一组属于预定义资源类型的资源。它们类似于任何其他编程语言中的OOP概念,其中对象是类的实例。在Puppet中,其资源是资源类型的一个实例。
抽象 [A]
抽象可以被认为是一个关键特性,其中资源独立于目标操作系统进行定义。换句话说,在编写任何清单文件时,用户无需担心目标机器或该特定机器上存在的操作系统。在抽象中,资源提供了关于Puppet代理上需要存在什么内容的足够信息。
Puppet将负责幕后发生的所有功能或“魔法”。无论资源和操作系统如何,Puppet都将负责在目标机器上实施配置,用户无需担心Puppet在幕后如何运作。
在抽象中,Puppet将资源与其实现分离。这种特定于平台的配置存在于提供程序中。我们可以结合其提供程序使用多个子命令。
层 [L]
可以定义整个机器设置和配置为资源集合,并且可以通过Puppet的CLI接口查看和管理。
用户资源类型示例
[root@puppetmaster ~]# puppet describe user --providers
user
====
Manage users.
This type is mostly built to manage systemusers,
so it is lacking some features useful for managing normalusers.
This resource type uses the prescribed native tools for
creating groups and generally uses POSIX APIs for retrieving informationabout them.
It does not directly modify '/etc/passwd' or anything.
- **comment**
A description of the user. Generally the user's full name.
- **ensure**
The basic state that the object should be in.
Valid values are 'present', 'absent', 'role'.
- **expiry**
The expiry date for this user.
Must be provided in a zero-padded YYYY-MM-DD format --- e.g. 2010-02-19.
If you want to make sure the user account does never expire,
you can pass the special value 'absent'.
Valid values are 'absent'.
Values can match '/^\d{4}-\d{2}-\d{2}$/'.
Requires features manages_expiry.
- **forcelocal**
Forces the management of local accounts when accounts are also
being managed by some other NSS
Valid values are 'true', 'false', 'yes', 'no'.
Requires features libuser.
- **gid**
The user's primary group. Can be specified numerically or by name.
This attribute is not supported on Windows systems; use the ‘groups’
attribute instead. (On Windows, designating a primary group is only
meaningful for domain accounts, which Puppet does not currently manage.)
- **groups**
The groups to which the user belongs. The primary group should
not be listed, and groups should be identified by name rather than by
GID. Multiple groups should be specified as an array.
- **home**
The home directory of the user. The directory must be created
separately and is not currently checked for existence.
- **ia_load_module**
The name of the I&A module to use to manage this user.
Requires features manages_aix_lam.
- **iterations**
This is the number of iterations of a chained computation of the
password hash (http://en.wikipedia.org/wiki/PBKDF2).
This parameter is used in OS X.
This field is required for managing passwords on OS X >= 10.8.
- **key_membership**
Whether specified key/value pairs should be considered the
**complete list** ('inclusive') or the **minimum list** ('minimum') of
the user's attributes. Defaults to 'minimum'.
Valid values are 'inclusive', 'minimum'.
- **keys**
Specify user attributes in an array of key = value pairs.
Requires features manages_solaris_rbac.
- **managehome**
Whether to manage the home directory when managing the user.
This will create the home directory when 'ensure => present', and
delete the home directory when ‘ensure => absent’. Defaults to ‘false’.
Valid values are ‘true’, ‘false’, ‘yes’, ‘no’.
- **membership**
Whether specified groups should be considered the **complete list**
(‘inclusive’) or the **minimum list** (‘minimum’) of groups to which
the user belongs. Defaults to ‘minimum’.
Valid values are ‘inclusive’, ‘minimum’.
- **name**
The user name. While naming limitations vary by operating system,
it is advisable to restrict names to the lowest common denominator.
- **password**
The user's password, in whatever encrypted format the local system requires.
* Most modern Unix-like systems use salted SHA1 password hashes. You can use
Puppet's built-in ‘sha1’ function to generate a hash from a password.
* Mac OS X 10.5 and 10.6 also use salted SHA1 hashes.
* Mac OS X 10.7 (Lion) uses salted SHA512 hashes.
The Puppet Labs [stdlib][] module contains a ‘str2saltedsha512’
function which can generate password hashes for Lion.
* Mac OS X 10.8 and higher use salted SHA512 PBKDF2 hashes.
When managing passwords on these systems the salt and iterations properties
need to be specified as well as the password.
[stdlib]: https://github.com/puppetlabs/puppetlabs-stdlib/
Be sure to enclose any value that includes a dollar sign ($) in single
quotes (') to avoid accidental variable interpolation.
Requires features manages_passwords.
- **password_max_age**
The maximum number of days a password may be used before it must be changed.
Requires features manages_password_age.
- **password_min_age**
The minimum number of days a password must be used before it may be changed.
Requires features manages_password_age.
- **profile_membership**
Whether specified roles should be treated as the **complete list**
(‘inclusive’) or the **minimum list** (‘minimum’) of roles
of which the user is a member. Defaults to ‘minimum’.
Valid values are ‘inclusive’, ‘minimum’.
- **profiles**
The profiles the user has. Multiple profiles should be
specified as an array.
Requires features manages_solaris_rbac.
- **project**
The name of the project associated with a user.
Requires features manages_solaris_rbac.
- **purge_ssh_keys**
Purge ssh keys authorized for the user
if they are not managed via ssh_authorized_keys.
When true, looks for keys in .ssh/authorized_keys in the user's home directory.
Possible values are true, false, or an array of
paths to file to search for authorized keys.
If a path starts with ~ or %h, this token is replaced with the user's home directory.
Valid values are ‘true’, ‘false’.
- **role_membership**
Whether specified roles should be considered the **complete list**
(‘inclusive’) or the **minimum list** (‘minimum’) of roles the user has.
Defaults to ‘minimum’.
Valid values are ‘inclusive’, ‘minimum’.
- **roles**
The roles the user has. Multiple roles should be
specified as an array.
Requires features manages_solaris_rbac.
- **salt**
This is the 32 byte salt used to generate the PBKDF2 password used in
OS X. This field is required for managing passwords on OS X >= 10.8.
Requires features manages_password_salt.
- **shell**
The user's login shell. The shell must exist and be
executable.
This attribute cannot be managed on Windows systems.
Requires features manages_shell.
- **system**
Whether the user is a system user, according to the OS's criteria;
on most platforms, a UID less than or equal to 500 indicates a system
user. Defaults to ‘false’.
Valid values are ‘true’, ‘false’, ‘yes’, ‘no’.
- **uid**
The user ID; must be specified numerically. If no user ID is
specified when creating a new user, then one will be chosen
automatically. This will likely result in the same user having
different UIDs on different systems, which is not recommended.
This is especially noteworthy when managing the same user on both Darwin and
other platforms, since Puppet does UID generation on Darwin, but
the underlying tools do so on other platforms.
On Windows, this property is read-only and will return the user's
security identifier (SID).
Providers
---------
- **aix**
User management for AIX.
* Required binaries: '/bin/chpasswd', '/usr/bin/chuser',
'/usr/bin/mkuser', '/usr/sbin/lsgroup', '/usr/sbin/lsuser',
'/usr/sbin/rmuser'.
* Default for ‘operatingsystem’ == ‘aix’.
* Supported features: ‘manages_aix_lam’, ‘manages_expiry’,
‘manages_homedir’, ‘manages_password_age’, ‘manages_passwords’,
‘manages_shell’.
- **directoryservice**
User management on OS X.
* Required binaries: ‘/usr/bin/dscacheutil’, ‘/usr/bin/dscl’,
‘/usr/bin/dsimport’, ‘/usr/bin/plutil’, ‘/usr/bin/uuidgen’.
* Default for ‘operatingsystem’ == ‘darwin’.
* Supported features: ‘manages_password_salt’, ‘manages_passwords’,
‘manages_shell’.
- **hpuxuseradd**
User management for HP-UX. This provider uses the undocumented ‘-F’
switch to HP-UX's special ‘usermod’ binary to work around the fact that
its standard ‘usermod’ cannot make changes while the user is logged in.
* Required binaries: ‘/usr/sam/lbin/useradd.sam’,
‘/usr/sam/lbin/userdel.sam’, ‘/usr/sam/lbin/usermod.sam’.
* Default for ‘operatingsystem’ == ‘hp-ux’.
* Supported features: ‘allows_duplicates’, ‘manages_homedir’,
‘manages_passwords’.
- **ldap**
User management via LDAP.
This provider requires that you have valid values for all of the
LDAP-related settings in ‘puppet.conf’, including ‘ldapbase’.
You will almost definitely need settings for ‘ldapuser’ and ‘ldappassword’ in order
for your clients to write to LDAP.
* Supported features: ‘manages_passwords’, ‘manages_shell’.
- **pw**
User management via ‘pw’ on FreeBSD and DragonFly BSD.
* Required binaries: ‘pw’.
* Default for ‘operatingsystem’ == ‘freebsd, dragonfly’.
* Supported features: ‘allows_duplicates’, ‘manages_expiry’,
‘manages_homedir’, ‘manages_passwords’, ‘manages_shell’.
- **user_role_add**
User and role management on Solaris, via ‘useradd’ and ‘roleadd’.
* Required binaries: ‘passwd’, ‘roleadd’, ‘roledel’, ‘rolemod’,
‘useradd’, ‘userdel’, ‘usermod’.
* Default for ‘osfamily’ == ‘solaris’.
* Supported features: ‘allows_duplicates’, ‘manages_homedir’,
‘manages_password_age’, ‘manages_passwords’, ‘manages_solaris_rbac’.
- **useradd**
User management via ‘useradd’ and its ilk. Note that you will need to
install Ruby's shadow password library (often known as ‘ruby-libshadow’)
if you wish to manage user passwords.
* Required binaries: ‘chage’, ‘luseradd’, ‘useradd’, ‘userdel’, ‘usermod’.
* Supported features: ‘allows_duplicates’, ‘libuser’, ‘manages_expiry’,
‘manages_homedir’, ‘manages_password_age’, ‘manages_passwords’,
‘manages_shell’, ‘system_users’.
- **windows_adsi**
Local user management for Windows.
* Default for 'operatingsystem' == 'windows'.
* Supported features: 'manages_homedir', 'manages_passwords'.
测试资源
在Puppet中,直接测试资源表示需要首先应用想要用于配置目标节点的资源,以便机器状态相应地发生变化。
为了测试,我们将本地应用资源。正如我们上面预定义了资源`user = vipin`。应用资源的一种方法是通过CLI。这可以通过将完整的资源重写为单个命令,然后将其传递给资源子命令来完成。
puppet resource user vipin ensure = present uid = '505' shell = '/bin/bash' home = '/home/vipin'
测试应用的资源。
[root@puppetmaster ~]# cat /etc/passwd | grep "vipin" vipin:x:505:501::/home/vipin:/bin/bash
以上输出显示资源已应用于系统,并且我们创建了一个名为Vipin的新用户。建议您自行测试,因为以上所有代码都经过测试并且是有效的代码。
Puppet - 模板
**模板化**是一种以标准格式获取内容的方法,可在多个位置使用。在Puppet中,模板化和模板使用erb支持,erb是标准Ruby库的一部分,可用于除Ruby之外的其他项目,例如Ruby on Rails项目。作为标准实践,需要对Ruby有基本了解。当用户尝试管理模板文件的内容时,模板化非常有用。当无法通过内置Puppet类型管理配置时,模板起着关键作用。
评估模板
模板使用简单的函数进行评估。
$value = template ("testtemplate.erb")
可以指定模板的完整路径,或者可以提取Puppet的templatedir中的所有模板,该目录通常位于/var/puppet/templates。可以通过运行puppet --configprint templatedir查找目录位置。
模板始终由解析器而不是客户端进行评估,这意味着如果使用puppetmasterd,则模板只需要位于服务器上,而无需下载到客户端。客户端在使用模板和将文件的全部内容指定为字符串之间没有区别。这清楚地表明,客户端特定变量在puppetmasterd启动阶段首先被学习。
使用模板
以下是生成tomcat配置以测试站点的示例。
define testingsite($cgidir, $tracdir) {
file { "testing-$name":
path => "/etc/tomcat/testing/$name.conf",
owner => superuser,
group => superuser,
mode => 644,
require => File[tomcatconf],
content => template("testsite.erb"),
notify => Service[tomcat]
}
symlink { "testsym-$name":
path => "$cgidir/$name.cgi",
ensure => "/usr/share/test/cgi-bin/test.cgi"
}
}
以下是模板定义。
<Location "/cgi-bin/ <%= name %>.cgi"> SetEnv TEST_ENV "/export/svn/test/<%= name %>" </Location> # You need something like this to authenticate users <Location "/cgi-bin/<%= name %>.cgi/login"> AuthType Basic AuthName "Test" AuthUserFile /etc/tomcat/auth/svn Require valid-user </Location>
这将每个模板文件推送到一个单独的文件中,然后只需要告诉Apache加载这些配置文件。
Include /etc/apache2/trac/[^.#]*
组合模板
可以使用以下命令轻松组合两个模板。
template('/path/to/template1','/path/to/template2')
模板中的迭代
Puppet模板也支持数组迭代。如果访问的变量是数组,则可以对其进行迭代。
$values = [val1, val2, otherval]
我们可以有如下模板。
<% values.each do |val| -%> Some stuff with <%= val %> <% end -%>
以上命令将产生以下结果。
Some stuff with val1 Some stuff with val2 Some stuff with otherval
模板中的条件
**erb** 模板化支持条件语句。以下结构是在文件中以一种快速简便的方式有条件地放置内容的方法。
<% if broadcast != "NONE" %> broadcast <%= broadcast %> <% end %>
模板和变量
除了填写文件内容外,还可以使用模板填充变量。
testvariable = template('/var/puppet/template/testvar')
未定义的变量
如果需要在使用变量之前检查变量是否已定义,则以下命令有效。
<% if has_variable?("myvar") then %>
myvar has <%= myvar %> value
<% end %>
超出范围的变量
可以使用lookupvar函数显式查找超出范围的变量。
<%= scope.lookupvar('apache::user') %>
示例项目模板
<#Autogenerated by puppet. Do not edit.
[default]
#Default priority (lower value means higher priority)
priority = <%= @priority %>
#Different types of backup. Will be done in the same order as specified here.
#Valid options: rdiff-backup, mysql, command
backups = <% if @backup_rdiff %>rdiff-backup,
<% end %><% if @backup_mysql %>mysql,
<% end %><% if @backup_command %>command<% end %>
<% if @backup_rdiff -%>
[rdiff-backup]
<% if @rdiff_global_exclude_file -%>
global-exclude-file = <%= @rdiff_global_exclude_file %>
<% end -%>
<% if @rdiff_user -%>
user = <%= @rdiff_user %>
<% end -%>
<% if @rdiff_path -%>
path = <%= @rdiff_path %>
<% end -%>
#Optional extra parameters for rdiff-backup
extra-parameters = <%= @rdiff_extra_parameters %>
#How long backups are going to be kept
keep = <%= @rdiff_keep %>
<% end -%>
<% if @backup_mysql -%>%= scope.lookupvar('apache::user') %>
[mysql]
#ssh user to connect for running the backup
sshuser = <%= @mysql_sshuser %>
#ssh private key to be used
sshkey = <%= @backup_home %>/<%= @mysql_sshkey %>
<% end -%>
<% if @backup_command -%>
[command]
#Run a specific command on the backup server after the backup has finished
command = <%= @command_to_execute %>
<% end -%>
Puppet - 类
Puppet类定义为资源的集合,这些资源组合在一起以便将目标节点或机器置于所需状态。这些类定义在Puppet清单文件中,该文件位于Puppet模块内。使用类的主要目的是减少任何清单文件或任何其他Puppet代码中的相同代码重复。
以下是Puppet类的示例。
[root@puppetmaster manifests]# cat site.pp
class f3backup (
$backup_home = '/backup',
$backup_server = 'default',
$myname = $::fqdn,
$ensure = 'directory',
) {
include '::f3backup::common'
if ( $myname == '' or $myname == undef ) {
fail('myname must not be empty')
}
@@file { "${backup_home}/f3backup/${myname}":
# To support 'absent', though force will be needed
ensure => $ensure,
owner => 'backup',
group => 'backup',
mode => '0644',
tag => "f3backup-${backup_server}",
}
}
在上面的示例中,我们有两个客户端,用户需要存在。正如注意到的那样,我们重复使用了相同的资源两次。一种不执行相同任务的方法是将两个节点组合在一起。
[root@puppetmaster manifests]# cat site.pp
node 'Brcleprod001','Brcleprod002' {
user { 'vipin':
ensure => present,
uid => '101',
shell => '/bin/bash',
home => '/home/homer',
}
}
以这种方式合并节点来执行配置不是一个好习惯。这可以通过创建类并将创建的类包含在节点中来轻松实现,如下所示。
class vipin_g01063908 {
user { 'g01063908':
ensure => present,
uid => '101',
shell => '/bin/bash',
home => '/home/g01063908',
}
}
node 'Brcleprod001' {
class {vipin_g01063908:}
}
node 'Brcleprod002' {
class {vipin_g01063908:}
}
需要注意的是类结构的外观以及如何使用class关键字添加新资源。Puppet中的每个语法都有其自身的特性。因此,选择的语法取决于条件。
参数化类
在上面的示例中,我们已经看到了如何创建类并将其包含在节点中。现在,在某些情况下,我们需要在每个节点上具有不同的配置,例如当需要在每个节点上使用相同的类具有不同的用户时。Puppet使用参数化类提供此功能。新类的配置如下例所示。
[root@puppetmaster ~]# cat /etc/puppet/manifests/site.pp
class user_account ($username){
user { $username:
ensure => present,
uid => '101',
shell => '/bin/bash',
home => "/home/$username",
}
}
node 'Brcleprod002' {
class { user_account:
username => "G01063908",
}
}
node 'Brcleprod002' {
class {user_account:
username => "G01063909",
}
}
当我们在节点上应用上述site.pp清单时,每个节点的输出如下所示。
Brcleprod001
[root@puppetagent1 ~]# puppet agent --test Info: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for puppetagent1.testing.dyndns.org Info: Applying configuration version '1419452655' Notice: /Stage[main]/User_account/User[homer]/ensure: created Notice: Finished catalog run in 0.15 seconds [root@brcleprod001 ~]# cat /etc/passwd | grep "vipin" G01063908:x:101:501::/home/G01063909:/bin/bash
Brcleprod002
[root@Brcleprod002 ~]# puppet agent --test Info: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for puppetagent2.testing.dyndns.org Info: Applying configuration version '1419452725' Notice: /Stage[main]/User_account/User[bart]/ensure: created Notice: Finished catalog run in 0.19 seconds [root@puppetagent2 ~]# cat /etc/passwd | grep "varsha" G01063909:x:101:501::/home/G01063909:/bin/bash
还可以设置类参数的默认值,如下面的代码所示。
[root@puppetmaster ~]# cat /etc/puppet/manifests/site.pp
class user_account ($username = ‘g01063908'){
user { $username:
ensure => present,
uid => '101',
shell => '/bin/bash',
home => "/home/$username",
}
}
node 'Brcleprod001' {
class {user_account:}
}
node 'Brcleprod002' {
class {user_account:
username => "g01063909",
}
}
Puppet - 函数
Puppet像任何其他编程语言一样支持函数,因为Puppet的基本开发语言是Ruby。它支持两种类型的函数,分别称为**语句**和**rvalue**函数。
**语句**独立存在,并且没有任何返回类型。它们用于执行独立的任务,例如在新清单文件中导入其他Puppet模块。
**Rvalue** 返回值,并且只能在语句需要值时使用,例如赋值或case语句。
Puppet中函数执行的关键在于,它只在Puppet master上执行,而不执行在客户端或Puppet代理上。因此,它们只能访问Puppet master上可用的命令和数据。已经存在不同种类的函数,用户甚至有权根据需要创建自定义函数。下面列出了一些内置函数。
文件函数
文件资源的文件函数是在Puppet中加载模块并将所需输出以字符串形式返回。它查找的参数是`<模块名称>/<文件>`引用,这有助于从Puppet模块的文件目录加载模块。
例如,`script/tesingscript.sh` 将从`<模块名称>/script/files/testingscript.sh`加载文件。函数能够读取和接受绝对路径,这有助于从磁盘上的任何位置加载文件。
包含函数
在Puppet中,include函数与任何其他编程语言中的include函数非常相似。它用于声明一个或多个类,这会导致评估这些类中存在的全部资源,并最终将其添加到目录中。它的工作方式是,include函数接受类名、类列表或类名的逗号分隔列表。
使用**include**语句时需要注意的一点是,它可以在一个类中多次使用,但只能包含单个类一次。如果包含的类接受参数,include函数将自动使用`<类名>::<参数名>`作为查找键查找它们的值。
include函数不会导致类在声明时包含在类中,为此我们需要使用包含函数。它甚至不会在声明的类及其周围的类中创建依赖关系。
在include函数中,只允许使用类的全名,不允许使用相对名称。
已定义函数
在Puppet中,已定义函数有助于确定给定类或资源类型在何处定义,并返回布尔值。也可以使用define来确定特定资源是否已定义或定义的变量是否有值。使用已定义函数时需要注意的关键点是,此函数至少采用一个字符串参数,该参数可以是类名、类型名、资源引用或形式为“$name”的变量引用。
Define函数检查本机和已定义函数类型,包括模块提供的类型。类型和类按其名称匹配。该函数通过使用资源引用匹配资源声明。
Define 函数匹配
# Matching resource types
defined("file")
defined("customtype")
# Matching defines and classes
defined("testing")
defined("testing::java")
# Matching variables
defined('$name')
# Matching declared resources
defined(File['/tmp/file'])
Puppet - 自定义函数
如前一章所述,函数为用户提供了开发自定义函数的权限。Puppet可以通过使用自定义函数来扩展其解释能力。自定义函数有助于增强和扩展Puppet模块和清单文件的强大功能。
编写自定义函数
在编写函数之前,需要注意一些事项。
在Puppet中,函数由编译器执行,这意味着所有函数都在Puppet master上运行,它们不需要处理任何Puppet客户端。函数只能与代理交互,前提是信息以事实的形式提供。
Puppet master捕获自定义函数,这意味着如果对Puppet函数进行一些更改,则需要重新启动Puppet master。
函数将在服务器上执行,这意味着函数所需的任何文件都应该存在于服务器上,如果函数需要直接访问客户端机器,则无法执行任何操作。
共有两种不同的函数类型,一种是返回值的Rvalue函数,另一种是不返回任何内容的语句函数。
包含函数的文件名应与文件中函数的名称相同。否则,它不会自动加载。
放置自定义函数的位置
所有自定义函数都实现为单独的**.rb**文件,并分布在模块之间。需要将自定义函数放在lib/puppet/parser/function中。可以从以下位置的**.rb**文件加载函数。
- $libdir/puppet/parser/functions
- Ruby $LOAD_PATH中的puppet/parser/functions子目录
创建新函数
新的函数是使用puppet::parser::Functions 模块中的newfunction 方法创建或定义的。需要将函数名作为符号传递给newfunction 方法,并将要运行的代码作为代码块传递。以下示例是一个函数,用于将字符串写入 /user 目录中的文件。
module Puppet::Parser::Functions
newfunction(:write_line_to_file) do |args|
filename = args[0]
str = args[1]
File.open(filename, 'a') {|fd| fd.puts str }
end
end
一旦用户声明了函数,就可以在清单文件中使用它,如下所示。
write_line_to_file('/user/vipin.txt, "Hello vipin!")
Puppet - 环境
在软件开发和交付模型中,存在不同类型的测试环境,用于测试特定产品或服务。作为标准实践,主要有三种环境:开发、测试和生产,每种环境都有其自身的配置。
Puppet 支持类似于 Ruby on Rails 的多环境管理。创建这些环境的关键因素是提供了一种易于管理不同 SLA 协议级别的机制。在某些情况下,机器始终需要保持运行,没有任何容忍度,并且使用旧软件。而其他环境则保持最新,用于测试目的。它们用于升级更重要的机器。
Puppet 建议坚持使用标准的生产、测试和开发环境配置,但是,它也允许用户根据需要创建自定义环境。
环境目标
按环境拆分设置的主要目标是,Puppet 可以拥有模块和清单的不同来源。然后,可以在测试环境中测试配置更改,而不会影响生产节点。这些环境还可以用于在不同的网络资源上部署基础设施。
在 Puppet Master 上使用环境
环境的重点是测试哪些清单、模块、文件模板需要发送到客户端。因此,必须配置 Puppet 以提供针对这些信息的特定于环境的来源。
Puppet 环境的实现方法很简单,只需在服务器的 puppet.conf 中添加预环境部分,并为每个环境选择不同的配置源。然后,这些预环境部分将优先于主部分使用。
[main] manifest = /usr/testing/puppet/site.pp modulepath = /usr/testing/puppet/modules [development] manifest = /usr/testing/puppet/development/site.pp modulepath = /usr/testing/puppet/development/modules
在上面的代码中,开发环境中的任何客户端都将使用位于目录/usr/share/puppet/development 中的 site.pp 清单文件,并且 Puppet 将在/usr/share/puppet/development/modules 目录中搜索任何模块。
运行 Puppet 时,无论是否使用任何环境,都将默认为 site.pp 文件以及主配置部分中的 manifest 和 modulepath 值指定的目录。
实际上,只有少数配置有意义地进行预环境配置,所有这些参数都围绕着指定要用于编译客户端配置的文件。
以下是参数。
Modulepath − 在 Puppet 中,作为一种基本的标准模式,最好有一个所有环境共享的标准模块目录,然后是一个可以存储自定义模块的预环境目录。模块路径是 Puppet 搜索所有与环境相关的配置文件的位置。
Templatedir − 模板目录是保存所有相关模板版本的位置。应优先选择模块中的这些设置,但是它允许在每个环境中拥有给定模板的不同版本。
Manifest − 这定义了哪个配置用作入口点脚本。
使用多个模块,Puppet 有助于实现配置的模块化。可以在 Puppet 中使用多个环境,如果主要依赖于模块,则效果更好。通过将更改封装在模块中,可以更轻松地将更改迁移到环境。文件服务器使用特定于环境的模块路径;如果从模块而不是单独挂载的目录进行文件服务,则此环境将能够获取特定于环境的文件,最后,当前环境也将可用在清单文件中的 $environment 变量中。
设置客户端环境
所有与环境配置相关的配置都在 puppet.conf 文件中完成。要指定 Puppet 客户端应使用哪个环境,可以在客户端的 puppet.conf 文件中为环境配置变量指定一个值。
[puppetd] environment = Testing
配置文件中的上述定义定义了配置文件所在的哪个环境,在本例中为测试环境。
也可以使用以下命令行指定:
#puppetd -–environment = testing
或者,Puppet 还支持在环境配置中使用动态值。开发人员无需定义静态值,而是可以创建自定义事实,根据其他客户端属性或外部数据源创建客户端环境。首选的方法是使用自定义工具。这些工具能够指定节点的环境,并且通常更擅长指定节点信息。
Puppet 搜索路径
Puppet 使用简单的搜索路径来确定需要在目标机器上应用哪些配置。同样,Puppet 中的搜索路径在尝试获取需要应用的适当值时非常有用。Puppet 在以下列出的多个位置搜索需要应用的值。
- 命令行中指定的值
- 特定于环境的部分中指定的值
- 特定于可执行文件的部分中指定的值
- 主部分中指定的值
Puppet - 类型和提供程序
Puppet 类型用于单个配置管理。Puppet 有不同的类型,例如服务类型、包类型、提供程序类型等,其中每种类型都有提供程序。提供程序处理不同平台或工具上的配置。例如,包类型具有 aptitude、yum、rpm 和 DGM 提供程序。有很多类型,Puppet 涵盖了需要管理的大量配置管理项目。
Puppet 使用 Ruby 作为其基础语言。所有存在的 Puppet 类型和提供程序都是用 Ruby 语言编写的。因为它遵循标准编码格式,所以可以像 repo 示例(管理存储库)中显示的那样轻松创建它们。在这里,我们将创建类型 repo 和提供程序 svn 和 git。repo 类型的第一部分是类型本身。类型通常存储在 lib/puppet/type 中。为此,我们将创建一个名为repo.rb 的文件。
$ touch repo.rb
在文件中添加以下内容。
Puppet::Type.newtype(:repo) do
@doc = "Manage repos"
Ensurable
newparam(:source) do
desc "The repo source"
validate do |value|
if value =~ /^git/
resource[:provider] = :git
else
resource[:provider] = :svn
end
end
isnamevar
end
newparam(:path) do
desc "Destination path"
validate do |value|
unless value =~ /^\/[a-z0-9]+/
raise ArgumentError , "%s is not a valid file path" % value
end
end
end
end
在上面的脚本中,我们创建了一个块“Puppet::Type.newtype(:repo) do”,它使用名称 repo 创建一个新类型。然后,我们有 @doc,它有助于添加任何级别的详细信息。下一个语句是 Ensurable;它创建了一个基本的 ensure 属性。Puppet 类型使用ensure 属性来确定配置项的状态。
示例
service { "sshd":
ensure => present,
}
ensure 语句告诉 Puppet 预期提供程序中的三种方法:create、destroy 和 exist。这些方法提供以下功能:
- 创建资源的命令
- 删除资源的命令
- 检查资源是否存在命令
然后,我们只需要指定这些方法及其内容即可。Puppet 会在其周围创建支持的基础架构。
接下来,我们定义一个名为 source 的新参数。
newparam(:source) do
desc "The repo source"
validate do |value|
if value =~ /^git/
resource[:provider] = :git
else
resource[:provider] = :svn
end
end
isnamevar
end
source 将告诉 repo 类型在哪里检索/克隆/检出源存储库。在此,我们还使用了一个名为 validate 的钩子。在 provider 部分,我们定义了 git 和 svn,它们检查我们定义的存储库的有效性。
最后,在代码中,我们定义了另一个名为 path 的参数。
newparam(:path) do
desc "Destination path"
validate do |value|
unless value =~ /^\/[a-z0-9]+/
raise ArgumentError , "%s is not a valid file path" % value
end
这是指定将检索到的新代码放在何处的值类型。在这里,我们再次使用 validate 钩子创建一个检查值是否合适的块。
Subversion 提供程序用例
让我们从使用上面创建的类型的 subversion 提供程序开始。
require 'fileutils'
Puppet::Type.type(:repo).provide(:svn) do
desc "SVN Support"
commands :svncmd => "svn"
commands :svnadmin => "svnadmin"
def create
svncmd "checkout", resource[:name], resource[:path]
end
def destroy
FileUtils.rm_rf resource[:path]
end
def exists?
File.directory? resource[:path]
end
end
在上面的代码中,我们预先定义了我们需要fileutils 库,require 'fileutils',我们将从中使用方法。
接下来,我们定义提供程序为块 Puppet::Type.type(:repo).provide(:svn) do,它告诉 Puppet 这是名为 repo 的类型的提供程序。
然后,我们添加了desc,它允许向提供程序添加一些文档。我们还定义了此提供程序将使用的命令。在下一行,我们正在检查资源的功能,例如创建、删除和存在。
创建资源
完成上述所有操作后,我们将创建一个资源,该资源将在我们的类和清单文件中使用,如下面的代码所示。
repo { "wp":
source => "http://g01063908.git.brcl.org/trunk/",
path => "/var/www/wp",
ensure => present,
}
Puppet - RESTful API
Puppet 使用 RESTful API 作为 Puppet master 和 Puppet agent 之间的通信通道。以下是访问此 RESTful API 的基本 URL。
https://brcleprod001:8140/{environment}/{resource}/{key}
https://brcleprod001:8139/{environment}/{resource}/{key}
REST API 安全性
Puppet 通常负责安全性以及 SSL 证书管理。但是,如果希望在集群外部使用 RESTful API,则需要自行管理证书,因为尝试连接到机器时需要证书。Puppet 的安全策略可以通过 rest authconfig 文件配置。
测试 REST API
Curl 实用程序可用作测试 RESTful API 连接的基本实用程序。以下是如何使用 REST API curl 命令检索节点目录的示例。
curl --cert /etc/puppet/ssl/certs/brcleprod001.pem --key /etc/puppet/ssl/private_keys/brcleprod001.pem
在以下命令集中,我们只是设置 SSL 证书,这将根据 SSL 目录的位置和使用的节点名称而有所不同。例如,让我们看一下以下命令。
curl --insecure -H 'Accept: yaml' https://brcleprod002:8140/production/catalog/brcleprod001
在上面的命令中,我们只是发送一个标头,指定我们想要返回的格式或格式以及用于生成生产环境中brcleprod001 目录的 RESTful URL,这将生成以下输出。
--- &id001 !ruby/object:Puppet::Resource::Catalog
aliases: {}
applying: false
classes: []
...
让我们假设另一个示例,我们希望从 Puppet master 获取 CA 证书。它不需要使用自己签名的 SSL 证书进行身份验证,因为这是身份验证之前所需的内容。
curl --insecure -H 'Accept: s' https://brcleprod001:8140/production/certificate/ca -----BEGIN CERTIFICATE----- MIICHTCCAYagAwIBAgIBATANBgkqhkiG9w0BAQUFADAXMRUwEwYDVQQDDAxwdXBw
Puppet Master 和 Agent 共享 API 参考
GET /certificate/{ca, other}
curl -k -H "Accept: s" https://brcelprod001:8140/production/certificate/ca
curl -k -H "Accept: s" https://brcleprod002:8139/production/certificate/brcleprod002
Puppet Master API 参考
已认证资源(需要有效的签名证书)。
目录
GET /{environment}/catalog/{node certificate name}
curl -k -H "Accept: pson" https://brcelprod001:8140/production/catalog/myclient
证书吊销列表
GET /certificate_revocation_list/ca curl -k -H "Accept: s" https://brcleprod001:8140/production/certificate/ca
证书请求
GET /{environment}/certificate_requests/{anything} GET
/{environment}/certificate_request/{node certificate name}
curl -k -H "Accept: yaml" https://brcelprod001:8140/production/certificate_requests/all
curl -k -H "Accept: yaml" https://brcleprod001:8140/production/certificate_request/puppetclient
报告 提交报告
PUT /{environment}/report/{node certificate name}
curl -k -X PUT -H "Content-Type: text/yaml" -d "{key:value}" https://brcleprod002:8139/production
节点 - 关于特定节点的事实
GET /{environment}/node/{node certificate name}
curl -k -H "Accept: yaml" https://brcleprod002:8140/production/node/puppetclient
状态 - 用于测试
GET /{environment}/status/{anything}
curl -k -H "Accept: pson" https://brcleprod002:8140/production/certificate_request/puppetclient
Puppet Agent API 参考
在任何机器上设置新的代理时,默认情况下,Puppet 代理不侦听 HTTP 请求。需要在 Puppet 中通过在 puppet.conf 文件中添加“listen=true”来启用它。这将使 Puppet 代理在启动时侦听 HTTP 请求。
事实
GET /{environment}/facts/{anything}
curl -k -H "Accept: yaml" https://brcelprod002:8139/production/facts/{anything}
运行 − 使客户端像 puppetturn 或 puppet kick 一样更新。
PUT /{environment}/run/{node certificate name}
curl -k -X PUT -H "Content-Type: text/pson" -d "{}"
https://brcleprod002:8139/production/run/{anything}
Puppet - 实时项目
为了执行在 Puppet 节点上应用配置和清单的现场测试,我们将使用现场演示。可以直接复制粘贴此演示来测试配置的工作方式。如果用户希望使用相同的代码集,则需要与代码段中显示的命名约定相同,如下所示。
让我们从创建一个新模块开始。
创建新模块
测试和应用 httpd 配置的第一步是创建一个模块。为此,用户需要将他的工作目录更改为 Puppet 模块目录并创建一个基本的模块结构。结构创建可以手动完成,也可以使用 Puppet 为模块创建样板。
# cd /etc/puppet/modules # puppet module generate Live-module
注意 − Puppet 模块生成命令要求模块名称采用 [用户名]-[模块] 的格式,以符合 Puppet forge 的规范。
新模块包含一些基本文件,包括一个 manifest 目录。该目录已包含一个名为 init.pp 的 manifest 文件,它是模块的主 manifest 文件。这是一个模块的空类声明。
class live-module {
}
该模块还包含一个 test 目录,其中包含一个名为init.pp 的 manifest 文件。此测试 manifest 文件引用 manifest/init.pp 中的 live-module 类。
include live-module
Puppet 将使用此测试模块来测试 manifest。现在我们准备向模块添加配置。
安装 HTTP 服务器
Puppet 模块将安装运行 http 服务器所需的软件包。这需要一个资源定义来定义 httpd 软件包的配置。
在模块的 manifest 目录中,创建一个名为 httpd.pp 的新 manifest 文件。
# touch test-module/manifests/httpd.pp
此 manifest 文件将包含我们模块的所有 HTTP 配置。出于分离的目的,我们将 httpd.pp 文件与 init.pp manifest 文件分开。
我们需要将以下代码放入 httpd.pp manifest 文件中。
class test-module::httpd {
package { 'httpd':
ensure => installed,
}
}
此代码定义了 test-module 的一个子类 httpd,然后为 httpd 包定义了一个包资源声明。ensure => installed 属性检查是否安装了所需的软件包。如果未安装,Puppet 使用 yum 实用程序安装它。接下来,是在我们的主 manifest 文件中包含此子类。我们需要编辑 init.pp manifest。
class test-module {
include test-module::httpd
}
现在,是时候测试模块了,方法如下
# puppet apply test-module/tests/init.pp --noop
puppet apply 命令将 manifest 文件中存在的配置应用于目标系统。在这里,我们使用 test init.pp,它引用主 init.pp。--noop 执行配置的预演,它只显示输出,但实际上什么也不做。
以下是输出。
Notice: Compiled catalog for puppet.example.com in environment production in 0.59 seconds Notice: /Stage[main]/test-module::Httpd/Package[httpd]/ensure: current_value absent, should be present (noop) Notice: Class[test-module::Httpd]: Would have triggered 'refresh' from 1 events Notice: Stage[main]: Would have triggered 'refresh' from 1 events Notice: Finished catalog run in 0.67 seconds
高亮显示的行是 ensure => installed 属性的结果。current_value absent 表示 Puppet 检测到 httpd 包已安装。如果没有 --noop 选项,Puppet 将安装 httpd 包。
运行 httpd 服务器
安装 httpd 服务器后,我们需要使用其他资源声明启动服务:Service
我们需要编辑 httpd.pp manifest 文件并编辑以下内容。
class test-module::httpd {
package { 'httpd':
ensure => installed,
}
service { 'httpd':
ensure => running,
enable => true,
require => Package["httpd"],
}
}
以下是我们从上述代码中实现的目标列表。
ensure => running 状态检查服务是否正在运行,如果不是,则启用它。
enable => true 属性将服务设置为在系统启动时运行。
require => Package["httpd"] 属性定义了一个资源声明与另一个资源声明之间的顺序关系。在上述情况下,它确保 httpd 服务在安装 http 包后启动。这在服务和相应的包之间创建了依赖关系。
再次运行 puppet apply 命令来测试更改。
# puppet apply test-module/tests/init.pp --noop Notice: Compiled catalog for puppet.example.com in environment production in 0.56 seconds Notice: /Stage[main]/test-module::Httpd/Package[httpd]/ensure: current_value absent, should be present (noop) Notice: /Stage[main]/test-module::Httpd/Service[httpd]/ensure: current_value stopped, should be running (noop) Notice: Class[test-module::Httpd]: Would have triggered 'refresh' from 2 events Notice: Stage[main]: Would have triggered 'refresh' from 1 events Notice: Finished catalog run in 0.41 seconds
配置 httpd 服务器
完成上述步骤后,我们将安装并启用 HTTP 服务器。下一步是为服务器提供一些配置。默认情况下,httpd 在 /etc/httpd/conf/httpd.conf 中提供一些默认配置,这些配置提供 webhost 端口 80。我们将添加一些额外的主机以向 web 主机提供一些用户特定的功能。
将使用模板来提供附加端口,因为它需要可变输入。我们将创建一个名为 template 的目录,并在新目录中添加一个名为 test-server.config.erb 的文件,并添加以下内容。
Listen <%= @httpd_port %>
NameVirtualHost *:<% = @httpd_port %>
<VirtualHost *:<% = @httpd_port %>>
DocumentRoot /var/www/testserver/
ServerName <% = @fqdn %>
<Directory "/var/www/testserver/">
Options All Indexes FollowSymLinks
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
上述模板遵循标准的 apache-tomcat 服务器配置格式。唯一的区别是使用 Ruby 转义字符从模块注入变量。我们有 FQDN,它存储系统的完全限定域名。这被称为系统事实。
在生成每个系统相应的 puppet 目录之前,会从每个系统收集系统事实。Puppet 使用 facter 命令获取此信息,并且可以使用 facter 获取有关系统的其他详细信息。我们需要在 httpd.pp manifest 文件中添加高亮显示的行。
class test-module::httpd {
package { 'httpd':
ensure => installed,
}
service { 'httpd':
ensure => running,
enable => true,
require => Package["httpd"],
}
file {'/etc/httpd/conf.d/testserver.conf':
notify => Service["httpd"],
ensure => file,
require => Package["httpd"],
content => template("test-module/testserver.conf.erb"),
}
file { "/var/www/myserver":
ensure => "directory",
}
}
这有助于实现以下目标:
这为服务器配置文件 (/etc/httpd/conf.d/test-server.conf) 添加了一个文件资源声明。此文件的内容是前面创建的 test-serverconf.erb 模板。我们还在添加此文件之前检查 httpd 包是否已安装。
这添加了第二个文件资源声明,它为 web 服务器创建一个目录 (/var/www/test-server)。
接下来,我们使用notify => Service["httpd"] 属性在配置文件和 https 服务之间添加关系。这将检查是否存在任何配置文件更改。如果有,则 Puppet 将重新启动服务。
接下来是在主 manifest 文件中包含 httpd_port。为此,我们需要结束主 init.pp manifest 文件并包含以下内容。
class test-module (
$http_port = 80
) {
include test-module::httpd
}
这将 httpd 端口设置为默认值 80。接下来是运行 Puppet apply 命令。
以下是输出。
# puppet apply test-module/tests/init.pp --noop Warning: Config file /etc/puppet/hiera.yaml not found, using Hiera defaults Notice: Compiled catalog for puppet.example.com in environment production in 0.84 seconds Notice: /Stage[main]/test-module::Httpd/File[/var/www/myserver]/ensure: current_value absent, should be directory (noop) Notice: /Stage[main]/test-module::Httpd/Package[httpd]/ensure: current_value absent, should be present (noop) Notice: /Stage[main]/test-module::Httpd/File[/etc/httpd/conf.d/myserver.conf]/ensure: current_value absent, should be file (noop) Notice: /Stage[main]/test-module::Httpd/Service[httpd]/ensure: current_value stopped, should be running (noop) Notice: Class[test-module::Httpd]: Would have triggered 'refresh' from 4 events Notice: Stage[main]: Would have triggered 'refresh' from 1 events Notice: Finished catalog run in 0.51 seconds
配置防火墙
为了与服务器通信,需要打开端口。这里的问题是不同类型的操作系统使用不同的方法来控制防火墙。对于 Linux,6 版以下使用 iptables,7 版使用 firewalld。
Puppet 使用系统事实及其逻辑来处理使用适当服务的此决定。为此,我们需要首先检查操作系统,然后运行相应的防火墙命令。
为了实现这一点,我们需要在 testmodule::http 类中添加以下代码片段。
if $operatingsystemmajrelease <= 6 {
exec { 'iptables':
command => "iptables -I INPUT 1 -p tcp -m multiport --ports
${httpd_port} -m comment --comment 'Custom HTTP Web Host' -j ACCEPT &&
iptables-save > /etc/sysconfig/iptables",
path => "/sbin",
refreshonly => true,
subscribe => Package['httpd'],
}
service { 'iptables':
ensure => running,
enable => true,
hasrestart => true,
subscribe => Exec['iptables'],
}
} elsif $operatingsystemmajrelease == 7 {
exec { 'firewall-cmd':
command => "firewall-cmd --zone=public --addport = $ {
httpd_port}/tcp --permanent",
path => "/usr/bin/",
refreshonly => true,
subscribe => Package['httpd'],
}
service { 'firewalld':
ensure => running,
enable => true,
hasrestart => true,
subscribe => Exec['firewall-cmd'],
}
}
以上代码执行以下操作:
使用operatingsystemmajrelease确定使用的操作系统是 6 版还是 7 版。
如果版本是 6,则它运行所有配置 Linux 6 版本所需的命令。
如果操作系统版本是 7,则它运行配置防火墙所需的所有命令。
两个操作系统的代码片段都包含一个逻辑,该逻辑确保配置仅在安装 http 包后运行。
最后,运行 Puppet apply 命令。
# puppet apply test-module/tests/init.pp --noop Warning: Config file /etc/puppet/hiera.yaml not found, using Hiera defaults Notice: Compiled catalog for puppet.example.com in environment production in 0.82 seconds Notice: /Stage[main]/test-module::Httpd/Exec[iptables]/returns: current_value notrun, should be 0 (noop) Notice: /Stage[main]/test-module::Httpd/Service[iptables]: Would have triggered 'refresh' from 1 events
配置 SELinux
由于我们在 Linux 机器上工作,并且版本为 7 及更高版本,因此我们需要对其进行配置以进行 http 通信。默认情况下,SELinux 会限制对 HTTP 服务器的非标准访问。如果我们定义自定义端口,则需要配置 SELinux 以提供对该端口的访问。
Puppet 包含一些资源类型来管理 SELinux 功能,例如布尔值和模块。在这里,我们需要执行 semanage 命令来管理端口设置。此工具是 policycoreutils-python 包的一部分,默认情况下未安装在 red-hat 服务器上。为了实现上述目标,我们需要在 test-module::http 类中添加以下代码。
exec { 'semanage-port':
command => "semanage port -a -t http_port_t -p tcp ${httpd_port}",
path => "/usr/sbin",
require => Package['policycoreutils-python'],
before => Service ['httpd'],
subscribe => Package['httpd'],
refreshonly => true,
}
package { 'policycoreutils-python':
ensure => installed,
}
以上代码执行以下操作:
require => Package['policycoreutils-python'] 确保我们安装了所需的 python 模块。
Puppet 使用 semanage 使用 httpd_port 作为变量打开端口。
before => service 确保在 httpd 服务启动之前执行此命令。如果 HTTPD 在 SELinux 命令之前启动,则 SELinux 服务请求和服务请求将失败。
最后,运行 Puppet apply 命令
# puppet apply test-module/tests/init.pp --noop ... Notice: /Stage[main]/test-module::Httpd/Package[policycoreutilspython]/ ensure: current_value absent, should be present (noop) ... Notice: /Stage[main]/test-module::Httpd/Exec[semanage-port]/returns: current_value notrun, should be 0 (noop) ... Notice: /Stage[main]/test-module::Httpd/Service[httpd]/ensure: current_value stopped, should be running (noop)
Puppet 首先安装 python 模块,然后配置端口访问,最后启动 httpd 服务。
将 HTML 文件复制到 Web 主机
通过上述步骤,我们完成了 http 服务器配置。现在,我们有一个平台可以安装基于 Web 的应用程序,Puppet 也可以对其进行配置。为了测试,我们将一些示例 html index 网页复制到服务器。
在 files 目录内创建一个 index.html 文件。
<html>
<head>
<title>Congratulations</title>
<head>
<body>
<h1>Congratulations</h1>
<p>Your puppet module has correctly applied your configuration.</p>
</body>
</html>
在 manifest 目录内创建一个 manifest app.pp 并添加以下内容。
class test-module::app {
file { "/var/www/test-server/index.html":
ensure => file,
mode => 755,
owner => root,
group => root,
source => "puppet:///modules/test-module/index.html",
require => Class["test-module::httpd"],
}
}
此新类包含单个资源声明。这将文件从模块的文件目录复制到 web 服务器并设置其权限。required 属性确保 test-module::http 类在应用 test-module::app 之前成功完成配置。
最后,我们需要在我们的主 init.pp manifest 中包含一个新的 manifest。
class test-module (
$http_port = 80
) {
include test-module::httpd
include test-module::app
}
现在,运行 apply 命令来实际测试正在发生的事情。以下是输出。
# puppet apply test-module/tests/init.pp --noop Warning: Config file /etc/puppet/hiera.yaml not found, using Hiera defaults Notice: Compiled catalog for brcelprod001.brcle.com in environment production in 0.66 seconds Notice: /Stage[main]/Test-module::Httpd/Exec[iptables]/returns: current_value notrun, should be 0 (noop) Notice: /Stage[main]/Test-module::Httpd/Package[policycoreutilspython]/ ensure: current_value absent, should be present (noop) Notice: /Stage[main]/Test-module::Httpd/Service[iptables]: Would have triggered 'refresh' from 1 events Notice: /Stage[main]/Test-module::Httpd/File[/var/www/myserver]/ensure: current_value absent, should be directory (noop) Notice: /Stage[main]/Test-module::Httpd/Package[httpd]/ensure: current_value absent, should be present (noop) Notice: /Stage[main]/Test-module::Httpd/File[/etc/httpd/conf.d/myserver.conf]/ensur e: current_value absent, should be file (noop) Notice: /Stage[main]/Test-module::Httpd/Exec[semanage-port]/returns: current_value notrun, should be 0 (noop) Notice: /Stage[main]/Test-module::Httpd/Service[httpd]/ensure: current_value stopped, should be running (noop) Notice: Class[test-module::Httpd]: Would have triggered 'refresh' from 8 Notice: /Stage[main]/test-module::App/File[/var/www/myserver/index.html]/ensur: current_value absent, should be file (noop) Notice: Class[test-module::App]: Would have triggered 'refresh' from 1 Notice: Stage[main]: Would have triggered 'refresh' from 2 events Notice: Finished catalog run in 0.74 seconds
高亮显示的行显示 index.html 文件被复制到 web 主机的结果。
模块收尾
完成上述所有步骤后,我们创建的新模块就可以使用了。如果我们想创建一个模块的存档,可以使用以下命令。
# puppet module build test-module