- Python Falcon 教程
- Python Falcon - 首页
- Python Falcon - 简介
- Python Falcon - 环境设置
- Python Falcon - WSGI vs ASGI
- Python Falcon - Hello World(WSGI)
- Python Falcon - Waitress
- Python Falcon - ASGI
- Python Falcon - Uvicorn
- Python Falcon - API 测试工具
- 请求 & 响应
- Python Falcon - 资源类
- Python Falcon - 应用类
- Python Falcon - 路由
- Falcon - 后缀响应器
- Python Falcon - Inspect 模块
- Python Falcon - Jinja2 模板
- Python Falcon - Cookie
- Python Falcon - 状态码
- Python Falcon - 错误处理
- Python Falcon - 钩子
- Python Falcon - 中间件
- Python Falcon - CORS
- Python Falcon - WebSocket
- Python Falcon - Sqlalchemy 模型
- Python Falcon - 测试
- Python Falcon - 部署
- Python Falcon 有用资源
- Python Falcon - 快速指南
- Python Falcon - 有用资源
- Python Falcon - 讨论
Python Falcon - SQLAlchemy 模型
为了演示 Falcon 的响应器函数(**on_post()**、**on_get()**、**on_put()** 和 **on_delete()**),我们已经在内存数据库(以 Python 字典对象列表的形式)上执行了 **CRUD**(代表创建、读取、更新和删除)操作。相反,我们可以使用任何关系数据库(例如 MySQL、Oracle 等)来执行存储、检索、更新和删除操作。
我们不使用符合 **DB-API** 的数据库驱动程序,而是使用 **SQLAlchemy** 作为 Python 代码和数据库之间的接口(我们将使用 SQLite 数据库,因为 Python 对其有内置支持)。SQLAlchemy 是一个流行的 SQL 工具包和 **对象关系映射器**。
对象关系映射是一种编程技术,用于在面向对象编程语言中转换不兼容类型系统之间的数据。通常,面向对象语言(如 Python)中使用的类型系统包含非标量类型。但是,大多数数据库产品(如 Oracle、MySQL 等)中的数据类型都是原始类型,例如整数和字符串。
在 ORM 系统中,每个类都映射到底层数据库中的一个表。ORM 可以为您处理这些问题,而您则可以专注于系统逻辑的编程,而不是自己编写繁琐的数据库接口代码。
为了使用 SQLALchemy,我们需要首先使用 PIP 安装程序安装该库。
pip install sqlalchemy
SQLAlchemy 旨在与为特定数据库构建的 DBAPI 实现一起使用。它使用方言系统与各种类型的 DBAPI 实现和数据库进行通信。所有方言都需要安装相应的 DBAPI 驱动程序。
以下是被包含的方言:
Firebird
Microsoft SQL Server
MySQL
Oracle
PostgreSQL
SQLite
Sybase
数据库引擎
由于我们将使用 SQLite 数据库,因此我们需要为名为 **test.db** 的数据库创建一个数据库引擎。从 sqlalchemy 模块导入 **create_engine()** 函数。
from sqlalchemy import create_engine
from sqlalchemy.dialects.sqlite import *
SQLALCHEMY_DATABASE_URL = "sqlite:///./test.db"
engine = create_engine(SQLALCHEMY_DATABASE_URL, connect_args =
{"check_same_thread": False})
为了与数据库交互,我们需要获取其句柄。会话对象是数据库的句柄。Session 类使用 **sessionmaker()** 定义 – 一个可配置的会话工厂方法,绑定到引擎对象。
from sqlalchemy.orm import sessionmaker, Session session = sessionmaker(autocommit=False, autoflush=False, bind=engine)
接下来,我们需要一个声明性基类,它在声明性系统中存储类和映射表的目录。
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
模型类
**Students**,Base 的子类,映射到数据库中的 **students** 表。Books 类中的属性对应于目标表中列的数据类型。请注意,id 属性对应于 book 表中的主键。
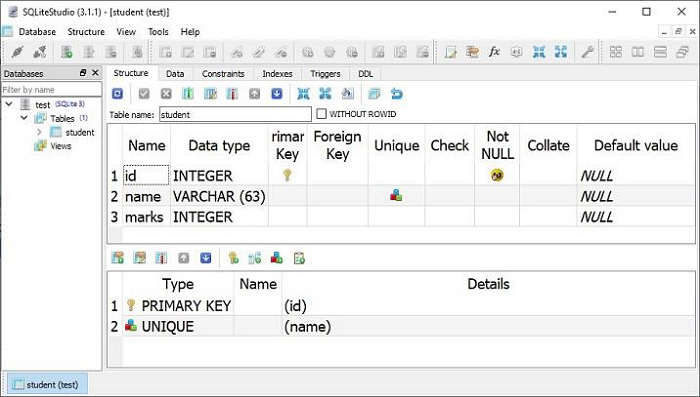
class Students(Base): __tablename__ = 'student' id = Column(Integer, primary_key=True, nullable=False) name = Column(String(63), unique=True) marks = Column(Integer) Base.metadata.create_all(bind=engine)
**create_all()** 方法在数据库中创建相应的表。可以使用 SQLite 可视化工具(例如 **SQLiteStudio**)进行确认。
现在我们需要声明一个 **StudentResource** 类,其中定义了 HTTP 响应器方法以对 students 表执行 CRUD 操作。此类的对象与路由相关联,如下面的代码片段所示:
import falcon
import json
from waitress import serve
class StudentResource:
def on_get(self, req, resp):
pass
def on_post(self, req, resp):
pass
def on_put_student(self, req, resp, id):
pass
def on_delete_student(self, req, resp, id):
pass
app = falcon.App()
app.add_route("/students", StudentResource())
app.add_route("/students/{id:int}", StudentResource(), suffix='student')
on_post()
其余代码与内存中的 CRUD 操作类似,不同之处在于操作函数通过 SQLalchemy 接口与数据库进行交互。
**on_post()** 响应器方法首先根据请求参数构造 Students 类的对象,并将其添加到 Students 模型中。由于此模型映射到数据库中的 students 表,因此会添加相应的行。**on_post()** 方法如下:
def on_post(self, req, resp): data = json.load(req.bounded_stream) student=Students(id=data['id'], name=data['name'], marks=data['marks']) session.add(student) session.commit() resp.text = "Student added successfully." resp.status = falcon.HTTP_OK resp.content_type = falcon.MEDIA_TEXT
如前所述,当收到 POST 请求时,将调用 **on_post()** 响应器。我们将使用 Postman 应用传递 POST 请求。
启动 Postman,选择 POST 方法,并将值(id=1、name="Manan" 和 marks=760)作为主体参数传递。请求成功处理,并且一行添加到 **students** 表中。
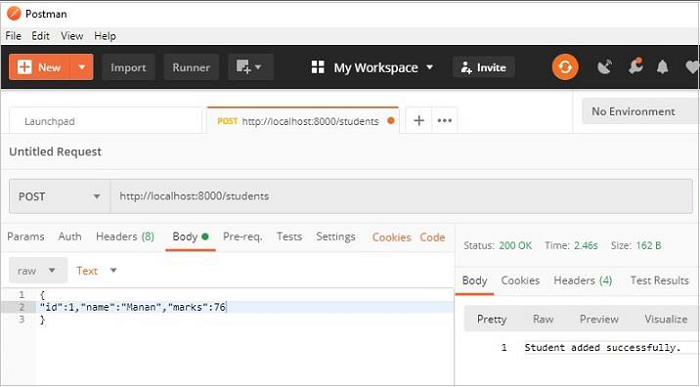
继续发送多个 POST 请求以添加记录。
on_get()
此响应器旨在检索 **Students** 模型中的所有对象。**Session** 对象上的 **query()** 方法检索对象。
rows = session.query(Students).all()
由于 Falcon 响应器的默认响应为 JSON 格式,因此我们必须将上述查询的结果转换为 **dict** 对象列表。
data=[]
for row in rows:
data.append({"id":row.id, "name":row.name, "marks":row.marks})
在 **StudentResource** 类中,让我们添加执行此操作并发送其 JSON 响应的 **on_get()** 方法,如下所示:
def on_get(self, req, resp):
rows = session.query(Students).all()
data=[]
for row in rows:
data.append({"id":row.id, "name":row.name, "marks":row.marks})
resp.text = json.dumps(data)
resp.status = falcon.HTTP_OK
resp.content_type = falcon.MEDIA_JSON
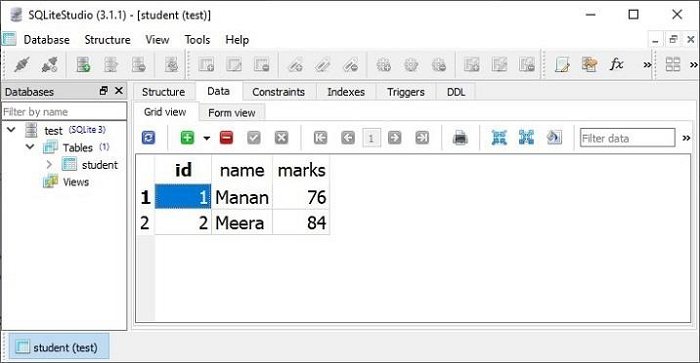
可以在 Postman 应用中测试 **GET** 请求操作。** /students** URL 将导致显示 JSON 响应,其中显示 students 模型中所有对象的的数据。
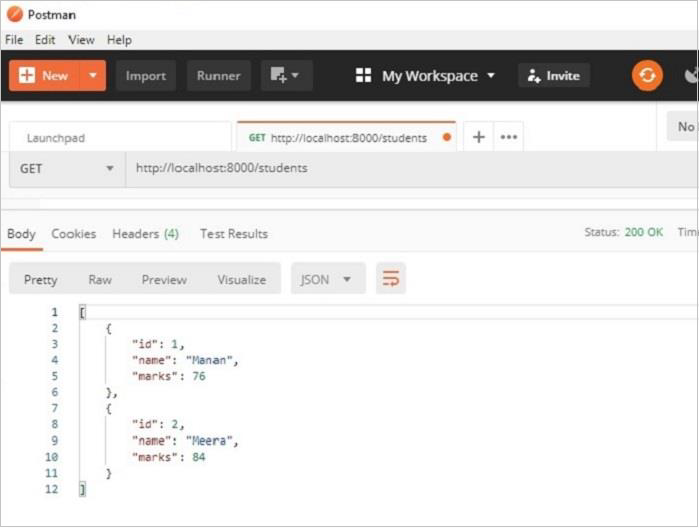
Postman 应用结果窗格中显示的两条记录也可以在 **SQLiteStudio** 的数据视图中进行验证。
on_put()
**on_put()** 响应器执行 UPDATE 操作。它响应 URL ** /students/id**。要从 Students 模型中获取具有给定 id 的对象,我们将过滤器应用于查询结果,并使用从客户端接收到的数据更新其属性的值。
student = session.query(Students).filter(Students.id == id).first()
**on_put()** 方法的代码如下:
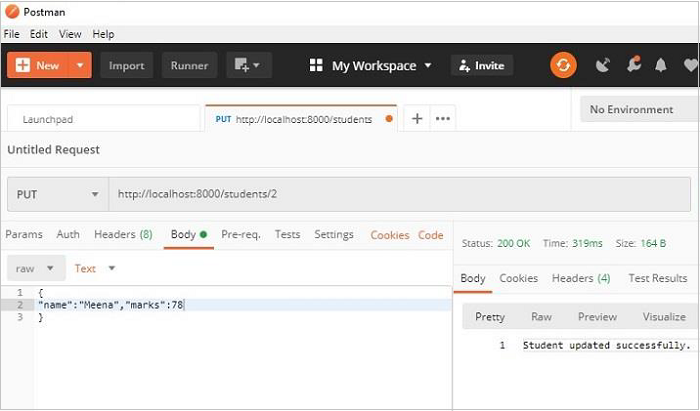
def on_put_student(self, req, resp, id): student = session.query(Students).filter(Students.id == id).first() data = json.load(req.bounded_stream) student.name=data['name'] student.marks=data['marks'] session.commit() resp.text = "Student updated successfully." resp.status = falcon.HTTP_OK resp.content_type = falcon.MEDIA_TEXT
让我们使用 Postman 更新 Students 模型中 **id=2** 的对象,并更改名称和分数。请注意,这些值作为主体参数传递。
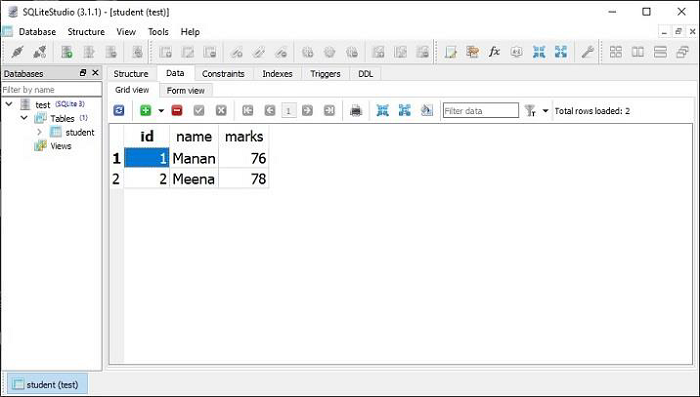
**SQLiteStudio** 中的数据视图显示修改已生效。
on_delete()
最后,DELETE 操作很容易。我们需要获取给定 **id** 的对象并调用 **delete()** 方法。
def on_delete_student(self, req, resp, id):
try:
session.query(Students).filter(Students.id == id).delete()
session.commit()
except Exception as e:
raise Exception(e)
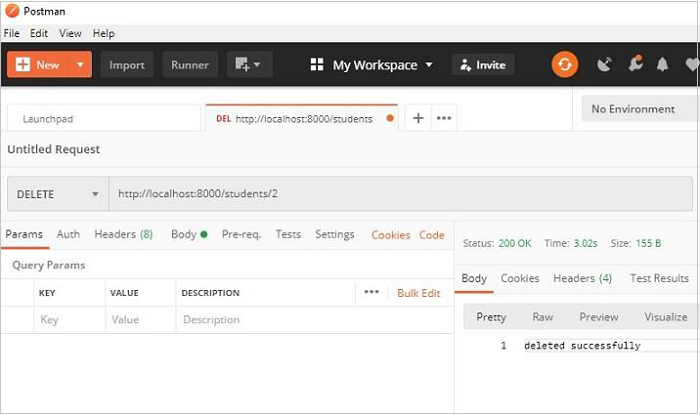
resp.text = "deleted successfully"
resp.status = falcon.HTTP_OK
resp.content_type = falcon.MEDIA_TEXT
作为 **on_delete()** 响应器的测试,让我们使用 Postman 删除 id=2 的对象,如下所示: