
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Python 进行回归分析和最佳拟合线
在本教程中,我们将使用 Python 编程实现回归分析和最佳拟合线。
介绍
回归分析是预测分析最基本的形式。
在统计学中,线性回归是一种对标量值和一个或多个解释变量之间关系进行建模的方法。
在机器学习中,线性回归是一种监督算法。这种算法根据自变量预测目标值。
更多关于线性回归和回归分析的信息
在线性回归/分析中,目标是一个实数或连续值,例如工资、BMI等。它通常用于预测因变量和一堆自变量之间的关系。这些模型通常拟合线性方程,但是,还有其他类型的回归,包括高阶多项式。
在将线性模型拟合到数据之前,有必要检查数据点之间是否存在线性关系。这从它们的散点图中可以看出。算法/模型的目标是找到最佳拟合线。
在本文中,我们将探讨线性回归分析及其使用 C++ 的实现。
线性回归方程的形式为 Y = c + mx,其中 Y 是目标变量,X 是自变量或解释参数/变量。m 是回归线的斜率,c 是截距。由于这是一个二维回归任务,因此模型在训练期间尝试找到最佳拟合线。并非所有点都必须精确地位于同一条线上。有些数据点可能位于线上,有些则散布在其周围。线与数据点之间的垂直距离是残差。根据点位于线的下方还是上方,这可能是负数或正数。残差是衡量线与数据拟合程度的指标。算法不断最小化总残差误差。
每个观测值的残差是 y(因变量)的预测值与 y 的观测值之间的差值。
$$\mathrm{残差\: =\: 实际 y 值\:−\:预测 y 值}$$
$$\mathrm{ri\:=\:yi\:−\:y'i}$$
评估线性回归模型性能最常用的指标称为均方根误差或 RMSE。其基本思想是衡量与实际观测值相比,模型预测的糟糕/错误程度。
因此,高 RMSE 是“坏的”,低 RMSE 是“好的”。
RMSE 误差为
$$\mathrm{RMSE\:=\:\sqrt{\frac{\sum_i^n=1\:(yi\:-\:yi')^2}{n}}}$$
RMSE 是所有平方残差均值的平方根。
使用 Python 实现
示例
# Import the libraries import numpy as np import math import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error # Generate random data with numpy, and plot it with matplotlib: ranstate = np.random.RandomState(1) x = 10 * ranstate.rand(100) y = 2 * x - 5 + ranstate.randn(100) plt.scatter(x, y); plt.show() # Creating a linear regression model based on the positioning of the data and Intercepting, and predicting a Best Fit: lr_model = LinearRegression(fit_intercept=True) lr_model.fit(x[:70, np.newaxis], y[:70]) y_fit = lr_model.predict(x[70:, np.newaxis]) mse = mean_squared_error(y[70:], y_fit) rmse = math.sqrt(mse) print("Mean Square Error : ",mse) print("Root Mean Square Error : ",rmse) # Plot the estimated linear regression line using matplotlib: plt.scatter(x, y) plt.plot(x[70:], y_fit); plt.show()
输出
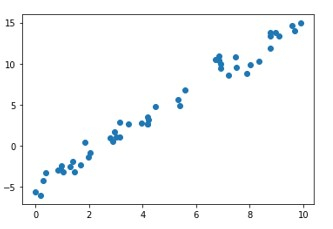
Mean Square Error : 1.0859922470998231 Root Mean Square Error : 1.0421095178050257
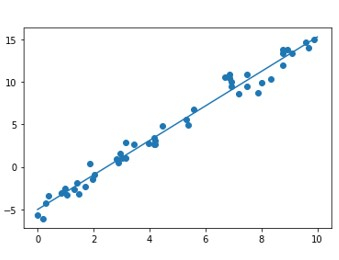
结论
回归分析是一种非常简单但功能强大的预测分析技术,在机器学习和统计学中都适用。其思想在于其简单性和自变量与目标变量之间潜在的线性关系。

浏览量 1000+
